var模型的建模步骤
向量自回归 v a r 是一种用于多变量时间序列分析的统计模型,尤其是在变量具有相互影响关系的时间序列中。本视频中我们介绍了向量自回归,并在 r 软件中进行实现。 为什么用项链自回归?为了能够理解几个变量之间的关系,允许动态变化。为了能够得到更好的预测, 一组时间序列由多个单一序列组成。我们在建立时间序列模型时说,简单的单变量 arma 模型可以很好的进行预测。 那么为什么我们需要多个序列?例子,如 cpi 反应的是通胀, cpi 高了,通胀风险大,而意志通胀最重要的手段就是加息。反之,当 cpi 很低就说明经济不景气,那么就需要降息,降息之后刺激经济增长。 因此,可能需要一个联合的动态模型来了解动态的相互关系,并可能做一个更好的预测工作。在观察 a, r, n a 和 gark 模型时,您会立即注意到估计和预测 是针对一个变量进行的。在现实生活中,这并不成立。实际上,还有许多其他变量可能会影响变量。市场参与者和经济学家总是对宏观经济变量与他们有兴趣购买的资产之间的动态关系感兴趣, 此操作可以帮助他们预测市场上可能发生的潜在情况。使用 vr 模型的基本要求是具有至少两个变量的时间序列。 变量之间存在动态关系。他被认为是一个自回归模型,因为模型所做的预测取决于过去的值,这意味着每个观测值都被建模为其治后值的函数 rema 和像量字回归模型之间的基本区别在 于,所有微骂模型都用于单变量时间序列,其中向量自回归模型是用于多变量时间序列。此外,微骂模型是单向模型,这意味着因变量受其过去值或至后值本身的影响。其中向量自回归是双向模型, 这意味着因变量受其过去值或另一个变量值的影响或受这两件事的影响。 什么是项链子回归?项链子回归模型是统计分析中经常使用的模型,他探索了几个变量之间的相互关系。 在开始建模部分之前,让我们先了解一下模型背后的数学 学。单变量时间序列的典型自会规模型 arp 可以表示为,其中 yti 表示较早时期的变量值。 a 是一个时不变的 k 成 k 矩阵, et 是一个误差相, c 是模型的拮据。 这里接触批的意思是最多使用歪的批滞后。 众所周知,项链资回归模型处理的是多元时间序列,这意味着会有两个或多个变量相互影响。因此,项量资回归模型方程随着时 间序列中变量数量的增加而增加。假设有两个时间序列变量 y 一和 y2, 因此要计算 y e t。 项量自回归模型将使用两个时间序列变量的滞后。 例如,具有两个时间序列变量 y 一和 y2 路 r 一模型的方程如下所示, 其中 y e t 减一是 y 一的第一个制后值, y 二 t 减一是 y r 的第一个制后指。并且具有 y 一和 y r 时间序列变量的 y 二模型的方程将如下所示。 我们可以清楚地了解模型的方程将如何随着变量和滞后值的增加 而增加。例如,具有三个时间序列变量的哇三模型方程如下所示。 所以这就是批职将如何增加模型方程的长度,而变量的数量将增加方程的高度。 选择模型的滞后数有两种主要方法可以选择模型的滞后数。经验方法,我们使用信息标准推理方法包括使用假设检验。 我们只考虑信息标准有三个,流行的信息标准及吃吃信息准则, aic, 施瓦茨贝伊斯 bake, 汉兰奎恩 hq。 实际上,最佳制后数是信息标准最小的制后数。然后我们估计 p 等于零到 px 的 vip, 并选择最小化 a, i, c, v 或 hick 的直 p。 以下是考虑标准的以下公式。 项链自回归模型的估计包括以下步骤,选择最佳滞后长度。信息标准 ic 用于确定最佳滞后长度,最常用的是 ak ic hana 昆准则。 平稳性检验下一步是估计变量的平稳性。一种广泛使用的估计平稳性的方法是增广敌机附勒检验和菲利普斯配龙检验。如果变量 是非平稳的,则应采用一阶插分,并以相同的方式测试平稳性。 斜整检验,变量可能是非平稳的,但具有相同接触的积分。在这种情况下,可以使用矢量纠错模型 like, 而不是向量自回归来分析它们。如果变量是斜整的,则在以下分析中应用歪痛,而不是向量自回归模型。 mac 被用用于非变换的非平稳序列,而向量自回归使用变换的或平稳的输入 模型。估计使用选择的滞后数和具有标准误差的系数运行向量自回归模型,并计算相应的提统计量以评估统计显着信 诊断测试,接下来使用 boss govern 检验对模型进行血液相关性检验,使用 boss pagan 检验。一、方差性和稳定性。 脉冲响应函数 i r f i r f 用于以图形方式表示向量自回归模型的结果,并预测变量对彼此的影响。 向量自回归在以下几种情况下很有用。向量自回归面临的一个批评是,他们是非理论的,也就是说他们不是建立在某些将理论结构强加于方程的经济理论之上。 假设每个变量都会影响系统中的所有其他变量,这使得对估计系数的直接解释变的困难。 尽管如此,向量自回归在以下几种情况下很有用,一、在不需要明确解释的情况下预测相关变量的集合。二、测试一个变量是否对预测另一个变量有用。格兰杰因果检验的基础。三、 脉冲响应分析,分析一个变量对另一个变量突然但暂时变化的响应。四、预测误差方差分解。其中每个变量的预测方差比例归因于其他变量的影响。 接下来我们在 r 软件中实现。 接下来我们在 r 软件中实现。 本视频中我们考虑 vr。 二、过程估算值简单, vr 模型的参数和斜方差距真的估计很简单,为了估计 vr 模型,加载并指定数据 y 和模型 比较。摩尔分析中的一个中心问题是找到滞后的接触以产生最佳结果。