fastadmin插件开源吗
大家好,我是写代码的猫叔,这节课呢,我们来通过一个简单的案例,学会 fastman 的插件开发,了解它的整个开发流程,还有里面需要注意的事项。 首先我们来做一下课程简介,通过这个课程我们能学到什么东西?首先是创建插件,怎么来快速的创建一个空白的插件,然后是对插件信息的修改,比如说插件名称了,插件介绍作者之类的。然后是修改插件的配置页, 配置页呢就是点开那个配置按钮啊,弹出来一个窗口,上面可以填,让用户填东西,这是配置页。 然后接下来呢是我们整个插件的核心方法,比如你的插件是发送消息的,或者是记录日志的,或者是做翻译的,或者是一个图书管理系统, 都有自己的一套方法。而我们这个课程呢,主要是讲的是一个简单的功能,把它封装成一个插件,所以呢这就有他自己的一个简单的核心方法。我们定义好这个方法之后,在其他地方只要安装了插件,在其他地方都可以调用它。 然后这个简单插件做完之后呢,就可以打包,然后在另一个项目里面进行本地安装, 这样呢这一个简单的插件就完成了,非常简单,非常简单,但是很实用。 你做完这个之后呢,就可以把我们常用的东西封装成,封装成插件,然后反复的使用,就不用每次去复制粘贴代码了,省去了很多功夫。然后接下来呢是进阶,我们可以用到数据库 库,把把那个插件里的数据给他存到数据库里面,然后呢还可以在左侧加入菜单,也就是说在那个 fastman 的后台左侧菜单列里面加上菜单,点击菜单里面内容呢,可以打开一个新的页面,可以查看我们之前存在数据库里面的数据, 然后学到这之后呢,我们整个的课程就完结了,那么你就可以来通过学到的东西来做一个自己的完整的插件了。 比如说我们在插件市场里面看到那些 c m s 系统了,图书管理系统了,员工管理、会员管理等等一个大的系统都可以做,因为那个系那些系统也就是一个个的页面,包括增商改查,包括数据库的使用,就这些东西,那么我们学完这些之后就可以举一反三, 然后去做一个大型的插件了。接下来我们来说一下开发插件之前的一些准备工作。首先你要明确要做的插件你是自己用呢?还是要发布售卖,如果是自己用的话, 我们就不用想太多,直接开始做就可以了。而自己用呢,一般都是把我们常用的工常用的功能封装成插件。

粉丝2315获赞9774
相关视频
 03:29查看AI文稿AI文稿
03:29查看AI文稿AI文稿fast almond 是一款我常用做游戏后台系统的开源软件,今天向大家介绍如何在宝塔上部署 fast alman。 打开宝塔后添加网站, 输入你要用的域名,我建议将带 double u 和不带 double u 的域名都填写上。 逗分享是我用来分享游戏资源而开发的网站。 数据库类型选 miss go, 填写好数据库的账号和密码, 填写好后点击提交按钮完成添加, 记得备份好数据库的账号密码等信息。 进入网站的根目录,点击上传按钮,上传 fast airman 的源码 解压锁, 开始设置网站。 因为 fast diamond 是基于 think php 框架开发的,需要修改运行目录为 public 目录,修改好后点击保存, 切换到伪静态,从下拉列表 表中选择 zink, 宝塔会自动填写伪静态所需的配置,记得保存。 完成网站的配置后就可以打开网址,准备安装网站,填写好数据库的信息和网站的信息, 设置好后点击安装 fast alman, 安装成功后就会跳到这个页面,在页面红底的框里展示了后台的地址,这个地址需要备份,记住省的后面忘记。 第一次点击后台地址发现报四零四错误。解决 方法也很简单,打开宝塔安装目录,打开 n jinx 坑 p h p 目录,打开 n jinx 当前 p h p 版本对应的配置文件,此处用的 p h p 七点四,所以打开七十四坑, 将 tri files rear e 等于四百零四这行代码注视掉,在行首加上井号符号,保存七十四 cunt 配置文件,切换到软件商店,重启 in jinx, 刷新页面,就能正常打开后台页面了, 您掌握了吗?有问题可以视频里评论留言。
27游戏创作大陆 05:55查看AI文稿AI文稿
05:55查看AI文稿AI文稿大家好,今天我们来学习如何下载与安装发射的命,那么首先我们打开他的一个下载页面, 找到下载,然后这里呢有几个不同的版本,这里我们下载发斯罗密完整包,我们将它放在 桌面。好,这里我们 已下载完成。好,我们将它放到我们的啊拉二梗的根部物当中。起,首先启动服务, 然后放到他的根部,那么我们将它解压。好,我们起个名称叫做 迈兽奥特力,那么他就相当于在拉二杠这个环境当中啊有一个新的项目,那么我们需要重启一下拉二杠,然后为他创建一个啊虚拟主机。好,我们看到这里 虚拟主机创业成功。好,那么接下来我们如何安装他呢?我们来输入我们的地址, 然后后边跟上他一个安装的地址,他的安装地址是固定的。 好,我们看到啊,这里他需要输入相应的数据库的信息,那么我们现在是没有这个数据库的,那么我们首先需要来建立一个我们 这个电子商城这个项目的一个数据库,那么在这里。 好,我们新建一个数据库,我们叫做埋哨。好,大家看到里边现在是啊没有 啊,数据表示没有的啊,这不影响我们先进行安装,那么我们数据库名称刚才就是新建的麦哨 啊,用户名默认是这个入特,就是我们这个数据库的用户名密码呢,也是数据库的密码是为空的。