机器翻译经历了哪三个阶段
什么是翻译?从广义上讲,翻译是指把一个事物转化为另一个事物的过程。现代汉语词典解释为把一种语言文字的意义用另一种语言文字表达出来。 牛津英语学习词点解释为,把书面或口头内容转换为另一种语言的过程。从一种语言转换为另一种语言的文本或作品。百度百科解释为, 翻译是在准确、通顺、优美的基础上,把一种语言信息转变成另一种语言信息的行为。那么,什么是机器翻译?机器翻译又称为 自动翻译,是利用计算机将原语言转换为目标语言的过程。用机器进行翻译的想法可以追溯到电子计算机产生之前,发张过程也经历了多个犯事的变迁。从机器翻译系统的组成来看,通常可以将其抽象为两部分,资源和系统。 构建一个强大的机器翻译系统需要资源和系统两方面共同作用。在资源方面,随着与料库与研学的发展,以具备研发机器翻译系统所需要的与料基础。因此,在现有与料库的基础上,研究人员把精力都集中在系统研发上。 实现机器翻译往往需要多个学科知识的融合,最终呈现给使用者一套机器翻译系统。虽然翻译这个概念在人类历史中已经存在了上 千年,但机器翻译发展至今只有七十余年的历史,在人类形成语言文字的过程中,逐渐形成了翻译的概念。一个标志性的证据就是罗赛塔石碑。这个石碑制作于公元前一百九十六年, 据说是可攻考证的最久远的记载平行文字的历史遗迹石碑由上至下刻有同一段埃及国王诏书的三种语言版本,最上面是古埃及象形文,中间是埃及草书,最下面是古希腊文。可以明显看出碑上中下雕刻的文字的文理是不同的, 故很多人认为罗塞塔什杯是标志翻译或人工翻译的一个起点。在此之后,更多的翻译工作在文化和知识传播中开展,其中一个典型的代表就是宗教文化的翻译。在中国唐代, 有一位世界性的文化人物玄奘,他不仅是佛学家、旅行家,还是翻译家。玄奘西行归来后,共翻译佛教经论七十四部,树立了我国古代翻译思想的光辉典范。 人工翻译已经存在上千年,而机器翻译起源于何时呢?机器翻译跌宕起伏的发展史可以分为萌芽期、受挫期、快速成长期和爆发期。 早在十七世纪,很多学者就提出了采用机器词典克服语言障碍的想法,这种想法在当时很超前。随着语言学、计算机科学等学科的发展,在十九世纪三十年代,使用计算模型进行自动翻译的思想 开始萌芽。当时法国科学家提出使用机器进行翻译的想法,因为那时没有合适的实现手段,所以这种想法的合理性无法被证实。 随着第二次世界大战爆发,对文字进行加密和解密成了重要的军事需求,这也使得数学和密码学变得相当发达。在战争结束一年后,世界上第一台通用电子数字计算机于一九四六年研制成功。至此,使用机器进行翻译有了真正实现的可能。 一九四九年,沃伦维福撰写了一篇名为 trendslayson 的备忘录。在这个备忘录中,微服提出用密码学的方法解决人类语言翻译任务的想法,如把汉语看成英语的一个加密文本,将汉语翻译成英语就类似于解密的 过程。在这篇备忘录中,第一次提出了机器翻译,正式开创了机器翻译的概念。这个概念一直沿用至今。虽然在那个年代进行机器翻译的研究条件并不成熟, 包括使用加密解密技术进行自动翻译的很多尝试很快也被验证是不可行的。但是,这些早期的探索为后来机器翻译的发展提供了思想的火种。 特别的是,早期基于规则的机器翻译中也大量使用了这些思想,启动了第一次真正的机器翻译实验。 翻译的目标是将几个简单的俄语句子翻译成为英语翻译系统,包含六条翻译规则和两百五十个单词。这次翻译实验中测试了五十个化学文本句子,取得了初步成 功。在某种意义上来说,这个实验显示了采用基于词典和翻译规则的方法可以实现机器翻译过程。虽然只是取得了初步成功, 但却引起了苏联、英国和日本研究机构的机器翻译研究热,大大推动了早期机器翻译的研究进展。 一九五七年, norm trump's key 在 syntactic structures 中描述了转换生成语法,并使用数学方法来研究自然语言, 建立了包括上下文有关语法、上下文无关语法等四种类型的语法。这些工作最终为今天计算机中广泛使用的形式语言奠定了基础,而他的思想也深深地影响了同时期的语言学和自然语言处理领域的学者。特别的是,早期基于规则的 机器翻译中也大量使用了这些思想。基于规则的机器翻译大多需要人工来定义和书写规则,主要有两种方法,一个是基于转换规则的机器翻译,图中左边就是一个例子,它通过形式文法定义两种语言之间的翻译规则, 引入原语言和目标语言中的语言学知识进行翻译。基于转换的方法可以通过词汇层、据法层和语义层完成从原语言到目标语言的转换过程。但是会导致一个实际问题, 假设需要实现 n 个语言之间互议的机器翻译系统,采用机语转换的方法,需要构建 n 乘 n 减一个不同的机器翻译系统,这个构建代价是非常高的。为了解决这个问题,一种有效的解决 方案是使用基于中间语言的机器翻译方法。基于中间语言方法的最大特点就是采用了一个称之为中间语言的知识表示结构,将中间语言作为独立原语言分析和独立目标语言生成的桥梁。