问卷信效度太低怎么办
毕业论文文卷消毒滴该如何调整?

粉丝39获赞441
相关视频
 00:42查看AI文稿AI文稿
00:42查看AI文稿AI文稿好,第六步呢,就是根据我们第五步的公式的各个维度开始形成问卷设计问题。但是如果想让问卷的信效度好的话,那么设计问题最好是递进性的。我举个例子,比如说我今天中午吃饭,跟我晚上看电影,我第一个题是今天中午吃饭。第二题,我今天晚上看电影,那么 这两个问题实际上毫不相关,所以说那么这样的问卷我们就判定是无效,真正的问卷应该是我今天中午吃饭。第二个题,我今天中午吃的米饭和菜。第三个问题,我今天中午吃的菜有红烧茄子,有鸡腿。 第四个问题,这个鸡腿是红烧的还是清炖的?是大的还是小的?这样依次递进的问卷,他的性效度做出来的才好。
611学姐讲升学 00:10
00:10 12:11查看AI文稿AI文稿
12:11查看AI文稿AI文稿大家好,这一次的内容是信度分析,信度分析里边啊,尤其是关注于这个信度不达标的时候,怎么样去处理它啊?或者是说其实更多的是讲解这个信度分析它的一个原理性的东西,以及呢出现问题之后我们怎么样去解决它啊? 那么首先你要需要知道第一个问题,什么样的数据适合做信读,一定是两表数据啊,两表啊,这个要全程的话叫做李克特两表。什么叫李克特两表呢? 指的是你,比如说你的选项里面有是一种态度性质的,不是事实现状的,而是一种态度。比如说啊,你对于这个啊,消费升级的态度怎么样?你觉得消费升级这个啊,概念会得到啊,这个大家的 认可吗?或者是说你认为消费升级确实是符合当前的这个消费水平吗?然后你的下面有几个选项,分别是不同意啊,非常不同意,不同意啊,普通 同意,非常同意,或者是说你对这个当前的生活水平满意吗?啊?下面答案是非常不满意,不满意啊,还可以,一满意,非常满意,就类似于这种的数据是态度型的数据啊,而且上面有几个选项, 那么这种才叫做我们的两表数据啊。啊,也叫做理科特两表啊,你不管是下面选项是四个还是七个还是九个还是五个,最常见是五个,对吧? 那么这种数据叫做我们的这个两秒数据,只能针对这种数据才能做,呃,叫做我们的这个叫什么信度,或者叫做啊个人吧 特性做分析啊。那当然了,你住的时候会出现一些问题,那么啊,比如说你这个共同八号系数去测量他的时候,一般需要设置一个限度,系数大于多少?零点六五,一般就可以啊,越大越好,他最大值是为一。 那么如果说你出现小于零点六啊,或者是说小于零点五了,那你比较糟糕,那怎么办呢? 一般有一,那首先你要找到原因,为什么会出现这种情况?是不是你的这个烟雾量太少了?比如说你,你的你放飞机箱有五个,结果你的要么就二十个,太少了, 一般是十倍以上吧,最少五倍以上。比如说你分析五个两秒题,对吧?就分析五个分析项,那么你的原本量二十五个以上吧,这是最低最低要求啊,最好五 十个以上,十倍吧,是不是你的样本上太小了?这是第一个问题。那第二个呢?还有一个是你,你要本量是准确不准确,是不是有无下的样板,是不是有乱填的这种情况,这是第二个。第三个呢? 还有一个就是提前预防,那你可以先收集一部分数据,然后先来测测看你的数据有没有问题。那第三种情况下,像这种提前预防的通常是什么问题啊? 通常是由于说其实那个英文也真是回答了,也是在认真回答了,英文量也收集还有很多啊,但是呢,你的那个问题他有点问题, 就你那个两秒提的这个问法上有点问题,让别人有的时候你问题设计的比较糟糕,问一个问题叫做啊,我让别人会感觉到模棱两可啊,你比如说你问一个叫做消费升级是好事吗?哎, 那这个就有可能有点模拟两可,别人有的会觉得这确实是好事,那有的人会觉得说这个很糟糕,这个因为他没有消费水平,对吧?他可能会产生非常明显的这种 啊偏差的这种差异性太多,也或者是说,呃,你收集的有一类人群他是很明显的是很认可,有内人群他很不认可,那像这种呢,他就有可能导致我们的这个性格不达标 啊。功能把号修价低。那么像这种情况呢一般你需要提前注意一下预测。是啊,收拾收集几十份样本,然后注意一次分析, 看一下这个信度系数怎么样。如果说发现问题今天预防啊,那还有一种处理方法啊。最后一种处理方法啊。嗯,你把所有的这个两秒数据 也可以综合注一次,相当于所有的这个两秒题啊,把它放在主一次相当于什么意思啊?你意味着你所有的两秒题都在测一个东西, 而不是分别做几次啊?那我一会会举个具体的例子来讲解啊,然后我们接下来还有这个具体解读啊啊都有具体的说明啊,我们接下来以这个 sps 由系统为例啊来说明一下。 比如说我们这里有 abcd 啊,四个维度啊,有四个维度。其实像这种有四个维度啊,一个维度 a 是有四个体表示的, b 是四个体, c 是 三个题,第四三个题表示的啊。那么你住的时候呢?其实真正上去住啊,他是要分别住四次啊,你就分别放进去这里住一次啊啊必须放进去住一次,我们看一下啊,摸着就这 克隆八号系数啊,克隆八号阿尔法系数吧,啊,或者叫阿尔法系数,克隆八号系数啊,出来的时候你只需要看一下啊,这个小数位有点那个,我把这个小数位调成标准啊,小数位调成标准,让我来看一下 零点八五九是不是带零点六的啊,说明这个数据很好的啊,没有问题啊。还有项目前面还有两个,一个叫 c i t c 值,还有个项羽删除的二发子,他实际上是辅助你分析的,什么意思啊? 你比如说这个 a 一对外是零点八四零,他说明什么意思啊?说明呢?如果说把 a 一这个题删掉,就留下二三四这三个题做分析,那么他的进度系数应该是零点二, 把这三个铁放在一起,二三四放在一起做,应该在零点八四零啊,你要不信的话可以自己尝试一下,是吧?零点八四零,那这就是啊啊,我们的这个 效应删除的阿尔法系数的意思,他是帮你辅助,帮你判断有有没有出现问题的一个题,如果出现,你可能尝试把那个题给他删除掉 啊。还有一个角质系数的 cit, 这只如果说这个指甲他和这个进入吸收是有管理的,如果说这些纸都很大啊,那么这个纸也会很大的啊, 如果说这个 cit 是指,比如说很小,比如说小零点三,有可能他就会干扰到这个总体的二发子,当然你最终其实就看这个整体的二发子,你前面这个 cit c 和项羽删除的二发子,他只是中间分析的一个过程,你可以用这个最简化的一个格式来分析就可以了。 好,接下来我说明一下,如果说出现问题,如果说你这个纸啊,你包括你比如说我换一个啊,换一个,第,第一、第二、第三,看他会不会低一点,他这个零点七七零啊, 也还是可以的,我假设这个是零点五七零或零点四七零吧,说明他不达标了,那怎么样去处理他?第一种办法加大样本,对吧?你要不然两百你再加大。为什么呢? 信助分析的这个信度系数啊,他会受两个因素的尴尬,第一个是数据的这个验目量啊,第二个是说这个分析项的个数, 你比如说这三个,你要放在四个的话,正常情况下这个只会更加,因为从计算公式的话,他就会受项目量和这个啊非影像个数的影响。所以说如果说你是两个的话,你这仅仅是两个的话,那这个还偶像这个数据 质量都很好了。