清华开源chatglm部署教程
清华清华他们开源出来的一个新的一个语言模型叫 web g l m。 web g l m 的话呢,它是在 chat gp 呃 chat g l m 的基础上,对这个开放式的网络生开放式的这个问答的这样的一个引擎,它的最大的优势的话呢,就是可以去 自动的根据你这个问题,去互联网上查一些问题,查一些搜索的结果,把这个搜索结果自动的去选择准确的去回答这个用户提出的这种各种各样的开放式的问题。那么这种它这个模型呢? vip g l m 这个模型呢,它的网络还是比较小的,它只有大概一个币,它是一个比较小的这样的一个 网络啊。但是呢,他的那个准确度,他要比一些大模型更加要有优势。我们可以看一下他这个里面也稍微讲了一下,他对比了一下,这个是他们的这个实币的一百亿的这样一个模型叫 web glm, 他要比这个一千多亿的 web gpg 的这个模型要更厉害一点,就是类似还当然他还是没有达到这个人类的这个水平,人类的这个样的一个水平,他已经接近了。他比原来的这些小模型要回答些开放型的问题,这个精准度要大幅提升了。那么我们来看一看他到底是怎么来实现的。那 web g l m 的话呢,它第一部分的话呢,它还是要经过在呃在它的那个基础模型的基础上,它的基础模型应该是 chat g l m, 在 chat g l m 六 b 的这个模型的基础上,再进行了一个微调,微调也是利用了这个, 根据这个问题,然后在互联网上找到各种各样的这个 web 页面的,根据这个呃答案进行微调。这个是第一部分, 微调完了之后,他还有一部分是比较重要的,那么他就根据这个 web g l m 这个 q a 的这样的一个数据集,他会回答一些问题。那么 web g l m 的话呢,他也会一些答案。然后呢,他也会根据这个人类的这个 偏好,他会选择选择一个人类最喜欢的这样的一个答案。这个有点像那个呃这个人类反馈强化学习的这部分啊,就昂烂的 qa 的这个论坛,让用户的不喜欢去选择这些答案,到底哪个答案是用户最喜欢的,他是通过这种方式 来做的。这个叫排序获取,这个叫产生内容。产生内容之后,他在排序他经过这个三部分之后生成的 web g l m 的这样的一个模型。这个模型它是可以自动的 到互联网上,他其实是联网的,他可以自动的到互联网上去获取一些搜索的一些结果。他这个搜索结果他也是用了一个商业公司的一个解决方案,他也也 需要用他的这个 api 的话呢,就是类似于你提供一些关键词,然后到 google 上面去搜索,然后返回一些搜索结果。他等于是这样的,他要把这个两个结合,那结合起来之后,他这个模型回答出来的这个问题就会比较。 那么他他的准确度达到什么程度呢?我们可以看看他的一些实验的这个数据,这个是他的一些实验数据,目前看下来的话呢,就是 w g l m 的话呢,还是比较有优势的,他相对来讲准确度啊,错误率都是有一定的优势。这个是他那个公布的跟个 g p d 三杠 腰起五臂这样的一个对比的一些结果啊。如果是一些开放型的自然问题,那么它的准确度要达到百分之六十点八,但是 g p d 三的话百分之三十左右,百分之二十九点九。我也把一些相关的问题呢, g g p d 三是达到了百分之 四十一点五,那么 webglm 的话达到了百分之六十三点五。这个属于他还是如果一百分来算的话,他还是属于处于这个平均线之上的,所以他比七的 g 第三的这个版本 性能要更好的。而且他又是一个很小的实币的这样一个模型,所以他消耗的他的准确度又比他翻了将近一倍啊。所以这个就是他的带来的贡献和价值。做 一些开放性问题,他还是回答这些问题的话还是有些价值的,他等于是这样。我们还是可以看看他这个里面的一些原理。虽然我们看到这个 gp 三的他吃了互联网上的所有的这些数据,他几乎把互联网里面的大部分的数据都都吸收了,但是沉淀为他这个网络里面的这个数据。但是为什么 他在回答一些问题的时候,没有通过这个外部的搜索把这些知识点夹杂呃放在这个 context 里面。 我们昨天讲的叫 rag 的这样的一个模型的提示工程里面也有一种技术检索增强产生的这种内容。为什么他没有这种方式产生的回答出来这个问题更好 的核心主要还是就是说我觉得 pp 三里面的这个数据太多了,太庞杂了。那么也有一些东西是干扰你这个问题的回答的,所以他是有这样一个问题的。但是如果你把它通过精准的搜索,能够 搜索到跟你这个问题比较最相关的一些上下文的这些内容和信息,通过这些内容和信息进一步的去增强 你回答这个问题的这个能力。我们通过各种各样的技术和报告就会发现,他的确实要比你这个纯的 l l m 的这个大模型回答出来的更准。小模型可以战胜大模型,他的基本原理在这。所以如果是要做一些 开放性的问题,它的 web g l m 的这种方式中,呃也是一种不错的一种方式。它等于是呃,你可以看到它需要的是增加这个 key, 这个 k 要收费的。这个 k 它要去 google 这边,要去搜索这个关键词,得到相应的一些 web 的文档,我把它把这个 web 的文档要 要加进来,作为一个 context 的上下文的一些内容,再进行回答这些问题,他是这么来做的。所以这个模型其实对我们来讲也是有。当然他你也是可以立刻马上就要用的这个 web g l m 你可以把它做 有一个开放性的问题,可以马上来使用这个东西也是可以的。当然它这个模型有一个不好的地方,它它它的 a p i 是斜死的,它必须要通过这个 web 的这样的一个必须依赖于这个工具,它才能搜索到互联网上面的这个数据。它不像最近的欧本 ai 开放的这个直接开放出来的是这个欧本 a p i, 那么他这样的话呢,灵活度会更高。其实我建议他后面他这个模型可以往 open 的 ai 这个方向再靠一点,他直接是可以让的 这个 vivo g l m 它可以去对接开放的这些接口啊,然后通过这些接口才能拿到一些内容,再混合起来去用,回答一些问题,通过这种方式,它这个模型会更加灵活。好吧 好。今天这个项目 vip glm 清华开园的这样,最近刚刚开园的这样的一个模型,我就跟大家就介绍到这。因为现在的知识库的这样的一个知识问答的这样的一些,基于 vip 开放问答的这样 一些应用场景就非常广泛,所以他们清华这边也开放出来的这样的一个专用的一些小模型,那么他的能力也非常强,准确率也非常高,他不比,甚至要比大模型更强。好吧好。那就聊到。

粉丝4.6万获赞34.0万
相关视频
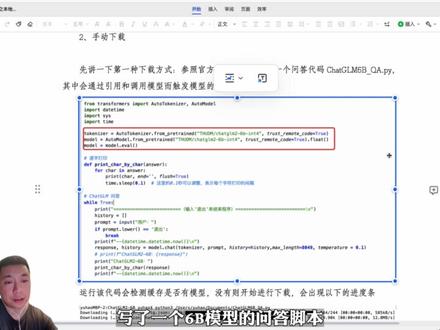 02:31查看AI文稿AI文稿
