fooocus增加图生图怎么搞

粉丝46.5万获赞593.0万
相关视频
 05:55查看AI文稿AI文稿
05:55查看AI文稿AI文稿快看过来, focus 重大更新支持添加控制图片了!这次升级让 focus 更加强大,完全可以替代并超越 me journey, 不仅添加了电图功能,还拥有了 ps 贝塔的局部重绘和图像扩展能力。接下来让我们一起看看 focus 界面有哪些更新和如何使用吧。 首先我们打开 focus 的界面,升级后的界面改变的地方是下方插件栏多了一项输入图像按钮,打开之后分别有三种不同的类别, 分别是高档或变化、图片提示、局部重绘或扩展图像贝塔高档或变化。这项功能作者是根据没哲理的工具栏为灵感进行制作的。我上传一张效果图,在右侧可以选择是变化还是分辨率提升,比如我选择变化微妙,提示词况中我不填写任何的内容。点击生成, 可以看到生成的图片和效果图非常类似,但是仔细看细节又是完全不一样的。然后修 修改一下输出图片的尺寸,这里我如果选择强变化,还是同样的参数,点击生成一下, 生成的图片和原图看起来就完全不一样了,但是图片的内容和风格又很好地参考了原图的形式。原图是一张卧室的照片,生成的图片依然是类似装修风格的照片。 高档也很好理解,就是将图片的分辨率放大一点五 x, 即是在原基础上放大一点五倍,二 x 就是放大两倍 fast 二 x 可能就会牺牲一小部分图像质量并放大两倍。 再来看第二栏的功能,这里有四个图像区域可以选择,点击左下角的 avest, 我们看到有三种控制方式,分别是风格迁移、 parakeni 和 cpds。 现在我们来进行几个实际的案例,让你立刻明白这几个功能的作用。案例一,不填写提示词,只上传一个效果图, stop at 值调到一, wait 值调到一, 生成的图片识别出来了风格和内容,并且卧室的细节也非常相似, wait 值调整到零点六, 生成了卧室的图片,也同样是写实风格,效果也是非常不错。案例二,填写提示词, living room 客厅 stop at 值为一, wait 为零点六,点击生成, 可以看到风格被很好的迁移了过来。同样是写实风格,类似的木地板和深色的墙壁,甚至沙发的色系与床的色系都完全一样,真的是惊到我了阿里。三,提示词修改为百种卧室再上传一张风格图片,我希望在图一的基础上添加上一些植物的元素,让画面更有生机。 图一的参数不变,图二的参数保持默认。点击生成,生成的图片在卧室的基础上添加了绿植,并且整体风格还是保持第一张的类似。 四,如果想要风格更加偏向第二张,只需要将其 wage 值调高即可。以上都是功能一, image prompt 的效果,接下来讲一下结合 paracani 的效果。案例四,将刚刚上传的第二张效果图删掉,将同样的效果图移放到第二栏。选择功能为 paracani, 将其 stop act 值调整到一, 填写提示词, pos 粉色的墙点击生成这个功能我是觉得是真的很牛,可以看到生成的图片,整体的物品摆放没有任何修改,将墙壁修改成了粉色,并且自动将床的色系修改的和墙壁类似,整体图片看起来效果更加统一。 hira kenny 的效果就是能够自动识别图像的边缘,并且根据这个边缘去生成出来的图片。如果用过 control net 的同学能够很容易地理解,其实就是类似 kenny 的效果。阿力五,将刚刚的那张效果图作为 image prompt 删除提示词参数,这样调整 可以看到生成的效果达到了。房间还是这个房间,但是风格迁移了。 paracani 的可玩性很高,大家可以使用更多的参考图,再结合提示词,可以有很多的用法。最后我来讲一下 c p d s 的用法, 可以简单的理解为 c p d s 可以识别图片的深度效果,将其转化为灰白色的图,让生成出来的效果也有相同的空间深度。案例六,还是使用卧室这张效果图,功能调整到 c p d s stop at 和 wait 的直兜调整到一, 输入提示词 item。 在只使用 c p d s 的时候,如果不使用图片作为提示词,就一定得写一些文本提示词,因为从 c p d s 输入的信息中是不包含任何这张图片的信息的, 所以得让 ai 知道你生成的图片主题是什么。点击生成,生成的风格就不再和参考图一样了,但是空间透视和整体房间的布局都被保留了下 下来具体生成什么风格就可以通过提示词去描述或者添加图片提示词都可以。最后就来讲一下局部重绘或扩展图像功能。我们先演示一下局部重绘的效果,将需要修改的图片上传到这里,然后点击图片右上角,这里有一个笔,点击之后就可以在图片上进行绘制。 