卡方检验的x2分布界值表怎么看
大家好,今天我们来谈一谈卡方检验,那么我们的数据啊,不是所有的都是等距等比这样的变量,有时候呢还会借助称名量表或等级量表获得计数的这种资料。计数,比如说民意调查,那么大家的意见呢,可以分为赞成、反对和不确定这三类, 那么我们分别可以统计的到,选了赞成,选了反对,或者选了不确定他的人次数,这是一种。那么还可以在产品质量评价当中,我们可以分为,比如说产品质量很好、较好、中等较差 和很差这五类,那么选择每一类这样的一个人数,我们是可以统计的到的,其实他就是一种离散的数据,大家感觉到没有发卡方检验,他就是这种计数的离散的这样的一些数据。那么有的时候呢,我们其实也可以将一些连续变化的数据转化成为计 的数据。注意这是在我们实际的研究当中,根据需要还可以进行一个转化,比如说按照一定的分数线将学生的考试成绩化,为什么呢?合格和不合格两个类别,体制达标和不达标两个类别,那这样的话呢,我们就将计量的资料转化成了计数的这样的一个资料,那么我们这里面还列出了他的应用情形,比如说品牌调查, 比如说第二个态度偏好品的品牌调查当中呢,有这样一个情形,就是外包装 abcd 啊,这样的四个不同包装的产品摆在超市的货架上,那么因为他的外包装不同呢,所以一定时间之后啊,那么他的销售量,这个是技术我们可以得到的,四十二、五十九,四十八、五十一,那么我们想知道这样的一个销量, 能否推断顾客对四种包装设计的喜好存在的差异呢?那么这个就是用到卡房检验。还有第二个在态度偏好当中,比如说要了解学生对高考新模式的一个态度,我们抽取了九十个学生, 男生四十,女生五十,那么这里面就存在着态度有赞成、反对无所谓这三种类别。那么性别男生跟女生对高考新模式的态度有没有差异呢?也就是性别对于这种态度来说,赞成反对无所谓,是否有差异,这个也是用卡房建议, 那么他这就是一种离散型的随机变量的统计检验问题,注意离散型的随机变量的统计检验问题。大家都知道我们心理学研究的逻辑起点,那就是变量啊,一切都是从变量引申出来的, 那么所以这里面研究离散型随机变单呢,我们就用卡方检验好,这是关于卡方检验它的一个定义和它应用的情景。那么接下来呢,我们继续深入的来了解什么是卡方检验,那么在这里面看到这个图啊,那么其实卡方检验呢,它是一种非常 检验,用来处理离散型随机变量的统计问题。那么我们要进行这种离散型随机变量统计呢,首先你就要进行一个虚无假设, 然后呢去污假设,我们一般都是认为什么什么什么香的,对吧?像前面那个例子,那就是 abcd, 他的外包装啊,并没有引起销售量的不同,这就是没有差异,顾客对于 abcd 四种外包装啊,没有显著的差异,他的倾向,这就是零假设。 那么在这样的一个零假设的前提下,第二步我们就是要检验样本平数的分布是否在抽样误差允许的范围内波动,是吧?那就是你是否会超过他的临界值,如果超过了临界值呢?那么我们认为 假设就不成立好,零假设就不成立,那么我们就要选择被子假设,拒绝零假设好,这是这个问题。看到这个图呢,这个零戒指啊,就是这个白 白色的区域和阴影区域,这个卡方阿尔法和 n 啊,这里面这个竖线啊,他就是临界值,那么这里很清晰的说明了,临界值啊,可以理解为在显著性水平 r 上,拒绝虚无假设所必须达到的最小卡方值。拒绝零假设 必须达到的最小卡翻值,那么很显了,大于零借值的话呢,我们都是拒绝零假设。好,这是大家一定要记住的,否则你后面你进行卡翻几天,你进行数据分析,你都不知道该怎么去分析呢。那么我再强调一遍,他的 虚无假设就是不存在显著性差异啊,他们是相等的是吧?回到前面的问题,那就是男女性别对于高考新模式,他的观点啊,他的态度没有不同是吧?是相同的,就这样的一个意思,那么接下来呢,你就去计算他的卡房值,计算啊,统计量卡房值,那么看他跟临界值的一个 对比,他跟零戒指的对比是大于他还是小于他,如果大于零戒指,那么就拒绝虚无假设啊,那么你就选择变色假设,如果小于零戒指呢?小于零戒指,那么我们就接受虚无假设,接受零假设, 就这样的一个过程,这个大家一定要非常熟悉的,那么接下来呢,我们也可以看到,当卡房值很大的话呢,就代表了观察平数与七万平数啊,相差很远。对,我们反复的强调一个是观察的平速,有的人说观察的次数都可以,是吧?能次数吗? 人次数,观察的次数和我期望的数如果相差很远呢,那就会大于临界值,大于临界值就会落在阴影区内,这样的话就超出了车样误差允许的范围,所以我们就拒绝林建设啊,那也就是说明啊,样本所在的总体,他不符合我们的期望。 那么卡分检验呢,有两个用途啊,一个是变量多项分类的资料检验,观察次数与期望次数是否吻合,这就是适应性检验。第二个呢是独立性的检验,独立性的检, 因为两个或两个以上变量,每个变量又分为多个类别,这个时候呢,我们需要检验两个或两个以上变量之间是否独立啊,检验的是它是否独立。一个变量呢,就是检验观察时速和七万的时速是否吻合, 这叫适应性的建议啊,七万这个次数就是你给出的,比如说我们这里面,在这个品牌调查当中啊, abcd 四个货物,它的外包装,那么它分别是销量四十二、五十九、四十八、五十一,那么它总共是两百个嘛?总共两百个,那么我们七万的品质就是每个产品是五十嘛,每个产品是五十, 那么每个产品五十的话,我这是我的零假设,这是我的零假设,那么我就要去检验我的卡方值跟我的临界值的一个大小的问题啊。如果比他大我就拒绝,如果比他小我就接受零假设。好,这就是我们再讲卡方检验好他的一个基本的原理。

粉丝405获赞1811
相关视频
 00:33
00:33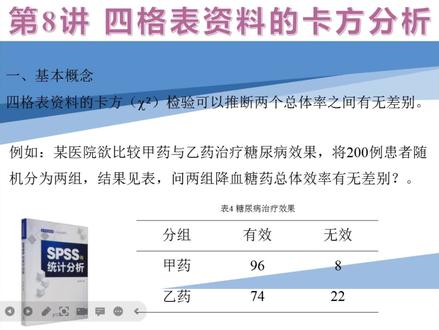 03:59查看AI文稿AI文稿
03:59查看AI文稿AI文稿大家好,今天给大家讲第八讲四个表资料的卡方分析。四个表资料的卡方分析,这个不是 x 平方,这个字母是卡方,它主要是用于推断两个总体率之间有差别 啊,比如说实力,某医院与比较假药与饮药治疗糖尿病的效果,将两百例患者随机分为两组。 啊,这个分组结果见这个下表,他主要是用来比较这两组。呃,降血糖药总体率有差别。 好,我们可以看一下分组,我们分为假药和饮药,疗效分为有效无效,假药的有效是九十粒,六粒无效是八粒。饮药的 有效是七十四米,无效是二十二米,总共是两百粒。而我们怎么用统计学方法来对它统计软件对它进行分析,我们可以看实力。 好,我们打开这个 sps 这个软件,事先我已经将数据已经录录,已经录入这个十八式软件了。 好,我们现在啊,首先这个像这个卡方分析,我们首先要对数据进行的加权,我们选择数据,这里加权个案选择这个值 啊,把直径加全,然后点确定啊,就 ok 了。然后这个呃,这个结果栏它会出现一个五 a 成败,五 a 成败就是加权的意思, 把直把直加全,位置败直。好,我们再进入这个。呃,进入这个软数据仕途里面,我们就要进行分析,分析到,我们选择 选择这个啊,描述统计,然后再选择交叉表,将疗法调入行,将疗效调入力,然后我们再统计量,选择卡方, 然后就 ok 了,其他的都是默认的。好,我们直接点击确定。 好,这里有出,出现了一个三个表,第一个表是一个呃,一个数据的,一个 呃一个整体情况,那个疗法和疗效总共是两百粒啊,缺失、黏腻, 所以呃这个数据的律师版本好,我们这个疗效疗效与疗法的一个交叉治表,这就是刚才那个四个表的一个呃一个表, 这个假药九十六粒有效无效八粒也要有效七十四粒无效二十二粒,这个是这个呃治的这个表格 好,我们最最主要是看这个,第三个表示卡方检验的一个结果啊,我们首先看的是我们主要我们就就是看这个,呃,这个卡方偏是卡方,然后看这个词是酒店零七五,然后这个 df 等于第 衣服就是这个 n 紧, n 紧,你们两组,两组二减一是一, 然后这个渐进的 sig 双侧零点零零三,我们主要看双侧吗?这个是零点零三,呃,远远小于零点零五,说明他们之间统计学有差异, 说明甲法和乙法啊,在治疗这个糖尿病的时候,他们的他们的总体率是不一样的,咱们的效果是不一样的啊。谢谢大家,今天就讲到这里。
73gzz 09:59查看AI文稿AI文稿