02:31查看AI文稿AI文稿清华发布的 chat jm 第二代模型是否比 gpt 四还要厉害?是否可以断网运行?粉丝小伙伴一直有问到这些问题,我准备接下来换点时间,通过几期实测分享来回答这些疑问。 cat g m 六 b 是清华大学 k e g 实验室今年发布的黑本地部署大约模型,六月底推出了六 b 的第二代版本, 有着更长的上下文和更高效的推理能力。今天先分享如何不输安装 chat j m 二、六 b 模型,并用模型完成简单问答。目前在基站有完整的安装攻略,在 先安装项目仓库到电脑上,然后执行这条指令,安装相关医疗文件。执行完以后就可以下载六 b 模型了,通过手机运行调试代码就可以自动下载,比较简单。我参考官方设立写了一个六 b 模型的问答教本,其中会通过引用和调用六 b 模型来触发模型的下载动作。这里 要特别讲一个问题,所有的本地大约模型的推理对内存 g p u c p u 的要求都比较高,六 b 也是一样的道理,你的电脑配置不行, 那推理会特别慢,待会会给你们看我电脑的运行效果。小伙伴需要根据自己的电脑配置,在六倍模型加载代码进行相应的初始化设置,需要根据有没有 gpu 显存和内存的大小进行不同的初始化, 甚至因为没有独显和内存过小,我们只能用炼化后的模型。我这里根据官方的提示,整理了五种不同电脑硬件配置对应的模型加载蛋白段,大家可以暂停看看 继续运行概念码会检测是否本地已下载模型,没有则开始下载,会出现以下的进度条。溜冰模型总共会有七个变味键,因为是从 honky face 下载,可能会因为网络产生中断,比如这样重新执行交款会继续断点下载。这里还是比较人性化的 模型,下载完以后,脚板就可以进行提问了。这个是小伙伴可以打开 cpu 和内存的占用率监测,可以看到占用率基本都会百分之百拿满,反正我的电脑是这样。我先让六倍进行自我介绍,为了直观看到问答的问题间隔,我加了时间显示, 简单的问答基本都要三到四分钟。再问一个需要思考的问题,比如如何学习 ai 知识, a few moments later, 直接等了十多分钟, 哎,该换电脑。对了,官方的代码仓库提供 gradu 界面的网页版代码,执行这条视频就可以打开网页。 从简单的问答来看,因为我这个破电脑的限制,回答的速度肯定没有 gpt 是快,这也是本地模型和云端模型不同的效果,不过对于推理的准确性,我还要再仔细研究对比一下。大家可以持续关注,希望今天的安装教程对大家有帮助,有用的话记得点赞收藏。
416暴躁哐哐 02:24查看AI文稿AI文稿
02:24查看AI文稿AI文稿超越 taggbt 四点零的中文理解能力, chitgmm 二正式开源公布,这是一款由清华大学出品的 ai 大语言模型,直接部署到本地就可轻松运行,而且对配置要求在逐渐降低,增加了逻辑思维和语言理解能力。接下来大家跟老张快速的体验一下。 首先我们打开对应的一件包,在这个一件包当中呢,咱们会拿到以下这四个对应的内容。首先咱们先说安装包,安装包是本次运行必备的环境之一,必须要把它先进行安装一次, 安装成功以后,咱们接下来需要先把这个一键安装包,对应的工具就是咱们说的一键启动器,把它解压出来,解压出来在这就是对应的这样的一个效果啊,有一个快速启动咱们可以看到,然后这个解压出来之后,紧接着第二步咱们需要做的就是把 把这两个对应的模型也就解压出来,这个模型是咱们今天的主角 chin gm 二,号称可以和 chintpp 四点零掰手腕的国产 ai 模型,这一款呢是我们程序儿界啊非常好用的专门写程序的代码模型,今天老张就不做演示了,如果你需要,你可以把它给下载下来, 然后解压出这款内容。之后呢,咱们把解压出来,他是一个对应的文件夹,咱们把这个文件夹复制,然后放到咱们当前的一键包中, 找到这个 models 文件夹,把它直接粘贴过来,这样的话就可以在一键启动器上找到咱们的 check gml 二对应的这个 an 模型, 找到之后呢,咱们可以直接在这选择快速启动好,然后在这选择对应的模型,因为咱们我这呢有两个模型,咱们要的是这个,对吧?拆个 gm 二杠六 b, 然后这款模型启动完成之后呢,咱们首先先根据您 的显卡来进行选择,比方说老张是八 g 闪存的,我就选择这一项,如果您是四 g 闪存,直接选择下一项就可以了,对吧?根据您对应的内容来进行调试, 可能首次加载他的时间会非常的长,咱们可以稍作等待,如果说他出现了一些报复原因,你一定要检查是不是你电脑显存不扣导致报显存等相关问题。好的,当咱们进行重新之后,你可以看到有一个编个地址栏,可以把这个地址复制,直接就可以打开了,这个就是咱们对应的模型选择, 咱们可以在哪呢?可以在这个模型选项中进行看,对吧?这是咱们这个模型,这是没问题的。好,然后咱们这是文本驱动器,在这就可以直接进行对应的应用效果呢?如果您的电脑配置够好,效果还是非常不错的,但是如果电脑配置一般的兄弟们可能要稍微的差一点。
2896程序员老张(AI教学) 03:32查看AI文稿AI文稿
03:32查看AI文稿AI文稿不用联网,不用付费,家用显卡即可部署全代码开源的大语言模型 chat j l m 三就在本周发布了,本期视频提供 chat j l m 三全网最简单的一键部署包,解压后即可一键运行,无需联网,无需配置六 g b 以上的显存,即可流畅使用, 还不受任何约束的随意微调,再也不受 open ai 这类 gpd 厂商的限制了。我们的主角 chat jlm 三是由清华大学智普 ai 团队在本周刚刚发布的最新最强的开源大语言模型, 短短几天已经霸榜 get up, 获得了四千家的 star。 官方在八个中英文典型数据集上进行了性能测试,所有指标对比二代模型已有大幅提升,已经超越市面上所有百亿参数以下的大模 模型,在轻量级的大语言模型中遥遥领先。宇同行部署之前,我先介绍一下电脑的运行环境,我们的电脑必须拥有一个六 gb 以上现存的银微点显卡,虽然此模型可以使用 cpu 运行,但是效果非常的不好,下面我们开始介绍部署方式。 首先第一步,打开 invidia g force experience 控制面板,点击驱动程序,这里找到 n 卡最新版的驱动程序,点击下载并且安装就可以了。我们进行第二步下载扩大,我们进入这个网址,这个网址可以在本期视频的专栏里找到,这里找到我们对应的操作系统,这里我选择 windows x 八六架构,然后选择我的 windows 版本 windows 十一,点击 e x e 安装包这里直接点击下载就可以了,下载好以后我们进行安装,然后 这一步就结束了,我们升级好 n 卡驱动,并且安装完扩大以后就要对电脑进行重启,重启完毕以后进入命令提示服,对刚才的安装进行验证,输入这个命令 in vdr 杠 smi, 这里显示我的扩大版本是十二点三, 如果想让模型运行取得一个比较好的效果的话,我推荐十二版本以上。好,我们进行下一步 下载好本爬爬虾提供的这个一键部署包,我已经将这个安装包打包并且上传到网盘了,需要下载地址的话,可以三连后加关注私信我,我们将这个安装包解压好, 解压好以后得到一个这样的目录结构,有三个文件,我们直接点击这个运行脚本,可以看到它自动开启了一个浏览器的窗口,这里显示模型正在加载, 需要耐心等待一段时间。模型加载好以后,这里显示出了我的显存大小,由于我使用的是一个笔记本,这里是三零六零的显卡,所以说只有六 gb 大小的现存。这里使用量化 inter 四版本进行运行,我们跟他对话一下,看一下效果。 这里官方提供了三个主要界面,一个是普通对话,第二个是 tools, 这里就可以接入各种第三方工具,比如说查询天气啊,查询股票这种功能。 第三个是 code interpreter, 这个是增强了他的代码功能,也就是说输出代码的一些功能。如果本期视频点赞超过两千,大家对这一块功能感兴趣的话,我会专门出一期视频来 讲一讲。这里是技术爬爬虾,我会定期分享一些有趣实用的编程项目,分享一些提升效率的黑科技软件。今天的视频就到这里,感谢大家,我们下期再见。
