halcon 可以在APP上用吗

粉丝1.4万获赞5985
相关视频
 03:09查看AI文稿AI文稿
03:09查看AI文稿AI文稿今天花三分钟教大家怎么用黑奥看实现条形码的机器视觉的读码,先打开这个软件,然后打开案例, 这个是他自带的案例,然后选择一维码识别,选择嗯,条形码的识别,然后选择第四个巴克的, 呃,然后把我们就是相机拍到的这张牛奶的照片,比如说保存在这个位置,然后命名为一 n 二零二二,这个是案例的位置,然后将名称 原来案例中幺三零五的名称改成二零二二,好,然后就能运行了,这些都是他的算子, 反正这个就是应该是读取图片的算子,这个是读取尺寸的算子。呃,还有一些么?就是读取二维码呀,还有以及旋旋转图片角度的算子,其他的什么都不用改,只要改一下图片名称就行了。 然后点击运行,按 f 六,啊,竟然出现了,我们现在拍到的这张牛奶的照片, 可以放大或者缩小, 然后再按 f 六继续下一步往下一步,这他都是一步一步, 之前我也没有学过,只是最近突然就看懂了。 这片下面这一条指令是把它框了出来, 主要 使用的这条指令翻的拔扣的,这条指令运行之后就会自动读取这个二维码, 然后这边的变量窗口就会读取到哦,条维码的值就是我们的六九零七九九二五零七零九五, 非常简单,读条微码什么都不用改,只需要改一个图片名称。
944叶强讲电气PLC编程调试 04:21查看AI文稿AI文稿
04:21查看AI文稿AI文稿各位同学大家好,欢迎来到由西动智能科技出品的浩肯入门班,我是主讲刘嘉欣,安装完成后,在我们桌面上的这个图标就是浩肯。打开 首先看我们的菜单栏,在文件菜单中点击浏览例行程序,可以看到薅啃官方内置的薅啃历程,其中包括了绝大多数算子的用法,同时为我们在项目开发中提供思路。我们打开一个历程, 这个历程可以看到是关于药片识别的,那么以后我们在做识别检测项目的时候,就可以参考这个相关历程。 我们来看下面这个导出功能,可以将蒿肯编写好的代码导出为 c c 加加 vbc、 萨普等编程语言,方便我们开发人员的调用。我们桌面上这个程序就是我们浩肯导出的 c 煞普程序, 大家可以看一下。这是我们薅啃自动生成的代码,这个是读取图像功能,是薅啃读取图像的一种方式, 选择好需要的图片点击确定即可, 我们也可以直接写出读图语句,与刚才自动生成的代码是一样的。接下来来看助手菜单, 我们常用到的有图像采集助手 标定出手 测量助手,后续用到的时候会为大家仔细讲解。这个是窗口菜单,查看我们所需要使用的窗口, 这个是图形窗口,这个是程序窗口, 这个是变量窗口, 在我们窗口散乱的时候,可以点击排列窗口进行整理。 现在我们来看工具栏中的常用按钮,这个是保存按钮,对我们的项目进行保存, 这两个分别是撤销按钮 和重做按钮, 这个是运行按钮,让我们写好的程序运行起来。 这个是单步运行按钮,让程序一行一行的运行。 这个是重置程序 按钮,将程序重置到没有运行过的状态。现在来看我们的工作区域。首先是图像显示窗口,用来显示我们处理后图像的状态, 下面的是变量窗口,变量窗口分为图像变量和控制变量,图像变量显示的是程序运行过程中图像的变化过程,他也可以显示在图像窗口中。控制变量显示的是图像在处理过程中某些相关数据的变化, 如图像的角度、中心点的坐标等。程序编辑器就是我们来编写薅啃图像语句的地方, 如果还有同学对我们薅啃整个界面菜单有些不理解的地方,我们不用着急,在后面我们 会经常用到这些菜单和工具,我们会对其进行更深的了解。那么本节简单的介绍 ho 肯的课程到此结束了,我们下节再见。
