spss线性趋势卡方检验步骤

粉丝2150获赞1.8万
相关视频
 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿六十秒教你学会 spss 交叉卡方检验,可带座指导。第一步,我们把数据导入,即复制后点击分析描述统计交叉表。 第二步,将我们需要分析的变量分别放入变量框中后,点击统计卡翻继续可以勾选显示粗壮条形图,点击确定 我们需要的结果就出来了,我们勾选的显示粗壮条形图也出来了。第三步,将结果粘贴复制到 excel 表格中并进行整理,汉会图可以参照图片琐事整理结果。 第四步,把我们整理好的结果粘贴复制到五二吨档中,可以参照图片琐事进行分析。
49艾吖法数据 00:33
00:33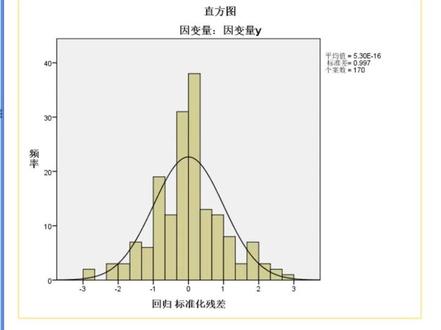 01:47查看AI文稿AI文稿
01:47查看AI文稿AI文稿sbss 操作步骤讲解系列第二十一课一元现性回归分析 回归分析主要目的在于了解自变量与因变量之间的数量关系,通过普通最小二乘法进行回归系数的探索,且通过回归方程的相关系数检验、 f 检验和 t 检验对系数。 第一步,将数据导入 spss 中并进行复制后点击分析回归线信。 第二步,进入图中对话框后,先将对应的变量放入对应的变量框中,点击统计,勾选估算值模型拟和置信区间得并过森,点击继续。 第三步,点击图,勾选直方图,正态概率图,且在散点图中 y 里放入 spread, 在 x 里放入 spread, 点击继续确定。 然后一元现性回归的模型摘要欧 nova 表系数残叉统计,即勾选的图结果就出来了。 将结果粘贴复制到表格中进行整理。首先将系数表的结果粘贴复制到表格中,将显著性后的部分删除后,将模型摘要的二二方和调整后二二方,即 n o 外表中的 f 值,根据显著水平标记对应的心数放入表格的下方。 学会了吗?记得点赞关注哟,可带坐指导学习交流!
330艾吖法数据 01:41查看AI文稿AI文稿
01:41查看AI文稿AI文稿每天学一个吹定 vivo 实用指标今天学的是 bolin 的 bands regression forecast, 使用传统布林带仅能识别当前价格区间,却无法预判未来波动率的扩张与收缩趋势。本期将为您介绍布林带回归预测指标 bolin 的 bands regression forecast, 通过本次专业讲解,助您提前掌握价格未来运行区间,提升反转信号捕捉与趋势判断的精准度。该指标对经典布林带进行了预测化升级,在保留移动平均线精准与标准差动态包落的基础上,新增限性回归模型, 可直接外推未来 k 线对应的布林带轨迹,形成平滑漏斗状预测区间。无论市场波动率处于扩张还是收缩阶段,均可提前识别趋势变化, 避免因价格已形成走势后才被动应对的局限。该指标为了满足操作者实际需求,有以下五大优势,其一,回归引擎可精准预测未来布林带走向。其二,动态通道宽度随标准差与斜率实时调整,与真实市场波动率高度适配。 其三,自动标注实时上下预测点位,无需人工计算参考值。其四,当价格突破不灵带边界时,将自动显示三角形标记,便于快速识别超买超卖反转节点。其五,精准线可随短期趋势变化调整颜色, 清晰指示趋势方向,且支持颜色自定义功能,灵活性极强。该指标不仅适用于趋势操作,同样也适用于回归操作,只需重点掌握三大核心应用场景, 一、趋势判断场景。若价格沿上轨预测线运行,表明趋势动能强劲,可考虑延续持仓。第二,反转捕捉场景,当出现三角形突破标记时,结合成交量数据进行确认,可精准把握均值回归操作机会。 第三,盘准应对场景,当回归预测显示布林带收窄时,需提前做好波动率收缩的应对准备,避免盲目追涨杀跌。记得点赞关注哦!
1690小海豚指标 00:32查看AI文稿AI文稿
00:32查看AI文稿AI文稿毕业论文数据分析卡方检验建议收藏备用。卡方检验主要处理分类变量之间是否存在显著关联,比如男女得病的比例是否一样。在 spss 中点击分析描述统计交叉表, 将性别选入行,是否得病选入列统计量中选择卡方,点击继续。单元格中选择型百分比,点击继续,点击确定就可以了。
752论文小助手! 02:12查看AI文稿AI文稿
02:12查看AI文稿AI文稿一百五十秒教你学会 spss 多选题,单选题的交叉卡方检验可带坐指导。 第一步,我们将数据导入 spss 软件中并复制后,我们先定义好多重响应的定义电量,及后点击分析多重响应分析交叉表。 第二步,将我们需要分析的变量放入对应的变量框中。住分组变量需要定义变量分组数的最小值,看最大值后点击选项勾选行越,点击继续点击确定, 然后我们需要的结果就出来了。第三步,将多重响应交叉表的结果整理成如图所示的结果 后,将图中右侧结果导入到 spss 软件中。注, spss 软件分析需要具体的数值才能进行分析。 第四步,我们整理出来的结果需要对人数进行个案加权处理,如图所示。点击数据个案加权。进入个案加权处理后,将需要加权的电量放入个案加权框里,点击确定。 第五步,对人数进行个案加权后,点击分析描述统计交叉表, 将需要分析的变量放入对应的变量框中,点击统计勾选卡方,点击继续单元格,勾选十册齐旺百分比里的行业, 点击继续确定。然后我们需要的交叉表的结果就出来了。 第六步,我们将结果粘贴复制到一个调表格中并进行整理,可以整理成如同所示的结果。 第七步,我们将整理好的结果粘贴复制到沃尔顿党中,并对结果进行文字解释。看三线表地制作可以参照图中进行分析。
252艾吖法数据 07:32查看AI文稿AI文稿
07:32查看AI文稿AI文稿大家好,上一张呢,我们介绍了我们的参数检验,那这一张我们讲一下非参数检验,那参数检验呢,是吧,在已知总体分布形式的那个,就知道那个总体分布对我们总体的一个若干个参数啊,君子啊,方查的进行检验,这个呢是我们的参数检验, 但当很多情况我们对总体那个数据啊,分布啊,不知道的情况下,未未知的情况下。然后呢,我们要通过样本啊,来检验我们那个总体分布的那种假设啊,这种检验方法呢,就是非常显眼。 那非仓鼠检验呢,应用范围也也很广,是统计我们发现方法分子那个方法中的一个重要组成部分。相对于仓鼠检验呢,非仓鼠检验所需的假定前提条件比较少,不依赖我们总体的一个分布类型,不依赖整体 根部类型啊,就可以用来检验啊,我们数据是否来自同一个总体啊。然后我们本章呢介绍卡方检验,二项检验,邮箱检验啊,单样本配置检验、 两独立样本检验,多独立样本检验,两配的样本检验和多配的样本检验啊,这些非常的检验。首先呢我们来介绍第一 解啊,卡芳杰,卡芳杰,那卡芳杰的目的呢啊,就是通过我们样本数据的一个分布来检验总体分布啊,总体分布与我们的期望分布,或一或其他的一个某一个理论分布啊,是否一致? 那零假设呢,就是我们的样本的总体分布啊,与我们的期望分布啊,或者理论分布啊,我无显著的差异。下面呢我们就通过一个具体例子啊, 来看一下卡房节应该怎么进行。首先我们打开数据, 第六张零六零一打开啊,这个呢是正 制筛子的一个制筛子的一个鞋,总共呢制了四十二次啊,整只制了四十二次也筛子筛子的点数就一二三四五六,一二三四五六,我们现在呢就要啊利用卡放检验啊, 说来检验我们这个筛子的点数啊,是否是均匀分布的,是否是均匀分布的,也就是你认筛子那个点数啊, 都是随机的,随机的,首先呢我们分析非常的检验 打方挡住我们卡板间的一个对话框,左边呢就是我们那个变量,这边呢是需要检验变量的一个列表,需要检验一个变量的一个列表,好,那是吧, 我们这边就让我们的筛子点数选入我们这边的简变变了列表。