pytorch hub怎么使用

粉丝7898获赞2.7万
相关视频
 08:03查看AI文稿AI文稿
08:03查看AI文稿AI文稿这期视频我来教大家如何安装拍 touch 以及配置 gpu 的环境,那拍 touch 我相信不用我多做介绍了,既然你能看这个视频,那么你肯定是冲着来学拍 touch 来的,对不对?好, 想要安装拍 tous 的话,你就打开浏览器吧,然后呢,在地址栏输入拍 tous, 点挖机啊,这个是拍 tous 的官网,那怎么下载呢啊?往下翻, 那这里有个安装拍拖次,下面呢就提供了最新版本的拍拖次的一个安装方式,但是我还是比较建议不要去安装最新版本的拍拖次,因为很有可能会有兼容问题, 所以呢,我还是比较建议啊,点,这里就是历史版本的拍拖词,点击进来之后呢,有这么多版本,我们应该找哪 一个呢?啊?其实啊,这是要分情况的,如果你的电脑没有显卡,没有英伟达的显卡,那么你就可以去安装 cpu 版本的,那 cpu 版本的 ipods, 它一样可以用来训练做预测,只不过是比 gpu 慢很多而已。 那你如果是这种情况的话啊,那么,呃,你这里随便下一个版本都可以,那比如说啊,我就下这个一点一,二点一这个版本的,那么我们这里找哪个呢?那 linux and windows, 然后呢,下面有个 cpu only, 也就是说你电脑上没有英美达的显卡的话啊,那你就直接 copy 这样一个命令,然后呢打开你的控制台,也就是命令提示符,把这命令一贴进去,然后回车就可以安装了。 这个是非常简单的,安装完了之后基本上就不需要去再做任何的一些配置了,这就是安装 cpu 版本的拍特词的一个方法,非常非常的简单啊,只要输命令就可以了。好,如果你跟我一样电脑里面有英伟达的显卡,那么你还需要装一个东西,那就是酷的, 那酷打是什么呢?酷打就是呃,英伟达公司推出的一个并行计算的一个架构,也就是说拍 top 的 gpu 版本,他需要用酷打这样一个依赖来进行计算的加速, 这也就是为什么 gpu 版本的拍拖时,在训练和预测的时候是比 cpu 快的啊,原因就在这,用到了哭打。那么这个哭打我们应该怎么样来装呢?首先我们先要确定一下我们自己电脑上的 显卡的驱动的版本号。呃,怎么看呢,也很简单啊,打开命令行,输入一个命令,就是英伟达 n v 连,然后呢 s m i 回车, 然后大家可以看到啊,它输出了这么一个东西,那这里有一个 driver version, 那这个就是显卡驱动的版本, 也就是说我现在这台电脑的显卡驱动的版本是四六二点二幺,好,记住这个数字,那有了这个数字之后呢,我们走到第二个网站啊,就是这个, 这里列出了几乎所有扩大版本所需要的最低的显卡驱动的版本号,像我这边是四百六十二,那么理论上来说啊,我能安装的最新的那个扩大版本是十一点二点二是这个版本, 但是呢,这只是理论上的啊,我曾经试过啊,我这台电脑也装过十一点三啊,但是呢,理论上来说啊,最新的就只能装到这里了。 现在我们知道了我们能够安装的哭打的版本号,那接下来就是要去安装哭打,那接下来走到第三个网站,那,这里呢就列出了所有哭打版本的下载练习,比如说我要装这个十一点二点二,那我就点进去, 进来之后呢,这里可以看到一个操作系统,那我这边是 windows, 所以点 window, 然后呢,很明显是叉八六六十四的,然后我的系统是 win 十,所以点这个十,那这里有一个 logo, 有个 network。 我还是比较建议啊,装这个 logo, 也就是这个安装包,直接给下下来点 一下。好,然后这里有个 download, 点击就可以下载了,那我这边已经是有了,所以我就不去下载了。 好,下完之后呢,我们就可以打开我们的安装包啊,我这边是在这有个库档,我这边其实是下了个这个十一点一点一的啊,好,我们可以双击, 这个时候呢,我们可以看到啊,他说,呃,他要去解压到一个路径里面,那这个路径其实随便了,你爱解压到哪里,解压到哪里,我比如说这里就直接默认了。 