从图中可以发现,中间语言知识表示处于最顶端, 本质上是独立于原语言和目标语言的,这也是基于中间语言的方法可以将分析过程和生成过程分开的原因。虽然基于中间语言的方法有上述优点,但如何定义中间语言是一个关键问题。严格上说,所谓中间语言本身是一种知识表示结构, 承载着原语言句子的分析结果,应该包含和体现尽可能多的原语言知识。规则的使用和人类进行翻译时所使用的思 想非常类似。可以说,基于规则的方法实际上在试图描述人类进行翻译的思维过程。虽然直接模仿人类的翻译方式对翻译问题建模是合理的,但是这一定程度上也暴露了基于规则的方法的弱点, 这也成为了后来基于数据驱动的机器翻译方法主要改进的方向。虽然基于规则的方法有种种优势,但是该方法人工代价过高。所以研究者们开始尝试是否可以更好地利用数据, 从数据中学习到某些规律,而不是完全依靠人类来制定规则。在这样的思想下,基于数据驱动的方法诞生了。 该方法的基本思想是,在双语句库中找到与代翻一句子相似的实力之后对十 实力的一文进行修改,如对一文进行替换、增加、删除等一系列操作,从而得到最终一文。这个过程可以类比人类学习并运用语言的过程。 人会先学习一些翻译实力或者模板默认文本,当遇到新的句子时,会用以前的实力和模板做对比,之后得到新的句子的翻译结果,这也是一种举一反三的思想。这种方法对翻译实力的精确度要求非常高。 一个实力的错误可能会导致一个巨型都无法翻译正确实力,维护较为困难。实力库的构建通常需要单词及对齐的标注, 而保证词对其的质量是非常困难的工作,这也大大增加了实力库维护的难度。尽管可以通过实力或者模板进行翻译,但是其副 覆盖度仍然有限。在实际应用中,很多句子无法找到可以匹配的实力或者模板。 统计机器翻译兴起于上世纪九十年代,它利用统计模型从单双语语料中自动学习翻译知识。 具体来说,可以使用单语语料学习语言模型,使用双语平行语料学习翻译模型,并使用这些统计模型完成对翻译过程的建模。整个过程不需要人工编写规则,也不需要从实力中构建翻译模板。 无论是词还是短语,甚至是句法结构,统计机器翻译系统都可以自动学习。人更多的是定义翻译所需的特征和基本翻译单元的形式,而 翻译知识都保存在模型的参数中。随着机器学习技术的发展,基于深度学习的神经机器翻译逐渐兴起。自二零一四年开始,他在短短几年内已经在大部分任务上取得了明显的优势。 在神经机器翻译中,瓷串被表示成实数项链及分布式项链表示。此时翻译就不再是在离散化的单词和短语上进行,而是在实数项链空间上计算。 因此,与之前的技术相比,他在词序列表示的方式上有着本质的改变。通常,机器翻译可以被看作一个序列到另一个序列的转化。在神经机器翻译中,序列到序列的转化过程可以由编码器、解码器框架实现。 好了,今天的分享就到这里结束了,感谢观看!

粉丝194获赞4606
相关视频
 02:42查看AI文稿AI文稿
02:42查看AI文稿AI文稿机器翻译是一种计算机技术,它可以将一种语言的文本转换成另一种语言的文本。该技术已经成为全球范围内跨语言交流的重要工具,有助于帮助人们在不同语言之间进行沟通和交流。在本文中,我们将更深入地 了解机器翻译的工作原理、应用领域以及挑战和限制。首先,让我们看一下机器翻译的工作原理。 机器翻译通常分为两个主要阶段,文本与处理和翻译模型。在文本与处理阶段,计算机将输入的文本转化为可处理的数字格式。 然后,在翻译模型阶段,计算机使用训练好的翻译模型,将输入的文本翻译成目标语言的文本。这个过程中,机器学习算法可以帮助机器翻译系统学习,如 和江云语言文本翻译成目标语言文本。这种算法可以根据训练数据中的模式和规律自动进行翻译,因此在翻译大量文本时可以提高效率和准确性。其次,机器翻译的应用领域非常广泛。 机器翻译技术可以用于多个领域,包括商务、旅游、政府、科技和医疗等。例如,在商务领域,机器翻译可以帮助企业进行跨国合作和交流。在旅游领域,机器翻译可以帮助游客和旅行者更好地理解当地文化和传统。 此外,机器翻译还可以用于文学、新闻和娱乐等领域。然而,机器翻译也存在一些挑战和限制。首先,机器翻译无法理解文本的语境和含义,因此可能导致翻译的不准确或不自然。其次,机器翻译 意还面临着语言差异和文化差异等问题。例如,在英语中,有时候说我很喜欢这个人,但在中文中,这个表达可能是我很欣赏这个人。这样的翻译误差可能会影响交流和理解。总之,机器翻译技术已经取得了很大的进展, 在跨语言交流中发挥了重要作用。然而,他仍然存在许多挑战和限制。例如,机器翻译往往无法完全理解文本中的上下文和语境, 从而导致翻译的不准确或不自然。此外,接气翻译还面临着词汇和语法差异等问题, 这些问题可能导致翻译的意义和原意的偏差。因此,在进行任何重要的翻译时,最好仍然需要人类翻译的帮助和审查,以确保翻译的准确性。谢谢大家收看这个视 频,如果你觉得这个视频有帮助,请给我点赞和评论,同时也请不要忘记关注我的频道,以便在未来获得更多的有趣内容。感谢大家,么么哒!