209西安西动智能科技有限公司 03:41查看AI文稿AI文稿
03:41查看AI文稿AI文稿想支持 apple 就常按大拇指按钮,体验一秒三年的快感吧。今天我们来安装一下 hellken 二十二点一一,这里呢我们选择二十二点一一, 或者选择这个 steady 的也就是稳定版,这边呢我们就选择我们这个 windows, 也可以选择我们的麦克 os, 然后我们点击我们的完整版就可以开始下载了。 好,我们打开我们的这个压缩包,然后选择这个 song, 然后等待一下,然后这里呢我们更新一下我们这个 song, 我们不更新呢也是可以进行我们这个安装的 好。更新完成之后呢,我们看到这是我们安装好的一些黑欧肯,我们点击我们的这个安装包, 然后呢点击我们的这个设置,这里呢有我们的这个安装的一个目录,还有我们的这个仓库的一个目录,但会根据自己的需求来进行选择。 那这里呢我们选择我们安装到 m 盘,把我们的地呢都改上 m, 好,让店保存设置,然后就可以点击安装,这里呢我们可以选择我们的这个安装的一个内容,这里我把我们的这个图像过去的模块呢安装一下, 我们选择对应的这个版本就好 好。选择完之后呢,我们在这里选择下 derek show 跟 derek field, 这里呢我们选择一下这个 vs 的这么一个插件,一个呢是我们的二零一九之前的一个版本,或者是我们二零二二的之后的这么一个版本,我们都选择安装一下。好,我们点击我们的应用, 然后他会等待一下这个修改。 好,这里呢我们拖到最下面, 然后点击安装好,他就可以开始安装了, 这里呢是安装我们这个 vs 的这个二零二二之后的这么一个版本的东西,我们这里没有二零二二,所以我们这里点击 close, 这里呢是安装 vs 这个插件是二零一九之前的这么一个版本,他们店里面装了二零一五和二零一九,所以呢可以进行一下安装 好我们这里的勾选上二零一九跟二零一五,然后点击安装,然后他就可以进行安装了, 安装完成之后呢,我们点击插呢就可以把它关掉了,然后我们的二十二点一就安装完成了,然后我们把我们的 nices 放入呢,就可以运行了二十二点一一了。 如果喜欢我们的视频,感谢大家一键赞美哦!
68外星眼机器视觉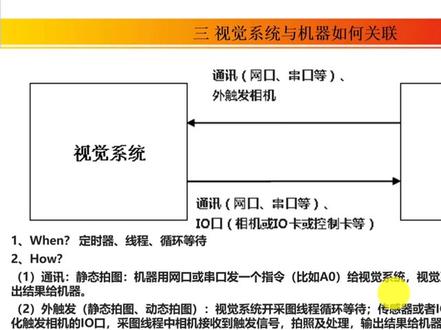 16:39
16:39 01:55
01:55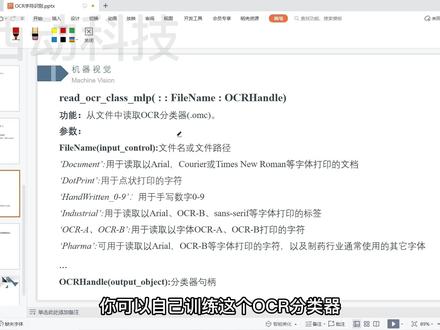 26:37查看AI文稿AI文稿
26:37查看AI文稿AI文稿how can? how can? how can? how can? how can? 零基础入门课堂同学们大家好,欢迎大家来到 halt can 零基础入门课堂,我是主讲李源。这是我们的 qq 群,大家有什么问题可以加群, 今天我们来学习 ocl 自负识别。 ocl 自负识别就是指光学自负识别,是用电子设备,比如说是扫描仪或相机打检查打印的自负,通过检测按量的模式来确定其形状,然后用自负识别的方法将其翻译成 计算器文字的过程。自服识别在日常生活中和工业生产中的应用非常的多,比如我们常见的车牌识别,食品、日用品以及药品的包装上的文字识别,还有各种工业零件容器表面的喷涂 文字都需要进行识别。今天我们用 holk 来识别工业零件上的字符,我们打开 holkan, 首先关闭窗口, 然后读取我们的图片, 得到图片的框高, 然后打开窗口, 这里我们选择这个算子,这个算子就是让我们的窗口来自适应图片大小,显示 限时图片。 