mj如何用文生图(国风)教程

粉丝80获赞241
相关视频
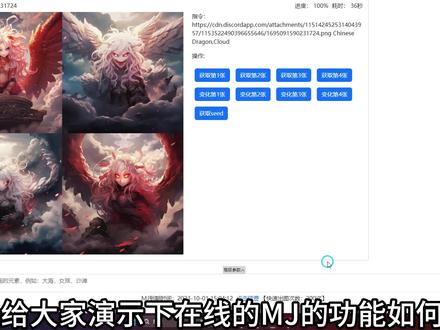 02:36查看AI文稿AI文稿
02:36查看AI文稿AI文稿今天给大家演示下在线的 mj 的功能,如何使用软件支持 mj 的文声图,图生图,反推提示词融合图片功能。先给大家演示文声图,直接通过中文进行图片生成, 这我用 m g 演示绘制怪兽平时做推文经常要用到的加速绘制中, m j 绘制需要用到的命令都整理到参数设置当中,我们按需添加即可。 这里我简单演示绘制机械哥斯拉,这是 sd 模型,很难绘制出来的, 当我们觉得当前图片不错时,就可以获取高清化或变化当前图片。 接下来演示下 m j 的图生图功能,就是生成相同画风或者相同构图的图片,这里我设置一张图片进行绘制,并设置好提示词,绘制完成后,我们可以看到和我们选择图片相同的构图, 接着演示下反推提示词,我先选择需要反推提示词图片。 m j 的混合功能就是将两个或者多个图片进行混合,绘制成一个图片,这我选择两 个图片进行测试,将两个图片风格内容进行融合,这我选择两个图片进行测试,将两个图片风格内容进行融合, 融合比较慢,我给大家说明下参数,这里参数都是 m j 常用命令,我们制作之前可以把 m j 命令先设置成,我们想要的效果都有中文说明,很简单, 这里给大家演示下软件的局部重绘的功能。先选择一个区域作为重绘区域,之后提交即可。 这里我们可以看到重绘出来的图片,就是只修改了我们需要修改的区域。最后我们来看看之前融合的效果,图片相当,把两张图片融合一起了。软件在视频简介觉得不错,请一键三连支持下。
55小郎君说漫画 02:03查看AI文稿AI文稿
02:03查看AI文稿AI文稿哈喽,大家好,我是超级 pro。 上一个视频我们认识了 mg 的界面,今天我们来学习一下基本操作。在这个界面中,我们最需要关注的是屏幕下方的输入框,所有的指令和关键词都是从这里输入的。首先我们要用英文输入法输入斜杠,调出指令面板, 在指令面板中选择 emagine, emagine 翻译成中文是想象,就是让他根据你的提示词想象一下画面,这就是纹身图提示词,也就是我们常说的周语关键词。这里注意一下,提示词必须是英文, 只能写在 prom 框里,如果写到框外是无效的哦。比如生成这张图的咒语是这样的,很多人看到这么长的英文就蒙了,其实不用怕,我们来分解一下。首先描述主体,一个微笑的女孩。其次是风格,插画风格的,有未来感的,不是照片。二 d 加三 d 感觉的,有荧光色的,比 话的感觉。关键词的整体思路是,我们要的主体是什么,要的风格是什么?三、我要的感觉是什么?四、图片的比例,当然如果你有更详细的需求也可以写进去, 生成的结果会更加接近你的想法。这里要注意一点,每个关键词都要用逗号隔开哦。发送指令后,我们会得到 mg 返回的四张图。 图片是有顺序的,记住分别是一二三四,对应下方的 v 一至 v 四, u 一至 u 四。如果你对四张图都不满意,可以点击刷新按钮,让 m j 重新绘制。 u 一至 u 四是 upscale 的首字母,就是放大的意思, 比如我对图片已满意,可以点击 u e 放大它会得到更加高清的图片。 v 一就 v 四,就是 vry 的首字母,是变化的意思。比如我觉得第三张图还行, 但又不是特别满意,可以点击 v 三,会基于这张图重新生成四张变体。好了,学到这里,相信你已经可以用 mg 生图了。如果你还有疑问可以给我留言,我会第一时间回复你。 今天的内容就到这里,下一课我们将讲解关键词的写法和框架,让你生成更加符合预期的图片。关注我,学习更多 ai 技巧!
1226设计师HOTBRO 00:56查看AI文稿AI文稿
00:56查看AI文稿AI文稿哈喽,大家好,我是好久不弱,上一个视频,我们讲解了种子数值,可以保持住图片的风格,今天我们来讲解一下以图升图,就是给 m j 一个参考,让他照着参考的感觉来升图, 说白了就是按摩机抄作业哦。比如老板说这张中贴的图感觉不错,让你做张类似的海报,但是别人的图咱也不能直接用啊,怎么办?难道去建模渲染吗?每隔一周时间搞不定吧,到时候节都过完了, 咱们把它交给 mg 吧。我们描述一下图片所包含的内容,用谷歌翻译成英文,然后发送,会得到这样的图,嗯,差别很大,风格调性都差很远,怎么办? 我们双击加号,把图片传给 mg, 然后复制图片链接,后面加上刚才的提示词。看哦,现在出来的图感觉就很像了,几乎一模一样,怎么样,学会了吧,快去抄作业吧!下个视频我们会分享图像混合功能,关注我,学习更多 ai 技巧!
