eviews描述性统计结果怎么导出

粉丝529获赞848
相关视频
 01:13查看AI文稿AI文稿
01:13查看AI文稿AI文稿描述性统计是通过数学方法和图表形式对业务数据及其分布情况进行概括性的描述和分析。它可以分为集中趋势统计、集中趋势统计和静态分布统计三个主要方面。一、 集中趋势统计通常使用平均数、中位数和重数等指标来描述数据的中心趋势,这些指标可以帮助我们了解数据的集中趋势和典型体。二、 其中趋势统计则使用四分为差标准、差方、差、偏度和风度等指标来描述数据的离散程度和变化范围, 这些指标可以帮助我们了解数据分布的离散程度和波动情况。三、静待分布统计则是通过 k、 s 检验、 p、 p 图、 qq 图、 w 检验和动态法 等统计方法和图形工具对数据进行静态分布、检验和离合。这些方法和工具可以帮助我们判断数据是否符合静态分布,为后续的统计分析和模型应用提供依据。好了, 这集就聊到这,以上是个人总结,难免有不足和纰漏,希望多交流,共同提高。
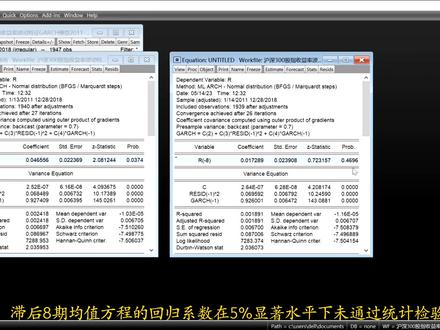 08:35查看AI文稿AI文稿
08:35查看AI文稿AI文稿基于 gark 模型的沪深三百股指收益率波动分析。一点一描述性统计打开收益率序列, 绘制实序图、直方图描述性统计表,点击 view 选择 graph 末日 ok 持续图表明大部分数据以零为中心值,上下波动,大部分处于负零点二、零点二之间。 点击 view 选择描述性统计 histogram and stats 直方图 stats table 统计表 看均值及大及小值,标准差,标准差小,说明选取的数据差距小,数据呈现聚集趋势,存在聚性特征。 从直方图可以看出,大部分数据聚集在正负零点零一二五之间, 风度为负,说明数据又偏,风度九点五二三大于三,说明比正态分布数据陡峭。 g、 b 统计量的伴随概率 p 值为零,说明选择的数据不服从正态分布。 据偏度、风度 j、 b 统计量分析可以看出,收益率具有右拖尾减 分布,不服从正态分布的特征。 一点二平稳性检验对收益率进行 a、 d、 f 检验,选择其他检验也可以 依次选择检验形式。只要存在一种平稳情况,都可以说该序列是平稳序列。 为了使结果好看一点点,尽量选择最小的结果,比如 a、 d、 f 值最小或 p 值为零。 基于 a、 d、 f 检验法及 sig 准则,收益率系列的原系列的 a、 d、 f 统计量是负四十四点八七九一三,伴随概率为零,体值 小于零点零五,可以认为该序列通过了平稳性检验。一点三二 g 效应检验第一种方法直接看该序列的自相关检验结果, 直接看 a、 c、 park p 值,先找 p 值小于零点零五十对应的至后期 本例中滞后六七开始 p 值小于零点零五,说明可能从滞后六七开始存在二级效应。 其次看 a c 和 pack 中是否有一项的数值的绝对值超过零点零五,超过零点零五说明在某阶存在二级效益。 本例中,之后七七时 pack 超过零点零五,之后八七时 a c 和 pat 的绝对值超过零点零五。最终选择七阶还是八阶,需要建立 gark 模型,通过技术显著性判断 第二种建模。利用残差判的 arch 效应模型可以按论文情况构建。本例只举例两种初步回归模型,在回归窗口中选择一方叉检验中的 arch 检验, 观测至二方对应的伴随概率 p 值为零,说明在百分之五显著水平下存在二级效应。利用第二 种模型判断二期效应, 重复 r g 检验步骤,伴随概率 p 值为零,存在 r g 效应,可以建立 gag 模型。 利用残差项判断 gark 模型中自变量应选择之后多少期, 和第一种直接利用收益率序列判断接触的方法一致。 在 p 值小于零点零五时,对应的至后七期 pack 大于零点零五,至后八期的 a c 和 pack 大于零点零五。 