开源语言模型7b是指什么
开源大语言模型 mistro 七必发布,该模型号称最强的开源 l l m, 在多项测试中都击败了具备一百三十亿参数的 naomi 二模型。 此外, mistro 七币还具备很强的编程能力以及更快的响应速度。根据多组测试结果可以看出, mistro 七币在推力、知识库理解能力、数学能力以及代码处理方面都超越了拉玛尔旗下的三种模型。 最重要的是, mistro 七毕竟拥有七十亿财属,在理解能力和推理方面却和具备二百亿财属的浪漫二相当。 因此该模型不但可以节省内存空间,对算力的要求也会减少百分之七十。 mistro 七 b 同时支持文本语音输入,例如要求其写一段求职信, 系统就会快速提供答案。然后 mistro 会把生成的文本转换为音频并播放使用中文输入问题还能要求机器人输出一段简单的游戏代码。 mistro 起笔非常适合作为微调模型,同时具备八 k 的上下文能力,对 gpu 的要求也很低。感兴趣的同学可以到粉丝群获取地址尝试我是凯哥,关注我,获得更多恋爱干货!

粉丝5681获赞3.5万
相关视频
 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿插播一条最新消息,阿里云今天发布了同一千万七币的开源模型,同一千万七币是今天中午左右开源出来的,目前在哈根 face 上面已经提供了七币和七币 chat 两个模型要下载。这个评测数据相当的炸裂,这个模型一经推出是直接超过了市面上大部分同规模的模型的 兄弟们,新一代的大模型卷王他来了,总之这个数据是看起来非常非常惊艳的呀,实际使用效果有待后续的验证。模型的上下的长度大概是在八千 tokens 左右,同时这个模型是针对插件相关的调用做了优化了,能够有效调用插件以及升级为 agent cbt 的。这个模型是针对 api、 数据库模型等工序的调用做了特殊优化的,基本上可以看出案例为了推出这个模型是做了不少准备的。关于模型的使用协议,这两个模型是允许商用的,在项目的威力密中也提供了使用这个模型进行推你的视力代码,你也可以在 model scop 社区里面体验同一千文的问答。项目第一天开展出来,获得了将近五 百颗星,感兴趣的兄弟们可以去体验一下,或者是把模型下载到本地实际测试一下。模型占用空间大概是十五个 g 多一点,模型量化之后最低是需要七点几个 g 的显存来跑,不做量化的话,正常是需要十六个 g 以上的显存。
2326云影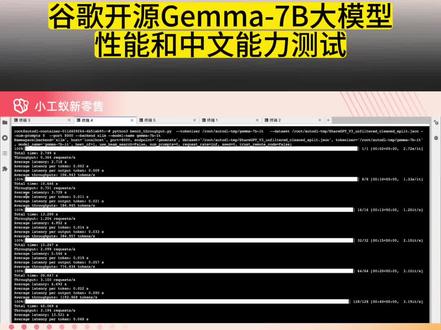 02:49
02:49 02:59查看AI文稿AI文稿
02:59查看AI文稿AI文稿今天有一个不大不小的新闻,有一个叫 militch 七十 b 的医疗大语言模型正式开源发布了。本来大语言模型发布也不是什么稀奇的事情,不过我查了一下,似乎他是第一个在七十 b 上进行开源发布的医疗模型, 他是根据拉巴兔的底层模型进行微调的,再加上医学的数据论文,并且知识库更新的日期是二零二三年八月,知识库也是非常的新。今天我来分享一下如何下载这个模型,并且和他进行本地的对话, vnos 和麦克版本都可以用。 首先进入一个网站,点击下载,点击 macos, 下载完成之后解压搜就得到了这个欧拉巴特的文件,双击运行,然后他会提示让你安装,我们把它点击 move to applications, 点击 install 之后他会提示你输入用户名和密码,输入好以后他就安装完成了。然后我们 打开命令行,点开 lunchpad, 然后输入 tomino, 在命令行里输入欧拉玛论 medicher 七十 b, 如果你想运行七 b 的模型,那就把七十 b 给删掉,我这里来运行一下七十 b 的, 我这台电脑是六十四 g 内存的好,这个完全没有压力。好,开始第一次的话他会下载一下,大概是四十六 g, 需要一点时间,不过下载好就可以本地完全离线运行了。 可以问他问题,肚子疼有什么治疗的办法吗?他给我生成的几种方法,如果是食物中毒的话应该怎么办?如果是胃病的话,那会怎么? 因为还可以。质量上来说嘛,肯定不如 g p t 四,但是比三点五强。我们在这里输入 back 退出。接下来讲一下 windows 五操作,下载完成之后,打开这个软件,他就会出现一个欢迎界面,我们点关闭,在搜索栏里面输入 我们的麦克,然后点击哦,这个时候就可以把可用的模型全部都给搜索出来了。这个模型是已经经过转换的,所以我们可以看一下它上面有一二三四五六七八九十这个数字标在那里, 其中如果数字越大,说明模型的丢失率越小,如果数字越小,那就说明模型的丢失率越大,当然如果模型丢失率越小,相应来说模型的体积也越大,这个就根据你电脑的性能来权衡一下, 我这里就挑一个 q 五的,然后进行下载,如果你的电脑性能足够强大的话,你可以试一下七十 b 的下载次度也不会很慢。 