前后端分离session如何解决

粉丝7453获赞2.6万
相关视频
 02:15查看AI文稿AI文稿
02:15查看AI文稿AI文稿你觉得一个项目该如何实施前后端分离?二、而且前后端分离之后呢?后端一套接口可以提供给很多类型的前端使用啊,比如什么外部网音,比如呢,手机的 app, 对吧?再比如什么微信小程序啊,还有一些什么 h 五页面啊等等等等啊。 然后第三个阶段就测试阶段啊,基本上要保证的是前后端独立可测试啊。那前端主要就是什么页面呢?跳转呢?展示呢?输入对吧? 还有一些什么船舱响应数据的展示啊等等等等这些测试对吧?那后段子主要保证数据接口的提供,数据格式啊,教验呢,异常情况啊,数据的什么一致性问题啊,还有甚至一些权限问题啊等等等等,对吧?所以这是测试。那最后一个阶段,我觉得也特别的关键,那就是所谓的叫部署上线阶段啊, 前后端分级之后,前后端项目独立可部署,我觉得这个非常重要啊,就在以前那个 gsp 模板时代啊,前端呢, h 天面啊,页面 cs 样式,还有 gs 的效果,全是后台来驱动的是吧?那个时候所谓的这个叫项目部署, 就是发版本上线是吧?其实指的也是后端项目的部署吧,因为前端的东西是塞到后端项目里去,一起做,一起部署上线,对吧?前端要改一个东西发版本的,你也得去求着后端来做是吧? 但是前后端分级之后呢,他事情就不一样了啊,前端所有的事情呢,都可以全部自己单独去做啊,前端项目呢,也可以去单独独立的部署,而且呢,前后端发布上线可以完全独立啊,双方可以按照各自的这个版本规划来发版本的,前端发版本呢,不受后端约束,后端发版本,前端也可以完全不知道,不管互相透明了,对吧? 而且还有一个呢,我们知道哈啊,很多公司里,对吧,后端项目可以通过什么类似这种接更系统去做这种持续发布啊,一键部署。 同理,前端项目也应该有自己的 c i 系统,也可以去持续发布,一见不属那巴拉巴拉说了这么多啊,最后一个问题是哈,前后端分离确实是很适合复杂项目对吧,看起来很好对吧,那他真的就没有缺点了吗?啊,这个问题呢,就要回到刚开始我们所讨论的问题了啊,就是为什么会有前后端分离这件事情的出现。 帕杰吧,很多公司为了前后端分离而去做前后端分离啊,从上面的讲述中啊,大家应该可以听得出来,前后端分离是需要成本的啊, 尤其是你想做一个彻彻底底的前后端分离啊,不管你是人力成本呢,开发成本呢,工具成本的,还是什么部署成本呢,其实都是不小的啊,有些小团队或者说小项目,对吧,你如果不顾自己的实际需求来强行前后端分离式开发,只会给自己找麻烦,因为你只要前后端分离某一点做的不彻底,他就会带来非常多的负担,而不是便利性的啊。 所以说呢,并不是所有项目都适合前后台分离啊,这个其实要看性价比的啊,还是那句话啊,前后台分离不分离,他本身并不是一个技术问题啊,而是一个工程考量的问题,喜欢记得点赞加关注!
19疯狂程序员 03:21查看AI文稿AI文稿
03:21查看AI文稿AI文稿后端开发如何修改前端页面? liked 命是前后端分离的后台框架,系统刷好瓦或者 pp。 后端开发的朋友部署好之后,一开始不知道怎样才能修改前端页面,今天教你三个步骤实现修改,一、 npm install 二、 npm 装第一位三、 npm 装 b 的现在分别演示一下,进入前端原马木路耳的秘目路,执行 npm install 安装前端依赖, 因为我之前已经执行过 install 母乳了,所以说安装会比较快,如果 npm 命令执行不了,要安装漏的环境,如果 install 音赖很慢,可以使用国内淘宝竞相员。第二步,执行 npm run。 第一逼,开启前端开放模式,实时动态,可以实时动态预览,这边生成了一个本地实施预览的路径,我们复制进入浏览器打开, 第一次打开的话会加载会比较慢,现在整个界面已经加载出来了。举例来说,如果我想把今日数据和更新时间做一个调整的话, 我们找到对应的页面, 比如改成昨日数据持续更新时间, 大家看我一保存的话,这边我没有刷新页面,这里就发生了变化,这个 lacdon 并点 logos 的点康是我 本地正式的环境,刷新界面,它还是显示今日数据更新时间,所以我们要执行第三部 npmofu 的编译。发布前段代码, 先结束开关模式,执行 npm beauty 的过程会比较慢, 大家看 bu 的成功之后,这边会多一个 的目录,我们要将这个目录放到 前端自愿文件这边进行一个覆盖,就完成了这个代码的编译和发布。直接把它拖过来放到帕布里克目录,接着把原有的前端目录可以删除, 再进行重命令,这时候我们来刷新一下真实环境, 大家看这个就是编译后的结果,通过这三个步骤就能实现 like me 前端页面修改了,还是很轻松的。欢迎点赞加收藏,更多干货持续分享!