我们运行一下,这里我们看到我们的图片是一个三筒的图片,然后我们为了后续的一个处理,我们将其转化成回读图片。 然后接下来我们在自服识别之前,需要对我们的自服区域进行一个定位,这里为了快速定位,我们选择手动框选的方式, 点击这个绘制 l y 去选择绘制着平行句型, 点击右键, 然后插入我们的代码, 这里就是我们插入进来的带。这个是得到我们一个轴频型句型,这是他的左上角的坐标,这是右下角的坐标, 这个就是将我们的两个区域给他整合成一个区域,然后这里我们刚才框选了三个 r y 区域,所以这里使用了两次合并区域的算子,然后我们运行一下, 接下来我们用 radiostome 来裁剪图片, 这个是我们要裁剪的图片,这是我们刚才框选的三个 ry, 去,这个就是输出的一个被裁剪后的图片。 接下来我们就需要提取我们的字符, 我们点开灰度直方图,然后点击预值,滑动我们的最大值来进行筛选。 可以看到由于我们弓箭表面铁锈等因素的一个影响, 我们直接使用全局预支的方法来分割图片,效果不好,所以我们这里考虑考虑用局部预支来分割图片。 我们调用好啃的局部一只蒜子, 我们点击右键打开帮助文档,在这里可以查看这个算子的一些详细解释,我们把它放到 ppt 上来进行一个查看。 这个算子的功能就是使用局部预值分割图片,然后这个参数是我们的原始图像,这是处理后的图像,一般我们指的是用均值率播中值 绿波的绿波处理后的图像。然后这个就是我们的输出参数,他是分割以后的区域, offset 是我们的一个回度值,偏移量一般在五到四十是最好的。然后最后一个参数是我们要提取区域的类型, 他总共分为四个类型,就是暗区、亮区、相似和不相似区, 然后我们的字符可以看到是 是比较暗的,然后我们这里就选择按去, 然后我们的灰度偏移一亮就设置为三十。 so, 在局部预值之前,我们首先要用小,首先要对图像进行一个绿波处理,我们这里用均值绿波来对图像进行处理。 同样我们也在 ppt 里看一下这个算子的一个解释, 他的功能就是对图像进行均值绿波处理,这是输入图像,这是我们绿波后的输出参数, 然后这个是我们平滑模板的一个宽度和高度均值绿波就是对目标像素以及周边像素求平均之后再填充目标像素来实现绿波目的的方法。比如我们下面这幅图,左边是我们要进行绿波的图片,中间这个是我们的三成 三的平滑模板,然后最右边这个就是我们绿波后输出的一个图像。我们首先将我们的平滑模板放在图片上,然后求这个覆盖区域所有像素的一个平均值,然后把这个值付给我们的中心像素, 然后继续继续向用滑动,滑动到这个区域以后,然后计算这个区域所有像素的一个平均值,然后将这个值付给我们的中心像素,这个值算下来大概是六十九, 然后坚持绿波,他就是通过这种方法来实现对图像的一个绿波处理。 一般我们平滑模板的尺寸越大,他所提取的区域就越大,然后根据经验,我们模板尺寸的大小一般设置为要提取目标直径的两倍,这里我们可以看一下我们一个字符的宽度大概是多少, 这一个字符的宽度大概是七十四、七十五,所以我们这里设置为一百五。 我们运行一下, 我们把经过军职绿播后的图像给我们第二个参数,往这里运行一下, 这个就是我们提取的字符,可以看到除了我们字符区域以外,还有许多我们不需要的区, 接下来我们就要去除这些区域。 首先断开取, 然后我们用形态学中的开运算来去除掉一些面积较小以及粘连在我们字符上的一些部分。 这里我们使用圆形结构的开运, 圆的半径我们设置为二点五, 可以看到他去除掉了一些面积较小的区域,以及将我们粘连在支付上的部分也断开了,但是我们注意到他这个虽然断开,但是他们仍然属于一个区域, 这不便于我们后续进行一个处理,所以我们再调用一次。 