剪映bytebench是什么文件
然姐,这豹纹数据解析太难了,头都大了。是关于豹纹解析的哪方面呢?然姐来帮你梳理一下。之前刚弄明白,二禁止十禁止十,六禁止转换,可这豹纹里的 bt 组合和拜特组合实在是搞不清楚, 明明都姓 b, 明明都叫特,怎么就还不一样了呢?哎呀,那宝马车和宝来车他们都姓宝,都叫车,那能是一回事吗? 这样啊,我们首先看看 bit wait 和 bit 字节的区别。当 bit 出现的时候,我们就知道这是二进制, bit 表示的是二进制的喂,它是计算机存储处理信息的最基本 最小的单位了。一个二进制位 bit, 他只能表示两种状态,要么是零,要么是一。然姐啊,这不都是计算机基础知识吗?我一个学汽车的,我还得学这个啊。哎呀,你学汽车以后你想干点啥呀?我要搞智能车开发测试,无人驾驶多带劲啊。你 想学无人驾驶那是好事啊,学无人驾驶出来比学传统车赚钱可是多多了。无人驾驶汽车呢,又叫高级别的智能网联汽车,听听智能网联汽车中的网,那又指车载网,又指车联网, 所以你要学无人驾驶呢,你得先学网,那你要学网呢,你就得明白啥是为啥是自己。那我这么说你明白了吗?那好吧,你刚才说了 be 的是为那啥是自己啊?好,我先问问你啊,你认不认识这个词啊? bite dance? 咦,这不字节跳动吗?就抖音啊,认识认识?对呀, fight dance, 字节跳动,这里的字节用大写的 b 来表示,一拜等于八 bit。 还记得吧,我们刚刚说的位,一个字节 bit 是由八个 bit 八位组成,两个字节,两个 bit 就可以存放一个汉字国标码。所以下次呢?你要搞不清楚 bit 和 bit, 你就想想字节跳动的名称叫 bite dance。 下节课然姐跟你讲讲字节中的高低位。

粉丝6677获赞3.2万
相关视频
 01:37查看AI文稿AI文稿
01:37查看AI文稿AI文稿欢迎大家来到例子说英语,那有同学提问说 bites b y t e 啊,加 s 和我们的 beets b i t s 啊, b i t s 这两个单词有什么区别? 那首先呢,我们的这个 bite 啊,也就是 bite 原型,这俩单词呢,都是跟计算机有关系的啊, bite 啊, bite 它的意思是字结,而我们的这个 bit, 它是二进制的这种数字,也就是零和一。那这里边有一个 bite 这个单词,学术上的一个讲解,我们一起来看一下。 那首先呢,我们来看一下这个 bite 是什么解定义啊,他说的是这样的, a unit of information store in a computer equal to eight beats 什么意思呢?也就是说他翻译成这个信息的存储的一个单元,在计算机里边好, bite 这个 单词的意思就是计算机里边的一个信息存储的这么一个单元,后面那个 equal to a bits, 那相当于是八个这种二斤制的这种数字,也就是八个零和一,那是这样的。 好,那我们刚刚看了一个 bite 这个单词的解释,接下来呢,我们再看一下什么是 bate, bate 这个单词呢,其实就是我们这个二进制啊,我们知道二进制当中就是两个数字,零和一啊这两个数字,所以这个 bate 呢,在计算 专机这种专业的数据当中,就相当于二进制的数字,而我们的这 bide 呢,就相当于多个这种二进制数字组成的这么一个字结,是这个意思。 那因此呢,我们可以说 bike 要大于 beat 啊,就可以简单这样理解,你学会了吗?好,以上就是本视频所有内容,感谢大家观看,如果你也喜欢李子老师视频的话,请多多点赞、留言、关注、分享本视频,拜拜!
