图像识别pycharm租服务器教程

粉丝416获赞1344
相关视频
 05:53
05:53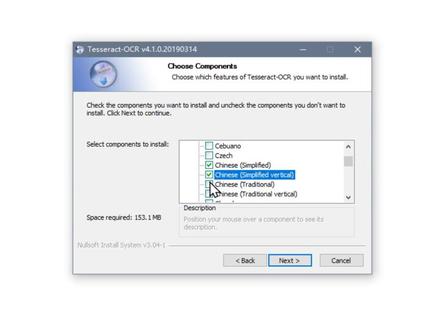 07:48查看AI文稿AI文稿
07:48查看AI文稿AI文稿大家好,今天我们使用拍摄来实现一个 ocr, 这光学自负识别, 我们使用的是 tsurt ocr 这个开源的项目,这是他给他按不成一个主页,大家可以看一下详细的说明。那我们以 windows 为例,如果你使用的话,我们首先得安装一个 exe 的程序, 那目前我们安装的是这个安装包,售后我会提供给大家下载。双击启动安装向导,那这里目前他在解压缩 在向导界面上,我们单击下一步 max, 然后同意协议,然后针对所有的用户安装到本机计算机安装的时候有一个选项,就是关于语言的数据,我们要找到所有一千例子开头的一方, 方便我们识别中文简体或者中文繁体的字符。好,然后我们点下一步,他安装的位置,默认是 c 盘不够 pro 跟上 fm 录像,因为我们安装的是六十四位版本。好在这一步 就是告诉我们安装语言包的时候呢,他会告诉我们需要我们联网啊,在线请求下载,那这个时候我们点确定 好,这个时候呢,就安装过程中他有联网下载扩展的一些语言包,方便我们识别非英文友爱的一些其他的字符。 那这里边我们主要是方便他识别中文,所以安装了以千亿字开头的几个简体和繁体的几个包。安装完 windows 的 ex 之后呢,接下来要到 拍摄我们的虚拟隔离环境,我们之前创建了一个虚拟隔离环境,然后接下来如果想实现我们的店铺代码的话,我们要安装基于拍摄版本的一个库,那配平时都安装拍 ts。 好,这个时候呢,我们下载了拍摄版本的一个扩展库,那稍后呢?因为我们要读取图片,我们要安装 plpl plus, 基于拍摄三等针对拍摄二里边的 prl 库的一个兼容版本。 在我们编写代码之前呢,我们首先到 c 盘的目录下看一下刚才我们安装的那个对象装到什么地方了。刚才我们安装的 ese 程序是在 c 盘的扑克上面 beaus, 然后 tsuritocm 录像,那这里边稍后我们使用拍摄编写代码的时候,还会调用一个 ese 程序, 就是我们目前看到的特斯瑞 x 点 ex e, 那可是这些文件,也就是说我们识别提取的工作主要是由他来完成的。然后我们复制两张图片过来,非常简单的,零一是一个包含有英文字符的图片。 好,零二呢是包含一个中文字符的图片,那个图片都比较小啊,没关系。然后接下来我们来写一个简单的 dm, 首先我们要导入一个库,就是我们刚才安装的拍 tsux。 好,到了之后呢,我们把它取个别名,比如说这个 pt 吧。然后接下来从 pl 就是 ps 了,包下边导入一枚就方便我们待会打开那张图片。 第一件事情,我们要找到刚才安装 ex e 的那个可执性文件,因为它是我们核心提取识别的工具,把它路径给得到。然后呢,我们 找到刚才那个路径,找到刚才完整的文件,名称叫 tsurig 点 ex e, 那稍后要把它交给我们拍线库的一个组件去使用。那我们说刚才导入过来的拍 tsurx 就 pt 的对象,他下边的拍 tsur 下边有一个属性叫 tsurk cmd, 就是用来识别的那个命令是谁,那你就把刚才的 pass 给他,就是找到确切的一个自己所在的位置, 然后使用 emax 下边的 oppo 方法打开,我们要识别的图片交给 emg 这个实力。 然后文字呢就非常简单呢,我们直接找 pt, 他下面有一个方法叫以 mate 图 steen 把图片上的文字提取到字符串,把图片传给他。那接下来我们 pro 打印一下。 好,我们看一下刚才我们这张图片呢,那比较规整,那文字呢,也比较清晰,用拍摄运行一下,戴帽点拍,这个时候很快他就识别到上面所有完整的文本,并且打印出来,你在这样就实现了你的图片上文本提取 这个过程。好,这是我们讲的英文,那接下来我们看一下中文,那这里边有张零二点这笔记有一个,接下来播放有自动播放这几个字。 那接下来要识别的话,我们直接跟刚才的方法一样,只是把文件名有零一改成零二,但这次我们发现呢,他并没有正确的识别到上面的中文字符, 那中文字符刚才我们就安装的有扩展的语言包,那这个人怎么办呢?那我们在刚才一没的特思追的方法后边除了指定图片之外的,加上音浪就是兰博基尼,语言为 c h i 杠, c 就是简体中文。在这里又泡了一个错,那告诉我们说刚才你安装的沐浴露下边是不是有 tst a 他这个沐浴露他下边有 c h i 杠性,那有一些训练的一些数据, 那看一下这个里面其实也有,那可能是刚才在下载安装的过程中呢,他并没有下载完整,那这里我们重新把它安装一下。 