代谢组学入门工具书
啊,各位老师好,今天呢,我想跟大家聊一聊关于代谢组学的一些知识,以及代谢组学是如何在植物的研究中发挥重要作用。和植物代谢组学还在文章的一些思路和策略, 我的分享呢分为三个部分,首先呢,咱们看一下什么是代谢组学,代谢组学呢 是系统生物学中一个非常重要的组成部分,那么系统生物学围绕着中心法则包含了核算组学,这里呢包括基因组学和转入组学, 以及蛋白质组学和代谢组学。那么不同的组学在系统生物学中的定位呢,是不一样的,如果说 核酸组学是从一个底层的原因来探索生命科学的问题,蛋白质组学是从一个表层的原因来反应 生命科学的问题,那么代谢组学就是从一个结果的层面来去探索生命科学的现象。那么从某种角度上来说,代谢组学可以属于分子症状,或者我们可以称之为分子表现, 那么这也是代谢组学一个非常独特的优势。那么在这里我们找到 到了一个非常有趣的例子,那么这篇文章呢,他是对十四对体赘有体重有明显差异的成年同往双胞胎进行一个血量的分析,那么如果我们看到体重存在明显差异,也就是说 这些人他们的胖瘦都是有一个非常明显的区别的,但是由于他们是同卵双胞胎,他们的基础几乎完全性同。可是作者呢,对他们的脂质代谢进行分析发现哦,在脂质代谢层面,对胖和瘦的这种 样本来说,或者说这些呃个案来说存在了一个明显的差异,因此胖瘦的一个我们可以肉眼观测到的表型的差异,在代谢组学的层面上得到了一个非常好的体现。 因此我们可以认为代谢组学呢是更接近于生物体表形的一种组学。因此呢,我认为代谢组学就像是一座桥梁,它关联起了我们能够肉眼观察到的生物体的表形以及生物体的内在 一个发生发展的内在机制。那么代谢组学也像是一把钥匙,可以打开我们去探究生命体内在的一个规律的大门。那么由于 代谢组学呢有种种的优点,近二十年来对代谢组学的关注度呢也是越来越高的。那么这张片子呢,我们展示的是在今年七月份去以代谢组学为关键词搜索的一个结果, 我们可以看到近二十年来代谢组学的整个的文章数量的发展成一个指数增长的趋势, 那我们看到截止到今年七月份发表文章的数量已经超过四千篇,那么我们可以预见到今年年底的时候,代谢祖学的文章的数量一定是会超过去年的。 那么就我自己的理解,代谢组学呢是通过一些高通量、高灵敏度、高分辨率等等的现代分析手段,那他的目的呢,是尽可能多的去获取有用的代谢物的信息, 然后从这些海量的信息中使用化学剂量学的手段,例如模式识别端统计分析等等去提取一些有效的信息,然后呢再进行下一步的分析。 那我们下面呢就简单的从取样技术平台定性、数据库,数据处理和应用各方面呢,还去简单的介绍一些代谢组学的一个研究的思路和流程。 代谢组学在取样的重复性的要求是比较高的,那么这里呢,指的是每一组的样本的重 不幸的,一般至少不不少于六到八个以上,那么根据不同类型的样本呢,他的要求呢,还有所不同, 那么这在这一点呢,这种取样要求的重复性的是严格,是比基因组学和代谢组学的都更加严格的。那么一般来说,基因组合代谢组,呃, 基因组合蛋白质组的缺氧重复性的一般是三个就可以了,但是呢,代谢组,尤其是我们做非法苗代谢组学的时候,缺氧的重复性的要求是比较高的。那么代谢 需要关注的是一些我们内源性的小分子代谢物,这些小分子代谢物呢,有一些特点,首先呢,这些物质的动态范围较宽,我们怎么去理解这个概念,那么即使就意味着不同类型的代谢物,他的浓度有比方说低的 和高的,但差距呢,可能会很大,至少达到十个七次方的一个数量级。那么这些代谢物呢,尤其他是一些小分子的化学结构的物质,它的结构很复杂,并且呢数量是非常庞大的。那么就植物代谢 组学来说,植物呢,由于有数量庞大的自身代谢产物,那么代谢物的数量呢,会超过二十万,那因此很难实现一个全通量的高通量全氛围的检测。 