midjourney IP形象教程

粉丝33.5万获赞243.7万
相关视频
 02:11查看AI文稿AI文稿
02:11查看AI文稿AI文稿这是一个美的珍妮的教程视频,这个视频会带大家学习如何以图深图,并介绍这种质感图标的制作方法。首先我们需要找到合适的参考图,可以在各大素材平台上搜索关键词,比如三 d 毛、玻璃、科技感等等。 将参考图保存到本地,我们之后会用到。接下来进入 majorny 的界面,先点击输入框左侧的加号按钮,再点击上传文件,将刚刚保存的参考图上传并发送。发送成功之后,点击任意一张参考图, 我们可以看到在屏幕左下角有一句提示,在浏览器中打开,点击这句话,并在新的页面复制图片的网址。回到输入框中,用英文输入法打出斜杠,并选择 imagine 指令。这里不明白的同学可以去看我的上一个视频,了解一下没整理的最基础操作。下一步在 promp 指 后面把参考图的网址粘贴进去,注意网址后面要输入英文的逗号和空格,方便之后输入其他关键词,这是我用 major 你生成的图标。我们来解读一下 promp 的写法。首先描述主体,一个表示文件存储的图标, 下面是图标的风格描述,蓝色具有一定毛波力效果,半透明且带有科技感,还要有一些工业感。为了方便抠图,可以将背景设置为白色,同时将光线设置为工作室照明。 最后是建模和渲染相关的指令,比如三 d ccd, blender 之类的,还可以命令画面具有高保真的细节, 如果不约束图片比例默认就是一比一的。我们再来整体看一下写 prompt 的思路,告诉 ai 一我们要的主体是什么?二、我们要的设计风格是什么?三、描述主体的细节质感 四、描述主体的背景和光印。按照这个思路,我们完全还可以轻松的制作出暗色模式的图标,只需要替换一些 promp 即可,比如暗色辉煌配色黑色背景。 发送 pro 之后,我们会得到四张 ai 返回的图片,图片下方的两行指令,不明白的同学请看我上一个视频,里面有详细的描述,所有美追女生成的图片都是可以直接下载保存的,对 ai 绘画感兴趣的小伙伴可以关注我,我会定期分享更多 ai 绘画思路。
5.8万设计师doo 02:27查看AI文稿AI文稿
02:27查看AI文稿AI文稿上一个视频有人好奇这样的人物用 mid jennie 要怎么做?这个视频我就带大家来拆解一下这个案例,看完你也能轻松的做出这样的图。首先来了解一下 mid jennie 最基本的制图原理,简单来说就是人机交互, 人类输入文字作为指令来向 ai 描述我们想要的图片,而 ai 返回给我们相应的图片,结果最终的出图质量与 ai 的理解和计算模型有关。这部分其实普通用户很难控制, 我们能控制的部分是对文字指令的描述,文本越精准,得到的图片就会越符合我们的心意。所以这个视频主要来讲一下文字指令的基础写法和框架。第一个部分客观描述,第二个部分,风格细节。第三个部分,基础设定。 第一部分是对画面元素进行限定,比如谁在哪里,什么时候做什么事,以及是怎么做的。我们 我们可以命令 ai 产出一个可爱的女孩,在森林里,在晚上去探险,而且是跑着步去的,可以把短语组织成完整的句子,或者也可以直接将短语发送出去, 结果都是差不多的。这张图就是 aig 于刚才的简短指令给我返回的图片,我们对照一下关键词,基本上很完美的还原了我想要的元素,而且画风也很不错,甚至已经可以直接用了。而如果我还想要其他的设计风格,就要进入到第二个部分,也就是对画面的风格进行设定, 比如我想要增加三 d 效果,就可以加入相应的关键词,比如三 d 艺术、 csd 等等。与三 d 效果配套的是常用的渲染模式,同时我还想要盲盒的感觉,就添加泡泡玛特关键词。同理,小羊相恩的黏土质感与比克斯风格都是做人偶很好用的关键词。在上一步的基础之上,我们 再把风格关键词加入。这张图是增加了风格指令之后, ai 重新给我返回的图,可以很明显的看到画风上更加有三 d 动画一般的立体感,而且人物的表面也有了一定的黏土质感。最后一部分是一些基础的设定,比如怎么打光,怎么摄影,怎么增加细节质感 后缀,再加上图片比例和没整理的版本,完整的 prompt 就写好了。 最终得到的效果图大致就是这样的。我们可以看到,在追加关键词的过程中, ai 很称职的不断的尽力满足我的需求,所以如果能好好的编写 promp, ai 工具还是比较听话的。如果你觉得这个视频有用,请关注我,第一时间获得更多实用的设计资讯。