重新安装的过程呢?这里边并没有录上,那重新安装之后,我们重新再运行一下,点拨点拍好,这次他正确的识别了,只要接下来播放,那后边有自动播放,那发现呢?他有一些乱码,就是说他并没有完整的,百分之百正确的识别, 这些呢,是有一定的误差,所以这个的话心里要做好准备,特别是你的图片不够清晰,或者有一些近似于文字的图案图形的时候。好,那这里实现 呢,我们命令行的版本,他代码的总共几行,那我们看到总体的代码量的并不多,那主要是实力画脸的对象,然后调养方法识别就可以了。 那为了方便日常工作中使用呢,这里包括开发了一个窗体版本,就基于 t k 开发的 gvi 的版本,好代码呢?也不多,总共五十几行代码。那我们看一下,那我使用的这个 t k 开发的窗体版本,那使用的效果 说拍摄帮我运行一下 ocr 点派创体版本,打开之后呢,我做了这么几个基本的组件,首先一个选择按钮,打开,选择一张图片文件, 然后路径显示出来之后,点一下提取文本,他就会将刚才我们选择那张图片上的文字提取到下边的文本框里边。好,那我们换一张,比如说刚才的零二点借笔记,那我们点一下提取文本, 那这里边是中文,那也提具成功。接下来我又准备了一张零三点揭秘记的图片,包括的文字多一些,那时候是一首古诗的,我们接下来使用创题版本的来识别一下,那这个图片比较规整,字符呢比较清晰,然后选择刚才的零三点揭秘记, 然后点一下打开,目前只是记录了他图片的路径,还没有真正的交给我们代码去执行,点一下提取文本,这个时候呢就把刚才零三年记不记的图律图片实力打开,然后正确识别里边的所有的文字。 最后完整的代码和刚才你的 exc 安装包呢,提供给大家下载安装,关注我们的微信公众号,注意是微信公众号,并不是私信回复 ocr 下载原码和 exc 安装包。 最后说明一下,他毕竟是一个开元的项目,如果说你认为他的精度那并不能够满足你的项目需求,你可以考虑使用国内或者国外开发的一些第三方的付费的欧 cr 识别的 app, 所以说不要对开元的项目有过多的一些奢求。
492优特编程 00:06
00:06 15:46
15:46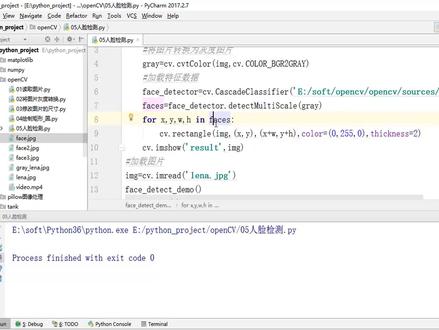 14:31查看AI文稿AI文稿
14:31查看AI文稿AI文稿上次课呢,我们讲解了人脸检测,而且呢是一张图片,里面呢只有一张人脸执行。看一下,我们对丽娜这张图片呢进行了人脸检测,对他这个人脸呢做了一个正方形啊,把它呢画出来。 那如果我们那个图片里面有多张人脸,例如我们这一张图片,以及我们的费时啊这一张图片,以及我们的费时三啊更多张啊,这个图片,这些人脸是否呢都可以对他进行检测?我们创建一个呢批发文件, 我们要检测多脏人脸, 要导入我们的模块, 第一步呢肯定要加载图片 c v 点儿 i m read, 比如说我们要加载的呢就是我们的 fish 这个 g pg 返回 image 嫁接好这张图片以后,我们接下来 调用一下人脸检测这个方法,我们写着 face detect demo, 让当前这个图片可以呢一直写是 c v 点 v k 零执行完以后我们要释放内存 啊吊,用 destroy all window 那人脸检测这个方法,我们把它呢 d e, d e f 那劫色的时候呢,我们首先要将图片灰度啊,灰度怎么样?灰度呢? c v 里面有一个方法, c v t colour, 我们要将 a 妹子制造图片 调用 c v color b j r two green, 返回一个呢 green, 接下来我们要加载特征数据, 这个加载特征数据呢,跟我们刚才啊这个呢是一样的,接下来加载完特征数据调用 调用呢我们的 detect monty scale 这个方法进行人类检测,返回我们的 face, 这个 face 里面有检测到的 x 和 y, 就是我们的坐标以及 w h in 我们的 face 在检测到区域,我们可以把它呢画绘制啊,对他来进行画出来 c v 点儿 re attago 在 a 妹子这张图片上面,我们呢进行画第一个左上角的点, 右下角的点及我们的 color。 如果呢,我们有使用红色啊,红色的话呢? b j r 零零二五五 sickness 当前你绘制的这个边框,它的宽度啊,我们呢给一个二,绘制出来以后,显示 显示我们这段图片点右 c v 点儿 m so result image 看一下,我们检测的是 face 啊,就是 face 这一招 图片,他呢里面有三张脸,我们呢检测看一下,是否呢可以都检测出来,看下这三张脸啊,都呢绘制了我们这个正方形。 