随机森林和xgboost的区别
我们来看一下集成学习的另外一个分支, boosting 模型,其中就包含大名鼎鼎的 x g boost, light gpm 和 cat boost。 集成学习有两大主流思想, bagging 和 boasting, 它们的目标呢都是把一群比较弱的模型组合成一个强的模型,它是怎么组合这些模型?它们的实现路径是不同的。 首先 baging 呢是少数服从多数,这个典型的就是我们上次讲的随机森林,它呢就是有放回的采样, 我同时并行训练 n 棵树,然后每棵树呢都准备一份不同的训练的数据,随机采样,对吧?然后呢对于所有的特征呢,也是随机选举,让它进行分裂,让每棵树呢都学到不同的视角。 最后呢,综合所有的树的意见,让它们并行来做预测。综合一下,如果是回归问题呢,就投啊,就取均值,如果是分类问题呢,就投票,这样就是得到了最终的结果。 而 boost 顶模型呢,更像是一场接力赛,就是它是串形训练的,我先训练一棵树,然后我看看它差多少跟最终的结果,我再训练第二棵树,尝试把这个误差给修复了, 然后呢会发现它还是没修好,我在训练第三棵树,在修炼,在修补剩下的误差,这样不断的串行的训练,一棵接一棵, 每一棵树呢都专注于修复前面所有的树加起来剩下的误差,这样最后我们在预测的时候呢,让它们都预,把它们的预测结果累加起来,就得到了最后的结果了。它的代表算法就是就是各种,就是 x g boost, let gbm 和 cat boost, 呃,简单来讲,我们可以用无论是接力赛还是用打高尔夫,这个可以来理解一下 boost 模型在干什么,比如说打高尔夫,我们的目标呢?呃,三百五十米远,把它给打进洞, 就是我们首先挥了第一杆,其实就是我们训练的第一棵树大力的开了一下球,他呢可能飞了三百米,离着球洞还差五十米, ok, 那 么我们第二棵树呢,就不再是训练这三, 呃,三百五十米,我就是补上这五十米的误差,最后呢,可能我们最后训练结果是四十五米, ok, 离球洞还差五米,我再训练第三棵树,再补上这五米,可能打了四点五米,离球洞还有零点五米, 然后我就第四竿,哎,终于比较近了一下就打进去了,最终的结果呢,就是把这几棵树的给它加起来,就得到了最终的预测结果了。这个就是 boosting 的 精髓,每一个模型呢,都在你和前面模型的残差,然后接力合作,最后呢,逐渐逼近真实的答案。 我们来做一下简单的对比啊,就 bagging 模型呢,当然它的点呃,典型就是随机森林, boosting 呢就是提度提升数,就就是今天我们要讲的内容。首先它们从训练上就是不太一样的,随机森林呢,是多棵树并行的训练的, 而 boosting 呢,必须得一颗一颗的训练,对吧?因为第二期这一颗要修复前面的树加起来的的误差嘛,所以说就必须得是串形的训练,就会稍微慢一点。 每棵树的目标呢,也不一样,就是 bagging 中呢,每棵树呢,都在学习最初始的目标,对吧?因为它们是并行,每个人都在尝试做预测,而 boasting 呢,都是在学前面的残差。 在展开介绍 boasting 模型之前呢,先给大家解释一个最容易被大家误解的概念,呃,我们知道, 呃, boosting 模型呢,就是通过不断的训练新的数来让残差越来越小,这样你逼逼进最终的真实结果。所以说呢,很多同学会认为,那我的名字就叫残差下降决策数就可以了,但实际上它的名 boosting 模型的一般的名字叫做什么呢?梯度 提升决策树 gradient boosting decision tree。 大家会很好奇啊,那为什么会用残差就可以了?你为什么要讲梯度?而梯度不应该是越来越小吗?为什么要讲梯度提升?这是怎么回事?实际上呢,这先给大家讲一下结论啊,呃, 梯呃,残差只是当损失函数是 mse 的 时候的特殊情况,在其他情况下都是梯度。然后呢, 而提升并不是指的梯度越来越大,而是指的是这颗他用的方法是梯度,而他的提升呢,是指的这棵树的能力越来越强,而不是指梯呃,梯度越来越大。所以说呢, dc 任翠很好理解,他就是用的决策树嘛,对吧,所以说呢,是用了 用了梯度下降的方式,让模型的能力越来越强,其中呢,用的是决策树, ok, 那 么来具体来看一下啊,梯度 啊,梯度提升数呢?他的模型呢,就是多棵树的累加,对吧?但我们怎么让他不断的来逼进真实的值呢?他又不像限行回归这种是有固定的参数的,他每次呢,优化的方式是在每一轮后面新增一棵树,对吧?我都是这些数呢,是逐渐加起来的, 那经典的梯度下降呢?每次我有参数,我就是下降的方向呢,就是负梯度,往负的梯度的方向走就好了。梯度下降那节视频我们讲了,最后更新方式呢,就是让之前的参数减去学习率,乘以这个梯度,其实就加上它的负梯度就可以了, 对吧?而对于梯度提升决策数呢,他的每次优化的对象呢,就是这个函数,然后他他的方式呢,他的方向啊,也是负梯度,这个是一模一样的,只不过是他的梯度并不是对于参数求呃,求梯度了,而是要对函数来求梯度了, 求出来之后呢,他也求出来他的是一个负梯度啊,也是往负梯度的方向去乘上一个学习率,加起来。 这个其实呢,其实跟我们的公式是是特别像的,所以它的核心呢,还是梯度梯度下降的方式,然后每次呢,我们就是给这个每个样本计算,它的负梯度,就是当前模型最该修正的方向了,然后我们去训练一棵决策树,让它来拟合这些负梯度的值, 对吧?最后呢,我们让它成把训练出来的这一棵决策树呢,就是一个新的模型了,我们让它乘上学习率,加到现在的模型上,相当于沿着下坡呢,走了一小步乘以学习率,就是为了走一小步,而不止一次让它 把残差都给逆和了,这样是非常容易形成震荡的。这个对学习率的方式呢,跟梯度下降也是一样的, 所以说当我们损失函数是 mse 就是 军方差的时候呢,就是二分之 y 减,就是 f s 的 平方,对 f s 进行求导呢,正好把它乘过来呢?然后它的负 t 度呢,就是 y 减, f s 正好就是残差了,对吧?又说只有 m s e 下负的 t 度才正好是残差呢? 这也是为什么前面我们举例子的都说你和残差,当我们把损失函数做一下变换,比如说不用 m s e 了,用 ma a e 或者是对数损失的时候,我们就会发现它不再是残差了。 所以说呢,我们会就是用更通用的名字叫它梯度提升决策树,而不是残差下降决策树。 所以说呢,梯度就是指的用负梯度这种方式来引导每棵树的学习方向而提升,尤其是这个提升啊,不是指的让梯度越来越大, 而是指的呢,让多颗弱的决策数逐步叠加,让模型能力不断地增强。这有点翻译的误解啊,如果我们翻译成梯度增强决策数,可能会稍微好一点。 ok, 那 了解了这些之后呢,我们就来看一个就是梯度提升决策数,大概它的实现过程,大家就能把它的原理全都明白了。首先呢,还是引入一些必要的库,这个我们就把 decry 就是决策数的给引进来就可以了。首先呢,我们来先呃模拟一个数据啊,就是带着噪声的正弦曲线,对吧?呃正弦曲线,然后给他加一些呃噪声。然后呢, 我们再来训练,训练的时候设一些初始的学习率,然后我们把每轮的数呢也都记下来,然后每次的函数呢也记下来,第一次的函数呢,因为我们也没法训练,就直接用它的均值 给他,就是当呃把他均值就当成第一个的函数就可以了,然后开始对他进行训练,然后第一次呢就是就,呃每次训练的时候呢,我们刚才讲的步骤,对吧? 看一下啊,呃,计算负梯度,这个呢,然后负梯,呃,在 mse 的 时候就是残差了,然后呢再去训练一棵树,去拟合这个负梯度,拟合这个残差,然后呢训练出新的数来,再乘以学习率,让他一加就可以了, 看一下我们写的代码,其实就是这几步啊,第一步呢,计算出残差来就是负梯度了,然后呢我们再训练一棵树呢,来拟合这个残差,我们这个树呢让它最多就是两层用决策树。 然后呢我们去训练它特征呢还是这些特征,我们也不做随机的取样了,就是用全部的啊,全部的训练数据,然后呢给他训练的结果呢就是这个残差, ok, 我 们训练出来了之后呢,我们让他做一轮预测, 做一轮预测呢,然后并先把这个把训练出来的这个数呢给存起来,因为一会我们要看一下, 好,我们也把预测的值呢,然后把它给乘上,就是这个预测呢,最后我们更新,怎么更新模型呢?怎么让它变呢?其实就是让学习率呢,让它乘上一下学习率,然后把它给加进去。最后呢我们可以可直观的来看一下我们的结果, 可以看到啊,在前三轮的时候,我们训练前三轮的时候呢,因为第一次就是平均几乎什么都没一只有一棵树的时候,反而求出来均值,就是这样子的,这个是真实的加上了噪声之后的数据啊,蓝色的, 红色的线呢,就是我们训练出来的模型,这个可以说是完全不像呃,第二次呢,加了一棵树之后呢,可以看到 mse 呢,就小了一些了,就是残差小了一些了。第三次呢,大家会发现这个越来是不是相对而言越来越接近了,残差越来越小,是不是啊?可以看到啊, 残差大家会看到啊,随着树的增加呢,越来越,你会越来越往残,让残差变得越来越小。到第九棵树的时候,基本上感觉已经非常吻合了,只有这一小点, 所以说呢,每棵树都是在查漏补缺,模型一轮比一轮精准,这个就是 boasting 模型的核心理念了。 然后我们当然也可以单独来看一下残差的分布的变化,刚才只是看的数字,可以看到这黄色的就是在残差。第一次呢,可以说残差几乎跟 分布是一样,因为你写的是均值嘛,残,大家可以看到这残差是慢慢地逼近零这个线的,是不是啊,到了最后的时候,基本上就是在零的这个线的上下了,可以看到就是这就是 pos 模型逐步纠错的过程。 然后呢,我们所以看一下就是梯度提升决策数的一些优缺点。首先呢,它预测的精度是非常高的,所以说呢,这也是它在 基本上就是在卡购竞赛的呃,里面呢,是最最常用的了,因为它的精在结构化的数据上就是表格这种,对吧,有几行几列的这种数据,它的精度是非常非常之高的。 然后呢,他也特别呃,既能处理回归问题,也能处理分类问题,而且呢,他也像,因为他用的是决策树嘛,我们也能看出特征的重要性来,同时呢他对特征的缩缩放呢,就是对于特征也不太敏感,对他的所以也不用做标准化或者归一化,而且呢损失函数也比较灵活,我们可以设各种各样的损失函数, 但它有一些缺点,因为它是串形训练的嘛,所以它比较慢,而且呢是呃在噪声大的时候呢,其实也是容易出现过你核的现象的,并且它对超参数呢也特别的敏感, 所以说训练起来也不太容易。如果说我们对于一些高维稀疏的数据的时候,在做 onehot 的 时候呢,它也是特别占空间的,然后对于特征的处理呢,也需要我们手工进行编码,不太方便,所以说呢,在业界 就对它产生了各种各样的进化。第一个呢,其实就是二零一四年诞生的,就是 x g boost, 这个也是在卡狗竞赛中用的最多的了, 它呢就是可能也是继续学习历史上最有影响力的开源项目之一了,就是对于最最普通的梯度提升决策树呢,做了一些优化,首先呢它就加入了政策化,因为它是非常容易过你河嘛,就是政策化,这个大家有印象的话,还知道对于一些呃 呃叶子的数量还有叶子的权重之间呢,用了 l l 正则了来惩罚你,就说如果过度的过你核的话。第二呢,它还用了就是二阶梯 二节提度,其实就是如果大家对于高数还有点印象,泰勒二次展开其实大概就是经典的就是呃提度提升决策数呢,只用一个一一节的提度,我们就知道下降的方向,方向往哪边了?如果我是二节提度呢,就知道他下降的该快一点还是慢一点了, 这一导数吗?一节的导数呢,我们可以理解为就是速度,对吧?相对于为时就是为为宜,相对于时间就是速度。而二节梯度呢,就可以理解为加速度,速度到底是变得越来越快还是越来越慢了,这样我们就能在选特征分界点的时候可以更精准。 然后呢,他还做了大量的优化,其实都是为了让他训练的时候呢,可以更快更快一点,也就是说他是在精度和速度之间的平衡,所以在竞赛中用的是最多的。当然如果说我们知道他的 x j boost 呢,它默认的时候,在训练的时候其实会找所有的数据点,就是对于特征啊,去找分裂点,所以说呢,其实本身它就是串,每棵树之间就是串行的。然后呢,如果说一个我们的数据中啊, 我们的特征中的指示特别多的时候,它的训练就特别慢了。而二零一七年呢,微软就推出了 light gbm, 就 一看 light 我 们就大概知道它就快, 它的就是在数据量比较大的时候,它的训练速度大概是 x g box 的 五到十倍等等,它怎么做到这一点的呢? 就是首先就是说它其实第一个就是在特征分裂的时候啊,它并不是把特征里面所有的值都去试一遍,看看到底用谁基尼系数最基尼系数最小了,是不是啊?它不是,它首先呢就是把你这里面的给你做了一下呃,离散的脂肪图,每次就是在脂肪,比如说有一千个数据,我就给你分成了二十五个桶, 每次呢,就是只看二十五个桶的边界上的值就好了,我不会把你所有的数据都看一遍的,我只看桶的边界。这样呢,其实就是让特征分裂呢,变得明显变快了,而且呢,它还做了一些带深度限制的。就是 呃,生长策略啊,就是传统的决策树呢,是一层一层整齐生长的,就不断的分裂嘛,就是每个都要看。而 let gbm 呢,其实就是谁的残差最大,就沿着谁去走, 就是一条路往直接就往下走,这样其实在大数据的情况下,他还是精确度能非常高的,但是呢,树可能会有点不平衡,有容易出现一边特别长,而且呢,还做了另外的一些。呃,黑科技啊,让训练速度变得越来越快, 其实在大数据的情况下用它是更合适的。然后呢,呃,同时在二零一七年呢,俄罗斯的互联网巨头 youngass 针对于类别特征呢,处理了 cat boost, 就是 有 category boosting, 对 吧,它在处理有大量的类别特征的,无论是说你是做分类任务,还是说你的特征中有大量的类别这种呃类型的数据,用它是最快的, 它它首先它就原生的就支持了类别这种特征了,你就不用自己用 onehot 把那个特征进行自己去编码了。 这个如果大家在看数据预处理那节课还有印象的话,就知道这是在干什么。尤其是啊,当你的类别的里面的值是特别多,比如说你只有男和女,那么你用零一和一,零甚至零和一就行了。但如果说你的特征里面你的分类有一千个 哇,那你要用 onehot 的 话, onehot 毒热嘛,那就可能是有一千位,其中只有一位有用,这个是极其浪费的,而就是看 boss 呢,可以原生的处理这种情况。