若是两个的话,通常情况下就是什么都一样的情况下,两个的系统吸收,而法则通常会会更低一点,所以说一般情况下你最好 还是放三个或者以上来进行分析,那因此呢,第一个解决办法是加大压力量,第二个是呢,加大分析项的个数,所以说在这个解决办法里边啊,他就有一个叫什么啊?综合注意事吗?综合注意是他其实就是把所有的分析项 放进去,住一次就可以只得到一个综合的阿尔法吸收者,他年龄是在于说综合做一次的话,那个叫什么啊?综合做一次他有助于说那个从公司的角度啊,分享更更多了,要么你不变分享个数更多了,他更容易达标啊。第三种方法呢,是 发现有没有无限样本啊?如果说你发现有无限样本,就是说没有真实回答的,在乱回复的,这个他会干扰,肯定会干扰的,你随意的乱回答的这种数据会干扰信徒的。所以说那个数据处理里面有个这个无像样本功能啊, 比如说你把这个选中啊,做一个如果相同数字超过百分之八十或者七十或者六十吧,超过六十就是什么意思啊?一个人有百分六十的答案,就这十四项,那就是说 六十乘以十四等于多少啊?八个题左右吧,都选择完全相同的一个答案,那这个你认为他是无效的,对吧?啊?确定确定之后,他给你标识一下新生存的一个标题,来标识一下,那么你在做的时候呢,要注意一下筛选, 把有效的给他筛选出来,对吧?啊?有效的再做分析啊,这个反而肯定了啊,为什么?因为你现在样板量又变低了,所以说他有可能变低,这很正常的。但是这种做法呢,正常情况下是针对于第一个你的这个数据,确实你认为他有无效样的时候才能 处理啊,或者是出现问题了之后,你要去解决它的时候,你想去提高这个耳法习俗,然后怎么样去?哎,去通过各种方法去尝试去处理啊,这是正规范的一种处理方式啊。第一个是啊,加大量不量,第二个是说啊,分音箱的够数尽量多一点, 然后无效药门啊,无效药门的这个处理啊,当然了还有一个处理啊,这其实是属于分析的这个过程里面的,我把 a 二、 a 三、 a 四放进去啊,决定着 零点七六零,对吧?因为放啊,这个没有办法去,我把这个全部放进去吧啊,比如说刚刚你不达标了,第二种操作方法综合做一次就指的是什么意思啊?你把所有两百题放在那边只做一次分析啊,我发现这个题 高的零点八四三啊,然后呢?呃,还有一种呢,有的时候也会你的分析像啊,放多了,他其实有的时候也会有问题,因为有个别的题他会干扰我。举个例子啊,比如说 如果说这个值为九四七零点九四七,零点九四七是不明显大于零点八四三,对吧?啊?举个例子哈,那么如果说出现这种情况,那意味着什么意思啊?意味着说 啊,这个题删除掉更好,那么你可能需要把这个题直接移除掉,那你所有的后续分析就不相当于没有这个啊题了 啊,这也是一种处理方法啊,最好的一个解决办法呢。其实在做吸毒的时候你要提前预防一下,就是其实简单的收集一些数据,注意一下预测试啊,发现,哎,预测试 没有问题,再正式的分析,大面积的发放这个什么速度问卷去搜集数据,那一般也不会有什么问题啊, 以及更多的一些说明啊,关于如果说你还不知道怎么分析啊,什么具体的意义啊之类的,这个帮助手车里面还会有更多的啊,更多的一些说明啊,包括了,嗯,我们的这个飞两表数据。那你又想做性格分析?嗯, 那其实呢,那你肯定是做不了这个二法系数了,那你可以用文字去描述你的这些数据确实是 真实有效的,那么这也叫做星座,只是他不叫做阿尔法克隆巴赫阿尔法系数而已,他也叫做星座。星座啊,星座分析啊,简单来说呢,就是说星座只是告诉别人 我这些数据是真实可靠的,对吧?那你怎么样告诉这别人真的可靠?你把详细的过程描述出来,那就是说明呢,你而且是别人信你的这个东西,这个数据来源呢?那么这种就叫做我们的这个真实有效啊。那就是,呃,可信 数据是有效的,那个可信的直接相信的就是有信度吗?这是我们这一次的内容啊,关于信度分析的,谢谢大家。
362SPSSAU 14:19查看AI文稿AI文稿
14:19查看AI文稿AI文稿大家好,我是君磊。嗯,上一节课呢,我们主要介绍关于探索性因子分析的一些基本操作。嗯,这一节课呢,我们就主要是解决一个问题, 就是当我们这个因子分析的结果不是很理想的时候,我们通过一些什么样的操作能够使得这个结果可能变得好一些。嗯, 你在介绍这些操作之前呢,我们先看一下啊,什么样的数据,他是啊,效度是好的,所以说或者是效度好的数据他是什么样的?嗯,我国家总结为这样这么两点就是,嗯,维度内的提供呢,他们的相关性要强, 维度间的题目他们要相关性要存在啊,相关性强,要强到什么程度呢?呃,如果用 p 二三相关系数来说呢, 最好是能达到零点五以上。呃,维度间的题目相关性存在指的是什么?就是说维维这个维度的这个题目跟另外一个维度的题目他们之间也存在一定的相关性 啊,这个相关性呢?他,呃要比我维度内的这个题目的相关性要弱,但是我们之间这个相关性是存在的,可能是我相关性系数只有零点三或者零点四,而我们维度内的题目的相关性呢,要,呃可能是有零点零点七、零点八。这样。 好,我们我可以用一组随机的数据来跟大家展示一下,就是说,呃,好的数据它是什么样子的啊?好,我们先用一个 excel 表格,这些 excel 表格,嗯,我们把它放大一下。然后呢,我用一个 ae 代表 a 二、 a 三来代表 a 这个 a 这个维度,然后用 b b 一、 b 二、 b 三代表 啊 b 这个维度,然后呢我们呃用随机就生成一些数数据来代表,这个就模拟一下这个题目下一些数据啊,用就一个人的笔寸 从一到五,然后我们样板少,就用五十个样板吧,五十多个样板。好,我们每个站自己给他搞一些死基数, 呃,随机的数,那么这些随机的数据呢?他们是相关性肯定是不好的,对吧?然后呢我们啊给他增增加一些,增加一些 组内的相关性,增加一个组内相关性,我们手动手动增加,就是啊,随便给他加一些,比如说我们啊这个的随机时间数呢,我们给他乘以零点五, 再加上 a 一这个音字啊,乘以零点五,比如说他这里面有百分之五十是,呃,与 a 一是相关的啊,可以说相关系数大概是在零点五左右。那么这个呢,我们给大家乘以零点五, 再加上啊这个乘以零点五,然后这个的数据跟他啊可能会具有零点五的一个相关性,那这个也一样,我们给他这样就硬造一个数据啊,硬造一个数据跟这个跟实际数据肯定是有不一样的啊。 好,然后呢阿姨说,呃,这两个题目他们跟这个 b 一就一定相关性,这两个题目他们一 呃 b, a 一就有一定的相关性,那么因为他们 a, a 二跟 a 三跟 a 一有一定相关性,所以 a 二跟 a 三之间呢,他们俩是有一有一定的相关性的,但是呢,他们呃 b 这个维度跟 a 这个维度之间,他们现在是应该是没有任何的一个相关性的,因为都是随机生成的嘛,所以我们把这个数据呢, 给他放到那个 spss 零,我们先把 sps 打开,然后呢我们把这个,把这个处理器复制一下。 好,然后我们把课表这里,然后我们改改改名字啊,就是这是 a 一, a 二, a 三, b 一, a 二 a 三。好,然后呢我们对这啊,这六个题目啊,大概是,哎,我记得不是五十多个样本吗? 啊?是不是都一样的?