101钟富桂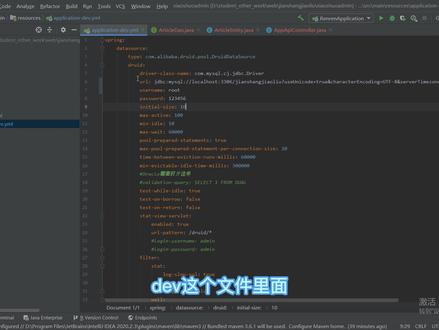 03:28查看AI文稿AI文稿
03:28查看AI文稿AI文稿我们来看一下一个前后端分离的网站项目的一个代码结构。前后端分离的网站项目,首先他有三个文件夹, 一个前端用户端的一个代码,一代码文件,然后一个针对于后端开发的后端语言开发的代码文件,然后还有一个后端管理员端的一个前端的代码文件,然后就是一个文,一个数据库的文件,这几个文件缺一不可。 然后我们用 idea 把我们的后端后端接口文件打开,这里我们是用的佳瓦斯 bingbot 框架进行开发的后端,然后这是他的一个目录结构,打开我们的后端开发 代码,一定要先看他的数据库连接部分,在这里在因为硕士的这个 opticsdev 这个文件 里面,然后这一块就是他数据库连接部分,如果你不知道数据库连接的代码在哪里,可以用 i d e a 的这个查询工具, 不知道他在哪个菜单,我们就用快捷键 ctrl shift 加二调出我们的查询替换,替换的这个框,然后我们就搜索卖烧烤,然后就会相应的就会搜索到相关的文件,然后这是只卖烧烤的一个版本,然后我们往下看看这里这个文件 就是我们数据库的连接部分,项目打开一定要先看数据库的连接部分,有的代码他可能和他数据库的配置和你本地安装的配置不一样, 那么你就要去这个地方相应的去进行更改,更改了之后才能访问我们的数据库,不然项目代码运行起来看不了数据。而且加瓦是不是木头框架他比较严, 连接不上数据库,他在运行的时候就是点击这里,他会进行一个报错。当数据库连接部分核对无误之后,我们就打开,用这个打开相应的代码文件,打开我们的前端 h t m 没有,我们不用 list 加问的,刚刚把那个覆盖了,打开我们后端这里用新的窗口把我们这三个端的文件都打开, 然后看它的前端到底是用什么框架来写的。你先要看看它的目录结构,你看这个目录结构,它有 park a 几点儿 jason 就说明它是用 v u e 框架进行编写的,然后用 v u e 框架进行编写的话,你就必须要下载它相应的一个管理管理 包的工具 note, 然后还必须从文档里面知晓它所它使用 note 的一个版本。不同的, 现在的漏斗他高版本可能兼容不了低版本,低版本也兼容不了高版本,所以拿到项目要必须要先清楚他漏斗的使用版本,然后相应的进行安装。安装好了之后,这有一个 turmino 使用漏斗的秘密。 note 里面包含 n p m 就是一个包管理工具 d e v n p m run d e v 运行这一步的前提是我们要已经安装了 note 的一个插件,就是 load model 这个组件,你看这个木木结构里面没有,所以我们要先进行安装 好。我们这一节就主要讲 mac 口数据库,一个连接核对的核对的一个讲解。下一节我们就在讲 note 怎么去安装运行 v u e 框架的前端代码。
129平姐开发 08:36查看AI文稿AI文稿
08:36查看AI文稿AI文稿之前呢,有学员问到我这个前后端分离的一个事情,我给他解释了一下,前后端分离其实就是前端防爆,后端的 api 接口,然后 api 那是后端的防爆数据库,嗯,把这些数据啊通过接口返回给前端,然后前端也展示给用户, 基本上就是这么个流程,因为之前这个前后端风力,之前可能是说前段有些模板要套在后端后端的一些代码上边, 最后由后端生成一个 atml, 就是前前端和后端融合在一起的,在现在已经分离开了。前端呢,就是从前端项目那里边不包含用户数据,对吧?他没有用户数据库的,他没有数据库里边的数据,数据呢,都是从后端接口来的, 但是广听可能理解起来比较困难,所以说我给他写了一个很简单的例子,我来演示这个现象。然后里边就是用了一个 六的前端项目,布了一个 fastrapi 的后端的项目,然后运用了一个 mcq 数据库。很简单的东西, 我们这个相关文档都放在这个公众号上边了,有需要的可以自己上去看一下。就是我们先布一下数据库,我们通过这 doctor 的方式来布数据库,直接复制粘贴, 可以看到 mac 口已经启动起来了,然后我们进到 mac 口里边充电 包,这个错误可能是它它还没启动成功呢。嗯,稍等一下再执行就可以了。然后我们创建创建库, 然后充电表, 然后插入用户数据,其实有表就是两个东西,一个是用户的 id, 一个是用户的名字。就是很简单的一个例子, 我数据库充电完了,然后下下边就是装 python, python 已经装过了,所以说这边就不演示了,然后安装 python 的,安装 python 的包, 这里边公众号里边这少了一个,少了一个库,然后我修改了,他可能还没生效,然后少的库是这个, 我们在这复制一下,然后给他装上,因为我之前装过了,所以说很快他就装完了。 然后把一下代码复制一下, 我们在地盘下边新建了一个 type 的目录,然后在这个目录下边再创建一个目录,要买 api, 然后在下边 编辑这代码文件的 p y, 修改一下里边东西, 把这代码粘进来,注意修改一下数据库的 ip 地址,这里边我的 ip 地址是幺七幺点幺二八, 然后保存, 然后把这个符骑起来,按住 shift 右键打开 powershale 粘贴回车,行了就骑起来了。 吸起来之后我们去看一下,复制这个 u l, 那能访问到纯棉, 嗯,一切正常。然后我们再补一下前端的项目,我们还是说到这个 test 目录里边,在这输入 c m d, 然后回车就打开 c m d 窗口了。然后我们 之前要装一下这个 note g s 啊,通过这个地址下载,下载之后安装就行了。先装一下 p n p m 哎,就是一个前端的包管理器,然后配置一下它的 国内源,国内源配置上之后就下载包的速度更快一些,然后装一下 vivo, 常见 vivo 的目录之类的。那这项目名也可以自定义,或者直接都回车,全都回车 就可以了。