81小莉讲故事 01:18查看AI文稿AI文稿
01:18查看AI文稿AI文稿翻译的过程是不断境界的过程,每一个资深的翻译都会经历这三个翻译的境界。第一层境界,不得其门而入。这时候的情况分两种,一种是知道自己不知道,另一种是不知道自己不知道。这个阶段靠的是兴趣支撑, 坚持下去才会发现翻译之美。第二层境界,入的其中,困于其内。这也分两种情况,要么是对原文理解困难,要么是理解了表达不出来。这个阶段靠伊力支撑,每日一练,突破指日可待。 第三层境界,入乎其中,出乎其外,游刃有余。更甚者是基于一文读者的需要,对原文恰当地拔高或者升华。这个阶段知道翻译很辛苦, 但是得乐其中,每次输出都胸有成竹。志在必得。故天将降大任于斯人也。必先苦其心志,劳其筋骨,乐其体肤,空乏其身,行拂乱其所为。所以动心忍性,增益其所不能。翻译就是这么一个过程,你做好准备了吗? 顺便问一下,你到哪一个阶段了呢?关注海纳百川翻译,带你一起了解更多专业的翻译知识。
 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿文本预处理是机器翻译的第一步。它是将输入的文本转化为计算机可以处理的数字形式的过程。它的作用类似于人类阅读文本之前的初步处理,例如去掉无用的字符、标点、符号和空 格等。在机器翻译中,文本预处理是为了让计算机能够更好地理解和翻译文本。首先,文本预处理的第一步是去除不必要的字符,如标点符号、空格 和特殊符号等。这是因为这些字符在机器翻译中没有实际的意义,只会增加计算量和时间。因此,去掉这些字符可以帮助机器翻译系统更快地进行翻译。 其次,文本预处理还包括将文本转换成小写字母。因为在计算机中,大写字母和小写字母是不同的字符,因此,在将文 门转换成数字形式之前,将所有字母转换成小写字母可以避免计算机在处理文本时出现错误。另外,文本与处理还需要对文本进行分词。在自然语言中,文本通常是由单词组成的。然而,在机器翻译中, 计算机不能像人类一样识别单词,因此需要进行分词。分词的目的是将文本分成一系列的单词, 这些单词可以被计算机理解和处理。最后,文本与处理还包括将文本转换成数字形式, 以便计算机能够进行处理。在这个过程中,每个单词都会被转换成一个数字,这个数字对应着一个单词的含义。这个数字形式的文本可以背计算机用来进行下一步的翻译工作。总之,文本与处理是机器翻 翻译的第一步,他是将输入的文本转化为计算机可以处理的数字形式的过程。这个过程包括去除不必要的字符、将文本转换成小写字母、对文本进行分词和将文本转换成数字形式。这样处理后的文本可以背计算机更好的理解和翻译。 谢谢大家收看这个视频,如果你觉得这个视频有帮助,请给我点赞和评论,同时也请不要忘记关注我的频道,以便在未来获得更多的有趣内容。感谢大家,么么哒!
10小莉讲故事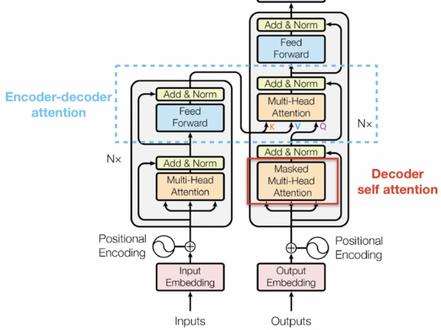 00:55查看AI文稿AI文稿
00:55查看AI文稿AI文稿突然 summer 有三个 ten 涮层,输入一句话我爱你 pp, 共五个字,形状为一行武略,经过词嵌入和位置编码,形状为一 五五幺二。经过 self 单涮特征提取,形状为一五五幺二。经过惭愧神经网络,形状为一五五幺二。说出一句话 i love you 批,共四个单词,形状为一行撕裂,经过词嵌入和位置编码,形状为一 4512。 经过二次 mask, 形状为 14512。 经过与编码器的输出进行特征提取,形状为 1 4512。 经过 n 离你而曾,形状为以死。博客,博客为单词表的大小,经过 softmac 输出最大概率的单词,形状为以死。
29豆芽 02:01查看AI文稿AI文稿
02:01查看AI文稿AI文稿人工智能从上个世纪六十年代到现在经历的三个阶段。嗯。第一个阶段是我们试图人去写规则,嗯,把自己对世界的理解,嗯翻译成一种计算机语言,嗯,让他学会,嗯,如果这样就怎样?嗯说。那时候我们称一下专家系统,嗯,专家系统也是人工智能的一部分,嗯, 但这样的一个做法最后失败了。嗯,我们有二十年时间看到的人是没有办法通过写个程序,把自己的聪明才智对世界的认知,嗯,通过一个算法告诉机器,嗯,这个规则机器学不会,嗯, 那随后就开始走向了一种成长学习的方法,嗯,就是我们不要尝试把自己的意志搞出机器,嗯, 而是给他一个算法规则之后,让他像真实的数据,嗯去学。我告诉他这个是谁的声音,这是谁的脸,嗯,让机器在里面去做一个,通过数据驱动,嗯,让他得到这样的一种智慧。 这是人工智能。第二个阶段,我们称叫学习算法,对吧?学到今天的话呢,我发现在这种统计规则里面找到了更先进的做法,嗯,就是我们称叫一个,叫深度学习。那第二个阶段是人设法把世界建模,把一个人脸,一个声音,我们提起出中间有效的叫特征,嗯, 人主动找的特征,把这特征交给机器,并且告诉机器答案是什么。那遇到一个瓶颈在于,说人去找特征的时候,也想不清楚最好的特征是什么。但凡你在里面描述一个特征的时候,嗯,其实我们就丢掉了其他的信息。对你描述不准确。对, 那直到两千年后,我们用深度学习方法是采用了更大的数据规模,嗯,更多计算,我就我们不要人去找特征,嗯,我们把原始数据给机器,嗯,就告他自有这么多点,嗯,然后让机器说我数据让你给你更大,你在里面去做计算。 所以他是在学习系统当中模拟人脑的神经元的结构模拟,用完全压试图像人的思维方法一样来做这样一个学习,以适应不用靠人 去描述这个世界的特征,嗯,让机器自己在里面去找规律的。这样一套做法叫深度学习。