比如我想在图片的这个区域趴着一只狗,我将这片区域进行绘制,然后在提示词中填写 dog, 点击生成 图片,就在对应的区域生成了一只符合透视和光影的狗。再换一个,我想把这幅画换一张,换成梵高的星空。绘制豪蒙版区域之后输入对应的提示词,点击生成, 还是符合透视正确,光影正确,甚至绘制的画作也确实的梵高的画作一样,这就是局部重绘的能力。然后展示一下扩展图像的功能。点, 点击这里清除画面上的蒙版,然后选择要扩展的方向,比如我想要将图像的左右两侧扩展的更宽,就选择上左边和右边。然后还有比较重要的一点就是需要调整画面的尺寸,比如我现在的图片是方形的,扩展两侧,所以生成的画面应该是横着的长方形, 我选择这个一一五二乘八九六的尺寸,不填写任何的提示词,点击生成可以看到画面将左右两侧自动地补全了。 以上就是这里 focus 更新的几个非常实用的功能了,这期让我感觉主要有几点比较吸引我,主要是出图速度、出图质量、应用性、风格、迁移效果这几个。而且我感觉使用 focus 比 major need 更简单。我将 focus 的安装包放在了视频简介或者粉丝群中, focus 的基础操作和安装可以去看我之前的这期视频,我有对 focus 的功能详细讲解,相信看完就能熟练掌握 focus 的使用。以上就是本期视频的全部内容了,我是设计师,学 ai, 教你实操,正于虚言,我们下期再见。
651设计师学Ai 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿这些都是同一个提示词生成,你敢信?接下来我手拉手教你复刻组文生图。打开复刻后,我们输入一个提示词,这样就可以生成了。 接下来我们选择高级选项,可以看到效率和分辨率、图片数量、反向提示词以及随机种子风格。这里保留 focus v 二选项,勾选其他风格。我们再次点击生成 内置的一百九十多种风格,不仅可以单独用,还可以组合使用,总有一种能满足你,这里就不一一演示了。得益于 sdxl 大模型,这里几乎不用任何设置。最后我们来看下生成的记录,除了可以看到生成的图片,还 能看到每个图片的详细参数,正反向提示词和福克斯自动扩展的提示词。看到这里你就明白为什么要推荐勾选福克斯 vr。 好了,快去试试吧!下期介绍福克斯图生图,喜欢的别忘了一键三连!
 03:18查看AI文稿AI文稿
03:18查看AI文稿AI文稿很多人说现在 focus 升级了,打不开或者生图不成功,一直在那里不动,因为升级了预设也会自动升级,自动升级的文件会自动去爆脸下载模型。这是官方 focus 二点幺点八六四版本的更新内容, 把之前的三个预设都调整了,模型也升级了,默认预设对应的模型由 v 六升级为 v 八。动漫预设对应的模型由蓝铅笔升级 为阿尼玛 pencil xl, 显示预设对应的模型由 realistic stock photo v 十升级为 realistic stock photo v 二十。 这次更新直接升级了模型,是一次重大的更新,蓝雀 focus 现在已经升级了 v 八为默认预设,我测试了各大云平台,还是用之前的老模型,这期我教一下大家如何手动更新模型和预设。这三个模型我已经转载到里部上面了,你们先 把模型下载了,放到对应的文件夹,然后把我给你们准备好的三个预设文件也放到对应的文件夹 resets 文件夹内。如果我们想默认改为动漫预设的,我们就在 focus 文件夹这里找到 focus mv 文件。最后这里加入这个代码,空格 reset and 美食保存文件,然后重启一下。因为这个操作在之前的视频已经详细讲解了,具体你们可以看这个视频。如果我们想默认改为写是预设的,最后这里加入的代码应改为对应文件名的名字, 空格 preset realistic 二十,记得保存重启。现在简单用一下三个新模型出图。第一个当然是 v 八了, 然后动漫的 最后写时的 补充两点一,打不开或者声图不成功,一直在那里不动,按刚刚的操作一遍就可以了。 二、有些云平台如果在历史记录这里出现了看不到图片的情况,可以以下操作,在 focus 文件夹这里找到 web boy 拍文件,打开文件, 在 blocks pass 上面异形添加 allow pass 等于 root owners and guy t m p bookest outputs 保存文件,然后重启一下就可以了。 其他云平台如果也有这个问题的,也可以私信一下我。这三个模型真的不错,你们也快去体验一下吧! 今天的分享就到这里,关注我的频道。通俗易懂的教程,手把手教你云端学 ai, 记得点赞收藏哦!后面还有更多的干货,我们下期再见!
