stata如何加注释
同学们大家好,欢迎来到极乐数据课堂,我是倪老师,今天给大家介绍的一款软件叫斯贝塔,它是一款统计软件, 我先介绍一下我们的课程特色啊,相信大部分同学都去网上看过一些视频,特别是连老师的视频啊, 林老师的视频其实讲的非常好,每一个视频的时长也是比较长的,内容讲的非常的细,主要是从理论然后实践操作这么整个过程来说。但是对于刚入门学习斯蒂达同学来说啊,这类的视频我还是不建议大家去看,因为 通过一个半小时的学习下来,你可能真正掌握的内容其实只有一点点,比如说你只会导入的一个数据,对吧?但是你浪费了你一个半小时。我们这个课程的特色呢,就是经练啊,比较干货,并且偏应用。 大部分同学来学习我们这个软件主要还是为了去啊做一个实证分析,然后完成你的毕业论文,或者是头一片好的旗开。 那么我们的应用其实就非常重要。这个课程啊,我们的特色就是啊,在较短的时间里,然后让你掌握斯德塔,并且能够自己去做一篇论文。 那么我们啊讲了我们的课程特色,那相信大部分同学啊,还不知道实证是什么东西,那我这边先给大家简单的介绍一下什么叫实证实证,简单的说就是去用数据验证我们的一个结论。 那怎么用数据去验证我们的结论呢?我再举一个粗俗的例子啊,比方说我们现在有一个研究主题,就是想研究饭量对上升高的一个影响啊,我们都 知道饭吃的越多,人就长得越高,对吧?这个其实就是我们的一个理论预期,现在我们去找一份数据,比方说你把全国所有人的一个 饭量以及身高的数据被统计下来,然后我们去研究这两者的关系,基于这一份数据去研究这两者的关系,并且得到了 饭量是促进长升高的啊,那你现在做的就是一个实证分析,就是通过数据去得到一个结论。好,那么 我们现在来看一下整一个课程啊,我们会讲到哪些东西啊?接下来我们所有的课程就是按照这一个思路来的,那这个思路我主要是按照实证分析的啊,一个框架给大家梳理的。那么在做实证分析之前,大家都知 知道啊,我们需要有一份数据,那这份数据我们肯定是要对他进行一个整理和清洗,不然的话你是没有办法进行实证分析的啊,除非你这份数据是哪里买来的,对吧?相信大家自己下载下来的数据啊,都是一份一份零散的,必须要进行清洗和整理。 那整理完数据之后,我们要做的就是实证分析了,实证分析主要分为四个模块,第一个就是对于你对于你前面那份数据的一个描述性统计啊,它里面主要分为五个,一个是 n 就是你的样本量, me 就是样本的一个均值啊, m i n m a x 就是样本变量最小值和最大值, sd 就是标准差,主要包含这五项指标来对你的数据进行一个详细的描述,做完数据描述之后就进 我们的第二步主回归,主回归就是去验证我们这篇文章的一个主题结论,也就是主要的结论 还是从我们前面的那个例子来说,我们想研究饭量对长身高的影响,那么你的主回归就是要去验证你的饭量对你长身高的影响是什么?是促进的还是意志的?那当然这种影响我们必须存在于一些模型去做。 接下来我们的课程中啊,会讲 ous 模型,也叫混合回归模型, fe and r e 这个叫固定效应模型和随机效应模型, gmm iv 啊,以及 did。 did 这个模型呢,其实和前面的模型差别有点大,它是一个啊,独立的模型,就是跟前面其实没什么关联啊,为什么要讲 did 这个模型?因为这个模型现在比较流, 而且他发好的期刊非常好发,所以说我把它单独拿一块出来讲。第三部分叫扩展研究,也叫深入研究, 也就是把我们的文章的结论进一步挖掘,我们验证了饭量会促进一场升高。那么如果我把这份样本划分成两份,一份是男性,一份是女性,我们去比较男性和女性之间的一个差异,也就是吃同样的饭,男的长得高还是女的长得高, 这个其实就叫深入研究啊,也就是我后面给大家列出来的一个分组回归这么一个东西。当然我们后面还会介绍更多的一个深入研究啊,就是中介效应以及调节效应。 第四部分就是我们的稳健性检验了,稳健性检验主要是对我们的主回归进行一个进一步的验证,也就是你前面做了一次,结果其实 存在一定的偶然性,不太可靠,我们让这个结果更可靠一点,就要做一个稳定性检验。稳定性检验 啊,主要是包括以下三种方式,一个是替换变量,一个是变换模型,一个是数据样本的变换。 我们前面用吃饭,用饭量,呃呃,我们前面去研究饭量对长身高的影响,那么饭量如果我们前面是用一天吃饭的次数,就是吃一次饭还是两次饭,吃三次饭来衡量的话,呃,我们可以得到吃饭的次数越多, 你的身高越高,其实也就是验证了饭量越大,你的身高越高,对吧?那么如果我把这个次数 啊变成另一个东西,就是饭量,我不用次数来衡量,用我一天吃几斤大米来衡量,那其实吃的大米的斤数越多,也其实能够 说明我们的饭量越大,对吧?从而也是验证了我们饭量对长身高的影响,就是说把次数换成了吃几斤纳米, 这个就叫做替换变量的五金星。