219设计师HOTBRO 06:32查看AI文稿AI文稿
06:32查看AI文稿AI文稿五分钟学会纹身图,大家现在都已经装好了软件,那我们就一起来画一下第一张图,画之前呢,我先简单介绍一下一会要用到的一些功能, 这里我们选一个基础模型,这里我们选中维生图,这里是写正向和反向题词的,然后这个参数调一下,这个参数调一下, 这里设置一下出图的尺寸,最后这里要调一下这些配置。好,我们一会点击生成图像呢,就会生成到这里, 好,我们开始底膜呢,我们先选一个二次元的试试吧,这个 anything v 五然, 然后我们写正向提示词,告诉 ai 我们想要什么,这里我推荐大家按照这个分类啊,把词分行去写,后面方便你写修改,还有整理。 首先元素,我们写一个女孩,你看我们打字打到一半的时候,他就会弹出这个他推荐的这个词啊,我们鼠标单击就可以把词加进去,然后写场景,我们写个卧室, 下一是构图,构图呢,写个上半身 坐姿 细节, 呃,细节,比如人物的表情之类的,我们写一个微笑啊,让他开心点。画风,画风这里因为我们先让他画漫画,写漫画画风就行。 接下来质量,质量,这里先打一个 q u a, 你看这他就会给我们推荐啊,质量的一些词,我们选几个啊,加进去就行,高质量什么好?正向词写完了,我们现在还需要告诉 ai, 我们不要什么, 按照刚才的几个分类,我们依次来写一下哪些东西不要,其实重点就是不要低质量的图 题。日词写完了,我们调整一下参数,一个一个来, 先看这个迭代步数,他这个数字越大,出图越精细,时间也会越长,一般我们按照二十到三十步来做就好。 然后是采用方法,这个你可以理解为配合模型出图的一种算法,有些模型作者会推荐适合这个模型的算法,如果没推荐呢?我们就这样画,二次元的话用这两个, 写实的话就用这几个啊,不会出错了。尺寸的话,我们第一张图就五幺二乘五幺二,分辨率就可以, 先不用调提示词强度,这个数字越大,他图呢会越跟从你提示词的描述越小,他就越会自由发挥。好。参数我们调完了来检查一下,最好是养成这个习惯。 哎,你看这里我就忘了个东西,我们在反向词里面加几个词,省着他出一些我们不想要的东西。 好,现在点击生成。 ok, 成功画出第一张图来看一下啊。嗯,还不错,那到现在我们的水平啊,其实已经 超过一半的同行了啊。来,我们接着看,我们在画面元素里给他加几个词,让画面更丰富一点, 然后再点击生成。 哎,不错,我们刚才加的那个词都画出来了,你看这个台灯,桌子,女孩枕头,床,对吧? ok, 我们试一下,让他一次画五张图,挑一挑,把这个总批次数调到五,然后再点击生成,这次他一口气画出五张来。 ok, 画了五张来看一下,你看你更喜欢哪? 接下来我们把 p 四数这里改成一,然后尺寸给他改一下,我们画一个五幺二乘七六八的图,竖图来试一下,好,效果也不错。 那现在我们可以尝试一下写实画风的图,先把这里选一个写实的模型,我们就选这个麦菊大佬的模型, 然后因为我们要画写实画风了,那提示词的画风这里给他改成写实相关的词,然后相应的反向词这里也改一下 这里因为这个模型作者有推荐适合他的模型的这个采样方法, 那我们就选他推荐这个这个,然后点击生成, ok, 看一下啊,效果还不错,一个女孩在卧室里, 那现在我们写实风格的卫生图也学会了下来,大家可以自己去尝试更多的模型啊,画风啊之类的。 但是有人可能说我们现在这个图呢,感觉有点糊,不太清晰。 ok, 那下期我们一起学习一下纹身图里面怎么画出更清晰,质量更高的图。
179金自省AI 18:14查看AI文稿AI文稿
18:14查看AI文稿AI文稿哈喽,大家好,我是 ai 小王子,欢迎来到我 stable diffusion 教学的第二期,今天给大家详细的讲解纹身图的原理和 stable diffusion 的掌控方法。如果你还没有安装部署 stable diffusion, 可以看一下我的第一课。在正式进入今天课题之前,我 想先告诉大家,只要你把 stable defusion 基本原理搞懂,搞清晰,搞明白,你就会发现 stable defusion 真的是非常的简单, 所以不要害怕,跟着我的教程来,你一定能听懂。本期视频我会说一些简写啊,比如说 stable diffusion, 我会简称它为 s d, 然后 tag 就是我们常用的 prompt 关键词 t a, g。 当我们打开 s, d, y, b, u, i 的时候,就会看到这个界面最左上角的这个 stable diffusion 模型,简称 checkpoint, 就是我们所说的大模型。大模型是干嘛的? 如果把 s d 比作为一个人的话, check point 大模型就是 s d 的心脏,就是 s d 的灵魂,没有 check point 你什么 都做不了。它的作用是什么呢?主要是来定义出图的一个风格,一般文件的大小是非常大的,在两 gb 到十 gb 不等,也有可能更大的,它是汇集了成百上千甚至上万的图片的一个总和合成的一个大模型, 一般是以 safe tensors 或者是 c, k, p, t 结尾,见到这两个结尾一般都是大模型,当然有的时候 laura 也会用到 safe tensors。 我们比较常见的是哪几个呢?就是 chilomix, anything 威武,这三个有什么区别呢?我们看一个图片,其实就明白大模型是干嘛的。 ok, 我们看一下这张图啊, 首先我们不不用管左边的 va e 这些啊,这个一会我会给你讲这三个。第一个是 anything v 五 checkpoint 大模型做出来的图片,我们看三个有很明显的区别。