09:59查看AI文稿AI文稿各位同学大家好,这里是 sps 学堂,我是一鹏, 很高兴可以通过视频的方式跟大家分享本节的内容。本节的内容为卡方结业讲解系列的第一个内容,卡方结的基本原理。 在真实讲解前,先简单介绍一下我自己,我叫韩婷婷,大家可以叫我一鹏。管理学硕士,研究方向为管理会计,主要着重研究企业财务绩效,为探会计 擅长的数据分析软件由 evoss、 pss 等等。欢迎志同道合的学术界的朋友们一起探讨学术问题。 那么接下来我们步入正题,来看一看本节课我们都会学到什么呢? 一、什么情况下我们会使用卡方检验?他又是如何定义的呢?他的基本原理又是什么呢? 第二,一个小案例,让大家看一下卡方结业中相关参数是如何设置的,他又分别对应着什么样的含义。首先我们来看一看卡方结业是什么呢? 卡方检验是现代统计学的创始人 coplas 于一九零一年提出的一种具有广泛用途的统计方法,一般可用于两个多个滤间的比较技术资料的关联度分析, 礼盒优度检验等等。卡方检验法也有一个别称,也叫卡方礼盒优度检验。一般对于分类资料的假设检验都可以用卡方检验。 那么我们的卡方检验是以卡方分布为理论基础的。卡方分布指的是一种延续型分布,其唯一的参数为自由度。 那么这里就有一点是需要大家注意的,由于卡方分布是连续性分布,而实际应用的资料是分类资料, 根据其计算出的卡方值是非连续性的,属于离散性分布。因此只有在样本量比较大时,我们可以忽略两者的差异。一般使用时 减一样本量不应小于三十。同时,每个单元中的期望平数不能太小。那么在这里我们可以看到 s p s s 二十六版本中卡芳杰所在的位置。接下来我们看一看卡芳杰的元甲蛇是什么呢? 卡蜂节的原假设是样本所数的总体分布,与理论分布无显著差异。在公式中, f 零是实际观察平数, f e 是期望平数。当观察平数与期望平数越接近时, 我们的卡方值就会越小。此时我们不能拒绝原假设,也就是我们刚才提到的零假设。观察平数与期望平数相 相差较大时,我们的卡方值也会要越大,那么此时我们是没有证据来支持我们的原假设的。那么在一般的卡方结中,我们是使用概率屁值来判定是否拒绝原假设。 如果卡方的概率屁值小于写注性水平,我们一般拒绝零假设,认为样本不是来自服从母分布的总体。 反之,如果卡方的屁值大于写注性水平,我们不能拒绝零假设,可以认为样本来自服从母风度的母体。 那么在接下来的几期视频中,也会给大家以具体的案例进行操作,告诉大家如何进行判断。在这里我们注意到泡泡 右上角有一个表格,图标所示两个变量均为定位数据时,比较其差异时,可以选用卡通检验打电。我们以医学为例,在医学领域的临床研究中,卡方检验就非常常见, 比如比较不同药物或不同手术方式对某种疾病的疗效是否有差别。那么接下来我们就以具体的案例来看一看卡方结的相关参数。 首先我们来看一看这个案例的背景,我们以人们对数字有没有特别的偏好为例,以五十名受访者为观察对象,在数字六至九中选择一个数字,那么我们打开我们的 sps 数据, 就如大家所看到的这样,在哪里找卡方简页呢?我们点分析,然后有一个非参数简页中有一个旧对话框,我们点击卡方命令就会弹出卡方简页对话框,在这里我们可以看到他有简页电量链条, 此时我们只需要把约药检验的变量放入其中即可,那么在这里是需要提醒大家的,如果说我们有多个变量,那么我们可以依次把它放入检验变量列表,我们 spss 会分别对各个变量进行卡方检验。 我们在这里还看到了期望范围的一个选项组,这个选项组呢是用于确定卡方结的数据范围,系统默认的是从数据 中获取,那么 spss 将使用数据中的最大值和最小值作为我们的铁范围, 那么当然我们可也可以使用指定范围,此时我们需要手动输入我们的上下线崩点是多少,这里还有一个期望值的一个选项组, 那么这个选项组是用于设置总体中各分类所占比例,包括所有类别相等和值两个选项。 那么所有类别相等是指系统的默认选择,那么一般就是指节约总体是否服从均匀分布。 如果说我们选择的是值,那么我们大家需要输入指定分组的期望值。在这里我们需要注意的是,我们只输 的顺序要与我们节变量递增的顺序相同。那么在右边我们可以看到精确和选项两个按钮, 我们如果单击精确按钮,则会弹出如这样精确结业的一个对话框。此时我们就可以看到用于设置计算显著性水平的方法是有三种,我们分别来看一看,他是什么呢?第一个,警戒警察, 这一般是系统末日设置表示信显著性水平的计算。基于借鉴分布假设,借鉴方法要求足够大的样本容量, 如果说我们的样本容量偏小,那么这个方法就会失效。第二个,文特卡洛法,一般用于不满足借鉴分布假设的巨量数据,那么 我们在使用时需要设置我们的置信读级别和我们的样本数,这里是需要大家手动输入的。第三个,精确, 这个方法可以得到精确的写注性水平,但有一个缺点就是计算量过大,所以一般我们可以设置相应的计算时间,只要超过开时间, spss 将自动停止计算,并将我们所需要的结果进行输出。 这个就是我们精确检验。在此案例中,我们选择系统默认设置,此时我们点击选项按钮,我们则会看到这样一个选项对话框。 我们可以看到包括了统计和缺失值两个选项组。在统计选项组中,我们用于设置输出的统计量,包括 描述性和四分位数。那么甲丁我们此案例只看描述性,那么我们只需要点击他即可。 那么缺失值选项组是用于设置缺失值的处理方法,一般包括按结业排除个案和按陈列排除个案。那么我们第一个指的是,如果指定多个检验,我们将分别独立计算每个检验中的缺失值。 如果说是后者的话,我们表示是从所有分析中排除任何变量具有全是指的个案。我们假定此时已经选择完毕,点击继续。 此时该界面的相关参数设置我们都已介绍完毕,我们来看一看输出结果,我们点击确定。此时我们可以 看到第一个表格中给出了个案数,平均值,标准差,最小值,最大值这些描述性统计量。第二个表格给出了实际个案数,七万个案数以及我们的盘差值。 那么最后第三个表格,也就是我们比较重要的一个表格,他给出了相应的结业统计量,从该表中我们可以看出他的借鉴写字性是零点四五一,那么我们表示不能拒绝原假设,所以 我们认为人们对数字六至九没有特别的偏好,这就是该案例。以上就是本期内容,更多 spss 知识请关注 sps 学堂微信公众号。
133SPSS学堂 04:23查看AI文稿AI文稿
04:23查看AI文稿AI文稿卡方分,因为前面的分析他实际上只是算出来这个觉得这个数值,或者这个觉得这个比例,那么这题要统计用通过统计量去比较的时候呢?这个时候我们就要去通过分类变量计算这样一个卡方 这个统计量。统计量呢?好,通过这个统计量去比较,这个统计的这个系数就跟我们刚才说的这个相关系数和这个回归系数的时候,我们都有计算的一个统计,这个标准叫什么?叫 p 值。那么同样的这个卡方也一样,我们可以先给他计算出一个 礼盒优度,这个礼盒优度就是我们所说的这个卡方这个值,那么这个卡方值越小,说明二者的这个差异越小。如果卡方值等于零的时候呢,就说明这两者是完全一致的,说明这个某个分那边呢?在不同那边之间是不存在显著差异的,对吧?但如果卡方很大的话,那么就说明 这个各个类别之间某一个变量在各个类别之间的分布是有显著差异的。那么在这,在这个调查或者在这个具体这个运营过程中啊,卡方通常用于检验某个变量在不同变量之间的这个显著差异,对吧?比如说细面对保险品的影响,比如说收入差异对网购平台偏好的影响, 那么收入差异实际上很多人他不会告诉你具体的收入是多少,比如说我,我只会告诉你我的收入在两百万以下,或者是在这个三千块钱以上, 对不对?我不会告诉你这个具体会具体收入是多少。那么这个网购平台呢?他可能是这个在淘宝,在京东,对吧?或者在拼多多,对吧?各个平台上他都可能是去购买的,那么这个时候呢,我们就可以通过这个卡方分析 去做检验,那么卡放飞机他是有一定的这个使用要求的,首先呢,他要求他的这个电量属于这个离散性, 另外呢就是说对样本的要求哈,样本的要求他更适用于大样,大样本的这个数据,理论上啊,这个需要有超过五分之四的这个平数,超过五以上的这个数值,那么这个统计上的大样本,首先你至少就说不管是学 t 减还是这个 f 减,至少要有三十个,三十个样本以上嘛,你分析数据, 你的样本要求应该是你的样本量应该有多大,这个时候实际上去取悦你的提量,一般来说你的提量越多的时候,你的样本量要尽可能大一些,如果你有一百道题,你只收一百个问卷, 肯定不不行,对不对?如果你有二三十道题,我们一般来说你至少要有五倍以上的这个样本嘛,就是你的样本量是你这个提现了五倍以上嘛,那五到十倍甚至十倍,那可能就比较好了,对不对?所以这是取决于你的这个样本量了多少。那么在卡方呢,是要求你的超过五分之四的这个数据的这个评数啊,要在五以上,不能所有的都是零。呃, 那么卡方简约的这个卡方分析的这个步骤哈,首先第一步就是我们说要计算这个卡方的这个值,卡方只要同时你还要确认这个卡方的自由度,这个自由度呢,实际上就是我们所说的,你要根据你这个类别,比如说这个变量一和变量二,变量一呢是有这个三个 水平,然后变成二呢有两个水平,那么他所需要的这个,呃,就是比如说自由度就是三减一就是二,对吧?就是自由,自由度就是二, 然后你计算出了卡方的这个值,然后你又知道了这个自由度,你就可以通过查表,查表就得到这个自由度。对的这个边界的这个边界值和这个 p 值,如果卡放的值小于边界值, p 值就会大于零点零五,就说明在这个不同类别之间是没有显著性的差异的。 如果你的这个卡方是大于零点值,一般你的 p 值是小于零点零五的。小于等于零点零五,就说明你的变量之间是存在显著差异的。这里面呢,也有 也有一个简单的这个视力,哈,简单的这个视力就是说不同的职业啊,和不同职业上在不同收入水平上是否存在差异。这同样的,其实在做这些分析的时候,有一些比较嵌入式的软件,他就可以直接做出来,如果你在其他这个其他软件做也可以,比如说 sps, 他也是相对来说会简单一点点, 也是需要你花个两三天去熟悉一下。这里面呢,我们给大家举了一个例子,就比如说计算出来这个卡方的值,他得他等于一百七十多了,对吧?一百七十多,超过一百七十了,这个卡方就很大了,他的 p 值肯一般就是小于零点零五了。小于零点零五我们就会发现得出了这个职业差异在收入水平上存在 显著的差异。然后同学说这不是废话吗?当我们这只是个例子哈?我们只是个例子,不是说我们要把这个作为研究问题。同时我们也跟大家说,其实统计,统计分析,呃,分析数据就是分析你的 这个模型或者这个方法,他只是一个工具,最重要的还是你要分析什么问题,分析你的选题。