然后这时候我们按照他的命令执行就行,先进入到这个目录里边,然后 p n p m。 面试到这边我们还要单独装一个库,用于接口防风的, 哎,装完之后 p n p m d, e v 就可以给它启动起来了,然后通过这个 u i l 就可以返回到这前端项目了, 前端项目就是这样的,然后我们再复制前端项目的这些代码, 然后我们到这个 view 的项 下边, s r c 下边打开这个 a p p 点儿备用, 给他盖,给他覆盖一下,全杀了,覆盖一下保存, 可以看到我们已经能看到数据了,这显示一共有两位用户,就刚才我们添加的这两位 哇, id 是三和四,我们点击查询啊,就能查到他的名字,就把这个四的是硬太子的,然后这个三呢是 mates 的,然后它具体是怎么交互的?按 f 十二,然后打开这个网络,然后选择这个,然后 我们再刷新一下,可以看到我们访问了一个接口,就是刚才我们布的这个后端的这个接口,他会给我们返回两个值, id 和三, id 和四其实都是从数据库里边拿的, 然后我们点这个查询,查询三,他会返回他的用户名,也是通过这接口一个 pos 的接口啊,返回了这个用户名, 你可以到数据库里边查一下,这个 可以看到啊,数据库里边就是这样的, id 是三的, id 是四的,然后这时候我们都可以 找着刚才的搜索语句,我们再插入,插入两条,在这改一下 b b b, 我们再插入两条数据库中, 插入成功了,然后我们再看这个,这个刚才是显示三和四,我们刷新一下那四位用户了, a a 和 b b b, 这就是一个前后端交互的过程,对吧?前端的项目访问后端,后端访问数据库,整个流程就是这样的。这个时候我们如果是说 把后端的项目停掉啊,他访问不到数据,前端就访问不到后端的数据了,嗯,他 页面上东西就这样了,就是空的了,因为他获取不到任何数据,他这接口也就报错了。 啊啊,这节课大概就是这些东西。
5运维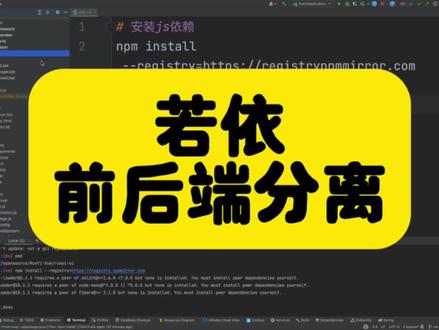 02:26查看AI文稿AI文稿
02:26查看AI文稿AI文稿今天来讲一下若一这个开源项目前后端分离的情况,是怎么启动前端项目的。首先找到这个大码下面的这个前端项目,这个是前端项目第一步是安装这个 gs 依赖,这个是安装的这个命令,下面的话是这个安装的这个结果, 这个是安装,安装成功,安装成功之后,这个 gs 依赖 gs 文件全部都被安装到这个目录下面去了。乐的模块 在这里就当前目录下面的这个 note 模块,这是伊娜的 gs, 包含这么多安装我们的依赖之后,我们接下来就是可以启动这个前端项目, 这个是启动的命令,我们来看一下执行结果,这个是启动的这个命令,这个是启动日志,到这里就是变异成功,就是启动成功。接下来就是访问这里 显示的点这个地址访问就可以了,我们的这个界面登录界面就是长这个样子,接下来就是登录,登录的话就是输入这个默认的用户名密码就可以了,这个 在这里输入登录就可以了。注意刚才讲的是前端项目,这里访问的这个界面登录界面也是前端项目,现在我们想要登录的前提是我们后台的项目也要启动后台的项目我们之前是已经启动过,这个是启动成功之后访问了这个首页的这个界面, 这个是八零八零的端口,这个是后台项目启动成功。刚才的话这里是前端项目,如果是登录,那么就是必须要请求到后台项目去,这里可以看到后台项目已经启动成功。接下来就是我们登录,我刚才第一次登录的时候,这个验证码输错了,这里提示异常,就是后台项目这里的日 提示这个异常,我们再次登录,现在就是已经登录成功,这个是登录成功之后的这个首页,所以我们可以看到前后端分离的项目和没有前后端分离其实是基本上是一样的, 唯一的区别就是把那个前端的代码把它给拆分出来,作为一个独立的项目,方便开发和运维功能的话,其实都是一样的。什么用户管理菜单呀,这些精神任务监控这些基本上是跟之前完全是一样的, 唯一的区别就是做的这个代码的这个拆分,我们可以看到登录成功之后,这里都是有这个登录成功日志的,点击那个查询菜单这些功能,查询用户信息这些功能这里都是有这个日志的,表示这个前端的代码的请求已经转发到这个后台代码里面来了。
104Java个体户 01:31查看AI文稿AI文稿
01:31查看AI文稿AI文稿前后端分离怎么实现?前后端分离是一种软件开发架构,他将前端和后端代码分离开来,让他们能够独立的进行开发、测试和维护。下面是一些实现前后端分离的方法。 one restful api 使用 restful api 是实现前后端分离的一种常见方式,前端通过调用后端提供的 rvstf api 接口, 从而获取数据和完成相应的操作。二、前端单页应用前端单页应用 spa 是一种以 javascript 为核心的应用程序, 能够提供良好的用户体验。前端单页应用可以通过 ajx 调用后端 api 来获取数据,并将数据动态的渲染到用户界面上。三、前端框架使用现代前端框架,如 vx 呜或 angle, 可以使前端代码更加模块化,提高代码的可维护性和可扩展性。前端框架可以将前端应用程序划分为组建,并使用单项数据流来管理组建之间的数据传递。 四、后端服务将后端代码打包为服务,并通过 api 将服务暴露给前端,这样做可以使后端代码更加模块化和可维护。 总之,实现前后端分离需要前后端开发人员进行协作和沟通,确保各自的代码能够协调工作。此外,还需要选择适合自己开发团队的技术站,并确保代码的稳定性和安全性。
37大数据老司机 13:34查看AI文稿AI文稿