当然我们的方法还有后面两个啊,这个在后面的课程中我们会给大家强详细的介绍。经过上面四个步骤啊,其实我们就把 整个实证分析给做完了啊。在做完实证分析之后呢,我们其实还要讨论一下文章的一个内存性 啊,内生性它是一个问题,它会造成你回归结果的一个偏恶,所以说这个问题啊非常重要。为什么重要? 因为我们在发一些比较好的期刊的时候,神高老师只要看到你的文章中没有去讨论这个内存性,你的文章一定会被 d 稿,所以说我把它单独列为一个专题来给大家进行详细的讲解。 呃,接下来就是我们显著性调整的一个专题课,因为我们理论是理论,实际是实际,真的我们去做一份实证的时候,你做出来的结果往往是不显著的 啊,基本上两篇里面就有一篇是不显著的,那这个时候你怎么办呢?不是说直接换个题目对吧?或者是重新再找一个数据去做,我们其实是可以通过合理的计量方法给他调整到显著的啊,所以说这一个专题课程呢,实用性非常的高, 到这里为止,我们整个实证分析就已经做完了,那么接下来你就是要去写你的一个 论文的文字了,那么论文的文字其实它里面也有很多的讲究,也有很多大家不了解的东西,接下来我会给大家梳理,就是论写论文的一个重点是在哪里?就是每一个 章节里面到底该怎么去写他,你的导师才会喜欢,省高老师才会喜欢,文章才会更好发。最后就是我们的一个实战训练营,就是基于我们前面学过的一些内容,我会给大家进行一些实战训练啊,来巩固我们所学的一个内容。 最后的话我再给大家看一个呃,实证做完的一个呃案例是怎么样的? 刚刚我们讲过啊,实证分为四个模块,一个是描述性,那其实这个就是我们描述性统计的一个表格做出来的样子,就是这样子的啊,其实这个表格并不需要我们手动去做啊,斯贝塔 会给我们直接输出出来,最后就是长这样。第二块就是我们的主回归,也就是去验证 x 对外的一个影响 啊。最后做出来的表格是这样子的,这个其实软件也会直接给我们说出来,通过银行代码就可以了。 第三部分是扩展研究,其实我们这里做的扩展研究也就是对样本进行了划分,分为的 state 为零, state 为一的两个样本,然后去研究这两个核心,解释变量对你应变量的一个影响是怎么样的 啊?这里其实就是做了一个分组回归。最后第四步骤就是我们的稳定性检验,也就是 啊对主回归的结论的进一步验证。这里用的方法是替换变量啊,但是这里做了两个,一个是替换了 y, 还有一个是替换了 x。 前面我们可以看到用的都是罗恩佩特的,一,这边换成了罗恩佩特的,二替换了音变量,然后前面用的都是 siri ems, 二,一,这里替换成了 siri rms, 二, 替换了你的核心音变量,这个叫替换,呃,变量的一个文件性。好,那我们第一节课就先上到这里。

粉丝1624获赞6691
相关视频
 13:01查看AI文稿AI文稿
13:01查看AI文稿AI文稿我们今天主要来说一下,当我们去做时政性论文的时候,导师或者学校要求我们去做 state 面板数据回归的时候,我们要去做的一些板块。那么首先的话就是说我们面板数据的一个适用性,它的话比较适用于我们的金融、经济、会计、统计等等这些啊,偏经济类型的这个专业, 我这些专业的话,可能,呃做这个面板数据回归的话,他的嗯通过率会稍微高一点,那么下面的话就是做这个输了面板回归的这个主要内容。咱们这一次的这个 呃视频的话,主要是针对我们的这个说论写作的啊,主要是针对写作内容去进行的一个说明。那么我们写作内容的话主要分成这以下八个板块, 第一个描述性,第二个多重贡献性,三相关死模型啊。到第八个,那么我们针对每一个板块进行一个简单的说明。首先就是我们的描述性分析这块,我是截了一个已经发表的这个论文,那么这个文章的话,呃,我们看一下描述性分析,一般情况下他的这个模式就 下面这个图表,哎,他第一列就是咱们的变量,第二列是个数啊,就是你收集了多少组数据,然后我们一般情况下去标注的数值就是极大、极小和均值标准差,那么通过极大值、极小值还有我们的均值的话,我们大概就能知道这个变量他目前处在哪一个。呃,分级上, 比如说我们这个 to be q 值,他指的是这个企业绩效,那么我们看最小值零点七,最大值十三,他的均值在百分之,呃在二,那就说明我们所收集的这个研究对象,他整体来讲企业绩效是处在较低水平的,对吧?他二和零点七,呃,零点七和十三,哎,我们去去取他的均值的话,可能在七左右 啊,六左右,那么呃实际上他的均值在二,那他远远小于我们理论上算出来的均值。所以啊,这块的话,我们可以通过这种就是比较简单的方式去描述一下。那么标准差的话,他指代的就是我们说了我的整体他处在一个中等偏下的水平,那么各个企业之间的差异大小情况是怎么样的?