21兰雀AI云教程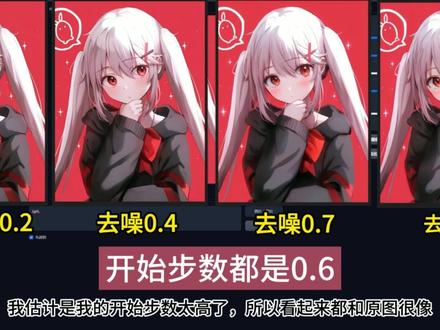 08:55查看AI文稿AI文稿
08:55查看AI文稿AI文稿ai 绘画的门槛已经降低到这种程度了吗?如此简单的操作,页面直接内置将近两百多种风格,骑手式,喜欢什么风格点什么,其实只是录一个 one girl 的提示词,出图的质量也媲美 misony, 甚至风格之间还可以随意搭配,产生意想不到的效果。 不更改提示词,一键更换风格,预设 ai 绘画简直不要太简单,并且作者宣称最低电脑配置要求 四 g 显存,二八 g 内存就可使用,对新手还有电脑配置不好的人真的太适合了。没错,他就是我上次给你们详细介绍过的福克斯 最近进行的更新,发布了新的 vr 版本,可以称之为 sd 叉二整合包。然后经过另外一个作者魔改,新增了 ctrl 那个功能,可以上传任意的图片,利用 ctrl 呢对图像进行风格化处理,还新增了图声图的功能, 这也是你们一直想要的。还有图片之间元素融合的模型,接下来我就看看怎么一回事。整合包我会放在粉丝群 还有视频下方。点击万启动页面,先在底部提示实框输入一个简单的网格哦。点击右边的生成,可以看到图片的效果已经捍卫成另一样了。再把下面的高级设置打勾,可以看到右边多出来的设置。第一个,速度代表迭代步数,三十步去画图, 生成图片速度会快一些。第二个质量代表迭代步数,六十步去画图,产生的图细节会更多。第三个是这是新更新的,可以自定义迭代步数,他还是一样可以自己设置迭代步数,这里我们就选择质量也就是六十的迭代步数。去画图之前,这里的分辨率选择占用的位置很大, 所以作者更新后把分辨率的选择更改为这样的下拉式菜单,不会再用太多画面风格,骑手似的预设也是一样, 并且新增了几十种风格预设,还可以多选风格,可以多种风格搭配一起使用。这里的快速扩展也是被二版本的更新勾选上后,会在你的原始提示词的基础上,为你动态的新增提示词。下面的图片数量就是你想一次生成多少张图片,你就拉到多少就行了。 这个很好理解,我就设置唯一一次出一张图,封面提示词也不用多说了。下面这里就是种子,上次的视频也详细讲过,不知道的可以去看。今天重点来讲新增的图生图功能, 还有后面的跟出游乐的功能。图声图这里分为两个部分,这里的勾选其实就是我上次讲的 sd 的 revision 功能,勾选它后会多出四个可调整的参数,最多可以对四张图进行元素融合。我先讲下面的图生图参数,这个 revision 放后面讲,前面两个是正负提示词的强度,也就是提示词的权重,你可以让 动更改数值,从而决定提示词对图像产生作用的大小。下面这个开始步数,如果步数越大,最终生成的图片就越像原图。相反,如果数值越小,最终生成的图片就越不像原图。比如点击加载图片倒输入,可以上传自己的图片。以我上传的这张图片为例,由于时间原因, 我提前生成了四张开始步数,零点七代表图声图过程中绘画到百分之七十才开始对图片进行改造,等于只改了后面的百分之三十,所以他原图最像开始步数零点零五, 基本上是一开始就对原图进行改造,所以是变化最大的。下面这个去照强度我测试了一下,对原图的影响不是很大,也给你们看一下测试的结果,如果有更多的见解,评论区告诉我,我估计是我的开始步数太高了,所以看起来都和原图很像,这样就代表 开始步数零点六以上去照强度,对原图的影响就不是很大了。图像比例,也就是放大图片的功能,最高可以放大到两倍,我测试过几次,放大图片的速度很快,分辨率会放大两倍。如果你要使用图生图,就点击左边这个上传图片,一定要记得把这里的图生图打上勾, 不然会没有作用,然后再调整一下右边的参数就可以了。接下来讲这个微微信的功能,把修改打上勾,你必须先上传你需要融合的图片, 点击右边这个加载图像进行修订。我就随便上传两张,就这两张吧,按住 ctrl 键进行多选,只上传了两张, 就只需要控制上面两个参数即可。图像一代表左边的一张,图像二代表右边的一张图,一的元素容和数值拉到一点二。二、图像二的元素容和数值拉到一点五。三、使用微微震功能,记得一定要把图声图的勾选 去掉,可以不写提示词,直接点击生成。由于图像二的融合数值更大,所以生成的大概率是人,同时在人的基础上又融合了图像一的元素,所以最终就是这样的效果。背后的风景,还有人物身上的颜色都有图一的元素。这里再把图像二的融合元素增多一些, 把图像一的融合元素减少一些,颜色明显没有上张图深了。