draw things 模型教程
大家好,我是阿顺,今天跟大家简单介绍一下怎么使用这个软件。首先我们在这里不对,这里项目这个地方新建一个项目, 这个项目新建出来,然后点重命名,重名写上你喜欢的名字,比如说这个,这是我之前做的一个项目,跟大家建展示一下。名字取好之后点设置,设置 模型,我们就选这个模型,这个模型是可以涂上视频的。好,这边的 logo 我 们就先不用控制,也不用就默认的强度,这里写文本到视频种子 点多点点随机图片大小,因为我这个图进去的时候是三,就是一个横屏的嘛,横屏我们选个差不多横屏就可以了。 这个图片的大小建议先不要选太大的,它这个影响生成的速度。呃,生成出来的效果其实跟你导入的图片有一定关系,你生成图的时候申请高清图就可以了,这个步数一般都是八步 帧数的话,这个东这边就是涉及到你的生成的秒数,如果你配置很高的话,我建议直接拿到十秒,因为五秒,有时候提示时复杂了,生成出来 生成的不完整,可能是一半,这后面文本指导一点零裁按,这都是默认的,默认的好,然后在这里 点击一下,我们选择我们要上传那个图片,比如说我就是选择这张美女的照片,美女照片,然后下面就是提示时生成一个走路的视频,图中人物慢动作行走, 扭胯,然后有个三六零圆形环绕,运镜旋转丝滑,氛围感强。然后再点这个地方,点 好就会进入这个深层的界面,深层界面,这就是我们用到的模型,一些参数好,这个就会显示启动,启动这里就会有时间,等我们这个时间走完了之后,这个视频就会 就会生成完。好,这里暂停一下啊,把它停止掉,这是我生成好的一个,这里已经,哎,不对,不是这一个好,这是我已经生成好的一个,可以放给大家看一下, 它这个还有声音, 你把它保存下来的话,分辨率还是可以的,感谢大家的观看。

粉丝9892获赞2.3万
相关视频
 06:54查看AI文稿AI文稿
06:54查看AI文稿AI文稿现在让我给大家介绍一下 l t x 二。 l t x 二是业界首个高校的音视频联合基础模型,关键是它还是开源的,支持文声影音以及涂声影音。 几天前 ltx 二点三已经发布,相较于 ltx 二有全面提升。从 drawthings 的 开发进度可以看出, ltx 二点三正在紧锣密鼓的支持当中。 ltx 二已经正式支持有一周多的时间,这也是 drawthings 软件上首个支持音频生成的模型。 ltx 二 the first model on drawthings that supports audio generation。 在 drawthings 里,要怎么正确地使用 ltx 二呢? 那么今天的视频主要是给大家分享我在 drawthings 当前的部署下所探索出来的一些经验以及参数,分享给大家。所有的实践所得大部分都是在 m 五芯片 ipad pro 下本地运行的结果,也有少数是云计算上的经验。 第一部分 ltx 二运行建议 ltx 二分为 dev 版和 distyle 的 蒸馏版,那么在普通消费级硬件上,大家还是老老实实的跑八步的。蒸馏版跑八步的方法我个人习惯直接用 distyle 的 底膜下载的文件大小构成,大家参考一下。 也有人使用 dev 版加 distilled lora 的 组合,它们的区别在哪里?我这里给大家展示一个对比, now let me introduce ltx two to you now, let me introduce ltx two to you。 可以 得出结论,后者组合的效果还是要好一些,尤其是文字渲染的准确度。 dev 版的模型以及 distilled 加速 lora 的 大小约为十八 g 和八 g, 与 one 二点二等视频模型一样,我仍然强烈推荐大家使用 draw things 的 云计算服务来生成。当然,如果用量过多,社区云计算会遇到排队等问题, draw things 家相对有更好的服务。 必须要说明的是, ltx 二比 one 二点二更适合本地跑,尽管 distil 版需要八步生成,经实际测试也要远快于 one 二点二的四步生成。在 m 五 ipad 上跑十六比九,小尺寸七百零四乘以三百八十四,一百二十一针,约五秒钟,只需要二百二十秒左右,也就是三到四分钟就完成了。 下面这张表有一些不同尺寸不同帧数的参考的生成时间,云计算如果不排队,会极快的完成。 第二部分, ltx 二运行参数和对应样例 ltx 二官方说的最高支持二十秒的长视频生成, 在 draw things 里面,单次最高帧数的取值是二百五十七帧,也就是十秒钟。 ltx 二在 draw things 里面的默认帧率是二十四 fps。 我 们最常用的生成的帧数一般是一百二十一帧,或者是一百六十一帧,也就是五至七秒钟。 ltx 二八步蒸馏版本所需要关注到的一些参数是,步数设为八步, c f g 设置为一。唯一要特别给大家分享一下的是,对于 dt 里面 shift 值到底应该是多少? 在这里,我通过摸索 ltx 二的源代码以及 drop in shift 值的实现, 我发现官方的八步蒸馏工作流用到了九个手动固定的 sigma 值,而通过 drop in shift 值与 sigma 之间的公式关系,通过 ai 辅助,我算出了三个最佳的 shift 值,可以最为接近 ltx 官方的 distilled manual sigma 部署, 以下推荐仅为我的个人建议,不代表 draw things 官方。当 shift 为五的时候,八步生成,这也是 draw things 的 默认推荐设置,也是一个相对稳定的参数。其优缺点如下,对应的生成案例如下, how do i get to the nearest chinese restaurant? wow, how did this happen it's so amazing i am definitely going to break my previous record this time do you know ltx 2 3 is coming to draw things our research into ltx 2 shows unparalleled stability, but how does it handle high frequency textures in long d rations? 当 shift 为六的时候,九部生成对应的案例如下, this temple has been hidden for centuries, it's been raining for a solid week when will it finally stop i am waiting for someone, but perhaps she won't come。 而当 shift 为七点八二时,追求稳定的结构和前期轮廓的生成对应的案例如下, fast is easy, winning is hard, i am right here i wanna fly oh my god that's a long way to go i'm lulu i am showing you ltx 2 on draw things in the kingdom of the blind the one eyed man is king that is the funniest story i've heard all week i told you it was a day to remember。 需要说明的是,在 laura 列表里也有一些 ltx 二的 laura 可以 使用,大家可以自行测试。我这里给大家演示一个镜头稳定性的 laura life is boring let's coding life is boring let's coding。 加载了这个 laura, 可以 看到生成的画面除了主体动之外,背景基本上是非常稳定的。 在本期视频发布的时候, ltx 二点三在 drawthings 里面已经内部测试部署完成,并即将公开发布。 ltx 二点三拥有更为丰富的细节,更好的画面,更出色的运镜,更好的肖像,以及原声支持的空间放大。我将会在后面的视频里为大家介绍,我很享受做一个 vip code, 谢谢这个伟大的时代。本期视频所有的参数我都将分享出来,欢迎大家持续关注,工具狂的后速跟进,我们下期再见!