一点四 bark 模型结果命令 l s r 二七和 l s r 二二负八。最 massive 的选择 arch auto regressive 比较之后七七和八七模型的回归系数, 之后八七均值方程的回归系数在百分之五显著水平下未通过统计检验本例模型中的变量,因去之后七七收益率。 关于 dark p q 模型中 p 和 q 的取值,常用取值为一和二, 建立 gark 幺一, gark 一二, gark 二一、 gark 二二这四个模型对比系数显著性,并利用 age, s, c, h, q, c 最小 原则选出合适的模型。只需要改变 arch 和 gark 的数值 对比 a 一个 s, c, h, q, c 干儿个一一模型中的三个数值最小, 且 gark 一一模型的系数均在百分之五显著水平下显著。本例选择 gark 一一模型分析收益率波动特征。 一点五模型结果分析,上半部分是均值方程,下半部分是方叉方程。 reside 一二的系数表示二取项系数, gark 幺的系数表示 gark 项系数。二取项和 gark 项系数之和接近一,说明收益率的冲击存在持续效果或条件方差,所受的冲击是持久的。 gark 项系数零点九二七四零四,说明早期的收益率波动对后期的收益率波动具有显著影响, 存在风险溢价现象,波动越大,风险越高,收益率越高。 一点六 h a m 检验, 检验结果,线上建立的 gark 模型已经不存在二期效应,说明 gark 模型是有效的。一点七伏二值计算,点击 prag, 选择 make gark variance, 建立一个新序列。 根据新序列计算,在百分之九十五致信水平下的 var 值。 一点六五为百分之九十五制性水平统计值。 将计算出的 var 值复制到 excel 表格,用 var 预测值减收益率的绝对值筛选出结果为负的情况, 结果为负代表当天的预测失效。
150热爱散步的蟹鲸 04:511计量君
04:511计量君 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿今天我们讲一位数数据分析的第三集就是做统计描述,昨天我们讲了就是在统计描述,主要是两个方面。第一个就是做图,做图我们昨天讲了今天做表,今天讲个做表。做表这一块呢,就是说首先你需要双击点开数据,就是看这个数据的详细信息, 然后这个统计描述这一部分主要是在在 vivo 里面。第三个这个是 party octantist。 啊,这里面有这么多的选项。嗯,先说第一个就是黑斯普尔曼斯蒂克斯,就是他会把你帮你当成脂肪吐出来,让你看看他这个数据的分布什么样,然后这边就是一些相关的信息,比如说均值 那个中位数对大直对小直,然后标准叉,然后这个是正态性的一些检验,然后再往下再点击的话,就是 st table 这三个,他只把均值这些统计量把你给你放在一个表里边,你可以直接复制粘贴到一个 sir, 然后再往下。第三个就是史雷克盘,把爱 服务普及,什么意思?就是这就是分组统计,比如说你还有一个变量叫分组变量,比如说男女男女在这个变量上有什么区别?你这个地方就属于这个赛克斯,比如说你一个变量就是性别的话,那你要统计的变量就是在这个地方,比如说这是均值,这是求和中位数,大值对小值,然后这个百分位数,然后正态性的一些检验,分组检验、 统计描述基本上就是这些,大家后面可以自己操作一下,点我主页有干货。
102论文小助手! 02:5912计量君
02:5912计量君 02:23查看AI文稿AI文稿