68技术视野 04:05查看AI文稿AI文稿
04:05查看AI文稿AI文稿机器翻译是只使用计算机程序将一种自然语言翻译成另一种自然语言的过程。随着深度学习的发展,尤其是自然语言处理领域的技术进步,机器翻译的效果得到了极大的提升。其中, gpt 模型在机器翻译任务中的应用 成为了近年来的一个研究热点。 g p t 模型是一种基于 transformer 架构的寓意训练语言模型。它通过海量的语料库数据进行无监督训练,可以自动学习到自然语言的语法结构、词汇和上下文关系, 从而生成高质量的自然语言文本。在机器翻译任务中, ppt 模型可以根据原语言的输入生成对应的目标语言翻译结果。与传统的机器翻译方法相比, ppt 模型 具有以下几个优势一、模型效果更好。 g p t 模型可以自动学习到更多的语法结构和上下文信息,从而生成更加准确、流畅的翻译结果。 二、适应性更强。 g p t 模型可以基于不同的语言对进行微调,从而适应不同的翻译任务和语言环境。三、可解释性更高。 g p t 模型可以通过对中间层的输出进行分析, 解释模型在翻译过程中的决策和思考过程,有助于翻译人员更好地理解和修改翻译结果。 ppt 模型在机器翻译任务中的应用不仅提高了翻译效率和质量,还可以为人们的跨语言沟通和交流提供更多的可能性。例如,在国际商务、跨文化交流和教 偶遇领域,机器翻译技术已经被广泛应用。然而,与此同时, g p t 模型在机器翻译任务中还存在一些挑战和问题,例如一、 数据不足。尽管 gpt 模型可以通过大规模的无监督训练获得更好的表现,但是在翻译任务中需要有足够的带有标注的数据集来进行有监督训练,而这些数据集的准确性和质量对模型的性能和效果有着决定性的影响。二、 语言差异。不同的语言之间存在着不同的。语言之间存在着巨大的差异,包括语法、词汇、语意和文化背景等方面。这使得机器翻译的任务变得更加复杂和困难。例如,一些语言可能不存在对应的词汇,需要使用更 为复杂的翻译技术来实现翻译。三、语境理解。机器翻译需要对文本的语境和上下文进行深入理解,以确保翻译结果的准确性和流畅性。然而,在某些情况下 及其难以识别某些词汇或句子的语境,导致翻译错误或不准确。为了克服这些挑战和问题, 研究人员们正在进行一系列的探索和实验,以进一步提高 gpt 模型在机器翻译任务中的表现。其中一些主要的研究方向包括一、数据增强。研究人员们正在努力扩大数据级的规模和范围, 以获得更多的文本数据和多样性的语言样本,以提高 gpt 模型的性能和效果。二、模型优化。 通过改进模型架构和算法、油画训练过程或抄参数调整,以提高这批题模型在机器翻译任务中的表现。三、语言对其和文化背景理解。通过研究语言对之间的差异和文化背景, 设计更为精准的翻译策略和算法,以提高机器翻译的准确性和流畅性。总之, gpt 模型在机器翻译任务中的应用 为我们提供了一种更加高效、准确的翻译方法。随着技术的不断发展和优化,我们相信这种方法将会得到进一步的改进和推广,为人们跨越语言和文化壁垒提供更为便捷和可靠的支持。
 03:32查看AI文稿AI文稿
03:32查看AI文稿AI文稿从鼎盛时期到为爱取代六年翻译新衰史我是一八年进入翻译行业的,到现在差不多已经有六年。今天我就给大家聊一聊翻译行业的收入,以及翻译在这六年他的收入经历了一个怎样的变化。 因为我马上就要出去,所以呢就边收拾就边给大家讲。短短六年,算是见证了翻译行业的一个发展史。然后我们把这六年可以分为三个阶段。第一个阶段呢,是一八年到二零年。然后第二个阶段呢,是二一年到二二年。 然后第三个阶段就是二三年,也就是现在。我们先说第一个阶段,第一个阶段也差不多是我刚入行的时候,是一八到二零年, 这个时候差不多是翻译行业的一个鼎盛时期了。每天都要在会场上,然后公司也是大大小小的会议,就每天就排的特别满。说到口艺的收入,两天差不多是在五千左右,是没有人去压价格,然后这个时候报价高, 然后呢会议也特别多,口艺员不愁没有会议,差不多一个月下来,他们接个十几场左右,然后不想接就推掉了。这个阶段的口艺员,他们不用去发愁什么接不到会议,不用去找一些培训机构,也不用去接额外单子,他们正常接口艺的会议,差不多每个月的收入有五万左右。但是呢, 这个阶段维持的时间不是很长,马上呢就到了二零年,大家也知道二零年是什么样情况。然后呢就是第二个阶段,二一年到二年,我们称它为寒冬时期。这个时候的收入真的是断崖式下跌的。 呃,我们做翻译公司本身就是资源的提供方的,有一段时间就疫情比较严重,就一整个月就翻译公司,他都是在靠比议和一些其他的业务作为支持,根本就没有口议。所以这个时候呢,一元的收入几乎也是零收入啊。不过后来呢,就有一段时间会议转到了线上,就是大家开始看线上会。 这个时候呢,就是线上同城传艺会议有了一定的发展,但是他会议的总体的量是减少的。嗯,他肯定是不能和正常情况下会议的数量相比。那时候一元的一个整体收入差不多是在几千到两万左右, 其实这个两万已经是很难达到了。这时候是没有会议,就是任凭你再优秀的话,你接不到会议,你是没有收入的。紧接着呢,就到了我们的二三年。二三年情况大家都知道啊,疫情结束了。 