那如果呢,我们还可以在当下这个正方形里面呢绘制圆 circle img setter 大家绘制它的圆心 x 加上一个 w 除以我们的二 y 加上个 h, 就出上我们的二。想在我们的正方形里面来看一下,比如说这是我们的正方形,这是我们的正方形 咬绘制的他这个圆,这是我们的 x, 这是我们的 one, 这是他的宽度,这是他的高度。那我们这个圆心,他的这个坐标的话呢,就是 x 加上二分之 wone 加上二分之 h 发的是半径 w 则除上我们的二。 因为是我们的正方形啊,所以用 h 整除二和 w 整除二是一样的。 接下来是我们的卡染,卡染的话呢,我们换一种颜色,比如说零二五五都好,零 bg 啊,这就是我们的 green 绿色 second is 同样我们给一个二来执行,看一下这红色的这个正方形里面,我们又会这一个绿色的这个圆,对这三张脸呢都进行了检测,那如果我把这个图片呢画一下,画成我们的菲斯。二, 这次呢进行执行啊,这次呢进行执行执行,看一下我们这个图片里面的话呢有这两张脸啊,这两张脸呢他没有检测出来这两张脸没有检测出来,以后 我们调整一下,在 detective monty scale 里面呢有几个参数,看一下有一个 scale factor, 它呢就是你进行检测的时候,如果我们这个区域 他可以进行缩放啊,这个缩放你那个比例, my nick bear 啊, nick ber, 这个呢就是 你当前至少要检测多少次以后他才是我们目标,你还可以给定当前这个区域检测的时候最大的大小以及最小的大小。 这呢就是我们这几个参数啊,这几个参数,那我们看一下,你调整一下 skill factor 给称呢我们的一点一, my neighbor, 我们给称我们的三来,这次呢进行啊执行,看一下,跟我们刚 才呢一样啊,跟刚才呢一样,这个区域把它呢去掉,可以呢看一下这个区域的话呢要比我们这个上面这个呢要大一点。 我们可以将 xywh 呢进行一下输出, 看一下输出,输出的话呢最后啊下面这也就是他的坐标和坐标,坐坐标最大的这个地方,看一下他是输出的是六十啊,六十,他可以通过 my size 就是我们的 max size 啊进行呢调整,如果呢我改成一点零一啊,他这个缩放比例,这 次呢进行执行啊,执行的时候呢大家可以看一下我们这个人脸的话呢他已经圈住了,那如果我再增大一点,改成我们的一点零五, 这次这两个脸还是没有圈住,那我们呢改成一点零三 还是没有一点零二, 一点零二的话呢?这个有了,但是这个地方啊,这个呢是没有。 那调整一下,我们给测一点零一,他呢给测我们的五,最少呢检测五次。 这个地方啊检测那还是给测我们的检测 这三次呢, 检测三次的话呢,这时候刀切这个检测区域看一下,他已经有了,有了的话呢,但是多余的这个地方啊有特别呢特别多。 这个最大的这个区域啊,我们可以呢通过最大的啊 max size 看一下他这个区域的大小的话呢,这个地方最大的 max 赛车的七十三。但是我们正常的区域一般呢都是二十几啊二十几,这个呢是我们的二十九 二十八的, 如果我们给他加一个 max size, 加一个三十三十来执行加一个三十三十,这个地方啊,他没有。那如果我们改成四十 啊,四十四十的话呢,这时候选中了啊,但是还有我们的多余的地方 看一下他是三十几,三十三啊三十三 啊三十三。这时候 最大的三十三,我们还可以呢,再设一下他的最小 my size 二五二五。 如果呢,我们射程二七二七 二八, 嘴睁大 看一下,如果在测二九的时候呢,这个地方肯定是正好呢等于我们的二九,那我们呢把它呢改成二八, 我们修改一下这个参数,改成五。 同样啊,该抽五的时候呢,他还是写作不了, 别测我们的三。 改成三的话呢,这个地方可以选中,但是我们的这个还是有多余的,这个多余的部分的话呢,我们要看一下他的 这个范围, 这个范围的话呢可以看到我们正好的话呢都都等于我们的三十啊,三十, 如果我直接把最大的范围调成我们的三十, 三十一 这个还是没有 三十二, 在精准的时候呢,调整这几个参数啊,可以呢选中我们当前这个人脸啊,也就是 现在的话,我们这个图片上面的话呢,如果选中啊选中的这个人脸,也就是调整我们这个缩放比例啊,比较呢小一点的时候, 当前虽然说我们加了 max size 和 max size, 但是其余的部分里面这个尺寸大小正好和我们的这个人脸圈住的这个范围啊,他的大小呢是差不多的,那我们再看一下啊另一张图片看一下我们的 face 三, 这个费是三,费是三的时候,首先呢我们把 后面的这个参数啊,把它呢去掉,直行看一下这个费是三啊,这个呢特别好啊,这张图片的话呢,我们这里面的人脸呢都被 啊就是识别了啊,都被识别了,就不需要呢调整我们这个参数,比如刚才我们调整那几个参数啊,可以呢对当前这个人脸 进行啊,识别呢精准度啊进行一下调整,这呢就是识别呢我们多张人脸。
