rvc变声器install教程

粉丝2954获赞6.0万
相关视频
 04:10查看AI文稿AI文稿
04:10查看AI文稿AI文稿我靠,大哥你这变声器给我调的真牛逼!最新优化的改良版变声器教程来了,现在再不存下,你很难再找到这么详细的变声器教程了。哦对了哦对了,其教程所使用的音色呢,是软件内的玲珑,你还在用那个会炸弹的 i v c 变声器呢?就这 你还在用连宝宝凤凰都说不清的变声器吗?啊哈,你以为自己用的很好,其实早就破绽百出了,不信你就去试一下,现在请你打开电脑,启动你的变声器, 下面测试一下。长得很拉粑粑,我走走我走走我走走,红红火火你自己听听的对吗?你看,遇到难回答的问题又不说谎话了。 现在 r v c 的 口误问题已经是人尽皆知了,只要稍微懂一点的老板让你说以上的话,你就露馅了。科技一直在进步,你还在原地踏步,那你说你的队友还怎么给你让大红呢?接下来给大家带来一款全新的变声器软件,下面测试一下咬字问题, 宝宝宝宝宝宝乌鲁鲁乌鲁鲁乌鲁鲁红红火火红红火火,是不是没有任何问题?最最重要的是这个防止口误的功能,你之前的 ic 模型同样可以使用,软件我已经帮你们打包好了,放在视频的结尾,赶紧转发给你还在用 ic 的 兄弟们来学。 软件下载完成之后,直接右键点击解压到此文件夹,跳过解压过程,找到刚才解压出来的文件,双击打开,然后再双击打开 exe 程序,登录完成之后进入编辑界面。我们先来搞定你们最关心的咬字问题, 首先点到基础设置,再点到性能设置,看到没,这个最下面的咬字算法,打开这个文件夹,我们首先要在里面放一段你自己说话的音频,大概三十秒左右的样子,原理呢就是采集你说话的声纹特征, 这样子呢就可以让编辑的效果和你说话的语气更加搭配,同时顺带就解决了你的咬字不清还有口误的问题,这是我们的独家算法,改良,全网无。第二家咬字问题解决了。那么接下来我带大家设置编辑的基础跳线, 我们返回到音频设置这里,这里有常用工具,点击这个安装虚拟声卡,他会弹出一个 excel, 我 们直接点击一下,把这些弹出来的广告都擦掉,要不我们点到旁边的工具箱, 点到这个,打开声音设置,这个时候我们先看到播放这里,它会多出来三条轨道,我们首先把上面这个跟下面这个都给禁用掉,只留中间这一个,然后再把默认设备选择为你的耳机。第二步点到录制这里面, 也是把下面这个跟下面这个都给禁用掉,只留中间这个威士密的 out 库。然后这个时候我们在嘴巴对着麦克风说话,它会有声音波动的,这个就是你的原始麦克风了。 最后我们来设置一下变压器里面的声音通道,把这些软件都插掉,然后我们回到声音设置这里,先点击一下刷新设备列表,然后看到音频设置这里, 我们把音频输入设备这里,选择威士忌音 put, 然后把监听设备这里选择自己的耳机,然后点保存设置, 最后我们点到我的声音里面,选择这个加载模型,把自己的模型加载进来,然后音调拉成跟之前一样的,但是你仔细一听就会神奇的发现,你的声音变得完全不可糊了,咬字特别特别特别清楚,现在我们来简单的测试一下。 嗯嗯嗯,哦哦哦,宝宝宝宝宝宝,完全没有问题。因为现在咬字算法所独取的音频是你本人录制的,所以你现在使用变声器的效果是更加贴合你的人声的,也就是更加自然更像真人了。 好啦,文件已经打包好了,如果你也想用这个变声器呢?那你就在评论区回复一个夏天变身,我看到的都会回复,拜拜。
8773夏天变声调试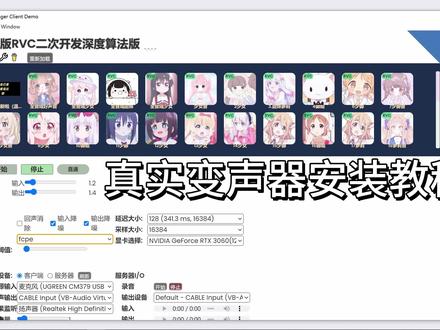 02:27
02:27 04:35
04:35 04:09
04:09 07:23查看AI文稿AI文稿