我们就从通过标准差去进行一个说明,标准差 他越大,说明各个企业之间的波动程度越大,这是这个描述性分析。那么描述性分析他的目的主要就是去说一下我们整体收集了一份数据,那这个数据假如说我们是对企业去进行描述的,那我们收集了这些企业的分布情况,大致一个怎么样的一个情况?有没有一些极端值? 比如说这个透明 q 值,我们都知道企业绩效,那如果说我有一个极大值,他是几千或者几万,那可能这块就有点问题。我们通过这样子简单的一个排布就能够看出来我数据第一个我数据有没有问题,第二个我数据的这个均值情况,他是否符合现状啊?跟现状去对比一下,如果跟现状严重不符合的话,那也说明我们的数据是有问题的。 所以这块的话就是去简单看一下数据的分布情况,看一下数据是否贴合实际情况,那么我们做描述性分析代码的话,这是一个呃简单的代码,然后第二个的话就是多重贡献性检验,这个的话,嗯,其实有一些争议,就是有些人觉得呃不应该去写这个多重贡献性,就没有必要去写,有些人他又觉得这个多重贡献性 他是呃比较有必要的,那么我们在这块的话就可以根据实际情况啊,就是说如果我们你可以看咱们学校呃历年来的一些文章,他有没有写这个都是关键性,如果没有的话,那咱们也可以不写,如果有的话我们就给他加上,或者后期导师要求加上的话,我们就给他加上。 那么这个多重贡献性的话,他的本意是想去说我所选择的这几个变量,他的多重贡献性就是他的,他们之间没有一个强相关性, 那呃啥意思呢?就是说假如说我选了 x 一到 x 七七的变量,那如果说我 x 一和 x 二它们两个的这个相关性非常强,比如说 x 一和 x 二相关性零点九几, 那那是不是就说明 x 一和 x 二他们所解释的东西啊?有百分之九十的这个信息都解释的是同一个,那我 x 一 x 二保留一个变量就可以了,对吧?那多重贡献性的话,他其实就是去呃降低因为变量和变量之间相关性太高而导致的。对,最后我们的回归结果的一些差异,那么我们通过多重贡献性检验, 我们主要是通过这个 vif 的值,如果 vif 是小于十的话,我们就认为没有严重的都是贡献性,那如果有的话,我们就得把有都是贡献性的那个值给他剃掉,然后他的代码啊,就是这个代码。 然后第三个的话就是咱们的相关性啊,相关性他的表格的话展现就是这样子,一个倒三角的形式,然后里面的这个值的话,就是我们的相关系数啊,一般是负一到一之间,那这个相关系数的话,嗯, 也是有一些问题,就有些人觉得相关系数是不是越大越好,或者啊负向的越大越好,其实这个值的话就是多少就是多少,我们主要看后面的这个显著性。当然如果你的相关性太大了,他并不是一件好事。就我刚才提到的,如果相关系数,就你的所有变量之间的相关系数,他都非常大,比如说都大约的零点八、零点九, 那么我们就可能啊变量之间存在这个严重的贡献性,哎,导致你后面的结论可能有问题。那么我们一般的这个思路就是我先做一个相关,然后我通过相关发现,哎,我的这个系数啊,我的相关系数的话,他都比较正常,就是,哎,零点几啊,零点一, 一级,二级啊,三级啊,这些其实都正常的啊,如果没有那种满天都是零点八、零点九或负的零点八、零点九,那么我们就不用做,都是贡献性。如果你满天都试的话,你就得做一下,看看要不要去提出变量, 这是相关性分析。然后这是他的一个代码啊,这个代码简单说一下,这个前面的这个的话就是他的命令,然后后面这个变量的话,就是你要做相关性的所有的变量,把他的名字给他打上去,然后销会说啊,他就会输出来这样子的一个表格。 然后接下来的话就是我们要做回归分析,那么相关性分析论初步论述了两两变量之间的一个相关性,那么我们要进一步去论证因果关系的话,是要去通过回归分析。那么面板数据和洁面数据不一样的点就在于我们在用 面板数据去做回归的时候,是要有一个检验的,就是面板数据他有三种模型,第一个模型叫做固定效益模型,第二个叫做随机效,第三个叫做混合效益模型。那么这三种模型的话,并不是说我预先一开始我就知道我要用哪一种模型,然后我就直接用,他是要根据我们的数据去进行检验,然后 得出来我的数据最适合于哪一种模型,它是这样子的一个思路。那么对于我们经济学来讲的话,我们一般情况下用到的模型最常用的就是固定效率模型, 然后对于一些比如说,呃,心理学呀啊这些这些专业的话,他可能就更常用到的随机效应模型啊,最少用到的就是咱们的混合效应啊,如果用混合的话,那其实可能就说明我们的这个面板数据他,嗯 啊,这个不太适用于啊,不太适用于去做一个面板数据了,所以在这块的话啊,有一个这个模型检验的这个图,这个图的话就是我们分别要做的检验,然后这个 f 检验的话,我们只带就你做 f 检验,可以从这两个模型里面去挑出来一个你,我们就发现这个检验他只能从凉凉里面去挑,所以 我们要从三个模型里边挑出来一个最适用于的模型,最适合的模型的话,我们至少得做两次检验。