然后呢我们啊做下英子分析,好,英子分析,然后把六个题目放进来, 然后我们,呃用 k m 把他理,然后抽取,这地方我们啊都不动,然后学员成分举证,再再发杀法,然后这里还是这样得分,我们这里就不管了,然后 然后用这个均值贴下去,呃,用呢均值贴在,确实我们这里没缺值啊。嗯,大家排序,这里给他改成零点三。嗯,好,我们点击确定。好。呃, 我们直接看学院什么举证啊?学院什么举证?我们看。因为,呃, b 二和 b 三都是与 b 一相关的, a 二和 a 三都是与 a 一相关,所以 a 一和 b 一的合法就非常高,非常高啊,但是呢,呃,现在有个问题是什么?因为他他们俩之间,这个,他们俩之间的相关性很 很低,所以就造成什么造成啊?这个 km 值很低啊,那怎么办呢?我们可以啊。呃,增加一点什么增加一些啊?组内之间的 就是维度和维度之间的相关性来看一下啊, 比如说现在啊,我们找个找个题目,随便找个题目,我们可以先看一下啊,他们之间的相关性啊,我们用片的相关系数。 好,我们来看一下这几个之间相关性,我们来看 a 一, a 二 a 三,他们这几个,他们之间相关性都是零点六左右的,但是 a 一跟 b 一, b 二 b 三之间,他们之间是没有这个相关性的, 所以说这个啊,这个数据呢,他虽然看上去很好,但是,嗯,做验证性因子分析呢?他,是啊,肯定是不通过的,因为他组建他没有相关性的。另外呢啊,这 kmo 值他也很低的,对吧?所以说我们就要需要适当的增加一点他的那个相关性。 那么怎么增加啊?我们就是,呃,找,随便找找啊,就是比如说这个地方,因为他们都是一的嘛,都是一的,对吧?我们都给他,都给给,给人一,给人一之后,呃, 他们之间的相关性就高一些了,嗯,就赶上一,那么这就说这些,这个样本他是都是一的,我们增加一些这样样本都是一,都是一,都是一,都是一,然后都是二, 那么都一样就相关性很高嘛,对吧? and 都是二,然后呢?都是三,都是四 啊?我都是,我,好,我这随便改啊。当然我们现实中,呃,做销售研究,我们不能这样改啊,就是我现在是硬造着出去给大家展示一下这个因子分析的这个原理啊。好,我们再去看一下它的相关性, 那么你看这 a 一到这个 b 一, b 二 b 三,他们之间就是有一定的这个相关性的嘛,对吧?然后我们再去做一下这个燕子分析。 好,我们看这个 km 无值就提高了,而且这个累计的防差几十度也提高了, 另外这个地方都是不变的。好,那我介绍这个呢,是为了介绍什么?就是说,嗯, 什么样的数据他是好的呢?一个就是说我们,呃,我们还看这个,我们首先题目和题目之间内部就是 a 二 a 三,他内部之间他是具有一定的这个想法性,很强的一个想法性,就是说啊, 基本都是我这个一个组内的这些这些数据啊,我这个人,我在这个这三个题目之间答案基本差不多的,或者说是一样 这样的,就我都填了五或是五四四类似这样的一些数据。嗯,那么我组和组之间呢?我组合组之间他是也有一定的相关性,但是相关性没有我组内那么强,那么这样的数据呢?他就是一个啊笑度比较好的数据。嗯, 那么这样就是他为什么这样呢?就是为了能够体现出我们量表设计的那个呃原则,比如说跟我们量表设计是匹配的啊,所以说明他的效果是好的。嗯,下完了这个什么样的数据是好的呢?我们 就跟大家介跟大家就介绍一下,我们可以通过一些什么样的手段能够去提升这个效果好,我们这里有这几个方法 好,首先一个是删,一个是第一个是删题目,第二就是删样本。呃,下什么样的题目呢? 刚才我已经说过了,我们呃在呃那个做因子分析之前啊,你最好是先自己先测一下这个,呃,维度跟维度之间相关性, 我们可以测一下,再去测一下这个相关性啊。哎,啊,这刚才有一个相关性了,假设啊,假设我们啊 b 一它是本来是属于 a 二 a 三的,但是呢,第一跟这个 a 二 a 三之间的相关性都非常的低, 就是啊,只有零点二或零点三,而其他三个因子之间呢啊,三个题目之间都是零点六零点七的一个相关性,那么这时候你就有必要把这个 b 一从 a a 一这个啊 a 这个维度之间就踢掉,就不要让他参与这个因子分析了,这是一种方法。另外什么叫山药本呢? 上面就是指的是,比如说有的样本呢?他,嗯,他可能就是呃,乱填的。什么叫乱填呢?比如说他有的题目,本来这三个题目描述的是很相似的一个内容啊,比如说都是在描述我不喜欢这个公司, 我都,我对啊,一件事情都不喜欢,只不过我表达方式不一样,因为某个词不一样,但是呢,他有个,有一个词填的是个五,有个词填的是一是一, 那么这在同一个维度之下呢?这个题目啊,他这样,这个题这样就是很不理想的,那么如果是你发现有这样的样本过多的话,你可以适当的删减一下这样的样本, 也会提高你的这个呃,这个呃效果,嗯,这是一种方法 啊,如果这两个方法都不可,一个是删题目,删样本,怎么办呢?就要重新设计你的维度了,维度了。什么叫重新设计你的维度啊?有一种方法就是你可以去重新审视一下你自己的这个现有的结果啊,比如说,嗯,明明你是想 到 a 一 a 二 a 三他们在一起,结果呢,发现 a 一跟 b 二, a 一跟 b 一 b 二在一起了,那么这时候你要重新审视一下你的这个题目的设计,比如说,呃,可能你的题目设计的 呃就是他 b 一 b 二跟着 a 应该在一起,而不是 a 二 a 三,嗯,那么你就给他给他改一下,就会跟跟导师讨论一下这个是不是呃合理, 就是音可以不可以改一下,如果不能改的话又怎么样?你就只能说重新重新设计你的题目啊,你设计的咱们这题目的时候呢,最最好是怎么样?最好是这个 a 一 a 二一三这同一维度下的题目啊,都描述的差不多 啊,用词尽量尽量一样,这样我我一个位置的会啊啊,回答者呢,就是做做工业的人呢,他能够去把这些题目其他数字啊或答案都基本一致,这样就能保证我们的效果,就是啊基本是合格的, 嗯,还有一种方法是什么呢?就最后就是重新设计题目。什么叫重新设计题目呢?就是说呃,你这题目的表达啊,他是很影响这个呃问卷的,呃答题者他的回答的,嗯,你可以有时候改一下描述呢,可能会使你的这个题目的回答就质量就变高 啊。这个你呃比如说有这个题目,比如说 a 二这个题目,他在回答的都是呃偏低的,都是在一二上的,而这个我录下其他题目都是在啊五啊啊四啊这个之上的,那就说明你这个题目就很有问题啊,你就可以重新审视一下你这个题目的设计啊。 好,嗯,今天讲了这这么多呢,就是说,呃,我们可以通过一些的方法来改善我们的这个效度,其实主要用这个还是哎山题目和山样本,嗯,所以说呢,就是在我我个人是建议在我们做这个呃 问卷分析之前啊,尽量使得这个唯独你的题目啊,你尽量设计的多一点,比如你本来设计是设计的是三个题目或者四个题目, 你可以多设计啊,几个题目,比如说你设计五六个题目或者七个题目,这样给自己留点余地。嗯, 为什么这样说?毕竟是因为我们自己设计量表,不是,也不是那种,不是像那种成熟量表那么合理,所以说给自己留点余地呢,就是方便我们删题目啊,你删的,比如说你本来这个维度下面,他啊有三个题目会在会在一起的,那么你就用这三个题目来表示你这个维度就可以了。 而啊把那些不在你唯独这些题目都给删掉啊,这样也是可以的啊,我个人,我个人平时用的最多的就是删这个,删这个题目啊就是,嗯,有少看到的时候就删这个样本,删题目是比较合理的。 嗯,好,那么我今天这个视频就录到这里,下一个视频咱们就介绍一下这个验证性因子分析啊,他的一些操作。好,嗯,今天到这里,谢谢大家。