而且呢,呃另外一个呢,其实就是对于 呃普通的梯度提升决策树呢,它其实是有一个隐患的,就是预测偏移,这个大家其实并不用呃,大概了解一下就行的,如果去详细了解这理解这些模型的时候,可以看一下它相关的设计,其实最主要的就是说你在计算残差和你在做下轮预测的时候都用这个值了, 你都用这个样本了,而它就会模型的,其实就相当于模型在训练的时候就看答案了,它就会偏向于呃,就是容非常容易出现你和而就是 cat boss 呢,就大概解决了这问题,我每次我只用你前面的值算参差,不用你算,我就不用你特意的不看答案。 另外呢,其实它强制呢,就是因为强制生成的决策数是完全对称的,这个就让推理的速度就变得快了,注意啊,是推理的速度快,并不是训练的速度快,这些是不一样的, 这个就是 cat boost。 那 么我们在怎么做选型呢?一般说在呃卡狗竞赛中,因为它的数据量不是特别的大,但是对精度值,因为大家是比赛嘛,所以要看谁 训练得更准。一般呢,其实就用 xbox 的 就行了,当数据量特别大的时候就用 light, 就是 就是 light gbm, 或者是先用 light gbm 跑一个再去,或者甚至用它俩进行叠加,也是 呃在竞赛的时候的一些常用的技巧。但是呢,在工业界,实际上因为工业界一般训练数据量会大一些,所以说 light gbm 的 应用是非常广泛的。如果说我们数据中有大量的特类别特征,这种时候呢就用 cut boost 就 行了, 对吧?当然 cut boost 也能做数值,也预测,也能做类别预测,但如果说你的特征的数据里面类别信息特别多的时候,用 cut boost 就 非常合适。 然后呢,呃,我们呢就给大家演示一下用 x ray boost 来预测加州的方向,并且呢和随机森林呢做一下对比。 呃,看一下。首先我们加载一下那个加州房价的数据,这个和前面的几乎都是一样的,划分训练级和测试级,然后可以打印一下,会看一下它对应的数据情况, 然后呢看,接着看重点。首先呢就是我们要把 x g box 从一个单独的,就是把那个 x g box 的 模型呢,从一个单独的包里面需要安单独的安装这个包。 剩下的就是随机森林啊,这些都在就是塞克林里面了,就不用加载了。首先我们先看一下用随机森林,我们记录一下它的大概的时间啊,就是 star time 和最后的 n time 呢,我们都把它看一下它耗时是多久,然后呢当然也对它进行一下训练,然后那个 大概呢深度是十二百棵树,然后就是全火力把所有的 cpu 都给等,让它开始利用了,对它进行训练,然后看一下它的时间和它预测的做一下预测,然后再看一下 x ray boost 的 呢,它大概也是一样的。 然后呢也是二百棵树,同时呢最大的深度是五,我让它深度稍微小一些,那宁瑞特呢?是乘零点一, 呃,然后呢, sum 就是 sub sample 和那个,这个是 colum sample。 备份是什么意思呢?其实就是每次训练的时候用多少比例的样本和多少比例的特征,这和随机森林稍微有点像,我每次呢,也不是用全部的样本和全部的特征的。 然后呢,也是让满 cpu 运行看一下,把时间也计算一下,把预测值看。我们打印看一下, 可以看到啊,它们 m s e 训练随机森林的零点二九,然后 x g boost 会比它稍微的小一点,零点二一,而方呢,它能到零点七七,而 x boost 的 呢,是能到零点八三,可以看到,并且呢, x g boost 的 耗训练耗时也要少一些。 所以说呢,可以看到 s 是 boss 的, 可以说是在这方面呢,还是在无论是为什么在比赛啊,中啊,或者是在工业界呢,就是 boss boosting 模型会比随机森林用的稍微多一点,也是因为这个可以无论是在训练结果上还是在训练速度上,都是有一些明显优势的。 然后呢, xbox 呢?还有一个好处啊,就是有很多时候呢,其实刚才不是说了用那个,呃,比较初识的就是提图提升决策树,你设学习率是一个技巧,设不好就容易震荡,设的太小了,设的太大就震荡,设的太小了,就训练特别慢,那怎么办呢? 所以说我们的数的数量也不知道选选多少,但是呢,呃, x g box 在 这方面特意做了优化,支持早亭就是 early starting, 它干什么呢?比如说呢,我们可以设置一个很大的,就是一万棵树,对吧?设置一下上限,然后学习率呢,也是用非常小的学习率, 对,这个都是一样不变的,我们让它去做训练,你会发现啊,它其实并不会训练,呃,真的是训练一一万轮,或者是九千九百九十九轮, 对吧?你会看到他会发现训练到一千二百零五轮的时候,他就不怎么训练了,他就停下来了,就是,所以叫 early stopping 嘛,就是应该他是什么时候停下来的时候呢,他就会发现啊,当他的精度不再变化的时候,基本上他就给停下来了, 所以你就不用纠结到底该设多少棵树了,直接就设一个比较大的让算法自己,当它的不再下降的时候呢,就自己找一个就好了,就自己就能停下来,这也是 x ray boost 的 一个优势。我们如果格式化这个训练过程呢,就会发现 可以看到啊,就在最开始的时候,这是什么呀?就是 rms 一 啊,它的下降的速度在最开始的轮数呢,下降的就是误差呢,下降的是非常非常之快的,对吧?但是呢,会发现到了一千一一千二左右的样子就不再变化了,有时候模型的训练就停下来了,最佳轮数呢,一千一百八十六, 给你设了这一千多棵树就好了。最后呢,对于我们讲的决策树,随机森林,还有就是也就是我们的梯度提升,决策树呢,做一下对比, 决策树呢,就用一棵树,而随机森林呢,是并行的多棵树。呃, x g boost 这种 boosting 系列呢,其实用的就是串行的多棵树了,它们的集成缩列呢,就一棵树也没集成了,所以说呢,它的问题相对而言就会比较多。而随机森林呢,其实用的是 bagging 的 思想, 它无论是说,对于分类问题呢就投票,对于回归问题呢就求均值。然后 boosting 呢,是逐渐的增加,逐渐各各个树之间呃, 不停地累加就行了,它呢是并形的对吧?它是串形的,增加出来单棵树的特点呢,就是可深可浅,这个随便你了。而随机森林呢,是比较深的,而,呃,哎,就是 boasting 系列呢,相对而言用的是比较浅的。 核心的目标呢,决策树在最开始的时候可以做基线模型,而随机森林呢,实际上是为了降方差的。而就是刚才我们也能看到啊,就是 boasting 模型呢,实际上是为了降偏差的,对吧?过你河的风险呢,相对而言,随机森林会更低一些。 所以说呢,决策树呢,我们可以用它来做啊, base line 模型,而且呢比较简单,符合直觉对吧?随机森林呢,用了 bagging 的 思想,让多棵树呢并行的投票就把方差给降下去。 就是啊,这个 boost 性呢,这个就是让多棵树串形的纠错来降低偏差,所以说,而但是呢,在日常不会直接去使用。我们在用的呢,都是二零一四年,二零一七年等,最近比较近,反而经过各路大神优化出来的 s g boost, light, gbm 和 cat boost 好关于决策术啊系列呢,甚至关于基层学习,我们就介绍到这里。在其实呢,关于监督学习,我们积极学习的监督学习系列呢,我们就介绍到这里。在下节课呢,我们就开始介绍无监督学习,其中呢,主要就是, 呃,一个呢是剧类,一个呢是降维, ok, 这个视频就先到这里。

粉丝5.7万获赞15.9万
相关视频
 02:58查看AI文稿AI文稿
02:58查看AI文稿AI文稿今天主要讲的是随机森林算法,它解决的是单颗决策素对数据的微小变化会比较敏感,会导致可能整颗决策素都变了,也就是说他的辱爆性不佳的问题。 辱爆性就是说一个系统在面对异常的输入的时候,还能保持正确输出的能力好,然后随机森林算法是怎么解决它的呢?它 他是通过有范围的材料,利用原始数据去构建了很多新的数据局,然后构建了很多新的决策数,然后在最后所有的决策数输出他们的预测结果, 然后收集到所有的预测结果以后,通过投票就是少数服从多数,然后输出一个最终的结果, 然后解释一下有放回的材料,就是说啊,这个袋子里有十个数据,然后我们的原始数据机就是这十个数据,然后你在构建第二颗第三颗决策树的时候 啊,你拿数据的时候是拿一个放回去一个,然后重新从这十个里面拿,所以说你拿到的新的数据集里面可能是有重复的内容的 啊,那这个没关系,好,随机随机生成算法,就是啊,这样子就构成多棵树,然后最后少数服从多数去进行一个投票来输出最后结果,然后他的进一步优化,就是说你你里面的树长得差不多的话,大家的 大家的就是效果就不太好嘛,投票的时候希望树的随机性,随机性更更强一些,树都长得不一样点,那这个时候你在每次选择特征的时候,可以从一个随机子集里面 去选,而不是说每一次都从所有可以选的特征里面去选,选你这一次要用的特征。好,然后接下来讲 s g boost 的, 它是对随机森林算法的进一步优化,它就是在我们 第一步是有放回的彩样,构建了很多数嘛,然后第二步是数的随机性增强了,然后现在第三步是说你这个不是,不只是随机性增强,你是有刻刻意学习的成分,刻意学习就是说你放过对的,然后反复去练习,你不会的 就是反复练习你预测错误的,所以你的决策数就是根据你预测错误的去去构建 啊,这样子的话,你的你的这个这个这个随机森林算法的的的预测准确性就会更高嘛。然后最后是决策树和神经网络的差异和他们的适用场景,也就是说 啊,决策树更适用和用于结构化的数据啊,神经网络适合用于任何数据非结构化数据,就比如说图像、音频啊,文字这种。 然后呢,但是神经网络训练很慢,然后决策树训练很快,但是神经网络可以用于千金学习啊,就这样。
29哔哔哔在家 17:04查看AI文稿AI文稿
17:04查看AI文稿AI文稿我们来看一下决策树,这可以说是最符合直觉的机器学习算法了。想理解决策树呢,我们可以先从一个小问题开始。小张是一个网球爱好者,周末经常就会去打网球,但具体去不去呢,又要取决于当天的天气状况。 下面这个表就记录了过去十个周末的天气,还有小张有没有去打球的一个记录,我们来看一下它有几个特征,具体今天的天气状况,湿度,温度,是否刮风。最后是标签数据,小张有没有去啊? yes or no? 这是一个典型的二分类问题, 那么我们可以呢,用之前的课程介绍到的逻辑回归训练一个模型来预测小张是否去打球。但是有时候呢,我们又想细究一下,具体这个周末小张到底为什么去了,为什么没去? 逻辑回归会给我们预测一个结果,大概率也是准确的,但是呢,却给我们解释不了他做判断的依据。 如果我们对这个依据特别感兴趣,或者非常迫切的了解,比如说在一些金融场景,借银行是否放贷啊,包括一些医疗场景,医生做一下判断,肿瘤的识别啊,可能它的证明,它的证据链也是一个很重要的事情,这种时候呢, 决策树就可以给我们很好的一个证据支持。假如说我告诉你这个周末的一个具体的天气情况,让你来判断,没有模型,就是让你用大脑来做一下推理,想张会不会去打球。其实你仔细观察了一下这些数据啊,自己背后也会能够看出一些端倪来。 首先呢,你就可能就会看一下天气情况,你会发现只要是多云的情况,风雨无阻,只要是多云,你会发现小张都去了, 所以说就会看是否多云。是啊,不是,他是晴天,那么是晴天的情况下呢,你又观测了一下,发现这个晴天的时候啊,他确实是有的时候去,有的时候不去的,但是不去的时候呢,湿度都是 high 对 不对啊? 丧尽都是 high, 去的时候呢,你会发现湿度就是 normal, ok, 可能你脑袋里面就有了一个想法了,湿度高的时候就不去,湿度正常的时候他就去了。 如果是雨天呢,你又会观测发现,雨天的时候有什么规律呢?你会发现啊,就会跟是否刮风多少有一定的关系,不刮风他就去了,刮风的时候呢,就会发现他没去, ok, 所以 最后我们在大脑中呢,就会画一个这样的一个决策的路线图,用于辅助我们做判断。 实际上呢,思路过程呢,就是决策树。决策树就是用来模仿人类决策时层层提问的方式的一个机器学习的算法,它将数据就按照不同的特征进行递归的分裂,最终就形成一颗倒立的树状结构,所以说就称之为决策树。 决策树里面有几个点,第一叫内部节点,就是代表对某个特征的判断的问题,我们前面这些问题呢,这些菱形都可以说是内部节点在不断的提问吗? 还有树枝的分支,就代表判断之后的不同的答案否,一般是左边否右边这样子的,但有可能是三个答案。二、分类的时候会简单一点,如果有多种情况,就会答案有不是是否的时候就会复杂一些,这个图最后呢,还有叶子节点,就是最终的决策结果, 也就是这个图中圆形的去或者是不去。当然决策树除了可以做解决分类问题,也可以解决回归问题,它呢算均值啊等各种各样的方式来给你预测数值也是可以的。我们只是在这用分类问题举例子, ok? 决策树呢,他的解释性就非常强了,可以看出来,如果我们在医疗场景、金融场景做了一些判断的时候,他的决策路径呢,是非常清晰的,他为什么做这个决策很清楚的就告诉你了。所以说呢,决策树的预测的过程是非常简单的, 那么难的是什么?我们如何构建出一个决策数来?因为我们上面举的例子的一共就几个特征,人用肉眼来看的大概率也能看出规律来,但是面对着特征极其复杂的时候,你有时候用眼睛就看不出规律来了。那么机器是怎么学习的, 怎么在众多的特征中就挑选出那一个最适合分裂的特征来,对吧?就像是某门模型,怎么知道第一步该问天气而不是温度呢?最核心的就是一个纯度的概念, 我们如果说啊,按着温温度进行分组,它的纯度呢,我们就称之为比较低,为什么呢?我们就会发现,温度啊,在按着不同的温度,既有去的时候,又有不去的时候, 混杂在一起,它是非常混乱的一个,我们就说它不纯,它分出来的结果,如果说按着天气分组呢,我们就会发现啊,多云的时候全都是去了,我们就管这个就叫比较纯纯度的概念。 ok, 知道了这个概念之后呢, 我们再来了解一下,用纯数学的方式来评估什么叫纯,什么叫不太纯, 这个就是我们重要的一个数学指标了。商与信息增益就是决策树,在选择最佳的分裂特征的时候呢,就用一个数学指标来量化节点的混乱程度,或者叫纯度, 这个就是商。商呢,是一个来自于物理或者信息论和信息论里面的概念,用来衡量一个节点,就是一个状态,它就是混乱程度,它的不确定性度在我们这里面呢,就是一个节点中各种类别分布的混乱程度, 如果说一半都去打球,一半不去,在二分类中的问题的话,就百分之五十对五十,悬念是特别高的,他的伤值就非常的高,最混乱了,如果说全都去或者全都不去伤,他的伤就为零,是最纯净的时候了, 这种时候伤就是最小的,所以这就是伤的概念。