
粉丝2357获赞5211
相关视频
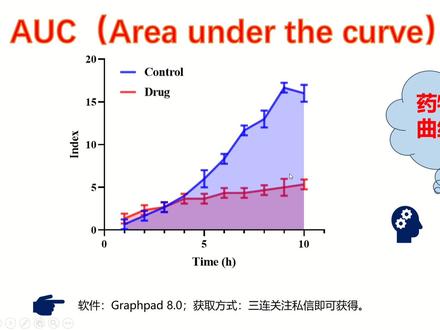 03:39查看AI文稿AI文稿
03:39查看AI文稿AI文稿hello, 各位小伙伴们大家好呀,这里是阿瓜今天这期视频呢,我们来学习一下如何使用 great preparations 来计算 下的面积,也就是 led under the croft, 也就是 a u c。 左边这个图呢就是我的一个计算过程以及绘制图形。 好的,接下来打开我们的软件,把我们的数据输入进来,这里的话我是一个实验纸,一个药物纸,在不同时间的处理下,他一个指数的一个变化。首先我们给他绘制一个图形, 在这里呢我选择这个图形,就是,呃,在 x 这个里选择 x y, 然后这里选择这个 呃折线图,然后点击 ok, 然后我们稍微给他啊修改一下颜色,我们选择自己比较喜欢的一个颜色, 然后大小呢,就是线条的大小,给它修改一下,在这里呢我们不需要横坐标,不需要那么大, 这改为零和十,听到十就可以了,然后这 你给他 那把这两个 我进来把这个删掉,然后这个它基本就绘制成我们现在这个图形,但是我们现在需要计算它的一个形象的一个面积。呃,有好几种方法,在 data one 这里你可以直接点 analyze, 在呃这里选择 s y analyze, 选择 a real under the crof, 然后把这两个都选上,然后点 ok, 都可以,然后图这里呢也可以点,也是一样的操, 操作要点 ok, 那在这里呢话,呃,其实你点 ok 之后啊,后面的参数 看你自己的需要进行一个啊选择,一般这里的话我都不动他,然后点击 ok, 他就会出现一个报告表,也就是一个结果。 在这里可以看到空臭组,他的一个整个的一个面积是七十二点三三,呃。药物组呢,他是三十四,然后以及他的一个误差 等等等等。这个就是整个的一个呃,计算他旗舰下面积的一个方法,是不是非常简单呢? 其实这个方法它就是通过计算它的一个呃积分嘛,然后来计算它的一个面积。 呃。 preparation 呢?他是完全利用这个方法来非常简便的一个操作来实现他的一个数据的一个呃,简便操作,然后达到我的一个目标。好的。今天的内容就这么多了,感谢大家的收看,希望本期内容对你有所帮助,拜拜!
103想看雪的瓜 05:01查看AI文稿AI文稿
05:01查看AI文稿AI文稿hello, 各位小伙伴们大家好呀,这里是阿瓜在上上期视频当中我们学习的如何使用 grape paris 来计算曲线下的面积,也就是 a u c。 那么有时候我们问如何对它进行一个显著性分析, 以及绘制他的一个自转图呢?好的,接下来进行我们的操作,还是打开我们之前这个数据,这是我们之前绘制好的一个图形,然后我们在这里是我们原始数据,在新建一个数据表格, 在这里的话我们给它设置成呃,这个第一个就可以了,点击 create, 然后我把我们的数据输入进来, 这复制进来, 复制进来之后呢,我们点击 analyze, 在这里我们还是选择 earlier undercrow, 这是我们对每一个都进行一个计算,他的一个面积,点击 ok 还是点击 ok, 那他就会跳到这个页面,这个页面呢我们可以看到他的一个总的面积, 七十二,七十一,七十四,这这个都是一样的。