6.6万设计师doo 01:12查看AI文稿AI文稿
01:12查看AI文稿AI文稿体验一下 ai 绘画,把我画的我自己变成盲盒形象。要让 ai 画的图跟你的设定完全一样也不是一件容易的事啊。 我试了这么多次,我总结出了三个非常有用的点。第一个就是电图,只用文字描述出来的图会非常的单薄,于是我就电了一张我自己画的图一下,这个图就更像了一些,但是他好像还是不能明白我想要的那个飞行员的帽子。我又电了第二张网图, 再看他这回的帽子,一下就对味了,追加了一下描述,现在帽子更香了。后来我又做了一版,但是他始终抬不起手,于是我就又垫了一张网图, 然后他马上就明白我的意思,把手都抬起来了。第二个超有用的,当你试出几个不错的图之后,一定要用这个 bland 把图放进来,他就会混合两个图,更贴合你的意向。第三个经验就 就是屁,我把这张的帽子扣下来,挪到这上去,微笑的嘴巴,我也要,衣服改成我想要的红色,这张我喜欢的鞋也给他挪过来。行了,这就是我最终想要的成品了。 我又把我画过的另外一个也做成了盲盒,这个做的就跟原型更像了。尝试了两次对比来看,还是挺有进步的, ai 绘画挺好玩。
3.7万画久久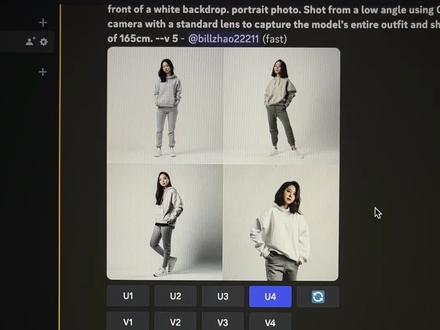 01:29查看AI文稿AI文稿
01:29查看AI文稿AI文稿如何用 ai 绘图生成一个模特,并让他穿上你指定的衣服?给大家看一下最终的效果,是不是可以帮你省掉请模特的成本。这里用到了 me journey 图生图的一些关键技巧,但整个实操并不复杂。 首先任选一件商品,这里以女士卫衣为例,截图保存,然后用 a 绘制一个适合这件衣服的女模特。这里有一个关键点,就在商城时也指定他的上衣为一件任意的卫衣,以便视线换装。 ok, 在 discod 中输入我们的需求,生成一个中国的女模特,穿着卫衣,身高一米六五,白色的背景,指定的相机型号以及拍摄角度,让 ai 来模拟生成。 这里要注意的是使用的 mini journey 最新威武模型,因为一会要用到图胜图的能力,然后 m j 就会帮我们生成好了。四个模特,选择一个我们最满意的, ok, 接下来就是最关键的部分, 这里我们不通过修改提示词或电图的方式来实现换装,而先用 ps 等软件简单处理一下,像这样把衣服移到模特身上就可以。然后再用这张图来进行图生图,把这张图先传到 discod 来获取链接,然后刚已 match, 输入这张图的链接,让 my journey 按照这张图来进行绘制, 之后添加描述,这里注意要完全 copy 生成模特的提示词,最后添加参数。除了指定的 v 五模型外,还需要加入 iw 参数,用来标识生成的图片和我们电图的相似程度。这里的二表示相似度最高。 ok, 放大看下效果,这样我们就实现了模特的换装,你学会了吗?
6.6万小旻说 01:01查看AI文稿AI文稿
01:01查看AI文稿AI文稿超高相似度的弥征令人像变脸来了!上两期分别说到两种人像变装玩法,相似度并不够理想,这一期用 inside face 精准变脸插件解决人像相似度好,直接上测试。首先安装 insi face 插件,选择添加到自己的房间,点击确认,接着授权再验证一下我是人类。 好,这样就把插件添加到自己的房间啦。进入房间看到这行字就表示可以用了,接着输入斜杠 c 位置指令,然后点击上传最拉风的照片,接着在一个内幕后面随意输入个名字,点击确认,可以看到已经创建好 id。 接着可以选择你想变脸的图啦,就例如把这主图变脸,右键点击,然后找点 app, 再点击 inswoper, 好,可以看到已经变脸了,放大看一下,相似度还是蛮高的。当然你也可以选择灯张进行变脸,都是一样的操作,但是 inside face 它就 在 disco 的里面,是没有的,但是可以通过打开链条直接安装,需要链条的评论区留言链条敬抖音粉丝全制,取链条资源就好,这期就分享到这八十八嘞!