506技术爬爬虾 03:12查看AI文稿AI文稿
03:12查看AI文稿AI文稿今天给大家分享乐凯和 chat glm 搭建本地知识库项目,该项目是由清华大学发起并已开园,这是我配置好的整合包。先给大家演示一下效果,点击脚本启动微博语, 启动完成就能看到使用界面,页面右边可以切换对话模式,选择知识库模式,可以在这里新建知识库,也可以选择之前建立的知识库,随便选择一个之前创建好的知识库, 可以在这里随时加载保存文件,只需要把文件拖进去就可以了。 这是我下载的关于 transformer 的 pdf, 一共十七 m b 两百八十四页,拖进去保存一下, 加载完成了。然后我们问一个 pdf 里的问题,测试一下回答质量, 回答的好像还可以,并且给出了出处, 出处也是比较准确。 接下来讲解一下该项目的基本原理和流程。该项目整体使用 lancan 作为应用框架, lancan 支持自定义链式调用, 可以将自定义工具和各种模型结合起来,开发出不同应用。该本地知识库项目是将向量数据库和 chat g m m 模型结合起来。首先就是加载文档并读取文本, 然后对读取的文本进行分割处理,得到一段一段的文本数据,接着将这些文本进行商量化处理,并存入本地史量数据库中, 此时我们的文档数据都已保存在数据库里了,这些数据将会在问答过程中被楞看调用,并经过大语言模型生成生成最终回复。接下来我们一起看一下问答过程的基本流程。首先会将用户的提问信息进行向量 画,得到向量化文本。接着进行数据库查询,得到相似度最高的前几条数据。 最后将匹配出的文本作为上下文和问题一起添加到 prof 中,并提交给 l l m 生成回答。这样我们就得到想要的答案了。我们的模型可以是 track g l m, 当然也可以是 lama 或者自己训练好的。其他模型都可以 通过来看进行集成,做出各种各样的应用。本期视频到这里结束了,大家有什么问题可以在评论区留言,我都会一一解答,再见!
240pickkkiy 02:25查看AI文稿AI文稿
02:25查看AI文稿AI文稿今天我们运用清华大学叉 g l m 开源模型搭建完全自有的叉 g p t, 一杯咖啡的时间即可完成。在代码网站我们可以看到此模型运行需要最低显存为六 g。 安装过程需要用到 gig, python 和 peterk, 先到网站下载 gig, 下载之后一直点下一步安装就行了, 然后保证你能够访问 get, 复制这个 g 命令,粘贴到命令行,这是已经下好了。然后我们 cd 进入文件夹,接着我们要安装棉的 com, 里面包含了拍葬在简介中的网址,下载就好了,也是直接安装,安装的时候要选择添加到 p t h。 接着我们还需要安装拍 torch, 我们到官网复制命令,这里如果没有 p p 三的话就改成 p p, 然后等待下载就可以了, 如果慢的话可以百度一些 pip, 更改国内镜像。接下来我们要安装叉特隆需要的包, 然后再安装硅 do 包显示网页,这样我们的环境就配置好了。接着我们需要修改一些 webdaino 派参数,才能在六 g 显存上跑,这里的 cash 填点就不会下模型到 c 盘,然后矿台子会四倍量化,节省显存。 接着就是漫长的下载,模型一共有十六 g, 如果中间出错了,就需要删掉没下完的文件重新下载,具体下了哪些文件可以对比赫根菲斯仓库, 然后就会开始加载模型也是很慢,请确保你有足够的内存和显存用于加载,建议十六 g 内存八 g 显存。以上让我们直接跳到结尾,发现加载完八个模型,我们可以打开任务管理, 监控他的执行,可以从任务管理器里面看到,开始吃显存就是可以了。然后我们打开一二七点零点零点一比七八六零,就可以看到叉 glm 的界面,跟他打个招呼吧, 这样你就自己搭建了一个私有的叉 g p t 了,可以随时随地的放心使用。下面是构建好的叉 g p t, 我们一起来看看吧。 当然你可以将它应用到各个领域,例如编程、股票、大数据,办公等等,你还可以用它来写剧本杀,当做搜索引擎工具。本期视频就到这里,关注我,每天学习新知识。
23创新Bar 07:26查看AI文稿AI文稿
07:26查看AI文稿AI文稿刚给大家演示一下那个 chat glm 的一些功能啊,一些他这个模型的一些基础功能啊,我主要是演示以下这几几个方面啊,主要是一个自我认知啊。写,呃,提纲写作,文案写作,然后邮件写作,然后他也可以做一些角色扮演啊, 然后也可以做些呃这个评价的比较啊,然后还可以做一些本地知识库的一些问答啊,然后我就给大家演示一下啊, 先我们看一下他那个 cat g a m 的那个自我认知啊,界面打开之后的话,选择这个 l l m 的话呢,主要是这个机器人对话啊,这个知识库问答的话呢,就是利用本地的这个知知,知识库就加载这个知识库可以进行问答,他等于是这样我可以看一下。 对,我先问你是谁啊?你好你是谁,他就会比较好的回答, 介绍一下你的优缺点啊, 强大的对话功能,灵活的知识库,友好的界面设计,实时的更新他主要的缺点。 好,我让他帮我写一个培训的提纲。 这个是什么东西啊?啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧啧。 然后我让他写一篇新闻稿新闻稿, 然后我让他写个邮件, 再让他写一个视频的脚本 角色扮演。角色扮演就是他是以比如说是一个那个新闻工作者的这个角度去报道, 他也可以对 这些东西进行比较。 最后一个我们来看一下 这个是不基于这个知识库的这种回答, 我们看看 g 知识库的回答, 基知识库回答的话呢,其他先在本地知识库里面去寻找跟这个问题最相关的一些文文档,然后再根据文档的这些内容,加上那个 l l m 的这样的一个文字逻辑的这个能力,然后再回答。 那么基本地知识库的回答的话,相对来讲它它会更加精准,更加基于这个企业的这样的一个 内容啊,回答出来的问题的话呢,就会更加准确一点,然后如果不记知识库的话,你可以看到就是他回答出来的东西比较通用啊,比较 宽放,他等于是这样啊,所以,呃,各有各的优势啊,如果在企业内部应用,如果你要准确回答一些问题的话呢,你还是要给他一些,呃,支持他,等于是这样给他一些内容啊。 好,这个就是恰特 glm 杠六 b 目前能做到的一个能力啊。他目前的话呢,我看他十五号也更新了一个新的版本啊。呃,一点一这个版本啊, 他这个一点一版本的话呢,据说是主要更新是因为他平衡中文和英文之间的这个翻译的问题,但是我看他好像这个 bug 没解决,上述内容翻译成专业英语, 因为我看到他的那个中英文还是还是在乎 还是有这个中英文混的这样的一个问题,当然比原来会好一点,比那个一一点零版本会好好好一些的这个,但是他那个英文还是有些问题,他这个可能跟他的那个 chat g l m 里面的那个编码规则是有关系的。嗯, 可能他是中英文混编的,会导致这个中中文和英文之间相互创客,他存在这样的一个问题。好啊好,今天的话就跟大家就演示到这了。
