utf-8编码怎么设置
粉丝43获赞150
相关视频
 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿下面给大家去说一下如何把文本改成 utf 八的一个编码。首先我们在这个文本上点右键选择编辑或者记事本,编辑啊或者没有的话点打开方式,在打开方式里面选择记事本啊都是可以的。 打开之后呢,我们看一下这里右下角,右下角这里有显示 a n s i, 那怎么去变成 u t f 八呢?首先我们在文件上点右键选择另存为,另存为的时候的话,然后我们在这个 编码上面选择 utf 八,然后点击这里的一个确定,然后我们点是 就可以了,这样的话这个文件就变成 u t f 八的一个编码了,我们在打开的时候可以看到右下角这里是 u t f 八,这样的话特别是有在一些旧系统里面做的一些资料,用新版的开发软件啊,就不会导致乱码的问题。
402凯迪软件 01:51查看AI文稿AI文稿
01:51查看AI文稿AI文稿今天教大家如何去解决优盘音乐歌词显示乱码的问题,其实出现这个问题的根本原因在于咱们大狗所支持的歌词编码格式是 utf 杠八,然而咱们优盘音乐里面的歌词文件编码是 ansi 编码,由于两者的不匹配,导致咱们大狗显示出来就是一个乱码, 只要将歌词改成 utf 杠八,咱们大狗就可以正常显示里面的歌词内容。现在我来教大家如何将 ansi 编码格式改成 utf 杠八格式。修改文件编码格式需要在电脑上完成,所以首先我们应该将优盘插入电脑中,然后在电脑上打开 u 盘中的文件, 打开音乐文件之后,咱们选择歌词右键打开,打开歌词之后,咱们可以在右下角看到这个歌词的文件编码格式是 m n s i 文件格式,咱们 需要将它转化为 utf 杠八。操作的话就是右上角的文件,然后点另存为继续存在优盘当中,然后选择所有文件编码格式修改为 utf 杠八, 然后点保存,点保存之后他会弹出说这个歌词文件已存在,原因是因为他本身存在一个 ansi 编码格式的歌词,所以才会出现这个提示语。我们需要点四进行覆盖, 覆盖完之后咱们可以再确认一下,再去打开这个文件,右下角就可以看到咱们已经修改成功为 utf 杠八了, ok, 这就是如何去修改 ansi 编码格式为 utf 杠八,只不过这种操作的话适合文件比较小的情况下,如果需要大量的批量修改,需要用到一个批量修改的工具,工具可以在网上自行去寻找,原 也是同样的这个原理,只是将编码格式修改为咱们大狗支持的 utf 杠八即可。 ok, 本期视频的话到这里就结束了,觉得有用的话麻烦点个免费的小红心,谢谢大家。
496伟强同学🚗 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿当中注意啊,在文件转换这第一步里边,很多时候呢,咱们导入文本文件很有可能会出现乱码,那一旦出现乱码了,你就在这里边改一下咱们这编码格式,比如说你可以尝试一下 utf 八,或者呢找到下边会有简体中文 gb 二三幺二,你可以都来切换一下试一下。 那么如果没出现乱码,你就点击下一步点一下,那么这个窗口是不是看着挺眼熟的?这什么工具? 这个呢,其实就是刚才提到的分裂工具,你看数据已经进来了,说按照分格符分裂,这个很简单,咱们就快点来啊,按照分格符分裂,点击下一步, 按哪个分割符呢?按照其他当中的什么符号还记得吗?中文全角逗号,写完之后,数据呢被分开了,再点击下一步,在这一步当中呢,你可以指定一下每一 列的格式,有没有需要指定成文本格式的,对吧?也不多说,在这里边呢,可以指定一下数据载入到哪里,我们已经选了 a 一,所以这个呢不用改了,然后点下完成。大家注意一下,现在呢就能把文本文件的数据给全部都抓取过来,并且做好了分列到这里呢,咱们就把数据。
56应龙学子铺 01:18
01:18 07:14查看AI文稿AI文稿