02:23查看AI文稿AI文稿如何用 evox 分析数据?哈喽,各位小伙伴大家好,本期我们将推送关于使用 evox 软件进行数据分析的内容了,新内容将更加注重实战。 本期我们将分成四个部分,关于 evox 是什么,他的应用领域、功能以及操作的步骤。 首先我们来看一下 evos 软件是什么以及能做什么吧,我们来打开百度看一下关于 ewoss 介绍, 度娘里面是这样介绍的, evoyos 是关于 econ markex, vivo 的缩写,通常称为计量经济学软件包,而他的旨意呢就是计量经济学观察,通常为计量经济学软件包,他的 本意是对社会经济关系与经济互动的数量规律采用计量经济学方法与技术进行观察。下面来我们一起看看他的应用领域, 主要应用于应用计量学总体经济的研究和预测,销售预测、财务分析、成本分析和预测等等。 而他主要有三个功能,我们来分别看一下,第一个功能是数据检验的功能,如梯形检验,方差分析等等。 二是对变量进行简单的处理功能,如变量的相关系数,斜方叉以及直方图。第三是对数据进行模型的求解和模拟。最后让我们来做一下 evos 数据的导入过程。要导入 excel 数据,首先就要 新建一个文件,在这里我们新建文件时,打开 evox 就会让你新建,经过上一步柔软件就会提醒您设置数据的时间格式, 其格式为年月日,否则就会提醒您创建失败。在这个步骤之下,选择你选需要导入的文件, 这样数据就成功的导入了。下面我们再一起来看一下数据导入的过程,一共有以上两种哦。 好了小伙伴,这期的内容就到这里了,在今后的一段时间,我们将围绕该软件做一些数据分析的教程,欢迎大家关注。
338mason学长留学干货站 00:25查看AI文稿AI文稿
00:25查看AI文稿AI文稿毕业论文数据分析、频率分析,建议收藏备用。频率分析主要用于分析分类变量不同类别的战绩问题,比如男女比例等。点击 sps 分析描述统计 频率,将景别和年级选入变量,点击确定,就得到男女和年级的比例数据了。
126论文小助手! 01:51
01:51 01:14查看AI文稿AI文稿
01:14查看AI文稿AI文稿今天我们继续讲有位置数据分析描述统计下面几个选项。首先我们点开数据,点开数据之后还是在 vivo 下面 excel、 tvctstist 后面这三个选项。第一个是简单的假设检验,比如说,哎,你想看一下这个数据的均值是不是等于某个值可以检测这个,这个就是我们其他软件里边就叫单样门 单向本体检验,这个是方差分析,比如说你想检验这个数据的,他平均他这个方差是等于多少,是不是等于多少他的概率。然后还有一个中位数的检验, 然后另外下面是一个另外一个检验是分组的,就是比如说这个均值这一块,你说是有两个两个分组和三个分组,两个分组就是都这样的,天然三个分组就是, 嗯,三个分数计以上就是方案分析。然后对于君子的不同组织之间比较,比如上面他有一个性别的话是 x, 有男女的话那就是单位 tm, 然后下面是君子相对比的是标准差, 就是下面都是双杀其性的检验一个。然后再往下一个就是关于他这个数据是不是符合某种分布的检验,比如说这就是替分布, 哎,你把它插入书上踢分布里边两个中的值,第一个就是个六,就是个君子,然后下面有个标点叉,因为这个替代分布看他是不是符合正在分布,下面还有一个卡方分布,呃,还有一些什么老机和谁的分布,这些大家可以都可以看一下,点我主页有干货。
74论文小助手! 13:42查看AI文稿AI文稿
13:42查看AI文稿AI文稿好了,我们已经讲完了这个一个大概的一个步骤之后,我们接下来看一下我们的一个 具体的一个操作。比如说这里是我们之前做过的一个东西,比如说他的要求是要求出国留学人数与居民消费水平以及研究生在学人数的一个影响。 那么首先其实我们拿到数据的第一步啊,肯定这个数据处理啊,就是看有没有缺失值,以及以及呃异常值对不对?而对于我们的这样的一个数据,特别是我们看了一下,特别是我们看下这样看这样的一个数据,你看一下出国留学人数,他是其实是一个占比, 而居民消费水平是个员,对不对?单位。而研究百研究生债权人是个外人,其实他们的亮纲不一样。