然后我又上传了四张图片进行融合,分别调整了一下他们的融合数值,可以很明显的看到四张图片的元素都融合进去了,我就不多讲了, 你们可以自己去试一试。接下来讲一下这次新增的 ctrl 的功能。由于模型是 sd 叉 l 的,所以作者只增加了开力,还有大指深度。先演示一下开力的使用,你要使用哪个就勾选哪个。下面这些数值都是和 sd 是一样的,前面两个是检测边缘的玉值,对于模糊一些的图片,这两个值越低, 检测到的边缘会越多。这里的开始就是开立开始介入的时机。下面的停止就是开立结束介入的时机。先点回图声图,上传一张图片作为演示,然后把分辨率更改他原图一致, 不然最后出图会拉伸或者扭曲。我是想把古人的图片变成写实的风格,还原古人的面貌。我这里就选择这个电影风格的预设吧,我懒得找摄影风格了。再回到 ctrl 的设置页面,可以让开力全程介入。开始记录设置为零,停止介入设置为一,就是全程介入。最下面这个就是开力控制的权重, 我想应该按照我原图的人物轮廓生成,所以我把它拉到了一点三。同时我调整了开妮停止记录的数值,还是留给 ai 一些发威的空间。接着写上提示词,一位中国古代诗人的数码照片真实,最后点击生成,可以看到这个还原效果还是相当 不错的。而且我写的提示词极短,开立主要就是用来检测出图片里面的边缘,然后根据边缘深层清图,这些数值不是死的,要学会灵活调整,从而达到最佳的效果。 关闭看,你再把 type 深度的勾选上,数值也都是哈拉斯是一样的,我就不多解释了。我这里把数值调整为哈拉斯的默认数值一样,也就是全程参与控制。写一下新的提示词,一个戴着帽子的机器人,再把预测的风格换一下, 选上生地风格,再搭配上霓虹朋克风格,看看会产生怎样的效果。这个效果还挺酷的,用 depth 深度去控制图片, 真诚的图更有空间感,也就是层次感会更好,同时 ai 发挥的空间也很大。接着往下看,这里是模型的选择位置。我为什么说福克斯四 sd 叉 l 的整合包呢?因为它可以用来装领所有的 sd 叉 l 的模型,而且可以随意选择更换。比如我这里, 你换了一个我从 c 站下载的大模型,下面这些是 lola 选择的地方,也是可以随意选择的,旁边是权重的调整。我从 c 站复制了一份提示式过来,试试切换的这个大模型怎么样。风格预设,这里我就选择了一个游戏马里奥风格。 这个图片的质量真的比 sd 一点五模型要好很多了。很多人因为电脑配置用不了 sd 叉 l 模型,但是福克斯对配置要求并不高,而且非常容易上手, 是韩小白,也是开源免费的。感谢这些作者,我也下了一个劳拉,我们测试看一下效果怎么样。底膜就继续用刚刚下载的大模型,调整一下劳拉的权重提示,水位也复制过来了。记住劳拉的使用还是和 sd 是一样的格式,还是这样写就可以, 我就加快速度了,我这里就是换了几次提示词,还有大模型,这个风格我还挺喜欢的。暗黑系列来到采用这里,都是 sd 的参数, cfg 值,还有颗粒跳过程,还有采样方法,这些都是 sd 的参数,就不多讲了。采样清晰度,上次的福克斯视频也讲过,值越高,图片越立体,越锐化。终于讲到最后一项了,这里也是新更新的,作者还是很贴心,你可以选择要输出 png 格式的图片还是 jpg 格式的。 下面的。将原数据保存为之神,顾名思义就是把作图的参数保存为之神文件。右边这个是把原数据保存在图像中,方便你下次直接调用。来到这里,点击加载提示,然后上传做的图片就可以调用上次的参数了。 我会把所有需要用到的模型打包整理好给你们拿到解压急用,等于是把我的这份打包给你们了。这里压缩了很久,顺便告诉你们模型放置的位置。点击这个文件夹,再找到 model 文件夹,这个文件夹 是装模型的位置。你如果下载 sd 叉 l 大模型,就放在叉 point 这个里面。下载 sd 叉 l 的罗拉模型就放在这个里面。 ctrl 模型放在对应的文件夹里面。微微字模型放在微字文件夹里面,当然我已经把这些都放好位置并且压缩好了,你解压后 只需要把你喜欢的 sd 叉和大模型还牢牢模型放到对应的文件夹里即可。我也会把作者的教程还有详细说明放在视频下方,你也可以自行下载。能看到这里,证明你是个非常爱学习的人,关注我,让你在 ai 的学习上少走弯路。
1108带你吃火锅 23:082像素洋葱
23:082像素洋葱 02:46查看AI文稿AI文稿