26栗子说英语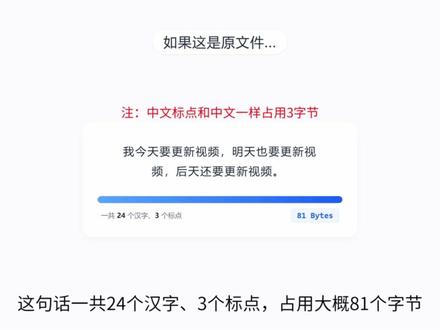 02:08查看AI文稿AI文稿
02:08查看AI文稿AI文稿有些 e、 g、 b 大 小的文件能压缩到几十兆,而有些文件压缩之后,大小却几乎没有任何变化,文件到底是怎么被压小的?今天我们讲文件压缩的原理。在了解压缩原理之前,咱们先来了解一下数据的大小。我们都知道,电脑上的所有数据本质上都是由零和一组成的, 一个零或者一个一就是一个比特,而八个比特就等于一个字节。那一字节有多大呢?我们新建一个空文本文档,在属性里可以看到,现在是零字节,这时我们输入一个英文字母,大小就变成了一字节,也就是说一个英文字母就是一字节。那汉字呢?在 现在通用的 u、 t、 f 八编码下,输入一个汉字,通常会占用三个字节,一千零二十四个字节,等于一 kb, 换算下来, 一 kb 大 概能存三百多个汉字。了解了大小,我们再来看压缩是怎么回事。假设下面这句话是还没压缩的原文件,这句话一共二十四个汉字,三个标点,占用大概八十一个字节。而压缩的底层逻辑,简单说就是找规律或者找相同。在这句话里要更新视频,这五个字 重复出现了三次,压缩软件就会把重复的东西简化掉。比如建立一个字典,用数字一来代替要更新视频, 压缩完之后,这句话就变成了这样,体积瞬间缩小一小半。又比如,原文件是二十六个英文字母,压缩软件发现规律后,就可以直接记录成 a 到 z。 再比如,有一串数字,压缩软件不会傻傻地全部记下来,而是会把它压缩成十个七 八个八。通过这几个例子我们就大概明白了,压缩的本质就是找出文件里重复和有规律的地方,然后用更短的代码来代替它。 那文件到底能被压缩到多小呢?这完全取决于文件内容本身。如果文件里有大量重复的、有规律的数据,比如文本文档、未压缩的 b、 n、 p 图片,或者很多空文件夹,自然可以被压缩得很小。那些压缩后大小几乎没变的文件, 是因为这些文件本身已经没有多少规律可找。比如 m、 p 四格式的视频、 j p、 g 格式的图片,它们在生成的时候其实就已经被各种算法压缩过一次了,水分已经被挤干,再去对它们进行压缩,自然就挤不出什么东西了。
5.0万曼波课堂 07:04查看AI文稿AI文稿
07:04查看AI文稿AI文稿今天我们来学习 nativebitbuff 和 btbuff 的一个工作原理啊啊,然后呢, btbuff 是咱们的 gdk 自带的 nio 里面提供的一个 btbuff 啊,也是有缓冲的,是不是?然后呢, btbuff 是咱们那个 nit 的啊? 好,然后呢,我们来讲一下为什么有了那个 gdk, 那个 nl 里面的比赛八分?为什么内地还要弄一套比赛八分啊?好,首先呢,当然是在某件场景下啊,接地 k 自带的一个比赛八分啊,比赛八分,这个应该比赛八分 八炮性能啊,不是很令那个 nike 满意啊,而且呢,他的使用比较复杂,所以呢, nike 团队啊,就重新设计了咱们的比德巴夫,重新替代咱们的一个比德巴法啊, ok, 然后呢,我们接下来啊,我们就会来讲一下他们两个的分别的一个工作原理啊。好,首先第一个我们来讲一个比德巴法的啊,比德巴法的啊, 比他爸恩爱欧里面的啊,恩爱欧里面呢,他也会,他分为这个读写模式,是读模式和写模式, ok, 然后我们看一下这个图啊,读模是什么意思呢? 多么是,就是咱们首先要知道他比的八五,这里面有三个啊,三个这个你把它理解为变量啊,变量也可以啊,三个变量。然后第一个叫跑赛车啊,里面挡还有开不死的,对吧?开不死的, 然后呢,他这里面第一个咱们跑在这啊,指的就是你读的位置啊,从哪开始读啊?读的位置,然后黎秘特呢,就是你的先人,你可以读到哪里啊?归读到哪里。