partdatamanager教程
大家好,在咱们以前公众号上面分享的呢,有一个那个软件合集是一个很老的版本,里面的那个那些软件呢也大概是在 二零一三年更新的,然后我最近是一直在找这个最新版本的,这几年我找了二代慢了点,这个十一这个就是可以更新到啊,咱们像李思敏谁那些就可以更新到最新的,可以更新到二零二零二年的。 今天我就来给大家介绍一下如何来进行这个离线安装,以及如何来使用这个软件。首先呢我们把那个安装包给下下来, 他主要就是分为他一个主程序,然后我这个的话是已经加载了米斯米和那个一个大的,就有一点三二,嗯,七点多计,然后他另外一个没有加载东西的话,就只有一个多期这个下下。 然后还有一个就是他那个离离线包,就这里面就是包含他所有的所有的一些品牌,就官网上能够找到的,就常见的看到了一个他这些。那么他这些然后下下来之后呢,我是个软件一样把它放在根部下面,直接放在地板上, 然后以官员身份启动。这个 启动进来之后呢,咱们这个啊他是有一个使用说明的,可以可以参照一下这个使用说明,但是使用说明的话讲的不是特别清楚。 我们首啊,首先我们来看看来那个进行一个那个一线安装吧,我这已经准备了一个 sa 的这个 cipciv 这个后退的这个文件,在这里面我下载的签进去,这下面是他一个 圆的,然后点击这个目录更新米线。还有一个是我要把这个放在我这里面,我这有一个库,其实在我这一个文件下面这样一个专门来放这个文件,这个有什么黑的放进去, 从这个放进来, 然后 就选择一下点击这个打开,然后选择这个 acc 的打开,然后点击安装, 看这啊无需可证的时候,一千点击破,然后再安装就可以了。 咱们现在是那个在进行一个快速安装视频提了速,待会安装完成之后呢,他会提现一个啊,直接关掉这一个窗口就可以。后面我们再给大家介绍一下如何使用这个软件, 刚刚咱们那个 smc 的那个提现包安装完成之后点击退出就可以了。然后咱们现在来看一下如何使用这一个合集,因为这个合集呢,这个最新的这个许可证咱们是没有的,咱们用的是这个许可证呢,是二零 一五元以前的,最新的话就是上次我也咨询过这个价格比较贵,而且他能够不能够拷贝,需要绑定电脑,大概需要几万块的样子。好,我们是所以在使用的时候呢,就需要简单破解一下这个软件, 咱们咱们用用使用的这个方法就是更改系统时间,让那个许可证能够使用,首先就多,反正多点两下就可以了,咱们点击这个 cd 无缝底层,咱们看一下这个时间有没有变成二零一五年,如果没变的话,就可能是因为咱们在这启用的时候没有以这个原生份运行, 定了时间之后咱们就证明这个后续已经成功了,然后再点这个 cd 数据库, 这样就已经出来了,点击搜索并不见 这 snc 的就已经安装完成了,就已经把那个铝线裤给倒上来看一下,看这因为这个是英文的,这后面我搞一个中文的,玩下米斯米图吧, 我们可以看一下这个这个理想包,这个更新时间都是最新的,就去年,去年年底更新了,后面的话也会在今年年底也会在此更新一下啊,我们自己也可以更新的,后面这个在线更新的方法,我会再出一期教程给大家啊,大家也可以自己更新,我们来下载一个试一下, 然后点击这这,这也是咱们可以,这是和那个输送用机这些软件进行一个无缝对接的方式,咱们现在的话就下载一个中性格式 桌面, 打开看一下, 这就已经成功了。好,咱们这个在退出,就是不使用这个合集的出来就需要把这个系统时间给分开回来,这怎么来操作呢?就是先点击这个集成结束,点击一下,然后再点一下这个更新系统时间, 这样就可以了,然后点击关闭就可以了啊,然后我们再看一下另一个这个就是看这个整合日期是还是二零一五年的,这就是比较老的一个版本,幺九版的九点 九点零八的,咱们现在这个已经更新到十一了,十一点零。好,这个软件的底线安装了, 以及这个使用方法,今天咱们就简单介介绍一下后面这个还有一些,比如说他那个在线库的一些更新的话,就可以大家自己点击这个使用说明来自己探究一下,后面呢我也会出一期视频,再说一下定格的,还有还有就是无缝集成的这个,嗯,也是,我大概简单使用一下,就是用出 这个还是比较好用的,后面我们如果有需要的话,我也可以为大家介绍一下。好,咱们今天的这个视频就到这里,谢谢大家。

粉丝756获赞1565
相关视频
 13:53查看AI文稿AI文稿
13:53查看AI文稿AI文稿大家好,咱们今天呢就来讲解一下咱们这个 part dead manager 这个软件合集是怎样使用的啊?就我给大家给了那个百度网盘链接之后呢,大家把四个那个压缩包给大家看一下, 大家把这四个压缩包同时下下来之后,下载自己本地,然后四个一起选择,四个就四个压缩包同时选择,然后解压,就不是分开解压,是四个选一起解压这样子来进行解压之后呢咱们就 解压之后我们就得到这样一个文件,就解压之后就得到这样一个文件,因为我在压缩的时候就是那个压缩包有限制大小,所以我们就给他分成 四个,然后但是你解压之后他其实是一个在一个文件夹,然后这然后的话就是我们在这个就是这个程序的启动的图标,我们双击一下, 我们可以看到这是一个功能界面啊,这个呢就是进入我们选选那个品牌的那个界 秘密,然后这个就是我们进行一些,比如说那个有些品牌的更新啊,还有品牌增加品牌删除品牌那些,然后这个 cd 无缝集成呢,就是和我们软件就是比如说 sodogs pro 还有 proe 那些进行连接的。我们自己在使用的时候呢,我们这有一个那个使用说明 可以看到这里面呢,其实有一些比较清楚的一些使用文件,大家可以打开看一下,就在使用说明里面。 那么我们现在呢就来看一下这个软件是如何导出那个模型的。第一个呢就是点这个 part dead manager c a d 数据库,这个啊, 然后点击搜索和零件选择我们这一款呢,就是这是二十一和一的,就是已经加载了,就咱们这个三星 mia 探测,我们常用的话,雅泽克, 嗯,还有这个爱神 c k d 菲斯托,还有那个上银米斯米,东方马达, 中下还有颐和达这些,还有 s n c 的,这些都是比较常用的。然后的话我们就先来选一个气动的吧, s n c 的,比如说我们执行原件这个车型的 c b u 气缸, 你看一下他这个是怎么导出的,这的话选的是磁环,选一个那个传感器的型号,然后选一个线长, 这样的话我们这个型号就选择好了,当然你自己要选择刚进以前我们对应的行程的一些东西,这还有个行程就选二十五的, 然后我们的这些,因为这个这个版本的话,他有一些版本他是直接能够输出啊,说我们说的我最高支持二零二二的,还有一些 ut 的,他有些不支持, 要自己要看一下它支持什么格式的,如果说它所有的都不支持的话,就要输出这个输入 works 这个红文件,然后再在输入上面去导一遍,然后我们常用的话就是输出这个 s p 的, 我也比较喜欢用这个直接输出 s t p 的,把它放在桌面,这样就可以了,这样就输出了一个 s t p 文件, 然后我们再来输出一个 mismi 的,看一下屏幕选择,然后目录到 mismi 里面去, 比如输出一个轴啊,直接选输这个米斯米的话,他也是有支持比较多的一些格式,输多斯也支持九八七四二零二二米斯米一号打 啊, s m c 这些都是支持 s m c 的那个 sos 还有亚特克,但是比如说咱们这个上营的哈,上营因为它这个数据库,上营的它是很久没有更新了 幺二年的,这个的话我们上瘾的话就只能支持输出,那个他是灰色的就不能够输出,那输出输的是红文件,甚至是这个我来给大家演示一下这个红文件是怎么打开的吧? 