批量配置SVC什么意思

粉丝3.4万获赞9.7万
相关视频
 02:32查看AI文稿AI文稿
02:32查看AI文稿AI文稿svgsvcsvg 是英文 staticvar generator 的缩写,是禁止蜈蚣发生器,也被称为禁止同步补长器 statcom。 svc 是英文 staticvar compensator 的缩写,是蜈蚣补偿器。 svg 分为电压型和电流型两种,其既可提供滞后的无功功率,又可提供超前的无功功率。 简单的说, svg 的基本原理就是将自换箱桥式电路通过电抗气或者直接并连在电网上,适当调节桥式电路交流侧输出电压的向位和扶植,或者直接控制其交流侧电流,就可以使该电路吸收或者发出满足要求的蜈蚣电流, 实现功率无功补偿的目的。 svc 用于无功补偿典型的电力电子装置,它是利用经炸管作为固态 开关来控制接入系统的电抗气和电容器的容量,从而改变书电系统的倒纳。按控制对象和控制方式不同,分为经闸管控制电抗器 tc 二和经闸管头切电容器 f c 配合使用的静止无功 补偿装置 fc 加 tc 二和 tc 二与机械头切电容器 msc 配合使用的装置。 svg 是典型的电力电子设备,由三个基本功能模块构成,检测模块、控制运算模块及补偿输出模块。其工作原理为由外部 ct 检测系统的电流信息, 然后精油控制芯片分析出当前的电流信息,如 pfsq 等,然后由控制器给出补偿的驱动信号,最后由电力电子逆变电路组成的逆变回路发出补偿电流。 svg 禁止蜈蚣发生器采用可关断电力电子器件,也就是 ig bt 组成,自唤香桥式电路经过电抗气并连在电网上,适当的调节桥式电路交流侧输出电压的扶植和向位,或者直接控制其交流侧电流迅速吸收或者发出所需的无功功率,实现快速动态调节无功的目的。作为有圆形补偿装置, 不仅可以跟踪冲击型负载的冲击电流,而且可以对斜波电流也进行跟踪补偿。以下是 svg 与 svc 具体比较。
 02:05查看AI文稿AI文稿
02:05查看AI文稿AI文稿上一篇我们说到在视频通讯领域中 svc 区别于 avc 的原理优势,本片我们将聚焦于那些关于 svc 常见的认知混淆,继续为您揭开 sbc 的神秘面纱。 svc 是互联网视频的代名词吗?不, svc 不仅是应互联网和移动互联网,也普遍适用于政务网、企业专网、行业专网 正时,因其卓越的网络适应性,才能恰到好处地实现互联网高清视频应用。 svc 是软视频的代名词吗?不, svc 是一种更先进的编码算法, 在各种专业会议、会商、高规格视频通信等场景,拥有低延时、高质量、高安全的特点,正好是硬件会议室和个人软件应用的最佳结合。 svc 占用 带宽比 avc 更大吗?不, svc 和 avc 的编码算法都是 h 点二六四、 h 点二六五等,算法层面上的压缩能力是基本一致的。不同之处在于 svc 是策略的变化,无论是真率还是分辨率, svc 的多层都不适直接的数字相加。从参考针的角度来看, svc 比 avc 在理论上可能大一点, 可在实际的视频会议场景中,由于图像的变化量本身不大,因此这个差别几乎可以忽略不计。在考虑到 svc 本身允许在网络有丢包抖动的情况下丢掉一部分数据,则实际对网络的要求会更加低而不是更加高。 基于这种可伸缩、可分层的编码特性, svc 架构的应用优化了网络传输,提高了视频对 对网络丢包的容忍性,让 mcu 不再全边全解,只做视频路由分解转发,减少延时,实现实时交互,无需传统视频会议的专线要求,在互联网及移动互联网环境下,完全满足商用及视频应用需求, 网络贷款费用与硬件设备费用实现大幅降低,让更多的人享受到专业视频应用带来的便利。
12小鱼易连 01:28查看AI文稿AI文稿
01:28查看AI文稿AI文稿康康小课堂,我是技术指导毛毛,批量配置工具你真的会用吗?用对之后事半功倍!首先到服务支持下载中心桌面应用软件,选择工具软件,找到海康工具管家下载打开找到批量配置工具, 打开批量配置工具,勾选需要配置的局域网内的设备进行添加 状态显示,在线添加成功。勾选设备,点击批量配置,选择已经配置好参数的设备作为模板, 勾选需要同步的类别, 点击确定显示配置成功就可以了,还可以批量修改 视频参数哦。 先导出模板, 打开导出的模板,填入需要批量配置的参数,建议同型号同版本设备进行操作哦。模板编辑号之后导入模板就可以了, 批量配置工具还可以进行批量升级等操作哦。小课堂下期预告,摄像头如何自动存储到电脑上?关注我,你一定用得到!
588海康威视客户服务![#ai主播 #ai 如何接入so-vits-svc?用什么版本?4.1版为什么会报错?运行哪个程序?在哪下载?
