vg自动化神器如何设置内置浏览器
哈喽,大家好,今天主要跟大家介绍一下 vm 捞给你的新功能,就是浏览器自动化测试工具。 首先我们打开官网,点击教程文档,这里有一些软件的使用说明和教程,那我们找到 vm 捞给你浏览器自动化测试工具这个文档,打开这文档是使用方法和解说,还有工具下载的地址复制这个链接下载安装, 目前仅限于 windows 系统,那我已经提前下载好了,我们来演示一下具体的操作方法。 首先打开浏览器自动化工具和我们的后台,这里的 api talking 需要在后台生成主页,点击 logo, 你登录后台, 在我们的账号下面有一个 api 令牌,生成一个随机的令牌,点击提交,复制后填写在这里点击检测 talking, 今天主要演示 vm 劳格印自动化设置这个功能,没有任何技术,也可以完美操作。首先我们登录客户端,我的账号打开,启用浏览器自动化设置,设置监听端口和监听地址保存,监听端口可以随意修改, 我们把设置好的地址和端口填到这里,填好之后点击检测,这里会显示端口正常开放。 下面我们添加指定配置 id, 这个 id 需要在客户端的浏览器配置文件中查看,我已经提前设置好配置文件,点击编辑配置文件,最下边这里有一个 id, 我们复制后填到这里就可以了。 如果添加多个 id, 需要用分号分隔, 我们先测试一下谷歌,打开谷歌网页, 复制网址,点击添加动作,动作类型选,打开网址,复制谷歌网址,点击确认 添加强制等待,这里显示的是好秒填写两千就是两秒,正常情况下选这个选项,我们用百度示范一下, 打开百度后,按 fn 加 f 十二,然后点这里,把鼠标放在框里,在右边这里能看到空间 id 等于 kw, 那我们只需把 kw 写在这里,点击确认即可。 那有些网站没有这个空间 id 值,我们就要选这个选项。同样的操作,在右侧这里可以看到内幕等于 q, type 等于 test。 我们回到教程里,这里有个视力复制动作内容后,把 password 替换成刚查到的 q 和泰斯特, 点击添加动作,选择 snicky, 输入一个想要搜索的词,我这边以浏览器自动化为例,确认 选择强制等待两秒,这里还是跟上面的方法一样, 点击这里,鼠标放在骨骼搜索上,右边可以看到内幕和 type 分别等于什么,然后回到文档里,复制这行进行修改, 修改好后点击确认选择,点击这里可以微空,再选择强制等待 确认,这里就设置完成了,然后点击开始自动化测试,大家可以看看效果。由于我设置了两个浏览器配置文件 id, 所以这边第一个打开操作完成后会自动关闭, 然后第二个会继续开始。那有的人问,如果我设置了多个,其中一个打不开怎么办? 还会继续进行吗?这个可以放心,会跳过之后继续运行。有的人可能会问,如果我想用一个浏览器打开多个不同的网页可以吗?当然可以, 我们再添加一个网页示范一下,我们选牙胡试试,还是按之前的流程添加网页。强制等待 空间 id 强制等待 空间 id 强制等待 之后,我们再点击开始自动化测试看看。先打开谷歌, 然后是牙壶 第一个浏览器配置文件网站,完成后,第二个也自动开始。同样的操作流程, 我们的设置也可以进行导入和导出,先创建 个文档,然后点击导出动作, 直接粘贴就可以,保存即可,也可以直接修改进行导入,点击复制,点击导入会直接导入,也可点击呆萌视力查看。 大概就这么多了,如果想要写出自己想要的效果,动作脚本还需要用户自己从简单入手,了解原理后再添加动作,完成一些比较复杂的需求。这里的介绍起个抛砖引玉的作用,谢谢大家。
粉丝3148获赞3.2万
相关视频
 01:56查看AI文稿AI文稿
01:56查看AI文稿AI文稿今天给大家介绍 power automate 中浏览器的自动化,首先我们在操作区找到浏览器自动化,在里面找到 web 穿体填充, 里面有一个启动新的浏览器这个选线,它里面有 i 浏览器,火狐浏览器、谷歌浏览器和 我们微软自带的 edg 浏览器。首先我们把启动谷歌浏览器拖至窗口,然后这里可以设置初始网页,我这里粘贴一个初始网页, 这个网页呢是我们国内的一款制作 ppt 的网页,大家有兴趣的话也可以使用一下。然后下面有高 设置,比如说清除缓存,等待加载页面,加载网页,加载超时是六十秒,然后可以生成便练这些, 然后点保存,我们来运行一下,可以看到我桌面上没有启动浏览器的啊,看他直接就打开了这个做 ppt 的网站。 在我们的网页打开以后,我们还要继续往下操作,比如说在这个窗口输入我们想要的内容,或者单击某一个我们想要操作的按钮,那么这些怎么完成呢? 关注我每天一个办公小技巧,我们会在接下来的课程中给大家一步一步分享,让大家独立设计自己的办公自动化小程序。
