amos路径系数显著性是什么意思
大家好,这是我们一个学员构建的结构方程模型,它构建了三个字变量,两个音变量。我们来计算一下,这是他自己通过调查问卷收集到的数据, 那么这是计算结果,我们来具体看一下。我们首先来看一下皮值,皮值显示有四条路径的皮值都大于零点零五,那么总共有一二三四五六六条路径,那么四条都不显著, 很显然这个结果是非常不理想的,那么在我们的帮助之下,经过调整,最后模型变得非常理想。 下期视频我们来展示一下我们调整之后的模型结果。点击关注,每天学习统计知识。

粉丝375获赞814
相关视频
 11:27查看AI文稿AI文稿
11:27查看AI文稿AI文稿今天呢,我们来看一下第三节的内容,验证性因子分析的结果解释。做完验证性因子分析之后,我们需要对做出的验证性因子分析的结果给出一个合理的一个解释。首先呢我们来看一下验证因子分析做完之后,我们主要来关注的是哪些指标 阴性分析的结果呢?我们主要关注以下几点指标,第一个咔方值,也就是模型拟合出来的咔方值, 第二个是自由度,第三个是咖方除以自由度,也就是第一个和第二个咖方除以自由度的比值,这个比值呢,一般小于五就是我们可以接受的一个标准, 如果说最理想的就是让他小于三,越小越好,一般小于五就可以接受,小于三的话更加理想一点。第四个是金丝误差军方根,金丝误差军方 根的话,一般让其小于零点零八的标准就就属于可以了。然后如果你想要再进一步让这个模型更好的话,一般就让他小于零点零五,当然也是越小越好。 然后 cfi 大于零点九是 cfi 和 nfi, nfi 呢有时候也叫 tfi, 他俩呢都是一个关于验证性分析的整体的拟核的一个指标,这两个指标呢都是越大越好,一般大于零点九就可属于可以接受的范围了。 呃,在看完这个验证芯子分析需要关注的一些指标变量之后,我们再来看一下验证芯子分析做完之后,一般是一个一般要做成一个什么样的一个结果。 一会我们还会结合这篇文献来对大家进行一个讲解,我们大家可以看一下这个作者呢,在这个文献中,他提出了有八个浅变量, 相当于他首先做的是要做一个八因子模型,我们上次课所讲的也是老师数据所对应的一个五因子的一个模型,对不对? 八因子模型做完之后呢,我们还需要将因子进行一些合并,比如说他的七因子模型给出的就是工作家庭冲突,妻子的工作家庭冲突和丈夫的工作家庭冲突 合并为一个变量之后,和其他六个变量构成了一个七因子的模型。大家可以想一下,七因子模型肯定不止这一种组合方法对不对?还有其他的组合方法,但是呢,作者不可能将所有的都列出来,所以一般的学术界的处理方法,就是说 我们在做的时候呢,将随机的进行一些组合,也可以是根据一些文献的,根据一些自己研究理论的一个需要。当然这个比如说这个就是工作妻子的工作家庭冲突 和丈夫的功能加强冲突,他们俩更可能归于一类去,所以呢七英子模型里边这一展示就是这个,当然你也可以展示别的,然后相应的呢,他分别做了七英子、六英子、五英子、四英子、三英子、二英子、单英子, 最终呢得到这样一个表格,最终的验证结论呢,就是说我们首先来看这个八音字模型,他的各个指标呢,喀方除以 df 小于五金丝误差,军方跟也小于零点零八, 然后 csi 呢大于零点九, nnfi 也就是 tli 虽然只有零点八八,但是也非常接近零点九的,也可以作为我们的一个合理的一个解释。 再来看呢,就是七因子、六因子、五因子、四因子、三因子、二因子、单因子。模型之后呢,他的咔方值明显变大了,就变差了,而 msea 呢就误差近似误差,军方根变大了,也变得不好了, cfi 和 nfi 也有减小的趋势,就是不符合我们的预期了。因此呢,我们就说我们最终构建这个八因子模型呢,是一个理想的模型,是符合我们预期的需要的。 在看完这个之后呢,我们通过数据来实际对大家进行演示。首先呢现在回顾一下我们上节课是怎么做的,我们上节课绘制完模型图之后呢,我们先需要选择数据对不对?我们把把老师给的这个数据呢选择进来之后点击, ok, 在这个分析属性里边呢,我们还需要设置一下输出选项对不对?我们这里呢让他输出一个标准化的结果,这样我们在模型图里边呢,就可以呈现出标准化的一个输出结果在模型图里边, 然后点击完这个之后呢,我们就直接可以点击呃那个运算,运算呢,这里就会呈现一些运算的过程,就说他通过十一步的叠 代取得的这个最小值,最小值已经达到了他给出的一些结果,就他给出的这里简单的给出了一个开放值和自由度。 我们首先来现在已经是已经是那个标准化的视图了,已经是那个结果呈现的视图了,如果我们点击左边这个,就会切换为那个数据模型图的视图,然后我们点击这个就会切换为这个数据结果的视图,然后我们可以在这里呢进行切换,选择非标准化和标准化的一个结果, 不管是标准化,非标准化,我们在这里都可以看到一些简略的信息,我们我们需要的一些信息,比如说我们可以看到咖方处理自由度,我们可以看到金丝乌纱,军方跟可以看到 cfi, 你可以看到 tli, 也就是 nnfi, 可以看到这些值。如果我们想要进一步的分析看一下所有的结果的话,我们就 点击 vipast, 这里呢给大家呈现的就是所有的一个数据分析的一个结果。首先呢我们来给大家逐个来讲解一下数据分析所有的结果是一个什么样的一个情况,这个呢是一个分析的汇总,就说呈现了分析的日期,时间以及标题, 这个呢是群组的分析的一个注视,我们这个这个群组呢只有一个群组,总共样本量呢我们可以看出来是两百三十三个,在下一个呢就是变量的一些摘要,这里给出的一些呃浅变量,观测变量以及以及那个浅变量, 同时呢还给出了一些变量的一个汇总表,就说我们总共用到的呢四十五个变量,其中有二十个是可以观测的变量,有二十五个是不能观测的变量,有二十五个外省 面量,有二十个内胜变量,以及这个就是变量的一些汇总,同时呢还会给出的是一个呃参数的一个汇总,我们大家点击这个就可以看到参数的汇总,在这里呢我们可以看到固定参数, 有这个标签,有飞机标签,还有这个总和,同时呢这里有呃回归的,有有相关的,有方差的,有均值的,有拮据的,有所有的,就是说所有的变量,所有你要估计的一些参数都在这个表里边给你汇总出的一个 一个数据的一个分析结果,方便大家进行一个查找。然后这个呢就是模型礼盒的一些,这个是模型的一些信息,模型的信息的话就说我们这个模型呢,总共是 总共用到的这个自由度,他给你的自由度,同时还给你的一些结果,自由度的话就是说我们这里边呢就是呃模型的 nobods, 第一次 summom 次是两百一, 然后第三个拍二米特图比森的,是的是的呃五十,然后他两个相减之后呢,我们就得到我们的自由度是一百六。我们这个模型结果里边呢给大家说的是我们的最小值呢,已经达到了, 我们的最小值已经达到了,同时呢这个咖方值呢是三百一十一点零一三,自由度呢是一百六,然后咖方值所对应,在这个自由度下,咖方值呢所对应的显出性屁值是零点零零零, 就是小一点点零零一的意思。下面呢再给大家看的就是这个呃估计的一个参数,估计的一个结果, 我们可以看到呢,就说 a 这个浅变量有四个测量变量,他的估计值呢这个是给出的是一个非标准化的一个估计值, 可以看到下面呢就会给出标准化的一个估计值,大家都可以就是说既可以看非标准化的,也可以看标准化的,我们就可以看到呢,所有的这些拟核指标,所有的测量变量在这个题项上都是显著的,这个虽然标出来是零点零三六,但是也小于零点零五的标准也都是显著的,对吧? 这是非标,这是标准化的一些结果。然后同时呢也给出了这个斜,这个方斜方叉,斜方叉矩阵,就是说 方差,斜方差就说 a 和,就说因为时间的性子分析,所以两两之间都会有个斜方差,斜方差的值呢,我们也给出来了标准物 cr 值,然后他的 显著性 p 值也都给大家进行的标注,还有相关系数,同时呢还给出了变量的值,这个所有的变量,我们我们的浅变量,包括我们的这个误差,各个误差项都给出了一个结果的,然后这里呢还给出了一个最小化的计算过程, 我们在刚刚的参数的分析过程中呢,模型的分析过程中,我们就看到总共这个模型,通过十一步迭代我们找到最小值,那么他这里就给出了你的十一步迭代分别是一个什么样的样子。 同时呢还给出了一个模型礼盒的一些信息,这里边呢就是一些参数信息,我们可以看到这里边呢就是咖方值, 还有一些 rmig, f i, 然后还有一些基准的模型,还有一些还有其他的一些参数的一些结果, 近似误差,军方跟呃信息量, ecvi, 霍特林统计量的一些检验结果,这里都给大家进行了一个呈现,这个就是呢以上呢就是本节课程所讲解的关于验证性因子分析的一个结果的一个解释部分, 下面呢我们就再简单的通过这个文件来对大家进行一个讲解, 我们打开这个文件,然后我们就可以看到, 我就可以看到这个,在这个在这个文献中呢,验证因子分析是这样应用的,就是说 学者现在提先提出的一个理论假设,然后根据相关的理论假设提出了相应的研究方法,收集了相应的数据。