那比如说我先我一般的,我们一般的常规速度,因为咱们是固定小于模型,就是这个 f e 模型,这个是固定小于模型,然后这个 p o l 是我们的混合 r e 的话是随机 效应模型,那我们一般呃选择的是固定效应模型,所以咱们的顺序就是先做一个 f 检验,那么做 f 检验我们显著呃这个 f 检验的这个结果通过了,那么我们就说我在呃固定效应和混合效应模型里面选择了固定效应,但是随机效应我们还没有检验,所以我要再进行一个 hostman 检验, 进行下面的这个笔检验,那么下面的这个检验就能从固定和随机里去挑出来一个。当你的 f 检验和 hostman 检验同时都通过,就是 p 值小于零点零五的时候,我们就选择固定。当你 f 检验通过, hostman 检验没有通过的话,我们就选择随机啊,这是这个,然后分别呃下面的话分别就是它的两个代码, 然后这块有我们需要改的就是这个 y 指代的就是咱们的音变量, x 指代的是自变量,到时候我们要把对应的自己的 y 和 x 带入就行,下面也是一样的, y 和 x 是要变的,其余东西都不用变。下面的话就是咱们的回归分析啊,或者说啊回归分析里面我们包含一些中介机制呀,调节机制的检验,那么我们一般会把表格做成这样子的一种形式啊,做 这种形式,然后他的这个,嗯,代码的话,我们就在这边啊,一般情况下我们选择固定效应模型的话,就上面这个代码,当然这个代码的话,他他并不是说唯一的这个代码是最简单的一种代码,就我们直接一看我大家就能记住了,哎,这就是做固定效应模型的一个代码,那么如果我们想通过代码把这个输出的结果,因为他用这个代码输出的结果,嗯,非常的这个 就是不像,不像这块这么美观啊,不用你再去调整啥,你这个做出来的那个表格的话,他还需要你后期进行整理,整理成这个样子,所以啊,这个这个代码他就不是唯一的,我们还有一些其他的代码,但是比较复杂一点,他能够帮助我们去把表做成这个样子啊,这是我们大概了解一下, 这是回归分析,那么回归分析的话,我们主要就是去解释在这一块的时候,他就跟相关系数,相关分析那块不一样了,那我们通过相关分析可以简单的去描述一下边两两两之间的一个相关性,那么在回归的话,你就重点得去解释一下我们的回归系数是正的还是负的啊?是大于零还是小于零,然后解释它的显著性是 在多少的水平下显著,对吧?然后括号里的值,我们一般把它叫做呃 t 检验的值,这个值其实跟星号他们两个所代表的呃就是他们俩,他们俩所所展现的内容其实是相同的,都是在说我得到的这个回归系数他是显著的, 然后呃基本上星号和这个 t 值是呃对应关系啊主,然后如果,比如说我们自己的数据呃不太显著,然后有人把这个数据给他改了,哎,比如说,比如说这个值对吧?负的零点五六二六,那他本来是不显著的,然后我们呃可能有些人把它改成了显著,然后他下面的 t 值没有改那么一眼,那就是咱们了解 stata 的人一眼就可以看出来这两个是不对的啊。这是这个回归分析 下来的话,就是咱们的一个稳健性,检验稳健性的方法非常多。啥叫稳健性呢?就是我用另外的一种方法去验证一下我刚刚得到的这个结论是不是正确的,或者说我得到的结论是不是一个偶然性的结论。那么我们稳健性的方法的话,就比如说最常用的替换变量法,第二个的话就是改变呃 年份,就比如说你原来研究的是呃一零年到二二年,那我现在把它改成一五年到二二年,再次做上面的回归,看一下结论是否一致。那么替换变量法的话,顾名思义就是把我们某一个关键变量的量化方式给他换掉,那么咱们一般替换变量主要是替换音变量, 因为应变量是贯穿始终吗?不管你哪一个分析,他应变量都要参与,所以我们一般就把这个像这个企业绩效,他原先用的是这个 topico 值,我们就可以把它换成比如说这个企业的资产报收率啊,企业的净资产收益率啊等等这些指标。那么把这些变量换掉之后,我再一次去做上面的这个回归,看一下结论是否有差异 哦,但是要注意的是这个结论是否有差异,并不是只代到我的回归系数一定要相同,或者我的显著性一定要相同,这块指代的就是我所用两组数据做出来的结果。哎,他的正负性是否一致啊?他的显著性是否都显著,不用去管那一颗星,两颗星还是三颗星,只要他都显著就行,这是稳健性。嗯, 我们先从这个内生性检验的含义来讲,他就是说这个模型中一个或多个解释变量与误差项存在相关关系,那么说白了,这个解释变量就指的是咱们的音变量字变量,误差项指代的就是我们对音变量有影响的其他变量。那我举个例子,比如说我们去论证学习态度对对学习成绩的关系,那么 存在内生性的这个从他的含义来讲的话,就是我们的这个自变量学习态度和影响学习呃,成绩的其他变量存在相关性。