101第一播放室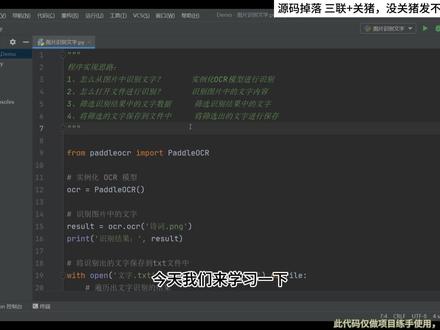 02:24查看AI文稿AI文稿
02:24查看AI文稿AI文稿我们来学习一下怎么样拍损程序来识别图像中的文字,这里的话呢,我准备了两张图片,呃,里面这是一个散文,荷塘月色,然后这个话呢,可以看到有很多很多的字,我们想要通过代码把这里图片里的所有字呢给它识别出来。 另外呢还准备了一篇诗词啊,水调歌头。那接下来呢,我们通过程序的方式来简单的运行,看一下结果。运行好,首先的话呢,我们来识别,第一个是识别诗词,就是我们刚刚所看到的这个 水调歌头的诗词,那么可以看到目前正在识别,哎,然后呢提示,我好像已经识别成功了,对吧?那接下来后呢,请注意看,在左边这里出现了一个文字点 txd 记事本,然后就可以看到在这就是我们刚刚所识别出来的文字内容 啊,明月几时有,把酒问青天,现在我们将诗词这个图片换掉,换成什么呢?换成散文,换成散文,也就是说我要让他去识别这个散 文当中的文字内容,这个文字就比较多啊,那么我们来试一下同样的啊,这个是诗词,我们先关掉关掉,然后重新运行一下这个程序。 好,正在运行,那么这里的话呢是一个图像处理,所以他的相对来说时间会久一些,如果你的图像当中文字越多,那么所花费的时间也会越长,如果文字越少的话呢,所花费的时间他也会越短。我们可以看到我们这个散文里面有好多个字啊, 他是有非常非常多字的,所以话呢相对来说速度会慢一点,那这里我们需要稍微等待一小会,好,然后可以看到现在基本上就出来了啊,他已经识别完成了。接下来我们再来看一下我们 识别的文字,用也是在这里边,我是用的 a 的方式追加,那么打开看一下,然后可以看到这是前面那一篇识别的诗词,然后下面这款呢,就是我们刚刚识别的荷塘月色的散文内容啊。最后是但热闹是他们的,我什么也没有确认一下是不是这个呢?但热闹是他们, 我是妹妹, ok, 没错,那这样的话呢,我们就十倍完成了。看一下整体的代码结构吧,代码部分其实主要分为四个部分,第一个部分就是,哎,我们要通过什么方式去实现?这里话呢?使用是 这个 print o r c 啊, o c r 这个库来进行实现了,那么这里先实画一个模型,然后呢读取这个图片文件进行识别,识别完之后,这里是识别的一个结果, 然后再将识别结果他的一个数据呢,进行拆分,进行便利啊,得到我们想要的那一段文字信息,而其他的信息的话呢,我们就不要了,作为筛选剔除掉,所以第三步就是筛选我想要的文字数据,然后第四一步呢,就是将文字数据保存到一个文件当中 啊,那这就是我们程序的一个功能,直线,好的,如果需要元宝同学呢,可以一键三连加评论区留言或者后台私信领取我们这个元。
 11:35查看AI文稿AI文稿
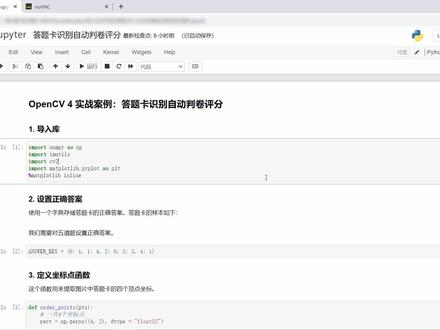
11:35查看AI文稿AI文稿大家好,今天我们来看 open cv 实战案例,在这个案例中,我们将使用 open cv 对答题卡进行识别和变换,并自动进行评分。 我们来看一下具体的实现过程。第一步,导入所需要的库,导入蓝派,导入 open cv, 我们运行一下, 然后第二步,设置正确答案。在这个案例中,一共有五道题,每道题我们都设置一个对应的正确答案。 然后是第三步,定义坐标点的函数,那么这个坐标点的函数主要是用来提取答 答题卡的四个顶点的坐标。首先生成一个四乘以二的一个邻居者零数组,他用来存储四个点的坐标信息,然后提取左上、右下以及右下、 右上、左下四个点的坐标,定义透视函数。透视函数是一种重要的结合变换, 他的作用是可以利用变换矩阵将需要转换的目标进行投影,变成任意的多边形,也可以将不规则的事变形转换成为规则的矩形。 所以这里有一个要进行是透视变换。首先要知道透视变换的矩阵,在 oppo 提供了一个函数,可以计算得到透视变化,来举证有两个参数,第一个参数是输入图片的点点坐标,第二个参数是输出图片的点点坐标,所以要进行透视变换。 要计算透视变化的转换取证,我们必须要知道输入图片的顶点坐标和输出图片的顶点坐标就可以了。 然后知道了变换矩阵之后,我们就再利用 open cv 的透视变化函数,利用变换矩阵对原图像进行一个透视变换。 在这个案例中,我们主要利用透视变换将不规则的事变形转换成规则的事变形。因为我们对拍照的时候打 体卡并不,我们拍的照片答题卡并不是一个非常规则的矩形,他是一个有一定倾斜度的四边形,所以透视变化能很好的处理这个问题。