rollup构建输出流程图
同志们,我们今天讲 af 的 uf 统计功能,它的适配场景是呃,对于车间和设备某些共有的属性来进行统计。 呃,第二种这个场景是对同一个设备的不同数,这个属性之间做统计啊。我再重复一下啊,对于相同的设备,他的共有属性做统计,还有是说对同一个设备的不同属性之间做统计。 嗯,我们看一个这么一个场景啊。呃,假定一个车间里边有四个设备,或者是一个企业里边有四个这样的产线, 我们有时候需要将这个左侧的进料啊,或是右侧的出料做一个这样的汇总统计, 然后统一显示到一个数上。那么这种场景是说对不同设备做统一。呃,最同一个设备的话,可能把这个进和出啊,两边一加或者一剪,剪完之后,然后看看他的这个,呃,页位是不是是不是平衡 啊,这个这个,这个流量是不是是不是平衡,是不是要这样的这样的场景。我们下边看一下他的这个做法。先看第一种 家庭,我有这个泵啊,四个泵可以看哈,我这四个泵其实做的是一个饮用,做的是一个饮用。那么我要从这个泵的副节点,这个彩电烧 做分析啊,做了一个出量统计,做了一个尽量统计。做统计的时候,呃,还是一样哈。新建新建一个分析,注意分析的类型,选 ro up。 注意他的旋转好之后,他的图标变成了一个啊,这种转圈的方式,这个转圈的方式大概是等于是那种叫卷机是吧?卷机。注意他做的其实并不是一个积分啊,就不要为了图标,他只是一个图标,不要被他所误导。 那么建好这个量之后,我们下边就需要来对这个量来进行做配置。嗯,先是看有两个菜单,一个是紫元素,一个是元素的本体, 嗯,因为我们这个是说是对泵下边的这个具体的四个设备,然后来做统计,所以说要选择的是第一个叫紫元素,紫元素 其实你只需要选择这个,在这个内幕里边选上进口流量,只要是这个名称是对的啊,我们可以从这边给他看出来,他已经 自动把你这个属性能全部匹配好啊,一二三四啊,都已经打上钩了。注意这边是不能操作的,你想你想靠手工方式,在这点一下打钩是是没法做出选择的,只能是自动方式。然后来做就是通过你搜索这个属性的名称, 他自动选中这这个这个属性,然后下边这个彩蛋是说对这个属性的计算的方法啊,有求和,还有求均值最大最小啊,这还正是我们现在目前用的是一个求和啊。打钩之后, 嗯,你还可以在这有个输出,输出之后,嗯,那我们就要需要从他的上一级菜这个这个这个这个设备中需要先建好这么一个量啊,就是总进量或者总出量。 我们选好这个量之后,倒入一下,这就拆个印一下,一样的哈,他这个计算方式也是有这个周期方式还是这个出这个事件出发出发方式。那么做好之后,这个我们到这边来看一下这个数据啊,尽量出量, 我这已经做好这个这个量了哈。对于这个量哈,你看可以来点右键,然后看他的曲线,看他的曲线, 嗯,我们可以看一下。哎,这个出量跟进量,一个是这个时间戳是在变化,一个时间戳没有在变化。 这个原因是在于什么呢?是在于我这两个量是否要进行保存,我的尽量里边我做了一个开的特点,用于保存这个数据,说他能够看曲线, 而出量里边我只是要显示了这么一个数。我们看看这个数据本身他应该是在变化的 啊,树本身是在是在,是在变化。但是这个值因为他并没有保存,说他的数据只能显示数据,那个时间出跟曲线是没法看的。我看他的这个曲线。 嗯,这个你可以认为他是一个小 bug, 或者是说是他故意是这么设计的。因为这块的计算功能,他占用的是一个呃,就是客户端的这个这个资源, 怕引起来这个冲突。所以说紧凑到这一步,这个位置就没有再往没有再往深去做 啊。这是对同一个设备的这个同一同一种设备的这个属性做的统计。 还有一个方式说是我对同一个设备下边这个进出料来做一个统计啊。我们选择这个螺丝封机下边的 nice six, 我已经做好了一个叫啊平衡平衡计算, 那么这个时候依然需要在这选择这个呃属性,比如说叫出口流量,注意看哈,如果选中他之后的话,那么这个时候他帮我选择一个。 呃。而我们想做的其实是想把出口和进口相相加啊,如果是个复数的话,他可以把它给那个相,那个相加,那么这时候是不好来选的。请注意,这时候应该是要应该要使用通配服啊流量,那么这时候他选中是两个,嗯, 从这个官方的文档中去查看的话。呃,能够选中这两个的方法,其实就仅有这么一种方式。嗯,其他确实是不太好。不太好的好操作。 比如我想先选进口流量,然后打上勾,然后再选出口流量,再打勾。这种方式是我试了试是不行啊,是没法做这样的一个操作。 嗯,然后拆个印。所以说我们对这个嗯入 f 这个功能其实并不需要做太多的这个解读,因为它不是极品模块,不是极品模块。同时还有一些功能是来受限的。 去世图跟跟这个时间说,这里边有一点点那个小 bug, 这个 bug 是属于 osi 公司已知的,但是嗯也并不打算去做进步开发的这么一个 一个一个点。嗯,我们在趁着这个机会啊。接着把这个呃,另外一个这个跟他相关的一些这个这个知识点大概一块串一下。 注意看这个图标哈。这是一个状态,就是这个公式的这个状态。然后韩哥是说 t 啊,带一个小小 t, 就 necesee 是福尔姆参谋谁的啊?这是一个,这是一个状态。 这表示什么意思?表示是这个分析是来自于模板,也就说是我除了设备的模型做模板之外,设备的分析过程也可以做模板。 方法是在 library 里边啊,对于泵上有个分析模板啊,分析模板。 嗯,这个这个选项是吧。这个勾啊。注意这个勾啊,叫以内部国内的 cs。 就当你一一创建的时候,就通过这 这个模板,一派生这个对象,他就自动启用了,我们可以看出来,到对象里边来看一下, 嗯,我的这个这个分析过程,他其实就来自于模板的派声。而这边的这几个分析就是我手工在这建的,手工在这就是扭一个出来的啊。这是这个,这是这个状态。还有个是叫奥特曼 take 瑞克雷神自动重算。自动重算功能, 这只显示的是一个标记,就是哪一个分析过程已经启用了自动重算的功能。而这个的管理过程是在门内之门的, 没那门子,然后将近我选中其中某某一个。这个计算过程之后,在 这个右侧有一个齿能,或者说是这个禁用他的就是自动重散功能。 其实关于自动重散功能本身,这个呃他的原理和他的一些注意事项,本身就可以作为另外一个章节去来做。我们现在仅是知道呃,在这来进行管理。我说我们很多场景里边不需要扣的那个系,那就这个这个颗粒度 啊。我们继续打到这个艾伦门槛这边来。嗯, 哦,还有在这个上面可以能显示的这个啊,叫菜单的这个列的这个名称啊。假设要是把它选全了的话,在这上面点点右键啊,点右键,你可以来选择这个需要的这个列 啃飞杆和这个丢丢丢器。这就是刚才我们底下的这个配置。其实装刚才主要就是还说是这个上面关于最左侧这四列菜单的这个四列,这个图标的这个说明。 嗯,上一次已经讲过这个就是百克菲林,就是回田回田的这个标记了啊,这次我们趁这个机会把这个左侧这个撕裂,要一块把它说明, 那这就是一个派的 ro up。 其实我们看出来他的嗯,功能的话,其实相对来说比较简单,相对比较简单哦,谢谢。