那么我们怎么来衡量它呢?就是信息增益了,用某个特征进行分裂之后,我们看看混乱程度下降了多少,就信息增益呢,就等于是分裂前的伤减去分裂后的伤,就是分裂之后,我们看看他有多不多纯了, 用这个特征进行提分之后,消除了多大的不确定性,信息增益越大,就说明特征区分的能力就越强了, 用这个是可以的,之前大家都用这种,但是这种实际上是用到一种对数对数的运算的,而计算机在处理对数运算的时候呢,会 效率会低一些,而且呢用信息增益的方式啊,会趋向于对于大的特征呢,会出现于过你核的情况。所以说在后面我们就发现另外一种基尼系数,也叫做基尼不纯度,来解决伤的计算复杂性的问题。 它的公式非常的简单, p 就是 k 呢,其实就是在这个数据集,第一就是数据集嘛,这个 k 就是 它里面有多少个类别。我们把 pk 就是 当前这一个分类的概率, 我们可以理解为这个公式看起来稍微有点难,但其实这么来看就会这两个公式是等价的。看后面就简单了, pk 乘以一减, pk 把每个的分类都给它算,加起来算一遍,这是什么意思啊?就是随机从节点中取出两个样本来,它们属于不同的概率, 比如说有有红红黄绿三种颜色的时候,我就是在一个箱子里面,我随机取出两个球来,它们属于不同颜色的概率有多大? 把三个的是黄色和不是黄色的概率,乘一下连续发生的概率吗?在是红色,不是红色,不是蓝色,他们的对应的概率相加,其实这两一乘的话,其实就是易减,它这种时候就知道它的这就是叫做基尼系数,或者基尼不纯度。 进级系数越小呢,就说明节点越纯,越大的就说明它不纯,所以它叫不纯度嘛,也叫进级系数,所以完全纯净的时候,进级系数就是零。只有一种的时候, 它的特征是它只有乘法和加法了,所以说呢,它的计算速度呢,是非常快的,就没有做对数运算嘛。在工业中呢,这个基本上是默认值了,我们用的 ck 的 楞中的决策数呢,默认也是用它做指标的, ok, 我 们用这个来算啊,说节点该不该分分点,哪个节点的增益是最大的,我们就来看看我们构建一个决策树的过程了,其实这就是一个典型的递归的过程。首先呢,我们就把各个节点中的特征都进行 所有的特征都划分,算一下他们的经济系数,选到经济数是最小的那个,就按照这一个进行特征分裂。分 分裂之后呢,我们再对每个子节点,再对他子节点里面所有的特征看一下经济系数,再多分裂,不断的做分裂,直到呢都只只剩叶子节点,或者是我们会要求分裂的一定的高度,不能再分裂了,这种时候就能把这个决策树给构建出来了。 说的可能稍微有点抽象啊,我们带着大家看一下代码就非常明白了。首先呢我们用一个数据集,这个是塞克伦默认自带的数据集啊,原尾花的一个数据集,它里面呢大概是有一百五十朵花的,有四个特征,其中有三个品种,想让我们区分一下里面的品种, 我就把数据给加载了一下呢,为了方便大家看啊,我们把特征给翻译成中文名了,先看一下前几行的特征,看一下他们的数量问题呢, 它大概就是这样的特征,就是它是有花蛾的长度,花蛾的宽度,还有花瓣的长度和花瓣的宽度,最终的分类,但前五条都是山原尾了,它其实是有三个分类的,就可以看到它,三种呢都正好就是这三种, 山原尾,变色原尾,维金亚原尾,这个分别都是五十个, ok, 大 概数据就是长这样子了,我们怎么给他分类呢? 可以看一下,首先呢还是得划分训练级和测试级,这个是我们的老套路了,我们在前面呢引用一下,在 cray 里面呢,引用一下 decision tree, 分 分分类器, 给它分类的时候我们手工啊,其实这个不指定也没关系,但是我们手工呢,给它指定一下,是用经济系数给它限定一下,我这个数呢最高就是三层,你不要给我无限的分裂, 对它进行训练,训练完了我们就预测,预测结果其实是非常不错的,我们还可以什么就把这棵树给它画出来,我们训练完了之后呢,实际上是可以画这棵树的,给它画出来之后呢,大概看看是什么样子的啊? 会看到这个我们的决策的过程,给大家解读一下,这节点上这些都是什么意思啊?第一行呢,花瓣宽度啊,花瓣长度小于二点四五,这个其实就是它用的特征跟分裂 这个特征用的一个具体的值是多少?基尼系数就是表示用它当前的基尼系数是多少。三炮呢,是说它里面的三炮的个数一百零五个,训练级嘛,因为只有这些 y 六呢,实际上就是这三种分类分别的个数是多少? plus 就是 当前默认的变默认的分类,并不是最终的结果啊,因为他现在基因系数还比较高,我们希望基因系数降到零左右, ok, 如果说呢,花瓣长度小于二点四五的都被分到这个组里面了,大于二点四五的都在这个分组了,他就看这一个里面的基因系数呢,就会找到 基因系数呢几乎就是零了,他会发现,因为他里面所有的分类呢,就会发现,你会看到三十一个样本,其中三十一个全都是山原尾,就说明 ok, 只要是长度小于二点四五的,基本就是山原尾。我们看看大大于二点四五,他又按着长度又分了一个, 还是按小于四点七五来进行分类。基因系数呢大概会是零点五,有七十四个,它里面现在只有两种样本了,大概现在默认给了它的分类, ok, 再对它用小于四点七五进行分类。 分了之后呢,我们就看看这个宽度问题了,到这个分组里面基因系数现在已经比较低了,其实因为你看啊,其实就是三十二和一一个了,认为大概率就是了,只不过是他又对他宽度做了一下区分, 发现宽度小于一点六的基因系数变成零了,纯是变色原位,如果大于这个不是小于一点六就是大于一点六吗?那么基因系数也是零,那么就是维基亚原位。 对于这边我们看到啊,对于长度是大于四点七五的情况下,我们也看一下宽度,就是这种时候零点二基因系数还是比较高的, 就是按它里面我们来看,就能看出来样本里面有个这样的五个,二三十六个那样的,我们按照宽度呢,再对它进行一下区分,我们就会发现宽度小于一点七五的时候呢,其实这个是有点不太好的,因为里面还是有两个样本,基因系数是零点五,就是我们刚才讲的 一半去一半不去,那么概率就是零点五零点五了,这是最不纯的时候了,进一系数就是零点五,所以基本上这个是区分失败的,他需要继续往下划分,但是我们因为限制了我们数最多就三层,所以他也不继续进行分裂了。 但是我们可以看到,如果说他的他的宽度是大于一点七五的时候,纯度几乎是已经降到零,只有一一个礼拜基本就是维金亚原位了, 所以说它我们通过格式化呢,就可以看出它的决策的路径来,就会发现啊,基本上看花瓣的长度和花瓣的宽度就可以做决策了,跟花额其实没多大关系。 若更数字化的一点来看呢,我们可以看到几乎在它的分类还是非常准的,有好几个节点呢,都是零或者接近零了,只有一种情况下, 其实就是在这种花瓣长度大于四点七五, and 其实也就是我们最后这个节点,他们颜色不够深,在代码中呢,其实颜色 颜色越深的话,其实就会分类会越准,我会发现这个几乎就是没分好零点五吗?其实你看零点五零点六的时候都是白色,没有分好的,我们就能看到规律啊,基本上说花瓣越短就可能是山原尾,因为小于,你看小于最开始这一个小基本上就是小,全都是了, 一看就能看出来,小的就是最小的,这个就是山原尾了,花瓣中等的就是变色原尾,花瓣最长的时候呢,大概率是为基架原尾,但是呢在这个期间呢,是有重叠的,这是模型容易误判的区域, 可以看到他的可解释性是非常强的,但是呢,我们也说了,在如果说我们不做任何限制,决策树是非常容易出现过逆河的,他会肆意的生长,直到把每一个异常值都给分对了,长出无数的分支来,就过逆河了。这种时候呢,我们需要剪掉多余的细节,保留核心主干。 有两种做法,一种叫做预减值,其实就是咱们现在这个 demo 中用的,我提前就设定规则了,最多就是三层,限制了最大的深度,或者是我也限制叶子节点最少样本数,就是说当你一个节点下只有二十个样本的时候,就不要分裂了, 这种时候它实现非常简单,计算量也小,实际上工业界普遍都是用这种,当然我们也可以后减值,先让数毫无保留的长。 最后呢,我们再从下到上去检查,剪掉一些影响力比较小的分支,这种肯定效果是更好的,但是呢,数据计算量太高了,用的相对而言就没那么多了, 基本上我们解决过,你核呢,就用预减支了。最后做一下对于决策树的总结,决策树呢,它的最大的优点就是非常的直观,而且容易理解,解释性是非常强的。 而且呢,其实他还有几个好处啊,可以看到我们并没有对特征做什么处理,他对数值的大小呢,其实并不是非常敏感,因为他都是自己来决定,算出来分裂点用哪个特征,分裂值是多少吗?对,他自己算的,所以他对数值的大小也不敏感,这也是他的一个核心优势, 它既能处理回归问题,又能处理分类问题,其实也比较全能,优点还是非常多的,它最大的缺点呢,就是太容易过泥河了,稳定性是比较差的,我们刚才那个例子就能看出来,其实有一个到最后了,进泥系数还是零点五呢, 所以说我们后续要怎么优化它呢?就是我们接下来要讲的内容了,既然一棵树容易犯错,那我们就种一片森林, 这个就是集成学习我们接下来学习的内容了。集成学习里面有两类啊,一个叫做随机森林,其实就是构建非常多互相独立的决策树,每次呢都是随机抽取部分的数据和特征,这样呢就大家一块来决策,举手投票 就是少数服从多数,来降低一个误判的风险,这个还是挺好用的。第二个呢,其实就是梯度提升数的家族,就是我们常见的,尤其是在竞赛中的大杀器就是 x j boost, 如果数据量大的时候呢, light gbm 用的是非常多的卡购,竞赛传统用这个是特别计算量,在计算量,样本处理还有准确度上是有个非常好的平衡的。它其实随机森林可以称为并行的多个森林,一块来做决策,大家共同决策,最终投票。而 我们讲的梯度提升数这个家族呢,它其实是一个串形的,数和数之间并不是独立的,而是前赴后继的。我们先来训练一个数,当成 face line, 在 第二给它算出它和真实的标签的残差来。 第二棵树呢,专门来纠正第一棵树的残差,我只来训练你的错误部分,想办法达到你的残差。第三颗呢,来修正第二颗,渐渐不断的叠代,我们把各个加起来,这样就把模型的精度就推广到极致了, 所以说呢,在接下来呢,主要就和大家介绍集成学习里面这两种思路啊,但是他们的前提都是决策树,所以说呢,这个决策树的一些核心理念我们还是要理解一下的。 ok, 这个视频就先到这里。
4451谦行AIing 05:04查看AI文稿AI文稿
05:04查看AI文稿AI文稿各位同学大家好,很多同学在学机器学习的时候,经常会遇到一个困惑,单颗决策树容易过你核对数据造成特别敏感。比如在训练级上准确率百分之九十五,一到测试级就掉到百分之七十。 那有没有一个方法,既能保持决策树的可解释性和处理非限性数据的能力,又能大幅提升泛化性能呢?答案是肯定的。今天我们花五分钟时间彻底搞懂这个堪称机器学习瑞士军刀的算法。随机森林。 随机森林的核心思想用一句俗话就能概括,三个臭皮匠顶个诸葛亮。他不是让一棵树去做出完美的决策,而是让成百上千棵树一起投票,用集体的智慧来做出最终决定。 这里有两个关键问题,第一,这些树之间不能完全一样,否则投再多票也没意义。二、每棵树不能太差,至少要比瞎猜好。那随机森林是怎么做到的呢? 它通过两个维度引入随机性,一个是样本扰动,用 bootstrap 抽样构建不同的训练子集。另一个是特征扰动,在每次分裂时随机挑选部分特征后选。 这两种随机性叠加在一起,保证了森林中每棵树的多样化性。我们先看第一个随机化的来源, bootstrap。 假设训练级有 n 个样本,我们每次做有放回抽样也抽 n 个, 这样每个样本大约有百分之六十三点二的概率被抽到,剩下的百分之三十六点八就留作带外测试级。这个过程重复 m 次,我们就得到了 m 个不同的训练子集。在每份子集上训练一棵决策树,最终得到 m 棵树, 这就是 bagging bootstrap aggregating 的 简称。它的好处是每棵树只看到了部分样本,避免了记录全部数据。 带外数据可以天然的运作模型验证,无需额外划分验证级。第二个随机化的来源是特征扰动。 传统的决策数在做分裂的时候,会从所有特征中挑一个最优分割点。如果所有数都是用同样的特征做分裂,最后会产生高度相关的数。 随机森林的解决方法非常巧妙,限制了特征后选范围。通常在每次分裂时,从全部第一个特征中随机选出 k 个作为后选分类问题 k 约等于 d, 回归问题 k 约等于 d, 除以三, 然后用这 k 个特征来寻找最优分裂。这意味着每棵树可能用完全不同的特征维度来做拆分,大大增强了树之间的差异性。训练好了 m 棵树,一个新样本来了,怎么决策?分类问题,每棵树给出一个类别预测,然后投票, 获得票数最多的类别作为最终输出。回归问题,每棵树输出一个数值,所有树的预测值去平均,这个过程叫做集成学习中的 bagging 策略。研究表明,随着树的数量增加,泛化误差会收敛, 模型不会过你和方差持续降低。这是随机森林最迷人的特性之一,在达到一定规模后,增加更多数,只会让模型更好,不会变差。那随机森林比起单棵决策树到底强在哪?你看过你和 单棵树容易记住训练数据中的噪声,随机森林通过随机采样和投票机制减弱了噪声的影响。二、特征重要性森林可以计算出每个特征对分类的贡献度,天然具有特征选择能力。 三、处理缺失值,可以用同类样本的种数除以中位数进行填充。四、高维数据友好特征随机化,使得它在特征维度很高的场景下也非常高效。当然,随机森林也不是万能的。第一,可解释性差, 你可能知道预测结果啊,但很难解释森林内部到底发生了什么逻辑。第二,占用空间大, 假设有一百棵树,就至少需要保存一百棵树的参数。第三,对极端值敏感,回归场景中树木数量不足时,极端值影响较大。第四,训练速度,因为要训练多棵树,计算量限性增长, 适用场景中等规模表个数据需要特征选择,对可解释性要求不那么高。最后,我们来做个总结, 随机森林等于 buying 加决策树加特征随机化。它的核心思想就是通过两个维度引入随机性,构建一群多样化的决策树, 让它们集体投票。相比于单棵决策树,它有更强的泛化能力,更好的抗噪生性能,天然的特征选择能力。 如果你在处理表格数据,想要一个即插即用,不需要太多调参的极限模型,随机森林绝对是最佳选择之一。如果你觉得今天的内容有帮助,记得点赞、收藏、转发,我们下期再见!