第一,竖列就是动漫风格,因为 anythingv 五他是专门产生动漫的一个大模型。第二,竖行 v 一杠五,他的风格就是国外一些真人写实风格。第三个 chill out mix, chill out mix 这个做亚洲脸其实是非常好看的啊,这就是这三个的区别。当然还有更多大模型,我就不全部给大家介绍了,我就先介绍这三个。那么 checkpoint 这个东西是安装到哪里呢?在我们的 s, d, y, b y, 然后 models cbd fusion, 把所有拆库的大模型都安装到这里,我们可以看这边啊,都是很大的,两 g 起到七 g 不等。下一个我们看一下模型 vae, 大家有可能比较模糊,这是干嘛的? 它的全称叫做 variational auto incoder 变分字编码器,它的作用其实就是增加一些图片的色彩和滤镜,还有一些细节调整, 主要是可以降低画面的一个灰度。我们常用的 v a e 模型就是八四零零零零,一般默认选这个或者不选择都 ok, 这个看自己的想法。然后我们回来再看这个图啊,我们看竖排,这三个不同模型,我们看当没有 v a e 和有 v a e 时候, ve 这个色彩其实比没有 ve 的时候更加有亮度,光泽。我们看一下这个第一个,然后最后一个,感觉就像加了一个增白的滤镜,然后让整体画感更加具有饱和度,这就是 ve 外挂模型的一个作用,然后 va e 的安装地点在哪里呢? 还是 stable diffusion y b y, 然后点击 models, 然后这里有个 ve, 你要把 ve 下载到这里就 ok 了,然后下一个看一下。 creep 跳过层是干嘛的? creep 跳过层全称叫做 contrastive language, image per training 语言与图像的对比与训练。它是用来让我们的 tag 和图 图形建立一个关系,或者我们可以理解为 s d 数据库里的处理模块。它这个数值如果是非常高的时候,关键词和图片的关系就会越来越低,数值越低的时候,关键词和图片的关系就会越来越高,它是一个反比例关系, 一般我默认不动,就在一就好了,不要调太高啊,我告诉大家为什么不要调太高?我们看一个例子,我们主要看这一数列的 cleve skip。 这边我做了一张零到十二的一个对比图,首先我们看零到四 steps, 我一会会讲啊,不管你的 steps 是多少,其实这个图片已经挺不错的,当 steps 越高的话,这人物的细节就会越多一些,然后我们看到六六也 ok, 所以到零到六这个值都 ok。 然后到八的时候,他就开始变奇怪了啊,就整体关键词和图片的关系就会越来越低,他会用更多的 ai 想法去给你做这个图, 不管你的关键词,他会无视你的很多关键词,因为我本来这关键词是一个女孩的关键词,他直接变成一个男的了,并且脸部还是有很明显的变形的。然后到十十二更高的时候,他就开始做一些九宫格的图,所以说你这个东西不要调太高,一般默认就好了,一到四 是一个不错的选择啊。这个范围我弄了一个零啊,按理说他是不能调到零的,我给大家讲一下,他这个范围是一到十二,一般不用去改这个参数,想让关键词的权重多一些,就不要动他了,我们看下一行,我们看哇,这一行好多东西啊, 看就感觉是不是要很多要学的。其实并不是啊,后边都是一些设置和插件,具体当时用的时候我会告诉大家。目前来讲,只要搞懂文生图的所有参数,还有图声图了一个 denoising, 还有一些高清化,这个都是特别简单的东西,剩下的你就全部就掌握了, 很简单, ok, 首先我们看提示词啊,提示词和 meat jenny 来讲呢,提示词这里分两个,第一个是提示词,我们叫做正向提示词,第二个是反向提示词,它区别很容易理解啊。第一个就是你想让图片出现什么,你就往这个框框里加,你不想让图片出现什么,你就往这个框 创立家。举个很简单例子,我想让整张图片有 girl 是女孩,那我不想让他出现男孩,我就写个 boy。 再举个例子啊, instability fusion, 他经常会出现一些多头,多手指,多脚多腿的一个情况,所以我们在看关键词的时候,我们会发现别人经常会写 extra hand 或者 extra legs, 多手多腿的情况出现,我们都会把这些放到反向提示词。我们先讲一下内容性的态度,我们描述的时候描述什么呢?这个是根据不同场景不同你想出的图去定的,如果是人物写实的话,我们会先写人物和表情,然后服装特征,场景环境,然后镜头,然后是灯光 和风格具体描述这些,然后再加一些其他的元素细节词到里面。嗯,除了这些描述人物特征,我们还要描述一些画面的一些细节,比如说质量,我们常见的 alt details, insane details, 然后 有些渲染器引擎,比如说我们想要三 d 的 octan ranger 啊, detail unit cg, 然后就是画面的风格,假如说我们想要插画风啊, oil painting, 油画风,写诗风等等等等,都可以往里面描述。然后给大家分享一个国内大神整理的超全的元素风格整合包,都在这里边, 你可以在这里边出任何什么镜头,人物,服装,表情等等等等等等。然后还有这个东西啊, 大家到时候可以自己看一下啊,这个连接呢,我会直接放到我的交流群和 d c 里边,大家可以直接拿下面给大家讲一下。 tag 的格式目前还是只支持英文啊,所以英文还是要好好学的。 的确有那些你打个中文就会出英文的小插件,但是我依然不建议大家太过依赖啊,因为你学好英文真的是对你有很大帮助。