好,整进去我看一看下这边的期望全剧,期望全剧 从数据中获取啊,这个对表面我们检验的那个必然那个所有数据啊都参与检验,都参与检验或者指定使用指定的范围,就是用我们用户呢可以制定一个取值范围啊,在上线和那个下线中 输入啊,整数值只有在这个范围内的那个数据呢参与检查验结,那我们这里呢就是所有数据都参与检验期望值啊,所有类别相等,所有类别相等就表明我们表示我们这个期望期望的分布呢是均匀分,均匀分,如果是值 啊,那我们就在这边啊,我们自己输入我们期望平数值,期望平数值,然后比如说我们输入一,然后添加输入二,添加输入三,添加输入三点,所以现在我们在输入值的时候呢,这个顺序很重要,顺序很重要, 比如我们设定一个是吧?顺序,比如我们一添加二添加,三添加,一添加,二添加的话,这样的话我们就得到一个顺序,是吧?一比二比三比一比二,这个呢顺序呢与我们检验别人的那个类别值啊,顺序呢是相相对应的, 就你在这边输入的那个比例啊,期望分布有我们这边检验背下的那个啊,顺序是需要一一对应的,是一对需要一一对的,所以这边的顺序很重要,顺序很重要,那我们这边呢是因为检验的是均匀分布啊,所以说我们是所有类别相等 啊。下面看一下精确按钮弹出一个,是吧?紧接进法,紧接进法他这个适用于啊,样本数据服从鉴定分布啊,或者样本较大。那第二个 模模模特凯瑞啊,模模特凯瑞,这个呢是自信度样本数啊,在这边叫自己输入,这个呢是主要适用于啊,样本不符,不满足见你分布啊,或者压本较大,或者压本很大。 那我们的金券呢啊,每个检验的时间设置为五分钟,是吧?他们主要是适用于小样本,系统默认那个检验时间呢?是五分钟,系统默认检验十五分钟啊,那我本领呢,我们就选选择紧接力法,继续 选项卡放前的一个选项啊,第一个呢是关于统计量描述性十分位数,那描述性呢, 就是输出我们检验片的那个描述统计量描述统计量那十分,为什么呢?就是输出检验片的第二十五,五十,第七十五啊,百分位数,那比如说我们都给他选上,下面呢就是两个啊,确实指的处理方案。第一个呢,按检验排除个案,按检验排除个案,就在分析过程中,我们仅剔除在变量 为缺失值的个案啊,在被量上,就在我们分析的时候用到的被量如果打成了缺失值呢才给踢出。而另一边排除个案呢,就是说踢出所有含有缺失值的缺失值的个案,就我踢出含有缺失值的所有的个案我都要踢出。报告答,参与参与参与分析啊参与参与分析, 我们这边呢就按检验啊排出个案,继续好,设置完毕以后我们确定看一下我们卡方检验的一个输出结果。好,首先呢是一个描述统计表是吧?那我们这边 筛子点数就是我们的那个需要经验的那个变量数值四十二,就是我们有四十二个格案,平均值啊,平均差最小,最小值一,筛筛筛子嘛,一点最小,六点最大。好,下面的散字点数啊,散字点数,观察到我们的散字点数是吧?散字点数为一的 七次,二的六次,三的七次,四的六次,五的八次,六的八次,六的八次。而他们预期的,因为我们是均匀均匀分布吗?所以说每一个都是七次,他们残差是减相减零负一零负一 加起来肯定等于零的。下面就是一个检验统计啊,检验统计,我这边可以看到一个卡方啊,卡方值零点五七,只有总的数五,总的是三十点数六进行写注信,零点九八九远远大于我们的零点零五,远远大于零点零五, 所以说呢,我们不能拒绝我们的零假设啊,那么零假设就是说我们样样本的数据的那个分布啊,与我们七号分布呢,是没有显示差异的,也就是我们的色色点数的次数啊,是均匀分布,均匀分布。好,我们卡方奇就给大家介绍完了。
120质性分析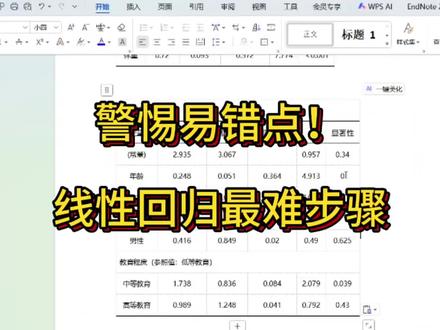 07:45查看AI文稿AI文稿
07:45查看AI文稿AI文稿那下面的话我们看一下,如果是三分类变量怎么办?首先三分类变量我们是不可以直接把它放到模型里面去的,它会显示什么呀?不允许存在制服串变量。但是呢,如果我们把这一个全都调成数字了,然后包括这里我们也给他改成数字,这样我们就可以了吗? 那还是不行的,因为你如果直接放进去,他会给他认为是连续变量,而不是一个三分类变量,那这里就跟二分类变量不一样了,这种情况下他的数值是会改变的,会影响到我们的结果。所以如果是三分类变量,我们要怎么操作呢? 首先要点击转换,然后点击创建需变量,然后把我们这个三分类的变量放进去,这里的根名称我们就随便选择一个,但是我的建议是要用英文去输入,然后在这里的话啊,点击省略第一个需变量或者不选都可以,然后点击确定, 然后它就会生成三个值。这里要注意一下,如果是三分类的变量,它会生成三个值,然后如果是四分类,它就会生成四个值啊。然后我们可以观察一下每个值它的特点是什么? 这里的话只要是这个中等教育水平,只要是中等教育水平,第三列它就全是一, 然后只要是这个低的教育水平,第二列就全是一,然后只要是啊,这个高等教育水平这一列就全是一。那其实我们这几个变量都对应什么?这个是高等教育水平, 这个是低等教育,这个是中等教育, 然后我们给它命名完了之后呢,我们就可以把它放到我们的回归模型里面, 但是这里要注意一个点,我们如果它是一个三分类变量,我们只需要放其中的两个就可以了。比如说我们把 d 还有中放进去, 千万不要把高也一起放进去,因为我们做虚拟变量之后呢,是只需要放 k 减一个变量进去的,我们不是三个完全放进去,然后哪一个你留在外面,它就是你的参照变量。然后我们点击确定这里面的话, 这一个低等教育水平,它的显著性,还有包括它的系数都是相对于什么来说的,相对于高等变量来说的。 所以你在解读这一个回归分析,尤其是三分类变量的时候,一定要明确这一个 d 它是相对于高而言,它是这样一个数值,然后这个中等它也是相对高而言,它得到的是这样一个结果。然后如果我们现在要啊换一个,我们现在不要用 高等作为参照了,我们可以把这个低等放出来,然后再把高放进去,然后这样的话,哎,我的我们的模型就会出现高等的教育,还有中等的教育,然后我们这里面就会发现,哎,高等教育他相对于低等教育他是不显著的,但是中等教育他这里是显著的 系数系数的话,它如果是大于零,代表它是一个正向的,如果它是负值,代表它是一个负面的一个变量,那就是它是一个正向的,相比于低等交易它是一个正向的一个影响。 然后就是这个就是我们的一个回归分析了。然后像这个的话,我们来教一下大家怎么做这种分类变量?它的回归的一个表格, 像这一个的话,我们还是一样的,这些标题啊,啊,就是我们是完全可以参考上面的,我们先给它复制过来, 然后年龄体重这个也是一样的,我们复制过来,然后这个是二分类变量,对吧?这里就要注意一下,我们要首先啊在上方插入一个行,然后这是二分类变量,我们就给它定为性别好了。然后这里的话啊,下面这一个啊,我们就写男性, 这里记得要打括号 参照值, 女性。然后这个就是我们的一个效应变量啦,然后这个你可以不管合并也好还是不合并也好,都是没问题的, 然后记得把它弄到左边过来,然后下面这一个也一样,我们先在上面插入一个行,然后这个是什么呀?这个是教育程度或者文化程度,然后我们这里纳进来的是什么变量?中等还有高等。那我们的参照值是什么呀? 参照值就是低等教育, 然后这里就是中等教育,这个是高等教育,然后这一个的话就是我们最终得到的一个模型啦, 这个就是我们要呈现的结果,我们还是一样的复制好,我们先给它变成紧凑先,然后把这一些全都挪到左边,这样看着漂亮一点 啊,一起放到这边 带格式粘贴,然后记得不要选到第一个啊,这样我们才可以作对。