好,那么他这有一个啊表前缀,就是他在生成,安装成功之后呢,他会生成一些啊巴斯特的命,他对应的一些表 啊,他自带的一些表,那么他会添加一个 f a 的这样一个前缀。好,那么这里呢管理,这用户名就是我们登录后台 创建,就是我们安装成功之后需要登录的后台当中,那么这里就需要一个登录所用的一个用户名和密码,用户名呢我们就使用奥特曼不变 密码呢,我们使用六个一啊网站名称,那么这里我们就可以写上我们这个电子商城的一个名称,我们叫做起个名称叫优品商城, 点击安装好,安装成功,这里显示安装成功了,那么啊这里他还有一个提示,请将以下后台更多入口添加到你的收藏夹啊,为了你的安全不要泄露,以及 啊不要泄露给他人,那么为什么我们需要将他添加到我们的收藏夹呢啊,因为为了安全起见,发生的命会在安装成功后啊生成随机的一个后台入口,那么这也是,所以呢我们需要 把它啊放到我们的收藏夹当中,便于我们的访问。好,那么我们首先来访问一下后台,因为这就是我们要进行在后台进行一个数据的管理,我们点击 好立即跳转,那么就是用户名,就是我们刚所说的啊,我的命密码就是我们的六个一。 好,我们看到 这里已经啊进入到我们的后台当中了这个名称,这个商城的名称就是我们的刚才起的名称叫优品商城。好,那么接下来呢,好,我们来看一下啊数据库,我们刷新一下这个表,我们看到里边多了啊, 很多的这个啊表,那么这里呢这些表呢就是发射命他一些啊自动生成的表,里面包含了一些用于管理用户信息啊,权限认证等功能的表,通常呢,我们不需要去管,不需要去管他啊,不需要去管他, 那么我们就将这个后台添加到我们的收藏夹当中,好便于我们下次的一个访问。好,那么到这里呢, 我们的发色和命就已经安装成功了。好,下节课呢,我们将讲解如何使用发色的命来管理数据库中的数据啊,这也是我们这个商城项目中所需要的一个主要的用到的一个功能。好,今天的课程就到这里,谢谢大家。
26lqqhwei 05:50查看AI文稿AI文稿
05:50查看AI文稿AI文稿观众来们大家好,我是你们老朋友大元哥。今天的话,大元哥在用这个发誓的命运做项目的过程当中,呃,需要做一个导入的功能啊, 我们来看一下,也就是我这个街道的话,我需要的话直接导入进去,我们可以看到使用这个发射的命 crud 一键生成之后,他是没有导入功能的。那导入了要怎么实现? 首先我们可以看一下,你用百度去搜索一下实现导入,你会发现一直你翻到第十页哈,他都没有一个真正能解决你这个问题的 一个比较好的帖子。那我针对的话,这个问题的话啊,实战的去操作了,然后也并且给他解决了,我们会看到最多的,好像最多的是这个东 关于这个导入的一个写法,但是你直接按他这个稿是没有用的,所以我在这个基础上做了些完善。我们来看一下,这一步是有用的,他需要在你的控制性里面继承一个阴迫的方法,这个的话我们带大家来做一下吧。 嗯,首先来说我们要找到我们的这个控制器,控制器的方法里面这个东西是没有的,刚开始是没有的,你需要了,哎,把这个东西他这里有吧,给他复制一下, 这里的话需要写一个这样的音破的一个方法啊,然后他这个是继承的。好,这个写完之后我们看到第二步,第二步的话要在 index h 的苗里面这个洞里面添加音破的 啊,这个的话就是没有的。我们来看一下啊,你直接打开这个 englex 微信秒你找不到那个东西的啊,所以这个的话没有用。呃。第三个 gs 里面要添加硬破的 url, 我们找到这个结实,这个是自带的啊,就是你直接一键生成的话,这个东西是有的啊,如果没有的话你就自己加,但是大部分地方是有,所以不需要管 啊。那核心的话就是要去处理的,就是解决这一步,这一步的话我们来看一下,这可能是老板的,老板他是这个样子,但是新版的话没有,没有的话我们要自己去写,我们来理解一下,理解下这个页面里面的话。 呃,他有几个东西看见没有?这些这些东西其实就是八档按钮,有添加、编辑、删除以及更多,这里面 指的就是这几,指的就是这些按钮啊,这些这些按钮。呃,所以我们要添加这个导入的话应该怎么弄啊? 啊?应该怎么弄啊?那就是应该在这个页面里面去这是个删除按钮吧,对不对?我们可以把这个删除按钮啊,给他复制一个,复制一个,我们可以看一下 啊,这里多了一个,我们要把这个删除按钮改成这个导入,所以我们继续继续改吧。迪类的,所以我们要改成 input, 然后这个地方也要改成硬泡的, 这样的话文字就已经改过来了,然后我们要把图标跟颜色也改掉啊。呃,他这个颜色应该不是单着吧,我们改成蓝色,因否这个 改成音破的,然后这个禁用的话就不要了啊,我们是随时随刻都可以导入的。好,这里这里的话就是要添加的方法,这个方法和结实里面要顺相关,结实里面的话是这个音破的,所以我们要把它给改掉,去 这个低摇要给他删掉,就改成硬泡的。然后呢我们再来检查看一下啊,这个地方这是图标,这个图标的话我们就不用这个垃圾桶吧,应该是用什么?用一个上传吧, fold, 好,我们再来刷新看一下,哎,这样的话这个导入是不是好了,我们来试一下啊,这样的话就可以去导入数据了,我们带大家来做一下这个导入数据,有什么要求?