项目地址:https://github.com/Ikaros-521/AI-Vtuber
相关整合/半整合包发布 https://github.com/Ikaros-521/AI-Vtuber/releases/
夸克网盘:https://pan.quark.cn/s/e6755e65dc05
阿里云盘:https://www.aliyundrive.com/s/JRWomhcpeN9
我训练好的4.0的模型:https://github.com/Ikaros-521/so-vits-svc/releases
4.0的旧版本整合包在网盘
羽毛佬视频:【AI翻唱/SoVITS 4.1】手把手教你老婆唱歌给你听~无需配置环境的本地训练/推理教程[懒人整合包]
https://www.bilibili.com/video/BV1H24y187Ko
羽毛佬笔记:https://www.yuque.com/umoubuton/ueupp5
网盘资源大概更新会慢一步,尽量优先GitHub
合集:https://space.bilibili.com/3709626/channel/collectiondetail?sid=1422512
如有bug,欢迎issue](https://p9-pc-sign.douyinpic.com/image-cut-tos-priv/c938e04c79e895207bcc981544b62c4b~tplv-dy-resize-origshort-autoq-75:330.jpeg?lk3s=138a59ce&x-expires=2092154400&x-signature=UYgex9IfcTfQ5snml5X%2FfEP29TA%3D&from=327834062&s=PackSourceEnum_AWEME_DETAIL&se=false&sc=cover&biz_tag=pcweb_cover&l=202604220234227239A92174BA0D3E696E) 12:06查看AI文稿AI文稿
12:06查看AI文稿AI文稿ok, 欢迎大家收看本期视频,那么这期视频来讲一下所有 v i t s s v c 的一个相当的配置,其实我之前是讲过的,讲过一次了,在刚接入这个所有 v i t s s v c 的时候,我已经讲过一次了, 大家可以直接去看这个,那我现在是再讲一次,因为是有些版本问题,当时是没有讲到。 ok, 那其实我这个文档其实是有写了,但如果赶时间的话,我现在就给大家讲一下,如果你是四点一的版本,你可以直接看这边 faq 他们的使用过程,这边有一个报错,因为相关的项目的报错,我基本上都会写在这边 报错,这边有一个这个 a p i 的这个运行的时候的会报一个错,四点一的版本 你需要修改一下这个代码,三十八行这边是传餐啊,接收参数少了一个,就是这个问题。 ok, 那我们先来展开讲一讲,搜索 bics cc, 重新讲一讲一遍啊,再完整一点, 补充下来,官方仓库 word 模型以及使用教程 好,以及修改的内容模型和配置文件。这边也再次的强调了一下这个四点一版本的问题。 ok, 那我们实际来演示一下, 我们两个都演示一下,我们先试看一下四点零旧版本, 这版本现在是没有下载了,我自己是把那个就传了一遍。我们启动的是这个 fast api, 这个脚本是我自己写的,给大家看一下里面的内容。 大家需要注意的是,你这边启动 web ui 的时候,这边它其实是有写相关的命令的,你要看它的 web ui 这边是使用这个 work emv 下面的 python 去运行的,然后我们这边 fast api 发送也是使用这个 python, 然后直接运行这个可以了。那么在运行之前我们先配置一下我们的这个 模型和一个配置文件啊,用用 mitis, 用 miss 的吧,然后在下面 model name 我这边写两个,其实把前面就删了就是了。 嗯,模型地址, logs 四四 k 一卡的一个模型,那么这个模型一般你训练的时候都会生成在这个路径,所以说你训练的时候 啊,但那万一你没训练,你没有训练的话,你就自己创建他。这模型是在的 logs 四四 k 下面,你放这边,那你放别地方,你路径改一下也可以啊,无所谓。然后模型这个名字, ok, 路径写好,然后配置文件是在 config 下面有一个 e 卡的点 jason 可以看一下,它里面有 speaker, 这边是 e 卡,那么 一刻之后要填到我们配置文件里面了。 ok, 那么这个两个都配置好之后,我们就运行我们的, 我就用脚本运行,那么我们的 v i t s 啊,不是搜 v i t s s v c 运行还是比较慢的,我们稍微等待一下, 那么同样四点一也是一样的处理啊,这些不用,这是刚才说的,刚才在最开始已经说过一遍了,就是一样的,只不过他有个代码在新版本的包里面是写错了,所以导致, 导致这个有用户在运行 plask a p i for song 的时候 会报错。哎,我前面是不是读错了,算了,我们这边同样也是这个配置好,这边没配 哦,这边是我训练我新训练的模型,所以说刚训练出来的他是这样子的,然后看下 config 吧,他这 config 训练之后,他就是保持在 config 里面的。 ok, 对上也是一样的, 看一下启动怎么样了。 ok, 启动成功了,看一下运行的这个地址,幺二四七点零点零点一,冒号一一四五, 这个是我们的本地的一个服务啊,这个其实你本地 api 本地的一个 ip 地址,就是局网内也是可以访问的啊。另外的话,我们这边是开了一个 vits faster, faster 在这边做 t t s ok, 那么两个都开好之后,我们运行我们的 g i 哦,已经运行过了,这是一个新的 bug, 就是我们的 gi 运行之后,他有个线程,其实是没有删干净啊,他挂在后台了,所以说导致我们这个监听啊,监听,监听不上了,这个 map server, 所以说我们需要手动的去结束一下这个 python 的这个进程, 然后我们重新运行。 ok, 运行成功,我们配置一下 银河神,用 vits fast, 那用其他的也行啊,用 fast 测试比较快,然后的话往下翻搜 vits vc 启动是配置路径,这边应该要改一下了,我现在是移到 e 盘去了, 没改成一坛的。这个康菲一个死。这个路径。对的啊,端口 ip, 端口说话人音调夹的默认就可以了。 ok, 保存一下, 保存成功,看一下这边搜 mits 啊,已经运行好了,我们直接运行啊,那我们用 mitits 就是看不出效果,因为我们这个, 我们这个啊啊,我们这个两个都是一卡的。没事,我们直接看输出结果,放大一点 啊,你好, 看下日志。你好,可以看到我们这边是 fast 的输出结果,这边就是这个 搜 v i t s s v c, 在调研后,它是有一个这个 will two way 的一个请求啊,这请求是反应的,返回了一个两百,也是没有任何的报错信息。 ok, 我们是合成成功了,不过是有点慢,第一次有点慢,我们看第二次,你知道什么?第二次很快了。 ok, 那就是我们四点零的版本,我们看一下四点一的,那四点一我们刚刚也看到了配置文件和这个模型 也是配置好了,我们也是还刚才说的那个代码需要改一下,就是这个 flask api for 送这边往上翻三十八行这一块,这个 这个传餐少了一个,我们随便加一个就行了,他反正这边没有用到,随便加一个变量在这边就可以了。 ok, 补上,这个我们可以运行了,我们还是到出来运行这边,同样也是看一下这边 y b y 它这个原来是怎么运行的, 也是这个也是这个命令啊。 