那么基于代谢物的特点,我们现在代谢组学最主要使用的检测技术呢,是左边的两种色谱和纸谱连用的技术, 那么想到这里,各位老师有一些疑问,我有的时候也会在文献中看到,例如核磁共振技术 nm 二,还有一些毛细管电影制服技术 ce max, 那么这两种技术呢?呃,他呢,目前应用的不得不太广泛,其原因是在于核磁共振技术,他虽然是最早应用于大学组学研究的,但是由于他的灵敏度和分辨率都不如所布置个人技术,因此呢,现在应用的比较少。 那么毛细管电用直普技术呢,他对急性的化合物分离很好,但是呢,由于这种技术目前还不太成熟,现在呢, 研究的文章比这种研究性的这种报道更多。那么我们所见到的百分之八十以上的代谢组学的这种文章呢,都是使用色谱 直普联用技术来完成的。那么色普直普连用技术呢,它有如下的优点,首先呢,直普的检测系灵敏度很高,那么在有色普的一种分离的加持, 使得他非常适合有含量代谢物的检测,而且呢,色补应用于他的分离效率非常高,可能会使一些取补上无法去分辨的同分异构体在色补上得到一个很好的分离,因此大大提高了定性的准确多。 还有,我们直谱已经形成了一些标准化的店里模式,例如,呃,这 cmax 的标准化的 ei 源,它可以提供一个非常高处现的碎片,那么还有一些高分辨的直谱可以得到一个相对比较准确的分子式, 那么结合上是化合物的结构碎片,可以形成代谢组学专用的数据库,那么大大提高了定性的准确性和重现性,因此呢,色补之虎联用是代谢组学科研的一个首选的技术平台。那么代谢组学呢? 技术平台我们刚才可以看到哈,他是分为两种平台,一种是 jc max, 一种是 lc max, 其区别在于前端的色谱的分离 的方式是不太一样的。那么可能有的老师也会有一些疑问,我们为什么要选择两种技术平台?我使像蛋白质组靴一样,我使用一种技术平台可不可以? 那么答案是这个样子的,那么这两种技术平台呢?他的适用范围有交叉,但更多是一种互补。 例如我们看左边的这些 mac 平台,如果您想去分析,比方说植物一种挥发性的小分子物质,例如一些贴膝,单贴,背半贴等等,那么由于他的挥发性非常强,所以他只适合我们这些 mase 来进行分析。那么相反,还有一些物质,他的,比方说他的分子量比较 大啊,挥发性很差,或者说加热就会分解都例如例如我们说的一些花青素,或者呢,比方说啊,诺贝尔奖获得者这个星蒿素,那么我们想去分析这种 植物的这种代谢物的时候呢,他就适合于使用这 lc max 来进行分析,因此这两种技术呢,是存在一个互补的 关系。那么那可能老师有些疑问,那我想去分析我的样本是采用哪种样,哪种基础平台呢?那么结论还是说,根据您的样本以及您想关注的代谢物,我们来再去深一步的考察。那么这张 箱子呢,展示的是从在线通路的角度,然后来看一下这些 max 和 lc max 的一个呃适用的范围,我们可以看到哈,他们还是各有 侧重,互为补充的。那么在刚才介绍介绍到技术平台的时候,我们已经着重指出了代谢物的定性呢,是非常依赖有代谢数据库的,因此呢,我们现在市面上可见的一些商品化的数据库呢,有非常多的种类。 那么在这张表中呢,我们列举的是一些非常常见的这些 mate 和 lc max 的数据库,那么上面三种呢是 jc max, 下面三种呢是 lc max, 例如这些 mace。 我们很多的定性呢是属于腻子的库,那么这个是一个仪器自带的一个数据库,虽然话他所包含的物质的含那个数量非常多,但是呢,对代谢物的这种的解析呢,相对来说并不是很专业。那么代谢组学呢,还有一些,比方说,呃,会有 一些实验室自建的数据库,例如代谢组学的创始人阿拉伯费,他的实验室就会建立了一个废的数据库,包含了一千多种代谢物的标准体系。一, 那我们鹿鸣生物呢,在这些 max 的数据库上下了一个有自主知识产权的啊,专利的这么一个 lug 数据库。 那我们数据库的包含的类类型的是比较多的,包含了至少十五大类,两千五百个以上的代谢物的信息。那么我们的整个数据库的定性的这个可靠性呢,也要比商品化的提高百分之十的百分之三十。 并且呢我们提供的这种代谢物的信息呢,是十分全面的,除了直补的信息以外,还有一些类呃代谢通路,例如 kecc 的这种呃通路方面的信息有助于我们进行一个代谢物功能的研究。

