spss如何使用arima模型预测
如何预测天猫双十一成交额?微博预测演示,第一步,整理二零零九至二零二一年天猫双十一成交额。第二步,上传数据至 spro 系统,选择分析方法 virgm 预测。第三步,让 spring 系统自动输出最优模型, 选择向后预测七数为两,一键得出预测值。二零二二年成交额预测五千八百五十三点二零八亿元二零二三年成交额预测六千三百零三点四一七亿元。你学会了吗?

粉丝3.9万获赞19.7万
相关视频
 03:50查看AI文稿AI文稿
03:50查看AI文稿AI文稿sbss 操作步骤讲解系列第三十六课 rea 骂模型时间序列 rea 骂模型自回归综合移动平均模型的检验步骤为, 首先通过系列图对模型进行初步的分析,看是否平稳,然后通过自相关或偏字相关分析对模型进一步的识别与定阶确定模型的 pdq 接数值,确定模型后进行参数的估计后进行模型的预测。 第一步,定义时间,将数据导入 spss 中,点击数据定义日期和时间, 进入定义日期后,选择数据对应的日期格式并定义第一个个案日期后点击确定。当结果 果界面出现,图中语法表明日期定义成功。第二步,模型初步分析,点击分析时间序列预测序列图,进入图中序列图勾选框,将音变量放入变量框中,点击确定 序列图,结果就出来了。根据图中序列图结果可以知道本次数据不平稳, 从结果可以看出不平稳,因此需要进行差分处理,在序列图勾选框中勾选差异,从一阶差分开始尝试。 第三步,确定 am 模型的 pq 截值,点击分析时间序列预测自相关,进入自相关勾选 选框后,将因变量放入变量框中后勾选转换下的差异,并填入差分接触,点击确定 字相关偏字相关的模型描述。个案处理摘要,字相关性字相关图偏字相关 篇字相关图,结果就出来了。在进行字相关和偏字相关接触判断时,常采用两种方法,一字相关和偏字相关性表进行判断,若数据快速,将为零为结尾,反之为拖尾。二字相关和偏字相关图进行判断, 通过看图是否有为零的,若有为结尾,反正为拖尾。接触判断由第几个进入二 sd 范围前一个数算几届。第四步,而以骂模型 操作步骤,点击分析时间序列预测,创建传统模型,进入时间序列建模器后再变量勾选框,将因变量放入因变量框中并勾选方法点条件,进入条件设置框后填入对应的批 一 q 的接值转换勾选自然对数,点击继续默认勾选统计,点击图勾选图中红框标记像默认勾选输出过滤, 点击保存勾选,保存变量下保存的预测值和致信区间上下限,并修改变量名,前缀最好改为英文字母。最后点击选项勾选并修改预测日期,点击确定 b 骂模型的模型描述,模型摘要,图表模型拟核度模型统计预测结果 残差的字相关和偏字相关图,预测图结果就出来了。第五步,结果整理,将预测结果表粘贴复制到表格中, 并加入平稳二方的值后,将整理好的结果及预测图粘贴复制到沃尔顿党中,进行三线表的制作及文字描述。 学会了记得点赞关注呦,可带坐指导学习交流!
546艾吖法数据 07:55
07:55 00:38查看AI文稿AI文稿
00:38查看AI文稿AI文稿线性回归一般需要满足条件, spsa 便利出各种可能的模型组合进行模型构建,并且结合 a 最小这一规则,最终得到最佳模型。上传数据至 spsa, 选择 arima 模型,拖拽样本至右侧分析框,输入预测期数开始分析, 最终找出最优模型为 arm 二幺,得到预测值和可视化折现图如下,你学会了吗?
145SPSSAU 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿时间序列数据预测分析方法汇总预测时间序列数据,可以帮助我们了解未来的趋势和模式,从而作出更准确的决策。常用方法有以下几种,一、指数平滑法常用于数据序列较少时使用,且一般只适用于中短期预测。二、 灰色预测模型可针对数量非常少,比如仅四个、数据完整性和可靠性较低的数据序列进行有效预测。 三、 arima 模型是最常见的时间序列预测分析方法,适用于平稳时间序列数据。它包括三个部分,自回归 a、 二叉分 i 和移动平均 ma。 四、季节 threeam 模型 是 arab 模型的一种扩展,用于处理具有明显季节性变化的时间序列数据。五、 vr 模型如果需要同时考虑多个变量的预测时,此时可以使用 vr 模型进行多变量预测,你学会了吗?
283SPSSAU 00:14
00:14 08:28查看AI文稿AI文稿
08:28查看AI文稿AI文稿大家好,我是顾伟。本次案例汇报的内容是基于 airma 模型对乘车订单总额未来七天的预测, 主要分为五个部分展开,分为前沿数据建模、基本步骤、 aim 模型实现、模型检验以及模型预测。首先看前沿部分, 本研究针对某乘车运营公司二零一八年一月到五月的日订单总额建立 airma 模型,并进行模型检验及预测。 从时间上看呢,这个订单量的时间序列有两个明显的特征,第一个就是他是具有周期性的,也就是说他每天的订单量的变化趋势都是大致相同的,而且他在午高峰和晚高峰的订单量 是较为集中的。第二个就是实时性,当天的订单量可能会受天气等因素影响,呈现出整体的上涨或下降,那么预测可以反映未来司机承担的情权情况,能给运营部门及时调整有效的运营策略。 预测又有好几种方向,有基于订单总额的预测、基于乘客目的地的预测、基于上车地点的工序预测等。这里我们主要是阐述一下订单总额未来七天的一个预测, 然后看一下数据建模基本步骤。首先获取被观测系统的时间序列数据,之后对数据进行绘图,观测是否为平稳时间序列。对于非平稳时间序列,我们要先进行 dj 的差分运算,化为平 平稳的时间序列。经过第二步处理呢,我们已经得到了平稳的时间序列,那么要对平稳时间序列分别求得其字相关系数 acf 和偏字相关系数 psf, 通过对字相关图和偏字相关图的分析,再得到最佳的阶层批和接触。 q, 那我用以上得到的 d q, p, d q 和 p 得到我们的 a r i m a 模型,然后开始对得到的模型进行模型检验,然后看一下我们这个 a r i m a 模型的一实现, 那这里我们主要是用 python 来详细解析后三个步骤的实现过程。文章主要使用到了以下的基础库,对其进行一个调用, 获取数据。我们把乘车乘用车的日运营报表,订单总额数据提取出来进行分析,那么这数据的前十行如下,也就是说他是以日期和订单总额构成的一个数据列表,是按日进行划分的, 可以看出这个订单总额呢,他他是呈现出一个比较呃,波动性比较强的一个情况。