未来新的 ai 出现,可能还是先是从英文开始,如果你用的起 他已经有一个很不错的提词器了,比如说我们想打一个 masterpiece, 我们不知道怎么拼,哎,他就这里出来了。然后第二个就是我们可以以单词的方式写, 也可以一个词组一个词组写,还可以短句来写,短句是我非常推荐的,因为你同样的词组以短句来写的话,他的图会更精确。如果你一个词一个词泵,识别性会降低一些。 stable defucent 的识别关键词非常非常多,而且他识别的细节也会很多。 但是如果你很长的句子全是一个单词,一个单词往外蹦的话,他一看这么多单词,他可能自己用自己的想法去排列组合他了。 如果你是一个句子的话,他会直接以你的句子去生图。单词与单词之间就是用逗号分割,然后靠前的关键词权重是最高的,并且是优先被 sd 识别出图。所以我们在出图的时候把重要的元素往前放就 ok 了,特别是主体,或者当你写了 一堆 tag 的时候发现,哎。我这个假如说 forebody shot 全身怎么没有出现呢?我们就把 forebody shot 提到前面,它大概里出了图就会出现你的一个全身照。然后接下来给大家讲一下权重怎么用。 因为 sd 里边的权重分好多种。第一种我们叫做括号法则,大括号,中括号,还有小括号。假如说我们描述一匹黑马 black horse, 把它括一个括号,这个时候权重就变成了一点一倍了。如果说我们加两个括号行不行? 我告诉你是可以的,加两个括号,他权重就是一点一,乘上一点一倍,我们加三个括号行不行?可以,就是一点一的三次方,加几个括号就是一点一的几次方,我们加四个可不可以?也可以,你加十个都可以啊。 下一个我们讲一下大括号啊,大括号的话,他加了权重会略低一些,他是乘上一点零五倍,加两个大括号是一点零五,乘上一点零五,这是增加权重。那么有没有减少权重的 好方法呢?有,加一个中空号就是减少一点一倍,加两个中空号就是减少一点一的二次方,减少一点二一倍的权重。下面讲一下第二个权重方式叫做数字法则,就跟 midi 很像啊,就是在后边打个一点三左右的权重,然后我们要把这个东西包起来啊, 然后这个 black horse 在整篇 tag 里边权重就会增加一点三倍。那如果说我们想让它减少呢?就是网一以下的单词去写,如果写成零点五的,就是说 black horse 这个 tag 在整体关键词里边,它就变成零点五倍的权重。 这个是权重法则啊,我们用这个比较多啊,刚刚那些加一堆大括号,只让大家知道有这个东西,但并不建议用啊。你加一堆括号,你最后乘着乘着也不知道是多少了,你加零点五,直接这个比较清晰明了。然后权重建议尽量保持在零点五到一点六这个范围里边,如果你写成 二,写成三,写成两百两亿,那你的图片肯定是会崩的,大概率就会成一个花图。然后下面教大家一个按的大法,叫做混合大法,大写的 and 啊。假如说我想让一个老虎和一个牛去做混合,把按的放中间,我们看一下它出了图, 我们看一下,其实能明显的看到这个身体是老虎的,他这个头其实像一个牛头,对不对?按的大法就是用两个做混合,第二种混合方法叫做中括号,然后中间放一个竖杠,这个也是台跟,然后右边写个靠,我们先看一下他的效果, ok, 这样你看就是牛头更明显了,然后是虎的身体,这两个效果什么区别呢?括号混合大法,他是交替算法。假如说我这个步数一共是渲染十步,一三五七九,他渲染的是老虎,二四六八十,他渲染的 是牛,所以最后就混合成这样子了, ok, 这个是混合大法,下面我要讲一下采样步数,就我们刚刚讲的 something steps, 就是他渲染出一个图的步数,他的这个值是一到一百五,当你把它往右调,调的越高,画面的细节就会越多,渲染速就会越慢,调的越低, 他画面的细节就会越少,渲染的速度越快。如果太低的话,这个整个图片大概也是模糊的,或者是全部是噪点。我建议一般做图的话,二十到四十就够了,你调一百五,可能一张图你显卡好的话还好,你显卡如果不好的话,你可能要等十几分钟甚至半小时。 给大家看个例子啊,我们先第二行,第二步到第八步左右,他其实就是一个去造的一个过程,然后到第十步的时候,其实这个图片你可以用了,从二十五到四十,脸部变化其实非常小,他为什么是说细节变了?我们看这个衣服啊,这边 褶皱一点点,然后多一点,多一些,然后褶皱更多,这就是他的一些细节,然后还有一些头发细节。大部分采样器二十都已经足够了,如果你想把一个图做的非常非常清晰,那你就用到四十左右就 ok, 下面我们看一下采样器 something method, 哇,我们一看,哇塞,这么多采样器,我们到底用哪个比较好呢?我们可以把采样器分为四个不同的类别, 采样器里边带 a 的,采样器里边带 carrust, d d i m 和 p l m s, 最后一个是带 d p m 的,然后这个 here 和 uni p c。 我分开讲啊,只要是带 a 的采样器,我们都叫它 ancestral sumper, 比较古老的采样方式, 它的特点就是采样时很随机,但缺点呢,就是无法集中的采集造点,并且有的时候它识别的关键词可能没有其他采样器识别多一些,然后是 carros, carros 特点就是它去造的一个过程是比默认的要快的, 然后下一个 d d i m 和 p l m s。 其实这两个是 stable d fusion 刚出现的时候最先出现的两个采样方式,但后面出现的这些都是吸取了它的优点,并且把它的缺点也更改了很多。 d l m s 就是 l m s 的一个升级版,它渲染的速度是比 l m s 更快,更清晰。 这两个用的比较少,大家可以暂时过滤掉。我一会可以给大家看一个所有不同采样方式的一个例子。 