然后这个就是不同的一个,呃, 做的一个实验组的一个旗舰项的一个面积,然后把它复制一下,在这里新建一个, 选择 data, 点击 create, 啊,这里给它设置成三,点击 create, 在这里呢,我们刚把刚刚复制的数据输进来,然后 a 组呢是空凑组, 那这个是药物种, 然后我们就绘制它的一个图形,选择柱状图,点击 ok, 这里的话我们需要对它进行一个啊完善,让它更加美 画一点,把它选中全部它的一个这状图的一个呃, 粗细,它的一个宽的粗细设置成一,然后分别对它进行一个设置,它的颜色,这些呢针对你的发论文的一个要求的一个进行选择你的颜喜欢的颜色就可以了。 呃,这里是 elia 百分百的一个单位,这里呢给它设成四十五度会比较好看一点,然后上面的把它删掉, 稍微给他拉伸一下。接下来呢,我们需要对他进行一个做 t 检验的一个分析。嗯,回到 datastruity 也这里也可以直接在这个 grip 这里直接点 analys, 在这里的话我们选择啊 color and analys, 选择 t 检验,点击 ok, 然后这里也点击 ok 就可以了。在这里的话我们就可以看得到他的一个体检液,体检液是小于零点零零零一的,还有四个显著性的一个分析。那在这里的话我们给他标上就可以了, 双击它给它设置成,当然人设 你都是可以改变的哈。点击 ok, 给他设置四个, 给他加粗一点,也可以让他变大一点。然后的话我们选选中他所有的,给他设置成新罗马字体,这样可能会更加好看一点。 哎,他没有对,这样的话就基本就绘制成功了,就是可以计算他的一个 t 检验,来达到我们分析我们的显著性分析, 然后以及绘制它的一个自转图。好的,今天的内容就这么多了,感谢大家的收看,希望本期内容呢对你有所帮助,拜拜。
80想看雪的瓜 04:16查看AI文稿AI文稿
04:16查看AI文稿AI文稿各位小伙伴们大家好,欢迎收看本期视频, 在这一期视频中,我将向大家简要介绍一下如何用二语言来对二元逻辑回归模型的 c 指数进行计算,以及二元逻辑回归模型中 c 指数和 auc 制的区别。 我们在构建完了逻辑回归模型之后呢,往往需要对我们的模型进行一个评价, 比如说我构建的是一个疾病的预测模型,那么我这个模型能否准确的预测出患者是否患病,那么我就要用相关的统计指标来进行评价,一般我们最常用的就是 c 指数以及 auc 指,这两者的这个区别在哪 哪里呢?啊?我首先先说我最终的结论就是在二元逻辑回归的范畴当中, c 指数和 auc 指是没有区别的,下面呢,我将通过一系列的这个计算来给大家展示一下为什么是没有区别的。 首先我们还是来先看一下我们的数据,这个数据呢还是我在 excel 表里用随机数生成的啊,分别代表着我们的洁具变量以及我们相关的自变量啊, 连续分类变量都有。好,然后呢,我们来对这个呃,我们的这个呃进行一个运行, 我首先呢还是加载相关的包,然后把数据进行一个读取好,最后呢再构建货就没有回归,然后并且计算我们的 auc 纸和 c 纸数。好,现在我们已经完成了,现在我们大家来看一下啊,这个 a uc 值和 c 指数分别是多少?好,大家可以看到我们算出来的两者全部都是零点八零六,这两者是完全一致的啊,为什么他们是完全一致的呢, 就是不光是他们这个数值本身是完全一致,就是他们的百分之九十五执行区间也都是一致的,这个有兴趣的小伙伴可以自己试验一下,我在这里由于篇幅的原因就不展开了。 我们这个 c 指数也就是一致性指数呢,它是对所有的我们的这个预测结果当中和就是预测出来的和实际结果一致所占的这么一个比例 啊,他呢是为了把预测结果和实际观察结果他们一致的这么一个比例展示出来的形式就是我们的一致性指数。