爬虫URL无效怎么解决
好,同学们,好,那本节课程跟大伙来讲咱们的一个叫请求网址, 请求的网址及统一资源定位符,咱们的简称叫 url, 它可以唯一确定我们呃,说请请请求的资源的一个地址。 ok, 那我们还是拿它来跟大伙来讲啊,举个例子,比如说啊,我们当前的这一组地址我们怎么识别啊?它的一个组成呢?我们先把它复制一下, 复制完毕以后我们在这里面给大伙来解析一下啊。好,往这边看,第一个他是来自咱们的一个叫万维版的协议啊,协议对吧?然后后边的话从这里开始啊,就表示咱们的一个域名 这个页面的话,一般我们是把它放置一个叫 ip 地址, ip 地址啊,它们是两个,是进行一个指向的一个 ip 就这一块啊, ok, 然后我们从 ip 之后的话往这边走,就是我们对应的一个叫查询路径, okay, 就放着我们对应的数据在服务器里面的哪一个位置,我们使用它来进行一个声明。 okay, 好,那我们对于一个常规的 evo 例子还包含一些数据啊,比如说咱们的查询参数,好了,我们再打开给大伙来看一下啊,往这边拉。好,我们在这里在这里面 搜索的一些内容,那么他会啊把这个参数附带跟咱们的跟咱们的服务器来进行一个接收,然后呢服务器接收我们这里面的这个查查询的参数,然后呢在场数就会里面获取内容,再返回给咱们的前端, 好去肯定掌握搜索项目来。 好,那这里面就展示对应的项目啊,好了,我们再来看咱们的包里面有没有数据,看文档 pos 的来,同学们,看到没有项目就已经有了, 对吧?我们把它统称为叫查询字幕串,当时他走的是对应的 pose 的请求。好,那我们再来看一下他能不能找对应的 get 请求 啊,来,从里他还是 pose 的啊,对不对?好,那我们来看对应的百度,他应该是属于 git 型球啊,百度 来打开一下,我们来 so doing 的 python, 对吧?我一个回车,那么它这里面的话就会展示啊,与 python 相关的内容,对不对?好,就是它这里面就是一一长串的啊,查询参数啊,那 你把它简称完之后的话,它就只有那么几个参数啊,就 w d 等于 python, 看到没有 表示查询 python, 那我们把它们全部删掉啊,来删除后边都可以删掉啊。回车,是不是查询对应的 python 好了,我们再把 把它拿过去啊,这个 wd 等于拍摄,就是表示啊,我们从这里面把对应的拍摄传给传给百度服务器,进行一个接收,百度服务器接收对应的拍摄参数,然后再从数据库里面查询与拍摄相关的内容啊,然后再返回给到你。 ok, 所以我们把它称之为叫查询自我创, 也可以称之为叫查询参数。 会传输点服务器服务器去 数据库里面查询, 根据你的一个关键字词去数据库里面查询数据,返回 game 前端。 好,如果说我们能够把这一串给他理解清楚的话,那我们就能够更好地来学习对应的爬虫技术。 okay, 好,那行,那我先把这个视频给大伙来暂停一下,同学们可以好好的把刚才跟大伙讲的这个东西啊啊?去捋一下思路, okay。 然后我们再来看一下啊,一个地址,它的组成是由 协议、域名、路警查询参数做成,好, ok。

粉丝811获赞926
相关视频
 07:24查看AI文稿AI文稿
07:24查看AI文稿AI文稿大家好,我是雪顶的猫,本节呢我们来独立的构建一下这个 oppo 呢是用 oppo 的方式呢来创建一个请求,那么这个呢是在之后伪装这个 ip 地址的时候会用到,然后呢我们还会讲到这个异常处理, 那么接下来呢我们就来构建一下这个 oppo 的,那么 oppo 呢到底是什么呢?首先呢导入一下 usb 里面的这个快速模块,这是百度的一个网址,然后呢这个嗨点色,这个呢请留头,我们已经写好了。然后呢接下来呢就开始写一下这个返回值, 这一步呢写完之后,我们接下来呢就来获取一下这个欧喷的对象,这个欧喷呢呢他也是一个只是一个方法, 这个 oppo 呢对象呢我们呢使用这个 usb。 第二杯筷子 里面呢这个创建欧喷的也就是建立构建 beaud open 的, 然后呢调用一下这个 oppo 呢里面的这个 oppo 方法,然后呢把这个瑞斯棒子往里一传 iesp, 然后呢最后呢我们直接打印下结果就可以了,这只是一种这个一个方法, 然后呢我们来预先一下 好,那这个结果呢他也是成功的, 但是呢尤其是在写网络程序的时候,我们呢经常会出现些异常,这些异常呢他不一定是代码错误,有可能是网址的错误, 所以说呢对于这种情况,那我们之前在基础的知识过程当中呢讲过这个异常处理,那么网络请求当中的异常处理呢, 它主要包括两类, usb 点挨着点 u r l, 这个呢就是来捕获 usb 点水快速产生的异常,使用这个瑞森属性呢可以返回,这个原因, 还有呢就是 htvp 的挨着,那用于处理呢 http 和这个 htvps 请求的错误,那么他也是包括扣的响状态码 re 粉这个错误码的原因,还嘚瑟响应头的这个信息,那接下来呢,我们还是来用程序演示一下, 那我们这里呢,来访问一下这个谷歌的这个网址,我们来搜一下,看一看能不能搜一下谷歌的网址。