自己设置的量表用探索性因子分析吗?

粉丝1848获赞5366
相关视频
 01:44查看AI文稿AI文稿
01:44查看AI文稿AI文稿sbss 操作步骤讲解系列第十九课探索性因子分析 探索性因子分析用于检验量表的结构效度情况,先采用 k 梦和巴特利特球形度检验检验数据是否适合使用探索性因子分析后采用主成分分析提取供音子最大方差法对提取的供音子进行旋转。 第一步,将数据导入 spss 中并复制后点击分析降为因子。 第二步,进入图中对话框后,先将量表提像放入变量框中,点击描述勾选 k 梦和巴特利特球形度检验,点击继续旋转,勾选最大方程 夸法,点击继续选项勾选排除小细数绝对值如下,框中输入零点五,点击继续确定。 然后探索性因子分析的 k 梦和巴特利特球形检验供因子方差,总解释方差成分矩阵,旋转后的成分矩阵结果就出来了。 结果出来后,将旋转后成分举证结果粘贴复制到表格中后,将供应子方差下的提取数据放入表格右侧,再将 k 梦和巴特利特检验结果,即总解释方差中的初始特征值和累积方差百分比放在表格的下方。 观看完记得点赞关注哟,可以带座指导学习交流!
768艾吖法数据 14:01查看AI文稿AI文稿
14:01查看AI文稿AI文稿嗯,大家好,我是君磊,上一个视频呢,我们呃简单介绍了一下关于信度分析如何去操作,以及啊我们通过一些方法来改善这个信度值。 从这几个开始呢,我们就连续做几个视频来去介绍这个笑度检验如何操作。嗯,笑度检验呢,可能是在我们做假设检验之前啊啊做的最大的一个检验了, 当然有的同学可能是用的非常成熟的量表啊,这一步呢,有可能会跳过啊,但是啊,我们发现啊,就是即有的同学即使是用了非常成熟的啊量表啊,导师依然会建议你去把这个笑度再做一遍啊,这也是有可能。 所以说,嗯,这一步呢,你需要跟自己导师啊去沟通,如果是你是用了成熟的链板,你需要去沟通确认一下你是不是要做这一步啊。如果是你是自己设计的文件,那么一定是要去做这一步检验的 啊。我们可以先看一下他的,看一下他的定义啊,这个定义是我自己写的啊,跟一些概念啊,可能啊,不太一样,但是表达大家都是一样的。嗯, 效度检验其实它代表一是数据的有效性啊,也就是说啊,通俗一点讲,就是你心中所想的,跟你实际所测量出来他是有一致性的,嗯, 如果一致性比较高,就说明你数据的有效性较高啊。放在我们的这个问卷的分析当中呢,就是说你的量表的这个设计啊, 跟你的实际测量出来这个维度啊啊和音子他是一致的,或者是基本是一致的。比如说你有二十个题目,你设计的六个因子, 那么我们用探索性因子分析呢去把它给呃探索出来哎呃,刚好你这个探索出来因子跟你实际所设计的是一致的。 ok, 那么你就说明这个消毒是通过的, 那我们应该用呃什么样的呃呃特征来去表征这个效应呢?或者说用什么样的指标来去探来去验证这个效应呢? 那我们我一般是会把这个度减压区分三个难度啊。第一个难度呢就是用 k m 和巴特利求生减压来去操作啊。其实是,其实说呢这个这两个指标呢,他并不是来去减 的这个笑度,他是来去啊来去呃看一下这个数据是不是适合做这个因子分析。嗯,但是呢就是,呃 嗯,原则上讲这不是消毒检验,但是我发现很多的文献当中都是把这个当成一个消毒检验,这个很有意思啊。所以说呃当你的当你的这个笑度实在吞不过的时候,你可以哎浑水摸鱼一把,然后只用这个。呃 啊,只用这两个指标就去表扬这个笑度啊,当然可能会不会通过啊,也可能也有可能会被通过。嗯,好,那么一般呢,我们是用探索性因子分析啊去做这个笑度的言,这是啊用的最多的,最多的一个。 嗯,他其实是在我们积极学习当中他是一种降为的一种方法啊,我们叫 啊因子分析,降为嘛啊?在这里叫他投降因子分析,他本身上是啊有 n 个题目,有二十个题目你给他降为降成了四为或者五为,然后呢我们能通过因子和载去呃找到这个因子下他跟哪些题目是 啊比较亲密的,因为他哪些题目是归属到哪个因子的,那么这种呢就跟可以跟我们的设计呢所哎呃有一个匹配关系,如果匹配比较高就说明你的效度比较高,我们叫 efa 探索性因子分析,那么嗯, 另外一个比较高难度的这个消毒检验呢,我们叫探索性因子分析加验证性因子分析。嗯,简单来讲就是我们探索出来这个因子之后啊, 再用啊结构方程或者是啊验证性因子分析啊,去跑一下,看一下你这个啊,你探索出来这个是不是一个良好的一种啊?结构啊,这两个用探索性因子分析加验证性因子分析呢, 这种方法呢,他是呃最能够让人幸福的,当然他的一些指标想达标的话也是最难的,所以说啊, 一般本科是很难很少去做这个这两个呃分析来做泄露检验的,一般是研究生阶段呢会用这个分析, 本科生我建议就是用探索性因子分析就够了。好,我们今天呢就先讲这个探索性因子分析。 好,我们还是先看一下这 这个呃表格的样式。呃,因此分析呢,他有很多种表格样式。嗯,但是这种呢是我觉得呃是最方便的。因为什么呢?因为他是直接可以从 spss 中呃 去输出的,也是直接可以用的啊,我觉得不需要再大改了。嗯,当然也有其他一些比较啊,综合的形式啊,那种也是可以的啊。嗯, 好,我们先先介绍一下这些表格。第一个表格呢,他是啊刚才我说的 km 和巴特利群体验这个指标呢怎么看呢啊?首先要看 kmo 值啊,这个值呢?呃,也是要看他是不是大于零点六, 嗯,也有的时候要看大本,嗯,是不是大于零点七,这个不是很严格,一般大于零点六我觉得就可以了。呃,当然你要看你导师是不是, 呃,要求你大于零点七啊,或者零点八,呃,然后通过这个,这个通过之后呢要看他这个屁,再看那个他的群里面的配置啊,这个配置如果是小学零点,呃, 小于零点零五,那一般他都是小于零点零一的啊,他,呃,这很容易通过的。这个如果这两个都通过呢,就说明这个数据啊,他可以进行因子分析。好啊, 嗯,可以做印子分析。之后呢,下面我就就开始看那个音。嗯,主持分的 t 恤以及宣传成本矩阵。好,我们下个这个表怎么看呢?嗯,这个表出来之后呢?嗯,首先要看这一列我们叫什么叫啊?特征值。 这节车上知道要看他是不是大于一,或者说要看一下他大于一的有几个,能够大于一的有吗?有四个, 有这四个,也就是说我们,嗯有十三个题目,十三个题目呢,他提取出来四个音字,而这四个音字呢?