我们看一下 我们这个表的话,嗯,这个表的话一共有南极列 房, 一共有三列, id 是自增长的,然后这里有街道啊,春色,那我们这个要导入这个 excel 的话要怎么写?哈,要这样去写,打开这个 test 就会写。好的,我们,呃,首先第一行这个 街道跟春色这个还一定要加,不加的话是导入不了数据的,这个东西必须要和你数据库里面的这个叫什么?应该是备注吧,备注的话应该是要保持一致啊,不能 错,跟这个注射一定要保持一致,不能错,下面的话才是填你正是这些数据,我们可以带大家试几条哈, 我这里插入了六条数据,好保存一下,好关掉取,然后我们导入看下能不能成功, 找到一个泰式的 好提示成功,我们也看到这个数据就正常的全部插进插入进来了啊,但是关于这个发射的命怎么样去写这个导入的功能 啊,这样的话是不是很简单呢?好,希望学会的朋友可以多多点赞啊以及评论,谢谢大家。
158大轩哥 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿朋友们新年好呀,我是 lactume 开源团队老钟,过年在家捋了捋新一年的 lactume 免费开源后台管理系统发展方向,很多朋友建议我们不要把开源的语言版本弄那么多,主抓一两个版本做好就行了。这个建议特别的好, 毕竟后台管理系统这个领域很多替代方案,所以今年的重点必须是集中精力把一两个版本做的深入,做出特色,其他版本因为有远程伙伴的支撑,保持迭代是没有问题的。 另一个重点就是围绕开源项目进行商业化,没有合情合理的商业收入就没办法支撑项目的发展。商业收入围绕提供技术支持,例如定制服务、开放插件机制支持、付费插件销售、现成的系统模板等三方面进行。虽然 like me 开源项目不复杂, 但是走通逻辑一点都不轻松,要做的事情还是非常多的,程序员写代码个个都很棒,但是做销售、做营收就会遇到各种问题,要有足够的耐心投入进去。感谢大家的关注!
68钟富桂 01:26查看AI文稿AI文稿
01:26查看AI文稿AI文稿十、款开元免费的磁力插件十、样条云找插件。这款插件可以通过样头线的动态来控制头发对象,只需要形状跟排列的样头线跟头发对象对齐,就可以通过插件来控制头发。他可以帮助你来创建神锁、编织物或任何类型的 纤维编织类东西。九、动力鞋物体连接插件这款插件可以在四 d 中快速制作连接物体之间的碰撞。动力学动画像逼真的链条、项链和褶皱啥的都是可以做的。他会考虑到对象的大小和尺寸,这在对象之间准确放置脚链。如果没有这个 插件,这个过程通常更复杂,需要大量的工作,现在只需要点几下就可以轻松的完成。八、螺丝杆模型预设这是一个螺丝杆的预设,他这有不同的螺丝头,你可以轻松的调整他的尺寸,细节啥的。他这个都是表达式驱动,用起来非常的方便,而且呢不 也是非常合理的,你再也不会因为一个螺丝钉而花时间去建模了。七、海洋生成器一会可以让你在 cd 模拟海洋表面的插件。它可以控制风速、热量、高度、不掏汹涌泡面生成等。使用这个插件,你可 可以轻松渲染出逼真的海洋表面。六、松石模拟插件这款插件可以让你做出松软 q 弹的模型动画,而且支持多做对象。 可以通过手表来控制模型什么位置摆动,哪个地方更硬,可控性非常的强。当然你也可以轻松的控制变形强度,内部半径,外部半径的衰严,对向弹性,吸收值,角度啥的。需要的找我打包发你能能能理解吗?下课。
1617雪人不会化 01:01查看AI文稿AI文稿
01:01查看AI文稿AI文稿提到 r p c q, 友们可能首先会联想到 g r p c java r m i 等熟悉的名字,但近日,一条重磅消息公布,腾讯宣布 t r p c 框架正式开源。 t r p c 将核心功能抽象封装成独立插件。它具有多语言、高性能的特点, 首批支持 go 和 cpp 两种编程语言,让不同编程语言的开发者都能找到属于自己的舞台。他还设计了爱面管理接口,让服务管理变得触手可及。育儿 pc 的丰富插件生态和可扩展性为未来的技术创新奠定了基础。 它支持流逝 rpc, 适用于大文件上传、下载、消息推送、 ai 类语音识别和视频理解等多种应用场景。 trpc 框架的开源是腾讯对开源社区的重要贡献,预示着 rpc 开发将迎来新 新的里程碑。让我们一同期待 t r p c 如何引领我们走向更为广阔的技术未来。
48InfoQ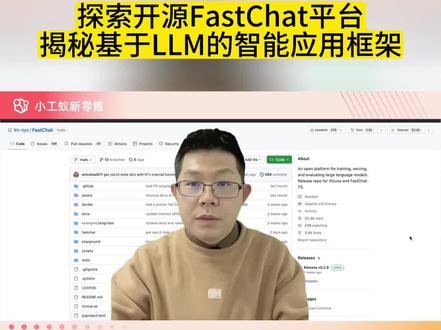 05:59查看AI文稿AI文稿
05:59查看AI文稿AI文稿今天跟大家介绍一个开源的一个项目,这个项目之前是也是一个非常有名的组织,叫 l m c 斯伯克利分校,他们经常会公布这样的一个全世界的这个商业的或者开源的 l l m 的大模型的,这个性能排名第一的是恰克基第四。开源排名第一的话呢是这个叫 为库纳杠杠十三 b 的一个模型的话,也是有这家组织叫 l m c s, 他们来来管理来开发的,他等于他这家公司的他。这个组织还有一个非常好的一个开源的一个项目 叫 fast chat。 我今天跟大家一起来交流一下这个跟我们国内的一些,因为我也用过一些国内的一些类似的这种框架,这个框架它也是个开源的,基于 apart 二点零的这样的一个 开源的一个框架,它所有的这个源代码什么的都是 open source 的,都是可以进行商用的。那么它这个项目里面最大的一个亮点呢,它是什么?