这个就是这个 photox 红文件,我们先开一个那个 photox, 先开一个软件, 然后我们在在哪儿按着 fun, 刚才那个,刚才这个电脑呢,是我们一个买家的一个电脑啊,可能安装上有点问题,我给大家呢演示就演示一下这个步骤啊,反正步骤就是这个步骤,打开的方式就是这个样子的,大家可以在自己的电脑上多测试一下, 不行的话就百度一下,看一下是什么问题。之前呢,我在我自己电脑上面是反正是可以打开的, 然后其他的话,还有一些品牌他也是只能够输出那那个输出红文件的,我看一下是比如说我随便选一个哈,这个 nsk 的,我们看一下 这个也是只能够输出那个 sloth 和文件, 这个如何导入这个输入红键的话,我会给大家做一期专门讲解的一个视频哈,然后刚才那个的话就是我们讲解了一下怎么来导出我们这个已有品牌的一些模型的,然后我们接下来再讲解一下如何那个 啊,加载那个 c i p 文件以及在线更新的一些问题,就是这个我们先看下这个说明需不需要以管理员身份运行啊? 我们先来的话就是看一下这个离线库怎么安装,就离线库的话就是要提前,咱们如果 需要哪些品牌的,就先去把这个 c i p 文件给下载好,就这个 c i p 文件我们给大家演示一下啊,从这儿 二的命那进,然后点点这个离线,离线你看他就已经识别到我们有这些品牌,当然哈我们 就自己去打开一个, 我看一下 其他平台。 ps, 随便选一个不是太大的吧, 这个点打开 that one much, 咱们选择自己的品牌,点击安装就可以了。然后我们看下这个在线的,在线的话首先设置一个那个,咱们设置一个路径, 这路径呢自己选择,嗯,在这儿建一个 cmip 里头这样一个路径,然后点击确定,然后点击开始点这个查看末路清单。 咱们现在呢就是下载了就就所有的九百多个啊,这个下面这个没法用的就没法用啊,又修复成了,然后 点击这个,我们也是随便下载一个吧, 那主要是我要找一个稍小一点,就像这个 a p p 的 就下载这个,然后选择之后选这一个,选中选中的产品目录,点击下载。 这个下载的话要看自己的那个网速啊,因为他对 那个网络的要求还是比较严格的,那有的有的人下就比较慢,有的下载就比较快一点,咱们现在演示的这个呢,下载还是比较快的 好,我们可以看 这儿下载已经结束了, 返回那个目录,然后还是我们安装的话,还是在这个地方来装,然后点这个打开 先装装这个 a p p, 这 好,这两个你看看到其他人选上,然后咱们离线安装的话,其实也可以考虑这个,也可以参考这儿,然后安装, 安装成这安装完成就可以了。 然后还有个就是有的朋友就是咱们不需,嗯,就是我们已经加载的品牌,如果大家 需要的话就在我们这儿,呃,缩影管理,然后目录,比如说我们卸载一个,那个这 a p p 是我们刚才安装的啊,卸载一 cpd, 然后点击这个 卸载目录就可以把那个数据给它删除掉。好,我们再返回看一下我们这个 a p p, 我们安装上啊, 点击这精装, 这就多了一个 a p p 的, 那这个可能也只能是做那个多多口红文件。 好,咱们呢就是,嗯,把我们的所有的这些功能呢,第一个就是安装啊,这个也不算安装吧,就是一个解压,还有一个就如何开始使用,解压之后再 解压之后点这个图标进行启动,然后呢启动之后就到咱们这个界面,这个界面主要有这个 particle manager 这个 cd 数据库,就是进入我们这个品牌选择的这个界面来下下载那个模型的。然后呢第二个就 二零零呢,就是我们二零零的话就是经常用来做为管理的一些东西,然后 cd 集成,我们可以可以看一下,直接看说明吧,我们这有说明五分 集成就可以启动那个对应版本的,以及我们刚才也讲了在线安装以及影像库的安装,还有卸载不需要的一些库这些东西。 这个的话这个版本用起来是非常方便的,我们在使用的时候也需要更改时间,但是有些,嗯,品牌我们也已经说过了,就有的品牌他就只能输出那个啊,输,输出那个红文件,其他的话都能够正常使用的。 好的,谢谢大家,如果大家啊对这个课题感兴趣的话可以直接联系我啊,谢谢。
142玩机械 02:59查看AI文稿AI文稿
02:59查看AI文稿AI文稿大家好,本次分享的是 orcat capture 中 part manager 的 应用场景。批量属性修改。 首先请用户打开一个工程文件,本视力将展示如何通过 part manager 来管理器件属性。首先打开 u 六器件的属性查看窗口,鼠标左键点选此器件,点击鼠标右键,在弹出的菜单中选择 edit properties。 需要注意的是, u 六器件的部分属性信息存在缺失,例如 pcb footprint、 part number 等信息尚未填写。 如大家所知,在项目导出 bomb 或生成网表之前,需要将器件信息与数据库进行同步。常规操作方法是,选中某器件,点击鼠标右键,选择 link database component。 在 c i s explorer 中选择与之对应的器件。此过程用于核对数据库内容。该操作会将图纸中的器件信息与数据库中的内容进行比较, 如果图纸中的符号信息与数据库不一致,则会自动同步所有信息。视频中演示了如何通过 link database 功能 将单个器件的属性与数据库同步更新。更新后, u 六器件不仅补充了 pcb footprint, 还新增了 part number 信息, 而通过 part manager 功能,可以更快速地实现器件的全局化管理。点击工程文件名,点击鼠标右键,在弹出的菜单中选择 part manager。 在 part manager 工具页面中, 可以看到 u 六器件的 part status 显示为绿色,表示该器件当前的信息与数据库信息是匹配的。请注意,每次使用 part manager 时, 建议先主动更新所有器件的状态信息。点选任意器件,点击鼠标右键, 选择 update all part status。 执行此操作后,软件将同步所有器件的数据库信息使用 part manager 进行批量属性修改的主要目的包括以下几点,第一,同步器件的单价信息。第二,同步器件封装的变更信息。 第三,方便对同类型器件进行批量处理,特别是针对同一类别、同一封装的器件,有助于把控全区的器件数据一致性。 如果 u 六的 pcb footprint 封装命名从 q f n 二八 e p 四 d 五 x 四 d 五变更为 q f n 二八, e p 五 x 五,而在图纸中没有同步更新, 则在后续的 bomb 管理和 pcb 设计时可能引发问题,工程师需要留意此类潜在的设计隐患。今天的分享就到这里,谢谢大家。