呃,我们再往后看后看,这里有一个累计 多少多少,我们叫什么叫累计的方差解释度啊,这个呢是百分之七十六点几 啊,这个是比较好的啊,这个累计发达。呃,几十度呢?这个呢也没有一个非常严格的标准,有的地方呢说达到百分之六十,有的地方达到百分之七十啊,这个确实是没有谁严格的标准,反正是越高越好。嗯, 你大家记住,主要是看这个 t 恤度,还有就是这个,呃大于一的个数。好,然后呢,看完这一个之后 啊,我们会看一个碎石图,嗯,这个碎石图呢,我们要看一个拐点,比如说这个地方大概是在这个地方出现拐点, 这地方出现拐点之后呢,我们就会说他,呃,提取二到五个啊,之间就可以了,而不是说他拐点出现在哪里,你就说提取几个适合,这个是没那种绝对的啊,比如说他拐点出现在这,你就说他 说是三到六啊,这样来表达就可以了啊,你看这里,嗯,在这前五数出现平缓之前继续下降,所以提取四个比较合适啊,其实他就是在五出现之后呢,然后说四到六个就比较合适,然后就说啊,提取四个合适,这样好,下面就是我们重头戏 叫悬崖成分矩阵,嗯,这个悬崖成分矩阵呢,他是这样的,就是每个题目呢,在 每个因子下面都有一个值,但是他最大的那个值呢,是他的那个因子的归属, 这里是都有直的,只不过我们把它给省略掉了啊,给他删掉了,因为我们只保留他最大的那一个,所以说我们取最大的这四个呢,那么这啊, t 第一就要提第三、第二、第四这四个题目就属于英子一,那么这三个题目就属于英子二 啊,这三这几个题目都数银子三啊,这都排序好的。好,然后下面你就解释一下啊, 根据学院成分得学院学院成分基本得知。然后啊,哪个题目是属于啊?哪个因子,然后他因子喝了有多少,这里的他解释就比较啊,就比较简洁,如果你想凑字数的话,你就可以啊啊,这个题 他的因子喝的是多少啊啊?写一下,然后他都是打游戏的,然后都可以问他命名为什么好,那下面呢,我们就接着一个数据来操作一下,给大家看一下啊,操作呢也比较简单, 但是有些细节需要好好的注意啊,我来操作大家一定要看清楚。首先我们点击这个分析,分析里面有一个降维降位,里面有因子分析,然后呢我们就把你的量本的题目给它塞进来, 比如说我们把这里的这这个这几个题目给他塞进来啊,加上这个吧。 好,然后呢我们一个一个点这里呢,先点这个描述,描述里面我们需要点什么?点这个 km 和巴特利,这个是一定要点的, 继续,然后抽取,这里呢我们是要点啊,这里我们就不动,一个是觊觎特征值的一个抽取啊,这里是我们不动的啊,有时候我们的抽取效果不是很好,比如说啊,我们 本来想是呃抽取四个,结果他就出来三个,那么这里呢,你就点他强制抽取四个,这里输入一个四,然后你看他出来是什么样子,你就可以去简单的看一下,但是呢我们还是要去看刚才说的特征值的。 好,我们先点他,然后四十图啊,就在这里点个四十图。好,然后我们点这里就旋转,旋转什么?就是旋转成分矩阵嘛,对吧?然后我们这里用最大方叉法好,其他方法就不需要了解,你就记得记得一个最大方叉法就可以了啊,这个是我们嗯 最常用的一个方法。好,我们今天继续,然后得分,这个保存为变量呢,一般是在,嗯, 在哪里会用到呢?就是在那个,呃呃,财务类的这个,因此分析里面,主持人的分析里面会用到这里呢,因为我们主要讲一部件分析吗?这里暂时先不讲了啊。嗯,我们这个也可以点上。好,我们再点这个选项,这里注意啊,我们 有这么一个注意的事项,一个是使用均值去替换这个确实值,然后呢按大小排序,这个是一定要点的,然后取消系数,这里我们点到零点三, 取消系数就是我们呃把那些呃因子核载低于零,低于零点三的我们都给他不敢试,然后我们就确定 好,那么这个就出来了。好,我们可以看一下,其实这个表格呢, 就是我们那刚才我展示的那几个表哥的样子,只不过我们稍微稍加去修饰了一下。好啊,这个就是 kmo 值和巴特利啊,他,他是零点八七七,还是比较高的,然后配置也是良好的。 好,这里呢就是刚才我说的那个啊,特征值,我们看他是不是大于一啊?大于一的有六个,也就是说这六个呢,也就是说这二十一个题目提取了六个因子, 然后累计解释百分之七十二点四的一个方差,这个是比较理想的。然后这个就是,那你就啊,这个地方其实没那么严格,你就大概说一下啊,他是在七这地方出现了 一个拐点,所以呢啊,从五到八提取五到五到八个因子是可以的,所以说我们提取六个因子是合适的,这是六吧,这六个因子是合适的。 好,然后这是成分矩阵,这个成分矩阵跟后面那个矩阵他是不一样的,这是还没旋转之前的,我们不管这个直接看这个。好,这个就是旋转成分矩阵。 那么这个举证呢?你们看他就是啊,这一堆是在一起的,然后呢?我们,呃,这零点,你看这是零点四吧,这零点四我们要看他大的,所以我们要从这开始看,从零点八这地方开始看,然后这停止,然后在这里看, 他给你排泄好了啊,这个地方就是一个宣传成本举证。嗯,那么关于制表呢,我在这里就不多讲了,大家只需要把啊这个宣传成本举证跟这个解释, 磨砂还有开摩托力啊,给他复制一下。这天他到表哥里面已经稍加休啊,稍加那个加工就可以啊,直接 coffee 到味道里面去了。嗯 嗯,燕子飞行到这里就并没有结束,因为我们还要解决一些问题啊,一些我们很常见的一些问题 啊,比如说我们的因子因子分析的效果,比如这指标不达标,我们怎么办?还有就是啊,我们出来结果啊,学院成分举证并不是我们想要的结果,我们怎么办 好这些这些问题呢?我们放到下一节课来处理啊,今天我们就不不多讲了,好啊,我就啊先到这里这个视频,谢谢大家。
344Junlei_D 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿论文两表常用分析方法二、效度分析效度用于测量题项设计是否合理,用于分析测量项是否真实有效地测量自己希望测量的变量效度按照研究方面的不同可分为以下四类,内容效度、结构效度、 区分效度、收敛效度。具体说明见下表。内容效度使用文字描述。结构效度使用探索性因子分析进行测量。区分效度和收敛效度使用验证性因子分析测量。在 spa 骚系统中选择分析方法效度 上传数据后,拖拽样本至右侧分析框,一键得出分析结果,你学会了吗?