疫情结束了, ai 时代到来了啊。大家是不是觉得我会说一下 ai 对于翻译行业影响?其实不是目前对于翻译行业有实际影响了,还是大环境的影响。因为现在这个阶段钱不好挣了。 然后呢,好多人都开始省钱了。国际会议他办的比较谨慎了。总体来说,现在还是赶不上,就是鼎盛时期的。这时候的翻译的一个收入其实 是属于比较波动的一个情况。就好多自由翻译,他已经不倾向于在做自由翻译了,开始去找一些固定的翻译的工作,就比如开始去公司做一些翻译岗,或者是去一些培训机构。嗯,因为他做自由翻译的话, 就是完全靠自己,压力真的特别大啊。但是一些老牌的翻译,他们并没有转去机构,他们还是可以做啊,自由翻译的啊。不得不提的一点就是翻译这个行业,他真的非常持资源,就你有资源和没有资源,收入真的是一个天上一个地下。 所以呢,这个阶段的医院收入,我们说的具有普遍性一些吧,就没有必要说一些特别优秀的收入,差不多维持在呃八千到 一万五这么一个收入啊。另外我还要再提一下,就是翻译行业的收入,他具有非常不稳定性,就有的人可能收入远高于这个,然后有的人可能收入就完全不能维持生活。这个我就不再提了。我现在说的这个收入是是有一定经验的一员,他的一个通用的一个收入。翻译本身他比 并不是一个独立存在的行业。就翻译行业的发展,他还是取决于其他行业对于翻译的需求。因为我下午还有活动,所以画了一个商务装。好了,今天就先到这里,我们下期见吧,拜拜。
877我是大KK 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿机器翻译一百问第一问机器翻译到底是什么? 和我们小时候学习英语不同,机器并不会学习明确的语言规则。比方说,什么是过去完成时,什么是定语从句。相反呢,他更像母语本身就是英语的人一样,多听多看,他自然就学会了。比方说,他总是看到新年快乐呗,翻译为 happy new year。 慢慢慢慢,他就学会了,把新年快乐翻译成 happy new year。 正所谓熟读唐诗三百首,不会作诗也会。当然,我们这边说的多啊,可不止三百首这么简单。一般需要上千万乃至上亿的句子。大数据驱动才是积极翻译的财富密码。 对于比较大的一种像是中文和英文的会议。现在成熟的商业积极翻译系统已经不会输给普通的英语学习者了。用信达 雅的标准来讲,已经达到了性和答的标准。但是呢,在一些专业的里,或者需要意义的句子,可能比起专业议员来讲,积极翻译常常还是会。详情见畜。所以我们学习语言,同学们不用担心失业,再要求零错误的场合,或者文学性比较强的文本,我们人类的智慧还是牢牢占据了高低。 当然,积极翻译的使命也从来不是取代人类,而是在像日常生活、工作、旅游这些场景当中,减少人类的工作量,极高效率。 火山翻译是自己跳动的积极翻译品牌,能够在九十四个语言之间互相翻译,每年都要用上万亿字符。在二零二零年,我们拿到了国际积极翻译大赛的七项冠军,其中就包括专文到英文的翻译。同时,我们还拥有七十多项海内外专利,四十余篇学术论文,其中也包括在这个领域最 有影响力的权威会议的最佳论文。总之,这是一个技术实力雄厚、产品服务成熟的积极翻译品牌。如果你还没用过火山翻译,你就落伍了,赶紧打开评论区第一条试用吧!
23火山翻译 01:45查看AI文稿AI文稿
01:45查看AI文稿AI文稿机器翻译,简称 vmt, 是计算语言学的一个分支领域,研究如何使用计算机软件将文本或语音从一种语言翻译成另一种语言。这篇文章介绍了占主导地位的序列转导模型, 积极于编码器和解码器配置的复杂的神经网络。此类模型通过注意机制将编码器和解码器连接起来。 在完成了两个机器翻译任务实验之后,本文还提出了一种基于注意力机制的新型网络结构,此结构不需要地规和卷机,单个模型有一点六五亿个参数,在英逸德的翻译中达到了二十七点五步路, 翻译效果得到了大幅度提高。这篇文章讨论了基于联合学习的神经机器翻译踢出神经网络机器翻译的目标,即建立一个单一的神经网络,可以最大 大限度的提高翻译性能。文中还探讨了如何建立一个编码器解码器的神经机器翻译模型, 由一个编码器将原句子编码成一个固定长度的项链,再由解码器从这个项链生成翻译。 这种新方法在英法翻译任务上取得了与现有的最先进的基于短语的系统相当的翻译性能。这篇文章探讨了如何将二人人编码器一马器学习短语表示的方法用于统计机器翻译的数据信息。提出了一种由两个地规神经网络把人人组成了新的神经网络模型。 一种二人年将一串符号编码成固定长度的项链,另一种二人年将其结码成另一串符号。运用二人年编码器剪节码器计算,可以使统计机器翻译系统的性能得到改善。
4042夏木小树屋 06:05查看AI文稿AI文稿