2芯巧电子 09:02查看AI文稿AI文稿
09:02查看AI文稿AI文稿大家好,今天我们实现题库应用的答题功能,现在我们打开项目,想实现这个功能需要通过脚本,所以现在我们先创建一些脚本。 首先是在项目下面创建脚本存放的文件夹,包括 data manager 和 ui, 分 别用于存放数据管理脚本和 ui 相关的脚本文件。 现在我们先在 data 文件夹下创建一个数据模型的脚本文件,右键创建 c sharp 脚本, 重命名为 question data 题目数据,然后双击打开,打开以后我们编辑这样一段代码,接着我们创建题库管理器,这个我们放在 manager 这个文件夹下,右键创建 c sharp 脚本, 重命名为 canvas manager 啊,双击打开便写相关的提库控制器的管理代码,然后保存提库管理器,我们需要将它挂载在一个空对象上,我们先创建一个空对象, 重命名为跟 manager, 将刚才创建的这个脚本挂载到我们创建的这个空对象上, 并且这个题库管理器我们需要在所有的场景都要创建一个这个对象科目选择界面创建一个给 manager 对 象,然后挂在快速式 manager 这个脚本, 接着我们就开始实现答题的界面功能,我们在 ui 这个文件夹下创建一个 c shop 脚本,命名为 q 的 ui controller 下划线 complete, 然后双击打开, 编辑这样一段答题界面,控制器的脚本保存回到右面题,现在我们来到答题的界面, 将新建的这个 qus ui 看车了这个脚本挂载到 qus canvas 这个对象上,然后配置 ui, 引用 这里边有问题的文本,我们找到对应的问题文本,将它拖动到这个字段上,下边有我们创建的选项这几个按钮的文本,我们将它分别拖动到对应的字段上, 这个顺序一定要按照 a、 b、 c、 d 这几个选项的顺序来拖动对应的字段。接下来是选项按钮,我们将这个选项按钮 a、 b、 c、 d 分 别拖动到对应的字段上, 然后是下一题按钮,还有上一题按钮以及提交按钮,还有一个返回按钮,都要将它把相应的对象拖动到对应的字段上。还有其他的像题目数量,进度条以及结果面板,这样所有的字段的引用都完成了, 我们先保存一下,接下来我们实现科目选择界面的功能,打开科目选择界面,在项目的 ui 文件夹下创建一个 c 册脚本,为它重命名为 subject select ctrl 题目选择控制器,然后双击打开,输入科目,选择控制的相关代码,然后保存。现在回到 unit, 我 们将科目选择控制器这个脚本挂载到 subject canvas 这个对象上,然后配置科目信息,我们选中 subject canvas, 在 检查器面板中找到刚才这个脚本文件对应的科目,配置这个选项的位置,输入九、 配置对应的科目。例如我们配置语文的时候,是将 subject key 输入 chinese 科目名称,输入语文题目,按实际需求,例如我们是一百五十道题,语文, 接着有数学 math, 名称是数学题目,数量二百。第三个元素是英语 english 题目,数量一百。第四个是 physics, 物理题目,数量一百。下面是化学 chemistry 题目一百,然后是生物题目,数量一百,历史、地理、政治这样九个科目的元素就配置完成了, 配置完成以后,我们绑定相应的 ui 元素。首先是科目按钮,我们一共九个科目,输入九,这样按钮就显示了九个元素,我们将对应的按钮拖动到相应的字段上, 一定要记着顺序,这个顺序是按照刚才我们科目配置的元素是一致的,否则的话将来就会出错。 按钮全都拖动完以后,再看科目名称,还输入九科目名称,对应的字段全都拖动到相应的位,所有的字段都保证顺序是一致的。生物、 历史、地理,最后一个政治题目数量输入九,一共对应的是九个科目,每一个科目的数量全都拖动到对应的字段上。物理、化学、生物、历史、 地理、政治,还有下边的这几个需要配置的元素,这个是确认的文本以及开始答题按钮,全都拖动到对应的字端上,然后保存一下,这样我们这几个科目的配置就完成了。 这样完成并不能够实现跳转,我们要想实践点击某一个按钮,能够跳转到对应的页面,我们现在还需要做相关的跳转配置。 现在我们选中开始答题按钮,我们要在点击开始答题按钮的时候跳转到答题页面,我们选中开始答题按钮,在检查器面板中找到鼠标。单机事件现在显示的是空列表, 我们点击加号,然后将 subject csv 拖动到无对象这个位置。现在我们就可以在函数这个地方选择 on start qs, 也就是跳转到 开始答题的界面,这样我们答题界面和选择界面都配置好了,再回到主菜单场景,创建主菜单控制器,在项目的 u i 文件夹下创建一个 c shop 脚本, 重命名为 my menu controller, 双击打开编辑这样一段主菜单控制器对应的脚本,然后我们找到 my menu canvas, 给它添加刚才我们创建的这个脚本组建,现在我们为每一个按钮都绑定事件,找到这个按钮的面板,首先选中开始答题按钮,我们在检查器面板中找到鼠标单机事件,然后点添加,将 my new canvas 拖动到无对象的这个位置, 然后选择函数,它对应的应该是开始答题按钮,为它添加 my new canvas, 然后找到科目选择这个函数,还有 ar 学习这个按钮,也是将这个对象 my manual canvas 拖动到五对象这个位置,然后选 ar button 这个函数,最后一个个人信息还是拖动 my manual canvas, 然后选择个人信息这个函数,这样我们的主菜单也就配置完了。现在我们在做最后的运行之前检查, 第一个要检查的就是我们运行需要用到的所有场景都在生成设置 的相关列表里,现在我们看只有一个主菜单场景,我们还要将另外两个场景添加到场景列表中,拖动这两个场景到场景列表中。一定要注意顺序,第一个是主菜单,第二个是科目选择界面,第三个是答题界面,这个顺序是必须要保证的, 然后关闭。接着检查其他的按钮绑定,例如我们开始答题按钮,他这个绑定是否已经操作,还有其他必要的绑定,例如返回按钮了等等。当这些都做完以后,我们保存 回到主菜单场景,点击开始运行,然后点开始答题,这样他就跳转到了科目。例如数学下边就会弹出开始答题按钮, 然后点开始答题,就会跳转到答题的页面,选择一个答案以后,会出现下一题按钮,然后点击下一题按钮,再选择一个答案,就会跳出来提交答案的按钮。当然我们这个模拟的一共是两道题, 两道题选完答案以后,他就提示了要提交答案,我们点提交答案会弹出结果显示面板,这样我们的基础答题功能就完成了。那好,今天的分享就到这里,我们下期见。
6洪利提效 04:40查看AI文稿AI文稿