然后像这样,那我们这一个就已经整理好了, 我们可以看一下最后的一个效果,不显示区框。 ok, 那 就是这样子, 就是注意一下分类变量一定要标参照值,然后分类变量是两个变量的,二分类变量的话,它是会显示有一条数据,然后如果是三分类变量,它就是显示两条 四分类变量,那就是三条。然后我们再检查一下这里面的效应量啊,这些有没有满足我们的小数点要求啊?其实是没有满足的,对不对?我们之前怎么跟大家说的呀?如果是效应量 标准物标准化系数 t 值都是保留两位数字即可,只有显著性是要保留三位有效数字,那我们回到这里, 我们只需要怎么样啊?把这些勾选起来,右键设置单元格格式,选择数值,然后这里是两位数值,点击确定,然后包括下面这个也一样,设置单元格格式,数值确定。 然后这个是最后一行的,这里记得给他补个零,然后这里应该是什么?小于零点零一, 这个给他补个零。 ok, 那 我们再把这个复制回来, 记得我们不要贴紧这个表格去粘贴,很容易把两个表格粘到一块的。 然后这个还没完成,记得我们从第二行开始往下拉,点击三线表, ok, 那 这个就是我们最终做成的表格啦。 嗯,好啦,这个就是我们的一个限性回归的啊,一个操作,还有最终要呈现的表格,当然这个只是其中一个部分啦,包。
31KK学长鸭 02:15查看AI文稿AI文稿
02:15查看AI文稿AI文稿sbss 操作步骤讲解系列第二十二课多原线性回归分析 多元线性回归分析主要研究多个自变量对一个因变量的影响关系数据需要满足的条件。与一元线性回归分析一样,区别是由于自变量较多, 因此需要考虑自变量之间多重贡献性问题。方差膨胀系数微服饰衡量多原线性回归模型中多重贡献性严重程度的一种度量。一般问卷数据 f 值在五以下,超过可能存在贡献性问题。 操作步骤第一步,首先需将处理好的数据导入 spss 中并复制后点击分析回归线信, 进入图中对话框后将需分析的变量放入对应的变量框中后点击统计勾选制性区间部分相关性和偏相关性得,并过深共性线诊断,点击继续 点击图,在散点图碗里放入 spread x 里,放入 spread 后勾选直方图,正太概率图,点击继续确定。 然后多元限性回归的模型摘要 ono 发表系数表,贡献性诊断残差统计脂肪图标准化的残差正太星 pp 图,散点图结果就出来了 江 spss 里得系数表结果粘贴复制到表格 格中,去除显著后的致信区间的上下限相关性和共性线性的 ff 内容,然后在表格的下方加入模型摘要里得二方, 调整后二耳方和 annova 表里德 f 值,根据显著性标记心术,然后将整理好的结果粘贴复制到 word 文档中进行文字描述及三线表的制作。 学会了记得点赞关注哟,可带坐指导学习交流!
1078艾吖法数据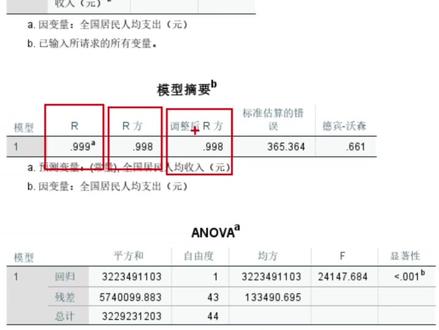 42:32查看AI文稿AI文稿
42:32查看AI文稿AI文稿限行回归是最基本的回归,也是所有回归分析的基础啊,那么限行回归要求变量之间的关系,也就是一变量与自变量的关系,是限行关系,也叫直线关系,因为他们的回归线是一条倾斜的直线,我们讲相关是回归的前提,只有有相关关系才能做回归分析 啊。那么关于相关性分析,在之前的上课的时候已经讲过了啊,在这里我就不赘述了,如果大家还没有看过,可以翻看一下之前的视频 啊。那么先回归的模型表达式呢?是 y 等于百分之一 x 一 加百分之二, x 二加加加一直加到百分之 x p, 再加上一个误差项样本,那么这个表达式里面百分之表示回归常数,那百一到百分之呢,是指的是回归系数样本,是随机误差,也叫预测误差。 那么其实这个表达式呢,是一个理论表达式啊,使用价值并不大,为什么呢?首先它有一个误差项,这个误差项是算不出来的啊,那我看讨论区有同学讲,万一算出来误差项,因为你如果能算出来误差项,那么你这个人太牛掰了, 也就意味着你可以精确预测,就说你预测未来的一件事情,或者或者是预测预测未来的一个东西,你可以百分百准确的预测,那这是不可能的啊, 我之前已经说过了,那么基于这个表达式呢,我们衍生出了一个经验回归方程啊,那么这个回归方程呢,是 y h 等于 beta 零 h 加 beta 一 h x 一 加 beta 二 h x 二加加加一直加的 beta p h x p, 那么这个数字呢,就去掉了这个误差项,因为这个误差项算不出来,你把它戴上不是累赘吗?没有用对不对?但是为什么这个 y 要戴个帽子呢?而且 beta 零啊,一直到 beta p 也戴帽子呢? 因为这里面就不能等于 y 了呀,因为去掉一个误差项,它跟 y 是 不一样的,所以这个预测值呢,就叫 y hat, 加上一个帽子,那么 y 与 y hat 是 有差异的,那这个差异呢?就叫残差,对不对?就是我们的误差项。那么为什么 beta 也要加个帽子呢?因为我们在实际应用过程中,这个 beta 包括 beta 零,一直到 beta, 屁是用一个样本去求出来的,我们求出来的只是这个 beta 的 一个啊,估计值叫做无偏估计值,因为你用你的样本算出来的 beta, 和我用我的样本算出来的 beta 可能是不一样的,但是都叫无偏估计值,都是可以用的,所以 beta 也加个帽子,叫 beta hat。 那么先行回归也有自己的信用条件,我们简称叫 line, 加上自变量不打架。 line 是 四个条件,包括限性、 linear、 独立、 independence, 这个正态性,正态分布是 normality, 那 么这个方差奇性呢?叫 equal variance。 那 么无多重贡献性,就是这个自变量,不打架,无多重贡献性,指的是自变量间无相关关系,无很强的相关关系, 那么主要用于多元性回归,就是自变量 x 有 多个,有大于等于两个啊,那么关于这个使用条件啊,在国内有一个很著名的统计学老师,大学老师他 做了一个很形象的比喻,但是这个比喻不太恰当,他把回归呢啊,比作结婚娶老婆啊,我们知道在我们医学里面啊,那么性染色体 y 是 不是表示男性, x 表示女性,那么我们的这个回归也是研究 y 与 x 之间关系,如果 只有一个 x 啊,也就是一元回归,那么我们叫一夫一妻制啊,那么如果有多个 x 叫一夫多妻制,那么这个无多重贡献性呢?指的是这个自变量啊。 x 他 之间不能有很强的相关关系,比如说你娶老婆,假如说你娶了多个老婆就一夫多妻,那么你这些老婆之间的关联不能太强。我举个例子, 假如说你娶了五个老婆,就一夫五妻,对不对?其中三老婆是一家的亲姐妹,三全让你给娶回来了,你想一想,这个家庭可能稳定呀,是不是 按照宫斗剧的一个情节,这三个老婆应该先联合起来干掉另外两个,然后他们三在内斗,最后只有一个能成为正宫娘娘,能成为这个皇后,对不对?那么这个家庭是不稳定的。那放在模型里面,如果多个 x, 其中有些 x, 它的关联性太强了,那么这个模型也是不稳定的, 懂不懂?放在家庭里面,家庭不稳定,放在模型里面,模型也不稳定。所以说这个其实道理都是相通的。在人类社会也是啊,就说你一夫多妻制的这些国家,你娶了多个老婆,他们关系不能太好,就这些老婆之间最好是互相不认识,如果 互相认识的话,也不能太熟悉啊,如果太熟悉的话,容易拉帮结派啊,这这样一个道理,虽然不太恰当,但是很容易帮助大家理解啊,是这样一个意思,那么先有回归要求,资源量 x 啊,比较宽松。资源量 x 可以 是计量资料,也有数值性资料,也可以是等级资料,也可以分类资料。 