 07:14查看AI文稿AI文稿
07:14查看AI文稿AI文稿以最简单通俗的方式学习知识。大家好,我是赛过小白,今天给大家带来的统计主题是卡方检验。卡方检验用于检测观察到的类别变量的分布与期望的是否不同。我们最常用的卡方检验有两种,单一速卡方检验 也称为卡方粘合度检验以及二因素卡方检验也称为独立性卡方检验。那么接下来我会将这两个方法清楚的讲解。首先是卡方粘合度检验,卡方粘合度检验主要用来确定一个分类变量的预期频率 与观察到的频率之间是否存在显著差异。那么我来举个例子,假如我有一个骰子丢了三十六次,骰子,每个面丢出来的分布次数如下, 我们发现好像点数高的被丢掉的次数会更多,那么我可能觉得这个骰子是有问题的,因为我们知道我们会预期最正常的结果是每个点数都接近六次,比如说点数一是五次,点数六是七次,这样的话我们可能会更容易接受。但是呢,出现这样的结果,我们说骰子是有问题的,那么这个时候就会有人说这个只是巧合。我丢三十六 是骰子出现这种分布的情况是很正常的,并不是骰子有问题。那么遇到这种情况的话,我们是无法反驳的,但是你也不得不承认,很有可能会发生这种情况。那么这个时候我们使用卡方检验,就可以根据卡方纸告诉我们我们丢出来的这个分布到底是不是巧合,从而可以从正面回答这个骰子是不是真的有问题,或者这一次丢出来的只是巧合。 首先我们需要提出我们的假设,我们的零假设是期望值和观测值之间没有显著差异,我们只需要证明这个假设成立的可能性 特别低,那么就能够说明这个假设是不合理的,因此拒绝这个假设。而一般情况下,我们会选择显著性系数 alpha 等于零点零五,也就是当批值小于零点零五时,则可以拒绝我们的假设,也就是认为期望值和观测值之间是存在显著差异的。 那么为了拒绝这个假设,我们就需要计算卡方值。卡方简单的公式非常简单,这里我带大家迅速掌握这个公司的构造。那么首先是卡方,也就是我们要求的目标,当我们的卡方值大于我们的卡方临界值时,我们就可以拒绝我们的零假。 而这个符号 sigma 代表的是求和的意思。接下来是 f o, f 代表的是频率的意思,这个 o 所指代的意思是 observe, 也就是我们所观察到的频率。而 f 一中的一则代表 expect, 也就是我们的期望频率。所以我们只需要先估计出我们的期望频率,然后再根据我们实际中所观察到的频率 用公式计算,就能求到卡方值。回到我们的数据,现在我们已经有了观测频率,观测频率就是我们实际中筛子的结果,而期望值我们会认为每个面的概率都是一样的,所以三十六次,我们会认为每个面都是六次,这就是我们的期望值。根据观测频率和期望频率代入公式,就能求出卡方值 计算过程在这里列出部分,大家可以之后自己再算。那么卡方多大才能达到我们的要求呢?或者说卡方的临界值是多少呢?这就需要我们去查表或者卡方临界值。卡方临界值有两个因素决定,一个是显著性水平,也就是我们设定的 up 值为零点零五。另一个是自由度,自由度等于我们的组别减一,组别用 k 代表,所以在这个例子中,自由度等于六,减一等于五,所以我们查 发表可以得到卡方的临界值等于十一点零七零。也就是说,只要我们计算中的卡方值大于我们的卡方临界值,就可以拒绝我们的零假设,认为观测值和期望值之间是存在显出差异的,也就是说筛子是有问题的。然而我们计算中的卡方值为三点三三,卡方值小于临界值,所以我们只能接受零假设,认为观测值和期望值之间是没有显出差, 也就是筛子是正常的。那么这个时候可能有同学会问,如果期望值不是均分的会怎么样?也就是期望值之间是不同的。比如有个学校调研团体说, 我们学校有百分之五十的人每天运动,百分之三十的人一周运动四到六次,有百分之十的人一周运动一到三次,百分之十的人不运动。那么为了检测这个团体说的对不对,我们可以随机抽取学校的一百个学生, 询问他们的运动次数。期望品质为,百分之五十乘以一百等于五十,百分之三十乘以一百等于三十,百分之十乘以一百等于十,百分之十乘以一百等于十,然后再将期望品质和观测品质带入公式,求出卡放值即可。其实这一点和丢骰子是一样的, 筛子的每个面的概率都是六分之一,因此每个面的六分之一乘以三十六都是六,所以我们的期望频次是该类别的概率乘以总观测频次。接下来是卡方独立性检验,卡方独立性检验的作用是检验两个类别变量之间是否存在关系。比如我们想知道心理学、物理学和管理学的学生在思考方式上是否存在 差异。这里设计两个变量学科和思考方式,那么我们假设思考方式和学科之间是相互独立的,也就是并不存在关系。那么首先我们从大学的三个学院中收集了一千个人的数据, 那么有了观测值,我们还需要期望值。这里需要注意的是,独立性检验中,期望值并不是用一千除以六得到,每个单元为一百一十六点七个人,而是需要我们计算出行与列的和,然后再求期望值。期望值的公式为该行品质之和乘以该列品质 之和再出一种人数。所以我们需要计算出所有的列之和,宇航之和,然后再使用期望值公式,用每个单元对应的航之和乘上列之和。比如心理学感性思维是四百 乘以三百八,除以一千等一百五十二,其他以此类推。这样我们就得到了所有单元的期望值。需要注意的一点是,期望值的计算过程中出现了小数是可以的,哪怕是某些技术单位并不可以被记为小数,但是在计算期望值中,小数是能够存在的。那么在确定了观测值和期望值以后,我们需要确定我们的显著性水平 up 和自由度 up。 一般情况下设置为零点零五, 自由度则是 r 减一乘以 c 减一,也就是我们的行数减一乘以列数减一,两个类别变量的组数减一,然后相乘。那么在这里我们的自由度就是二减一乘以三减一等于二。差表我们可以看到阿法等于零点零五,自由度等于二十,卡方临界值为五点九九一,因此只要我们求到的卡方值大于五点九九, 就能够拒绝零。假设在卡方独立性检验中公式依旧值之前的卡方公式,我们将观测值和期望值带入公式,就可以计算出卡方值等于六十五点四九零四。计算过程这里也列出部分,大家可以之后自己再算。因为我们的卡方值大于零介值,所以可以得出结论,思考方式和 这三个学科之间是存在关系的,并不是相互独立的。好了,现在我们已经基本掌握了卡方检验常用的两个方法,这两个方法满足绝大多数需要使用的卡方的情况,但是除了搞清楚卡方的基本概念,我们还需要掌握卡方使用的前提假设。首先是第一点,既互吃又互补。 我们的每个观测值都会落入一个类别,并且只可以落入一个类别。比如说数据中的观测值要么归类为理性思维,要么就归类为感性思维。一个观测值,或者说我们的一个学生并不能同时把它归类在理性思维, 然后再把它归类在感性思维都进行记录。第二点,观测组之间相互独立一个杯式,一般来说只能被归类为一次。比如说我们检验性别和三部动作电影偏好之间的关系。一般来说,一个人只能对一部电影做出评价,这是最为稳妥的。 因为如果一个人他不喜欢动作电影,那么他很可能对三部动作电影都打低分。相反,如果一个人比较喜欢动作电影,那么他可能对三部动作电影都打高分。因此,最好的办法是一个倍数只能计算一个观测值,观测次数等于倍数数。第三, 期望频次期望频次不能太小。对于期望频次的要求,有很多理论比较好的规则是每个期望值都大于五,如果当自由度为一时,则每个期望值大于十。我们知道期望频次和我们的观测总数有关,也就是说最好观测次数不能太小。如果当我们观测次数够多时,一般并不会出现问题。更详细的内容,大家可以参考相关的统计书。 好了,最后快速总结一下。卡方检验用于检测观察到的分类边梁的分布是否与期望的不同。一般情况下,我们用到的卡方检验为两个卡方粘合度检验和卡方独立性检验。 卡方你和度检验也可以被称为单因素卡方检验,因为他只设计一个类别变量,他主要用于检验我们关注的类别变量是否遵循我们的期望分布而计算。自由度为 k 减一 k 为该类别变量的主数。 期望值一般是根据理论预期来的,那么我们会预期每个面丢出的概率都是六分之一,又或者是有相关的报告或数据给出某变量的数据比例,比如说分布为百分之五十,百分之三十,百分之二十,那么期望值一样用该组的概率乘以 我们的观测总数。接下来是卡方独立性检验,又或者是二因素卡方检验,他是在两个类别变量的情况下使用,他主要用于检验两个类别变量之间是否存在关系。自由度为行数减一乘以列数减一,也就是每个变量的主数减一后相乘,而 期望值是相应的单元格对应的列观测值之和乘以行观测值之和除以总观测次数。而两个方法都是用相同的卡分公式以及相同的前提。假设好了今天的统计就到这里, 点赞和关注是更新的最大动力,之后有什么想看的心理学实验或者是其他内容也可以在评论区告诉我,感谢大家的支持!