而对于我们这样的问题话,我 我们经常就是对它进行一个取自然对数,明白吗?就是保证他们的亮缸是一样的,这里再取一个自然对数,同样方式我每个都取了之后再拉下来, 然后这里是我们的一个 y, 对不对?然后这里是 x 一,那么这里是 x 二,那么我们再把这个数据放到我们的 ebuse 里面,再进行一个具体的操作。首先我们说打开我们的一个 ebuse, 打开 ebas, 我们看一下它是一个时间训练的一个模型,从一九八八年到二零一八年,对不对?二十一九八八年到二零一八年的一个数据,就在这里 create 一个六的一个 evius, 就在这里啊时间训练,这个是我们的一个时间训练模型, 这个是我们的洁面数据,这个是我们那个面板数据,就是我们关于时间训练,他就分为时间训练、洁面以及面板,面板数据就这三个模型,那么我们现在是时间训练模型,他是 这是频率对不对?一,每一年对不对?他是从一九八八到二零一八年,这里就是我们说所命名这个数据的一个名字啊,你可以写可以不写啊,我经常是没写的 好。这样之后那我们是不是要输入我们的个数据了?输入数据的时候在这里 dat 不区分大小,写这个 dat 我们要输入的数据 y, x 一以及 x 二,它们的中间 用空格来隔开,这样打按 inter 键确定之后,我们再把我们这个数据啊,怎么办呢? copy 一下,就这个复制过来就可以了, 像 ctrl c 加 ctrl v 是不是就可以了?然后这得到了我们这样的一个数据,那么我们的第一步这样可以删掉了,这是个,那么看一下这是不是就在里面了? 那我们看一下,首先第一个我们要做的是什么呢?单位跟检验对不对?我就以一个为例啊,单位跟检验以一个 y 为例,我们说打开右击 open, 他 open 直接打开的是一组数据了,单位一个边一个数,一组数据他打开就是一组数据。 service 就是我们如果知道拍子的是不就是一个 service, 那我们看一下在这里面单位跟检验在哪里啊?在这里有类似 rest 打开,首先我们选的是 adf 检验,对不对?一般来说 adf 检验这个就是我们的 adf 检验。首先我们第一个是要怎么样? 首先第一个是不对原序列进行一个检验,第一个是在这里原序列,我们第一个要选的是带有洁具项以及趋势的点个, ok, 得到一个结果之后你会发现这 p 值是不是 他这里有一个原甲册 y 就是有存在单位根,那么批值大于零点零五,我们就接受这个原甲册,就是不能否认他没有原位单位根就是只能接受他有原根的,对不对? 档位跟对不对?那么先给他设置一下,那么第二步我们在这个技术上重新再进行一下,那么在我们我们第二个要选的就是我们只带有解具项的一个,再进行一个检验, 然后同样想我们再固定一下,冻结一下,那么第三个再选的就是我们那个既无有没有趋势也没有结局项的一个,那么再来看一下,得到了一个三个, 其实这三个是不是都是接受一个元甲的批值都是大于零点零五的,对不对?那么其实都认为他有单位跟,也就是元训练不平稳,那么我们到时候写上去的时候,其实我 你们可以看一下,其实我们就可以用这个批子比较小的这一个当做我们的一个结果来出出进出放到我们的一个论文里面 就可以了,明白吗?那么同样的我们就可以删掉了,是不是第一个,那么接下来是不是他的原序列是不平稳的?那么我的第二个部分是不是要进行一阶三分呢?就在这里进行一阶三分,进行一阶三分的之后选择一阶三分序列之后同样的方式 还是首先第一步进行有洁具有趋势向的一个单位跟检验, ok, 这里是不是直接就平稳了?平稳了之后我们就可以不用往后坐了,明白吗?那我们直接把这个结果放进去,就是我们可以得到结果,他是一阶差分平稳的,明白吗? 所以说我们单位跟着检验他是有步骤的。