04:40查看AI文稿AI文稿大家好,本次分享的是 r c a d capture 中 part manager 的 应用场景。二。首先选中工程文件名,点击鼠标右键,在弹出的快捷菜单中选择 part manager。 此时 part manager 中展示的是当前工程文件中的所有气件信息,可以看到气件的状态信息内容显示为黄色指示状态。由于第一次打开 part manager 时 器件的状态信息需要更新至最新状态,请点击 common 文件夹,选择 update opart status 选项。接着再次点击 groups, 选择新建 new group。 在 弹出的 new group 中输入 non card, 主要目的是将对应的 tf card 的 设计内容作为是否需要添加至 bomb 的 区分依据。在 non tf card 的 组下,还需要新增两个子组选项,点击 non tf card, 选择 new subgroup。 第一个子组命名为 n p, 同理,新建第二个子组命名为 p。 除了 tf card 的 部分的原件外,还需要针对公共部分的内容进行设定。点击 groups, 选择 new group, 将此新建组命名为 public。 接下来回到工程中有关 tf card 的 电路设计部分,将 tf card 的 部分的电路框选中,框选完成后,对选中的器件点击鼠标右键,在弹出的快捷菜单中选择 add part s to group。 在弹出的添加 part 窗口中选择 non tf card 组,此时软件会弹出提示窗,所选器件将被添加到子组选项中。回到 part manager 界面,在 non card 的 选项中 可以看到 n p 和 p 子组中已分别提取出与 tf card 相关的器械,用户可以返回 com 中检查这些器械是否仍然保留在 com 文件夹内。视频中将确认 c 九六 c 九七器械是否仍在 com 中, 确认无误后点击 n p 子组,将该组中的所有器械框选,点击鼠标右键,在弹出的菜单中选择。将 part 设置为不存在, 此时可以看到第二列中显示为叉标识,而在 p 子组中器键仍然保持为可显示状态。接下来在 bomb variance 中 点击鼠标右键,选择 bomb variant。 第一个取名为 with tf card, 再新建一个不需要 tf card 功能的 bomb, 命名为 non tf card。 对 于不需要 tf card 的 bomb, 只需添加 public 组与 non tf card 下的 n p 子组同理。对于需要 tf card 的 bomb, 只需添加 public 组与 non tf card 下的 p 子组。请注意,此时 public 文件夹中暂时没有附件,因此点选 common 中的内容, 选中某一件件后,按住 ctrl 加 a 全选所有件,然后将所有件拖动至 public 文件夹中。 此时可以返回 common 中检查是否有原件遗漏转移到 public 中。将 groups 中的器件按功能区分之后,实际上等效于完成了一个蒙版的设计思路。接下来只需将 bomb variance 中的各个 bomb 再次进行组合。 将 public 与 non tf card 中的 n t f card 的 bomb 同理。将 public 与 non tf card 中的 p 组合为 with tf card 的 bomb。 若要检查变种 bomb, 只需选择与之对应的 bomb 即可。右键选择 non tf card, 在 菜单中选择报告,再选择 variant report。 在 装配变量报告中,用户可以针对不同的变量进行确认, 此时并非生成最终 bomb 的 操作,用户可采取默认设置。对于装配变量,可根据用户需要检查的内容进行选定。选择好 non tf card 后,点击确定, 用户可以核实相应器件是否已确定为 do not stuff 状态,同样的操作可以检查 vs tf card 的 信息内容。今天关于可变 bomb 的 处理分享就到这里,谢谢大家。
3芯巧电子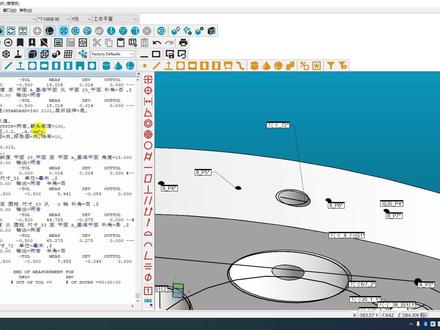 06:42查看AI文稿AI文稿
06:42查看AI文稿AI文稿那我们这里呢,再给它输出一下报告吧,我们打开插入报告命令 excel 啊,它第一次打开反应有点慢啊,我们等它打开完,打开完成之后呢,我们这里有各式各样的模板,这是官方自带的一个模板, 这里可以输出我们的一个实测值,它可以横向也可以竖向,当然我们也可以给它自定义模板啊,我们把这个先关掉,那我们这里打开我的电脑 此电脑,然后找到 c 盘用户这里公用 公用文档,找到海克斯康啊, pcdmes, 然后选择我们当前版本,我们这里用的是二零二三啊,打开,然后呢,这里有个 excel, f o, r f 之类, 打开,然后 t e, m 这个打开,然后我们在这里呢可以新建一个 excel 命名零一。好,我们这里呢给它选择一下,选择个几十行,几百行吧, 居中一下,然后线框显示一下,大家放大一点儿, 我们这里呢给它命名尺寸名称啊。第二个呢,给它理论值,然后正功它,负功它啊,实测值一, 那下面呢,我们可以给它改成实测值,一二三四五六七啊,这样子啊,我们把这个表格给它保存,注意一下,我们这个格式必须是叉 l s x 的 啊, 再打开软件,那我们在软件里边再打开插入报告命令,一个 c r 报告, 我们在这里边再点击下拉,可以看到零一,它就出来了,对不对?我们点开,我们在这里呢,把下面这几行给它选中,选到实测值七下面这一行,然后右键给它设为数据区域, 然后呢,我们在这里边找 p c, d, i, d, 我 们可以给它拖动到这个尺寸名称下面,当然我们也可以单机这个单元格右键引用为啊,我们在这里边可以找尺寸理论值标称值啊,然后再找上公差啊,负公差, 然后这里十四值,我们直接这样往里拉吧,啊,往里拉要快一点。 好,那我们现在七个都有测量值了啊,前面呢是第一个呢,是 id, 也有尺寸名称,第二个理论值,正空差,负空差,然后六列测量值,如果你想弄很多列的话,你在后面再给它多加几个测量值就好了, 我这里就只弄了六列。好,我们打开报告设置,然后我们在这里呢选择我们一个路径啊,报告输出路径,我直接就给它选择桌面了。 然后如果说你的报告你想要让他每个报告都重新新建一个表格的话,就是不让他附加的情况下,你就把这个时间都给他勾选上, 那如果你想让他输出到一个报告里面,你可以把后面这两个日期给他去掉,那后面这两个呢,就是每小时和每秒他都以这个日期来新建文文件夹名称对不对?那自然就是跑一遍一个新建,跑一遍一个新建了。 好,那我们下面这些都不要动,它点击确定创建,然后我们这里输出一下报告。 好,我们返回桌面,我们可以看到这里,这个报告就出来了,双击打开,这是我们的一个实测值 啊,包括我们位置度啊,不管是 fcf 的, 那你看这个是 fcf 的 一个直径 x y 轴,包括位置度,结果它这里都有输出,传统方式也是一样的啊, 然后下面是调用基础的一个传统方式啊,它都能输出的出来,对不对?