ok, 好,解压完了之后呢,就会开启这个酷打的安装程序,那这里呢,就直接投一并进去啊。 好,然后这里的话,嗯,经检和自定义其实都可以啊,我还是比较喜欢学这个自定义啊。 下一步啊,这里呢,我一般都是直接全部勾上的,然后下一步。好,这里呢会有三个路径啊,其实这三个路径里面啊,这个路径才是最重要的,因为这个才是库达的本体 啊,所以呢,如果你怕出问题啊,你最好把这样一个安装路径记住啊,或者是呢,你自己挑一个你想要安装到哪个目录里面去的一个路径,好吧,这里呢,我就直接默认了啊,下一步, 下一步之后呢,然后就 understand, 然后 next, 然后这个样子呢,就可以开始安装了。安装好之后呢,我们需要去验证一下这库达有没有装好,那验证 也很简单,打开命令行,然后呢输入 n v c c 空格杠,大写的 v, 如果你敲完回头之后可以看到这样一个类似的界面的话啊,那么就说明你的 q 档已经是装好了。 装好库呢之后呢,我们接下来啊,就得去找我们对应的拍 top 十的版本, 比如说我想安装这个一点一二点一的拍拖式版本,那么他的一个安装命令呢,就是往下走啊,这另一个是按着 windows, 然后这里面呢有什么哭打十一点六,哭打十一点三,哭打十一点二,对不对? 而我这边自己的版本是幺幺点幺,他不在这个里面,那是不是就不能装呢?其实也可以啊,我们可以挑一个 距离版本最近的,比如说一一点三,然后我们可以把这个命令复制过来,复制好了之后呢,就可以在我们的 cmd 里面把这他的命令给贴过来,然后回车。那这样就是在下载并按着我们的拍拖者 好拍拖尺装完之后呢,我们需要去验证一下有没有装好,对不对?那么我们可以在拍套里面进行个项目啊,比如说我这边叫叫拍拖尺克斯,嗯,然后呢,我新建了一个魅点 py, 那想要验证很简单,首先 import torch 啊,注意啊,不是拍 torch 啊,是 torch。 好,如果你是 cpu 的版本的拍拖子,那么你这样直接运行,如果发现是没有问题的,那就像 这个样子,那么你这个拍拖尺就算装好了。但是如果你装的是 gpu 版本的拍拖尺的话,那么你还要做一件事情啊,就是打印一个东西啊,拿什么呢? tous 点扩大点椅子 valuable 这个函数就是检测我这个扩大到底能不能用,如果能用就是返回一个处,不能用就是返回 force, 那我们运行一下,如果发现打印出来是处,那么就说明你的 gq 版本的拍拖尺就安装成功了。
1147Shady的混乱空间 04:08
04:08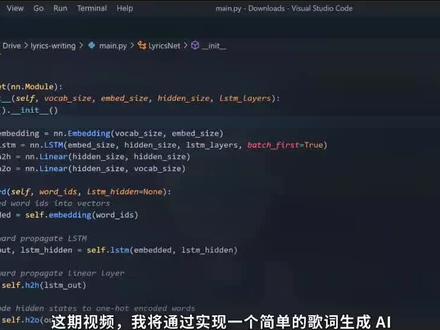 13:23查看AI文稿AI文稿
13:23查看AI文稿AI文稿视频呢,我将通过实现一个简单的歌词生成 ai, 带大家快速了解深度学习的基本流程,以及拍 touch 这款必备的深度学习框架。首先我们要知道,深度学习或者说神经网络的本质其实是一个数学问题。 我们可以通过训练让一个神经网络学习输入到输出之间的数据映射关系。例如,当神经网络看到这张图片时,他应当知道输出一条狗。 在拍拓器中,构建神经网络的核心数据结构是一个叫做 tensor 的东西,它和我们之前讲到的 number 数组非常类似。不过 tensor 的运算可以被放在 gpu 上执行, 利用 gpu 的并行运算来加速整个计算过程。在吞色之上呢,我们可以构建各种复杂的数学模型,拍 torch 也同时提供了梯度的自动计算。 那为什么需要梯度这个东西呢?梯度你可以简单理解成导数在高维度上的推广。这是因为对于神经网络的训练,或者说一般的最优化问题,大家都会用到一个核心算法梯度下降, 而拍 touch 将偏导数的计算链式、法则这些细节全部都隐藏在了框架中,因此我们可以更加关注与解决实际问题,而不是这些繁琐的计算细节。除了这些基本的计算功能以外,拍 touch 对神经网络还有各种模块化的封装, 比常见的卷基层、线形层、 pulling pying, 各种激活函数、 c, n, r, n, transformer 模型等等等等。