13:34查看AI文稿AI文稿说人话,中式站讲干货。你好,欢迎来到 it 老习的架构三百奖。我是你们的 it 私人顾问老齐。到今年呢,我从业已经十八年了,一直做扎瓦与架构的研发工作。目前呢,已经录制了十多门与编程架构相关的课程。 同时我还会提供点对点的简历优化、模拟面试、 offer 选择、解决方案、加购指导等服务。总之呢,只要是我有经验的,能给兄弟们帮上忙的信息呢,我一定坦诚相待。有需要的小伙伴呢,可以看一下评论区或者我的个人描述,希望能有我的经验,帮你少走弯路,找到更好的工作。 那今天呢,咱们来学习一个非常实用的技能啊。我们来了解一下在多端的情况下,采用前后台分离的开发模式,如何保证我们的用户在每一类设备上呢,是唯一登录的。 那下面呢,我们就直奔主题。在我们现在绝大多数的互联网应用下,都是基于前后台分离的,这种形式,也就是我们的客户端和服务器之间呢,他呢彼此是结偶的。那比如说现在我们有这样的一个长久。 现在呢,我们开发了一个什么什么应用,那他现在呢有分别是手机端, pc 端,还有 派的端。那么这每一类设备呢,他们呢都可以接受用户的输入。比如说这个用户呢,哎,用自己的密码 adm, 一二三四五六 分别呢,在这些设备上呢来进行登录的时候,首先呢请求呢,会发送给认证授权的服务,他们一判定,哎,你这个用户名密码是对的。所以呢,就会有认证授权服务向每一个客户端 呢,颁发不同的 token 令牌,也就是我们常说的 jwtjc web token。 那这里呢还有个细节哎,每一次所申请的这个 jwt 的令牌呢,他都是不同的。 那么紧接着作为我们每一个具体的设备来说,他呢可以在持有了这个 jwt 令牌以后,你看这一二三呢,分别就对应了不同的令牌。然后呢,在 通过网关呢转发给目标的服务器。那这样呢,咱们就完成了这个吊用的标准过程。 作为目标服务器呢,他去教练我们 jwt 的这种有效性和是否过期提取出关键的信息,这是一个标准操作。但是呢,现在我们遇到一个这样的情况,虽然不同的设备之间,我们 呢持有着同一个用户所生成的不同的 gwt 令牌啊,是可以的。但是呢,如果在同一类客户端,比如说我现在有三台电脑,那针对这三台电脑呢,我们现在在认证授权以后, 虽然都是艾德米一二三四五六这个用户,但是呢,他们采用相同的这个呃 pc 端来登录。那按照业务要求,我们只允许唯一的,也就是最后登录的这个客户端呢,来进行访问。 而之前登陆的这两个客户端呢,在下一次发起请求的时候,应该收到当前你的这个用户已经失效,请重新登录的这样的一个错误提示。那像这种要求该如何做到呢?这里呢,我给大家提供一种解决方案和思路呢,希望冬对你有帮助。 首先呢,作为咱们现在的整体加购来说,还是要分成两个阶段,在生成的时候和较硬的时候呢,我们都要额外的增加一个组建,这个组建就是大名鼎鼎的分布式缓存组建 readys。 那我们看一下它的执行过程吧。首先看一下这种没有冲突的情况,每一个不同种类的客户端呢,在发起的时候,除了附带 adm 一二三四五六以外,还要附带我们自己设备的类型哎。 移动端呢,比如是一 pc 端呢,是二派的呢,是三,那一二三向服务器来进行发送。那认证输传中心对用户们密码来进行认证。授权以后,他在生成了 jwt 令牌的时候,他同时呢也会往 ready 词中呢保存这些 jwt 的状态。因为是三个客户端,所以这里呢它生成了三个 k。 这个 k 的规则是统一以 tk 开头。哎,以什么开头,你自己来定义。然后三八零一呢,则是我们这个 idme 用户在数据库中所对应的 usb 用户编号。 这个三八零一你肯定是可以拿到呀,因为你想你在进行数据库较厌的时候,艾德米一二三四五六,你肯定能拿到这个唯一的用户数据。那这个用户数据编号为三八零一。 而后面的这个一呢,代表的就是我们设备的标识。一呢,就是移动端二, pc 端三,我们派的端。而具体的这个 y 六值呢,就是我们生成的这个对应的 token 值哎。比如这里的 x 一 y 一 z 一啊, x y 二 z 二 y 三 z 三。同时呢,我们在为每一个 k 呢设置了最大的这个生存时间。那以上呢,就是咱们在 readys 中额外存储的一份数据。那当然了, 我们在存储完了以后,刚才所生成的偷看令牌呢,他也会随着响应呢,返回给对应的自己的这个客户端。那下一次咱们在 发送请求的时候,当然我们每一个客户端都会在请求头呢,将之前所生成的令牌呢,随着请求头再次的发向目标服务器,那在 进入目标服务器之前,肯定要通过网关,网关的作用呢?哎,额外,现在增加了一个叫做叫宴令牌的过程,他会把刚才我们所收到的这个 jwt 和 tip 类型呢,发送给认证授权服务器。认证授权服务器呢,根据这个 jwt 披露的载鹤中所存储的这个三八零一, 没错,你看到的无论是 x 一、 y 一和 z 一,还是 y 二、 z 二、 y 三、 z 三,因为之前登录的时候都是三八零一的用户,作为这大楼梯呢,他呢是可以保存这些用户的非敏感信息的。所以呢,在 认证授权服务的时候,他呢可以把这个 jwt 呢来进行一个反向的解析,提取出来当时放在 jwt 中的 usaid, 然后用这个 ucaid, 再结合 参数中的这个太婆一二三呢,在 k 中来进行查询。那么在查询的时候就可能会出现两种不同的情况。 第一种情况是 t, 它存在,比如说 tk 三八零一,冒号一。且当前咱们传入的这个 x 一、 y 一、 z 一和数据库中,也就是在 ready 词中保存的 x、 y 一、 z 一呢,是保持一致的。 说明呢,这个认证授权是正常的。那我们网关收到了以后,继续向后执行,允许放行。 那如果 t 呢,他是不存在的,那只有两种可能。第一个,作为当前的这个 jwt 令牌呢,是假的啊。第二个呢,就是之前呢,你可能确实登陆过,但是呢,超过了三十分钟,在 release 超过三十分钟以后,这条数据已经被自动的删除了。所以呢,它是说明不存在。那这里呢,客户呢,应该提示您还未登录,请您重新登录或已超时,需要重新的登录。哎,就这 大概这个意思吧,你就知道客户端呢,需要进行重新登陆了。现在呢,目前在正常情况下会存在这两种状态。但是呢,呃,咱们再来看一下另外一种情况。假设呢,现在咱们登录的三个客户端都是 pc 端的,会出现什么问题呢? 