5296天牛AI 02:29查看AI文稿AI文稿
02:29查看AI文稿AI文稿今天跟大家分享一下如何制作不同风格的人物头像。做头像这个问题其实最困难的是要和人物保持相似,很多人尝试做自己的头像,但是都不是很像,我研究了一下午,发现了一个比较万能的公式,基本可以保证 百分之八十以上的相似。但是首先有一个前提条件,就是第一个你的原图,你的照片一定要足够近,因为如果一旦距离比较远的话,画面中呈现的内容就会很多,这个时候无论你再怎么样描述,都很难 保持人物是相似的。第二个就是你的清晰度一定要高,最好是用相机拍摄的那种质量。今天我们拿这个启圣来做了一个案例,用到的公式其实只有一个,保持动作、发型、面部表情、服装形状和外表的一致性。 有这一句你也可以直接用我这句中文来翻译成英文来使用,然后再加上我们的风格关键词。 我先做了一个三 d 风格的,这里我们看这张是比较像的,然后我又尝试了这种卡通插画类型的,然后我又换了一个虚幻引擎五风格的,这个也非常像左下角这一张,然后最后试了一个。我个人最喜欢这个新川洋丝的风格,很简单,万能巨石加一个新川洋丝的风格,然后设定一下这个参数, 这个公式加上一个风格是可以做到像,但是如果你要做到质感好的话,需要我们在这个风格下再加一些相关的一些词。比如说单纯的要做这种三 d 风格的,我只要加一个三 d art 或者是 皮克斯风格就可以了,但是配套的我最好给他加上一些三 d 高质量八 kocr 渲染等等的,跟三 d 风格配套的一些提升他质感的一些词,这个就是大家自己去探索发挥,但是如果像的话, 用这个万能趋势基本可以保证。最后跟大家说一下,为什么这个图片的质量非常重要?我在他的官方文档里面看到 ai 作图的原理,他其实是最初形成这样的一个噪声场,我不是很专业,大家也可以把它理解成先出来一个模糊的点,然后我再来慢慢的进行 ai 运算,算的他越来越清晰。 但是呢,当我们的图片质量非常低的时候,我们的像素点就很少,这个时候就像一根用一根很粗的笔来描这个画一样, 他自然就有很多不太像的地方。当你的像素非常高清,他就像用一根很细的笔来画你这个内容,这个时候你 面部有足够大的话,他就会把你的轮廓和你的五官画的非常接近,我个人的理解,所以说,所以说做头像你的图片一定要高清,大家可以自己去尝试一下,在评论区交一下作业。
6236大桶子AI 02:23查看AI文稿AI文稿
02:23查看AI文稿AI文稿那这个图呢,其实不仅有啊,我们想要的卡通形象,而且这个小姑娘呢,也没有版权的问题,他是在网络上独一无二的生成的唯一的一张脸,所以你可以用在产品图片上,博客的配图上,基本上你不需要再去请模特拍产品了。 nice chat, gdp 加上 made journey, 能不能成为跨境卖家的一个大杀器呢?我们今天来实地测试一下。首先呢,我跟我告诉他的一个指令,我想做一个产品包装设计,请你做一个设计师的角色,帮我出一些主意,请问你能听到我的指令吗?如果听到了,你就回我八八八,那我们看他, 哎,他听懂了。 ok, 那我们就要让他帮我们出一些建议了啊,我想做啊,一个啊啊餐盒啊的包装设计,带着苏州的元素啊,有颜色,色调偏啊,黄色,呃,包装盒要求有质感啊,有现代感啊,请做出一些 推荐。好的,它的第一个呢是设计主题。好的,那 madergent 给了我们很好的建议,从印刷工艺,色彩搭配,结构设计,还有一些附加的苏州元素。那其实这个地方写的非常详细,那我们让它从 madergene 的角度去写一些 madergende 的指令,方便我们作图。 ok, 好的,我们看到他给出了很简单的一个指令,那我们接下来让它变成一句话,发给 made jenny 啊,然后同时变成英文,因为 made jenny 对英文的识别度更高一点。 