02:46查看AI文稿AI文稿大家好,今天给大家介绍一个最新的文字生成图片工具,同时它也是一款可以帮助我们赚钱的工具,它就是福克斯。众所周知,二零二三年是人工智能元年,各种代工具百花齐放, 其中最让人眼前一亮的工具就是根据文字生产图片,有些有先见之明的人已经靠这个工具实现财务自由了,比如我们在抖音刷视频时,经常刷到这些视频,除了美女视频,还有风景壁纸、可爱萌宠等等, 这些都是可以通过 a 工具生成的,已经有好几个类似的号,已经几十万粉丝了,按照播放量计算的话,一个月赚两三千是没什么问题的。 如果大家熟练掌握了今天这个工具,也可以像他们一样在自媒体平台赚点零花钱。这个软件是开源的,现在的使用人数也挺多, 为了防止视频审核,不过稍后我把地址放到评论区,有需要的可以自己下载。福克斯可以安装在本地的,将代码下载到本地之后,点击一键运行脚本即可。不过这类 a 工具对电脑的性能要求比较高,我们试用的话 可以采用云服务的方式运行这个软件,我们点击这个按钮,系统会自动跳转到云服务器界面,然后我们点击这个运行按钮,等待几分钟,出现这个链接时就说明服务器部署成功,然后我们点击这个带字母的域名, 就进入到了软件系统中。我们先来生成一个星空的照片,关键词虽然都是英文的,这个大家不要害怕,这些都是我用翻译软件生成的,大概不到一分钟就可以生成一个图片,而且生成的图片都非常的高清,没有版权限制, 这种风景图片是非常漂亮的。我们再来看看生成美女图片的功能,美女的关键词也比较多,大家有需要的可以在评论区留言,或者大家私信我,我单独给大家发。关于这款软件的用法还有好多没有讲到,也可以私信留言, 看到后都会第一时间给大家回复。最后我们来欣赏一下这款工具生成的图片吧!
 02:01查看AI文稿AI文稿
02:01查看AI文稿AI文稿想玩 ai 生图,又胡老王上 ai 生图小程序都要钱,来试试这个新出的 ai 生图软件 box, 真正的一款适合每个人的 ai 绘画工具,一键打开,一键生图,而且完全免费,美女美景、美食、萌宠、豪车产品图等等各种图片任意生成, 只有你想不到,没有他做不到的图来,下面我带大家感受一下。文件解压出来以后,双击这个 ren, 等待一下就会跳出使用界面的。用过 vip ui, 对于 fox 应该不会陌生了,他把这边做到极简,非常的清爽,仅仅保留了常用的一些功能,其他杂七杂八的功能都没有加进来。主打就是一个专注创意生图, 且哪怕现在你什么都不用操作,点击生成他也是可以自动的出图的,而且图片的质量非常高。如果你要定制图片也是非常简单,直接在这个框框里面输入就可以了,但注意一点,并是老外的软件,他是需要输入英文 文的,但是不懂英文也不用担心,可以找到翻译网站翻译。来,我给你们演示一个,直接描述你想要的图片就可以了,然后写一个,好吧,站在街头的老爷爷牵着小女孩的手,哎,翻译出来管他对不对,直接复制过去就可以了。来再次生成, 可以看到我们描述的东西都有了,而且生成了两张质量也非常高的图片。 ok, 那么他有进阶的操作,左上角有个按钮,点开他 打开高级选项,右边这里选项是可以设置的。第一个就是出图的时候要速度优先还是质量优先,质量优先的话速度会慢一点,但是细节会更多,效果会更好。来,我选一个质量优先,再次生图对比一下效果,可以看到现在比之前的图片的光感更好了, 细节也更加丰富了。在下面就是图片的比例,软件默认是一一五二乘以八九六,如果不适合的话就自行调整图片数量,默认是两张,就是一次 出两张图让你选,然后上面风格选项,这里就是你可以选择的图片的风格种类非常多,问的就是电音感,所以刚才出来的图质感都非常好,很有电音感。我们再换一个漫画风格,然后 不换我们再尝试一下。哎呀,现在出来就是漫画风格的,完全没问题,然后至于其他的风格,大家自行尝试就可以了。想要获取工具评论区留言或者私信我。