ok, 我这边好像没有写那个,我们刚好直接趁这个机会我们先复制一下,趁这个机会直接写一下吧。启动,直接叫启动 a p i 吧,简单点,反正也我自己用啊。 然后把这个编辑一下,复制一下这个 flask 的文件名替换一下,这个前面的这个 eq 就不要了。 ok, 保存 变形, 我们现在就直接盯着他来看,把这个也开起来,这样的话我们可以看到他们的动静了, 如果长时间没有运行的话,可以回车几下,可能卡住了, 哎,应该没有别的漏奖的地方吧,我们顺便在直播间出发一下也可以啊。啊,先不说了啊,待会报错了,哎,可以看到给大家看下报错是什么报告,你好,现在是没有 a 片,还没有那个 就有报错啊, can the connect to host 无法连接到我们这个主机啊,这边报了一个错, ok, 这边开起来了, 我们再来一次,这边看合成啊,这边有一个开始的一个日志 数出了二百 站好,没有声音。 四点一可能还是有点问题啊,但大致是没留神,我记得之前是测试成功有声音的,我记得第一次是没没声音,第二次就有声音了,反正也挺奇怪的,我再来一个,你好,有了,有了,第一局没声音啊, 你叫什么名字啊? ok, 那么我们四点一也测试完毕了,那我们最后再来讲一下 在哪下载,当然一般你既然知道这个的话,你肯定知道在哪下载,我们直接在 b 站搜搜 b i t s s b c, 然后就可以看到羽毛佬的整个 包了,再加一个整合包,你们老四点一整合包,他其实是有这个。再来简介文档,文档进来默认是首页,我们点 crosscass, 然后这边右侧目录下面下载完整版,有 google 和百度云的这个网判,这个就是新版的,下载一下 sene, ok 搞定。 那么这就是我们的搜 v i t s s v c 四点零和四点一的相关的一个接入的一个讲解, 那么希望大家在使用的时候能理解一下, 你也不要把这个其他的模型啊乱七八糟的,别的地方的模型考过来就乱用啊,他们有的模型是不兼容的, 那 v i t s 和所有 v t s c c 也是不一样的,你们不是要随便一个模型弄过来就就往上一搞啊,就不能用,不能用。 ok, 那么本期视频就到此说,我们下期视频 name, 拜拜。
 12:19查看AI文稿AI文稿
12:19查看AI文稿AI文稿前两天的时候,我们讲了一个 ai 变声翻唱软件 sorry ssvc, 这个软件他对这个电脑的配置要求很高,很多人可能电脑配置达不到要求,没法使用,今天我们再介绍另一个 ai 翻唱变声软件,就是这个,他呢这个软件对电脑配置要求比较低一点,甚至你显卡两 g 的现存也能使用,而且感觉这个效果也还不错,下面给大家演示一下效果。 下面我们演示一下具体操作。首先我们先安装软件,他这个项目地址里面有这个安装教程,对代码比较熟悉的可以根据他这个教程去安装。今天我们用这个一键整合包去安装,然后这个对新手小白呢也比较友好,这是一个备战大佬然后做的, 将这个压缩包下载到电脑上来,然后解压出来。接下来我们先去准备音频素材,这个素材呢最好你是录制的非常干净的高清的纯人声, 然后你要是声音要是感觉不干净有杂音的话呢,你可以用一个软件去提取一下,就是这个软件,如果你的那个音频文件不是干净的 纯人声的话,你可以用这个软件提取一下,过滤掉一些就是杂音配乐啊,然后只提取出这个纯人声,这个软件我也在网盘里面给共享了,这个软件使用很简单,就是在这地方选择你这个带提取人声的这个音频文件,然后下面选择输出目录, 下面勾选这个 gpu, 然后下面这个选择仅输出人声,点击开始提取就可以了,然后他就会提取出干净的纯人声,而你把所有的那几个音频文件都提取好,这没单个音频文件时长最好在二十分钟以内, 如果这个时长太长的话,你用这个提取的时候,他可能会报现存错误,可能现存就会报了,然后会报错,然后你把它分成几个小音频,几个 个二十分钟以内的短音频去处理就可以了。这个音频都处理好之后呢,我们准备留着使用,然后你把这个软件下载下来之后呢,然后解压,解压之后呢你双击这个启动,我不要啊 这位 vr 界面启动之后呢,我们先点击这个智能音频切片,然后对这个我们提取好的人声,让我去分割它, 你复制这个音频文件所在的目录,然后到这里面,然后你点击这个加载原始音频,他显示加载成功,然后下面这些音频文件文件名给你,这个 音频文件名一样的话就说明没问题。然后你选择这个输出目录,输出目录的话我们还放在这个目录下,输出目录我们就放在这这个旁边 创建一个输出目录文件夹,然后这个保持默认就可以。然后我们点击这个开始切片,他就会把这个这文件夹里面的这几个音频,然后切分成三到十五秒时长的短音频。 切成这个短音频之后呢,方便他系统去训练处理,他显示成功的时候呢,就是说 已经切分完成了,这边可以看到总共九百零四个小音频,可以看一下这个九秒,这是五秒,他就切分成了这种非常短的小音频。这音频切割完成之后呢,然后我们再去训练, 点击这个训练按钮,然后他让你把这个分割好的这个数据机放在这个文件夹下,就是这里面切分好的这刚才 这些这个小音频,然后复制一下,然后放到这个这个文件夹,然后这个文件夹,然后这个文件夹下面,然后把它 小音频片段放全都放到这个文件夹下面,点击这个一键划分数据集,然后生成一个验证集音频,验证集音频就是在这里面,这边就是验证集里面的音频, 这里面你最好不要超过十个音频文件,然后太多的话会影响那个速度,这画风完成之后呢,我们选择这个编码器,编码器它上面都有说明每个 选项的话都有什么样的效果和用途,你可以根据你自己的需求选择就可以。然后你这选择之后,选择好之后呢,你点击这个数据预处理,点击预处理他好了,他下面这个 显示百分之百之后呢,然后上面没有输出其他错误的话,就说明这个数据预处理完成了,然后这完成之后呢,你就可以去设置训练了,他这个需要设训练两个模型,一个是 ddsp 模型,一个是扩散模型, 他那里面这些参数的话,大多数保持默认就可以,主要就是这个批量大小,如果你现存是六 g 以上的话呢,你就设置四十八, 如果是小于六 g 的话呢,你就是适当的减小这个,然后太大的话可能会超出现存。还有这里 如果你显存很大的话,你就选择这个,如果显存不大的话就选择这个,这个的话呢他会速度会快一点。还有这下面这个训练数据类型,如果你是那个显卡 三零一以上的系列呢,你就选择这个。如果三零以下系列,比如说二零一零几那样的文卡的话,你就选择这个,这个这两个他速度会快一点。如果你训练时候报错了,这两个都不支持的话呢,你就选择这个, 比如说你你选这个,你选这个,你训练时候他提示不支持的话呢,你得更换完成之后,再重新写点一下,写入配置文件,然后再去训练。 比如说我们比如用这个,然后这些都设置完成之后参数呢?设置完成之后呢,你点入这个写入配置文件,他提示你配置文件写入完成之后, 咱就可以下面开始训练了。你第一次训练呢,就点击这个从头开始训练,然后点击这个训练,他这两个模型是要分开单独训练, 然后你点击这个训练,点击从头开始,然后点击这个训练模型就可以了,然后你点击训练之后呢,他就会打开终端,我这是选择了继续上次进入接着训练的,就是你点击开始训练之后呢, 他打开的终端会提示你这个训练信息,这些信息其他大部分你都不用看,你主要看这个训练步数,还有看这个值,他就是这个训练步数呢,他越大越好,比如说你训练个两万步,三万步以上,你越大的话,他那个音频转换效果越好。 还有就是说你训练的时间越长呢,他这个值就会越小,越趋于稳定,没有太大变化的时候呢,你就不用再去接着训练了,这个软件他不需要训练太长时间,一般的话你 你训练一两小时可能就可以了。