ok, 下一个 dpm pm 加加 sd, 这个是用了非常多了,这个做人物形象的时候非常有用,我用的最多了,其实就是这款 采样方式。先讲一下 dpm 二啊,他对关键词识别是比较精准的,但是渲染的速度比较慢。 ok, 我给大家看一下他们的区别啊,我们主要看这边的啊,从哪个方面去评判他的好坏呢?步数越少,渲染的图片越清晰的时候,那就是一个很好的采样器。我们先看前两个, 前两个大概到第八步,第十步的时候这个人形已经出来了,但第三个话 lms 他的步数可能要高一些,到二十五才把真正的人形打出来, 和 lms 不推荐大家去用。下一个就是 him, 他是一个生造去造的一个过程,刚开始全全部造点,然后慢慢慢慢去造,然后到也是到第十步的时候,差不多已经把图片做出来了, 大家看一下,我就不一一去讲了,我主要讲一个哪个呢?叫做 dpm fast。 当用 dpm fast 这个采用方式的时候,他渲染的速度是非常快的,但是有个问题啊,他要很多的步数才能把真正的人形给打出来,这边到四十步的时候才能感觉啊,这个人形已经完全出现了,他虽然快,但是需要的步数很多, 我也不建议大家用这个 dpm fast, dpm adaptive 这个太牛逼了,这个两个步数就把人给渲染出来了。即使你到四十步,最后四十步 和两步的区别几乎是没有什么太大的变化,因为 dpm adaptive 渲染的斜率是平的,你不管多少步,他直接渲染出来,就是跟渲染四十步数的是感觉是一样的。我们总结看一下, 第一个 ok, 第二 ok, 第三个不行,第四个 ok, 第五个也可以,第六个就不行,第七个可以,这个也这个也不行。然后 dpm fast 大家直接略过啊,就不要用这个 adaptive 也可以用,当你显存很小的时候,把步数调低,直接用两个步数就可以弄出来了。 这个是采样器,这张图我会分享出来,大家一看就是明白具体要哪个采样器了。然后下面面部修复,无缝贴图和高分辨率修复 一个。如果你想生成带人物的图片的话,一定要把面部修复给勾上,勾上的话 sd 会对你的面部做一些更细节的一些调整和渲染。无缝贴图没事的话就不要点他了,你要点他的话,我给你看一下这个 one go 无缝 贴图出现的话就是一个花图,一般是做纹理图案或者壁纸的时候用的,比如大理石瓷砖比较常用啊,就把一些纹理给贴上去。第三个高分辨率修复,这个什么我们后边会讲这个其实就是 x 差不多是一样的,就是把模糊的图片变清晰,嗯,然后下面宽度和高度,这就是图片的分辨率,都是以像素为单位的啊,一般常见是五幺二乘五幺二或者七六八乘七六八。这个跟显存也是有关系的啊,如果你显存不够的话,你一般用五幺二乘五幺二就好了, 因为他很占用显存。假如说你想生成的图片,你弄成二零四八乘二零四八,你显存不好的话,你很容易去报显存,就会报一个错误啊。 stupid feel 上一些常见的报错误之后会给大家总结一个表的啊,下一个是生成次数和每次数量啊,这两个其实好多人都没有讲清楚啊,我给大家讲一下什么意思,生成次 数的范围是一到一百,就是你想让他生成多少张图,假如说我想让他生成三张图,我就把它调成三就好了,然后这边就会给我生成三张图, 然后下一个每次数量。假如说我把每次数量调成二,我们先看一下这两个区别在哪里的。生成次数是一张一张给你渲染每次数量,调的话,你假如说调二,就是你同时给你渲染两张图 和一次一次给你渲染两张图的区别。如果你显存不好的话,不要点它显存,如果很好的话,四零九零之类的你 点他也可以,但一般常见的我们都是点生成次数,其实时间差的不是很多啊,但是每次数量这个 batch size, 你要把它点高的话,他会把你显存直接给顶满,甚至报错。我给大家报个错看一下啊, 然后一零二四乘一零二四四个 batch。 哎呀,这回没有报错成功啊,下回有 机会再给大家演示怎么报错啊。下面我讲一下。 cfg scale, 中文叫做提示词引导系数,它的意思就是你图片的相关性啊,数值越高,你图片就和提示词更相近,数值越低, ai 的想法就会多,一般低不要太低,高不要太高。零到一,我一会给大家看个例子。 ok, 我们看一下啊。同样的关键词, cfd scale 是零的时候他就是花的,零到一几乎都是花的,二的时候可以,因为我的关键词是 fully cover 的,所以这个关键词识别的不是特别好。然后往后看之后的这些关键词和图片的关系就比较多一些了。 比如说四到十左右,你看到十二的时候,图片就开始损坏了,一般你不要超过十,我都不建议一般九差不多了,你看从十之后图片就全部损坏,全部损坏,全部损坏,这也可能因为采样器的原因,当然还是不 建议调的太高,也不建议调太低。下面讲一下随机种子,这个随机种子就是一个 ai 产生绘画的一个随机数。我先给大家讲一下这个骰子和循环标志是干嘛的,如果我们说,哎,这张图片风格我觉得很不错,在哪里看他的 seed 呢?在在这里我们可以直接复制给他,粘贴到这里是一个办法, 我们也可以直接点击这个循环符号,把这个就直接复制过来了。骰子是干嘛的呢?骰子就是把种子调成负一,为什么是负一呢? 只要这里是负一,那你 ai 出现的图就是全部随机,一般我们用负一多一些。然后下面这个种子差异度啊,我就不跟大家讲了,因为几乎是用不到的。这个东西也是有点像混合的意思啊,就是让两个种子做结合,假如说这是种子,我用五, 然后这种子我用六,他就会把两张种子的风格合成一张图,然后差异强度。假如我们调到中间的话,就好比 一半是五的种子风格,另一半是六的种子风格,这个大家下去可以试一下,我这里就不讲,因为它的用处不大。再接下来看就是这些插件,我会主要讲 ctrl nine, 会专门做一篇 ctrl nint 的用法教程,然后下面这个脚本,这篇视频我先讲到这里,下节课我会讲脚本, 本期视频我讲的所有内容都整理到了思维导图里面,链接我会放到评论区,免费供大家学习使用,里面有做重点标注,比如这些红色的字体是比较重要的,大家要反复观看黑色字体大家可以选择性的观看啊,因为有一些东西你不必要太去深究, 大家了解一下就 ok 了。如果我的视频对你有帮助,希望你可以一键三连支持我一下,我会有更多的动力生产更优质的 ai 教程,关注我,让你轻松掌控 ai。