那么一面的 y 呢,只能是计量资料,比如说先违规的 y 只能是数值型资料啊,那我看讨论区讲,万一是其他的,其他的怎么办呢啊?如果他是等级资料或者分类资料,我们有办法处理,等一会我会讲那个逻辑回归的时候,大家就明白啊,我们后面再说啊,这里我们先讲这个先性回归, 那么先性回归根据自变量 x 的 个数可以分为一元性回归和多元性回归,一元性回归就是一负一期,对不对?那么它的理论表达式呢?是 y 等于 b 零加 b 一, x 一 加 f 这种,但是我们讲理论表达式不使用。我们有个 经验的回归方式叫做 y height 跟 b 零 height 加 b 一, height x 一, 那么一元线回归主要是研究音标的 y 与影响它的最主要的那个因素 x 一 啊之间的关系啊,那么一般是研究最主要的这个因素。那么多人线回归是应用的是比较广泛,那么它的理论表达式是这样的,那么经验回归方式呢?是底下这个标红的, 那么我们接下来就用实际的案例,用 space 操作,如何做这个信用违规?首先是一元信用违规,那么还用刚刚的这个例子,就是全国居民的平均收入与平均支出之间的关系,我们做这个信用违规,我们讲这是一夫一妻对不对?就是一个 y 和一个 x, 但这里的 x 啊,自变量就是收入,阴变量就是支出啊 y, 那么这个数据呢?在 test 二十五数据啊,刚刚讲的,这是一个真实的数据啊,是从一九八零年到二零二四年四十五年的这个国家统计局的一个数据,我们打开 space 啊,找到这个 test 二十五啊,输入与支出打开, 那么刚刚我们已经展示过那个散点图了,它是存在限行关系的,对不对?它的那个回归线是一条直线,那么我们直接做这个,先回归,我们点分析回归限行,回归好,我们的页面量就是 y, 就是 这个全国居民人均支出,那么自变量 x 就 一个,就是输入, 那么底下的这个方法呢?就是输入 y 与 x 的 一元回归,那么只能输入,就像娶老婆,这个方法呢,就是这个自变量 x 进入模型的方法, 也就说你娶老婆,你是怎么把这些老婆娶进门的?那么这个输入呢?是强制啊,录入,强制纳入模型,比如说啊,娶老婆,你是强抢民女娶过来的,无论这些个 x 对 你有没有意思啊,这个 x 有 没有意义,有没有同学意义,也就说你娶了这些老婆,无论这些老婆喜不喜欢你,你喜不喜欢她,都要强制取进来,对不对?这就叫输入, 全部都丢到模型里面,那么底下四个呢?等我们讲这个,等一会,我们讲这个多元回归的时候,我们会说具体就说一下这几种方法的区别。我们一元回归啊,一般选输入好,这边统计 啊,他默认的有两个,一个是估估算值,一个是模型几何啊,通常我们还要选这个描述统计,因为我们的这边的 x 是 计量资料,可以输出一下这个均值和标准差。 那么底下一个共线型诊断呢?共线诊断是用来多元回归,有,也就是说 x 的 个数大于等于两个数才要做共线型诊断。就是你的这些老婆之间有没有太强的关系,这个共线诊断就是带他们去验个血,看你的这些老婆之间有没有血缘关系,有没有太强的关系,对不对?是不是就是检验这个共线性,那么底下还有一个 残差啊?那么有个 davidson 是 检验独立性的,我们不是要求这个,这个先有违规的几个条件啊,有一个叫独立条件对不对?这个是验证这个,但是呢,这个通常我们不做,为什么呢?因为这个只是帮我们检验它在数学上的独立性,数字上的独立性, 那么但其实我们更关注这个专业性的独立性,也就说你的实验设计上的独立性,如果你是独立设计的,独立撑组设计的,那么我们更关注于这个,所以我们经常不做这个。 davidson, 那 么为了给大家展示,我把它勾下来, 等一下带大家看一下这个结果是什么意思啊?通常我们不做,那么这个各项呢,我们一般用这个离群值三个标准差,也就是说他会把这个比这个均值小三个标准差以上,或者大三个标准差以上的 定义为离群值,就是异常值,会帮我们找出来,好,就是点继续。然后这个图呢?这这个呢,是帮我们验证这个方差奇性要求和正态性要求的。我们一般做一个三点图啊, x 轴呢,通常是预测值,就是 z pre 的, 叫标准化的预测值,那么 z reside 这个是标准化的残差,作为 y 种,然后这个直方图和正态概率图呢,是检验正态性的,我们点继续,然后这个保存呢,我们可以输出一个未标准化的预测值,就是我们通过这个分析不是得到了一个回归方程吗?这个回归方式的 y pad 就是 未标准化的一个预测值,那么就是模型的预测值。那么残差呢?我们可以勾选一个未标准化的残差, 我们讲残差,就是真实的观测值与未标准化的预测值之间的一个差值,就叫残差。我们未标准化的意思就是预测值的原始值,我们一般输出这个未标准化的比较实用一些,那么我们点继续, 那么这是布进法条件,这个我们不用动,因为我们选的是输入,对不对?不是布进法,就是 stepwise, 就是 那个边进边出的那个。这个方法里面,方法里面有一个叫布进法,叫 stepwise, 就是 自变量进入模型的 p 值要小于零点零五, 如果想把一个变量剔除出这个模型,那么这个 p 值要大于零点一。啊,就是这个意思。这个在方程中包含常数项,那一般是默认勾选的,我们点继续,底下两个样式和把选法我们都不选,我们直接点确定。 啊,这个反应比较慢。 好,我们从上往下看,第一个表格是描述统计,就输出一个平均值,标准差啊,该数值是四十五,因为我们是输入了四十五年的收入与支出, 那么它底下是一个相关性矩阵做的 p 二三相关,那么这个相关系数零点九九九, p 值是零点零零零啊,那说明这个相关性是非常强的啊,是不是底下是输入或除去的变量,我们选的方法输入 enter 就是 强制录入啊,底下是一个模型载料。这个表我带大家看一下,什么意思,就包括这个 wos 啊, 我们来看一下。好啊,这个 r 值呢,是一个负相关系数啊,这个是相关性是非常强的。这个阿方呢叫做决定系数,就是 支出的变化有百分之九十九点八,是由我们选定的这个自变量决定的,由于自变量能多大程度决定一变量啊,这个意思零点九九八是非常大的,那么这个调整后的 r 方是什么意思呢?调整后的 r 方是对前面的这个 r 方进行一个较真 啊,阿方呢,他有一个缺点,就是你纳入的自变量 x 越多的话,这个阿方会越大,那么如果你纳入了一些无关紧要滥竽充数的 x, 就是 你的 x 数量非常多,那么就不公平了,对不对?那么我们要对这个进行一个乘法进行一个调整,调整啊,就是排除那些滥竽充数的自变量的影响,那么会有一个调整后的,一般这个用于这个多元回归,就是你的 啊 x 个数比较多的时候啊,如果他们俩差值非常大,说明你纳入的这个自变量有很多是滥竽充数的,很多是这个不显著的或者意义不大的。那么这这是一个 davidson, 就是 我们刚刚的检验这个独立性 啊,这个值呢是等于零点六六一,这个值有点小,一般 davidson 这个结果一般是零到四之间啊,越接近于二,那么这个独立性越好,一般在一点五到二点五之间是可以接受的,这个稍微有点小了。好,底下这个 n、 o、 r 检验就是对这个模型进行检验 啊,就这个模型,你建立的这个回归模型有没有意义?有没有效果?有没有意义啊?那么这是有意义的。那 p 值小于零点零零一,说明我们建立的这个模型是成功的, 那么底下是一个系数,我们给大家看一下啊,那么这个是 b 啊,这个叫系数,他写的是 b, 其实应该是 b, 常数项就是截距项是三百五十八点 三九九,那么这个输入啊,这就是 x 的 系数啊,这个回归系数是零点六八幺。