07:14查看AI文稿AI文稿大家好,我是克莱梦。之前呢,我们用两节课的时间去说了怎么去读写 t x t 的数据,那么有的同学就会发现,如果跟着我的代码一起打一遍的话,可能有的同学他读到的数据是乱码,比如说我这里有一个文本文档,里面有姓名这些 字母这些汉字,如果我们去读取的话,有的同学他就会发现,用我之前的读取数据的方法读出来的是一堆乱码,这是为什么呢?因为我们的 t x t 文件,它在系统在保存的时候,它默认是保存为 u t f 八的, 但是实际上呢,我们的 v b a 里面用的是什么呢?我们 v b a 里面用的是 a n、 s i 这两种不同的编码方式,所以它用 a n、 s i 的方式去读取 u t f 八,它就 肯定会出现错误,那么我们怎么去解决这个错误呢?我们有一个简单的方式,如果你只是读取单个文本文档的话,我们把这个文本文档在这个另存为这里用记事本打开,然后把它另存为在这里我们把编码方式,把这个编码改成 ansi 就可以了, 然后保存,把原来的给替换掉。这样呢,我们再执行这个代码,我们看一下 他执行的就是正常的银行,银行的数据了,那么如果我们这样有很多文件的话,我们这样改就很麻烦的,那么我们有没有一种方法可以直接读取到这个系统默认的 utf 八这种编码方式的 方法呢?当然是有的,今天我们就来做一个新的对象,叫做 a d o d b, 这个 a d o d b。 我先来说文解字一下啊,什么叫 a, d, o, d, b 呢?这个 a 是 active, 这个 d 是 data, 然后这个 o 是 object, d, b 两个的意思呢?就是 data base。 有人说这几个英文我都懂啊,拼到一起我就不懂了,其实你就可以理解为活动数据对象数据库,那么这个对象是干嘛用的呢? 他可以按照任何一种编码方式去读写我们的文本文件,那么我们怎么去用它呢?我们首先还是跟之前的那些东西一样,我们要在引用里面,他是要在引用里面引用的, 我们首先要在引用里面勾选这个 active data object, 然后勾选了之后我们点确定,这样呢我们就可以直接去 对他进行一个声明了,所以我们第一步就是定去声明一个 ado db 这个对象,比如说我就声明,我就把名字,把这个对象名就叫做 ado 吧。 d o, s new, 我们建立一个新的 a, d, o, d, b 对象,我们声明一个新的 a, d, o, d, b 点 stream 这样的一个对象,然后我们怎么去使用这个对象呢?按照我的这个格式来就可以了, a, d, o 点 open, 就是打开这个对象,然后下一句是 a, d, o 点 type, 这个 type 是设置一个参数。设置什么参数呢?就是设置你是用二进制的方式去打开这个数据,还是用文本数据的方式去打开。我们这里肯定是设置成二,因为我们要打开的是个文本嘛,我们如果设置成一的话,就会设置成二进制, 如果我们设置成这个二,就是这底下的这个 text, 左右打数字二就可以了,我们这里直接打数字二就可以了,然后再下一个参数,我们就是重中之重了,我们不就是想用这个方法去打开它的 utf 八吗? 所以我们在这里要给他设置一个很重要的参数,就是 char set, 就是设置我们打开的这个编码方式,我们在这里输入 utf 杠八,好,这样呢我们就可以去读取数据了, 下一句就是读取我们的数据,读取数据呢,我们用这个 not from fear, 就是从文件里面去加载,在这个后面呢,我们就写我们想要获得的文件的路径,比如说这里 今天文本文档,刚才我已经把文本文档给改成这个 nsi 了,我现在把它改回 utf 八,就是给大家看一下怎么去读取 utf 八,它也是可以读取的,我们把它的路径给粘贴过来,然后我们就可以获得它里面的数据,比如说 ado 点 red text 这句呢,就可以获得它里面所有的文本数据,然后我们可以把它付给一个字符串,比如说我们付给 or, 这是我自己起的 or text 好,这样就付给他了,然后我们就可以把它关掉。 