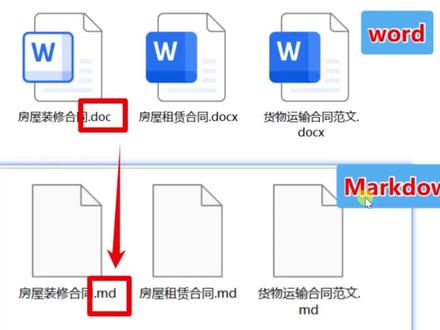
wps如何转markdown
最近看到微软开源了一个工具,这个项目在 github 上已经有十万新出头了。一句话说,它就是帮你把各种乱七八糟的资料直接转成 markdown, 后面更方便进 obsidian, 进知识库,继续交给 ai 处理。因为 markdown 本来就是 obsidian 最顺手的格式,你手里的 pdf、 word、 excel、 ppt, 甚至网页、音频、在线视频链接,这些资料格式都不一样。 东西虽然有了,后面要搜索、整理双向链接或者继续喂给 ai, 其实都不太顺。这个项目做的事情很直接,就是把这些资料尽量都转成 markdown。 比如一份 pdf, 以前你可能只能截图复制,凑合存进去,现在可以直接转成 markdown, 全文搜索链接、整理 ai 总结后面都会轻松很多。 它特别适合这种场景。你平时就在用 obsidian 存资料,你最近想搭自己的知识库,你手里的文件格式很杂,而且 markdown 这种格式对 l l m 本来就更友好,也更省 token。 如果你平时就有很多资料要整理,这个工具可以留意一下。我是 ai 知识派,关注我,带你挖掘更多好用的 ai 工具,下期见!

粉丝8367获赞5.0万
相关视频
 00:54查看AI文稿AI文稿
00:54查看AI文稿AI文稿macdunk 凭着简洁的语法和跨平台的兼容性备受大家喜欢,那我们如何把这里多个 word 文档批量转换成 macdunk 文档呢?今天教大家一个方法,不管多少个文件都可以一键转换。我们首先打开这里的批量处理工具, 在 word 工具中选择格式转换,点击这个添加我们需要转换的所有文件,这里可以是任意多个文件。这里的页面非常强大,我们既可以转换为这里的长线格式,也可以将 word 整为图片。 在这里我们选择 m d 的 blockdown 格式。同时这里我们可以看到还有非常其他度的格式,我们可以根据自己的需求选择选择转换后的文档保存的路径, 这样我们就批量转后完成了 word 转 markdown, 你 学会了吗?
15鹰仔不加班 02:15查看AI文稿AI文稿
02:15查看AI文稿AI文稿说白了,你还在手动改 markdown 格式,其实这都是没必要的,浪费时间。咱们直接看今天拆解的这个工具, markdown, 微软开源的文件转 markdown 神器,花十分钟看完, 你能搞定所有文件的格式转换,还能避开百分之九十的坑。接下来我会拆解它的底层逻辑实测核心功能,曝光九个必踩的坑,最后告诉你它到底适合谁用。说白了, markdown 的 核心不是简单的格式转换,而是靠 留信息识别和转换器体系。留信息对象就是他的眼睛,能看懂文件的格式、编码路径。而文档转换器就是他的手,不同文件对应不同的转换器,比如处理音频,先提取原数据,再做语音转录。处理 pdf, 先识别文字,再还原标题和表格, 这种模块化设计让它能轻松扩展新格式。咱们直接看实测数据,对比 markdown 和 python 处理 docx 文件公式,准确率差百分之二十。 处理代码的 pdf markdown 能完美还原表格结构, p d o k 经常乱码处理音频文件, markdown 能提取作者时长等原数据,还能转录成文字,批量转换没问题, 只要配置对路径,一次能转上百个文件。最厉害的是,它还能集成 cloud 桌面版,让大模型直接读取本地文件。 敢说真话, markdown 的 坑全在依赖安装和版本升级音频转录要装语音识别库和音频处理库,版本不对就报错,还要装 fanpack, 系统环境不配,根本用不了。转换 dok x 公式乱码是因为公式解析没开,这个设置藏的很深,版本零点一零有三个破坏性变更, 升级后老代码直接报错。说白了, markdown 不是 所有人都适合,适合经常转多格式文件的人,适合用大模型处理文档的人, 适合只转纯文本的人,不如用在线工具省事。不适合不会用 python 的 人,学习成本略高。对比同类工具,它胜在集成度高,但依赖管理比较麻烦。敢说真话,用好用透。 market down 的 关键是自定义转换器, 哪怕是冷门格式,只要写几行代码就能适配收藏起来。下次转文件直接照着做。关注我,下期拆解自定义转换器的开发,还有 cloud 集成的进阶技巧,咱们把工具用到极致。