三 w 点估狗,这个点 c 呢是可以访问的,然后呢我们先来访问的是这个点 com, 这个点 come on, 其实我们是不可以访问的,那我们来看一下这个失败的原因是什么?这个 ufo 本身呢,他是没有错误的,只是说呢,我们不可以访问,然后呢我们执行一下这个踹, 然后呢如果说有问题的话呢,我们就执行一下这个 ufc f, 然后呢 ur led 这个 l 里面的这个 uir l, 然后呢起个别名是一,然后呢打印一下这个错误的原因一点蕊粉, 然后呢我们来运行一下, 这个时间呢,可能会稍微久一点, 好,终于呢,等了很久之后,我们呢得到了这个结果,由于呢连接方在一段时间后没有正确的答复,或者是连接主机没有反应,连接尝试失败,所以说呢,这个程序呢, 就是一个 url 的一场处理,然后呢我们再来写一个 htvp 的这个一场处理, 那这个 uil 呢,我把它换成这个豆瓣电影, 动漫电影的网址呢是 mori 点豆瓣点 com, 那这个网址呢是可以访问的,但是呢我们不给他加这个请求头,也就是不加呢这个浏览器的这个标书符, 这里呢我们就使用 usb, 然后呢这个是点 l, 这个叫做 htvp l, 但是呢这个呢他并没有什么错误,那我们直接打印一下,这个叫响应状态码, 所以说你是可以访问,但是呢获得信息呢是不全面的。 然后呢再来打印一下这个想要投的数据, 然后呢我们来运行一下 这个返回值呢不是这个二百,所以说呢他就是有问题的,这以四开头的,所以说呢这个数据呢就是这个不全面的。然后呢接下来呢他访问的是这个 htvp 的这个摄像头的一些协议的信息。
13黑猫编程 00:32
00:32 02:09查看AI文稿AI文稿
02:09查看AI文稿AI文稿在网络爬虫开发中,使用代理 ip 可以实现隐藏真实 ip 地址,绕过访问限制和提高访问速度等目的拍,但提供了丰富的酷焊工具,使得设置代理 ip 变得简单而灵活。本文章介绍如何使用拍登来更改设置代理 ip, 帮助你在网络爬取过程中充分发挥起作用, 让我们一起来了解吧。一、使用 requests 库设置代理 ip 一、安装依赖首先在命令型中运行 tpinstyle request 来安装 requests 库。二、导入依赖,在拍散脚本中导入 requests 库 m pro requests。 三、设置代理 ip 使用为快事事故提供的 proxys 参数来设置代理 ip, 将代理 ip 的地址和端口以字典形式传递给 proxys 参数即可。二、使用 olive 库设置代理 ip 一、导入 不依赖,在拍上脚本中导入 orleap 库, import you around label quest。 二、创建代理处理器使用 orleappox 一、汉乐累了创建代理处理器需要存入代理 ip 的地址和端口。三、使用第三方库进行代理 ip 设置 除了 request 是汉 ole 库,还有一些第三方库可以帮助你更方便的私自代理 ip, 如 proxy pro b sox 等。你可以根据个人需求选择合适的库进行设置 制。最四项焊进阶技巧一、代理 ip 可用性确保所使用的代理 ip 是可用的, 否则可能会导致请求失败。会员词过高,可以从可信的代理服务商获取稳定可靠的代理 ip。 二、代理 ip 词管理如果需要批量使用代理 ip 进行爬取,建议使用代理 ip 词来管理焊,切换代理 ip, 以实现更高的稳定性、焊 可用性。通过本文的介绍,你已经了解如何使用拍三来更改设置代理 ip 进行网络爬取。无论是使用 vcos 还是 olab 库还是第三方库,你都可以根据自己的需求选择合适的方式来设置代理 ip。 在实际应用中,记得确保代理 ip 的可用性, 并遵守爬虫道德规范。希望本王能够对你在网络爬虫中使用代理 ip 有所帮助。如果你有任何问题或需要进一步了解,请随时与我交流。祝你在爬虫开发的旅程中取得成功!