30SPSSAU 01:33查看AI文稿AI文稿
01:33查看AI文稿AI文稿有同学问汉化以后的量表进行一个探索性因子分析, 发现因子下对应的题目跟原问卷他是不同的,那是怎么办啊?那首先啊,这样的一个分析其实是错误的,一般而言,汉化以后的一个量表,我们是不是不进行一个探索性因子分析? 探索性因子分析一般用于自设的一个量表,或对国外的量表进行了一定的一个修改了以后啊,这时候去进行一个应用,那其过程其实就是一个降维的一个流 降尾的一个过程,就是将量表里面的一个问题按照其关联性啊分为几个维度。 所以这时候就所以当汉化以后的一个量表,他其实已经对量表里面的问题进行了一个维度的一个划分,因此就不需要进行一个探索性因子分析。 那对于汉化以后的量表一般怎么做呢?一般都是采用印证性因子分析去进行分析啊,以此去评价量表他的一个结构效度。好,那这就是这个问题的一个回答,谢谢大家。
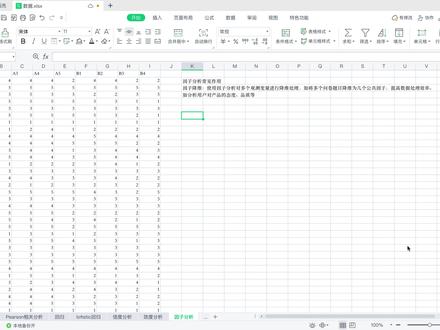 06:28查看AI文稿AI文稿
06:28查看AI文稿AI文稿哈喽,大家好,上两个视频呢,我们主要介绍了性度和效度分析,那今天这个视频我们就来聊聊因子分析。 因子分析他最常见的作用呢,也就是因子降维。什么是因子降维呢?也就是通过因子分析对多个变量进行降维处理,把这些多个变量归纳为少数的几个工因子,用这些少数的工因子来衡量整体, 用来提高数据的处理效率。比如说我们在分析用户对产品的态度以及品质等,这样的量表数据就可以进行因此降为 啊,我们今天使用到的数据还是前面两个限度效度的数据,也就是 a 一到 b 四这九个量表 题。然后我们来介绍一下英语分析的操作步骤和结果的解读。先把这些数据复制一下, 要带上这个变量名一起复制,然后打开一个新的 s p s s 文件,嗯,再点击鼠标右键, 选择与变量棉一起粘贴,这样数据就粘贴到 s p s s 里面了。然后我们来做因子分析,点击这个分析降为因子, 然后把这些变量都选到右边的变量框里,再点击描述,勾选 k, m, o 和 buttlet 求行检验,然后点击提取。这里使用的方法主要 是主成分分析法,然后这里都可以使用默认的值,基于特征值,这里选择大于一,然后点击继续, 再点击旋转,然后在方法这里选择最大方插法,点击继续,再点击得分,然后选择因子得分系数矩阵,点击继续, 再点击选项,然后可以选择这个禁止显示小系数,这个绝对值呢,我们可以设置成零点五,然后点击继续, 这样就设置好了,点击确定就可以了, 这个就是因子分析得到的一些表格。首先 看一下 k m o 和巴特利的检验,就是上一个视频中我们提到的效度检验,这里效度检验主要看 k m o 的值, k m o 大于零点八,那也就说明这份数据是通过了效度检验的, 然后这里显著性也是小于零点零五,也就是说明这份数据是适合做因子分析的。然后看一下公因子方叉这个表,这里面就是嗯,对 a 一到 b 四这九个 题目对他进行提取的一个解释程度,这个提取值越高,也就是说明这个变量被解释的变异程度是越高的。然后再看一下总方差解释这个表,这个表里面就可以 看出我们一共提取了几个主成分,这里可以看到,嗯,一共是提取了两个主成分,然后这两个主成分一共的累计解释贡献率也就是这个百分之六十八点四八。 然后再看一下旋转后的成分矩阵,这个就是呃对两个主成分进行的划分,每一个主成分主要包含哪几个小变量? 可以看到第一个主成分主要包括 a 一到 a 五,然后第二个主成分主要包括 b 一到 b 四, 然后我们主要需要看的也就是这几个表。呃,再回过头来看一下总方差解释,这 这里可以看到,如果我们提取两个主成分的话,那他累计的解释方差也就是百分之六十八点多,这里其实我们一般是要这个累计方差百分比要 呃大于百分之七十的,现在他是小于百分之七十,说明这两个主成分对整体的解释程度可能不是特别好。 然后我们看一下,假如说可以提取三个主成分的话,那他的累积百分比就达到了百分之七十七了,这个时候就说明他的呃 三个主成分对整体的解释效果是比较好的。那现在我们怎样提取三个主成分呢?就要重新回到因子分析这里点击分 息降为因子,然后在提取这里可以看到,因为我们刚刚默认的是提取机遇特征值大于一的,现在我们想让他提取的百分比大于七十的话,那就要提取三个因子嘛,这里我们就手动输入三, 选择固因子的固定数目,然后输入三,再点击继续,这样的话他就会生成一个三个因子的结果,点击确定看一下 哦,总方差解释这里你看就提取了三个主成分嘛,这个时候他的累积百分比就达到了百分之七十七点四九七,这个效果就 是比较好的。然后看一下旋转后的成分矩阵,这个时候就是提取了三个主成分,然后第一个主成分主要包括 a 一到 a 四,第二个主成分主要包括 b 二到 b 四, 第三个主成分可以是包括 a 五 b 一这两个小维度的,这个就是呃,我们手动的选择提取几个主成分的方法。 好,以上就是因子分析的操作步骤和结果的解读。