实证检验结果呢,就说他做了八因子、六七因子、 六英子、五英子、四英子、三英子、二英子、单英子的一个模型图。验证性子分析呢主要就是作为这个一个使用,同时呢验证性子分析也会在后期的同源偏差检验里边也会发生一个作用,这得看就说单因子的模型你和结果与八因子模型相比没有显著显著变差, 说这结果表明呢,同源偏差并不是一个严重的问题,也就是说呢,验证性子分析也会用在同源偏差这个检验中,希望大家注意。 然后好了,分析完这些之后呢,我们来看一下我们第三章呢验证芯子分析的过程,现在所有都讲完了,那么我们现在来简单回顾一下验证芯子分析所讲解的内容。 我们首先讲解的验证性因子分析的概念,验证性因子分析是什么?验证性因子分析与探索性因子分析的一同,同时呢,我们还讲解了如何绘制模型图来求解 分析这个求解过程也对大家进行了详细细致的讲解。最终呢,今天的课程我们还讲解了验证因子分析的结果解释,结果解释呢,都逐条的带大家进行了一个回顾。 然后以上就是呢验证性因子分析的内容,希望大家学习完验证性因子分析的内容之后,能够熟练的运用 emox 来处理验证性因子分析的相关的理论,相关的模型。 我们这节课程呢就到这里结束了,我们下次课程呢会着重介绍路径分析的内容,希望大家能够在学习完今天的课程之后,对路径分析进行一个预习,我们下次可见,谢谢大家。
223贰壹壹项目数据分析服务 14:37查看AI文稿AI文稿
14:37查看AI文稿AI文稿各位同学大家好,很高兴今天我们能够相遇在二幺幺统计网络课堂,我们来接着学习俄罗斯入门教程的后续章节。在前面的课程中,我们已经介绍了俄罗斯如何来绘制结构方程模型的一个理论图, 同时呢,上节课我们也对模型的估计方法进行了一个讲解,那么今天呢,我们来看一下结构方程模型第四节的内容,模型修正 做出来的模型呢,一开始呢做出来的肯定不会就是我们想要的那么完美的一个状态,那么呢我们就有必要来对模型进行一个修正, 那么模型修正是有一个严格的一个理论基础的,我们需要按照严格的一个理论来指导我们来一步步的来进行修正,不能自己主观的异策,主观的来根据自己的主观意愿来进行相应的修正, 那样的话你所修正出来的模型是没有任何理论保证的,同时呢,你也不会可能不会得到一个预期的满意的一个结果。那么我们今天来正式学习模型修正部分 模型的修正呢,就是说我们所提出的理论假设模型,然后我们用我们所得到的一个数据进行验证之后,我们发现我们的这个模型图经过匹配度检验之后,无法与官司数据适配, 那么就说我们的模型有进一步的修正的一个必要,因为如果我们不修正的话,我们现在得到的一个结论无法满足我们理论上的一个需要, 那么这时候呢,我们就需要对模型来进行修正,修正的话呢,它是有一个理论或者说经验的一个依据,第一个呢就是说我们将不显著的一些路径删除,就是我们在绘制模型图的过程中,我们不是添加了浅边量 哥哥之间的一个影响关系,比如说我们的模型图就有 a 到 a 到 c, 然后 c 到 c 到 e, 然后 b 到 d, d 到 e, 有这样一些路径的关系。如果说我们这些不显著的话,我们就需要将可以将这些不显著的一个路径进行一个删除, 那么这样的话呢,就说我们少验证了一个假设,那么这个要想删除路径的话,必然也要和理论上找到一个相应的依据,就是我们不研究这个路径了,或者说有一些其他的方面的一个解释,这个大家在删除的时候一定要进行一个慎重,然后同时呢将不合理的路径也删掉, 就比如说我们得到的我们想要验证的他是一个正向的影响关系,但是呢我们最终得到的他是一个负向的影响关系,或者说呢,呃,我们影响程度两个大小的影响程度,我们 我们想研究 a 和 b 都对 c 有影响,我们我们的理论假定呢是 a 对 a 对 c 的影响更大于一点, b 对 c 呢相对来说小一点, 但是呢如果说我们验证出来的结论是 a 对 b 的影响路径反而小, b 对 c 的影响路径反而大的话,那么这时候我们就出现了一个不合理情况,那么针对这种不合理的情况,我们应该如何处理呢?我们就会根据我们的经验或者理论,我们会进行将这些不合理的路径进行一个删除, 那么删除得到之后的呢?那么就符合我们的预期了,但是这样也存在一个问题,我们就是我们将不合理的路径进行了删除之后,可能就会导致我们研究的问题 已经不再是我们最初所要设定的那样一个假设来进行一个研究的了。所以说大家在删除不合理的路径或者不显 的路径的时候,一定要慎之又慎,不能主观的自己随意的进行一个删除。那么还有就是说我们这里今天要着重要讲的就是说我们可以根据我们的修正指数来对模型进行一个修正, 修正指数是一个什么呢?就是说根据 amose, 根据根据我们模型现有的数据和模型的一个匹配情况,我们算出来了最有可能去改进模型的一个方向, 我们通过修正指数呢,我们就能够看出来我们去往哪个方向来进行一个努力,可以使得我们的你魔性的你和指标更加的好。然后关于修正指数的曲值呢?不同的学者提出的一个不同的一个意见, 这两个学者呢,在一九八八年,他们认为只要修正指数大于三点八四,那么我们这个模型就有必要来进行修正。 邱浩正呢,他认为啊,就是说只有说只有说这个呃,修正指数大于五的时候,我们才有必要来进行修正, 究竟是大于三点八四还是大于五呢?这个标准呢?选择呢,需要根据我们的研究问题来来进行一个确定,因为根据我们不同的研究问题,如果说我们选择把五的把大于五的进行修正之后呢,我们最终修正得到的一个结果 啊,非常符合我们的预期,也非常符合我们的理论,我们能够根据修正后得到的结果给出一个合理的解释,那么这时呢,我们就没有必要再按照三点八这个标准来了。 如果说呢,我们在大于五的,我们再把大于五的修正指数全部进行修正之后呢,模型依然无法得到一个满意的结果,那么呢,我们这时候还可以再考虑将再小一点的 修正指数再进行一个相应的修正,看看是否会得到一个更加满意的结果。当然呢,也有就是说我们将所有的路径,我们将大于三点八四的路径也都修正指数的也都进行了修正之后呢,可能我们也是无法得到一个 呃满意的一个结果,这种情况是一个客观存在的一个事实,大家一定要进行注意。不是说修正指数我们 按照修正指数来就一定能得到满意的结果,修正指数呢,只是给我们提供了一个一个大的方向,当然也要结合其他一些具体的情况。然后修正指数呢,只是作为一个呃最主要的一个参考,当然他也不是全部的, 在使用修正指数的时候,我们需要注意哪些哪些点呢?就说修正指数仅仅只用来作为一个参考,我们在进行调整模型图调整的时候,仍然需要结合 我们所研究问题的一个结论,才能进行一个相应的修正。最终呢,就算我们如果我们说没有按照我们的结论来进行修正的话,那么我们最终修正出来一个模型,我们可能没法在理论上给出一个合理的解释, 没法给出合理的解释的话,那我们这个模型呢也就不具有太多的这个现实意义。因此呢,我们在做修正指数的时候,一定要结合现有的理论的基础之上来进行一个参考。 同时呢就说如果有多个修正指标较大时,应该逐步的放宽,比如说这里有修正指数做出来之后有一个五七八九十,有这么几个修正指数都是大于五的,我们有必要来进行修正。 那么我们首先呢就是说我们逐步的来进行修正,首先呢我们把食的最大的食的先进行修正,食的修正完之后,我们重新跑一遍 之后呢,可能得到的修正指数就不再是剩下的五七八九了,可能就会有一些相应的变化。然后呢我们再根据放宽之后的,我们再根据把实的已经修正之后得到的这个新的修正指数,我们再来逐步的把最大的一个 来进行一个呃修正。如果修正完成之后呢,我们再来看一下我们得到的模型能否得到一个合理的解释,如果能够得到一个合理的解释的话,那么我们就可以进行停止了,如果还是不行的话,我们就可以逐步的将大的修正指数 逐个来进行一个放宽,那么这样的话呢,才能保证我们最终得到的一个结论是不至于太过。呃,我们如果说严格按照修正指数来的话,可能我们得到最终的结论就没法进行一个合理的解释。因此呢,我们通过这样逐步放宽之后,每放宽一步,我们就根据我们的理论去进 一个检验,如果说我们能够得到一个很好的解释的话,那我们就可以考虑放弃这个修正指数了,因为我们如果说我们已经在理论上得到一个很好的解释的话,那我们就没必要再对模型进行逐步进行更进一步的修正了,因为现有的模型已经能够 解释我们所有的问题的,所以说呢,这是在使用纠正指数的时候,大家一定要注意的两点。那么讲完这些之后呢,我们通过我们上节课绘制的模型图实际来给大家进行一个演示。 那么我们首先来看一下,这是上节课老师绘制好的一个模型图,我们绘制的 abcde 四个,前五个前面量,各自的前面量,先用的测量题目也都给他加上了, 同时我们还命名了这个残渣象,每个残渣象都进行命名,保证不冲不漏,那么这样之后呢,我们这个模型就已经成型了。然后呢我们 再接着做什么呢?我们把数据选择进来,我们我们先选择数据对不对?