209Junlei_D 00:13
00:13 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿大家好,今天为大家讲解一下在论文中经常用到的一个分析方法,信度分析。信度分析十分就是做分析的前置条件。 在 sps s 做信度分析的时候,主要关注的是克隆巴克系数,如果克隆巴克系数高于零点八,则说明分卷性度较高。如果克隆巴克系数接于零点七到零点八之间,则说明问卷性度较好。 如果克隆巴克系数介于零点六到零点七之间,所说明温卷性度可接受。如果克隆巴克系数小于零点六,则说明温卷性度不佳。 一般要求克隆巴克吸收在零点七以上,如果低于零点六,就需要考虑对问卷的题目进行删减或者重新拟定问卷题。然后下面我们说一下在 sps 中的具体操作步骤。 首先用 sps s 打开数据,然后点击分析标度可靠性分析,然后把需要分析的题目选中, 按住事故的选中,然后拖到右边的框中,然后点击确定出来的结果就是我们得到的克隆巴克系数。
1105spss数据分析 11:06查看AI文稿AI文稿
11:06查看AI文稿AI文稿大家好,我是君磊,这期视频呢,咱们来讲一下这个因子分析的优化方案啊,那本期视频的一些资料呢?可以在公众号上回复因子分析优化来获得啊, 那因此分析的这个结果不好,通常呢有两种情况啊,第一种就是这个 kmo 值太低啊。啊,这个呢是一般是与那个相关性有关啊。那第二呢,就是那个维度数与自己预期的不相符合啊, 一种情况是与自己预期的那个数目低啊,另外一个是与这个预期数目高。那下面呢,我们来讲讲这个两种情况啊。 好,那第一种情况呢,就是这个 kmo 值,泰迪亚,那这个情况呢,一般呢就是与我们的这个数据的相关度有关啊。那 什么是数据相关注呢?我们举个例子啊,呃,就比如这样一份数据,这个数据是一个比较良好的一个数据,我们可以先测一下这个相关性啊, 看一下。那这个相关性呢,是一个呃比较理想的一种相关性呢,就是相关性程度在零点三零点四左右,就是说我这个自身这个题目跟其他题目有一定的关联,但是关联性又不是 那么大,如果都是零点七零点八的那种,或者零点九以上这个相关性就是就是他自己可能本身就已经没有什么自己独特性了啊, 像这样一个题目,他与其他题目有一定的相关性,他又又有自己的个性,那这样的一些一个数据呢,是一个比较良好的数据,所以一般这样的数据去做这个因子分析啊,他是 kmo 值啊,一般他都是都是不低的啊,我们可以看 给点拇指把它里,哎,我们来做一下这个行为,这款橘子。 好,我们可以做一下啊,哎,这个值呢?你看他那个 kmo 值呢?是在零点八啊,这个已经是非常不错的了啊,提取了两个因子啊,提取两个因子,嗯,那这个数据呢,我们再去操作一下啊, 如果呢,我们把他的这个,嗯,我在事先呢给他排下序啊,把那些都是选五的,这样的给他排在前面,如果我们降低他的相关性,就比如我们把这都选五的给他删除啊, 或者前面这一堆,这前面这一堆都是比较相关的啊,我们来删除一些,删除个一些样本,我们破坏一下他这个相关系啊,然后我们再做一下啊,再做一下。 好,你看这时候的这个 km 就是从零点零点八,对吧?零点八下降到了零点七八,对吧?零点七九九下降到了零点七八,这就说明我是把原始数据那个相关性给他打破了啊,给他破坏了一些,然后呢他的数据他 km 就降低了啊,那我们再看看例子啊, 我们新建个数据,然后这个呢,这时候是我事先准备的一个, 呃,前有 random, 就是那个,呃,那个那个 excel 的一个函数啊, random 比拖延一和到五就是生成了一个随机的数数字,对吧?也是 也是这么一些数据,我们用这个随机申请的数据去测一下这个 k m 值,对吧?然后我们做一个分析,那这数据是完全都是随机的啊,完全都是随机的, 那随机的数据他们之间是相关度是比较低的,那么这时候啊, km 这零点零点四,其实这还是算比较高的了,这说明这随机的数据里面他也有一定的一个相关度,我们测一下。 呃,你看零点一几还是有一定的啊?有一定的,只是说啊,不显著吧?不显著,但是也是有一定的一个相关度,零点二几年的啊? 嗯,我的想表达什么意思呢?就是说 km 值是与相关性密切相关的,那 如果我们想提升我们的这个 km 值啊,一个是要把我们的核载比较低的那些题目给他删除,因为核载比较低的题目,他的含义就是说跟自己维度的那些那些题目相关性 比较差,所以优先可以剔除相关啊,和在比较低的题目。那第二呢,就是在样本入手,从样本入手就是说你可以增加一些样本啊,再去调验一些样本,他说不定就提升了 啊。所以啊,这个 kmo 值的这个优化基本呢就是从样本和题目这两个角度去入手啊,题目的话就是那个删除和再低的样本的话,你要知道什么是好样本,什么是差样本啊。那么对于这个 kmo 值来说啊,这个这样的样本随机的这样样本是不是差样本? 那这样的样本呢,就是都是选五的那种样本啊。啊,这种对刚才我身上那些样本,这样样本反而是一种好样本。 好,我们再来讲第二个问题啊,唯独数不符,那这个问题可能是我们做问卷分析遇到的最头疼啊,最难解决的问题 之一了啊。那这个问题呢,就是我给大家提供一个思路作为参考啊。嗯,首先我们把握一个原则, 第一个就是原则,就是啊,我们这个维度命名啊,以那个核载较高的占多数题目为准啊, 就是我们不要上来就期望他提出来那个因子刚好跟我维度设置的啊,一样啊,那个太理想了啊,我们是以那个维度内的占多数的那个题目啊,核载较高的占多数题目为准啊, 那么允许少数题目跑到,跑到其他维度下,就是说如果有一两个题目创造了其他题目下,你是可以保留的啊,可以保留,但是你如果觉得实在不想保留,你就把它删除啊。好,那我们有这两个原则之后,再去看对应的这个情况,我们 进行处理哈。好,那我们接着这个数据来看一下这两种情况啊。第一个就是这个大于预期啊,也就是我们抽取出来那个数量是大于我们实际想要那个数量的啊, 我们看一下这个数据啊,我们做下这个因子分析,那这个因子分析呢?我实际上是想抽取两个因子,也是 f r 也是 pi, 那我们可以做一下这设置,我都设置好了哈。好,那实际上出来之后这个结果我们可以看到啊,特效只能大于一的有三个,也就是说它实际上是 踢出来三个啊,踢出来三个意思。我们看一下这个因子和仔的一个相声比赛啊,我们看一下他这个四五六 p i 的四五六在一起了,对吧?然后呢?一二三在一起了,然后又把 fi 的另外一个因子给拖过来了,对吧?有人说 pi 一二三加上 fi 四形成了一个因子,然后 fr 一二三形成一个因子,那这个地方呢?我们就可以进行删减了哈, 那我们再来分一下这个结果啊,那 fr 一二三他们是没有问题的,那么我们可以用这个三个题目,也就是维度三来作为 fr, 对吧? 然后问题就出在前面这两个因子,我们保留。