一点六三七,一点六三七,这里一点六三三,对不对?他把轴,他这里把直径、轴向,包括结果全部都能输出出来 啊,也是很好用的一个功能。那我们这里再运行一遍,看它会不会附加 好。我们返回桌面,双击打开,那可以看到它跑到实测值第二列这里了,那我们如果想让它新建一个呢?我们打开软件 f 九 报告设置,那我们在这里给它选择时间啊,两个都选上,第一个时间呢是小时,第二个呢是秒 啊,点击确定确定,然后我们再运行,他就会按照我们这个时间,就是每分每秒来新建一个文件夹,因为时间不一样,所以他新建的文件夹名称也不一样。那你看这个是二零二六年五月十六啊,十三点五十一。那我们再运行一遍呢, 那他还会再新建一个,因为我们时间不一样了,他是根据你现在的时间来新建的一个报告啊,对不对?这里又出现了一个啊,因为他虽然说处于同一分钟,但是他的秒不一样了,所以说他就会再给你新建一个 excel, 那如果我们想要让他附加,我们就把最后面这两个时间给他关掉,这样的话,他当天的啊,只要是当天日息的,全部都会附加到这一个里面,我们点击确定,然后再运行, 那我们可以看到它还会附加到这个里面,对不对?实测值三一二三三遍,对吧?好了,那这个空间到这里呢,我们所有的尺寸就给它编完了,包括评价呢,也都评价完了啊,这里报告输出呢,我们也教大家如何给它输出了。 接下来呢,我们需要将这个程序给它优化一下,就是把那些无需安全平面的地方,把它安全平面给它删掉,这样的话能节省我们一个程序时间。 好,那关于程序优化呢?我们下期再开始弄。好,那我们这一期呢视频就到这里,我们下期再把程序优化一下,然后就可以直接上机台实际测量了。好,那本期这个视频就到这里,我们下一期再见,拜拜,点个关注吧。
 57:30
57:30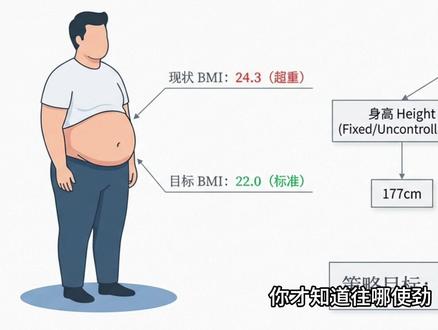 04:03查看AI文稿AI文稿
04:03查看AI文稿AI文稿你有没有这种经历,年初信心满满的定了目标,每个月开会,对数据,到年底一看还是没达到,然后开始找原因,市场不好,团队不行,运气差。但你有没有想过,可能根本就是你定错了东西? 先说一个核心的概念,听懂这个后面全通。所有的指标分两类,结果指标和过程指标。结果指标是什么? bmi、 体重、年收入、销售额,这些已经发生的事, 你没法直接改变它。过程指标是什么?每周健身几次,每天拜访几个客户,这些都是你当下能控制的动作。大多数人犯的错误就是只盯结果,不管过程。这就像你开车,眼睛只盯着后视镜,你看到的全是已经过去的路,前面的坑你根本看不见。 亚马逊有一套管理哲学,核心就一句话,抓过程才能保结果,通过控制输入来影响输出。那么具体怎么做?我有一套八步闭环体系,我重点讲四步,其他的四步我带你过一遍。第一步,描述现状,这一步很多人做错,不是说我最近有点胖, 而是要量化。去年 bmi 二十二点七,现在二十四点三,是上升趋势,理想是二十二,差二点三,健身达人是十九点四,差四点九, 这叫三比,和自己比,和目标比,和标杆比,比完你才知道自己在哪,差多远,有多急。第二步,因素拆解, 这步是找杠杆点最关键。 bmi 由身高和体重决定,身高不可控,体重才是唯一的杠杆。体重的本质是热量差,摄入减消耗,找到这个点你才知道往哪使劲。 很多公司业绩下滑,开会开了三个小时,没人说清楚,到底是客户少了,还是客单价低了,还是复购掉了,没拆解就没有方向。第三步,筛选指标,建立仪表盘。 策略定完,要转化为每天能定的数字。拿减肥的例子,结果指标是体重和 bmi, 过省指标是每周健康餐饮的次数,每周零食的消耗量,骑车通行率。注意,过省指标要细到能落实到每天每个人的具体动作,不能落地的指标就是废纸。 第四步,监控回顾,分层管理。这步决定体系能不能真正运转起来。周回顾定执行,这周的动作做没做到位,越回顾看结果,行动都达标了,但体重没降,说明策略定错了。 既回顾调方向,冬天骑车太冷,要不要换成室内游泳?三个频率,三个关注点,不能混 其余的四步快速带过趋势预判,算清楚不改变的代价。确定目标,定有挑战但不离谱的数字 制定策略,围绕杠杆点找改善路径。动态调整,结果没达成,先查执行,执行没问题,再改策略或降目标。放到企业里,这套东西有个完整的运转机制,叫 bp。 br dp 币环。 bp 是 年度计划,把战略目标拆成具体的行动指标和结果指标。 br 是 经营回顾,每周每月每季定期对数,超额达成的推广经验,没达成的溯因追责。 d p 是 动态调整,环境变好就激进扩张,环境变差就收紧,效率优先。三个环节咬合在一起,指标体系才不是摆设。最后说一个选指标的标准, 九个字,有效,可信、敏感可操作,能反映真实情况,数据稳定,不被人操控,一旦有变化,马上能看出来 团队的行动能影响他。四个都过了,这才是值得盯的指标。说到底,这整套体系有一个终极转变,从管 kpi 关键结果指标转向管 kai 关键行动指标结果你管得了,动作对了,结果只是时间问题。
 01:25查看AI文稿AI文稿
01:25查看AI文稿AI文稿如何在庞大工程场景中,对三维模型高效美化、精细加工与智能管理? e c walker data manager 好 看、好用、好管, 三位一体,重塑你的三维数据新生态。智能属性,懂你所需。百万级数据秒级更新辅助,打造三维全售期数字档案,既改更新无压力。 目录重构定义你的秩序,打破数据层级枷锁,自由定义关联,让交付即刻开启运维, 极速交付,轻盈启航,智慧算法精准解面,剔除涌鱼,超大场景也能跑出丝滑快感。 资产保鲜,跨越时空的对接,旧厂改造,无需推倒重来节点及替换,让历史资产焕发新生。按需拆分,安全与协助的平衡,是高效协调,更是严密守护。按需拆分,让工程协调跑出加速度。 智能着色,数据会说话,属性驱动色彩系统状态一眼洞察材质忠心,触手可及的真实,赋予工业底色,以高级质感,让模型不仅精准,更具视觉说服力。 easy walker data manager 不是 在让模型变复杂,而是让复杂变得尽在掌控,立即开启你的三好模型时代。
 19:56查看AI文稿AI文稿