我们把数据选择进来之后呢,就说我们选择这个,呃,第五章,第五章的一个配套数据, 让我们点击, ok, 这样的话数据就已经进来了,我们我们相应的把边上列表进行拖拽,因为这个是老师重新打开了一遍模型,所以他可能链接的数据老师当时没有保存,所以说呢就是 呃,老师需要重新连接一遍数据,如果说大家接着上节课的内容来进行演示的话,就没有必要再打重新打开数据了,因为我们能够把前面能够把测量面料拖进相应的框中,就说明我们的数据已经进到我们的俄罗斯模型里边去了,我们直接运行即可。 那么做完这个之后呢,我们就点击分析属性里边的一些设置,我们在输出设置里边呢,我们选择上标准化的同时,我们要选择上这个修正 指数的,因为只有选择的修正指数模型才会最终给我们输出一个修正指数的一个结果,同时呢我们可以选择这个直接效应,尖尖效应一些情况,一些值,其他的属性值呢,大家也可以进行相应的一些设置,设置完之后大家可以运行一下,看看最终输出来是一个什么样的一个结果。 然后我们设置分析,设置完这些分期属性之后呢,我们直接点击运行模型,我们就能得到一个结果,那么我们来看一下 这是非标准化的,然后这个呢是标准化的一个结果,标准化的结果就是说我们的 a 对 b 呢是零点七四, a 对 c 呢是零点七四的影响,然后 c 对 e 呢是零点八零, d 对 d 呢是零点九七, d 对 e 呢是零点一六。那么我们就能看出来这个各个模各个潜面量之间的一个影响系数的一个大小,同时呢也能看出来一个方向 负影响关系,同时呢我们也能够看出来各个测量变量和浅变量之间的一个呃权重的一个系数,这些我们都是可以看到的。那么我们今天来主要来给大家看一下我们的修正指数是一个什么样的? 大家现在大家现在记一下我们的卡方值是呃,我们的卡方值是三百一十六点六零四,自由度是一百六十五。那么我们来看一下我们这个分析的一个结果,我们直接来看一下分析,来看一下这个修正指数,我们看一下修正指数有非常大的,对不对? 呃,最大的是最大的是一十和一十七,他是二二十一,不对?最大的是一六和一十七,他是三十一,对不对?如果说呢?我们现在根据我们的理论,一六和一三十一,不对,一六和一 e 十七, e 六对, e 六和 e 十七是最大的,对不对?那么我们这样的话,我们来看一下如果我们的 e 六和 e 十七,如果我们在理论上有一个, 他们两个确实是有一个相关关系的话,那么这时候呢,我们就点击回,我们现在刚开始是切换的是这个结果变量图,因为我们这些现在按钮都不没法选择,我们切换为模型图之后,然后我们加一个这个 e 六到 e 十七, 我们加一个供电,这个线不是出去的吗?那么我们来对他进行一个调整,大家还都记得这些操作是一个, 大家还都记得这些操作吗?是一个什么样子的吗?看到没?我们进行拖拽,他就可以进行一个方向的一个转换,那么我们还记得吗?我们是逐步进行修正,对不对?我们刚开始 看到这个三十一比较大,除了三十一比较大之外,还有二十一也比较大,对不对?那我们这时候呢,我们就需要逐步的来进行放宽,大家来 我们我们现在已经相当于我们放宽了一个这个,呃,我们把一个修正指数进行了一个修正,对吧?我们修正之后呢,我们重新运行一面模型,我们发现我们的卡方值进行了改变,对不对?这些指标也都进行了一个改变,指标明显都变好了,对不对? 我们现在再来看一下我们的分析结果,然后我们直接来点击分析属性,我们来看一下现在刚开始还有一个二十一点几,对不对?那么我们将 e 六和 e 十七进行修正之后, 那么这时候呢,二十一点多的已经不见了,现在最大的呢变成了十五,如果说呢,我们对现在这个结论还是不太满意的话,那么还可以对他再进行一步修正, 发现一十和一十七还是不太好,对不对?我们将一十和一十七也给他加上,我们还是单击回模型图的列表,点击这个箭头,一十和一十七 我们给他加上好了,加上之后呢,我们再来跑一遍模型,看看会出现一个什么样的一个结果。 模型运行完成之后呢,我们点击这个 vo test, 我们就可以看到,我们还是直接到分析属性里面去,我们看这时候呢修正指数已经没有大于失误的,对不对?通过我们的两步修正呢,相信一般这样这种情况的话,我们的这个呃最终得到的这个模型呢就非常符合我们的预期了。 再接着呢,我们进行完修正者生之后,我们就可以来看一下模型的这些整体指标是否符合我们的预期,如果整体指标符合我们的预期通过的检验,同时呢我们最终 的理论上能够有一个合理的解释,那么这时候就可以直接来进行一个相应的结论的分析了,就没有必要再把这些大于十大于五的,或者或者说按照另外一个学者的大于三点八四的修正指数都进行一个修正,我们就没有那个必要了,我们只要得到一个满意的解释就可以了。 那么以上就是呢,我们今天所讲解的关于修正指数的一个内容,然后大家记得修正指数的使用呢,一定要呃是一个,只是一个参考,所有的修正呢都需依,都需依赖于我们的一个理论的一个基础, 同时呢多有多个修正指标较大时候,我们一定要逐步来进行放宽,因为我们在进行第一步修正之后,可能后面的修正指数的情况就会进行个改变,那么我们需要根据改变后的一个情况重新来进行新一步的修正,因此我们一定要做到逐步 放宽,不能一次把所有的都进行了放宽,那样的话我们就没有必没有没能保证我们放宽的是我们呃按照逐步的来保证的这个结果,呃可能就会得到一个不太满意,不太理想的一个结果。那么以上就是我们今天所讲解的关于呃修正指数的一些内容, 下节课呢,我们将会对模型的结果进行一个详细的解释,谢谢大家,我们今天这节课就到这里,谢谢大家,我们下节课见。
255贰壹壹项目数据分析服务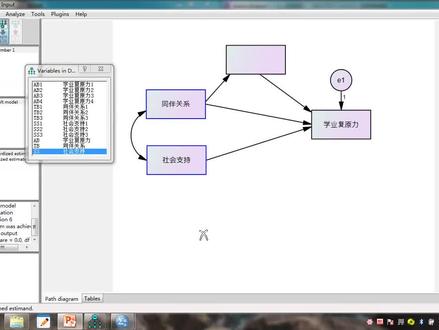 05:02查看AI文稿AI文稿
05:02查看AI文稿AI文稿好,那么我们拉完相关之后呢?我们说这条相关线啊,他会,他代表了什么,是吧?我们说,哎,在非标准化的情况下,他就是一个斜方叉啊,在标准化的情况下呢,他就是一个 皮尔,是相关系数,那我们来看看哎,我们的结果,结果你看这一条就是我们刚刚拉的 a b, s s 和 t b 这两个的相关啊。 来看,这是一个 covidence, 在非标准化的情况下,他就是斜方超,在标准化的情况下,他就是相关系数零点四四五。来,我们来看看,我们直接从 sps 里面来跑一个相关 t b 和 s s o k 跑完是不是零点四四五啊?是吧?那么 这个这条线也是有标准的,我们来看相关系数应该什么?小于零点七零,如果高于零点七零呢?那就会存在什么贡献性,如果高于零点八五,那贡献性就十分严重。 那么如果有贡献性应该怎么办呢?很简单啊,你把他删掉就行了,把其中一个删掉就行了。这是我的意见啊,就是我觉得吧,如果你高于零点七零,你可以把他们保存下来,但是如果不高于零点八五,我建议这是我的建议啊,因为其实这种 所谓的标准也是人定的,也是人定的,所以我的建议是什么?把他们其中一个删掉就行,如果高于零点八五,把其中一个删掉啊, 你自己选啊,选一个最好的结果,因为其实高一点点八五的意思是他们两个可能就是一个变量了,可能就是一个变量了, ok, 那其其他的结果,非标准化是不是还是那个路径系数是否显著?残差是否为正前显著啊,然后标准化,标准化, 哎,各种画画了,变成了各种画路径系数大小, s m c 大小,是吧?也一样,也一样,其实没什么要说的,在这里的话,那么这节课就给大家讲了一个回归, 回归模型在 a 模式里面应该怎么去实现,而且为什么这条相关线我们需要拉,我们需要拉,然后呢?这条相关线所说的外升变量呢?是整个模型的外升变量,他不是那种 中介变量啊,不是那种中介变量,记住了。然后来我们再来给大家提这个预告一下啊,下一张我们的一些啊要点,首先下一张一整张呢,都是会讲这个浅变量建模与结果归纳, 然后在这里在我们现到讲到现在哈,我都还没告诉大家应该怎么去得到一个拟合指数和一个路径系数 以及那个截图啊,怎么截图这些我都没给大家详细的说啊,应该怎么去得到这些表格 和图形,那么我们会在 s 一一八到 s 二零这三节课来讲讲怎么获得这三个重要的结果,大家可以直接跳到那里去看,如果大家不想学这种 简变量的店模,当然这里给大家提要一下。一,一般来说呢,你和指数啊,一般来说你和指数在显变量的模型中其实很少用到显变量,简单模型中很少用到。 带队只是跟大家提一下,我们在十八节会详细说哈,会详细说,为什么说这个写明了用这种就不不不,太想,不太需要用这种啊,不太需要,为什么呢?因为,呃,其实 一般我们之前说的这个中介,之前在想中介的时候来这里的话,我们可以看到有礼盒指数了,还可以看到有礼盒指数,哎,这里也没有了,这里也没有了,这因为这是饱和模型, 一般不会产生这种离合指数,一般不会产生离合指数。然后之前我们说的一个路径分析来, yes, 这种我们来看看离合指数的时候,它也是不会有的,因为它也是一个饱和模型,所以 在你用这个简单的模型啊,用显变量简单模型来跑的时候,你其实很多时候你跑不出来, 你会跑不出来,就算跑出来了,那个礼盒指数其实我觉得意义也不大,当然这是我的意见,这是我的意见。今天很多期刊还是需要大家提供,所以接下来我们会讲讲接下来 十八节的时候我们才在讲啊,这些结果怎么去获得,大家可以直接跳到那里去看。 ok, 那这节课就到此结束,我们下一章再见。