粉丝1386获赞2908
相关视频
 17:42查看AI文稿AI文稿
17:42查看AI文稿AI文稿哈喽,各位观众朋友们大家好,今天我们来学习这个泰普斯科学,这个帝豪十一常通过这个 rap 呢去构建这个 ts 项目。 那为什么我们要选择这个 rap 呢?啊?我们看一下这个 wipe 呢,他打包出来的体积呢?比较大,那 ruap 呢?打包出来体积呢?比较小,嗯,开发一些小的框架呀,就是空气或者做一些小项目,那用这个 rap 是完全没有问题的。 ok, 所以说我们今天来使用这个 rap 构建这个项目, 然后我们先生成一下这个文件啊,首先我们先生成一下这个电子文件,能通过这个 npme 的杠 y, ok, 然后我们再建一个这个 ufo, 看我这个 叫 ts 那 rof 的配置文件,他默认的导出一个对象。 然后我们还需要生成一个这个目录, 比如说我们叫这个 lice c, 我们再搞一个 party l c 下面有这个阴代的这个 ts, 巴不得我们搞一个 nice 点这个啊, html, 我给你出个实话去, nice 点这个 ts 的话,我们就随便写点东西。 小满 好短。 ok, 老科技啊,那大概的目录结构就像这样,我们还需要生成一个这个 铁丝的配置软件, ok, 那大概就齐全了。然后我们需要装一些依赖,装一些依赖的话,大家直接复制一下我这个,那拍个阶段就可以了,那直接 npm 扫一下就行了,那我就不在这一个一个装这些东西了,那浪费大家时间, 就这样直接粘过来,你扫一下就可以了, 让他把这些依赖都装一下。然后我们来说一下这依赖是干什么用的? ok, 装完了, 那首先这个 road 呢,它是有一个入口和一个出口的,那我们有一个音铺的一个入口,入口的话就是 s 下面这个 max, 这个 ts, ok, 那出口呢?就是这个凹凸铺的。 你个废物,废物的话我们先给你碰一下这个 pass, pass, 我们通过 pass 来给他拼一下这个路径。第二内,我们输出到这个当前目录下面的另一个下面的这个 index ts, ok, 然后我们输出的格式给大家指定这个啊, umb 那个,因为我要通过这个那 sque 的给他引入,那我们就指定这个 umb, ok, 然后这个 ts 呢? 这个这个 rap 他是不认识的,所以说我们需要装一插件来让他支持这个 ts, 那么刚才已经装过了,那就这两个分别是这个 tabus cup 和这个 rap plus tablesque 的二,那这两个东西, 然后让我们来引路一下,那您碰到一下这个 ts 啊,然后我们这个如啊普普拉跟泰普斯口的二,那就这个,那它是一个插件,我们需要在一个 pla plus 一块给他注册一下。 ok, 那这个东西呢?他会帮我们去读这个 ts, 咖啡有点节省。 ok, 然后让我们再配置一个秘密, 那命令的话,我之前我们重新写一遍吧。 啊,来个 beaute build 的话就是 rob 杠 c, 那杠 c 是什么意思?杠 c 的话他就是会读这个当前目录下面这个 rob craft, 这就是 c 的意思。然后我们可以打包试一下 啊,我们需要改一下这个铁丝钢废的,我们需要把这个 come 阶层给他改成这个, 也是二零幺五。 ok, 这个大家记得改一下,没问题。 ok, 他已经达到这个地步下 已经生成了,没有问题。然后我们可以通过这个柜柜可以引入一下。 ok, 那这是打包,我们需要开一个本地服务,那我们再配一个这个,那第一位,那第一位的话就是这个 row up, 杠 c, 杠 w, 那杠 w 是什么意思?杠 w 其实就是刚刚卧尺啊,就是我们这个 rowper 可有点借它的一有改动呢,他就帮我们去重启这个 row up 的服务, 那这个就是个 w, 我们可以把这个删了,然后我们在 mpm 上这个 dv, ok, 那是外婆的服务呢,是起来了,没问题。然后呢我们还需要再起一个这个前端的服务啊, html 的服务,你们可以一下这个 sover, 那荣华普这个普拉丁这个骚味,那这个呢?这个这个差距就是用来帮其这个前段服的。 那我们可以指定一下这个 open 配置目录文件,那就是当前目录下面这个 party 下面这个 index 的这个电视机没有。 ok, 然后呢我们还可以指定这个 open open 呢,是,就是我们要不要打开这个玩意,那我们是 还有这个 part 呢,只能制定于这个端口,比如说要一九八八,老铁,那我们再保存, 那发现他这个网页呢,已经帮我打开了,然后这个卡瘦呢也输出了,没有问题。然后比如说我们再改一下这个 nice ts, 那后面我再加个 ssss, ok, 演变,演完了,但是我们这个网页呢,他没有变化,那我们用这个热更新服务,那我们得手动刷新啊,这样的话就比较麻烦了,所以说我们这时候可以接一下这个热更新服,那这些包呢?我们之前都装过了,然后我们直接现在直接使用就可以了, 通过这个叫樱桃的这个利用瑞露的啊,这个包就是帮我们去做这个热更新的,那么它是一个函数,那这个 啊掉用现象, ok, 他又重新启动一个, 那现在小满号的 sss, ok, 那我再给他改一下,那我再把时间给他删掉,保存,那正在变异, ok, 飞行完成,那发现那这也变了,那我们这个热更新是没有问题的。 ok, 然后呢我们还需要配置一些,比如说这个代码压缩呀,这些东西代码压缩的话是通过这个 如画谱 plus 这个东西,它也是一个函数。 