20智能办公小助手 02:00查看AI文稿AI文稿
02:00查看AI文稿AI文稿自动化测试浏览器大小设置。大家好,这一节我们继续来看一看浏览器常用操作模拟,我们在这主要关注一下浏览器的一个大小的设置, 那我们可以在这里边呢做最大化的操作,还有我们最小化的操作以及全屏化的操作,还有一个固定大小的设置。那什么是最大化?什么是最小化? 给大家看,打开我们的浏览器,大家会看到我们的右上角呢,这个就是我们最大化的一个图标,我一点了他之后,当前这个窗口他会占满我们整个屏幕,除了我们的任务栏,那我最小化呢?最小化就看不到他了, 那我做全屏画,也就是把我们的任务栏的位置他也给占满了,那这个效果我们在拍下里边去看一看。我们先来做一个我们的最大化, 做最大化是因为我们在打开这个浏览器的时候,他默认并不是最大化的,哎,那我们就可以比对着去看一看了。好,最大化完了之后我们来一个最小化, 好,最小画完了之后我再给他一个全屏,画好,最后的话我给他设置一个固定的大小。 设置这个大小的时候呢,我们是需要传参数的哈,那传参数我们主要是要去传一下我这个窗口他的宽度和他的高度,宽度和高度的设置呢,我们单位就是一个像素, 同时的话呢,大家也可以根据我们当前这个电脑一个分辨率去做设置,就不要有特别大的那种偏差,好运行一下我们看看,大家看这是我们默认打开的这个浏览 大小,没有沾满全皮,这是我们最大化的一个效果, 这是我们最小化就看不到他了,这是我们全平化,大概这一块呢也被他占了,这是我们这个固定的一个大小设置。 ok, 这一小节的内容呢?主要就到这里。
20川石教育 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿今天继续给大家分享办公自动化神器 power automate 的操作流程,在我们之前的视频中讲到了从浏览器中爬取数据, 那么数据在爬取下来以后,我们有多种操作,比如说写进 excel 表格中,或者直接去使用,那这里我们给大家分享如何写入 excel 表格中,在这里我们可以找到 excel 表格,有一个写入 excel 表格中, 然后拖拽到工作区,在弹出的窗口中,我们首先找到要写入的值,在这里 x 代表着变链,我们之前从浏览器中下载出来的数据就存在变链中,比如说这个我们点选择,然后可以写在指定的单元 格中,或者命名的单元格中,我们可以写,比如说 a 列一行,然后点保存,怎么样,是不是很简单?关注我,每天学习一个 power alt mate 操作流程,让你轻松设计自己的办公自动化机器人。
13智能办公小助手 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿懒人采集器不用设置复杂的采集规则,我要采集一个网站上的文章,复制列表网址作为采集入口, 点击下一步配置,软件就会自动识别出要采集的列表信息。如果没有识别出你要采集的列表,清空自断,手动选择一下列表,也就是两秒钟的事情, 自断不需要了,可以点击里删除。新增自断后,直接在列表上选择要采集的内容。 要采集分页列表,可以点击这里自动识别分页,成功识别出下一页按钮。如果识别不出来的话,那就手 动设置分页,查找分页,标记分页,选择下一页按钮,这样分页就设置好了。要打开文章采集来画 在下面的数据表格这里找到标题链接这一列,如果没有链接纸短,就新增一个, 选中其中一个网址,点击右键深入采集,这样软件就会新开一个标签页,我们可以在这个新页面上采集文章信息。新增自断需要采集哪些内容,在网页上直接选择就可以了。 任务配置好之后,输入一个任务名称,保存并退出运行采集,看看采集效果, 非常完美。好了,我就先讲到这里,如果教程对你有帮助的话,请点赞加关注,拜拜!