 14:01查看AI文稿AI文稿
14:01查看AI文稿AI文稿嗯,大家好,我是君磊,上一个视频呢,我们呃简单介绍了一下关于信度分析如何去操作,以及啊我们通过一些方法来改善这个信度值。 从这几个开始呢,我们就连续做几个视频来去介绍这个笑度检验如何操作。嗯,笑度检验呢,可能是在我们做假设检验之前啊啊做的最大的一个检验了, 当然有的同学可能是用的非常成熟的量表啊,这一步呢,有可能会跳过啊,但是啊,我们发现啊,就是即有的同学即使是用了非常成熟的啊量表啊,导师依然会建议你去把这个笑度再做一遍啊,这也是有可能。 所以说,嗯,这一步呢,你需要跟自己导师啊去沟通,如果是你是用了成熟的链板,你需要去沟通确认一下你是不是要做这一步啊。如果是你是自己设计的文件,那么一定是要去做这一步检验的 啊。我们可以先看一下他的,看一下他的定义啊,这个定义是我自己写的啊,跟一些概念啊,可能啊,不太一样,但是表达大家都是一样的。嗯, 效度检验其实它代表一是数据的有效性啊,也就是说啊,通俗一点讲,就是你心中所想的,跟你实际所测量出来他是有一致性的,嗯, 如果一致性比较高,就说明你数据的有效性较高啊。放在我们的这个问卷的分析当中呢,就是说你的量表的这个设计啊, 跟你的实际测量出来这个维度啊啊和音子他是一致的,或者是基本是一致的。比如说你有二十个题目,你设计的六个因子, 那么我们用探索性因子分析呢去把它给呃探索出来哎呃,刚好你这个探索出来因子跟你实际所设计的是一致的。 ok, 那么你就说明这个消毒是通过的, 那我们应该用呃什么样的呃呃特征来去表征这个效应呢?或者说用什么样的指标来去探来去验证这个效应呢? 那我们我一般是会把这个度减压区分三个难度啊。第一个难度呢就是用 k m 和巴特利求生减压来去操作啊。其实是,其实说呢这个这两个指标呢,他并不是来去减 的这个笑度,他是来去啊来去呃看一下这个数据是不是适合做这个因子分析。嗯,但是呢就是,呃 嗯,原则上讲这不是消毒检验,但是我发现很多的文献当中都是把这个当成一个消毒检验,这个很有意思啊。所以说呃当你的当你的这个笑度实在吞不过的时候,你可以哎浑水摸鱼一把,然后只用这个。呃 啊,只用这两个指标就去表扬这个笑度啊,当然可能会不会通过啊,也可能也有可能会被通过。嗯,好,那么一般呢,我们是用探索性因子分析啊去做这个笑度的言,这是啊用的最多的,最多的一个。 嗯,他其实是在我们积极学习当中他是一种降为的一种方法啊,我们叫 啊因子分析,降为嘛啊?在这里叫他投降因子分析,他本身上是啊有 n 个题目,有二十个题目你给他降为降成了四为或者五为,然后呢我们能通过因子和载去呃找到这个因子下他跟哪些题目是 啊比较亲密的,因为他哪些题目是归属到哪个因子的,那么这种呢就跟可以跟我们的设计呢所哎呃有一个匹配关系,如果匹配比较高就说明你的效度比较高,我们叫 efa 探索性因子分析,那么嗯, 另外一个比较高难度的这个消毒检验呢,我们叫探索性因子分析加验证性因子分析。嗯,简单来讲就是我们探索出来这个因子之后啊, 再用啊结构方程或者是啊验证性因子分析啊,去跑一下,看一下你这个啊,你探索出来这个是不是一个良好的一种啊?结构啊,这两个用探索性因子分析加验证性因子分析呢, 这种方法呢,他是呃最能够让人幸福的,当然他的一些指标想达标的话也是最难的,所以说啊, 一般本科是很难很少去做这个这两个呃分析来做泄露检验的,一般是研究生阶段呢会用这个分析, 本科生我建议就是用探索性因子分析就够了。好,我们今天呢就先讲这个探索性因子分析。 好,我们还是先看一下这 这个呃表格的样式。呃,因此分析呢,他有很多种表格样式。嗯,但是这种呢是我觉得呃是最方便的。因为什么呢?因为他是直接可以从 spss 中呃 去输出的,也是直接可以用的啊,我觉得不需要再大改了。嗯,当然也有其他一些比较啊,综合的形式啊,那种也是可以的啊。嗯, 好,我们先先介绍一下这些表格。第一个表格呢,他是啊刚才我说的 km 和巴特利群体验这个指标呢怎么看呢啊?首先要看 kmo 值啊,这个值呢?呃,也是要看他是不是大于零点六, 嗯,也有的时候要看大本,嗯,是不是大于零点七,这个不是很严格,一般大于零点六我觉得就可以了。呃,当然你要看你导师是不是, 呃,要求你大于零点七啊,或者零点八,呃,然后通过这个,这个通过之后呢要看他这个屁,再看那个他的群里面的配置啊,这个配置如果是小学零点,呃, 小于零点零五,那一般他都是小于零点零一的啊,他,呃,这很容易通过的。这个如果这两个都通过呢,就说明这个数据啊,他可以进行因子分析。好啊, 嗯,可以做印子分析。之后呢,下面我就就开始看那个音。嗯,主持分的 t 恤以及宣传成本矩阵。好,我们下个这个表怎么看呢?嗯,这个表出来之后呢?嗯,首先要看这一列我们叫什么叫啊?特征值。 这节车上知道要看他是不是大于一,或者说要看一下他大于一的有几个,能够大于一的有吗?有四个, 有这四个,也就是说我们,嗯有十三个题目,十三个题目呢,他提取出来四个音字,而这四个音字呢?呃,我们再往后看后看,这里有一个累计 多少多少,我们叫什么叫累计的方差解释度啊,这个呢是百分之七十六点几 啊,这个是比较好的啊,这个累计发达。呃,几十度呢?这个呢也没有一个非常严格的标准,有的地方呢说达到百分之六十,有的地方达到百分之七十啊,这个确实是没有谁严格的标准,反正是越高越好。嗯, 你大家记住,主要是看这个 t 恤度,还有就是这个,呃大于一的个数。好,然后呢,看完这一个之后 啊,我们会看一个碎石图,嗯,这个碎石图呢,我们要看一个拐点,比如说这个地方大概是在这个地方出现拐点, 这地方出现拐点之后呢,我们就会说他,呃,提取二到五个啊,之间就可以了,而不是说他拐点出现在哪里,你就说提取几个适合,这个是没那种绝对的啊,比如说他拐点出现在这,你就说他 说是三到六啊,这样来表达就可以了啊,你看这里,嗯,在这前五数出现平缓之前继续下降,所以提取四个比较合适啊,其实他就是在五出现之后呢,然后说四到六个就比较合适,然后就说啊,提取四个合适,这样好,下面就是我们重头戏 叫悬崖成分矩阵,嗯,这个悬崖成分矩阵呢,他是这样的,就是每个题目呢,在 每个因子下面都有一个值,但是他最大的那个值呢,是他的那个因子的归属, 这里是都有直的,只不过我们把它给省略掉了啊,给他删掉了,因为我们只保留他最大的那一个,所以说我们取最大的这四个呢,那么这啊, t 第一就要提第三、第二、第四这四个题目就属于英子一,那么这三个题目就属于英子二 啊,这三这几个题目都数银子三啊,这都排序好的。好,然后下面你就解释一下啊, 根据学院成分得学院学院成分基本得知。然后啊,哪个题目是属于啊?哪个因子,然后他因子喝了有多少,这里的他解释就比较啊,就比较简洁,如果你想凑字数的话,你就可以啊啊,这个题 他的因子喝的是多少啊啊?写一下,然后他都是打游戏的,然后都可以问他命名为什么好,那下面呢,我们就接着一个数据来操作一下,给大家看一下啊,操作呢也比较简单, 但是有些细节需要好好的注意啊,我来操作大家一定要看清楚。首先我们点击这个分析,分析里面有一个降维降位,里面有因子分析,然后呢我们就把你的量本的题目给它塞进来, 比如说我们把这里的这这个这几个题目给他塞进来啊,加上这个吧。 好,然后呢我们一个一个点这里呢,先点这个描述,描述里面我们需要点什么?点这个 km 和巴特利,这个是一定要点的, 继续,然后抽取,这里呢我们是要点啊,这里我们就不动,一个是觊觎特征值的一个抽取啊,这里是我们不动的啊,有时候我们的抽取效果不是很好,比如说啊,我们 本来想是呃抽取四个,结果他就出来三个,那么这里呢,你就点他强制抽取四个,这里输入一个四,然后你看他出来是什么样子,你就可以去简单的看一下,但是呢我们还是要去看刚才说的特征值的。 好,我们先点他,然后四十图啊,就在这里点个四十图。好,然后我们点这里就旋转,旋转什么?就是旋转成分矩阵嘛,对吧?然后我们这里用最大方叉法好,其他方法就不需要了解,你就记得记得一个最大方叉法就可以了啊,这个是我们嗯 最常用的一个方法。好,我们今天继续,然后得分,这个保存为变量呢,一般是在,嗯, 在哪里会用到呢?就是在那个,呃呃,财务类的这个,因此分析里面,主持人的分析里面会用到这里呢,因为我们主要讲一部件分析吗?这里暂时先不讲了啊。嗯,我们这个也可以点上。