105阿硕讲ai 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿是什么免费的神仙软件让收费的 ai 绘画公司都开始骂人了?不是复杂的 stable diffusion, 也不是每月二百的 meet journey, 而是只用一键安装,最低只需四 g 现存和八 g 内存。开源免费的 focus。 再看看这炸裂的出图效果, 真香!哎呀!默认的绘画界面十分简洁,输入框描述你想要的提示词,点击左边的 generate 就可以出图了,这也太简单了吧! focus 实现了 s d x l 模型的最佳配置自动化,能够忽略复杂参数,像 meet journey 一样专注于书写提示词就行。而面对你的进阶需求, 只要点击 advanced, 就会弹出同样简洁明了的高级选项, performance 选择出图偏向、速度还是质量。下面是设置图片分辨率, image number 表示每次生成几张图片。 negative prompt 输入的是负向提示词,取消勾选 random 可以设置随机种子。更贴心的是 style, 这里预设了各种绘画风格,简直对新手太友好了! advanced 选项可以设置使用的基础模型和 lora, 默认即可。下面的 sampling sharpness 数值越高,图片的锐度和细节度就越高,可根据出图效果自行调整。安装更是简单无脑,只需按照项目指引下载压缩包并直接解压, 然后点击 run band 就可以一键启动了。注意,首次启动会自动下载 sdxl 的 base 和 refiner 模型。网络不好的小伙伴可以我的粉丝群给你安排上,我是局大,分享更多 ai 干货!
2791橘大AI 03:56查看AI文稿AI文稿
03:56查看AI文稿AI文稿今天的这个视频呢,对上一讲视频的一个补充,我们上一次的视频呢,我们打开的是这个 run 点 bat 的这个程序,那么下面呢还有两个程序,一个是 run enemy, 还有一个 run realistic, 那么这个 enemy 呢,就是动画的意思, 下面这个 release take 就是真人的意思。其实这两个启动程序呢,和第一个启动程序打开的内容其实是一样的,它主要是给你设置了两个预设,一个动画的预设和真人的预设,它的预设在风格选项这里面呢,给你预设好了动漫的风格, 在模型选项卡里面给你设置好了他要使用的这个模型,还有他的高级的选项参数,就是一些预设的参数而已。那么其实你在 focus 这个文件夹里面,你可以找到 presets 这个文件夹,将这个文件打开呢,这里面你可以看到有 enemy 的 js 文件和 realistic 的 js 文件, 他利用了就是这两个预设,我们可以打开这两个 js 文件,看一下他的这个预设,他的内容呢就是一些设置的参数,主要是针对你如果生成动漫,你可以启动这个动漫程序预设,如果你是真人的话,可以启动真人的程序预设, 这些预设在生成,不管是生成动漫还是真实的人物场景,他的一致性都挺高的,这是官方生成的 一些样例图片,大家可以看一下。那么在你启动这两个程序之前呢,他会下载不同的 sd xl 大模型,那么你可以来到他的官方的这个连接地址,你可以预先呢将他的这个模型连接复制到你的下载器里面,将 模型呢先给他下载好,放入到拆个 prong 的文件夹里面,这样的话在启动的时候呢,他就不会去自动下载这个模型了,这样的话你直接能启动这个程序,先下载好这些模型,再去启动这些预设,是比较快速的选择。 那么今天呢,包括是官方又给我们更新了其他的三个预设,一个默认预设,还有一个 s a m 的,还有一个 s d x r 的预设,那么这些预设我们如何打开呢?我们来到他的根部路里面,其实呢我们只需要复制我们这个启动程序, 然后呢在编辑里面,我们讲把后面的这个杠杠 precise 后面的这个参数这个名字给他改一下,将这个 an name 呢给他改成我们 jason 文件的文件名就可以了,后面的 jason 呢 可以删除掉,不要只输入前面的文件名就可以启动 jason 的预设。除了这些 jason 预设的,我们也可以创建自己的预设,就是在我们的 focus 这里面,我们设置好这些参数和风格之后呢, 我们可以将这些风格参数给它复制到 jason 文件里面,比如说对应的模型,精修模型,还有 lora 模型下面的采用器设置,将这些参数一一对应修改到这个 jason 文件文本文档里面之后呢,代表我们已经保存了我们自己的预设, 我们下次自己创建一个启动程序,将后面的这个预设呢给他修改一下你的预设 js 文件名,这就是你自己的预设启动器了,那么就是这个意思,那么这样操作起来呢,可能感觉比较复杂,但是我觉得之后呢 focus 作者啊会将这个 focus 呢做的更人性化一点,更方便一点,那么今天的关于这个 focus 呢就分享到这里,那么下一期视频呢, 将给大家分享一下,就是他这个,他这个图像缩放放大之后呢他的这个放大模型呢,和我们 sleep defusion 或者是康菲 ui 放大模型进行一个对比,让大家看一下它的效果如何。今天的视频分享呢就到这里,如果大家觉得这个视频呢对你有所帮助,那么请为我点击关注加三连,这样的话可以帮我增加平台的权重,那么谢谢大家。