模型比较通常机遇信息标准,例如 a, i, c, v, ch, u。 通常由于其有利的小样本预测功能, a i c 优于其他标准,但是贝克 h t 又在大型样本中效果很好。在此视力中,我们使用 a i c。 通过查看 summary word ache, 我们 可以看到 aic 建议使用 r 的技术 仔细观察结果。我们可以将真实纸与模型的参数估计值进行比较,所有估计值都相对接近其真实纸 脉冲响应。一旦我们确定了最终的沃尔摩型,就必须解释其估计的参数值。由于沃尔摩型中的所有变量都相互依赖,因此单个参数值仅提供有限信息。 为了更好的了解模型的动态行为,使用了脉冲响应 i r。 他们使音变量对脉冲变量中的一次性冲击的反应可以绘制音变量的轨迹,从而产生在许多宏观论文中 都可以找到的那些波浪曲线。在下面的视力中,我们想知道序列二受到冲击后的行为。指定了我们想要脉冲响应的模型和变量后,我们将时间范围设置 n 点, ahead 为 20。 该图给出了序列 r 的响应。 请注意,正将选项很重要,因为它说明了变量之间的同时关系。 要了解这一点,还可以计算并绘制累计脉冲响应函数,以了解总体长期影响。 我们看到,尽管序列二对序列一中的反应在某些时期是负面的,但总体效果却是显著的正面。

粉丝1205获赞6006
相关视频
 20:27查看AI文稿AI文稿
20:27查看AI文稿AI文稿哈喽,大家好,那么今天这期视频呢,给大家分享一下呃,时间训练数据比较常用的模型,也就是 也就是向量字回归模型,就是我们通常所说的 var 模型。那么向量字回归模型呢,主要是把系统中每个内声变量都作为系统中的 呃所有类声变量的一个最后值函数来构造模型。呃,从而使这个单单变量的时间序列可以推广到多变量的时间序列,然后建立这种向量字回归模型。 那限量字回归模型通常是用于描述多变量时间序列之间的一个变动关系。嗯,是一种比较呃非结构化的模型,那么操作相对来说是比较简单。呃,因为有一套比较成熟的流程,所以使用比较广泛, 那么后面我们都简称 v a r 模型。嗯,接下来我们就直接开始吧,然后还是跟之前一样。嗯,首先呢,左边是我的数据,右边是呃一些主要的代码。嗯,那么首先还是要介绍一下我的数据情况, 我这个其实就是把呃,很我我,因为我之前的教学都是围绕面板数据吧,所以这个数据其实就是我把面板数据就是 调整了一下,然后改变成了时间序列数据。嗯,那我我我选的是一九七,我就把它命应该是我改改的, 改成了一九七八年到二零二二年的时间训练数据,然后面是音变量 y, 然后自变量 x, 控制变量 c 一到 c 一到 c 七,这样子,大概这样子, 那么这里强调一嘴,就是这面的空处。呃,控制变量本身呢,也是自变量,只是我们习惯把本次研究重点关注的变量叫做核心解释变量或者是自变量,那么其他这些相对不那么重要的变量,我们就叫控制变量,实际上在做模型的时候呢,都是一样的处理方式。 呃,这就是我的一个数据情况,那么再强调一下就是做 vr 模型最重要的就是一定要弄清楚里面的操作逻辑, 必须遵循一定的流程,因为我做模型教学是我手上有什么数据就用什么数据,那么可能会出现什么你和优度差检验不通过这些情况,大家在做的时候呢,就按照每个检验和模型要求来,如果通过就做那一步,不通 过就在哪一步吗?然后接下来我们就一步步的开始吧。呃,首先呢时间训练,数据最重要的就是一定要平稳,要不然很容易会出现违回归现象,那么 vr 模型也是要要求所有的因子数据要通接斜诊,也就是 n 个自变量, 应该是 n 个变量里面如果有一个变量数据不平稳,那么就要做,就要全体做差分,一直到平稳为止啊。那么首先我们直接开始,首先我们是要设置的一个时间序列,这个比较简单, 我的时间训练是我的时间变量是 year。 然后接下来我们进行单位跟检验,单位跟检验就很简单,我们就代过我们先做我们的 y, 呃,很明显这里是零,呃,零点二二,就是明显是没有通过的皮值,那么我们要对它进行呃一定的差分, 差分呢就是 d 点 y 就可以了,就是 y 的差分比较简单把音变量 y 就是差分一接,然后就通过了单位跟检验,那么接下来呢?我们做 x 也要把它进行之后一接和差分一接, 我们看到 x, 呃插分一阶之后也是平稳的,那我们可以尝尝试一下做一下它不插分之后是什么样的。你看 x 它 也是不平稳的,就是原始的 x 不平稳的,所以要是差分后的 x 它就是平稳的。那么我们再做一个呃,控制边做一个 c e 吧。 呃, c e 也是之后差分一。不好意思,我总是把差分和之后总是喜欢读错。嗯,差分之后,嗯, difference 差分,然后之后是 lag a 二点 c e 就是 c e 的,呃,之后 d 就代表的是差分, 呃,他差分了一阶之后也是显著的,我们也可以试一下他不差分的,他的原始数据是否是平稳的, 也明显是不平稳的。所以我们我们是做到了同阶斜正,嗯,就是我们所有的变量同时差分一阶是平稳的,那么既然他差分之后才做平稳,嗯,所以我们需要做 下鞋诊检验。如果说我们做的时候原始数据就是平稳的,我们可以直接进行隔难检检验之类的。如果他不平稳,那我们就需要做一下鞋诊检验,这里他虽然原始数据不平稳,但是他是呃一节差分后是平稳的,所以做鞋诊 写真检验,我们是 y x 和 c e, 我们是这样的一个回归,先跑个回归模型,然后保存一下相关数据再来检验 写真也比较简单,到时候我会把带我会把这个文章都放在知乎文章里面,嗯,大家可以去复制粘贴学习。 