然后我们可以再来看一下这个变异之后的代码,那发现呢他已经压缩到一行了, ok, 这个是代码压缩,但是这样的话会引出一个问题,那比如说我们要看一下这个代码,比如说这张代码出问题了,然后点一下,发现他这个压缩成一行,这我不好调试啊,那这时候我们就可以开启这个 sus ma, 那给他设置为处,在这开没有用,我们得在这个 ts 搞废格里边也得开一个,因为我们真正现在应该是空的,对,这边都是空的,其实我们真正的文件是这个铁丝文件,所以说这也得开,大家不要忘了 在这 抖友们的大片一碗, 然后我们再来刷新一下我们的点烟,我发现呢,他已经找到这个原文件了,应该是这 ts, 那我们在这个第四行输出的,那没有问题,这个是什么? 让我们再看一下,那这样基本的配置就完成了,当然可能有的同学呢,还想需要这个环境面料,像维优一里边呢,他就提供这个环环境变量,帮我们来区分这个开发环境,还有这个生产环境。那周外婆的话他其实也是有的, 我们之前装过的一个是这个 cross, 这个 lv 这个东西,那还有一个是这个,那瑞佩斯 那怎么使用呢?是通过这个可以看一下,是通过这个 cross, 因为 然后后面呢是跟一个名字,这名字你可以随便起,然后呢是一个直,因为 vu 一里边呢,他叫这个六的音为,我们也就起这个名字就可以了,我就直接粘过来了, 有这个 dv 前面也是我们起这个,让第一位的时候,帮我们这个漏的环境变量里面增加一个东西,加到这个 dv 这个 ddy 里面的这个东西。那打包的时候呢,我们去再添加一个这个 part, 这样我们就能区分了,他是生产还是开发啊,通过这两个东西就可以了。 那这个东西一定要装对,因为我们之前装过了,不然他是用不了的。然后我们可以看一下,比如在这我们可以输出一下, 烙一下这个,他会放到这个菩萨子里边 点这个银微, 然后是太快了,他这 这个我们先把这个杠 w 先给他取消了。 那我们找一下,太多了, process 也都在这儿,那 no 的已经为 dewyman, 那没有问题啊,执行这个 dv 命令,那我们再执行一下这个 bell 的, 然后我们再找一下,那发现这也变了,变成这个普萨克萨,那是没有问题的。呃,但是这个东西呢,它是 note gs 那边东西 post, 因为浏览器是没有这个东西的, 你的声音我们现在可以改回去了, 然后我们这还是个 w ok, 太开的太多了,再关几个, 但是我们浏览器呢,是没有这个东西的 no 的,哎呦喂, 对,他就他就直接报错了,没有这个东西的,那这时候我们就可以通过这个瑞普利斯帮我们去往浏览器注册一个这个东西, 通过这个 robe plug 点点 replease, 那就是这个东西, 那里面的名字大家可以自己定义,那我这就叫 osa lv 点这个 漏的烟味, 然后呢,然后就是这个 把这个 no 的解释里边不知道啥是因为注册到这个浏览器里面, 这个是 notenon g s 里边啊,然后呢通过这个方法就帮我们去注册到这个,那 g s 里边全局都可以使用, 那有点类似于那个歪波派克,那个底翻趴的那个东西,其实跟那个差不多的意思,你还可以自己盯着别的话,比如叫 a 什么,然后 后面点两名啊,你还可以自己定义,那我这就暂时先定一个,这个就是跟微微已基本都一样的 ok, 也是输出了,没有问题,那你问他。 然后我们可以写一个呆萌 pro sax, 因为如果我们是这个 dy 的, 这是一个开发,那否则我们得了这一个生产, 现在肯定是开发, 那弹出来啊,没问题,有点黑,那就这个看。 然后我们现在还有一个问题,就是比如说我们打包的时候, 打包的时候发现他还会把我们这个页面给他 编一下,他就弹出一下,这时候我们就可以通过这个黄金面料去给大家判断一下了。比如我这搞一个那函数,我叫那一子第一位, 那我给他蕊套一个这个 cross offices are you with the note, 因为是不是这个 development 啊?就是这个, 如果他是底外的门的话,我们就给他进行这个日更新和这个开服务, 我们直接可以用这个短路逻辑。 然后还有这个对,我们生产环境是不需要这个的,所以说我们可以加一个判断,那这样就没问题了,我们可以来试一下, 我们在打保险。 ok, 那没有帮我们起页面了, 然后可以履行一下这个 htm, 我们通过这个 啊,六色味,那帮我们起一下, 你发现他现在已经打印成这个生产了, 没有问题,那我们再起一个本地的, 那开发没有问题,那环境变量呢?已经给他生效了,那这些呢?大概就是 road 的配置,那这个穿梭的话里边他还有些别的配置,比如说我们这个 composer 卡包色呢,他有一个这个罩子抗色的,那这个可以帮我们去删我们这个代码里面的可色 log, 比如你写太多了,你懒得删了他,他可以帮帮助你,帮助你该删掉的 一二三, 然后我给你找一下,发现这里边已经没有,没有, 所以你帮我删掉了,那么应该打印不出来了,对,应该打印不出来,我可以通过这个给他去删掉。 ok, 那这个项目呢?大概就完成了。
15小满zs 15:00查看AI文稿AI文稿
15:00查看AI文稿AI文稿其实刚才我介绍了整个 rap 的一个工作方案,接下来我想讲更多关于 rap 的一些讯息和更多的一些内容,可能比较高阶,比如说, 呃,像如何向 there two 去转移网络,从 there one 向 there two。 首先如果都在一个撩 rob 系统中,其实非常容易,比如说你都在 z k 或者都在 opt mate 里面去进行一个交易是非常简单的,就这就跟你在 都在以太访中进行交易是一样的,就是所有的账户都是在同一个系统中,那么交易就是非常简单, get 费也非常低,速度也非常快,这个就并不多讲了,就是这是一个非常简单的事情,就跟你在以太访上转账是一模一样的,而且比他价格便宜,速度要快。 那么第二个部分就比较重要,就是说将资金如何转出 rap 系统,从以太坊上转到 op 上,或者从 op 上转到这个以太坊上,这样的费用就会贵一些,因为这个时候你需要在 在一层网络上发布更多的数据,包括你的这个协调者需要去计算你的数据,比如说爱丽丝想要去将这个一百美金从 你在网上转到 o p 上,那么这个时候就得通过协调者首先来计算,哎,你转这个钱,你的账户余额有多少,到 liar to 的账户有多少?整个的一个作用,而且这些所有的信息,所有的签名信息都要进行一个交互,所以这就意味着更高的一个交易手续费,包括你从 liar to 上翻下去也是一样的。 