我们通过画图呢,可以看出他的订单走势如右图所示,那么他他他显然他是一个非平稳的一个序列, 那么接下来我们对它做一个时间序列的差分,这个 l i m 模型对于时间序列的要求是平稳型,因此当得到一个非平稳 时间序列时,我们首先要做的就是做时间序列的差分,直到得到一个平稳的时间序列。如果对时间序列做第一次差分才能得到一个平稳序列,那么我们可以使用这个 vima pdq 模型,其中这个 d 呢就是它的差分次数。 我们这里就来做一个时间序列的一阶差分图,然后我们得出画出他的这个差分图,如右图所示。 实际上我们还可以做一个二阶的差分,那我们通过运算呢,发现这个二阶差分他的均折方差和一阶差分他是差不多的,所以我们这里就只用一阶差分就可以了, 然后我们就可以得到一个合适的 pqp 以及 p 以及 q, 那么得到 得到了这个平稳的时间序列后呢,接下来就是要选择合适的这个模型。第一步我们就要先检查一下这个平稳时间序列的字相关图和篇字相关图, 那通过作图呢,我们看到这个他的这个字相关图片字相关图如这两个图所示。那么通过观察这两个图我们可以发现呢,字相关图显示他之后有三个阶都超过了他的一个制性边界。 而偏色相关图显示呢,在之后一至二阶时,他的这个偏色相关系数超过了知性的边界,从这个七之后呢,他的偏色相关系数值缩小至零了。 总有以下的几个模型可以供选择,比如这个 rma 的零一模型, 那么也就是字相关图,在之后一阶之后它缩小为零,且偏字相关缩小至零,则是一个接数 q 等于一的移动平均模型。 还有这个七零的这个模型,也就是在之后七阶之后缩小为零,且字相关缩小至零,它是一个阶层 p 等于三的字规模型。还有这个七一模型,也就是使得字相关和片子相关都缩小至零,这是一个混合模型。 那么有这么多可以共选择的模型呢?我们通常要采用这个 i c 法则来判断一下,那么我们判断这上面我们说的这四个模型,它的这个 a i c, b i c 以及 h two i c 的 值,可以发现这个第一行的这个就是我们做的这个七零的这个模型,那么这个模型他的这个 aic 是三千零一点几, bic 呢是三千零二十九点多,然后以及这个 hqic 的他的这个值是三千零一十三点多,他的这个值都是最小的,因此他就是最佳的模型。 那么在指数平方模型下,我们观察这个 a r i m a 模型的残差是否是平均值为零,且方差为常数的正态分布,同时也要观察它的连续残差是否是自相关的。 那么对我们选出的最佳模型所产生的残差做一个自相关图之后,我们做做一个 dw 检验,还要做一个观察是否为正态风度的一个检验。首先 做他的一个残差的自相关图,如这个图所示,那么他是他的这个都没有超出他的这个执行区间。然后 dw 检验呢?这个 dw 检验他是目前检验自相关性最常用的一个方法,但是他只适用于检验一阶的自相关性。 他的这个检验规则如下,那么当这个 dw 值显著的接近于零或四的时候,他是存在自相光性的,而接近于二十呢,就不存在这个一阶的自相关性。 这样我们只要知道这个 dw 统计量的概率分布在给定的显著水平下,根据临界值的位置就可以对原假设 h 零进行检验。那么通过这个 这个函数呢,我们 print 出来这个 d w 的值得到的检验结果是一点九六 幺九六,那么他就是一个呃,在这个零到二之间,那么他不存在自相关性。 之后我们还要再观察一下他是否符合状态分布,这里我们使用 qq 图来看, qq 图呢就用于直观的验证一组数据是否来自某个分布,或者是验证两组数据是否来自同一分布。 那么常用的就是来检验数据是否来自于正态分布。然后做一下他的这个 qq 图,可以看出他,呃右尾和左尾其实还不是太好,但是大部分也都是位于这个线上的。 那模型确定之后,我们可以开始进行预测了,我们对未来期间的数据进行一个预测, 那么最后得到的结果就是这样子一个走势的, 我汇报结束,谢谢大家。
90数苑统计 12:16查看AI文稿AI文稿
12:16查看AI文稿AI文稿要的内容是基于 arma 模型对我国人口出生率的分析与预测。本文统共分为五个方面,一个是研究背景与意义,然后是数据的整理与统计, 接着是 arma 模型的理论分析,然后是 gm 二分析,最后是结论与建议。那第一部分的研究背景与意义? 人口是保证社会和经济持续发展的重要载体,是整个社会最基础的部分。庞大的人口总量不仅能为经济持续高质量发展提供充足的劳动力, 同时也能在科技创新、艺术创作和体育竞技等众多人文领域发挥充足的人才优势。但当前我国人 口发展呈现勺子化、老龄化、区域人口增减分化的居日性特征,持续低迷的 低生态态势。低生于态势,影响着中国社会总体可持续发展。中国正处在人口非常态发展的历史转折点上,从人口增长转向人口缩减, 未来充满了风险和挑战。不合理的人口增长速度和人口结构会导致社会和经济发展受到阻碍,进而影响人们的生活水平和质量以及社会的长期稳定发展。而本文的研究目的是 人口预测数据是国家制定人口经济和社会发展宏观发展战略规划中最基础数据。人口预测能够为社会经济发展规划提供重要信息。 预测的结果呢,也可以指明经济发展中可能发生的问题,可以帮助制定正确的政策。随着近年来人口生育政策适度调整以及中国人口结构变动等因素的影响,中国人口发展速度 和结构各方面都变得越来越复杂,同时人口与自然环境的关系,人口老龄化程度都在不断加深。 关于如何对未来人口变动趋势做出准确判断的问题,不仅是人口学领域的研究重点,同时也是也是经济学研究的领域。 人口基础数量和人口结构对我国经济发展有重要的影响。本文的研究方法呢,是先通过阅读文献获取我国目前人口的 现状,在查阅这个统计年间,统计我国近四十年来的人口总数,建立 aima 模型进行短期预测,并利用阿语言建立你和优度高的 aima 模型。 接着预测了未来十年我国人口总量以及增长趋势,最后根据人口预测趋势和结果分析其原因,并提出相关建议。 那本文的数据啊,来源于同一年间。这个表意列出了一九八零到二零一九年近四十年明年年末的人口数, 然后其中一九八零一九八一年的数据是户籍统计数,一九八二一九九零二零两千年,二零一零年的数据是当年日口普查数据的推算数, 其余的年份是年度人口抽样调查推算的数,这是数据。 接着是 a r m a 模型理论分析这个模型的原理呢,它是一种时间序列预测方法,其中这个 a r 是自回归部分,然后 m a 是移动平均部分。 