怎么让重复数据只计算一次
论文降重啊?其实挺简单,但是一些攻科论文关于计算的数据一旦重复了,这不太好办。我告诉你一招,把这些数据用公式编辑器给它编辑一遍。哎,以这个形式出来,你试试。

粉丝1.0万获赞15.4万
相关视频
 02:45查看AI文稿AI文稿
02:45查看AI文稿AI文稿有同学问,重复的数据在求和的时候如何只算一次?比如两个重复的编号,那么他额度都是一百,那算的时候呢,只算一百,这个呢只算两百,嗯,这个呢就是三百,这个呢只是四百把多余的不掉,不算。 那怎么弄呢?其实呢,有很多种方式啊,你可以去删除重复项,把重复的编号去了,剩下的就是不重复的,然后你去求火,但是呢,很多时候呢,数据不让你动啊,你不要把它删了,原始数据要保留。 那这个时候我们算的时候呢,就可以参考这样的一个公式去算,你看啊,就等于我们给个上盘后做客户用数组的形式哈,比如说是用这个数据啊,用这波数据去除以 connieve, 然后左括弧啊,条件区,这个这个区啊,逗号, 条件呢?哎,还是个条件。那然后呢,有客户,有客户,最后呢按三键输出,按 ctrl 加 shift, 加 inter 键,然后呢就可以得出结果了。 那这个计算是什么原理呢?其实很简单,注意看这一段 ctrl e f 啊,实际上就是统一出。对呢,每一个编号出现了多少次,我们选中以后,按下 f 九,你就可以看得到,看到没,十一、十二, 那总共四个对吧?他分别出现了两次,两次,两两次,对吧?然后十三是一次对吧?十四是出现了几次?三次,对呢?是三个十四和去三个三了,对吧? ok, 然后呢,得出这个玩意以后呢,选中这个啊,看一下这玩意干啥的? i have, 就用这里面的数字对应的去除以他重复的次数。本来呢,他就是说是, 原来这这一波是十一,他等于一百呗,对吧?那你求和的是直接算,他不是算两百的吗?但是呢,我用一百除以二是不是就五十?那这个一百又是除以二,他是不是又是五十?也就是这个十一最后就变成什么了? 就是两个一百变成一个一百了,是这么个逻辑,后面的两百也是一样的道理,是这么算的哈,那我们可以把它这一段啊选中以后啊,按一下 f 九,实际上呢算出来的时候是什么?就是去了一半的数据 额度呢?原来都是一百的,对吧?你看一百、两百,三百,最后就是少一半,然后呢五十,五十,然后这个是两百的变成一百,对吧?然后三百的还是三百的取工额,他总共一个,不重复嘛?剩下来有这个多个的,三个四百的,他就求出 了啊,一百三十三点三三三这样的状态,那么最后用上盘对他进行求和的时候,是不是就是说是排除了重复的一个额度了?那就直接得出一个正确的结果了,就这么个原理学会了吗?点个赞哦。
715山竹Excel表格教学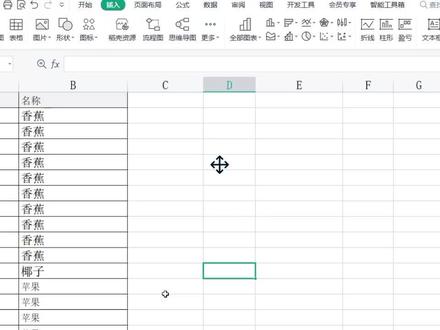 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿今天我们来学习多条件重复值如何只计算一次,比如说名称相交里面对应的月份有好几个,那么我们希望的是每个月份只算一次就可以了,那应该如何统计? 首先第一步我们一定是你这两个条件是互相牵制的,名称会影响到月份,所以你这两个都必须全部选中。点开数据下找到重复项,删除重复项。 那删除重复项的时候一定不是单独选月份或单独选名称,那你这样肯定是错误的。以一个为条件,现在这两个都是我们的条件,所以这两个都得选中,我们再删除重复项,点确定。 这样你看同样都是香蕉,但他并没有删除,因为月份不一样。保留完以后,我们依然是直接点插入数据透视表,在他旁边插入一个 数据透视表,点确定,我们去统计一下他的次数,这样你看香蕉一共有三次,他就给你统计出来次数了。 所以题如果不错的,关键我们不用公式,就在于你删除重复项的时候,这两个都是条件,那你这两个都得同时选中,不能单独选一列进行删除重复项。你学会了吗?点赞、收藏加关注哦!