第一个总结一下,第一个就是我们从原训练一节差分以及二节差分依次来,而当我们原训练的时候,他又分为了三个步骤,第一个是 选择有趋势和拮据,第二个是选择有拮据,第三个无趋势和无拮据的,就这样三个来看,哪个就按照这三个步骤到哪个步骤平稳的就可以不用往后面坐了。如果都没有平稳,你就可以选择 批值最小的,你或者选任意一个也行,但是你选择批值最小的那一个放进去,作为你的不平稳的一个证明,其实也行,明白吗? 这,这是一个结果,那么其他的 x 一和 x 二我们就不用看了啊。那么第二个就是他们都不是平稳的,之后我们说可以用它进行一个斜诊检验,那么斜诊检验什么?呃,这 group, 这,我们在这里,在这里选择这个选择 j, 看到没有?打字 view 里面,在这里一个在选择这个之后结束,对不对?之后结束,我们说之后二结,我们看一下,其实看见没他他的写的结果是什么?当我的 long 什么意思啊?就是当我看我的 p 值,就是说这里当三个变量没有一个 没有变量存在鞋子的时候,他是拒绝原价,是不是对不对?而也是莫斯的一和还是莫斯的至多有一个,至多有两个数,其实这里都是零点零五,大于零点零五,其实我们如果的目的可以选择用零点零,零点一作为标记,如果小于零点一,其实我们都可以当做一个拒绝啊, 所以说这个是可以表示他是存在一个鞋子的,明白吗?鞋子完了之后,然后就干什么呢?建立一个 vr 模型对不对? 那么确定之后结束我们就默认,等你之后结束我们就默认就行了,默认了之后我们这个确定就在这里面, 就是这里,然后再选择这一个,我们就根据他们来,我们总共应该我们最后多选八 g 就可以了,在这里面这里看,那么不行最多选八 g, 不行就表示不行,就是那么我们就往后面调 七看,行不行也不行,那么选六届啊,选六届就可以了,之后我们就看一下,看一下这些值啊,就哪一行带信号比较多的,你看一下, 但信号比较多了,比如这里是六阶,对不对?你看他六阶信号比较多的时候,那我在这里再点一个 st max, 在这里我就改为六,那我们就得到我们一个模型了,之后我们说了,得到我们的模型之后,我们是不是要判断这个模型的稳定性呢?模型的稳定性之后就是我们的一个 a r 根,看见没?这是 a r 根的一个 表,这是一个图,我们经常用图啊看一下,我们发现所有的点是不都在这个圆内,那么说明我们这个模型是稳定的,明白吗?那么这个模型就是可以的,那么就最后六阶 之后,六节之后我们就开始看,进行一个脉冲,就在这里脉冲你可以,这是我们的, 这叫慢松冲击这个变量,这是反应,这个面,我们就以第一个吧,就把这个这个打开,对,就以这个, 这样,就 y 对他 y 本身吧,就这样我们来看一下,你看一下这样的一个结果,其实我们最好的一个结果就是这上面是他的一个误差线,我们最好的结果就是他们收敛,收敛在这一条线上其实是最好的, 他们就得到这样一个结果之后我们看这是 y 对他自身一个冲击的一个,呃,那个脉冲响应,我们来看一下他怎么解释,就是这个解释,是不是在第一期的时候他会 开始下降啊?就等于说第一期的时候自身就给自身一个压力,就比如说出国留学人数,对不对?在第一期的时候可能就可能太疯狂了,对不对?第一期就出了很多的错,所以就开始有时候下降了,结果这这样降到第四,这个不行,降的太多了, 那么资金降的太多了,那是不是又开始升了?升的时候又开始降,对不对?他其实就是成一个来回拨动的一个情况,对 不对?那么我们再换一个,比如说我们换一个 x 一,对他的一个影响看一下,那么 x 一我们这样讲的, x 一是什么? x 一是不是居民消费水平啊?对不对?在第一期的居民消费水平是不是就给他一个正的指南?所以我们 是这项影响使得他开始增加,出国人数比较多,对不对?他可能出国的比较多了,用的钱比较多了,然后消费水平又降低了,没有多少钱了,对不对?他出国人数又开始降低了,降低了之后,哎,又赚钱了, 是不是又出国的人又多了,对不对?其实是不是就这样理解就可以了?那么这样脉冲响应完了之后,我们说了,那我就什么呢?