以上呢,是对拍拓去的一个非常粗略的介绍。拍拓去单装还是比较容易的,我们可以在这里选择对应的操作系统扩大版本 的康大其实不是必须的。最后复制下面的命令到控制台安装即可。 训练的第一步呢,是准备我们需要的原始数据。数据级通常很容易被我们忽视,但是深度学习中相当重要的一环。有时候即使你的模型再好,但是训练的数据很差,最后也很难得到一个好的结果。这里我使用的呢,是这个中文歌词与辽阔。 在下载的原始数据中,我们可以看到很多非中文歌曲。有些歌词中的格式不工整,有些歌词的前面包含了不需要的信息。因此我们需要对这些原始数据做一些预处理,并将数据转换成我们需要的格式。 这里呢,我写了一个很简单的脚本,过滤掉不需要的歌词,去除多余的文字,并以斜杠来分隔歌词的每一句每一行呢是一首 首歌的歌词,最后存放在一个纯文本中。接下来呢,我们可以利用拍 touch 提供的 data set 和 data loader 来读取这个歌词文件。这两个类封装了基本的数据操作,比如切分训练数据,随机打乱数据,或者对数据进行简单变换等等。 这样我们就不用自己去造轮子了。我们可以通过继承 data 类来定义我们的歌词数据集。接下来,我们可以在一列弹数中加载之前的这个歌词文件,并将所有的文字转化成一个个缩影。 这里我们定义两个 dict, 用来保存缩影到文字,以及文字到缩影的映射。接下来我们需要实现两个函数,第一个函数 lens。 我们需要返回样本的总数。这里我们将所有的歌词文本拆分成一个个长度为四十八的序列, 所以样本总数等于文字的总数除以序列长度四十八,这里为什么减一?我们马上讲到第二个函数 get them, 我们可以根据指定的下标返回对应的文字序列。 这里返回的数据呢,可以被分成两部分,一部分代表网络的输入,另部分代表网络的输出。输入和输出刚好相差一个字,因为输出的文字刚好是对下一个字的预测。 定完毕之后,我们对刚刚代码进行一下简单测试。这里我们可以创建一个数据级对象,然后根据下标随便获取其中的一个样本。 可以看到这里返回的一个整数序列长度为四十八,其中的每个数字代表一个文字的缩影。我们当然也可以根据之前创建的映射将他们再还原成一个个字符。这部检查 打灯确实很有必要的,不然一步错,步步错。在定义了 data set 之后呢,我们需要再创建一个 data loader 来访问其中的数据,主要是因为 data loader 允许我们随机打乱数据或者按批次读取数据。 但这里我还进一步将数据分成了两部分,一部分用来做训练,另一部分用来做测试。原因我们在之后训练的时候讲到。 接下来呢,我们来定义我们用到的这个神经网络结构。在拍拖器中,我们可以通过继承 n n 中的猫九雷来定一个神经网络。这里最关键的是这个 forward 弹数, 他定义了我们网络从输入到输出的整个计算过程,比如数据会经过哪些层,层与层之间有应当如何连接等等。大家在定义模型的时候有一点非常 重要,不管我们要解决的问题有多么复杂,最好都先从构建一个最基本的模型开始,这样会大大降低训练和调试的难度。并且我们在增加模型复杂度之后,可以以这个最简单的模型做参照,确保复杂的模型是否真的表现的更好。 其实对于文本生成问题,使用当下最流行的 transformer 架构应该是更好的选择。不过这里呢,我们先用一个更加简单基本的 rnn 模型来做演示。 首先,我们会将这里输入的文字经过一个 embedding 层转换成一个像量,因为高维的像量能够更好地表示不同文字间的语意关联。接着我们将这个像量传入一个 l、 s, t、 m 单元, 最后通过一个线性层转换成输出的文字。和所有的分类问题一样,这里的文字是使用弯号的像量来 编码的。另外, lstm 单元同时有个隐藏状态的输入和一个隐藏状态的输出。正是因为有这个隐藏状态,才使得我们的神经网络具有记忆的能力,因为我们不希望深沉的歌词前言不搭后语,我们需要让魔性记住文字前后的关系。 如果大家对这里的 inbeding 或者 lstm 不是那么熟悉,也没有关系,大家可以先将重心放在数据的流向输入还有输出上。 