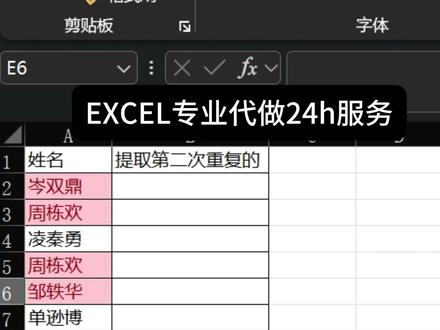 00:44查看AI文稿AI文稿
00:44查看AI文稿AI文稿提取重复的第几个,那有粉丝留言说他希望这类姓名里面提取姓名重复的第二个,那跟着大圣一起来学,像提取重复的第几个,那我们就换位思考,我们就统计它出现了几次就行了,那我们就用 ctrl f 函数,第一个函数我们选择 a 二单元格,那这首输入冒号,那 自动补齐 a 二,那再输入逗号,再输入一个 a 二,那这时候技巧来了,条件区域里面第一个 a 二,我们要按 f 四锁死,那这时候补齐反括号,那双击填充,那可以看到,比如朱栋华这个人,那当他第二次出现的时候,这里就是二,那如果说他有三次,那就是仨, 所以我们提取第二次的,我们直接添加一个筛选按钮,那这里筛选两次的,那就自动出来了。学会吗?老板好,本期的分享就到此为止,我们下次再见。
 00:30查看AI文稿AI文稿
00:30查看AI文稿AI文稿你把这些重复的商品去掉,再计算出他们的销量总和你说,然后你就一个各复制粘贴筛选两秒钟的活,你要干一天吗?你先输入等于优逆口函数, 然后选中要去重的数据,按回车,重复的数据就全部去除了。接着输入等于 sumf 函数,第一个参数选择条件区域逗号,第二个参数选择条件,第三个参数选择要求和的区域,按回车双击向下填充就计算好了,简简单单。
5.3万办公知识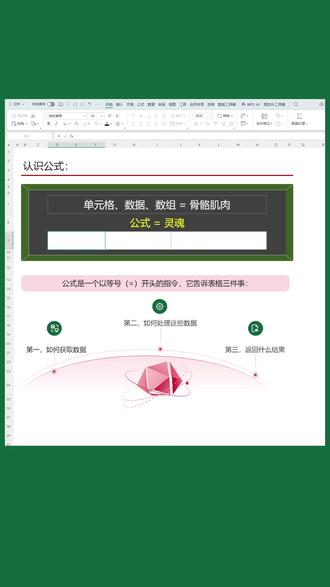 01:22查看AI文稿AI文稿
01:22查看AI文稿AI文稿如果说单元格数据数组是表格的骨骼和肌肉,那么公式就是表格真正的灵魂。在第一个单元格中输入十,在第二个单元格中输入二十,手动算结果等于三十。 更改 a 一 为二十,需要重新计算。那么用公式算,直接在单元格中输入,等于一个单元格,加上第二个单元格, 回车立刻得到结果四十,把二十更改为五十,结果瞬间变成七十。没有公式,我们只能手动算,反复算。有了公式,你只需要写一次, 剩下的交给表格,数据一变,结果自动更新,永远不会出错。公式其实特别简单,它就是一个以等于号开头的指令, 它告诉表格三件事,第一,如何获取数据。第二,如何处理这些数据。第三,最后返回什么结果。掌握了公式,你的表格就彻底不一样了, 从一张静态的记录纸,变成了一张全自动的智能计算器。
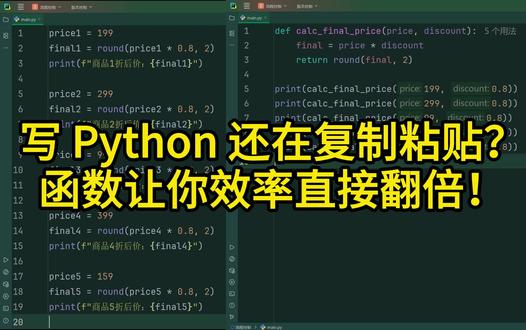 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿算个商品折扣要复制粘贴十遍代码,百分之九十的 python 新手都因为不会用函数,写出来的代码又臭又长。 python 里用 df 关键字定义函数,后面跟函数名和参数缩进里写业务逻辑 return, 返回计算结果。比如算商品折扣价, 把公式封装成函数,想用直接传,参数调用,不用重复写逻辑。重点来了,这是拍摄函数最经典的坑,十个新手九个踩,千万不要用列表字典这种可变对象。当默认参数,比如写一个给商品加标签的函数,连续调用三次标签居然越记越多。 因为默认值只在函数定义时计算一次,每次调用都在同一张列表里加内容。调用函数有两种传餐方式,按位置顺序传值,或者用参数名关键字传餐。关键字传餐不用在意顺序,例如这里只提供第一个位置参数, price 值为两百九十九。 下面通过关键字进行传餐,可以不按照顺序进行传制,写个小功能,还要单独定义函数,用莱姆达一行搞定。命名函数适合写简单的单行逻辑,比如给商品列表按价格排序,代码特别优雅。 总结一下,函数封装附用代码,避开可变默认参数坑,位置加关键字传餐,莱姆达经典写法都是 python 函数的核心必会点,想学更多 python 实战技巧,关注我,下期干货不断!