2213spss小师姐 17:57查看AI文稿AI文稿
17:57查看AI文稿AI文稿哈喽,大家好,今天给大家讲一下毕业论文常用的量表的问卷分析的一个全流程。我们以生育对女性职业发展影响及其对策研究为案例进行一个全面的讲解, 从最开始的问卷设计,到数据收集整理,再到最后的数据分析思路方法以及软件操作,进行一个全面的讲解。那么第一步呢,就是问卷的维度设计, 这里我们要从三个方面去入手。第一部分呢是要简要说明部分,也就是我们要去介绍此次调查的目的,让被调查者能够放心真实的作答。第二点呢是要从基本情况入手, 主要是了解被调查者的年龄、生育状况、文化程度、职业等基本情况。这个呢是我这次收集到的全部的问卷,我们可以看到从问题一到 问题酒都是我们的基本情况部分。 那么第三部分呢,是要也就是我们的问卷调查问卷的主体部分,我这里呢从自我认知、职业投入、职业发展困境、外部支持这四个维度入手,来调查生育对女性人员职业发展可能产生的影响。 那么我们来看一下这份问卷。嗯,这部分呢主要是采用理科 特良表法,我这里使用的是四等量表,也就是被调查者通过选择非常不同意、不同意同意以及完全同意这四个选项来表达自己的态度程度,并且根据轻 到重的影响程度富裕一到四分分值越高,表示生育对女性职业发展的影响程度越大。 那么数据的收集部分呢,这里是使用的问卷网的样本服务,可以短时间内高效的收集到我们的想要的问卷数量, 我们可以看到在这里一共是收集了二百零八份问卷。那么第三部分呢,就是我们 的问卷分析的思路部分,我们可以看到量表问卷分析呢,可以从这六方面入手,第一步呢是信度分析,第二步是笑度,然后用户画像,样本特征,行为相关关系以及差异性分析。 那么这里呢,是我们问卷分析当中可能会用用到的分析,也就是说在一份问卷当中呢,并不一定需要使用这里所有的分析方法,研究者呢可以根据自己的问卷酌情选择合适的分析方法。 那么下面呢,我将会从这六方面一一进行讲解,还有软件的一个操作。第一步呢就是信度分析,信度分析呢是用于检测问卷中量表样本 是否可靠可信,通俗的讲,研究样本是否真实回答了我们的问题,测试作受访者是否有好好的答题。具体来说就是用问卷对调研对象进行重复测量时,他们所得到的结果是否是一致性的。 那么这里主要是使用这个科隆巴赫系数来测量问卷的信度,那么这个系数值越高的话,他的问卷的信度越好。我们通常呢, 嗯,只要阿拉发只大于零点六都是可以的,如果小于零点六六的话,就要考虑重新设计问卷,或者重新发放个问卷。那么在我们的这份案例当中呢,他的信度分析主要分只要是从两 两个方面去考虑,第一步是总体的信度分析,第二部分是各个维度,也就是也就是这四个维度的信度分析, 那么我们先来看一下这个数据,数据预览没有问题之后呢,我们点击开始分析。信录分析呢,是在问卷分析当中。呃, 第一步呢,我们是要去看一下问卷总体的新读分析,问卷的主体部分呢,它是包括四个维度,一共有三十个题象,我们把这三十个题象全部拖入到变量框当中,点击开始分析, 我们可以看到输出结果一呢就是这个克隆巴克系数值,他的值为零点九三八,说明该问卷的 进度非常的好,然后输出结果二呢是删除分析项统计汇总, 我们可以看到删除向后的科龙八和系数值都是小于整体的这个零点九三八的,所以说我们的问卷其实是不需要调整的。那么同理 我们要去看一下这四个维度的信度分析,在这里指眼是自我认知维度的。 嗯,自我认知维度呢,是从问题十一到问题十八, 我们把它拖入到背亮框当中,点击开始分析,我们可以看到它的 克隆八和系数值为零点八二零,同时他删除向后的克隆八和系数值都是小于零点八二零的,所以说他的这个性度也是不错的,并且他的体相是不需要进行调整的, 那么其他维度以此类推,这里就不演示了。嗯,第二步呢,我们是要去进行这个笑度分析,笑度分析呢,在于研究问卷题目的设计是否是合理的,也就是测试 能够测到被测量对象的真实水平的一个程度。效度好呢,就是说我们问卷的内数据内部一致性比较好,也就是说每个维度的所有题目的选择基本上是一致的,维度划分 真的比较好,这里呢是效果分析的平换方法。那么首先呢,你做效果分析要先通过 呃 kmo 和球形检验, kmo 大于零点六,同时呃 p 小于零点零五,说明他是存在相关性的,那么就是符合因子分析的要求。 然后呢,再看,再去看这个累积方差减税率是大于百分之五十,同时提相在对应因子上的因子在和系数是否大于零点四,并且不存在提相与因子对应关系出现严重偏差的情况。最后是要看共同度大于零点四, 那么我们这份问卷呢,它的主体部分是包括自我认知、职业投入、职业发展困境、外部支持四个维度, 所以我们在进行效度分析的时候呢,这个因子为度要设置成四个因子,然后我们把三十个问题全部拖入到变量框当中, 点击开始分析。首先我们要看一下,嗯, kmo 和球形检验 kmo 大于零点 七,同时批是显有显著性的,所以他是可以做因子分析。