嗯,好了,我们可以看到写写整检验这里,呃,因为百分之五的临界值应该是负的两点七六,然后这边的统计值它是 呃一点六,所以说意味着是不能拒绝不存在携程关系的原假设。因此呢,这呃我们的 y、 x、 c、 e 是存在一定的,呃是存在着长期稳定的均衡关系的,所以我们可以进行后续的一个模型分析。 那么斜针检验,那么单位跟检和斜针检验是比较简单的,呃,接下来就回归到正题,就是我们的 vr 模型, 那么 vr 模型呢,最重要的一步就是要确定一个呃最优的之后接触,因为后面之后的所有操作都是在这个最优的之后接触中进行的。呃,那么确定最优之后接触也比较简单, v、 r、 s、 o、 c 就可以了,然后后面加上变量笔 y、 x、 c、 e, 确定最后之后结束, 呃,确定最后之后结束,就是把呃寻找这个里面信号最多的那一行就是最右的之后结束。我们可以看到这里他之后一阶是有两颗星,但他之后二阶有一、二三有 三颗星,所以我们呃基本上估计是选择确定了最优的之后二键。 那么这边强调一下就是,呃,很多时候大家呃一方面是想要使得之后接触足够大,我们可以充分利用所构造模型的变量信息,但是呢,另一方面之后接触是不能过大的,因为之后接触越大,需要估计的参 数越多,模型的自由度就会减少,所以如果数据有限的话,可能是不足以估计模型的。那么这个例子中我们选择之后两件, 那么接下来呃确定了最后之后结束我们就进行呃,我们就建立 vr 模型,其实建立 vr 模型这一步是最简单的, 然后给大家强调一下,这前面就 vr y、 x、 c、 e, 大家都看得懂,后面的 lex, 这里的 n 的意思就是,呃,选择一到 n 七都进行分析,那么这里我如果我们选择是之后二,也就之后一阶和二阶都进行分析,我们可以看到这里的之后, 我们讲这里的之后一阶、二阶的回归结果都出来了,那么我们也可以单独设置指之后二阶,因为我们前面确定,最后之后接 呃确定呢就是两阶,所以我们这里也可以只做两阶的一个 vr 模型,那么我们只需要不是呃,只需要把这个 n 分之一 n, 这里直接写着之后二阶也可以就是只只做之后二阶的一个回归模型也是可以的。 那么这里我强调一下就是,呃,如果我们的原序列数据是非平稳的,但是经过差分后平稳,呃可以将,然后斜针减也是通过的,我们可以将同阶单诊的变量建立 vr 模型,那么这时候我们应该是对这个原始数据,我这里是对 原始数据建立的 vr 模型,因为这些变量是同阶单枕的,就是我我前面做了单位跟和斜枕吗是同阶单枕的,这至少是存在一个斜枕关系的,那么这些变量的一个线性组合是可 可以平稳的,那么这样我们是可以建立 vr 模型的,但是呢,我们也可以呃利用差分后的序列建立 vr 模型,但是模型的意义是差分后的序列,那么不是原始序列的 vr 模型可能是有不一样的,那么这里强调一下, 呃,如果我们的原始数据不平稳,呃,但是不斜整,那我们可以用差分后的序列建立 vr 模型,或者是建立 v e c 模型, 那么我这里直接建立 vr 模型是可以的。呃,那么 vr 模型建立之后呢,我们首先要进行一个单位跟的单位源的检验, 嗯,因为只要特征跟在单单位源里面就是稳定的,那么单位源检验也可以也很简单,但是他必须是在呃完成 vr 模型之后才能刨出来的啊, 大家这个顺序不要混淆了,然后他会出现一个图,那么这就是单位源的检验,你们可以看到这里面的点都在这个单位源里,说明我的变量是稳定的。呃,可以进行后续的一个脉冲响应和翻插分解分析,这里都在里面。 呃,那么单位语言检验做完之后呢,我们要进行一个格兰洁因果检验,那么格兰洁因果检验是检验统计上的一个呃,时间先后顺序,并不表示说这真正的存在了一个因果关系,那么是否是因果关系,我们还是要经过 呃,通过一些理论啊,经验和模型来敲定。那么呃 state 做格兰结应该解是比较简单的,就直接输入 vr, 然后格兰结就行了,但是这个命令也 也是在 vr 模型之后,呃,输入 vr 模型之后才能出现的。呃,那么很多人会用 evius 来做呃,格兰洁英国检验,因为那个做出来结果比较明了,就是比较好看。 嗯,这里我给大家解释一下这个这个隔难检验的检验怎么看。那么首先我以这个为例,这里 原假设是 x 不是 y 的格南街英国原英国原因,那么我们这边最后的 p 值是小于零点零五, 呃, p 小于零点零五,也就是要拒绝 h 零,我刚才说了 h 零是 x 不是 y 的格兰结约原,呃,英国检验,那么我们拒绝了,也就是 x 是 y 的格兰结英国原因,然后我们就可以用 x 的过去值来预测 y 的未来 材质。呃,所以我这个 vr 模型建立这个格兰洁英国检验是可以的, 所以我们一般是只要是有单项的。嗯,格兰姐,英国检验都可以是做脉冲分分析的,但是要注意的一定是解释变量,对, 必须是背结式,背结式变量的一个格兰结原原因,那么没有格兰结因果,原因可能就不特别不合适做脉冲脉冲分析吧, 但这里有很多争议,然后,呃,我觉得我的水平也很有限,我只能给大家讲解那种最常见的呃,一种情况吧。 那么这边格兰杰英国检验是通过,然后接下来我们就可以进行后续的一个脉冲 响应分析。脉冲响应分析代码比较简单,就是 i r f, 然后我们,呃,首先先创建一些, 首先创建一些文件,然后再来泡螨虫响应, 那么这里的脉冲响应我们需要改变的也就是我们这里的,呃,呃,这个是 y 是为响应的。