40华科云商-金木 01:06查看AI文稿AI文稿
01:06查看AI文稿AI文稿拍散爬虫遇到需要登录的网页该怎么办?分三种情况解决。第一种,如果登录的表达比较简单,咱们使用瑞筷子库或者 cam 自动填写用户名和密码,登录了以后获取库 k, 进行后期的爬去。第二种情况,如果需要验证码, 对一些简单的验证码,咱们可以使用一些相当酷,自动识别得到他文字,然后再提交这个登录表单,实现模拟登录。而有些验证码别的复杂,比如说需要你拖拽或者说转圈圈,或者说把掉了的文字给正过来,这种验证码非常的难,大家可以放弃,咱们记住第三种。 第三种方式其实半自动化,咱们可以手工的方式先登录,应是人工登录,咱们输入用户名密码,手工的拖着验证码或者手工的把这验证码给搞定。登录了以后,咱们用人工复制一下浏览器的 q k, 把这库克是有文本复制咱们的拍摄代码里铝筷子也好, cd m 也好,那么铝筷子 cdm 就可以带着 coke 去爬取,登录后的内容就可以搞定。爬虫是一门非常有意思的技术,下方购物车的课程呢,就包含了爬虫部分的内容,推荐给你。
859Python导师-蚂蚁 03:01查看AI文稿AI文稿
03:01查看AI文稿AI文稿哈喽,我是冰冰,今天教大家不用敲代码就可以轻松爬举到玩音数据,这个需要用到一个软件加入八爪鱼,这八爪鱼我们直接上百度搜索八爪鱼,然后去他的一个官网去下载就可以了, 直接去爬取一些网站的数据是不用费用的啊,我现在用的是一个免费版, 怎么去爬取呢?首先我们安装完这个八爪鱼之后,我们打开,然后这里一个新建自定义任务,然后这里是任务组,我们随便给他命个名,这里就是我们要爬取的一个网址,我们输入我们要爬取这个网站,点击这里保存设置, 已经打开了这个网站之后,我们看到它上面这里是分两个页面宽,它上面这一个是我们要爬取的一个网站,下面这个是爬取下来的一个字段, 然后右手边这个是操作提示,操作提示他这里是翻页并才提多页数据。比如说我们这个招聘网站,他上面有十页的数据,那他会自动翻另一页,总共有多少页,就啊把多少页的数据给爬取下来。然后 这个是要点击列表中的一些链接,然后并采集下一页的数据,比如说这里是他的每一个招聘信息,他都可以有链接点进去的。如果你要采集里面的一些详细的信息,那你可以点击这个,那我们先采集他目前所有的一些招聘信息,那 我们直接这里是深层采集设置,这里点击保存并开始采集, 点击启动本地采集雷条,然后他采集完了,总共用时是一分十二秒,采集了二百七十一条信息,其中有一条是重复的,然后我们这里点击导出数据, 然后这里是去重数据重复的,我们不要找出为 excel 文件, 然后我们可以倒出在低盘, 这样子就完成了爬取的一个步骤了,是不是很简单呢?今天的分享到这里,明天给大家分享数据分析的全流程,记得关注我哦!