然后呢,这个就是代表他一个容量,就是咱们的一个比特帕,他直接是一个速度,是不是就代表他的一个容量,他一个容量的打一个十,他们那排到容量十啊?然后我们现在来举个例啊, 举个例子就,嗯,这个例子,等会我在这一起,在这一起讲嘛,然后我们先来讲一下咱们这个写模式啊,写模式什么意思呢?写模式的时候啊,就是这个菩萨 就代表从哪开始写,从哪可以开始写,我们肯定在我们可以的空的空,空闲的位置里面开始写,是不是?就像他说现在我们这里面已经写到这里面了, 写一写,这里是已经写完了,我们肯定在这个嗯空闲的地方开始的地方开才能开始写,是不是啊?那么这个时候呢,这个 limita 和 kpc 也是一样的,这个 limita 这个时候代表的什么意思呢?代表的他就是能够写到哪,能够写到哪,就是他们还剩多少空间,我可以给我来写啊啊,我们给大家进行解释一下。 好,我们现在给他第一举例啊,假如现在我这个 kfcd 是十,对吧?我这跑车是零,零分的是五,那么我这个在读模式情况下,我这个只能 读零到五的位置啊,五到十这个还没有被写过,所以呢,他读不到数据,所以也不给他读了啊。然后在写模式的情况下呢,有 boss 在身上,假如是五,是不是 boss 身上是五,那么有代表呢? 跑三十五,然后里面的 capac 里他都是屎啊,这个什么意思呢?就是 position 只能从五的位置开始写,因为在零到五的这个位置啊,已经被写过了,所以你就不能再写了啊, ok, 这就是比赛八分的一个 都线模式的工作原理啊,都线模式工作原理,大家高兴的都不是爸爸,有一个点就是你们的个 cvct 啊,还有 pose, 是他们每个在不同模式下,他的分别代表的是什么意思啊? ok, 然后鼻子 buff 呢?就相当于就是好理解一点了啊,理解一点,然后他这里面主要是通过三个,也是通过三个变脸,但是呢,他通过一个读 indixe 的啊, ready indicas, reddix 啊,两个。然后呢,再把这个缓冲区啊分为三个部分,就是可丢弃部分和可读部分和可可写部分啊, ok, 可以不问,然后我们再再来看一下,然后我们看下这个初始位置啊,我们就是咱们 我们这个内地里面比德巴夫啊,比德巴夫这个初始位置什么意思呢?就是相当于是咱们那个 ready nikes 和 reidaynakes, 其实他是一样的,都等于零,是不是就是初始位置啊?初始位置,然后科普斯里就代表他一个容量,那么这个时候呢, 就是这么一部分啊,这个内容啊,都是可写啊,可写的部分,可写部分,也就是咱们的这一部分可写部分啊,可写部分, 二手还不能没有可读部分,因为呢,我还没写过,所以呢,他没有可读部分。好,然后我们现在来写了一点数据,就往这个 b 的八幅里面写一点数据,之后啊,会成什么样子呢?首先我写了一点数据,我不肯定是 ready x 的吧,我写的部分往前挪了,代表呢?我这我写过的这一部分肯定是可读的,是不是?所以呢,这么多是可读的部分, 然后呢,我没写的部分肯定还是可写的部分,也就是说我从未来的引这个词之后到 cafe 这里,这个这个部分全部都是可写部分,也就是说这么部分 可写部分啊, ok, 好,因为我这时候其实是只写了没有读吗?所以咱们的 red, 你这个词还是从零啊,还是零啊?好, ok, 然后呢,我这里面现在就开始,我读了一点数据之后啊,会什么样呢?我读了假如这个数据, 借啊借,借代表是一假如是一个位移的一个变量的,一样的意思啊,就是我代表这么多数据,然后读到这里呢?之后呢?然后就是形成这样的一个,嗯,区区域分布了啊,然后首先我读的 被我读的那些东西,那些那些数据内容,是不是全部变成可丢七部分啊?也就是他左侧变成可丢七部分, ok, 变成可丢七部分,然后他右手呢,怎么去读呢? 右手他叫 ready, 你这个词到 read, 你这个词这个部分啊,还是可读的,因为他还没读过,但是呢,这部分又是被写过的,是不是?