方差分解在哪里? 方叉分解就在这里,方叉分解。我们打开这个就是 deck, 是表示的是个表,就是我们方叉分 表的结构,这个就是所有的图,有几个图我们给大家看一下。先从第一个表,表的结构就是这样的,就表的这么这样的一个结果,你看一下 刚开始的第一期的时候,我是不是 y 出国留学人数百分之九十五都是自身影响的,对不对?有四点几,是不是都是 x 一影响了? r x 二的影响为零,那么随着我们的一个 时间的推移的话,其实看一下自身的影响就慢慢的在降低,对不对?而我们 x 二的影响是不是增长的时候,到这里的时候,到第四期达到最大的时候又开始降低, 降低之后降低对不对?降低到了十八期时候,又开始有缓慢的增长,对不对?而我们的 x 一等于他的影响刚开始就有一点影响,然后他突然间增加到二十一了,然后再又突然间降低啊, 再到十八,然后再慢慢的增长,对不对?他是这么一个趋势啊,就是这个的话,其实还有 图,这是一个图的表示,就这么一个图,就说你看你们自己喜欢哪种形式,你们就用哪种形式,那么我们就帮他分解。之后我们最后就是一个什么预测,预测,这是个动态预测,这是个静态预测,我们来看一下动态预测的,命名一下他们的结果有什么不一样, 这是个动态预测,然后我们再选择一个静态预测,我们就对比一下吧,对比一下我们的, 我们再把这个 vr 模型你可以删掉,也可以不删,我们不删吧,我们就把我们的 y 这三个拿出来 it's group 之后,在这里 b u 给你发个 group, 是个图,对不对?我们来看一下, 看一下其实每一个其实都礼盒的其实挺好的,对不对?你看一下每个是不是?但是你们发现我的 y 是每一个都礼盒的一个挺好的一个东西, 我,哎,有点搞不清楚哪个是 y d, 我们来看一下,有点分不清,刚分不清哪个是哪个线的,是吧?我们来看一下图,对不对?那么第一个是 y d, 其实每个线都礼盒的其实挺好的。按照道理来说的话,你看一下我的那个 绿色的线,其实可能稍微更好一点,看到没?绿色的线就稍微好一点,绿色的线啊,明白吧?绿色的线就稍微 更吻合一点,但是红色的也差不多,这个结果差不多,所以说这个动态的和静态的其实差不多的一个,明白吗?这个就是我们整个的一个 vr 模型的一个步骤。
382小徐在上课H 05:50查看AI文稿AI文稿
05:50查看AI文稿AI文稿哈喽,大家好,欢迎回来,我是武松老师,刚才呢我们说了初级,说一说如何进行同居学描述的,第一种叫做频率 sps 实现方法,我们呢现在再来学一下, 我们还研究身高啊,你 选其他的就可以了,那我们还研究身高,我们用另外一个 功能点分析秒统计,我们选第二个叫做描述。 ok, 好,点描述来,第二个功能窗口就出来了,功能窗口是不是一样的?是不是?松哥以前说过的套路还是一样的吧,对不对?他至少包括两个锅,一个锅里面就是我 这个数据库中包含了也变量啊,然后呢,还有一个空锅,你现在想对哪个变量放到锅里面,想烧,想进行研究,把它放过来就可以了。放有两种方法,一种呢就是点身高点右肩,点身高点右肩, 另一种呢就是双击身高,他就自动跳过去了。 ok, 好,我们把身高放进去之后呢,我们右边呢再点三级参数窗口,点选项,点开选项之后我们发现呢比较简单,包括 这最大值方差 范围,也就是机叉身份位数啊,这个是标准物,下面还有风度和偏度啊,风度偏度,哎,我勾选一下吧,不然大家心中有困惑,为什么这两个是干什么事情呢?是不是? ok, 我们勾选好了之后,我们发现,哎,这 一个描述啊很简单,我们刚才频率啊,很多,对不对?频率的时候有很多,咱们描述很简单,但是有两个他是没有的,一个是什么?一个是中位数,是不是 描述不能做?还有就是四分位数间距和百分位数描述也不能做,而中位数和四分位数间距主要是用于描述偏态分布的,而偏态分布的进 描述不能做,也就是说描述这一项功能,他只适用于对称和正态分布。