15佛圆 01:08查看AI文稿AI文稿
01:08查看AI文稿AI文稿十秒删除几万重复数据,简直不要太香!安排有几万条数据要删除重复,千万不要一个个去删了,干到腰间盘突出都做不完!学会这招,十秒搞定!看我鼠标 点击加号得到一个新表,回到原来界面,全选数据内容,右键复制回到新表,点击任意单元格,右键粘贴为数值,把列宽拉大一点,送你一个超级无敌公式在这里,右键粘贴左键,双击格子右下角自动填充,右键 复制全部内容回到桌面,右键粘贴到文本文档中,右键全选,右键复制回到新表,右键粘贴文本选完并列,按键盘 ctrl 加 g 键选空值,点定位,右键弹出定位框,删除 整行,确定重复内容秒删除。选完剩下的内容,右键复制回到原来表格,右键粘贴为数值。把下面多余部分删除,轻松拿捏。有问题请到讨论区留言, unbelievable!
 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿有一个函数可以取为一值,目前有两列数据,我想把只出现一次的名字呢放在这一列,那我们第一步呢,就是把两列合二为一,直接等于 t o 选择凸靠,直接选择这个区域, 然后逗号让它忽略空值,好压回去,他就把它转成一列了。转成一列之后呢,我们直接使用 u n 函数去除重复值, 这个如果说你直接去重呢?他会把重复的去掉一样留一个,但我们要的呢不是这种,我们要的是这个。第二天时我们继续写逗号,他说按行按列,你们不用管,再按逗号。 最后一点,你看他返回只出现一次的,像选他按下回车,这时候呢,他就只找出来出现一次的名字,你学会了吗?
748老六Excel 07:05查看AI文稿AI文稿
07:05查看AI文稿AI文稿哎,你最近有没有关注 a r x 上的新论文?我昨天看到一篇哈工大深圳团队发的叫 can i buy your kv catch, 标题就挺有意思的,直接把 kv 缓存当商品来讨论了。哦, kv 缓存还能买卖?这我得听听。我之前只知道它是 l l m 推理时的工作记忆啊。 对,咱们先从最基础的问题聊起,就是 l l m 推理里的计算用余。你想啊, l l m 推理分两个阶段对吧? prefill 和 decode。 prefill 就是 处理输入的阶段,会生成 k v 缓存,相当于模型的短期记忆。后面生成 token 的 时候,就不用再重新算前面的内容了。 这个我熟,但荣誉是怎么来的?问题就出在自注意力的特性上。 prefill 的 计算成本是跟着输入长度 l 平方增长的,就是 ol 平方扩回。你想啊,现在 rag 或者 a 阵的场景里,好多用户或者 a 阵的会读同一份热门文档,比如一个爆款 pdf。 现在的模式是每个请求都得重新做一遍 prefill 啊。对啊,比如一万个 agent 读同一份五千 token 的 pdf, 那 就是一万次 ol 平方计算,这确实太浪费了。 所以这篇论文的核心思路特别直接,把这份文档的 kv 缓存算一次,存起来当可附用的资产。后面谁要用,直接买或者加载这个缓存就行,省掉重复的 prefill。 这不就跟 cdn 缓存静态资源一样吗?他们叫这个 prefill cdn 模型, 听起来很合理,但具体怎么实现呢?总不能随便存个缓存就能用吧?哎,这就到第二章了,人家专门定义了两个核心操作, self kv 和 generate from kv self ev kv 就是 发布者把文档和模型一起跑, prefill 生成每一层的 key 和 value 张量,然后把缓存和原数据一起存起来。原数据很重要,得保证用的是同一个模型架构和数值精度,不然加载了也白搭。 那 generate from kv 就是 用户这边加载缓存是吧?这里面有没有什么坑?有两个关键点必须严格控制,一个是 position ids, 新生成的 token 位置得从原文档的长度 l 开始,不然位置编码就乱了。另一个是 attention mask, 新 token 得能看到缓存里所有的 token。 他们用矿三四 b 做实验,加载缓存生成的 token 和从头 prefilled 完全一样,只是 logit 有 一点点微小差异,还是 gpu 内核的非确定性导致的,逻辑上没问题。那这个效率提升到底有多大?