呃, y 是脉冲响应,然后 x, 这里的 x 是冲击变量, y 是响应变量, 这里 respond 是响应变量,一般是背景是变量 y, 然后这里的是冲击变量 x, 但是这里可以不止一个 x, 还可以 s e x 二、然后我这边的数据我就放一个 x 和一个 y, 那我们跑完之后,它就会出现一个脉冲响应图。 呃,那我这个脉冲响应图很明显是不行的,因为一个合适的脉冲响应图,呃结果最后都应该是趋于零的,因为冲击最后都会呃消失的。如果是我最后是这种发散状的,说明是,嗯错误的。那么我这个 呃我的数据因为是我随便选取的,所以图不是特别合适哦,我是不是应该找一篇文章给大家分析一下,大家稍等啊,我找一个脉冲图给大家讲解一下。 呃,我这边我这里随便找了一篇,我之前呃一篇小文章里面的一个脉冲响应图,就是这种响应图,它最后 最后的是趋于零的,因为冲击最后肯定会趋于消失,所以我这里做的发散状呢,很明显是错误的。那么像这种呃脉冲响应图就是可以的,也就是我们当呃给予一个正向冲击后,呃,那么 y 他的反应是, 呃反应是都是在零以上,零零轴的上方,也就是响应是正响应,那么其实响应的方向是次要的,重要的是响应的一个剧烈程度和响应消失,呃,也就是响应的响应的一个时间。 那么我这篇文章,我我这里假设的,我的呃,我的是气温是冲击变量,然后我的秋,这里的秋是指我秋天的粮食,也就是气温对粮食的影响,那么秋天的粮食产量,我是作为一个响应变量, 所以我的气温前面这个是冲击变量,后面的这个是响应变量。那么我这张图显示,那么气温对粮食对秋粮的秋天粮食的产量,那么在前前大概三期左右是有一个明显的递增的正向冲击,那么且在第 第第三、三期达到一个最大值,然后到第四期,大概第四期那么冲击逐渐减少,那么到第十期以及以后就趋于零,那么影响逐渐消失,那么这种脉冲响应图大概就是合适的, 然后大概就是这么一个解释,呃,其实也比较简单,那么脉冲响应图一个是看他在临走的上方还是下方,然后看他一个,呃响应的一个剧烈程度和响应的个时间, 以及他消失的时间,那么如果他响应的时间很长,那么可能这个政策,嗯,那么那么可能这个政策,呃,对他的就是就是某一个事物对这个政策的反应是比较之后的,那么可能这个政策在短时间内是看不出来一个实施效果的, 所以这应该算是脉冲响应图的一个关键,那么具体还是要结合大家的理论知识去分析。 呃,脉冲响应图做完了之后,接下来就是做一个方叉分解,呃,分析每一个结构冲击对内声变量变化的一个贡献,我们可以反映对内声变量产生影响的,呃, 各个随机扰动的一个相对的重要信息,呃,也就是分析每一个冲击变量对结构冲击对变量的一个贡献程度, 然后通过方叉大小评价不同结构冲击的一个重要性。这里的 graph 的图,然后后面就是做表的一个 不好意思, 接下来做翻叉分解,然后我们先跑这个, 嗯,这边就是方叉分解,那么方叉分解的作用就是自变量 x 对应变量 y 的一个方叉贡献程度的大小,那么研究变量之间一个相互影响的程度,那么这张图 显示,那么排除自身的影响之外, x 对 y 变动影响的贡献度,我们可以看到,在前 前五期内吧,前六期,前七期吧,呃是呈现一个快速增长的一个态势,那么在后面之后就可以这个增长趋势逐渐进行了一个缓解, 也就是 x 对 y 变动影响的贡献度,那么在前五六七,在前七吧, 差不多前期七类,呃呈现快速增长的态势,那么第七期之后那么增长态势逐渐缓解,第七期,第七期啊,感觉读起来好拗口啊。 然后大概这就是 vr 模型的一个整体的一个流程,那么最后就是一个预测了,嗯,预测,首先先跑这个代码, 然后后面我要我们需要变的就是 p y, p x, 然后面也可以 p x 一 p x 二 p x 三就可以了,就对它进行一定的预测, 那后面这个 step, 这个就是呃跟呃是预测的一个数量, 二零二二一直到二零三零,大概就是这样子的,因为我这里写的是八嘛,二二二年加八,也就是 二八年,不对,二二年加八,三零年,不好意思,我怎么 什么智障?然后大概就是这个是 y, 他未来八年的一个预测值,这边是 x, 他把未来八年的一个预测值,因为我这边的我的 y x 是没有什么实际含义的,就是我把一个数据改一下,那么大家就根据自己的理论含义进行分析, 然后结合,呃,你结合理论政策之类的,然后对他为什么会呈现这么样一个结果前后进行分析, 那么整体 vr 模型就讲完了,嗯,相对来说它有一个固定的流程,所以比较简单。 那么他但是 vr 模型有一点很复杂的啊,就是他检验不通过的时候应该怎么处理,很多时候都存在争议,那么我的水平有限,不可能把所有可能出现的情况都一一的 就是列出来,大家可以根据自己的数据情况,那么遇到一个问题超文先解决一个,只要你觉得有依据,有支撑啊,那么其实没有那么多绝对的 相对,这就是一,那么相对来说这就是一个大概的一个流程,那么每个人的数据情况都是不一样的,大家就具体问题具体分析了。呃,那么今天这期视频就到这里结束了,非常谢谢大家的支持。
343小菲stata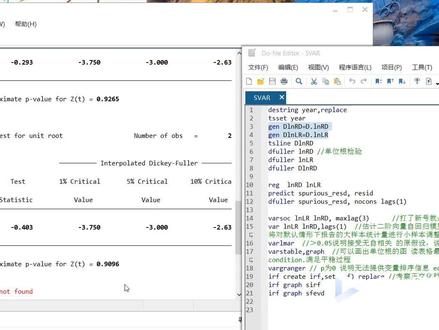 04:08查看AI文稿AI文稿