第二步呢,是要看这个结式,总方差,也就是特征跟大于一 累计百分比大于百分之五十,我们这里嗯,可以提取,说提取四个月 因子,这个呢是我们的因子在和系数, 因为数据比较多,所以看着会不太直观,热力图呢,也看的不是很明显,所以我这里截了个图,大家看一下这个截图。 呃,我这里只举例了两个维度,像第一个是自我认知维度,理论上呢,在因子二上的因子在和系数应该是四个因子当中最大的,但是我们可以看到问题十四以及问题十六,嗯, 他的因子一的值大于因子三,所以我们可以考虑删除这两个问题,或者把它归类到属于因子一的这个职业投入维度这方面。那 那么职业投入为度呢?也是同理理,理论上他在因子一上的因子在核系数应该是四个因子当中最大的,而问题二十二呢,他在因子四的值大于因子一, 所以我们可以考虑把二十二知道问题给删除,或者把它归为其他的类别。 那么其他两个维度呢,也在表格当中,在这里就不一一讲解了, 我们再来看一下。第三步是我们的用户画像分析,这里呢主要是,嗯,统计一些,呃,类似于性别,年龄,学历、工作等的分布情况,我们一般是要去使用平数分析,我们来看一下操作, 平数分析呢,在描述性分析里的第一个,我们把问题一到问题九全部拖入到变量框当中, 点击开始分析,那么输出结果一呢,是对整个数据的一个汇总过程, 然后输出结果二到后面是每一个问题的一个图形展现,在这里我们可以选择不同种类的图形,以及要展示的数值还是百分比。 那么我们来看一下我们的背景,我们可以看到接受调查样本中,二十六到 三十岁的女性占比最大,达到了百分之五十五点二二八八,文化程度呢,整体偏高,像本科,本科以上的话,他的占比达到了七十多。专业呢以及职业类型这块呢,我们可以看到 是普通职员以及专业人员占比较多,工龄呢分布较为平均,集中是在十五年以下,婚姻情况已婚居多, 生育数量一个占比最多,达到了六十二点五。 那么孩子三岁之前主要的照顾者分布比较的平均 花销,这里呢我们可以看到一半接受调查样本每月孩子开销占双方夫妻收入的百分之三十以上,我们可以看出孩子的花费已经成为了大部分接受调查者样本家庭的主要的那么一个支出。 那么我们可以真通过这个表格对我们用胡画像进行一个汇总。 第四步呢是我们的样本特征行为分析,嗯,呃,我们也是要从四个维度去入手,那么针对自我认知维度统计分析呢? 这里,呃包含了八个体相,八个体相呢又分为两部分,分别是工作满意度和职业发展 展动力。那么我这里呢也仅仅演示这个工作满意度,同样我们也是要去使用这个平数分析工作满意度呢,它主要是从十一题到十四题,我们把它拖入拖入到边缘框当中, 点击开始分析, 我们可以看到这个被调查的这的一个满意情况,嗯, 我们可以看到百分之五十二,五十七点二一的人对现在的工资收入和福利待遇不太满意,百分之六十九的人认为自己目前的职位或低于日 七。大部分的群体认为生育二,生育孩子之后对工作越来越不满意,百分之五十七认为生育后工作上没有获得成就感。那么我们根据 这个情况可以反映出大部分的接受调查,呃,样本对于工作的满意度是中等偏下的,然后他们的不满的主要集中集中在对当前的工资收入啊,还有这个福利待遇, 以及目前的职位或者职级和预期之间的差距这两方面。那么像只像这个 之后的职业发展,职业投入,职业发展困境,外部统计呢,都是以一次类推,这里就不掩饰了。那 那么做完了样本特征行为分析呢?第五步,我们是要来做这个相关关系分析,也就是我们在完成量表的提项之后,各维度的描述性分析之后呢,我们可以使用相关分析去研究关系情况,为我们后续的回归分析做一个准备。 在数据有着相关的前提之下呢,在研究回归影响关系才会具有意义。因回归分析需要放在相关性分析之后,并且通常情况下需要使用回归分析去验证假设。 例如我们这里呢,要分析四个维度中两两维度的这么一个相关关系。我们,呃,第一点呢,比较简单,就是我们可以直接将四个维度的提像取平均值之后再去进行分析,或者我们可以也可以使用这个 因子分析浓缩成一个因子,计算出这个因子的分。之后呢,我们再去做这个相关分析。在这里呢,我是直接取的这个平均值,我把这个数据导入进去可以看到,嗯,我们取了这个平均值嘛,然后点击开始分析, 点击相关性分析里的相关性分析,如果我们要使用这个普选的相关分析呢,它的数据要满足这个正态分布,如果不满足正态分布呢,我们可以使用这个 soper man 相关系数, 我们把这四个维度数据拖入到边两框当中,点击开始分析 这个输出结果一的相关信息数表,我们可以看到它都是 具有显著性的,所以可以得出,呃,两两边梁之间是存在相关性的。 那么最后呢,我们可以通过对比不同人群的看法,分析其是否存在差异,验证自己的结果是否具有普世性。 因为我们这里的数据是满足状态分布的,所以我们在这里是可以使用方叉分析,如果不满足的话,可以使用多样本独立这个 kw 检验, 这里呢也是指列列举出不同年龄对女性人员职业发展可能产生的影响的这么一个差异性分析。 在这里我们使用这 这个单因素方差参数检验当中的单因素方差,将年龄拖入到定类变量,将这四个维度拖入到定量变量当中, 点击开始分析 输出结果五呢,是这个方叉分析的结果表,我们可以看到在这里职业投诉维度以及职业发展困境维度,他是有这个显著性差异的,而且他两个维度呢是不具有显著性差异的,所以我们可以得出, 呃,不同年龄的群体在职业投入以及职业发展困境维度是存在差异性的。 然后输出结果六呢,它是有一个差异性程度,我们可以看到都是这个中等程度的差异。 那么按照以上流程的话,我们整个论文的数据收集到分析部分就已经全部结结束了,大家可以对分析到的数据进行一个汇总,那么感谢大家的一个聆听。