下载完之后呢,我们在这里就能看见有两个模型,一个大的一个小的,我们点击这里对话,我们点这里加载模型。由于我 windows 电脑内存不是很大,所以我加载一个 gb 的模型,加载需要一定时间, 我们可以在左边看见他占用的内存和 cpu。 加载完毕之后,我们就可以开始新的对话了,点击 new chat, 然后把下面的提示框给关掉。同样问问题,肚子疼应该怎么办?但是你有点心理准备哦,七 b 的模型可是很水的,他肚子疼可以帮我扯到牙齿上面去。 我的天呐,这个还不如问切 gpt 三点五呢,对不对?好了,这就是我今天的评测,七十币表现还不错,有特殊的应用场景,七币的话我们就当个玩具玩一下就可以认了。
185科技爆 15:22查看AI文稿AI文稿
15:22查看AI文稿AI文稿嘿,你好,欢迎回到 x 谷歌的肩膀模型啊,算是开源模型里面的一匹黑马,关心 ai 大圆模型的朋友非常有必要了解一下,今天呢,就跟大家讲解一下肩膀的特点,三大特色,如何最简单的开箱即用,以及两种本地部署的方法。 最后呢,我们再聊一下,为什么我觉得对于普通用户来说呢,本地部署并没有太大的用途。谷歌呀,一直以来号称 ai 为先的科技巨人啊,过去的一年呢,被 opana 各种挤兑,暗地上摩擦, 比如二零二三年的三月啊,谷歌刚刚开了一场经验的发布会,展示了在谷歌的工作空间当中集成的令人兴奋的 ai 功能,但是呢, openi 紧跟着随手就推出了 gt 四,后面的故事啊,大家都 知道了。然后谷歌卧薪尝胆憋了一年的大招,终于在二月十五日发布了一百万上下文的杰木乃一点五, 结果 open a 又在同一天寄出了 sorry。 一周之后,谷歌再次发布超强的开源模型解码,至此呢,开源模型就形成了三国鼎立的局面,分别是谷歌的解码,刚刚被微软注资的 mister 以及 meta 的拉玛 two。 好,我们来到谷歌这么的首页,他这一句话的介绍就体现出了这么开源家族的两大特点,首先,一系列的轻量级先进的开放式模型, 一系列说明他推出的不只是一个模型。那实际上呢,本次 j 码推出了两种尺寸的模型,分别是 j 码二 b, 也就是二十亿参数以及七十亿参数的两种模型。而且呢,每一种尺寸他都有预训练和指导调优的变体,这个是什么意思呢? 当我们要去选模型的时候呢,我们可以看到每一种尺寸的模型,它会有两个变体,比如这个七十亿参数的模型啊,它是 jama instruct 七 b, 那还有一个就是直接 jama 七 b, 那这两个的不同呢,就是 jama 七 b, 他就是一个预训练的模型,而 jama instruct 七 b 呢,他就是一个经过指令调优的模型。所以你要想体验原汁原味的模型,你就用他的预训练的版本, 你要想他有更强的能耐呢,你就用他的经过指令调优的 instruct 的变体。好,我们回到他的介绍,他的第二个特色呢,就是他采用的是跟创建 gm 的模型相同的研究和技术。 杰木乃模型是谷歌目前最为先进的大圆模型了,刚刚推出了杰木乃一点五 pro 的版本,在之前呢推出了杰木乃一点零 rtr 的版本,所以谷歌用它的旗舰模型相同的技术来构建开源的模型,那这点还是比较良心的。 也因此呢,在詹玛的三大特色当中啊,首先最引人注目的呢,就是他的卓越的性能了,我们可以看一下他的比较 好,下面就是他的一个基准测试的一个对比图,这只是其中的一项。那参与对比的呢,就是我刚才提到的开元三国,这两个是买塔的开元模型拉玛兔,分别是七十亿版本和一百三十亿参数的版本, 中间这个是 mister 七十亿版本。那这边首先是解码最小的一个模型,就是二十亿版本的,以及解码七十亿版本的模型,那仅从 从这个对比上我们就可以看到,解码七十亿版本的模型呢,他已经超越了 mister 七十亿版本,甚至远远的超越了拉玛兔的一百三十亿版本的模型。而最轻量级的詹玛二十亿版本的这个模型呢,他的性能几乎与拉玛兔的七十亿版本的相当。 那除了这么的性能之外呢,另外一个引人注目的特点呢,就是他的框架灵活,而且易于使用, 这是什么意思呢?首先在 jama 的网页上呢,他就提到框架灵活,可以通过 carrots 来兼容三大机器学习的框架,他也可以很容易地通过 kego 啊,或者他自己的 collab 来进行使用, 也可以在谷歌云上面进行训练和部署,而且还支持哈根 face, 还有英伟达的尼某。当然这些呢对于非开发人员来说可能并不熟悉, 那么我这边总结的易于使用,对于非开发人员来说呢,我们主要关心的就是两点,开箱即用以及本地部署这两种方式。那么我们首先来看一下最简单的尝鲜接码的方式,就是开箱即用, 我们可以通过至少两种方式来使用 jama, 一种是 hugging chat, 还有 pue, 比如我们先看一下 hugging chat。 