还有他这个你可以查看他这个训练状态,比如说你训练的是这个模型,然后你点击这个模型,然后点击打开他,然后查看这个控制台,等到他输出这个信息之后呢, 就说明你可以查看了,然后复制这个网址,复制他,然后在浏览器记得点里面打开,然后就能看到这个训练状态,就是你看着这个训练步数差不多时候呢,还有这个变化不大的时候呢,你就可以停止了,按键盘上的 ctrl c 停止训练,如果你由于其他原因停止训练的话,你还想继续继续训练的话呢,你就可以点击这个接继续上一次的训练进度,然后点击这个按钮,他就会接着上一次训练。等到你训练感觉满意了之后呢,你可以 训练下一个模型了啊,你就点击这个从头开始训练,然后点击训练这个扩散模型啊,然后他就会打开这个终端界面,然后显示这个显示这个训练信息。比如说你在训练这个扩散模型的时候,他这个中转里面提示你有错误,然后 是这样的错误,什么时候你前面这些你看不懂的话可以不用管,你看到这后面是 b f lvt 十六,就说明你这地方他这个数据类型不支持,比如说你 bf 十六呢, 比如说这个 bflvt 十六,就是这个 bf 十六,就说明他不支持,不支持的话呢,你就选择朝前选一个,然后点击写入配置文件,然后再重新训练扩散模型就可以了,如果中文里面还是输入错误 信息,还是说你这个有错误不支持,然后你就继续再朝前选一个就可以了,然后再点击这个,然后再点击再训练,你感觉训练可以差不多了之后呢,点击键盘上的 ctrl c, 然后中指训练,然后模型都训练完成之后呢, 你就可以点击这个推理,然后点击这个刷新选项,然后这里面就可以看到 训练好的模型,你模型你选择训练步数最大的那个,这里面选择好这个扩散模型,然后这两个都是默认的配置文件,然后你这选择好之后呢, 你就可以上传你的音频文件,下面这些选项都保持默认就可以。然后你可以直接点击这个音频转换,他下面显示这个推理完成,就说明这个音频 转换完成了,然后你可以播放试听一下,也可以点击这个下载,把这个转换好的音频下载到你的电脑上,你播放这个音频,你感觉高音部分或是某些部分他比较沙哑,或者是有有异常的声音的话, 他就说明可能是你那音频素材里面他没有高音部分,然而你转换那个歌曲里面他有高音部分,那样的话呢,他可能就没法转换你的高音,他就会生成那些有异常的声音, 那样的话呢,你就只能重新整理你的音频素材,让他包含高音和低音,就是多个音域部分。然后那样的训练的模型的话,你转换一条歌曲的时候呢,他可能效果会更好一点,但是有时候你那个模型里面他有高音低音, 但是你转换歌曲他还是会有异常的声音,那样的话你可以选更换一下这个提取算法,然后再重新点击转换一下看看,他可能就是声音就会正常了,就是你出现这些就是破音的话, 他无非可能就是你那个音频素材的问题,要么就是算法的问题,你可以试一下。还有他这个软件呢,自带声音实时转换,就是你打开这个软件的这个根目录,然后在这地址栏里面输入 cmd, 然后回车 启动这个命令提示不见面之后呢,你输入这个命令,复制这个命令,然后在这个里面右键粘贴,然后粘贴这个命令呢,然后回车去运行他,然后就可以启动这个呃 声音实时转换界面了。先你选择你训练好的模型,然后这下面选择扩散模型,先你都设置好了之后了,你就可以点击这个开始音频转换, 然后他就会对你输入的声音,然后进行转换,输出这个转换后的声音。还有大家在使用这个的时候,尽量只训练自己的声音,不要去训练别人的声音, 如果你要训练别人的声音的话,你最好获得别人的授权,然后这个你仅供你个人研究学习使用,然后个人娱乐使用,最好不要去做一些违规的事情。好了,大家有喜欢的话可以去试一试吧。
204AI画师大阳 07:53查看AI文稿AI文稿
07:53查看AI文稿AI文稿无功补偿装置在电力系统中必不可少,它的主要作用是提高供配电系统的功率因素,从而提高输电设备和变电设备的利用率,提高用电效率,降低用电成本。 另外,在长距离输电线路中,在合适的地点加装动态无功补偿装置,还可以改善输电系统的稳定性, 提高输电能力,稳定受电端及电网的电压。无功补偿设备经历几个发展阶段,早期的典型代表为同步调相机,体积庞大,造价高, 已渐渐淘汰。第二种是并联电容器的方法,主要的优点是成本低,易于安装使用,但是需要根据系统可能存在斜拨等电能质量问题,纯电容已经趋于少见。目前,串联 电抗器的电容器补偿装置是提高功率因数广泛的一种方式。当用户系统负荷为连续性生产,负载变化率不高时,一般建议采用 fc 的固定补偿方式, 也可以采用由接触器控制的分布头切的自动补偿方式,这个对于中压、低压供配电系统都适用。当负荷变化较快或者为冲击性负荷时,需要快速补偿。例如橡胶行业的密链机 系统对于蜈蚣功率的需求同样变化快速,但是由于一般的蜈蚣自动补偿系统所采用的电容器从运行状态断开退出电网后,在电容器的两极之间存有残压, 残压的大小无法预知,需要一到三分钟的放电时间,所以再次投入电网的间隔至少要等到残压通过电容器内部 的放电电阻消耗至五十伏以下时,才能进行第二次投入使用,所以无法做到快速响应。另外,由于系统存在大量斜拨,由电容器串联电抗器组成的 lc 调斜式滤波补偿装置需要大容量的投入来保证电容器的安全, 但是同时也有可能造成系统过度补偿,令系统呈荣性 s v c。 于是禁止无功补偿装置 s v c static war compensator 诞生了。 其典型的 s v c 代表是由 t c r ferrister control reactor 加加 f c fixed capacitor 组成的,即经闸管控制电抗器加固定电容器组,通常需要串联一定比例的电抗器。静止蜈蚣补偿装置的重要性是,它能够通过调节 t c r 中经闸管的触发延长 直角来连续调节补偿装置的蜈蚣功率。 svc 这种补偿形式目前主要在中高压配电系统中应用,对于负载容量大、斜拨问题严重、冲击性负荷、负载变化率高的场合特别适用, 例如钢厂、橡胶、有色野金、金属加工、高铁等。 svg 目前随着电力电子技术的发展,特别是 igbt 器件的出现和控制技术的提高, 另外一种有别于传统的以电容器、电抗器为基础元器件的无工补偿设备应运而生,就是 svg static y generator, 即静止蜈蚣发声器,它通过 p w m 脉宽调制控制技术使其发出蜈蚣功率呈溶性或者吸收蜈蚣功率呈感性。 s v g 由于没有大量 使用电容器,而是采用桥式电流电路、多电瓶技术或 pwm 技术来进行处理,所以不需要使用时对系统中的阻抗进行计算。 同时,相较于 svc, svg 还有体积小,能更加快速地连续、动态、平滑地调节蜈蚣功率的优点,同时可溶性感性双向补偿。 svg 与 svc 无功补偿装置的对比分析一、工作原理不同一、 svc 可以被看成是一个动态的无功源, 根据接入电网的需求,他可以向电网提供溶性蜈蚣,也可以吸收电网多余的感性蜈蚣。把电容器组通常是以滤波器组接入电网,就可以向电网提供蜈蚣。当电网并不需要太多的蜈蚣时,这些多余的溶性蜈蚣 就由一个并联的电抗器来吸收。电抗器电流是由一个可控硅阀组控制,借助于对可控硅触发向角的调整, 就可以改变流过电抗器的电流有效值,从而保证 s v c。 在电网接入点的无功量,正好能将该点电压稳定,在规定范围内,起到电网无功补偿的作用。二、 s v g 以大功率电压型逆变器为核心, 通过调节逆变器输出电压的浮直和向位,或者直接控制交流侧电流的浮直和向位,迅速吸收或发出所需的蜈蚣功率,实现快速、动态调节蜈蚣功率的目的。二、响应速度快 一般 s v c。 的响应速度是二十到四十毫秒,而 s v g 的响应速度不大于五毫秒,能 更好地抑制电压波动和闪电。在相同的补偿容量下, svg 对电压波动和闪变的补偿效果最好。