所以你会看到当你使用这个 optimistic 的这 getaway 它的这个交换桥的时候,整个的盖子手续费都是相当相当高的,因为这意味着, 嗯,整个的协调者需要进行非常大量的运算,付出的成本也会非常高。所以从 rap there two 到 there one 上面的一个费用是非常非常高的,这个 guess 位远高于你在 there one 上的一个交易。所以其实最佳的方式 是你要么转很多钱一次性到 l q 上,要么你在 l q 上的钱就放在 l q 上不要动。因为如果一旦你去进行这样一个操作,其实这样子就会非常非常的困难,和和不是困难就是成本会非常非常多。 那么还有另外一种情况,就是说将你的资金从一个 rap 系统中转到另外一个 rap 系统中,那么这样子要么通过一层网络,就像我刚才说的,你从一个你从 liaretro 上翻回仪态房,再从仪态房上通过另外一个 git 为翻到另外一个 liaretop 上,那么这样子肯定是 哈这样子的一个,这个成本会非常非常高,因为相当于说你完成了两步第二个部分的这么一个操作,所以这样子就会很难。那么第二个呢,就是通过 liar to 的这个跨年桥来进行,那么跨年桥的这么一个操 做就会成本会比较低,也会比较简单,相当于说可能没有第二步需要的这么一个钱多,所以通过桥接的方式可以来进行。那么在接下来我们将讨论关于跨年桥的一些相关的讯息,跨年桥是如何工作的,他是否是安全的等等等等这些东西。所以呢, 其实你使用 rap 系统在 layer two 和 layer one 之间的交互是非常贵的,然后你在两个 layer two 系统之间交互其实也是价格很高的, 因为这这进行交互相当于说你换了另外一个共识,那么在其中需要进行大量的运算,那么协调者也会去收取更多的一个费用。所以整体来看, 嗯,如果你想使用 rap, 使用这种 later two 的解决方案,你最好是进行大额资金的一个操作,否则你进行小额资金的试错其实成本很高。在 optimistic 没有更新之前,我去试 使用 op 进行,因为 synthetics 是第一个支持 optimistic 的这个 dfi 协议,我在其中去用一百个 synthetics 做了一个测试,那么那个时候 synthetics 一百个大概是价值 一千美金左右,一千二百美金左右吧,那么整个的 gas 费翻上去,翻下来,翻下来,翻上去,可能就要花费将近八百美金,所以 整个来说费用是非常非常夸张的。那么同样从另一个系统中转到另外一个系统也是很贵的,通过跨电桥呢?虽然说成本会没有就这种这种很蠢的方式贵,但是这个价格也是不低的,所以这些都是一些现实的一些问题所在。所以呢, 如果你想要从第二层转移资产,其实整个的一个费用还是挺高的,所以在这里面也希望各位去斟酌来进行大额自己的操作会比较好。 那么以上部分就是对 row up 交易的一些基本概念,接下来我想谈谈这方面的发展,因为这是一个非常重要的部分,就是所谓的这个 z k e v m 这基本上是使用这些证明程序的一种基本方式。这些 snarks 并不是在 rob 系统中用户之间进行基本交易, 而是编写整个运行 roll up 系统中可靠程序的一种方式。这是一个叫做由 z k e v m。 的东西来进行实现的,它不仅为简单的交易生成证明,而且还会在 ro up 系统中运行的整个程序的正确执行来生成相关的一个证明。 所以这种工作方式基本上是在 rob 系统中运行的每个代步都需要考虑的将单位交换和复制到 rob 系统中,那么 rob 系统中的每个代步都会有一个迈克尔数,莫克尔数的页结点,与之进行关联并不简单 单呢,是在夜间点中进行储存余额,这个夜节点也会包含这个 dap 的一个状态,所以这是非常重要的一部分。 那么这个样子呢?各种数据结构,这些所有的数据都将会写入 rap 系统中的 mac 数的这个页解点当中去。现在如果有人去调用运行在 rap 系统中的 dap 时呢,协调器就会将执行操作或者是 执行与该应用程序相关联的这个程序,结果是在这个页结点中对应应该应用程序的这么一个数据从旧的状态更新成为一个新的状态,协调需要做的就是生成 该状态转换的这么一个有效证明,就是说当有其他状态转变发生的时候,协调器需要利用这个 z k e m。 来进行生成相关的有关的证明来进行。所以协调器不仅仅能够简单生成交易的已完成的一个证明,实际上还能够有 证明整个程序在新旧状态上正确的一个运行,写在数,写在这个默克数中的这个内容就变成了一个数字根,那么这些东西都是使用另外一个更重更重要的一个零知识证明系统来完成的,那么又是成为一种 角 z k e v m 的 stark 技术。所以之所以能够实现,是因为其实 stark 技术已经发展的非常先进,也可以来证明整个程序是正确运行的,所以这也是一个很重要的东西, 这就是这里所说的协调器可以生成一个简短的 selected 程序的 stark 证明来进行执行,那么意味着至少在原则上将运行在 liar one 上。以太坊上的 deb 牵引到 liar two 上面是 非常非常容易的,这相当于是去兼容你的虚拟机了。那么当然如果你想要对代步进行交互时,那么其中中心化就也会降低,因为你是在 liao two 上进行的嘛,而且你的交易成本也会低, 交易效率也会高,所以这是一个这个领域非常重要的一个发展,那么可能会在今年晚些时候上线,所以那个时候在 diy 上代步牵引到 liter 处上也会非常容易和简单。 那么现在我想换个角度来讲一个稍微不同的 row up 实现,叫做 optimistic row up, 其实 optimistic 和 arbitram 已经在部署在了上面,那么 up optimistic row up 和 zk row up 的运行原理是基本上一样的,但是 zk row up 的这个复杂的部分实际上是让协调器为他处理大量的信息,并在每一个时期生成一个证明。但是 optimistic 做的实际上是一个相相同的事情,但 并不产生一个 stark 证明。因此呢,协调器会把所有的交易数据和更新的摩卡尔数来发布到区块链上,但他并不会更新在 并不会更新这个包含 star 证明的一个东西。