1993AI小王子 带你轻松掌控AI 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿用迷的圈扭连续创作有多牛?可否让道?要么命留下,要么东西留下。哼,可惜了 啊啊 啊啊啊。
707品牌术士.南柒 02:38查看AI文稿AI文稿
02:38查看AI文稿AI文稿大家好,上期视频给大家介绍了如何安装 stable defusion 以及简单的纹身图功能。本期视频我们继续探讨那些强力的模型网站以及高级的纹身图玩法。在上一期视频中让大家了解了如何从启动器里面下载你想要的模型,今天给大家带来一些更加优质的网站介绍。 save time docum, 也就是大家一直提的西站。在这个网页里有很多非常强大的模型,各种画风的分类也很全面, 大家可以看到很多小姐姐模型还要长到十八岁才能看呢,我替大家看过了,不是很好看。这里需要强调一下的是, stabled fusion 大模型的功能是决定图片的整体画风, lower 模型则是在不改变整体画风的情况下增加新的修饰场来影响整体的输出结果。模型的左上角带有 checkpoint 字样的则为 stable division 大模型,左上角带有 lola 字样的则为 lola 小模型。我们随机点击打开一个 doctorships 模型,进来之后我们可以看到这个模型的相关信息介绍,我有评论以及大家上传的用这个模型生成的作品。我们点击这些作品右下角的感叹号,可以看到生成这个作品的相关参数信息。真相, prompt 副项, prompt 采样类型、模型名称、提示指引导系数等。 点击右上角的 download 下载这个模型,将它粘贴到 swab, ui 是文件夹中的 models, stable diffusion 文件夹,重新启动 ybui 就可以在左上角选择我们下载的这个模型。大家在刚开始不知道如何去写参考词或者想生成又类似画风的作品时,可以参考这些优质作品的参数,我们将这些参数复制到自己的页面中生成,看看效果。 这里我们选择一批生成数量为四,图片尺寸设置成宽五百一十二,高一千零二十四像素,点击生成就可以得到四张根据我们选择的模型填写的提示词参数得来的小姐姐作品。我们来看看填写的提示词代表什么意思, 这里有杰作、最佳质量等通用的真相提示词,还有白发、复杂的裙子等描述细节的提示词,这些都能够告诉 a i。 我们需要什么类型的作品。当你脑海里有画面,但是不知道怎么去描述一些提示词时,给大家推荐第二个网站, number one i type 生成器。这里有非常多常用的提示词, 我随机来选择一些,比如 go to face、 who d 连帽三等,点击复制粘贴到 y b y 中生成看看效果。这里我们就得到了相同画风,但这是根据我们自己提示词而生成的好看的小姐姐,这些图的细节都做的非常到位, 同样如果大家手上有一些别人深层的图,但是不知道其中的参数,再给大家推荐一个网站, stable d fu 正法术解析,我们将已有的照片拖入到这个网站,就可以看到这个图片深层使用的模型、提示词和采样方式等所有参数。 今天给大家介绍了纹身图的高级玩法,以及三个优秀的网站后面的视频,我们将会对图、声图、 ctrl 奈等功能进行实战介绍。欢迎大家在评论区积极留言讨论,大家下期见!
9440Ai风向标 01:47查看AI文稿AI文稿
01:47查看AI文稿AI文稿用微信小程序也能玩微生图了,风格多样,效果也不错。人像风景的真实感拉满,用来还原古诗词的意境也是轻松拿捏, 还能一边聊天一边画画。这是鹅厂混元大模型新增的绘画功能,实际用起来怎么样?我们抓紧实测了一波,先来复刻一下之前里水里爆火的九十年代情侣。 这里呢,有一个小技巧,提示词要用生成,再加上真实感或摄影风。这样生成的图片穿着和背景都挺有年代感,人物的姿态和脸部看起来也挺真实,你觉得复刻成功了吗?再让他还原两个景点,布达拉宫和鸟巢旅馆。 蓝天星星、白墙黄金顶以及这西京的倒影,还真被他抓到了精髓。接下来,我们用古诗词和中式菜名考考他的中文理解能力。先画一幅描绘古诗词的水墨画,总体意见 还不错,但细节还不够完美。这时,我们可以发动 ai 的多轮对话能力,向他提问,要准确表现这句诗词的画面细节应该怎么描述,他就会给出更详细的提示词,并按这些要求画出来。这次生成的画增加了飘雪的细节,质感也更好了。我们还可以顺手把描述变成指令。 以后呢,只要点开对话框旁边的按钮,就能快速调用了。下面让他画一下红烧狮子头、夫妻肺片和老婆饼,他不但准确理解了自己的中文菜名,还画成了很好吃的样子。除了以上这些,他还有 n 种风格口味, 我们搭配上提示词灵活使用,就可以用插画风,可以同时画 q 版肖像,用赛博朋克风生成自驾哪吒、敖丙手办,或者用动漫风搭建一个末日游戏的三 d 场景, 平均不到半分钟就能出图,画完还能一键转发给好友,更适合射牛体质,这样一通测完后,总体体验感还是很不错的。你觉得他怎么样呢?你想用他来画什么呢?