首先 找到输入的输入的坐标信息,然后计算不规则四边形四个边的长度,这是计算出他的 宽度,计算出他的高度。由于我们是要把它变成规则的矩形,所以取他的最大值, 那么这个最大值就作为我们变换之后的举行的宽和高。知道了宽 高之后,知道了变换之后的宽和高,我们就可以以变换之后的左上为圆点 四个点的坐标就可以得到。知道了四个点的坐标,知道了原始点的坐标,我们就可以利用 oppo c v 的函数来得到透视变化取胜。 知道透视变换矩阵之后,再使用 oppo cv 中的透视变化函数对他进行不规则图片的透视变换。 定义轮廓排序函数,这个函数主要用来进行轮廓的排序。 message 默认为从左到右,那么就只会处理,将这个参数是 force, 就从小到大进行排序。当 mac 的设置为从右到左或从下到上,或者是的时候,这个参数设置为 q, 就是一个生序排列。 如果 message 从上到下或者是从下到上,哎等于一。使用 open save the bonding rack 礼盒一个最小的轮廓取证,再使用下面的 这段代码得到一个,得到一个轮廓信息,以及他最对应的最小举行的一个坐标信息。 上面把一些函数定义完成,我们来接下来就对答题卡进行处理。首先读取答题卡,可以看到原始的答题卡,他不是一个横,不是一个规则的矩形,然后对答题卡进行挥读变换, 再进行高斯模糊。高斯模糊主要是为下一步的边缘检测做准备, 我们调用 open cv 高斯 bar 对他进行一个高斯模糊的变化。 然后第九步使用 carny 进行边缘检测,使用 open cv 的 carny 进行边缘检测, 得到边缘检测 函数,我们就可以提取他的轮廓。使用 open cv 的 finecons 对边缘检测结果进行轮廓提取。 当使用轮廓提取时,他可能会得到多个轮廓,但是我们这一步主要是用来对他进行透视变换,使他变成规则的矩形,所以我们主要提取的是最外面的这一层大的轮廓。 所以下一步我们需要对轮廓进行一定的一定的筛选。 首先是确保轮廓检检测到轮廓,当轮廓的个数大于零,那么我们就首先将轮廓进行 一个排序,从大到小进行排序,便利每一个轮廓计算他的周长。由于原始的 图片中轮廓是一个不规则的多边形,所以使用 open c 位的一个多边形函数对他轮廓进行一个离合,得到多边形轮廓。 我们最后的目的是提取最外面的外轮廓,所以当多边形的轮廓等于四的时候, 就是我们要提取的外轮廓。得到了外轮廓,我们就使用透视变化函数定义好前面定义好的透视变化函数对他进行透视变换。下面就是我们的一个 使用透视变换之后得到了结果。经过透视变换之后,答题卡变成了规则的矩形,得到规则矩形,我们就可以 使用规则的句型来进行匹配了。我们将变换好的句子进行二字处理,使他变成二字图像, 然后找到每一个选项的轮廓。使用 open cv 的 find accounts 找到每一个轮廓,此时使用, 此时就得到了每一个轮廓信息。有多个轮廓信息,但是我们要处理的是要找到每个选项的轮廓信息。根据 实际的不同,当轮廓的长和宽都不小于二十,且长宽比例在零点九到一点一之间,就是每一个选项的轮廓。所以根据实际的情况, 我们就给定了他的探点条件,利用他的长和宽以及长宽的比例 选出每个选项的轮廓。选出每个选项轮廓之后,我们就可以使用每个选项轮廓进行来匹配,找到他图写的是哪一个轮廓。 由于我们需要便利所有的轮廓,而便利所有的轮廓。首先是从上到下,然后进行排序,排序好之后,再 再对每一个轮廓从左到右进行排序,然后选出每一行的他图写的轮廓。那么怎么写?怎么找到图写的轮廓,我们来看,所以首先对他从上到下进行排序, 对五个选项来说,再从左到右进行排序,便利每一个结果。使用于 得到锁印以及锁印对应的轮廓信息。制作一个 max, 然后使用 一个比 beat rise and, 也就是像素和像素之间求和与运算。 当是二五五的时候,被图写的被图写的轮廓是二五五,二五五转换成二进字都为一 而一,与任何数求与他还是一如而没有被吐血的则为零,而零与任何数为作,与运善则为零。所以根据这一个 与运算,他就能得到一,然后再统计岩麻中零的个数,就可以选出哪一些选项是被我们铅笔吐血的, 然后得到哪一些元素。被铅笔涂写了之后,就可以根据我们前面给定的标准答案得到这一题的正确答案。再通过比较正确答 和我们检测得到了他吐血的选项,就可以统计他正确提速的个数。 然后就是显示阅卷的结果,这里给定了一个分数,除以五再乘以百分之一百,就是他的正确率。 可以看到原始图像第四题他写错了,其余的四个题都是正确答案,所以他正确率为百分之八十。 这就是使用 open cv 来进行答题卡识别,自动判卷评分的过程,谢谢大家!