2863SPSSPRO数据分析 03:42查看AI文稿AI文稿
03:42查看AI文稿AI文稿哈喽,大家好,上一个视频我们聊了什么是性度检验,那这个视频我们就来分享一下效度检验,同样的效度检验也是要和大家聊一下这三个问题。第一个, 那消毒检验是干嘛的?消毒检验它主要是指测量结果与想要考察内容的吻合程度,如果这个吻合度是越高的,那就表明效度也是越高的。 第二个,什么样的数据需要做效度检验?效度检验也是适用于量表型的数据,一般像量表类的数据他都是需要做信度和效度的。 第三个,消毒分析的操作步骤和结果的解读,我们使用的数据也是性质检验的数据,就是 a 一到 b 四, 然后这些都是一些量表型的问题,他主要包括一到五这五个选项,然后我们把这些数据复制到 spss 里面 啊,整理成这样的格式,我们点击这个分析,然后降为因子,把这些量表数据都放到变量这里, 然后点击描述这里面勾选一个 k m o 和 butt later 球形检验,然后点击继续,再点击确定, 这个就是效度检验,我们需要看的表格,然后我们主要需要看这里的 k m o 值和显著性的值,这个是量表整体的效度检验,然后我们也可以测一下氛围 度的性能检验,步骤是一样的,点击这个分析刻度因子, 然后如果需要测 a 的维度,那就可以把 a 的这些变量放到这个框里,然后描述这里,我们已经勾选过了,所以可以不用设置,然后直接点击确定 这个就是 a 维度的消毒检验,再点击分析,降为因子,然后把 b 维度的数据放到变量里面, 然后再点击确定这个就是 b 维度的效果检验。我们把这三个 kmo 的表格,然后放到 excel 里面整理一下,就是这样的格式,它主要包含了 tmo 的值以及这个显著性,我们主要需要关注的也就是这两列。然后可以看一下这里面如果显著性是小于零点零五的,那就说明这个数据是可以做因子分析的。 然后这个 k m o 值它也是有一个取值范围,然后每一个范围对应的它的效度好坏, 如果这个 k m o 值越大,就说明它的效度是越好的,每一个取值范围对应的含义就是在这个表里面了。大家也可以根据自己的数据算出来的 k m o 值,来看一下你的效度情况如何。 然后针对这份数据,我们测出来的效度,他的值可以看到都是大于零点七的,也就是说问卷 整体以及各个维度的效度都是比较好的。然后显著性的值小于零点零五,也就是说这份量表数据是可以继续做因子分析的。 下一个视频我们来讲一下如何做因子分析,以及因子分析的结果怎么看。
1561spss小师姐 02:31查看AI文稿AI文稿
02:31查看AI文稿AI文稿亮表啊亮表,找到他有三招。由于亮表设计的困难性,为了保证论文研究的准确性,通常建议人生同学不自行设计,而是选择已被广泛使用认可的成熟量表进行数据收集和分析。 选择合适且成熟的亮表需要遵循两个原则,第一,根据选研究对象选择尽量选择该领一领相对权威性效度较高的亮表。 第二,根据使用的统计分析法,选择容易收集数据、分析起来较有把握的量表。那么,合适的成熟量表去哪找?海量搜索,你直接在百度、谷歌等搜索引擎输入熟悉量表的关键词,看搜 搜索结果是否有相同的量表推荐。但这种方法无异于大海捞针,很难找到自己合适且熟悉的量表。二、互联网问卷平台搜索 目前使用较多的网上问卷平台有问卷新、腾讯问卷、问卷网, 你可以登录这些平台搜索问卷调查模板,会有大量存在该平台发布过的相关问卷亮表出现。这个方法虽说可以找到很多相关亮表,但缺点在意,难以甄别该亮表是否 成熟的亮表诱惑、该问卷是否经过修改,性效度能否得到保证也是你难以确定的。三、织网解锁浏览相关主题的硕博论文作者 一般会在亮表设计部分说明采用的亮表来源和依据,且在复录后会附上亮表的题项内容。我们可以根据来源去找到这份成熟亮表,亦可以直接参考复录后的问卷。 这种方法不管是对数据收集还是寻找合适的陈述量表,都是相对可靠且有效的。 对于找到的陈述量表,如果不完全适用,也可以对其删减部分题目进行适当的修改,或者只选择该量表中适合的维度对应的题目进行数据收集。当然,无论是否经过删改过的陈述量表,在数据收集回来后 都必须重新进行性效度分析。欢迎来看我每晚的直播,谢谢!