总不能为了这点麻烦得不偿失吧。 第三张就专门测了这个数据,还挺震撼的,短上下文两百五十五 token 的 时候复用缓存比重新 prefill 快 八点六倍,到三千七百七十四 token 的 时候直接快了四十九点七倍。因为 prefill 是 平方级增长,而 decode 的 步骤只是限行增长,越长的文档差距越大。 哇,这个倍数够夸张的,那经济上什么时候开始划算呢?他们算了一个收汁平衡点, n 星就是 c prefill 除以 c prefill 减 c look。 实测下来,这个数在一点零二到一点一三之间。 啥意思?就是只要一份文档被访问,第二次作缓存就开始省钱了。这么低,那热门文档岂不是省爆了? 对啊,他们举了个例子,三千七百七十四 token 的 文档给八千万 agent 用重复 prefill 的 成本是一百五十万美元,用 hosted kv 复用的话直接降到三万美元,差了五十倍。 但等等, kv 缓存的体积应该不小吧,存这么大的东西,存储成本会不会吃掉节省的计算成本?你说要点子上了?第四张就专门讲这个矛盾, q n 三四 b 的 话,每 token 大 概占零点一四八兆, 三千七百七十四 token 的 文档生成的缓存就有五百五十七兆。为了省计算钱,得存这么大的文件,还得考虑传输的问题。 那压缩行不行就是量化一下。他们试了 int 八量化,确实把体型减半了,但代价是生成的内容不再和原输出完全一致, 十六个 token 之后就开始发散了。所以结论是有损压缩适合普通推理,但如果要保证完全附用的准确性,就得用无损压缩或者接受大文件。那这么大的缓存怎么分发呢?总不能让用户自己下载吧。 第五章就分析了两种分发方式, shipping 就是 把缓存文件发给用户, hosting 就是 由 openai 这种服务商自己托管缓存,用户付费访问,结果算下来, shipping 根本不划算,因为云服务商的出网流量费太贵了。具体怎么算的? 传输五百五十七兆的缓存,按标准费率零点零九美元,但重新 prefill 同样文档的计算成本才零点零一九美元, 你看浪费电,重新算都比船缓存便宜。所以可行的路径只能是 hosty 的 服务,服务商自己维护缓存,这样就没了出往流量费,还能独享那五十倍的计算节省 哦,难怪现在商业 api 里的 prompt catching 都是给 cash token 打九折,原来就是基于这个成本差啊。哦,对,正好在论文测的九到五十倍的节省范围内。 最后第六章就聊了未来展望和局限。首先他们现在只关注了完全前缀附用,就是缓存文档得在 prompt 最开头,要是想融合多个不同缓存,比如好几份 pdf 的 缓存,就得更高级的技术,还得做精度和速度的权衡啊,还有什么局限吗? 还有就是 k v 缓存现在是和模型绑定的, gpt 四的缓存不能给拉马三用,这就限制了可一致性,除非行业能搞出标准化架构或者跨模型的翻译层。 不过总的来说,随着上下文窗口越来越大, agent 越来越多,从数据分发网络转向计算分发网络肯定是趋势。那这篇论文有没有提到相关的其他工作? 有啊,结尾引用了几个,比如 catchblend 是 做多缓存融合的,正好和这篇的单缓存复用形成对比。 mat kv 证明了 kv 缓存可以存在闪存里。给这个方案打了技术基础, spectrum kv 做混合精度压缩,解决缓存体积的问题。 还有 cashcraft 是 专门管 r a g 场景下的 chunk 缓存管理的,都是这个方向的重要工作。这么看来,把 k v 缓存当商品卖 不只是个脑洞,已经有实实在在的技术和经济基础了。对,现在的问题已经不是该不该缓存计算,而是怎么最高效的存储和变现这些缓存资产,说不定以后咱们用 ai 的 时候,背后都在悄悄买别人预存好的 k v 缓存呢。 哈哈,那以后 ai 行业又多了个新行当, k v 缓存中间商谁知道呢,反正技术发展总是超出咱们想象。今天这篇论文聊下来,是不是对 l l m 推理的成本优化有了新认识? 确实,原来里面还有这么多门道,以后再用 r a g 或者 a g 的 时候,可得想想背后的计算成本到底怎么省下来的。错了,今天咱们就聊到这,要是你有什么新想法,欢迎来评论区一起讨论,咱们下期见!