粉丝815获赞1911
相关视频
 10:14查看AI文稿AI文稿
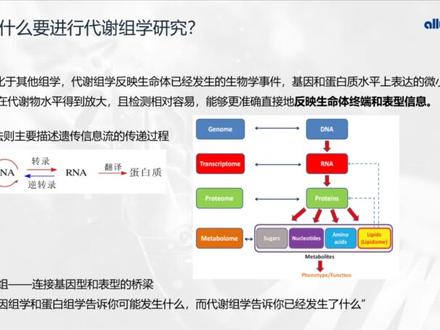
10:14查看AI文稿AI文稿嗯,好的。嗯,大家下午好,我是北京奥维森基因科技有限公司质朴事业部技术支持。那今天我们分享的主题是代谢组织数据挖掘思路与结果解读。 呃,主要内容包括三个方面,代谢组学简介、代谢组学数据挖掘思路,然后以及代谢组学数据的一个解读。那首先看一下代谢组学简介部分, 我们了解一下代谢组学啊,了解一下什么是代谢组以及代谢组学的概念。 那代谢组是指生物体内源性代谢物质的动态整体,而代谢组学的概念呢?是。呃,最早的时候是由由英国的一位科学家于一九九九年提出来的,主要目的是对于生物体所有的代谢物去进行定性定量分析, 从而来研究生物体受刺激或扰动前后大量代谢产物的整体动态变化,从而来阐明生物体代谢相关过程。而代谢组学他的研究对象大都是一些相对分子质量小于一千道尔顿的内源性小分子物质。 那了解了代谢组学概念之后呢?我们看一下为什么要进行代谢组学的一个研究啊?基因,我们知道基因是遗传信息的携带者,而机体中的遗传信息的传递是遵循了中心法则的规律 啊,即遗传信息从 dna 传递给 rna, 再由 rna 传递给蛋白质,即完成遗传信息的啊转录和翻译过程。而蛋白质作为生命活动的执行者,他会通过代谢活动去产生包括糖类和苷酸、氨基酸啊,脂类等等的一些代谢物质,从而 去发挥它的一些功能和嗯,与我们的一些表情去发生关联啊,因此代谢组它是连接基因形和表形的桥梁 啊,而且能够反映机体已经发生的一些变化变化情况,而对于基因和蛋白质水平上表达的微小变化,会在代谢代谢物水平上得到放大啊,而且对于代谢物的颜呃检测来说相对比较容易 啊,能够更加准确直接的去反映生命体终端和表情的一些信息 啊。所以说代谢组学的研究是啊,非常非常重要的,也是非常有必要性的。那既然这么说,那代谢组学目前能够应用到哪些领域呢?那我们接下来就看一下啊,从代谢组学文章的一个发表数量来 哎来看的话啊,代谢组学他的一个研究是呈现了一个逐年递增的一个趋势的,也就是他的研究,是啊,越来越多的啊,也是已经广泛在应用在各个领域了啊,在临床医学和药学药物学方面呢啊,可以去研究疾病的一个生物标志物啊, 呃药物的他的一个药效鉴定,然后以及对于疾病的一个呃分型,以及他的一个精准精准治疗。那在食品方面的话,呃可以对食呃食品的一个安全性去进行一个研究,以及对于呃肉制品、乳制品的一个品质去进行研究。 那在农业和畜牧业方向呢啊,我们可以对动植物的一个遗传育种、治病寄礼抗进机制,然后以及它的一个生长发育机制等等去进行研究啊, 除此之外呢,在微生物领域也是有了广泛的一个呃应用,然后去研究这些微生物它的一些呃治病剂理耐药机制等等。 那前面是对于代谢呃代谢组学以及代谢组学的应用啊,有了大致的了解之后呢?那我们接下来我们就看一下代谢组学的一个数据挖掘思路, 如何从海量的这种呃代谢组织数据中去呃快速的找到这种关键的一些数据信息啊,从而便于我们去进行这种呃数据或呃数据的一个挖掘以后以及文章的一个写作。 那我们首先看一下代谢组学他整体的一个研究思路啊,从前期的这种课呃课题设计到样本的一个啊处理的商机检测,然后以及后续的一个数据嗯数据分期的 整体流程。