它里面能够支持比较 多的一些模型。它这个里面讲,因为 l m c s 它旗下有很多各种各样的模型的,所以它它会测各种各样的什么羊驼 a, 什么 volta 卡,包括中国的 chat g l m 杠六 b, 包括 我经常讲的还有一个模型叫 r w k v 呀啊,它就是这是类似的这些模型,它这个框架都能够兼容,而且比较简单,切换起来会比较简单,它等于是这样, 那么它也能够支持一些单 cpu 单 gpu 多 gpu 的这些包括是只有没有 gpu cpu, 它也是可以跑的。所以它这个框架的话呢,相对来讲会比较灵活啊,如果你没有太多的内存,它是可以跑在量化的,这种操作就是叫八 bit。 之前我们也是介绍过,如果你的 gpu 是三零九零,四零八零对吧, 或者为一百的这种十六 g b 的 g p u, 那么你可以通过这种量化装载八 bit 的这种模型可以比较用少的 g p u, 也可以跑一些它。等于是这 那我也把它给跑起来了。所以给大家来介绍一下他这个项目,这这个是一个优势,他就支持非常多的这个模型。第二个优势,他他的整个一个脚本,他可以直接做微调服务,评估他的整个一个 呃,所有的基于这个 chat robots 的这样的一些核心功能,它其实都是有才是比较好的。另外一个的话呢,它还有一个好处,就是我看到它提供的那个 open api 是跟那个 open ai 的这个 rest for 的这个 api 是完全兼容的。呃,所以的话,有些应用的话呢,如果你是用那个 open ai 的 chat gpt 的应用,它直接可以导到 这个 fast chat 提供的这个 rest for 的这样的一个接口上面,所以你的那个程序根本就不用换它直直接可以跑它。等于是这样。好,那我基本上已经把它跑起来了。我给大家介绍一下。先给大家看一下演示一下啊,这个是它的一个界面,我跑还是跑的是这个 chat g l m 杠六 b 的这 这样一个模型,那么我还是一样,我试了一下,感觉就是说他的那个速度确实要比较快一点,比我平时用的要快一点。 我也跟他他回答的质量,因为也是基于这个 chat g l m 杠六 b 的质量的话呢,还是类似的,因为我用了那个 chat g l m 杠六 b 的比一点一的这个模型跟我原来看的都差不多,功能上差不多,但是我感觉它的性能好像会更好一些,我给大家看一下,把它已经忘掉了。那我们 生成一个视频脚本,因为我看了一下,他性能是非常好的。短视频脚本,我看他性能输出的这个字,性能好像比我原来好像用的好像更好一些。那我就根据让他生成一个短视频的这样的一个脚本,他就很快的能够帮我给生成出来,有画面有文字的。是这样来讲 我感觉还是不错。好,那事就到这,我给大家看一下他到底怎么安装和使用的。安装他主要我是根据原代码 装的第一个命令主要是从原代码上面把他的这个原代码给拉下来,拉下来之后的话,进入这个目录去升级一下 cip 的这样的一个命令。命令生成完之后,用本地的这个东西安装就可以了。所以他安装起来的话还是比较简单。安装完了之后他是这样的,我用的是拍 touch 二点零的这样的一个。呃这个这个基本内裤的,所以他也是能支持的。 安装完它就可以跑了。它启动的话呢,它主要是启动三个东西,这个要比一般的要复杂一点,它 fast chat 启动的话,它启动三个东西,一个呢叫 control faster server controller。 第二个的话呢,叫 work 的话呢,它主要是装载这种类似于大模型的,它是真正的这个 work。 ctulor 呢,它相当于是一个协调者,那它还可以起一个 web server, 这个 web server 就是我大家看到的就是我这个操作的这样一个界面。当然它也可以起一个 a p i 的这样的一个 server, 我也看过,它也可以起一个类似于欧本 a p i 的这个 ser, 它也是可以的,骑起来就可以用。那么它你不管用什么样的模型,它都能兼容欧奔 ai 的这个 rest for 的这样的一些 a a p i, 这样我们可以用这种模式的话,可以跑 开源的其他的这些项目都可以跟它兼容。像那个 long chan, 包括还有我原来讲过这个 long cha 的那个低代码平台,叫 long la landflower, 它其实都是可以完全兼容。这个是它的一个界面出来的这样一个界面。前面也给它 大家展示过,我跑的那个 faster chat 使用的是 chat g a m 杠六 b 的话呢,它在机油的内存,它大概用了十十二个 g b, 那个也差不多,跟我原来也没有用,所以这个也是正常的。好吧,大概是这个项目 我就跟大家就介绍到这。这个项目的话,目前热度也是非常高的,他星星非常多,星星二十二多,两万两千多颗星星,星星还是非常多的,而且功能也是比较强劲。我前面讲的这个两大的这个优势, 他如果是要用一些其他的模型会很方便,你只要把这个模型下载下来,把它装载起来就可以了。他支持非常非常多的一些模型,比较方便。而且他还有一些很高级的功能,你这里面也是讲你不同的 gpu, 他可以装载不同的这个模型,他直接通过这个 ctrl 来去帮你调度 它,这个能力也是有,这个功能也是蛮强的。我看了一下它,它这个里面还特地讲了一下,它能够能够兼容,它跟 face 的 a p i 也能兼容 long chain 的这个 a, 这个 api 啊,也能兼容这个欧奔 ai 的这个 python 的这个 library 啊,它完全是能够兼容的。然后它还有一个评估自动化评估的这样的一个东西,它也能够支持微调。我看了一下, 他这个里面也稍微讲了一下,他能支持微调,他也给了一个他们用力库纳杠七币,在 logo 的这个 gpu 上进行微调的,这样的一个一个一个一个代码。当然的里库纳七币他要微调的话,要 a 一百四块 gpu, 每块 gpu 四十 gb 的内存。他是这样的。好。开源项目就跟大家就介绍到这。