好,我们再点这个选项,这里注意啊,我们 有这么一个注意的事项,一个是使用均值去替换这个确实值,然后呢按大小排序,这个是一定要点的,然后取消系数,这里我们点到零点三, 取消系数就是我们呃把那些呃因子核载低于零,低于零点三的我们都给他不敢试,然后我们就确定 好,那么这个就出来了。好,我们可以看一下,其实这个表格呢, 就是我们那刚才我展示的那几个表哥的样子,只不过我们稍微稍加去修饰了一下。好啊,这个就是 kmo 值和巴特利啊,他,他是零点八七七,还是比较高的,然后配置也是良好的。 好,这里呢就是刚才我说的那个啊,特征值,我们看他是不是大于一啊?大于一的有六个,也就是说这六个呢,也就是说这二十一个题目提取了六个因子, 然后累计解释百分之七十二点四的一个方差,这个是比较理想的。然后这个就是,那你就啊,这个地方其实没那么严格,你就大概说一下啊,他是在七这地方出现了 一个拐点,所以呢啊,从五到八提取五到五到八个因子是可以的,所以说我们提取六个因子是合适的,这是六吧,这六个因子是合适的。 好,然后这是成分矩阵,这个成分矩阵跟后面那个矩阵他是不一样的,这是还没旋转之前的,我们不管这个直接看这个。好,这个就是旋转成分矩阵。 那么这个举证呢?你们看他就是啊,这一堆是在一起的,然后呢?我们,呃,这零点,你看这是零点四吧,这零点四我们要看他大的,所以我们要从这开始看,从零点八这地方开始看,然后这停止,然后在这里看, 他给你排泄好了啊,这个地方就是一个宣传成本举证。嗯,那么关于制表呢,我在这里就不多讲了,大家只需要把啊这个宣传成本举证跟这个解释, 磨砂还有开摩托力啊,给他复制一下。这天他到表哥里面已经稍加休啊,稍加那个加工就可以啊,直接 coffee 到味道里面去了。嗯 嗯,燕子飞行到这里就并没有结束,因为我们还要解决一些问题啊,一些我们很常见的一些问题 啊,比如说我们的因子因子分析的效果,比如这指标不达标,我们怎么办?还有就是啊,我们出来结果啊,学院成分举证并不是我们想要的结果,我们怎么办 好这些这些问题呢?我们放到下一节课来处理啊,今天我们就不不多讲了,好啊,我就啊先到这里这个视频,谢谢大家。
342Junlei_D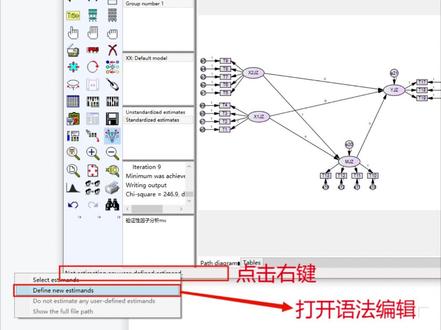 05:16查看AI文稿AI文稿
05:16查看AI文稿AI文稿amos 操作步骤讲解系列中介效应检验,中介效应的检验,不管在什么软件上的检验步骤不会变,首先检验自变量到应变量的影响,然后自变量到中介变量的影响,最后检验自变量焊中介变量对应变量的影响。 在 excel 表格中对数据进行预处理后,导入 spss 中并保存好数据后打开 imas 软件进行路径关系的检验。 调整界面,打开界面后点击 view interface properties 界面选择在画布选项中选择横向最大前变量的构建,点击椭圆, 在右侧白色画布中画出对应的前变量个数。显变量的构建,选中显变量,添加图标后在前变量上添加对应题像数的显变量框。 变量整体调整,选中旋转图标,点击前变量框旋转到合适的位置, 变量整体移动,同时选中保持整体和移动图标,然后将所有的变量移动到对应的位置。 导入数据,点击。导入数据后点击 file name, 找到对应数据保存位置,并选择对应的数据后点击 ok。 显变量放入显变量框中,点击数据展示,将对应的题像拖入 显变量框中。变量名称修改,点击变量设置,在名称框中填入变量名。路径关系构建,选中单箭头从自变量框指向应变量框 残差项的添加箭头指向的变量均需要添加残差项, 添加未命名的变量长指残叉点击点击 poppins name and observed variables 添加未命名的变量名称 选项勾选,点击选项设置后勾选标准化系数模型,修正差异零界比值效应值 have boots prep 下的抽样次数上下线 结果运行,点击运行,跳出提示后选择继续分析模型保存,点击运行后选择保存的地点,按保存名点击保存。 运行完成,在运行过程中未出现报错情况,即图中红色箭头变红,按红色方框中显示结果,表明结果运行完成。 结果查看,点击结果查看模型是配度结果,点击 model fit 就可以看到 模型的适配度指标,一般主要看 c m, d f, 即 baseline comparisons 中的指标,重要的 resear 指标, 路径关系,路径关系显着性及标准化的路径系数效应值。打开 estimates 下的 mattresses 里的对应效应,查看中介效应的结果。 路径关系命名伤及路径关系箭头后,点击 prematers, 在 regression weight 中填入对应的字母,命名该条路径。 语法编辑,打开右键,点击对话框的左下角出现一下对话框后点击 define new estimate 语法编辑,在对话框中编辑好直接效应,中介效应,总效应,对应的值。点击保存语法语法保存 语法保存到模型同样的位置,编辑语法的结果,根据前面结构方程模型的运行步骤,点击运行后在结果 estimates 中的 status 下的 user defined estimates 查看。这样的方式结果更容易查看 模型图,将标准的因子在荷系数含标准化的路径关系系数添加到模型图中,首先选中标准化,然后点击上方红色箭头后复制模型图 结果整理,将结果复制粘贴到 excel 表格中。首先整理的是模型适配,读 seeming, d, f, risa 等指标,整理路径关系系数级选择性情况及个效应值。最后 可以展示模型图后将结果复制粘贴 word 文档中,进行三线表的制作。汉文字解释 学会了吗?记得一键三连呦,可以代作指导!
388艾吖法数据 07:37查看AI文稿AI文稿
07:37查看AI文稿AI文稿各位同学大家好,很高兴今天我们能够相遇在二幺幺统计网络课堂,我们来接着学习俄罗斯入门教程的后续章节,我是本课程的主讲老师阿 sir。 在前面的课程中,我们介绍了验证性因子分析,上一章呢,就验证性因子分析,我们介绍了验证性因子分析是什么,验证性因子分析与探索性因子分析的一同,如何利用 omes 来求解验证性因子分析,同时对于结果的如何来进行解释。 从这张开始呢,我们将主要来学习路径分析和探探索性和验证性的分析相似,我们路径分析的讲解思路依然是按照上次的上次验证性的分析所讲解的那样基本相同。首先呢,我们会介绍路径分析是什么,介绍一些 路定分析的基本知识,同时呢,我们会介绍如何利用 omes 来求解路定分析,同时呢,对于路定分析的结果如何来进行一个合理的解释,我们也会进行详细的讲解。 以上就是呢,路径分析整个章节的行文的一个讲解的一个思路大的框架。今天呢,我们先来看一下第一节路径分析的基本思路, 路电分期是什么呢?大家首先来看一下我们绘制的一般绘制的模型图,我们大家就能发现,呃,我们假设这个模型图呢有三个浅变量,每个浅边量呢,分别对应的有三个测量变量, 然后我们就将每个浅边量与相应测量变量所组成的这一个模型叫做测量模型,就说用这三个浅边量来用这三个测量变量来测量这个浅边量的一个测量模型,这里边呢 测量模型就有三个,对不对?然后我们将中心这个三个浅边量的这个模型呢,就叫做一个结构模型,那 他们两个总共合起来这个大的模型呢,我们就叫做结构方程模型。我们今天呢先来看的是路径分析的内容,结构方程模型的内容呢,我们会在下节课的介绍过程中对大家进行讲,下一章中重点得来讲解这个结构方程模型, 因为俄梦斯呢主要就是用来分析结构方程模型的验证。性子分析和路径分析只不过是结构方程模型分析中非常小的一个辅助的一个分析分析的一个过程。然后我们今天呢就就先来简单的看一下路径分析是一个什么样的过程, 就说如果说每一个的每一个的前面量,每一个的前面量,他只有一个测量变量的话,那么这一 测量面料就是不是就能够百分之百的来解释这个浅面量呢?你答案是肯定的对不对?就说如果每一个都是只有一个浅面,都有只有一个测量面料的话,那么这个浅面量是不是相应的就可以直接用这个测量面料来进行替代呢? 如果可以的话呢,那我们就产生了这个,呃,我们我们今天所介绍的第一个模型,路径分析的模型叫做 pa 杠 ov 路径分析,这个什么意思呢?就是 pa 就是路径分析的意思,拍死 analyze, 然后杠 ov 呢就说它对应的类型, ov 呢就说 observed variable, 就说根据测量变量所构建的一个路径分析的一个模型,就叫做 p a 杠 ov 路径分析模型,大家以后见到这个名词的话,不要觉得陌生,不要觉得奇怪就行。呃,一会呢我们还会介绍一个 ca 杠 lv, lv 呢,就是 leiternflurry 吧,就浅变量的模型路径分析图,那么在介绍这个路径路径分析的时候呢,我们就会发现,我们将路径分析呢现有的理论界呢,主要将路径分析分为这两种, 第一个叫做地规模型,就说残渣颠未甲定有相关关系,也就是我们下图的我们这个左边这个图所展示的,这样就说这两个这两个残渣之间呢没有相互的影响关系。 