所以这个时候我们就应该提问了,就是说如果没有这个证明,你如何去验证这个东西是真的呢?那么 op 用了一个另外的一个方式,就是他会给验证者几天时间来进行审核这个验证。如果这个发送交易无效呢?那么 任何人都可以提交希腊证明,并且赢得奖励,那么这个 rap 的协调者就会被受到惩罚。所以通过这种方式来进行呢,他并不像 zk 一样需要发送一个证明给到 这个二六二万,而是说他给验证者几天时间来进行一个验证。谁都可以来挑战通过欺诈证明这个东西来去赚钱,如果有了问题,抓捕协调者就会被惩罚,如果没有问题,大家一切皆好,所以通过这种方式来进行一个运作的。所以这样子做呢,也是一个比较 ok 的方式,他的优点 就是它可以完全的去兼容以太保虚拟机来万上那些大夫啊,可以比较方便的来部署到这个 lt 上,比如部署在 op 上,所以你会看到 unisworp 呀,像 csi text 呀,都可以部署在 optmasic 上来介绍。那么 rp trump 的锁仓也是提高到了一个非常高度的一个 tv 啊,这也是为什么 op 和 arbitram 收到了非常多的一个支持,而 zk 现阶段还没有进行运作,因为 zk 的技术比较复杂,所以现在并没有任何一个项目使用 zk 来进行,那么大部分都是使用这个 optimatic 来进行这个解决方案的。还有就是 arbitram, 其实本质上他们是一样的,只是说他们在 虚拟机方面有一些不同,所以这种方式呢,乞讨者的工作量就会变少,他不需要去验证如此这个东西,而且来进行一个最最后的一个啊,验证结果小派的这么一个输出,嗯,所以这样 双子座其实整体来看,用 op 这种方式是将大量的一个时间交给了这个验证者,那么他去用这个时间来进行审核,但是这样有一个非常难受的缺点,就是你在 op 上,在 rb 创目上他会有一些挑战期,比如说, 呃,在 o p 上面是七天,你无论是发送什么样的资产,从 o p 上回到 number one, 你都需要等待七天,这七天就是验证者来去进行相关的一个验证, 还会提交欺诈证明,如果这笔交易会有问题,那么就就会来惩罚协调者,就会来进行这种东西。所以其实在 o p 上面,如果你想将你的资产来翻回来,其实你是需要等待这么一个七天的,那么这个时间就是来,嗯,交给验证者验证的,那么好处就是 他不需要像 z k 一样让协调者占据那么多的工作,然后付出那么多的钱,而且技术又非常的复杂,所以这也是他 一个好的方式。再就是他能兼容虚拟机,这也是一个非常非常优势的一个点,你兼容虚拟机才能让这些莱尔万上面的好的 dfi protoco 去使用你的这个 rap 解决方案。如果你不能兼容,那么整个的技术开放,成本优惠非常高。所以对于 我们实际上面来讲的话,目前 o p r trump 都是一个非常好的 rock。 但其实 z k 虽然我们花了非常多的时间来介绍啊,什么是 z k rock, z k rock 的一个好处,以及他要做的一个事情,包括说可能理解起来并不是特别难,但是 zk 在真实的情况中,在真实的 defi 赛道中使用的是非常少的,几乎是没有任何的协议。目前能使用 zk, 因为它的技术实在是太难了。 协调者发送的这个莫克尔数跟发送的这个证明都是一些非常非常高难度的东西。对于协调者来说,验证所有的东西,并且在链上进行一个验证,并且去验证这些相关的一个 跟那个所有的一些交易以及所有的交换,都是非常非常困难的点。所以与其这个样子,现在大部分使用的都是这个简化版的奥盘 max 这个系统。那么不需要说啊,让这个验证者花费非常多的时间去验证这些东西,而是叫 这些东西来交给时间,我去慢慢的验证就 ok 了,我不需要立刻验证完成,我慢慢的进行验证就可以来进行一个解决。而 optimistic 也是被微神认为是最最最原声 rap 的一个解决方案。那么这种方式其实虽然牺牲了一些时间,但是 对于这个协调者来说,工作量降低,而且它最好的优势就是它可以去介入你探访虚拟机,所以这都是一些非常非常好的一些优势。那么在这里面我们想对于这个 z k 做一个更加深度的一个理解,就是我们在这里有 z k s y n c 和 z k porter 来进行一个对比, 那么都知道其实这个如果协调者他是一个中心化的,其实整个的系统就崩盘了,因为如果中心化的他可以去自由的去进行数据的篡改,并且发送给这个链上的东西,所以如果是中心化的话,这个逻辑就有问题,但是实际上结果并不是这样子的, 如果一个协调者工作,用户可以立刻找到另外一个协调者来进行工作,但是这样子就会遇到一个非常复杂的问题,就是如果你找了一个新的协调者,那么这个协调者需要当前所有的账户的这么一个信息, 如果借到协调者已经去停止了一个运行,那么这个时候如何去获取信息呢?那么这个时候就有两个解决方案, z k s y n c 和 z k potter, 他们将会同时来并行进行一个工作,那么这里会做一个简单的介绍, z k s y n c 呢?就是将所有的交易债要都储存在 level one 上,也就是区块链网络上, 比如说储存在以太坊上,那么 layer one 只批量接受这个交易的进行处理,如果他包括所有交易的一些招摇信息啊等等等等,那么其他的协调者可以根据 layer one 上面的数据去重购 layer two 的一个状态。 但是这样缺点就是你知道所有东西都存在以太坊上,那么他的一个费用会很高,那么他的一个呃整个的交易费也会很高,所以这样子就会使用一些高净值的一些资产。比如说如果你钱多,你用这个方式是完全没有问题的, 那么对于另外一种方式就是这个 zk potter, 那么 zk potter 是一个比较对于小白来说,或者对于一些资金并不是那么多的人,是一个非常好的选择, 它是由一组协调者来进行一个储存的,那么所有的数,所有的这些数据都是另外储存的,所以呢,当一个协调者出现问题,他荡击了,他停止使用了,另外一个协调者,可以用这个另外的数据来进行储存,就可以来进行了。所以 通过这种方式你可以选择,如果你的钱多,就用 s, y, n, c 来进行一个储存,如果你的钱少,就用 power 来进行储存。一个是储存在链上,它非常安全 啊,他可以让协调者通过 number one 上面的真实数据来去构建。