好,这边就是哈根 chat 的界面,本次视频当中用到的所有的链接呢,我都会把它集中放在我的一篇博文里,那博文的链接呢,我会放在描述栏当中,大家到时候去看就可以了。 那这里呢就是 hagging chat, 我们可以看 hagging chat, 在左边 model 上面就可以选你所使用的模型,那么目前支持七个模型,这是 mister 八乘七币的一个模型,这个模型也很不错。 好,这边呢,谷歌 jama 的七币 i t 就是表示它是经过调优的模型, instruct 模型,那么点击我们就可以选上它, 那这时候呢,我们就可以进行一下测试了,而且 happy chat 的好处是它可以进行网络的搜索。我们先不用打开它,我们简单的测试一下,那这边就会显示我们刚才选中的模型的名称。好,简单,测试呢,就用我的测试三板斧。 首先我们可以看他的代码能力啊,编一个贪吃蛇的游戏,那 jimmer 呢?我们可以先使用英文来对他进行测试。 好,快速的完成了代码的编写,我们直接测试一下,看能不能正常运行。 好,演砸了直接出错,那我们接下来再看看他。第二个问题,树上有十只鸟,猎人开枪打死了一只,请问树上还剩几只鸟?新开一个绘画,答案是九,这个表现就有点弱。好,我们再看一个推理题,安德鲁从上午十一点到下午三点有空, 琼尼中午到下午两点和下午三点半到五点有空,还哪中午半小时有空,然后下午四点到六点,那这三个人要是一起开会,那什么时间是合适的呢?当然,这个题可能对这些模型有点难度有点高,因为即便是 gpt 三点五,你直接丢给他都有可能出错,我们来试一下吧, 所以不出意外它的答案是错误的。好,那我们看看有哪个模型跟它类似,我们可以对比一下的,我们看看它的对比,它实际上是强于 mister 七 b 的,我们看看 mister 七币,我们就用 mister 七币,也是 instruct 模型,首先贪吃蛇,我们来试一下, 好,也是出错,我们就不去解决这个代码问题了,我们再找一个更强的模型,看看能不能一次成功。八成七币, ok, 一点废话没有, 蛇呢,没有出错,要吃的东西在,但是蛇不知道在哪,我们再来一个更强悍的模型, mister large, 好, mister lush 果然是更强的模型,这就是一个正常的探 只蛇的游戏,没有任何问题就可以运行。好,刚才我们顺手做了这几个模型的代码测试啊,我们再简单总结一下, gem 和 mistro 七币编的程序直接出错, mistro 八成七币呢,程序不出错,但是蛇没有了,但是 mistrolas 呢,完全没有问题,一次运行成功, 那这两个问题的表现呢?见面有点让人失望,但是呢,我这两个问题啊,完全算不上是严格的测试,不能把它当做评价模型能力的一个标准。 好,接下来我们看一下我们第二种开箱即用的方法呢,就是使用 p o e, p o e 呢,也是一个很好的集成了各个语言模型的一个工具,而且它的更新很快, 新发布的模型呢,很快就会寄生到他的系统里面去。好,进了 poe 之后呢,我们在这就可以看到接码的模型了,如果你看不到呢,我们直接点他的搜索 图标,然后去找就可以了,我们就可以找到摘帽模型,比如这边是一个哦,飞手官方的,那我们就是点这个,我们先试用这个,同样我们给他一个十只鸟的问题, ok, 证明模型还是一样的 好,这就是 pue, pue 也是一个大家适用各种语言模型的好地方,那这些热门的语言模型这里面基本上都有,包括前两天我的短视频里面说到的 mistrola, 这里面也都有。 好,这就是开箱即用的办法,只要我们能上网,能访问到这些网站,不用我们去做任何的工作,我们就可以去尝鲜试用各个语言大模型。 那接下来呢,我们就再看一下两种本地部署的办法,把语言大模型运行在我们自己的电脑上。本地部署呢,有两个办法,一个是欧拉玛,还有一个是 l m c d 六,我们可以先看欧拉玛。好,这就是奥特曼 的网站,直接下载就可以了,然后根据你的操作系统来进行选择,我是 macos, 我就选 macos, 下载下来是一个压缩包,双击打开,我来把文件双击运行好,运行起来之后就是一个小窗口,然后我们直接点下一步 安装命令。行工具,直接点安装就行了。好,他需要管理员权限,然后我们把密码告诉他,他运行模型的命令就是这样,奥拉马 ra, 然后后面跟模型的名称 就完成了。这边是它 github 的网站,可以看一下它支持哪些模型好,这就是它支持的模型的列表。 jame 七 b 是四点八 g b, 我们看一下它的要求,运行要求,如果运行七 b 模型呢?至少需要八 g b 的可用内存,我的电脑是十六 g b 的内存啊, 运行七 b 应该是没有问题了,我们就直接把这个命令拷贝下来,因为它是个命令行吗?我们直接就打开我们的 terminal。 好,他需要下载,需要等待一段时间,就加速把它跳过去。好,这边已经成功了,我们就可以给他一个消息 prompt, 然后看看他给出什么样的结果了,还是一样,我们就用猎人打鸟。 