如果有这种关系的话,我们就说,哎,可能会存在内生性问题, 那么呃,他并不是说,哎,他这个含义是这样子的,但是并不是说产生内生性就只有这一个原因。我们产生内生性的原因非常多,这里我们主要说 写作过程中最常遇到的第一个叫做遗漏变量。这个遗漏变量的话,其实就是在说我们文章中,因为你一篇文章研究的内容是有限的,你不可能把所有的东西都研究透,所以肯定会存在遗漏变量问题,那么你遗漏的那些变量就可能会与你的字典 有关系,就我刚才说的这个学习态度,他可能和一个我们没有研究到的,但是能够对音变量学习成绩产生影响的啊,有关系,他们俩有关系就可能会有内生性问题。 第二个的话就是互为因果,互为因果的话就是主要指咱们的呃解释变量和背解释变量,也就是字变量和音变量之间,我们理论上是认为字变量去影响音变量,就学习态度会影响我的学习成绩,但是有有很多情况哎,比如说我觉得这个例子 反过来也是可以的,就是当我的学习成绩比较高的时候,我的学习态度其实也会有一个变化,这个就是互相影响,互为因果,那么互为因果的话,他也会导致我们的内生性问题。当然还有一些其他的,我们这里就比如说一些呃存在测量误差呀等等等,我们在这块就不再去赘述,因为他呃没有办法解决啊, 就是在我们的写作过程中。然后第三个的话就是我们当我们存在内生性的时候,我们常用的最常用的办法叫做或者说呃文呃写作过程中最常用的办法叫做工具变量法,但是还有些其他的,我们这块就不过多展开。 然后我们对工具变量找寻的要求的话,有下面这两个要求,第一个的话就是要与 x 有关,第二个与 y 呃影响 y 的其他变量无关,也就与我们的残差项无关。那么这块怎么样去解释呢?就是内生性问题,我们用工具变量法去呃去检验它的时候的逻辑其实是这样子的, 是我们现在说 x, 它和我没有研究到的,但是能影响 y 的变量,它有关系,所以导致了内生性。那我现在能不能去找一个工具变量,它既能够, 嗯,跟 x 有关系,就是它既能够代替 x, 然后它又与这个影响麦的其他变量无关。那如果我能找到这个变量的话,我就可以拿这个工具变量指代我的字变量去进行回归分析,那这样子的话 就能够确保我的这个自变量就是咱们的工具变量,到时候就变成了自变量嘛,就能够确保咱们的自变量和呃残差效是没有关系的,那这样子就能够确保最终的结论他是不存在内生性的呃,但是往往呃我们工具变量的找寻的话,它的难度非常大。就是我们 如果是说论或者不是论文,甚至本科论文,如果我们要去做内生性的话,其实一般都不建议我们自己去创造这个工具变量,我们一般都是去别人的论文或者文章里面去找,比如说我还是刚才的例子,我们去验证学习态度和学习成绩等。然后现在我导师说了,这有内生性问题,你得去找一个工具变量, 我们就在织网里这两个变量作为关键词,去搜别人研究的相关文件,去看一下别人在去解决内生性问题的时候用了什么变量,我们直接照搬过来啊,当做我们的工具变量直接去进行使用就行。 下来的话就是最后一个我们的抑制性分析啊,抑制性分析的话他呃就比较简单了,他实际上就是把研究对象去分类,然后重复的进行回归分析,他实际上,呃,因为有,有时候有有些人把抑制性他叫做检验,严格来讲的话抑制性我们一般是一个分析的内容,就是我对回归分析的进一步说明,那我回归分析,假如说论证出来 这个自变量对音变量有一个显著的正向影响,那我的意志性就是我把我的研究对象给他分成呃细小的类。比如说刚才是对企业 进行分析的,那么我们把企业分成了这个江苏,把企业按照不同的省份给他分类了,分成了江苏省和浙江省,那么我对不同的省份去进行一个回归分析之后发现,哎,是不是浙江省和江苏省他们两个之间的回归结果是有差异的?那如果有差异的话,我就要去解释一下为啥这两个省之间有差异。 当然这个分类的方式的话,他并不是唯一的,也不是说固定的,我们要根据自己的研究内容,比如说你是企业,那你就可以分成国企、非国企,那如果你是研究污染相关的,你就分成污染企业和非污染企业,还有咱们的一些呃,大规模呀、小规模呀,甚至企业成立的时间等等。
4928实证分析小布丁 02:22查看AI文稿AI文稿