而 r o c 曲线呢,则是也是通过我们的预测指 和实际纸分别计算他的 force positive right 和出 positive right。 然后呢把相关的我们的这些啊纸作为坐标绘制在一张曲线上面,然后这种曲线下方的面积也就是我们的 auc 纸。 我们的这个 c 指数呢,一般是在零点五和一之间啊,其中零点五那就相当于就是一半对一半百分之五十的概率,那和瞎蒙一样,那就是没有什么预测作用,一呢,就是预测作用比较强,就介于零点五和一之间。 auc 指同样也是如此的 啊,我们 auc 呢,一般是反映的是我们二元逻辑回归模型的预测能力, c 指数呢,他反映的其实呢是可以更多一些的啊,他是可以对各种模型的预测结果都可以用来这么一个评价,我们可以简单的这么理解,就是 c 指数 auc 值的一种扩展,而 auc 值呢,是 c 指数的一种特殊的情况,它特殊在哪里呢?就是只针对二元回归模型啊,就是针对我们的最终我们的应变量是零和一,是或者否一个 t 和破 ct 换病和不换病这种二元情况来进行的一个比较 啊。然后我再稍微多讲一下我们的这个教准曲线,卡里布瑞森科五啊,也就是我们常说的这种教准图,它呢是实际发生的概率和预测概率的一个散点图,它这种教准曲线呢,就是把我们的 homeslet show 这个你和优度检验进行的一个可视化啊。然后呢 调整曲线呢,是我们这个用来评价我们的逻辑回归和 cos 回归模型的,也是一个非常常见的这么一点。好,那么我们这个本期视频呢,就到此结束,感谢大家的收看,我们下期再见。
14雯雯最可爱 00:34查看AI文稿AI文稿
00:34查看AI文稿AI文稿深度学习多样性计算方面的专家蓝海大脑对 ok 指标有哪些方面的问题给出这样的解释, 奥克施 rock 曲线下面的面积奥克可以解读为从所有政例中随机选取一个样本, 在从所有复利中随机选取一个样本币。分类器将判为正力的概率比将比判为正力的概率大的可能性。 ok 反映的是分类器对样本的排序能力。 ok 越大,自然排序能力越好,其分类器将越多的正力排在复利之前。
8金蓝海 09:07查看AI文稿AI文稿
09:07查看AI文稿AI文稿大家好,欢迎你在视频中和我一起探讨乱和 ac, 我会详细解释他们的概念。要注意的是,这个视频是在混淆矩阵灵敏度和特异度的基础上展开的,所以如果你对这些还有点模糊,不妨先看看我关于这些的其他视频。 今天我们会用到逻辑回归的例子来帮助理解 rock 和 auc, 他们不只适用于逻辑回归,不过你也可以先看看逻辑回归的其他基础。 先让我们看看数据。在外轴上,我们有两个类别,分别是肥胖和非肥胖。蓝点是肥胖的老鼠,红点则是非肥胖的。而 x 轴呢,那就是我们关注的体重。 这只老鼠的体重倒是不小,但他并不肥胖,他一定是只肌肉猛鼠。而这只看起来轻飘飘的老鼠,他的体型却被认为是肥胖的。接下来,我们要根据这些数据来画一个逻辑回归曲线。在逻辑回归中,外轴变成了一 只老鼠是肥胖的概率。现在我们只关注这条曲线。如果有人告诉你他们有一只重量不小的老鼠,那么曲线就会告诉你这只老鼠有可能是肥胖的。反之,如果有人说他们有一只体重轻飘飘的老鼠,那么曲线就会告诉你这只老鼠可能并不肥胖。 这就是逻辑回归告诉我们一只老鼠根据体重是肥胖还是不肥胖的概率。但是,如果我们想要把老鼠分成肥胖和非肥胖两类,我们就需要找个方法把概率转成分类了。 我们可以设置一个预值,比如零点五,只要肥胖的概率超过零点五,那么这只老鼠就被认为是肥胖的。如果肥胖概率小于或等于零点五,那么他就被归为非肥胖。 