13AI算法_TT 16:31查看AI文稿AI文稿
16:31查看AI文稿AI文稿hello, 大家好,呃,今天跟大家分享一个在线数据分析软件,叫 omega med states, 呃,今天我们去呃做一个全流程的临床预测模型的一个分析, 首先这个软件的网址是在上面,呃,大家可以输入输全,然后去呃进来就可以做了,然后不要用二三四五这个加速的浏览器,其他浏览器都是可以的。 然后点进这个临床预测模型的这个模块,大家可以看到啊,进来这个页面了, 这里提供了几种数据上传的方式,其中是有呃自己的数据也可以传进来,然后它本身提供了一些势力的数据。 呃,还可以从基建分析,比方说这个基建总监差异这里得到得到的数据,呃,然后呃传过来,或者是从回归分析部分的数据呃传过来。 呃,那么我们今天就以呃它内置的视力数据来走一遍这个流程,全程不超过五分钟,然后我们就可以得到临床预设模型的全部的结果。 呃,然后这这里还提供了一些统计的原理和教程,就是呃关于各个分析各个步骤是干嘛的,然后呃点进去就相当于进了一个帮助中心这里,然后可以找到 呃临床预测模型的模块,然后点进去,这里就提供了所有的呃关于模块的一个概述。 呃,一个临床预测模型的开发的流程包括哪些步骤?然后模型评估的指标包括哪些啊?然后它的含义是什么? 然后这个结果我们得到 a、 o、 c 结果怎么解读?然后较短曲线是怎么解读?然后电量筛选的方法哪些? 然后自己学习模型的一个简单的一个介绍,然后得到了这个 sa 图或是 p d, p i c e 的 模型的一些解释, 还有用我们方法部分的一个拷写的一个模板,英文的,中文的,然后结果解读的一个指南,那 aoc 它的值是怎么样,怎么样就是能证明它的, 它的效果是好的,然后就能取现 dca 的 解读,然后杀普图的解读,然后还给出了一些常见问题的一些啊,注意事项啊,然后或是解决方案, 最后是一些参考文献,呃,大家如如果看了这个还有不懂的,可以进一步的去问豆包啊,问 deepsea, 呃去获得更详细的一个介绍 啊。我们回到这个临床 b 测模型这里,然后用它的视力数据,首先点击视力数据,然后点击加载视力数据,然后就得到了它的这个视力数据已经加载,然后可以看到这个视力数据的预览情况, 然后这里呃进行一个变量的设置。左下角这里是呃划分训练级和测试级的一个比例,我们默认是百分之七十 作为训练机。然后划分的方法可以随机划分,或者是分层,或者是按时间分层啊,我们一般都是随机划分,这里种子是可以自己设置一个种子,然后这里点一下确认变量并划分数据, 然后就可以得到数据划分的一个结果。下一步我们进行变量的诊断, 然后呃 v i f 预值一般五或十,然后我们严格一点就是五,呃也可以通过相关系数的预值去进行贡献性的诊断, 然后可以自动排除贡献性较高的一些变量,自动记到其中一个,然后进行诊断,然后这个结果就出来了。呃, v r f 结果显示这几个变量的 v r f 都是非常低的,然后都是比较正常的,然后是不需要去除变量的,然后下一步就是 变量的筛选,变量的筛选,呃,这里提供了几个方法,单因素回归,蓝色回归,水域森林和 roto, 呃,算法都选上,然后单因素的 p 值的筛选域值我们可以自己设置零点一或者是零点零五, 然后这些参数也可以自己选择,一般就是默认就可以。然后呃,下面进行一个列表筛选, 然后这里右下角正在运行变量的筛选。啊,筛选结果出来了啊,比看到单因素分析的结果啊,包括 o r 值,执行区间和 p 值都有了, 这里根据这个预值啊,有有这几个指标被选中。蓝色回归筛选的结果也是这五个变量,然后随机生成重要性, 然后这个 prot 特征筛选的,呃,筛选出来的结果绿色的部分,然后这里纳入变量,就是我们筛选完变量之后,进一步要纳入变量建模,我们是 采用哪一种方法?就是这四种筛选方法可以采用并集,就是说任何一种方法筛筛选出来的我都用来建模,还是说交集,而就是说,呃, 这个变量必须被每一种方法都筛选出来,我才用来建模,还是说啊,多数投票就是啊,其中有一半的方法以上选出来这个变量,然后我就用来建模, 还是说其他的自定义,这里提供了另外的手动调整的方法,我,我一定要把这个变量拉进这个建模的模型里面还有强制排除的变量,可以在这选择, 那我们这里就自动地呃选择默认多数投票的方法,然后使用筛选的变量,下一步就是使用这些筛选的变量去进行建模。模型构建, 模型构建,这里面提供了大概十来种机器学习方法, 呃,都是我们比较常见的,那其中支持向量机,然后神经网络,它的呃算法的复杂度,呃, 它是三四方级别的,这个是二四方级别的,它的耗时比较久,这里演示的话就不选支持向量机和神经网络,其他的相对快一点。 然后这里可以提供了一些基本的这些稍微复杂一点的机器学习模型的参数,可以进行一个调试 啊,这里交叉印证,默认五折,然后点击运行训练模型, 好了,我们继续回来,我们可以看到这个模型已经训练好了,然后这里显示了模型的系数,就相当于呃老七这个回归的一个多因素的一个回归的结果。 然后这是训练好的模型,下一步我们进行模型的评估。 模型的评估,这里首先显示的是测试级的性能指标的一个评估,呃,另外评估的话我们需要用训呃训练级建模测试级去评估,然后运行评估 屏幕的话是比较快可以看到这个测试级性能指标的。啊,非常直观的一个结果,这个上面显示的应该是老 g c 回归的结果, 然后这个是测试级的 l o c 曲线,就是各个模型的 l o c 曲线的一个图,然后这是校准曲线,这里是给了老 g c 回归的,然后 左下角可以去选择多多个矫正曲线的一个比较,然后选择的话它就会显出来,然后包括 呃执行区间都是可以选的,然后 t c a, 也可以选择多个,多个模型的比较, 这一期也显示了,然后 e c, a 多个模型的比较,然后测试级的详细的性能指标啊, a o c 啊,准确度推度, p v n t v f b 啊, r s go 啊等等。 然后这里还给了给出了训练级的所有的结果, 训练级的所有的所有的结果。 对,还可以进行两者的一个对比, 记得直接对两者的 a o c 啊,然后准确度啊,灵敏度啊,进行一个直接的比较,然后性能差异的,然后这段曲线对比的, 然后下一步是格式化,格式化这里面是包含 numbergram, 是 我们周论文非常重要的一个模型结果的一个格式化,这里可以进行一个字体的选择, 对于 numbergram 这个字体大小也可以发动去改变, 使它更适应这个整个的主型的 b b, 然后坐标轴的字体也是可以进行调整的。对,然后配色的方案, 然后多模型的一个比较,训练级,测试级啊,简单的一个相同的比较,然后模型的解释性,这里提供了一些 java, java 分 析的都给它勾上,然后其他的解释性的分析,然后 b c 这块还是比较快的 啊,特征重要性啊,然后特征一的关系啊,个体预测啊,然后贡献的扑克图啊,然后啊 p d, p i s e 啊, 具体的每一张图代表什么,大家可以在下面再仔细地学习研究一下,然后高级的诊断, 这里可以需要点击一下我这期的曲线,可以看到训练级和测试级基本上是没有太大差别的,证明这个你的效果没有过,你和然后是相对比较好的, 然后交叉验证,结果也都非常平均,这个模型也是比较稳定的,然后缩小曲线的一些结果 模型的验证啊,我们刚才是内部的训练级和测试级的啊验证,这里也提供了 dos trap 内部的验证,就是刚才说了一些验证,然后 是内部测试级进行验证的一个记录,然后这个 dos trap a o c 的 disk ratio, 你 看到一个百分之九十五之一区间啊, 包括测试级的结果的印证,然后这里还提供了外部独独立的外部印证,就是你们如果有小伙伴有外部数据,然后 只需要与训练级的变量名完全相同,然后包含真实的结局的变量,然后变量类型也都一样,然后通过这里上传上去,然后就可以进行独立的外部印证,这里啊就不再演示了。 此外左下角还提供了一些一个独立的工具,然后是多变量的一个模型的比较, 这个就是呃,我想有的人,有的有的同学就是想用不同的变量的排列组合,我这一次用六个,下一次用五个,下一次用三个变量,然后我是呃多用六个,但是变量的,呃 电量的值不完全相同,然后去排列组合,去探索哪一种是呃相对更好的,然后,嗯,需要用统一的算法,然后去这样比较,然后可以去去这样做 对,然后构建,然后进行训练啊,先对比啊,这里,呃我们只只只两个,这里输入呃可以输入个数模型,构建模型的个数,然后进行比较,然后 点了四个,然后这里呃数出了四个,四个,然后包括 delete text 的 两两之间的一个差异的 p 值,然后 各个变量,呃用呃哪些变量,各个模型用哪些变量,然后 photoshop 内部验证啊等等,都是可以实现的啊。 对,今天的呃分享的内容大概就是这些,就是临床预测模型的全部的过程, 大家可以非常方便的在这个网址上去实现,欢迎大家前来体验,目前还是免费的。全全全部都是免费的。好,谢谢大家。
 01:06:39查看AI文稿AI文稿
01:06:39查看AI文稿AI文稿想象一张 ct 片,医生要判断有没有肿瘤,单个医生可能疲劳,也可能被某个模糊阴影带偏。那医院遇到疑难病例时,通常不会只让一个人拍板,而是让五位医生各自独立读片,再把意见放到一起看。 如果五个人里四个都说有风险,这个判断就比一个人说有风险更稳。集成学习,英文 assemble learning, 干的就是类似的事儿,而是让一群模型一起判断。 这些模型各自会犯错,但只要它们不是同时犯同一种错,组合起来就可能变成更强的模型。 这一期,我们先把集成学习的总框架搭起来。什么是弱学习器?什么是强学习器?为什么一群模型能比一个模型更稳?以及后面会出现的两条主路线先给定义。 集成学习就是把多个模型组合起来,形成一个整体模型,参与组合的每个模型叫机学习器 base learner。 这里的弱,不是说他完全没用,而是说他单独拿出来能力有限,可能只比乱猜好一些,或者对训练数据很敏感。多个弱学习器训练完之后,对一个未知样本分别给出预测,最后再通过某种规则把这些预测合并。 合并后的整体就叫强学习器 strong learner。 这个强学习器不一定是一个新的复杂公式,它可以很朴素,武魂术个头一票,谁多谁赢。也可以稍微复杂一点,每棵树的话语全不同,准的模型票更重。 先记住一句话,集成学习的核心不是发明一个全新的单体模型,而是设计一套组织方式,让多个模型联合起来做判断。换成机器学习场景,我们要判断一封邮件是不是垃圾邮件。先训练五、五 版决策树。每棵树都看邮件里的特征,比如发现人是否陌生,标题里有没有中奖,正文里有没有链接。现在来了一封新邮件,五瓣树分别投票, 数一说垃圾,数二说垃圾,数三说正常,数四说垃圾,数五说正常,最后票数是三比二,就判为垃圾邮件。这种谁多谁赢的合并方式叫多数投票,英文 majority vote。 注意,这里有两个层次,单棵树只负责给出自己的判断,整体系统负责把五个判断合起来,画面上可以把它想成五条之路,汇到一个投票箱里,投票箱输出最终类别。这个例子里我们用的是分类人物, 如果是回归任务,比如预测房价,也可以让五个模型各自预测一个价格,最后去平均值分类常用投票,回归常用平均都是聚合规则,那一群模型为什么会比一个模型更强?关键不是数量本身,而是错误不完全一致。 看一个虚构式,一单颗决策数在测试级上大约百分之七十二准确。五函数单独看也都差不多,可能是百分之七十到百分之七十四。 如果这五函数犯错的位置不同,多数投票就有机会把单棵树的偶发错误抹平。比如某封正常邮件,因为标题太夸张,被数一误判成垃圾,但数二数三、数四看到了发件人和历史联系人判正常,最后整体就能纠正数一的错误。 反过来,如果五步数完全一样,训练数据一样,参数一样,随机种子也一样,那他们每次都会给出同一个答案,单颗数错,五数数一起错,单颗数准,五数数一起准。这个时候集成没有任何增益,只是把同一个模型复制了五份。 所以集成学习真正依赖的前提叫差异性,英文 diversity。 模型之间要有不同视角 组合才有意义。理解了差异性,下一步自然就是问怎么制造差异。集成学习里最主流的两条路线就是 begging 和 boasting。 begging 全称 boost trap aggregating, 中文常意成装带法或自助聚合。 它的思路向多人会诊,每个模型看不同的数据子集,彼此独立训练,最后平等投票。随机森林 random forest 就是 这条路线的代表。 boosting 中文常一层提升法或增强法,思路向接力查漏。第一个模型,先学后面的模型,重点补前面没学好的地方,最后再按模型表现加权投票。 add boost g b d t x g boost light g b m 都在这条路线里。 先不用急着记细节,本期只记一个方向感。 bagging 是 并行求稳, boosting 是 串行纠错。一个重点,降低模型对数据扰动的敏感。一个重点,把前面没学好的规律继续往下补。最后把几个容易误会的点收一下。 第一,集成学习不是模型越多越好,如果一百个模型都长得一模一样,它们还是只相当于一个模型。第二,弱学习期不是越强越好, 某些集成方法反而喜欢简单模型,因为简单模型容易互补,组合之后才有空间变强。第三,集成学习不是只能用于分类,分类可以投票回归可以平均,核心都是把多个预测合成一个预测。 这一期我们讲清了三件事,集成学习就是多个模型加聚合规则弱学习器单独能力有限,组合后形成强学习器。组合有效的前提是模型之间有差异,没有差异就是复制粘贴有差异,投票和平均才可能抹平偶发错误。 下一期我们正式拆开两条路线,白给怎么并行求稳,布斯汀怎么串行纠错?下期见,欢迎评论区留言讨论。 上一期我们说集成学习不是简单复制五个一样的模型,而是让一群想法不同的模型一起判断。那这一期就接着问差异到底怎么制造,还是五位医生读 ct? 第一种组织方式是让五位医生同时看病历,但每个人手里的病历库不同,看完之后平等投票。第二种组织方式是第一位医生先看漏诊的疑难篇,专门交给第二位,第二位漏掉的再交给第三位,最后按每位医生表现加权投票。 前一种就是 begging, 后一种就是 boosting, 他 们都是基层学习,但气质完全不同。 begging 病情求稳, boosting 串行纠错。这一期我们只解决一个问题, 同样是多个模型,为什么一个靠抽样制造差异,一个靠接力修错制造差异?先看 begging。 begging 的 全称是 boot to strap aggregating, 中文常译成装袋法或自助聚合。它分两步,第一步 boot to strap 抽样,也就是有放回抽样。 假设原始训练集有一千条样本,我们随机抽一千次,每抽完一条就放回去,所以同一条样本可能被抽中多次,也可能一次都没被抽中,这样重复五次就得到五份。