那么同样的,他的缺点就是他的交易手续费太高了,只适合于高建的资产。 如果你用抛车呢,那么他的所有的数据是由一组写到者维护的,如果一个出了问题,另外一个可以补上,但是他是另外储存的,所以这就意味着可能会出现一些安全性的问题,但是呢,他的这个交易手续费也就很低,所以这个时候你可以使用这种方式来进行小额资产的一个储存, 那么用户可以去进行选择协调者来进行如何储存你的一个资产,所以这些东西呢,都是非常非常简单,也是给用户一个选择。其实在这一帕中,嗯,这位教授花了非常多的时间 来介绍 z k rock 的一个解决方案和关于 z k rock 的一个基本逻辑。因为 z k 其实是关于 rock 的一个比较好,也是一个最明确的这么一个 z rock 的一个方案,这是一个非常好的例子。但是实际的 d five 应用中, jk 并没有任用到任何一个低发协议中去,那么广泛应用的其实是 optimistic 和这个 option。 所以如果你想要更加深入的去实践中了解目前 defi 协议使用的是哪种 rap, 你需要去看很多的现在已有的项目。 所以这位教授只是站在学术的角度来介绍了 z k 有多好, z k 有多强,以及未来可以使用的这些 z k porter 和 s y n c 来可以储存一些数据。但其实目前这些东西都并没有真正的商用商业运用化,最好的还是 arbitram, 那么其次是 optimistic, 所以这些东西都。
20守护话心 04:21查看AI文稿AI文稿
04:21查看AI文稿AI文稿大家好,很多人都说二零二三年是 z k 去世,那我们今天就来客观的讲一下这个使用 z k e v m。 的 z k rob 项目 score 它是什么啊?如果你觉得视频的话还不错,记得点赞收藏。如果你对其他项目感兴趣,可以到主页项目介绍这一栏中浏览。其他的项目都知道,以太坊二层网络的建立其实是为了对主网进行 力度的拓容,从而提升整个链上的吞吐量,然后降低他的 gas fee。 那么目前姨太坊二层其实通过这种技术解决方案可以简单的分为这么几类型,是 op rope, 然后 z k rope plus 码 veding 等。如果你对这个技术方案的这种分类的模式不是很清楚,可以看我这个主 主页的置顶视频去简单了解一下。那么今天要说的这个 score, 它就是使用 z k row up 来提升整个性能的。先说一下 score 这个项目的背景,那么他在二二年的时候就完成了三千万美元的 a 轮融资,在二三年的时候他又融了这个 五千万美元,那么整个的这个投资方包括像是 politchen capital 呀,红山中国呀,像是贝恩资本等等,那么目前他的这个融资总额也达到了八千多万美元。果尔,他成立于二零二一年呃,做这个项目的目的就是 希望通过这个呃零知识证明技术来拓展以太坊的性能以及安全性啊,那么从而达到他这个大批量提升这个以太坊用户和量级的这么一个愿景。 我们来详细讲一下 score 项目的核心特点,那么第一个特点就是 z k e v m e v m 你可以把它拆分一下去理解,那么就是指的是零知识证明 与这个以太仿虚拟机的结合,那么零知识证明就是前半部分,然后虚拟机就是 evm 这个后半部分,这证明它其实是一种加密技术,那么目的是为了在不泄露任何敏感信息的情况下,证明某个事物的真实性。举个不那么恰当例子就是我可以在不看你银行余额的 情况下知道你是个富豪啊,就这么一个例子,就是我,我在不知道对方明细的情况下能证明啊,能知道他是一个呃某一个论证结果的这么一个事情。所以在这个 score 项目中啊,这种技术是用于验证整个智能合约执行的正确性的啊, 同时呢,在执行过程中能确保整个隐私跟安全,那么这种结合呢,就允许在整个二层的这个网络上执行智能合约,同时保证于这个 e t h 主链它的一个兼容性啊, 这就意味着什么呢?就是说啊,原本我在这个 e t 池上是用这个 send it 来编写这个智能合约,对吧?那我现在在 score 上面其实不需要对整个这个智能合约进行大片的修改啊,就相当于我创建了一个 e v m 等效的东西, 在整个兼容性上面又远高于这个 e t h 啊,所以实现了一个最兼容 e v m 的 z k rop, 这样可以让整个开发人员把整个以太坊上的 dep 啊,基本上 无缝迁移到整个的这个 layer two 网络上面。那么第二个核心特点就是呃 score, 它作为一种 layer two 的解决方案,对吧?它可以显著地提高这个以太坊的吞吐量跟降低它的这个呃交易成本。因为我们原来整个视频也讲过,就是它的实现方式就是通过将一部分的计算存储, 然后放在 lair two 上去执行,那么把最终的这个结果提交到主网上去确权,然后核对,然后从而实现这么一个目的。这样子其实整个 eth 网络就可以处理更多的交易啊,同时呢也可以保证他整个驱动性化以及安全性。 那么这个 score 项目第三个核心特点就是它的安全性啊,整个项目就是通过使用这个啊零知识证明技术啊,确保在整个二层网络上面执行智能合约是安全的,而且防止这个恶意攻击。因为因为我们知道安全性对一条链来说非常非常重要,所以很多主链会去牺牲一定的这个拓展性能,然后来保 保证它的安全性啊,从而预防一些这种恶意攻击。那么总之其实 sport 它作为一种这个呃基于以太仿的这个这个 z k e v m 而土的解决方案, 目的是为了提高这个仪态房它的性能以及安全性,那么同时又能够保证与主链的兼容性。那么其实对于开发者来说,他开发 depth 就是说迁移这么一个 depth, 他的一个成本就要非常低,那么对于用户来说,由于整个链上他速度越快,而且整个的这个 呃交易成本也会降降低很多,那么用户体验其实会更好的。以上说完这些,其实听起来这个 z k 项目本身非常厉害啊,但是,呃,其实呢, z k 系的产品由于技术本 实现的难度问题,很多项目的落地难度其实是要比 op rap 系列项目的这个难度要高很多,而且目前很多 jk 项目的产品估值其实是比较偏高的,也就是说市场对于整个项目的预期是有点 过高的。因此对于很多项目,大家应该 d y o r 了解这个项目到底是做什么的,做好研究,谨慎决策,而不要盲目的冲进市场里面,就觉得这个好那个好,对吧?