然后还有一个呢叫做非地规模型图,非地规模型图呢,也就是意思就是说他们假定了残叉间有相关关系,那 那么他俩的区别主要在哪里呢?区别主要就在这里,大家可以看到这是两个有有向右的也有向左的箭头,他们是两个双向的一个过程,就说有相关的关系,但是呢 大家一定要注意这个相关关系跟我们这里所讲解的他们两个相关关系是不一样的,因为这里是两个单向箭头,这里是一个双向箭头,他们所代表的是完全相反的两个概念,完全不同的两个概念,大家在后续的分析过程中一定要谨慎的小心,这一点 一定要来进行合理的一个区分。然后这个就是我们今天所讲解的第一个 p a 杠 ov 路径分析模型图的一个大致的一个情况。然后求解过程呢,我们会在下节课的内容中进行一个非常细致的一个讲解 啊,大家首先今天呢就是先来学一下路径分析究竟是什么,是一个什么样的一个形式,再下来呢?我们看一个 pa 杠 lv 模型图, lv 的话就是刚才给大家已经说了 latten to vrog 不是大家买的 lv 的包包哈, lv 白天的 frey。 不就说浅变量的一个路径分析模型图,大家想这样一个情况,就是说每一个浅面量都是有两个测量变量,那么我们的模型图就应该是这样一个样子,对不对? 是每个前面量都有两个测量面料,每个前面量都有两个测量面量,然后他们之间的影响关系大家也都绘制好之后,那就是这样一个形状的, 大家还要考虑一个情况,就是说大家都是多于多于一个的,对吧?这个就是说这现在图形中所绘制出来的四个前面量都是有多于一个的测量面量的,那么如果说存在只有一个测量面量的呃前面量的话,那么应该如何处理呢?就是首先我们来看一下下面这个东西, 就说如果是这样一个图形的话,右上三角的这这三个前面量都相应的有两个测量面量,但是 左下角的这个测量浅面量呢?只有一个测量面量,那么我们是不是可以用浅面量,直接用这个测量面量来替代这个浅面量做做在模型中呢?他应该呈现出来一个是这样一个理论模型图,但是为了更加直观,更加符合我们的分析的一个思路呢,我们对他进行一个处理,我们就会看到我们进行这样一个处理, 大家看到变化在哪里了吗?刚才这里直接是一个浅面量,刚才这里直接是一个测量面量,然后我们现在呢将浅面量画在这里,然后这个浅面量呢完全由这个测量面量来进行估计,这个就跟我们所看到的这个是一模一样的,对吧?只不过他的测量题目有一个也有两个,有多个, 他的测量题目呢只有一个,但本质上呢已经是完全相同的相等的一个概念了。那么这个呢就是 p a 杠 lv 的路径分析的两种情况的一个模型图 的一个介绍。那么介绍完这些之后呢,我们关于路径分析的一些知识呢,基本就介绍完成了。我们路径分析呢,主要就是讲解的路径分析是一个什么样的过程,讲解的路径分析的两种分类, p a 杠 lv 和 p a 杠 o v, 同时还讲解的地规模型和非地规模型。 希望大家通过本节课的学习呢,能够对路径分析的不同分类路径分析的概念有一个相详细的一个了解,大家有不懂的可以自己查阅一些相关的资料,加深一些印象。 在下节课下,后面的后续的课程中呢,我们会对 pa 杠 lv 和 pa 杠 ov 的模型图都会对大家进行一个求解,实际的来对大家进行一个演练,让大家对这两种模型图的求解都有一个更加直观的一个印象,最终呢还会讲解这个求解出来结果如何,进行一个详细的解释。 然后以上就是呢本节课程所介绍的路径分析的基本知识的内容,我们下节课见,谢谢大家。
 04:26查看AI文稿AI文稿
04:26查看AI文稿AI文稿amos 操作步骤讲解系列验证性因子分析验证性因子分析需要采用 amos 软件进行检验,验证性因子分析用于检验数据的内容效度情况,它属于结构方程中较为简单的一种模型。 amos 软件可以直接打开,也可以在 s p s s 中打开,但需要安装同版本的。在 excel 表格中对数据进行预处理后,导入 s p s s 中并保存好数据。打开 amos 软件进行内容校度的检验。 打开 amos 的界面。前变量的构建,点击椭圆,在右侧白色画布中画出对应的前变量个数。 显变量的构建,选中显变量。添加图标后,在前变量上添加对应题像数的显变量框。变量整体调整,选中旋转图标,点击前变量框旋转到合适的位置, 变量整体移动,同时选中保持整体和移动图标,然后将所有的变量移动到对应的位置。 导入数据,点击导入数据后点击 file name, 找到对应数据保存位置,并选择对应的数据后点击 ok。 显变量放入显变量框中,点击数据展示,将对应的题像拖入显变量框中。选中前变量框,点击单手指图标, 选中前变量框。变量间连接相关线,点击 plug in stroke variances 变量间的相关线就连接好。调整相关线,点击改变形状,放在最外层,拖动到想要的位置, 现调整。点击变量为调,点击想调整的地方取消选定,点击取消选定变量。名称修改,点击变量设置,在名称框中填入变量名, 添加未命名的变量。长指残叉,点击点击 propines name an observed variables 添加未命名的变量名称勾选选 项,验证性因子分析中只用勾选标准化系数即可。模型保存,点击运行后选择保存的地点,按保存名点击保存。 运行完成,在运行过程中未出现报错情况,即图中红色箭头变红,按红色方框中显示结果,表明结果运行完成。 结果查看,点击结果查看模型是配度结果,点击 model fit 就可以看到 模型的适配度指标,一般主要看 seeming d f, 即 baseline comparisons 中的指标。重要的 reserve 指标系数结果,点击 estimates, 在右侧结果框中有对应的结果标准化的因子在和系数看标准化的相关性,系数结果添加,将标准的因子在和系数看相关性添加到模型图中。首先选中标准化,然后点击上方红色箭头 模型图,即结果复制,点击复制,将模型图就可以复制到表格中。 结果整理,将结果复制粘贴到 excel 表格中。首先整理的是模型适配度, seeming d, f, v, c, r 等指标,然后是根据标准化的因子载合系数计算 evernu 和 c 二值后根据标准化的相关系数与 ever 的平方根进行比较, 最后展示模型图,然后将整理的结果复制粘贴到 word 文档中,进行三线表的制作及文字解释。 学会了么?记得一箭三连呦,可以代作指导。
391艾吖法数据 11:59查看AI文稿AI文稿
11:59查看AI文稿AI文稿嗯,大家好,我是君磊,那今天咱们来讲几个关于问卷分析比较重要的一些常识和建议啊,那这些常识和建议往往是我们在做过问卷分析之后,我们才能意识到啊,那对于萌新来讲,我觉得提前知道要比他之后知道要好啊, 如果我们提前知道的话,我们在做一些分析,遇到一些情况,我们就会显得没有那么慌张啊。那 首先呢,我们要了解我们的问卷分析在我们一篇论文当中的这样一个位置哈,那一般呢,一篇论文它包含了我们的中数部分和数据分析部分这两个大的模块哈啊,当然还有一些其他的小模块咱们先不说了啊, 那文献综数部分它是用来提出假设的,然后呢,数据分析部分是用来验证这个假设,那数据分析部分呢,它又包含了两个模块,一个是数据的有效性和可靠性 论证,另外一个就是假设验证。那中间呢,还加大了一些啊,简单明确统计啊, 那一般呢,就是我们是从前往后这样逐步地进的啊,对吧?那对于问卷分析来讲呢,后面这个假设验证啊,他往往是比较容易成立的啊 啊,虽然有的同学觉得啊,我做这个假设不显著啊,感觉很难那,但是对于一些啊,实验类的分析或者一些其他的分析来讲,问卷分析这个假设是比较容易啊成立的,那么 那他既然比较容易成立,所以为了让他显得没有那么草率啊,需要前面两个铺垫啊,一个铺垫就是你的完线综数这个假设的提出要足够的合理啊,足够合理。另外呢就是这个数据的有效性你要经得起推敲啊, 我要做些什么信度检验啊,信度检验啊,更多方案赔查等等,那这些检验都是为了去验证你这个数据是可靠的,是能够做的,那有了这两部铺垫之后,我们才能够做后面这个假设的一个验证。 好,我们来举个例子啊,他左边呢是有四个变量啊,是自我相同感、情感关怀、幸福感和社会资本。那右边呢?有六个模型啊,简单中间模型、 调节效应模型啊,这个是并行中介啊,这个是有调节的中介啊,调节了前半段和后半段啊,那这个呢是链式中介啊,这个是只调节后半段的这样一个有调节中介。 那。呃,就这四个变量来讲,我们先不管什么理论支撑了啊,我们就从数据层面来讲,这每个变量其实他都可以在这个模型当中任意位置,也就是说,呃,这个每个变量他 其实既可以作为自变量,也可以作为中介变量,也可以作为调节变量,也可以作为啊音变量啊 等等。那呃,什么叫模糊的这样一个理论导向?就是你开始的时候可以只定准这个模型的部分, 比如说我可以开始啊,就限定幸福感,就作为一面量,自变量是自我相同感。