07:23查看AI文稿AI文稿今晚这视频教你们使用 r v c 变声器,如果你对变声器感兴趣的话,那么就请往下看。 r v c 变声器是需要结合声卡和拍摄环境的,如果没有 实体声卡,可以用虚拟声卡 matter 代替。可以打开浏览器,然后去找到这个 vs matter, 直接去下载就行了。点到 vs matter 这个官网里面去,在 vs matter 里面去下载这个专业版的, 在这里往下滑,这有个大脑子,下载谁下载好就行了。然后拍摄的话就也是一样的,去搜索拍摄,然后进入到拍摄的官网里面, 然后在这里 download 去下载你对应的信用版本就行了,一般都是下载 windows 的拍摄的安装,在我的往期视频也有讲过,可以自行去看,不会的。而 rvc 是一个免费开源的一个软件,主人在电脑上面使用,经过迭代更新,目前已经支持 a 卡, 可实用了。可以在 github 的官网上面可以看到它有英伟达的工版安装包和 amd 的工版安装包,你在 github 官网里面直接搜这一串东西就行了,你就可以找到这个。在这的话我推荐你们用 n 点不下载,或者说哎点不下载,这样子下载速度比较快一点。跟着他们这个网站上不去的话,可以在我的粉丝群链接里面去取,也可以在我的主页上面 可以看到绘制地址。安装猫下的之后,之后它是一个压缩包,你需要给它解压出来,解压出来之后你可以进入到这个文件里面,然后往下滑,在这里有一个 ui 启动程序,双击这个启动程序就可以运行起来, 运行起来之后是这样的一个界面,这是公版的一个喵经过美化的一个简版的这变声器,它是自带的四个模型,够你去使用 用的,在这个模型文件夹里面是有模型的,然后第一个 pth 文件的话,就是选择这个里面的随便一个文件,比如说第一个,然后选择打开,然后第二个是一个声音首页文件 点击,然后又选择相同的名称的,然后这样打开,这样模型就选择好了。下面这个是输入输出设备,这里输入的话是选择你的麦克风的一个地址,比如说你是电脑上自带的麦风的话,就得选择 麦克风,这里如果你是耳机的话,就要选择耳机的,然后必须是 me 结尾的,你选择这些,其他的是没用的,这是一定要注意的点。然后下面的输出设备这里,这的话就建议大家直接选择这一个 虚拟声卡 input m a m 结尾的,不要去选择其他的,这方便后面要操作的东西,但响应预则就要默认拉到 负六十就行。音调的话男变女就是正常的十二,女变男的话就是负十二,同性变音的话就是零的。左右下面的 index 就是一个音色滑块,你拉的越高,那么你输出出来的一个变声过后的音色就跟你的模型音色就会更像, 拉的越低就伤害是没有变身,一般来说拉到零点五以上,九点零之下就行了,下面的高音算法的话, 直接无脑选择最后一个就行了,材料长度是一个计算速度,你拉的越低,那么你的颜色就会越低,但是相对你的配置的话 也是非常有要求的,如果你拉的是变出来的效果会卡,那你就往高出来一点,下面的近程数的话就保持他的一个默认就行了,不用管单除单数强的话也是保持默认就行了。这个额外推的时长的话不能拉的太高,你拉的太高的话最 显卡的一个压力就比较大,另外来说给他到一左右就行了。全部都设置好之后,就可以点这个开始转换,等待这边的命令框把代码跑起来,好,现在是一个正常跑灯状态,然后下面这个推移时长,这里就有数值的跳动,可以用证明点击这个正常的运行,然后再去找到你的 信神卡,他是一个 b 开头的,然后去选择这个六十四位的就行。你们第一次安装的话,他不会跳出这个面板的,他是你安装过后,过了一个月之后他才会跳出这样的一个面板,这的话你等他下面的道具是跑完之后,你就给他擦掉就行了。在这个面板中需要调的 数值并不是很多,前面的这五列都是麦风的推子,一般来说的话会方便,都是用第一个点击一下这个上面的去选择你的一个麦克风就行了。他每 每一组麦克风都是有两个驱动,随意选择一个驱动就行了。如果你发现哪一天你的驱动变成红色的,而且还在跳的话,你就可以给它换成另外一个驱动,换成 mme 或者是 wdm 的。 再到这边的话这个 ae 这里,这是一个输出的一个驱动选择,这里也是每一套设备都有两个 驱动,和这边的麦克风的是一样的,选择好就行了,然后往下走,这里的这三个是输出的区域,当你把 a 点亮之后,这里面所有的 a 都代表的是耳返和监听的一个意思, 所有的 b 一都代表是输出的意思。