516小工蚁 01:47查看AI文稿AI文稿
01:47查看AI文稿AI文稿还是 chat glm 二代的那个模型。嗯,已经发布了。然后我自己在机器上跑了一下,完全都是可以正常跑的。然后原来的那个 api 的话也不用改,我看他原来跟原来的那些都是兼容的,只要模型升级一下,原来的应用几乎就不用动就可以跑了。 它的整个一个模型,我自己看了一下,它下载下来大概有十几张,十几个 g, 一共有七个大的文件,一共有七个, 六个文件的,每个文件大概在两 g 左右。还有一个第七个文件,大概是在一个 g 左右。那么还有一个呢,就是 token size 的一个 model, 大概是在十兆左右。差不多啊,这个构成的加在一起大概就十几 g。 这个模型。这个模型我目前本机上跑下来,看上去还效果还可以,给大家演示一下。看一下,问一些问题,介绍一下中国古代经济学家还出来的这个字 速,速度还挺快的。还有一个让他翻一个阴影虫看一下,那么很明显他目前的这个就是 token 已经增加到了这个八 k, 他等于是这样。这个地方爆串啊,为什么? 看看网络的问题,他字出来的话,我感觉还挺快的。让他对比一下这两个翻译。我看了一下他的整个一个内存的消耗, gpu 的消耗也跟原来差不多,大概在十二个 gb 左右。因为我现在用的是哈弗的三十二位十十六位半半精度的。这样的一个模型。 跟原来差不多。我看了一下, gpu 应该跑到百分之五十,应该比原来好像更快一点。感觉内存的话大概是在十几个 g, 二十个 g 峰值是在二十个 g 之内,峰值在二十二个 g。 二十三个 g 就是内存比较 多一些的,但 gpu 的消耗我看还是跟原来差不多,没有太大的变化。好,这个就跟大家就演示到这。
248小工蚁 05:27查看AI文稿AI文稿
05:27查看AI文稿AI文稿亲爱的, gbt 平替版直接安装到你的电脑,让你打造属于自己的人工智能 ai 哦, 今天老张给大家推荐由清华开源的 chat g m l 直接一键部署到你的电脑上,由你自己来进行开发,进行使用,任意调教,任意搭配,可以轻松实现人工智能兑换,而且无需科学,无需模仿。接下来大家跟老张一起来看一下, 来咱们先一起体验一下这个 chat gml 啊,他究竟有多么的强大,因为呢, chat gpt 很多人是无法访问的,但是这款 ai 啊,虽然他现在模型较小,但是绝对是现在够你用的,咱们可以来测试一下,比方说你好让他发送, 他会给咱们进行一个对话过来响应速度跟咱们的电脑配置有一定的关系,大家看到了吗?他来了,然后当他说简单做一个自我介绍 好走你速度啊,可能稍微慢一点,但是他呢,会慢慢的提示,慢慢的调教,你想把它打造成什么,他都可以去做,我看现在很多人网上说打造什么猫娘什么,我也听不懂, 但是咱们这个就是他会根据你所提问的一些环境,提问的一些方法,打造属于你自己的人工智能 ai。 大家可以看到啊,这个自我介绍已经出现了,他呢是由清华大学开发的,所以说功能呢,对标基本上是一个小的闻心音研, 目前呢,目标是打造成 chitgpt 三点五的一种模式,所以大家可以完全放心使用。接下来老张教大家如何把它搭建到您自己的电脑上,进行自己的调教吧。 咱们来看一下啊,目前呢这个位置啊有三个包啊,就是这个三个压缩包,咱们需要把这个三个压缩包呢都下载到您 自己的电脑上,然后这三个压缩包的大小呢,非常的大啊,他起码得有三十个 g 左右,所以大家一定要找一个可以运行的网盘,千万别放到 c 盘里啊,这 c 盘直接给你干满。然后呢咱们首先第一步把这个压缩包,就是这个 check gm l 杠 ybgy, 把它解压出来,放到这个位置。 好,放到这个位置之后,咱们接下来再分别解析 model 和环境包,然后大家需要注意的是这两个包在哪去解压呢?把他们两个同时的放入这个外边 ui 这个文件夹里,然后呢给他比方说咱们给他拽进来,然后在这右键把它解压到这个位置, 解压到当前文件夹,然后呢您会在这个地方产生一个叫做 model 的文件夹出来,然后这个呢咱们就可以拿出去了。好,同样的道理,环境包也是一样,把它先放进来, 然后右键直接解压,到时候会产生一个叫做 p y 三幺零加 get 啊,产生两个这个内容。所以说大家到时候呢你直接看一下目录,跟我这个一样,就是没有任何问题的, 是不是很简单啊?然后接下来要做的事就是根据您自己电脑的显存,就是您的显卡配置,我这呢是八 g 显存,所以说我在这双击打开这个位置,我给大家双击打开一下,大家来看一下,我把这个先关掉啊,先关掉,这是我之前开过的, 好,把这个关掉,直接双击打开,打开过程中啊,他会下载安装一些东西,大家不用着急啊,咱们可以稍微的等一会,等他把这个地方跑完,我给大家来看一下什么情况啊?当然如果说您的显卡呢,比方说是八 g 以下,或者说你想用这个 cpu 运行都 可以有对应的选项,如果电脑配置极好,十二 g 以上的用这个就更加哇塞了啊,大家稍微等一下,看这个等他跑出来啊, 好的,大家可以看到啊,如果他当前这个位置呢,给咱们一个润运行中,大家可以看一下这是运行中,然后告诉咱们一个地址,就证明你这个项目是跑起来的。如果大家看到这爆了错误,也不用担心,咱们只需要安装一个软件就可以解决。老张给大家都准备好了 这个哭的软件啊,就是咱们说加一个哭的,就可以成功的解决你的问题,然后他的安装方法呢,也非常的简单,大家跟着我来过一遍,因为我这已经安装过了,所以说我这边呢,再稍微给大家跑一下, 有一个非常重要的选项,我需要给大家做一个提醒。好,然后咱们看到这选择同意并安装,然后选择自定义,千万不要是精简啊,自定义,然后 下一步,然后大家找到第一个 call 的选项中,打开有一个这个 vs 开头的,对吧? vs 开头的把它取消掉,剩下的就没有什么需要注意的了啊,把这个取消, 也就是你点开以后的第三个取消掉,剩下下一步就可以了,因为我已经安装过了,所以说我不给大家再演示安装了,你注意事项告诉你,剩下就下一步就 ok 了, 安装完成以后,你再次重新运行,你就会发现很神奇的就跑起来了,跑起来之后呢,咱们就可以在这个位置一刷新,你会发现你的人工智能就已经成功了,然后你想让他问什么,当然他默认说英语啊,你到时候你跟他说一声,让他说中文啊,他就会说中文。咱们来一个比方说,哎,行,写, 请介绍一下你自己吧,一下你自己,对吧?就跟哎咱们开始演示的是一样的啊,所以说这款人工智能 ai 真的是非常的好用啊,而且呢部署到本地无用,不用你打开什么对应的工具,自己无限玩无限用,而且还会根据你的这个使用习惯来给你进行一些对应的一个调整,定制化的 ai, 而且还有很多的调教指令,后续老人当然会给大家陆续更新啊。 好的,这里是程雪老张定期分享互联网知识以及好用的软件推荐,希望大家多多关注,想要领取的可以加入老张的粉丝群。