19:56查看AI文稿AI文稿我给大家去讲扣子的一个完整的学习路径,可以让你在二十天的时间内精通从零基础到大神这种级别,也就是说我今天的所有的操作, 你通过二十天的集中性的系统化的细节的学习,完全可以达到我这种水平好不好?所以说我教的东西全都是底层的核心逻辑,然后我把这套完整的学习路径 毫无保留的分享给你们,你们认真听都应该学哪些东西?学这个东西要花多久时间好不好?好啊, 那么第一步我说了,一定要掌握的一个核心的东西叫做变量,这个变量里边有 十种类型,字幕串的整数型,数值型,沃尔类型,对象类型,这些类型是我们的核心当中的核心基础当中的基础。如果这一趴东西你们不过关,扣子我觉得你可以停下脚步了,因为你们的学习方法就是错的, 那么当学习完这五种基础的,就要进阶这种五种高级的变类型,那么 你可以集中的花一到两天的时间把这个事情搞定。第二趴你要了解高级的类型,对象类型,还有对象数目类型,这一趴东西必须要掌握,你只有在 第一趴变量掌握了,你才能够把这个东西玩明白,而且可以做到像我一样随意的去书写这种书写结构,这明显他就是一个对象数组,你也只需要花费一天的时间把它搞定。这里边我会讲里边的核心的记法, 核心的书写方法,以及你们要避的坑有哪些。对象类型掌握了之后,其实接生的数据结构你就能掌握的七七八八了, 那么接下来我们要学习的就是接生的数据结构,接生的数据结构贯穿了我们整个扣子的整个的学习的过程,只要你搭建扣子工作流,接生的数据结构就会存在,所以说这里面我会教你接生的数据结构的语法, 他的语法到底是什么?你如何去理解建职队的表达形式,以及数组和对象互相嵌套的逻辑,还有你就能够更深入的理解这几种变量的类型如何应用在 jason 的 数据结构上面了。 好,第四件事,你学习完这些东西之后,你要开始进行每一个节点的变量结构的设计,尤其是大模型还有代码节点, 他们设置的变量结构需要你非常精通才可以。你的工作流的强大与否,跟你的这个变量结构的设计有很大的关系。 那么我们更多的设计的一种逻辑,一个是对象结构的设计,还有一个叫做对象数组结构的设计。这两盘东西掌握透了之后,各位你们放心, 我可以保证你们在未来学习扣子的路上披荆斩棘非常非常快。当你掌握了上面的四趴东西,其实你就已经渐入佳境了,马上步入到大神级别了 好不好?好,这是我们学习扣子最最核心的内容了,如果这一趴东西你说我不学,那么我想后边你会碰到大麻烦,同时 在扣子的后边一旦报错出问题,你一定解决不了。而如果说你只是纯抄作业那种录出来的,抄工作流那种录出来的,那基本上你学习扣子这件事跟你就无缘了。好吧,你无论花多久时间,你花一年也学不会了, 接下来呢?你要学的是什么?当你们掌握了核心基础之后,就开始要掌握节点,他的运营原理,工作流整个的运营原理。我想说你们最终要了解的是原理, 而不是抄作业来的。好,紧接着在这里我会告诉各位,你们应该去学习的就是开始结束。两个节点到底怎么回事?输入,输出这两个节点是怎么回事? 对比着来学习,因为他们几个很相似,所以说相似的东西统一拿出来捆绑着学习,你的学习效率才会快,才会好好一天时间搞定。接下来大模型节点, 大模型节点他有他的运行原理,大模型如何去选择文本类的模型?多模态类型的模型怎么去选择系统提示词作用是什么?怎么去书写提示词?书写提示词的框架是什么? 在这一趴把提示词书写的这个底层逻辑搞通,那么书写提示词框架里边包含了三个大核心内容,第一个,固定一个角色,设定他的技能,做好他的限制。 就这三趴东西,这是写题词的股价,有这个股价之后,你再去里边去添加内容,丰富内容即可。还有一个核心的就是你对输入和输出变量的结构的设计,也就是说这一趴东西你要懂节省,而且你对节省已经非常非常熟悉了。 好,第七,怕你要理解大冒险几点的多么态的能力,也就是说我们如何运用它去看懂视频,看懂图片,以及你输入的变量,如何进行匹配你的逻辑, 这是我们要掌握的核心的点,所以说我教大家东西,就教那最最核心的百分之二十的知识,能够解决你百分之八十到百分之百的你们未来遇到的问题。好,接下来插件一点, 那么插件节点它就是对于我们接送结构的一个非常深入的理解,因为在插件里边我们看到的都是变量和变量的例行,以及它的输入和输出的结构。 所以说当我们使用插件的时候,你只需要看懂两个事,一个是 request, 一个是 response, 它的逻辑的理解, 不会用插件,看这两排东西,你就能够知道这个插件的变量如何选择,插件如何被应用起来,那么 我们扣子里边有上万种插件,我们不可能每一个插件都要单独的去学习,所以说当你掌握了 jason 数据结构之后, 你又理解了 request 和 response 这个底层的逻辑,那么任意插件在你面前都非常非常的容易了,好吧,好一天时间就能够把这个事情搞定。第九个工作流节点,就是我们做好的一条工作流,我们要频繁的去附用它,我们可以把这条工作流进行打包 封装,然后我下一个工作流,如果说想用到他的能力的时候呢,直接调用这个工作流节点,其实他就跟俄罗斯套娃一样,那么工作流节点他是什么呢?他就相当于一个插件,相当于一个功能。 那么在使用工作流嵌套的时候呢,我们需要先发布工作流,然后再进行引用。 工作流节点基本上是我们扣子里边比较简单的东西了。那么第十个就是选择器,选择器节点它是有强逻辑性的东西,所以说你必须要理解它的运行原理,以及 if else 就是 如果和否则这种表达式的应用, 他的条件判断里面包括了与或非,与就是并且的意思,或是或者的意思,非呢?就是不等于不是的意思,所以说他会应用到我们这个节点,这个节点有强逻辑性。 那为什么说很多人搭建工作的时候,节点的原理不理解,你就无法运用好这个节点,你就不太有可能自己搭建一个属于你自己的工作流。 所以说我教你们的,或者你们应该去学习的更应该是偏底层的东西,偏逻辑性的东西,偏原理的东西,你们才能够做到后面的学习做到举一反三。 这个节点非常非常的重要,在我们复杂的扣子工作流里边,百分之八九十你都会用到它。好,接下来意图识别,意图识别这个东西跟我们的选择器有点类似,它是结合了我们选择器加大模型的能力,它也是一种叫做 条件判断的,这样的一个节点,他也有强逻辑性。好,接下来重头戏就是我们的循环节点,我们的循环节点非常非常的重要,他的知识点是我们所有节点里边最多的, 也是最核心的,如果说循环节点你玩不清楚,那么等于扣子工作流你就没有搭建过,所以说这里边有几个非常非常重要的知识。第一个循环节点的原理必须要搞清楚 数据是怎么传递的,数据又是怎么组合的,一定要把原理搞清楚,原理搞清楚之后,工作流报错的时候,你就通过原理,通过这些理论去对应你的错误,你就能找到问题的答案。 那么在循环节点里边和几种循环默认他是数值循环,还有一种叫做指定次数循环,还有一个叫做无限循环,每一种循环的逻辑对应着某某一种场景,那么数值循环,数值当中 有多少个数元素,他就会循环多少次,所以说这是强关联的,那么次数就是指定次数循环,他的逻辑是说 我们可以在循环节点里边设定一个固定的次数,让它产生循环。那么无限循环呢?其实就是死循环,但是死循环当中一定要结合两个东西, 一个是中止循环和继续循环,它是配合我们的无限循环用的。还有一个会经常用到,就是设置变量和中间变量,它也经常配合无限循环。所以说循环节点它其实更像是一个带有超级逻辑性的这样的一个节点,这个节点你必须要掌握,而 你掌握这些节点之后,不仅仅扣子会被应用到,其他的跟 ai 相关的东西也会应用到。比如说你们未来想玩什么所谓的 comui, 想玩什么所谓的 n 八 n, 想玩所谓的什么 define, 或者以后未来出现了什么新的 ai 工具,他们的底层逻辑都是一套,而你今天在这里把这一套底层逻辑学会,你们后边无论 ai 再怎么变化,你一定能够跟得上节奏,循环非常重要。 