340小工蚁 06:37查看AI文稿AI文稿
06:37查看AI文稿AI文稿好,今天我来看一下这个 fast gpt 究竟应该怎么使用。呃,那首先这里是它的官网 fast gpt 点 roll, 然后这里是 get up, 这是一个开源项目,所有代码都在这里。 那发子 gp 的作用是什么呢?就比如说 ai 叉 gp 也好,还是其他的 ai 也好?他有一些知识是不知道的,比如说我个人的信息,比如说某个项目的信息,某个产品的资料,他是不知道的,那么通过发子 gp 呢?我们就可以把这些资料喂给他,让他呢就能做出对应的回答了。 那么常见的应用场景有这个 ai 客服,智能助理等等啊,这个介绍的话就不多说了,我们直接开始,然后呢走个流程演示一下,大家就明白。呃,立即开始进来,那么这里有一个应用和知识库是比较 核心的两个东西了。首先我们要建立一个知识库,知识库是什么呢?就是你想传输给 ai 的资料,那我们点击新建知识库,然后呢随便取个名字,我这边就用 love 知识库来命名,然后确认创建。 确认创建之后呢,我们点导入数据,选 q a, 拆分,然后呢选择一个文件,嗯,我这个文件是 love 的那个中文的 redmi, 我点击打开,啊,大概就是这些东西啊, love 的一些介绍,然后我点击确认,导入确认, 然后我们等这个变成可用就可以了。好,这里已经状态已经变成可用了。呃,点进去看一下,就是他就拆分成了这些问题,我们当然在这里也可以手动修改一下,比如这里多余的就把他删了,然后确认呗, 变更。然后呢,我们找到应用新建一个应用,比如说我们叫 love 小助手, 点击这个知识库,加对话引导,确认创建。然后呢这里有很多设置啊,比如说对话开场白呀,这个 a 模型我们可以选择哪一种?一般来说还是这个 呃 g p t 比较好用。呃,然后这里需要关联一个知识库,我们点选择,就是我们刚刚创建的那个知识库,点击完成,然后保存。 这样就是说呢,我们这个应用接入了这刚刚我们创建的那个知识库,他就懂得了 love 的一些知识,我们现在问一下 love 是什么? ok, 他已经明白了,那我们问一个他不知道的问题,比如说 love 的 作者是谁? 那如果说我们觉得他回答的不满意呢?呃,我们可以这进行一个 修改,我们我们的问题是作者是谁?他说 love 的作者是谁?谁谁,我们觉得不对呢,我们就去改一下,比如说我们改成 love 的作者是马老板,哎呀,然后确认导入。 好,我们再问他一下,比如说 love 的作者是谁?好,他已经把这个答案给改掉了, 那基本的功能我们就已经演示了,就是新建一个知识库,然后呢选一个应用和这个知识库匹配上选一些模型等等。那么 v 四版 版本呢?更新了很多其他功能,这个高级编排我们最后再说稍微复杂一点,然后首先是这个外部使用,外部使用呢,就是我们创建一个免登录的窗口,发送给别人,别人直接就可以用啊,我们这里创建一个 test, 那么金额给他个十块钱, 然后选择明天到期,然后呃确认,然后我们来复制一下这个链接,打开 好,就是你把这链接发给其他人,其他人就可以用了,他还是知道我们刚刚训练的知识的。 love 作者是谁。 ok, 然后呢,这有个 a t i 访问。呃,在之前的教程里我 我们也展示了,就是我们把把它接入这个飞书啊,接入企业微信用的就是这个 api 访问,什么意思呢?就是说我们创建一个密要可以通过 hdp 请求来请求这个接口,就可以实现这个问答的功能,跟接那个官方 gpt 的接口是一模一样的。 既然有了接口呢,我们当然就可以把它接入到任何的套壳 gp 中。呃,我这里用 clus 给大家演示一下吧。嗯,进入 clus 之后呢,这里有个模板市场,然后呢选择这个 next 外部 部署一下,然后这里的 k 我们就随便写吧,我们用不到就随便写一个,然后部署确认, 然后跳转到应用详情,等这个应用部署成功。 ok, 这道运行中就是部署 完毕,然后我们点击访问一下,那部署成功之后,我们点这个设置它,这里是可以填我们的接口地址和这个 a p i k 的接口地址,填什么呢?就填这个 a p a 服务器,点击一下复制,然后呢把它 贴到这里就好了,然后这里有个 a p a k a p a k, 要稍微注意一下,我们先把其他的删掉。嗯,你首先要创建一个密要新建密要,然后复制好的,然后把这个密要贴在这里,然后在这个密要最后加一个横杠, 然后呢我们再去复制一下这个 appad, 就这个密要是有两部分组成的,一个是我们复制过来密要,第二个就是我们的 appad, 在这个后面再把 appad 粘贴进去,然后保存。 啊,这个没有保存按钮啊,输入就是保存,然后点击回来,我们再问他 love 的作者是谁啊?发送, 然后我们就通过了这个呃, a p a 接口,把它给接入了任意的这个套口, g p t 啊,你想接入自己公司的产品等等都是可以的。 本来这个视频想讲一下这个高级编排怎么用的,但视频时长现在已经挺长了,然后这个功能稍微还有点复杂,呃,我打算下个视频再说。 然后呢,在这之前大家可以看一下这个 fast cpt 的文档,它这里关于高级编排的部分写的也还可以,给了很多这个视力,有这个联网搜索以及操作数据库等等。那我们就下期视频再见吧。