用零点五作为标准,我们会认为这只老鼠是肥胖的,而那只老鼠就不肥胖。如果有一只老鼠体重和前面一样,那我们就会认为他是肥胖的。相反,如果 有一只老鼠体重特别轻,那我们就会认为他不肥胖。为了评估这个逻辑,回归在分类预知为零点五十的效果,我们用我们已知的肥胖和非肥胖的老鼠来进行测试。这是我们有的四只非肥胖老鼠的体重,以及四只肥胖老鼠的体重。 我们知道这只老鼠并不肥胖,而这个逻辑回归也在预支为零点五十,把它正确的归为非肥胖。这只老鼠分类正确,但这只老鼠却被分类错误。我们知道他是肥胖的,但他被标记为非肥胖。 下一只老鼠分类正确,而这只又被分类错误。最后的三只,我们现在要创建一个混小举战来总结这些分类结果。这三个样本被正确分类为肥胖,而这个样本被预测为肥胖,实际上却不是。 这三个样本被正确分类为非肥胖,而这个样本被预测为非肥胖,事实上却是肥胖的。一旦混淆矩阵填 满,我们就可以计算灵敏度和特异度来评估这个逻辑回归在肥胖预值为零点五十的效果这里有个小惊喜,因为这些都只是复习。现在我们来讨论一下,如果我们改变预值,会对样本是否被认为肥胖有什么影响。比如说,我们非常重视准确判断每一只肥胖的老鼠,那么我们可以把预值设为零点一, 这样一来,所有四只肥胖的老鼠都被正确分类了,但同时也增加了假阳性的数量。降低玉植还会减少假阴性的数量,因为所有的肥胖老鼠都被正确分类了。如果说改变玉植让你感到惊奇,那就想象一下,我们要判断样本是否被埃博拉病毒感染。 在这种情况下,正确分类出每一个被埃博拉感染的样本至关重要,这可以降低疫情爆发的风险。这意味着我们需要降低预值,即使这会导致更多的假阳性。另一方面,我们也可以将预 值设置为零点九。在这个场景下,我们能和设定预支为零点五十一样准确的分类肥胖样本,而且不会出现任何误判为阳性的样本。同时,我们能准确的分类更多的非肥胖样本误判为阴性的样本数量。和之前一样, 针对这些数据较高的预值在分类肥胖和非肥胖样本上更胜一筹。不过,预值我们可以在零到一之间任意设置。 我们怎么确定哪个预值最合适呢?首先,我们并不需要对所有可能的预值进行测试。举个例子,有些预值可能会得出完全一样的混淆矩阵。但如果我们为每个重要的预值都创建一个混淆矩阵,那结果可能会是一大堆令人眼花缭乱的混淆矩阵。 因此,为了避免淹没在混淆矩阵里, rock 曲线提供了一种简化的方法来总结所有的信息。外轴表示的是真阳性率,也就是灵敏度。这个指标是 真阳性样本数处以真阳性和假阴性样本的总和。在这个例子中,真阳性样本就是被正确判断为肥胖的样本,假阴性样本则是被错误的判断为非肥胖的肥胖样本。 真阳性率就是告诉我们正确分类的肥胖样本的比例,而 x 轴表示的是假阳性率,也就是意见取特异性。假阳性率是误判为阳性的样本数除以误判为阳性和真阴性样本的总和,误判为阳性的样本就是被错误的判断为肥胖的非肥胖样本, 而真阴性样本则是被正确判断为非肥胖的样本。假阳性率就是告诉我们被错误判断为肥胖的非肥胖样本的比例。 为了更深入理解 rock 是如何工作的,我们用视力数据绘制一个完整的 rock 曲线。首先设定一个预值,让所有样本都被判断为肥胖,这样我们就得到一个混淆矩阵。首先我们 计算真阳性率,有四个真阳性样本而没有假阴性样本,一番计算后就得到一,当预值非常低,以至于每个样本都被判断为肥胖时,真阳性率就是一,这就意味着每个肥胖样本都被正确的分类了。现在我们计算假阳性率,在混淆矩阵中有四个误判为阳性的样本 而没有真阴性样本,一番计算后得到一,当预值非常低,以至于每个样本都被判断为肥胖时,假阳性率也是一, 这就意味着每个非肥胖样本都被错误的判断为肥胖了。