作为这三个 tc 端呢,在登录的时候输入的用户名都是相同的,他的太婆也都是二。那么在认证授权生成了 gwt 以后呢,他同样的会根据前后顺序在 reds 当中呢来进行相应的存储。 但是这里有个细节,按照时间顺序后登录的他呢是后生成了这个 gwt 令牌,他会覆盖掉前面的这些已经作废的数据。比如说 现在呢,咱们登陆的顺序呢是一二三,分别升成了外一,外二和外三是吧?好,那么在 reds 中,他的轨迹也是一开始先生成了外一,但是呢,紧接着外二出现了, 外二呢,就替代到原来的外一。然后最后呢,外三呢,替代要替代到原来的这个外二。通过这样的方式呢,等于在三个客户端分别登陆以后,他呢最新的最后的这个 令排值呢是外三。那知道这个原则以后,那下面呢,咱们就可以看了在实际运行中会产生什么问题了。 那这里呢,其实就会产生三种情况了。第一种情况就是假设外三在操作的时候,因为他附加的 jwt 的令牌呢,哎,按照组织, 外三太婆等于二,认证授权服务器就会在 release 中找到三八零一冒号二。同时呢,他一看, 哎,你这里当我们当前的歪三和你前台传来的外三那是保持一致的。那这样呢,我们就认为你当前的是已经登陆的客户端,所以呢,哎,就急于放行。 但是呢,如果比如说是歪一和歪二的情况下,他在登录的时候,虽然发现三八零一 冒号二他也是存在的,但是呢,发现我们自己的 y 一 y 二和这个 reds 中的存在的 y 三不同, 则认为当前我们这两个客户端实际上已经被其他客户端所生成的 gwt 呢所取代了。那么当前的客户端呢,应该提示出来您的账户 一再可其他客户端登录,请重新登录的这样字样。当点击确定以后,好,这个客户端呢,回到登录页面,他重新登录。最后呢,又会把现在最新的外三踢掉,然后用比如外四呢来进行替代。是这样的意思。 第三种情况呢,就是如果 k 不存在的时候,那说明当前的这个令牌要么之前就没登陆过,哎,是假的。要么呢,就是已经过期,直接被删除掉了。 以上呢,通过这样的方式呢,我们就保证了在登录的时候多端的唯一性。因为首先我们是通过太婆决定了不同的这个啊, 客户端的类型呢,使用了不同的 k, 他们彼此不打架。除此以外呢,就是按照时间顺序呢,我们去依次的 将之前生成的 token 呢,在 reds 中来作废掉,然后通过 token 直的比对,确定当前登陆的是哪个啊。那么在这个过程中还有一个延伸的问题,咱们是需要考虑的, 这是涉及到性能,因为我们在整个的应用过程中,每一次发送请求,他呢都是要向认证授权服务器呢来验证 令牌,而这个是通过网络来的。一方面呢,这个啊通信的延迟会增加。另外一个呢,就是如果每一次都要验证的时候,认证授权服务器呢,他爷爷是不是有可能扛不住,那怎么办呢? 这个时候啊,我就给大家提供了一种方案呢,这种方案叫做闪电缓存。什么叫闪电缓存?就是生存期非常短的一种缓存,我们把它称为闪 电缓存。啥意思呢?就是我们在第一次甭管是哪个客户端,在访问三八零一冒号二的这个 k 的时候,他呢在把数据提取出来以后,也会返回到网关这个层面上。那么网关里边这个 缓存呢,它的数据和 release 保持一致,但是呢,最多只有三十秒的有效期。也就是说无论是在们任何一个客户端发往网关以后,在 本地持有了缓存,那么之后的三十秒呢,那他就不再发起任何验证的令牌,而是直接将这个验证是否通过呢?哎,直接返回去。 那么这样做的一个好处是什么呢?我们就避免了这个每一次哎验证令牌的过程。但是呢,这里边也有 一个问题,那就是因为我们的数据是三十秒钟刷新一次,代价就是如果说比如说还有其他客户端来进行登陆以后,而这个网关呢,他是第一时间不知道这个变化的。所以呢, 其他的客户端在经过网关的时候,可能可能就会产生一致性问题,因为后台的数据已经发生了变化。但是前台呢,因为是通过网关的嘛,他呢网关没有发生变化。那么他呢就认为现在我们还可以登录,直到三十秒以后,现有的本地缓存失效, 重新的拉起最新数据以后再次比较,他才会这个看到正确的结果。那这个种业务呢,往往来说在于多端登录的时候,这个三十秒的时间差甚至更长。三分五分,其实在很多业务中也都是允许的,并不是 必须要求时效性。所以呢,我们通过增加闪电缓存的方式呢,解决了这个效率的问题。好,那么如果你觉得今天我的分享对你有帮助的话,麻烦给老习点个赞,谢谢大家了。
7IT老齐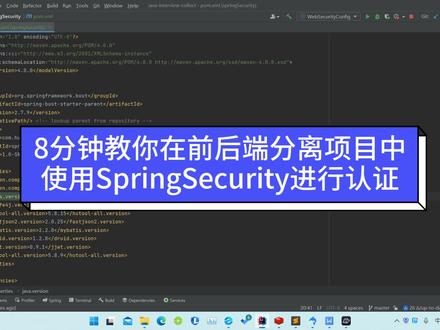 08:16查看AI文稿AI文稿
08:16查看AI文稿AI文稿大家好,今天这个视频我们来看一下怎么在前后端分离的项目中使用 spring security 进行认证。当前使用的 spring boot 版本是二点七点九。我们先来规划一下想要实现的功能,一个自定义登录接口, 返回 g w t 格式的偷看。一个验证偷看认证结果的测试接口。一个自定义退出接口, 用来清除 redis 中的缓存信息。首先在泡沫文件中引入 security 的 starter 以及数据库。 呃,发自解散 redis 和 g w t 相关的一些依赖。 application 的样貌里边不需要进什么配置。数据构表结构我们,嗯,这里只用到一个右侧表, 因为我们用到了 mabet plus, 它需要签订一下它的扫描范围。 菜叶键在这个启动列上加上 map skin spring security the starter, 严重后默认就自动生效了。不过它是前后端部分里的表单登录方式, 登录后自动跳转到目标页面,是通过 search 进行状态管理的。我们想要实现前后段分离,就首先需要去掉默认的登录表,通过这个接口 接受登录请求。我们新建一个 security 管理类,加上 configuration 主键和 enable versculity 主键。在 security 管理类中新建一个认证,并实现它里边的 authenticated 和 support 这两个方法。 