1525程序员老张(AI教学) 02:06查看AI文稿AI文稿
02:06查看AI文稿AI文稿今天听说清华大学的国产大语言模型 check glm 六比开元公测了,迫不及待的下载部署,简单体验了一下,回答速度挺快的。我觉得最大的优点是可以本地部署,对配置要求也不高,只需要七 gb 的现存即可。 不过由于规模较小,只有六十二亿参数,而叉 g p t 是一千三百亿个参数,还是差了好几个数量级。 正如他官网所说,还是有相当多的局限性,比如事实性、数学逻辑错误、可能生成有害、有偏见、内容 较弱的上下文能力等。这是官方博客上的发展路线图,可以看出目前还是迭代了好几个版本了。以下是我这次的对话体验,除了我打字部分做了加速处理,他回答的部分都是元素。播放。 好了,这就是今天视频的全部内容了,如果你也想体验一下,但又觉得官方的部署工作很麻烦的话,可以在视频下方留言,给大家准备了懒人安装包。
51Neo.me 01:40查看AI文稿AI文稿
01:40查看AI文稿AI文稿csgvt 问世已经有一年,相信有很多朋友想要体验,却被无形的墙给挡住了,或者是各种的延迟封号等原因,用起来就很不顺心。那么就在几天前开源了一个号称一百亿数据以下的最强模型, 除了正常的多轮对话以外,同时支持工具的调用,代码的执行,最关键的是他在一般的电脑也是可以运行的, 显卡有六 g 就可以了,为了方便新的朋友,我也整合好了解压机用,然后这是缺了。 glm 三有提供了三个交互界面,其实他们的功能都是一样的,只是界面的样式不同而已, 随便打开一个就可以了。要打开以后,他会先加载模型,然后会显示你的显卡的型号,并且会自动帮你调整成适合你显卡的模式来运行。要进入界面以后就可以正常的输入聊天了。这里我讲一下大语言模型对话的一些小技巧。 就像左侧这些参数,我们不知道他是干什么的,如果此时我们直接复制给他,他是回答不了任何东西的,因为他根本不知道你想要的是什么,就像你和你妈说话是吧,你不可能说 top t 零点零零,一点零零 t e m 就你妈都以为他生了个智障,就显然是不行的。我们要明确你的问题,你可以这样问我在 check g l m 三里面看到的这些参数是代表什么,然后再把刚才的复制给他,那么他现在就能回答出来了,然后他还可以调用一些工具来辅 注回答,例如我问他现在广东的天气怎么样,然后他就会调用一些工具来获取最新的信息,从而进行更精确的回答。所以说 ai 大模型对我们学 学习和生活里面带来很多的便利。我现在打开电脑第一件事就是打开这些大圆模型,有什么不懂的,有什么不明白的直接就问他就完了。那么需要工具的朋友可以直接进群免费获取。
148阿硕讲ai 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿基于 u x e 和国产大模型 check g l m 六必实现基于本地知识库的自动问答,代码开源,可离线部署,也可以在线体验,欢迎 skar。 下面介绍在摩达社区在线体验本地知识库的自动问答。 首先我们选择 combating model, 然后上传本地知识库。我们支持 markdown 格式、 word 格式和计时本格式。这里以 check glm 六 b 的 liam 蜜为例, 我们上传下面有几个参数可供选择,包括 top, p, tab, pressure 等。然后我们在输入框中输入我们的问题, 然后回车或者 点击发送,稍等返回出结果,浏览一下, 效果还是很不错滴。当然项目还有很大的优化空间,欢迎大家进入地址关注并参与。
207左右不是人 07:38查看AI文稿AI文稿
07:38查看AI文稿AI文稿中国,中国开源的类似于这个 chat g p t 的这样的一个模型,它是中英文双语的一个对话语言的这样的一个模型,这个给大家一起来介绍一下。那么这个项目它是 给大家看一下这个项目的话呢?他也是昨天,昨天在 gap 上面就是开源出来了啊这个项目,这个项目是我看了一下,他是中国人拔的清华系的一家公司做的这样一个项目,他也把它开源在 gap 上面,整个一个模型是六十二亿的这个参数, 我也在我的机器上安装了一下,也可以跑一跑,他对那个中文他会比较友好一一一些,他是这样的,那么安装,呃,也是比较简单的,主要你根据他的这个 redmi 的这样的一个说说明,你就去安装。而他但他我自己看了一下,他必须要要 windows 或者是 linux, 它在苹果电脑上是不支持的,在我自己苹果电脑上装是失败的,所以我就找了一台 linux 的机器去装, 它是可以成功跑起来的。那么它也是由网页版和所谓的这个就是命令行的这个版本,我跑的是这个命令行的这些版本,这个项目它也是如果不用 cpu 它也是可以的,我看它这个文档上也可以讲的,它就是用 cpu 去部署, 只要那个十六 gb 的内存就可以了,但是他会推理的话,他会推理会比较慢,他整个模型下载的还是蛮大的,我自己看了一下,他大概两个 gb, 大概有八个,两个 gb 的大概这种文件有十几个 g, 那你要那在 k 叉不上面,他要把这个与系列模型给下载下来,他这个整个一个 他这个模型的话呢,叫 chat g l m 杠六 b 这样,这个模型的话呢,他有些功能啊,他女他们这个文章当中也讲了他有叫自我认知,你可以问他你是谁,他会自己回答的。他可以写这个写作的即纲,他可以写这些文案的,写作都是中文的,他这个都可以,包括邮件写作助手, 他也是能够支持,他也可以做收取信息的一些收取角色的扮演,你可以让他扮一个二,扮,扮一只狗,让他让机器人扮演这个二,是一只拆家的狗,你可以跟他去对话,他这些功能都能支持。另外他也可以做一些评论的比较,他们举了一些例子, c 罗跟梅西他也可以去,谁厉害他也可以去比较啊, 那么他也可以做一些旅游的向导。我也问了一下他,我前面问了一下,就说在在上海能否推荐一些旅游景点,那他就给我推荐了一些旅游景点,什么外滩上海博物馆啊,城隍庙,什么田字坊啊,迪士尼乐园,对对,海洋世界啊,什么什么。我又问他,就是能不能详细的给我讲一下上海迪士尼乐园,那他就输出了一二三四, 他有什么景点,他有什么旅游设施,他有什么样的演出,他有什么样的餐饮,他就可以跟你像聊天一样,大概是这样的一个功能。好,这个是一个最基本的 一个功能。我跟大家我们再来讲一下这家公司开源的这个项目,他是他背后的这家公司叫智普 ai 啊,他是清华记下面的一一家 ai 的一家公司。然后我们看网, 他这家公司的原来可能在中应该是有点名气的,只是说还没这么出名啊,主要也是做这个这个大模型的,就是人工智能的这种与训练的这种大模型,他他也开发出好多的这种模型,但他有一个模型是比较有名的,叫 g l m 杠幺三零 b, 就是有一千三百, 有一千三百亿的这样的一个参数。