53量子位 00:59查看AI文稿AI文稿
00:59查看AI文稿AI文稿支持文生图,图生图的手机 ai 绘画软件他来了,多种风格模板供你选择,而且使用次数不受限制,操作也非常简单,下面来演示一下。打开文生图页面,在这里输入关键词,不会写的可以根据系统推荐的文案点击就能切换。 接着选择风格模板,支持两个模板叠加使用,同时可以更改图片画质和尺寸,点击生成,稍等片刻就能得到想要的图片了。打开图声图功能,上传一张图片, 输入描述词,选择相关参数,点击生成,就能生成出和上传图片相似的作品了。 这个软件还支持自己训练模板,只要上传几张图片,点击训练,等待一段时间,属于自己的模板就做好了。软件已经整理到工具箱了,感兴趣的小伙伴进入粉丝群,小助理一一安排。
98风林自媒体-小海 01:40查看AI文稿AI文稿
01:40查看AI文稿AI文稿一分钟教会你用 mj 训练自己专属的风格模型。首先打开,你在聊天框输入斜杠,找到 tom 指令,输入提前准备好的提示词,这个提示词适用于生成炫光照射人物的输入,完成后直接发送之后 mj 会给出选项,第一个选项分别对应着 十六到一百二十八组不同数量的图片风格采样生成。每种选项消耗的出图时长也是不同的,可根据自己对风格的精细程度需求来选择。 我们这边选择十六组来测试。第二个选项分别是默认和原声,我们这边就选择默认,选择完毕,点击确认之后等待生成。如果你选择的风格采样图片对数越多,等待的时间就越久。 生成之后 mj 会提供一个链接,打开这个链接会跳转到一个选图页面,首先上面有两个选项,第一种是按足选图,左右是选项,中间是弃选。 第二种是逐章选图,根据需求一张一张的选图,我这边直接按图选择,挑选自己需要且统一的风格。选择完毕之后,在下方会生成一串代码,这串代码就是我们选择的图片的风格代码。复制这段代码到 mj 中 备用。主体关键词加两个横杠,赛欧空格加代码,我们来说输入一个女孩来尝试一下,这个炫光照射风格的女孩就生成了。 当然选择采样图片数量越多,风格就越明确清晰,你也可以使用其他主体关键词来搭配这个风格。但是这个时候我想到一个问题,既然训练出来的代码需要放到提示词后面去使用,我把原有训练时的提示词改一下,主体 是不是也可以生成这种风格的图片呢?我个人觉得这玩意 pm 积累,那么你觉得这个训练模型的功能好不好用?关注我们,希望人人都能学好 a 爱不焦虑。
245Well AI 01:39查看AI文稿AI文稿
01:39查看AI文稿AI文稿文生图工具用什么好?首选当然是 mid journey, 但问题是呢,刚学会一点,人家就收费了,一个月要六十美刀呀。那开元的这个 stable defusion 倒是不要钱,可是你得给他配显卡啊,你还得折腾他。 那有没有一款上手就能用的工具还不要钱的呢?那有人可能说了,说这个病的 crave 因为也能用,可是他那出图质量实在是不敢说是吧?那百度的文心依言还可以出夫妻肺片? 所以呢,这些乱七八糟的工具我们不看啊。有没有一款能达到这个商业出土水准的还免费的工具呢?还真有一款硕果仅存啊。咱们就先来看看他的图片质量 怎么样,是不是一点都不比你专业差。这就是 leonardo dot ai, 它不但效果炸裂啊,而且它的这个操作界面也非常简单, 你不管是图片的大小,图图数量,然后他的分辨率,选什么样的模型,包括模型的参数,你都是可以在界面上直接选择的啊。只有 problem 需要你自己写。这就比最初用 discover 的做界面的捐任要方便多了是吧。 我们看左上角啊,他有一百五十个点的免费额度,这个一百五十个点是每天都会自动恢复的。那么他意味着什么呢?就是你出一张幺零二四的图啊,只用消耗一个点,所以你基本上每天都可以白嫖了是吧? 啊对,他还有一个优点啊,就是他不需要魔法,直接就可以上,这对咱们就非常非常友好啊。雷欧娜朵唯一的一点门槛就是他注册的时候。这个咱们下回再说。
129跟上 AI 的脚步 06:04查看AI文稿AI文稿
06:04查看AI文稿AI文稿今天呢,我们教你来绘制相同人物的不同视角,有很多人呢会面临这样的问题,也就是说我想做一个人物的不同视角的设计,尤其是在游戏开发或者游戏角色的一些设计里边,往往面临这样的问题, 那怎么做到这一点呢?那这个命题听起来是不是和我们上一个视频讲的完全是一个相反的概念,那上个视频是在讲怎么让你绘制不同的人脸,而这个视频是在讲怎么绘制相同的人脸,其实呢只是场景不同,那到底怎么才能绘制出同一个人物的不同视角呢?那今天呢,你来看我的操作流程。 这次实验我们使用的模型呢是 xx mix 九 realistic 使用下面的提示词来生成一个美女的图像,两个女孩穿着金色和绿色长裙子,然后黑色的长发,并且呢是一个露肩装。 在参数设置里边,我们唯一需要注意的就是图片的宽高,由于呢我们要生成两个人物,所以说呢宽高要设的略微宽一点,这样我们设置的是幺零二四乘五幺二,来看设置的结果,大概率的情况呢,你得到的可能是一个人物,也有可能是两个人物, 这个呢就完全取决于整个模型的一个表现力,因为有很多模型呢,他的训练数据可能只有单人物或者是单连孔,那这个时候你得到的肯定只有一个人物, 那如果模型的泛化能力比较强,可以表现多个人物,那这个时候呢,你得到的可能是两个人物。 如果你想得到两个人物,并且呢是相同的连孔的话呢,我们需要在很多方面做工作,他想到的第一个方法肯定是使用 cartronite 的 openpose 来控制人物出现,那在这个里边呢,其实我们使用 openpose 仅仅是为了 出现两个人物,所以说呢,在权重控制方面呢,我们并没有更多的要求。