哎,果然没错,确实是 gm 七 b 的模型,但是呢,你要把它装到本地,只是这么玩肯定是没什么意思的,装到本地更好的。用它的办法呢,就是用它的 a p i 这样的一些支持大原模型。 a p i 的一些 app 呢,就可以直接用到你这个原模型, 比如在他的 d table 页面下方呢,就有很多可以使用到这个模型的一些集成的应用,那有兴趣呢,可以去 玩一玩。那接下来我们再看一下我们如何用 l m studio 来进行本地部署这些开源的大圆模型。好,这边就是 l m studio, 它跟奥拉玛类似,也是用来下载和本地运行这些大圆模型的。这边提示谷歌的 jama 已经支持了这两个参数的版本。 同样我们需要下载安装,我是麦克电脑,选第一个好,下载完成是一个安装包拖过来 ila studio 安装之后就是这个界面,首先显示的它的 release note 更新说明,我们直接在这搜索它的模型 好,输入解码之后,这会出来很多呀,那么我们就选一个点赞数比较高的七币的这个模型。那这边呢,又有十五个文件可以供你下载,那这些文件有什么区别?如果你想了解一下呢,可以 你看这边的说明,那这边相当于他的质量啊,是一个从低到高,我们下载一个稍微中间点的吧,我们下载这个五 gb 的版本好了。好,下载完成呢,我们就可以在他的对话窗头啊,哎呀,对话窗口头去使用了。 比如我们在 test 窗口里面,我们就可以选择模型装载一个模型,上面这个就是五 gb 的这个版本。 同样我们还是问他老问题,猎人打鸟的问题,答案依然是九只鸟。为什么要说 still 依然是九只鸟呢? 为什么要说依然呢?同样用 l m studio 把 jame 在本地安装运行起来之后呢,你除了可以跟他对话,就像我们刚才用奥拉玛通过命令行跟他对话一样,这边呢,他还可以作为一个 服务来启动,相当于它可以提供 a p i 的服务,对外的服务同样也是类似于刚才的奥拉玛一样,你就可以在其他的 app 里面来使用 l m studio 给你运行起来的本地的这些大模型了。除了开箱即用本地部署之外呢, 谷歌呢,还给开发人员提供了很多的方便的途径去使用 jama, 比如他可以跟谷歌云的整合,可以通过 what xai 来使用 whataxai。 在我之前的视频当中也讲过,作为开发人员,你可以用各种姿势来使用 jama, 但是呢,对于普通用户就是非开发人员啊,你也没有打算去用 ai 来自己开发或者制作什么产品的话,就是日常的使用。那么本地部署一个开源的大圆模型,那么它的使用场景除了玩一玩练练手呢?我想不到还有什么 更合用的地方,因为本地他的优势啊,就是本地吗,免费,不用联网,也没有任何的使用限制,想用就用,但是他的缺点呢,就一项本地的模型,他是很弱的, 就算是七 b 的模型,它的能力也是一般般。那么更高一些参数的模型呢?你要想用好它呢?你的显卡的价格估计也不低了,比如我们看到的这个图表,一个简单的一个性能对比,最末的一个拉玛的七百亿版本的一个模型。 所以呢,如果你目前呀能够访问到以下任何一项服务,去用这些主流的大模型, charge, gpt, jim night, go, pilot, pue, proplacity, 还有 mystery ai 等等,那我就觉得你完全没有使用本地模 型的必要了。比如我最常用的一个场景呢,就是翻译,那目前用的就是 gp 三点五的 api。 如果说我要用一个七十亿版本的开源模型,甚至是二十亿版本的一个开源模型去做翻译的话,那还不如直接使用谷歌翻译或者 dprl 翻译来的更简单。 当然,如果你有真正需要本地部署语言模型的应用场景的话,也欢迎分享给我,咱们一起讨论。如果你希望让 ai 提升你的效率啊,那么我分享的免费的内容以及付费的课程呢,就是你在 ai 世界里面最好的帮手。请打开网址 x 留点 ai, 进入到 ai 精英学院, 免费福利,点击这里就可以了。当然,我更希望你能看一下这两门关于 ai 应用核心能力的课程。这两门课程是在帮你打造 ai 的基础能力,而不是教 教你一些昙花一现的技巧。我把我数百个小时的学习实践融合到我的课程当中,我希望能帮助那些即便是初次接触 ai 的人,也能最终把 ai 变成自己强大的助手。 我的课程能教会我自己的孩子和家人如何使用 ai, 善用 ai 同样也会为热爱 ai 的你提供巨大的价值。
259回到Axton 04:54查看AI文稿AI文稿