好的,我们把这个指令呢发给我们的 journey 啊,点加号啊,点斜杠,然后呢,点击 imagine promote, 那我们在这个指令里连踢掉刚才的那个指令, 我们发送给 mate 这里,我们可以看看 mate 这里能够给我们生成是不是我们想要的那种图片。好的,那结果跑出来了,我们可以看到他其实做的,呃,做的做的产品啊, 还是非常漂亮的,清新简洁,有现代感,而且带着苏州的元素和文化,色调是偏黄的,基本上满足了我们所有的一个要求。 那我们最近那我们又要设计一个包装,比如说我们想给他一个指令,那这是啊,我们在 chad gp 生成的,想要一个巧克力的啊,一个盒子,带着卡通的形象,那同时带上一个小女孩,带上人物,因为只有有人物才才能有场景和代入感。那 chad gp 给我们非常好的一啊几个案例, 那我们觉得,哎,这个蛮不错,或者这个蛮不错,那我们就可以生成一个大图,那这个图呢,其实不仅有啊,我们想要的卡通形象,而且这个小姑娘呢也没有版权的问题,他是在网络上独一无二的生成的唯一的一张脸,所以你可以用在产品图片上,博客的配图上,基本上你不需要再去请模特拍产品了。
2.3万品牌出海小李总 02:39查看AI文稿AI文稿
02:39查看AI文稿AI文稿大家好,我是老克,最近用上了 mid juni, 配合 stable diffusion 强大的 ctrl nine 插件,可以玩出很多花样。今天的小案例,我们就拿 mid juni 里面出的线稿到 stable diffusion 进行立体化。 这里有几张 mitigoni 生成的卡通动物线稿,不得不说同样的关键词用 mitigoni 出来的效果更加的讨喜,但 mitigioni 的可控性不如 stable defection, 拿它来做起稿还是蛮好的。我们就拿这只卡通变色龙的线稿到 stable defection 里面转散地,在默认的纹身图模块。 先看一下大模型,还是选择我最喜欢的 ref animated 模型外挂。 v a e 选择的是这个。首先加咒语, 先来一段万金油骑手式,把一堆三 d 效果的形容词对叠在一起,然后再加一段卡通造型的描述词,盲盒玩具和迪士尼风格反向提示 还是老三样。再加上一句黑白稿,把宽高改成五幺二乘以七六八,迭代步数三十,生成五批。打开 ctrl net 插件,把线稿图拖进去,打上,启用前面的勾预处理器,选择标准线稿,提取白底黑线反射 后面的模型,选择线条化 line hot 点击生成,可以看到现在生成的图案有光感,但没有色彩。曾经有小伙伴也碰到过类似的情况,那是因为提示尺的问题,对主体的描述不够明确。 我们百米的纠理里面生成卡通角色线稿的描述语,去掉线稿,然后把它拷贝过来,再次点击生成,可以看到 step 选的纹身图,很好的理解了这道描述,并且准确的赋予角色质感。我们选择一张比较满意的,点击发送到图生图模式,打开 ctrl 的插件,把选中的这张图拖再进来,别忘了打开启用预处理器,选择 tire 三 pro 分块重采样后面的模型选择 tire 分块,把输出尺寸调大到七六八乘以一零二四。 打开 artimate s d upscare, 选择从图像尺寸放大放大两倍就可以了。算法选择 r s 跟四 x, 加其他的参数保持默认。点击生成一只三 d 造型的卡通变色龙就完成了。 用同样的方法,我测试了其他的几张线稿图,用这个方法都能够很好的输出富有创造力的图案。 当然先搞三句话,有无数种途径可以达成。 ai 发展实在是太快了,我觉得我们在学习 ai 作图技术的时候,还是要以效率和效果为导向, 因为有些技术没等你掌握,他又已经升级了。有些以前很难完成的东西,现在也变得非常的简单。好了,今天的分享就到这里,我是你们的老朋友,设计师老客,我们下期见。
2.5万设计师老克 01:19查看AI文稿AI文稿