298EvelynMo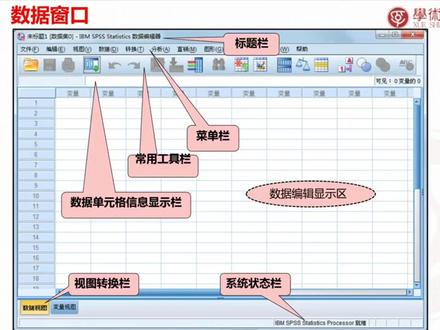 22:46查看AI文稿AI文稿
22:46查看AI文稿AI文稿欢迎大家来到今天的数据统计分析软件 spss 入门的课程。那我们想 spss 的时候,我们主要是看三部分内容,第一部分是我们要讲一下 spsss 的概数,第二部分是 spss 的数据管理,第三部分是 spss 的统计分析功能。 那我们先讲第一部分 spss 的概数,它分为简介,还有窗口介绍跟数据库的构建。我们先来看一下什么是 spss。 spss 是世界上较早的一个统计分析软件,广泛应用于通信、医疗、银行、证券、科研、教育等许多领域和行业。 它的基本功能包括数据管理、统计分析、图表分析、输出管理等, 具体的内容包括描述统计总体的均值比较、相关分析、回归模型分析、剧烈分析、时间序列分析和非参数检验等多个大类。 那我们来看一下他的这个特点,他包含了各种成熟的统计方法与模型,为统计分析用户提供了全方位的统计学算术,还提供了各种 数据准备与数据整理技术,自由灵活的表格功能,各种常用的统计学图形,比如说折线图、四线图什么的。还有他的就是界面比较友好,操作简单,容易上手。那我们今天就来先看一下他的界面。 首先是刚打开 spss 会出现的一个弹窗,他这边是可以载入历史记录的,如果你不想载入历史记录的话,你就不需要理会这个弹窗,直接去 直接去这个界面里面的文件这边打开新的你需要的数据就可以了。我们来看一下这个数据窗口,上面是标题栏,然后是菜单栏,下面是常用工 工具栏,在下面一行是数据单元信息显示栏,然后中间的一大块区域是数据编辑显示区, 左下角是仕途转换栏,右下角是系统状态栏。那我们比较常用的就是我们的菜单栏跟呃数据编辑显示区,还有仕途转换栏。 我们看一下左下角仕途转换栏,切到变量仕途以后的界面就是这个变量窗口,他有变量明变量类型、变量宽度小数位数、 变量标签、变量值、标签跟缺失值。一般我们比较常用的就是呃变量名跟类型, 还有宽度小数。 我们来看一下结果输出窗口 左侧是导航窗口,右侧是显示窗口。我们来看一下图表编辑窗口, 我们把数据跑出来以后,如果出现了图表,我们可以双击这个图表,我们就可以进行图表编辑,就是右边这一个一小块的图表编辑窗口。 我们来看一下程序编辑窗口。我们在文件中找到新建语法,我们就可以打开程序编辑窗口。 我们双口页面介绍已经讲完了,我们来看一下数据库的构建,它有两种构建方法,第一个就是我们现有文件的导入,第二个就是直接录入数据。 呃,我可以给大家演示一下小屏幕, 大家可以看得到屏幕吗? 我们打开 spss, 这样我们就不需不需要导入历史文件,我们就点取消。 嗯,然后我们在文件中我们打开,第一种就是打开我们的数据,像我这边就已经有一些数据,比如说我们打开这个数据,我们直接点打开就可以了, 然后我们还可以打开,比如说, 嗯, excel 文件,但是我这边没有 excel 文件,我们看一下桌面有没有,桌面有没有,就是如果你的数据是 excel, 你就直接在这边选择它的类型,然后再再寻找你想要的这个文件。 呃,然后这个我们就先把它关掉, 我们继续来看课件。 我们接下来看一看 spss 的数据管理功能。第一部分是 spss 的数据整理, 我们来看一下数据合并。数据合并是我们比较常用到的一个功能, 他可以将若小的若干若干小的数据文件合并成一个大的数据文件文件,他有纵向合并跟横向合并。我们先来看一下纵向合并, 重量合并,就是几个数据集中的数据纵向对点 组成一个新的数据集,新的数据集中的记录数是原来的几个数据集中的记录数的总和,他有合并条件。第一个就是带合并的 spss 数据文件,他的内容合并是有实际意义的。 第二个是不同数据文件中数据含义相同的列,最好起相同的名字,变量类型跟变量长度也应该尽量相同。那我们来看一下 什么叫做纵向合并。 我们打开一个数据, 呃,我们打开数学一吧, 我们把它纵向合并的话,就是在数据里面找到合并文件,我们选择添加个案, 然后再找到你需要合并进来的数据,我们就是数据二,继续 这些数据,你可以选择你想要的合并进来,你也可以把他们全部合并进来。 那我在这里我选择把他们全部合并进来, 然后我们看一下 他已经合并成了一个新的数据级,大家可以看一下,数据一的这些数据和数据二的这些数据都已经合并在一起了,这就是纵向合并, 现在关掉。 那我们来看一下什么是横向合并。横向合并就是按照记录的次序或者某个关键变量的数据 时,将不同数据集中,不同变量合并为一个数据集。新的数据集变量数是所有原数据集中不重名的总和, 实质就是将两个数据文件的记录按照记录对应一一进行左右对接。合并的两个数据文件的变量不同,但具有相同的个案例数,他的合并条件 就是如果不是按照记录号对应的规则进行合并,那么两个数据文件必须至少有一个变量名,相同的公共变量, 这个变量是两个数据文件横向合并的依据,称为关键变量。