所以呢,这个区间啊,代表可读的还是可读部分好,然后剩余的咱们这个还是一样的, 还是可写部分啊, ok, 然后第四种情况什么意思呢?第四种情况的话,就是当我这个口丢记部分,也就是被我读过的这些部分被听力之后啊,会变成什么样呢? 好,变成这样子,首先 ready ins, 因为他读过的数据啊,全部被丢弃教了,所以呢,你这个时候啊,你知道 ready insalex 啊,还是变成零了?又会变成零了,是不是?好,又是变成零,然后呢?我们这 ready ins 变成多少呢? 因为他这个位置就相当于本来是这里面的十个空间,是不是十个空间,然后这里面你丢弃部分是占三个,然后是在十个减三个等于七个,是不是?那么我这个 ready 你那个词是变成七,好,相信呢,到我们这里面的话,就是我丢弃了这个界部分, 借借代表是,嗯,借借位置的一个读的内容啊,就他大家把他理解人数左啊,就零到借的这个内容被丢掉了啊,丢掉之后呢?然后 瑞的肯定变成零了,变成零了,就这一部分抹掉了,这个变成零了,然后这个 i 啊,本来这个长度是 i, 是不是?所以呢?这里面可写部分的开始位置就是 i 简介是不是?然后瑞你这个词,瑞你这次这个区间部分就叫可读部分,然后这个 i 简介后面到 cos 底这个部分就变成可写部分,好, ok, 这个是彼得巴夫的一个工作的一个原理啊,好,大家可以,这个大家可以掌握一下就好啊,掌握一下就好,然后呢也理解一下他和那个彼得巴父的一个区别啊,大家掌握这些就好。好, 今天这个内容啊,就给大家介绍到这里,然后我们下节课我们就来一个比较实战性的一个内容啊,就是我们去会去写一个咱们那个,呃,聊天室系统啊,聊天室系统简单啊,简单版的聊天室叫不能生产环境需用啊,只能借鉴思想啊。 ok, 我们看一下,首先给大家预告一下,预告一下呢,这这里面呢?他这里面有一个那个服务端回 啊,大家和那个我发过的一些数据啊?好, ok, 然后他这里面会一个相当于一个群聊的一个效果啊,就是你连接的都有客户端,进入之后呢,他的消息都会群发给别人啊,是聊天室啊,不是单聊啊,单聊的话我们后面的话,有机会我们会去写一个咱们那个聊天。 嗯,一个爱爱们的爱爱们跟咱们聊天啥是不一样的啊?好,他需要更多的一个设计。好,今天内容先到这里,谢谢大家。
18乐哥聊编程 02:00
02:00 02:11查看AI文稿AI文稿
02:11查看AI文稿AI文稿咱们今天分享一个勾当当中容易踩坑的地方, bit 跟 ro, 通过表面咱们可能会发现它们是字母类型的不一样,那么如何直观的感觉到它们不一样呢?在 go, go 当中,咱们可以通过 false 循环就能够直观的看到它的区别, 它们两种的表现形式在勾当当中其实是根据 false 循环的不同体现的。嗯,咱们先定一个字母串,比如说 go 编程, 然后咱们先写 beat 吧, beat 这个类型,嗯, beat 它在勾浪当中,它的范围是零到二百五十五,它是正的那,但是它在其他语言当中也可以表示成负到正的这个区间,但是它的整个长度还是那个零到二百五十五这个长度。呃,咱们直接打印吧。咱们, 呃,这个是,呃, for i 等于零,然后巴拉巴拉写条件,然后 i 加加这个打印出来,它其实是 bit, 然后咱们通过另一种打印方式,通过 for range 这种方式进行打印,它出来就是 round 这个形式了这个格式了。 呃,在勾当当中我们主要有两种编列方式,就分别是这两种,第一种是 for i 等于零,写个条件写个 呃,取完这个条件之后它怎么样变化?第二种就是 forward, 这种是比较快速方便的,但是通过这两种循环,通过这两种便利出来的东西,它的类型其实是不一样的,咱们可以验证一下。 呃,会发现最开始这种,它的类型是用 int 八它的,它的长度是可以到达,呃,它的缩影是到了七,长,长度就是八。第二种的话,它的缩影是到了五, 它的本质其实就是 int 三十二,但是需要注意的是它其实三十二位都没有占满,二十一位就可以把这个 wrong 这个东西给它占满了。呃, wrong 它在其他编程语言里面有其他的表述的方式,这个需要注意一下。 呃,但那个,但是 wrong 这个东西它已经是那个呃 uncle 的 它的最大的一个表示了。