3468Psycho小白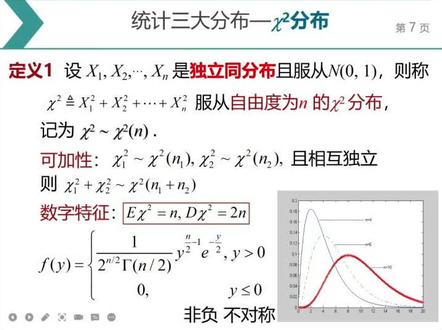 03:06查看AI文稿AI文稿
03:06查看AI文稿AI文稿今天我们给大家来讲一个统计中的三大分布之一,卡方分布。对于卡方分布,我们只需要掌握它的四点内容就可以。第一点,卡方分布的这个构造 法方分布是怎么构造的呢?我们先看这个定义。设 x e i 到 x n 是独立同分布,里面记清楚独立同分布,且服从标准正派分布, 那么我们给它继承 x 一方加上 x 二方加到 xn 方这种形式,它就服从于自由度为 n 的卡方分布。记住它的构造是由若干个 标准正太分布的平方,然后求和,有几个他就是自由度为己的卡方分母,这是第一点。 第二一点是要记住卡方分布的可加性,比如说卡方,卡一方服从于自由度为 n 一的分布,卡二方服从于自由度为 n 二的卡方分布,他们两个是相互独立的,然后 把一方加上卡二方就服从于自由度相加的这个把方分布,这是我们讲的把方分布的作家性。第三一个是记住他的数字特征。 什么是数字特征?也就是说是卡方分布的期望和方差,对于卡方分布的期望就是我们这个自由度 n, 他的方差就是二倍的自由度 n 是二 n, 这是第三一个。 第四一点我们要理解,或者说是你能够看清楚啊方分布的弧形, 他的这个图像是一个靠左比较高的一个非富的不对称的图像。 我们为什么要记住这个图像呢?因为我们后期在学日进期间和假设检验的过程中可能会用到这个图像,因为他的这个不对称相, 我们在他的这个右侧分为数的时候可能会用到,这对于卡方分布的这个密度函数大家可以不用去记,为什么?因为卡方分布的密度函数里面高含了一个高浓度, 所以说对于 big 比较不像你的耳朵,所以不用记。因此对方分布我们只需要打过这四笔,第一勾当,第二加性,第三字的特征,第四它的无限的一个本事。
714混饭工作者 07:36查看AI文稿AI文稿
07:36查看AI文稿AI文稿这节课我们一起来学习列连表与独立性检验,主要包含五个知识要点,以及两种题型。第一个知识要点,分类变量与列连表。第二个知识要点呢,二乘二列连表, 一等高堆积条形图。第三个直要点,卡方独立性检验。第四个直要点,为何卡方检验可以检验变量之间的独立性问题?第五个直要点,卡方的独立性检验,常用的小概率值和相应的临界值。 另外我们会实行两种题型,第一种题型呢,是独立性检验,解决实际问题的四个步骤是什么?第二种题型,独立性检验与反正法。那么我们主页来看一下。先来看一下第一个持有点 分类变量与列连表。首先了解分类变量,他的一个概念,用以区别不同的现象或性质的随机变量成为分类变量。分类变量呢,我们要注意两点,第一点呢,分类变量他是 理想型的,如果我们把性别分为男和女,那么在这里呢,分类必要它是分为两类。 另外呢,分类变量它是可以大量存在的,不仅可以分为两类,比如说我们说商品的等级可以分为一级品、二级品、三级品、四级品等等等等。 分类变量的取值通常呢我们可以用时数来表示,比如说在这里男和女,如果男用零来表示女呢,我们可以用一来表示。 在高中阶段,我们学习的是两个分类变量的问题,那么接下来我们来研究两个分类变量,而且每一个分类变量呢,它的取值只有两个的信息。那么接下来我们看一下二乘二类点表,假设有两个分类变量, x 和 y, 他们的直域分别为 c、 x 和 y 一 v 二即样本平数列列表呢,在这里我们把它给写出来了,就成为二乘二列列表。在这里呢,分类变量是有两个,而且他们的取值呢,各只有两个的一个情形。我们来看这个二乘二列列表, 既满足 x 一,又满足 y 一,他的平数呢为 a。 既满足 x 一,又满足 y 二的,他的平数呢为 b。 那么 x 一的平数呢,为 a 加 b, x 二的平数呢,为 c 加 d。 同时外一的平数呢,为 a 加 c, y 二的平数呢为 b 加 d。 最后在这里 a 加 b 加 c 加 d 呢,就是样本容量。我们从这个二乘二列列表呢,我可以看出成对分类变量数据的一个交叉。 八分类评述的一个问题,那么了解了以后,我们来做一下相应的练习题。某些为了检验高中数学新课标改革的成果,在两个班进行教学方式对比试验,两个月后呢,进行了一次检测, 试验班与对照班成绩呢,这里给出了二乘二列连表,其中问的是 m 的值为多少, n 的值为多少?我们刚才有讲, a 呢,表示既满足 x, 又满足外一的一个平数,而 x 一,他的一个平数之和呢,为 a 加 b, 同时 x r, 它的一个平数之和呢,为 c 加 d。 注意哦,我们来看一下, y 一的平数之和是为 a 加 c, y 二的平数之和呢,是为 b 加 d。 好,所以我们来看一下事业班,它的平数 之和是等于五十。对照班,它的平数之和呢,也是等于五十,说明二十四加上 m 是等于五十的,二十四加上 m 是等于五十,因此呢,我们就能求出 m 的纸, m 的纸呢是等于二十六, 当然我们也可以用八十分以下,他的平数之和呢是等于四十四,那么十八加上 m 的值是等于四十四,用这个方法求出 m 的值呢,也是等于二十六这样的一个值, 所以 m 的值呢是等于二十六。好,再来看一下 n 的值, n 表示的是什么? n 表的是 a 加 b 加 c 加 d 的值,它是样本容量。五十六加上四四是是等于 n, 五十加五十是等于 n, 那么 n 的值呢,是等于一百加的一个值,所以根据两种方法让我们都能求出 他们的一个值,这里嗯代表的是样本容量的一个情况,同时我们要注意二乘二列的表给出了成对分类变量数据的一个交叉分类平数。 接下来我们再来看一下卡方独立性检验。刚才我们有讲二乘二列连表,两个分类变量,一个为 x, 另外一个为外,对于每一个分类变量,他们的取值呢都只有两个,得出了这样的一个表格呢,就称为二乘二列连表。那么我们再来看这样的一个公式,卡方是等于 这样的一个式子,其中嗯呢表示的是样本容量。那么由这个公式得出的卡方的纸用来推断分类变量 x 和 y 是否 独立的方法呢,就成为卡方独立性检验,这就是卡方独立性检验。那么在利用卡方进行独立性检验的时候呢,一定要注意哦, abcd 这四个指呢都不小于,我们还要注意另外一点,卡方越大,说明 x 与外有关系,成立的可能性越大,为什么有这样的一个结论呢?我们一起来证明一下。接下来我们来学习为何卡方检验可以 检验变量之间的独立性问题同样还是回到刚才吸烟和患肺癌,他们的一个二乘二列联表,我们假设 h 零吸烟和患肺癌呢,是没有关系。 判断假设是否成立,我们把 h 零呢,称为零假设,或者又称为原假设。那么假设现在给出来了。接下来我们看一下非吸烟的人中换肺癌的一个比例。 非吸烟在这里,欢呼,雅儿在这里。所以呢,他们的一个平数是为 b, 而非吸烟者,他的一个平数呢,是 a 加上 b, 所以用 b 比上 a 加上 b。 另外再看一下 吸烟的人中患肺癌的一个比例,吸烟者在这里患肺癌呢,是 d, 那么 d 比上 c 加上 d 这样的一个指。 如果我们要 h 零成立, h 零说的是吸烟和患肺癌呢,是没有关系,那么这样的两个笔直呢,是大致要相等的,这样要相等。我们先交叉相乘来看一下, 交叉下车以后呢,这里有一个 b 乘上 d, 这里有一个 b 乘上 d, 两个消去,那么左边呢,剩下一个 b 和 c 相乘,右边剩下一个 a 和 d 相乘,他们约等于我们把左边移到右边,得出 a, d 减去 b, c 呢,是约等于零。 那么得出刚才我们所说的那个结论, a 乘 d 减去 b, c 的绝对值如果越小,说明吸烟与患肺癌之间的一个关系呢,是越弱的。 a 乘 d 减去 p 城 c 的绝对值越大,说明吸烟有患肺癌之间的一个关系呢,是越强的。又回到刚才我们首先的卡方独立性检验的问题,嗯呢,表示的是样本容量。 a 加 b 表示的是非吸烟者的一个平数, c 加 d 呢,表示的是一个吸烟者的平数。 a 加 c 表示的是没有患未来的一个平数。 b 加上 d 表示的是患肺癌的一个频速。 n 呢,是一样本重量。那么只要在这里确定他的一个值, a 乘上 d 减去 b 乘上 c, a 乘上 d 减去 b 乘上 c 刚好是交叉的一个信息 八的平方,如果在这里他的平方呢,是越小,那么说明他们之间的关系呢,是越弱的。如果这里分子的值呢,越大,说明他们的关系呢,是越强的。正式利用卡方独立性检验就可以检验变量之间的一个独立性问题。
635滴答课堂 09:40查看AI文稿AI文稿