18立剑 02:14查看AI文稿AI文稿
02:14查看AI文稿AI文稿脚本制作完成后,如何快速打包成独立的软件分享给他人使用呢?启动 ex 一开发工具, 点击文件新建项目,输入项目名称,选择项目保存的位置, 选择简单模板确定, 选择窗体上的运行空间,在属性面板那里找到 sky pass 这个属性,选中之后,点击右边的小按钮, 选择我们要打包的脚本, 点击生成脚本和运行器, 确定生长, 点击生成 ex。 一组程序生成完毕,我们创建的程序就自动启动了。点击开始运行,测试一下脚本的运行情况。 脚本完美运行, 那么我们生成的软件他保存在哪里呢?选中项目管理, 这里可以设置主城区的保存位置、文件名以及文件图标等信息。右键点击项目管理浏览目录, 我们生成的软件默认就保存在这个名称为生成的文件夹里。想要在其他电脑上运行我们生成的这个软件的话,复制这个文件夹过去就行了, 里面这个就是我们软件的主程序,双击就可以运行。怎么样,够简单吧? 如果你也想创建一个属于你自己的工具软件,不妨动手试一试。
30立剑 06:53查看AI文稿AI文稿
06:53查看AI文稿AI文稿哈喽,大家好,今天给大家介绍如何使用 pool 奥特妹子去做一个简单的爬虫,爬虫其实指的就是批量去网上获取一些数据,那么今天就以这个招聘网站作为例子,去抓取一些我想要的数据。 好的,首先还是新建流,给他起个名字, 好,稍等让他加载出来。好的,那么他出来以后我们第一件事情就是让他打开一个嗯,浏览器,我们来找一下浏览器自动化 启动新的这个浏览器实力,那么要告诉他一个网址,网址的话我们可以把这个复制过来, 这边会出现个知识点,我们直接把这样复杂的网址输进来,他会报错的, 我们可以。呃,对,他没有点保存就已经报错了,他说值无效,那么无效的原因其实是因为他这里面出现了百分号,那么如果有关注过这款软件或者看过我其他几个视频的观众可能就知道,因为这个百分号在帕瓦奥特曼特里面指的就是变量, 就被他框起来的,是会作为变量来运算的,那么这么密密麻麻的百分号,那当然他这个网址就是会爆错的。 然后我们要做的一个动作就是把这个百分号替换成两个百分号,就把一个百分号替换成两个百分号,这样就没有问题了,全部替换, 然后再把这个数据粘回来保存,那么这样子他就可以启动这个 h 浏览器,然后会直接打开这个网址, 好看到没有问题。那么接下来我们要做的事情就是外本数据提取,在这里面选择从网页中提取数据, 那么我们要做的一件事情是在这个窗口打开的状态下,去点击我们要提取数据的网页,好,它会自动跳出来一个新的窗口, 那么这个新的窗口我们先把它放在一边,接下来我们要去右击我们想要的数据,比如说这个只为名是我想要的,然后右击它,哎,这个网址好像有点卡住啊, 现在可以了。然后呢,你可以点击就右键,以后他会出来这么几个选项,我们需要点击提取元素值, 那我需要他的文本刚才没点到好,行政专员,你会发现他就已经出现在这个窗口里面了。