43跨象乘云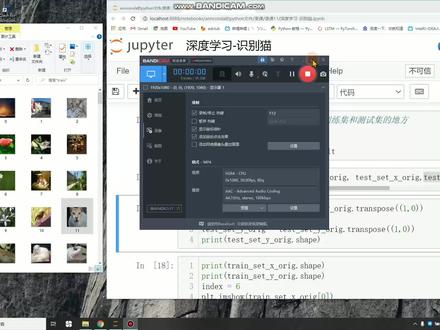 05:53查看AI文稿AI文稿
05:53查看AI文稿AI文稿今天我们讲深度学习,哎,深度学习啊,深度学习,这个识别猫就是用计算机判别一张照片他到底是猫还是不是猫,他用的框架就是拍照的框架,然后网络结构,先用一个最简单的网络结构,全连接结构啊,比较简单。然后我们先看一下我们的数据题, 我们的数据题是吹,里边就是呃训练级,训练级那么有二百零九张照片,那么这这些照片有的有的是猫,有的不是猫,然后来训练这个我们的网络,然后当然还有测试题, 然后但是我们现在只只需要看这个,只需要看我们的呃那个数据集就行了,数据集有一个春 h 五文件,还有一个呃,太子城 at 五文件,这两个文件,那就是一个是训练题,一个是测试题,那我们先讲 训练器吧,然后那么首先我们导入这个库,这个库就是放数据,放,放数据的地方有数据训练器和测试器, 那么导入南派,还有导入 h 五 p y, 导入这个呃画图,画图,画图的工具,然后然后我们我们运行,然后我们把测试题,测试题 x, 测试题五 训练级 x 训练级外,还有测试级 x 测试级外可以加载出来,加载出来之后我们把这个测试级给转置一下,然后我们打印一下他这个他这个测试级的标签的一个呃的的的大小 就是一个睡谱,他的他的维度我们运行,我们运行发现他是二百零九和二百零九个数据, 也就是二百零九对应的是二百零九张照片的呃呃他是猫还是不是猫?然后我们看一下,我们看一下照片, 那么首先打印的是,呃,打印的是训练级的一个维度越小,这句话不对, 那么首先打印训练级的维度,训练级 x, x 的维度是二百零九张照片,然后图片大小是二六十四乘六十四乘三的一个 rgb 文件啊,然后然后我们显示第一张图片,第一张图片的所以是零,我们显示一下,我们显示, 我们看一下第一张图片是西,是一个夕阳的一个照片,哎,发现他已经显示出来了。然后再然后再显示他的一个标签,他的标签是零,他的标签是零,也就代表他不是毛。然后我们在显示, 我们在显示第十一张照片,第十一张照片他是一个,他是一个猫,然后他的标签是一,他的标签是一,证明他是一个猫。然后 然后我们要把这个数据转换成套拍套器框架下面套起的一种 格尺就是张量,转换成张量,我们运行我们的数据已经转换成套起套起格之下的数据了,然后我们创建一个,呃,创建一个类,就是生成我自己的一个数据级的一个类,然后 运行这里边生成我们自己的数据集了。之后我们要把数据集分批的分批的装装,装载到一个加载器里面,然后运行一下我们,我们设置我们的排气塞子,大概三十二,三十二, 然后继续运行这里边网络架构,网络架构我写的是一个全连接的架构这边,嗯,第一个参数是输入大小的维度,然后隐藏底盘层的大小,还有输出大小的维度。啊?那我们运行, 运行了之后,运行之后,然后我们把我们的模型定义为定义为六十四乘六十三乘六十四乘三的一个呃 输入,输入的维度,然后隐含层的是一百一百个节点,然后输出层是两个节点,也就是零和一, 然后这里我们定了一个交叉交叉商损失函数,呃,通过交叉商损失函数反向球传递,呃,传递求求取误差,然后呃 优化层,优化层我们选 sgd 优化 sgt, 不过这这里边用了啊,这里边用了 momon 枪,他还是其实还是 awmes oms 优化方法,然后问一下,嗯,然后我们定义我们的一个损失和一个准确度, 然后这里边把模型定义为训训练模式,然后开始训练, 稍等一下,这训练有点慢,正在运行, 然后运行结束,运行结束了之后,我们看一下这个他的误差,他的误差和准确度, 那么首先画的是准确度,准确度除以二百零九,对吧?除以二百零九才是才是全部的准确度,然后他的准确训练器的整整个准确度还是挺高的,接近于一, 然后误差基本上接近于零,那这就是一个呃深度学习用拍照性框架全连接结构训练识别图片是不是猫?