04:54查看AI文稿AI文稿本月初,阿里云开源了千万七 b 和千万七 b trace 模型,最近我们又开源了基于千万七 b 的大规模视觉源模型千万 vl 模型在主流的四道多模态任务测评中均取得了同等通用模型代表下的最好效果显示。首个支持中文开放预定位的视觉源模型。本次开源的模型均免费可商用,现已在摩大社区上线了。 首先我们来对模型做一个基础介绍,多模态一直是与训练大模型最重要的技术方向之一,从单一改观仅支持文本输入的语言模型,到五感全开让大模型接受文本、图像、音频等多个类型的跨步态信息,这其中蕴含着大模型智能跃圈的最大可能。 千万 vl 是阿里尼在千万七币语言国行的基础上,以欧根 keeper vip bg 作为视觉编码器的数字化,中间加入单层随机数字化的 cross attention, 经过约一点五 b 的部分数据训练,得到可支持知识问答、图像问答、细度、视觉定位、多图理解等开发场景。同时,在千万 b l 的基础上,公益千万团队使用对齐机制打造了基于 l m 的视觉 ai 助手千万 b l chat, 开发者可基于该模型快速搭建具备多模态对话能力的引用。那么接下来我们先看一下千万 vl check 的模型能力,这里可以通过摩大社区充空间直接体验该模型。 首先是多轮视觉问导,比如说我们先给他一张电影的海报, 我问他这是什么电影,他回答这是乱世佳人,并回答了作者信息。然后我们在 问他女主角是谁,他回答绯闻力是正确的。然后我们再来一个视觉定位的问题,我们上传张小杨的头像,然后问他当初所有的小杨 可以看到他框出了显示框,然后我们再问他一共有几只,他回答是四只是正确的。接下来我们来看一下模型文字理解的能力,我们先给他一张路标,然后我们问他去广州有多远, 他识别出来了有二百九十三公里。然后我们再给他一张更复杂的图片,我们给他一张医院的指示牌,然后直接问大模型外科应该去几楼,他找到了,在三楼三个。我们再测试一下模 型的图片理解的能力。我们先来一道简单的题目,我们给他一张图片,然后我们让他写一首七言绝句, 他回答,远山青青近水柔,小舟荡漾月如钩。写的不错,还押韵了。然后我们再给他一个随机手绘的漫画,我让他根据图片写一个搞笑故事, 啊,确实挺搞笑的。测试了文字和图片的理解能力后,我们再来测试一下篇推理类的问题。先给一个数学公式的图片,然后问大模型等于多少, 他得出的结果是四六七五六是正确的。然后再给他一张图标,问他这张图描述了什么,他回答了这张图片的具体信息,然后我们再追问他一下订单的输入标是多少, 可以看到他给出了准确的数字。最后我们再来试一下更复杂的多图理解问题。我们给出两张城市风景图,会员大模型分别在哪里? 他回答了分别是重庆和北京,也进上了相关的信息,那么我们再来问他能不能给一个第一张图的旅游计划, 嗯,好的,大模型给出了一个非常详细的计划。以上就是千万 dl chat 模型的基本演示,那么对于想要进行本地部署的开发者们,我们最后再来演示一下模型的推理。 首先是贝斯模型的推理,点击运行,我们先进行模型的加载,然后输入张图片,生成这张图片的标题并画框,可以看到模型正确的生成了标题,并且生成了一张图片,图片中框出 出了女孩和狗,然后我们再来看一下圈子模型,点击运行,这里也是先导入模型和图片,然后问他图片中这是什么,可以看到模型也正确的生成了秒数内容。这里我们再让模型输出狗的检测框,然后我们来看一下他的图片, 可以看到他正确的框出了其中的狗,那就是千万也有模型的相关介绍。未来结合行业数据计,多模态通用大模型,可在医疗、教育、游戏等领域做 smt 训练多模态行业模型。 后续摩大社区也会推出多模态大模型的训练和微调方法,欢迎开发者们一起体验更多的模型玩法。
1552阿里云 01:12查看AI文稿AI文稿
01:12查看AI文稿AI文稿咱国产的开源大模型这是要崛起了呀!我今天注意到昊天 face 刚才公布了一个最新的开源大模型排行榜,你要知道,这是目前全球大模型领域最具权威的榜单了。通一千问七百二十亿参数的版本的大模型,竟然力压长期霸榜的 mita 的七百亿参数的羊驼二,登顶开源大模型的榜首。 另外值得注意的是,通易千万的十四 b 和七 b 也出现在排行榜的前列,加上最小的一点八 b 以及视觉理解模型千万 vr 和音频理解大模型千万 audio, 这使通易千万成为了目前首个实现全尺寸、多模态的开源大模型, 将可以满足不同层次的开发者需求。这个十二月初才宣布正式开源的通一千问七十二 b 大语言模型高达七百二十一参数,在十个权威基准测评创下了开源模型最优成绩。 在英语任务上,千万七十二 b 在 mm lu 基准测试中取得了开源模型的最高分。而在中文任务上,千亿七十二 b 霸榜了 c awhile、 cmm、 mu、 高考、奔驰等基准得分超越 gbd 四。在数学推 方面,千亿七十二 b 在 gms 八 k max 测评中断层式的领先其他开源模型,所以这次发布后登顶 holding face 也就不意外了。此外,在国内外多个榜单中,千亿七十二 b 大模型也取得了很好的成绩。国产大模型的崛起,让追赶超越 opni 不再成为一句空话, 同时也打破了国内企业和科研发展的技术壁垒。而作为中小企业或者个人开发者,开源也使 ai 更加普惠。