 11:26查看AI文稿AI文稿
11:26查看AI文稿AI文稿mac 上最好用的 stable diffusion 客户端 draw things 详细演示上一期大狂为大家介绍了 diffusion b, 而事实上,到目前为止,我在 mac 上的主力 ai 绘图工具正是今天要为大家重磅推荐的 draw things。 这款专为苹果生态打造的免费 stable diffusion 本地 ai 绘图软件,是集控制参数、出图速度、 ui 界面、更新频率等等多方面综合实力最强的 micossd 客户端。如果是苹果电脑,尤其是 apple silicon 芯片,想本地跑 sd 出图,可以闭眼手选下载这款软件使用。我说的下面,大狂将从两个方面为大家详细介绍和演示一下这款软件,希望通过整个过程 为同位麦克用户的您提供参考。第一部分,软件界面概览和综合比较 draw things 可以直接从苹果应用商店 app store 免费下载。这款软件在最近一周极为激进的进行了两次重磅更新,界面已经全面支持中文展示,非常友好。 在选择 drop things 之前,大狂就一直在寻找最适合在 m 一上本地跑图的方式,包括 stable diffusion web ui 出图偏慢, diffusion b 出图快,但不支持 laura, 可控制项还有些偏少 defuser、 marchi 等。要么模型少,不知池字定义,要么可控制项太少,难以生成目标图片。 通过多款软件的综合比较, draw things 可以说轻松胜出。打开 draw things 这款软件界面,每一项设置都有中文说明,我相信大家通过简单理解和实际操作,都会最终 知道每项设置会怎么样影响出图结果。我们从左往右看,第一项,模型系统内置了丰富的可选模型。值得一提的是,这些内置的模型可不仅仅只有 stable diffusion 的模型,还有一些基于其他训练的模型,比如最近刚刚更新的 candyski v。 二点一 就是在大规模图像、文本数据及 land high rest 上进行训练的,可以生成非常高质量的图片。因此 draw things 实际上是一个极大成者,并不单单只是 s d。 一般而言,这些内置的模型下载之后足够大家玩了,但如果您还不满意,可以去 siva 上下载,然后选择导入自定义的模型。 第二项, draw things 是支持 lora 模型的, lora 是一种用来微调大语言模型的技术,通常 lora 模型并不大,仅有几十或上百兆左右,结合着大模型 使用,可以得到自己想要的风格或效果。下载内置 lora 或导入外部 lora 与第一部分的 checkpoint 是一致的,只是大家要注意把相应 lora 的触发词要填好,这些触发词在 savtai 网站相应的模型页面都有写的很清楚, 所以前面两种最主要的模型, checkpoint 和 laura 在 savatar 和 hotting face 网站上有很多,建议大家不要疯狂的毫无目的的下载,因为每一种模型都有自己的风格和咒语,一定要到模型的具体介绍页面,搞清楚他到底怎么玩,适合什么样的采样器,是否内置 vae, 是不是混合模型,大概需要多少步骤等等才能真正的生成想要的图片。所以模型很多,不可贪下,毫无意义,而且给硬盘造成巨大的压力。第三项, control net 内置的已经很全面了,同样是建议大家搞清楚 controlled 每一种模型的玩法,在按需下载。比如大款,我最经常使用的就是一种控制对象姿势的 pose。 还有一种是限稿生图的 scribo。 第四项,种子是随机数,如果需要图生图或者生成主体内容一样的照片,种子数不要变。 如果要生成一张新图,点击种子数会随机更换种子模式,默认不变就行。第五项,图像大小最大支持两千零四十八乘以两千零四十八,内置了一些固定比例的分辨率, 同时也支持自由比率拖动。 第六项,放大器支持把图片无损放大。内置了主流的 relax again 放大模型,不仅可以把生成的图片无损放大,还可以把本地你自己想要的任何图片无损放大。 后面的部署、文本指导、采样器、图像指导等都是最常用的设置选项,参数可以根据需求自己微调一下。 没想到这款软件可以 skip 也是支持的,可以跳过数值,大家一般选择疑惑二就行了,太高的可以 skip 会让计算机专注于某一个单词,而不是他们的组合意义, 比如说一位在河边玩水的戴帽子的小女孩。偏高的 crit, skip 的值可能只会得到一个小女孩的图像,亦或是一条河的图像,而不会得到你想要的更全面的图像。下面的人脸修复内置的 restore former 模型 也非常实用,可以用于修复扭曲的人脸,但是说明也很清楚,比较适合逼真现实的图像。如果是动漫或者艺术图,效果不理想,我们生成的图片可以自定义选择保存本地文件夹, 同时我们所有编辑和生成的历史记录都会在云端存储。从软件的右侧可以看到 最后一项 textural inversion 也是支持的。这个文件通常非常小,仅有几十 k, 但却能实现一些特别的风格和效果。我使用部分内置的 textural inversion 生成了一些案例图,供大家参考。 容易被忽视的是,底部的像芯片一样的图标设置非常关键,点击进去可以看到这里面的设置事关图片的生成速度,因为它是支持 apple silicon 的 neuro engine 的。 但是如果你选择了使用 coremel, 每次用一种新模型或者新的模型组合的时候,都会进行模型的转码,再首次使用。转化为 coremel 文件花费一定的时间, 同时增加硬盘的消耗,但是后面出图的速度会有显著提升,这一点需要给大家告知清楚。 右侧的顶部就是正面以及负面的咒语框了,贴心的是,这款软件为咒语框的编辑提供了一些便捷的按钮,比如全选到文首文末,快速选择单词以及 textural inversion 等等,方便修改。 而顶部有一个蓝色横条,容易被忽视,拖动横条可以查看往期所有的咒语修改记录, 非常方便。最底部的这些按钮主要是用来做图声图的时候使用的。第一个类似魔棒的图标可以快速选择图片中的对象,比如我生成的一张马斯克开特斯拉的照片。魔棒快速选择马斯克之后,然后咒语框内输入乔布斯的描述,就会把马斯克替换成乔布斯, 这样一张照片就生成了,效率非常高,大家可以自己摸索玩一玩看。而最右侧是一些编辑记录的按钮,每个按钮都有说明, 右下角有一个类似图层按钮的图标,点击进去有一些高级的操作,很多适用于 ctrl nine 相关的控制。下面大 狂将通过实际作图的过程为大家进行演示,更好的理解这些参数和选项的作用。第二部分,软件作图详细过程演示首先我比较喜欢现实逼真的模型,于是我在 savta 网站上看到 shown in photoreal 比较对位口, 所以把这个一点九九 g 的主模型文件下载下来,随后在软件内导入,同时图像的风格我喜欢高对比,深色一些,暗掉一些,让整个图片更加的黑酷和冷静。于是我又在 simita 上面发现了 lower, 这款 lower 仅有七十二兆,但是却能让最终生成的图片完全进入我需要的状态。 好了,有了这两款主要的模型文件,我就开始作图了。咒语的描写是有几个常用的语法的,比如圆括号加 权,或者后面加冒号百分比数字来表示权重,或者用中括号来降权等。越是重要的描述词,要越往前面放。咒语的描写有很多工具网站,大家可以去这些网站生成, 我们要生成一张 elon mask 看火箭发射的图片,选定主模型后再添加 lower 模型,咒语框内会自动加上 low r a 的出发词 dark film。 使用上述咒语出图的质量不错,但是出现两个马斯克, 所以我就调整一下咒语,在正向描述里新增 only one people, 并增加他的权重,再出图就只有一个人头了。但是我们发现画面中没有火箭,于是再到描述词里单独新增一个 a big rocket, 于是大火箭就出现了。 我逐步的优化调整画面逐渐趋向于我的意下。再来一张图片,这一次我没有加权重,而且把我暗黑系的 lora 给禁用了。 这一次出来的图片非常自然,而且光线比较明亮,可见 laura 的影响效果还是非常明显的。 马斯克的人脸也是非常像真人的,这就是整个作图的过程,其实很简单,而且出图的质量非常不错。最后非常值得注意的是,作为 apple silicon 芯片的用户,一定要启用 coremel 的开关,这样虽然会转码占用一定的存储空间,但是会充分发挥 new role 真正的效能, 可以观察到跑图的速度会更快。 这就是今天为大家介绍的目前我的核心 ai 绘图工具 draw things。 上述讲解如有不对或不周之处,欢迎大家留言区补充和指正,让我们共同进步。 我是工具狂大狂,效率提升专家,欢迎大家关注或订阅工具狂。