support 这个方法是判断当前请求的参数 是否由该认证并进行处理 or send k 的。这个方法就是具体的认证逻辑了。这是从前端获取到的用户名凭证,凭证就是密码。 这个 user details service 的 lower user by user name 是自带的一个键 接口。通过实验这个接口从数据库中获取我们需要的用户信息。我们这是从右侧表对用户名进行查询,他如果不会空,就把它封装到这个 logo 右侧中。 这个就是我们自定义的 user details 的实现类认证,并建好后就要写接受外部请求的 login 接口,也就是这个接受一个 login user, 根据传入的用户名和密码构建出 username password authentication token, 然后调用前面在 security 管理类中定义的认证,并根据 认证编的逻辑,我们可以知道 principle 对应的就是这个 lower user by use name 返回的这个 logo user, 所以我们可以从中获取到对应的 user 对象, 然后就可以用 user 的 id 生成对应的投根串光,后续的投根传递使用啊。最后我们把完整的用户信息存入 redis 中, 那个 user id 作为 k。 接下来就是验证 token 认证结果的测试接口,我们需要能对前端传入的 token 进行处理啊,这里就需要新建一个 token 认 正过滤器,我们这里继承 one super request filter, 这个过滤器可以避免请求被多次处理。从 request the header 中获取偷看信息,验证它是否过期, 如果没有过期的话,从中解析出游戏 id, 然后根据用户 id 查询用户信息, 如果有的话,我们需要更新一下用户信息的操作时间,然后把用户信息封装一下,然后传入 security context hold 中, 供过滤器后续的业务逻辑使用。最后方形和 hello 接口就是我们的透根认证结果测试接口,测试 通过的话会显示这一串走不串。登录接口开发好以后,还需要在 security 管理类中对这个接口进行放行。在 filter 亲 这个方法中,把 login 接口配置为允许匿名访问,因为我们现在是前五段分离通过头根进行认证的,所以这里 就不使用 session 进行存储信息了。最后把 g w t 这个 filter 放到用用户名密码认证前面,不然的话会先被用户名密码认证过滤器抛出认证异常。认证异常可以通过实现 authentication intric point comments 方法来进行处理,过滤器抛出的异常需要使用 response 的 get a writer the print 进行输出。我们这里还需要对密码进行一下加密处理,毕竟不能在数据库里直接存铭文密码。 我们可以在这个 password incode 这个 being 中设置需要的加密方式,然后在这个 认证并中可以对输入的密码和系统保存的密码进行比对。我们测试的时候可以用他的这个 inco 的方法生成加密的密码。最后就是 自定义退出接口,我们在这里可以清除 redit 中的还在 信息,因为退出那肯定是已经登录的时候才需要的,所以说我们可以从前端获取到 tok, 通过这个认证过滤器 把用户信息存入 security context 勾搭中,在这个 log alt 方法中可以直接获取到用户信息,最后根据用户 id 删除掉 redis 中存储的内容就可以了。我们来演示一下, 我们先看一下异常,因为我们现在这个投片已经过期了,所以说我们这边直接返回这个海捞这个接口可以看到可以返回一个用未登录的异常,这个异常就可以被这里拦截到, 朋友们登录一下,输入用户名和密码,复制一下返回的这个图片,把这个内容替换掉,可以看到这个内容就是我们 接口里边打印的内容,因为我们这里边,嗯,每次调用这个都会有更新,我们可以看一下,现在是三十三秒, 可以看到可以正常的更新退出,也需要使用这个图片退出成功, 这个时候就没有了,我们再来访。 hello, 这是能正常的打印出这个用户认证失败,这个异常。好了,上面就是在前后端分离的项目中使用 spring security 进行认真的演示,希望能对大家的 工作学习有所帮助,谢谢观看下个视频,再见。
199猫扑蝴蝶 21:39查看AI文稿AI文稿
21:39查看AI文稿AI文稿每年计算机的毕业生都会为毕业设计发愁,无论基础好坏或者忙着考研,毕业设计都是计算机学生们遇到的一个难题。今天给大家带来一款工具,让大家不用写基础代码就能一天完成毕设。 或者对于基础好的同学,可以为其减少搭建底层代码逻辑的时间,直接在这个圆码基础上增加自己想添加的算法,可以有效节省闭射时间。下面让我们看看如何详细使用这款工具制作闭射吧。 首先在浏览器输入若伊,查找若伊官网,官网里面有好多种代码可以下载,我们选择目前比较流行的前后端分离框架代码进行下载。可以看到若伊官网将代码托管到马云上,我们可以使用马云账户登录下载代码,也可以使用本地安 装的 p 工具来获取代码,最终效果是一样的。这里我是用 p 工具来下载代码,下载过程有点长,感兴趣的同学可以看一下如何使用 p 下载的, 到这里原码就全部下载好了,和直接下载 gpr 缩包效果是一样的。我们来看一下代码内容,其中命运文件夹是前端文件,其他的都是后端文件夹。 这里我用 id 编辑器打开后端文件夹,用 bscode 编辑器打开前端文件夹。如果电脑里面没有这两个工具的,可以去百度下载一下这个视频里需要用到的软件链接,我会放在评论区里面供大家安装使用。 用 ida 编辑器打开后端文件夹后,会自动下载一会,这二包可以通过设置 map 本镜像员来加快下载速度,如果不设置也没有关系, 等待一会也会下载。