这个模型呢,是通过差分运算将非平稳时间序列转化为差分平稳序列,然后利用因变量的之后之后随机误差向建立模型来达到这未来值。预测这个目的。具体的数学表达是是这样的, 然后它的平稳性检验,因为这个 ama 模型需要呃数据是平稳 才能进行模拟,所以啊,平稳性检验有一个是图示法,他呢是粗略判断他模型平稳的方法啊,要精确判断的是这个特征根判断, ar 模型好,可以简写为这个。然后特征根判断呢,就是假如说这个栏目的一到栏目的 p 是评选序列 xt 线性差分的 p 个特征根,然后我们任意取个栏目的哎,带入特征方程,那就录下这个式子, 那么如果这个方程所有特征根都在单位源内,那么这个序列就是为平稳序列。 然后这个数据还有啊,满足随机性,那这个他们俩证明了这个 l p 统计量 是近四伏,从自由度为 m 的开放粉库,他的数学表达是乳腺,其中的这个 n 是观测期数, m 是延迟期数。如果这个 lb 的统计量小于临界水平,那我们就拒绝原假设, 认为序列为非白造成序列,可以继续弥合弥合模型啊。证明完他们两个之后 啊,就要对模型进行选择啊。我们,嗯,建立模型的时候会有几个模型都通过上述两个检验,所以我们就要采取啊如下的这个基本原则来选择相关模型, 他们仨,他们俩是啥的时候,然后对应的模型是进行这个。最后 说一下这个最小二乘估计,在 a r m a 模型场合,把这个最小二乘估计跟 其他的是其实一样的,就是使残差平和达到最小的参数,这就是他的最小而成估计啊。然后模型预测呢,我们用这个 etl 衡量预测误差,那这个预测误差越小,预测精度是就是越高的。 现在最常用的预测原则就是预测方差最小原则,也就是这个方差最小时候。 ari m a 模型的建模分析,我们要利用 a、 d、 f 检验判断序列是否是平稳的,然后还有用白噪声检验判断序列是否为随机的,因为这个 a r m a 和 a r m a 都需要这个时间序列满足平稳型和 非白噪声的要求,所以我们用差分法和平滑法来实现血液的平稳性操作。那一般情况下,其实一阶差分就可以实现这个序列的平稳性了,但是有的时候也需要二阶差分 啊,我们看这个一九八零到二零一九年啊人口数的这个持续图,我发现他这个是近四十年来人口是稳定增长的。 当我们对这个数据进行一阶查分后啊,发现这个 adf 检验啊并没有通过,所以我们进行二阶查分, 二节查分后失去图,是啊,如图二所示,我们发现啊,他这个具有一定的平稳性啊,那我们就 再检测一下他随机性。这表三是白噪声检验 原序列啊,各阶数下的 lb 统计量的批值均小于一级,二级都小于百分之五的零级水平,所以可以拒绝原点设,也就是 认为我国这个总指数二阶差分序列是非本造成序列,可以直接拟合模型, 接着就要对这个模型进行识别与定阶。图三、图四是我国一九八零到二零一九年人口总数的二阶差。二阶差分的后序列。字相关和偏字相关图, 这个是字相关图,这个是偏字相关图,我们可以发现有这两个图,我们无法确定具体是几阶结尾啊,或者是拖尾,所以我们就是可以初步先啊,你和几个啊, 就是先你和这个 aima, 这是零二一啊,零二二一二一,还有一二二,然后我们观察 aic 值啊,最小的就是最终的这个你和模型, 那在 r r 在序列自动定结中给出了合理模型,其实就是这个零二一,所以加入这个模型的 aic 比较中。 接着就是模型的定阶 a r m a 模型,你和效果啊,是这个表四, 那我们发现是不是 a i m a 就是零二一的时候,它的 a i c 是最小的,所以这个 a i c 就作为这个礼盒的模型啊,然后再通过这个这个 零二一这个模型的显著性检验,我发现他这个呃统计量的批值都显著大于百分之五零阶水平,所以 这个零二一的时候,这个残差序列是白噪声序列,也就是这个离合模型是显著的。 接着是模型的预测啊,我们看这个图六,可以看出未来十年的这个增长趋势,其实和之前的 历史波动趋势是大致吻合的。具体的数据呢?看具体的预测数据是标五啊,在这数据我们发现也是稳定增长的。 最后就是啊,关于我们的这个结论与建议啊,结论是啊,我们本文通过啊,我针对我国总人口的预测问题建立了相关的 lma 模型, 然后人数总数的二级序列是呈现趋势平稳的,也通过这个纯随机性检验了, 然后根据偏自相弯和自相弯图,它一结合建立的模型,这个是零二一,它的 aic 值是最小的,同时这个零二一他的模型也是显著的,所以就选择了这个零二一的模型啊,对我国未来人口做出预测,而且这个预测结果与历史的波动趋势是相吻合的,说明我们啊选择的就是比较好的。 最后是一点建议,根据啊我国这个人口总数预测, 而且还有现在的情况,我国年轻一代就是目前是普遍晚婚晚育,所以应该重点解决我国年轻一代的这个 就业问题和住房问题啊,因为就业问题和住房问题得到缓解以后,那个生育压力也就小了,所以这个生育水 要想提高的话,那就要解决这个就业压力和住房压力,生育水平提升以后人口增长率也会随着提成,我国经济发展同时也会得到提升 啊。还有就是之前我们开放了二胎政策,但是其实开放二胎政策以后, 人口出生率并没有显著的提升,说明这个商业政策其实还应该在提升啊,前段时间也是开放了三海政策,所以我相信未来几年人口应该会有一个明显的提升。
255数苑统计 14:10查看AI文稿AI文稿
14:10查看AI文稿AI文稿本次报告的题目是某市高速路车流量的分析与预测, 我将从这四个方面进行报告。续论车流量预测理论介绍高速公路车流量现状分析、基于二维码模型的高速公路车流量预测分析。首先是续论部分 研究背景,为了解决城市道路交通发展过程中出现的一系列问题,大力发展城市高速公路交通建设工程成为了实现城市空间拓展的一项重要举措, 同时也为交通拥堵环境的环节以及区域经济进一步的优化提供了新的转机。随着城市高速公路建设脚步的不断推进,串联的高速公路主干 线网的通车里程及所涉及的城市也呈现增多趋势。截至二零二二年底,全国公路通车总里程达五百三十五万公里,其中高速公里通车里程十七点七三万公里,稳居世界第一。 根据中国政府网,二零二二年我国机动车保有量达四点一七亿辆,其中汽车保有量为三点一九亿辆,超过此前美国创下的二点七八亿辆世界纪录。 因为车流量太大,造成了交通拥堵、交通事故发生率提高等一系列的问题,那么如何科学合理的经营和运营城市高速公路,成为了摆在每个交通人面前一项等待解决的重要问题。