有重叠但不完全相同的训练子集。 第二步, aggregateing, 也就是聚合五份子集,各训练一棵树。预测时,五瓣树同时给答案。分类任务,用平权投票、回归任务去平均。这里最重要的是三个词,有放回、并行、平权。每棵树看的数据不一样,所以学到的边界不一样, 每棵树互不依赖,所以可以并行训练。最后一棵树一票没有谁的话语权更大。这里引入一个术语方差,英文 variance 模型。方差大意思是训练数据稍微换一换,模型形状和预测结果就大变。决策树就是典型例子,某个特征刚好排在前面,树的根节点可能就完全不同。 算法的做法不是让一棵树变得更聪明,而是让多棵树从不同数据自行出发,各自过拟合到不同方向,最后投票或平均,把这些随机波动互相抵消。用一个虚构试一看,单棵树测试准确率可能在百分之七十三到百分之八十三之间。来回晃 武挞 bagging 之后,平均水平可能更高,重训波动也明显变小。这里不要死记数字,记机智,只要每棵树的错误不完全重合,平均就能压掉一部分,随机造声。 所以 bagging 适合高方差模型,尤其适合决策树,它不太适合拿来拯救已经很稳定但本身能力不足的模型。 再看 boosting, 中文长一层提升法或增强法,它不是让五个模型同时训练,而是一个接一个训练。第一个,弱学习器,先学全体样本,学完以后标出哪些样本错了。第二个弱学习器训练时就更关注这些错样本, 第二个学完,再把它没处理好的地方交给第三个,这样一棒一棒接下去。每一棒都在补前一棒的不足。最后预测时也不是平权投票,而是加权投票。表现好的学习器话语权更大,表现差的学习器话语权更小。 这里有两个权重,不要混。训练阶段调的是样本权重,英文 sample weight, 也就是哪些样本下一轮更重要。最终投票阶段用的是学习器权重,英文 learner weight, 也就是哪个模型最后说话更重。 a 大 boost 会把这两类权重写成显式公式,后面会专门推 boosting, 主要解决的是学不够。这里再引入一个术语偏差,英文表述,模型偏差大,意思是模型能力不足,学不到真实规律,比如深度等于一的决策状,只能问一个问题,单独做分类很容易欠你和 bagging 把五坎很浅的树拿来平均通常也只是五个浅判断,互相投票能力上限变化不大。 boosting 的 策略相反,我就承认每一棵树很弱,但让后一棵专门补前一棵没学好的地方, 第一棵树抓大方向,第二棵树补第一批错题,第三棵树再补新的错题,整体边界就一步步变复杂。用一句话区分, bagging 是 和一棵树太容易斗, boosting 是 和一棵树太学不深,前者主攻方差,后者主攻偏差。 也正因为 boosting 一 直追错题数太多或学习节奏太猛时更容易过泥和,所以后面会看到学习率和早停这些控制手段。把两条路线放到一张表里, 第一看数据 bagging, 每个模型看有放回抽样出来的不同子集。 boosting 通常看全量数据,但每一轮会调整样本重要性,或者像 g b, d t 那 样泥和残差和负梯度。第二看投票, bagging 是 平权投票,一棵树一票。 boosting 是 加权投票,或者把每一轮输出按权重累加。第三看训练顺序, bagging 里每个弱学习期相互独立,可以并行训练。 boosting 里后一轮依赖前一轮的错误,必须串行推进。第四看代表算法, bagging 的 代表是随机森林 random forest。 boosting 的 代表包括 a r boost、 g b d t, x g boost 和 light g b m。 选型时可以先用一句话判断,想要稳,先看 bagging, 想要炸精度,再看 boosting。 实际工程里常见做法是先用随机森林拿一个稳基线,再用 x g boost 或 light g b m。 看复杂度换来的精度值不值。 这一期到这里,我们把基层学习的两条主路线拆开了。 begging 的 关键动作是 boost trap, 抽样并行训练,平权投票。它让每个模型看不一样的数据,主要用来降低方差,也就是减少模型对训练数据变化的敏感。 boosting 的 关键动作是串行训练,关注错题,加权组合。它让后一轮补前一轮的不足,主要用来降低偏差,也就是补模型能力不够的问题。 这一期点到但没展开的有三件事儿, boost 里没被抽到的代外样本怎么用?留给随机森林 a w boost 的 样本权重和学习期权重公式留给 a w boost 的 章 g b d t 和 x g boost 为什么不总是显示点样本权重?留给后面的 boosting 系列? 下一期我们先沿着 bagging 这条线走,进入随机森林,它不止让每棵树看不一样的数据,还会让每棵树在分裂时看不一样的特征。下期见,欢迎评论区留言讨论。 上一期我们讲 bagging, 让每棵树看不同的数据子集,最后平权投票。随机森林英文 random forest 就是 bagging 思想最经典的落地版本,但它比普通 bagging 多加了一层限制, 还是医生会诊的类比,五位医生看的病历库不同,这已经能制造差异。但如果所有医生都最先盯同一个指标,比如一个特别强的肿瘤标志物,它们的判断路径还是会很像。 随机森林会在规定一件事,每位医生每做一道判断时,只能从一小部分检查指标里挑,这样有人先看年龄和血常规,有人先看影像和体温,意见来源就更分散。这一期我们讲清随机森林的核心,既换数据也换视角。 随机森林可以拆成一个公式式的定义,随机森林等于 buying, 加决策树,再加特征随机。第一,机学习器用决策树,决策树本身方差高,训练数据稍微变化,树形就可能大变,所以很适合被 buying 稳住。 第二,每棵树用 bootstrap 抽样,得到自己的训练子集,这叫样本随机。第三,也是随机森林比普通柏林多出来的部分。每个节点分裂时,不让全部特征都参与竞争,而是先随机抽一部分特征, 再从这部分里找最优分裂。比如一共有二十个特征,每个节点只随机看四个左右,这样强特征不会每次都压倒其他特征,树和树之间的结构差异会更大。 预测时仍然很朴素。分类任务,评权投票回归任务去平均。先看第一层随机,也就是 boost 抽样。假设原始训练集有一千条样本,每棵树都从这一千条里有放回递抽一千次,形成自己的训练子集。因为有放回,同一条样本,可能出现多次, 也因为是随机抽不同数,拿到的子集不会完全相同。这里有一个很重要的平衡,每棵树的训练级既要有差异,又不能完全忽视。如果完全一样,所有树容易长的一样。 如果完全不重叠,每棵树只学到一小块片面信息。投票也不可靠。有放回抽样,刚好让子集之间有交集,也有差异。 直觉上,每棵树都见过大部分核心规律,但又各自带着不同的样本偏好。这样投票时,每棵树既不是克隆体,也不是只懂局部的孤岛。再看第二层,随机,也就是特征随机。普通决策树在每个节点分裂时,会扫描所有特征,选最能降低不纯度的那个。 问题是,如果某个特征特别强,比如泰坦尼克数据里的性别,很多树都会优先用它。当根节点 树一旦从同一个根节点开始,后面的结构也容易相似。投票时,就像五个人都按同一本答案册做题。随机森林的处理方式时,每个节点先随机抽一小批,后选特征,只在这批里面选最优。这个限制看起来会让单棵树变弱, 但能显著降低树和树之间的相关性。集成学习要的不是每棵树都最强,而是整体投票更稳。 随机森林愿意牺牲一点单数能力,换来更多视角差异。训练完以后,随机森林预测很直接。分类时把新样本交给所有树,每棵树投一票,票数最多的类别就是最终结果。回归时让所有树各自预测一个数,再取平均。除了预测,随机森林还有两个常见副产品, 第一个叫 o o b, 英文 out of bag, 中文叫带外样本。因为 bootstrap 抽样时,总会有一部分样本没被某棵树抽到,这些样本可以临时当验证样本估计模型泛化表现。第二个是特征重要性, 树在分裂时,会记录每个特征带来多少不纯度下降,把所有树汇总起来就能得到哪些特征,更常帮模型做判断。本期先点名,不展开工程用法。下一期讲 a p i 时,会看到这些概念对应到 op, score 和 feature 迂迂的重要性。 这一期到这里,随机森林的主线很简单,它是 begining 的 代表算法,即学习期用 botoshop 让每棵树看不同带有交集的数据。 第二层随机是特征随机,让每个节点只从部分特征里挑分裂,减少树之间抱团。两层随机的目的都是同一个,让树独立犯不同的错,再用投票和平均把这些错抵消。 点到但没展开的内容有三件数的数量怎么选,后选,特征数怎么调, o o b 和特征重要性怎么在代码里拿到。下一期我们就把这些思想落到 random forest classifier, 再用泰坦尼克生存预测跑一遍。完整流程,下期见,欢迎评论区留言讨论。 上一期我们讲随机森林的两层随机,每棵树看不同样本,每个节点看部分特征。这一期把思想落到代码 s k l 里,对应的类叫 random forest classifier, 它看起来参数很多,但不用被吓到。 真正需要先抓住的只有几类,森林里有多少棵树,分裂时看多少特征,单棵树要不要设深度刹车,是否开启 bootstrap, 以及随机种子怎么固定。 然后我们用泰坦尼克生存预测,把流程跑通,处理缺失值和类别特征。训练随机森林,做网格搜索,再看特征重要性。注意所有准确率都要以同一环境的真实结果为准,这里不写固定成绩。 random force classifier 可以 按四组理解。第一组是规模 estimates, 决定森林里有多少棵树,树越多投票越稳,但训练越慢,收益也会逐渐变小。 第二组是随机性, boxtraff 控制是否有放回抽样。 max features, 控制每个节点最多看多少后选特征。 第三组是单棵树的刹车,比如 max steps, min sample split, min sample sleeve, 它们和决策树里的含义一样,用来防止树长得过细。第四组是附线 random state, 固定随机过程方便我们比较实验结果, 机手配置可以很朴素。 un estimates, 先用一百分类任务 max features, 用 s cut t boost trap 保持 true random state 写固定值调。随机森林不要一上来把所有参数塞进搜索表, 先按优先级来。第一优先是 estimates, 数太少时投票不稳,先拉到计算能接受的数量。第二优先是 max features, 它直接控制数之间差异。 分类任务常用 s k r t, 如果模型过拟合,可以适当减少后选特征,让树更不一样。第三优先才是 max depth。 随机森林本身靠集成降低方差,所以单棵树可以比普通决策树放得更开,但样本量大,特征多,训练很慢时,限制深度仍然有价值。最后才看 minsimples split 和 minsimples leaf 这种细刹车。 还有一个版本坑,旧资料里常见 max features 等于 auto。 新版本 s kler 已经不推荐分类任务,直接写 s k t 更稳。接着看泰坦尼克生存预测,这个案例的任务是根据乘客信息预测是否生还。数据里既有数值特征,也有类别特征,还有缺失值。 流程可以拆成六步,读入数据,删除明显无用或泄露风险高的列。填补年龄和登船港口的缺失值。把性别和登船港口做编码,划分训练级和测试级,然后训练 random forest classifier。 这里随机森林的好处是不需要像限性模型那样强依赖特征缩放也能处理非限性特征组合, 比如性别、船舱等级、票价、年龄之间可能有复杂交互数,模型能自然切出这些规则。这里先讲流程,不承诺具体准确率,真正运行时再用 score 和报告里的数字做评估。 基础模型跑通后再做两件事。第一件是 great search cv, 它会把我们给出的参数组合逐个试一遍,再用交叉验证比较表现。随机森林里最适合先搜的是数的数量和最大深度,再加上 max features, 搜索空间不要太大,否则训练时间会膨胀。第二件是看特征重要性。随机森林训练完以后,会给出每个特征在分裂中贡献了多少不纯度下降?泰坦尼克里常见的强信号是性别、船舱等级、票价、年龄这类特征。 注意,特征重要性不是因果解释,它只能说模型在这份数据和这组特征下,经常借助哪些猎作切分,真正下业务结论时,还要结合数据采集过程和领域知识。这一期把随机森林从思想落到了代码。 我们先把 random forest classifier 拆成几组参数数的数量后选特征数、 boost trap 开关、单数刹车以及随机种子。 然后用泰坦尼克案例串起数据清洗、类别编码训练评估、网格搜索和特征重要性。随机森林这条线到这里基本完整了,他用并行的树两层随机和平权投票,把高方差的决策树变成稳健基线。 下一期开始,我们换到 boosting 路线。和随机森林的平权投票不同, ad boost 会让错样本变得更重要,也会让表现好的弱学习及话语权更大。也就是说,下一期开始,模型之间不再并行投票,而是串行接力。下期见,欢迎评论区留言讨论。 前面随机森林的规则很公平,每棵树一票,大家平等投票。 ada boost 不 这么做。 ada boost 全称 adaptive boosting, 中文可以理解成自适应提升。他相信两件事,第一,上一轮分错的样本,下一轮应该更重要。 第二,表现好的弱学习期,最终投票时应该更有话语权,还是会诊类比。第一位医生看完以后,漏诊病例被重点圈出来,第二位医生必须多看这些疑难片。最后,开会时历史上更准的医生发言权更大。 这一期我们不急着手算十个样本,先把 a 大 boss 的 两个权重和两个公式讲清楚。 a 大 boss 的 最终输出是一个加权投票。每个弱学习期给出一个预测,通常记作 h t、 x, 它可以投正类,也可以投负类,但每一票前面还成一个系数,叫学习期权重通常记作 r 八 t, 整体就是把所有 r 八 t 乘 h t、 x 加起来再看符号,大于零判正类,小于零判负类。这个形式和随机森林差别很大,随机森林是一棵树,一票 a w boost 是 谁更准,谁的票更重。学习器权重不是拍脑袋给的,而是由加权错误率算出来。 错误率越小,算法 t 越大,错误率接近零点五。算法 t 接近零,错误率超过零点五,说明还不如随机猜,这一轮弱学习器就不合格。学习器权重的公式是,算法 t 等于二分之一乘 l n, 括号里是一减一普斯隆 t, 再除以一普斯隆 t。 先不要被公式吓住,把它当成一个从错误率到话语权的转换器。 一普斯隆 t 是 当前弱学习期的加权错误率,也就是按当前样本权重统计出来的错误比例。