2729冰云数据 01:45查看AI文稿AI文稿
01:45查看AI文稿AI文稿那恭喜你,你被封 ip 了,前面视频教大家如何使用爬虫去爬取豆瓣电影的详情,但是很多小伙伴跟我反映说我刚爬了几十条,结果就提示我 ip 异常了。那恭喜你,你被封 ip 了。 其实呢,也没什么大不了啊,封烟皮在爬虫的过程中非常非常常见的现象啊,过一段时间呢,网站可能就给你解封了,但是这终究不是长久之计,那怎么办? 这个时候呢,咱们就可以使用代理 ip 啊,代理 ip 呢,又可以称之为代理福气,那之前是咱们的客户端向豆瓣的福气发送请求,那当我们使用代理 ip 以后,就是我们通过一个第三方中转站 代理 ip 的福气,向豆瓣的福气发送请求,得到请求以后,这个代理 ip 再将请求到的内容返回给我们。那当然了,如果你的代理 ip 一直使用一个的话,对方的服务器同样会检测到他是一个爬虫行为,还会把他封掉。这就相当于如果你一直薅一只羊的羊毛,那肯定最后就薅成那谁一样了,那一眼就知道你是个爬虫。那怎么办呢?咱们养一个代理池, 这个池呢,就相当于一个大牧场,里面有非常多的羊,第一次你耗这只羊,第二次换了一只羊,第三次再换一只羊,这样的话就不会频繁的用一个 ip 去访问对方的福气了,所以你也就不用担心封 ip 了。 那市面上有非常多的代理福气,有的一些是免费的,有一些收费的,那既然是免费呢,他就有一定的延迟性, 同时呢,他也可能被很多网站加入了黑名单,你再访问也无效了啊!所以推荐大家使用超能力购买,收费的福气,因为他更加稳定,响应更加迅速,而且有更多的代理 ip 可以选择。今天的视频就分享到这里,再见!再见!
 07:38查看AI文稿AI文稿
07:38查看AI文稿AI文稿各位观众老爷大家好,我是憨憨少年小木木,一直游走在摄影边缘的理工男,通过本期视频,你将了解到如何使用 xl 完成网站上的数据扒取。 本视频完全适用于纯小白和零基础的朋友们,当然了,拍损爬虫大佬们也可以给点建议啊,木木甚是感谢,看在木木这么有诚意的份上,动动小手点个赞吧!本期视频将会从以下三个方面进行分享,一、简要介绍数据分析的流程。 二、详细讲解 xl 数据爬起的实操过程及相应知识点。三、数据可视化的呈现。本期内容极干,请自带水杯。话不多说,让我们马上进入第一个环节,数据分析的流程。其实数据分析主要由四个环节 组成及数据获取、数据处理、数据呈现和数据发布。其中数据获取主要是爬取网站上的数据,实现可操作性的编辑。 数据处理模块主要是用于数据的预处理,将获取的数据进行格式调整,方便后续使用。常用的 office 组件为帕沃奎尔和帕沃 perwit。 数据呈现模块主要用于数据可视化、动态的展示数据结果。 最后的数据发布部分则是实现数据的动态展示以及与终端设备的动态交互。由于内容庞大,本期视频主要关注第一个环节数据获取部分。 数据爬取的目标是将网页中展示的数据爬取到可以编辑的文本工具中,从而实现批量操作。在具体的爬取过程中, 经常使用的工具有 xl 和 pass, 要说哪款工具最好用,可能闭着眼睛都会选 pass, 同时 pass 的优点可能会一直讲不完,但是当我们看完 pass 的代码后,对于小白的我来说,内心是这样式的。