比如这里你输入一个字,网络会帮你预测下一个字,然后我们将输出的文字连带隐藏的状态再次传递给神经网络,这样循环往复下去,就得到一整串的句子。 接下来我们来讲一下模型的训练。在训练的过程中,我们会每次抽取数据的一小部分,我们称之为一个 batch, 然后我们会一个 batch 接着一个 batch 的训练。当所有的数据都被训练过一遍之后,我们称之为一个 epoch。 通常我们也会对模型训练若干个 epoch, 让他更好地去拟合训练数据, 我们可以在循环中实现整个训练的过程。对于每一个 app, 我们会一个 batch 接着一个 batch 的训练。这里这项代码呢,单纯代表将训练数据上传至 gpu, 这一步呢是必要的, 因为我们使用 gpu 来加速训练的过程。接下来我们将数据传入之前创建的模型,让模型预测一个输出, 然后我们会去计算这个输出与标准答案之间的差异。这里我们会用到经常听到的损失函数 last function。 但对于不同的问题,我们会用到不同的损失函数。比如对于纯数 数值类型的输出,像温度,房价,这个 los 可以简单是输出与标准答案的绝对值或者是平方差。而对于我们这种情况,由于我们输出的是弯号编码的文字,因此我们会用到交叉箱 cross entry。 但大家可以简单的将这个 los 理解为输出与标准答案之间的差异。通常我们希望这个 los 越小越好,这样代表预测的结果与标准答案更接近。 而我们训练神经网络的目标呢,就是通过缓慢调节网络中的各种权重来降低这个 los。 用到的算法就是我们之前讲到的梯度下降。关于梯度的计算,我们可以轻松的通过调用一句 backward 完成。 然后我们可以调用 optimizer 的 step 函数,通过计算得到的梯度自动修改网络的权重。 这里第一行的 zero grad 也非常重要,他会在计算之前先将梯度清零,避免我们得到一个累加的梯度值。刚刚我们提到的 optimizer 是优化器,它可以通过计算得到的梯度自动更新网络的权重。 adam 和 sgd 是两个非常常用的优化器, 可以看到这里我使用的呢是 adam。 另外优化器还有一个额外的参数,学习速率,他会影响每次权重变化的大小。学习率越大,神经网络权重的变化量就越大。 但学习率绝不是越大越好,过大的学习率会让 los 无法收敛,甚至可能出现随着训练还增大的情况。学习率设置的过小会降低训练的速度,甚至可能让你的神经网络学不到任何东西。当然也有人尝试使用动态的学习率, 比如随着训练的推进逐渐降低学习率。关于学习率和优化器的选择又是一个很宽泛的话题,这里我们就不讲该讨论了。另外,在训练的过程中,我们可以将 los 打印出来,以方便我们跟踪模型的训练进度。 这里我们还可以用到 tensor board 这个库,我们可以调用 at scaler 来绘制像 loss 精确度这样标量的数据。虽然这一步不是必须的,但是图表呈现的信息往往比数字要直观很多。 除了训练之外呢,通常我们还会加入一个模型评估的环节。还记得我们在视频的开头将数据分成了训练和测试两部分吗?通常我们会预留少量的数据做评估,这部分数据并不会拿来做训练。评估的代码和训练非常类似,除了我们不会计算梯度来 更新网络的权重,我们同样会输出一个 los, 然后观察这个 los 下降的情况。因为单纯训练 los 的降低并不能代表模型表现的很好,模型也有可能过度拟合了我们的训练数据。 也就是说,我们的模型对于训练数据表现的很好,但是对于从来没有见过的数据却表现的很差。为了避免这种情况呢,我们会同时关注训练和评估时候的老师以及精确度这些指标。 在真正训练之前,我们最好对之前的代码做一个最最基本的验证。因为训练一个模型通常会花很多时间,有时候一两天都有可能。 如果等你训练完了以后才发现模型根本不工作,那么尼玛当场去世。那么具体我们应该怎么验证呢?比如我们可以修改这里的 data loader, 让我们暂时只使用第一个 batch 的数据,而且我们只用 batch 中的前两个样本来做训练。