919喻教授谈硕士论文 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿哈喽,小伙伴们大家好,今天呢主要是给大家想要分享一下是如何编制一个量表。编制量表的一个流程呢,主要是包括三个步骤,第一步是建立量表条目池,第二个是形成量表出稿,第三步是形成量表中稿。那么如何去 行建立量表调目词呢?我们首先是最好是要有一个理论的指导,其实没没有理论那也没有没有关系,但是最好是要有一个理论去指导, 告诉你怎么就是你在什么样的理论下去建立一个什么样的呃量表。然后第二个的话就是我们一般是通过文献回顾或者是自信访谈,也可以是二者结合文献回顾和自信访谈来建立一个量表调目词。 第二步的话就是形成量表出稿,我们使用的方法一般是专家咨询或者专家会议,第三步的话形成呃,这是呃形成一个正式量表,也就 形成亮本的忠告。我们主要是通过预调查和真实调查,预调查的话我们主要是一般调查三十到五十人,我们目的是为了优化调目的一个措辞,一个表达方式, 然后正式调查的话,我们主要是通过一个项目分析,性度分析和效度分析来最终确定料表的中稿,然后下期的话我们再来给大家讲怎么来做专家咨询以及怎么来进行这个呃项目分析,性度分析和效度分析,大家敬请期待哦。
110小四月爱音乐🎶 06:21查看AI文稿AI文稿
06:21查看AI文稿AI文稿今天主要来说一下为什么我们再去做这个硕士论文或者本科论文,我们再去研究这个变量之间因果关系的时候,我会强烈要求大家去做量表类型的这个问卷。那么首先的话,我们要了解一下什么是量表,什么是问卷啊?这两个是有区别的。量表的话,它是用于测量被访者对于事情的态度或者看法, 他量表的设定是需要一定的依据的,就不是我凭空去捏造的,我肯定是参考了某一个学者他的成熟量表,然后进行了改编,形成我自己的量表。那么我们最常用到的就是理科特量表,理科特五点,理科特七点啊,其中我们的这个理科特五点计量法,他是啊最常用到的,那么问卷的话, 他就不像量表这样子,他需要他的这个编写需要一定的依据,那么问卷的话,他主要是针对某一个主题去设计相关的题项合集。只要能够探究到我们想要研究的这个问题啊,那他都可以作为这 问卷的这个一部分。比如说我们调查年龄啊,调查性别,调查职业,调查我们对某一个问题的这个嗯,现状啊等等,他不需要有理论依据,这个就是亮表和问卷。那么我们直观的来看一下啊,什么是亮表?这个就是亮表类型的体项, 我们可以看到一般情况下量表类型题像,他会在呃这个表之前去写我们的这个量表,他的一个计量方式,一代表,二代表,三代表,这个是理科的七点计量法,他就有七个这个感官,那么我们根据题像啊,对这个题像做出自己的一个呃反应,就是我们这块说的对于事情的 态度或者看法,实际上就是你针对这个题项又有怎么样的看法,你是非常同意呢?还是非常不同意?我们通过这个打分去进行一个呃数据的收集,这个就是亮表,那么这个问卷的话,他就非常直白了,你直接看他题项的这个,呃,看他这个题项的这个选项啊,他就不是这种打分制的啊,不是 这种打分式,他就是我们的问卷,那么量表和问卷他在我们实证分析过程中能够分析的内容是有区别的。如果说啊,我们是去做一篇这个论文,然后你想做这个影响因素,那么不巧你又把这个设置成了问卷的题项,那么你就要注意了,如果你是问卷的话,我们只能做简单的描述性分析,就是 看一下你这个问卷在第四,比如说第四个题项里面有多少人选择了 a, a 选项,有多少人选择 b 选项,这个就是简单的描述性分析,那么它的信效度是不能做的啊。非量表题项都不能做信效度 分叉分析的话,也就是咱们呃比较常常说的体检验,这个的话只有部分可以做啊,然后相关回归是肯定都做不了的。然后但是我们的这个问卷的话,它可以 对针对每一个提项去进行分析和说明,就是我刚才说的针对提项一去进行分析,提项二分析,提项三分析,大家再去选择这个在这个提项一上怎么样的一个选择结果 啊?这是问卷,那么我们量表的话,他就可以做以上的这些比较深入的这个分析,所以这个也就是我们在去做这个影响因素研究的时候,为什么强烈的建议去做量表?是因为啊,看过很多人他呃设计了一个普通的问卷,然后拿来说,哎,要做这个影响因素啊,要做相关,要做回归分析,但是实际上他的这个问卷他确实是做不了的, 然后我们就浪费了很多时间,包括你收集数据收集了那么长的时间,结果数据全都不能用,对吧?所以这个就是我们在去呃进行确定了你的研究内容之后啊,比如呃确定了研究内容之后,你就一定要先去呃在这个量表上,在这个问卷,在这个数据收集的方法上面要去做一个啊考量,这是我们他的一个分析区别。 再下来的话就是我们比较关注的量表和问卷的一个应用啊。像这种的话,如果我们想我们想要论证的是因果关系或者变量的影响机制,或者某一个变量他影响因 的强弱关系啊,就比如说我想去探究这个呃某某某的满意度,那么满意度有 a、 b、 c、 d、 e、 f、 g 有这么多的影响因素,我想知道这些 影响因素中哪一个对满意度的影响是最大的,哪一个是最小的,哪一个是没有影响的?我们就要用到量表体向了影响因素,那变量机制的话,比如说你去研究这个中介机制呀、调节机制呀,对吧?这些机制我们都要做量表研究因果关系的话就不用说了,只要你的题目设计 对 b 的影响,或者 a、 b、 c 三者的关系, a、 b、 c 三者的影响研究,那么他们全部都属于英国关系研究,要做量表性的这个体象, 那么问卷题像的话,他的这个研究内容一般是对某某某的现状分析,或者对某某某的现状研究,或者对某某某企业的现状说明啊,就是这一类的啊,他比较 呃多用于我们的一些案例型的文章啊,时政性的文章的话,他如果只做一个现状研究的话,他就太简单了,八成他可能后面会出很大的问题啊, 是他的一个应用。最后的话就是我们在去设计量表的时候的一些关键点啊,第一个点的话就是我们的量表啊,量表就是一个萝卜一个坑,就是说我们一个变量会有一组题项,不同的变量是不同的体项,你不能说我的 a 变量用的是一到五题, b 变量用的是二到四题啊,这两个就重合了,这就有问题。 第二个的话就是我们题项选项应该尽量去统一,就说我如果再去设置这个量表的时候,我用了我第一个变量,用了立刻到五点,那么我的第二个、第三个、第四个我尽量都用立刻到五点,这样子的话, 咱们后期做回归的时候,这个系数的话,他就不用再去呃进行一个标准化啊,不用再去做这这样子的一个步骤,当然如果 有必要就是去去设置成,哎,这个是立刻特五,那个是立刻特七的话,这个也没关系,我们到后期回归的时候就得看那个标准化的系数啊,这个就是后化了。