713三分钟实验室 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿lacked me 免费开源后台管理系统到底好不好用?拿它做项目到底方不方便?速度快不快?这些问题其实我们每天都在反复的问自己,后来发现想太多也没用,通过实践检验才是最好的方式,其他都是纸上谈兵。 有关注 like 的命开源项目的朋友应该都能注意到,最近一个月已经上架了五款基于 like 的命开发的应用模板,涉及家政跑腿支持付费单商务商的系统等细分领域,特别是支付费系统,成功推出了 pp 和 java 双后端语言模板, 这其实就体现了 like 命多后端语言的优势,尽可能的服用前端接口和数据结构。在应用模板开发过程中,我们也让 like 命核心团队成员参与了部分业务逻辑的开发,让大家不要脱离实际场景, 这样才能切身体会到痛点。总之,征途还很遥远,少说也要再花两年的时间持续打磨,才能称得上是好用的后台管理系统吧。再次感谢各位程序员朋友们在 kitty 上给到的宝贵建议,非常感谢!
77钟富桂 12:38查看AI文稿AI文稿
12:38查看AI文稿AI文稿这个项目是微软开源的,叫 deep speed faster gen, 它是对比了 deep speed 的 inter 呃 inference 呃,它实现比那个 呃 v l l m 更加高速的这样一个推理啊,那么它这个论文里面讲的它的这个性能要比 v l m v l l m 这个推理性能还要高两两倍左右啊,它等于是这样,那么它这个实验是用了拉玛 two 七十 b 的这样的一个模型啊,跑在 a 一百四块的这个 gpu 上面进行测试的, 它这里面呢,是用到了几个技术啊?今天我们一起跟大家一起来聊一聊啊啊!第一个技术呢,就是 brock 的 k v catch 啊,这个技术的话呢,就是 v l l m 啊,他们之前呃 这个首创的这样一个技术,就是把 k v catch 进行块状啊,进行做缓存啊。那么第二种技术呢,它这个称之为叫 contino 呃呃 ban 啊,这个就是持续的这个批处理啊,这个的话呢,是之前有一家公司啊, v l m 也实现了啊,这个家公司叫欧卡,这家公司是实现了这样的一个首创的这样一个技术, 后来很快被 v l m 呃暴露在他的整个一个项目里里面。第三个技术 dymatics spirit, 呃, few few use 啊,这个技术的话呢,是微软啊他首创的啊,目前是在 deep speed fast gen 这样一个项目里里面,他是实现出来了啊,我们回头一起来看看啊。 第四个技术之高性能的扩大的一个内核的实现啊,这个是微软之前在 dipsb 的这个项目里面,他已经实现出来了,所以他把这几个技术整合起来之后啊,他又跟 vlm 进行对比,然后就实现了这个性能比他快两倍的这样的一个内评测。好,我们一起来看看啊,这样的一个项目, 这个项目的安装也是比较简单的,我也我也装过了啊,他主要是用这样一个命令啊,去安装一下就行了,安装完了之后的话,你可以用这个 api 直接的就 paplin 啊,直接的可以让他去生成,那么他这个速度就会非常快啊。 好,这个是简单的一个使用啊,分块 kv 缓存,这个我们就不介绍了,之前我也是介绍过的, kg 的 attention 啊,如果大家有兴趣的话,可以看一下我之前的视频啊,讲了好几期啊,连续批处理这一部分啊,连续批处理的话,我们可以今天再给大家介绍一下啊,他是怎么来弄的啊?他就是 啊,假设这个服务器上面有多个请求啊,他是同时进来,那么这个时候他是为了提高这个 gpu 的利用率啊,他呢就会等待一段时间,把几个请求啊变成一个批次,直接再到 gpu 里面去推理啊,他通过这种方式,他叫 连续 p 处理啊,那么连续 p 处理呢?它也有两种实现方式,呃, t g i 和 v l l m 呢?它是属于这种。呃,它把这个连续 p 处理的话,把它分成两个阶段,一个呢叫提示处理,把 prompt, 嗯, print 和呃做困的生成分成两个阶段分别去处理了,这个也是他目前比较慢的一个主要的原因啊。另外一个欧卡他们实现的啊,他呢把这个两个东西是放在一起来处,他 他是把这个两个阶段放在一起来处理的,他没有把它严格的区分开啊,他是等于是这样啊。