23zg 00:44查看AI文稿AI文稿
00:44查看AI文稿AI文稿ai 刚挖出 linux 史上长达九年的漏洞, copy fail, 二零一七年以后的所有发行版全部中招。这个漏洞它有多离谱?提前脚本只有七百三十二个字节,它通过仅四字节的内存写入改写了系统页缓存,实现了从普通用户导入权限的无感月签。 最阴险的地方在于,它只改内存,不碰瓷盘。你拿安全软件扫文件,哈西只完美匹配,完全没爆毒。但其实系统的提前程序早就被它在内存里改掉了,而且容器也不能幸免。容器虽然隔离了空间,但共享的是宿主机的液缓存,这打破了以往容器安全的标签。如何防护 升级内核或完全禁用 i g f i 的 模块?目前这个提前脚本已放出,想了解自查方法,判断设备是否受影响的,可以评论区留言交流,关注我。哎,不落伍。
2099程序员雨未凝 02:18查看AI文稿AI文稿
02:18查看AI文稿AI文稿弱电系统千四连,什么故障最影响你体验?评论区留言,下期为您揭晓答案!为什么运营商的一千兆宽带实际下载速度只有一百多 mb 每秒?一个视频给你们讲清楚,就比如文件大小一 g b 等于一千零二十四 mb, 一 mb 等于一千零二十四 kb, 其中的 g b mb, kb 中的大写 b 代表 的是字节。大部分人分不清大写 b 和小写 b, 实际上它们都是计算机数据的表示单位,也就是大写 b 字节和小写 b 比特。 其中比特是计算机中最小的数据单位,它的值只能是零或一。为了让你们好理解,简单来说,比特是虚拟的,没有办法能呈现出来让我们看到,而想让我们看到就 只能进行换算。就比如把流量单位比特换算成存储容量和传输容量单位。字节在计算机中以任意形式的文件呈现出来,字节是计算机信息计量的基本存储单位,同时为了能够表示更多的字母,采用了八个比特,也就是一个字节包含八个比特。 什么是阿斯基编码?有兴趣可以自己去了解,我们这期指教怎么换算。既然 e 字节的文件就等于流量中的八个比特,也就是 e 字节等于八比特,那么运营商一千兆宽带实际表示方式为一 g b p s 或者一千 mb p s。 而下载文件的时候转化成字节的方式呈现。换算过来的理论最大下载速度 就是一千 mb p s。 除以八比特等于一百二十五 mb 每秒,那为什么除以八可以得出理论最大下载速度也就呼之欲出, 其实就是将一千 mbps 中的小写 b 比特转化为大写 b 字节,从一个虚拟的没有办法能呈现出来让我们看到的小写 b 比特转化为一个计算机信息计量的基本单位大写 b 字节。那为什么我的一千兆宽带下载,就连一百 mb 每秒的下载速度都不一定有呢? 其实在我们下载数据时,对于网络而言,都是由无数个数据包组成,这些数据包从服务器或者其他人的电脑上出发,会经过多个网络节点,穿过很多个网络设备,最后进入你家的光猫和路由器,被分发到你的电脑。而这些数据包每经过一个节点和网络设备,都可能因为设备的性能、带宽等各种原因产生损耗, 甚至相互连接的网线和光纤都会产生损耗,优包延迟等,这些都可能导致数据包损失数据。而且数据包的开头和结尾也有用于进行数据校验和安全认证等非下载数据战略。所以因为这些多重因 素,你的千兆宽带很难跑满。速度感觉学到了,那就点赞加关注,下次更新不迷路,点个关注再走吧!