好的,我这边已经设置了黑粉路径,现在开始下载这二包需要我们等待一会,在等待过程中,我们可以打开前端文件夹进行 配置, 现在前后端文件夹都打开了,我们来配置一下数据库, 这个 sql 文件夹就是存放 sql 文件的路径。我们使用 nikecat 工具来新建和管理数据库, 浏览一下 fql 文件的内容,大概寻找数据库叫什么名字,不过在这里面没有找到我们想要的答案, 这里 尝试下可不可以直接导入 sqio 文件运行,结果报错了,看到报错原因是没有找到这个数据库,看来还是需要先新建一个数据库才可以。 翻看一下若依的官网文档,观看前后端部署教程, 这里面提到了前端的部署方式以及后端需要配置的内容,不过还是没有找到数据库需要起什么名字。 这一步 粉是将来发布到服务器上需要的教程,不过现在我们暂时不太需要。 最后我们直接新建一个名字叫必设的数据库,里面的编码格式选择 apple 八格式即可。 数据库新建完后,将两个 sql 文件依次导入到数据库中,看到 successful 就证明运行成功了。 导入完数据库后,需要对后端链接数据库的配置文件进行修改,我数据库的链接密码微弱,需要将配置文件中的密码修改为我数据库的密码。这里找一下配置文件, 使用搜索功能可以很快的找到配置文件,这是一个找文件的小技巧, 将此处修改为数据库密码即可。这个配置文件中还配置了 ready 的数据库,大家可以去百度下载一下 ready 的数据库,安装上即可。安装过程很简便,不需要过多配置。 修改好配置文件,我们将后台启动运行一下, 这里已经提示运行成功了 后,我们来将前端启动。首先打开中端命令型, 在官方文档里面找到他的运行命令,输入到终端当中。这里运行命令需要等待一会,等家再好中间没有报错后再执行下一条启动命令。 这里可以设置一下淘宝的国内镜像源,设置后下载速度会明显加快,不会的同学可以看一下我之前发的攻略。 现在 install 命令已经运行好了,我们来运行下一条命令。同样的也是 需要运行一段时间 人的手,但偏偏已境界,难道我看你不见?还有, 运行成功后,他就会自动在浏览器打开网址,弹出网址,也证明部署成功了。接下来我们开始正式使用工具来完成我们的必设。首先尝试正常登录到系统中, 发现忘记密码后,尝试去若伊官网的演示功能中寻找正确用户名和密码, 原来密码是 m 幺二三,现在回到我们系统进行登录, 现在就正式登录到系统中来了。可以看到有多个菜单节点,同时也给我提供很多的基础功能。如果刚进来系统大家感觉眼花缭乱的话,后面我们教大家如何隐藏这些多余的节点。 这个系统已经是具备前后段分离和用户管理等大量基础部分功能了,必设的基础框架也已经搭建完善,现在我将教大家如何继续开发我们的功能。 开发我们自己的系统,需要增加我们系统中的特色功能模块,例如我要开发医院管理系统,那肯定少不了医生管理模块。 下面我们就是用这套代码自带的代码生成功能来自动生成代码,来减少我们大量的代码出血时间。 在表中我们依次添加需要的自断, 例如印姓名等。注意这里我们当做数据铺的主见设置自增属性。如果不明白什么是主见的,可以将主见理解为 编号,是一条数据的唯一标识。 自断都写好后,我们进行保存和启明, 如果后面怕自己忘了这个表功能,可以写上注释,方便自己或者其他人查阅。 下面就可以使用生存代码的导入功能,将刚才新建的数据库表导入进来, 注释可以添加清楚,这样在代码生成的时候会对应生成上去。 在编辑里面对数据进行 规条,比如出现在哪个菜单下,名称是不是规范之类的, 修改完后点击提交,然后点击生成一份代码就会生成好了。 打开代码并解压,这里面 三个分别是生产的前端、后端和数据库文件了。先运行 spr 文件导入数据库, 再按照文件加路径,将前端文件和后端文件存放到对应位置, 这里看到 js 的剑是存放到这里的, 然后 fu 存键是存放到这里的, 最后是后端文件夹也放到对应位置。 因为代码生成时候勾选的是在 sister 模块下生成文件,所以也需要存放在 sister 文件夹下, 这个提示是提示是否加入 p 列表的,不需要管点取消就行。 文件都存放好后,我们将项目重启,再次启动,看看新加入的代码是否生效, 因为前段视频框架存在热部署方式,不需要重启,直接看菜单栏,这里面多了一个医生菜单栏,这里我们是下增加一条数据,看看数据库是不是也同样增加一条数据, 这些数据都可以随便填写。 保存之后刷新下数据库,发现确实新增了一条数据。医生模块添加完成,按照同样代码 生成方法,可以新增其他功能模块,这比之前自己手敲代码节省了大量时间。 这里注意到一个细节,就是性别没有添加到增山改插里面,原因是因为在生成代码时候将性别设置为了下拉框,而不是输入框。 想要加入性别也可以修改为输入框,不过想要下拉效果的话,也可以设置下拉框并进行配置,增加字典值。 在医生的菜单栏上,我们发现缺少了 icon 标志,这个可以在数据库进行修改。数据库中打开 menu 表,里面是菜单栏的数据, 找到 icon 这一列后,找到一生这一行,只要我们将警号 替换成对应 icon 名称,菜单栏就会显示对应 icon 呢。 同时在 menu 表中还存在 vis 破裂这一列值,代表是否在前台隐藏菜单,零代表不隐藏,一代表隐藏。我们将需要隐藏的菜单值修改为一,就可以隐藏不需要的菜单了。 这里我还想隐藏若伊官网这一列,就将它的值改为, 同理也可以隐藏这些恋。 最后我们来修改下若依这些标识,让系统离开若依的影子,更加像自己的必设。按下 cprl 加 shift 加二键进行全局替换,将若依字样都替换为自 系统名字,比如老李,替换成功后重启下系统看看效果。 这里发现若伊的字样都已经替换掉了,如果大家感兴趣,将来还可以更新修改原代码报名中若伊的字样,让整个代码脱敏,这也是目前众多企业拿到代码后首先要做的事, 这就是今天,所以讲解,有需要的话后续还可以继续更新,感谢大家观看!