第二个就是如果使用关键变量 进行合并的对应,则两个数据文件都必须先按关键变量进行深序排序,这个是比较重要的,如果没有进行深序排序,他就会出现一个错误弹窗, 然后你的数据也是没有办法进行合并的。然后第三就是为了方便 spsss 的数据文件合并,在不同数据文件中,数据含义不相同的列便亮明,不应取相同的名称, 这个是纵向合并,我们看一下很像合并,就是在新建不对,在数据的合并文件中找到添加变量 my 还是找数据一跟数据二演示一下? 嗯,还是还是。 我们打开数据一, 我们先要对它进行横向合并,我们在数据里找到合并文件,添加变量,我们找到数据二, 然后我们在下面点击按照排序文件中的关键变量匹配个案,然后没有办法把它设置为关键变量,然后我们会出现一个弹窗,是我们 他在提醒我们有没有进行顺序排序,我们可以先尝试一下, 然后你看我们的文件,它跳出来是错误的,为什么?因为它没有进行深序排序,我们把它进行深序排序, 然后我们这时候还需要打开数据二,也对他进行一下顺序排序, 数据二, 我们对他右键顺序排序,让我们给他进行保存一下,就可以关掉了, 然后这边我们也进行升至排序以后,我们就可以进行合并数据了,增加变量数据二, 好,这次我们就已经合并成功了,大家可以看一下,这就是合并成功的一个结果, 然后现在我们就是讲下一个步骤,我们把它关掉, 嗯,然后我们来看一下数据拆分,拆数据拆分这个功能是为按某一个变量值进行分组,数据仍在同一个文件中, 但是以后进行数据统计分析时,将根据拆分结果进行统计。那我们等一下用一个案例来看一下他会有怎样的变化。我们先给他进行拆分,然后我们再拆分以后 再给他进行统计,我们可以看一下这个案例, 找到, 找到这个案例他,我给他取名叫七刊,好, 我们现在可以看到七开他这一列,他是乱的。然后请,然后我们看一下把它进行数据拆分以后是什么样的。我们在数据 找到拆分文件,然后我们拆分选择比较组,然后我们的分组方式就是期刊就是这一列的数据, 好,让我们看一下他就是已经是有一定的顺序对他进行排列了,第前三本是 c 西康, 后面四本是 n 期刊,然后是 s 期刊,然后我们这样对他进行是呃,数据统计,我们在分析里找到 描述,统计找到频率,然后我们是看 就是每所学校在每一本期刊里发表的期刊数量,所以我们的变量是机构,也就是我们的学校, 我们可以看一下结果,我们可以看到结果, c 期看北京的学校有一本,清华有两本,所以他总共发表了三本。 m 期看北京两本,清华一本,四川一本, sc 期刊,北京两本,四川一本。这是我们看到的一个结果, 我们先将关掉, 他这边 就是也是通过这个机构,然后就是他因为他的数据比较大,所以他这边跑出来的结果就是也是比较多,北京二十八,清华三十五,四川五,但是总体是跟我刚跑出来的结果是一样的。 然后我们再来看一下数据排序,数据排序是将数据 按指定的某一个或多个变量的值进行深序或者降序,重新排序,所指定的变量称为排序变量。 那他有两个情况,第一个是单值排序,单值排序就是排序的变量只有一个多重排序就是排序变量,有多个 多重排序的第一个排序变量称为主排序变量,其他排序变量依次称为第二排序变量跟第三排序变量。 然后等一下我们要用案例进行一下实操,我们的要求是要求职称按身序排序,工资按降序排序,那我们现在,嗯,就打开, 就打开我们的这个工资数据, 嗯,我们找一下这个数据,应该是, 应该是职工,哎,没错,我们看一下他的要求是 职称按照身序排序,工资按照降序排序,所以我们需要在数据里找到排序个案。职称 我们要进行深序排序,所以我们下面排序顺序这边选择深序工资我们要选择这样去排序,所以我们要在排序顺序 这边选择降序。 好,我们来看一下结果, 指称已经变成了低级中,哎, 稍等一下, lay tail, 什么情况?什么情况?什么情况?接下来我们来讲数据排序,数据排序是将数据按指定的某一个或者多个变量的 直进行深序或者降序的重新排序,所指定的变量称为排序变量。 第一个我们有两种情况,第一种是单指排序,排序变量只有一个。第二种是多重排序排序变量。有多个多重排序的第一排序变量称为主排序变量, 其他排序变量一次称为第二排序变量和第三排序变量。那我们来看一下案例, 我们打开数据,我们的案例叫职工, 我们要对他进行排序,我们在数据中找到 排序个案,我们找到工资,我们对他进行降序排序,降序排序,我们就是要在排序顺序里选择降序,点击确定,我们可以看一下结果, 降序最高的就是工资最高的人,好,接下来我们来看一下数据排序, 将数据按指定的某一个或者多个变量值的生序或者降序重新排序,所指定的变量称为排序变量。他有两种 可能,第一种是单指排序,排序变量只有一个。第二种是多重排序,排序变量有多个多重排序的第一个排序变量 称为主排序变量,其他排序变量依次称为第二排序变量跟第三排序变量。接下来我们来实操一下, 我们打开数据, 我们对他进行公司的降序排序, 我们在排序顺序里面选择降序排序。好,已经排序成功了,我们可以看一下结果, 现在我们将它关掉, 接下来我们来看一下。
819学术进修课堂 09:06
09:06