ado 点 close, 这样呢就可以把它关掉,然后我们为了验证一下,我们可以设置一个 message box, 我们把这个 or text 就是我们刚才获得的这里面这个文件里面所有的字符,这个字符串,我们就把它给输出出来。 啊,这个,这个不是数据,是文本文档。好,我们来看一下, 看,这样呢,他就把里面的文本全部都放到了这个 or text 里面,这样我们就可以获得 u t f 八编码的这个文件格式了。那么我们能不能把它变回 a n s i 呢?当然可以了,我们之前不是学过写入吗?我们之前有个代码是写入,我们把这个写入给它复制过来,把它放到下面,我们把它隔开。啊,之前我们不是这个代码是写入吗?在这个写入这里, 我们直接把原来的覆盖覆盖掉,我们直接不用这个了,我们直接 print, 我们打印什么呢?我们我们直接把这个奥 text 给打印进去,这样的话,其实这一串其实实现了一个什么了?实现了一个把这个文本文档从 utf 八直接转变成了 a n s i, 因为这个 v b a 在执行写入的时候,它在执行这个写入过程的时候,它永远把这个文件变成 a n s i, 这其实就可以实现一个从 u t f 八转变为 a n s i 的这样的一个过程。 我们来看一下,这里要打个井号一 好,现在它已经完成了这个呢,其实它已经是看着好像没有变化,其实它已经变成了 a n s i。 不信的话我们来看一下,这里另存为看 它这里我刚才没有调,它自己就是 a n s i 了,我们怎么确定它是 a n s i 呢?我们用 input 再去给它看一下就行了,这里我们用 input 去读取它一下, 看 input 就可以读取它了。之前我们读的时候是不是乱码,现在它就不是乱码,所以就是这样的一个方式。然后我们总结一下这几个参数啊,这个是肯定要打的,这个是打开,这个是打开 ado, 这个是设置参数。注意啊,这里的一是 二进制,二是文本,然后这里是编码,打开这个文件所用的编码,然后这里我们用到的是一个 red text, 这个 red text 不加参数可以获得里面所有的文本。 对,就是这样的一个步骤,这就是这几个参数的作用。前面的这一段呢,就是读取这个呢,就是把它重新写入,就会把它变成 a、 n、 s、 i, 这这个讲的有点长,如果不懂的话多看一下,就跟着跟着这些代码念一遍,比较好理解一些。
 06:00查看AI文稿AI文稿
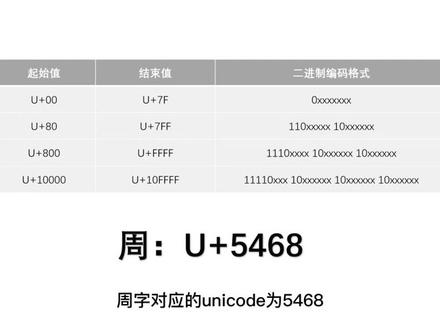
06:00查看AI文稿AI文稿在计算机中,我们会用零和一来表示音频、视频、文件、图片以及制服。最早的阿斯卡玛就是用零和一来表示制服的,只不过他只能表示一百二十八个制服。随着计算机的普及,一百二十八个是不够用的, 所以就出现了 uniq 的和 u t f 八,那么他们之间有什么关系呢? uniq 的也可以叫做全球码,也就是用零和一来表示全球的各种制服。比如我的名字周对应的 uniq 的为五四六八,与对应的 uniq 的为七四五 c, 这里的五四六八是十六。金枝树转成二金字则为幺零幺零幺零零零幺幺零幺零零零。所以周至需要两个字节来表, 是用力扣的,也兼容呢。阿斯卡马,比如字母 a 对应的用力扣的为零零四幺,前面两个零可以省略,转成二进制为幺零零零零零幺,只需要一个字节来表示。 所以在 uniq 的中,有的制服需要一个字节就能表示,有的制服则需要两个,有的制服则可能需要三个、四个字节。 我们可以按照 uniq 的的方式,把一个字符编码为二进字,之后存到文件中。但是当我们反过来,我们从文件中读到一个二进字数时,比如下面这一个,那么我们怎么去解码呢? 当我们读出一个字节后,我们怎么去判断这个字节是单独表示一个字符呢?还是和后续的某几个字节一起表 表示一个字符呢?此时就需要我们的 utf 八。 utf 八规定,如果一个字符对应的 uniq 的编码在零零到七 f 这个范围中,那么就需要用一个字节来进行编码,并且第一个 b 的位为零。 