那么这边还有一个是标准化的 beta, 那 么这个我们一般用在多元回归,就是它可以用来比较这些自变量的重要性,如果标准化的 beta 绝对是越大,说明它对这个音音量的影响越大。 底下是一个 t 值,一个 t 值,那么他用的是 t 检验,对不对?底下的是一个残差统计,我们看都是四十五个,对不对?我们没有缺失值,还有预测值残差,标准化预测值和标准化残差, 那么底下这是一个脂肪图,是检验正态性的,我们说这个正态性啊,稍微有一点点差,这里面缺失了一小块内容,是不是?然后这一点有点高了,是不是他稍微有点偏离正态分布了?那么底下有个 p p 图啊,最理想的结果是所有的点都在这条直线上穿着,就跟穿这个冰糖葫芦一样,这其实有一点偏差,对不对?这边有点 偏离这个直线,还有这这这个地方,这个地方有点偏离这条直线,那么底下是一个散点图啊,就是用标准化的预测值和标准化残差啊,做出来一个散点图,这个散点图最理想的形态是什么呢?这个散点图最理想的形态是所有的点都在一个矩形框里面 啊,都在一个矩形框里面,这显然这个地方就缺了一小块,这个地方也缺了一小块,这地方也缺了,对不对?这中间缺了一些,那么这个 结果就这么多啊。这是最后一个图,那么这是一元现金回归,是非常简单的,那么我们接下来看一下多元现金回归 啊,这是刚刚的我们的那个散点图,就是以收入为 x 九,以,这是为 y 做出来的一个散点图,你看它的这个啊,回归方程就是 y h 等于三百五十八加上零点六八 x 啊,注意啊,这里我教大家如何写这个回归方程,如何写这个公式啊?我们得出来的这个系数是不是这样的?看 好 我们得出来的这个常数项是三百五十八点三九九,那么唯一的这个 x, 它的系数是零点六八幺,那我们的这个方程就可以写成 y hat y y y 也就表示这个指出就等于常数项三百五十八点三九九, 加上这个系数是零点六八幺,零点六八幺 啊,乘以收入是不是?是不是这样?那么这就是它的一个回归方程的一个写法,就是用这个啊,系数对不对?就是用这个 beta 啊,好,这是回归方程的一个写法。好好, 我们再看这个多元性违规,所谓多元性违规就是一夫多妻制对不对?一夫多妻就是有多个 x 大 于等于两个 x, 那么我们想研究父母身高对女儿身高的影响啊,我们知道父母的身高是会影响子女的身高对不对?但是对男孩和女孩的影响啊,是不同的,那么我们这里研究它是女儿的身高与父母身高的关系,那么其中父母的身高呢,就是两个自变量,记作 x 一 x 二,那么女儿的身高呢?记作 e 变量 y。 那 么这个数据呢?在 test 二十九这个数据里面, 因为这是一个多元回归,所以我们要勾选这个公式型的,我们打开 test 二十九, 打开,那么这是两个 x 和一个 y 啊,我们直接做这个回归吧,我们点分析回归,有一个新回归,跟刚刚一样,我们的音面量就是女儿的身高,这里是女孩,其实是女儿的身高啊,两个字变量呢,是父亲和母亲的身高。 那么下面这个方法刚刚我们讲过,这个方法就是字面的 x 是 如何进入模型的,那么 sbs 一 共提供了这个五种方法,分别是输入步进,除去后退和前进, 那么这个输入也就是 enter, 我 们刚刚已经讲过了,它是强制纳入模型啊,就是不管你的自变量 x 和一变量 y 有 没有关系,关系显不显著, spass 会把你选中的所有自变量一次性全部都扔到模型里面去做, 那放到娶老婆的这件事情,就是所有的后人你都要把它取进来,不管他喜不喜欢你,或者你喜不喜欢他,那么先取回来再说。 瓜甜不甜,先尝一口才知道对不对?那么这就是输入强制纳入。那么第二个呢,是步进 stablewise, 它是怎么做的呢?就是 bus 系统先挑选一个 最强的自变量,也是最优秀的那个自变量进入模型,然后再从剩下的自变量里面再挑一个最强的进去,再挑一个最优秀的进去。它还有个特点,就是每加入一个新的自变量,那么系统会回头检查这个新的自变量,如果旧的自变量因为新的自变量的加入而变得不太显著, 那么 spras 会帮我们把这个旧的不显著的自变量剔除出模型,那么就是边进边出对不对?边娶老婆边修老婆, 那么大家可能有疑问,那么加入一个新的自变量会对这个旧的自变量产生影响吗?是会的,就拿娶老婆这件事来说,假如说你刚开始只娶了一个老婆,你俩很恩爱对不对?但是呢,你有一天又娶了一个老婆进来,那么你第一个老婆会不会心里面有点不舒服呀?会不会对他有影响呀? 那是会的,那你想啊,你娶了第二个老婆,你第一个老婆肯定就会想呀,我那么爱你,对你那么忠诚,你还三心二意的又找了一个小三,还把她娶进来了,那我就可能就不喜欢你了,对不对?对你没那么喜欢了,那么如果他对你不喜欢到了一定程度, 那么我们说这个布丁法就会帮我们把这个老婆休掉,对不对?他既然不喜欢了,就放他走,是不是这样一个道理? 那么第三个呢?叫除去啊,叫 remove, 这个呢,我们用的非常少,选了除去,那么这些进入模型的自变量最终一定会被剔除模型。这听起来非常奇怪,就像你娶了老婆,你把老婆娶回来,最后一定会把这个老婆休掉, 那这是非常少见的。但是也有这种情况,比如说家族联姻,比如说政治联姻,你自己无法控制,那这个老婆是你皇额娘安排进来,是太后安排进来的,你不娶也待娶,但是呢,等有一天你有实力了,能做主了,你一定会把这个老婆休掉,那么这叫除去。这个除去大家不用去仔细深究它。除去这个方法呢,我们很少用,那么第四个呢,叫后退。 呃,那么后退呢,叫 backward 啊,就是先全部放入,然后再逐一检验,就是他会帮我们把 所有的后选的这个自变量全部放入模型,然后他找那个最没有用的,比如说屁值最大,最不显著的那个变量,把它踢出去,然后重复这个过程,直到剩下的所有的变量都是显著的停止,那这叫后退。就先把所有老婆娶进来,然后找那个对你最没有意思的,你们俩 互相最不喜欢的,先把它修掉,然后剩下的再找内个对你最没有意思,或者你对他最没有意思的内个老婆,再修掉,直到剩下的所有的老婆对你都是忠诚的啊,你都是喜欢的,或者他都是喜欢你的结束,那么这个前进呢?啊,就比较有意思了, 前进是从零开始,逐个增加,就是刚开始这个模型是空的,那么他先找一个最有用的自变量,最优秀的自变量放进去,然后再从剩下的自变量里面再挑一个最有用的,最优秀的放进去, 然后一直重复这个过程,直到剩下的所有的自变量都达不到标准啊,都不显著了,那么停止。那么这个前进与步进有什么区别呢?步进是边进边出,前进是只进不出 啊,前进就是你娶老婆,你把老婆娶进来了,即使这个老婆最后不喜欢你了,到最后你也不喜欢他了,但是你一定要把他留着啊,不会把他休掉,这就是前进啊,那么我们通常只用其中四个,除去,我们一般不用。大家能不能理解这五种方法 啊?我想大家应该是能理解的啊,这个步进和前进他是不一样的,步进是边进边出啊,你娶老婆,如果前面娶的老婆到后面对你没有意思了,你要把这个老婆放走,放他自由,对不对?但这个前进不一样,前进是你只要娶了这个老婆,你就不能把他休掉啊,一定要把他留在家里面,是不是 啊?好,这是这个,我们先用这个输入,就是强制纳入啊,这个方法做一遍,然后这个统计呢,我们要勾一个勾线型诊断 描述,我们也看一下吧,这一次我们就不选这个 wos 了,我们选一个个人诊断吧。那么贡献性诊断就是判断这两个自变量,它们之间有没有很强的贡献性啊?我们点继续这个图,我们依然做一个残差散点图 啊,也做一个正态概率图和直方图,点继续保存,我们这里面就不保存了吧,我们拆掉这个选项呢,这就步进法的原则,刚刚我们不是选了输入吗?