当你把 a 一点亮之后,那么你就能听到你变声过后的一个声音效果,当你把 b 一点亮之后,他就会输出声音到你的语音通话中,这旁边的麦克风也 是同理,这边的 a 也是监听,然后 p 也是输出到语音通话中,在第三个轨道,这上面的 a 是代表的是也是监听的意思,但这边是属于媒体的一个音量, 比如说这里,比如说你运行一些听歌软件,那么都会在这里显示出来。你需要把这个 a 点亮之后,才能在电脑上面输出声音, 否则是没有声音的,这个面板就只有这么多。然后就是关于最重要的跳线的部分,你需要打开设置,在设置里面找到声音设置,在声音设置中,你需要跳线的话,那么这个输出的话,你要选择这个虚拟声卡 vl 三 input 这个这里选择好之后再输入这里,这里的驱动要选择这个区域声卡 output 这里,这样选择好之后才是跳线成功。其他的软件就可以通过变声器 输出声音了,下次微信打电话就可以使用变声器的声音去输出声音。但是有些软件是需要二次跳线的,比如说 qq, 我这里以 qq 为例,给你们演示一下该怎么跳线,我先把 qq 登录上去,然后点击 qq 下面的设置,进入到他的语音设置里面, 这里微笑二三讲往下,好啊,找到语音视频通话这里,在这里的话他的麦克风是要进行一个二次跳线的,就和系统的设置是一样的,这的话也是需要选择 output 这个训练声卡,然后扬声器的话 就要选择这个 viao 三的这个训练声卡,这样设置好之后在 q 里面去进行发语音或者是打电话,才会使用到这个变神器需变出来的声音,然后所有的媒体都是通过这个训练声卡面板来控制 音量的输出和音量大小的。另外一个 rvc 版本是我自己美化过后的一个 rvc 版本,也是可以进入粉丝群里面去领取的,这就是美化过后的一个变声器版本,如果有需要这个 美化过后的版本,可以进群自己去领取。它里面的一些设置跟公版的设置是一模一样的,没有变化,只是把界面做的比较好看了一点。 美化之后的模型是全部都要放在这个 models 这个文件夹里面,这里面是专门存放模型的一个文件夹,你每个模型需要给他单独建立一个文件夹,方便回内,这是要注意的一个点,然后所有的,然后变质的所有操作就只有这么多,兄弟们可以自己去尝。
5.7万大叔and小淑花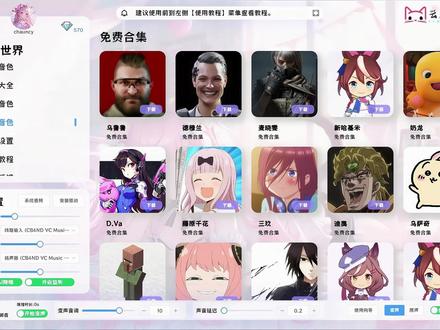 00:34
00:34 07:20查看AI文稿AI文稿
07:20查看AI文稿AI文稿哈喽,大家好,现在这一段声音是大家平时听到我原本的声音,这一段声音呢,是我用朋友的声音炼制的声音模型,接下来这一段呢,是我家楼下大爷的音色,接下来这一段呢,是我用自己的声音推理出来的歌曲。 没错,今天我们来分享一个关于训练声音模型的技术。其实训练声音的模型很早就已经接触了,但是一直没有准备做教程来分享,因为呃声音的训练和推理就像是这个二维码一样,都是比较敏感,容易在很多诈骗的场景被使用我所以我基本一直是自己来自娱 自乐一下。但是呢,前几天做了一件事,让我感觉这项技术其实可以拿来做很多非常有意义的事,比如说把家里人的声音训练成声音模型,或者是把照片训练成 sd 的模型。在一些非常遗憾,人力不可抗拒的情况下,这样的赛博飞升其实真的是非常有意义的。所以今天准备跟大家分享这个呃 有趣的技术吧。我们接下来进入正题,开始训练之前呢,首先要跟大家讲一下,这个软件其实还是利用 gpu 来训练的,所以对显卡有一定的要求,经过我的测试,应该是二零系的显卡基本都没问题了。 当然我们的显存尽量要大一点,最低最低最低应该是要六 g 甚至六 g, 我估计可能是训练不了模型,但是你可以用已有的模型来推理,保险一点的配置应该是八 g 的显存。首先呢,我们需要下载这个软件,软件的名字叫做 rvc, 这也是一个大佬基于这个技术原理来集成的一个这种 ui 界面,类似于 s d 的 y, 大家如果想去了解更多的这个使用知识,可以去 b 站去关注一下这位大佬,这个软件呢我也放在了链接当中,大家可以自行去下载, 下载完之后呢,我们把它解压出来,解压了之后我们打开下面这个 r v c, 在里面呢,我们找到有一个勾 v 点 b a t, 我们双击打开这个,这样的话我们就到了 ui 界面,这个 ui 界面里面呢,我们其实只要用 其中的两个功能。