如果 uniq 的编码在八零到七 f 这个范围中,就会用两个字节来进行编码,并且第一个字节的前三个必头位为幺幺零,第二个字节的前两个必头位为幺零。 如果用力扣的编码在八零零到 ff f 这个范围中,就会用三个字节来进行编码,第一个字节前四个必投位固定为幺幺幺零,第二个固定为幺零,第三个固定为幺零。如果用六扣的 编码在幺零零零零到幺零 ff 这个范围中,就会用四个字节来进行编码,第一个字节前五个 b 的位固定为幺幺幺幺零,第二个幺零,第三个幺零,第四个幺零。 举个例子,周至对应的 uniq 的为五、四、六、八,所以处于八零零到 f ff 这个范围内,所以周至对应的 utf 八的编码就会用三个字节来进行表示。 比如说周对应的 uniq 的编码的十六进制为五、四、六、八,对应的 uniq 的编码二进制为幺零幺零幺零零零幺幺零幺零零零。对应的 utf 八编码格式为如下,那么我们就可以利用这些信息去组装出来周至 对应的 utf 八最终的二进制数。我们可以一步一步进行替换,比如我们先替换最低位的六个臂头位,然后再替换中间的六个臂头位,然后再替换高位的三个臂头位。还剩下一个臂头位没有替换,我们直接补零。 所以这就相当于 u、 d q 的的二进之数是包含在了 u、 t f 八的二进之数中的。 替换下来之后,我们就得到了周至对应的 utf 八的二进制数,然后把它翻译成为十六进制数则为一五九一 a 八, 这就是我们 utf 八的编码,我们可以在撒不烂中进行验证,我们在撒不烂中去写入一个周字,然后把它保存为 ut f 八的格式,随便保存到哪里。保存完了之后啊,我们再尝试着用十六精致的方式去打开我们的文件, a 不就是一五九一 a 八吗? 验证通过后,我们再来看一下 utf 八的解码过程。当我们拿到二进入住后,我们可以按编码的反过程来进行解码,比如我们发现第一个字节的前四个 b 头位为幺幺幺零, 那么对应的二进制格式为第三种情况,也就是我们需要用三个字结来表示一个字符, 那么我们就取出前三个字结,然后按照对应的模板,从 utf 八二进之数中按模板取出 uniq 的所对应的二进之数,从而就得到了 uniq 的的二进之边, 从而对应的 uniq 的的十六进之数为四一零九,从而对应的 uniq 的制服为三。这样我们就知道了前三个字节对应的制服为三, 那么我们再取出后续的一个字结,同样我们也发现前四个 b 的位为幺幺幺零,也是对应第三种情况, 所以我们也是利用这个模板取出中间的 uniq 的二进之数,然后翻译成为十六进之数,则得到了最后三个字结对应的字符年,所以合起来就是三年,这就是我们 utf 八的解码过程。 总结一下 uniq 的规定的单个字符对应的编码,可能需要一个字结,也可能需要多个字结。 utf 八则规定的 一个字节留中拿几个字节对应一个字符。谢谢大家的观看,我是图宁课堂周瑜,关注我学习更多的技术干货。
671Java小叮当 52:41
52:41 07:38
07:38 07:33查看AI文稿AI文稿
07:33查看AI文稿AI文稿大家好,今天我们来讲一下 csv 文件操作,我们先来讲一下什么是 csv 文件,这里有一个案例,我们可以近次的把 csv 文件看成一个表格, 但是每行以逗号分割一行是一条数据。 这个 csv 文件我们可以看作一个三行系列的表格,它是可以用 excel 打开的,我们右键点它 open in, 右键打开方式, excel 打开,我们发现是乱码,我们点数据,从文本, 然后我们找到 dsv 的文件,点一下它, ctrl shift 加 c, 我们输进去,把文件名给去掉,进入到他文件夹回车来中他, 我们把编码就选成 u f u t f 杠八就好了,加载,这样的话我们就以表格的形式呈现起来了。 那我们今天就讲如何操作这种文件。