145Stellar Tang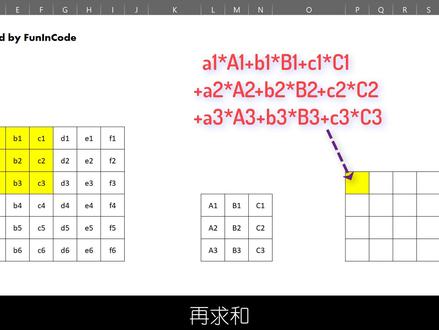 08:13查看AI文稿AI文稿
08:13查看AI文稿AI文稿数字到第八集,今天我们分享的主题是康复路线哦,牛肉耐托卷基神经网络模型,以下简称为 cnn 模型。 cn 模型通常用于影像识别案例中。通过模型训练,计算机系统也能像大脑一样识别出图片、影像中的物体符号等等。 比如可以用于人脸识别,快速匹配身份信息。在医疗领域,通过对核磁共振 mri 影像进行分析,对病情进行诊断或预判。 另外,在开始了自动驾驶奥特拍了模型中车载摄像头可以获取周边三百六十度影像。经过 cnn 模型的训练,对道路上及周边出现的各类车辆、物体标识进行识别。这里我给大家介绍两个 cnn 模型的在线 应用展示。第一个影麦界列为丧尸给我们知道声音可以转化成光谱图。在这个应用中,我们可以上传不同的图片,让计算机输出其联想的声音。 这里有两个 cnn 模块在同步进行,其中之一用来识别上传图片的内容。第二个 cnn 模块将音频转化成光谱图并进行训练,让其输出结果和第一个模块的识别内容越来越接近。 第二个应用方面,在这个例子中,不同的字体根据其相似程度聚类在一起,其中的字体特征正是由 cnn 模型进行提取的。 在今天的节目中,我将首先通过一个非常简单的例子介绍 cnn 模型的基本架构和原理。在这之后,我会使用一个非常有用的在线工具 cnn excel, 进行一个完整的穿行测试,巩固本期节目的知识点。 我们知道图片是由像素点构成,而且最终的成像效果是由背后像素的颜色数值所决定的。在 xl 中,我们有这样一个由数值零一组成的六乘六的区域, 当我们把零设置成黑色,一设置成白色,最终呈现的效果是不是很像数字七呢? 而西恩模型能够告诉我们这样一个六乘六的像素图是不是数字七,或者返回他属于数字零到九的概率分别是多少? 下面让我对这个 cn 模型进行分解。第一步,提取图片特征。在这个流程中,我们需要使用卷机盒,也可以称为特征过滤器提取图片特征。 通常这个卷积盒会是一个三乘三的像素图。本例中,我们需要提取的水平和垂直两大特征部分分别在两个三乘三的卷积盒中得到充分体现。 提取特征的计算规则,我们需要按顺序提取原始图片中三乘三的像素区域, 再将其每个像素单元依次和卷基盒内相对应的像素值相乘,再求和,然后把结果记录在新的四乘四的像素图上。整个计算过程 我们在 xl 中也进行了模拟, 计算完成后,我们就会得到一个四乘四的特征图。在特征图中,我们可以根据像素值的大小设定颜色的深浅。 在这个例子中,我们可以看到原始图片中的七的垂直部分特征被很好的提取出来了,而水平部分特征却没有被提取出来。 这是因为在进行特征提取计算的过程中,像素图从原来的六乘六被降为成了四乘四,边缘的特征丢失了。 因此,为了解决边缘特征的提取问题,我们会使用一种被称为拍领的扩充方法,将原始的六乘六图像先扩充成八乘八,扩充部分的效 像素值均设为零。这样在进行特征提取计算后,转化后特征图的像素同为六乘六,我们就可以看到垂直和水平特征都得到了完美提取。 现在我们进入到 cnn 模型的第二步,最大磁化 max pro 零。 这个过程的目的是将图片和数据进一步压缩,仅反映特征图中最突出的特点。 我们将六乘六的特征图用二乘二的网格分割成三乘三的部分,然后提取每个部分中的最大值, 最后放于最大磁化后的三乘三网格中。磁化后的数据保留了原始图片中最精华的特征部分。 第三步,扁平化处理。我们把磁化后的数据进行扁平化处理,把两个三乘三的像素图叠加转化成一维的数据条, 数据条录入到后面的全连接隐藏层,最终产生输出结果。扁平化之后的流程和我们之前介绍的 a、 n、 n 模型是完全一致的。 这里简单提一点,全连接隐藏层意味着这里的任意一个神经元都与前后层的所有神经元相连接,这样就可以保证最终的输出值是基于图片整体信息的结果。 而在输出阶段,根据我们之前激活函数的那期节目,我们可以使用四个末位函数返回零到一的值,代表该图片是否是七的概率。 也可以使用 soft max 函数返回,它分别属于零到九的概率。到这里,一个完整的 cnn 模型数据流就完成了。 现在来到 cnn xplaner 在线工具页面,我们可以用刚才介绍的原理去理解一个更加复杂的 cnn 模型。 在这个模型中,我们需要判断输入图片的物品类别。这里我们选取的图片是彩色的披萨。 在输入端,模型根据其 rgb 值将原始图片分成三个颜色输入通道,三个颜色通道分别被三个三乘三的卷积和进行特征提取。 这里我们可以看到原始六十四乘六十四的图片提取后成为了六十二乘六十二的 特征图像,因此这里的模型并没有使用之前介绍的拍顶扩充方法。提取后将三个颜色通道的特征图片进行叠加,并考虑偏差 bis 生成了十个卷基层的特征图。 在这之后,模型使用了 red 函数过滤了所有负值,然后再进行了一次卷积和特征提取,将六十二乘六十二的像素图大小进一步缩减成了六十乘六十。 随后经过 red 函数和最大磁化的处理提取其精华特征,同时将特征图大小降为到了三十乘三十。 后面模型又进行了一次相同的特征提取 v i 六和最大磁化操作。最终磁化后的特征图片为十张 十三乘十三的像素图。接着模型将十三乘十三乘十的像素图数据扁平化,处理为一六九零乘一的数据条,经过全连接隐藏层和 suvp 正 max 输出函数 产生该图片属于各个类别的概率,可以看到其属于披萨的概率超过了百分之九十九。 总结一下今天的内容,我们先通过简单的 cnn 模型介绍了其主要原理,然后通过 cnn xbany 的复杂模型进行了穿行测试和讲解,那么现在大家是不是觉得 cnn 模型已经不再那么神秘了呢?那么让我们下期节目再见吧!