然后第三个的话就是如果存在反向积分需要特别标明,比如说啊,我们有一些就是你 的某一个变量,他一共有十个体项,那么前九个体项他都是正向的,都是那种,哎,我愿我看到什么什么东西我会很啊开心呀,类似于这种的,但是如果你有一个反向积分的,那就是,哎,我看到一,我看到这个东西我很悲伤,那你的我们的选项一般是 a 的话,就是非常不同意,对吧?呃,然后 b 的话是非常,呃是不同意, c 的话是一般。那如果你有一个反向积分的话,你是要在分析数据之前要进行一个反向积分的转换,所以如果存在反向积分的话,你要特别标明,我们要,呃在分析的过程中去转换。 最后一个的话就是一个体外的啊,就是我们的控制变量他是不需要遵守以上的,就是我们量表的话里边也有控制变量,控制变量的话他就不需要说理科的五点呀, 按照实际情况就按照那个问卷设计的这个方法,比如说我们的性别、年龄、受教育程度,我们的职业等等,都是按照实际情况去编写就行。最后的话就是我们展示一下,呃,通过问卷星,哎,我们设计的量表题项,然后问卷星 收集回来的数据,大概就是这样子的一个形式啊,前面都是他的一些呃数据,呃,前面是一些这个基础性的这个东西,然后后面的话就是咱们的量表题项,他最后得出来的这个数据,你看他的每一个基本上都是这个负三的话是,呃,前面呃筛真别题的话,他是剔除掉了的, 看他的基本上都是理科的五点计量法,理科的五点,他全部都是这样子的话啊,拿到这样一份问卷,嗯,这个量表性的这个数据的话,我们后期啊分析那些东西都会比较顺风顺水一点啊。然后这个就是咱们这次的内容。
1350实证分析小布丁 02:40查看AI文稿AI文稿
02:40查看AI文稿AI文稿hello, 大家好,今天我们来分享一下量表数据中反向积分的题目如何进行重新复制。 那比如说我们现在还是有这样的一份数据, a 一到 b 四,它都是一些量表型的数据,然后它的曲值都是一到五的 啊,一到五的范围分别代表的是非常不满意到非常满意。但是这里面呢,假如说 a 一和 a 三这两个变量,他是反向积分的题目, 那就需要把它的曲直来颠倒一下,就是一到五转化成五到一,这个我们就需要点击这个转换重新编码为相同的变量,因为我们是要直接在原题上 进行改他的得分就可以了,那我们就选择这个重新编码为相同的编量就行了。 然后刚刚说的是 a 一到 aa 一和 a 三这两个是需要重新编码的,那你就把它选进来就行了。如果有几个反向积分的题,都可以把它都导到右边这个数字变量这个框里, 然后我们进行重新复制的时候,他就会把这个框里面所有的变量都给他的数值都给反过来, 然后点击这个旧值和新值,比如说旧值是一,那新值代表的就是五,然后我们点击添加,旧值是二,新值代表的就是四,旧值为三,新值也是三,然后旧值为四,新值也是 二,旧值为五的话,新值就是一,然后点击添加,这样我们就把一二三四五给他返成五四三二一了,然后点击继续,再点击确定, 然后我们这里面的数据就已经是调转后的,可以看到原来这这个应该是取之为四的,现在已经变成二了, 这个就是我们对量表数据中反向记分的题目进行重新编码, 那我们对这些数据进行重新编码之后,就可以继续后续的一些变量的计算呢?以及变量的一些相关回归分析或者差异性分析都是 可以的。好,以上就是如何对量表数据中反向积分的题目进行重新编码。
569spss小师姐 05:21查看AI文稿AI文稿
05:21查看AI文稿AI文稿是完成或者被成熟模式所取代,现在我们看一下测查的顺序及方法。首先我们要确定主册年龄, 现在的计算机系统都会根据孩子的出生日期和测查日期自动换算出孩子的时机月龄。 检查者可以以孩子的实际年龄为主册年龄,也可以结合孩子的临床表现确定主册年龄。 在检查的过程中,一般的顺序是,先做适应性和精细动作两个能屈的项目,再做语言和个人社交两个能屈的项目。最后 做大运动能去的项目。做完一种体位的所有项目,再测查另一种体位的所有项目。 用一种工具的项目测试完后再测试另一个工具的项目。这里要强调一下,检查者在做完一个项目后,应尽量的收走测试的玩具,再进行另一个项目。 那么格斯尔发育诊断量表的评定标准是什么呢?我们来看一下。当发育上 dq 大于等于七十六小于等于八十五时,该儿童为边缘状态。 当 dko 大于等于五十五小于等于七十五时,该儿童为轻度缺陷。 当地 q 大于等于四十小于等于五十四时,大儿童为中度缺陷。当地 q 大于等于二十五小于等于三十九时,大儿童为重度缺陷。 当 dq 发育商小于二十五时,该儿童为极重度缺陷。 葛塞尔量表呢,具有较强的专业性,能够相对系统准确的判断儿童的发育水平。 但其应用时呢,对测试人员的要求也比较高,需要具备一定的儿科、临床、儿童保健、儿童发育的经验或精力,且经过标准 的培训并取得资格的医生来完成测试。过程中呢,要求态度和蔼,使用标准的测验工具,并严格按照指导语进行操作。 针对结果呢,要结合养育行为进行标准化的解释,以避免出现结果的主观偏移和错误。 测试人员必须遵守职业道德,遵守保密原则,不能将测试方法和评分标准公开宣传, 影响其使用的标准性,以至失去测试的意义。不能将测试内容作为教学或训练的内容, 以避免给被视带来损害。葛塞尔发于诊断量表,是以适应性能驱作为儿童发展水平的总体代表, 但因五个能屈的结果体现了儿童行为发育的各个不同维度的水平。 进行结果分析时,需要针对每个维度的行为模式进行分析,而不能以计算的总和或者是平均值代表儿童的发育水平。 对于婴幼儿来说,不能将心理测评与神经病学检查截然分开。如果在婴儿期行为发育完善、质量好、速度正常,证明 大脑皮层发育是完整的。若没有损害事件发生,大脑皮层的完整性将继续保持。 由于行为发育的结果受生物学因素、社会心理因素的同时作用,所以在预测儿童未来发育水平尤其是智力方面具有很大的局限性。 因此,不能认为测查分值越高,儿童的智能发育越好,或者未来的成就就越高。 对于具有听觉障碍、肢体运动障碍或语言行为问题的儿童,易造成测验结果的偏移,需要结合儿童的具体行为方式,分析结果的真实性、客观性及其 影响因素。发育诊断是根据儿童发育成熟程度分析儿童的发育状况, 并不试图直接测试智力水平,而是结合临床表现估计智力潜力。谢谢大家。
134儿保介