如果一普斯隆 t 等于零点一,说明它错得很少。一减一普斯隆 t, 再除以一普斯隆 t 很 大,取对数后,阿发 t 就 大。 若一普斯隆 t 等于零点四,它只比随机猜好一点,阿发 t 就 比较小。若一普斯隆 t 等于零点五,分子分母一样,比值是一,对数是零,说明这棵树没有投票价值。这个公式同时满足两个直觉,越准越有话语权。半斤八两就别说话。 加入的公式负责更新样本权重,每条样本都有一个权重,记作 d t i。 第一轮开始时,所有样本通常一样重要。如果某条样本被当前弱学习期分对下一轮权重就乘一的负尔法梯次方,也就是变小。 如果分错,就乘一的 r 法 t 次方,也就是变大。最后再除以一个归一化系数,让所有样本权重加起来仍然等于一。这个动作的直觉很直接,已经会做的题,下一轮少花点注意力。做错的题,下一轮放大给后面的学习器看。 注意, a 大 boost 不是 把错样本复制出来,而是在损失计算里给他更大的权重。后面的弱学习器为了降低加权错误率,自然会优先照顾这些难样本。 a 大 boost 还有一个容易忽略的要求,机学习器通常要统治,也就是说要么全都是决策树,要么全都是逻辑回归。 不要这一轮用数,下一轮用 k n n, 再下一轮用限行模型混搭不同类型,更像溢购继承,不属于这里的标准。 a double boost 主线最常用的记学习器是决策状,英文 decision stump, 也就是深度等于一的决策数。它只问一个问题,比如酒精含量是否大于某个预值。 三个决策庄很弱,但正适合 boost 定。他不会一口气把训练级吃透,而是每一轮只补一点。 ada boost 的 强来自很多个弱判断,按顺序接力, 而不是某一棵树本身特别深,特别复杂。这一期先到这里, ada boost 的 机制可以押成两句话,训练时分错样本,下一轮更重要。投票时错误率更低的弱学习器,话语权更大。 公式上 r 发 t 把加权错误率变成学习期权重,样本权重更新公式,把错题放大,对题缩小,再归一化。到这里,我们只讲了公式的意义,还没有真正把它刨起来。 下一期会用十个 ev 样本,首算三轮,先出场,每个样本权重为零点一,再找第一个分列点,算错误率,算 r 法更新权重,然后看错样本怎样一轮一轮被推到前台。下期见,欢迎评论区留言讨论。 上一期我们有了阿达 boost 的 两条规则,错样本,下一轮更重要,准学习器最终话语权更大。光看公式可能还觉得抽象,这一期我们把它套进一组十个样本,首算三轮,数据很简单,特征 x 从一到十,标签只有正类和负类 弱。学习器也很简单,决策中只用一个切分点,把数轴分成左右两边。我们会反复做四步,用当前样本权重找错误率最低的分列点算学习期权重。 l 法 把分错样本权重调大,把分对样本权重调小,最后归一化。看完这期,你应该能把 a、 d、 b、 s 想成一张会移动注意力的错题表。 千百数据,十个样本按编号零到九排开,特征值是一到十。标签里样本零一二六七、八是正类,样本三四五九是负类。第一轮开始时,我们还不知道谁难谁简单,所以每个样本权重一样,都是零点一。 决策庄的后选切分点是相邻 x 的 中点,比如一点五,二点五,一直到九点五。每个切分点还要是两个方向,左边判正,右边判负,或者左边判负,右边判正。 当前样本权重权相等。所以第一轮的加权错误率就是分错样本书乘以零点一,找出错误率最低的切法,就得到第一个弱学习器。第一轮实力给出的最优弱学习器错误率是零点三,也就是按当前权重算,错样本合计占百分之三十。 把 eiffel 一 等于零点三,代入公式, r 法一等于二分之一乘 r n, 括号里是一减零点三,再除以零点三,约等于零点四二三六。 这个 r 法一就是第一个弱学习期的最终话语权。接下来更新样本权重分对的样本乘一的负零点四二三六次方会变小,分错的样本乘一的零点四二三六次方会变大。 初一化以后,分对样本大约变成零点零七一四,分错样本大约变成零点一六六七。 也就是说,第一轮错掉的样本,下一轮的注意力已经变成普通样本的二倍多。表格上要把这些错样本的原点放大,一眼就能看到 a 大 boss 的 注意力转移了。第二轮不再从均匀权重开始,而是从刚才的新权重开始。 也就是说,第一轮错掉的样本现在更贵。新的决策庄为了降低加权错误率,会更愿意照顾他们。视力计算结果里,第二个弱学习期的话语权约为零点六四九六。第三个弱学习期的话语权约为零点七五一五。 你不需要把每个小书都背下来,真正要看的是趋势。每一轮的分列点会因为权重变化而改变样本权重会在不同错题之间流动,后面的学习期会补前面的缺口。 动画上可以这样呈现,第一轮后样本六七八变大。第二轮后,另一组男样本被放大,第三轮再换一组 at a boost, 向一个老师哪里错得多,就把红笔圈到哪里。三轮结束后,我们不是只保留最后一棵树,而是把三盘弱学习期都留下来,最终强分类期长。这样, h x 等于 sine, 括号里是零点四二三六乘 h e x 加零点六四九六乘 h 二 x 加零点七五一五乘 h 三 x。 这句话翻成白话就是,第一盘数的票乘零点四二三六,第二盘数的票乘零点六四九六,第三盘数的票乘零 点七五一五,然后加总,总分大于零判正位,总分小于零判负累。如果要验证某个 c x, 必须先让他依次通过三颗弱学习器拿到三个正负票,再按这三个算法加权求和。 这个结尾很重要, a 大 boost 的 每一棵树都很弱,但弱树不是一次性消耗品,它们被按话语权保存下来,共同形成最后的强分类期。这一期,我们把 a 大 boost 的 循环跑起来了,每一轮都做四件事, 找当前权重下错误率最低的决策状,按错误率算学习记权重,放大分错样本,缩小分对,样本再归一化。 三轮之后,强分类器不是最后一棵树,而是所有弱学习器的甲醛组合。手算的价值是让我们看见注意力怎样从一组错题移动到另一组错题真实数据当然不会只算十个样本,也不会只跑三轮。 下一期我们把这套流程交给 sklearn, 用 a r boost classifier 跑葡萄酒。二、分类重点看三个工程,旋钮机、学习器、弱学习器数量和学习率。下期见,欢迎评论区留言讨论。 上一期我们手算了 add boost 的 三轮循环,找当前权重下最好的决策状,计算学习器权重,放大分错样本,缩小分对样本,十个样本还能摊开算。换成葡萄酒数据就不该手算了。 原始数据有一百七十八瓶酒,每瓶有酒精含量、色泽等特征,类别来自不同产区。我们要把手算流程交给 sklearn add boost classifier, 让它自动训练很多颗决策状,再把它们按权重组合起来。 危机的重点不是追一个固定分数,而是跑通一条工程线。怎么把三类葡萄酒改成二分类,怎么做标签编码,怎么拿单颗决策桩做基线, 以及 estimate n estimates learning rate 这三个旋钮到底控制什么?先看数据。葡萄酒原始标签是 class label, 取值一二三。 这个案例为了贴合 a w boost 的 二分类讲法,先去掉类别一只,保留类别二和三,特征也只取两列。 alcohol 表示酒精含量, hue 表示色泽。为什么不用全部特征? 因为教学演示里两个特征可以画在二维平面上,后面比较单棵树和 a w s 的 决策边界会更直观。接着用 label encode 把类别二和三转成零和一。这里注意 s k, l 可以 接受零和一标签,也可以接受负一和正一的标签。 我们按代码习惯用零和一。最后用 train test split 划分训练级和测试级,固定 random state, 避免每次运行结果漂移。 集成模型上场前,先训练一颗单独的决策树作为基线,这里用 decision tree classifier 设为 entropy, max steps 设为一, max steps 等于一的数就是决策庄,他只能问一个问题,比如酒精含量是否超过某个预值,或者色泽是否超过某个预值。这个基线很重要,因为 ad boost 的 效果要和它对比,而不是孤零零看一个分数。 胆克决策庄通常会欠你喝它。边界简单,训练级和测试级都不会特别高,但这正适合 ada boost。 ada boost 不 指望每棵树都很强,而是希望每棵树只抓住一小段规律,再通过很多轮加权借力,把简单边界组合成更复杂的边界,接着实力化 ada boost classifier。 第一个参数是 estimate, 也就是 g 学习器。这里传入刚才那颗深度为一的决策树。老版本 s k l 里这个参数叫 base estimate, 新版本统一叫 estimate。 第二个参数是 n estimates 表示最多训练多少个弱学习器,案例里设五百,意思是允许五百克决策桩接力。第三个参数是 learning rate, 案例里设零点一,它会缩放每轮学习器的话语权,也会间接影响样本权重更新速度。 learning rate 小, 步子稳,但通常需要更多 estimates 配合。 learning rate 大, 前几轮推进快,但更容易被噪声带偏。 工程上不要单独拧一个旋钮,要把轮数和学习率一起看。训练和评估时流程很朴素,先 fit 单科角色装,再在测试级 score, 再 fit add up boost 也在同一份测试级 score。 注意不要提前写死一个漂亮准确率,除非已经用当前环境真实跑过,并且记录了数据文件、随机种子和库版本。 这里更重要的是解释差异来源。单科决策庄只能画一条简单分界线阿大 boss 的是很多条简单分界线的加权组合,所以边界会更灵活。 它通常能比单科决策庄更好,但不保证永远胜过所有模型。随机森林 a 大 boss g b d t。 在 小数据上分数差距可能只有几个百分点。评价模型不是被结论,而是在同一切分、同一指标、同一随机种子下做公平对比。最后受三个坑。 第一,积学习气,不是越强越好,把 max steps 从一改到五,单棵树自己就可能把训练级学得很满, a lab boost 的 接力纠错空间反而变小,测试级还可能因为方差变大而下降。第二, learning rate 和 estimates 要连调, 学习率降到零点零一,却仍然只训练几十棵树,模型很可能欠拟合,学习率很大,要训练很多棵,可能追着造声跑。第三,注意 api 名称, 旧资料里常见 base estimate, 新版本应该写 estimate。 到这里, a w s。 的 机制手算和 api 实战就串起来了,它用样本权重传递上一轮的错误, 下一条路线会换一种通信方式。不再说哪条样本更重要,而是直接告诉下一棵树还差多少。下期见,欢迎评论区留言讨论 how to boost, 告诉下一棵树的是哪些样本错了,所以要多看。 g b d t。 换了一种说法,不要只告诉我错没错,直接告诉我还差多少。比如真实年龄是一百岁,第一棵树预测八十,残差就是二十。 第二棵树不再重新预测一百岁,而是专门学习这二十岁的缺口,预测十六。现在累计预测变成九十六,残差只剩四。第三棵树再学四预测三点二,累积就到九十九点二, g、 b、 d、 t 的 直觉就在这里。每棵树不是重做整道题,而是补上一棵树漏掉的那段差。这期我们先讲提升树的残差接力,再把残差推广成负梯度, 解释为什么 g、 b、 d、 t 能从回归走到分类。提升数的关键定义是残差 zero。 残差等于真实值,减当前预测值,记作 r 等于 y, 减 f x, 它带方向,也带大小。残差为正,说明当前预测低了。残差为负,说明当前预测高了。绝对值越大,说明还差的越多。 dm 函数训练时,目标变量不再是原始 y, 而是上一轮的残差。训练完以后,把这棵树的输出加到当前累积预测上,再重新计算残差,这个过程会反复进行,直到树的数量达到设定值,或者残差已经足够小。 用商品八十二元的例子看,第一棵树才五十,残差三十二。第二棵树学三十二,预测二十,残差十二。第三棵树学十二,预测十,累计八十,已经接近八十二。现在把 a 大 boost 和提升树放在一起看, 它们都属于 boosting, 都是串行训练后一棵树依赖前面已经训练出的结果,但传递的信息完全不同。 a 大 boost 传递的是样本权重,这条样本上一轮错了,下一轮请多看它。 原始标签不变,只是每条样本的重要性变了。提升数传递的是残差,当前模型在这条样本上还差多少,下一轮就直接选这个差额。对回归来说,残差比权重更直接,因为它同时包含方向和大小。 预测八十岁,但真实一百岁不止是错了,还低估了二十岁。下一棵树知道这个树就能专门补二十,而不需要重新猜整个人的年龄。那为什么还要引入负梯度?因为残差这套说法只在平方损失下,特别自然, 平方损失可以写成二分之一乘真实值和预测值差的平方对预测值求导,再取负号,结果正好是真实值减预测值,也就是残差。 所以在平方损失下,残差就是损失函数下降最快的方向。可一旦换成别的损失,比如分类里的对数损失,或者抗离群点的绝对损失,普通残差就不再等于最合适的修正方向。 g b d t。 的 推广是,下一棵树不一定你和残差,而是你和损失函数对当前预测的负梯度。 negative gradient 负梯度,告诉模型当前预测往哪个方向修损失下降最快。 g b d t 还有两个容易忽略的细节, 第一是初识化,回归平方损失下最好的常数。初识预测通常是训练及目标值的均值,因为均值能让平方误差最小。后面的数不是从零开始,而是在这个基础上不断修正。 第二是 learning rate, 也叫 shrinkage, 每棵树算出的修正量不会一定全额加进去,而是先乘一个小系数,比如零点一,再加到累积预测里。 学习率小,模型每一步更谨慎,通常泛化更稳,但需要更多棵树。学习率大,收敛快,但可能过冲,也可能更快。拟合造声,你可以把 g b d t 想成梯度下降的树模型版本,每棵树给一个方向学习率,控制每一步走多远,把这一段收成一句话, 提升数,你和残差 g b d t 你 和负梯度在平方损失下,两者刚好是同一件事。 add boost, 用样本权重告诉下一轮哪里更重要, g b、 d t 用负梯度告诉下一轮往哪修,修多少。 这个变化非常关键,因为它让 boosting 不 止适合二分类,也能支持回归分类和其他可归损失。后面用 skl 的 gradient boosting crispr 时,我们不需要手写附体度库,会根据损失函数自动算。 真正要理解的是框架先有初始预测,再一轮一轮算当前模型的修正方向,用一颗回归数,你和这个方向,最后把所有数的修正量累加起来。下一期我们把这套机制放进具体数字里。手算 g、 b、 d t 怎样从均值一步步靠近真实值? 下期见,欢迎评论区留言讨论。 g b、 d t 的 概念已经有了,先给一个初识预测,再让每棵树拟合上一轮的负梯度。