综上所述,对城市高速 公路交通车流量的精确预测,可以对高速公路相关管理单位在未来制定运营管理措施、路面设备的升级改造以及路面养护的成本预算估计等方面提供有利的证据, 同时也可以有效的缓解城市交通路网的交路道路拥堵现象,缩小城市间经济发展的差异性,促进城市地区经济建设的可持续性发展。 研究意义是通过运用 arima 模型对城市高速公路的交通车流量分析预测, 同时利用最佳模型对高速公路这个研究实力的未来城市的日军交通车流量变化趋势进行预测分析,系统分析其变化趋势对交 交通路况的实质影响后,提出针对不同交通车流量的交通路况运营和管理策略,用以改善未来的城市高速公路交通拥堵问题。首先是车流量预测理论介绍 交通车流量预测理论是预测学在交通运输行业上运用一种非常典型的实际应用产物。 在交通规划领域中,主要以三种常见的预测原理作为交通车辆预测过程中的重要指导理论,分别是连续性原理、类比性原理和因果性原理。 首先是零连续性原理,是根据连续性原理的思路,对未对象的未来发展趋势,可以 通过其过去以及现在的数据和基本信息与未来的联系进行趋势延伸, 最终可以实现对目标未来情况的预测的目的。类比性原理是通过对相似现象之间相关关系进行研究分析, 可以根据不同事物之间的相似或类同共共性,对具有相似特征的研究目标和未来发展状况作出精准的预测。 通过类比方式的不同,我们可以分为定性类比法和定量类比法 研究因果性原理是任何客观事物的发展变化都不是完全孤立的,是与存在着直接或间接联系的各种事物之间相互协作下完成的。在实际分析中, 违规分析预测便是因果关系这种思想原理的最典型的应用。最常见的预测方法有两种,定性预测法 是运用自身的知识、经验和分析判断能力,对研究对象实现未来趋势的分析,然后再根据对各个方面进行综合评估,从而得出最终结论。优点是自由度相对较高,不过也有缺点 就是在实际应用中常用的定型预测方法会被研究人员自身的知识、经验和能力束缚和限制。常用的是主观概率法、德尔非法和情境预测法。定量预测法是根据已用 的历史信息,运用一定的数理统计模型对数据做出分析,所从而得出变量之间的相关联的信息。优点是将历史统计数据与客观测量数值资料共同作为预测过程中的重要依据, 受主观因素影响较少,并且得到的结果也相对具有客观性。缺点是在预测过程中操作比较机械,不容易被研究者灵活掌握。 最常用的定定量预测的方法有回归分析法、指竖平滑法以及 arima 模型等,而本文的预测模型构建方法是 arima 模型。 arima 模型 行的数学公式来描述是这样的,对于交通规划领域的研究, arim 模型对稳定的常识和短时交通车流量数据的分析都具有优异的表现。 不过也有缺点,第一是对于具有周期性变化特征的交通车流量数据分析存在一定的欠缺。第二是模型在车流量数据出现突然性的增长和下降时,模型表现具有一定的滞后性。第三是模型在应用于车流量 建模过程中较为复杂,因此我们可以将实际模型优化成这个样子。其中此处的 s 指的是季节变动不长, d 是指的季节性差分的次数 b, s 指之后算子。本文用的车流量预测软件是 evils 软件, 然后进入第三部分高速公路车油量现状分析。数据来源于该市高速公路股份有限公司近十二年的公司经营相关数据,本文查取到了该高速公路二零一四年一月至二零二二年十二月的数据, 对原始数据进行格式保存,然后再通过 evius 软件操作对数据进行可视化展示。 然后再利用二零一九年的一月至十二月高速公路月度车流量数据作为验证级数据,对建立模型 的预测效果进行评估。首先是数据数据整理描述,我们将原始数据导入到 evils 软件中,通过软件指令对交通车流量原始数据绘制成了时间序列线性趋势图,如图所示。 我们一方面可以观察到二零一零年一月至二零一八年十二月高速公路的月度日均交通车油量呈现逐年上升的趋势,并且在二零一二年的九月开始,高速公路车油量的增长趋势出现增速提高的现象。在一三和一四年期间, 车油量出现大幅度增长,并且波动也出现加剧的形式。本文分析主要是由于从二零一二年九月三十日开 实行了小客车节假日高速公路通行免费政策,加之一零年之后,中国消费水平发展速度较之前有了明显的提升,因此人民群众的出行需求发生变化, 最终出现了高速公路交通车油量的快速增加以及波动幅度增大的现象。进入第四部分基于二维码模型的高速公路车油量预测分析。 对现有学者研究的情况来看,发现 rm 模型作为一种常用的时间序列分析方法, 在对于交通条件较为平稳的高速公路交通车流量预测具有一定的优势,因此本文也打算采用二维码模型来预测。通过刚刚对数据的可视化结果的观察,发现了高速公路的车 透亮数据伴随时间变化,具有季节性和周期性变化规律,因此二维码模型基础上可以进一步优化。采取季节性变化的 s 二维码模型对 城市高速公路阅读日军交通车流量数据进行预测分析,进而加进一步增加模型的预测精度。数据平稳化。本文研究选择的 a、 d、 f 检验模型进行单位跟检验, 我们将数据输入到 reviews 中进行 a、 d、 f 检验。通过 a i、 c 和 s c 准则筛选出的最佳检验模型如表四点一所示,通过检验结果可以发现,在显著性水平为百分之一、 百分之五和百分之十条件下, a、 d、 f 单位跟检验的结果中屁值明显比显著性水平要高出很多,这表示其检验结果在三种显著性水平下远。假设不被拒绝,证明这三种检验模型下该时间序列可能存在着单位根, 因此数据属于非平稳的持续数据。由于采取 arima 模型对原始交通车流量数据存在一定要求,因此我们可以做一阶差分对原始数据进行平稳实践。序列的转化 还是利用 evius 软件对序列。通过意见差分后得到 d y t。 数列。可以直观地发现 d, y, t。 数列的持续图如图所示,不 不具有任何上升或下降的趋势,而是呈现水平方向上的均值近四为零的波动。因此认为一阶差分操作有效地提取了原始序列 y t 的现行趋势。差分后的序列 d, y t 是平稳时间序列。 我们通过 d y t 序列的 a d f g s 结果可知, t 统计量为负三点六六一一三三大于显著性百分之一的临界值,但远远小于百分之五和百分之十的临界值。因此,序列 d y t 检验结果在百分之五和百分之十两种显著性水平下,序列的原假设 h 零都被拒绝。表示在三种 a、 d f 检验模型下,该时间序列未找的单位根,可以认定序列 d s 外 it 已经是平稳世界系列。