6444赛文乔伊 07:21查看AI文稿AI文稿
07:21查看AI文稿AI文稿也是介绍过啊,阿里的这个通一千万的这个模型,他啊,他这个最大的特色呢,就是他对这个 api 的这个调用,他的这个能力啊,他要超过 gd 四的这样的一个能力 啊,它对工具的这个选择的这个能力,它要超过啊,超过一些一些主流的一些模型,你可以看到它这个 g p t 四,它的工具选择的准确性,它只有百分之九十五, 但是通一千分这个七 b 的模型的话,他准确性可以上升到百分之九十九,他大概率都是会对的啊,那而且他错误选择之不到百分之十啊,那像 gd 四的话要百分之十五啊, gg gpd 三点五的话要达到百分之七十五啊,所以这个通一千分这个模型,他对这个工具的使用 选择,让那个大模型跟其他的 a p i 结合,这个方面的能力是非常强的啊,所以我们今天来讲一下这个方面的一些功能啊,好,我们看看啊。啊,这个代码我已经已经用了 一下啊,这个也是通过他的这个,他的这个商铺的这个例子啊,啊,稍微改了一下啊,给大家看一下啊,他这个例子里面呢,他的工具的话呢,他会有四个啊,四个啊,有一个搜索啊,有一个数学方程式计算啊,数学公式计算的这样的一个工具的增强 啊,还有一个啊,查询论文的这个 api 啊,还有一个是拍审这个代码的这个自我的运行啊,他有这样四个工具啊,我主要是测一下这个啊,因为其他这个两个,这两个是要有 api 的这个支持的,就像你要有一,他是有收费的 api 的 key 啊,如果你没有的话,你可能就做不了啊,他这个事情啊, 拍摄他因为他这个环境要拍摄三点九版本啊,所以我这个也没跑起来啊,我这个是三点八的,所以我主要撤几个给大家看一下啊,他大概是怎么跑的?首先呢肯定还是要定义这个工具啊,这个定义这样一个工具,你要 告诉他这个工具是干嘛的啊?这个这个工具的名称是什么啊?他这个里面会讲啊,如果你要去,你要去回答一些,要去搜索到里面要去搜索一些 ai、 a, r x i v 的这样一个文档的话,你就可以利用这样一个工具啊,它的这个参数啊,它主要是输入一个字符串的这样一个参数啊。 啊?他的 a p i 主要是这样的啊,他会介绍一下,他的 a p i 主要是这表这个函数,他等于是这样。好,我们可以看一下是他的这个工具的模板啊,因为他用一个 reaction 的这样的一个提示的工程啊,他这个提示工程,他主要是经历这四个阶段,就是问题要去思考,要去行动,要去观察,再要去思考 啊,最后去回答这个问题啊,他要经过这几个步骤啊,他要经过这样几个步骤,要去判断这个模型目前是处于什么样的一个阶段, 然后要做一个什么样的动作,他在这个里面循环,循环完了之后,他最后去根据你这个问题去回答,他主要是做这个啊,这个主要是 beau 的这个提示工程的啊,这个里面会讲啊,你用些什么工具,对吧?你要回答一些什么问题?你要做一些什么事啊?他这个这个里面 提示工程,提示工程的话就把这个里面前面那些东西把它给录入进来,他主要做这样一件事情,他只要做一个 reaction 的这样一个提示模板,他的核心就是 构建这个提示模板这部分代码,他主要是装载啊通一千万的这样的一个七币的这样一个模型啊,因为我本地已经下载了,所以我要他要下载一下啊,啊,装载模型完了之后,这个地方的话呢,他主要是要去就要去调用啊,调用这样的一个帕拉格印的这样的一个 api 啊,然后他调用完了之后 要去分析分析这个 plug in 的那个参数到底是什么?掉哪个 plug in, 然后掉的参数是什么?它主要是做这样一件事情, 那么他会根据这个反馈这个模型反馈的这个 action 和 action input 和观察到的这个数据去调这个,调这个参数,调这个 plug in 的一些参数啊,这个地方就用这个 plug in 啊,就调用这个 a p i, 它主要是, 那么这个是主函数的话呢,它主要是把上面所有的这些东西给串起来啊,那么首先他会根据你这个问题和你选择的工具,他首先要去做一个计划啊,要做前面这个东西就做啊,问题思考、观察行动,对吧?观察最终答案,他要做这样一个 计划,计划完了之后,他会根据他的这个观察到的这个情况去做这样的一个反馈,他会把这个结论会拿到啊,他会根据这个反馈的这样的一个东西是最终去回答输出这个啊,那么我呢,就简单的,他这个问题,就是编号是这样的一个论文,他讲了些什么啊?如果你用大 模型的话,因为他是缺乏这个方面的知识的啊,他是不知道这篇论文的啊,所以的话呢,他会选择这样一个工具啊,备选的工具注视,把它注入进去啊,这个是他的反馈的情况啊,你可以看到啊,这个 answer for in question for best you, 这个就是提示工程,然后 他会把这个工具给输入进去啊,然后这个参数到底是什么,对吧?