三、低电压特性好 svg 具有电流源的特性,输出容量受母线电压的影响很小。 这一优点是 svg 用于电压控制时具有很大的优势。系统电压越低,越需要动态无功调节电压。 svg 的低电压特性好,输出的无功电流与系统电压没有关系, 可以看作是一个可控恒定的电流源,系统电压降低时,仍能输出额定蜈蚣电流,具备很强的过载能力。而 svc 是阻抗型特性,输出容量受母线电压的影响很大,系统电压越低,输出蜈蚣电流的能力成比 降低,不具备过载能力。因此, s v g 的无功补偿能力与系统电压无关,而 s v c 的无功补偿能力随系统电压的下降线性降低。四、运行安全性能提高 s v c 以可控规调节电抗,加多组电容作为无功补偿的主要手段, 极容易发生邪震放大现象,导致安全事故。系统电压波动大时,补偿效果受很大影响,运行损耗大。 svg 配套电容器不需要设置滤波器组,不存在斜震放大现象。 svg 是有圆形补偿装置,是采用可观断器件 igbt 构成的电流源装置, 从而避免了斜震现象,运行安全性能大大提高。五、斜拨特性 svc 利用可控硅控制电抗器的等效激波阻抗, 不仅受到系统斜波影响大,而且自身会产生大量的斜波,必须配套采用滤波器组滤除 svc 自身产生的斜波含量。 svg 采用三电瓶单向桥技术,单向可输出五电瓶电压波形, 采用再拨一项的脉冲调制方法,不仅受系统斜拨影响小,还可以抑制系统的斜拨。与 svc 相比, svg 采用多重化、多电频或麦宽调节技术等措施后,大大减少了补偿电流中的斜拨含量。六、占地面积小 在相同的补偿容量下, s v g 的占地面积比 s v c 的减少二分之一到三分之二。由于 s v g 使用的电抗器和电容器比 s v c 少,因此大大缩小了装置的体积和占 地面积。 s v c 中的电抗器不仅本身体积比较大,而且考虑到相互间的安装间隔,整体占地面积较大。综上所述, s v g 无功补偿装置具有响应速度快、 斜拨含量少、蜈蚣调节能力强等优点,可以大大改善电网的电能质量,目前已成为蜈蚣补偿技术的发展方向。
166电气联合战线 06:12查看AI文稿AI文稿
06:12查看AI文稿AI文稿ai 孙燕姿火遍全网,以 b 站为例,由孙燕姿翻唱的各种歌曲都异常火爆,不过由 ai 孙燕姿生成的歌曲过于真实,导致互联网上出现了很多反对的声音,因为此类型的歌曲很可能会导致侵权行为。 不过,由于针对此类音乐的版权法规还未出台, ai 孙燕姿音乐仍然可以在 b 站 youtube 平台播放。 ai 孙燕姿的制作主要使用了 sovics svc, 这是一个开源的人生克隆项目,由 b 站的羽毛部团开发。 so with 可以通过输入人生样本训练模型并模拟某个人的音色。现在我就为大家演示一下操作流程。在开始前,你应该准备一 一张支持 code 现存六至以上的英伟达显卡,以及 windows 十及以上的操作系统。今天所用到的工具和数据及小微已经整理完成, 感兴趣的同学可以通过电子邮件联系小微获取百度网盘下载地址。值得注意的是,为了尊重音乐创作者的版权,请大家不要在未经授权的情况下制作音乐或者商业化使用。 第一步,下载最新版的 solids svc 四点零整合包,完成下载后解压文件即可启动 webui。 第二步,准备高清的声音素材,用于 ai 学习。值得注意的是,为了获得最好的音色, 大家应该使用无损的人物原声作为训练素材。如果你有歌手的 cd 唱片,则可以提取音轨并保存为 flac、 alac wave 等格式的文件, 或者直接下载 flac 格式的音乐。第三步,使用专用软件提取人声。 进入 google 搜索在线人声提取词条,选择第一个搜索结果 vocal remover 从本地上传一个音乐文件, 等待几秒钟后,系统就会完成人声音乐的分离,把分离后的文件下载到本地即可。如果你觉得处理的音频不够清晰,也可以使用专业开源的 ultimate vocal remover 工具,也叫做 u v 二五,完成最佳的人声提取。 uvr 同时支持 windows 和 macos 系统,大家可以点击下方链接,在 uvr 官网或 gap up 下载最新的版本, 下载并安装最新的 uvr 五点五版本,点击 select input, 从本地上传需要分离人生的歌曲。 select output, 选择输出的目录即可。 在此我建议大家选择位格式输出,选择三二零 k 的音质。关于其他的参数设置,大家可以参考右侧对照图,按照这个方法上传尽可能多的歌曲,并完成人生分离。 如果提取出的人声有杂音,也可以使用 adobe audition 或者 r x 十 adio editor 完成降噪处理。第四步,切割音频 一般来讲, vivo 格式的歌曲文件往往在三到五分钟之间,文件容量也比较大。 而在训练模型的时候,我们则需要把一个歌曲分割为十秒左右的文件,以保证模型训练的速度和质量。点击下方链接,进入该放,选择下载这个名为音频切片机的开源工具, 完成下载后,运行 audio slicer, 把分离后的音频文件重命名,建议英文和数字组合,然后批量导入分离后的人生文件。设置好输出路径,点击 start 按钮,完成音频的批量分割。 把分割后的文件夹复制到 so with the data set raw 文件夹中。第五步,训练模型完成了前期的准备工 工作,我们就可以开始训练模型了。打开 webui, 选择训练,点击识别数据及参数,保持默认值,点击写入配置文件,点击从头开始训练即可开始训练模型,点击下方数据预处理,开始训练模型。 根据显卡的性能不同,该过程会持续一定的时间。第六步,模型推理,点击刷新模型,选择一个训练好的模型,然后选择配置文件,最后点击加载模型。在此小薇选择一个训练了两万步的模型。 下一步,上传一段不带背景的人生,在此小薇使用 so 二生成一段简短的歌曲, 然后使用 vocal remover 工具完成人声和背景音乐的分离, 下载人声并上传到 service, 点击转换按钮,等待少许时间试听一下效果。 现在我们就完成了今天的操作,今天用到的工具请联系小微获取。最后再使用 sovis 的时候,一定要严格按照版权法规定,不要做出侵权的行为。今天的视频就结束了,感谢大家的观看,欢迎大家点赞、订阅、转发本频道, 如果你有任何问题可以在视频下方留言或者联系小微,欢迎大家收看本频道的其他节目,再见!
967ChatGPT人工智能 00:24查看AI文稿AI文稿
00:24查看AI文稿AI文稿很多人不知道啊,咱们抖店的后台产品是可以进行批量设置的,包括什么呢?批量下架、批量删除、批量设置等等啊,有很多的这种这个操作,有很多这样的工具可以用。那么批量设置是什么?给大家讲啊?来,我全选上, 然后点击这个批量设置,看到没?哎?可以去批量设置运费模板,然后库存、发货时间、退货策略以及尺码信息这些都可以去选择的,明白吧?完全可以一下子搞定啊?
188咖具足 04:01查看AI文稿AI文稿