 02:17查看AI文稿AI文稿
02:17查看AI文稿AI文稿通过一周空余时间开了一个前后端分离的权限系统,细化到按钮权限控制,动态菜单,动态路由,动态面包蟹 type 接口,安全较验。使用 judge, 适合入门学习和司机。项目企业二次开发, 代码超规范,无任何勇于代码干净简单,代码注视全功能模块结合框架写,不是从开源上拉取下来的。二次开发需要马原的联系我, 请我喝奶茶。前端使用 view 三点二加 element plus, 后端使用 spring boot, 二加 spring security, 加 drew, 加 redis, 加 my betas plus。 验证码有多种类型,选择算数、中文、英文与数字动态验证码。
 01:12查看AI文稿AI文稿
01:12查看AI文稿AI文稿现在主流的开发模式是前后端分离的模式,但很多人是不知道为什么要做前后端分离,特别是学生党,自学了史宾布特之后,做了类似于学生管理系统的这样子的项目,就信心爆棚,感觉掌握了开发技术。 那实际上这种学习时做的项目,基本上我们都叫做 o e one 的项目,就是前端后端都写在一个项目工程中,那为什么现在我们要前后端分离呢?但这个跟科技的发展是有关系的, 之前系统基本上只会运行在 pc 电脑上,所以前端只要适配电脑屏幕即可,而且前端界面相对功能简单,动态效果单一。 而现在一个系统不仅要运行在 pc 电脑上,还可能会运行在平板电脑、手机甚至智能手表上,这时对前端的要求就高了,要适配多种不规则的屏幕,并且前端的 功能和效果花里胡哨的,开发难度也高。所以项目在开发时,后端团队开发后端根据需求提供数据接口,那前端开发团队调用数据接口获取服务端的数据 制作界面进行展示,也就是术业有专攻,后端的程序员主攻后端技术,而前端的程序员主攻前端技术。
73程序员喜哥 04:04查看AI文稿AI文稿
04:04查看AI文稿AI文稿同样的高度,为什么这个字唱的上去,那个字就唱不上去?今天跟大家一起来讲一讲后边呢,我会带你做一个测试。那在这呢,我们要渗透到一个概念,就是前后端肌肉分离,哪个是前端肌肉?唇齿折牙,负责吐字咬字工作的后端肌肉呢,就是咽喉位置,咽壁或者是声带周边的肌肉, 所以前后端肌肉分离才能够让他们自己做自己的工作。首先我们要发一个啊音的时候,你看好啊,嘴唇打开,牙齿都在打开,舌头自己摆放在这个位置,所有的肌肉都在统一,然后呢做好支撑,这个时候你就可以发声了啊 啊,这个时候我们可以口型不动的,也不动声色的把高音逐渐逐渐的通过声带单纯的变形去进行发声。但是啊音可能简单,当你的前端肌肉唇齿生涯变成 另外一些音,比如说咦的时候,你可能会出现这种情况,咦 就会有好多肌肉开始进行拉扯,这个拉扯就是前后端肌肉不能够完全分离,当你声带想要变形,逐渐变成往高演唱的时候,这种拉伸形态的时候呢, 由于你没有经过科学练声去做好声带独立变形拉伸的这个肌肉操作,你就会后端肌肉向前端肌肉去借一些啊,招兵买马,我要怎么样做这样的提喉,哎,做这样的一个下颚的一个僵硬的动作,或者是皱个眉头怎么样?这些肌肉一旦上手帮忙,帮的全都是倒忙。 所以我们必须要通过科学的发声练习,做到前后端肌肉分离,才能够在你无论是前端肌肉,唇齿舌牙做任何吐字咬字,哪怕他是变形咬 咬字的过程当中都可以在各种高音上做科学的发声。那接下来呢,我来带大家做一个测试,如果你通过测试的话,就证明你前后端肌肉的分离度特别好,在演唱歌曲的过程当中呢,也可以前端肌肉呢只做自己吐字咬字的工作,后端的声带周边的肌肉呢,只负责控制震动和高音的变化, 互不相干涉,才能够唱好歌,拥有唱高音的耐久度。那我们测试的内容呢也比较简单,从 c 四,然后到 e 四,然后到 g 四到 b 四,哒啦滴哒抖迷骚西。然后我们的要求就是呢用啊一乌鱼,但是口型必须按照我的严格要求, 他一旦做了之后就不要乱动了,看我啊 啊到你了 怎么样?如果你在发声的过程当中一直跟着我走,然后口型没有被带动,也没有说前端想要向后拉伸的这种感觉的话,基本上你就可以过了这个初期测验了。接下来跟我做进阶测试, 吐字咬字口型要开始进行改变,在每一个音上面做一二三四五六七来模仿我,我做一次,你做一次, 一二三四五六七, 再到一个 high c 音乐。 那如果刚才这个测试你也跟着完全做完的话,那你前端肌肉跟后端肌肉真的是做到完全的独立了,这 这个时候在唱歌的话呢,基本上就不会受到任何吐字咬字和不同高度的影响。好了,今天的测试呢,我们就到这,虽然歌曲里面不会像我们这样练的这么集中,但是我跟大家说过一句话,就是练习是加法,演唱是减法,练习必须做到最大化,演唱当中才能够发挥相应的水平。 所以希望没有通过测试的朋友们呢,会发现自己现在演唱当中的一些问题,如果想学习的话可以随时来找我,我们下个视频,不见不散,拜拜。
1376大宝哥教唱歌