他在这个文当中也是他们在官网当中也是介绍了他是二零一一年斯坦福大学的这个大型模型中心,对全球三十个主流的大模型进行全方位的评测,那么这个 glm 杠幺三零并是亚洲唯一路选的这样的一个大模型,所以他也 他们这家研究机构也是在跟 oppo、 ai, 包括谷歌啊、微软脸书啊等这呃,这种大门进行比测啊,那么他也供了这样的一个报告啊,我也看了。呃,跟那个 g p d 三啊,当然是没有微调过的 g p d 三,他说相差也不是太大,包括在准确性、辱棒性、因性上面,他其实跟 g p d 三 啊,不是太大了,但是它跟那个就是 instruct g p g 的话呢,差异还是蛮大的,就是它比较的是一个没有微调过的 g p d 三的这样的一个模型, 如果经过那个提示学习,微调过的叫 instruct g p t 的话,那它的距还是蛮大的,差距还是蛮大的。我们看到 包括它的一些所谓的一些误差偏见啊,有毒,因为 structure g p g 的话呢,它确实背后就是 g p g。 呃, chat g p g 背后用的那个模型确实要比中国的这个模型还是要领先的,它的意思是这样啊,但是我看了一下他们目前的公布了, 这个模型跟 g p d 三的差距不是太大,跟我前几天讲的那个叫 g p g 杠 n e o x 模型有二十 b 的这样的一个参数,就是有两百亿个参数,他比那个要更强一些。但是他这次开源出来的不是幺三零 b 的这样的一个大模型,他是有一个六 b 的这样的一个模型,他其实是个小模型,他是可以跑在单个单个 cpu 上面的,他是这样的, 我们就介绍到这啊,换了他推出了一些其他的一些开源的项目啊,包括我前面讲的就 g l m 杠幺三零 b 的这样的一个大模型,他也开源出来了,那么我们可以看看他这次开源出来的叫 chat g l m 杠六 b 的这个模型, 这个模型我们可以看一下他的元代码,我们一起可以来看一下,我们看一下他的元代码,他其实开放出来的话,我看了一下他,他并没有把怎么训练恰恰的 gl g l m 杠六 b 的这个模型给放出来,他只是给了一个 demo 的例子,怎么样像我前面给大家演示的 天的这样的一个功能,聊天的这样的一个功能,他把它给放出来。这个原代码我自己也看了一下,也是比较简单的,他也没有用什么人类反馈强化学习的那些算法,他没有用,他还是比较简单就直接去问 大模型,去要一些预测一些啊,一些内容,然后直接可以聊天啊,是这样,他也没有把那个极微调的指令到底用些什么数据,对吧?来在这个开源的文档当中去分享,他也没有这样做,我们可以看一下他用了哪些内裤,他还是基于的 transformer, 呃,不来进行 开源的这样一个内裤去做的。所以的话呢,我估计他们这个 at g l m 杠六 b 的这个模型的话呢,也是基于这个开源的这些 g p t 三或者 g p t 模型去啊,为了一些中文的数据,然后去喂养的啊。这个是这家公司在哈根 face 上面的这样的一个空间,这个空间里面的话也讲了他们开源了一些八个模型,八个这个大模型他也把它给放出来,这个模型这次开源出来的是这个模型 chat gbl 杠六 b, 但这个模型里面呢,它还是没有怎么训练,用哪些语料库它是没有讲的,它主要还是还是把这个训练完成的模型给放出来,让大家去使用它等于是这样。 这篇文章当中,他们的那个官网当中,呃,也也讲了他们目前开放出来的这个 chat g l m 杠六 b 的这个模型跟那个 gpd chat 还是有些差距的。在技术上面,嗯,他等于是这样。但是对我们来讲他有个好的地方是,呃,我们可以利用他的这个模型可以非常快速的搭建这样的一个智能的一个聊天机器人, 这个能力是可以的。好的,这个是哈根 face 上面,这个是 gap 上面,他们的主要的一些一些开源的一些其实公司,其实,呃开源那么多项目的,之前可能大家不是太关注,但是这次他把这个模型放出来之后的话呢,很多人又开始去关注他,他等于是这样。 那我还是给大家稍微再演示一下,他到底是怎么来用的啊?这个是其实跑起来还是比较简单的啊。他有一个提示框,就是用户,用户输入,对吧?目前是应该没有上下语境的这些功能的,我估计他是没有的, 他还是可以的。我前面跟他讲的是迪士尼,我让他推荐一些中餐,但我没有提到迪士尼,但是他马上就跟我讲了,迪士尼乐园提供了多种中餐,有什么小笼包啊、红烧肉啊,烤鸡翅是中餐吗?炒饭、无冰晶火锅是梦想餐厅的,他是这样的, 多少钱你知道吗?
1111小工蚁 00:46查看AI文稿AI文稿
00:46查看AI文稿AI文稿兄弟们,我拥有了自己的 gpt 大模型了,取名听我一言,他基于清华大学开园的 check gim 搭建,具有六十二亿参数,针对中文问答和对话进行了优化。想体验的朋友一定要看到最后,下面看下他表现吧。 先让他讲的科技加爱情故事回答的完全符合要求,再让他给刚毕业的我一点人生建议, 回答的也没问题。最后再让他写首诗,写的也不错,反正比我写的好。 总体而言,日常的对话需求是能满足了,虽然跟 chat、 gpt 有差距,但也比 siri 和小爱这些聪明多了,同时也必须认识到他可能有些常识性问题。想体验的朋友欢迎加入粉丝群。
83程序员AI超 10:13查看AI文稿AI文稿
10:13查看AI文稿AI文稿最近研究 ai 有点走火入魔,从绘画到聊天都在自己的电脑上部署了一遍。前几天看到一位大佬弄得本地部署 chat g l m 的视频,就是这个视频,居然能加在自己的知识库,出于好奇也想试试,毕竟是国产的,而且开源。 他整合了一个懒人包,在 github 上也有链接,先到他的网盘链接里面下载最新的这个文达的压缩包, 选择最新的这个日期里面这个压缩包就是了。 这里网盘下载可以用由后插件加这个 it mem 的小软件,直接网速拉满, 下载完成之后解压出来就是这个样子的。 我们下面这里有个 setting, 我们用记事本打开就可以开始设置参数了。我这里是复制了一个原来的 setting 备份放在这了。我这个看着不像记事本,是因为安装了一个阅读记事本的小软件,就是这个 notepad 三,想用的话你们可以自己搜索下载。这个其实无关紧要, 打开之后我们只需要设置几个参数就可以了。这个是模型的类型,可以选择三种,这个是 glm 原始模型,后面这两个我也不太懂,应该是不同的微调模型吧,只要下载对于的模型就行。这些网盘底也都有这个文件夹,里面就有两个。 如果网速一般的话,建议先下载原版模型就好了,不影响后面使用。另外一个没找到,但是 hogan face 上有这个人上传了很多版本,具体可以看他的 github, 下面也有中文介绍的链接, 这里我们之间进入这个里面找到七 b 的这个中英文的下载就行。 如果你的电脑内存和显存都不大,建议下载三 b 的,我的电脑是十六克内存八克显存用七 b, 进入的时候太卡了, 三 b 就好很多,但其实我不怎么用这种模式,因为很慢,可能我电脑配置不行。这个三个模型下载完了放在同一个文件夹里就行了。这里我是新建了一个 model 文件夹,当然这是我的老版本里面我也懒得移动过来了,我们再回到设置里面, 我们把对应的模型路径都复制过来,模型路径都填完了以后,其他参数我们大多都是不用动的。