现在在一一的位置画一个点,一个位于一一的点,就意味着虽然我们正确的分类了所有的肥胖样本,但我们也错误的把所有的非肥胖样本判断为了肥胖, 这条绿色对角线就表示了真阳性绿等于假阳性绿的位置。任何在这条线上的点都意味着正确分类 肥胖样本的比例和错误分类的非肥胖样本的比例是一样的。再回到逻辑回归,我们把预值提高,只有最轻的样本被判断为非肥胖,其他的样本都被判断为肥胖。新的预值就得到了这样一个混淆矩阵。然后我们计算真阳性率和假阳性率,并在零点七五一的位置画一个点。 由于新的点在绿色虚线的左边,我们知道正确分类为肥胖的样本的比例大于误判为肥胖的样本的比例。换句话说,新的玉值比第一个要好。现在我们把玉值提高,只有两个最轻的样本被判断为非肥胖,其他的样本都被判断为肥胖。 新的玉值给我们这样一个混淆矩阵,然后我们计算真羊性率和假羊性率,并在零点五一的位置画一个点。新的点离绿色虚线更远,显示出新的玉值,进一步减少了误判为肥胖的样本的比例。换句话说, 新的预值是到目前为止最好的。现在我们再次提高预值,创建一个混淆矩阵,计算真阳性率和假阳性率,然后画出点。现在我们再次提高预值,创建一个混淆矩阵,计算真阳性率和假阳性率,然后画出点 新的点,反映出预值正确的。把百分之七十五的肥胖样本和百分之一百的非肥胖样本分了出来。说白了,这个预值没有弄出任何误判为阳性的案例。接着我们再提高一下预值,标上一个点, 继续调高预值,再画个点。最后我们设定一个能把所有样本都判定为非肥胖的预值,然后也给他画个点零零。这个点就代表了一个预值结果是真阳性和假阳性都为零。 如果我们愿意,我们可以把这些点连起来,那我们就得到了一个 rock 曲线。 rock 曲线其实就是把每个预支下的所有混淆矩阵情况一并呈现出, 不用一一研究混淆矩阵,我就能辨别出哪个浴池比哪个浴池好用。再者,根据我能接受的假阳性样本数量,最好的浴池可能是这个,也可能是那个。就这样, 既然我们已经了解了 rock 的原理,那我们接下来聊聊曲线下面积,也就是 auc, auc 是零点九。就这样,有了 auc, 比较不同的 rock 曲线就变得轻松了。红色 rock 曲线的 auc 比蓝色 rock 曲线的 auc 大,那就代表红色曲线更优秀。 所以,如果红色 rock 曲线代表逻辑回归,蓝色 rock 曲线代表随机森林,你就应该选择逻辑回归。就是这样。好,我们快结束了。不过还有最后一点要说, 尽管 rock 图是利用真阳性率和假阳性率来总结混淆矩阵的,但实际上还有其他度量也试图达到同样的目标。比如,有时候人们会用精确度 来代替假阳性率,精确度就是真阳性样本处以真阳性样本和假阳性样本的总和。也就是说,精确度代表的是被正确分类的阳性结果的比例。如果非肥胖样本的数量远大于肥胖样本的数量,那么精确度可能比假阳性率更实用。 这是因为精确度的计算并不考虑真因性,样本的数量不会受到样本不平衡的影响。在实际操作中,这种不平衡经常会在研究稀有疾病的时候出现。在那种情况下,研究中没有疾病的人往往比有疾病的人多很多。就这样。 总的来说, rock 曲线让我们很轻松的确定最佳决策。预制,这个预制好,那个预制不好。 auc 能帮你决定哪种分类方法更好。红色方法好,蓝色方法不行。好了,我们又完成了一次激动人心的统计之旅。
135Eve的科学频道















猜你喜欢
- 4.1万财气冉冉
最新视频
- 1061家电维修老杨