呃,他现在呢,看到那个 vlm 和 tgi 里面就会有这样的一个问题,他 如果遇到了一些请求,这些请求他的提示词非常长啊,那么这个时候的话他会停下来,就这个时候就是拓客就不能连续产生了啊,所以这个时候他有一个比较慢 的一个过程啊,微软他们就开呃发现了这样一个问题,所以呢他就提出了这样叫 separate for use 的这样一个方案啊,然后呢他他是呃创新型的,就把这个两个东西啊,把提示词和生成 token 啊,进行一个组合的策略,他就提出了这样的一个算法啊,那么这个算法做出来之后呢,他会发现啊,性能确实会比原来 mlm 还要快啊,他是这样的,好,我们一起来看看啊, 他这个东西到底是怎么来来实现的啊?我们来看一下,那这个就是 v l m 和欧卡啊,他们的这个主要的一些问题啊, 他就是长提示词和短提示词,会导致长提示词和短字是提示词在生成批次的时候,他有一部分时间会中断掉啊,这样就会造成 token 的这样的一个处理,他的延时会增加啊,他有这样的一个问题的,那么第 exb 的它是怎么做的呢?它就是把那个长提示词呢,它平均连续划分啊,我不管你这个提示词到底有多少,我就帮你平均划分,平均划分之后呢,它就会扔到那个里面,把这个提示提示词的这样的一个把它给变小啊,变小它的处理 速度会更快一些,但是他会发现这个提示值他可能分两个到三个进行划分,划分的时候呢,他发现第一个如果还不需要生成摘药的时候,那么他再去拿第二个,在这个过程当中他就不需要等待,他直接就可以让他去后面的那个 token 就直直接可以生成了啊。所以他的主要的原理在这 它的本质上提高的其实是延迟啊,降低了这个大模型推理的延迟的性能啊,同时它因为它它这个动态的这个批次均匀的划分会导致它性能会比原来会更高一些啊,特别是在长提示词的这样的一个前提下,因为我们了解叉 g a 的这些硬硬 用的话,那个它的提示词上下的都会比较长啊,这样会导致其实你看上去短提示词这个 v l l m 它的性能还是比较好的,但如果你发现是长提示词的话,它的性能可能就不是有,有些时候可能就没有你想象当中这么快啊。那么 deep speed 呢,它就解决了这样一个问题啊。 好啊,这个是一个基础的一个呃,一个一个原理啊,他接下来呢就是进行了这个性能的评估,性能的评估啊, deep speed fast 店的话呢,他把上面四个算法都已经实现出来啊,所以他性能会相对来讲会比较好。 呃,他的评估他主要是一个是测他的那个有效的吞吐量,一个是测吞吐量的延时啊,你可以看到这个蓝颜色的就是 dips b 的 法师给这个呢就是 v l l m, 那么你可以看到他的延迟降低了百分之四十,同时的话他的吞吐量提高了两倍,这个是他的这个基础的原理,当然 这个是他是跑在四块 a 一百的这个 g p u 上面实现的,呃,因为我们没有,下次我有机会的话,我在四零九零上给大家再测试一下,再对比一下这个实际的这个情况啊,看看他是不是这个两个相差会有这么大。 它目前是用四款 a 一百的这个四零八零的这个 g p u 才能实现这样的一个两倍的一个增速啊。因为我们了解这 d p 的话,它本身就是一个 非常高性能的这样一个多个 gpu 联合的联合训练的这样的一个底座啊,所以它有天然的这样的多 gpu 协同,它是有很大优势的。我们之前也也是给大家介绍过啊,什么 zero stage 所以的这样的一些算法啊,它这个它可以在这个 g p u 里面进行滑块啊,划分这个 popline 啊,进行多 g p u 的这种处理啊,我估这个跟这个 disp 的它这个底座 本身性能也是比较好,是有一定关系啊,他在这个上面扩展啊,又进一步实现了这个 v l l m 的一些 page attention 啊,这这这这些相关的一些算法动态批次啊,呃,这个 sprite a few use 啊,这些算法之后啊,那么它的性能就得到了极大的提升啊, 他是这样好,那么这个是他这个提示词是在一千两百啊,一千两百的时候,他是这么多啊,如果他的提示词达到两千 六百的时候,它的性能,它的颜值降低的会更多啊,它的吞吐量是稍微下降了一一一下降了一些啊,它等于是这样啊,所以我们要去看它的这个提示词的多少也是比较重要的。嗯,这个是它的产生,它的产生是这个是六十个 token, 这个产生是一百二十八个 token 啊,它这个还是有些差异的好。后面他又测试了一下他的这个有效吞吐量,在他的这个测试里面, 你会发现他的这个有效吞吐量,呃,肯定还是要要高于,要高于。呃, v l l m 的啊,他的吞吐量会更高一些,但是我看了一下,在四块 a 一百八十 g 的,能打七十 b 的这样的一个这个里面,他每秒钟产生的脱坑也只有六个。他的啊, 性能也不是非常好,虽然他比 vlm 要快二点三倍啊。所以啊,这个技术,我觉得这个大模型的这样的一些推理的话,肯定还是要量化的啊,你不做量化的话,他消耗的 gpu 又多,同时他的推理性能也不是很 也也不是很好啊。你可以看到他这个每秒钟是六个,每秒钟四个,每秒钟两个啊,他这个基本上是没法用的啊,当然他的推,呃,他这个 sprite 呃, few use 的这个算法,我觉得啊,还是有价值的好。那最后他就测了一下他的那个延时啊,他的延时,呃,低延时是 disbe 的 fast 件,他这个是最有优势的。他这个啊,你可以看到他的这个延时确实是低一些啊,确实是要低一些啊,当然 v l l m 的他的延时本身已经够低了,你可以看到他这个只有零点零点七秒啊,那么他会更更快啊,这个的话就零点二秒。