 02:27查看AI文稿AI文稿
02:27查看AI文稿AI文稿what's the daddy you ready one in this morning, yet actually you get to fight never see your hands up in the air。 回来吧回来吧回来吧! one two one two three let's go。
208电子音乐 02:47查看AI文稿AI文稿
02:47查看AI文稿AI文稿你家一百兆比特每秒宽带为什么下载只有十兆每秒?你有没有遇到过这种情况?装的是一百兆比特每秒宽带测速软件,写着下载速度十兆每秒左右,瞬间怀疑运营商是不是偷了我百分之九十的网速。 别急,今天五分钟把宽带下载速度 b i t kb mb 一 次性讲清楚。 part one, 先搞清楚宽带到底是什么?我们平时说的一百兆、两百兆、一千兆宽带,这个兆不是你理解的每秒一百兆文件, 它的全名是一百兆比特每秒。重点来了,这里用的是 bit, 不是 bit。 你 可以把待宽想成一条高速公路,待宽等于公路有多宽,同一时间能通过多少 数据小车,它描述的是一秒钟最多能传多少比特,不是文件大小,也不是你看到的下载数字。 part two, bit 和 bit 的 致命区别接下来是整个视频最关键的一点,一 bit 等于八 bit。 记住一句话就够了,运营商用 bit 计费,电脑用 bit 显示, 为什么?因为 b i t 比特通信单位 byte 字节存储单位文件大小,下载速度,操作系统几乎全部用 by 的。 举个最常见的例子, 你将是一百米宽带一百兆比特每秒除以八等于十二点五兆每秒。理论极限下载速度十二点五兆每秒,所以看到十到十一兆每秒,正常看到十二兆每秒,状态很好,看到三兆每秒,那才有问题。 part three, k b m b g b 到底怎么换算?我们再把单位彻底理顺一遍。存储单位 byte 系一 byte 等于八比特,一 kb 等于幺零二四 byte 一 兆等于一千零二十四 kb, 一 gb 等于一千零二十四兆, 这是你电脑手机 u 盘硬盘看到的单位。网络单位 bitsy e k b 等于一千比特 satu n b samadhan three book copy e g b 等于一千 n b 是 的,这里很多厂商直接用一千,不是一千零二十四。所以你会发现存储单位和网络单位本来就不统一。 part four 为什么测速和下载数值不一样?你可能还会发现,测速网站九十兆比特每秒,实际下载十兆每秒,这不矛盾。换算一下,九十兆比特每秒,除以八约等于十一点二五 megabyte per second 再减去协议开销, tcpip 头部服务器性能,路由器网卡能力。 最后看到九到十兆每秒非常合理。 part five 几个常见宽带的真实下载速度,直接给你一张人话对照表。五十兆宽带约等于六兆每秒,一百兆宽带约等于十二兆每秒,两百兆宽带约等于二十五兆每秒 五百兆宽带约等于六十兆每秒一千兆以记约等于一百二十兆每秒。如果你加速度明显低于这个水平,再考虑是不是设备或线路问题。 总结,记住三句话,以后不再被忽悠。宽带的 m 是 m b p s 不是 兆每秒。 e byte 等于八 b 一 百兆宽带约等于 twelve megabits s 很 正常。下次再有人说我家一百兆网速只有十兆每秒,你可以淡定回一句,这不是慢,这是物理。
 00:38查看AI文稿AI文稿
00:38查看AI文稿AI文稿同学录源码已经开源,代码我已经部署在了 gitlab 上,或者直接进我主页粉丝群领取即可,后续如果我有时间的话, 也会在 gitlab 上进行更新。上期视频有许多人说做了这个也没人去看,真正有意义的东西不一定每天都会打开,平时不可能一直看,但至少以后回忆的时候还有东西能留下来。主包目前买了些 nfc 贴纸, 然后让他们都贴在毕业照后面,这样子基本上每个人都可以查看。代码之中可能还有许多不完善的地方,请大家谅解。最后感谢大家的观看与使用,再见!
49无间雨.