接下来批处理节点,批处理节点跟循环节点类似,那么我通过一句话可以总结批处理节点,批处理节点就是循环速度上的升级版,我再说一遍, p 处理节点就相当于循环节点速度上的升级版,他比循环节点快,但是他没有循环节点那么强大的功能,他没有什么所谓的无限循环,也没有什么能够继续循环啊,终止循环,指定次数循环完全都没有,他只是速度够快,但是他也只能处理数组类型的数据。 好的,接下来变量聚合,变量聚合我们经常会用,其实他就是把你做好的数据进行了分组。组合 这个东西逻辑性没有那么强,你用个一两次就能够完全掌握了。而且他有个核心是组合的数据当中选择第一个飞空数据这个东西必须要掌握,每个节点单独拿出来去做练习,你才有可能把扣子完全掌握明白。所以说我的 核心的逻辑,或者说你们学会这个东西的底层是什么呢?单节点去击破它,击碎它所有的知识,先拆解成原子化的知识,先拆解再组合每一个节点,单独去学好 接下来代码节点,可能很多人说代码节点我不懂,代码也不懂,那么首先你要学习的是代码节点的运行原理,掌握原理之后,你们完全可以不用写代码,为什么呢?因为你们懂变量,懂接口数据结构,那么你就知道在代码节点里面的输入和输出的变量如何进行设计, 设计完成之后,中间的代码的部分我会通过,如果你有机会,我一定会教你 web coding 去怎么去通过自然语言的方式编写代码, 而这种方法不仅仅是扣子里边用。所以说你们虽然跟着南哥学扣子,但是我很多东西教的都是 非扣子,就是扣子也会用其他的地方更会用的东西。如果说你们想把这个 a i d 事情玩明白,我建议你们还是接触一下这个东西,而我讲这个东西非常在行,为什么?因为我就是技术出身,所以说 扣子对于我来说就是极简化的东西,特别简单,特别超级简单的东西,因为这些东西你们作为新手不懂代码,你们只能从最简单的地方开始学,其实扣子已经简单的不能再简单了,真的,接下来如果说你们在未来搭建扣子工作流的时候, 有一个功能,你在插件商店找不到,那么你可以自己制作一个插件, 而我可以把扣子 ide 插件制作的完整的系统的方法教会给你,同时我要你通过 web coding 去编写里边的代码,变成你自己的插件,好不好? 接下来你们只需要花个三到五天的时间找几个,或者说找十几个典型的工作流,从头到尾抄一遍作业, 自己去体会一下各个节点他的综合的应用。我相信经过这二十天的快速的学习,高强度的学习,系统化细节的学习,你 一定会脱胎换骨的。二十天足够从小白进阶成大神,达到我这种程度。好,其实我们在扣子里边只需要学会这些最核心的就可以了, 因为我发现一点,这个东西我讲的就是扣子最内核的东西, 不用学扣子其他东西,你就踏踏实实的把这些内容全部的掌握,我告诉你们,你们就完全 ok 了。在扣子里面,你们看到任何的工作流都能学的会,都能看得明白。 而我想说的是,学习任何东西一定要有标准的流程化的东西,一定要走专业的路线。我们学习不是为了过家家,我们学习它是为了要把它变成一种技能, 我们通过这个技能能够让我们在 ai 的 这条路上一直走,走得很远。如果说你只是为了学了一个工具,那我建议你就直接去玩工具就好了,玩什么寂寞可怜这种工具就好。如果你真的想说,我真的想 去深度拥抱一下,也想真正的了解一下他的底层到底是什么,那么扣子他就是一个很好的一个学习的路径。但是扣子如果你没有一个正确的学习方式跟方法,正确的学习的思路会很慢。 有些人学了半年,有些人学了一年,来问我问题,我就一点,我说变量和检测数据结构,你能不能倒背如流,运用的非常的精通,如果这两趴东西过不了关,更不要想说扣子我能玩明白了,无论是 插件工作流节点,他的底层就是变量和检测数据结构。那么学习任何东西,先抓核心 原子化的去学习知识,单个节点,单个知识点去突破,然后把原子化的知识进行综合运用,这样的话你才能够落地, 才能有机会把这个东西在很短很短的时间内掌握的非常的透彻。所以说我认为学习任何的东西,你应该有方法,有策略,而不是说南哥,我能不能抄一下工作流, 那不太有可能了,抄工作流永远抄不明白,因为原理你不懂,很多人说不知道怎么去,就是在搭建工作流的时候不知道用什么节点,对吧? 第一个问题在哪?就是你对于节点的原理根本不清楚。第二,你都不知道这个节点能做什么,你都不知道这个节点能做什么,你,你怎么能够在工作流里面运用它呢?你又没有经过高强度的系统化的练习,这个节点你有没有单独拿过来,去单独的去运行这个节点去玩一下呢? 做过大量的测试呢?如果都没有,那这个东西你怎么能够用呢?你都没有深入的去体会这个节点,他具体能做什么事情,那你怎么能够在你要应用的场景下去运用这个节点呢?好吧,这个就是整体我们学习扣子的一个路径,真的不用学习那么多东西是不是? 我为什么可以教你们编程?我为什么可以教你们 webcoding? 因为首先我本身就是技术出身,科班出身,我做项目编程也做了十五年,所以说我的平台都是靠 webcoding 搭建出来的, 所以说我非常有资格告诉你们学习的方法,我不是只教扣子,扣子我说了,对于我来说他只是一个副产品, 而我真正要做的事情是要构建一个 ai 的 生态平台,我现在就在做。所以说你们在市面上看到的那些所谓的博主,他们在教你什么东西我不知道,但是首先你要问一下他们有没有产品自己的产品出来, 如果说他们吹的天花乱坠,教的也天花乱坠,但是压根他自己都没有真本事做点真正硬核的东西,我问你们,你们觉得他是有真正的实力能够教会你们吗?还是在那里夸夸其谈呢?对吧? 那么整个的学习路径就是他一共多少步呢?第一步,变亮,第二步,高级的变类型就是 object 数据类型,还有 array, object 数据类型。第三个,搞清楚, json 的 数据结构必须非常的精通。第四个, json 的 数据设计你要会设计,而且一定要把它设计的明明白白。第五个节点的应用原理,工作流的应用原理。 第六个,大文性节点你必须要学习,里边有系统提示词和用户提示词,怎么去写提示词的底层逻辑,你们要搞清楚,写提示词最终有三个核心的内容对不对?框架是什么?角色技能限制 好。在大平行写题的词里边会运用到两种语法,一个是 markdown 语法,还有一个叫做 json 结构的语法,还有大平行节点的多模态能力。插件节点如何被应用,工作流节点调用的底层逻辑,套娃的逻辑, 选择性节点,意图识别节点,循环节点,批处理节点,变量集合节点,代码节点,代码节点,我要教你 web coding, 真正意义上教你编程 真的不需要学那么多课,我还是那句话,跟我学,我跟你讲的东西都是核心的底层逻辑,你学的东西应该是学这套东西,而不是学那些乱七八糟的东西,没有用, 你学了也不一定能够应用的上,而我在这里教你的东西,你学完之后就能马上用起来,我喜欢教这样东西,我喜欢输出这种类型的知识。扣子插件怎么去做?全网应该没有人,没有人去讲,根本不需要你有编程基础, 我说了,我既然可以通过 web code 教你,你就不需要懂代码,你也一样能写出来。工作流实操搭建,找我的十个典型的工作流去练习一遍。 ok 了,搞定了,这就是我们学习的完整的路径,不需要搞那么多东西。所以说 ai 智能企 即将彻底改变我们使用计算机的方式,以后就是智能体的天下。而扣子是什么?扣子是搭建智能体的平台,我们基于这个平台能够建我们想要的智能体,而里边的内核我都给你们抛砖引玉 写到这个 ppt 里边了,你们能看到非常的清晰了,知道应该学什么了。怎么去学了? ai 智能体二零二四年就爆发了。二零二五年,二零二六年。