在平方损失下,这个负梯度就是残差。可如果只停在这句话,很多细节还是空的。残差表怎么来?每颗 cut 回归数怎么选?切分点 叶子值为什么是残差?均值预测值又怎么一轮一轮更新?这一期我们把 g、 b、 d、 t 当成一张竹轮修错账本来手算, 先用五个学期时长样本走通两轮,再回到主线十样本核对初始均值七点三一,第一棵树切分点六点五 以及 x 等于六十,最终预测六点六一。这个结果看完以后, g、 b、 d、 t 不 再是一串公式,而是一张能逐列更新的表。 先用最小例子建立流程,假设有五个年级,学习时长分别是五、六七、八、九小时。平方损失下 g、 b、 d、 t 的 初始预测,选目标值均值,五个数的均值是七,所以第零轮所有样本的预测都是七。 年级一的真实值是五,残差是五减七等于负二,年级二的残差是负一,年级三的残差是零,年级四是正一,年级五是正二。第一棵树要学的不是原始学习时长,而是这一列残差。 图上可以画一条 y 等于七的水平线,左边两个点在水平线上方,说明被低估。现在用残差作为目标,训练一个只有一个切分点的 cut, 回归数 后,选切分点是一点五、二点五,三点五、四点五。每个切分点把样本分成左右两组,每组用组内残差均值作为叶子值,然后计算残差到叶子均值的误差。平方和,也就是 s s 一, 以二点五为例,左边是年级一和二,残差负二负一,均值负一点五。左边 s s 一 是零点五,右边 s s 一 是二,总 s s 一 是二点五。 每举后一点五和四点五的 s s 一 都是五,二点五和三点五都是二点五,按视力取二点五。 于是第一棵树左叶输出负一点五,右叶输出正一。第一棵树训练好以后,把它的输出加到原来的预测上,年级一和二走左叶,原来预测七,加上负一点五,变成五点五。年级三四五走右叶,原来预测七,加上正一变成八, 再用真实值减新预测,就得到新残差。年级一是负零点五,年级二是正零点五,年级三是负一,年级四是零,年级五是正一。你会发现残差整体变小了,但不是每个点都立刻变好。 年级三原来残差是零,第一棵树之后反而变成负一,这很正常,因为一棵浅树只能做粗糙分段。 g、 b、 d、 t 的 思路不是一棵树解决全部,而是下一棵树继续修新残差。第二棵树从新残差出发,重复同一套谜句,严格按 s、 s、 e 复算。第二棵树最优切分点是四点五,左边年级一二、三四的新残差是负零点五,正零点五负一零,均值是负零点二五, 右边只有年级五新残差是正一,所以叶子值是一。更新后,年级一的预测从五点五变成五点二五,年级四从八变成七点七五,年级五从八变成九。残差不是直线归零,而是一轮一轮被压。小 动画上可以把每轮残差柱化成账本。第零轮平均绝对残差是一点二,第一轮约零点六,第二轮约零点四零,后面继续下降,再回到实样本主线,这里的目标值是五点五六,五点七零,五点九一,一直到九点零五, 出土化常数是目标均值七点三一。第一轮残差就是每个 y 减七点三一,比如 x 等于一的残差是负一点七四。 第一棵树每举切分点后,最优切分点是六点五,左叶残差均值约负一点零七,右叶约正一点六零。 第二棵树在新残差上继续训练视力,最优切分点是三点五。第三棵树再次更新切分点回到六点五。以 x 等于六的样本为例,最终预测是七点三一,加负一点零七,再加零点二二,再加零点一五,等于六点六一, 真实值是七点零五,残差还剩零点四四。继续迭代还能更接近。这套手算要抓住四个动作,第一,出土化不是随便猜,平方损失下用均值。第二,每一轮都重新计算残差,下一棵树的训练目标是新残差,不是原始歪。 第三, c r t 回归数,选切分点时,叶子输出是组内残差均值评判标准是 s s 一 最小。第四,最终预测一定要把初尺长数和每棵树的修正值全部加起来,不能漏掉。 f 零 训练时是竹轮,残差表,推理时是新样本,依次走过每棵树,把每个叶子值累加回归手。算到这里就完整了。 下一期我们把损失从平方损失换成对数损失,用 gradient boosting class f r 跑泰坦尼克二分类机制仍然是接力修正,只是残差表换成分类损失下的负梯度。下期见,欢迎评论区留言讨论。 随机森林那期,我们用泰坦尼克数据做过生存预测,随机森林的路线是 begging, 很多棵树独立训练,最后投票。现在换成 g b d t, 它仍然可以处理泰坦尼克二分类,但训练方式完全变了, g b d t 是 boosting。 每一颗新数都依赖上一轮模型的错误方向。分类任务里,这个错误方向不再是简单的真实质检预测值,而是对数损失下的负梯度。 好消息是用 s k learn 的 gradient boosting class f 二时,我们不需要手写这些梯度,只要准备好特征和标签,模型会把对数损失、负梯度数的累加都封装起来。 这期重点是把概念落到 pipeline, 数据怎么处理,参数怎么理解, great search cv 怎么调,以及它和 r f ada boost 的 工程差异。泰坦尼克案例的特征保持简洁直取 p class age, sex 三列,目标是 survived age, 有 缺失值。势利里用均值填充 sex 是 类别特征。 p class 虽然是数字,但本质上也可以当成均值填充 sex 是 类别特征。 sex 虽然是数字,但本质上也可以当成离散等级。所以用 get dummy 做 onehot 编码 处理完后用 train test split 划分训练级和测试级,并固定 random state。 这个流程和随机森林案例很像,因为模型不同不代表数据处理可以随便变,要比较模型,最好让它们使用同一份特征,同一套切分和同一评价指标, 这样最后看到的差异才主要来自模型机制,而不是来自预处理不一致。 gradient boosting classifier 的 核心参数和前面概念一一对应。 estimates 施数的数量, sklearn 默认是一百。 learning rate 是 每棵树修正量的缩放,通常和 estimates 联动。学习率小数要更多, 学习率大数可以少一些,但过拟和风险更高。 max steps 控制每棵树的深度, g b d t 里的单棵树通常不用太深,深度二到四就能作为常见搜索范围。 sub sample 是 每轮抽取多少比例样本小于一时会引入随机性变成随机梯度提升, 有时能提升。泛化分类默认使用 log loss, 也就是对数损失,使用者传零和一标签即可, 不需要手动把概率差、负梯度和 sigma 写出来。基础训练很直接,实力化。 gradient boosting classifier fit 训练级再用 score 或 classification report 评估测试级。这里不要把某个准确率当成固定结论,除非数据文件、随机种子和库版本都一致 讲解,重点放在流程和判断方式。调三时用 grid search cv 搜索 estimates 和 max steps 是 一个入门组合。 更完整的做法是把 learning rate 也纳入链条,比如学习率零点零五、零点一、零点二数数量八十一百二两百数深二三四交叉验证。 c v 可以 先设三,数据更稳定时再加大。 每次调餐都固定 random state, 否则模型之间的小差也会混入随机波动影响判断。到这里,本章已经有三个能跑泰坦尼克分类的集成模型。随机森林是并行训练,个数独立训练速度快,吊餐压力小,适合作为强际线。 a w boost 是 串行训练,主要通过样本权重强调错样本,即学习器常用决策状,对离群点和噪声会比较敏感,因为错样本会被反复放大。 g b d t 也是串行训练,但传递的是负梯度,通常准确率上限更高,参数也更多,训练速度比随机森林慢。 时间里不要默认某个模型一定赢。先用随机森林拿稳健基线,再试 g b d t, 看是否有明显收益。如果 g b d t 精度更好,但训练太慢,或者需要更强正则和更快。构思这一期,把 g b d t 从回归手算带到了分类实战, 核心变化只有一个,损失函数从平方损失换成对数损失。负梯度的具体数值变了,但串行修正框架不变。 工程上我们用 p class age sex 做特征, age 均值填充类别变量 onehot 编码,然后用 gradient boosting classifier 训练和貂参。 模型参数里 nst meters 决定数的数量, learning rate 控制不长, max steps 控制单棵树复杂度, subsample 增加随机性。 gbt 已经是很强的结构化数据模型,但它仍有两个不足,正则化没有 x g boost, 那 么系统训练速度也不够工业化。 下一期我们看 x g boost 怎样把 g b boost 升级成带二阶导正则向和工程优化的版本。下期见,欢迎评论区留言讨论。 g b d t 已经能用一颗颗数你核负梯度在结构化数据上很能打,但一旦进入真实业务,会遇到几个问题,树长太深会过你核,叶子输出太极端,也没人约束, 什么时候继续分裂,什么时候停止,很多时候靠 max steps 这类超参数应挡数据量大时每举切分点又很慢。 x g b d t 做成更强的工业级版本, 它不是完全换了一种算法,而是在 g b d t 的 框架上加了几件关键装备。二阶泰勒展开同时看一阶导和二阶导。目标函数里加入正则项,惩罚叶子数量和叶子值大小,分裂条件从目标函数推导出来。 工程上在配合直方图列产量缺失值处理和并行优化。 j b d t 的 核心是负梯度,也就是一阶导信息,它告诉我们损失往哪个方向下降最快。但对这一步走多远,主要还要靠 learning rate 和树的拟合结果。控制 x g boost 的 多看一层。二阶导也叫黑心,可以把一阶导理解成坡度,二阶导理解成坡度变化的快慢,也就是曲率。只看一阶导相当于用一条直线近似损失曲面,加上二阶导相当于用一条抛物线去贴这个曲面, 抛物线更知道附近形状,所以叶子输出可以推成 b 式公式,而不是只取残差均值。这也是后面目标函数推导里最重要的铺垫,每个样本不止传一个 g, 还会传一个 h。 第二个升级是正则向 x g boost 的 目标函数不是只有训练损失,还会加上数的复杂度。乘法。 复杂度可以写成两部分,干巴乘叶子数量, t, 再加二分之一乘 lamna 乘叶子指向量的平方范数。白话说,叶子越多扣分越多, 叶子输出值越大扣分越多,这样模型就不会为了追训练及上一点点误差随意长出很多叶子, 也不会让某个叶子给出特别激进的修正。 g b d t 主要靠 learning rate, max, steps, subsample 这些外部旋钮控制过,你和 x g boost 把正则直接写进目标函数里。这个区别很关键,因为后面的叶子值和分裂 gain 都会从同一个目标函数推导出来。 第三个升级是分裂准则,普通决策树可以用基尼指数信息增益, g b d t 回归数会看残差的平方误差下降。 x g boost 的 分裂 gain 来自目标函数本身,它会比较负节点不分裂时的得分,以及分成左右子节点后的得分。 只有左右子节点带来的损失下降超过新增叶子带来的,干嘛惩罚分裂才值得做。这样一来,停止条件就不只是人为设一个最大深度, 即使 max steps 还没到,只要继续分裂的 game 小 于等于零,这个节点就不该再拆。对工程来说,这比纯靠深度上线更有解释性。不是因为树被强行拦住,而是因为继续长叶子已经不划算。第四类升级是工程优化。 x g boost 的 常被说成快,但要注意它的 boost 定数仍然是串行的 dm 四数必须等前 m 减一速训练完拿到新的 g 和 h 才能开始。它的并形主要发生在单棵树内部,比如不同特征的直方图统计可以并行, 连续特征可以先分桶,不必每举所有原始取值,这就是直方图径四列产量,让每棵树只看一部分特征,既提速也增加多样化, 缺失值处理也更自动。分裂时可以尝试缺失值走左边还是右边,选择收益更高的方向,把这些机制叠起来, x g boost 才能在大规模结构化数据上又快又稳。把随机森林 g b d t x g boost 放在一张图里会更清楚。随机森林属于 breaking 个数独立,靠随机样本和随机特征制造差异训练可以并行调参,相对轻。 g b, d t 属于 boosting 个数串行后一棵树,你和前面模型的负梯度通常精度更高,但训练慢,正则不够。系统。 x 级 boost 仍然是 boosting, 仍然一颗颗接力,但每个样本传的是一阶导和二阶导。叶子值和分裂条件从带正则的目标函数推出来。工程上还有直方图和特征级并行。 记忆上可以这样区分。随机森林靠随机多树投票, g b, d t 靠负梯度竹轮修正, x g boost 靠二阶导和正则,把修正做的更稳更快。这期先建立 x g boost 的 全剧图,第一,它仍然是 boost 汀,不是把树变成并行投票。 第二,他比 g b d t。 多看二阶信息,所以不仅知道往哪修,也更知道修多少合适。第三,他把正则项写进目标函数,用伽马控制叶子数量,用 lama 控制叶子值大小。 第四,他用目标函数推出分裂 gain, 让是否分裂有更清楚的数学依据。第五,他通过直方图列向量,确实指默认方向和特征极并形,把数模型训练做得更工程化。 下一期我们进入最核心的数学推导,从损失加正则开始,用二阶泰勒展开,把目标函数变成按叶子求和,最后推出最优叶子值和分裂根。下期见,欢迎评论区留言讨论。 上一期我们说叉 g boost 比 g b d t 多了二阶导和正则项,但真正厉害的地方不是把这些词堆在一起,而是它能从同一个目标函数里推出两件事,每个叶子应该输出多大的值,以及一个节点到底该不该继续分裂。 g b d t 回归里,叶子值常常是残差均值差级 boost 的 不这么简单,它会看这个叶子里所有样本的一阶导之合,也会看二阶导之合,还会加上 lambada 作正则, 最后得到的叶子值是负极,除以括号 h 加 lambada。 分 裂时也不是只看误差下降,而是计算左右子节点带来的根,扣掉伽马的叶子成本。到这里,调参里的伽马和 lambada 才真正有数学含义。 先写 d t 轮要优化什么?前提简易函数已经训练完,所以每个样本当前预测值是已知的 d t 函数。要做的事是在当前预测上再加一个新函数 f t。 目标函数 objective function 由两部分组成,第一部分是所有样本的新损失,也就是真实标签 y 和当前预测加新数输出之间的损失。第二部分是新数的复杂度乘法。 复杂度乘法包含伽玛乘叶子数量 t 以及二分之一乘 lama 乘所有叶子值平方和。 这里要注意,前面已经固定的数对 dt 存数来说都是常数。