02:22查看AI文稿AI文稿大家好,我们本期继续讲解我们的 atml, 前面呢讲到了里面的标签语法和标签的嵌套,那今天呢我们讲讲语法中的规范。 首先呢我们在标签的区内写法中不区分大小写的,那比我们在前面几例的玻璃,那现在可以全部都是大写,也可以大小写啊,看叉写以及全部是小写都是可以,那在实现中呢,一般呢都会推荐大家的纯白的纯小写字母来实现, 那这个是我们在写法中的一个简单的要求啊,我们接下来是要纯小写字母去实现,那另外呢,我们在嵌套的过程中保持缩进,我们除了上下级的一个股市当中呢, 会统一项内四个股市的控股的写法,那这样呢,大码看起来更加的清晰,新的这是可以增加我们大码的裤堵性,一定要保持上下级是统一项内四个空格的写法, 并且呢一半呢会给大码呢添加上注视,一半呢会从可读性学考虑,比如我们注的写法是当前那个符号实现啊,我们一开始呢,大家可以输入一个鞭炮, 看好过连接符,我们实现了这个操作的期间,我们把我们的写放去,比如这个是我们的字符集, 这样呢可以给大脑增加口毒性。一般呢我们有个快捷键,可以按住仓鼠加斜杠癌症们的标题,但是在注视的体检中呢,也是有要求的,首先 注视不能签套,什么意思呢?那在当前的注里面,我们不能再签套第二个注视,如果你这么来写,再来签套第二个会出现一个错误,这是一个不能签到的斜发,记得哦, 注视不能在内部再来潜逃注视。另外呢,签名字当中啊,不能把他注视到标签的内部去填写注视,这是个要求。 那当前在我们实现后期的学习中呢,要当前的他的语法的规范,一二三点一定要去记清楚和搞明白,以及他的注视的实现和操作。那本节课我们就主要讲解语法规范,我们下期继续讲解。
 05:02查看AI文稿AI文稿
05:02查看AI文稿AI文稿现在我们讲解三零 p 二 c 程序的注视方法,我们看在这个程序里 它是没有注视的,也就是说在这个梯形图的这个里面没有文字说明,我们现在需要把这个文字说明放上去,这个文字说明对应的 x 启动停止的, 就是每一个触点符号对应的功能,我们怎么弄上去呢?有两种方法,第一种方法是单独注视,我们现在来演示一下, 点击菜单栏的编辑,然后我们点击 文档创建,然后点击软元件注视编辑, 这个时候我们看到这个位置就拉宽了,就是用来给我们写编辑的,用来给我们写注视的, 我们这个 x 零是启动, x 一是停止,怎么把它弄上去呢?我们把鼠标放在 x 零这里,双击两下,双击 x 零点两下,然后就弹出注视输入, 我们鼠标点在这里,然后在键盘上用中文输入法, 我们现在是个英文的输入法,然后键盘调整到中文输入法,打出启动两个汉字, 然后我们点确定,我们看到这个注视就上去了,我们再来 x 一再双击,再点到这里,我们在在键盘上打字停止,然后点确定, 我们看这个停止也上去了,启动和停止上去了。刚才我们讲了第一种方法单独注释,就是每一个元件一个一个的点注释,现在我们讲解第二种方法,统一注释, 我们现在来看一下在左边这个工程栏里面第三个软元件,第三个是全局软元件注视, 我们双击打开,然后这右边就多了一个栏目,我们看这边 x 零启动, x 一是停止, 然后这里还有一个 y 零和 y 一, y 零是我们再点击软元建筑师这里,我们首先这里输入 y 零, 然后回车,我们看所有的歪点都出来了,然后我们在这里打字,这个是灯一就是第一个灯, 我们再在这里打字灯二这是第二个灯,这就是统一注视,然后我们再输入 t 零, 再按键盘上的回车键,所有的 t 都出来了,我们这里输入计时器, 计时器一,然后这里我们输入计时器二, 这个如果说还有其他的计时器,我们可以一次性把它全部注视,这就是统一注视。然后还有一个 c 零 回车,这里是计数器, 统一注册之后,我们再点击这个程序,我们看一下 其他的程序,注视都出来了,还有一个 m 零没出来,我们再点击这一里,在这里输入 m 零再回车。 不灵是内部继电器,我们在这里输入内部辅助 继电器回车,然后再点击程序,这样我们看程序里面所有的注视都出来了, 我们看这个 x 零和 x 一是我们单独注视的,然后其他的注视都是我们统一注视的,这就是三菱 p 二 c 程序注视的两种方法。
599蓝羽 00:56查看AI文稿AI文稿
00:56查看AI文稿AI文稿电脑录屏软件怎么边录屏边实时注视?鼠标双击打开荆州录屏大师打, 打开后选择录制模式,这里小编选择全屏,然后还选择音频输入,边录屏边录音,根据需要选择,接着点击开始打, 打开需要录制的画面,倒计时三秒后开始录制。录制中点击悬浮框的画笔,可以对画面进行注视,可选择画笔颜色、半径,选择注视形状以及添加文字等。 注视完成后,点击刷子图标,即可一键清除所有录制完成,点击结束回到软件,点击前往导出文件,加位置查看文件,此时电脑边录屏边实时注视成功。
14金舟办公软件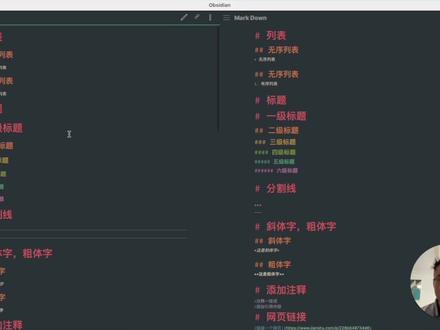 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿关于语言的设定 首先在页面左上角找到下拉式菜单, 点击设定选择关于,也就是啊, boss 在这里选择语言,我选择的呢是简体中文, 那现在我的面板语言已经变成纯中文了, 那如何进行反向设置呢?同样的,找到关于选择英文,重新启动应用, 这时候呢,我的控制面板已经变成了纯英文了。 最后呢,祝愿你尽快熟悉 fcd 人这个强大的生产力工具哦!