保留谁?我们可以将这个一二三四、 fi 四和 pi 的一二三都删除啊,只保留 pi 的四五六。将 pi 四五六来代表这个 pi 是第一种做法,第二种做法是我们把 pi 的四五六删除啊,然后用这四个题目来代表 pi 啊。我们可以先做一下啊,我们将这个,呃 pi 一二三和这个都删掉啊。 pi 一二三 这个删掉,我们来再做一下,我们看一下这个都符合两个音字,然后出来这个结果,那我们可以用这个结果作为我们的这个实际的啊,那个唯独设置, 大家有同学说我删这么多题目合适吗?还是一个乘除量表没问题啊?我们用因子分析去做的时候,我们可以将这个步骤作为我们呃,对量表进行优化,或者说我们对我们的维度进行优化,这样一个过程啊,删是没问题的啊,删没没问题你就勇敢的删啊。 然后我们再来试一下第二种做法,我们可以保留这个,保留一二三,我们把这个四五六给删除啊, 看一下这个还是啊?就是,呃,你看刚才我说到这个,允许有一个题目串到这个位置吧,对吧?我们可以将 fs 同这啊 pi 一二三一起作为这个 pi 啊,当然你就说一下,行了,我们以主要题目作为命名,将其命名为 pi, 对吧? 好,那么这是第一种啊,就是这个维度数啊,啊,那个大于这个逾期数啊。 好,咱来看第二种情况,这个小玉系数啊,那这种做法怎么做呢?呃,比如说我想提取四个因子,结果他就给我出来三个啊,那么我们怎么做呢?我们这时候就要强制提取,我们回到我们的因子分析, 然后在提取设置里面,我们把这个也搞进来啊,我们把那个提取设置里面在这里也设置,我他他出来三个,但是我实际想要四个,我们这里显示四,然后我们再做一下看一下,那这时候呢,他就有墙 制提取了四个啊,四个因子,那这时候要注意啊,如果你的数据本身质量不 不足以支撑四个维度,或者不足以支撑我的预期啊,你的预期那个维度设置,呃,他这里就是第四个特征值,就非常小,非常小,比如像这个零点七就不足以支撑啊,如果你这时候这个特征值在零点九以上,或者是 零点八九啊,是也接近零点九,那还可以勉强说他能够提取出来啊,四个维度啊,那首先你要看这里他是不是一个比较高的一个特征值啊?零点九是一个,呃,能够接受的一个一个标准啊。 好,那这个零点九的之后呢,我们再看下面这个旋转成分矩阵,如果他多出来那个维度啊,比如这里啊,他多出来一个 f f i 二,对吧?如果多出来这个呢?他刚好是 在两个或者是两个以上,对吧?呃,就是新做出来那个维度呢,在两个两个以上,那,那他构成了一个新的维度 啊,那这时候你就可以以新出来那个维度作为你的那个啊,少那个维度的命名了,对吧? 嗯,当然了,这个这完全是碰运气的样,有一可能是啊,有一可能是你前置踢了之后,他出来这个全都乱掉了啊,那这个呢?呃,实在不行你就把某个维度全部都踢出啊,全部踢出只保留那个啊,他踢出来那个样子啊。 嗯,那基本呢就是,呃,这几种做法,其实我们看到这个也没有什么特别好的办法,因为因此分析啊,因此分析呢,就是这样啊,他提出来什么样,我们就基本上以他什么样的那个为准了啊,只能通过这样的方法去 平合理的优化啊。当然我们还是建议啊,能用成熟量表就用成熟量表,毕竟成熟量表这个胎草性因子分析是可以跳过的哈。 嗯,那我们今天视频到这里了,我们下期再见,谢谢大家。
435Junlei_D 00:13查看AI文稿AI文稿
00:13查看AI文稿AI文稿问卷应该怎么做呢?本科论文建议先找问题,再回头做问卷设计十个问题发放三百分左右,线上线下各一半,看看这个方法,这样写就能过。
1354坑哥说论文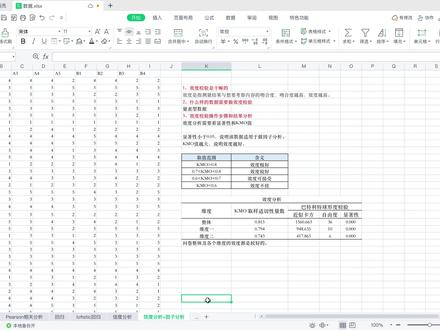 03:42查看AI文稿AI文稿
03:42查看AI文稿AI文稿哈喽,大家好,上一个视频我们聊了什么是性度检验,那这个视频我们就来分享一下效度检验,同样的效度检验也是要和大家聊一下这三个问题。第一个, 那消毒检验是干嘛的?消毒检验它主要是指测量结果与想要考察内容的吻合程度,如果这个吻合度是越高的,那就表明效度也是越高的。 第二个,什么样的数据需要做效度检验?效度检验也是适用于量表型的数据,一般像量表类的数据他都是需要做信度和效度的。 第三个,消毒分析的操作步骤和结果的解读,我们使用的数据也是性质检验的数据,就是 a 一到 b 四, 然后这些都是一些量表型的问题,他主要包括一到五这五个选项,然后我们把这些数据复制到 spss 里面 啊,整理成这样的格式,我们点击这个分析,然后降为因子,把这些量表数据都放到变量这里, 然后点击描述这里面勾选一个 k m o 和 butt later 球形检验,然后点击继续,再点击确定, 这个就是效度检验,我们需要看的表格,然后我们主要需要看这里的 k m o 值和显著性的值,这个是量表整体的效度检验,然后我们也可以测一下氛围 度的性能检验,步骤是一样的,点击这个分析刻度因子, 然后如果需要测 a 的维度,那就可以把 a 的这些变量放到这个框里,然后描述这里,我们已经勾选过了,所以可以不用设置,然后直接点击确定 这个就是 a 维度的消毒检验,再点击分析,降为因子,然后把 b 维度的数据放到变量里面, 然后再点击确定这个就是 b 维度的效果检验。我们把这三个 kmo 的表格,然后放到 excel 里面整理一下,就是这样的格式,它主要包含了 tmo 的值以及这个显著性,我们主要需要关注的也就是这两列。然后可以看一下这里面如果显著性是小于零点零五的,那就说明这个数据是可以做因子分析的。 然后这个 k m o 值它也是有一个取值范围,然后每一个范围对应的它的效度好坏, 如果这个 k m o 值越大,就说明它的效度是越好的,每一个取值范围对应的含义就是在这个表里面了。大家也可以根据自己的数据算出来的 k m o 值,来看一下你的效度情况如何。 然后针对这份数据,我们测出来的效度,他的值可以看到都是大于零点七的,也就是说问卷 整体以及各个维度的效度都是比较好的。然后显著性的值小于零点零五,也就是说这份量表数据是可以继续做因子分析的。 下一个视频我们来讲一下如何做因子分析,以及因子分析的结果怎么看。
1546spss小师姐 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿你还不知道死怕死?信度笑度分析怎么做?今天就教你快速学会信度笑度分析,懒人必学!信度分析是指收集到的问卷量表是否可靠可信。假设现收集到一份客户满意度量表,测量其结果是否可信。操作很简单, 只需将量表题拖入 spa spro 框中,点击分析即可生成结果结果。直接注释阿法值为零点八三八,说明该问卷的性度不错,小白也能看得懂结果。 效度分析适用于分析问卷题目的设计是否合理。假设现收集到一份客户满意度量表,测量其题目设计是否合理,将数据拖入 spac proco 中,点击分析,结果显示 k 猛值为零点八八八,符合因此分析要求证明该问卷设计有效。 总结来说,信度分析是用来测试问卷结果是否有效。笑度分析是用于测试题目设计是否合理。你学会了吗?快来试试吧!