09:40查看AI文稿AI文稿同学们好,我是二幺幺统计的主讲老师蔡老师这次给大家介绍的课程是卡方分析, 那我们今天介绍的是卡方独立性检验当中的四个表。独立性检验,那我们首先看到的是四个表的一般形式,有分组一,分组二对应的是 x、 y、 m、 n, a、 b, c, d 呢,分别是四个表当中对应的十字平数,那 a 加 b 加 c 加 d 就是它的总平数, 这个就是它的一般形式。那我们一所有的假设检验呢,都有一个基本的步骤流程,这个四个表就例行检验也不例外。首先我们给出它的原假设,假设两个变量是相互独立的,这里的两个变量 就用我们表格当中就是两个分组,就是分组一和分组二是相互独立的。倍,则假设就是说两个边量是相互不独立的。然后再计算我们的一个自由度 p, f。 所谓的自由度,我们上节课也讲到过,卡方分布的一个重要的参数就是自由度,不同的自由度对应的不同的密度函数。那这里呢,我们同时见肯定要计算一下它的自由度公式就是 r 减一乘以 c 减一。 r 和 c 呢,就是我们这个表当中行和列的个数,这是二乘二的四个表,所以我们的 r 和 c 呢,都是二。然后再计算一下我们的理论平数, e, i, j 等于 f, y, i 乘以 f, x, j 除 n 呢,就是我们的总数量,也就是我们的总评数。 a 加 b 加 c 加 d, f, y, i 和 f, x, c 呢,就是我们对应的。比如说我们 x 和 m 这一格的 a 是它的实际评数,我想求它的理论评数呢,就是 对应的 a 加 b 乘以 a 加 c 除以 a 加 b 加 c 加 d, 这个是对应的这个 a 这根的,如果是 b 这根呢,就是 a 加 b 乘以 b 加 d 除以 a 加 b 加 c 加 d, 这个就是理论平数的一个计算方法。然后我们再计算我们的统计量,他方的值等于这样的一个公式,这里的 f i c 就是我们的实际平数 e i, 这就是我们上联球的理论评述,可以换算成这样的一个公式,这个就是我们的卡方值的计算公式, 但是呢,他有一个适用条件,就是说当我们的理论平数大于等于五,并且我们的总数量大于等于 n 四十的时候,这个公式才是适用的。如果不满足这个条件的时候呢,我们有一个校正公式,就是下面的这样的踏方计算公式, 同样的都是这样的,这个时候呢,我们的 e i j 大于等于一,也就是我们的理论平数大于等于小于五的时候,总平数大于四十的时候,用这样的一个交通公式。 当时我们的 eig 如果连一都小于的话,等于小于四十的时候,我们就要用另外一个界面再做 非说精确性经验,那这个呢,就说明我们的卡方分析呢,是有一个适用条件的,这是大家需要注意的一个点。当我们求出来卡方值之后呢,就可以根据我们的卡方分布的临界表确定我们的拒绝欲和接受欲, 或者呢根据我们的对应的批值来判断是否拒绝或者接受原假设。这个就是四个表格类型检验的一个基本的步骤流程,希望大家能够记住, 下面就是我们给大家举的一个例子,希望大家呃一个是根据这个平数分布表, 以百分之五十的显著水,九十五的显著水平来检验我们的色觉与性别是否有关联的这样一个例子,我们可以看到 的平数,这个是他的一个实际平数,总平数呢是一千。根据我们上面的计算步骤,首先是我们的人假设是相互独立的,被子假设是不独立的,这串串的自由度呢就是二减一乘以括号,二减一等于一。 然后我们来计算一下他们的理论评数,这是他们的计算公式,计算公式这里面都是理论评数,然后是合计,总评数依然是一千。 然后呢再计算他们的统计量,卡方统计量对于那个就是分别计算的一个卡方,然后再把他们连加加起来,总的一个卡方值计算出来,乘以二十七点二,就是我们所计算出来的卡方分布的值。 那我们根据我们的卡方分布的临界表呢?可以知道,我们根据卡方分布的临界表可以知道,我们的自由度为一的时候,卡方零点九七五是这样的一个值, 卡方零点零二五是这样的一个值,我们所计算下来的卡方值是二十七点二,远远大于五点零二三九,所以我们拒绝原假设,因为我们的色觉与性别并不相关,这是我们的一个计算过程, 我们这样的一个过程同样也可以用 sps 操作软件来进行一个分析。首先我们是它的一个数字的录入,这是大家可能会需要注意的一个点,我们正常的录入不一样,首先我们是把它的平复一一录入进去, 我们可以看到前面的平数表格是四四二五十一四三十八六,这样的一个平数 录入进去是这样的,第一列是我们的评述,第二列是我们的性别,第三列是我们的色觉一呢代表的是男,二代表的是女,色觉一代表的是正常,零代表的是色盲。是这样的一个代表, 一代表的是男,二代表的是女,零代表的是色盲,一代表的是正常,这是我们的给他的一个指色标签。然后就是我们一个数据录入,这是大家需要注意的。然后呢我们并不是直接进行分析,我们需要对评述进行一个加权, 我们点击数据,然后点击加权个按,再找平数,将平数填入这个频率变量里面,进行一个加权, 才能够进行我们的卡方分析。然后呢是计算一个卡方值,点击分析,然后 描述,然后是交叉表格,就会出现这样的一个界面,我们将行整个性别列整个设节,也可以反过来将行和列进行交换,设置在上面,性别在下面,这个是呃都可以的。然后呢就是这样的一个界面, 然后我们点击我们的统计,然后点击卡方,再点击确定,这个就是我们计算要卡,计算卡方值的一个呃,选择, 下面就会出现的是我们的一个分析的结果,这个呢我们从这个分析结果可以看到我们的 care 信卡方值是二十七点一三九,与我们计算的差呃相差不大, 他的屁值是零点零零零,其实他是有值的,只不过非常小众,次于零,所以不论是从票圈的咖方值来比较,还是从屁值来比较,我们都是要拒绝人假设的,认为他们是不独立的, 这是我们的一个距离。同时我们再看再看一个例子,也是一个这样的平顺分布表,然后我们是还是百分之九十五的显著水平,观察实验组和对照组的发病率有无差别,原甲测试两个没有差别,背着 假设是两个有差别,依然是我们的计算数字,计算过程我们就不给大家再介绍了,这样同我们还是给大家介绍一下 统计软件的这样一个操作过程。同样的是数据录入是先看他的平数,十四八十六三十九十,然后是否发病,零代表的是未发病,一代表的是发病 组别呢?一代表的是实验组,零代表的是对照组。大家这个这两列呢,录入的时候也要注意,并不是不能都是一一零零,一一零零是需要有交叉的,这样的一样录入。 然后呢就是我们的一个评述的加权,这一步是必不可少的一步,将评述进行加权, 然后再计算我们的卡方值,将这两项分别选入进行计算。一个卡方值 计算的结果同样是我们的卡方值是四点一二五,我们的 p 值是零点零四二是小于显示是零点零五。 所以我们还是要注意点假设,认为实验组和对照组的发病率并没有显著性的差别,那我们这节课就给大家介绍,在这里谢谢大家。
 02:17查看AI文稿AI文稿
02:17查看AI文稿AI文稿卡方检验开 square trust 是一种统计方法,用于比较观察评数与期望评数之间的差异,从而判断两个或多个分类变量之间是否存在显著关联。他是非参数检验方法,适用于名义分类数据。 在卡方检验中,我们将观察到的平硕与期望平硕进行比较,通过计算卡方统计量来衡量观察平硕与期望平硕之间的偏离程度。卡方统计量的计算公式如下,等于观察平硕、期望平硕、期望平硕, 其中表示对所有的分类或格子求和观察评数是实际观察到的评数。期望评数是在假设不存在关联时,根据总体比例计算得到的预期评数。卡方检验的步骤如下,一、建立假设 零,假设 h 零两个变量之间没有显著关联被,则假设 h 一两个变量之间存在显著关联。二、设置显著性水平,通常为零点零五或零点零一。三、构建数据表, 创建一个列联表 contingency table, 其中型表示一个分类变量的不同类别,列表示另一个分类变量的不同类别。表格中每个单元格包含对应组合的观察评数。 四、计算期望平数在假设零假设成立的情况下,计算每个单元格的期望平数。五、计算卡方统计量根据上述公式计算卡方统计量。 六、查找临界值使用自由度和显著性水平来查找卡方分布的临界值,或者使用计算 机软件进行查找。七、做出决策如果计算得到的卡方统计量大于临界值,则拒绝零假设,认为两个变量之间存在显著关联。如果计算得到的卡方统计量小于等于临界值, 则接受零假设,认为两个变量之间没有显著关联。卡方检验在很多领域都有应用, 比如医学研究、社会科学、市场调查等。他可以用于比较两个或多个分类变量,例如性别与购买偏好之间的关联,或者治疗方法与治愈率之间的关联等。
21材料转AI 13:51查看AI文稿AI文稿