我们只关心新数 f t 怎么长,每个叶子输出多少,它能让目标函数下降多少。 直接优化这个损失很麻烦,因为损失函数可以是平方损失,对数损失也可以是其他形式。 x g boost 的 做法是用二阶泰勒展开 second order tail expansion, 把每个样本的损失在当前预测附近,近似成一个二次表达式。 这个表达式只需要两个数, gi 和 hi。 gi 是 损失对当前预测的一阶导,也就是坡度。 hi 是 二阶导,也就是曲率 展开后和心数有关的部分,可以看成 gi 乘心数输出,再加二分之一乘 h i 乘心数输出的平方。原来那项当前损失不含心数,是常数,可以丢掉。 这样一来,不管具体损失长什么样,只要能提供一阶导和二阶导,就能进入同一套求解流程。下一步是视角转换,一棵树训练好以后,每个样本都会落到某个叶子,落到同一个叶子的样本,心数输出值相同,都等于这个叶子的权重 w j。 所以原来按样本逐条求和的式子可以改写成按叶子分组求和。对某个叶子, j 把里面所有样本的一阶导加起来,得到 j j。 把所有样本的二阶导加起来,得到 h j。 于是这个叶子对目标函数的贡献就变成 g j 乘 w j, 再加二分之一乘括号 h j 加 landa, 再乘 w j 的 平方,最后再加伽马乘叶子数。这个转换非常重要,因为它把整棵树的目标拆成了每个叶子的二次函数。 每个叶子的最优输出值都可以单独求。现在对某个叶子的二次函数求最小值,它的形式是, g j 乘 w j 加二分之一乘括号 h j 加 lambda, 再乘 w j 的 平方。对 w j 求导,得到 g j 加括号 h j 加 lambda, 再乘 w j, 令它等于零,就得到最优叶子值。 w j 星等于负, g j 除以括号 h j 加 lambda。 这个公式很有直觉。 dj 是 这个叶子里所有样本的一阶导合力,告诉你整体该往哪个方向修。 h j 加 lamda 向阻力二阶导越大或者正则越强,叶子值就越保守。 对比 g b, d, t 的 残差均值 x g boost 的 叶子值,同时考虑方向曲率和正则,所以通常更稳定。 篮打越大,叶子值越容易被拉回零。把最优叶子值带回目标函数,就得到一棵树的打分函数。它可以理解成这棵树在当前结构下最多能把目标函数降到什么程度。分裂给就来自打分函数的差值。 先看负节点不分裂时的得分,再看分成左子节点和右子节点后的得分。左右子节点各自有 g 和 h, 负节点的 g 和 h 是 两边相加。分裂给等于左右子节点的收益之合,减去负节点原来的收益,再减去伽马。 最后这个减根码很关键,因为它代表多开一个叶子的成本。令大于零,说明分裂后目标变小,值得拆令小于等于零,说明新增复杂度不划算,就停在这里, 用平方损失做一个小数字。平方损失下, g i 可以 看成预测值减真实值。 h i 等于一。假设某个叶子里有三个样本, g 分 别是负二,正一,正三,那么 g g 等于二。三个样本的 h 都是一,所以 g g 等于三。 如果 lm 大 于一,最优叶子值就是负,二除以四等于负零点五。没有正则时,分母是三,修正幅度会更大。有 lm 以后,分母变大,叶子值被压小。 这个例子说明, x g boost 的 不是简单的把残差平均后直接加上去,而是在每个叶子里用 g 和 h 计算一个更谨慎的修正量。正则越强,修正越保守,过你和风险也会下降。把整条推导链收一下。 第一, x g boost 的 目标函数是训练损失加数复杂度。第二,第 t 轮里前面的数已经固定,新数是唯一要优化的部分。第三,用二阶泰勒展开,把复杂损失变成由 gi 和 h i 表示的二次进四。 第四,把按样本求和改成按叶子求和,得到每个叶子的 g j 和 h j。 第五,对叶子值求导,推出 w j 星等于负, g j 除以括号 h j 加 l d。 第六,把最优叶子值带回去,得到打分函数,再推出分裂 gain。 下一期这些公式都会变成 api 参数, learning rate 控制每棵树输出缩放,伽马控制分裂门槛, rigamda 控制叶子值。政策 max depth 控制树结构上线。下期见,欢迎评论区留言讨论。 上一期我们推到了 x g boost 的 叶子值和分裂 gain, 现在把公式落到工程,伽马会变成伽马, lama 会变成 ray lambda, 学习率会变成 learning rate, 树的数量会变成 estimates。 和随机森林 g b d t 不 同, x g boost 的 不在 s k l 里,需要单独安装。 x g boost 的 包 装好以后,它既有自己的原声 api, 也有 s k l 兼容的 x g b class。 费尔最后一期,我们用红酒品质预测收官三千二百六十九条数据,十一个特征,六个品质类别,而且类别明显不均衡。 这个任务比单纯调一个准确率更贴近真实项目,因为模型不止要会分中间档,还要照顾样本很少的好酒和叉酒。第一件事是安装 x g boost 是 独立库,不在 s k e l en ensemble 里面,所以要先 pip install。 x g boost 使用时有两套接口,原声接口是 x g b train 加 dimitrix, 适合生产训练、大数据和更细的早停控制。 esceller 兼容接口是 check g b classroom 和 check g b regressor fit predict score 的 风格和 esceller 模型一致,可以直接接 pipeline, grade c v 和交叉验证。 教学和快速实验里优先用 c g b classification, 因为它和前面 random forest classification, add boost classification 的 调用方式保持一致。需要注意参数别名,原声接口常用 e t r sklearn 兼容接口常用 learning rate 原声接口里的 lambda 在 sklearn 兼容接口里写 read lambda。 x g b philosopher 的 核心参数可以按理论分组。 estimates 是 最多见多少棵树,通常配合早停不一定全部用完。 learning rate 是 每棵树输出的缩放,也就是前面说的不长。 max depth 控制单棵树最多分几层,过拟合时先考虑降深度。 gammon 是 分裂 game 里的叶子,成分越大,节点越不容易继续分裂。 reg lambda 是 l 二正,则控制叶子值,不要太极端。 subsample 是 行材样比例, call sample b tree 是 裂材样比例,用来访过你核核提速。 objective 制定任务类型。二、分类常用 binary logistic, 多分类可以用 multisoftmax, 回归可以用 re squared arrow evo metric 则决定验证机上看什么指标。 x g boost 调餐时不建议死盯 estimates, 常见做法是把 estimates 设大一点,比如一千,再用 early stopping rounds 配合验证机, 只要连续若干轮验证指标没有提升,训练就停止。预测时使用验证表现最好的轮次,这样比拍脑袋决定数数量更稳。 gpu 口径也要按当前写法讲, 旧资料里常见 tree mesa 等于 gpu heist, 新版本更推荐 tree mesa 等于 heist, 再加 device 等于 guada。 没有 gpu 是 tree mesa 等于 heist, 也能用 cpu 直方图加速。 注意, gpu 和早停都不是为了改变算法思想,而是为了更快更稳地找到合适的树数量和分裂结构。红酒品质案例有三千二百六十九条数据,十一个特征目标是品质等级与 原始品质,常见是三到八分,代码里会减三变成零到五。这样做是为了符合多分类标签从零开始的习惯。 模型使用 x g b class, fear objective 设为 multi soft knocks, num class 设为六。 evolometric 可以 用 mirror 划分,训练级和测试级是一定要加 strify 等于 y, 原因是红酒品质类别不均衡,中间档样本多,极端好酒和叉酒样本少,普通随机切分可能让某些少数类在测试级里比例异常,甚至数量太少,评估结果不稳定。 分层切分能让训练级和测试级尽量保持相同类别比例。这个案例的重点不是只看 accuracy, 而是处理不均衡。第一版斧是 sample weight, 用 compute sample weight 的 balance 的 模式给训练样本分配权重,少数类样本权重大数类样本权中小。 然后在 fit 时传 sample weight, 这样模型计算损失时会更重视少数类。第二版斧是 stratify k fold, 做 grade 四十 c v 时用分层 k 折保证每一折的类别比例更稳定。第三版赋是 squing, 选 f 一 micro accuracy 会被多数类主导模型全猜,中间档也可能看起来不错。 micro f 一 会对每个类别的 f 一 做简单平均,少数类表现差会直接拉低总分。 红酒品质。这种任务 f e micro 比 accuracy 更诚实。完整训练可以分三步,第一步,先跑一个基础, x g b classifier, 拿到 classification report, 观察哪些类别, precision 和 recall 很 低。 第二步,加 sample weight 重新训练,重点看少数类召回是否改善,而不是只看整体准确率。第三步,用 great search, cv 搜索 and estimates max, steps learning rate 等参数交叉验证用 stratified k fold, 评分用 f e micro。 这里同样不要提前写死一个最优分数,不同 x g boost 的 版本数据文件、随机种子都会影响结果。 判断原则是如果 micro f 一 上升,同时少数类召回变好模型才是真的更适合这个任务。到这里集成学习,这一章就串完整了。 第一条路线是 begging, 代表是随机森林并行训练很多棵不同的树,通过投票或平均求稳。第二条路线是 boasting, 先从 adboast 开始错样本权重变大弱,学习记按表现加权, 再到 g, b, d, t, 不 再传样本权重,而是传损失函数的负梯度,让下一棵树补上一轮的差。 最后到 x g boost, 在 g, b, d, t 上加入二阶导正则向分裂 gain 和工程优化。实战上,先用随机森林拿基线,再根据精度、速度、可调性选择 g, b, d, t 或 x g boost。 不要只背模型名字,要记住每条路线传递的信息是什么。随机森林传差异性 a 的 boost 传样本权重 g, b, d, t 和 x g boost 传梯度信息。下期见,欢迎评论区留言讨论。
 03:06查看AI文稿AI文稿
03:06查看AI文稿AI文稿接下来我领大家看一下烟尾是几级。烟尾是一种美丽的植物,科大里面也有,我第一次来科大的时候,第一个来科大,第一个春天我就往校园去找。这是有三种烟尾, aries, west color aries, santa aries, virginia。 这里面一共有四个特征。第一个 sap 和 paddle, 分 别是花瓣和花叶的四个特征,分别是花瓣的长度、花瓣的宽度和花叶的长度,花叶的宽度。我们可以用这四个特征对三个样本进行分类。 我来来给大家看一下我写的代码, 这次的目的是让大家过一下有监督的算法。这是用最小二乘,也就是所谓的 linear regression 分 类的方法。它有四个特征,但是我为了能让大家看出来,我只用了两个, 而它本来有三类,我为了演示的目的,我划掉了其中一类,现在只选了两类。 上面的是一种烟尾,下面的是一种烟尾。这里的在测试级上准确率是零点九九,在验证级上准确率是一点零。之所以这么高,是因为它它俩本来就是线线可分的,所以你用任何一种线线算法都可以达到大约百分之百的准确率。 如果换成逻辑回归的话,当然也是小接近百分之百了。 supporting vector machine 自然也是百分之百,反正都是限性的,只要是限性、可分的、限性的,这些算法的准确率就一定是百分之百。 决策树,它的边界会不像原来一条线,因为它决策的时候是会按照你的 cyplus 小 于多少或者大于多少来决策,以及你的 cyplus 小 于多少或者大于多少来决策,所以它会是横平竖直的? 如果你决策树的每个节点都是某些特征,大于小于这种,你就只能是横平竖直。如果是你决策树每个节点也可以是它俩的线型组合,大于或者小于每个值,你就可以是斜线这种一般的决策树都是横平竖直的, 因为这样节省计算量,而且效果效果和有斜线的也差不了多少。紫荆森林当然有横竖直的,这里之所以有斜的是因为画图的原因,我没有把像素调得很高。 叉 g boost 也是叉 g boost 有 可能可以写。我不太清楚这个算法,没有仔细了解过。 这里有三本数据机。
16懿轩的思索时刻 00:46查看AI文稿AI文稿
00:46查看AI文稿AI文稿很多文章喜欢把 naso 随机森林、 z v m x g boost 全部堆上去,但模型越多不代表文章越好。医学 sci 里的机器学习核心是解决筛选和预测问题, 比如在大量差异基因里筛出最有诊断价值的标志物,可以用 naso 压缩变量,用随机森林排序重要性,再取交集,提高稳定性。后面必须用 i o c 曲线校准曲线、决策曲线和外部对列验证模型,否则只是算法展示。客户经常遇到的问题是图跑出来了,但审稿人问为什么这个模型有临床意义,答案要提前设计好。 比如这个模型能区分疾病和健康,能预测预后风险,或者能帮助分层高危人群。机器学习不是为了显得高级,而是为了把复杂数据转化成可解释、可验证、可应用的指标。纯生性项目想提升档次,可以加机器学习,但一定要有验证和临床场景。
 02:20查看AI文稿AI文稿
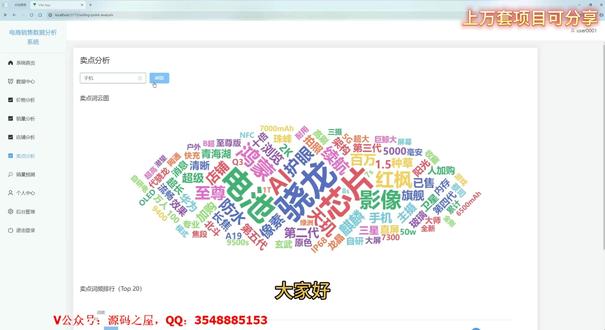
02:20查看AI文稿AI文稿大家好,今天给大家分享一个电商销售数据分析系统,该系统支持用户登录,提供商品数据查询、价格分布分析、销量与店铺表现对比,以词云呈现商品卖点,并支持基于机器学习算法的销量预测,同时提供个人信息管理与后台数据维护功能,为电商运营决策提供数据支撑。 you are the one who?