01:19查看AI文稿AI文稿总有不服气的说, major jenny 没有 sd 可控,马上让你看看 major jenny 的可控性怎么样。脚踩 sd 的这是老板发过来的衣服图片, 要做一组童装模特的照片。第一步,把衣服图片拖拽进 mitter 里,先选 discreeper 采集数提示语,分别点描述语下边的一二三四按键,生成四组效果草图。记得要在提示语后面加 c 的数值, 数值可以是任意数字。从四组草图中找到带有人物形象的一组,挑选一张或几张满意的图片,生成大图 一起下载。第二步,生成人物不同的环境。比方说人物要在教室里生成一张教室的图片,然后打开魔法工具,一键去除人物背景和服装背景。然后随便找个拼图软件,把背景、人物、衣服三张图拼在一起,看着差不多就行,不用太过多的修饰。第三步,把 写好的种子图扔进 mage 里,点引位置,把种子图的链接脱下来,复制刚才带有 c 的值的提示语,后面加 aw 空格。二、你看儿童模特就把衣服已经穿好了。 假如你想让模特把帽子也戴上,就在提示语的结尾加 hit。 你看帽子也戴上了,背景配饰都可以随意更换。想学 ai 绘画的可以直接找我交流,也可以在评论区留言。
1.1万礼帽大叔【收徒】 00:53查看AI文稿AI文稿
00:53查看AI文稿AI文稿三十块钱换一个小女孩穿着古装五件的照片,还立刻就要,那只能用 megene 了。先打开 chat gpt, 让 chat gpt 来描述一张小女孩穿着古装五件的照片,然后把描述词复制下来,进入 megene, 后面加上参数发送。爱爱爱 出来了,这张还不错,很可爱,再生成四张。这个好,就这个了,把它生成一个大图。接下来我们输入 severe 的指令,把这个漂亮的小女孩上传到 m j, 然后右键我们生成的这张图片,找到 app, 点击小女孩穿着古装五件的照片就完成了。来看一下最终的成果。
2.4万小A私人定制(教学) 02:43查看AI文稿AI文稿
02:43查看AI文稿AI文稿给大家演示一个 ai 绘画的完整的操作流程,我们用到的是 mi jenni, 点击这里叫妮妮贝塔,你会被邀请加入 mi jeni 的 disco 的社区,我们随便取一个名字, 点击继续。这里需要点击电子邮件进行认证,这里的密码不是邮箱的,是你 disco 的账户密码,点击完成认证账号。下一步我们需要去邮箱里面进行验证,这里咱们点一下验证电子邮箱,这就完成啦。点击继续使用 disco 的,接下来需要验证一下手机 输入国内的就可以。到这一步我们终于进入了 disco 的,点击旁边美娟妮社区,咱们就可以随便找一个房间进去使用 ai 绘画啦。不过的话还是自己建一个比较好,因为这样消息才能看得到。点击左边的加号,新建一个服务器,点击建 自己的,随便选一个,这里可以填,或者可以不填。点击接力。接下来咱们需要把免接内的机器人添加到咱们的服务器里面,点击这里显示成员名单, 找到美娟你的机器人,新增至服务器,选择咱们的服务器。点击继续。这里点击授权 验证一下就 ok 了。咱们回到服务器,看到这里他已经加入进来了,现在咱们用拆了 gpt 翻译一下咱们的需求,随便想一个场景 发送过去,然后我们把这串代码复制一下。这里咱们回到迪斯科的斜杠,呼出预备紧粘贴刚刚那段指令,咱们回车可能稍微等待一下, 可以看到已经出来了,如果你不满意的话,可以点击这里刷新一次,他会再重新生成一次,这时候他已经刷新出来了,现在咱们有两个选择,如果你喜欢其中某一张的话,你选择性能细化, 那这个时候就对应了上面的优一、优二、优三、优四,优一就是细化第一章优二细化第二章优三就是这里,优四就是这里。那下面是什么意思呢?下面的话是进行个扩展,如果你比较喜欢 嗯,左下角这种风格的,你可以点击一下,他会进行一个扩展,可以看一下 提交。好的,他根据 v 三的风格又生成了四张图,如果你喜欢其中哪一张,我还是喜欢第三张的话,咱们就可以点一下右 三,这个的话就是进行个细化,细化已经出来啦,可以看到这些细节已经完善的很不错了,这样的话就是一个完整的 ai 绘画的一个全流程,你学会了吗?