至于中间这个情感关怀和社会资本,他们中间是什么关系,你可以不去定准他,然后去探索。比如说是中介啊,还是有钱的中介,对吧? 啊?这样的话可能对于你来讲啊,更有利于你去撰写这篇论文啊,或者是你可以呃,定准了,我要做一条中介,但是至于他是调节前半段,后半段还是呃都调节,这个你不定准,然后去探索啊,这样 也行啊,就是我的下表达意思就是说你不要去一开始就将你的模模型给他定的特别的死,然后这样给自己一点余地也没有,这样特别不好。 那么所以呢,我们在做论文的时候啊,有这样两个套路啊,一个是啊理论导向,一个是数据导向啊。 那什么是理论导向?就是我先去整理文信啊,先去提出假设啊,然后呢再去对数据进行验证,然后不管数据结果显著与否,我都去尊重数据结果啊, 那这个叫理论导向,那理论导向也是我们,嗯,哎,比较正规的,或者是比较合理的,一种一种一种一种方法啊。但是这有个缺点就是那万一这个数据不显著,你是写还是不写呢?那那对 一个大佬,对一些大佬来讲,他们可能是啊,可能是啊,不显著也能是完成这个论文啊。但是对于一些呃毕业的学生来讲, 不显著是很容易被老师质疑的,那这个呢,这样一个现状我们是很难去改变的,对吧?那所以一般呢,我们去毕业都会想要一个比较显著的结果啊,所以由此就诞生了另外一个呃模式就要数据导向。 什么叫数据导向?就是我以数据结果为依据,我先不去找理论支撑,我先去测试啊。啊?哪测试中介效应,测试调节效应, 再去测试一下中介,我测试很多种方法,很多都模型,然后呢,找一个自己觉得能写论文的,然后回去再去找理论支撑啊,那这种呢就叫数据导向啊,显然数据导向是一种 带有功利性目的的一种导向。是呃不值得去我们去提倡的,但是为了一些毕业来讲是比较 啊有效的啊。那我的建议是呢,就是我们呃可以以数据导向为主,但是呢我们要也要以模糊的理论导向为辅助。那什么是模糊的理论导向呢?就是说我们 在做理论支撑的时候或者或者在做文献综书的时候,你不要上来就把自己的这个模型给定死了啊。比如有个同学啊,上来就假设一个调学效应,然后还正向调节啊。 那首先调节效应可能就是一个比较难以难出来一个一个模型,然后你又假设正向调节,那万一是出来一个负向调节,你是接受还是不接受呢,对吧?你可以先模糊的啊,去探 做出一种啊,磨变量 a 和变量 b 之间有一定的关系,但是你不要去限定住这个关系是中介,是调节或者是其他关系,你不要给他定死啊, 然后进行探索,探索之后你可以尝试不同的模型,然后确定一种模型之后反过去再去将这个关系给定准了啊,就行了啊。 好,我们看下一个问题啊,成熟量表还是自创量表?那显然我们还是建议啊,就是能用成熟量表,我们是尽量试用成熟量表,因为成熟量表他有好处是我可以跳过销售检验或是我只做一个 呃验证性因子分析就够了。那当然有的同学讲啊,我是成熟量表,那我做了探索心也做验证性可不可以啊?当然也可以啊,这也很好,那当然,我们用成熟量表,我们就有了一个选项,对吧?多了一个选项,但是如果我们是用自创量表,那我 我们就没有这选项,我们用自动量表就不得已要去做一下他的因子分析,对吧?万一那个结果跟自己不相符,我们要进行调整,所以呢,就比较麻烦啊,所以我们建议啊,能用成熟量表还是叫成熟量表 好。那如果我们还是用了自创量表呢?这里给大家提几点建议哈。第一个就是我们维度内部尽量多设计几个题目,那五个以上可能是一个比较好的结果啊,那为我们后面做那个 efa 啊啊,就也就是探索性因子分析啊,踢出题目啊,做准备啊。第二个就是呃 维度内的这样一个句式的表达尽量保持一致啊,因为有的同学可能维度内的这样一些题目他的表述还五花八门啊,那可能会给呃填完圈的人有一种错觉,就是这几个题目他可能不是在表述同样一件事情, 那么他可能就乱勾了哈。然后第三呢,就是呃,做好呢,做好我们 efa 出来结果跟自己预想的不一致的这样一个心理准备。 因为探索性因此分析很容易啊,他的结果跟自己想啊不一致啊,那如果不一致怎么办啊?我这个我尤其是没曾经讲过,大家可以去看一看啊,就是因此分析的结果跟自己啊摄像不一致怎么办啊啊?第四啊,就是尽量啊,少用反向题啊, 以我的经验啊,就是 eic 要剔除的那个题很容易就是反向题,所以少用它,少用它 好。关于中介效应还是调节效应啊,那我刚才也说过啊,就是中介效应和调节效应是都可以进行尝试的,但是我要说是中介效应,相对于调节效应来讲,它是更容易显著的一种 模型。那如果是你假设了是调试效应,你也不要把自己给限制住啊,给自己的假设多一个选择啊,可以尝也尝试一下中介效应,对吧。 那如果是你的条件下也不显著啊,你也不要慌啊,你可以找我咨询一下,我给你看一下你这个,你这个一个结果还有没有挽救的余地啊。啊, 好,我们再看下一个问题啊,那是层次回归呢?还是结构方程对吧?是 spss process 呢?还是 amos m plus, 那这是一个问题对吧? 嗯,那这其实是一个,呃模型选择或者是方法选择的问题啊,那本身呢,这个工具之间啊,是没有高低之分的啊,是可能是人他带了一点偏见啊。嗯,这里呢有有这么一个事实大家要知道啊, 那普罗塞斯或者 sps 回归呢,它相对于结构方程来讲,它是更容易得到一个良好的结果的。 为什么会这样呢?因为阿莫斯和 m plus 啊,它这个结构方程是要看你和度的,而你和度那些指标它是比较敏感的,所以一般呢,我们是比较难找到一个比较完美的你和度, 我们在写论文的时候可能勉强适配啊,或者刚好适配,或者接近适配我们就行了啊。那同时呢,这个 sps plus 它操作也比较简单啊。 那所以呢,我们是建议啊,就是可以先用 sps 和一个 process 啊,去测试一下啊这个结果,然后再去进行啊结构方程的一个尝试啊啊,当然了,结构方程在某些老师眼中啊,可能 更高大上一点,所以就你可以,如果是这样的话,你导致让你用结构方程啊,你可以去用结构方程,但是你不要忽略 poss 啊,万一你的结构方程结果不好,你可以拿着 pose 的结果和结构方式结果一起给老师看,对吧, 让老师去决定你用哪一个,对吧,这样可能好一点啊,好,我们再讲下一个,就是显变量和前变量啊。什么是显变量呢?显变量就是我们可以直接测量的那个变量,就是显变量 啊,显露出来的变量,对吧?啊,比如说我们那个问卷里面那些题目直接测量,那都是显变量,那什么是前变量呢?就是无法直接测量,需要用其他指标或者用显变量进行表征的这样一个 变量就叫前变量,或者叫前代的变量啊。那比如说举个例子,比如说那个幸福感,幸福感这个变量呢,他可能本身无法直接测量,但是他可以通过几个具体的指标啊显变量 进行测量得到,那么这个幸福感就是前变量,那么我们在做分析的时候可以将前变量进行显变量化,比如说我们将这四个题目求一个均值啊,先给他讲到这个地方层次回归啊啊,这个地方刨下的,我们都是啊将 前变量进行显变量化,然后再做后续的分析的啊,那显变量化的时候可以用均值,总分都可以,而均车总分对于结果是没有影响的啊。那啊,如果我们 是用结构方程,就需要构建这种前面量去做啊,所以,嗯,这也是我们要去了解前面量和前面量这样一个概念的一个原因哈。 好,我们今天的视频就到这里了,还没有关注公众号。同学可以关注一下我的公众号啊,我们下期再见。
263Junlei_D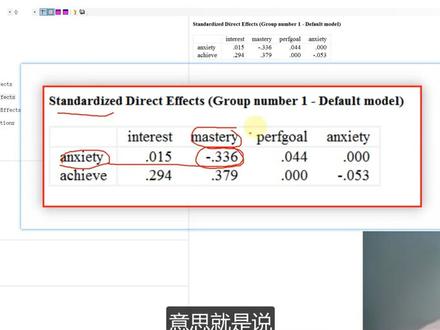 02:26查看AI文稿AI文稿
02:26查看AI文稿AI文稿amas 职责效应、竞争效应,首先我们打开要分析的 amas 的图表,这里有三个质变量,然后经过这个 anxiety, 然后就到达这个音变量时,而去我们点击这个运算, 然后看 mutex 生成这个爆爆表,然后在这个 up 当中,我们首先点 est estimate, 然后点, 然后这里会看到 total if 就是总效应,这个 diet if it 就是直接效应, in diet if it 就是竞争效应。那我们先看这个总效应,总效应他是标准化的总效应,这个表是这样看的, 首先我们例如我们看这个质变量,质变量跟这个音变量他之间的总效应是多少,就是看这个数负零点零二,这个质变量跟音变量他的总效应 就是这个负零点五三,这个是总效应,要记住的是它是标准化的总效应,标准化总效应的意思是当质变量 anxiety 它变化一的时候,音变量就会变化负零点五零五三就会变化这么多。 接下来我们看标准化的直接效应。标准化的直接效应就首先我们要看这个表, 在这个表单中我们会看到这质变量他是直接作用于这个这个音变量,他的关系是这里相对出来的,就是他的关系,他是标准化的直接效应,意思就是说当他变化一的时候, 这个 anxiety 它就变化负零点三三六,这个是直接效应。接下来我们看标准化的间接效, 首先我们看到这个表当中,他因为他说的是间接效应,所以他表当中 前三点他是跟这个气,他的关系是零的,就是说他没有间接效应,因为他他是直接效应的,所以他就是不能产生间接效应,所以他就必须用零来表示,零来表示,其他都是这样。 然后,呃,例,例如我们这个 interest 跟这个气他是没有没有直接关系的,所以他是间接关系,并且他间接关系现在看到了标准化的后的结果是负零点零一,就是说当这个 interest 变化机的时候, 这个气府他就会变化负百分之零点零零一,这些他要变化这么多。好了,这次学习就到这里为止,再见。