偏态分布不行,如果你要做偏态分布,请用频率。是这样概念。 ok, 好了,之后呢,我们点继续,下面就是展示的这个样式是系统默认的,我们不用管他啊。然后自助收样的本科生不要管他,他是最,他是干什么?他是在我们这个整个总体中, 整个总体中,然后呢,再设定一个抽样的样本量,抽样的样本的一个次数,然后呢反复抽样进行计算,这个结果好,我们不管他。 嗯,我们上理论课的时候还是不是说过一件事情,所有的正态分布可以变换成标准正态分布,是不是啊?那如果我们身高他是一个正态分布的话,能不能够变成一个标准正态分布呢?如何进行一个标准正态分布的一个变化呢?直接勾选这一个,将标准化 化值,标准化值就是那个 z 值或者是幼值,对不对?给它另称为变量就可以了。好,我们点确定,结果刷就出来了。 我们刚才发现什么了?我们选频率的时候,他结果好长,上下拖拖拖拖,拖了好长时间才能看完,是不是?我们研究频率?可是我们发现我们现在描述的时候他是什么?他好宽,刚才那个结果好长,现在结果好宽,那么这就是我们前面 所勾选的这些同级学指标对不对?你看最大值,最小值方差极差最大,还包括这个偏度系数和风度系数,偏度和风度的呢,是专门反应我们正态分布,他是不是左右对称的,是不是见效风和平过风的啊? 怎么看呢?可以参考一些同学书籍啊,防止我说的时间太长啊。那么这就是描 数啊,我们发现描述还是比较简单的,对吧?就这么一张表就可以了,你们在进行做的时候很多,如果 你第一次来定做,你发现你的结果和我的不一样,不是指素质不一样,是展示方式不一样,你们的结果都是带数格的,你的结果都带数格的,你要想改变一下,只要点编辑啊,选项编辑选项,在这个透视表里面,你们那个都是默认的,经典区省的默认的, 一定要选择 xdm 和学术型的啊,选择学术型的之后点应用,点确定,然后得到的结果就是我这样子的结果了, ok, 这就是描述,描述是不是简单?我们再回到我们的数据实图,发现 在整个数据的最右边,这是不是身高,这是 z 身高,就是标准正太变换后的,那么这一个标准自带分布的一个身高,标准 内分布升高,他有什么特征啊?什么叫标准的内分布啊?标准的内分布是以零为对称,中心是以一为标准差的, 我们来验证一下他到底是不是的,是不是?那我们这时候怎么办呢?当然了,也可以选分析,秒统计,然后再把 z 身高放入,对不对啊?然后再点确定。大家注意了,这个锅里面不是讲每一次只能够放一个,可以放多个的啊,我们点确定, 结果刷出来了,出来之后我们发现 z 升高的均值是多少呀?啊,在这地方 z 升高的均值是不是零啊?均值是不是零, 然后他的标准差是不是一啊?标准差是不是一,是不是这样概念,哎,或者刚才这样实现了,你再算的过程呢?有点有点慢,你可以什么啊?这就是我刚才又另存为变量的时候,他又又再次保存着这个,这就是回到我们刚才第一次操作的,你 直接点右键,然后描述统计,直接点右键描述统计,然后你立马就会发现他的均速是多少呢?是零,他的标准差是多少呢?是一,是不是? ok, 好,这呢?啊,这小节呢,我们讲的比较比较比较简单,比较顺利一些,就是 spss 的第二个统计描述的这么一个小模块,就是 更新秒统计里面这个描述。这个描述主要是针对什么的呀?描述主要是针对于对称分布和正态分布的。对称分布和正态分布的,而我们的前面的频率可食用于老大 老爱老三,老大老爱老三都可以,老大老爱老三都可以。哎,描述只能够用于老大,而且是对称分布的。 ok, 好,这一小节讲到这地方,下一集呢我们来讲探索。
66松哥统计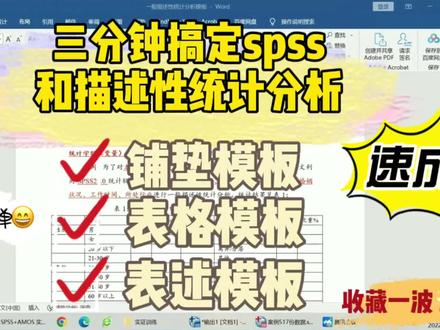 03:34查看AI文稿AI文稿