那课题设计这一块的话,主要根据我们的一个呃实验设计思路去设计不同的一个分组,然后去嗯收集样本,然后进行样本的个保存,之后呢,可以样本寄送到公司,由公司的实验室完成样本的一个前处理以及上机的一个检测。 嗯,上机检测之后呢,会对呃数据进行一系列的一个数据的一个处理,那之后由分信同事去完成这个数据的一个指控,然后以及后续的一个呃数据的一些分析内容。 那在我们到代谢组缺数据之后呢,如何从这些呃大量的这些数据中去快速的找到我们呃有用的这些信息,或者是呃这些数据具具体该怎么去分析,然后从中去能够挖掘出来哪些信息呢? 那我们这块是分了呃呃三三个分析方式,三个分了三步走的一个分析来进行了一个呃介绍,那首先在于呃基本分析这块, 那我们得到代谢物的一个定性定量结果之后呢,我们会对呃数据去进行样本的一个相关性分析,以及它的一个 p c a 分析,那从这个分析中呢,我们可以得到呃样本的一个组内的一个重复情况, 从而来判定啊样本的一个呃组内样本是否出存在这种离群样本啊。那出现这种离群样本 一种情况下,可能是因为个体差异较大而造成这种离群,那另外一个可能就是在前期我们的一个实验操作中啊,因为呃操作不当而引起了这种离群,那呃我们需要考虑的一点就是对于这种离 样本啊是否进行剔除,然后再继续进行后续的一个啊差异的分析,那第二步的话就是差异表达分析这一块,那基于这种呃定性定量结果之后呢,我们需要啊去找到比较组合之间的一些啊差异表达的一些代谢物情况, 那我们根据啊筛选差异代谢物的一个标准去找去筛选出来每个比较组合中差异表达的这些代谢物,然后去通过代谢物的数量,然后来反映啊组内的一个组间的一个差异情况。 通常来说呃组间的一个呃组两组之间差异代谢物比较多的一个情况下呢,也能反映出来两组之间的一个差异也是比较大的,从而来判定就是我们的一个呃实验 设计是否符合我们的一个预期啊。那第三步的话,就是针对于筛选到的这些可以代谢物,它具体有哪些功能呢?那我们这块主要是基于 kgg 数据库,然后对于 嗯这个呃筛选到的这些差异代谢物去嗯进行功能上的一些负极分析,去找到这些差异代谢物啊主要负极的一些功能情况啊,从而来分析呃呃从 啊从而来分析由于不同的呃实验处理对样本造成的这种呃呃呃造成的这种组间的一个差异,也是分析他的一个呃功能情况的呃功能上的一个 呃情况就是他的一个生长发育机制或者是疾病的一种呃发生发展机制等等啊,那在于数据挖掘这一块呢?呃如何去 更方便更快捷的去找到这种嗯去找到关键的一些信息呢?那这一块我们主要是提供的两个呃大的方向。那首先是从差异代谢物入手 啊,从啊找到这些拆一代修物呢,我们去给他进行啊通路通路的一个腹肌分析,然后去分析这些拆一代修他的生物学功能,从而来分析呃这种表情变化的一个机制。 那这块需要明确的一点是,呃有没有关注的这种目标代谢物,那针对于没有关注目标代谢物的一个情况下呢?那我们这边呢也是提供了三个不同的这种 三三个不同的方法去筛选啊这种差异代谢物。那首先第一个就是通过 vip 值或者是 f c 值去找贡献率较大或者是差异倍数较大的这些代谢物,那往往这些代谢物呢, 他受这种实验处理呃处理影响会比较大,那对于这些代谢物的一个呃分析的话,呃可能会得到比较有效的一些呃数据。 那第二种的话,主要是呃可以通过 vn 图去找共有和特有的这些代谢物。那这种那这这个方法呢,主要针对于呃多比较组合之间的一个分析。那如果 呃我们的这个拆代呃组别比较多,然后拆代谢物也是比较多的一个情况下,然后我们通过这种方法去找共有和特有的一些代谢物,从而来 啊缩小我们去的筛选的,缩小我们这个差异代谢物的一个范围啊,从而去嗯更快的去找到这些有效的一些信息,然后去进行后续的一个分析。