那么低延时在 数字人的这种呃动态的声音、语音的真诚合成上面啊,肯定有比较大的一些帮助的。他这个好,最后他又测了一下的负载均衡,他把 啊,因为 deep speed 它有一个好处是在于啊,就是它可以扩展这个 g p u 和它的这个 g p u 的服务器啊,所以的话呢,它在 通过这个 dp 的这个平台,他可以把这个请求均匀分布在多个服务器上面啊,他放在多个服务器之上的话,你可以看到他的这个吞吐量就显著上升了啊,他是成一个线性变化的啊,你可以看到他从呃他从哎 一个啊不断的扩展他的福气扩展到十六个啊,十六个的话呢,他每秒钟的脱盆大概达到了二十多啊,将近三十这样子啊,他说这个十六个副本的话,他的吞吐量达到了二十三点七每秒钟,性能还是非常差啊,性能我觉得还是非常差,跟我们之前用的 量化算法来比啊,他的这个啊,他这个还不是很好看,嗯,当然这个是为了他要保证一定精度的前提下啊,他比呃他这个大模型,有些时候他要跑在一定精度的前提下,那么他这个他也需要用这种技术去做呢,他也是一种比较好的一种, 记住吧,他除了用 a 一百做了一些性能的评测外,他们还用了 h 一百和用了一个 a 六千啊,分别做了一些测试啊,那么这个是用八个 h 一百的,那么你会发现这个 dipsb 的他 在 h 一百的这个 g p u 上面呃它的性能就显著提升,这个是因为 d x b 的它这个基座啊,分布式本身就比较强,之前我们是讲过的啊,如果你是一个或者两个 g p u 啊,其实那个它这个能力是没有, 嗯,没有这么夸张的。他这个,所以我觉得他这个 v l l m 对比跟呃 d s b 的他的利用场景有些不太一样,嗯,有些不太一样。嗯 啊,这个是 a 六千, a 六千它的性能就会差一些,你可以看到在 a 六千,它这个两者的差异就不是太大,两者的差异就不是太大,它每秒钟也只有达到了一点六啊,一点六个,那延迟就会比较高,它这个这个是它 client client 的这个数量。嗯, 好,那么目前我也测了一下它目前的那个 deep speed gain, 呃, gain 的这个模型的话呢,它只 支持三个。呃,三种模型的类型,一个呢是拉玛,一个是拉玛 two 啊,拉玛系列它都支持,还有支 支持一个 mister 啊,这个模型我们之前也介绍过。还有一个是 o p t 啊, o p t 这个模型我看它的原码库里面我也看了一下啊,它只实现了这三种,你可以看到在它这个原码库里面它只支持了拉码啊, mister、 o p t 这三种模型如果你去运行其他模型的话,你会发现会报错了啊,我前面跑了一个一模型 啊,他这个地方就报错了,他会告诉你啊,这个这个模型是不支持他,是这样的。好啊,我们再来看一看 啊,如果你要去支持其他模型,你要去实现啊,你要把它有三个类啊,它它有三个文件,你要把它去实现出来的啊,一个是 policy, 一个是 module, 还有一是这个模型的结构啊,容器 这个三个类你分别要把它给实现出来,那你你才能在这个 dips b 的 键里面跑他的,所以他目前支持的模型还是比较少啊,这个跟 v l l m 是一样的啊,有些中文模型都不支持啊,那么如果你要去支持这些中文模型的话,你自己还得要写一些适配的一些呃, 拍摄的代码啊,好,那么它这个部署它也跟你讲它有两种方式啊,一种基于 fast api 啊啊,它这个还有一种的话呢,它是基于,呃,这个,这个就是长时间的,就是基于 g r p c 的这个伏击的协议啊,它可以支持长长时间的管道啊, 他有两种方式,他这个是这样。好啊,今天我们就给大家就介绍了这个项目啊,叫微软开源的啊, deep speed faster 键这样的一个项目啊,就跟大家就介绍到这啊,这个项目的话目前在 给叉不上面也开源了,也开源出来了啊,在这他在这。好吧,如果大家有兴趣也可以去看一看啊,去了解一下。好啊,今天的话这个视频就跟大家去介绍个事。
137小工蚁 01:01查看AI文稿AI文稿
01:01查看AI文稿AI文稿fasjin 又爆出安全漏洞了?今日 fasjin 的作者发布了一个通知,表示 fasjin 一点二点八零及以下的版本呢,存在新的安全风险。刚开始听说这又是一个反序列化漏洞的时候呢,我第一直觉呢,这一定又和 fasjin 的奥特太夫的机制有关。 最后呢,我去查了一下官方的通告,发现呢,果然还是这个罪魁祸首,因为发自基层呢,在对类中的接口或者抽象类进行序列化的时候呢,会将子类型抹去,这样呢,反序量化的时候呢,就没有办法拿到他的原始类型,所以呢,就引入了奥特太补这样的机制。 但是呢,因为这个功能导致了很多反虚电话的漏洞,所以从一点二点二五版本开始呢,帕萨吉森就默认关闭了奥特太婆的知识,并且呢,加入了 check 奥特太婆的相关代码,而且呢,还使用黑名单加白名单来防御这种奥特太婆被开启的情况。 但是呢,本次发现的漏洞呢,在特定的情况下,是可以绕过默认的奥特太婆关闭的限制的啊,起到远程攻击服气的效果。解决的方式 也比较简单,那就是呢,要不呢,就升级到一点二点八三,或者直接升级到发射金森 v 二的版本,要么呢,是开启 sift model 来彻底不支持奥特太婆,再或者呢,就是干脆使用能熬多太婆的版本。
1355程序员Hollis