70每日Arxiv![#Excel技巧[话题]# :UNIQUE(数据区域,FALSE/TRUE,FALSE/TRUE)一键去重](https://p3-pc-sign.douyinpic.com/tos-cn-p-0015c000-ce/oQyTfeMfX50ZpTlW52iwAFfDm0EQg4I8AoUZlQ~tplv-dy-resize-origshort-autoq-75:330.jpeg?lk3s=138a59ce&x-expires=2098616400&x-signature=oDVhOtEpKQlCS0MT5%2BCaY8QnJXg%3D&from=327834062&s=PackSourceEnum_AWEME_DETAIL&se=false&sc=cover&biz_tag=pcweb_cover&l=2026070521265026AFA34555EF062862FA) 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿家人们,你们是不是在处理表格重复数据时总觉得麻烦?比如想把重复的香蕉去掉,其实 excel 里的 unique 函数就能轻松解决。今天我再给大家把这个函数的用法讲得更明白些。 首先在单元格输入等于 unique, 接着选要去中的区域,后面两个参数很关键哦,第一个参数选 for 是 竖向暗列去中,第二个参数选 for 是 同名,只留一个 选出就只保留只出现一次的数据。比如你要处理 b 三到 b 十里的重复相交,就选这个区域,输入 false 和 false。 另外 false 是 默认值,可省略,不输入,这样就能竖向去重, 每个相交只留一个了。要是 b 三到 i 三是横向的重复数据,选出和出就能横向去重,只留下只出现一次的内容, 是不是比手动伤方便多了?朋友们,你们平时用 uniq 函数时有没有遇到过特殊情况?评论区聊聊,咱们一起解决。
 03:48查看AI文稿AI文稿
03:48查看AI文稿AI文稿大家好,今天呢咱们分享一下生这个数据去重就是查找重复值,咱们日常录用的这个录的信息中啊,这个身份证号、地址等等各种信息中容易发生重复。发生重复呢,快速的去查找重复项 啊。第一个方法吗?可以去进行筛选,筛选这个身份证号,然后通过这个计数里面数据库为一的,那数据库为一的都是重复,或者下面这有一个筛选重复值啊,这样的话重复值就会出来了,这是第一个方法, 但是有的人这个版本里面没有这样的一个功能啊,那可以使用第二个方法,第二个方法也很简单,就是你选中选中这个,你要去重的查找重复值的这一列, 然后上面找到开始后面这个数据,点一下数据之后,后面有一个高亮重复项,点高亮重复项 啊,设置高粱重复项,设置高粱重复项呢,会弹出,他会弹出这样一个界面,然后你选择啊在这个前面精选匹配十五位以上的长数字,如身份证号、银行卡,把这个勾选上,然后点击确定, 这样的话,他这一些啊有重复值的啊,他就会自动的标成这种,呃,标成这种什么成 橙色,然后你进行筛选的时候,按照这颜色筛选,把这个颜色筛选,他就会把这个重复值啊筛选出来。但是这里面有一个地方需要注意的,就是如果,如果你这上面合并了单元格, 这合并了单元格什么,这个比如说这个单元格是什么名单,你再进行筛选的时候, 你进行筛选的时候,他就会出现,他就会出现无法去执行这个命令,这个需要这个时候就需要从去掉单元格这一部分,从身份证号上面这一部分,从这个地方进行去选择,不要选最上面合并单元格这一部分, 再进行数据去啊,进行去这个查找重复项,这样就可以了。 