我们来看生成的图像,你会发现这个人物呢,长相其实是大致差不多的,但是呢, 在很多方面呢,他也是不太一样的,比方说头发的长度以及穿的这个衣服,其实呢都不太一样,所以说呢,我们下边就需要通过各种各样的方法让他变得一样。 首先呢,我们使用 afterditler 这个技术呢,将人脸修复一下,让整个人脸看起来更加的精致。当然在这呢,我们用到了之前讲到的那个特殊的语法就是 sep, 并且呢我们两个人物让他的表情呢稍微有些不同, 一个呢是生气的表情,一个呢是微笑的表情。那这样的话呢,我们首先保证了人物脸的这个精致程度,当然呢,这个视角 还是有些问题的,由于呢有一个人物是一个侧脸,所以说呢,我们看的并不是特别的清楚。下边呢,我们来增加一些提示词的技巧,我们在提示词当中加入了 character shit of the same, exact go 这样的一个手法呢,其实借用了游戏设计的一些思路来说明他是同一个角色的两种不同的视角,这样呢可以保证人物看起来更像。 那你会发现生成的这个人物的话呢,他长得的确是变得非常的像,而且头发的长度啊,其他的部分呢,也比较的相似, 当然呢,在衣着方面呢,还是有一些差距的。那这个问题怎么解决呢?这样呢,我教给你一个技巧,你可以使用 ip adapter 来修正一下这个人物。在这呢,我们启用第二个 ctrl。 net, 然后上传一张我们之前生成的图片作为参考图, 然后启用 ip adapter, 当然这个呢,不用使用人脸的 ip adapter, 普通的 ip adapter 模型就可以了。这儿呢,你唯一需要注意的就是生成的这个人物呢,他的模型和你现在用的这个模型呢,尽量是一样的。 这个时候你来看生成的这个效果,那这个人物呢,不管是长相和他的衣着呢,其实都非常的像了。那这个呢,其实并不是什么个例啊,你可以再生成一张,你会发现这个人物呢?呃,其实呢,也比较的像, 下面我们解决最后一个问题,那就是怎么让他变成两张图片。在这呢,我们启用第三个 ctrl net, 上传一张这样的线框图来作为一个 candy 的一个参考图,然后预处理器呢,不用选。然后模型呢,选择一个 candy, 模型选中 一定要设的足够的大,这样呢,我们设置成二,大概率情况下,你会得到一个带边框的一个图片,那如果你想得到两张的话呢,只需要用图片编辑软件把它从中间裁切起来就可以了。 后面呢,就是你可以选择不同的模型,然后不同的一些参水,来看一下哪样生成的效果呢,会更好,然后得到你最满意的那一组图片。 那通过刚才的操作,你可能也发现了,其实呢,我们会知同一个人物的时候呢,有一些基本的先决条件, 比方说在同一次生成的时候,人脸呢,往往是一样的,因为你来想在同一次生成的时候呢,他的模型参数,各种的输入条件都是一样的,所以说输出的结果呢,也应该是一致的。那如果你不能保证同一次生成两张人脸的话呢,你尽量 保证是同一个批次,我们经常会设置白色 size, 指的是同一个批次里边有几张图片,这呢我们设置成二, 那你会发现呢,这两张人脸呢,往往也会比较接近,但是你注意啊,在同一个 pc 里边生成的人脸呢,不见得是完全一样的,因为在模型里边呢,有一些特殊的手法去防止梯度的消失和梯度的爆炸。比方我们经常用到的照跑 out, 也就是随机的丢掉一些参数,所以说呢,在同一个批次里边,可能我们用到的参数啊,基本上是一致的,但是由于呢,这种随机的丢失,会有一定的概率或者不同的因素出现,所以说人脸呢,可能会有一些差异,这个时候呢,需要不断的去抽卡。当然还有一个更大的前提就是模型本身, 有的模型呢,它本身训练的数据就是一个人物,所以说呢,出来的人脸呢,往往是一样的,而有的模型呢,它的泛化能力比较强, 包含的人物特征呢也会比较多,那这个时候声称的人脸呢,可能不确定性也会更大,这个呢,就需要你不断的去总结魔性的特性,还等什么,赶紧自己试一下吧,关注我,让知识变得更有意思!
447有趣的80后程序员 01:08查看AI文稿AI文稿
01:08查看AI文稿AI文稿只需要简单的一句话,三秒钟制作出属于你自己的图片、海报甚至视频,这简直就是职场利器,是我近期力荐的免费高质量的插件。 cover camera 本身就是一款久负盛名的设计工具,现在我们可以直接在 gps 上使用它了。打开 plugins, 搜索 camera, 调用 camera, 输入你的指令 gb, 可以在几秒钟内帮助你完成海报设计、 ppt 插图、 logo、 视频素材等等。最关键一点啊,和 mijoni 等 ai 绘画工具相比,生成的图片中可以直接写入文字元素,支持中文, 并且还支持在线修改。比如做教师节海报,通常的做法是去图片网站找模板,然后进入 ps 工具中修改,熟练操作可能也需要不少时间。使用这个插件后,我们只需要输入教师节海报, gbt 就会调用插件输出自带中文排版的图片模板。选择一款之后啊,点击查看即可进 入到在线修改功能,根据需求修改保存即可。整个流程操作下来,相比传统的方式节省了大量的时间。我们还能让他生成视频素材来丰富短视频的内容。同样你也可以使用它来制作招聘海报、餐厅菜单、视频封面等等等等。即使没有设计经验的人,也可以轻松创造出专业级别的设计,快去用起来吧!
621让包神先走

猜你喜欢
- 1.7万虚妄
最新视频
- 103黑山