5721喂鱼AI+IP自媒体 01:28查看AI文稿AI文稿
01:28查看AI文稿AI文稿mid jenny 最近又更新了五点二新版本,在输入框内输入设置指令,呼出设置面板,可以看到新版本的入口。相比于上一个五点一版本,五点二版本的成像效果更加清晰和锐利。 同时,当我们正常得到了一组四宫格图片之后,放大任意其中一张。以图二为例,我们会发现五点二版本对于单张大图多出了一些新指令。这些新指令具体是什么意思呢?第一排指令,高变化与微变化,他们都与变化相关。当我们选择轻微变化时,就能基于原图得到一组相似 的四宫格。而当我们选择新功能高变化时,得到的新四宫格之间差异性明显更大,画面更加灵活多变。第二行指令是本次更新的能调整画幅的大小。我们先来看最简单的指令,正方形,这是原图,执行 square 正方形指令能强行改变原图的长宽比,使之成为正方形。将原本没有的左右两侧内容自动补齐。一点五倍画幅和两倍画幅也很好理解,这是原图。当我们选择一点五倍画幅时,画面就能包含更多内容,四周图片的信息自动补齐。 而如果选择两倍画幅,画面能容纳的内容就更多了。随着画幅的增加,主体所占的比重降低,而 四周环境的内容不断增加,这让我们能够更好的调整画面构图。当然,我们还可以手动设置画幅大小,数值区间落在一到二之间。我是设计师 doo, 关注我,获得更多实用一手的设计资讯。
1141设计师doo 03:04查看AI文稿AI文稿
03:04查看AI文稿AI文稿我跟你们说,我用 ai 绘图赚了三千块钱,客户太着急了嘛,没办法才用的 ai。 客户要做一个扇子宣传企业。那首先肯定是选扇子的形状呢,我就选了这个飞仙扇,我觉得造型比较特别,而且也中性,男女通用性人群更多。这些嘛,花的圆的这种都很常见了,这个又太娘了,这个又太复杂了。我这么一说,客户也觉得对,所以我的设计就是 正面背面分两边,巨大的 logo 字写上,先遇到好图在右下角添,背面就是一条龙啊,飞上天,一条鲤鱼在下边, logo 编标题放左边,这样就可以了。 刚开始画图一点都不顺利,这个魔法风格不对,后来我就加入了卡通 style, 又进来了, 然后就有点复古呢。我感觉这个这个方向是对的,但是这个图案画的巨丑,好难看的,都不知道他画的什么,后来也被我发现了吗?这个鲤鱼和龙不要一起画,一起画他就画的乱七八糟的,我就让他单独画龙,你看他就画的漂亮多了吗?主要还是我比较聪明嘛。 但是呢,问题又来了,这龙画的好是好,但是太凶了,这么凶的龙和这么可爱的鱼,他也不配呀, 这怎么看也嫌弃不上啊,搞到这里的时候我都想放弃了,这幅感觉就没戏了。后来我就找到了一个这个图, 然后就让他自己及时控制一下,哎,就出了一大堆的这个关键词,然后我就用这些关键词又都生成了一些其他的图,我就发现这个风格对呢,而且这个鱼也 不用那么写诗,也不用那么可爱,这样就刚刚好,然后我就柔和了这里面的这些乱七八糟的关键词,看见没到这里的时候这个感觉就对了, 我还顺便学习了一下这个水彩的画法,我就学精了,我把龙和鱼分开生成的,你看这风格都很好的嘛,你看这些这个鱼就已经很美的,我也不知道为什么写中文他也能够伸出图来,也是对呢。得到了一条鱼,然后又用这个龙生成了一些其他的龙, 看其他的龙,在这其他的龙里面选择了其中的一个龙,就是这个龙,然后我就两个图,哎哎哎哎,我就呃就披上了,一起,我厉害吧,换到扇子里面去就做出来了嘛。和写下社区,说明他们是搞 美术教育的,所以就在艺术的道路上不断自我超越,终会成功啊。版画风格就是人人都能鱼跃龙门,过儿化脓,非常应景吧。 这个建筑你们猜我是怎么弄出来的?其实呢,就是用同样的关键词,不指定内容,让他自己去画,于是呢,我就获得了这个建筑, 嘻嘻。这下好了, ai 的费用也赚回来了。反正我是想明白了,不会搞 ai 就硬着头皮乱搞乱搞,反正总要搞出来。学会了,六六六,记得点赞,再见。
3.9万谢安妮野生设计师 03:00查看AI文稿AI文稿