然后进行模型定接, 我们最终可以确定备选模型是这三种。这四个模型 分别是参数 p 去零一二三四和参数 q 去零一二十所确定下来的备选模型。 在对四种备选模型进行模型选择中,本文将根据 i i c。 信息准则和 i c 准则对各个模型组合进行筛选, 其中值越小的话,模型就越精简,你和效果就越好。同时通过调整后你和优度 r 方最大的原则做取,做出最优模型 的选择。表四减三就是四个备选模型的建模后的检验结果,我们可以看四个模型的 i c 值和 sc 值。最终我们确定了二维码四一二零一一这个为最优的选择模型。 最后我们来进行模型检验,还是通过 evo 软件用最小二乘法对该最优模型进行回归。通过二维码四一二零一一模型的回归结果进行参数估计和检验,检验结果如图四点四, 可以看到参数检验和显示性检验均已通过。 下面来看模型的预测效果。 首先通过二维码四一二零一一模型对二零一九年一月至十二月该市高速公路月度日均车辆预测数据进行动态预测, 预测结果如土表四点五所示,可以看出这个模型的十二个预测结果中,模型的绝对百分比误差基本控制在百分之五以内, 其中有五个月份的绝对百分比误差低于百分之一,平均绝对百分比误差为一点八四一三百分之。 综合上述结果可以判断模型整体预测效果比较优秀,与该市高速公路西段阅读日均交通车流量真实数据相比,误差很小。
67数苑统计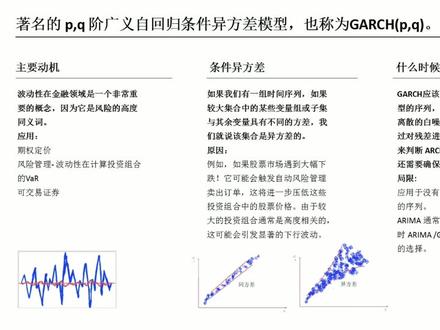 13:55查看AI文稿AI文稿
13:55查看AI文稿AI文稿本视频中我们讨论了自回归综合移动平均模型和自回归条件一方差模型及其在股市预测中的应用。 为什么要用 erim guarch 模型? 虽然 early 们研究价格水平或收益,但 gartch 广义自回归条件一方差试图对波动率或平方收益的剧类或聚集进行建模。波动率不是一成不变的,有些时候会很高,有些时候会很低,而 且往往有聚集效应。上图为某指数日收益率,可以看到收益率图是有极具点的,在极具点周围的波动率整体都很大。 序列自相关指数的一系列每日收益率变化似乎在临附近随机波动,这意味着几乎没有自相关。 这通过样本自相关函数图得到证实。我们看到自相关相当弱,都在零左右,因此很难使用例如 a r 模型来预测未来的结果。 armagarch 模型,自回归 a r 模型、移动平均 m a 模型和自回归移动平均 arma 模型。这些模型将帮助我们尝试捕捉或解释更多存在于金融时间序列中的相关性,最终,它们为我们提供一种预测未来价格的方法。 然而,众所周知,金融时间序列具有波动性剧类的特性,也就是说,该波动性在时间上不是恒定的。 这种行为的技术术语称为条件一方差。由于 a r, m a 和 r 模型不是条件一方差的,也就是说他们没有考虑波动性剧类,我们最终需要一个 更复杂的模型来进行预测。此类模型包括自回归条件一方差 arch 模型和广义 自回归条件一方差高尔驰模型集齐许多变体。高尔驰在量化金融领域尤其出名,主要用于金融时间序列模拟作为估计风险的一种手段。 一个 arma 模型有两个部分, ar 部分和 ma 部分。 a r 将自己过去 的行为视为模型的输入,并以此尝试捕捉市场参与者的影响,例如股票交易中的动量和均值。回归 m a 部分用于表征一系列冲击信息,例如意外的收益公告或意外事件,例如 bp 深水地平线漏油事件。 其中 l 是滞后算子, absalon 是白噪声。我们可以使用 p, a, c, f 涂来识别 a, r 之后接触和 a, c, f。 涂来识别 m, a, 之后接触或使用 a, i, c, b, i, c 等信息准则进行选模型。 arima 是 arma 的推广,通过添加一个待界的差分部分。对于非平稳过程, 本视频中我们讨论了自回归综合移动平均模型和自回归条件 一方差模型及其在股市预测中的应用。 著名的广义自回归条件一方差模型也称为 guarch。 guarch 在金融业中被广泛使用,因为许多资产价格是有条件的一方差的。 研究金融条件一方差的主要动机是资产收益的波动性。波动性在金融领域是一个非常重要的概念,因为它是风险的高度同义词。 波动率在金融领域有着广泛的应用。期权定价期权价格的 black scores 模型取决于标的的波动性。 风险管理波动性在计算投资组合的沃尔交易策略的下谱比率和确定杠杆方面发挥作用。 可交易证券现在可以通过引入波动率指数 v i x 以及随后的期货合约和 etf 来直接交易波动率。 因此,如果我们能够有效的预测波动率,那么我们将能够更准确的为期权定价,为我们的算法交易组合创建更复杂的风险管理工具,甚至提出直接交易波动率的新策略。 我们现在将注意力转向条件一方差,并讨论他的含义。条件一方差让我们首先讨论一方差的概念, 然后检查条件部分。如果我们有一组随机变量,例如时间序列模型中的元素。如果较大集合中的某些变量组或子级与其余变量具有不同的方差, 我们就说该集合是一方差的。例如,在表现出季节性或趋势效应的非平稳时间序列中,我们可能会发现序列的方差随着季节性或趋势而增加。这种形式的规则变异性称为一方差。 然而,在金融领域,方差增加与方差进一步增加相关的原因有很多。例如,如果股票市场遇到大幅下跌, 他可能会触发自动风险管理,卖出订单。浙江进一步压低这些投资组合中的股票价格。由于较大的投资组合通常是高度相关的, 这可能会引发显著的下行波动。这些抛售时期以及金融中发生的许多其他形式的波动导致一方颤 性是序列相关的,因此,一方差增加的时期为条件。我们说这样的是条件一方差的。 什么时候用 gartch 比较合适?那么我们可以采取什么方法来确定 gartch 模型是否适合应用于序列?考虑一下,当我们试图你和 ar 一时,我们关心的是序列相关图上第一个滞后的衰减。 但是,如果我们将相同的逻辑应用于残叉的平方,并查看我们是否可以将 ar 一应用于这些平方残叉,那么我们有迹象表明 guarch 过程可能是合适的。 请注意,格尔应该只应用于已经有适当模型的序列,该模型足以使残叉看起来像离散的白噪声。由于我, 我们只能通过对残叉进行平方核检查相关图来判断 guarch 是否合适,因此我们还需要确保残叉的均值为零。 至关重要的是, gartch 应该只应用于没有任何趋势或季节性影响的序列,仅没有明显的序列相关性。而来嘛,通常应用于这样的系列。此时而来嘛, garch 可能是一个很好的选择。 