然后我们打开特征脂肪图, 将一些面积较小的部分给筛选掉, 换一下颜色, 可以看到他把我们的字符也给筛选掉了,所以我们需要选择一个合适的纸 插入袋子 清除一下窗口,这里看到还有一个区域没有被筛选 出来,然后我们通过观察他的特征,发现他是列坐标最大的,我们可以根据这个特征来去除掉他特征,这里换为列坐标滑动这个最大值 用插入代码。 经过上面的处理,我们得到了我们要进行识别的字母区域,但是我们注意到这个二被分成了两个区域, 这不便于后续的进行一个正负识别,所以我们需要将这个区域给他变成一个一个区域。 这里首先想到的就是用形态学中的膨胀和避孕算来进行连接,在连接在连接这个区域之前,我们需要我们首先需要把这个整个区域给它整合为一个整体, 这个算子和我们上面的这个算是不一样的,这个是把所有区域整合为一个整体,而这个算子是只针对两个区域, 然后我们用圆形结构的膨胀 圆的半径设置为五,然后断开区域, 将我们断开后的区域和和整合整合为一个整体的区域进行求交集, 这里我们就使每一个字符都是一个单独的区域, 然后我们需要把这个横杠给他筛除掉,我们只需要识别出字母和数字就可以了,这个横杠我们可以通过高度这个特征来进行筛选, 下来我们就可以识别字母了。然后在识别之前,我们首先要对我们的区域进行一个排序,因为如果不排序的话,我们最后识别的结果将会按照这个顺序来进行排列, 就会就会复查中断,然后不利于我们进行一个查看, 所以我们要对对这个区域进行一个排序,我们希望我们的区域按照我们的阅读习惯从左到右,从上到下的进行排序。我们调一个好看的 selter raise 算了, 查看一下他的解释,这个算词的功能就是对区域进行排序,这是我们要 进行排序的一个区域,是排序后的区域,这是他的一个排序模式,排序模式总共有以下几种,然后这个就是我们按照第一个点排序,他就指的是我们一个区域 他第一行最前面的这个点,而我们最后一个点就是一个区域最后一行最后一列的那个点, 像这个就是外接矩形的左上角,这个是外接矩形右上角,这个是我们外接矩形左下角和右下角。然后我们想要从左到右,从上到下的顺序排列,可以使用 carico 来解决。 这里我们将排序模式 变成我们这个, 然后这个就是我们按顺序递增或者是按顺序递减,串就是按顺序递增,把锁就是按顺序递减, 最后一个算最后一个参数就是,呃,就是指的是我们先按行排列还是按列排列,这里设置为行的话,他就是先排行,然后再排列, 然后我们看一下他是否按照我们的要求进行拍摄, 可以看到他的顺序是正确的。我们这里说一下这个先按行再按列排序是怎样排序,先按行的话,他这个就是我们的第一行,然后这里面有许多的区域, 这时候他就会继继续按照列进行排序,这就是第一个、第二个、第三个这样的,然后这个是我们第二行,他只有一个区域, 这个是我们第三行。两个区域,他这会的时候就会按照我们按照我们的列列坐标进行一个排序。如果你这里设置为设置为列的话,他就是先拍我们的列,然后再拍我们的行, 就是这个是我们第一列,然后这是我们第二列、第三列、第四列,然后到第五列的时候,他有两个区域,这个时候他就会按照行,就是先拍这个,再拍这个, 这第五列也是同样的,他就是按照这样的一个顺序进行排序的。接下来我们就对字符进行一个识别,字符识别会用到两个算字, 一个就是我们读取 ocr 分类器的算子,另一个就是使用 ocr 分类器对多个字符进行识别的算子。我们首先看一下这个读取 ocr 分类器的这个算子, 这个就是我们的文件名或者是我们的文件路径,你可以自己训练这个 ocr 分类器,也可以使用 好很训练好的分类器,这个就是我们后面输出的一个分类器的一个句柄。 