1990funincode 06:08查看AI文稿AI文稿
06:08查看AI文稿AI文稿今天我们来讲一个图片分类的问题,图片分类在机器学习中应用还是非常广泛,而且也是非常常见的。 我们先打开我们的案例,今天用到的数据集是 fashion aminist, 这个数据集是由一张张图片组成的,图片中包括衣服、裤子、裙子、 t 恤、鞋包等等。而为什么选用这个数据集而不选用 aminist? aminist 的就是手写字体, 因为爱慕丽斯特用的太多了,而且太简单,所有每一个初学者都会用到爱慕丽斯特,而且最主要的一个问题就是爱慕丽斯特他没有什么实际意义。 当时用 facemelic 的创建一个模型,可以预测我们实际生活中某件衣服什么类型。本次项目主要分为八个部分,分别是参数设置, 加载数据、数据增强、数据预处理、模型定义、模型评估以及自定义服装图片识别。还有项目小结,我们先来看第一个参数设置,主要包括图片的尺寸设置,比如图片的高和宽,我们设置为二十八 通道,由于他是黑白照片,所以通道是唯一。还有训练过程中的一些设置,比如每次喂给神经网络的图片张数图样本数据的大小,如果你内存不太够的话,可以设置小一点。还有他的 迭代次数以及艾特姆的次数,这个艾特姆就是为了求一个,最后求一个平均艾特姆等于三级,说明最后训练出四个模型,而这个参数是一个图片真。 下面是对他的标签进行一个罗列,生成一个列表。然后第二部分就是加热数据,加热数据主要采用 tensuflow 的 date set, tenth flow date set, 它自带了类似的很多,一些数据级可以直接用 love 继续读取,可以看到他的训练级仓样本为六万张,测试级样本为一万张。 第三步就是数据增强,我们都知道机器学习或者深度学习中,数据是最重要的,数据越多,往往他的模式就越准确,训练的 模型就越好,所以采用数据增强的技术可以更好的训练模型。经过数据增强,我们可以看一下他最后 得到了效果就是训练级达到了十八万张,由于模型就在训练级上训练的,所以测试机没动,还是一万张。然后下一部分模型的定义,图片,尤其是图片的分类问题,一般采用的是 cnn, 我们这里也采用 cn, 在这里定义了一个函数创建模型,为什么定义这个函数,定义这个函数就是为了后续我们调用这个模型做准备。下面就是他的模型结构, 然后在下面就是模型的训练,这些就是训练过程,在下面就是模型评估,模型评估主要是以他的损失只是作为标准来保存最有模型的,我们由于我们前面艾特们设置的三,所以他有多个模型,这里用到的是一个 平均的训练级和测试级上面的损失值以及他的准确率,可以看到训练级上是百分之九十六,而验证级是百分之九十五,这个准确率已经特别高了。 下面就是对他损失值以及准确度确定以及绘制等等,以及模型的保存。下面是用单模型评估,选用的是第一个模型, 然后惠子涛的损失曲线以及准确率曲线,左边这个是准确率曲线,是稳步上升的,达到了百分之九十几,而损失值是稳步下降的。 显示随机样本的预测结果,分别显示了他的预测值以及他的真实值。绘制混淆举证,混淆举证可以 计算出他的精确度、召回率等等, fe 分数精确度和召回率等等。而最后我们来用我们自己的图片来进行测试, 要使用我们训练好的模型进行测试的话,首先我们需要知道他的模型结构,就是我们需要还原这个模型,这个案例保存的是 hdf 五文件,这个文件包含的就是我们模型训练最优模型的一些 权重和参数,所以前面那个第一的模型结构就用到了,就可以很方便的把模型定义出来,再入我们的参数, model 就是我们还原的模型。 我们可以先看一下我们所需要预测的图片长什么样子,可以看到第一个这个上面对应的就 是他的图片的名称,下面就是对的图片,可以看到有裙子、有 t 恤、有包等等。 模型重建完毕,我们就需要输入我们的数据,要预测我们的数据,首先我们需要把我们的图片变成神经网络可以读取的数据格式,这个数据预处理和前面是一致的, 我们先要变成黑板,然后对每个像素进行标准化,除以二百五十五。最后得到的结果 一共有十三张图片,有两张图片预测的出错了,第一个就是汉三,第七张图片应该是 t shirt, 他预测是汉三。还有第十 十张图片应该是 t 恤,他预测为了裙子,这个模型在实际生活中的鲁班性还不是特别好,需要更多的数据来进行模型的训练。好,那今天这个案例就到此结束,谢谢。
37跨象乘云