452MJ313131 06:26查看AI文稿AI文稿
06:26查看AI文稿AI文稿draw things 加入 focus in paint 模型也许是目前 sd 最好的 in painting 模型,今天继续为大家介绍一下 draw things 这款 mac 端 sd 工具的进化。因为该软件最近加入了基于 sdxl 的 in painting 模型,可以在更高级别的美学层面对大尺寸的图像进行填充、修复和扩图。 相信大家也都非常清楚 in paint 模型对于 ai 绘画的重要性,能够智能的修复和拓展图像。 focus 是中国 ai 开发者张云敏既 control net 之后推出的独立的 stable diffusion 绘图程序。 focus in paint 模型被认为是最佳的基于 s, d, x l 的修复变种开源模型。 该模型能够及时加入 draw things, 是一项巨大的进步和能力跃升。下面大狂将在电脑上为大家演示 focus in paint 的使用方法以及我的一些使 实践和发现。第一步,下载模型 focus in paint 是一个非常强大的修复模型,既可以以基础底膜的形式存在,也可以以 lower 的形式存在来搭配其他基于 sdxl 的底膜。 所以在这里请大家分别在基础模型和 lora 里面找到 focus in paint s, t, x l v 二点六来下载。建议大家下载巴贝特的版本,可以占用更小的空间,有更快的出图速度。第二步,使用方法演示 首先我们需要一张底图,我用 playground 生成了一张狗坐在板凳上的图片。 第一种情况,我们以 focus in paint 作为底膜来扩展图像,把原来的一比一的方图扩展成三比二的横图,两侧留出透明区域设置就和我们 s, d, x l 的出图设置是一样的,在这里我把我的参数分享给大家。 步数我选二十步,文本指导七、采样器用 d p m 加加二 m cares, 可以用橡皮擦稍微涂抹一点原图的边缘,也可选择不涂抹,大家可以自己对比一下。点击生成扩图的过程与 sdxl 出图的过程没什么两样,在我八 g 内存的 m 一上,用时二分三十秒,扩图成功, 大家看看这扩图效果非常的完美。 扩图完之后,我们试试填充效果如何,把狗变成猫试试,我们用橡皮擦涂抹掉狗提示词换成猫,点击生成, 这个结果大家还满意吗?或者把猫眼抹掉,只剩下板凳, 大家看看结果, 效果确实是非常不错,但是时间有点长啊,当然你们电脑配置高,就当我没说,我这个二分三十秒等的挺难受,但是别忘了有 lcm 和 turbo 加速模型啊, 在这里给大家省时间,大家在 lora 那里选择 lcm sdxl base, 然后采样,其选择 lcm, 步数调到四,文本指导调到一至二之间, 再点击生成,仅用时三十秒左右就可以完成。根据我十天左右的测试, focus 主模型搭配 lcm 的 laura 出图并不稳定, in painting 效果还好,但是 out painting 扩图经常会出现模糊没渲染 完成的结果。 所以为了加速,我一般不选择 lcm laura, 而是选择今天我要为大家重磅介绍的 sdxl turbo laura。 turbo laura 这个模型并不被大家熟知,它可以让任何 s d x l 基础模型得到 turbo 加速的效果。有了 turbo laura, 任何 s d x l 的底膜只需要四到五步,用 d p m 加加 s d carrots, 这样极少的步数就可以生成高质量的图片。 同理, focus in paint 是基于 sdxl 的底膜,搭配 turbolora 之后,我们把步数调到四,采样器 dpm 加加 sd carrous, 文本指导一到二都行,点击生成结果如下,经过我的长期测试, focus in paint 搭配 turbolora 是目前最佳的解决方案,速度有非常可观的提升, 同时出图的质量非常稳定。这也是大款我目前最常用到的填充和扩图组合方案。我把该设置保存为 focus turbo, 对于需要扩图的图片随时调用该设置效率高,同时效果非常理想。 第二种情况是 focus in paint 作为 lower 来使用,这样做的好处是它允许你搭配任何其他基于 sdxl 的主模型,有助于生成 风格一致的填充或括图。还是刚刚那张狗狗的案例图。我们在 lora 这里选择 focus, 那么主模型的选择面积很大了。主模型你可以选择一般的 sdxl 微调模型,比如 dreamship xl, 那么步数就得二十步往上,文本指导也要调到六到七,出图速度会比较慢,但是质量有保证。 最好的办法是主模型,你也可以选择基于 sdxl turbo 的融合模型,比如 dreamship turbo, turbovation realistic research turbo 等,那么你就可以基于该主模型的特点,以较少的步数快速扩图和填充了。 可以说 focus in painting 个基础模型,一个 laura 这套组合拳,再搭配上 turbo 模型的加速快车,让 draw fans 变得非常好用。再次把 ai 填充和括图提升到一个 sdxl 级别的水平,在 mac 端进行 stable diffusion 创作,我早已完全依赖 draw fans 这款软件, 也希望今天我的实践和分享可以帮助到同样使用 dt 创作的朋友。如果有任何问题可以添加大狂讨论,我们共同进步。我是工具狂效率提升专家,欢迎订阅关注。
131工具狂Toolbuddy 01:46查看AI文稿AI文稿
01:46查看AI文稿AI文稿继续上期,这次我们用同样的图片,但不同于上一次的事,我们换一个模型。上一次我们是用端侧 jama 四 e 四 b 倒推提示词, 在 drawings 里面得到了这张图片。 jama 四二六 b 的 模型看看到推出来的内容是否会比 e 四 b 要精确。我们打开 l m studio 加载模型,再导入图片 这张图片生成提示词。可以看得出来,二六 b 的 模型在文本生成方面确实比 e 四 b 要快了不少,需时三十八秒, 刚好抓分子迎来了一次较大更新, z e m h 系列迎来了小体积大能量的霸道比特 s 版本,同时 flux 二也迎来四 b 小 规格的两个量化版。先用 z m h 触波一点零八比特 s 试试效果。 这次还原度明显高了不少,起码大厅的穹顶效果是出来了,地砖的细节也没有像上一次那样混乱。接下来测试 this 的 效果,看起来细节有点虚化,尤其是在天花穹顶的部分, 我个人感觉是没有 z 一 米尺效果好。 用真马寺的四 b 和二六 b 反推提示词后,再利用目前比较好评的开原声图模型生成的效果,看得出来真马寺的多模态确实很强大。
232捞餐饮嘅地盘佬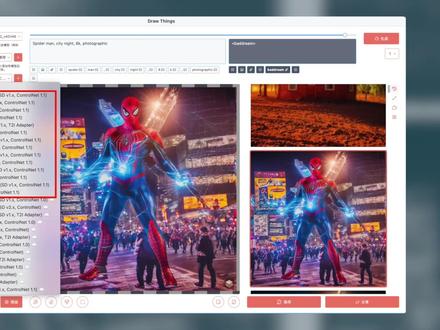 11:25查看AI文稿AI文稿
11:25查看AI文稿AI文稿如何在 draw things 上玩转 control net 这一期的内容计划了很久,今天才上线,很多 mac 用户也很期待,希望能有多一些的 draw things 教程视频分享。 在往期的视频中,大狂为大家介绍过 draw things 的基础界面以及 ai 填充和扩图,今天专门为 control net 而来,主要介绍下面十二种控制网模型在 draw things 里面的操作方法,希望通过我的实践为大家提供参考和帮助,有不妥不周之处,请大家直接留言指出,给我一个进步的机会。 control net 控制网的开发者是来自中国的张吕敏,让仅靠提示词天马行空的 ai 绘画可以受到人为的控制和约束,通过一些特定的约束模型,让 ai 出图变得可控。 control net 应该说和 stable defusion web ui 配合的非常好,一些 s d 玩家已经玩的不亦乐乎,但是很少有 a p p 能 能做到把 control net 进行很好的融入。在我眼中, draw fans 在这方面做的相当不错了,但是在操作方面有很多隐含的技巧需要大家注意。今天大狂特此与各位分享我的经验。 打开 draw fans, 大家可以把后缀为 control net 一点一的这些模型统统下载下来,其他的可以暂时不用管。第一部分,我们介绍线稿类的控制模型。 