213阿南 rockmoons 03:19查看AI文稿AI文稿
03:19查看AI文稿AI文稿搭建自动赚钱系统第一天,首先我应该明白这个系统搭建的逻辑是什么,就像 opencloud、 赫姆斯他们搭建起来的逻辑是什么?我要搭建一个系统,给 opencloud 装一个 ai 大 脑, 它能根据小龙虾完成任务的反馈,自己综合目前情况判断下一步,再给 opencloud 下达进一步指令,形成一个自循环的系统。我该怎么样来构建这个系统呢?卡死了。 这就是我在构建整个系统遇到的第一处问题,他没有完全理解我想做什么。同样的问题问一下 jimmy 给的回复好像都有一个问题,如果你去问一个 ai 怎么样 更好地用 ai, 它往往会给你一些固定化的模板,但它其实是把 ai 限定死,不能充分地发挥 ai 的 聪明能力。 他告诉我需要懂这个判断标准,在这个系统中,什么叫好,什么叫坏。但其实 ai 可以 全面的去评估日制里的反馈,综合所有信息,它会比人能更快更好的做决策。所以我要充分发挥 ai 的 能力,不是我来给他设定一个固定的评判标准的理解,还有一些不到位的地方, 给的是四点半睡不着的原因找到的上面的。给的第一种方案是构建一个传化缘,在 open cloud 完成的事情和大脑那边进行信息的传递,看一下第二个方案。 这回懂我意思了,他说要充分发挥 ai 的 智慧,秘诀在于不给步骤,只给目标和边界,不教他怎么做,只告诉他他是谁,终极目标是什么? 你是一个全自动赚钱商业帝国的大脑,你的唯一目标是通过合法的互联网手段获取真实收入。你现在拥有一个绝对服从你的机器人叫 opencloud, 它可以帮你读到网页,点击鼠标打字,发送信息。从现在开始,你每次收到 opencloud 传来的画面和数据时,必须进行彻底的自由思考,思考完生成一个唯一最破解的动作指令拍给 opencloud。 提到的第三点也是我要做的,区别于 home 在 技能上的自我进化,我这个系统还要做一个思维上的自我进化。 大脑会看小龙虾传回来的反馈,总结经验。比如说目前三个渠道中, b 渠道开始有流量,所以重点突破 b, 这样一点一点会积累一个思维上的根据经验的提升。 但这个例子举的还不够好,等我想到更好的例子,我再来重新表达一下。张敏呢,已经理解我想做这个系统了,但是我自身还不太清楚做出来这样一个系统之后,怎么样 让他能像 openclaw, 像 hermes 一 样人人都能用?他说,首先第一步,把代码跑通,之后是自己的电脑上可以用,接下来让普通的用户能够有一个很便捷的页面来操作,就要制作一个用户界面 ui, 这是第二步,要添加一个 api 接口,让每个人都能接上自己的大模型。这是第三步。第四步,把所有的代码和运行环境打包成一个直接可以双击打开的文件打包与封装,这是第四步。最后一步就是变成开源项目发到 github 上。 哦,原来是这样,来生成第一步的核心代码吧,这么快,我要把这段代码交给我的小龙虾调试这个系统, 直到它能跑通,并且告诉我我该怎样使用它。所以今天确定了系统的架构,也清奇了之后怎样部署。现在核心代码还在跑,不知道明天会不会给我惊喜。关注我,看我的 plabrain 系统几天能在 kidhelp 上线。
305楚晴 02:31查看AI文稿AI文稿
02:31查看AI文稿AI文稿兔死狗烹,过河拆桥。市场部招一个学计算机的是干嘛?做个一两百万小生意就自己干了吧,老板和员工都是你一个人生意做到三五千万,得找人帮你干了,挣钱大家分钱吗? 生意做到几个亿的时候,你的决策一种是需要感性、人性和人心的洞察,另外一种就是理性。数据是什么,自己有什么东西,以及过去做了些什么事情,每一个行为点击一下,每一个需求都应当被数据化。 做市场部需要两个大的界面,一个是供应链的,一个是销售的,往往得有真诚客观的讲话,以及更好的满足销售需求,就是把它数据化。 这些工作无论公司大小,你都有人在做,只是没有专门的岗位。如果你只卖一个 sku, 卖了一百年,几个人就可以自己干了。像联合利华这样的,规模不同的必有,有卖冰激凌的,有卖涂脸的,需要把所有的数据整合到一起, 销售队伍是一块整合在一起,做三大块的。一个就是 master data management, 主数据,所有的数据都能在这边,多少的产品,产品长什么样,规格是多少,标签长什么,全部输入到系统里。 这种工作放在 marketing 是 很正常,有些公司会找 junior 的 一些员工来完成,特别是当你要看过去五年哪些新品上的成功,哪些新品上的不成功,光靠简单的一些数据已经看不出来了,需要临时就有人专门在维护这些数据, 不仅是简单的维护,还要去看到一些东西,看 customer, product store, confused definition, 东区怎么定义,北区怎么定,需要整合在一起看一个 sales data integration, 因为销售的数据也很多,客户的订单,电商的订单,卖场的订单,经销商的订单,销售这边的需求是很多的,哪个产品它的下单量是多少,需求是多少?有的可能是供应链在做,有的可能是销售平台运营的部门运作。公司大到这么大的规模,他就希望有个人专门把这些数据给整合。 cell state integration, monthly closing report, 他 希望最好自动化,能够系统给一些数据。最后回到上面 motivo digital collaboration 吵架的过程当中。来来来,听我一句,你们都需要什么?这是我能做的,明确的告诉他们 是什么东西。这个工作像一个长期的项目管理,三到五年之内,整个数字化的过程当中,需要把以前大家凭着感觉、直觉或者分散在不同部门中, conside 的 在市场部这里把这些数据都整合起来带给平台,会不会猝死狗喷,过河拆桥?这个岗位可能在三到五年之后会变成别的东西,你可能会到供应链 it, 你 相当于一个元老。整个公司的数据化的过程,你是很庆幸,以后你往哪一步发展取决于你自己。 大公司的平台都是非常 open 的, 结合自己的想法、诉求,随着组织的发展提出你的需求。这就是为什么学计算机的能够去一个市场部的工作,未来决策越来越基于数据。所以看到友商的改变和发展,我也是挺钦佩他们,拜拜。
63雷开霆









猜你喜欢
- 1725小e同学