什么? 相比拍死 xo 清爽而绿油油的界面,清晰可见的汉字之夜难道不香吗?既然对比敲定了工具,那就让我们直接进入第二个部分, xl 数据爬取的实操环节吧。 在打开需要数据爬取界面的高级板块后,我们会发现这个板块主要是由三个模块组成的,一、目标网页。二、响应时间。三、响应标识。首先,目标网页很好理解,就是我们想要爬取数据的网址信息,此处以全国 是房价排行的网址为例。接下来是响应时间。通俗的讲,就是我们每次访问网站的点击频率,假如我们人为的访问网站,一秒内访问一次网站,网站会根据我们的点击呈现相应的内容。但 爬虫比我们能干多了,他不辞辛劳的一秒内向网站发送了 n 条请求,导致网站的防御机制识别到,这不是人干的事,立刻启动反爬虫机制, 阻断了网页内容的呈现。那有没有办法解决这些问题呢?当然有,限制爬虫次数后,将实际的爬虫过程伪装成人为点击就好了。这就是响应时间使用的精髓,有没有 get 到啊?关于响应时间标识,目前包括派森爬虫在内常使用 uzze 标识,但是问题又来了, uzza 标识是个 啥嘞?看完百度的解释以后依旧懵逼不打紧,木木来给你讲个大白话,其实吧,优质粘土标识就相当于每个浏览器的身份证信息,我们通过 xl 中的优质粘土标识 选择指定的浏览器进行网页内容的爬取,最终有效的爬取到页面内容。在使用爬虫的过程中,最为常用的浏览器为骨骼浏览器和火狐浏览器。那讲了这么多,是不是该实操一波了?让我们的友谊小车快快开动吧,抓紧哦朋友们! 第一步,获取浏览器的优泽粘图标识,此处以谷歌浏览器为例,打开浏览器,输入目标网址后,右键点击检查,在检查页面中点击 like you took 后重新加载网页,在检查 like you book 页面中单击 第一个网页信息,因对此 htm l 在右边出现的窗口 hanger 中将页面拉至底部,可查找到浏览器标识。 usbent 复制优质粘土信息即可。第二步,设置响应时间,伪装为用户访问。首先新建 xl, 打开 sl 后点击数据, 点击自网站,在弹出的窗口中选择高级选项,将我们需要爬取的目标网址信息粘贴至 url 位置处,同时在响应时间栏设置一分钟的响应时间。 第三步,设置浏览器标识,在 http 请求标头参数中下拉,选择优质粘土,粘贴浏览器的优质粘土信息。第四步,将数据 载入到 paotyoud 中进行预处理,建立网页链接后选择 top 零,选择编辑,进入 paogleogo 进行数据预处理。处理完数据后,依照惯例小小的制作一波数据可视化地图,来看看成品的效果吧。 最后让我们一起来回顾一下本节视频的重点吧。使用浏览器的检查功能获得浏览器标识, 在 excel 扒取中设置响应时间,伪装为用户浏览设置浏览器标识 uzz, 将数据 载入 paokil 中进行预处理,数据可视化制作及定时刷新是不是并没有那么难啊?相信聪明的你一学就会。 那么关于下一期的视频内容,可以在评论区或弹幕类留言评论哦,你的建议很有可能就是下一期视频的主题呢!好了,以上就是本期视频的所有内容,你的支持是默默更新视频最大的动力,感激!