首先任意选择一个大模型,我选的是 realistic question v 四零控制网选择 canad, 这是一个检测对象边缘线条的模型,对内部的细节检测并不精细。下面我们以这张图片为案例,生成一张新图, 注意在 ybui 里面使用 control net 都有一个预处理的过程,所以配备了很多类型的预处理器。 但是在 draw fans 里面,这个过程是隐藏的,也没有预处理器的按钮。对于 kenny 来说,你只需要把一张底图丢进去,然后进入描述词,就可以根据这张底图的线稿边缘生成一张同样边缘的不同对象。这种操作在 mac 里面更加直观简洁,而且出图比较稳定。 再次注意,对于 candy 来说,可以直接读取底图的线导边缘,但是对于 light art, scribble 以及后面还有的其他模型来说都不行。 控制网有没有起作用,可以从图片生成过程中的参数行直接看出来,这个是黄金判断标准。 lieart 是更为精细的线稿检测模型。要成功加载 liearte, 需要点击图框右下角的图层按钮,点选加载图层自定义,从文件中获取自定义。 经过这番操作,再点击生成 line art, 控制网就开始起作用了。 其他的控制网都可以通过自定义的方式来加载,而 kenny 是可以直接读取底图的。 line art 生成的结果我们可以看到,它不仅很好的控制了外部边缘人物内部衣服的纹理、褶皱,包括格子衫的线条都进行了控制。所以说 line art 是一种非常强烈的线稿控制网。 line art anime 是一种对卡通动漫效果更好的控制, 我就不介绍了。 soft edge 也是类似的,从名字可以看出它是一种柔和的边缘过渡,效果更好。你甚至可以理解为把 liar 进行了轻微的羽化就得到了。 soft edge 要在 draw things 里面起作用,同样需要加在图层自定义, 不同的是, scribble 这种属于非常粗放的草稿,不用于精准控制,随便画几笔快速生成大致的创意和想法是 scribble 干的事儿。在 clip drop 网站上有个类似的产品,大狂上次介绍过叫 stable doodle。 还有一种略有不同的是, m l s d 是专门检测直线的模型,对于建筑室内装饰是很好的选择。注意 m l s d 模型可以不需要加载自定义,在 draw things 里面 可以像 kenny 一样直接读取地图。 好了,第一部分线稿检测类的控制网讲完了, kenny、 line art soft edge scribble 以及 mlsd。 总结一下,在 draw things 里面操作预处理器是隐藏的, kenny 和 m l s d 是可以直接读取底图生成新图的。 light art soft edge scramble 是需要通过加载图层自定义,从文件中获取自定义来起作用的 线稿生图。在 drosins 里面还有一种很实用的玩法,就是生成艺术。字与场景的融合对于商业化设计很有意义。首先在 ps 里面准备一张黑底白字的图片, 比如六一八,然后选择 canny, 就可以让 ai 纵情发挥想象力,把六一八与各种场景融合起来。接下来我们来看 toyo 模型,这个模型我非常喜欢, 他是一种将图片高清化的控制网。和一般放大模型不同的是,他忽视原图的细节而生成全新的细节,但是保持大致的主体轮廓相同。 我们以刚刚通过 soft h 生成的一张图为案例,这张图分辨率只有三百二十乘以五百一十二,看着非常模糊,图像质量较低,这时候胎有模型可以很好的发挥作用。 我们把图像大小调整为原图的两倍,六百四十乘以一千零二十四,我们可以看到底图缩小到了画面的一半,这个时候我们点击画框左下角的倍数,选择两倍,将画框填满,然后点击生成,就会进行高清重采样,得到一张与底图轮廓基本一致的高清 大图,图片质量非常高。 接下来再看 depth map 深度图。深度图是一种展示图像纵深关系的黑白灰图片,深度图中的白色表示距离相机很近的物体,灰色为较远的物体,黑色为最远的物体。 通过深度图可以生成具有纵深关系和立体感的图片。在 drawface 里面使用深度图控制网同样需要加载图层,但是请注意这里面选择深度图,从文件中获取深度图,这时候右侧会显示黑白照片,再点击生成深度控制就会起作用。 但是我强烈建议大家在 draw fans 里面使用深度控制网,不要这么做,这似乎是一个 bug, 这个深度图有问题,不精确,建 大家在 ybui 里面预处理出深度图,在这里加载使用,或者直接通过大狂提供给大家的 hiding face 网页专门生成深度图 下载下来,然后再到 draw fans 里面加载这个深度图文件,这样生成出来的深度图控制效果要好很多。利用深度图同样可以生成这种立体感以及融合感更强的艺术文字图片,可以让设计效率大大提升。 接下来我们快速讲解一下 in painting, 因为在第十六期 draw things ai 填充及括图里面,我已经有过详细演示。 控制网 in painting 和主模型里面的 in painting 有一点不同的是,它允许你搭配任何微调风格的主模型来实现 ai 填充和扩图。还是刚刚生成的那张罗马巨石的图片,我们想在石头上长点苔藓,用橡皮 擦涂抹一块描述词,键入相关苔藓的提示词,石头就长出苔藓了。如果要扩图,可以直接面板缩放, 或者仅仅只想拓宽,在输出图像尺寸那里选择自定义,把宽度拉长就行。然后橡皮擦或者选区工具适当涂抹掉一点原图的边缘,点击生成,轻松完成毫无违和感的扩图。 然后我们重点介绍一下 openpose 姿势控制网,该模型对于生成特定姿势的人物效果出色,尤其对于电商图片摆拍等很有帮助。 我们拖入一张案例图,选中 pose, 该模型支持直接读取底图,可以直接键入提示词生成新图。 不过这张图在空间维度,手臂、手掌有一些交错。 draw things 内置的预处理器还是老版本的简易预处理器。我们点击右下角图层按钮,点击姿势,可以发现预处理器仅仅识别到了手腕的部分,手掌并未识别, 因此生成的图片在手部动作方面出现了差异。如果希望有更精确的动作控制,建议大家先进入 ybui, 在 ybui 预处理器里面生成包含手部的骨架图, 或者包含脸部表情的全身骨架图。这个预处理的过程很快,就几秒钟。把骨架图下载下来,放到 drophins 加再次定义就可以生成包含手部动作的图片了,当然也可以生成相同表情的图片。 openpose 的玩法很多,有一些第三方的网站支持自己编辑动作或者三 d pose, 包括 savtai 网站上 也有很多现成的模特摆拍的骨架图都可以直接拿来用。总结一下,普通的身体骨架图可以直接读取底图生成新图。全身骨架图需要先通过 ybyy 预处理,然后到 drafas 里面加载自定义来实现, 之后是 segmentation 语意分割。在 draw things 里面同样需要加载自定义来实现。他的预处理的过程是把不同的对象分成大的颜色块,然后根据提示词在这些色块里面生成新的对象。他比较擅长各种大色块对象的分割处理,然后在这些色块里进行变种。 事实上,羽翼分割生成的预处理图片中的颜色快对应的实体都是确定的,比如这种代号的黄色对应人行道,这种代号对应的紫色是床。如果你想进行高级的玩法,完全可以先预处理出 segmentation 色块,然后在 ps 里面编辑和组合各种 色块关系,然后导入到 draw fans 里面生成新图。剩下的两个有关风格转换的控制网用到的并不是太多, safo 需要加载自定义来起作用,通过将原图打乱,按照原图的风格重新生成新图。 他更多的用途可能通过与线稿类 control net 组合来生成新图。比如我用官方案例的蜘蛛侠的 kenny 和一个城市夜景的沙否进行组合,蜘蛛侠就与这个夜景融合到了一起, 而 instruct picks to picks 就更简单粗暴了。直接描述词让原图下雪他就变雪景,让他变成炎热的夏天,画面立刻变得炙热,需要变成凉爽的树叶,满地的秋天立马帮你实现。 这两种风格转换的模型还是非常有用的。以上就是大狂为大家介绍 的 controlled 一点一里面主要的十二种控制网模型,在 draw fans 里面的使用教程,要熟练掌握他们的用法,最关键的是要不停的自己去实际操作和试验,甚至还有多种 controlled 模型相互配合的情景,以及 controlled 的权重和介入和结束的时机,这些都需要大家去反复练习,我就暂时不扯远了。 如果觉得今天的视频对你有所帮助,可以送个小小的赞以示支持。我是工具狂,效率提升专家,我们下期再见!