广一自回归条件一方差 gartch 模型定义一个时间序列,在每个实力中 有以下方式给出, 其中 w 是离散白噪声, 均值和单位方差为零,并且 sigma 是 alpha 和 bater 是模型的参数。我们说是 p q 街的广义自回归条件一方差模型即为 guarch。 通常我们从模型的最简单情况开始,即 p 等于一, q 等于一的情况。这意味着我们将考虑单个自回归滞后和单个移动平均滞后。 接下来,我们 在 r 软件中实际操作,读取 r 中的数据文件,并将其存储在变量中。 绘制原始股票价格 原始序列插分 会图,拆分系列, 获取原始序列的对数,并绘制对数价格 对数差分价格合图。 要说 收益与股票价格的百分比变化相似, a r i m a 模型。 根据这种方法将选择具有最低 ah 的模型。在 r 中执行时间序列分析时,程序将提供 ah 作为结果的一部分。 但是在其他软件中,可能需要通过计算平方和并遵循上述公式来手动计算数字。当使用不同的软件时,数字可能会略有不同。 参数估计, 要估算 参数,请执行与先前所示相同的代码。结果将提供模型每个元素的估计。使用 arrms 三一三作为选定模型。结果如下, 请注意,根据我们编写代码的方式, r 将对同一模型给出不同的估计。 因此,残叉显示了一些可以建模的模式。 arch g a, r, c, h 对模型波动率建模很有必要。 顾名思义,此方法与序列的条件方差有关。 从 r 起到 r 八的 ah 级 减少,然后在 r 九和 r 十中 a h 增加 r 八式所选模型。 我们在分析中还包括 r 尺零,因为它可以用作检查是否存在任何 r 效应或残叉是否独立 执行 r g, a, r c h 模型的二代码 h8 的输出。 除第六个参数外,所有参数的 p 直均小于 0 05, 表明他们具有统计学意义。 此外, barks 个张检验的屁值大于零点零五,因此我们不能拒绝自相关的假设。残差的职 不同于零,因此该模型足以表示残差。 二零一二年七月二十五日,苹果发布了低于预期的收益报告。此 此公告影响了公司股价,导致该股票从 2012 年 7 月 24 日的 600 92 美元跌至 2012 年 7 月 24 日的 574 97 美元。 公司发布正面或负面新闻时,这是经常发生的意外风险。但是由于实际价格在我们百分之九十五的致信区间内,并且非常接近下线应, 因此我们的模型似乎可以成功预测该风险。 生成一步预测一百步预 预测预测图 计算 hg 条件方差 生成对数价格上限和下限百分之九十五的图。 对模型的最终检查是查看 a r i m a r 模型的残叉的 qq 图。我们可以直接从 r 计算出来,然后绘制 qq 图以检查残叉的正态性。
175拓端tecdat 11:48查看AI文稿AI文稿
11:48查看AI文稿AI文稿大家好,这一次的内容是这个马尔克夫预测啊,当他是一个预测模型,其实呢他的这个呢计算原理并不复查啊。 我们首先看一下这个帮助手册里边的一个啊说明啊,那在这个地方找到这个马尔克夫的话,很简单啊,说这个马尔克夫啊,或者是说他的这个英文单词啊,也可以啊。 哎,预测这个未来状态和当天状态的这种关系导致的一个明天应该怎么样子啊?那么那个简单的一个例子啊,一个简单的一个例子, 比如说啊,我们当前的这个啊,中国的这个通讯市场啊,那么有三个,三个大的这个 啊,公司的一个叫做啊,联通啊,移动还有电信,对吧?就这三家公司,那么他们呢,事实上各自有这个啊市场份额,比如说啊,我们简简单的一个假定,他的市场份额分别是 百分之五十五啊,百分之二十五和百分之二十啊,移动是老大啊,这其次是这个电信啊,最弱的可能是联通啊,那么嗯, 企业和企业之间呢,他都有这种竞争关系啊,竞争关系呢,就像我们当前有一个叫做啊携号转网,那就因为就说你本来用这个啊,移动的这个手机号,对吧?你可以不用换你的号码,然后呢变到这个联通里面 啊,这个通讯公司去,也可以编到这个啊,电信通讯公司啊,当然了,你可以保持原样啊, 还是使用我们的这个移动的啊啊,如果说哪家公司的这个服务质量差一点,你不满意,那你就可以自动的这种转网,对吧?啊,类似于说,比如说我们的这个啊,白酒市场啊,他也是一样的啊,那 假设说啊,大家都在竞争,你可能现在呢是喝这个五粮液啊,那明天呢,你可能是喝茅台,他是不是有这种转换, 那么啊我们的马尔科夫预测呢,就是基于当前的一个啊市场份额啊,就当前的一种状态,那么状态呢,就指的是说你现在属 处的那个环境,你比如说你当前在用移动的号,那么就属于啊你当前的一个状态情况,那么啊初始概率值呢,就是当前的一个市场份额情况,那么啊如果说这 个啊,基于当前的这个市场份额,就是当前的这个初始职的情况,然后呢你明年或者是后年啊,那有可能呢你的这个状态会转移啊?什么叫转移呢?你就刚刚说的,你本来用移动的啊,后面呢?你 边去用了这个电信,对吧?也可能是本来用移动的啊,那后面跑去用了我们的这个联通,对吧?他是有一个概率的,那么由这个概率组成的一个举证呢,就叫做我们的这个状态转移举证啊,状态转移举证啊,类似于我们图里边的这里啊, 一个叫做初始举证,初始举证呢就是当前的这个市场份额情况,然后呢这个状态转移举证呢,就指的是说啊以后他的这个转移状况,比如说这个当前你是使用我们的这个移动的, 对吧?啊?有百分之八十的可能呢,你接着还是使用我们的这个移动,有百分之十五的可能呢,他接下来要用我们的这个电信,还有百分之五的可能呢,他要用这个联通,对吧? 也或者是说我你当前使用我们的电信手机号,那么还有百分之二十的可能性呢,哎,以后你要用移动,还有百分之七十八的可能呢,你要用这个电信,就是你不转 转网呗。啊?还有百分之二的可能性呢,你要用联通,对吧?啊?那就哪一家服务质量更好,那么他可能被转移的这个概率会更高啊?啊?对吧? 那是这,这是我们的这个状态转移举证,基于这个转啊,状态转移举证不停的这样的循环下去,不停的这个循环下去,最终最终可能隔了很多年以后,这个是 市场情况应该怎么样子?最重要达到一个什么样的一个效果啊?他才达到我们的这种市场均衡状态。哎,这就是马尔克夫他能做的一个事情啊。啊,那么比如说这种呢?一般通常用于我们的这个啊市场份额的一个评估, 你比如说啊,当前的这个搜索引擎市场,或者是说电子商务,对吧?