1807数据农工老孙 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿htt 代理 ip 帮你解决爬虫受限问题有时候爬的时候会被 ip 屏蔽,那么应该如何解决这个问题呢?一用户代理伪装和旋转用户代理是浏览器类型的详细信息, 不同版本的浏览器有不同的用户代理,我们可以根据每个请求提供不同的用户代理,以要过网站的反爬虫机制 降低补货频率。定设置访问时间间隔很多网站的反爬虫机制都设置了访问间隔时间,如果一个 ip 的访问次数在短时间内超过了指定的次数, 访问将受到限制。由于爬虫的抓取速度远快于用户的正常访问速度,高频访问会对目标网站造成访问压力,所以在抓取数据时我们可以设置更长的访问时间。 三、使用 http 代理网站的防爬机制会检查访问 ip 地址,为了防止 rp 被屏蔽,可以使用 http 代理切换不同的 ip 抓取内容。简单来说, http 代理就是让代理服务器帮我们获取网页内容,然后转发回我们的电脑。
24东北吴青峰讲爬虫 01:43
01:43 01:14查看AI文稿AI文稿
01:14查看AI文稿AI文稿在爬虫过程中,我们可能会遇到解析不到数据这样的错误,那我们今天来看一下这个问题我们怎么来解决。首先来看这个问题可能产生的原因,他可能会有两个原因,第一个我们看到我在这里正常去做爬虫,我想获取这个网站当中的数据分析师这个地方,但是我在获取的时候发现得到的是空的,那为什么会出现这样的问题? 在这里出现的这个问题的原因呢?是因为这个网站给我反馈的并不是我在这里面看到的这个界面,他所给我反馈的是另外一个界面,大家可以怎么样呢?大家可以把自己请求到的数据来输出他的文本, 那在下面我们就会看到他的 html 代码,那我们会发现这并不是我想要访问的网站,这样也会导致我们在解析的过程当中解析不到自己想要的数据。还有第二种原因,当我们正常去访问的时候 来看到现在是可以,但是如果说我把这个路径去做一个修改,发现这样就没有了。那第二种原因就是因为我们的 xpans 的路径变小 有问题,或者获取的是有问题的,那这样也会导致我在获取数据的时候没有办法解析到对应的数据,我可以把路径编写正确,那他就能够取到数据。但面对这个问题的时候,大家可以借助于一些工具,比如 x max 本身提供的工具叫做 x past helper, 大家可以借助这个工具来验证自己的路径是否正确。那这个就是我们在解决爬虫过程当中解析不到数据的两种办法。大家关于爬虫的更多问题都可以在评论区进行交流。
16泰克教育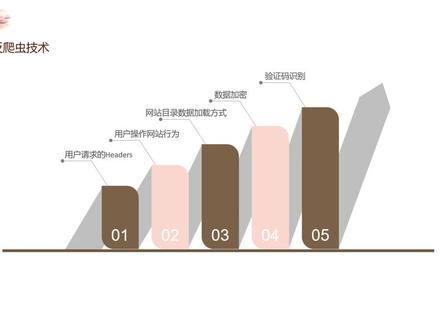 07:33查看AI文稿AI文稿
07:33查看AI文稿AI文稿好,现在我们开始学习第一章的第四个小节,反爬虫技术及其应对。 那么说到反爬虫技术的话,嗯,大体上有这样五类,分别是用户请求的 headers、 用户操作、网站的行为、网站目录、数据加载方式、数据加密以及验证码识别。 现在来讲,验证码识别是我们,嗯,这个比较头疼的。呃,一个技术啊,因为验证码技术发展的速度是比较快的啊,爬虫技术相对是比较之后的, 其他的都是有比相对比较完美的一个解决方案,只有验证码识别这一块,解决方案不是特别完美,我们并不是说不能解 解决他,而是说解决的方案不是那么的完美。好,下面我们依次来说。呃,首先是我们看下面这个图啊,反反爬虫技术吗? 先说是基于用户请求的 hiders, 对吧?用户请求的 hiders 的反爬虫最是最最常见的一个反爬虫策略,很多网站会对 hiders 的 usager 进行检测, 对吧?呃,如果我们遇到了这一类的反爬虫机制,这个实现起来就是非常简单,我们可以在爬虫代码当中添加 hiders 请求头,将浏览器的请求信息以字典数据格式写入爬虫的请 牛头。对于检测 hiders 的爬反爬虫,在爬虫发送修改或者添加 hiders 就能够很好的去解决。 这一类的反牌技术,可以说是非常的简单啊,非常的简单。