那么接下来,比如说我想知道他是什么时候发布的,然后这个岗位的月薪是多少, 然后他大概有一些什么样的要求,以及这个企业的名字。这个邮件又点不到,好, 看看能不能点到。这个好像把鼠标放过来,他这个民营公司什么的就被遮住了,哎,问题不大,就先这样,然后这个申请 请职位,我看能不能提取一下。这好像提取不到,那么就先这样子吧,然后看一下这个福利待遇啊,看看能不能提取出来,哎,也可以。好, 那么这样子我们就提取了这第一行的这个岗位的一些信息啊,那么我们要做接下来一件事情,让他批量的把这个页面上所有的信息都提取出来,那其实我们只需要去右键下一个岗位, 哎,再来一次,好的,这样你就会发现他所有的信息其实都被他读取到了。 好的,接下来我们要做的一件事情是把它拉到底,因为可以看到 它其实有好几页嘛,比如说,呃,我想要把后面几页都抓取到,我们可以点击这个就是下页的这个按钮去右键它, 他好像也是有点问题,他不让我点,然后可以点到了,然后呢,这边有一个将元素设置为页导航,我们来点一下, 好,再回来看,就可以看到这边有蓝色的虚线把它框住了。 那么这款软件我们的 rpa 就会把这个页面上的信息读取好以后,自动点击这个下一页的按钮,然后去读取下一页的信息了。好,这些操作都已经设置完成以后去点完成。 然后呢,他会问你要获取几页信息啊?那打个比方说,我们就获取前三个吧,不然可能会稍微时间有点久啊。 然后他会问你数据要存储成什么形式,那他默认是存储成变量的,那其实我希望他直接,嗯,生成一张 excel 表格就可以了。那么在这里选择 excel 电子表格,好填保存,接下来我们可以直接来测试, 稍等片刻。 好,可以看到 excel 已经跳出来了,那么可以看到他已经获取了三页的数据啊,还挺多的, 那么这样子就能比较方便的。呃,去做一些筛选啊什么的看看,比如说工资最高的 八到十二万一年,我还有一个月呢。八到十二万一个月,那我马上报名好吗?啊,在成都啊,那我不去了,那看起来这个工资都不是很高。 好的,那么这是一个爬虫的简单教程啊,如果大家平时会需要去一些网站上抓取数据的话,这还是挺有用的。 当然他不像拍摄那些软件支持的爬虫那么的。呃,完善以及有更多灵活的操作,他可能就相对基础一点,当然如果咱们没有编成基础的话,那他 其实还是挺管用的。好,如果有兴趣的话可以尝试一下,就这么两个步骤就可以完成了。好,那么这就是这期视频的所有内容了,感谢你的观看,拜拜。
687德叔探索世界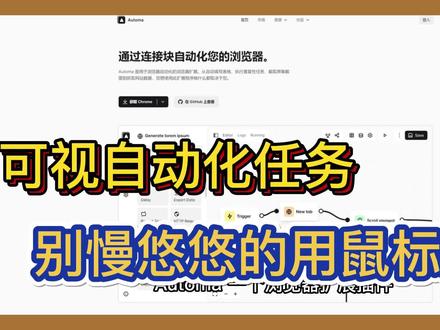 00:17查看AI文稿AI文稿
00:17查看AI文稿AI文稿沃通们,一个浏览器扩展插件可以帮助你实现一些网络自动化内容,比如从自动填写表格、执行重复性任务、截取屏幕截图或抓取数据,都可以通过可视化页面完成,大大提高一些需要在浏览器上重复操作的流程。
2332小明1994