有这个他吧,有 天猫,还有我们的京东,还有我们的这个拼多多啊,或者是说还有我们的抖音,还有快手,有很多家竞争对手,那么啊,如果说哪一家的这个服务不太好啊,那么你可能就转移去别的家去,或者哪一家 他的这个综合啊让你感觉到更舒服,那么啊你就更可能保留在这一家消费,对吧?啊?这就是我们的这 马尔克夫他要做的一个事情啊,那么我们接下来啊,呃,知道了这个大概的这个原理啊,事实上呢,他只有两个数据,一个就是这个促使概率值,还有一个呢,就是这个转移矩阵,对吧?啊,那你输入了之后呢,让这个系统办理自动办理器算就可以, 那么我们刚刚说过要最终要达到一种均衡,什么样叫做均衡呢?就是说来回的这个啊,变化的这个收敛的, 呃,条件达到什么样子啊?那么在这个地方可以选择一个参数啊,我们来看一下这个啊操作啊,当然了,这个啊系统里面有一个啊值啊,我们可以把这个数据啊自己去 对他进行这个手工的输入啊,或者是已经有了呢,进行粘贴也可以啊,比如说我们这个是零点五五,对吧?啊?零点二五, 还有一个是零点二零,这是三个初始的状态值,那么这个状态一二三呢?你可以换成叫做啊这个文字啊,比如说移动啊,电信,联通,对吧?第二个是我们的这个啊,电信啊啊,下面这个叫做联通, 然后呢这里会有这个啊,状态转移概率,对吧?啊?零点八,零点一五,还有一个是零点零五啊,对着自己输入一下,或者是说在 cu 里边已经有了数据,直接粘贴过来就可以啊, 零点零五,零点二,还有一个是零点七五啊,啊,我们已经输入完成,对吧?啊?这个收敛条件呢,我们是千分之一啊,什么叫 千分之一呢?就是说他不停的叠带啊,不停的叠带,叠带了之后呢,达到了这个这个精度,这个误差值在千分之一的时候呢,就让他停止啊,就让他停止啊,这是收敛条件,但可以选择其他的啊,千分之一是一个正常的啊,就是一个常规的一个字啊,我们开始分析, 分析出来第一个表格呢,就是这个初始概率啊,这个初始概率啊,啊,还有一个是状态转移举证啊,这两个其实都有了啊,只是说他重新展示了一下, 这里有个状态转移图,对吧?状态转移图呢,就是把这个转移的情况,你比如说移动现在的市场 是百分之八十,对吧?嗯,啊,不对啊啊,移动的这个市场份额现在是百分之五十五啊,这个状态转移图呢,是把这个状态转移举证的。这九个数字你有三种状态,对吧?啊? 三三得九,就九个数字,把它展展现在这个图上啊,比如说移动啊,后续他还是使用这个移动,那么他的这个可能性是零点八,对吧?啊?他的可能性是这个零点八,然后联通还是使用联通是零点七五,电信还是使用电信是零点七八啊?这个 他只是用一个图的形式来制啊,展示出来而已啊,这个图啊啊?然后呢?哎,最核心的就是这个啊,概率分布图啊, 比如说啊,你下一年的时候啊,当前的这个状态是这个啊,第零次就是当前状态,那么啊按照这个转移的情况,下一次呢?就是啊,是这样子,如果说你是一年为一个单位,对吧?就是明年是这样子 啊,那后年是这样的一个概念啊,再往后面,再往后面一直持续,那么啊最后要收敛,要达到一个市场均 均衡。什么叫市场均衡呢?就是说那个收敛条件我们刚刚默认是千分之一,对吧?啊?那么啊,这个,呃,这个大概是第十次的时候啊,其实已经就差不多了,那么最终就达到一种均衡, 本身呢,我们最初的时候啊,移动它的这个啊,市场份额是啊,百分之五十五,对吧?一共是百分之五十五,电信是二十五,联通是百分之二十,那么到第十次的时候啊,基本上就收敛了啊,移动会变成四十五,百分之四十五,电信会变成百分之四十二 啊,联通会变成百分之十二点七,对吧?啊,这里呢,系统会默认是会再多给出一次啊,多出十一,第十一次来验证,说我们的这个确实是千分之一的一个误差啊,这个值减去他肯定是千分之一啊,肯定是千分之一啊,一 机呢,其实第十次减去第九次的这个指啊,也小于千分之一啊,他也是小于千分之一的啊啊,这就是我们的这个啊,马尔克夫预测的一个啊 啊,说明啊啊,系统会多给出一次啊,多给出一次用于验证,确实是这个误差已经达到了千分之一。四十三年看的时候呢啊,看第十次啊,那么或者是看第十一次,其实这两个也差不多啊,因为他的误差很低了,你的目的是用于研究这个预测 啊,最后的一个市场均衡状态,那么你看这两个啊,第十次和第十一次的都是 ok 的啊,最后两次的都 ok 的啊,这就是我们的这个马尔科夫预测啊,那么除此之外呢,在这个系统里边啊啊,我们除了支持这样的 一个格式,这个格式很重要啊,一定是这样的一个格式, da 列呢,是要传出我们的这个出手概率值啊,后面是一个啊,状态转移矩阵,对吧? 那么有的时候呢,我们的这个数据啊,他没有这个初始概率者,这样啊,也没有这个啊,状态转移矩阵啊,这个,但是呢他有一个更原始的数据。什么叫更原始的数据呢? 他其实会有一个状态数据啊,状态数据。我们来看一下什么叫做我们的这个啊?状态数据啊, 其实呢就是一连串数字,你不就是像这种啊,就这个啊,就是这个状态数据,你比如就是说一代表说,比如说我们的这个移动,二代表我们的电信,三代表我们的联通,他不就是先用一再用二,然后又 用一再用三这样子来回的切换吗?对吧?这样的一个状态数据,那么啊如果说给定的是这样的状态数据呢, 那么也可以在系统里面呃,下拉选择啊,状态数据他就是一列单独的数据啊啊 啊,在这个选择啊,比如说我们这有个数据啊,单独的一列数据,全部都是这种一二三一二三的转移,呃的这种数据,那么系统也会自动帮你计算出来的啊, 但是绝大部分的情况下呢啊,都是我们的这个啊提供已经有了数字概率值和我们的这个啊对应的这个叫什么东西啊?将我们的这个状态转移取证,进而来来计算我们 最终的一个啊,市场均衡的一个啊,概率情况,或者叫做实际意义叫做市场分布情况,那么这是我们的这个马尔科夫预测啊,谢谢大家。
106SPSSAU 04:55查看AI文稿AI文稿