 06:26查看AI文稿AI文稿
06:26查看AI文稿AI文稿draw things 加入 focus in paint 模型也许是目前 sd 最好的 in painting 模型,今天继续为大家介绍一下 draw things 这款 mac 端 sd 工具的进化。因为该软件最近加入了基于 sdxl 的 in painting 模型,可以在更高级别的美学层面对大尺寸的图像进行填充、修复和扩图。 相信大家也都非常清楚 in paint 模型对于 ai 绘画的重要性,能够智能的修复和拓展图像。 focus 是中国 ai 开发者张云敏既 control net 之后推出的独立的 stable diffusion 绘图程序。 focus in paint 模型被认为是最佳的基于 s, d, x l 的修复变种开源模型。 该模型能够及时加入 draw things, 是一项巨大的进步和能力跃升。下面大狂将在电脑上为大家演示 focus in paint 的使用方法以及我的一些使 实践和发现。第一步,下载模型 focus in paint 是一个非常强大的修复模型,既可以以基础底膜的形式存在,也可以以 lower 的形式存在来搭配其他基于 sdxl 的底膜。 所以在这里请大家分别在基础模型和 lora 里面找到 focus in paint s, t, x l v 二点六来下载。建议大家下载巴贝特的版本,可以占用更小的空间,有更快的出图速度。第二步,使用方法演示 首先我们需要一张底图,我用 playground 生成了一张狗坐在板凳上的图片。 第一种情况,我们以 focus in paint 作为底膜来扩展图像,把原来的一比一的方图扩展成三比二的横图,两侧留出透明区域设置就和我们 s, d, x l 的出图设置是一样的,在这里我把我的参数分享给大家。 步数我选二十步,文本指导七、采样器用 d p m 加加二 m cares, 可以用橡皮擦稍微涂抹一点原图的边缘,也可选择不涂抹,大家可以自己对比一下。点击生成扩图的过程与 sdxl 出图的过程没什么两样,在我八 g 内存的 m 一上,用时二分三十秒,扩图成功, 大家看看这扩图效果非常的完美。 扩图完之后,我们试试填充效果如何,把狗变成猫试试,我们用橡皮擦涂抹掉狗提示词换成猫,点击生成, 这个结果大家还满意吗?或者把猫眼抹掉,只剩下板凳, 大家看看结果, 效果确实是非常不错,但是时间有点长啊,当然你们电脑配置高,就当我没说,我这个二分三十秒等的挺难受,但是别忘了有 lcm 和 turbo 加速模型啊, 在这里给大家省时间,大家在 lora 那里选择 lcm sdxl base, 然后采样,其选择 lcm, 步数调到四,文本指导调到一至二之间, 再点击生成,仅用时三十秒左右就可以完成。根据我十天左右的测试, focus 主模型搭配 lcm 的 laura 出图并不稳定, in painting 效果还好,但是 out painting 扩图经常会出现模糊没渲染 完成的结果。 所以为了加速,我一般不选择 lcm laura, 而是选择今天我要为大家重磅介绍的 sdxl turbo laura。 turbo laura 这个模型并不被大家熟知,它可以让任何 s d x l 基础模型得到 turbo 加速的效果。有了 turbo laura, 任何 s d x l 的底膜只需要四到五步,用 d p m 加加 s d carrots, 这样极少的步数就可以生成高质量的图片。 同理, focus in paint 是基于 sdxl 的底膜,搭配 turbolora 之后,我们把步数调到四,采样器 dpm 加加 sd carrous, 文本指导一到二都行,点击生成结果如下,经过我的长期测试, focus in paint 搭配 turbolora 是目前最佳的解决方案,速度有非常可观的提升, 同时出图的质量非常稳定。这也是大款我目前最常用到的填充和扩图组合方案。