每个参数什么意思,大佬也都有注视。 知识库类型,这里是我们可以自由搭配的,可以选择好几种方式,我这里选择默认的 r h 知识库融合模式。 inside, 这里要设置网址,在 plugins 这个文件夹里面能找到相对应的文件。找到 inside 的这个文件, 打开他对应文件看了一下,他应该是冰加另一个网址一起。 这里有个 site, 正好设置里面有个 site, 他默认的是共产党员网,我把它换了,下面这个我估计设融合的权重吧。 我把它改成了学术搜索加闭音搜索加组合搜索,默认的是 fas 搜索,因为 fas 打不开,老报错,不知道这个搜索啥用,所有我 把它换了,这里知识库显示默认是零,我改成了一改不改,看个人习惯吧。下面这个文件加名不用管,没啥用。在下面还有一个模型路径,同样是到他的网盘里下载这个文件,在四月九日的这个文件夹里面, 下载完成之后解压放到原来那个模型文件夹里面,再把地址复制到设置里面去, 后面这两个不知道什么意思,默认就好,设置好保存一下就可以了。我们再看解压包跟目录下有几个 bat 文件,上面这个就是跑默认的,我这里体验下来还是 gml 这个模型流畅一些。 另外两个模型不是卡就是慢,体验并不好。可能是我电脑的问题,你们可以自行尝试。加载的时间可能有点慢, 第一次应该更慢些。 加载完了,复制这个链接到网页上,打开 这就是他最新的界面了。右上角有两个开关,一个是打开知识库,一个是让他理解上下文, 我来演示一下输入,如果女朋友问我,他和妈妈掉到河里先救谁,应该怎么回答? 他的结果还是可以的,打开知识库再试一遍, 结果就不同了, 而且你每次问他都会有一点差别。下面有显示来源,这个就是我在前面设置里面改的,默认是不显示的, 他实际上是可以联网的,毕竟是在搜索引擎上搜索的结果。但是我输入今天的日期是他的,显示又是错的。 打开历史试一下,先纠正他的错误,看他能不能记住。他也跟着回答了正确的答案, 但当我在问的时候,他还是错的。这里我电脑因为开了录屏的缘故很卡,我又试了一次还是不行, 然后我又把知识库关了,再试一遍,还是一样的。所以你这个历史记录有个啥用? 历史这个打开我的电脑容易爆显存,打开之前好先清理一下历史。左边这些功能你们可以自己去尝试,这里我就不说了,正好昨天我的文心一言申请成功了,我们来对比一下。输入写一个关于春天的藏头七言律师。这里文心一言是写了个 七言绝句,在我提出问题之后,他还是答的一首绝句。 再看看文达,没开启知识库的时候,他也回答了一首绝句,开知识库后,他只回答了两句, 然后我把历史关了,再试一次,他直接写了一段文字,根本不是古诗,两者都不让人满意,而且藏头也不是很明显。再来对比一下,写脚本,文达有点不知所云,虽然格式有点样子,但是内容完全就不符合,应该是没有完全理解问题的意思。 文信一言写的倒是有模有样,看着也挺专业。 最后我们让叉 g p t 也来试试,他基本上都能回答出来,而且理解你的意思。 写代码就不用测了, g p t 完胜。今天就先到这里吧。 是,接下来呢,就不弹琴了 起, 欢迎光临,我到三楼。三楼。不是不是不是。二楼,三楼。
85wu5shen 09:23查看AI文稿AI文稿
09:23查看AI文稿AI文稿啊,当然啊,我们说相比幺三零 b 来说啊,六 b 这个模型还是会更加方便来进行实现一些的啊,所以我们在课程当中呢,也是选择六 b 这个模型来进行重点的讲解, 当然得益于六 b 更加清亮的啊,这样的个体量啊啊,所以六 b 这个模型现在在开元社区内的这个使用其实也非常非常的广啊,所以呢,也为我们的这个学习呢啊,相当于是提供了更多啊可以借鉴的一些思路和方案。 那么六 b 这个模型总共呢是六十二亿的啊,这个参数,那么它呢,是在呃 et 的 talking 量上来完成的模型的训练,并且更为难得的是啊,它这个训练的 et 的这个 talking 量啊啊,是 中英双语一比一的这个比例啊,来构建的这样的一个语料,那么可想而知,对于这个模型来说,它肯定是中文和英文呢啊,掌握的非常好,对吧。那么更加重要的是啊,在这一 一比一的这个语料当中的啊,其实中文的语料质量是要高于英文语料质量的啊,所以就 chat g l m 这个模型来说啊,他对中文语句的这样的问答的效果啊,是好于英文语句的这样的一个问答的啊,这点其实非常非常难得了。 那么此外啊,对于六 b 这个模型来说啊,清华大学是考虑到开源社区的实际使用需求啊,所以呢,是提供了很多个不同的实线的版本哈,总共呢是有三种啊,不同实线版本叫做 f p 十六啊, inter 八和 inter 四啊,三种不同的版本啊,当然 严格来说这三个呢啊,不是说三个这个模型不同的版本,而是模型它可以运行的三种不同的模式,三种不同精度的模式,那么 fp 十六啊,是最高精度的啊,这样的一个运行的这样的模式,然后呢 inter 八呢,精度稍微低一点啊,再往下 inter 四呢,这个精度 更低一点。那之所以啊,六 b 这个模型需要设置三个不同的这个运行的精度啊,实际上也是考虑到大家实际的这个啊,硬件的这样的一个环境啊,对吧,精度越低啊,当然对这个硬件要求呢,也会更低一些, 在最低的啊, int 四的这样的一个模式下啊,那么官方给出的这个硬件要求呢?是啊,我们只需要六 g 的这个显存啊,就可以来进行推理,然后呢七 g 的这个显存就可以啊,来进行高效微调。 当然所谓这个推理的指的是啊,我可以运行了,我可以跟他对话了啊,这个是这个是他的这个推理,他最低的门槛呢是六 g。 而啊所谓的高效微调呢,指的是啊,我需要围绕这个模型来进行一些额外的些微调,那么往往我们说微调一个大别模型,他需要消耗的这样的个显存,他需要占用的硬件资源肯定是要比他在进行推理的时候 啊,硬件资源要更高的,那么我们会发现啊,在最低精度的啊,这样的一个情况下啊,对于六 b 这模型来说,只需要六 g 跟七 g 就可以来进行运行跟微调了,这个门槛其实非常非常低的, 基本上我们说在一张二零六零的这个显卡下就可以运行,如果啊,你有一张二零八零太的这个显卡的话,那么啊,在最低精度模式下,这个推理呀和微调啊都能非常顺畅的啊来完成。 当然有同学可能会觉得说啊,那这个还是呃有一定的这个硬件门槛呀,对吧,毕竟他还是需要有张显卡哦你才能运行。 呃,确实是这样的啊,但是我想说的是,这个已经是大语言模型非常非常低的啊一个运行的呃门槛了,因为毕竟他还是一个大模型,而目前来说,大多数大模型的使用跟应用场景仍然还是工业级的啊,这样的应用场景在 工业级的应用场景当中啊,一个这么低的硬件门槛的要求已经是非常非常难得了啊。当然就这个硬件门槛这个问题,我们稍后呢会做专门的一段啊来讲解说,如果你要想用好六 b 这个模型的话啊,这个硬件呢应该如何配置?如果你想自己实验的话,应该如何配置?如果 你们是一个团队啊,想进行这个更加复杂的微调,应该如何来进行配置啊?如果是企业啊,想进行大模型研发的话,应该如何来进行配置?这个呢,我们稍后会有专门的一段视频来进行好好讲解。