04:01查看AI文稿AI文稿大家好,我是乔二波,今天我给大家介绍一款海康批量配置工具和海康设备搜索工具,当大家需要装很多摄像头的时候,怎么样去批量修改摄像头的 ip 和批量升级, 我给大家从下载到应用操作给大家大家好,接下来我给大家实操一下哦。如果是我们有项目有六七个摄像机要同时接上去去改 ip 的话,我们可以用这款软件 呃,做一个修改 ip 通道,如果是笔记本没有网口的话,大家可以买一个这样的 usb 网卡。 我们手机打开海康,然后工具管家里面有一个批量配置工具,我们打开它,打开它以后,我们刷新到有七个摄像头, 我们点全部选中,选中以后这边有个一键化配置,一键化配置这个是设置一个激活密码, 我们设置好以后点下一步,下一步修改网络参数这块我们打勾,打上勾以后,这里设置上头的七十 app 地址哦,网关, 然后选择下一步,下一步我们看一下这边有批量升级,呃,还有恢复默认, 还有雨刷,还有 onf 配置,有些其他功能都可以一次性设置。我们先来看一下这个设置 ip 地址,设置好 ip 地址以后,这边有个简单的恢复, 我们点选择这个简单灰,点击下一步后,我们点击确定,确定好以后这边全部选中,我们选择这边有个一键化操作,刚才点的是一键化配置,现在我们点一键化操作点,确定, 确定好以后,这边有个进度条,然后会显示你的进度是否串。设置好以后,这边显示成功了,刚才设了七个摄像头,已经设置成功,我们看一下这边显示配置成功,如果想预览的话,我们点一下, 看上这边摄像头的画面直接就出来了,接下来我们看一下批量升级,我们选择好自己的文件包,然后点击下一步,下一步点击确定, 确定以后,这里全选,全选以后还是这里点击一键,一键话操作,选择确定进入一键话操作以后,这边有个配置的一个进度表,我们看一下。 如果我们升级完成以后,在这里可以点击全选,全选,这边有一个系统配置,我们选择这个恢复恢复,选择完全恢复 就会恢复到默认状态,没有激活的状态,点击确定 配置成功,他这边就显示配置成功。然后你在下面再点刷新的时候,就是三个未激活状态,已经升级成功了,这个是下载的地址,大家可以问我要。 下载好以后点击安装安装搜索工具和批量升级工具。呃,打开批量配置工具,这里首先点的是一键化配置, 这一步是设置摄像头的激活密码,这里所说的 ip 是设置他的起址 ip 这里我们可以选择升级,也可以选择改 ip 和激活 都可以用,升级的话是选用相应的文件,这里是一个操作的一个步骤,前面是这里是个进度条升级的一个过程,我们在百瑞未来城负一楼扶梯对面海康卫视,大家有需要海康的可以联系我。
776在西安卖监控的二波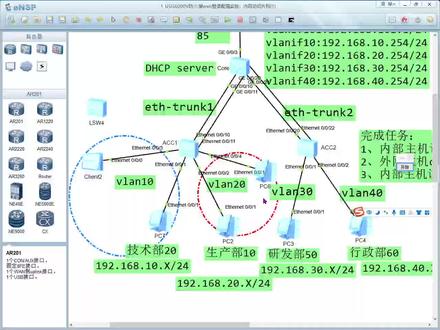 01:40查看AI文稿AI文稿
01:40查看AI文稿AI文稿那么我们在交换机上批量的去配置端口,那么其实呢比较方便,其实我们在这里呢可以去创建一个端口组, 这个端口组的成员呢,我们把它加进去啊,在这里我去看一下,一个是 at night 零杠零杠一,一个是 at night 零杠零杠三啊,这两个端口呢啊,我们加到这个端口组啊,加到端口组里写零杠零杠一, 还一个呢是 s night 零杠零杠三, 那这两个端口呢都属于围栏时啊,所以呢首先呢我们去配置交换机的端口的连接类型 x s 啊,这样的话大家 可以看到我一号端口和三号端口呢啊设同时都设置了端口的连接类型呢,是 x s 啊,这种端口类型啊,这两个端口我们去设置它的缺声与按数按十 啊,当我们这样去配置以后呢,也就说啊,我 pc 七啊,还有我们 clean 二啊, 这两台主机,我发往交换机的数据包进入交换机之后呢,他会打上伪烂时的标签啊,会打上伪烂时标签,当然如果这个当然这个标签呢,他是在我们交换机的内部,他是带着标签去同系的, 对吧?当然离开这个交换机的时候呢,他会玻璃蔚蓝式的标签啊,会玻璃蔚蓝式标签,那么这个呢就是我们端口啊进行片化的一个配置方法。
 02:25查看AI文稿AI文稿
02:25查看AI文稿AI文稿如果你的网络里面有有线办公电脑,有无线 ip 的业务,有监控摄像头的业务,那么记得一定要把每一种业务单独的划分网单,要不然你的网络会非常卡,非常慢。 那我们如何批量把每一些端口如何一次性划分到多个不同的微量呢?今天我们来去做一个详细的教程,那么我们一起来看一下这张图前面一到十个口呢,接的是有线办公,我们给他放到微弹石里面, 那么后面十一到二十口呢,是监控摄像头的业务,那么我们给他放到微烂二十码,接下来我们一起来看怎么去进行配置,那么我们通过 crt 软件呢,我们直接进到交换机里面,我们输 ss 进到系统识图, 那么第一步呢,我们先创建好两个微烂,那么这个呢,我们可以通过批量配置命令呢,那我们输入呃微烂十 和二十。好,这时候呢,我们就同时创建好两位呢,那么接下来我们需要进到啊啊,咱们这个用一个批量的一个配置命令呢,进到 g 零杠零杠一到 g 零杠零杠幺零。 好,那么进到这十个接口里面,我们只需要敲两条命令,第一条呢,我们输入修改这个接口的类型为 excess 啊,因为我们是接的终端设备啊,那么第二条呢,我们直接呢修改这十个接口呢啊,默认的微量呢为微量十。好,那么接下来呢,我们同时用同样的方式呢,我们 进进到这个零杠零杠幺幺到啊零杠零杠二零啊,这结果继续分,我们也是可以通过以前敲过命令呢,我们去调用前面两条配置命令。 好,第一步呢修改接口类型,第二步呢我们去加入这个接口为未来二十。 好,这个时候我们就把前面十个加到微烂石,后面十个加到什么?加到我们微烂二十了。好,这个时候我们可以对交换机我们做个保存,那么这样做完以后呢?那么同时在距离呢? 那我们就可以实现前面十个可能是接有线办公,后面十个可能是接监控摄像头。
1374网络工程师老张 03:17查看AI文稿AI文稿
03:17查看AI文稿AI文稿in this video, i will show you how to use kernels with svm to perform non linear classification as you know svm creates a line or hyperplane to separate data points into classes the fact that the boundary between classes is flat is a pro, because it makes svm easier to work with, but it is also a limitation because most data says in the real world cannot be separated by hyperplane a workaround to this limitation is to first apply a no linear transformation to the data points before applying svm with this technique we can easily achieve the desired effect of getting another linear decision boundary without changing how svm works internally this is extremely easy to do in python for example, we load our training data points and labels as usual, but now when we call svm's fit function we don't use x, but try their f of x where f of x is another near transformation of x geometrically this non linear transformation might look something like this svm will return a flat hyperplane separating the two classes as