13:51查看AI文稿AI文稿大家好,我是君磊,那这一次视频呢,我们讲第三种差异性检验,也就是卡方检验。那在我之前的视频当中呢,曾经讲过两种差异性检验,分别是 t 检验和单因素方差分析。那前面这两种呢,它是适用于类别对于连续变量的这样一个检验 啊。 t 检验它是二分类对连续变量,那个发差分析呢?是多分类对连续变量。那么卡方检验呢?它是适用于类别变量对于类别变量。那这里呢,我给大家分两种情况,一种是多分类,对多分类也不含,同时也不含二分类了啊, 那这个是一定是用这个卡方的,那在这种呢,就类别变量对于层级变量之后情况下,它既可以用卡方,也可以用那个 t 检验或者是放大分析啊。那什么 我们这层几边呢?就是内容有档次的啊,比如像年级啊,收入水分这种啊,是他是可以 既可以用卡方,也可以用方沙检验的。所以如果是你的这个检验,它里面设计这个设计这个层级啊,他你就可以去做两个尝试啊,既可以做卡方的尝试,也可以做这个呃 t 检验或者是方沙检验的一个呃一个尝试,然后选择一个对自己有利的结果去呈现就可以了。 那么关于这个卡方检验,我们如何判定他是不是显著呢?同样是去看批值,看批值是不是小于零点零五啊?如果他是小于零点零五的,那我们就啊说明他是显著那 但是呢,这个卡方结他比较特殊,你要根据他的产出的这两个值,一个是你的亚美量,一个是你的最小期望值, 当然主要是这个了,电本量我们自己都知道哈,那最小期望值以样本量的关系去对应的找我们的那个皮质,那如果是最小期望值大于五,且样本量大于四十啊,包含四十啊,那我们要去看第一行这个皮尔森卡方,以及对应的这个这个皮质哈, 那如果是我们的那个,呃呃,这个最小期望值在一到五一到五之间,那样本量在四十以上啊,那么这时候呢,我们就要去看第二行这个连续矫正的卡,网址也就是这里啊, 这行啊,这行,那如果是我们的这个 e 啊小于一,或者是我们的样本量呢,小于四十,那么这时候呢,他会给你产出一个黑色的一个卡放值,那么这时我们就看这个啊, 看这一行啊,呃,有的时候我们去做卡棒结呢,说他没有产出那个那个飞绳这一行, 或者是这个连续教育证啊,就说明你的这个地方只能用卡放啊,只能用那个 p 二三卡放了哈,你就直接用这个地方这行就可以了,也没问题哈。 好,那这是关于这个呃,这个 p 值的这样一个选择,大家看一下啊,呃,这个表一定要记住啊,就是这三个的关系啊,就这三种的一个选择,你要你要对应的去选择自己那个自己的那个 p 值啊,但是话说回来啊,就是我们如果是显著的话,一般是这三个是都显著的哈,都显著的。 好,废话不多说,我们开始那个讲操作哈,好,这个呢,是我们的这个测试数据啊,是这样的啊,呃,有三个变量,一个是性别啊,性别 男和女啊,然后有一个专业,哎呀老师和挖矿啊两个专业,然后我们要去做性别在专业上是不是有差异的这样一个 检验啊,我们可以点击分析,分析里面有一个免税统计啊,分析免税统计,然后这里有个交叉表格,或者叫你的版本呢,叫交叉列连,对吧? 他然后呢我们重置一下,然后把性别放在这里,然后把专业放在这里啊,那么一般是你如果是想去探究,比如说性别在什么上的差异,比如性别在专业上的差异, 不是你是以某个类别为主的,你要把这个类别放在这个行上,对吧?然后然后把另外一类别放在这样,这样这后面分析的时候好分析哈好分析,然后呢我们点击这个, 这就要把这卡方纸勾上,卡方纸勾上,然后呢我担心搁这里啊,我一呃,一般是点这行的这样一个百分比啊,因为好的百分比比较好分析,比如说性别在专业一上的这百分比和专业二上百分比,这样有个差,这样一个比较好,好比较啊,当然 有的人也喜欢比较烈的百分比啊,这个是一个个人的一个喜好啊,但是我建议是你分析行的啊,分析行的好,然后这样,这样其实就呃配置好了,其实很简单啊,我们点击确定好这里, 嗯,前面这个呢是百分比,对吧?百分比,然后下面这个是卡棒结的结果啊,刚才我们也说了,我们要对应的先去找那个最小的期望值 这里,对吧?最好期望这是十三点七五,他是大于五的,对吧?大于五,然后呢我们个案数是六十三,是大于四十的,那这时候我们就直接看第二行,第一行就可以了啊,第一行就可以了,如果这里是怎么着是一到五之间的,对吧?六十三,那我们看第二行,如果这里他是小于一的 啊,或者是我们样本量是小于四十的,我们直接看飞婶这个啊,好,那这个呢是关于我们的这 这个呃展示,那么下面我们看一个表格,好,这里呢给大家推荐一种常用的一种表格呈现的格式啊,就是这种啊,里面包含百分比啊,包含那个卡方检验的值和 p 值啊, 那当然在论文当中有很多种不同的格式啊,你可以根据自己的喜好去 diy 哈,那这里咱们先讲这种怎么去制作哈,也很简单,把这两个给他复制过来,然后复制过来,然后呢找一个新的一个表格给大家展现过来,然后呢我们把我们的这个这个和这个给大家挑出来哈 啊,放在我们这边啊,然后呢我们把删掉,把这个删掉好,然后这时候呢我们把这个给他删,删减减就可以了啊,然后我们可以把这个给他取消合并啊,放在这边 这给他删掉,然后这个地方呢给他换成一个百分比啊,技术可以,这样, 对吧?然后嗯,这个地方可以让等于这个等于这个就改成总数, 然后筛选,然后复制,然后再粘贴为止,把这个中公式给去掉,然后把这个给删掉, 然后这个地方改成性别好,然后再把这个地方给大家合并一下,这就叫性别啊,与,对吧? 专业的交叉交叉表,交叉表或是 交叉列连翻系,交叉列连卡方形好,然后呢这个地方给他合并一下, 好,然后这个地方改成卡黄值啊, p 啊,这样一个表其实就做的差不多了,对吧?然后我们这个地方给他换成改成性别好, 然后筛选,然后我们把这个去掉烟花换成宋体,好, 好,这样,其实这个表格就样式就样式就出来了,对吧?嗯,好,然后呢我们把这个合并合并好,然后我们这个地方给他选, 嗯, 好,那这样一个表格我们可以直接就是放在我们的论文当中了,然后呢我们就开始讲这个分析,那分析我们怎么分析呢?呃,一般是这样分析的,我们先加第一句啊,第一句啊, 先第一句总体分析,对吧?先总总总体分析,然后呢我们再呃分类别去分析,再分类别分析,按照 按照类别分析啊,总总体分析,怎么分析呢?就是说,呃,性别在专业上的这个卡方检验卡方值是多少? p 值是多少啊?所以啊,你可以在家里去 p 小于零点零五啊,所以性别在专业上是具有显著差异的,加这么一句话,对吧? 然后呢再爱类别分析,再聚焦类别,比如说在女性群体下,老师的占比是百分之七十二,七十四点二,而挖矿的占比是百分之二十五点八,对吧?那么这时候 女性啊,那个老师的这个要显著高于高于第二个挖矿嘛,对吧?就说明老师是在在女性权限下是占主体的,而男性全体下 啊,挖矿是六十二点八,而那个老师是三十七点五,那么这时候呢,是在男性热情一下挖矿是这样主体的,然后你再去那个,呃,在某个类别下再去进行分析啊,那这时候我们我找一个例子哈, 好,我们看看例子啊,这篇论文呢,是讲这个主场和客场在这个胜负上的这样一个卡方检验啊,然, 然后他这里呢?你看这里有 n, 对吧?也就是我们的这个表里的这个,这这只对吧?然后还有百分比,百分比,然后就是我们这个表里的这个, 哎,这这把按比对吧,然后呢?就要卡放个屁时,卡放个屁时啊,他这里就多了一个这样期望技术啊。啊,这个等会我跟你说,跟大家说怎么做哈。呃,然后我们看下分析,主要看下分析啊,就是先总,然后再分这样一个逻辑啊,然后就前面前面这两句话,对吧? 前面第一句话他是判定是用这个卡棒检验嘛,对吧?可以所有技术技术,嗯,大于五,这个应该是最小期望技术大于五,对吧?最小期望技术大于五啊,当然所有技技术里面包含最最小的期望,对吧? 然后且总量是大于四十,那这时候呢?用评论卡方,这句话是判定应该用评论卡方,然后呢?经卡方检验得知 p 小于零点零五啊,小于零点零一,所以怎么着?主客场在比赛胜负上是具有显著性差异的啊,主客场与在胜负具有非常显著的差异啊。这两句话就先懂得说,对吧?然后怎么再分开讲,就在分开讲某个类别下怎么怎么样, 那怎么讲呢?就是说在主场情况下,然后啊胜率高达百分之六十,对吧?那负率怎么着啊?说一下,然后在客场情况下胜率啊,至百分之四十,那这这类就用这句话去表达了,对吧? 然后由此可见啊,有出场优势啊,其实这这就是一个很简单的一个分析,对吧?先总,然后再分啊,大家可以按照这种逻辑啊,去啊,去跑啊,那这个,这个期望技术怎么来啊?很简单啊,我们可以看到再回到我们的这个数据, 我们点击我们的卡网解压里面这个表格啊,单元格这里有一个期望值,期望值我们搁上继续 啊,然后这里会出来一个预计的这样一个技术,这个预计的这样一个技术,就是我们的这样一个期望技术啊,期望。当然这个呢,他并不是我们一定要去放的,你想放的话也可以放一下,像就像他这种格式啊,可以可以按照这样的去放啊。 好,那这是第一个的例子啊,第一个的例子。好,我们再来看第二篇的这个格式啊,他这个格式呢,就相对来说比较简单了哈, 他这个呢,就是完全是呃, sps 的一个结果,没怎么没有怎么处理啊?那给他看一下我们我们那个结果,我们这时候点击这个交叉表啊,交叉表我们单元格里 就啥都不勾,只保留一个观色值,对吧?然后卡方我们依然是勾上,对吧?勾上,然后我们再跑,那这时候呢?