那么第第二类啊,第二类基于用户操作的,呃,基于用户操作网站行为的,我们一部分是通过检测用户的行为来判断是不是 真的用户啊,是不是真的人在操作,因为你一个真的人在操作网站的时候,你不可能一秒钟操作好多个网站, 对吧?你也不可能一秒钟操作十几个,二十几个网站,如果你一秒钟打开了十几个网页,那一定,嗯,绝大多数情况下这就是爬虫的行为,对吧?一个正常人类他不可能一 一秒钟呃,做很多,那么这就是基于行为的啊。基于操作网站行为的,呃。比如说同一个 ip 短时间内同访问同一个页面,或者说同一个账户短时间内进行相同的操作等等,这些他都会检测出来。 那么遇到这类的这个基于用户操作网站行为的这一类的反爬虫机制怎么办呢?我们使用 ip 代理, ip 代 ip 可以在 ip 代理平台上通过 api 的,呃,通过 api 接口获取, 每请求几次我们就换一个 ip 啊,每请求几次我们换一个 ip, 就是很容很,这样就很容易绕过这个关于这个 ip 检测这一块。那么还有一种解决方案呢,就是 在没几次请求以后,我们使用一些碳延时,对吧?碳模块的延时我们隔几秒再发送请求,隔几秒再发送请求,只需要我们再加入一个延迟的模块就可以了,这样的话也可以非常简单的解决掉这个第二类的反爬虫。 那么第三类基于网站数目录数据加载的这个犯法虫,呃,很多情况下咱们的网站有,呃,有很多网站是静态网站,我们上述的两种行为一般都是针对针对静态网站的,那还有一部分网站他是,呃,有 ajax 通过访问接口的方式生成数据而加载到网页当中的,假如我们遇到这样的情况的话,我们首先先分析他这个网站的设计,那分解网站 设计之后找到 gax 请求,然后分析具体的请求参数和响应参数的数据结构及含义,要解析他的数据结构及含义,然后用爬虫来模拟亚 x 请求, 这叫这样就我们就可以得到我们想要的数据,好吗?那我先说一下第四点,基于数据加密的,一般是使用加加微 script 实现数,呃,加密代码啊,一般是使用这个的,然后的话 我们需要分析代码的加密方式,然后在爬虫代码当中模拟其加密方式,再次发送请求,一般情况下都可以解决这样这一类的问题,但是呢,他花费的时间是比较多的 啊,他花费的时间比较多的,难度也是比较大的。那么还有一种方式是基于自动化测试技术的, 呃,它可以相对来说,呃比较简便的去解决到这个问题,它的呃原理是这样的,它是基于这个, 呃自动化操作,呃,自动化测试技术基于模拟人的一个行为来进行这个操作,就是模拟人的操作来进行操作,那就可以呃去掉数据加密这一块,因为他直接是渲染出来页面,我模拟一个人在操作, 但是这个技术是基于自动化测试技术的,我们在这里就不再过多的讨论了啊。那么第五点叫做基于验证码的,这也是现代,嗯,当下,嗯,这个在 爬虫这个领域啊,在爬虫这个领域,嗯,还没有一个 完美解决解决方案的这个一个内容啊,咱们在登录网站的时候,很多时候就可以看到有些网站有这个验证码,对吧?对于传统的验证码,比如说图片验证码,文字验证码等等,这些验证码相对来说我们还可以有一个比较 好一点的解决方案,比如说利用,呃,这个 oic 技术啊,依赖第三方平台啊,这都可以,这个很完美的解决。但是现在的验证码,嗯,技术发展的速度是比较快的, 因此这个爬虫技术相对来说之后,因此我们现在对验证码识别这一块不是不能解决,只是方法不是特别的完 好吗?一般来讲我们是依赖第三方平台或者是 o r c 技术进行识别。呃,随着深度学习技术的发展,呃,深度学习也可以应用到验证码识别这个领域,嗯,也是可以的啊,也是可以的。 好吧,那我们这随着这一节的结束,那么本章就结束了啊,本章我们主要学习了这个爬虫的类型,爬虫的定义啊,呃, 爬虫的搜索策略,呃,反爬虫技术以及应对等等这一些内容。那么下一章我们学习环境配置好了,本期就到这里,我们下期见。
62江哥伴你学 05:02查看AI文稿AI文稿