06:05查看AI文稿AI文稿这个是北京师范大学的 logo。 我之前说过这个英文呢,叫 nomo, 有 nose, 直译叫普通大学。好家伙,这么普通吗?其实所谓师范的这个范啊,就 铸造青铜的时候那个凝固铜水那个模具啊,所以模范嘛,这个词后来引申老师的意思。欧洲那个 nomo 呢,它本意呢,也是模子啊,所以才有这个标准化的意思。后来有了普通这个含义。所以我们经常会什么范本。自然他这个孬某和咱这个饭一样,也能引申成教师的含义啊。你看人类的语言,虽然能够互相翻译,但是它语义其实非常多。 如果各种对应,绝对不是 a 到 b, c 到 d 这样直接来的,有很多模糊的成分。如果直接强行了翻译,就会闹出所谓的鸡翻 t 是吧。没错,早在八九年前,法国一个叫早二十处理的工程师啊,就用纯机械制作了一个能容那数千个基本责任,然后进行一一对 英文翻译的这么一个机械脑。那要命的是,这东西查一个词,让大家觉得十到十五秒,他那个人查的快的。直到后来出现了电子计算机呢,才有真正这种机器翻译有着英文的可 可能。问题是呢,这种激发的思路呢,那是真机械啊。哎。比如说这是我前两天刚去的某厕所,里面看到一贴纸啊。进一步是文明,他硬给你翻译成 win step say 不来雷神。我了个天, c 不来雷神。这个 c v o 是城市的意思啊。那这个词是那种承邦公民,文明和塔很宏大,金字塔,斗守场那种。你说往前进一步,你还给我弄出二战后遗症了。结果一出门我去小心地滑比 careful sleep 小小心的滑。我天,你会用副词吗?早期这个积分的逻辑啊,就是这么迷惑啊。比比方说,我上周看了视频,那这个中文的,看的英语到底是 d 还是 watch 还是 look 还是 ree 的啥呢?那机器呢,就要掉出局库了。哎,看这个看到后面跟的是比赛啊,或者视频呐,这些卧室要是输呢,就是 read 等等啊。那这个积分过程中, 那就得找一下你英语老师,找语言学家,现在归纳固定这个规则,然后再和程序员删了你打写一个程序,再让这个程序对应规则 好起来啊。问题是,咱就不说这套模式要动用多少语言学家,找多少程序员,你还来个产品经理啥的,成本非常高啊。动者几年。如果这个时候咱在不是英语,是个日语啊,而且还更棘手了。因为那个中文和英文呢,好歹都是我吃饭这种主谓宾解。 日语呢,确实我的饭呢,吃了得干活这种啊。主宾位后面还加上粘着后热的结构,那这对于机器呢,很原地爆炸了啊。所以为了解决这个问题呢,到了八十年代呢,我们就想出了一个新办法呢,就是通 通过统计来翻译啊。咱现在不判断上下文了。同样一个看书,我把这艾瑞来,我是艾洛克 ic, 甚至 iobe zerber 不可全都列出来选啊。然后呢,再去真实的这个语言书语库里出现的各种频率,给直接翻译一大分。然后就发现呢,大部分都是艾瑞的布可啊,其他的几个不对,除了中国 写错的作文里边呢,都很少见。这样一来哦,一个好的发音就出来了。如果通过这个模式呢,也不需要那么多语言学家程序员了。你看,其实咱常的那个输入法,也是用这种模式,才让这个拼音 打字可以联想出最适合的这种词啊,让他辩解起来。那其实呢,咱们人类的母语取盟呢,也不是什么规则,他就是你大脑这个纯粹系统,在接触了大大的信息之后,会自然的判断出频率最高的一个用法,然后这个女的一个底层逻辑,然后构成句子说出来啊。所谓的语感, 那就是这么一个东西。但对于机器来说呢,这种统计呢,就需要海量的真实事业的文本。一般来说呢,各国政府公文里边的多语言翻译,以及各种名著艺术的 原文啊,都可以为大家使用。问题来了,如果这个模式我翻译这么一词,我看了啊,不然后三连了。语言学的规则里面,各种公文名著里头哪有啊普这个意思啊,是不是三连又是个啥呀?这里面呢,看又该用啥呀。 icf and 高 three, 这是个啥玩意?而且一个关键问题,啥也没有解决。我还是说,人类语言,它不比程序,它需要各种暧昧、模糊和误解,才符合我们的心理。所以激翻。到了这个时代,还是总被当做很机械很不靠谱的象征 唱出来着,也是层出不穷的。直到近些年,你可能越来越发现,好像机器翻译弄得是越来越准,越来越。这就是因为啊,在人工智能上,一种革命的改变,神经网络出现了。咱说啊,这任何物种的基因呐,都会带它的突变 啊,就是出错,然后再在这一万年的错误里面,自然界选择这种极少的适者生存的补丁,所以才从单细胞晒到了各种补补动物。但是再高级动物呢,也都难逃靠着基因自然的这个大筛器啊,才可以生存这么一个宿命。直到人类 类这个 bug 的出现,却改变了一切。按照语言学家乔姆斯基的看法,人类的大脑呢,突破了一种本能语法的能力,而是萨拉利的那个。人类检验师们也提到过说,比起任何物种,人类都拥有其特殊的虚构能力以及 国际本能。我们可以通过自己的大脑,把整个世界进行推眼迭代,然后灵活咱们。啦啦啦。神奇的妙笔生花,一代传给了后代。可以说,动物只有通过基因才能完成的犯错和选择,我们大脑的神经网的直接给解决了。那这样一来呢,无数 数学们的危机可以被你在一个小时之内推演,几千年的经验就可以被你在短短的十几年内学会。我们通过动物,只有通过无数大的突变,自然选择,才能迎来的进化,以自己的学识去对抗造物的危机。所以呢,随着机器的一代的算力提升,他也被开发出了堪比人脑神经元数那么一个节奏。而且因为他的速度要更快,所以呢,可以自己进行, 没有深度学习,自己出错,自己疲倦,从线上线下的海量宇宙中,自己训练出复杂的语感。然后呢,我们再给机器引入这个注意力机制,当他模拟人类阅读翻译的时候,挑出几个重点字,就来确定羽翼的过程。那这样以来,翻译他就会越来越人性,越来越有温度了。在神经网络翻译里面做的比较好,那就有我的老朋友的一个一直以 自然语言处理文明的科大讯飞啊。他们就是以自己精准语音转文字。这么个系统,结合神经网络,甚至可以解决与机器进行同声传译。这么一个翻译的天鼎星啊。他的逻辑其实很好理解。你看 一台讯飞翻译机,你对方一句外语翻译,先识别他说的是个啥语言,然后呢,就扒给转化成文字,然后再通过神经网络翻译成汉语,然后再还原成语音播放出来。