782SPSSPRO数据分析 00:15
00:15 15:00查看AI文稿AI文稿
15:00查看AI文稿AI文稿大家好,这一次的内容是这个结构效度不达标,怎么样去处理它? 这个结构效度啊,在这个问卷研究里边用的会很多,而且他是一种最普遍使用的一种方式,那么但是呢,这个测量他的时候啊,很容易出现这个不达标啊, 那么出现这种情况的时候,我们怎么样去处理他啊?这一次的内容就讲解这个东西,那么我们第一个啊,结构分析,结构效度啊,他其实首先我们需要知道的是什么样的数据才适合做结构效果啊?这和这个不达标的处理方式上有关系啊, 我们看右边这个框啊,什么样数据适合做这个结构?下端两表数据啊,比如说你有个两两表,他分为维度 a、 维度 b、 维度 c。 啊,维度 a 呢,又分为 a 一、 a 二、 a 三,维度 b, 有 b 一、 b 二比三,维度 c、 c 一, c 二、 c 三,那么这种数据呢,才适合做这个啊,结构效果分析,相当于说你,比如说你测量一个幸福感啊,这个两表叫做幸福感,那么维度 a 呢?叫做这个啊, 事业方面的幸福感,然后这个叫做我们的这个家庭啊,这个叫做亲人啊,或者叫朋友,或者你后面还有一个叫朋友的维维度啊,然后呢每个维度有多个这个两秒题去测量他,那么这个整组成的一个结构啊,一个结构他综合都是在描述一个东西,幸福感, 对吧?那么这样的数据呢,叫做量表结构的数据,那么结构下注他的原点就测量你整个这样的结构是否是啊?和你的这个专业 认知上是否一致的,就你收集的数据出来的结果和你的专业上预期预期也是这样的对应关系,那么 最后出来的这个分析数据收集回来,分析出来结果是否和你自己的预期是否一致的,如果说一致的,那专业上是这样的认为的,那么数据结果也基本上一致的,那么就说明呢?你这哎,数据确实是还 ok 的,那么这就说明有效的那个结构效度, 就他是整个测量结构,整个结构的这个逻辑是否和预期一致的一个研究方法,他的这个啊,真实的这个底层的这个数理角度的话,他是用的这个叫做探索性因子分析的这个东西来做他啊, 那就进行测量的。然后呢,最大的一个问题啊,在于效度不达标啊,那效度不达标的 时候,就是说你本来预期是这种对应关系,结果呢?事实出来的情况不是这种对应关系,那就很糟糕了,那么怎么样办啊?一种呢是删除不合理项,就是说你比如说这个 a 一,你本来希望他在维度 a 啊,你本来是希望是你的事业方面的这个幸福感,结果他跑到了这个朋友方面的幸福感里面去了啊,那怎么办?删除他啊,这是第一种处理。第二种处理呢是那个叫什么东西啊? 加大样本啊,为什么呢?因为这个样本量越大呢,它可能稳定性会越强,稳定性会会越强一点。 第三个呢是说如果说你的数据中有这个啊,无效的样本,因为无效数据就不合理的数据,就没有真实填写的数据,肯定会影响效度的啊,那么你要先做这个无效样本处理啊, 这同时呢,还有哪些做法?提前预防是一种很好的一个处理方式啊?什么叫提前预防?你先收集一部分数据预测试一下,看一下这个数据大概情况怎么样,我发现有点问题,赶紧去去去,把你的这一个这个问卷两秒的这个问法给他修改一下, 因为有可能这个效果啊,不达标。不是说这个样本没有真实回复,也不是说样本量少,而是说你这个本身这个题目问的就有问题, 那么这种情况那肯定会出现问题的呀。啊啊,还有一种做法来啊,这种做法是一种取巧的一种做法啊,叫做维度为单位啊。什么叫维度为单位?你比如说 a、 b、 c 不都是这么这个事业的、家庭的、朋友的,对吧?都是表示幸福感,你把这个所有的 a 一二、 a 三、 b、 b 二、 b 三十一十二十三九个题放在里面去,而且设置成一个音质啊,设置成一个维度来做,也或者是说 a 一、 a 二、 a 三做一次 啊,因为他都是代表你的事业满意度,或者叫事业幸福感,这个家家庭幸福感,这个叫做朋友亲人幸福感之类的,对吧?分别做三次。 为什么这样做啊?因为这样子做的话,你其实就不用考虑这种对应关系了啊,你默认就是他已经对应好这个啊,事业幸福感了 把。你默认这三个题就是表示这个了。那你只是说要测量一个东西叫什么,看他的这种对应情况是否。是啊,测量情况是否是比较好。 ok 的啊,所以说你相当于把这一个节能这个测量的这个做法给 简化了,那么这种是很容易达标的啊。当然呢,还有一些做法,包括也是取巧的做法啊,那就是说你不用测量这些关系了, 如果说你要求不严格的时候,你就不用测量这个结构关系,情况怎么样,你直接看一个简单的一个指标哎来判断,就那个 kmo 指标就可以。 那么还有一些如果说你怎么做都不达标,那其实说明了一个问题,要么你数据不认识, 要么就是说你的要么量太少,要么就是那个叫什么,你的这个问题设计的太糟糕了。所以说呢, 你尽量的要做一个前提是要做以下几点啊,第一个是说收集真实的数据,这个是样母量尽量大一点,这三个是要参考比较相对 ok 的 这个两表,你不要自己随意瞎拍脑袋的去设计,他设计这些两表题,这种永远不达标。 还有一个就是如果说你已经没有其他办法了,那就写下内容下肚吧,你确实认为说你的啊有些实际困难,比如说我的这个数据他只能收集五十个,因为你的这个研究就决定了只有五十个样本,对吧? 然后呢,你的这个测量项呢,也是参考着这个国外的这些文献走的,那还是没有办法,那怎么办?你就写一下内容消度,用文字来描述一下你的这个两表怎么设计的,你是参考什么文献的啊?那就是 也是能说明效度的,那效度的意思就是说明你的这些设计的两表填是 ok 的,你要用这个 a 一 l a 三去测量这个 a, 你要用 b 一比二, b 三用去测量 b, 那你确实是有原因的啊, 为什么要用这三个?是因为你参考了什么别的这个引用了别的地方啊,来设计的,那么这也是能说明效度的啊。 另外提前预防里边还有一个注意事项,这个有一种处理方法,这是排名第一的吧,或者是使用最常见的就是这个删除不合理,相应的这种处理,那么 你既然要删除,不和你像,对吧?那意味着你首先要有足够多的像来 预留,在那里才有删除的机会,对吧?你比如说这个 a 一 a 二三那三个,假设你删掉删掉,删掉两个,那就很糟糕了,一个测量,一个伪装,这没有这种说法啊,相当于说你要用测量这个什么事业嘛,事业的这个幸福感,你其实有好几个 题,好几个侧面去测量这个事业方面的这个幸福感,但是你最终就剩下一个题,你的事业满意吗?啊,对吧?其实他们一般要用几个,比如说你和这个领导的关系怎么样啊?和同事的关系怎么样,和下属的关系怎么样? 也或者说你对薪水满意怎么样啊?工作环境满意怎么样,对吧?是不是好几个题,好几个侧面才能表示一个综合的性格,叫做事业满意度吗?啊? 那么以及呢?那因此来刚刚说的,你首先设计的时候,你就要有这种预期,提前的思考,你可能要多设计 几个题,一般是设计四到七个题会比较好,因为你才有删除的空间,一般删除个两三个都还 ok 了,因为你四到七个题删除两三个,你还剩下三个左右吧,三四个左右,对吧?啊,一般 你你你也不会一次删除了太多啊,因此来年这也是一个叫做经验式的法则设计。这个如果说你要设计这个维度,或者是说 两秒的时候呢,尽量一个维度对应的四到七个题,四到七个两秒题,以便于你自己有删除不合理像的缓冲区间啊,这是我们的这个原理性的东西啊,那接下来我们以这个 s p s u 系统为例来讲解一下啊。 啊,在这个问卷研究里边啊,效果啊,比如说我这里 a、 b、 c、 d 啊,其实他总共是四个维度的,放进去,那么你的预期他就是四个维度,所以说你就设成四个维度啊,设成四个维度开始分析啊,那么第一个是看他对应关系,这不看他的这个对应情况吗?这就是他 他结果下周不要做的事情嘛。看对应关系,比如说 a 一, a 二, a 三, a 四,对吧?