125工具狂Toolbuddy 02:00查看AI文稿AI文稿
02:00查看AI文稿AI文稿大家好,今天我想和大家分享如何在 macbook 上快速体验 ai 绘画。方法是使用一款名为 gross ins 应用程序,该应用可以在 app store 中直接下载安装,安装完成后 首次运行应用程序会提示下载一个名为 stable diffusion 一点五的基本模型。接下来是操作界面,只需在两个输入框中分别输入所需的元素和不需要的元素, 然后按 generate 即可生成图片。但是基本的 stable diffusion 使用上手难度高,我自己写了些提示词。生成图片的质量我个人是感觉挺打击对 ai 绘画热情的。其实作为尝鲜, 我觉得直接用网上一些定制化的模型更有可玩性。而要使用网上一些炫酷的案例,我们主要需要关注 model, lore 和 sampler 三个参数。下面我将通过一个使用案例来介绍如何操作。首先我们需要在网站 cbt 上找到一个喜欢的模型和对应的提示词,比如我选择了 goof fm 三这个国风模型,并下载了它。 接着在 gross ins 应用程序中打开 model 菜单,选择 manage, 然后导入我们下载的 google fan 三模型。每个模型下载页面底部都有其他人制作的图片成品设立,我们可以选择一个喜欢的来访制, 点击图片,网站提供了详细的配置参数。下面这个案例,我们需要额外下载一个 low r a 文件,并将其导入 draw scenes 中。 low r a 的导入方式和 model 类似,选择 low r a, 下拉弹窗中的 manage, 然后导入下载好的文件即可。 准备工作完成后,只需输入相关参数,按 generate 不停生成即可。需要注意的是,提示词中也要包含 lore a 文件的名称。现在 网上已经有大量非常丰富多彩的模板供我们欣赏和使用。我希望这个视频可以帮助到大家,让大家体会到 a 二绘画的乐趣。
57永遇乐 12:01查看AI文稿AI文稿
12:01查看AI文稿AI文稿找,呃, mac 电脑上最好用的一个 ii 出图软件,它跟之前介绍的平罗超不一样,平罗超市可以安装各种 ii 工具,这个只是单纯的使用 stable division ii 绘图软件,它的优点就是 他也可以用所有的模型,比如 penguin vr, 这个基本上平替 l 三一三的效果。 呃,正在熬夜的别看。呃,主要介绍三个部分,安装基本出图到详细介绍最后一个模型,下载机安装,他的操作界面很简单,就是这样子的。 然后我先介绍它的安装,安装它可以在苹果 a p p 是导航里边直接搜索这个下载就可以了,它支持 ipad 手机什么,也可以到它的官网上 直接点着下载安装就可以了。然后介绍他的优点,他完全就是中文界面,而且功能也很齐全,而且也有内置的很多模型,也有 ctrl net 的所有控制。 优点就是他可以为认证,他也可以下载福克斯模型,就变成福克斯身份, 生图效果非常完美。我这边给大家展示一下,像这个用的是同一个漫威二的模型,等一下我会介绍怎么使用。他这边简单看一下他生图的效果,非常精细, 这个是 deal 一三生成的效果,它基本上可以 pd 它的效果。然后 介绍一下他的操作,基本操作界面他的基本操作界面。呃,左边这个是项目,这个就等于你做的这个项目,包括提示词所滑板,他是一个文件,等于是这样子,大家可以自己去新建,这个是基本高级全部,你点 这三个其实是一样的,只是显示的内容不一样,全部就等于把所有参数都显示出来而已,其实常用到的也就选择一个大模型,选择这底下有带呃云图标,下载图标的就是他内置的,但是还没下载,你需要的时候才下载。呃,不可能全部下载,因为这个太大了, 然后就可以换模型,然后这个是文本生图,如果你想要图生图的话,你就点到图生图,然后是控制权重图生图的方式,等于是你从这边加载一张图, 加上一张图片就可以了。自定义这个,从这添加图片 添加到这,他就会参考这张图,然后生成这个,相当于简单的点图 ctrl net 大家都知道,这也也是有很多功能,等下我给介绍。这个跟 step body 飞雪一样,就有所有的所有的模型,你需要的时候再去下载即可啊。这个 其实大同小异,都是限稿啊,空间什么之类的,还有这种子花花布,尺寸布数,所有的参数吧, 你点全部就是涵盖和上面两个,一般点基本的参数就够用了,比如生成及删除什么之类。这个是提示词,正线提示词,反向提示词,然后提示词底下有个功能,就是这个可以选择。呃,各种 风格吧,你点一下它就会自动生成提示值,按它前四风格。这个是密室积木,拖动就可以变换。这边是画板,就是生成完这边会有画板,这个是新建画板空的,然后生图,如果你随便点一张,这上面有图片,那 你再点到图层图,等于就是参考这张图生成,然后你可以把选中调高调低去生成。如果你要删除这些画板的那,那你点这个右键选择更多,就可以多选,然后删除。 这个就很简单,他操作界面就一二三四四个部分。呃,底下这脚本什么?这,这就不用管了,这个一般开发者用的这个也不用管,我们就可以了, 比下一个更不用管。这个是插图,比方说我要呃生成一张图,然后 就文本生图,如果你用到这个工具把它擦掉的话,那他再次生成的话,就是补上这块,如果你清除掉不用的话,他就是整张生图了。 第一个是魔术棒,等于是帮你抠图点一下,他会帮你选中的,不过这个不不好用,一般没什么的。最后一个是清除清除工具而已,这个是画笔,如果画多了,用这个恢复画回去,就这两个很简单。 然后我这边演示一下他的生图效果,他的生图效果就是如果我用这个橡皮擦 把它擦掉,它就会慢慢的生成我涂抹掉的这个区域,然后就会生成出我需要的,你可以根据你的提示 去生生成修改。然后电图的话方式就更简单了,就是在这个按钮里边添加一张图片到这画面来,然后这边选择图生图, 然后这个权重你看要跟原图相似的话,那百分百他就不变了,一般调低一点,然后提示词,最后他就会根据这张人物的电图生成先进的图片出来。这个就是默默简单的电图,不用 ctrl net 那么复杂的功能。 然后接着我就介绍基本操作的详细界面, 首先从最左边开始吧,点这个就是刚才我说的只是整体的项目文件夹设置,基本就是这三个,都刚才介绍过嘛。这这没什么,就是只是参数的显示的多跟少而已。一般选择基本就可以, 因为我们经常用到的也就是画布大小布书指导,文本指导 g f c 好像是。然后这个模型选择,点开它会有很多模型,我这边是安装了一个 playcome vr 模型,如果你要添加的话,记得在这里边点管理,然后 点添加,然后从这选择你需要的模型。下载下来的模型选择完之后记得这这个要调,这个要关掉,这也关掉,这也关掉。如果是 om 模型的话,要填触发词,这样子你在生成的时候用 om 模型就不用再去添触发词。 这个是 ctrl。 net 的啊。 moment 模型就是这个一样,它的添加与操作也也是有内置很多 moman 模型,添加与操作一样。 ctrl 就是 sd 经常用到的这个参考图,它上面总共分成这六大块的,大家可以对应一下。第一个是可能,这个就是把参考图转成向稿,参考他的动作, 这个 d p t y, 这个就是深度图,参考模型的深度,这个是参考比较粗的线条,这个是参考 pos 动作,这个是参考。呃,漫画线稿更简洁一点的,这个是参考建筑的直线的。呃,这个比较重要。 tell 提有不到,喷了,不知道叫什么。这个就是高清重绘的效果,一般模糊的图像,这个 ctrl 这个模型去高清重绘,他就会根据原图重新绘制一个更加高清的图, 这也很重要, ip 什么什么的,他等于是替换整张图的风格,用提示词跟参考图,然后换名的什么的。底下有一个换名的这个,这个我就简单介绍,大家可以细细的去用,就是基本的,根据。 net 的控制, 其实一般人用这个涂上涂自带的基本上点涂就够,因为他也做不来太复杂的。这个刚才介绍过了,就是一个选区涂抹涂抹区域修复的一个功能。 这个也介绍过,这个就是正向反向提示词,然后一些提供一些快捷方式的提示词,这个比较重要的就是提示词上面这一,第一个可以选择分格提示词,直接就 锁定了他的风格。这个刚才介绍过吗?就是一个橡木美边,所有的深的涂的 个。呃,文件夹吧, miss 积木吧,你可以选择添加删除或者导出什么。这个刚才也介绍过嘛,就是一个,呃添加参考图的一个,嗯, 添加文件的一个窗口,这是他帮你卖好的添加知识图,你就从这点进去,他就会默默帮你参考知识。 呃,这个这三个基本介绍就是如果你点全部就是非常完整的点,高级就是只显示一半点基础就选择最重要的,一般我们就选基本就可以,如果点全部的是你看他就所有的 s, d, 哎,深涂的参数全部展示,一般我们都不需要去修改啊,每天有这一步很重要。门板模糊,这个就是在你涂抹的时候,他 会根据边缘模糊模糊一点,不会那么锋利的去连接起来,所以这个一般挑一点五到二吧, 就是这个边缘他会羽化一点,连接的效果就根本根本就看不出来。不过这个虎妹吧现在修复模型都很厉害。 最后再介绍一下怎么安装模型的,比如我用的是朋友这个 open ii 开发的,跟戴小仪是同一家公司的,这个模型他深度震蓝效果就非常完美,所以我基本上就用它了。呃呃。打开他的网站,这些网址,什么素材信息我都会提供。在视频下方 打开他的官方分享链接,点开他的这个文件,点他下载这个模型就可以了。当然你也可以在 ic 站上面 目前最牛逼的一个免费模型分享玩家上面有三千个模型,都是很牛逼,一般选的就前面几个比较牛的吧,跟人们最多的, 然后通过刚才那边介绍的盗墓模型方式选择。这边有个。呃,有个特点,就是朋友官方 vir, 他只支持从幺零二四开始,其他他也不支持,这个是他缺点,其他全部尽量。然后点盗墓就可以了 啊,这点很关键。这点。嗯,电脑快的服务没电脑慢的可以把模型,因为下载的模型是 smile b t 的。呃,一个文件太大了。呃。生产出来效果是会好用点。这个下载完安装完,点这个右键转换成八 p t 的,等于减少一半文件,小声图就会快一倍。 呃,性能强的就不用做这个,因为你下载的时候他都是什么有鼻涕的一个文件,超级大。这个是同样大模型,就是以及内置很多各种风格,然后出图的设置也是这个是基本的参考,呃, 没有补即可,最低的这个参考就可以了。呃。然后还有一个技巧,就是我们一般设置完参数要把它包围成预设,下次就不用直接点这个预设就胜负了。 这边点保存,然后他会默默藏在这里面,下次你点这个就可以了, 然后这边我就点开,这就是我的意思,因为我点我一关完他就跑到 pan 了。如果我想用这个叫什么福克斯修图或者生图,我就点这个,这福克斯 这个模型他是默然在这里边预设有,但是他是不下载的,你需要的话自己点下载他就有了, 这个也是转成八 p t 的就可以了。或者哦,他好像提供的时候你可以选择八 p t 不用,是没有 p t 太大了。然后这集就是比较完整的一个详细介绍。