首先第一部分先教大家如何来训练我们的声音模型。首先需要准备素材,这个素材集呢,根据我的经验,我们需要准备至少 十到十五分钟的纯人生的素材,这个声音的质量是越高越好,而且不要有杂音,不要有混响。如果你没有专业的录制设备,其实我们现在的手机录音在一个安静的环境下就可以做得到。然后素材量呢,理论上是越多越好,但是一定是要在保证质量的前提下,呃,然后素材要注意的第二个点就是,如果我们训练出来的模型是想让他更多的用语说 话,那这个时候我们尽量就录制正常来说话沟通的这个声音。如果我们是想用来推理歌曲,想用来唱歌,那我们尽量素材就是我自己清唱的声音,不用担心唱的不好或者跑调,因为他最终训练的是我们的音色,但是尽量的要覆盖到高中低音,如果你的唱歌的声音里面全部都是低音, 或者你用纯说话的声音推理歌曲,他就会产生一些这种电子音或者是一些哑音的情况。当我们准备好了这个素材之后,接下来我们进入到这个 web ui 的训练界面里面。首先第一个部分,我们要给这个训练的模型起一个名字,然后呢这里的目标采样率我建议大家就保持默认,然后呢模型是否带有高音指导, 我们也是让他默认保持打开的状态。然后接下来版本,这里啊建议大家都是选择 v 一,因为 v 二目前不是特别稳定。然后最后这里呢就是除了在使用 gpu 处理的情况下, cpu 也可以辅助我们完成这个数据的处理,这个地方我们尽量给他拉满了,相对处理的会更快一些。第二步 这里我们要选择训练的文件夹路径,也就是说我们要把准备训练的声音素材,这个素材可以是一整段的,也可以是多段的,我们把它放到一个文件夹,然后呢复制这个文件夹的路径,然后粘贴到这里。然后第二步的其他所有的部分全部都是保持默认。接下来呢直接进入到第三个步骤,来填写一下他的训练设置。 首先我们先看一下总轮数吧,根据我的测试状态,如果你是有十五到三十分钟的素材,那么我建议这里的训练轮数是二百轮或者到三百轮,总轮数是二百轮。如果我们是五轮保存一次的话,那最后就会得到四十个模型, 其实没有必要的,所以这里建议我们改成每二十轮保存一次,这样最终我们就会得到十个模型来从中挑选。然后呢这里相当于一个并行处理的数量,这个越高的话处理的就会越快,但是越迟,我们的显存这里的话,它会自动根据我们的显卡来确定,我们保持默认就好。然后这里呢是说我们是否保存最新的一节是一般空间,也就说无论你这里填了多少, 如果你把这个勾选的话,他最后只给你保存最新的这个模型,我们当然是要选择否了,这个部分我们也可以给他选择否,然后最后这里是否在每次保存的时间点将最终小模型保存至这个文件夹。我们这里要选择是因为最终训练完的模型,我们要在这里找到他,接下来其他地方全部保持默认,然后我们点击 一键训练,这个时候我们就看到后台这里已经在处理,包括前台他正在处理数据,这里我们需要耐心做一个等待,做演示,我这里就不训练完了。训练结束之后,我们会看到一个英文单词 successful 的字样,就代表成功了,然后最后在结尾的时候,他会有一个二三三三三三这样结尾。当他整体训练完了之后,我们进入到这个 rvc 的这个根目录下面,然后我们在这个为此这个文件夹当中就可以找到我们训练完的,比如说这个是之前我训练过的,他就会显示,呃每一轮保留的一个模型,这些就都是我们训练好的模型。训练完之后,再当我们打开模型推理的时候,我们在下拉菜单 中就可以找到刚才训练的模型,到这一步我们的训练就结束了,那如果我们正常自己使用,其实在下拉菜单中找到进行下一步的推理就可以了。那如果我们想把训练好的音色分享给别人来使用,在 哪里找的?首先第一个我们需要把这个位词当中这个模型给他复制出来。然后第二个我们还要在这个 logs 里面找到我们刚才训练的这个音色,在这里面呢我们会看到非常多的文件,我们要找到其中的两个,一个是以 n p y 结尾的这个文件,另外一个就是上方的这个音 desk 结尾的这个文件,这三个文件组成了我们完整的模型文件。