03:00查看AI文稿AI文稿哈喽,大家好,这里是好姑娘的 ai 绘画日记,今天要跟大家分享的是如何把真人照片用 majority 做成不同风格的头像。这个教程总共分成了三个小的教程,这一期主要讲的是做三维风格的头像 照片。生成三维风格的头像公式就是真人的照片链接,加上环境氛围的描述,最后加上风格关键词,这样就可以啦。首先我们需要一张真人照片,这个照片可以是你自己的照片,也可以是用 major 那生成的。我们把真人照片上传到 discour 的对话框,点击图片, 然后点击浏览器打开,就能得到这张照片的地址,把地址复制到 imaging prompt, 然后空格,然后输入你想要的环境氛围和风格关键词即可,默认是打开 v 五模型的。首先我想做一张厚涂的色彩比较丰富的油画风头像,我选择了一些关键词,例如厚涂的丙烯插图,油画风的材质, 色彩斑斓的反射。嗯,我希望这个环境是在花园里面有很多花,然后我用了 flower garden, flower decoration 这些词,然后我希望这个人物头像呢是比较亮的,背景是压下去的,所以我用了一个明暗对照的关键词, 我还加了一个 cinema lighting, 让他的光更有氛围感。我选择了油画风里面的一个啊,艺术流派是洛可可,然后让这个,呃,因为这个洛可可艺术跟这个花啊,色彩斑斓啊是比较符合的。把这些关键词呢黏贴在这个照片真人照片的连接的后面, 中间用空格格开,然后就会生成了四张油画风格的头像,嗯,可以看到这个和真人照片还是很像的,而且光影和氛围都很美。如果想要生成的啊风格头像跟真人更像一些, 让 ai 的发挥少一点,我们就把图像的权重提高,也就是后面加上空格两个小杠,然后加 iv, 然后 iv 的值是最高 是二,这样就可以让最后生成的啊头像跟真人照片更像了。 iv 值就是图片权重,他在零点五到二之间,零点五就是跟啊你的照片,呃,更不像一些,二呢,就是跟照片更像一些。 接下来我想要再生成一张更 q 的三 d 头像,所以呢,还是在真人链接后面加空格,然后把后面的关键词更改了就可以了。我把后图油画风相关的关键词改成了三 d c, 四 d, ip character 啊, blender, 豆啊 啊,卡通啊等等这些词,大家也可以选择自己喜欢的一些三 d 头像相关的关键词放在后面,这样生成的图呢,就更 q, 然后更有三 d 动画片的感觉,和真人也是很像的。最后呢,我想尝试生成一张日韩风的厚图的动漫风啊,然后就可以把相关的关 禁词改成日本卡通啊,韩国动画啊之类的词,然后我还加了一个词叫 fly color, 因为我希望颜色更扁平一些,颜色更少一些啊,不要有那么多的 rendering, 然后不,不要那么的厚涂, 然后就生成了很精致的那种日韩漫画风,然后也很像那种养成游戏的插图,还有言情小说的封面,这也挺好玩的。人生中第一次录教程,真的是累死我了,搞了一天嗓子都哑了,下期我们介绍用真人照片生成二次元头像,敬请期待吧!
8168好姑娘的发现分享 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿你手里的命真令为什么总是词不达意?是你表述的不够清楚,还是 ai 自身的问题?这个视频将帮你解决与 mz 沟通的问题,通过这个小工具一步解决深层提示词的问题。赶紧点赞收藏,干货马上奉上!我们以这张看起来十分复杂的剪纸画面为例,在这里输入主体森林中里的月亮剪纸,设计 浅红和深蓝色的背景,然后在风格设置这里添加我们想要的效果。焊整体画风,暗色浪漫的插图,旋转色彩风格,有机雕刻多维依尼。 在这里给画面加上一个柔和的灯光,使整体感觉看起更舒服一些。最后可以把我们对画质的要求添加在属性描述这里,最高画质八 k 高清。如果你不想自己费脑子去想这些词,这里会根据不同的场景给你推荐比较匹配的提示词,到底好不好用,还得你们说了算。 完成之后点这里生成,就能得到一组调理清晰的提示词。将刚生成的提示词保存下来,返回 mj, 在下面输入框里执行姨妈证指令,张贴提示词,然后在最后添加二指令,把你想要的画面比例输入进去即可。 看起来这么复杂的画面,其实制作起来也就这么回事。接下来要做的就是根据出图的效果对提示时进行微调,比如颜色布局等等。想要试试这个小工具的同学们点个关注,免费领取!关注我,每天学点有用的知识!