03:34查看AI文稿AI文稿朋友们大家好,我是马老师,今天呢我们根据一般秒速与统计分析模板来教大家快速完成一般秒速与统计分析的转型和操作。首先在我们的铺垫模板部分,我们只需要对我们的售房对象和人口,我们进行特征变量进行替换即可。那么在本次的案例中的话,我们把售房对象切换成本次重要企业员工,把我们的人口 机学特征电量替换成性别,年龄,学历,工作岗位,收入,婚姻状,工作时间或手术环境。你可以根据你自己的研究的对象和人口同居去特征电量进行替换即可。那么第二点,针对我们的人口同居特征表,我们只需要计算出性命和比重。首先我们点开我们的十八式, 点击分析,点击描述统计,点击频率,然后把我们的人口统计学特征变量输入进去,包括性别,做出行业,点击进去,然后点击确定,我们就可以得出我们的聘率表,在性别方面,我们把 分别分别扣费进去即可。然后在年龄阶段同样的操作, 等我们全部把拼音和笔中填写完毕,然后再制作三十秒高,首先全选 统一,四号选五号,点击右键表格属性边框和底纹,把中间的线条和两边的线条全部去掉,再点击确定,然后选中第一栏,点击右键 表格属性边框和底纹,把下面的那一行点击,然后再点确定账号,我们三线表就已经全部完成。那么在完成我们表格之后,我们就需要进入文字撰写部分,首先我们 表一结构显示加文字描述部分,我们给大家准备了五种文字描述模板和表达方式,大家可以进行自由组合。首先第一点就是直接对比,一般是针对两个分类边量相性别。我们的模板是在什么什么方面? a 所在的比例会多了多少? b 所在的比例多了多少? a 比例略高于 d, 我大致相当于 b 比例。 例如,在本次的案例中,在售房的性别方面,男性所占的比例为百分之五十二点六,女性所占的比例为八分之四十七点四,男性比例略高于女性比例。 第二点,我们看集中趋势,一般只是针对三个或三个以上的分类变量,比如年龄、职业的,我们的模板是在什么人物方面主要集中在 abc 所占的比例为, 在本次的案例中,我们在年龄方面主要集中在三个趋势,分别是二十岁以下、二十一岁到三十岁,三十一岁到四十岁。所以我们在撰写过程中,在售房者年龄方面主要集中在二十岁以下,二十一岁、 三十一岁、三十一岁至四十岁年龄段所占比例分别为百分之三十五、百分之二十四点四和百分之二十点六。第三个,我们需要计算比例,适合我们的模板是在什么方面,主要集中在 a 和 b, 两者所占的比例高大多了多少?我们在本次单位中,在学历方面主要集中在大专和本科,两者所占的比例为七十六点二。 第四点,我们进行比例大学的排列,一般只接受前两位,我们不管是在什么方面, a 所在比例为多少?其次, b 所在的比例为多少? 在本善男中,我们在婚姻状况面,未婚的守望者所占比例为五十点一,此视为已婚者所占比例为百分之四十二点七。第五点,我们需要关注比例最小部分,我们的模板是 a 啊,共有多少人紧张? 比如说我们在本次案例中啊,数字学历仅以八,他所占的比例为百分之一点五。那么以上五种模板大家可以自由进行组合,结合自己用,灵活应用,不必担心。查图, 以上完整版的阿里描述就像这样展示给大家,那么更多详细版的视频讲解请到我们的主页上。第三天,一般描述与统计分析一到四的讲解,今天的课程就到这,谢谢大家!
762MA 学长 00:07
00:07 00:50查看AI文稿AI文稿
00:50查看AI文稿AI文稿这个主题谈单描述性统计的使用方法。描述性统计应用制表和分类图形以及计算 概括性数据来描述数据特性的各种合同。简单理解就是抽取样本后,对样本采用各种分析方法,找出样本中存在的规律信息,然后采取进一步的分析方法。常见的描述性统计方法有一样本精致,二、中位数、 三重数、四极差,五、样本方差、标准差,六、偏差。封路。包含了对样本分布位置中心气质散布程度的不良, 这是用命运推额做出来的描述性统计分数结果,这是重要的分布情况,这是底,是平均值和标层差,这里是最大值和最小值以及中位数,这是参数估计的百分之九十五自信期间。