04:55查看AI文稿AI文稿时间序列分析被广泛应用于预测和预报未来数据点的时间序列。 rim 模型是一种常用的时间序列预测方法之一。 本教程将介绍如何在拍葬中构建和评估瑞曼模型。瑞曼模型是一种用于分析和预测时间序列数据的统计模型。他针对时间序列中的常见结构提供了一种简单而强大的方法,用于进行精确的时间序列预测。 rima 代表自回归 auto regressive、 积分 integrated 和移动平均 moving average。 它结合了这三个关键方面, 自回归 ar 使用当前观测值和滞后观测值之间的相关性来建立模型。滞后观测值的数量称为滞后接数或批积分。 i 通过对原始观测值进行差分来使时间序列平稳 划分的次数称为 d。 移动平均 ma 模型考虑了当前观测值与过去观测值的移动平均模型的残差错误之间的关系。移动平均窗口的大小为接数或 q。 rim 模型的表示为 rima, p d, q。 其中 p d 和 q 是用整数值替代的参数,用于指定所使用的具体模型。使用 remain 模型时的关键假设时间序列是由基本的 remain 过程生成的 参数, p, d 和 q 必须根据原始观测值进行适当的选择。在你和瑞玛模型之前, 时间序列数据必须通过差分使其平稳。如果模型你和良好残差应该是不相关的,并且符合正态分布。总之,瑞玛模型提供了一种结构化和可配 配置的方法,用于对时间序列数据进行建模和预测。接下来的视频将介绍如何在拍放中你和瑞玛模型拍放代码视力。在本教程中,我们将使用开勾上提供的 netflix 股票数据来使用瑞玛模型预测 netflix 股票价格数据加载。 该势力会加载一个带有日期列作为所引的股票价格数据级。数据可视化可以使用 pandas 的 pro 函数来可视化随时间变化的股票价格和交易量。很明显,股票价格呈指数增长。 该视力的数据级已分为训练级和测试级,并开始对瑞玛模型进行训练,并进行了第一次预测。由于通用的瑞玛模型产生了平直的线,因此该视力决定尝试滚动预测方法。 注意,代码视力是 bug the new knot book 的修改版本处理时间序列数据时通常需要进行滚动预测,因为他依赖于先前的观察结果。一种方法是在接收到每个新观察结果后重新创建模型。为了跟踪所有观察结果, 可以手动维护一个名为 history 的列表。该列表最初包含训练数据,并在每次迭代时将新的观察结果追加到其中。这种方法可以帮助我们获得准确的预测模型。 模型评估该视力中的滚动预测。瑞玛模型相对于简单实现显示出了百分之一百的改进,产生了令人印象深刻的结果。接下来将对实际结果和预测结果进行可视化和比较。显然,该视力的模型进行 了高度准确的预测结论。在这个简短的教程中,我们提供了瑞玛模型的概述,以及如何在拍放中实现时间序列预测。瑞玛方法提供了一种灵活而结构化的方式进行时间序列数据建模,他依赖于先前的观察结果和过去的预测误差。 推荐书单拍葬从入门到精通第三版拍葬从入门到精通第三版从初学者角度出发,通过通俗易懂的语言、丰富多彩的实力, 详细介绍了使用拍藏进行程序开发应该掌握的各方面技术。全书共分二十七张,包括初识拍放、拍放语言基础运算符与表达式、流程控制、语句列表和原组字典和集合字符串。拍放中使用正则表 答式函数、面向对象程序设计、模块文件及目录操作操作数据库使用进程和现成网络编程、异常处理及程序调试、拍 game 游戏编程、推箱子游戏、网络爬虫开发、火车票分析助手、 数据可视化、京东电商销售数据分析与预测、 web 编程、 flask 框架一起去旅行、网站 开放、自动化办公、 ai 图像识别工具等内容。书中所有知识都结合具体实力进行介绍,涉及的程序代码都给出了详细的注视,读者可轻松领会开放程序开发的精髓,快速提升开发技能。
132编程学研 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿做临床的医生小伙伴应该都会接触大量的临床数据,但是如何利用自己手上的数据做出高质量的文章还是一个难题。今天小薇就给大家分享一个提升文章档次和内容的知识。用 spss 的 logistic 回归构建预测模型, 我们以下面这个案例来具体看看如何构建模型。某研究人员,你建立一个关于冠心病患者支架,介入书后再次发生 mais 事件 major advice cardiovascular events 主要心血管不良事件的风险预测模型。数据扩格是如下图所示,其中应变量结局事件为 event 自变量影响因素为,性别、 gender 年龄 h 索索亚 sdp、 吸烟、 smoking、 低密度脂蛋白胆固醇、 ldl 及官脉病变 syntax 群分 syntax。 下面 开始具体的数据分析,一、分析 analyze 回归 regression 二、元 logistic 回归 binary logistic regression。 二、将 in 变量 event 选入 in 变量 dependent 空中,将各个自变量选入协变量 coverage 空中。三、点击保存 save, 在预测值 predicted values 下勾选概率 probabilities, 目的是为了在数据库中新生成一个概率值,用于绘制 rock 曲线和较准曲线图。 四、点击选项 options 勾选 housemailed so goodness of fate, 用于输出 housemailed soul 你和优度检验的结果。五、 输出结果方程中的变量 variable in the equation 中输出了每个影响因素的回归系数, battle or 值百分之九十五 ci 以及批纸等信息。回归方程如下, logicp 等于 余减六十八点八,二八减十点二三三 jane 加一点二五七 aj 零点一九五 sbp 一点二零五 smoking 加十点三一二 ldl, 零点九四三 syntax。 以上就是今天的分享内容,是不是很简单呢?有了这个利器,你就可以把手里的临床数据利用起来了。
273云生信生物信息 00:22查看AI文稿AI文稿
00:22查看AI文稿AI文稿两步搞定灰色预测模型分析。第一步,导入数据选择分析方法,灰色预测模型分析。第二步,拖转样本查看结果,自动生成 gm 模型、 笔直表格模型构建结果模型预测值表格、 gm 模型、检验表模型礼盒和预测图分析结果超清晰,可以导出多种格式,还可以参考智能分析结果和分析建议哦!
413SPSSAU 01:53查看AI文稿AI文稿
01:53查看AI文稿AI文稿标准的瑞曼移动平均自回归模型允许只根据预测变量的过去值进行预测。该模型假定一个变量的未来的直线性的取决于其过去的值以及过去随机影响的值。 remax 模型是瑞曼模型的一个扩展版本,它还包括其他独立预测变量。 该模型也被称为像量瑞娜或动态回归模型。 remax 模型类似于多变量回归模型,但允许利用回归残插中可能存在的字相关来提高预测的准确性。本文提供了一个进行 remax 模型预测的练习,还检查了回归系数的统计学意义。