你看, 自然远的这个模糊问题,一个个被攻克啊,不在机器本身,而是在对我们的智慧,对文明真正的深耕里。这才有了所谓圣经里。门诺亚。那次大洪水,都没有跟到人类。人类齐心协力修建了一个巴别塔,想突破什么的限制。沈一看,好家伙,你要投到我们家厕所了。于是一抖机, 让人类说了不同的语言,然后才导致人类不能集中力量办大事啊。玩完了芭比扣啊。在有幸人类通过自己的无限可能性,以讯飞音乐为代表的神经网络积极翻译,可以突破 破这个接线,成为崭新的造物,让全世界我们都可以无障碍的智慧碰撞八别塔,螺旋上升,突破天界路,哪怕是神,也难以阻挡。传说二零四六年起点即将临近,人工智能将突破图灵测试。也就是说,人类开始分裂不出 如何你说话的究竟是人还是机器。那这样的故事没人在电影上也见过不少。为了让人类如何懂得掌握人工智能,如何驾驭人工智能,还需要各行各业能够把 a i 技术讲明白的人加入进来。也欢迎你来挑战。我用自己的方式科普 a i, 我们一起为人类科普人工智能。
196科大讯飞 08:26查看AI文稿AI文稿
08:26查看AI文稿AI文稿有个考研同学问我未来翻译的职业前景啊,这种事情啊,责任重大,于是我找了两个句子测试一下,看 check gpt 和几个重要的翻译软件的质量比较。底牌啊,谷歌百度有道。 为什么要做翻译的测评呢?因为这不同于其他的旧错啊,很多大神说拆的 jpt 啊,它生成的内容有误,那是因为语料库的问题或者提问方式的问题啊。测评翻译呢,就不一样了,因为它的底层呢,叫 transformer, 本身就来自机器翻译。 看翻译的质量,就可以在最重要的维度去测试这台语言发动机的参数,看看这台机器到底好在哪里,还有什么不足。 我不太可能像 ham 那样子多维度的去测评有些参数其实没什么必要啊,我只看结果也能分析出来这台机器的性能。所以呢,我就简单粗暴一点,手头正好在整理考研英语,随手拿了二零零三年考研一的第一篇的第一句啊,另一个呢,是老 sct 的长难句。为什么选择这种学术类? 学术类的句子呢,是考验对复杂语言的精细理解的程度。如果学术类的语调库翻译很强大的话,你就可以了解他到底具有多么可怕的学习能力啊,那就意味着他可以调用这个世界上最好的教科书,诗歌、戏剧、电影、小说,然后以任意形式输出内容,那就可怕了。 sct 呢,作为美国高考的重要的指标,就是学习能力的反应。先说结论吧,有待差性的进步。这次应该没有多少人会嘲笑激翻了对人物关系、层级关系、雌性逻辑,前后文推理啊,完全是另一个等级的存在啊。这也就为什么解释了谷歌的 bar 会垮。 有些逻辑翻译错到张冠李戴。其实百度不改变底层的话,我觉得也悬周围他只做汉语的内容,不做多语种。当然了, child gdp 呢,也有缺点。对于一些太文学性的东西啊,还有些缺陷。我们先看 看看第一句考研英语里的句子,也就是一篇正常的杂志的文章。他说德州的天气啊,可能已经在最近的极度的炎热天气之后啊,变得凉爽了。但是在这个月奥斯丁举行的周教育委员会的会议的气氛将会很热烈, 因为官员们将讨论如何在德州的学校里面去教授气候变化啊,差的,这毕业基本上准确的翻译了这句话的含义。先说他的优点啊,他将一个 since 的介词短语插入了句子中,不像另外的四个翻译啊,多了一个逗号,少了一个逗号呢,其实更容易理解,而且他看出了 will be high 与 istat 是时态的一致性。翻译成 it 套的翻译成了将讨论,非常棒啊,一般现在时是可以表示将来的,因为需要和 will 构成前后的逻辑关系啊。这个我在前面的视频里讲过这一点呢,低排骨骼,百度都翻译错了,都翻译成正在讨论啊,有道翻译对了啊,但是有道翻的错误呢,更加 基本性词呢,翻译成了音尾啊,这里面明显是个介词,因为性词后面没有谓语动词,所以他只能是个介词。而呃字呢,作为一个连词竟然漏意,这是原则性的错误啊,语言模型而言,词性是不能原谅的错误啊, 差的 gp 的缺点呢,就是 temperature, 他没有找到逻辑里的矛盾性,因为讨论呢,与 temperature 的关系只能是气氛热烈,而不是温度高。因为 temperature 的熟词 p 有个木的气氛这层字意,这是个算法的漏洞,其他的四个翻译软件也没有做到。熟词 p 呢,是语言的难点,对差的 gdp 也很难。 层逻辑的漏洞呢?应该是前后的算法出了一些问题啊,如果你不能找到逻辑的矛盾性,那么错误就很难查到。 child gdp 对一些单词的子级的逻辑需要加强,比如说 temperature 到底能和什么子级构成温度,又和什么子级构成气氛,这个 工程其实也不是很大,因为首次不多嘛,所以 p e 也是在可以理解的数量范围之内。我和 child gdp 聊天,说起来如何避免首次 p e 的问题,他也承认自有这方面的问题。他给出的方法其实是非常靠谱的, 用的是一种叫词意消棋的方式,也就说涉及到分析周围的单词和短语词性、句法关系和搭配,以确定单词哪个含义是在给定上下文中最合适。 真正难的是要找到逻辑的漏洞,知道自己错了。有人问拆的 gdp 有逻辑能力吗?我刚开始的时候也拿不准,后来我让他给我分析了一个句子的时候,用了逻辑性非常严谨的分析判断的方法,我确定很多逻辑路线已经搭设完成, 逻辑的神经已经搭好了一大部分,他一定有逻辑能力,而且是非常强大的逻辑能力啊。