同时呢里面有一个注意的,就是说有的时候用的过程中他数据可能发生错乱,或者是呃,就是更新完之后他有些标颜色标错,这个时候呢,同样的 就需要就需要你的数据进行再次的去设置啊重复项,重新的去设置一下重复项,他就会自动的去 啊,自动的去更新这里面那个更新的里面这一些标记颜色,但是如果你要想取消掉的话,就在这里面勾选掉,然后清除所有的重复项啊,先选中,选中这些列之后, 选中这些列之后清除下面清除高粱重复项啊,这个颜色就关掉了。当然如果说你这里面这个重复值,重复值是这个,嗯, 这里面这个重复值,如果说是啊,修改完之后,比如去随便修改完之后,比如说随便加一个啊,变成不一样,他自己颜色也就会消掉啊,这就是咱们的一个日常中常用的简单的一个两种,两种查找 这个重复值的一个办法,第一个就是通过这个技术和自带的这个筛选重复项,第二个就是用数据下面的高量重复项啊,就这两个长的两个办法比较简单,也不需要记公式。
15学悟组工实务 00:41查看AI文稿AI文稿
00:41查看AI文稿AI文稿让你把这些重复的商品去掉,再计算出他们的销售金额。你说品类太多不会操作,那我问你,当初入职你不是说精通表格的吗?今天教你两种方法,你先输入等于这个去重函数,然后选中要去重的数据,按回车,重复的数据就全部去除了。 接着输入等于这个条件求和函数,第一参数选择条件,第三参数选择要求和的区域,按回车,再向下填充就好了。 如果嫌麻烦,平时记的函数公式太多了记不住,还有更快的,直接表格甩给豆包姐,写上这句,需求立刻搞定!不用记复杂函数,快收藏起来,趁热打铁,亲自上手,反复练习,相信你是最有执行力的,加油!
77锦运来 00:20查看AI文稿AI文稿
00:20查看AI文稿AI文稿把重复的家电品类去掉,再计算它们的销售总额,输入 uni 函数,第一个参数选中要去中的数据,回车,重复的数据就去掉了。 再输入 sumif 函数,第一个参数选择条件,区域家电品类逗号,第二个参数选择条件,第三个参数选择求和区域销售额数据回车后下拉填充去重加求和就搞定了。
140办公急救包 01:24查看AI文稿AI文稿
01:24查看AI文稿AI文稿如何从一百个编码号当中找出我们指定的十个编码号?这是我们正式课学员的一个问题,这里我们给大家去提供两种方法,第一种方法,如果这两组号码他在同一个工作表当中, 这里我们只需要选中这个单元格区域,点击条件格式突出,显示单元格规则, 在这里我们选择重复值。好,这里我们给他去标识一个我们需要的颜色,点击确定,这个时候你会发现这里呢,他就帮我们把重复的编码,就可以帮我们给他去自动标识颜色了。好,第二种方法,我们可以借助于一个函数 叫 on if 函数。好,怎么去用呢?这里我们给它输入一个等号,输入 c o, u, n, 然后双击的函数,那技术区呢?我们就选择地列逗号,我们的条件呢,我们就选择第一个编码号,然后敲回车。 好,这个时候我们只需要把这个公式向下给它去填充。好,这个时候呢我们给它去 做一个筛选,那这里只要是数字为一的,那这样呢,他就是重复的了,我们就给他找出来了。学会了吗?关注我,学习更多办公小技巧!
43Excel田老师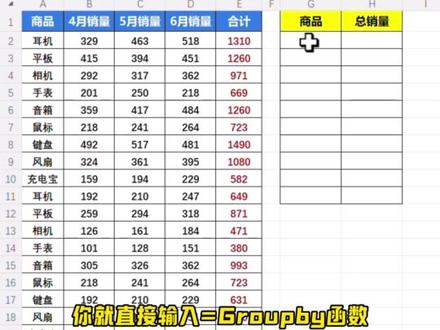 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿数据去重再求和,三秒搞定!要去掉这些重复的商品名称,再计算它们的销量总和。你就一个个复制粘贴,再计算几秒的活,非要干半天吗?你就直接输入等于 groupby 函数, 第一个参数行字段框,选整个商品列逗号。第二个参数值字段框,选合计金额列逗号。最后输入 sum 函数,自动求和,按下回车搞定。想学函数的,就看这本清华大学出版的函数书, 专门教你快速上手,零基础也能轻松学会全书以常见的工作为例,一步一图都是实用的职场干货。还有办公技巧、 ai 应用和问答实录, 附赠同步视频课、电子书,多套办公视频教程,想快速提高,点下方链接购买!
87文杰百宝箱