首先我们讲 csv 文件的写入吧,写入我们需要模拟一些虚假的数据, 我们可以引 pose faker, 这是一个第三方库,它可以用来模拟一些我们常用的一些数据,没有的话我们可以安装一下 p i p install baker, 安装成功。这个库用法很简单,我们先用一个变量 fak faker, 点 faker 括号, 嗯,传一个参数进去,因为要指定是中文嘛, local 等于 z h 杠 c n, 这样我们对象就创建好了。它的用法也很简单,我们尝试一下 faker, 点 name, 打印一下,它就会随机生成一个名字,曲阳,再运行一次。杨桂英, 那我们可以用这个库来模拟大量的数据,然后通过 csv 文件解入, 我们模拟一千条吧。 for i in 认知一千, 我们可以通过它 fake 点 name, 这是名字。再来一个 fak, 点 phone number 这电话号码 fake 点 s s n, 它就是身份证号码。最后我们来一个 faker 点 job 工作, 我们把它当做一个列表,定一个 user 来接受一下。 我们先打印一下,试试 print user, 我们这就有一千条数据, 第一个是姓名,第二个是 电话,第三个身份证号。第四个工作我们要通过 z s v 文件写入,也很简单, 我们可以在 for 循环的外面先打开一个文件, it's open, 起个名我们就叫 user data 吧。 点 c c s v, 我们要写入码为 w w 模式编码,我们指定为 u t f 杠八 as f, 我们打开一个文件之后,我们调用一下 csv 库, csv 等于 c s v 点 writer, 我们把 f 传进去, 这样我们就把 f 传进去,得到一个 csv 的对象,它是用来写呃,写入文件的, 我们 c s v 点 right 入, 直接把 user 列表传进去,那就是一行一行写,用我们一条一个 user, 一个列表,一个列表代表一行的信息。 retro 就是写一行接收一个列表,我们运行一下, 点开这个文件看一下,我们发现数据我们写进去了,但是中间有很多的空行, 可以在 open 的后面加一个参数 new li, 等于一个引号,什么都不加。我们再运行一下,点开,把监控好没了。 接下来我们讲一下如何读取 s v 文件,同样的,我们也是打开一个文件线, 也是 user data。 第二个参数,我们指定读 r 模式编码 还是 u t f 杠八。 这个时候我们用 c s v 点 reader, 我们把前面的线注释了, 把 f 传进去,因为我们要读文件嘛,我们可以直接用 for 循环 for line in c s v print 来,他用方循环取 csv 对象,那就是每次取就是一行,我们来运行一下, 发现数据我们也取到了, 本期的案例,就到这里,谢谢大家。
254八月也许是个程序员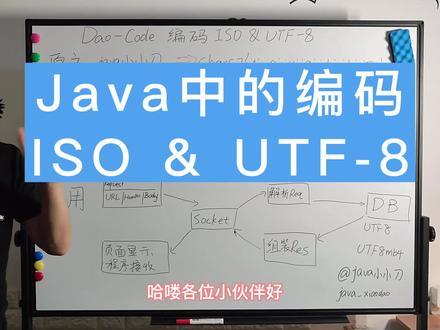 08:54查看AI文稿AI文稿
08:54查看AI文稿AI文稿哈喽,各位小板好,我是小刀,好久不见啊,最近在忙着九三年冲业绩哈,好,我们言归正传,今天我们高扣的和大家聊一聊加瓦中的编码,这些所谓的编码呢,我们以 iy i s o 和 utf 杠八和大家去举例说明一下。 首先从面试的角度来说,编码这一块呢,其实问的并不多,但是一旦问了这个问题你没答出来,那面试官觉得这个扣分就扣的比较多,如果答出来呢,加分其实加的并不多啊,因为大家觉得这是常见的问题,谁还没遇到过一个编码问题呢,对不对?好,这里呢,我们以这个加把小小刀为例子, 如果说我们在编程中会使用到这个字母串的话,我们会写一个 cs 等于六十对,然后把加二下到传进去,这个是跟我们人交互的时候去看到这些,但是我们跟计算机去交互的时候,计算机他是不会理解这句话的,计算机能够理解的什么,他只能够理解 零和一对,这个时候就有了这么一个需求,我们怎么能够让计算机去读懂这句话呢?