那第三个的话,就是呃进行这种嗯剧类分析,去找这种具有相同或相 表达模式的这些代谢物,那往往这些代谢物他可能具有相同或或者是相近的一些功能,从而去对一些呃没有,从而对于一些呃已知但呃未知功能的意思,已知代谢物的未知功能去进行一个分析。 那另外一个情况下就是呃有关注的目标代谢物的一个情况啊。又是就是前期我们做了大量的一些文献调研,或者是有实验积累, 知道了某些代谢物可能与我们的研究有相关性,也就是通过这种实验处理,或者是啊疾病的发生发展,然后已经要因为药物的一个干预,然后去导致可能会导致某些啊代谢物会发生变化。 那我们针针对于这些有关注的这些目标代谢物呢?啊去定性定量列表,然后以及差异代谢物列表中去进行一个 查找,看一下这些代谢物啊他是否在本项目中有被呃检测到,然后以及他的一个差异表达情况,然后,然后呢?再去对这些差异代谢物去进行呃,针对。
62洁美生物~谢楠 02:40查看AI文稿AI文稿
02:40查看AI文稿AI文稿物质缺失值比较多,应该对数据怎样进行处理?那一般的话就针对于我们开展这种质朴达到的这个代谢主角的下级数据之后啊, 有以下这么几个步骤。那首先的话呢,我们先去看一下咱们拿到的比方说啊,福利的,比方说我们用这个呃这个安静的内仪器啊,或者说我们这个 simo 的仪器,或者说沃特斯的这些仪器,对采集到的这些,比方说这个点洛的呀,或者点地的呀,或者点 lift 的呀,这些不同的夏季的植物园数据之后啊,对,那往往的话呢,用用用仪器的这个,这个这个 性能嘛,所以出现缺失时的这个情况其实是比较正常,那无非就是我们后续在针对于这个缺失时的这个处理的过程当中怎么去做。那所以回到就是刚刚我们, 呃这个提到的这么几个步骤上面,首先的话呢,一般的话就是我们会怎么去做,那首先就看一下第一步,我们看一下我们这个缺失的这个比例啊,能够在呃多少范围之内。那一般的我们的常用 这个就是一个方法的话呢,是看咱们每一个 pick 啊,每一个有效的 pick, 在我们所检测到的这些样本当中,看他的这个缺失的程度,比方说有没有达到百分之五十以上,一般的这个法治条件。 ok, 这是第一步,那如果说我们的这些 pick, 比方说举个例子,单个的 pick, 如果在我们所有组当中,他的这个缺失的这个比例超过了一半,两个百分之五十以上,那么可能就后续在分析的过程当中就不考虑了。好,那反过来如果说我们缺失的比例没有,比方说达到这个一半,比方说也就缺失了百分之二十或者百分之三十这种对,这个时候我们 接下来就要去做的一个处理,就是我们把它留下来,那留下来的话呢,就会接着我们要去思考,那该如何对它进行进一步的补值对不对?所以的话呢,那这个时候我们常用到的就是目前来说用的比较多的就会有这么几种类型。那第一种的话呢,是像统计学当中常用到的,比方说我们去看每一个 pick 在所有样本当中他的这个最小值的二分之一对不对?或者说平均值 值或者说位置对,这是比较常用的。那当然的话呢,尤其针对一些比方说项目量比较大的这种对列的项目,那有的时候我们往往会采用像这种 k、 n、 n 啊,或者说对,就 k 临近值的这个谱子的这种算法,他其实有点类似于,呃,就是这些学习算法的一些 啊,就是一种。然后的话呢,就是还有对那个像这个呃概率 pca 啊,或者说一些其他的这种就是对偏,就是非常规就简单的这些东西 就可以了,就是一些比较特殊的一些组织方式。当然其实还要回过头来我们要去进一步思考,不同的组织方式必然一般来说会带来不同的。 是的,对,所以其实对于我们使用上面来说,我们其实更多的是选择更加适合我的,比方说这个项目的一些处理方法,去针对于这些后续的补值啊,做一些进一步的这样一个选择处理,那其实就是我们具体问题具体分析,对,是要的。
1阿趣生物

