其实呢,我在去年在讲哈利波特那集视频里面有人问 我用的软件是什么,那就是我们自己开发的训练器,训练单词在特定的句子里的精确含义,训练的人如果阅读够精确的话,是可以规避这些错误的。这类似的一些数据我们已经有了两年多了。 另一种技术,他说是依靠大量的文本的数据训练的同级模型。但是大家知道,首词必须正与他的概率算法是冲突的。 pe 代表着概率上少的词,而他做的概率的计算是大几率的词汇。这个算法在某种程度上导致了他对文学性强的让人拍案叫绝的文字难以生成, 对写作有很强的文学性的人是一个福音。我又用了另外一个 i c t 的难句说在 starr 的一个寄宿学校里,通过严格的纪律来调和我性格中的不平衡,几乎导致了同样可耻的结局。只是我在最后一刻的假装自愿离校,在防止了我被排斥出 那些通往高等教育之路的特权人群。他删除了括号里的信息,专业的词汇翻译的不是很好,伪自愿是不对的,应该是假装自愿啊,而且他把指示 翻译成了只有。这又是一个首次 p e 的问题啊。其他的四个翻译软件其实在意思上就完全错误啊。 d p l 呢?说我被排斥了, 而谷歌说我阻止了我被排斥。百度的翻译呢?还有一个就是只有我在关键的时刻假装自愿的离开了这所学校,是我假装自愿的离开了这个学校。百度呢,犯了一个原则性的问题,就是雌性的问题啊。 综上,吉他四家翻译软件其实差别不大,都有致命的算法错误,对于复杂的文本,尤其是复杂的教科书及科学文献,有明显的阅读障碍,输出的信息的质量就会受到极大的制约。这四家仅仅是通过算例的增加是解决不了 问题的。我做过托付 stact 的句子模型啊,所谓的自然学习啊,就是忽略掉目前的语法学习的方式。我有一套,我记得我在前面的视频讲过,一个半小时就可以解决阅读的方法的问题了。所谓阅读的核心是在哪个地方断,在哪个地方连,步骤是什么,根本不需要那么多专业的定义。 传统语言学的方式,基本上就是一些自以为是的人,用复杂的方法对于学员这个简单的任务做了非常高的设定,简单的说是一帮捣乱的人。 结论,翻译这一块呢, chat gdp 断带领先四家翻译几乎惨败,这是 chat gtp 成功的基本。另外四个呢,都是断点和连接的问题,对接错误的背后是对修饰关系的算法的混乱。所以我刚才说骨骼做不出来,其他的也没什么希望。但 在另外一个方向上,骨骼可以不做复杂的多余种的模型,他不做精细的长阅读链条的文章,细化 使用领域。不是现在他也正在做这些吗?在我看来,这也是最后绝望的一搏而已,挺悲壮的。就 chatd 三点五这个语言发动机而言,下一步可能就是解决文学性的问题了。以前呢,有一个叫无限猴子的定理,让一只猴子在打字机上随机的按键,当按键的时间达到无穷时, 几乎必然能够打出任何给定的文字。比如说莎士比亚的全套著作,我们不讨论一个猴子可能只按一个键的情况哈,其实差的 gdp 离这个定理差的可能只是几年的时间了。 总结一下,差的 gdp 呢,距离完美的阅读可能只有很小的距离,剩下的是语言里最复杂的词汇的多重含义的问题。这个如果啊,他要解决的话,会直接影响到最大的文学艺术顶尖的作品,也就是在文学性上,在情感上,在首次 b 上。他还现在有缺陷,长链条有问题啊,比如 说我们的红楼梦说草舌辉现,福脉千里,他还做不到。目前拆的 gdp 解决的都是一些相对模式化的写作,比如说论文考试的作文编程等等。就翻译而言,留下的空间已经很少了,高端的翻译还有一点点空间,但是工作量会大幅减少。 留学的文书而言,顶级的文书还有距离,但是呢,对于套路性的模板的大公司是一个毁灭性的打击啊,为什么他难以取代呢?因为留学文书需要一个人不断挖掘留学生自己都不知道的潜力啊, 和大学招生官的喜好进行客观的关联。所以拆了 gdp 目前还不具有顶级文书的能力啊,虽然他现在已经有很强的逻辑能力了。 说个题外话,另外我和 ai 讨论过,他如果学习的话,他会选择什么专业。他说了三个方面的内容,一个是数学,一个是编程,一个是语言学。 ai 本身是解决语言学问题的,是数学和编程是实现的手段,不懂语言学的就不要在这里讨论拆的 gdp 的语言模型问题了。
1468虎爸教英语 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿多元文化交流已然成为现代人们社交的常态,想必大家或多或少都遇到过。在读外文书籍的时候可能会借助软件。每个人都知道什么是翻译,我们将信息从一种语言翻译成另一种语言。 那么机器是如何完成这个翻译的行为的呢?机器翻译背后的想法很简单开发计算机算法已允许自动翻译,而无需任何人工干预。最著名的应用程序可能是 goochunsa。 google 翻译基于 smt 统计机器翻译。这不仅仅是简单的单字竹字替换的工作。 google 翻译会搜集尽可能多的文本, 然后对数据进行处理来找到合适的翻译。这和我们人类很相似。当我们还是孩子的时候,我们从给词语赋予一丝含义,到对这些词语的进行组合、抽象和推断。但并非所有闪光的都是金子。考虑到人类语言固有的模糊性和灵活性,七 器翻译颇具挑战性。人类在认知过程中会对语言进行解释或理解,并在许多层面上进行翻译,而机器处理的只是数据、语言形式和结构,现在还不能做到深度理解语言含义,所以可能存在与异相差甚远的情况。那么大家觉得当前的翻译器有什么改进的地方吗?
104上海市机械工程学会