333吴杨峰 07:21查看AI文稿AI文稿
07:21查看AI文稿AI文稿嗨,孩子们,今天我将展示 c 的 vr 二。这是一个单部生成的超分模型, 在 drawings 内将其作为常规渲染模型下载。它会影响画布上的图像,本质上是以画布的任意尺寸重新渲染。这通常比原始图像的分辨率更高。我会展示工作流程并分享我的设置。 没什么难的,只是设置成渲染模型的方法不太明显。最后,我会展示如何编辑已保存的预设,以便重新加载时不会受到当前画布尺寸的干扰。这是 drawings 的 教程, 它是面向 mac, ipad 和 ios 的 图像与视频生成器。 drawing 在 应用商店里是免费的。它在设备本地运行人工智能生成式模型,无需订阅。今天的模型是 seed vr 二。 vr 代表视频修复,但我们将其作为创意放大工具,用于单张图像质量非常好,设置的当后非常干净。它适用于摄影和插画风格。 这实际上让我重新思考渲染工作流。也许我应该彻底停止使用 high 减 resix。 一 旦你理解了工作流程,这就会变得更有意义。所以,首先,该模型会加载到基本菜单下的模型下拉列表中。 然后将渲染尺寸设置为较大的值,并将图像加载到画布上。是的,注意我没用图生图。将强度保持在百分之一百,否则原图会透出来。这里没有提示词,所以我们直接生成。 现在快速看看。这不是什么 drawing。 在 高级设置下的 e s organ plus 模型处有一个超分下拉菜单。 cd vr 二不是这种类型的放大工具,因此将此下拉菜单设置为禁用。 该模型有两个版本,七 b 和三 b, 以及 drawthings 常用的量化选项。在模型下拉菜单中搜索 cdvr 七 b 大 约是八点五 gb, 三 b 显然更小。我其实没下载下来看。我猜这大概是为了 iphone 或者内存少于八 gb 的 任何设备。 量化选项包括针对 m 五及当前 m 四设备上 apple neural engine 优化的八减 bit s。 八减 bit s 是 新推出的,有关这种新格式的详情,请看我在四月发布的 m 视频。 六减 bit 适用于 m 三及更早的设备。这些量化版本是为了在低内存设备上提升效率,但未标记的版本也经过轻微量化以保留画质。 如果你有十六 gb 或更多内存,用七 b 应该没问题。现在我们来设置参数,在高级菜单下滚动到底部附近,起用分块解码,将高度和宽度设置为一零二四 x 一 零二四, 并将重叠设为一百二十八。对频谱扩散也做同样的操作,将高度和宽度设置为一零二四 x 一 零二四, 并将重叠部分设置为一百二十八。而且回到基础菜单,我们将步数设为一,引导值设为一点零, shift 设为五点零,并将彩样器设置为 dpm 加加二 m trailing。 渲染前,我会将此配置保存到设置中。在设置菜单顶部点击三个点的按钮,这是上下文菜单。选择保存配置,并将其另存为 c 的 vr 二。 现在,一旦我们开启了分块扩散界面,就允许渲染尺寸变得更高。 假设画布上已有图像,我可以将高度和宽度参数调整为当前尺寸的两倍,并在提示框正上方最右侧位置打开画布缩放工具,将画布重新缩放到百分之两百。图像应整齐的适配可见画布。 另一种方法是复制图像,并将其粘贴到调整大小的画布上,然后点击生成以渲染。 现在使用已保存配置的一个不变之处是,它可能会覆盖我们的画布尺寸。 这就产生了一个不必要的操作步骤顺序,导致我不得不跟尺寸设置较近。我得移动图片以适配可见的渲染区域。 这算不上世界末日,但挺烦人的。所以在最后一部分,我将展示如何通过编辑自定义配置文件来解决这个问题。我已将当前参数作为 c 的 vr 二保存到设置菜单中,现在退出 draw things。 在 mac 上的 drawings models 文件夹中找到自定义配置 j s o n。 它位于 users your username libraries containers, draw things data documents and model tool。 按日期排序文件,然后在文本编辑中打开自定义配置 j s o n。 编辑前请先复制该 j s o n。 文件。这个修复方法本身很简单,所以我会编辑原始文件。滚动到 j s o n。 底部,找到刚创建的配置。最后一行之一将是名称, 然后在字母排序的参数列表中向上滚动,找到宽度并删除整行,包括逗号及换行符。 接下来向上滚动,找到 height, 同样删除整行,包括逗号及换行符。保存文档,然后重新启动 draw things。 现在从已保存菜单应用预设将加载所有参数,除了宽度和高度。 在 ipad 上,自定义配置 j s o n。 位于 files 应用的 omepaddrawings models 点 com 出,但 ipad os 阻止我编辑 j s o n。 文件,因此你需要想办法绕过或下载第三方 j s o n。 应用。 这个就留给你自己琢磨吧。好啦,今天的时间就到这里了,一如既往,希望你有收获。 如果您觉得这个视频对他人有用,请点赞并订阅。已在您的动态中接收下一个视频,下次见。再见。
 00:11查看AI文稿AI文稿
00:11查看AI文稿AI文稿这是一个 busabel diffusion 模型,在进阿房里的 app 再也不用梯子,不用排队,永久免费,不怕服务商跑路,更多可调参数不受服务商限制了。
25软件库 04:43查看AI文稿AI文稿
04:43查看AI文稿AI文稿这样的艺术自用 ai 怎么做? draw things 内实现非常简单, ai 在艺术字创作方面是一个很好的应用领域,今天就给大家快速介绍一下这个实用的技巧。所有的操作都在 draw things 软件内进行,一分钟即可学会,且看大狂在 mac 电脑上为大家演示一下。一、模型下载 首先请大家在软件内下载几个必要的 control net 模型,今天以 s d 一点五为例为大家讲解,所以请大家下载 ip adapter plus 以及 depth map 这两个 s d 一点五的版本即可。 那么底膜也要对应是 s d 一点五的底模。在这里大款使用的是 realistication v 六零这个 s d 一点五的微调模型。二 二、准备文字图请大家在 photoshop 内准备一张黑底白字或者白底黑字的文字图,尺寸五百一十二乘以五百一十二,当然你也可以设置为其他合适的尺寸。考虑到文字字体会填充图案,所以请大家尽量选择粗体字。我这里使用的字体是京南波波黑, 写好字之后把文字图片导出。三、直接在 draw things 软件内创作艺术字 因为今天我们介绍的方法是使用 ip adapter 风格赋予来创作艺术字,所以首先我们需要一张电图,说白了就是你想要你的艺术字是什么风格的图片。 我在网上找了一张艺术字的样式图作为电图,我把底膜选择到 realistic vision v 六零 ctrl net 一个 ip adapter, 再添加一个,选择 depth map, 我们在右下角的图层这里选择创意板,把电图拖进去。 随后我们再选择深度图,把鼠标滑动到加载图层深度图,从文件中提取深度图。在这里务必注意,这里是提取深度图,不是获取深度图。这是作者最新加入的 depth anything 的深度图提取模型,首次使用会下载模型, 然后选择你的黑底白字的文字图,即可提取到文字的准确深度图了。这个时候我们既有了创意版的风格电图,也有了文字的深度图, 就可以直接点击生成了,不需要任何提示词。我同时搭配了 l c n 的 lora 来加速,只用四步就可以快速生成一张和电图风格一样的艺术字了。这个风格的 术语可以说真的是天衣无缝,你想要任何其他的文字都可以, 就是这么简单。 按照同样的思路,我还可以更换其他风格的电图,生成了海量的艺术字案例都是使用的。这个方法非常上头, 我使用的是 s d 一点五作为演示。如果大家使用 s d, x l 同样是支持的,那么在 control net 那里就要选择基于 s d x l 的 ip adapter plus 以及 dap map 了。所得到的最终结果是一样的, 如果你希望你的艺术字与背景有更好的融合效果, 可以适当的调整 depth map 的权重和结束时机,通过不断的调整这个参数测试来达到你想要的效果。 以上就是 ai 艺术字在 draw things 软件端的实现方式,除了 depth 之外,你也可以尝试使用 kenny 等其他类型的 control net 来生成,只不过我认为 depth 可以实现的效果更好。 今天的内容就到这里,我是工具狂,深度挖掘各类优秀工具,欢迎订阅关注!