usual, but in the original x space this corresponds to a non linear decision boundary mission accomplished right, should we stop here on call it today well, not quiet a first problem is that we need to choose what this nonlinear transformation should be, but as everybody knows emily enthusiasts are lazy people so the fewer choices we have to make the happier we are the second problem is that if we want a sophisticated decision boundary we need to increase the dimensional of the output of this transformation and this in turn increases computational requirements the so called camera trick was invented to solve both of these problems in one shot the idea is that the algorithm behind this vm does not actually need to know what each point is mapped to enter this not linear transformation the only thing that it needs to know is how each point compares to each other data points after we apply the nonlino transformation mathematically this corresponds to taking the inner product between f x and f x prime, and we call this quantity the current function for example the identity transformation corresponds to the linear kernel given by x transpose x prime the linear kernel gives a flat decision boundary which in this case is not good enough to separate the data properly a polynomial transformation like this one corresponds to the polynomial kernel note that the expression of the kernel function is simple and easy to compute even though the transformation itself is complicated intuitively a polynomial kernel takes into account the original features of our data set just like the linear kernel but on top of that it also considers their interaction it takes a single line of code to use this polynomial kernel with this vm and as expected this gives a curved decision boundary sometimes it is possible to give a kernel function for which it is hard or even impossible to find the corresponding transformation a prime example of this is the popular radial basis function kern not only is the corresponding nolinear transformation complicated it is actually infinite dimensional so it is impossible to use directly in a computer program, but the kernel expression is incredibly simple and again with a single line of code you can experiment with this kernel and you can play with this primate or gamma to make the boundary smooth or rough so in summary the kernel trick is so incredibly powerful that it feels like using a cheat code in a video game not only it is much easier to tweak and get creative with kernels, but we don't have to worry about the dimension of the output anymore。
1481AI有道 01:50查看AI文稿AI文稿
01:50查看AI文稿AI文稿兄弟们,今天接着上次的继续讲,这次我们讲操作系统的启动。我们在使用操作系统的时候,要开始执行任务调度的时候, 都会有一个这个开始任务调度的函数,这里是做了什么呢?我们打开看一下,可以看到又进入了一个会编函数。第一个这个就是八字结对齐, 因为部分操作涉及到八个字节。入站。后面这几句是把这个地址里面的参数取出来付给 msp, 也就是说初始化 msp 的地址。接下来几个就是只能中断等操作。后面这个就是重点, 他这个是调用 svc 中段传餐设置的是零。这里为什么要调用 svc 呢?因为他需要进入到中段里面,方便利用中段的特性。 要用第一个县城一对一出战。我们接下来看看他在 svc 里面做了什么。从逻辑上来讲,其实他这里要做的就是准备第一个县城的站空间。 这里首先是获取当前任务指针地址,然后把对应任务的占顶地址拿出来,放到了阿零寄存器,然后根据这个占顶地址将工作寄存器设四到二十一出站,然后将最新的阿零付给 psp, 也就是复制占顶地址。 接下来要做的就是恢复中断,接着复制是十四寄存器。这里需要注意的是按十四寄存器这里的特殊含义,这里的用法就是高速芯片退出的时候,使用 pfp 进行出。 这个时候程序就进入到了第一个县城函数中了,也就是启动成功,对应的文件连接放在了评论区,大家学会了吗?