他这个,你看这个表就对应这个表,对吧?没怎么处理,对吧?没怎么处理,然后这里加个电量,对吧?把这个就把这个一行专业就删掉,对吧? 就这样一个表,然后壁纸呢?就把这下面这个啊,把这个都删掉,把这个留下来,就是这个表,对吧?很简单很简单,大家可以这个表格样式可以灵活多变,选一个自己喜欢的就可以了啊。 嗯,那下面呢,我们再讲一种,再讲一个那个,有的时候啊,有的时候我们会呃,遇到这样这样一种数据啊,这样一种数据格式,嗯, 他是呃把两把,把那个每种情况给列出来,然后最终加个权重,也就是克数,那这种情况也是可以 去做我们的这个卡方检验的,只不过我们要在做卡方检验之前啊,再加一个加权啊。啊? 大家先对比一下啊,这两样格式是有差别的,是有差别的,这里是第一个数据,是每个的一个样本,对吧?他是性别一还是专业一,对吧?他每个样本他有个值,这里呢是每种情况下 他有一个权重,对吧?那这个时候呢,我们要先做第一步叫加权啊,点击数据,数据里面有个加权个案, 然后呢这时候呢,我们点击这个加权哥啊,然后把我们的权重拖进来啊,权重拖进来,然后点击确定,然后我们加权之后啊加权之后,然后再去做我们的这个分析啊。呃,交叉列连啊,对吧?然后我们再通知一下,把我们 性别啊这个换进来,然后再对应的选择我们的这个检验的一个勾选就可以了, 好啊,这样就出来了,对吧?啊?这个呢就是在我们数据是一种权重的情况下,我们应该怎么去做这个卡方检验? 好,那关于这个卡方检验的这样一些知识呢?我们选到这里啊,下期我们讲那个多层的卡方检验。啊,那我们今天到这里,我们下期再见,谢谢大家观看。
267Junlei_D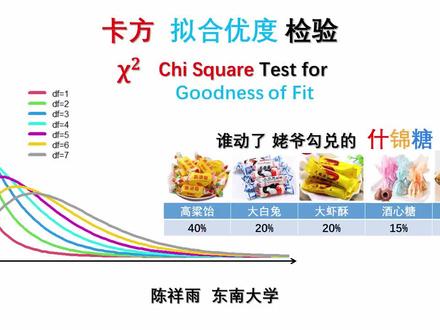 22:22查看AI文稿AI文稿
22:22查看AI文稿AI文稿大家好,今天我们来学习一下卡方检验。卡方检验 kai square test。 卡就是希拉字母, kai 方就是平方 square。 卡方检验一般就是指英国统计学家 cow pierce 在一八九六年发表的这种检验和分布。不过 pierceson 当时不知道,早在一八七六年,德国的地理学和统计学家 frederic robert helmet 也已经发现了这种分布。 在一八九六年发表的这篇论文中, pierce 首次将其命名为 kai square。 至于为什么选用这个希腊字母,我们不得而知,可能是 cow 与 kai 发音比较像, 也可能仅仅是 pierce and 的个人习惯而已。入门课中,我们只介绍两种最基本的卡方检验,卡方你和优度检验开 square goodness of feet test 和卡方独立性检验开 square test of independence。 这俩名字看起来也是相当的唬人,不过没关系,我们仍然来编故事,举例子。故事讲完以后,你就知道这些术语是什么意思了。本节课我们先介绍较为简单的卡方,你和优度。 我小时候在农村里,我姥爷开了一个小卖部,里面啥都卖,快过年的时候卖什锦塘,什锦塘就是把各种糖掺和在一起卖。老爷按照一个比例勾兑了一种什锦塘高粱仪,单价比较便宜,占百分之四十, 大白兔百分之二十,大虾酥,百分之二十,酒心糖百分之十五,巧克力最贵,只占百分之五。老爷把糖掺和在一起搅匀了,开始卖。各种糖的比例老爷公开贴出来,童叟无欺 卖了一阵,有村民来反映,说你这食锦堂的比例不对劲,说称了一百多块糖,巧克力才四个,没有五个不是百分之五。酒精糖也只有十三个,没有百分之十五。我姥爷怀疑是不是我整天蹲在小卖部里,把巧克力都给挑出来偷吃了。 我说我冤枉啊,我没有偷。老爷说,不要狡辩。我说你掺和糖的时候可能没有搅匀。老爷说,搅了好几遍,肯定都搅匀了。我又说, 每次抓糖的时候,谁能保证这么正正好好按照你勾兑的比例呢?多个两三块,少个两三块都很正常。 老爷想了想,觉得我说的也有道理,但是买糖的村民不同意,说不信,要亲自试一试。过年农闲时节,大家闲着无事,于是就开始做抓糖出样实验。 我们用二软件来模拟这个食锦堂的故事。首先,指定堂的种类一共有这五种。注意,我们趁机在这里引入一个概念,叫类别变量 categorical virule。 在这个故事中,类别变量就是糖的种类, 这个变量只有五个取值范围,不可能有第六种糖。再例如,性别也是一个类别变量,一般只能取男和女两个。只星期几 也是一个类别变量,只能取周一到周日七个值,不能取出一个星期三点五来。类别变量是可以穷尽的,取值是有限的。 与类别变量相对的是连续变量 continuous variables。 之前体检验中的分数就是连续变量, 例如零分、一分、十分等等。而任意两个数值中间还可以取其他值,例如零和一之间还可以取零点四分,零点四和一之间还可以取零点五七分等等。一般来说,连续变量是不能穷尽的,取值是无限的, 我们按照老爷给定的类别变量的分布比例,在二软件中构造出一个一千块糖的总体。为了给大家一个直观的印, 一千块糖的总体造出来是这个样子。在抽样之前,我们心中其实有个期望, 就是理想情况下,假如抽样一百块糖,各种糖的比例正好和总体中真实的各种糖的比例一模一样,也就是一百块糖中有四十块高粱仪,二十块大白兔,二十块大虾酥,十五块九心糖,五块巧克力。 我们把这五种类别的糖应该或者期望出现了次数,叫做我们对这个样本所期望的频次,英语叫做 expectation。 然后我们从这一千块糖中随机抽取一百块糖,相当于老爷把一千块糖搅匀了,再一把一把的抓,抓出一百块糖。结果这次抽样中 各种糖的快速如下,高粱仪三十八块,大白兔二十四块,大虾素十八块,九心糖十八块,巧克力两块。我们这个实际抽样中观测到等各种糖的次数叫做观测频次啊,不是 vision, 请注意,这里都是频次,次数都是整数,不是比例,不是概率,不是小数,也不是百分比, 这和我之前告诉老爷的是一致的,及就算总体绝对是没问题的,是按照老爷的比例勾兑的,但出样一次观测频次也不可能正正好好和期望频次完全一致。 讲到这里,大家应该也回想到英语总体成绩的均值抽样实验了,这都是抽样的随机性决定的,这个样本中巧克力更少,还 按照期望,巧克力该有五块,实际上只有两块,所以我们不能轻率的就说老爷骗人,巧克力放少了,老爷也不能轻率的怀疑我偷吃了巧克力。现在我们引入元甲社 h 零 总体中的各种糖的比例符合老爷的勾兑比例,我们把这个比例叫做类别变量的总体概率分布。注意,这里都是小数百分比,而不是频次,这几个百分比加起来必须等于一, 那么假如样本容量为一百,这就是期望频次和 h 零中的总体分布比例没有差异,但实际观测频次和期望频次显然是有差异的。于是我们自然会提出这样几个问题, 在 a 市零为真的情况下,抽一次样,观测频次和期望频次之间的差异算不算极端呢?或者说如何衡量这种差异的大小?再或者说出现这种水平的差异,是否考虑拒绝 h 零。 假如能把这个差异给算成一个数值就好办了。之前体检验证,每次抽样样本中的所有数据都可以用一个气质公式浓缩出一个气质来。 类似的,我们也可以把本力中的数据差异用这样一个公式浓缩出一个值来,这个值或者统计量就叫做卡方值,这个公式就叫做卡方公式。卡方值所表达的意思就是把一次抽样中的观测品 和期望频次之间的差异给算成一个数字。注意,公式中 n 不是样本容量,而是类别变量的种类。本粒中有五种糖,所以 n 等于五。不同的教材上使用的字母可能不同,请大家自行区别 每种类别的观测频次和期望频次之差的平方除以本类别的期望频次,然后所有类别加起来就得到了一个总的观测,频次和期望频次之间的差别和方差类似, 这里差值也是用的平方,也是因为差值有正有负,加起来可能会抵消,所以用平方的形式。当然,你问我为什么不用绝对值,我回答不了。分母上除的是 是期望频次,你也可能问我为什么不出一期望频次的平方,我也回答不了。大家可以去读一下卡偶 parson 的论文原作,本节课就不讨论了,我们把数据带入公式,公式展开是这个样子,计算得卡方等于三点五, 一次抽样样本中的所有数据浓缩成一个三点五,这个三点五代表着什么呢? 这时候希望大家仍然回想起之前英语高考成绩的均值抽样实验。再衡量一次抽样的均值史, 需要把它放到一个无数次抽样形成的均值分布中去比较类似的,我们需要造一个卡方值抽样分布,我们从这个 h 零为真的一千块糖的总体中每次抽 一百块糖,按照这个公式计算出一个卡方纸。假如进行一万次重复抽氧,就可以得到一万个卡方纸。把一万个卡方纸做成直方图,便可以得到卡方分布。 我们通过二软件来模拟一万次抽氧,可以看到随着抽氧次数的增多,脂肪图逐渐呈现出一个不对称的铃铛形状。 之前在方叉骑行一节,我们简单的讲解过 f 分布,这个卡方分布和 f 分布有点像,但两者是不一样的,大家不要搞混。 