53明鑫 10:34查看AI文稿AI文稿
10:34查看AI文稿AI文稿上一小节呢,我们介绍了通过 ddl 语句如何来操作数据库,那么接下来呢,我们再来介绍一下通过 ddl 如何来操作数据库当中所存储的表结构。 那么首先我们先来介绍一下表结构如何查询,我们介绍三种语法,第一种语法,通过数胎报词可以查询当前数据库当中所有的表结构, 前提是你要先进入到这个数据库,先要去通过柚子指令使用这个数据库, 完了之后再通过受 tabos 指令来查看当前数据库里面的所有表。然后紧接着第二个指令,通过 des c 指定表明可以查看这张表的表结构。接下来我们还可以通过一条指令叫做 sure crater table 指定表明可以来查看这张表的建表语句。 那么这次是三种查询的语法,我们先演示一下第一种,竖黑 boss 查询所有表。 好,我们打开命令号,那么现在呢,所处的数据库是 it 黑马,这个数据库,我们可以在这个数据库当中使用数嗨 boss 来查看。 好,返回了一个信息, empathy size 一个空的集合,也就意味着我们去查询这个数据库当中的所有表。这个数据库里面有表结构吗?没有,这是我们刚才才创建出来的新的 数据库,所以它里面是没有表结构的。那么接下来呢,我们切换到另外一个数据库啊,这个里面有一个 c s 数据库,切换进来之后我们再执行是 tabos。 好,大家会看到这个里面有好多的表结构,原因是因为 s 是一个系统数据库, 对吧?哎,这个时候就看到了系统库当中的很多的表结构,那这是我们演示的第一条指令,受胎 boss 查询所有表。 那么对于第二条和第三条指令呢,我们在讲解完创建表的语法之后,我们再来验证一下这两条指令。 好,那接下来呢,我们再来说第二个方面,关于表结构的创建,那表 结构的创建语法,先来看一下,首先关键字是 critical 啊,指定表明,然后指定小括号。好,那么小括号里面写的就是这个表中有哪些字段? 首先第一个字段,哎,然后空格字段一的类型啊,那大家有编程经验的话啊,就能够联想到我们定一个变量,变量是不是有一个类型啊? 哎,那么这个就是字段的类型。好,后面方括号里面写的也是可选的, comenc 代表的就是字段的注视,这个字段什么含义 啊?然后紧接着是自断二,然后自断二的类型,然后自断二的主视信息使用逗号分割,然后接下来呢是自断三,自断三的类型,使用 逗号分格。好,然后一直到最后一个字段,注意最后一个字段完了之后,后面是没有这个逗号的。好,然后紧接着后括号后面可以写这张表的注视,这张表是用来做什么的?哎,表的一个注视。 好,那这是他的一个基本语法,那么接下来呢,我们就来演示一下,通过可瑞特胎宝这个思后语句,如何把我右侧的这一块的表结构创建出来。 好,接下来呢演示一下,打开我们的命令航窗口。 好,首先啊,我们在这一块来把右侧的这幅图我们先截出来,哎,我们先放倒 这个位置,然后接下来我们打开另两行窗口,啊,好,通过一个指令,可瑞他胎宝。但是当你在去创建表之前,先想一下当前所处的数据库, 当前是不是在系统数据库里面,哎,所以在这一块我们要使用柚子 it cast, 要切换回我们自定义的数据库,不要在系统库里面执行任意的操作。好 好切换到 ag cast 的数据库之后,接下来我们创建一张表, currita table, 然后指定表明, 那么这个表明呢?我们在这一块来一个 tb 下划线 uzer, 当然你叫 uzer 也可以啊,然后紧接着这一块使用一个,哎, 小括号,好,注意,回车。这个思口语句写完了吗?没有,因为我们在讲解思口通用语法的时候提到思口语句 写完了,后面要加什么分号,以分号结尾,对吧?哎,这个时候我们就可以通过多行来编写这个社会语句啊,一个社会语句编写多行 好,那么接下来呢?指定第一个有一个字段,看,这叫做 id 好, id 好,那 id 是什么类型呢? a d 是一个数字,那么这一块就直接使用一个硬侧类型,好,注意,然后这个字段编写完毕之后,后面可以通过 comens 去加上对应的注视,好,那么在这一块我们就来一个 comens 啊,那么这个我们就来一个 叫做 id, 或者直接叫编号好,完了之后后面逗号再走。第二个字段内啊,内幕,再来一个第二个字段类型,内幕名称。这个字段类型是什么呢? 哎,这是一个字符串,加瓦当中字符串是 szrin, 那么在 my c 口当中字符串,我们这里面用 volta, 然后指定字符串的长度,比如我这一块指定五十位,好,接下来呢,这一块再来一个注视 comements, 好,我们再来一个姓名 好,逗号好,第三个字段是 aj, 那 aj 这个比较简单,也是一个数字类型,我们这一块直接 inter, 再来一个 comments, 那这里面我们来一个年龄啊,注视年龄 好,都好。最后一个字段是性别,那这一块性别字段名称叫真的 好,那么这个里面呢,我们也使用 low 叉,那对于性别的话,不是男就是女,是一个字符,我们这一块 low 叉一,好,这一块加上一个注视 come, 性别 好,注意最后一个字段不要加什么逗号,所以在这一块什么都不用加,直接回车后面加上一个小括号, 那如果这张表你要给他加一个注视好,我们在这一块依然可以使用一个考美测。