哎,这里是合在一起的,他都属于英子三,其实这个英子三叫什么名字,你自己才知道啊,他就是一个,比如说这个叫做事业满意度,对吧?啊,这四个题 他是合在一个因子下面的,说明这四个题稳稳啊,很妥的啊,稳稳的就表示了一个东西啊, b 一, b 二, b 三, b 四,对吧?啊? b 二 b 三啊,二三四,哎,你没发现二三四是合在一起的,结果 b 一跑到这个因子二下面了,你可能二三四表示的是这个家庭的这个幸福感,对吧?结果呢? b 一,他去测量了这个叫做嗯,亲人的啊,或者朋友的幸福感,对吧?他 就出现的这个叫什么啊?张冠李戴了,那说明这个 b 这个题需需要删除的,类似的, c 一 c 二 c 三还 ok 的,对吧?啊? 呃,我们的这个啊,呃,第一第二第三,对吧?第一第二第三这三个也是一样的,本来第二和第三挨在一起,或者是第一和第二挨在一起是比较合适的啊,反正总共会有一个问题出现问题,要么你就删掉第一 啊,要不要删掉这个第三?那么我们来看一下啊,我们先删除掉这一个 b 一的这种调整方式,先删除掉 b 一,就从这个模型里面移除出去啊, 再看这个对应关系, a 一二 a 三 a 四是 ok 的, b 二 b 三, b 是 ok 的,那么 c 一 c 二 c 三也是啊,第一第二第三,哎,这还是有点问题,那么你明显的删除第三更合适,因为第一第二在因子四下面,他们各自代表一个维度,对吧?啊, 把第三给删删除掉啊,再来再来之后呢?哎, a 二 a 三 a 四,哎,你发现 a 一又 出问题了是吧? a 一要删除掉啊, b 二 b 三 b 四在一起的, c 和 d 都 ok 的, a 一是不要删除掉啊,删除掉 a 一,哎,现在是不最终就 ok 了,那最终 ok 了,那就说明呢,这种结构是一种最稳定的一个结构, 对吧?那么这就说明呢,你删除题之后啊,这样的一种测量方式,这四个东西确实是能综合代表幸福感的四个侧面,包括这个工作、家庭,还有这个亲人和朋友,四个角度,四个维度, 这种关系是稳定的,那么最终呢,你的说明了,经过一系列的删除,最终呢,这个效度达标了,结构效度达标了啊,那么如果说,呃,这个,呃,嗯, 如果说你的这个二三四这里还剩下三个二三四, c 一四二四三,第一和第二剩下两个题还是 ok 的,对吧?如果说只剩下一个题,那是不是就很糟糕啊?因为一个题刚刚说一个题表示一个维度是很糟糕的事情, 所以说呢,而且我们刚刚的来回过程啊,其实是删掉了好几个题,那么因此呢,一定需要特别注意,在这一个设计问卷之前啊,就需要多设计一些题,以被留住这个删除的工作 啊,因为你很难知道说你的这个量表啊,他刚好就是非常的达标的啊。 那么与此同时呢,这个删除的过程啊,刚刚我们也进行了几次,那删除的过程不同呢?他可能结论出来的是不太一样的,这是正常的现象啊,这是正常的现象。比如说我现在删除 b 一还是三,先着什么第四第三,他可能出来的结果是不一样的,我说的是可能啊,而且很可能出来结果不一样,那也是没有什么问题的。我们做这个结构下的话,他更多的是从数学数理的这种角度去看待这个 维度和我们的这个测量项的这种对应关系情况啊,这是我们的效果分析、结构效果分析。那么刚刚说的这个简约办法,如果说你怎么样?对啊,这些都删的乱七八糟了,还是不行,那怎么办呀? 刚刚说完第一种方法呢,你可能说看有一种简单的方法,直接就看这个,这是最简单粗暴的一种方法,直接就看这个 kmo 值啊,大于零点六,说明有效度,这是最简单的一种做法啊,啊,就是说你直接不关注这个对应关系了,啥也不关注啊,就 看这个 kmo 值,那这个 kmo 值的代表什么意思啊?代表说这个测量项啊,他是否紧密的去描述了你的这个测量维度的意思, 越大越好,那大于零点六,零点八七六,那就说明在这些测量下呢,确实是表示很好的表述的这些为主,只是说 他可能只都是在表示同一个东西,但是呢,他的这个对应关系,比如说 c 一是代表着这个啊,亲人之间的这个,嗯,这个,这个幸福感 那,那你的预期是这样子啊,但是他是不管你代表亲人还是朋友,还是工作还是事业,还是说啊,那个其他的一些幸福感,他只是 came, 或者只是告诉你说这些测量项确实是啊,可以表示是这个维度,整个的这些维度啊,那么啊,这是 第一种啊,直接看这个最简单的,当然呢,还有这个用这个内容效果,就这些指标都不看了啊,直接用文字描述,那个更简单粗暴啊,相当于你放弃家族这个结构效果了啊。那么还有一个做法呢,刚刚说了,分别以维度为单位啊, a 二 a 三、 a 四放进去,那么设置成一个维度,他的原理是说我测的这个四个测量项啊,他就是在表示一个维度的意思啊,我就是表示一个维度,那么你再开始分析啊,那这种是更容易达标的哈,载合系数也很高,如果说这个载合系数也很低,把删除掉哈, 这是相当于这种做法,也是投巧的方法,他直接就不关注于这个,这个,这个叫什么啊?测量像和另外维度之间的这种对应关系了,他只是。
104SPSSAU 14:01查看AI文稿AI文稿
14:01查看AI文稿AI文稿嗯,大家好,我是君磊,上一个视频呢,我们呃简单介绍了一下关于信度分析如何去操作,以及啊我们通过一些方法来改善这个信度值。 从这几个开始呢,我们就连续做几个视频来去介绍这个笑度检验如何操作。嗯,笑度检验呢,可能是在我们做假设检验之前啊啊做的最大的一个检验了, 当然有的同学可能是用的非常成熟的量表啊,这一步呢,有可能会跳过啊,但是啊,我们发现啊,就是即有的同学即使是用了非常成熟的啊量表啊,导师依然会建议你去把这个笑度再做一遍啊,这也是有可能。 所以说,嗯,这一步呢,你需要跟自己导师啊去沟通,如果是你是用了成熟的链板,你需要去沟通确认一下你是不是要做这一步啊。如果是你是自己设计的文件,那么一定是要去做这一步检验的 啊。我们可以先看一下他的,看一下他的定义啊,这个定义是我自己写的啊,跟一些概念啊,可能啊,不太一样,但是表达大家都是一样的。嗯, 效度检验其实它代表一是数据的有效性啊,也就是说啊,通俗一点讲,就是你心中所想的,跟你实际所测量出来他是有一致性的,嗯, 如果一致性比较高,就说明你数据的有效性较高啊。放在我们的这个问卷的分析当中呢,就是说你的量表的这个设计啊, 跟你的实际测量出来这个维度啊啊和音子他是一致的,或者是基本是一致的。比如说你有二十个题目,你设计的六个因子, 那么我们用探索性因子分析呢去把它给呃探索出来哎呃,刚好你这个探索出来因子跟你实际所设计的是一致的。 ok, 那么你就说明这个消毒是通过的, 那我们应该用呃什么样的呃呃特征来去表征这个效应呢?或者说用什么样的指标来去探来去验证这个效应呢? 那我们我一般是会把这个度减压区分三个难度啊。第一个难度呢就是用 k m 和巴特利求生减压来去操作啊。其实是,其实说呢这个这两个指标呢,他并不是来去减 的这个笑度,他是来去啊来去呃看一下这个数据是不是适合做这个因子分析。嗯,但是呢就是,呃 嗯,原则上讲这不是消毒检验,但是我发现很多的文献当中都是把这个当成一个消毒检验,这个很有意思啊。所以说呃当你的当你的这个笑度实在吞不过的时候,你可以哎浑水摸鱼一把,然后只用这个。呃 啊,只用这两个指标就去表扬这个笑度啊,当然可能会不会通过啊,也可能也有可能会被通过。嗯,好,那么一般呢,我们是用探索性因子分析啊去做这个笑度的言,这是啊用的最多的,最多的一个。 嗯,他其实是在我们积极学习当中他是一种降为的一种方法啊,我们叫 啊因子分析,降为嘛啊?在这里叫他投降因子分析,他本身上是啊有 n 个题目,有二十个题目你给他降为降成了四为或者五为,然后呢我们能通过因子和载去呃找到这个因子下他跟哪些题目是 啊比较亲密的,因为他哪些题目是归属到哪个因子的,那么这种呢就跟可以跟我们的设计呢所哎呃有一个匹配关系,如果匹配比较高就说明你的效度比较高,我们叫 efa 探索性因子分析,那么嗯, 另外一个比较高难度的这个消毒检验呢,我们叫探索性因子分析加验证性因子分析。