05:02查看AI文稿AI文稿列表超出所以范围,这个原因是什么呢?原因是因为你解析数据的时候没有匹配到, 匹配到内容。对,你可以看一下,我把这个零给他取掉,因为我们这个正则返回出来,无论说你是正则,你匹配的东西啊, 他返回的是个列表,如果说你没有取到数据的话,他返回的是一个空列表,空列表里面没有元素,那你取零的话就取不到,是吧?这个时候的话有两个解决方式啊,有几个解决方式?第一个解决方法的话就是你有没有得到数据, 对啊,第二个,你看一下你数据里面有没有你想要的,比如说我想要的是这个内容,对吧?我看一下他有没有,有的话那看一下啊,如果说有的话就第二个,你的鱼法是不是写错了?你的鱼 法是不是写错了,对吧?解析这个语法是不是写错了?那我这里很明显这里是写多了两个空格吧,那把这两个空格给他删掉啊。哎,我们再取个零的话,我们就能得到 得到这个数据了,看到没有就得到这个数据了,是不是啊?这就没有问题了啊?那我们接下来啊,接下来的话,我们就是第 第七个报错,第七个常见的一个报错,我们继续啊,继续。我们来保存一下 vso pen, 对, vsopen, 我给个文件夹加上一个什么呢?我们的一个抬头,对吧?再加上我们的一个后缀点 txt model 的话用一个 w 啊, utf 杠八给个编码 f 点上一个 rat, 把我们这个抬头也写到这里面来。我站一起的话,他也会报错,他报的是一个什么错呢?来,他报的是 这个错误,这么个错误啊,这么个错误。第七个报错,这个错误的原因是因为,对吧?你没有这个文件夹,因为我们是给了一个 v 六的一个文件夹,那我们这个代码的这个地方,这个是相对路径,相对路在这里面没有 v 调的一个文件夹,那我干嘛得给他创建一个文件夹? 你要创建文件夹,因为你没有文件夹,因为你没有,是吧? video 这个文件夹,所以包错了,所以干嘛呢?你要创建一下,创建一下这个文件夹。好吧,那我再运行的话 就有数据了,看到没有就有数据了,那我就能保存了,对吧?我们的数据就保存在这个里面。对,保存在这个里面。好的,这就是我们第七个报错,来,再给 给大家见一个常见的第八个报酬,用这个抬头的话,我就换一个吧。好吧,我们是按照这个去取啊,按照我们完完完整整的,我按照这个去取,我用这个 啊,用这个,用这个边啊。文件名作为一个命名,哎,用这用他,对吧?用他啊,用他来,我们再运行一下,运行啊,他又会报错。一个类似的一个错误啊,类似的一个错误,对吧?看到没?五 s 的一个报错 在这个地方,我有文件夹了,但是他报这个错误,原因是什么?文件名命名的时候啊,命名的时候不能含有特殊之福, 哎。特殊之福,特殊之福是哪一个呢?这个斜杠啊,不,这个竖线。那特殊之福有哪些呢?有挺 多的啊挺多的,有好几个呢。来给大家看一下,我们截个图放这里,就特殊制服的话,像这个什么啊?两个斜杠啊,对吧?冒号,引号,问号型号对吧?两个监控还有竖线,还有我们这个换行服,这些的话都是属于特殊制服,那这个的话就要给他替换掉, 你可以用正折替换,也可用用瑞普利斯替换,但这里的话啊,建议大家是用正折,用正折的话会方便替换一些。我们这里专门用一个 nip 啊,去接受一下这个吧,用个 nip, 用个 nip 接受一下。然后呢用阿姨点一个 sub 啊,进行一个替换,这个怎么去替换呢?就把我们相应的一个这些东西都给他放进去,冒号、星号、问号、引号、监控号,竖线都给他替换,整个空的 空的。然后呢?从哪里替换?从我们这一个那里面替换。那我再用一个新的一个面料去接受一下,这样的话我们就可以进行一个保存了,他就会把那一个竖线给他替换掉。来我们再运行看一下, 看一下他就会把那一个竖线看到没有第一集中间那个竖线他就没了,他就没了。好吧,这就是我们常见的呃,爬虫常见的八个报错啊,八个报错。 如果说大家还有什么其他的一些常见报数的话,也可以在视频下方留言,对吧?如果说啊有其他的一些建议的话,也可以再加我们的一个视频上方的一个啊,学习娱乐群到群里面去提问也是可以的。 好吧,因为这次大家真的是会比较多问的比较多的一些问题了,问的比较多的问题了, ok 吧,那我们就下次再见。好吧,拜拜。