返回的是一个 jason 的格式,他会跟你讲的啊,然后 follow some, 这个是 format, 他是根据这个问题输入的这个问题,思考这个就是提示模板前面的提示模板,提示工程里面 啊,他这个问题是这个,他的反馈又来了,他思考这个模型,思考是我需要调这样的 a p i 来获取这个论文的信息,他就去调了啊,调的这个参数,他也准确的捕捉到了啊,他观察到的这个信息啊,那他的这个 publish 的时间对吧?他的这个标题 对吧?他的作者,他的 summary, 他的摘要是什么?他拿到这个信息了之后,他认为他可以去回答这样一个问题了,所以他最终的答案是啊,这篇论文是研究的是一个什么东西,对吧?他的摘要是什么?这个 还是蛮蛮好的,假设我的问题就是输入一个,你好啊,他会不会会用这个工具呢?那么这也是一样的,他这个提示工程,提示模板啊,他会看一下啊,他会告诉你 啊,这个回答概问题的帮助比较小,我将不使用这个工具直接回答,然后他的最终的回答是,你好,很高兴见到你他的事情啊,所以这个我们也可以反映出啊,他他的这个工艺千万的这样的一个模型啊,他可以通过这些工具的定义, 他可以通过工具去增强他的这个模型的这种能力啊。他,呃,如果他觉得他需要有必要用工具的时候呢,他就会去用啊,去把这个利用这个工具的这个能 把一些内容,能够能够获取到这个 contex 这个上下文里面,他根据大模型的这个上下文里面的内容去最终去回答你这个问题啊,他只是一种方式,另外一种的方式,他可能觉得,呃,回答这个问题不用这些工具也是可以的,那么他就不不会用这些工具就直接的去回答你这些问题啊 的话,这个通一千分的这个能力,我,我上次也是介绍过啊,他这个能力就会非常强,他这个模型是七 b 的一个模型,但他可以通过工具的这个使用的这个工具的赋能, 可以干更大模型的事啊。在这个 luncheon 里面,它其实也定义了啊,各种各样的工具啊,你可以把这个工具跟这个模型 集成在一起,然后去告诉他,当然你可以定制开发一些你自己的工具,用这些工具跟这个模型的结合,能够做出一个非常智能的这样的一个机器人出来啊,他不但可以回答你各种各样的问题,对吧?他也可以结合你的本地知识库啊,去做这样一些事情啊, 当然他也可以去做,就是是呃,利用你这个工具去拓宽他各种各样的能力,他等于说,呃,你这个工具他比如说是环境控制啊,你这个工具是调用一些 api, 你这个工具是那个查询数据库里面的一些结构化的一些数据啊,他其实都是可以作为一些增强的, 你这个模型跟其他的这个外部的工具能够做到一个非常好的支持啊,这样我们清楚之前恰的 g p t 它是有这方面的能力的啊,它是可以调用外部工具啊,它会可以去告诉你,你可以去调一些外部工具去增强恰的 g p t 的这个能力的。那么目前看这个独立部署的像 通一千问的这样一个模型,它也能去掉这个 a p i, 去掉外部工具去增强这方面能力啊,它也是非常强的啊,好吧,好。
202小工蚁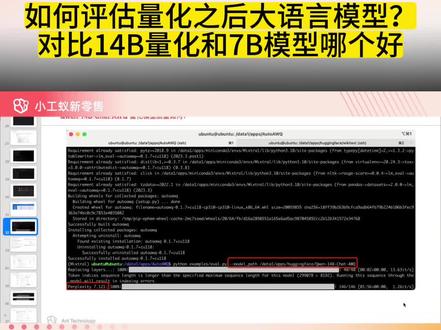 04:50查看AI文稿AI文稿
04:50查看AI文稿AI文稿亮化之后的他的这个模型的性能到底怎么样呢?我们今天主要是聊这个事啊,我们如何去测试一下叫当这个大模型被我们亮化之后,那么他的精度到底会损失多少啊?那么我们肯定是要进行一个测试的,我们首先给大家看一下,这个是一个截图,是通一千分十四 b, 恰恰经过 awq 亮化之后, 那么我们一般会用一个呃困惑度啊,来衡量这个模型被我们呃量化之后的这样的一个性能到底是怎么样子的啊?那么他这个困惑度的话是七点二一七点呃一幺二啊,他等于是这样啊,那么 我们一起来看看啊,那么这个困惑度呢?他一般都是呃就是大模型啊,他们一般都是用这个困惑度啊来测试啊,评价这个模型的好坏啊。对于一个相同的一个测试级来讲,那么困惑度越小的话, 那么他的准确率也就越高,也就代表了呃,大约模型啊,他就相对来讲越好啊,那么困惑度他是一个交叉商的这样一个指数啊,指数的这样一个形式。我们简单给大家介绍一下,什么是一个信息,信息的一个交叉商啊, 交叉商呢?我们认为有一句句子啊,原来他是原始的啊,这个就是我们的那个测试级,从 w 零到 w n 啊,这样,那么经过我们这个大模型啊,他因为能够自动生成这句另外一句的句子,所以呢,我们可以认为就说 经过大模型之后的那个句子,跟他实际他的那个句子的这样的一个情况啊,如果呃我们的那个 模型比较好的,他预预测出来的这个句子跟我们实际的句子,他其实就是越接近他的那个真实分布啊,这个这个就称之为把真实的这个句子的这样的一个情况, 跟我们用大模型预测出来的这样一个情况的一个比较啊,我们称之叫交叉商,那么交叉商越小的话,我们就认为他就越,他这个预测,他就越接近于他的那个真实分布啊,那么我们就认为这个模型就越强啊。