如果这里我们选了步进的话啊,我们就需要这里面的选项了,就是步进法 stepwise 不是 边进边出吗?那么字变量 x 是 如何进入模型的呢?只要它的 p 值小于零点一,我们就要把它剔除出去 啊,这个屁值呢,可以理解成你和你老婆之间的这个仇恨值,当你俩的仇恨值小于零点零五,也就是说你们的忠诚度达到百分之九十五以上,你就可以把这个老婆娶进来,但是娶进来,如果这个老婆后面啊对你的忠诚度下降了,低于百分之九十的忠诚度,比如说仇恨值大于零点一了,那么我们就要把这个老婆修掉,这是布进法的一个 啊,一个一个设置啊,纳入和排除的一个标准,然后我们点继续,其他的不用动,我们点确定好, 那么他会帮我们输出,结果我们还是从上往下看吧。好,那么这个描述我们不看了,这是相关性矩阵啊。啊,我们也不看了啊,这个大家应该能看懂,是输出了一个 p 二三相关系数和一个 p 值,那么这个方法我们选的是输入 enter 这个模型,摘药呢,这个也是非常的显著的,我们来看一下 啊,好,这个 r 值呢是零点九六九啊,负相关系数,也就说啊,我们其实相关性是非常强的,自变量与阴变量的相关性竟然达到了这个零点六,呃,零点九六九,那么这个 r 方呢,叫决定系数,也就是说女儿的身高啊, 百分之九十三点九,是由父母的身高决定的。那么这个调整后的阿芳呢,你发现他变小了,是不是说明呢?他对这个阿芳进行了一个修正啊,调整后的阿芳会小于这个阿芳啊,当然了,两个是差不多的,其实那说明我们选的两个 自变量都是很重要的自变量啊,都都没有偏差,没有太多的一个偏差,那底下呢?是一个 nova, 就是 对模型进行检验,那说明这个模型是成功的,它 p 值小于零点零零一,那么底下是一个系数啊,常数项是负的七点四五二,那么父亲身高的这个 啊,回归系数是零点五零二,母亲身高的这个回归系数是零点五零四啊。那么 父亲的身高和母亲的身高,哪一个是对女儿身高影响最大呢?那我们就看这个标准化的白塔,就标准化的一个系数回归系数,我们发现其实父亲的身高对女儿的身高影响是最大的,因为他的这个标准化的系数是零点七多,然后这个母亲身高的这个标准化的 回归系数只有零点五八七,是小于父亲的,所以父亲身高影响是最大的。然后后面是显著性啊,父亲身高和母亲身高都是显著的, 那么这个贡献性统计,这两个是进行贡献性诊断的。我们来看一下贡献性诊断,在这个表格里面,它提供了两种方法,一个是容差 tolerance, 一个是 v i f, 它两个互为倒数,也就是说它俩的乘积等于一, 那么这个容差呢?我们一般大于零点二就可以了啊,如果放宽一点话,大于零点一也行啊,大于零点一或者大于零点二,说是说明我们这个这个贡献性是满足我们的要求,贡献性不算太强,那么这个 v i f 呢,是一般是小于五,如果放宽的话,小于十也行,如果小于五或者小于十啊,也说明啊,这个贡献性是满足的,没有很强的贡献性。 好,这是公式诊断,那底下的也有公式,也是公式诊断的方法,那分别是特征值啊,条件标准和这个方差比例,但是我们通常看上面的这个容差和 v i f 底下的,你了解一下就行了啊。后面我们在 ppt 上再说一说,那么残差统计,这是预测值啊,残差标准化的预测是标准化的残差,底下呢是一个脂肪图,我们的正态性还可以,对不对?还可以, 那么这个 pp 图呢,基本上也都在这个直线的附近啊,偏离不是很多,说明侦测性还是可以。那么底下的这个 散点图呢,我们来看一下,这个散点图呢,大致基本上在一个矩形框里面,对不对?也还可以啊,这一块可能少了一点,但是整体还算可以了,而且这些散点呢,也不是很分散,就在正三到负三之间,对不对?一般一般还是可以的啊, 说明这一题呢,还是很符合这个适用条件的,那么这是一个多元信息违规啊,我们再回到 ppt 上,把这个关掉,再回到 ppt, 嗯,好,我们再举一个例子,再举一个多元回归的例子,研究年龄啊,身高体重啊,与体育课考试分数之间的关系,那么这个音变量就是体育课考试成绩自变量,有三个年龄,身高体重。 那么这是在 test 零三这个数据里面,当然这题也要勾选,勾选一整段,因为它是三个字,面量。好,我们在 sp 来操作一下, test 零三 打开, test 零三打开。好,这是体育课成绩和一些其他的参数,那么这其实应该是一个真实的数据。好, 我们直接来进行分析,我们点分析啊,回归啊,限性,我们的自变量呢,就是体育课成绩啊,不音变量,音变量, sorry 是 音变量,音变量是体育课成绩。那么自变量呢?有年龄,身高和体重, 我们选进去啊,那么这次呢,我们选择这个步进 stepwise, 就是 边进边出边取边修好,然后这个统计呢,工具性诊断,我们简单选一下吧,好不好? 图呢?也作图吧, 保存,我们不保存了,那这里面的购进呢?就有这个作用了,对不对?这个你娶老婆啊,这个他对你的这个仇恨值不能大于零点零五,那么你想把它修掉,那么仇恨值要大于零点一,对不对? 好,我们点确定。好,我们来看一下,因为这个数据量是比较大的。好,这是描述统计,底下是相关性系数啊,这是相关一个相关性矩阵,大家自己看看就行了。那么我们这个是步进,对不对?一共三个字,变量,体重,身高和年龄 啊,这个模型的摘药啊,这个阿方,阿阿方和调整后的阿方。刚刚我已经教大家怎么看了,这个阿方就是一个决定系数啊,如果是多个 x 的 话,一般我们看调整后的这个阿方,这个比较严格一点啊,如果你发文章的话啊,有的杂志可能会让你汇报这个调整后的阿方 啊,其实我们这个模型找的自变量不是很好啊,调整后的阿方就更小了,对不对?那么是这样一个情况, 好,这是 uno 检验啊,那么这个 p 值都是显著的,它一共帮我们建立了三个模型啊,第一个模型,第二个模型,第三个模型,好, 那么我们来看一下这三个模型的 r 和 r 方啊,乔治红的 r 方分别是这么多啊,其实这决定系数都很小,三个模型其实决定系数都不大啊,那么第三个模型,决定系数最大的,决定最大的才零点零三六,也就是说我们选中的这三个字变量,只能解释百分之三点六的阴面量变化啊,其实我们这个 就是这个自编量,选的不是很好,它建立了三个模型,第一个模型呢,只纳入了体重啊,第二个模型呢,纳入了体重和身高。第三个模型呢,纳入了体重,身高和年龄啊,好,页面量是体育课成绩, 那么三个模型都是显著的,那么底下的系数啊,第一个模型只纳入了体重啊,他对应的这个啊,白塔值就是回归常数啊,这个常常量就是回归常数,那么底下的是体重的一个回归系数,负的零点零四九,如果这个系数是负的话,说明体重增加,体育课成绩会变小,对不对?那么对应的屁值是显著的, 那么第二个模型呢,是纳入了体重和身高两个字面料,那么你们看他的这个屁值也都是显著的,那么跟身高的这个 回归系数,他是一个正数,是正的零点零七九啊,比如说当这个身高增加的时候,提格成绩也会增加,是不是?好,我们来看一下。那么第三个模型呢,他纳入了三个 x, 就是 把我们选中的这三个 x 都纳入了,那么他的一个 显著性都是显著的啊,那么年龄呢,也是这个正数,这个回归系数,这个正数,也就说年龄增加,那么体育课成绩也会相应的增加,是一个正相关的一个关系,只有体重是负相关,其他两个都是正相关 啊,那么我们来看一下这三个模型,这三个模型的话,我们应该选哪一个呢?我们看这个 iphone, 尤其是这个调整后的 iphone, 我 发现第三个模型其实是最好的啊,因为它能解释音面量的变化啊,是最多的,能这个做的贡献是最多的, 贡献值是最多的,最大。