04:08查看AI文稿AI文稿各位同学大家好,今天介绍一下关于这个恶魔型的建立,基于斯贝塔。首先的话我们就是打开这一份,就是导入你的数据之后,首先我们要进行一个年份的设定, tsa, 然后的话我们第一步做的就是单位跟减,单位跟减有两种方法,第一种的话就是通过代码生成一些差分之后用 dflur 命令来进行做,我们可以运行一下, 然后这边的话就是我们生成的一个单位跟的一个结果,然后可以通过这个表格可以看出这个是对 love led 做了一届差分之后的一个表格,他的那个 z 指师傅的六点六三五 p 值是等于零的,所以可以拒绝人员假设,说明经过一些差分之后他是稳定的,同样我们也可以对那个呃利润也做一个同样的一个底分了。 嗯,第二步的话我们就是要做那个斜针减压,斜针减压的话主要是通过一个回归产生一个残叉,这是我们残叉的一个名字,嗯,然后的话这个就是残叉名字这个地方是可以变的。然后我们做一个嗯, dfo 的一接的一个回归,我们可以看一下结果, 这个就是我们的一个回归方程, rack 是我们的回归方程,然后这个 predict 就是我们预测的一个残杀,然后对残杀做的一个单位跟检验,然后这是我们检验的一个结果,它是负的,二点八六零是比这两个的绝对值,这三个的绝对值都要达,说明我们的模型的残, 他是通过了卸妆检验,说明他是长期稳定的,长期存在均衡的稳定,因此我们可以建立旺膜型, 嗯,按摩型的话,他这里的话就是 visoc, 这里选择我们的两个变量 max like 就是我们这里可以选任何一个数字,只要比二代大就可以。然后的话我们就是选择我们这个 vi 模型的一个 比较合适的一个之后接触,然后这个看法主要就是看那个心在哪个上面,哪一行打多,我们就选几接,然后在一我们这边就选一接之后模型,所以的话我们在估计这个望模型的时候,这个 lens 就选一, 这个就是我们得到的一个估计方程,然后这个是分别这个这个的话就是让那个浪 l 而作为音变量,这是浪 l d, 而 d 作为音变量得到两个估计的回归方程。 接下来的话我们就是要做一个自相关检验,自相关检验的结果就是说他都屁直都比较大,这里我们直接可以看到他是没有自相关的,什么模型也是可以用的。下一步的话我们做那个单位跟检验, 就模型整体的一个模的单位跟可以看到他全都位于园内啊,这个位于圆边缘上的点到底是不是的话,我们可以看这里零点一零零七四六也是非常低的,我们可以就是说他满足了一个稳定性的假定, 即使就因为他低,高出来的部分很小,我们一般是要需要这个模式小于一的,但现在也不错。 接下来的话我们做那个格兰杰英国检验,嗯,通过这个表的话,我们可以看到这边的配置是比较显著的,上面的配置不显著, 所以我们就说 l l d 是那个他的啊,一个原因就是说 l l l l l l l d 的一个原因 就是它是 y, 它是 x, 而且是显著的,但是这边的话它就不显著,就说明它落完了 d 不能作为原因。然后的话,下一步的话我们就是考虑镇交化的脉冲小音图去衡量到底是一个什么样的变动。 这两行命令的话就是我的这个数据,他可能出来的图是看不到的,可能就是数据不太合适,但是我们的命令今天主要就介绍一下命令,所以这两个命令我们可以换在其他 他的数据,当样本量多的时候,他也就出来结果了。这就是关于 stat 里面恶魔型建立的一个整个过程,大家如果有需要代码或者什么的可以私信我,谢谢大家。
472恪纯博士 02:11查看AI文稿AI文稿
02:11查看AI文稿AI文稿实证分析啊,他进行一个,呃,描述性分析啊,首先我们点 s, 二选 nsn, ds, 呃, idp, 因为你这个数据啊,呃,你就变量选择了 太多了, interesting, 然后 interesting, let's go, let's go, 完了,我点不了了。 disco will come on, ok, 这是我们的结果,第一个结果 看我这个蛋跟点点怎么做, 看到没这水平,然后这个已经,这个,这个,这个三个是会点这两个,然后这三个下面是 就随便一点就行,两个符合就行即可。然后携程检验,携程检验我们一般是根据这后面做的 vr 模型,因为你这个模型啊,他这个 vr 呃出来的不是太好 啊,所以我只我没有全用所有的边量,因为有些边量他确实是,呃用不上的,好吧。嗯, interest, 然后是 led gdp, 然后 ds 这个余额,然后 fm, 嗯,然后呢? sorry, 然后我们直接 vr, 那我们先做个 vr, 看到没有?然后我们首先我们其实要做的这个信息准则,但是信息,呃,不是,不是信息准则,我们首先要做的是这个平衡性检验, 对,这个平衡线就说明, ok, 我们这个之后一期是同,呃是符合要求的。然后我们再去呃 做歌单结,这个,这个歌单结结果出来了, 对,这就是歌单结结果,这最后一期的结果你可以复制过去。
156stata小铺 06:14
06:14 14:05查看AI文稿AI文稿
14:05查看AI文稿AI文稿我们先来一起简单回顾一下概率嫩的基本知识。我们知道一个随机变量 x 可以用它的概率密度函数 f x 呢?刻画如图所示的是两个均值为零方差不同的正态分布的密度函数。随机变量 x 的均值和期望值表示为 ux 等于 ex, 也就是后面四指上表达的这么一个这个积分形式。随机变量 x 的方差通常即为这个 c 个码 x 的平方或者是 varence x, 它是这个 x 减去 e x 的平方的这个期望值。 对于两个随机变量 xy, 我们可以定义他的这个斜方参为 c 个码 xy, 也就是等于 c o v。 通常写成就是扣 variance of xy, 它是 x 减 e x 乘上 y 减意外的期望字。两个随机变量 xy 的相关系数弱 xy 定义为 c 个码 x 万,除上 c 个码 x, c 个码 y。 从上面的定义我们还可以看出随机变量 x 与 x 自己之间的斜方叉。 c 格码 x 的平方实际上等于 c 格码 xx。 