49Oxecho 00:46查看AI文稿AI文稿
00:46查看AI文稿AI文稿一款全能 markdown 转换工具,开源社区已经十一万萨尔,它能把各种格式的文档转换成 markdown 文档,比如像 pdf, word, 图片、语音等等。那为什么要把文件转换成 markdown 呢?因为这是大模型最爱读的格式,为给 ai 效果最好,还省偷啃。 那在安装 markdown 的 时候,需要 ppt 三点式以上,然后克隆项目到本地使用 ppt 去安装,依赖之后一行命令就能输出干净的 markdown 格式的文本。还支持图片的 ocr 音频转文字、 u two 字幕提取。最新的更新提供了 m c p server, 可以 接入 clock 自动化工作。说实话,这个工具虽说不太起眼,但在日常使用中确实非常方便,尤其是做本地知识库,或是需要批量处理文档的场景。感兴趣的朋友欢迎评论区交流。
30技术PP虾 00:39查看AI文稿AI文稿
00:39查看AI文稿AI文稿你有没有遇到过从 pdf 复制文本,结果格式全乱了的情况?微软开源的这个库 mark it down 简直就是救星, 使用方法超级简单,只需要导入 mark it down, 然后调用 convert 方法并传入文件名,就这么简单。它能完美保留 pdf 的 标题、列表等结构,并转换成清爽的 markdown 格式。更厉害的是,它不仅支持 pdf, 连 word、 excel 甚至图片里的文字都能转换。 这对于需要把资料交给 ai 处理的开发者来说,简直是神器!想要快速高质量的提取文档内容,用它就对了。
1845全栈系统工程师 02:29查看AI文稿AI文稿
02:29查看AI文稿AI文稿tikub 热门项目拆解第一期今天我们来拆解一个由微软 autogen 团队开源的项目, markdown。 它是一个轻量级的 python 工具,可以把各种文件格式统一转换成 markdown 格式。 markitdown 的 使用非常简单,命令行下一条命令,就能把 pdf、 word、 excel 甚至图片自动识别并转换成 markdown。 那 为什么是 markdown? 因为 markdown 是 最接近纯文本的格式,结构清晰,大,模型读取效率高。 我们来从代码层面看看它的架构。核心是 markdown 类,它管理着一个转换器列表,每种文件格式对应一个 converter, 比如 pdf converter 负责 pdf docs, converter 负责 word 文档。当文件输入时,玛基卡会先识别文件的真实类型。 玛吉卡是微软开源的深度学习文件类型检测工具,能够快速准确地识别各种文件格式。然后系统按优先级便利所有的 converter, 找到第一个能处理这个文件的,就调用它进行转换。 每种格式都有对应的 converter, converter 按优先级排列,系统依次尝试每个 converter, 直到找到能处理该文件的第一个。 这种设计的好处是插件化,如果想支持新格式,只需要实现 document converter 接口注册进去就行了。转换完成后,原本复杂的各种格式排版就变成了干净的 markdown 格式, 标题、列表、表格都能完整保留,结构清晰,体积小巧。 markdown 还有一个强大的插件系统, 通过 entry points 注册插件可以无缝集成到主引擎中。比如这个 marketon ocr 插件就是官方出品的, 它能在转换 pdf 或 word 文档时自动识别里面的图片,用 gpt 四 o 把图片内容转化成文字描述。 安装也很简单, pip install 之后加一个 use plugins 参数就行了,插件按需加载,不影响核心性能,非常灵活。那么以上就是本期视频的全部内容了,项目链接我会放在简介和评论区,我们下期再见。
233Lancelot1001 01:52查看AI文稿AI文稿