那么我们再看一下这个贡献性诊断,贡献性诊断呢,这个容差啊,都是大于零点二的,那这个 v i、 f 呢,都是小于五的啊,那么我们的这个贡献性啊,自变量之间没有很强的贡献性啊,是满足要求的。 那么底下的图形诊断就是特征值,条件指标和方差比例啊,我们都不看了,底下残差统计我们也不看了,底下还有个直方图,就是做侦探性检验的,那么这个侦探性啊,相对来说还是不错的,这个 p p 图呢,基本上都在一个直线上穿着,对不对?也很好。 这个散点图呢,其实也是比较不错的,我们来看一下,它基本上都在一个矩形框里面待着,可能这边稍微稀疏了一点,对不对?但是总体来说还是好的,所有散点都在负三到正三之间啊,那说明这个还是不错的。好,我们再回到 ppt, 好 好,刚刚呢,我们的所有的自变量 x 都是计量资料,假说自变量 x 还有这个分类资料怎么办呢? 比如说我们想研究年龄、身高、体重、民族和性别与体育课考试成绩之间的关系,那么这个自变量就有五个了,其中这个民族和性别都是分类资料,对不对?那么异变量外呢?还是这个体育课成绩,那么这样的先行回归我们怎么做呢? 涉及到这个分类资料,尤其是多分类资料的时候,比如说这个民族,它是个多分类,我们要设置假变量,因为这个 sports 在 做先行违规的时候,无法帮我们自动设置这个假变量, 那么我们要手动设置哑变量啊,但是性别是一个二分类资料,二分类资料是不需要设置哑变量的,因为它是一个天然的哑变量,它有天然的哑变量,不需要我们自己设置。那怎么操作呢?还是 test 零三这个数据,再回到这个 test 零三,那么再做一次啊,先回归,那我们再加入啊,这个 这个民族和性别,注意,这个民族呢,我们要先设置一下哑变量。 设置哑变量怎么设置呢?这个民族不是多分类吗?我们要把它变成若干的二分类,怎么变呢?我们点这个转换里面有一个创建虚变量,这就是设置哑变量的,我们要对民族啊设置哑变量,把它放到右边的框里面,我们这个根名称就是一个前缀,我们比如说民族,我们就前缀就是民族, 然后直接点确定 好,他们帮我们创建好了,其实我们的民族只有五个,对不对?回族、壮族、汉族、满族和瑶族,我们回到这边,哎,发现他是不是在右边 帮我们又多出了五行这个数据,对不对?比如说这民族一,我们看民族一是什么民族一就是回族啊,我们回到这民族一是回族, 如果对应的这个个案对应的这个个体,他是回族啊,他是回族,那么就标注成一,如果他不是回族就是零,这里面就是零点零零,对不对?我们都把它调成这个零位小数吧。 好,我们再回来,那民族如果他不是回族,那么就是零,如果是回族就是一,那么底下其实是有一的啊,比如说这个,那么他就是回族,对不对?那么以此类推,那么这个表示壮族,这个是汉族,这个是满族,这个是瑶族,对不对?那么我们再找到这个进行回归, 那我们性别直接加进去底下的这几个,这个设置的雅变量,我们不是有五个吗?我们只能放进去四个,因为剩下的那个是作为参照,那是其他四个民族跟我们的参照民族进行比较。我们一般可以把回把这个汉族 作为对比,因为汉族人数是最多的,我们把这其他四个民族都放进去满足,好,这个汉族就是我们的参照啊。我们其他四个最后分析结果都要跟汉族进行比较,那么我们可以选择布进,也可以选择输入啊,那我们还选择这个 步进吧,那其实民族有可能是啊,最后我们的分析结果有可能是不影响这个这个体育课成绩的,所以我们还是选择输入吧,看一下啊,所有的这个变量啊,是不是都有意义?我们选择输入,那么这个统计呢?我们还是选择这些啊,这些都不用动,我们直接点确定好, 我们来看一下这个结果,这是个描述统计,其实描述统计后面的就不需要看了,性别的平均值没有啥意义,只只看这个计量资料的平均值和标准差就可以了。底下的相关性矩阵也没有意义了,因为后面这几个这都是分类资料,对不对?你做 p 二 c 相关没有意义是不是? 那么底下呢?我们的这个方法是输入 enter, 那 么这个 r 是 零点二四三啊,这个字面量与一面量相关性其实不是很高,调整后的 r 方呢,是零点零四四 啊,那么其实啊,我们的这个模型建立的其实是不好的,因为这个二方太低了解释度,对页面量的解释度只有百分之四点四, 那么这个 nova 呢?哎,我们的这个模型啊,建立的还是有意义还是成功的,为什么呢?因为我们的样品量非常大,我跟大家讲过,当你的样品量不断增大的时候,你的 p 值就会相应的变小,等你样品量增大到某一程度的时候,那 p 值一定会小于零点五的,你只要不断的增加这个样品量,因为我们的这个样品是五百多的样品, 非常大。那么底下的这个相关系数呢?我们看年龄啊,这个常说相,常说相没有意义对不对?那么这个年龄呢?它是有意义的啊,那么身高也是有意义,体重也是有意义,性别也是有意义,底下的民族都没有意义对不对?都没有参考价值。 那么这个我们来看这个 v i f 这个方差膨胀因子,就是我们的这个空心整段看它其实都是小于五的,那么这个容差呢?也都是大于零点二,说明不存在强共性性的问题 啊。那么这个这个性别我们怎么看呢?这个性别他是有意义的,对不对?他的系数是正的一点五零二,什么意思呢?我们来看性别的赋值情况,找到这个我们来看看这个性别, 性别我们是一男二女啊,是大的跟小的比,就是赋值大的那个跟赋值小的那个比,就是女跟男比。我们再看他的这个相关系数, 相关系数是个正的,对不对?说明在其他的自变量一致的情况下,女性比男性就是负值大的那个比,负值小的那个要多一点五零二分,他的成绩要多女的比男的要多一点五零二分啊。 那么这个民族怎么看呢?因为我们刚刚没有把汉族放进去,汉族是对照,假如说这个 p 值是显著的,那么壮族它的这个 bet 值,也就是回归系数是二点 七二一,那么也就说壮族跟回族比啊,不是壮族跟汉族比啊。 sorry, 不好意思啊,壮族跟汉族比,壮族比汉族的这个体育课成绩要多二点七二一分。当然是在其他的这个自变量 啊一致的情况下,是这样解释的。那比如说回族,回族是负的零点五零六,如果他的屁值是显出来,也就说回族跟汉族比,他的这个体育课成绩会平均少零点五零六分,这样解释的。 那么底下空心性诊断呢?是我们不常用的三种方法,层次值、条件指标、放差比例,这个我就不赘述了,残差统计我也不赘述了。底下的这个侦探型检验一个指方图啊,侦探性相对来说还是可以的,那么这个也是可以的,对不对?这个 pp 图也是可以,那么这个啊,残差图呢?也是可以的。 好,那么我们再演示一下这一题,我们再演示一下这个步进啊,它是一个优胜劣汰的一个打法,我们选择步进,然后我们再选择确定好, 我们选择步进的时候,你会发现它的这个,它建立了模型。建立了几个模型呢?建立了四个模型,当然四个模型呢,都是显著的啊,因为步进法它建立的模型都是显著的啊,不显著的话它不会建立了,所以你这个这点放心,你可以完全相信这个 stepwise 步进, 那么我们看他的这个 p 值啊,基本上这个自变量啊,自变量,所有的自变量都是显著的,是不是?哎,你发现他四个模型里面都没有带这个民族,是不是?只有年龄,身高,体重,性别是不是?那么我们看四个模型,哪个模型最好呢?我们看阿方,谁最大?阿方啊,那么第四个阿方是最大的, 那他的 iphone 是 最大的,但是只有百分之五,对不对啊?我们的这个所有的自变量加一块只能解释一变量的百分之五啊,那么说明这个模型虽然建立成功了,但是这个模型的意义并不大,应用价值并不大啊,那么底下底下的应该都一样了,底下都一样了。