后面这一块来一个用户表,好,分好,分好就代表一条词口语句编写完毕了直接 回车,好,这样的话当前的这个数据库表 gduza 就已经创建成功了, 那创建成功之后怎么去验证这个输区库表创建完毕了呢?通过一个指令书 胎 boss 好,大家就会看到,在我们受胎 boss 的执行结果当中,有一条记录叫做 tb 下滑线悠然,那么这张表我们就创建完毕了。 那么接下来呢,我想知道这个表里面有哪些字段以及字段的类型,怎么办呢? 那这个时候我们就可以使用一个指令,叫做 b e s c, 就是我们刚才在这一块介绍的这个指令。 查看表结构来看一下 d e, s, c, t, b 杠 uzar 走好嘞,大家就会看到里面有四个字段, a, d 内幕, a, g 真的好,那么他们的类型我们也能够看到, 但是这个里面展示的信息并不详细,我们每一个字段内幕代表什么含义?哎,你看这有姓名,有年龄,有性别,是不?并没有完全的展示出来啊,哎,那这个时候如果要展示我们的详细信息,可以通过另外一条指令, shortcurita 来 sure crater table 指定表明 tb 下划线啊, uzer 走好,大家可以看到这张表的创建表的四口语句在这一块儿都已经 展示出来了,但是呢,大家还会额外的看到这张表当中啊,他所展示出来创建表的色库语句里面有一部分我们刚才并未编写,像什么呢?像 nj, 这是存储引擎,这个在我们 第二篇章 mac 股的进阶篇当中,我们将会详细讲解存储隐形的底层原理好,然后紧接着这个是默认的 dfouse 叉塞特默认的字符级 utf 八 mb 四 好,然后再往后走,靠了一次,这个刚才在创建数据库的语法当中我提到过是他的排序规则,这个也是默认的,那这两个我们可以不用指定好,那 这样的话我们就讲解完了我们关于表结构的查询的相关语法,以及创建表的基础语法。 那么这个里面呢,大家可能会有一个疑问,老师,我们刚才在创建表的时候,里面指定的印策 very 差 这些字段类型到底代表的是什么意思?那除了说印草和文差这样的字段类型,还有什么样的字段类型呢?不要着急,我们下一节课将会详细讲解。
480黑马程序员视频库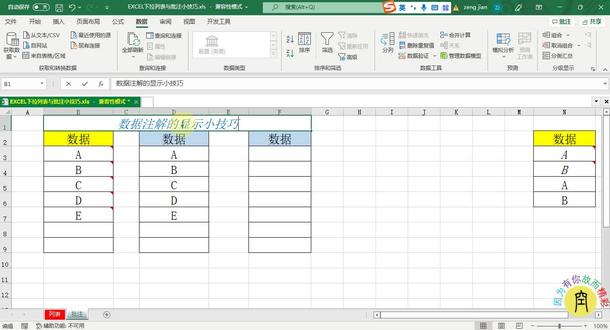 02:58查看AI文稿AI文稿
02:58查看AI文稿AI文稿今天我跟大家分享的是关于数据添加批注的一些小技巧,我们来看一下啊。 为了便于读者更好的了解我们数据的构成,我们经常为数据添加一些说明文字,当我们添加完之后呢,他会在右上角有个红色小点啊,小三角,这样会影响我们的美观好看。还有一点就是当我们的数据在最右侧的时候,我们要 点击单元格看批注的时候,他批注隐隐藏在这个框这个窗口的右侧,我们必须要把这个滑块拉过去才能查看到。我们的 这个皮柱有时候不好看,影响没关系,不便于操作。那有什么办法既能隐藏这个三角啊,红色三角,又能达到提示说明的作用呢? 方法是有的,来跟我继续学习下吧。比如像这种,我们点一下,他会弹出你好啊,他几乎会像这个批注一样显示的右侧啊,看嘛,来我点的时候,他会在这里,不会影响在旁边,他只会在当前这个列的中间区域显示 提醒作用,而且他不会挡住我们输入,这种效果是不是很好?首先我们选这种单元格啊,我们宁愿找一个地方啊, 点击数据,然后找到数据验证之前的版本,叫数据有条信啊,我们点击下它,然后在第二弹出的六号框当中,我们的第二个信息就是输入信息这里我们在标题这里,如果你要标题,你就输入一个标题,如果不要标题,那你 你就直接在这个输入内容里面输入啊,比如说啊,随便打几个字啊,随便打几个字, 如果你字比较多,你可以一行显示,你就不用换行,如果有两行显示呢?你再换行啊,有什么难行字啊?就是换行确定,然后我们点击一下他,你看他就有两个啊,就是那个意思,这样就不会影响我们的美观,他也不会挡住我们说你看他只在这个位置啊。 还有一点就是当我们在做数据有效性的时候啊,像这种他可以加那个标题,这个标题呢就是我们这个数据验证里面的这一块啊, 这个请输入,就是这个标题这块啊,内容就是说我们要输入内容,这个呢就是提示作用,不能点击输入,如果没有 制作数据下达类表,我们必须要利用数据下达类表来制作他的引用区域,或者是要输入的数据内容,在这里我们整个这个只是指到提醒作用啊,看如果没有选择输入啊,第一 你看他会自动跳,是不是很方便?你学会了吗?点个赞呗,谢谢大家。
 01:08查看AI文稿AI文稿
01:08查看AI文稿AI文稿stalk 是一种功能全面的统计分析软件包,具有一操作运行速度快、功能强大的特点。全书内容共分十七张。 第一、二章介绍 stot 操作入门级数据处理基础知识、描述性统计与图形绘制基础。第三至五章介绍假设检验、方差分析、相关分析等基础分析方法。 第六至十章通过相关案例介绍经典及放松各种假病条件的回归分析,包括基本泄性回归分析、泄性回归分析、诊断已处理、非泄性回归分析、因变量弥散回归分析、因变量受限回归分析等应用。 第十一至十六章以典型案例讲解主成分分析与音符分析、剧类分析、时间序列数据分析、面板数据分析、生 分析、多方程模型等高级分析方法。第十七章介绍如何使用斯达克进行高质量的综合性研究,讲解研究方案设计、调查问卷的制作、斯达克数据挖掘建模注意事项。
18全栈开发圈











猜你喜欢
最新视频
- 2576小小的老子