 00:47查看AI文稿AI文稿
00:47查看AI文稿AI文稿我是抓粉丝 app, 根据上面这段文字绘制的。没错,他是我通过这个 app 用上面描述的文字生成的。别眨眼搞定。 开衫颜色有点暗,我们来个颜色艳丽一点的大红色怎么样?描述词换成红色系开衫走,你搞定,再来其他颜色感受一下。 感兴趣的话可以到苹果 app store 下载 girl things 体验一下,只要你能描述出来,他就能画出来。没错,是啥都能画! 快去发挥你的想象吧,后期出更多玩法教程,换服装、换脸等各种用法。
29三哥教你玩 11:26查看AI文稿AI文稿
11:26查看AI文稿AI文稿mac 上最好用的 stable diffusion 客户端 draw things 详细演示上一期大狂为大家介绍了 diffusion b, 而事实上,到目前为止,我在 mac 上的主力 ai 绘图工具,正是今天要为大家重磅推荐的 draw things。 这款专为苹果生态打造的免费 stable diffusion 本地 ai 绘图软件,是集控制参数、出图速度、 ui 界面、更新频率等等多方面综合实力最强的 microssd 客户端。如果是苹果电脑,尤其是 apple silicon 芯片,想本地跑 sd 出图,可以闭眼首选下载这款软件使用我说的。下面,大狂将从两个方面为大家详细介绍和演示一下这款软件,希望通过整个过程 为同位麦克用户的您提供参考。第一部分软件界面概览和综合比较 draw things 可以直接从苹果应用商店 app store 免费下载。这款软件在最近一周极为激进的进行了两次重磅更新, 界面已经全面支持中文展示,非常友好。在选择 drop things 之前,大狂就一直在寻找最适合在 m 一上本地跑图的方式,包括 stable diffusion web u i 出图偏慢、 diffusion b 出图快,但不支持 lora, 可控制项还有些偏少 refuser、 mochi 等。要么模型少,不知池子定义,要么可控制项太少,难以生成目标图片。通过多款软件的综合比较, draw things 可以说轻松胜出。打开 draw things 这款软件界面,每一项设置都有中文说明,我相信大家通过简单理解和实际操作,都会最终 知道每项设置会怎么样影响出图结果。我们从左往右看。第一项模型系统内置了丰富的可选模型。值得一提的是,这些内置的模型可不仅仅只有 stable diffusion 的模型,还有一些基于其他训练的模型,比如最近刚刚更新的 candyski v。 二点一 就是在大规模图像、文本、数据及 lahares 上进行训练的,可以生成非常高质量的图片。因此, draw things 实际上是一个极大成者,并不单单只是 sd。 一般而言,这些内置的模型下载之后足够大家完了。但如果您还不满意,可以去 siva 上下载,然后选择导入自定义的模型。 第二项, draw things 是支持 lora 模型的。 lora 是一种用来微调大语言模型的技术。通常 lora 模型并不大,仅有几十或上百兆左右,结合着大模型 使用,可以得到自己想要的风格或效果。下载内置 lora 或导入外部 lora 与第一部分的 checkpoint 是一致的,只是大家要注意把相应 lora 的触发词要填好。这些触发词在 safety 网站相应的模型页面都有写的很清楚。 所以前面两种最主要的模型 checkpoint 和 laura 在 savatar 和 hotting face 网站上有很多。建议大家不要疯狂的毫无目的的下载,因为每一种模型都有自己的风格和咒语。一定要到模型的具体介绍页面搞清楚他到底怎么玩,适合什么样的采样器,是否内置 v、 a、 e, 是不是混合模型,大概需要多少步骤等等才能真正的生成想要的图片。所以模型很多不可贪下,毫无意义,而且给硬盘造成巨大的压力。第三项, control net 内置的已经很全面了,同样是建议大家搞清楚 controlled 每一种模型的玩法,在按需下载。比如大款,我最经常使用的就是一种控制对象姿势的 pose, 还有一种是现搞生图的 scribo。 第四项,种子是随机数。如果需要图生图或者生成主体内容一样的照片,种子数不要变。 如果要生成一张新图,点击种子数会随机更换种子模式,默认不变就行。第五项,图像大小最大支持两千零四十八乘以两千零四十八。内置了一些固定比率的分辨率, 同时也支持自由比率拖动。 第六项,放大器支持把图片无损放大。内置了主流的 relax again 放大模型,不仅可以把生成的图片无损放大,还可以把本地你自己想要的任何图片无损放大。 后面的部署、文本指导、采样器、图像指导等都是最常用的设置选项,参数可以根据需求自己微调一下。 没想到这款软件 crepe skip 也是支持的。 creep 跳过数值,大家一般选择疑惑二就行了。太高的 crepe skip 会让计算机专注于某一个单词,而不是他们的组合意义。 比如说一位在河边玩水的戴帽子的小女孩。偏高的 crepe skip 的值可能只会得到一个小女孩的图像,亦或是一条河的图像,而不会得到你想要的更全面的图像。下面的人脸修复内置的 restore former 模型 也非常实用,可以用于修复扭曲的人脸。但是说明也很清楚,比较适合逼真现实的图像。如果是动漫或者艺术图,效果不理想,我们生成的图片可以自定义选择保存本地文件夹。 同时我们所有编辑和生成的历史记录都会在云端存储。从软件的右侧可以看到 最后一项 textural inversion 也是支持的。这个文件通常非常小,仅有几十 k, 但却能实现一些特别的风格和效果。我使用部分内置的 textural inversion 生成了一些案例图,供大家参考。 容易被忽视的是,底部的像芯片一样的图标设置非常关键。点击进去可以看到。这里面的设置事关图片的生成速度,因为它是支持 apple silicon 的 neuro engine 的。 但是如果你选择了使用 corml, 每次用一种新模型或者新的模型组合的时候,都会进行模型的转码。再首次使用转化为 corml 文件,花费一定的时间, 同时增加硬盘的消耗。但是后面出图的速度会有显著提升,这一点需要给大家告知清楚。 右侧的顶部就是正面以及负面的咒语框了。贴心的是,这款软件为咒语框的编辑提供了一些便捷的按钮,比如全选到文首文末、快速选择单词以及 textural inversion 等等,方便修改。 而顶部有一个蓝色横条,容易被忽视。拖动横条可以查看往期所有的咒语修改记录, 非常方便。最底部的这些按钮主要是用来做图声图的时候使用的。第一个类似魔棒的图标可以快速选择图片中的对象,比如我生成的一张马斯克开特斯拉的照片。魔棒快速选择马斯克之后,然后咒语框内输入乔布斯的描述,就会把马斯克替换成乔布斯, 这样一张照片就生成了,效率非常高,大家可以自己摸索玩一玩看。而最右侧是一些编辑记录的按钮,每个按钮都有说明。 右下角有一个类似图层按钮的图标,点击进去。有一些高级的操作,很多适用于 ctrl nine 相关的控制。下面大 狂将通过实际作图的过程为大家进行演示,更好的理解这些参数和选项的作用。第二部分软件作图详细过程演示首先,我比较喜欢现实逼真的模型,于是我在 savta 网站上看到 shown in photoreal 比较对位口, 所以把这个一点九九 g 的主模型文件下载下来。随后在软件内导入。同时,图像的风格我喜欢高对比,深色一些,暗掉一些,让整个图片更加的黑酷和冷静。于是我又在 savita 上面发现了 lower。 这款 lower 仅有七十二兆,但是却能让最终生成的图片完全进入我需要的状态。 好了,有了这两款主要的模型文件,我就开始作图了。咒语的描写是有几个常用的语法的,比如圆括号加 权,或者后面加冒号百分比数字来表示权重,或者用中括号来降权等。越是重要的描述词,要越往前面放。咒语的描写有很多工具网站,大家可以去这些网站生成。 我们要生成一张 ailan mask 看火箭发射的图片。选定主模型后,再添加 lower 模型。