好 好,这是我们的这个假变量的设置,以及这个分类变量进入这个模型之后的一个分析结果的解释就是这样一个情况, 好,然后我们再看这个,这我在 ppt 上也提到了,如果你设置了哑变量,那么分析时只能将啊这个其中四个放入这个四变量框里面,因为留下的那个是作为参照,刚刚我们以汉族作为参照,然后在解释的时候,就是其他的所有民族跟汉族进行比较,那么回归系数的解释方法刚刚我已经说过了,这里呢,我也不追述了 啊,那么这四种的方法,我们常用的四个除去,我们不用,我们来看一下是什么意思,就输入 enter, 就是 强制录入,我刚已经讲过了,是强抢民女,就是娶老婆,你无论三七二一,先把所有的这个女的都娶进来再说,都娶进家门再说。 那么这个 stepwise 是 边进边出啊,那么优胜劣汰其实是不是那么后退呢?是先全部放入,再逐个剔除,就是 backward 啊,叫做后退法。那么还有前进,前进叫 forward, 优中选优,刚开始是空的,然后逐个加入, 那么除去呢?极少使用,我刚刚已经讲过了。那么这个残差的散点图啊,它的 x 轴通常是标准化的预测值,那么 y 轴呢?是标准化的残差, 那么最理想的状态是毫无规律,这些点毫无规律,所有点啊,都随机分布啊,那么当然是随机分布在这个零刻度线啊的附近啊,上下不超过正负三。那么如果是这样的情况话,它就是一个非常 nice 的 一个模型啊,也就是说所有的点都在一个矩形的框内, 能大致填满整个矩形框,随机分布在一个矩形框里面,那么如果是喇叭型的啊,比如说我们的这个是左边细右边粗,或者左边粗右边细的一个分布形态,那么说明防插不起,存在一防插性,那么这种情况下我们的分析结果可能是不不可靠的。那么如果是一个抛物线型的,就是这些点, 他虽然不在一个矩形框里,但是他也有规律,比如说他是个曲线型的,比如说明显成抛物线型,那么可能我们就不是一个线型的,我们做线型违规可能不是特别合适,是不是?那么如果有离群点,就是有些点已经超过啊,正负三了,正负三这个界限, 有的在正三上面,或者在负三下面,那么说明存在这个离群值,就是异常值。那么你要检查这个你录入的数据有没有错误啊,比如说一百七十厘米啊,你录成了一千七百厘米,那么这是录入的错误啊,你要去检查这些错误啊,录入错误是我们最常见的错误, 然后贡献型诊断有个容差,容差的范围啊,我们讲是大于零点一,其实啊大于零点一,这是一个非常宽松的要求,我们通常是零点二,大于零点二是比较好的,比较安全的,如果小于零点一呢,说明存在严重的贡献性,那么因为他们俩互为倒数, 这个容差小于零点一,也就是说这个 v i f 方差膨胀因子是大于十的,就说明存在严重贡献性,那么这种情况下,我们就不能把这所有的磁变量都放入模型了啊,就需要去处理 v f 方差膨胀因子啊,刚讲了容差与这个方差膨胀因子是会倒数的,乘积等于一,我们一般这个小于五啊,是比较这个安全的,当然你如果放宽一点可以,小于十也行,但是如果大于十的话,说明存在严重风险性,还有特征值,还有条件指标,还有这个方差比例, 那么这三个呢,不常用。那么先后回归里面我们通常会遇到哪些问题呢?这是我之前给你们的师兄师姐讲课的时候,他们提的一些问题,比如说分析结果与专业知识 啊,与专业知识或者常识明显不相同,或者相反的结果啊。那么举个例子,比如说我们研究各种因素对肺癌的,对肺癌的影响 啊,那么这其实啊,不是一个现象,回归了,对不对?那么肺癌发生不发生,这是一个二分类,其实是逻辑回归了。那么我们比如说对身高的影响,我们讲这个, 这个假如说有个自变量,是这个啊,是什么呢?是这个营养水平,如果营养水平越好,我们的常识是,如果营养水平越好,你的身高是不是越来越高,会会这个变得更高一些。 但是假如说你分析的结果,他们俩是互相关的,比如说你营养越好,你的身高会越低,这是违反我们的常识了,对不对?那么这是一种情况。那么第二种情况呢,就是整个回归模型,就是那个 nova 检验它的屁值小于零点 零五的,比如说整个模型有意义,但是每个自变量它的屁值都是不显著的,比如说每个自变量它的屁值都是大于零点零五的啊,也会出现这种情况。那么第三种情况呢, 就是某些变量在医学上有意义,但是在分析的时候却未被纳入模型啊,这什么意思呢?比如说我们研究这个, 这个营养水平啊,与这个身高的关系啊,我们从医学角度讲,从科学角度讲,你的营养越好,营养越高,就是你的这个生活条件越好,吃的越好,应该你的身高是越来越高的,但是你的分析却发现,这个营养水平跟这个 身高是一点关系都没有,他不显著,甚至都没有纳入模型,那么是不是也存在这种情况呢?可能是你的样本太巧合了,刚好分析出来他俩没关系,对不对?那么也存在这种情况,他的原因是什么呢?这些原因是什么呢啊? 第一个,第一个呢是你首先要检查一下你的数据存不存在异常值,出现这些原因可能是某些极端值导致的,那么还有可能是样本量不够啊。你比如说第二个,你每个自变量啊都不显著,但是总体是显著的,那说明可能是样本量不够,或者某一个类别的样本太少了 啊。那么还有可能是你纳入的自变量存在很强的贡献性,这个通常我们通过这个贡献性诊断可以得出这个原因。那么还有一个呢?第四点是, 呃,我们如果出现第三个问题,某些这个变量自变量在医学上有意义,但是未被纳入模型,那么这个时候呢,我们可以采取一种办法,就是强制纳入这些有专业意义的这个自变量,我们就用安特来纳入这些变量, 比如说我们这个,还以这个数据举例子吧。好,我们把这个没有意义的都把它移除出去。好好, 假如说我们还有一个是假如,还有一个什么假如还有个血型,这个血型呢?假定他跟这个体育课成绩有关系,假如你从专业角度上讲,血型就是跟体育课成绩有关系, 那么但是呢,我我们分析的时候呢啊,我们采用布进法分析的,得到的所有模型都没有纳入这个血型,我们可以把它强制纳入,那么前四个这个字变量,我们选择这个可以选择布进的方法,就是让他们自己 pk, 最后优胜劣汰,但是呢,这个血型是特殊的,我们特别关照的,我们点下一个,我们再把它放进来,然后这个我们选择 ctrl 输入。啊,那么这个血型呢?无论你怎么建模型,血型都会在模型里面,大家明不明白这个意思,就是有很多有专业意义的,但是你在数学分析的时候,在统计分析的时候没有纳进来, 大家在这个讨论区这个回应一下,能不能听懂这个意思,应该是可以能很好的理解的,大家都是很聪明的人。 好,那么其实第三个问题,其实第三个问题啊,反而这个咨询的比较多,就是你明明很有意义的这个自变量,但是呢你分析没分析出来。关于先性回归,大家还有没有什么其他的问题要问? 嗯,可能大家还没有真正去用心违规解决实际问题,大家在解决问题的过程中应该是会发现很多问题的,因为我自己在做的时候也会不断发现新的问题,然后我再去解决。啊,大家这个在实践中发现问题吧? 啊?好,行不行?那我们先违规,就先讲到这,接下来我们开始讲逻辑回归啊, logistic regulation。 好, 那么我们稍事休息一下啊,然后我们再来讲这个逻辑回归啊,我们休息十分钟好不好?大家有什么问题可以在这个讨论区啊,大家一起讨论一下。
83物语师兄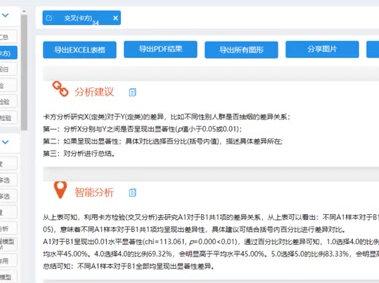 00:18查看AI文稿AI文稿
00:18查看AI文稿AI文稿今天教你做卡方检验,第一步,导入数据,选择分析方法。卡方检验第二步,拖转样本查看结果,分析结果超清晰,可以导出多种格式,还可以调整复制表格,调整图表样式,智能分析分析建议,帮助你进一步完善卡方检验。你学会了吗?如有其他疑问,请在评论区告诉我。
465SPSSAU