我把该设置保存为 focus turbo, 对于需要扩图的图片随时调用该设置效率高,同时效果非常理想。 第二种情况是 focus in paint 作为 lower 来使用,这样做的好处是它允许你搭配任何其他基于 sdxl 的主模型,有助于生成 风格一致的填充或括图。还是刚刚那张狗狗的案例图。我们在 lora 这里选择 focus, 那么主模型的选择面积很大了。主模型你可以选择一般的 sdxl 微调模型,比如 dreamship xl, 那么步数就得二十步往上,文本指导也要调到六到七,出图速度会比较慢,但是质量有保证。 最好的办法是主模型,你也可以选择基于 sdxl turbo 的融合模型,比如 dreamship turbo, turbovation realistic research turbo 等,那么你就可以基于该主模型的特点,以较少的步数快速扩图和填充了。 可以说 focus in painting 个基础模型,一个 laura 这套组合拳,再搭配上 turbo 模型的加速快车,让 draw fans 变得非常好用。再次把 ai 填充和括图提升到一个 sdxl 级别的水平,在 mac 端进行 stable diffusion 创作,我早已完全依赖 draw fans 这款软件, 也希望今天我的实践和分享可以帮助到同样使用 dt 创作的朋友。如果有任何问题可以添加大狂讨论,我们共同进步。我是工具狂效率提升专家,欢迎订阅关注。
127工具狂Toolbuddy 03:34查看AI文稿AI文稿
03:34查看AI文稿AI文稿大家好,今天给大家分享两个工作流,这两工作流的功能呢,都是一样的,他们都是主要来分析图声图,使用 inpent 遮罩重绘,我们来分析如何达到一个最好生成比较逼真的一个效果。我们首先来看这个第一个工作流,从上到下, 我们使用了三种方式来进行一个 input 的一个绘制。上面第一个方法呢,我们是使用了一个最普通的一个 inputting va e 的解码器来进行 input 的一个绘制。我们的提示词是一辆汽车呢, 行驶在路中,按照我对素材图像的左下角的部分呢进行遮照之后生成的这个汽车在路上是一段被截取的一个片段,这样的图像是不能用的。接下来呢,我使用第二种方法,就是使用这个硬喷子猫的 看迪士尼进行一个 input 混合的一个效果来正常看一下,结果图呢,仍然是汽车被截断的效果。接下来呢,我们就使用第三种方法, focus input。 这里呢需要我们去下载这两个模型,我们需要将这两个模型放在 input 的 这个文件夹里面,这个影片子的文件夹是在我们康威 ui 的 models 模型文件夹的目录里面的,它生成的结果图像会融合的比上面的两种方法会更好,这是 用 focus 生成的效果好,那我们去看一下第二个工作流,这是第二个工作流,它仍然是使用了 focus inpent 的节点呢来进行一个重绘,而上一个工作流,我们最后使用 focus input。 input 用的工作流方法是是一样的,只不过这次素材图像为他进行遮罩之后呢,我们要为他生成一个小猫的一个提示词, 让猫呢站在我们的车前面,结果图已经生成好了,那么我们可以看到生成的结果图,这只小猫的这个边缘呢,还有身体旁边的这个位置处呢,有一些 不规整的东西,然后我们又为他连接了这个节点,用这个节点呢再次去连接 v e 编码器加音喷子混合的一个新的节点,再次使用 focus 音喷子再次为他进行一次重会, 那么这次重会呢,我们要对这个节点里面的这个图像要再次来对他进行一个遮罩,这次我们要遮罩的地方呢, 就是我们这里面看起来边缘不规整的地方,为他去涂抹掉, 将边缘很明显的部位呢去为他进行一个涂抹,进行保存遮罩,然后我们再继续往下对他进行一个重绘,这是重绘之后的这个效果图,可以看到猫的耳朵呢也进行了修复了, 那么边缘有一些很明显的这种阔的位置呢,也进行了一个重绘修复,毛发这边呢也变得好多了。那么这就是第二个工作流的功能,是对第一个工作流呢进行一个继续的一个优化,那么这两个工作流呢我都会发在网盘里,大家可以去免费下载。 那么今天的分享呢就到这里,如果大家觉得今天的这个工作流呢,你需要他或者是对你有用,也请帮助我的视频呢增加一些平台的权重,帮我点击关注加三连,我们下期视频再见。



猜你喜欢
最新视频
- 3360无极🫥