那就是把它转用一个编码转成零和一,然后让计算机能够读得懂,这个时候就出现了不同的编码啊,有 rso 编码,有 utf 杠八编码,然后还有 utf 杠十六,就是 udq 的编码,就是这种, 我们看看啊,加把小小刀,他直接转成叉数组的话,这个就是接 av a 小小刀。然后我们这边有一个支点,就是在加法中你的每一个叉, 他和一个硬的数字,只要是可以画等号的,你可以直接用墙转把它转过来,那么我这边把这个尖用墙转,用数字转了之后,然后再给他改成转成十六星纸啊,就我们从十星纸再转成十六星纸,这就是一个结果,就是尖对应的六 a, 然后 a 对应的六幺啊,然后面小对应着五 c 零 f, 然后 到最近呢五二零零就是一个结果,那么这个结果呢?他实际上就是一个 utf 杠十六油离扣的编码,其实就是一个,那么除此之外,我们还可以把这个数字就是把这一串给他转成一个 rso 编码, 然后这个编码呢?我们看着啊,前面是半的数组,就是我们在转的时候,一定是先把这个字母串给他转成半的数组, 然后把这个半的数组,他这个是已经是二进制了吗?然后给他改成十六进制的一个展示方式。因为我们再去打开一个二进制文件的时候,基本上现在市面上提供的一些软件,比如 happy bland 各种之类的,我们去打开,包括打开那个加入的点可拉斯文件吗?大家看到的就是这些什么,呃,害死这些什么六 a 啊什么以及之类的所有精致的,我们常见的什么,大家还记得点 文件开头什么咖啡、 baby, 对吧?啊?那就是一个小知识点,那就是一个好,这边呢,我们看过来,他转到 iso 这边, 第一个是拜托数组先直接转过来啊,这边是一个实践制的表示,幺零六九七幺幺八,然后最后三个是比较那啥的啊, 六十三、六十三、六十三,就对中文来说,无论说我的中文是什么,他全部转成六十三,这为什么?因为 rso 他的一个编码他只有一个字节,他表示的范围非常非常有限,对于后面这些中文他没法表示的那么统一,都转成六十三,六十三他表示什么呢?就是个问号, 对啊,有时候看到自己的编码,哎,怎么就变成问号了?这个时候就是 i s 编码的,然后他转换不了,就给你转换成六十三,然后有个问号显示出来的。然后我们来看一下一个小知识点,就是六十三怎么能变成三 f 呢?对吧? 这有个东西啊,这边有个图例,我们六十三给他转成二进制,是不是就是零零幺幺幺幺幺,然后转成十六进制也非常简单,就中间画个线,这边四位就是 f, 这边四位就是三,对吧?这就是三 f, 还有是这个二进制非常越,非常便于阅读的一种形式。 好,我然后我们再看这个 utf 杠八这种格式,这种也一样,他首先是把你的这个字串啊 s, 然后我们有个方法叫什么 s 点盖的 bos, 然后后面传这个编码进去,对吧?我们传个 utf 杠八进去,就会得到这么个结果,他编码出来之后得到这个半的数组,前面 前前面英文字母里面还是一样的,然后后面到中文这一块时候就不一样了,前面还是一个半的去表示一个字符,对吧?后面的时候变成三个字节去表示一个字符了,这就说明我们 uti 杠八 他是一个变长的,他到底是用一位还是三位?这个呢?是根据你实际的转化的内容不一样,他是可以变化的,所以这里你看,我们是接 a、 v、 a 这三个字母是小,然后这三个 是刀。好,然后关于这一块呢,大家记得不需要太多啊,就是知道这么一个转化关系就可以了。面试方不可能说问你的,说我这个尖,你转成 utv 杠八密码是多少?他不可能这么问的对吧?他最多问,他最多问你就 utv 杠八跟 is 有什么区别对吧?你答个变长的就就就可以了, 而且这玩意都是死玩意,不可能问的。面试的时候最可能问的是什么呢?是下面这一块,医用这一块,就说我们这个边啊, 他是哪里用到的?像现在呢,我们都用 suprem boos 开发,基本上好像没遇到什么编码问题了,但是像以前我们在用那个外部点 xm 二,还是在用那个 super 开发的时候,你这个变 稍不注意设置就是你设置的,稍不注意就会发现,哎,怎么返回去又乱码了,哎,怎么我穿的参数又乱码了,今天就找这些问题,找到那个头都痛死了。