7581水煮鲁班 01:06查看AI文稿AI文稿
01:06查看AI文稿AI文稿这也许是全网最实用的镜头视角提示词总结,并且同时适用于 stable diffusion 和 meet journey, 让你能随心所欲控制画面构图,创作出有故事性的作品。首先,我们将这些提示词分为景别和角度两大类。第一类,景别是用来控制主体在画面中的大小, 而这与镜头距离远近有关,由近到远依次排序如下,标红的是 s d 常用提示词。其中近景部分展示局部特写,用于强调细节或人物情绪变化。中景部分展示腰部及以上, 能表现主体与环境的关系,也可以表现多人互动场景,叙事性强。远景部分展示人物全部或场景,多用于介绍背景环境、抒情过度等。此外,还有用于展示场景全貌的鸟看镜头,展示微观世界的微距镜头, 凸显画面张力构图的超广角加鱼眼镜头。接着是第二大类角度,水平方向的角度可以分为正面、侧面和背面视角。垂直方向角度可以分为这些,一般默认为水平视角 常用的是仰视和俯视视角。最后,景别加角度就等于取景。比如我第一张是男女主角的中景加测试图,第二张为男主的特写加仰射图,第三张为女主的特写加俯视图。三张串起来就是被壁咚后的对话故事场景。我是橘大,分享更多 ai 干货!
4697橘大AI 03:04查看AI文稿AI文稿
03:04查看AI文稿AI文稿如果你做的图片还停留在这个阶段,经常被人吐槽一眼 ai, 如果你想做出这样或者是这样的,连我都分辨不出来是照片还是 ai 的图片,那么你一定要看完这一期视频。 我通过横纵比较调优得出了目前全网最写实的通用模板,在此与大家分享。我的优化流程总共有四步,接下来我将简单演示一遍我优化的过程。 首先,在此之前我最常用的就是 margin realistic 写诗模型 v 四版本,提示词也只是简单地使用之前的通用模板, 调一下参数,打开高清修复。简单的来跑一张图,可以看出这个阶段还是演 ai 也是大多数人面临的情况。那么接下来我把模型换成最新的 六版本,该模型强化了肌肤感,还强化了人面部的颗粒细节。在此温馨提示,使用该大模型不建议打开面部修复。至于为什么我后面会提点击生成, 可以看出来图片已经有了很大的改善,整个环境和人已经十分真实。来到第二步,把提示词加上超高分辨率照片及真实感,再次点击生成, 可以看到人物的写实感在提示词下真的发挥了作用,所以还是别小瞧了提示词的威力。 来到第三步,换上我费尽心思在 c 站找到的最佳负面提示词 bad pictures 和 negative hand。 这两个东西是 embedding, 需要下载,不能直接使用。如果你实在找不到,那么没关系。在视频简介,我将挂上该视频的大模型和 lora 和 tech。 该作者称这两个负面提 誓词可以起到和其他负面 embedding 一样功效且不改变原模型画风我试了一下,确实是很棒,直接就是把通用的 ai 脸变成了我不太认识的亚洲脸。总之我很满意。来到第四步,也就是让图片实现飞跃的时刻,加上胶片风 lora, 真正的让你的图片变成照片。 我们来看看胶片风 laura 在不同权重下的表现。可以看得出,权重越大,人物的胶片感和真实感更足, 但是人物的肤色也会越黄。同时我还加上了开启面部修复和不开启面部修复的对比图。开了面部修复,面部会像磨了一层皮,不开面部修复就像化了一个浓妆。 有时候如果你喜欢素颜,可以开面部修复。如果你希望面部更加精致,更加有颗粒感,那就不要打开面部修复。接下来 我们换上拍立德 lora 出来的图片,会带有拍立德相机拍出来的风格。从对比图可以看出,该 lora 的权重越高,拍立德的感觉越强,但是人物会扭曲。所以如果你只想要一个更写实的效果,把权重调到零点六左右就足够了。最后 让我们来看看图片在每一次迭代后的变化。 视频到这里就结束了,如果你觉得对你有帮助,记得这次一定感谢观看。
1.3万吾五