经过一万次抽氧,我们得到了一个较为光滑的卡方分布,这个分布类别变量的种类 n 等于五,而你和优度卡方分布的自由度 df 等于 类别变量的种类减去一,所以这是一个自由度等于四的卡方分布。 我们来分析一下这个卡方分布。假设每次抽样的观测频次和期望频次完全一样的话,那么 oi 等于 ei, 卡方值都应该等于零。但实际上,由于抽样的随机性,卡方值等于零的概率非常小。 和均值分布类似,卡方值也是以一种概率分布的形式存在的。 由于公式限定,卡放值不可能是负的,所以卡放值最小就是零。不过卡放值理论上可以无限大,所以卡放分部是朝右边的尾巴尖倾斜的,英语叫 postivity execute。 卡放值越大,说明观测频次和期望频次的差异越大,所以样本越极端,越应该拒绝 h 零。如果卡放值越小,说明观测频次越接近期望频次,所以样本越不极端,越应该接受 h 零。 于是卡方分布中拒绝欲只在右边,不在左边。所以入门客中我们姑且把卡方检验看成一个天然的单边检验。有了拒绝欲的方向,我们来算屁纸。刚才抽样一次得卡方等于三点五, 于是在卡方等于三点五这里画一条线,比三点五含还极端的样本数量占总共一万次抽样的百分比就是壁纸。 我们用萨姆函数来统计比三点五还大的次数得四千两百一十三次,则卡方等于三点五的 p 值为零点四二一三。假如阿尔法设定为零点零五的话, p 大于二法,于是这个样本不极端,不显著,于是无法拒绝 h 零, 认为总体中类别变量的分布仍然符合老爷勾兑的比例,于是我就是清白的了,我没有偷吃巧克力。刚才的壁纸是用二程序数出来的,我们也可以通过茶表来估计。壁纸 和 t 临界指表类似,卡方分布也有临界指表。在计算机还没有普及的日子里,我们不容易算出一个精确的配置,所以查表是最方便的。本例中自由度等于四,于是我们 先找到自由度等于四这一行,然后算出来的卡方值是三点五,发现三点五介于表上的三点三五七和五点九八九之间,于是三点五对应的壁纸应该介于零点五和零点二之间,这和我们估计的零点四二一三是一致的。 现在我们回过头来看看一下什么叫做你和优度。 a 是零中总体的类别分布是这样,因此样本容量为一百的话,期望频次是这样的,然后观测频次又是这样的。 那么观测频次是否符合了期望频次呢?这个符合就是你和优度,就是指观测频次有多么好的符合了 期望频次,或者说样本有多么好的代表了总体。这就是你和优度的含义,而你和优度是可以用屁直来表示的。屁直越大,说明样本的卡放值越小, 观测频次和期望频次之间的差异也越小。样本越能,你和期望样本越能代表总体。 反之, p 值越小,说明样本卡放值越大,观测频次和期望频次之间的差异也越大。样本越不符合,期望样本越不能代表总体。 在卡方,你和优度检验中有两个需要注意的地方。第一本故事中各种糖的比例是这样的,我们通过重复抽样,得到这样一个自由度等于四的卡方分布。大家自然会问, 假如糖的类别是另外一种比例,例如,假如五种糖都一样,每种都占百分之二十的比例,那么卡方分布会不会不一样呢?我们通过程序来模拟,发现卡方分布仍然是一样的形状。 所以,一旦类别变量的种类 n 确定了,卡方分布的自由度 df 等于 n 减一,也就确定了,卡方分布的形状也就确定了,而和各种类别之间的比例分布无关, 这正是卡房分布的价值所在。当然,各种类别之间的分布比例也不能极端不平衡,例如,各种糖的分布比例是百分之九十六、百分之一、百分之一、百分之一、百分之一,这就比较极端了。在这样的总体中,就不容易抽出一个卡, 狂风不来,因为除了高粱仪之外,抽到其他糖的概率都很小,这属于研究问题,本身存在问题。 假如我姥爷按这个比例来勾兑石井糖,我觉得这就不叫石井糖了,这叫一大袋高粱仪,里面不小心掉进去几块其他种类的糖。 就这还要进行卡方抽样实验,没有太大的意义。所以卡方你和优度检验一般有一个条件及每种类别的频次一般不小于五。 一百块糖中假如只能抽出一两块大白兔,一两块大虾酥等等,这些糖就不要单独设一个类别了,干脆合并起来叫做其他种类就完事了。第二个需要注意的地方,在类别变量的总体比例分 各种类别用的是百分比 percentage, 百分比就是概率 probability, 所以老爷勾兑的比例就是类别变量的概率分布,这个分布是对总体而言的, 但是在抽样式,无论是期望频次还是观测频次,用的都是次次数,英语叫 times 或者 frequency, 频次不是百分比,而是数出来的次数。而卡方公式中用的都是频次,而不是用的百分比,这些大家一定要注意,不要用错。 我们举个例子,刚才是样本容量为一百,抽样品次是这样的,卡方值是三点五, p 值零点四左右,不拒绝 a 十零。假如我们把这个样本 中各类糖的频次扩大十倍,这样就得到了一个样本容量为一千的样本,样本中各类糖的比例和刚才是一样的,但是卡放值算出来就变成了三十五了。 卡放值三十五查表一看就是非常极端的抽样了,要拒绝 h 零了,这在直观上也是好理解的,抽样一千块糖,就是把总体全给抽了,总体里一共才二十块巧克力,姥爷说好的五十块呢,所以肯定要拒绝 h 零。 所以卡方公式中各个数据都是频次,而不是比例,比例相同的两个样本并不能算出相同的卡方纸,其根源在于卡方公式中份子上是平方,份子上没有平方,这都是纯 数学运算的东西,大家可以自己思考一下。本节课就不详细展开了。刚才的故事中,老爷勾兑的是五种糖,得到的是自由度等于四的卡方分布,假如老爷勾兑的是六种糖,就可以得到自由度等于五的卡方分布。 不同自由度的卡房分布是一组形状类似但又互相区别的曲线处。 在这个图中可以看到,自由度越大,卡方曲线越扁,且倾斜度越低,峰值越朝右边移动。以上讲解了卡方你和右度的概念和卡方分布曲线的产生。 下面我们在二软件中进行卡方尼和优度检验,其程序命令非常简单及 casquire 点儿 test 命令。 你和优度检验只需要两个参数,一个是样本的观测频次,一个是期望的总体类别概率分布。需要注意的是,这几个概率加起来要等于一,否则程序会爆错。 结果显示,这是一个针对给定概率分布的卡方检验,也就是你和优度检验 统计量。卡方值算出来是三点五,和我们刚才手工算的一样,自由度等于分类变量的种类减去一等于四, p 值等于零点四七七九,和我们刚才统计出来的零点四二一三差不多。下面我们举两个卡方你和优度检验的例子。 在社会统计中,我们经常做调查问卷,例如学校里有四个食堂,我想调研一下全校师生 是否同等的喜欢四个食堂。调查问卷的问题是,你最喜欢的食堂是哪一个选项是四个食堂,这是我们的 h 零,是全校师生同等喜欢四个食堂,也就是说四个食堂被选为最喜欢的食堂的概率都是零点二五。 我们在校园里随机采访路人,抽样得到这么一组数据,假如我们没学过卡方尼和优度检验,我们可能会说,第四食堂喜欢的人最多啊。第四食堂应该是最受喜欢的食堂, 但我们学了卡方检验,就在二软件中检验一下吧,看看这个较多的四十是否只是一种随机现象。我们在程序中输入观测频次和 h 零的总体概率分布,注意期望频次我们 不需要管的程序会根据观测频次算出样本容量,然后再按这个概率分布算出期望频次,结果显示 p 值等于零点五七二四。 这说明在 h 零为真的情况下,也就是全校师生对四个食堂同等喜爱的情况下,抽出这么一组,结果一点都不极端。 第四个食堂的这个四十并不能说明全校师生显著的更喜欢第四食堂,所以结论就是 h 零全校师生对四个食堂同等喜欢。再举一个例子,概率学中抛硬币、抛筛子都是最古典的实验模型。 之前我们说过硬币要均匀的,那么筛子也得是均匀的,不均匀的那叫出老千。如何判断一个筛子是不是均 均匀的呢?对于均匀的筛子,我们心中都有个期望,就是抛出六种点数的概率都是一样的,那么 h 零就是每个点数的概率都是六分之一, 我们抛同一个筛子六十次,得到这样一组观测频次,看起来不是那么理想,理想的话,每个点数都该是十次。那么我们是否就说筛子不均匀呢? 我们就用卡方你和优度检验把数据带入程序中,这是期望的概率分布,这是观测频次。 结果显示这是一个卡方,你和优度检验卡方值等于一点八,自由度等于六点一等于五, p 值等于零点八七六,一 p 值是非常不显著,所以不拒绝 a 是零,结论是 筛子是均匀的。以上就是本节课的内容,卡方检验中较为简单的一种你和优度检验。我们通过老爷勾兑食锦堂的例子,学习了类别变量、期望频次、观测频次、卡方公式、自由度等概念。 总结一下,卡方你和优度检验中只有一个类别变量,本故事中这一个变量就是糖的种类, 其检验的内容是样本中的观测频次是否你和了期望频次,而期望频次是根据 h 零中的类别分布和样本容量算出来的。好,这节课就到这里,我们下节课见。
868统计学陈祥雨大猫咪老师