相关系数一定位于负一到正一之间,如果大于零,则表示两个随机变量正相关。 如果小于零,这表示两个随机变量互相关。如果等于零,两个随机变量不相关。特别的,如果随机变量 x 等于 y, 那么他们的相关系数等于正一及完全正相关。如果 x 等于负万,这相关系数为负一,表示完全负相关。从现在开始,为简单起见,我们只考虑一次性及单期的 投资组合选择问题,而不考虑可以将投资收益用于再投资的多期问题。假设每种资产的未来收益用一个随机变量来描述其分布的规律,可以根据历史的数据或者其他的方法预测得到 收益的均值,也就是这个随机变量的期望值,用来衡量这种资产的平均的收益状况。 收益的方差或者标准差,标准差是方差的平方根,用来衡量这种股票收益的波动的幅度。 两种资产收益的斜方差表示他们之间的相关的程度。马克维斯所建立了模型的关键思想是, 投资组组合的收益也是一个随机变量,这个随机变量的均值或者期望值用来衡量投资组合的预期的收益, 而他的方差或者标准,他用来衡量投资组合的风险, 投资者自然希望收益最大化,风险最小。所以用数学的语言,这是一个双目标的优化问题。那我们首先来看看 用方叉来衡量风险是否可以解释投资风扇化的合理性,也就是说风扇化投资是否确实可以减少风险。假设两种 资产的收益率分别用随机变量 x 和 y 表示,其方差分别为 vans x 和 vans y。 当投资 xy 对应资产的比例分别为小 x 和一减小 x, 投资组合的收益可以表示为 z 等于小 x 乘大 x, 加上一减小 x 乘上大万。那么按照概念人的知识, z 的方差 very 是 z, 就应该表示成如下的这个形式。 例如,如果我们进一步假设 x 的方差和 y 的方差相等, 并且投资 x 和 y 的比例都是二分之一,也就是 x 等于一减 x 等于二分之一, 那么当 x y 的相关系数肉 x, y 等于二分之一,他们现在是正相关,那么可以计算出 vans z 就等于四分之三的 vans x。 如果相关系收入等于负的二分之一,这时候他们 x y 是负相关,那么 z 的方程 vansz 可以计算出他是等于四分之一的 farens x。 在接单情况下, 如果相关系数肉 x y 是等于一,也就是 xy 完全正相关,可以计算出 vans z 等于 vans x。 如果他们完全负相关,也就是相关系数肉 xy 等于负一,可以计算出 vans z 是等于零。可见 最的方差小于最多,极端情况下是等于 xy 的方差。分散化投资的风险确实比不分散时要下降, 除非 xy 完全正相关的时候,他们是不变的。这实际上是具有一般性的一个结论。虽然我们上面只是以几个特殊的例子来进行了说明,下面 我们通过一个简单的例子来体会马国际君子方差模型的建立和求解。这个例子中的数据在后面还会反复用到。假设可供你投资的只有三种股票, 即为 abc, 而且你已经收集到过去大 t 年大 t, 这里选择等于十二, 这十二年的历史数据如表所示。例如第二行第二年的数据一点三零零表示年初也投资一块钱,年底的时候其价值为一点三零元,也就是说年收益率是百分之三十。 其他数据的含义完全类似最后一列,我们给出的是当年股票指数的收益情况,这里我们暂时先不考虑他有什么用处。 假设你期望你的投资的年收益率至少达到百分之十五,那么应当如何进行投资呢? 将三种股票 abc 的收益率分别表示为二一二二 二三。投资组合表示为投资三种股票的资金的比例分别为 x 一, x 二, x 三。 这图纸组合的收音率 r 四 r 一 r 二二三。按照系数 x 一 x 二 x 三进行线性组合的结果, 因为 r 一 r r r 三为随机变量,所以 r 显安也是一个随机变量。 按照马可畏智的思想,其优化模型而向其决策的目标就是使 vr r 最小,也就是 vans r 最小,方差最小或者是风险最小,其约束条件是 r 的这个均值 e r 大约等于百 百分之十五。由于我们假设资金全部用完,不允许剩余,所以我们加上约束条件, x 一 x 二 x 三之和是等于一的。最后我们假设 x 一 x 二 x 三都是大于等于零的啊,不考虑融资融券,买空卖空这样这种情况。 这就是著名的马克维茨的君子方叉模型。 按照我们前面概念论的知识,我们把 i i 的期望值记成 mua, 把 r i 和 rg 的斜发仓继承 c 个码 ig。 那么前面我们所说的投资的组合 r 的收益 e r 就是 u i x i 的和,而决策的目标函数分论是 r, 可以根据概率中的知识进行相应的这个计算。最后我们会发现它实际上是写成一个二字形的形式,这里的 x 是表示的投资组合的构成的这个项链。而 ceo v 实际上是斜方叉矩阵, 一般来讲,斜方他矩阵是一个镇定矩阵,严格来说是一个非附近的矩阵。 所以我们最后得到的君子方差模型就是在一系列的线性约束底下优化一个二次的目标函数,可见这是一个二 规划模型,因为斜方差矩阵 c o v 一般是镇定矩阵,严格来说是非固定的,所以这个规划问题通常是一个突的 r 规划是具有有效的算法进行求解的。 剩下的问问题是如何确定模型中的参数 mu 一、 mua mu 三以及斜方差距正 c o v。 这是数理统计中的参数估计问题。及根据样本数据估计总体的参数。 我们用 rit 分别表示第七年、第二种股票的年收益,也就是前面我们表格中的数据。 但是前面表格中的数据我们表示的是收益,而不是收益率,也就是说把它减去一就得到了收益率。