咒语框内会自动加上 low r a 的出发词 dark film。 使用上述咒语出图的质量不错,但是出现两个马斯克, 所以我就调整一下咒语,在正向描述里新增 only one people, 并增加他的权重。再出图就只有一个人头了。但是我们发现画面中没有火箭,于是再到描述词里单独新增一个 a big rocket, 于是大火箭就出现了。 我逐步的优化调整,画面逐渐趋向于我的意向。再来一张图片,这一次我没有加权重,而且把我暗黑系的 lora 给禁用了。 这一次出来的图片非常自然,而且光线比较明亮,可见 laura 的影响效果还是非常明显的。 马斯克的人脸也是非常像真人的。这就是整个作图的过程,其实很简单,而且出图的质量非常不错。最后非常值得注意的是,作为 apple silicon 芯片的用户,一定要启用 coremel 的开关,这样虽然会转码占用一定的存储空间,但是会充分发挥 new role 真正的效能。 可以观察到跑图的速度会更快。 这就是今天为大家介绍的目前我的核心 ai 绘图工具 draw things。 上述讲解如有不对或不周之处,欢迎大家留言区补充和指证,让我们共同进步。 我是工具狂大狂效率提升专家,欢迎大家关注或订阅工具狂。
 04:01查看AI文稿AI文稿
04:01查看AI文稿AI文稿这个,这个,还有这个都是用 ipad 本地部署 ai 生成出来的图。对,你没听错,就是用 ipad。 首先在 app store 上下载这个 app, 然后打开刚刚下载好的 app, 你 看到这个界面 是不是眼花缭乱了?没关系,我们一个一个说。首先是左边第一个这个模型的选项,点一下下面的禁用,然后它会跳出来一堆推荐使用的官方模型,不用管它,直接点这个管理,然后点导入模型,自己导入一个。这里我使用的是 zefan 大 佬的 illustrator slow 下划线 a, mix 下划线 b, 十点零下载链接在简介里,当然你也可以自己选一个模型导入,不过是不是配我就不知道了。选完模型之后 点这个导入自定义模型,然后是第二个 laura 了,和模型一样,也是需要自己下载的,我推荐上西站去下载 laura, 网址我也放在简介里了。选 laura 的 时候要注意 一定要显示配自己模型的 lara, 还有就是要注意 lora 的 触发词,这里就按照我用的角色 lora 举例,是必战到老四倍,提果营泪的火花 lara。 这个 lora 触发词是 sparky, 就是要在题提示词的时候加上这个触发词,否则 laura 将没有任何效果。当然有的 laura 没有触发词,那就不用管了。如果要使用多个 laura, 请点旁边那个加号,然后说一下 laura 的 权重,根据我的测试,这个 app 里面的八十权重 就对应零点八权重,然后第三个控制嘛,我没用过,具体有什么用我也不知道。接下来是第四的强度, 官方已经解释的很明白了,这里就看过了。然后是第五个种子,如果你要生成图片,就点那个,生成时使用新种子,如果你要重绘,就是要选你想要重绘的那张图片的种子。第六个,图像大小,顾名思义,调整图像大小的, 如果你没有施求,保持默认就行。第七个步数,简单来说就是步数越大,质量越高,步数越小,升图的时间越短。第八个文本指导, 简单理解就是提示词的权重,一般保持默认就行。第九个采样器,这个好像根治模型的不同,采样器也要变,我推荐论文 ai。 好 了,接下来就是提示词了,我是找 ai 写的, 属于没有办法的办法,你们要是有别的办法可以分享一下吗?这里我是先准备好了一套提示词, 先填正面提示词,然后再填负面提示词,接下来点高级,把这个零赋指令关掉,然后点这个开始升图,等待升图完成好了,图片出来了,但是我们会发现 这个手画的很不好,那该怎么办呢?不用慌,看到那个调色盘按钮了吗?点一下,然后选择橡皮擦工具, 把你觉得画都不好的地方擦除掉,然后再选择这个图片的种子,接下来再点一下生成,就可以重绘了,这里就不演示了。好啦,这个教程到此结束,谁会的,小灰毛,可以发发弹幕吗? 最后说一下我为什么有笔记本不用,非要用 ipad 来跑本地 ai, 因为我患有脑瘫,还是生活完全不能自理的那种,所以每次要用笔记本的时候,就只能让父母帮我把笔记本放到床上。然而笔记本还不能直接放到床上,必须要有个东西垫在下面, 就像这样远远不如 ipad 方便,所以我就寻思能不能用 ipad 来代替一些笔记本的工作。想着想着,我就想到了苹果的发布会上经常提到的那个词, ai ai p u ai, 所以 我就信了一信,结果真让我弄成了看在我用语音控制制作这个教程前前后后用了一个月的份上,点点关注点点赞,谢谢了。
24闲鱼王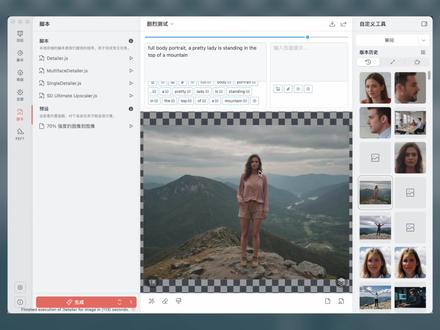 05:33查看AI文稿AI文稿
05:33查看AI文稿AI文稿drains, 一个小脚本轻松搞定面部畸形有了这个脚本,可以让你的每一张人物图都可以拥有一张完美的脸,不管是全身照 还是画面中有多个人物都可以解决,从此告别费脸。 首先我们必须要了解一下 stable defusion 的局限性,那就是生成人物的时候,大头照或者半身照可以很完美,但是全身照以及画面有多个人物时往往很难 hold 住,很大几率你会得到这样的出图结果。 这时候如果你需要一张较好的画面,就需要通过 inpent 模型去用橡皮擦进行局部重绘来修脸了。 在 s d y b o i 里面,你也可以选择通过 a d tailor 等插件来修复。 而在 mac 上的 draw things 社区,有网友就写了一款小脚本,能实现类似 a d tailor 的功能,目前仅限于面部,手部还不行。大狂先为大家演示一下这个脚本的功效, 该脚本目前演化了三个版本,一个是 single detailer, 针对当前画板中的单个人脸进行修复。第二个是 multiface detailer, 可以修复画面中的所有人脸。第三个是 detailer, 是生成图像的过程中直接修复人脸。 我们先看第一个 single detailer, 比如你生成了一张全身照,一个女孩在街道上走路,把面部放大,可以发现这张脸很奇怪, 直接点击脚本,点击 send god detailer 运行,便会自动识别人脸进行修复。 我们来看修复后的结果, 再给大家展示一下另外一个案例。 第二个脚本是应对画面中多个脸的,比如我们生成一张多个人在办公室里面的画面,一不小心生成了五个人五张脸, 不出意外脸部全崩了,个个都是怪兽。 这时候我们点击脚本 multiface detailer, 便开始一张脸一张脸的修复, 最终五张脸全部搞定,画面变得可用, 再给大家测试一个案例。 第三个脚本是直接出图的时候就修复了,我直接给大家演示一下, 比如我们生成一张一个人站在树林里全身照的照片,我们把模型参数以及提示词写好之后,直接点击 dtler 脚本就行。生成的结果可以放心,面部肯定没问题, dtler 就相当于自动执行出图之后的面部修复过程。 有了这三个脚本,全身照,多张脸的不完美问题都可以轻松搞定。最后大狂给大家 简单介绍一下这款脚本的原理,他首先用到了人脸自动识别的技术,随后实现画面自动放大到人脸部分,用一比一的方形画布,因为训练尺寸的画布在人脸的范围内,可以更好的修复人脸。脸部修复使用的是橡皮擦和百分之四十的图声图,并通过蒙版模糊及外沿实现自然过渡, 这些大家可以通过修复过程的参数发现。 那么如何在 draw things 里面导入这三个脚本呢?这三个 j s 脚本文件我放在网盘里面,大家下载之后找到 draw things 的数据目录,目录的具体路径如下, 直接放到 scripts 文件夹里面,重启 draw things 就会显示了,这是比较快捷的方法,如果不嫌麻烦,也可以通过点击脚本 创建,然后把下载的 g s 文件的代码复制粘贴进去也是可行的。 以上就是今天的全部内容了,通过简单的小脚本解决了面部生成的问题。 我是工具狂,挖掘各类优质工具,专注效率提升,欢迎订阅关注不迷路,我们下期再见!