74享受生活 10:56查看AI文稿AI文稿
10:56查看AI文稿AI文稿朋友们好,我是小小杰老师,今天给大家分享的是共同方法篇章的三种检验方法。 其实在检验共同方法偏差的时候,我们可以使用哪些软件去进行一个检验呢?第一个是 sps, 第二个是按摩时,这两个都是可以去进行共同方法偏差去进行检验的。那为什么我们在做 这种数据分析的时候需要去检验共同化偏差呢?呃,这里给出给大家给出了几下几个原因。首先我们来了解一下共同方法偏差指的是什么?这指的是同样的数据的来源或者评分,同样的测量环境,项目的语境以及本身特征所造成的 本身所造成的预测变量与绩效变量之间的人为共变。如果我们通俗的来讲哈,就是我们去看一个共建数据,他的具体表 表现在哪里呢?数据分布不均,挤在一坨就是我们的挤在一坨。如果是七级量表的话,他集中在六级和七级这种,那我们认为他就是这个数据是有问题的。我们常在检验的时候会用到以下三种方式,第一种叫 阿尔曼的单因子检验,就是用十八时去跑探索因子分析等等会我会给大家就是截了屏的,然后具体的一个操作过程,然后最后我也会给大家就是实地的去操作一遍,方便大家去做理解。 第二个是就是单因子验证性因子分析,那我们相当于是怎么做呢?哈,是呃,具体也会给大家进行一个解释,后面呃也有图形加入共同方法因子的验证性因子分析。 对,让我们见就是这三种办法,让我们现在来看第一种方式, par parman 的单因子检验, sps 探索因子分析,我们 的检验过程是什么哈?检验过程,但是在检验之前,这一个大家需要去注意什么特征值的最大因子解释率需要低于百分之四十啊,这个是非常重要的啊,等会会给大家指出来是哪里。 嗯,第一个我们先打开一个原始数据,然后进行就是呃点这一个分析,然后会,嗯看到这降为,然后我们做音质分析,音质分析之后,然后我们点右边进行最大方法偏差,然后点继续, 然后将,呃,首先要将这些嗯变量全部移到这个变量栏, 那这里是我求的一些君子,这个是呃序号,这个是性别,那我们需要把这个问卷题项的变量全部移到这个变变量框来,嗯,这 放反了哈,放反了,应该是这个在下面,这个在上面,这个在下面,对,让大家知道就行。然后完了之后我们就会得出了一个表,这个表我们主要去看这里 啊,总方差解释率,然后刚刚给大家提到的哈就是这个值,这个值我们的第一个值一般要求低于百分之四十以下,然后我们主要去看呃他的一个维度啊,他提取的这个因特征跟值的数量是和我们的一个维度数是相同的,这有三个 一二三啊,三个音质,然后的话我们这里你看啊,就是他的模型是这叫社会压力,我会在这啊给大家做一个模型,然后大家方便大家去进行一个理解,我在后期剪视频时会给大家剪出来,然后这是社会压力啊,这是家庭,家庭压力,这 是,呃,婚姻焦虑啊。就是这,你看刚好是三个维度,然后对应的单个因子必须得特征只三个因子,那证明我们这个是对的 啊。其他的我们还还需要去看一个旋转,旋转后的一个矩阵,这个矩阵我没有去截屏,没给大家截出来啊。你看这对一般要求百分之四十以下, 第二个哈,这这个就是这样的。第二个的话我们需要去做单因子的一个验证性因子分析啊,主要是在于方法。是哈,将所有参与检测的 的量表的题目一起做一个单因子的一个验证性因子分析,你和他的对比,像是你和度要比原来差的多,即可证明无 共同方法偏差啊。大概是这样的,就是我们在做的时候,原始的是这个是一个维度,这个是一个维度的题,这个是一个维度题,应该是这画了,画了一个维度,那我们将这些全部拆开,然后把它 弄成一个浅边量,本来是三个浅边量去,嗯,拉自自相关,然后拉相关,然后完之后去做一个, 嗯,就是模型跑模型,然后完了之后去做模型以后度的一个检验,然后我们现在将它做,做成一个单因子的一个验证性验证性因子检验,在这做一个浅边料啊,完了之后我们去跑他应的模型度应该要比正常的低。 嗯,你看到没?这个跑出来,我做出来这个的话就是我们单因子的一个模型离合度的一个图,那这个的话是什么?这个呢?就是 是我们正常情况下,然后去跑的一个检验的一个值,你看 cfi 啊,零点九三八啊,这些都是非常高的,你看没有非常高的啊,这个的话 rmsea 的话是低于零点零八啊,零点九二看没都是非常高的, 嗯,这,这里是。呃,像这个值就会差一点,那我们其实在实际报这个报告的过程中,如果说这个值哈它是比较低的。然后第一种办解决办法就是第一种是调数据,第一种是调数据 一种,第二种办法是什么呢?嗯,第二种办法, 第二种直接不汇报这个指标, 直接不汇报这个指标就行了,然后因为我们其他的是 go 的,然后我们有很多个指标指向,证明我们这个离合度是比较好的,那我们可以继续去进行一个分析。然后 还有一种做法是什么呢?我们加入共同方法因子的验证性因子分析,就是把呃,这个单独做了一个,就是浅面料加入共同方法因子与所有的假设量表提及去做一个单因子分析。 那模型图是什么样的哈?嗯,模型图,这你看呗,就是这个是一个我们常规的一个,就是 验证新颖的分析的一个图,然后完之后我们这单独做一个共同共同方法偏差的一个音质,然后直接全部都连上连上,然后去跑模型,然后跑出来之后他的一个评判标准是模型底模 新,它的一个评判标准是礼盒指标,比原来的模型变化不大啊,主要是 r m s 一啊, s r m 二变化不超过零点零五, d f i 和 t f i 变化不超过零点零一,即可证明无共同方法偏差。这个的话我当时做表的时候就没做这个表, 然后完了之后的,呃,在实际操作过程会给大家看一看是怎么做的,这个的话哈,现在来给大家实操哈,探索音质来去做一个功能方法。偏差,首先我们需要做什么?点到分析,然后完了之后的话,点降为点,音质 因此分析,嗯,这个时候我们需要将量表的体项全部选中在这个变量上看没到这来,然后完了之后的话啊,描述性分析,点个 kmo 巴特利,球特巴特巴巴特利 个球形检验啊,嘴瓢了,笔取相关信,这不用去看旋转,然后我们最大方插法点继续。嗯,这里的时候我们可以选四十次 四十,然后得分,我们可以不用管选项啊,可以选这,然后选择零点零四, 零点四,零点四,不是零点四啊,确定确定,只是我们可以看到哈,我们 km 零点六七八其实有点低了,然后我们正常的情况应该零点七或零点八以上,零点六的话他是达标了。然后我们如果对数据的要求不是特别高啊,比如说我们写个论文的话,其实是可以可以了,然后,呃,显著性是零点零一的一个水平上, 那你看到吗?这是刚刚给你们看的一个表,嗯,总方差解释率第一个因子三十八点八零七,嗯,有三个因子对应我们三个维度 对应三个维度,然后完了之后,这累积的话,我们一般在百分之五十以上啊,这大概其实是,嗯,效果是比较好的,看到没有?嗯,我们成分矩阵,然后我们看旋转后的啊,旋转后的是有三个啊,刚好是有三个。 对,这就是我们的一个探索因子去做的一个功能方法偏差,但是就是这样去做的,然后接下来我给你们说,嗯,用按摩式去跑,这个是怎么做的呢?我们就是将 原始的一个验证因子分析的一个图全部拆了,拆了之后啊剪变成一个维度,然后去把箭头做好,做好之后我们去跑模型就行了,我这样去做啊,相当于是我们需要做什么呢?这个 线全部都拆了,拆了拆了拆了拆了拆了, 把他移过来,移过来他就把这个我们删了,再做一个前面的,比如说我标注一一,这都没点标保存,他自己会保存,然后我们就把他先把 好,这个时候我们的这个单音质的一个不能画偏差的模型就画好,然后我们就点进行跑就行了。然后这边的话我是给大家做了一,我做了一个模型,然后完成我们直接用这个模型去跑就行了。 呃,这边的话,模型其实我是提前给大家画好了,然后节约大家的时间,然后这里就直接给他跑一跑,看一看,哈,直接跑一下, 然后这里点首 power, 然后我们去看 modify h 啊,移过来 forty five, 让我们去看一看, 自己看都 a a a g f i c f i 都变得很小很小了。对对对,你看没是这个模型的, 那完了之后的用现在正常的一个验证音分析的图给大家刨一刨,刨出来什么效果啊?一次点这里刨,然后完了之后这里去看一看它的 modifit, 看到没?这是 gfi, 是零点九啊, agfi 零点八七啊, pgfy 啊,这个是这个图是在呃原本的这个验证性分验证性因子分析的图上加入了,加入了一个共同方法偏差的一个因子去做单因子的一个模型的模型,然后就这画一个,看到没?就刚刚我跟大家讲了。