76普通的老木子 06:54查看AI文稿AI文稿
06:54查看AI文稿AI文稿通过简单问题了解网络原理,带你走进网络的世界。大家好,我是网络工程师陈锋。我们在配置华为交换力的时候,经常会有很多重复性的操作,比如把某些端口加入到指定位置啊,或者 djcp 十六、 pnf 的时候,一般都是一个一个端口进入后再配置, 可能大家说我可以用 excel 生成批量配置啊,然后再刷上去,虽然这样效率提高了,但还是比较麻烦,一般人都不会这样操作。 我们知道四科交换机有平衡配置的功能,而我们交换机也有吗?其实华为交换机默认也带了平衡配置的功能,早期交换机使用的是 poselo 来配置,现在新版本的交换机额外还支持英雄 fase、 led 来配置端口。平常配置这里有两种 种模式,一种是创建永久的端口组,就是所有端口配置完以后啊,这个组成员还存在,我们下一次继续配置。一种就是创建临时的端口组,这个在配置端口时候退出就不存在了,我们下次还想再配置的时候,需要额外配置 box、 glog, 这两个秘密模式都支持,当英雄飞行 rap 者只支持临时端口组。说了这么多,我们来实际演示一下吧。 我们登录一台交换机,我们先演示第一种,呃,永久端口组,我们把那个交换机的一杠一一口到二十口改为二十三十口,并把它加入到维纳二十。我们进入到配置模式下, 然后用这个 polo, 然后这里咪咪咪个名字,我随便起个名字,比如说我们就来取个叫开始, 然后回车,然后这里输入 hello, 就是说这里是加成员组了,成员组他这里支持之一的,然后支持还有 vlay、 hir、 face 都可以支持, 我们用狙击的吧,然后这里是球的端口号,比如说我们是双十一,然后这里有个兔, 就是说十一到十八口,就把十一到十八口都可以加进去,然后再输这个十八口,这样就穿 见了。我们看一下,如果别说他端口不连续呢,不联系我们还可以添加的,可以多多添加,比如说我们把它这个十九口,十九口啊, 还有个二十一口,而且这样还可以继续添加,我们再添加, 你看这里就把这个十一口,二十口,你看中间二十口就没有加加进来,我们直接这里直接可以配,可以配置很多的,只要我们配置端口组。以后呢 我们再来配置他的模式,我们先把短口模式改为 exs, 你看他这辆就批量配置上去了,都改为这个摔死了,我们再把它加入到维纳二十, 搅到五到二十里面,然后这样批量刷上去了,非常快。这里要注意一下 我们这个永久端口主啊,他可以建立三十二个永久的端口主,每个主里面呢端口向线,比如说这里接口啊,这里接口他最大可以 只支持四十八个,四十八个接口,如果不连续呢?不连续的接口呢?就用我们刚才的那个,可以直接直接添加这个端口,你添加一个,然后再添加一个,这样添加上去, 这个就是端口煮,永久端口煮,我们再来配置一下零食端口煮,看怎么配置的啊?也是 polo。 然后呢 他就这里就不是直接创建创建这个主名字了,我们直接他用 gluber, 然后加这个接口,就跟我们刚才一样了,然后到了一个口,你看零到十八,这个就是零食的, 然后你再把它加映的相应的一些秘密啊,改为端口模式,或者加相应的微量就可以了,这个就是临时的端口组,我们刚才说了还可以用英戳 facelook, 我们刚才还说了可以用英寸 faceline 来配置,对不对?我们来说一下,哎,好像没有这个指令,是不是搞错了?其实这个是版本的问题, 我们这个版本现在是为二零零二零零幺,他也是在二零零三的后期版本才支持这个命令,我们用真机来演示一下,我们登录一下, 登录以后我们用英雄 face rap 先这个就有这个指令了,我看一下我们这台版本啊,我们这个是二零幺幺的版本了,所以是支持这个命令, 我们用英雄 facebook 也是这个接口,跟刚才那个其实一样,你看你看,是八口,我们 把它接口改为 xs, 它这样平安创建了,然后再把它 加入到维纳二尺里面啊,这样就平量创建了,这个跟刚才的那个 pos 格罗密顶差不多。这就是华为交换机的批量配置功能, 华为交换机皮料配置功能非常好用,可以减少重复的配置工作,特别比如我们在开局的时候啊,需要把那个端口平常关闭, 然后做一些相应的描述,这些等重复性的工作非常的高效,你学会了吗?欢迎大家点个赞并关注一下,觉得我视频讲的不错,也可以分享给你的朋友,我们下期视频再见。
309华峰网络信息服务部 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿假如有一百台交换机让你配置,那么你一定要去学会批量修改配置脚本,那么今天我们来先讲一下一个非常简单的批量修改脚本的方法,我们可以借助 excel 呢,在里面直接写好脚本,比如 interface g 零杠,零杠啊,那么我们如果是二十四口的话,那么我们这呢就可以呃直接拉到二十四,那么我们比如说每个接口是一个尾蛋, 比如从幺零幺开始啊,那么这时候我们可以把两行同时拖选往下拉啊拉,比如说我们这里面就十五口,好,我们拉完以后他他自动拿编号封封好了,封好以后呢,我们直接复制粘在这个三不利这个软件里面去,在这呢我们可以在这个空白处用中间数 鼠标,就在中间滚轮键,我们去往下去拖,拖完以后呢,在这呢我们就可以直接敲回车,批量编辑多行啊,我们呃 pot 底说 d fort 啊啊,伪烂幺零幺啊,这样子我们做出来的东西呢,能直接啊点复制就可以粘贴在,咱们教你直接进行使用。
2890网络工程师老张