我们分别用样本均值 和斜方叉来估计总体的君子和斜方叉,也就是说我们的这个 mua 用 r i 的一半来进行这个表示,而这个塞格玛 a 键,我们用 下面的这样一个公式来进行表示。注意,在斜方叉的计算中,我们除以 t 减一而不是 t, 是为了保证 估计的无偏性,这在概率统计的书上都会有介绍。你自然会想到,如果 用过去若干年的历史数据来估计未来的收益,一个隐含的假设是,这些股票的未来表现应该与过去过去的历史表现类似。 这一假设一般只对历史比较悠久、业务比较成熟的公司的股票,如南筹股 近视成立。而对于业务刚刚起步,处于高速成长期的公司的股票,如创业板的股票就不一定合适。这时你可能就需要采用其他的方法来预测未来的收益了。具体根据前面中的表中的数据, 我们带入上面的公司进行计算,可以得到没有一,没有二,没有三和相应的 c、 o v, 也就是斜方差矩阵,可以看出股票 abc 的期望收益风险是一次增加的。 使用这些参数,然后再利用相应的优化软件,例如拎狗软件 或者买那个软件的优化工具箱进行计算,可以得到这个均值方差模型的最优解释,也就是说我们的最优的投资方案大致是投资 a 约占百分之五十三, b 约占百分之三十六, c 约占百分之十一。 这个优化问题的目标函数的值方差为零点零二二四一,也就是标准差为零点 幺四九七,期望的收益率正好是百分之十五,及约束条件正好取到了等号, 这是容易理解的。可以看出标准差近视也是百分之十五,这是一种巧合。如果我我们认为投资组合的收益近视服从正态分布的话,那么最后的收益率 位于期望收益的一个标准差之内,也就是位于百分之零到百分之三十的概率大约有百分之六十八。在下一节中,我们将一起来体会该模型的更多应用。
49高等教育出版社 03:46查看AI文稿AI文稿
03:46查看AI文稿AI文稿第二遍空三跑完之后呢,我们就会还是来到这个界面,就会多了一行提示,是吧?三个空着点有了完整点,然后其实这样呢,我们下一步就可以进行建模的操作了,建模我们在这里也操作就行,三维建,三维重建 可以进行生产,让我们进行一个设置哈,然后空调采用坐标系一样的,我们选择幺幺四度带。 然后呢这里呢我们可以进行左键的鼠标,左键呢可以对他的这个这个图形呢进行一个旋转,然后我们点击这个就可以对键模的位置进行一个修改,就是比如说修改 一些你不需要的地方,只要减轻这个电脑的负担, 那比如说我们现在就要这一些点, 这些这一块就足够了。那我们现在呢下面要进行一下切块操作,因为这个我内存不够大, 我们可以进行自适应切块,他说目标内存使用量的十六级币,那我们切成了八块,每一块呢可以使用十五级币来进行处理,核心呢就是我们的内存呢没有那么大,所以只有我这个电脑那个内存只有十六级币,那么就可这个边 来弄,比如说咱们那个有三十二级币,对吧?我可以到三分之二位置可以用二十级币,这时候呢哎,就可以这样切块,但是呢 我这个提示了达不到,对吧?我们还是用十六级币,这样的话单块使用十五级币,但是这个时候你进行缩小面积,他也会这些也会有有修改的。 好,那我们就按这个这点来处理,其他的基本上不用改,然后我们直接提交三新的生产项目就可以了,然后使用本地的引擎,然后我们做一下修改,生成三维网格,然后格式呢我们选择一下子,根据我们需要的格式 来选择,我们经常用的是 ovcd b 的格式,那我们就选这个, 然后呢纹理压缩,我们可以把 gp 的质量呢提高一些,这样看的会比较舒服一些。然后裙子呢,我们加上几个像素,像像素, 然后下一步空间层烤坐标系三度带 范围,这就是刚才我们画的那个范围,输出到那个文件夹里边,设置好了之后检查一下没有问题, 我们就开始跑就行了。点提交这个时候呢就开始了一个时间比较长的 一个建模的过程,那显示运行之后呢,其实就是我们的引擎已经开始工作了,如果说这个地方没有没有没有产生运行的图标,那肯定是引擎的工作这块有状况,打开这个引擎看一下。 好了,那现在我们的正常运行了,那我们就耐心等待吧。
533测绘侦查员 06:07
06:07 01:08查看AI文稿AI文稿
01:08查看AI文稿AI文稿如何在几分钟内快速创建出来一个模型?先导入我们所用的图纸,识别图纸楼层表, 点击自动分割,软件会自动将我们的图纸进行分割。 修改一下。索要生 模型创建出来啦!
151山东品茗科技 02:10查看AI文稿AI文稿
02:10查看AI文稿AI文稿大江无人机三维建模过程,打开 dj pad, 选择航线飞行,选择创建航线,选择倾斜摄影,选择测绘区域,调整要测量的区域范围, 系统自动生成多条航线,调整飞行参数,包括无人机的飞行高度、飞行速度等参数。 打开高级设置,把重叠率调高一些,其他的这些设置都可以选择默认设置完成后就可以起飞了。上传航线,后面就让无人机自己去飞吧。 五条航线全部飞完了,准备返航,这样倾斜摄影的照片就拍摄完成了。将拍摄好的照片拷贝到电脑上,注意要将照片放在 文目录下,下面进行三维建模。打开 smart 三 d, 选择新建工程,将拍摄好的照片全选导入这里。我将五条航线的照片分开了,也可以全部放在一起, 这些点点就是相机拍照的位置。提交空中三角测量 空中三角测量的时间比较久,主要取决于电脑配置和照片数量。通三运行结束就可以预览三 d 视图了, 这个不是最终结果,但效果已经显现了。然后点击新建重建项目, 点击提交新的生产项目,这个过程也是相当的慢,大家要有耐心。生产一小部分的时候就可以浏览三 d 仕途了,这个时候已经比上次的效果好太多了。 等待电脑跑图完成。 最后在项目的 production 文件夹中用 acute 三 d 就可以打开了。