所以这要给大家介绍一下 awq 这个模型的话,是用这个 l m ever 这样的一个评估啊工具来做这个交叉商的评估的,那么他的他的评估的话呢?他是用这个 vicky text 啊,来来来做这样的一个评估的,他就是去预预测啊啊,他是用这个 vicky text 啊这样一个数据集啊,就是 呃,来来做这样一个模型的这个质量的这样一个评估啊,他用的数据集是这个,那么他用的指标的话呢,就是前面讲的这个困惑度啊。这先 l m l 的话呢,它是一个开源的一个评估的一个框架,它是也是一个大圆 评估的一个框架,自回归的大圆评估的一个框架,这个框架呢?是呃,在哈根 face 上是比较火的啊,给大家看一下啊,星星也很多啊,三点二万个啊,那么像中国的一些些模型,他也是用这些用这些 啊, language model 的这样的一个评估的一个工具啊,去评估的啊。目前的话这个版本是零点四点零这个版本啊,他也有很多的这样的一个评估数据集,给大家看一下,他有非常多的这个评估的任务啊,这个是评估这个表啊,你都可以进行评估的啊, 它,那么我们这次是用那个 text vk text 啊,它主要是预测这个字符呃, word 的这个准确度困惑度的啊,我们是通过这个啊,当然你也可以通过这个模型去预测一下,像中国的这个 ever, 呃, c ever 的 下一个数据评测啊,他这个里面也有啊,这个主要是预测这个模型的准确度啊,他是等于是这样哈,所以我们是 是用这样的一个开源的这样的一个评估的一个工具做评估的。好,我们再可以看一下啊,那么 我们可以对比一下啊,如果是通一千万七 b chat 的跟通一千万十四 b chat 经过 a w q 量化的话,其实这个两个模型基本上是等价的了,因为是什么呢?我们呃,用 a w q 量化之后的话,他用的 呃,这个显存的话不多,也是通一千万七 b chat 的这样一个显存的这样一个量,所以我们拿这两个模型去对比一下,比较有代表性。这个是通一千万七 b chat, 它这个原始的,它的这个这个困惑度是八点六七一啊,它是等于是这样经过我们量化之后啊,通一千万十四 bcat 的这样的一个模型的话,你可以看到 啊,他的困惑度降低了七点幺二幺,那么就相当于是什么?这个就代表了就是相同的这个显存,相同的 g c u 的算力啊,可以用一个更大 大的一个模型啊,达到更强的这样的一个模型的这样的一个精精度啊,他等于是这样,那么我们在服务器上的,哦,这个已经跑完了啊,我们跑了一个三十四 b 的 一个模型,这个是我们跑了一个三十四 b 的一个模型,七十二 b 的一个模型,然后它目前的精度的话呢,是大概是在六点六点多, 六点二五三,稍等一下啊,对,差不多是六点二五三,这样就,呃,我们如果量化了之后的话,你可以看到这个模型越大的话,他量化出来他这个模型的性能是没有下降太多 啊,所以我们就可以通过量化的这些模型啊,尽可能少用这个 gpu 的显存和他的算力能实现呃,更好的这样的一个模型的精度,好吧。
143小工蚁 01:57查看AI文稿AI文稿
01:57查看AI文稿AI文稿大模型见了这么多,但是分集的这么详细的, vivo 大概还是头一个。今天上午 vivo 开发者大会,大会开始就植入主题,发布了最重磅的,也是外界关注度最高的大模型,蓝星大模型。蓝星大模型包含了十亿、百亿、 千亿三个参数量级,五个分级的大模型矩阵。这五种通用大模型其实定位分工是非常明确的。蓝心大模型 bb 十亿参数,是一个不依赖云算力的端侧模型,主要是文本总结类工作,这个大家应该都懂。 兰心大模型七币七十亿参数,钻银两用的大模型,主要是语言理解、文本创作等能力,可以帮助用户进行文案创作、聊天回答等。兰心大模型七十币七百亿参数,主要是角色扮演、知识问答和自然对话,从能力来看,更像是 踏着 gpt 的基础能力。当然,在表现上,蓝星大模型七零 b 在 supercool、 cf、 commo 等榜单上国内排名第一,至少体验是有保障的。蓝星大模型的千亿级参数模型有一百三十 b 和一百七十五 b 两个分级, 聚焦复杂程度不同的逻辑推理、任务编排等能力,比如编程等我们比较熟悉的大模型能力。大模型最终在用户册肯定还是要落地到实际的产品上。 vivo 这次推出了蓝星千寻应用,不仅是 vivo 手机可以使用,其他手机未来也可以在应用市场下载使用,体验 ai 乐趣。更让人意想不到的是,蓝星大模型竟然面向全行业开源,同步推出开发套件 book kit, 开发者可以更加专注地进行产品创新,同时还有至少一亿元的资金支持,这点好评。不过一亿元在 ai 行业能烧多久? 手机毕竟是绝大部分人日常生活中使用频率最高的终端设备,现在大模型好像成了手机厂商在 ai 领域抢占的高地,现在华为、小米都推出了大模型,自不自言的另说。未来我们的手机使用体验可能会发生翻天覆地的变化。
49趣写科技










猜你喜欢
最新视频
- 2487玖狐数码