01:52查看AI文稿AI文稿你有没有遇到过这种情况,想用 ai 分 析一个 pdf, 结果粘进去全是乱码。想让大模型读一下你的 ppt, 发现他根本不认识这个格式。问题不在 ai, 而在喂给 ai 的 那口饭。 大模型吃,文本最香,同样的内容,一段结构清晰的 markdown, 比一坨纯文本的消化效果好太多。标题曾记告诉模型,这是大纲还是细节。 表格的竖线帮助模型理解数据关系列表符号,让模型分清要点。 markeddown 支持十五种以上文件格式,文档类, pdf, word 的 d、 o, c x, pptx, 换灯片, excel 的 xls 和 xls。 媒体类图片, jpg markdown 的 架构很干净,核心是一个 document converter 机类,每种文件格式对应一个转换器,实现 convert 方法就行。 market 等最强大的地方在于它的 ai 集成能力第一,内置 m c p 服务器, 这意味着你可以在 cloud desktop。 有 人会问,这和 pendoc 有 什么区别? pendoc 是 文档转换界的瑞士军刀,支持六十多种格式互转。目标是给人看的, market down 只输出 markdown, 目标是给 ai 看的。 用法非常简单,命令行 market down, 你 的文件 pdf 直接输出 markdown 管道也行。 cat 文件 pdf 管道 markdown 输出到另一个文件 markeydown 解决了一个真实存在的问题, ai 时代的数据格式统一,幺幺幺 k 颗星,证明了这个需求的普遍性。微软 auto 站团队出品, mit 开源协议代码质量有保障。
39AI技术投降派 03:12查看AI文稿AI文稿
03:12查看AI文稿AI文稿今天给大家介绍一个微软开源的神器,叫 markdown。 这个工具的作用很简单粗暴,把你的 word、 pdf、 ppt 这些文档转换成 ai 最熟悉的 markdown 格式, 这样你在做 read 知识库或者让 ai 分 析文档的时候,效果直接拉满。 大家有没有这种感觉,扔给 ai 一 堆文档,想让他帮你总结分析,结果 ai 输出的东西乱七八糟, 原因很简单, ai 处理这些格式混乱的文档,他也很猛。你说一个 pdf 里的表格, ai 怎么知道那是表格标题,曾及他怎么分辨?所以问题就出在这格式和结构丢失了。 解决方案来了, markdown 的 思路非常聪明,它不是帮你做格式转换那么简单,而是专门为 ai 设计了一个翻译工具,不管你的原文件是 word、 pdf 还是 ppt, 它都给你转成 markdown 格式。 markdown 是 啥? 就是 l l m 最熟悉的纯文本格式,而且它能保留标题、层级、表格、列表、代码块这些结构信息。 g、 p、 t 四 o 这些大模型天生就熟悉 markdown, 所以 用 markdown 处理过的文档, ai 理解起来准多了。 大家最关心的问题来了,支不支持我的文件格式?放心, marketdown 支持的格式多到离谱。 word、 pdf、 excel、 ppt 这些办公文件不用说,它还支持图片、 ocr 识别, html、 网页、音频文件,甚至 youtube 视频都能直接转。 markdown 可以 说是覆盖了你在 ai 工作流里可能遇到的所有文档类型。 很多人会说,市面上转换工具那么多,凭什么要用 mark it down? 关键就在这,它不只是提取文字,它保留的是完整的文档结构。你原来的文档有三级标题, 它转出来就是三级标题,你原来的 pdf 里有表格,它转出来就是 markdown 表格。这些结构信息对于 ai 理解文档直观重要,没有结构 ai 只能瞎子摸象,有结构 ai 才能真正读懂你的文档。 那 markitdown 用在哪?最香?第一个就是 rack 芝士库,你做芝士库的时候,如果直接把乱七八糟的文档扔给 embedded 模型,效果肯定不好。 但你先用 markitdown 转成结构化的 markdown, 再送给 ai 去处理,那个效果是立竿见影的提升。还有文档分析, ai 工作流,配合这些场景。用过的都说好, 好东西不藏着。这是微软 autogen 团队开源的项目,完全免费安装,就一行命令, keep install markdown, 然后就可以直接用。感兴趣的朋友去 github 给我点个 star, 我 们下期再见。
18待续…