3909无人机三维建模 | 纵横 02:03查看AI文稿AI文稿
02:03查看AI文稿AI文稿大家好,今天展示一下做模型救轴的过程。牛,全部录完将就着看吧。 难得孤独啊那嘎达哇哇带去的可能蒙娜丽莎摩托古尼迪亚的哒哒哒还是没太阳的哆米哒 相信我,宁可等等的 马宋娜娜打开一萨玛卡塔连狗毛都没留过头发。
14.0万芝士派对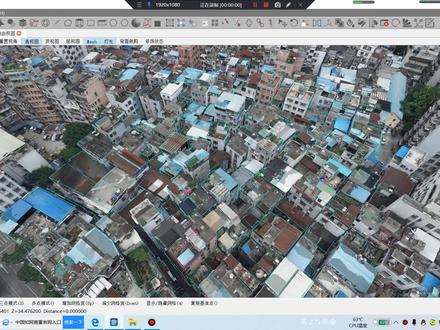 08:29查看AI文稿AI文稿
08:29查看AI文稿AI文稿哈喽,大家好,我是小斌,今天嗯开始给大家分享地皮 model 的嗯,一些操作流程 啊,那我们看一下什么是低屏幕的啊?先看一下他这个插件长什么样吧。啊?一个软件长什么样?插件, 这,这就是他的一个那个标志,我们把这打开,打开他基本界面是这样的,他具体是怎么个操作呢?他对于是操作什么呢?他相应的是处理那种行测, 呃,或者是嗯就行车影像,然后通过行车影像去跑出一些城市的商业模型,像类似于这种的那种 这种城区的三个模型,大家 看到他这个很真实的一个三维模型,一个一个城区的城中村的一个三维模型。 对于这种,呃,像那个无人机,然后通过照片,然后跑出很多照片,那种通过他的 特定的路线呢?或者是通过这种路线啊?问你会通过什么路线呢?也是通过这种,然后拐个弯,然后这么的 这么的这么的,然后他有一定的照片重合度,重合度之后,然后他会会拼接,他会产生空三,空三,也 也就是说他相应的那个嗯照片的位置位置信息,然后他通过这一系列呃空中三角测量运算,然后会他会得到一些嗯相应的点云, 然后从点穴,然后他再把照片再映射上去,然后我们会得到一个三维的模型,也就是大家现在呃在屏幕当中看到的这种模型, 那么这种模型啊,我那我既然已经模型已经出来了,我还要他要有什么用呢?嗯,那么大家会可以看到他这个模型啊。呃,其实 还是跟现实当中有些不一样啊,你像这种他这种是不是很虚啊?这现实当中不可能是这个样的, 就是他这个模型还是不是很完备,我们现在想通过这个软件想做什么呢?就是通过他然后去把这个模型进一步的优化。那我们看一下他具体优化能优化成什么样?我们把这个 max max, 也就他这底下的 这种啊图给它去掉啊。看到这就是也不是说很优化吧,这是半优化的一个中间文件。 嗯,具体的细节呢,我们还会进一步的去修改。这是整个的一个四边面的一个模型,这是整一个四边面的 啊,大家可以看到他是四面面的模型。那么对于这种麦斯呢? 慢死,他就是一个三角网的模型,他整个就是三角网的模型,当然这里边我是呃看不到他具体的一些细节的。 我今天呢想给大家分享的是什么?就是一个他这里边有个三个呃工具栏,一个是 ob 勾的修饰,一个 osgb 的修饰。那我们今天主要是说一下他这个剑魔的修饰。剑魔,首先 他肯定是啊通过这个啊 nice, 然后去生成他这个像我刚才给大家看的这个撕面面的模型。那通过这个撕面面模型我们假如已经建好了,建好之后呢?嗯,我就觉得 他这个贴图虚,特别特别虚,然后我还想想改他,那我们改的时候我们可能会想到我是通过 max, 嗯,通过三 ds, 然后去去改,改完,嗯给他那个 uv w 贴个坐标,然后嗯在 ps 里边,或者是通过一些其他软件,我把这个给 嗯分辨率调清晰一些,或者给他替换掉,这些方法都是可以的。那么我们嗯在这个软件里边他是怎么操作呢?那么通过这个一个 s 先选中这个面,然后 我再通过通过,这样我再给他这个小框框,也就是相当于一个呃,这种 uv 坐标的一个 一个框框了,那么我们现在选择这个位置,他无论你往哪选,他都是被房子给遮挡了。所以说,呃,我们找一个,找一个比较向外的吧。假如说选这选这之后, 然后呢?然后同样还是嗯, x 啊,大家会 看到他自动, 他会给我一个一个图,嗯,也就是他这个自动匹配的一个图,那么这边这些小点点呢?就是什么呢?这个小黄点的位置就相当于我这个, 呃,现在就这个房子,那么我这个小红箭头呢?也就是他的朝向,这个小尖,也就是朝向的朝向是哪?我可以去旋转,你看他这个小红箭头,他他会往哪去转? 那么我们他朝向正对面的这张图片肯定就是他的,嗯,比较正的位置 啊,我们比如选择这种,那那么这个和这个就一个相当于一个羊角的,然后还有一个就是 角度不是很大的一个图片,那我们选择一个比较合适的,一般都通过这种小红色的小箭头,然后我们去选择一个相对比较 辨识度比较高的,或者是他的位置比较正的一张图片,然后我们去选取他,像我像我现在这个图片呢,这个位置,这个位置,嗯, 这个位置,这个位置,这个位置他会有一个别的房子的一个墙体, 那我不想,不想要他这个墙体,那我怎么办?那我就自己选择一个一个图片吧,我自己选择一个图片,那么我就看到一个这样式的结果,我会给他调整一下子,我说我就现在想选这里,这就是他本来的一个一个面貌, 那我就选这里,选这里之后,然后我给他选取一下子 啊,大家会看到我直接给他选成全取掉了,他刚才那个部分是不是已经去掉了?那么这个其实,嗯,就是一个修模的一个过程, 我是一个给他映射纹理贴图的过程,嗯,当然,嗯,这个他的操作流程还有很多,那么我们今天也是简单的给大家介绍一下关于他这个究竟是干什么的,然后他有什么好处? 嗯,反正就我个人而言,他还是很全面一些的。然后嗯,后期我也会给大家着重去 啊,去了解这啊,这啊,这他的操作流程,他相关的一些啊介绍。嗯,那么今天就到这里,好,谢谢大家。
390二三维软件实验室