嗯,简单来讲就是我们探索出来这个因子之后啊, 再用啊结构方程或者是啊验证性因子分析啊,去跑一下,看一下你这个啊,你探索出来这个是不是一个良好的一种啊?结构啊,这两个用探索性因子分析加验证性因子分析呢, 这种方法呢,他是呃最能够让人幸福的,当然他的一些指标想达标的话也是最难的,所以说啊, 一般本科是很难很少去做这个这两个呃分析来做泄露检验的,一般是研究生阶段呢会用这个分析, 本科生我建议就是用探索性因子分析就够了。好,我们今天呢就先讲这个探索性因子分析。 好,我们还是先看一下这 这个呃表格的样式。呃,因此分析呢,他有很多种表格样式。嗯,但是这种呢是我觉得呃是最方便的。因为什么呢?因为他是直接可以从 spss 中呃 去输出的,也是直接可以用的啊,我觉得不需要再大改了。嗯,当然也有其他一些比较啊,综合的形式啊,那种也是可以的啊。嗯, 好,我们先先介绍一下这些表格。第一个表格呢,他是啊刚才我说的 km 和巴特利群体验这个指标呢怎么看呢啊?首先要看 kmo 值啊,这个值呢?呃,也是要看他是不是大于零点六, 嗯,也有的时候要看大本,嗯,是不是大于零点七,这个不是很严格,一般大于零点六我觉得就可以了。呃,当然你要看你导师是不是, 呃,要求你大于零点七啊,或者零点八,呃,然后通过这个,这个通过之后呢要看他这个屁,再看那个他的群里面的配置啊,这个配置如果是小学零点,呃, 小于零点零五,那一般他都是小于零点零一的啊,他,呃,这很容易通过的。这个如果这两个都通过呢,就说明这个数据啊,他可以进行因子分析。好啊, 嗯,可以做印子分析。之后呢,下面我就就开始看那个音。嗯,主持分的 t 恤以及宣传成本矩阵。好,我们下个这个表怎么看呢?嗯,这个表出来之后呢?嗯,首先要看这一列我们叫什么叫啊?特征值。 这节车上知道要看他是不是大于一,或者说要看一下他大于一的有几个,能够大于一的有吗?有四个, 有这四个,也就是说我们,嗯有十三个题目,十三个题目呢,他提取出来四个音字,而这四个音字呢?呃,我们再往后看后看,这里有一个累计 多少多少,我们叫什么叫累计的方差解释度啊,这个呢是百分之七十六点几 啊,这个是比较好的啊,这个累计发达。呃,几十度呢?这个呢也没有一个非常严格的标准,有的地方呢说达到百分之六十,有的地方达到百分之七十啊,这个确实是没有谁严格的标准,反正是越高越好。嗯, 你大家记住,主要是看这个 t 恤度,还有就是这个,呃大于一的个数。好,然后呢,看完这一个之后 啊,我们会看一个碎石图,嗯,这个碎石图呢,我们要看一个拐点,比如说这个地方大概是在这个地方出现拐点, 这地方出现拐点之后呢,我们就会说他,呃,提取二到五个啊,之间就可以了,而不是说他拐点出现在哪里,你就说提取几个适合,这个是没那种绝对的啊,比如说他拐点出现在这,你就说他 说是三到六啊,这样来表达就可以了啊,你看这里,嗯,在这前五数出现平缓之前继续下降,所以提取四个比较合适啊,其实他就是在五出现之后呢,然后说四到六个就比较合适,然后就说啊,提取四个合适,这样好,下面就是我们重头戏 叫悬崖成分矩阵,嗯,这个悬崖成分矩阵呢,他是这样的,就是每个题目呢,在 每个因子下面都有一个值,但是他最大的那个值呢,是他的那个因子的归属, 这里是都有直的,只不过我们把它给省略掉了啊,给他删掉了,因为我们只保留他最大的那一个,所以说我们取最大的这四个呢,那么这啊, t 第一就要提第三、第二、第四这四个题目就属于英子一,那么这三个题目就属于英子二 啊,这三这几个题目都数银子三啊,这都排序好的。好,然后下面你就解释一下啊, 根据学院成分得学院学院成分基本得知。然后啊,哪个题目是属于啊?哪个因子,然后他因子喝了有多少,这里的他解释就比较啊,就比较简洁,如果你想凑字数的话,你就可以啊啊,这个题 他的因子喝的是多少啊啊?写一下,然后他都是打游戏的,然后都可以问他命名为什么好,那下面呢,我们就接着一个数据来操作一下,给大家看一下啊,操作呢也比较简单, 但是有些细节需要好好的注意啊,我来操作大家一定要看清楚。首先我们点击这个分析,分析里面有一个降维降位,里面有因子分析,然后呢我们就把你的量本的题目给它塞进来, 比如说我们把这里的这这个这几个题目给他塞进来啊,加上这个吧。 好,然后呢我们一个一个点这里呢,先点这个描述,描述里面我们需要点什么?点这个 km 和巴特利,这个是一定要点的, 继续,然后抽取,这里呢我们是要点啊,这里我们就不动,一个是觊觎特征值的一个抽取啊,这里是我们不动的啊,有时候我们的抽取效果不是很好,比如说啊,我们 本来想是呃抽取四个,结果他就出来三个,那么这里呢,你就点他强制抽取四个,这里输入一个四,然后你看他出来是什么样子,你就可以去简单的看一下,但是呢我们还是要去看刚才说的特征值的。 好,我们先点他,然后四十图啊,就在这里点个四十图。好,然后我们点这里就旋转,旋转什么?就是旋转成分矩阵嘛,对吧?然后我们这里用最大方叉法好,其他方法就不需要了解,你就记得记得一个最大方叉法就可以了啊,这个是我们嗯 最常用的一个方法。好,我们今天继续,然后得分,这个保存为变量呢,一般是在,嗯, 在哪里会用到呢?就是在那个,呃呃,财务类的这个,因此分析里面,主持人的分析里面会用到这里呢,因为我们主要讲一部件分析吗?这里暂时先不讲了啊。嗯,我们这个也可以点上。好,我们再点这个选项,这里注意啊,我们 有这么一个注意的事项,一个是使用均值去替换这个确实值,然后呢按大小排序,这个是一定要点的,然后取消系数,这里我们点到零点三, 取消系数就是我们呃把那些呃因子核载低于零,低于零点三的我们都给他不敢试,然后我们就确定 好,那么这个就出来了。好,我们可以看一下,其实这个表格呢, 就是我们那刚才我展示的那几个表哥的样子,只不过我们稍微稍加去修饰了一下。好啊,这个就是 kmo 值和巴特利啊,他,他是零点八七七,还是比较高的,然后配置也是良好的。 好,这里呢就是刚才我说的那个啊,特征值,我们看他是不是大于一啊?大于一的有六个,也就是说这六个呢,也就是说这二十一个题目提取了六个因子, 然后累计解释百分之七十二点四的一个方差,这个是比较理想的。然后这个就是,那你就啊,这个地方其实没那么严格,你就大概说一下啊,他是在七这地方出现了 一个拐点,所以呢啊,从五到八提取五到五到八个因子是可以的,所以说我们提取六个因子是合适的,这是六吧,这六个因子是合适的。 好,然后这是成分矩阵,这个成分矩阵跟后面那个矩阵他是不一样的,这是还没旋转之前的,我们不管这个直接看这个。好,这个就是旋转成分矩阵。 那么这个举证呢?你们看他就是啊,这一堆是在一起的,然后呢?我们,呃,这零点,你看这是零点四吧,这零点四我们要看他大的,所以我们要从这开始看,从零点八这地方开始看,然后这停止,然后在这里看, 他给你排泄好了啊,这个地方就是一个宣传成本举证。嗯,那么关于制表呢,我在这里就不多讲了,大家只需要把啊这个宣传成本举证跟这个解释, 磨砂还有开摩托力啊,给他复制一下。这天他到表哥里面已经稍加休啊,稍加那个加工就可以啊,直接 coffee 到味道里面去了。嗯 嗯,燕子飞行到这里就并没有结束,因为我们还要解决一些问题啊,一些我们很常见的一些问题 啊,比如说我们的因子因子分析的效果,比如这指标不达标,我们怎么办?还有就是啊,我们出来结果啊,学院成分举证并不是我们想要的结果,我们怎么办 好这些这些问题呢?我们放到下一节课来处理啊,今天我们就不不多讲了,好啊,我就啊先到这里这个视频,谢谢大家。
342Junlei_D