在读取了 ocr 分裂器以后,我们就可以对字符进行识别了,这个是我们要识别的字符,这是我们要识别字符的回读图像, 这个就是我们刚才那个 ocr 分类器的句柄,这个就是我们输出的一个识别结果,这个是识别结果的一个精度, 因为我们选择 holk 肯训练好的工业字符分类器, 因为我们这里又有数字又有字母,所以我们选择零到九, a 到 z 的这样一个来气, 这里是我们的回族图像, 运行一下,然后点击我们的控制变量,看他识别的结果是否正确, 我们可以看到识别结果是正确的,并且我们的识别精度也比较高。 接下来我们就要将我们识别的结果进行一个显示,我们设置颜色为红色, 设置边缘显示, 然后显示我们的回购图片, 显示我们排序以后的区域, 你学一下, 接下来就显示我们识别的结果。首先设置一下显示字体的格式, 这个是我们窗口的区别,这是字体的字号,这是字体的名称,这个是加粗,这个是倾斜。然后我们调用 hopen 的显示算字, 这个是我们窗口距离,这是要显示的识别结果,这个是我们显示在 窗口坐标系还是图像坐标系,这个是是我们显示的一个位置行列坐标, 这个参数是我们字体的一个颜色,我们这里将颜色设置为绿色,然后做标系设置,为我们的图像做标系。 boss, 我们这里选择不需要这个 boss, 我们的坐标设置为 七百五和五百, 这就可以看到他把我们的识别结果显示在了图像上,然后我们 不想让他这么显示,想让他显示在我们字符的下方。我们可以使用 holk 的球最小外界巨型的算子 来得到我们每个字符他的一个最小外界举行的左上角和右下角的坐标,然后知道这两个坐标以后,我们就可以知道他左下角的坐标。根据这个坐标我们就可以将我们的识别结果显示在字符下方, 然后运行一下, 这就是我们最终的一个显示结果。到这里我们就完成了一个字符的识别, 我们下节课讲尺寸测量。
151西安西动智能科技有限公司 00:34查看AI文稿AI文稿
00:34查看AI文稿AI文稿学 hell can 深度学习的同学注意啦! hell can 深度学习工具零点六先行版发布,现在在 mv tech 官网即可下载使用了呢,你下载了吗?网址是这个,拿走不谢哦! 深度学习工具零点六允许用户在训练其深度学习模型时选择不同的增强选项。此外,分类验证现在也可以在未标记的数据上执行, 对你提高标记速度非常有帮助。最后,如果系统上有多个 gpu, 则可以选择专用 gpu 啦!
12外星眼机器视觉 00:59查看AI文稿AI文稿
00:59查看AI文稿AI文稿我们今天介绍一下 happy 下载安装以及 nice 的下载和安装啊。首先我们是有一个论坛的啊,三 w 五幺嗨给你看名字很好记。 呃,然后我们打开论坛之后呢,在论坛左上角啊,这里有不同的版本,你看最新的是十八点一,然后我们点击, 点击进去之后呢,这里你首先要注册一个论坛的账号啊,注册之后,然后登录,我们就可以看到这里有下载链接,他包括温子系统的一个安装包,深度学习的以及运行环境的一个配置啊,我们这里提供一些链接下载,然后把它下载之后呢,然后就进行一个安装操作。 安装操作同样我们在论坛的最上面有一个黑粉安装啊,黑粉安装,然后大家打开这个链接之后,可以仔细看一下,根据步骤操作,我们这里主要讲一些细节啊,讲一些细节要注意的地方,呃, 在第五步这个地方啊,注意,因为如果说我们图片很大,我们建议大家选择 x 六十四有六十四位系统, x 八六是上车位。