那第二步我们如何来进行声音的推理呢?首先我们需要把模型放到我们文件夹当中的位置里面, 然后在推理音色这里我们就可以找到刚才放进去的模型。我给大家展示一下,如果我们用这一首歌来做推理的话,首先第一个我们一般下载的歌曲都是带伴奏的,这个时候呢我们就要把伴奏跟人声 进行一个分离,这里呢推荐一个简单的工具,这个软件呢我也会把它放到链接中,他的使用其实非常简单,打开之后呢,我们直接选择他的输出路径,确认输出路径之后呢,我们就把这个想要分离的这个音乐给他 进来,处理完之后,在这个输出目录他就会生成一个文件夹,这个文件夹当中呢 ocas 就是我们的人声,然后上面一长串就是分离出来的伴奏,我们所需要用到的是这个人声,然后这个变调这个部分, 如果我们是男生转男声,或者女生转女生,音调是差不多高的,我们就默认保持为零。那如果原音是男生转为女生模型的音色,相当于他做了一个声调,那这里呢,我们就要填写十二。然后呢,如果是原音是女生,我们要转成男生的音色,那又给他填写负十二。我们这里呢,因为这个原音 是一个男生,我的这个声音也是男生,所以就不用给他做变调。然后这个地方的路径呢,就是我们之前保存那个 indesk, 如果这个模型是别人复制给你的,那我们 就是要把它放到 logs 里面,我们给它新建一个文件夹,然后把这个 indesk 给它放进来。如果是我们自己练的就不需要了,它自动已经就在这里了。然后其他的地方我们都不用去管它,直接点击转换, ok, 这样的话最终在剪辑软件里面把伴奏跟人声合在一起就完成了,学会的话就赶紧去尝试一下吧。
1.5万大桶子AI 03:37查看AI文稿AI文稿
03:37查看AI文稿AI文稿亲爱的观众朋友们大家好,随着 ai 技术的发展, ai 变声器作为生成式人工智能技术的具体应用, 在近年来迭代出了更强大的版本。本期视频主要介绍常见的三种变声器以及各类变声器的特点。如何选择适合自己的变声器。 第一种,传统语音变声器,我们以录音频变声器为例,这类变声器是对语音信号进行处理, 通过改变变输入声音频率,进而改变声音的音色音调。音调通过预设的支架效果,可以实现模拟不同的音色,动手能力强力强度,还可以手动调节音色音调 来实现更适合自己的变身效果哦。优点就是响应速度快,资源占用低,可调节的参数多。缺点就是有一定的上手门槛,无法筛选人生。 第二种就是大饼 ai 变声器, ai 变声器如果你近期经常看直播,一定听到过这样的声音。大饼 ai 变声器作为一款免费的 ai 变声器,提供了几十种预设音, 并且无需手动配置虚拟声卡,做到了点开即用,最适合新手小白,有需求的用户也可以付费,可以付费定制自己的音色来实现自己的专属变声效果。优点就是上手门槛低,更新频率高, 预设效果好。缺点就是资源占用较高,对吃 cpu 的游戏有一定的影响,可调节的参数不多,延迟比较高。 第三种就是 rvcai 变声器, rvc 是基于 vits 统一合成系统的一款开源工具,提供了实时变声和功能,更多的外部 ui 可以使用自己,可以使用自己训练或者别人分享的模型进行实时语音变声和音频合成的功能, 同时也可以使用音频文件进行模拟训练来定制自己想要的模型。提供了多个可调节的参数来实现适合自己的变瘦效果。也可以通过第三方插件将 音频输出到其他设备,是功能最强大的变声器之一。优点就是功能强大,变声效果最好。可调节的参数有很多, 缺点就是配置要求高,上手门槛高,资源占用高,需要配置运行环境。 如果你是小白,仅仅为了娱乐大饼, ai 变声器上手最容易,并且有较好的变声效果。如果你有更高的变声要求和一定的折腾能力,则可以选择 ivc ai 变声器体验惊艳的变声效果哦。 但是如果你的设备配置不高,带不动 ai 变声器的话,则建议使用传统变声器实现 较为稳定的体验哦。本期的视频就到这里喽,感谢大家的观看,欢迎各位在评论区讨论自己的看法,后面的视频将教你如何使用 ai 创作自己喜欢的图片。
1767小污是个憨憨