后来呢,你就得到一个经验,就是但凡你只要能看到设置编码地方,全部设置成 udf 杠八啊,说不定你把哪个一设置就好了。 当然这个这种方式能解决问题,但是我们还要细致看一下有哪些地方可以设置编码的,我们从一个请求过来看的啊,我们有驴筷子的,驴筷子里面有 ui, 有嗨的,有包里,对吧?这三个地方是都有可能出现中文的, ur 里面可以可能出现中文吗?是可能出现的,对吧?我们如果盖子请求公众号后面传的参数的话,哎,比如说用户名,我们是一个中文传到后台去,对吧? 然后我们嗨段里面有没有可能有中文呢?也有可能,因为你嗨段里面兴趣可以自定义嗨段吗?你也考里面塞着中文,然后包里面就更不用说了,对吧?现在基本上 你提交一个表单,你提交一个表单到后台的话,基本都是都会有中文的。 这三块他会存在一个编码的问题,就在这边先进行编码,先给他全部变成二进制的,然后通过说 k 的,然后到你的死喷这边之后就开始解析这个流 cast。 那解析的时候呢?也是分开解析的啊?第一个是 ur 这边解析我们通过什么啊?最原始的方式就是先不讲四川那些猪肉的方式,就最原始的方式的话,就是瑞筷子的点开的拍照美团,对吧?瑞筷子的点开的包底, 然后这时候去解析,那怎么去设置编码呢?我还记得以前对于每一个 sol like 进来的时候,都会去写一遍 readows 的点赛的 carry, 那个 carrk encol 定去解析,然后 resparas 点赛的 carrk encol 定,这样都设置一遍,才能把这个中文正确的给他解析出来,然后正确的给他 返回回来。那现在大家用了十分 boss 之后呢?基本上就只需要把你的页面两个地方,就是第一个是我们返回过去之后可能会返回给页面吗?也有可能会返回给这个程序接收的,对吧?我们只需要把这个页面给他设置成 那个 utf 杠八的,然后整体基本上这个中文就能够正确显示了。那么前面这一块实际上是外国这一块, 后来发现呢,就是你往数据库存的时候也会有一个编码问题啊,在数据库编码呢,还有额外的问题,就 utf 杠八和 utf 八 mb 四,这两个有什么区别?大家可以现在看一看,打开你的数据库,看一看你的表的编码是什么?如果是以前老的表的话,他的编码可能是 jbk 的, 那么现在基本上新建的表的话,都用的是优铁不钢八 mb 四,这两个有什么区别?这个面的话会喜欢问的,那么注意啊,只有这个才是才,才,才才是那个蚂蚁色购中真正的优铁不钢八编码 基本都用这个。那其实呢,如果从实践来问的话,有这么一个问题,就比如说,哎,现在大家起的微信名啊,都有什么表情啊,各种符号啊,资金的东西,那么请问你的数据库怎么样才能够去存储这些东西,对吧?这个问题出来之后, 立马就要想到编码一定要设置成 uto 杠八的开心,然后你这个 gdpc 的这个 url 后面也有一个,那个什么开出特型扣的那个参数也要设置好,两个相对应起来, 哎,然后这个这这这个什么表情就可以存到数据库里面去了,然后就可以也可以成功返回了,我的上家公司是吃过这个亏的啊, 当时那个数据库就是一个用户,然后我当时通过用户名去匹配的,然后发现他用户名就塞了表情,然后这个用户给我们反馈说,哎,怎么死活都登不上,然后这个订单怎么就搞不了,往后面一查,发现,哎,原来是这个,我们我们以前老酷啊,所以 都是 gpk 的编码,那时候存的都是汉字吗?谁能想到突然出来个表情,出来了,对吧,然后就就就就就坑了,然后再往后面就我们就所有的表都是用前刚把 mv 四了。 好,以上就是和大家聊了一个编码的问题,总结一句啊,编码这个问题,您只要把对应的设置好就可以了,对吧?我们一个请求 编码,然后这边一个解码,然后再编码,然后再解码。只要把这两个地方给他设置好啊,给他对应设置好,基本上就不会出现编码问题了,而且现在 suprem bos 已经已经都给你设置好了。好,今天内容就先到此结束,如果对你有帮助的话,记得帮忙收藏点赞加关注,我们下期再见!
14小李不理