但不管怎么样,我们说更低的啊,这个硬件使用门槛 也让啊六 b 这个模型呢在开运设计上得到了非常好的啊一个传播和使用。当然啊,这里面我们可能还需要解释一下到底什么叫 f p 十六, inter 八和 inter 四啊,这三种不同的这个精度,其实哈啊,这三种其实也不难理解, f p 十六啊, 指的是全参数进度, inter 八呢代表的是它的参数,总共呢只保留八位数。那么 inter 四呢代表了它,它的参数呢?总共啊只保留四位数。 那么对一个神经网络模型来说啊,肯定是有非常非常多的参数,那每一个参数呢,肯定都是有好多好多位对吧啊,这个时候呢,你当然是保留的位数越少啊,那么你参数呢, 这个损失的信息呢就越多啊,但是呢,计算速度呢就会越快啊,是这样的一个过程,所以 inter 四呢,代表的是总共的保留四位参数啊,然后呢, inter 八呢是每个参数呢啊,总共只保留八位啊, f p 十六呢是全参数精度啊,大概是这样的一个情况, 那么呃,这里我们需要说明的是,它虽然是给出了三种不同的精度啊,让你去选择,让你去运行啊,但是 inter 四的这个情况下呢,它的这个呃,由于参数本身的精度呢 是比较低的,所以它最后结果其实并不会非常非常的准确啊,所以大多数情况下,我们的实际运行呢,可能都是在 inter 八啊或者 fp 十六下来进行运行啊。不过如果你只想跑通这个模型的话, inter 四呢啊是没有什么问题的。 然后啊,同时对于这个模型来说,还有一点可能需要注意的,就是啊,这个模型呢,他会伴随着你的多轮对话的这个次数不断增加呀,他需要占用的这个显存呢啊,也是会不断增加的啊,所以尽管啊,我们说 啊,在 inter 四的模式下,最低六 g 的线存你就可以跑起来啊,但是你多对话几次的话,它的显存占用量呢,会非常非常的多啊,所以我们还是推荐大家如果是一个使用啊这个把它跑通这个模型,并且想测试它的 多轮对话的话,那么最好呢还是上二零八零太,二零八零太的话呢,呃,总共呢是有十一 g 的这个显存在 inter 四的模式下运行六 b 这个模型完全是 ok 的。好啊,当然你说如果啊,你希望我他是以全精度的这个模式来进行运行的话啊,并且是进行多轮对话,他需要占用很多现成的话啊,差不多需要二十 g 的啊,这个现存的量, 那么二十 g 的显存量消费级的显卡可能至少也得是三零九零啊这样的一个级别了啊,这个呢啊,我们先简单说明一下啊,我们稍后呢会有详细的这个硬件配置这样的讨论, 但不管怎么样啊,我们说正是得益于六 b 这个模型非常低的啊这个使用门槛,所以呢他在目前开源社区传播也是非常非常广啊,尤其是中文领域的这开源社区传播是非常非常广的,那么也是自啊六 b 这个模型诞生之后, 现在呢啊 get up 上也有非常非常多的啊,围绕六 b 呢来进行的一系列的啊开源的项目, 那么其中啊最有名的啊四个项目呢,我给大家列到这啊,因为这些项目呢,我们后面呢或多或少都会来进行一些讨论啊,大家感兴趣的话也可以先自己去看一下。那么首先第一个呢啊,就是 chat glm 六 b 加 petuni v 二的啊,这样的一个微调的这个项目, 当然啊,大家会说这个 v ptuni vr 是个什么东西啊?首先这个呢,是个微调框架啊,稍后呢,我们会来讨论啊,这个微调框架到底是什么样的一个含义,以及什么样的功能? 那么 p tony vr 呢,它本身也是清华大学提出来的一个微调这样的一个方法,并且这个微调方法呢,是非常非常 适合啊,这个六 b 这个模型来进行微调的啊,所以清华大学在推出六 b 这个模型之后没多久啊,就开源另外一个项目,就是 chat glm 六 b 加 ptoning vr 来进行微调的啊,这样的个项目,那这个项目现在目前也基本上可以看成是啊,所 所有的你要去学六 b 这个模型,微调这个必不可少得去学的啊,这样的项目非常非常具有这个指导意义。那么第二个啊,就是 chat gm 六 b 加 lora 微调啊, lora 微调是另外一个微调的框架,稍后我们也会来进行讨论啊,那这个呢,同样啊,也是 这个开源社区里面目前讨论的非常火的啊,未来的一个研究的方向啊,就是去看各个不同大语言模型啊,在 lorr 下如何来进行微调啊,那么六 b 这个模型,同样啊,在 lorr 下进行微调呢,也能够调,也能够有一个非常好的这个微调效果,这个项目呢啊,也是属于非常火的一个项目, 那么同时呢,还有一个啊, chat j l m 六 b 加 long chan 的这个项目啊,那 long chan 我们就开始提过,提过一嘴,对吧啊,它呢是用来去构建一些 ai 应用的开发范式,那么六 b 呢,同样也是可以和 long chan 来进行无缝集成的啊,这个项目呢,在啊,开元社区目 目前也非常火啊,但是这个项目目前他基于 longent 这开发,主要是啊,这个围绕本地智库来进行一些问答啊,是这样的一些呃功能。但这个项目呢,同样啊,也是国内第一个啊,用六 b 和 longente 来进行协同开发的一个项目啊,这个项目呢,也是非常具有参考价值的。 那么此外啊,对于六 b 来说,由于它本身是一个这个对话类的这个模型嘛,啊,所以开源社区里面还有一个非常火的项目啊,就是把它这个对话呢,搬到这个网页端啊来完成。 那么这我们现在这个看到的啊,实际上就是一个 web u i 的一个对话展示的项目啊,这个项目同样我们说如果你需要去使用 g b t l 六 b 这个模型来进行对话的话来进行调试的话,有一个外部前端啊,肯定是会方便很多。那么这四个项目也是目前啊,整个围绕着六 b 开源社区最具有代表性的啊,这四 的项目,那么后面呢,也会啊,在正式的课程当中啊,来好好讨论一下啊,这些项目分别是如何来进行实现的?
27九天Hector 01:18查看AI文稿AI文稿
01:18查看AI文稿AI文稿我们从未离 gb 四如此接近,直到叉 jml 推出了它的第三代版本,下面呢,我简单总结一下啊,今一代版本当中,咱们的国货之光升级了哪些个功能?第一件事啊,就是全面支持咱们国产芯片的推理和训练,卡伯这件事咱们可再也忍不了了。 第二点呢,推出了更小的一点,五 b 版本,换下来说移动端能做上的,这才是满足但大众用户的需求。第三是啊,给大本当中说明了,十 b 以内我最强啊,吊打其他的国内大模型。第四点啊,增强了 a 阵的一个能力, 这个 a 真的简单来说就是你绕这个模型做一些复杂的推理的事,以前理解不了,但是在新一代把手当中,哎,他能把这个理解能力做的更优了。第五点呢,增加了一个多角色对话,角色这个东西啊,就比如说你这大模型啊,说你扮演 律师,帮我分析个案件,你拜个老师教我一些课程,这回他能模仿的更像了,更会 cosplay 了。第六点,也是最重要的,他引入了一个叫做方身靠领的一个功能,这个功能啊,翻译过来就是说,以前啊,咱们的大模型想连接工具, 还得通过一些中介去去做啊,就有一些二道贩子在中间卡着,咱们现在不用了啊,我直接能跟供应商联系上了,有什么工具咱们直接内部就可以调用了。
726迪哥Ai大讲堂