如果在这种情况下, lost 都不会降低。也就是说我们的模型都不能过度拟合,那我们的代码肯定哪里有问题,需要进行调试。 可以看到这里在训练了几十个 app 之后, los 一直在持续下降,并且预测的精确度呢,也达到了百分之百。到这一步呢,至少可以说我们的代码没有出现明显的错误。 接下来我们可以开始真正的训练。在训练的过程中,我们还可以每间隔一段时间让目前的模型生成一段输出。 这里的 january 弹数我们马上讲到,它会让模型生成一段歌词,并且每一句以深度学习。开始这一步主要是为了实时观测模型的预测结果。可以看到从一开 是几乎不能预测任何内容,到后面生成相对完整的句子。我们模型的输出随着训练有显著的提升。 这里我还做了一些改进,比如我们使用两层的 lstm 单元,并在输出之前额外增加了个线性层。与之前的模型相比较,新的模型进一步降低了 last, 并提高了预测的准确度。 虽然不是每一个修改都能保证模型效果的提升,不过模型优化确实需要我们不断的进行尝试。通常我们在 los 不再降低的时候就可以停止训练了。我这里手动将 apple 设置成了十五个。最后,等模型训练完成之后,我们让他来进行一段作词。 无法忘记你的美,可以让你不再流泪,深深的爱上你度过了多少个 春秋,学会珍惜,习惯了你的温柔,我的心在等待着你回来,是否我已经不再啰嗦,不再来私底里的等待。不错, 一个人的时候,键盘敲着时间的钟,三十年的时光连着我和你。 嗯,不错,狗屁不通。这里生成歌词的间内位弹数稍微有一点点长,不过总体来说,他会将我们规定的首字符先传递给神经网络,然后让神经网络自由创作,直到这一句结束,也就是遇到了斜杠分割符为止, 这里的 next word 函数会将当前字符传入神经网络,然后返回预测的下一个字,中间也会维护一个隐藏状态黑灯。这里的这几句呢,其实只是在对数据格式做变换而已。
7367大神开发 04:28查看AI文稿AI文稿
04:28查看AI文稿AI文稿好,我相信大家现在已经学会了如何使用拍 touch 进行图像分类了,对不对?那么接下来呢,我来带着大家做一个小项目啊,就是过这样一个 h capture 的验证码。 呃,这个验证码的话,其实还是比较常见的啊,因为很多网站里面都用到过, 所以呢还是有一定的商业价值的,而且这个小项目也是从我之前接过的单子里面抽出来的一部分 啊,当时这个单子还给我贡献了五千块钱人民币的一个收入啊,还是比较不错的好,如果你想打开这个 h cap 蛇的话,你就打开浏览器,然后输入这样一个网址就行了。 那进来之后呢,我们来看一下啊,要往下滚,滚到这的时候呢,你会发现有这样一个东西啊,那很显然就是一个打开验证码的大门嘛,对吧? 那这里什么茄子萝卜啊,其实你可以不用选的,然后呢可以点这个,我是人类,点一下。 好,然后呢就会出现这样一个验证码的一个界面,是不是?那他是说请单击包含每个体育场的图片啊,就是找体育场嘛,那就是这个,这个,这个, 还有这个,是不是?然后点下一个,然后呢又是体育场,那就是他他他他,对吧?然后检查 好这样一个验证码就过了。好,这就是进入 h capture 这个官网的一个体验验证码的流程,那么如果我们想让程序来模拟我们人的动作,把这个验证码给过了, 应该怎么办?那既然要模拟我们人的动作的话,那是不是也是一样啊,要打开浏览器对不对?然后呢进入到这样一个网站,然后呢进来之后呢就要往下滚,是不是啊?比如说我再重新刷新一下啊? 啊?比如说进来了,进来了之后呢就要往下滚,滚完之后呢,然后就点这个,我是人类 之后呢,那就是要让程序来帮我们自动的点这些图片吧,对不对?那我程序怎样才能知道哦?这个是体育场,这个是城堡,这个是体育场,这个是城堡, 那这样一个步骤啊,我们就需要去做图像分类,是不是?那把分类的结果算出来之后,那么我们应该就能知道啊,到底哪些图片是城堡, 是不是?那知道哪些图片是城堡之后,我们就让他去点,是吧?点完之后呢,然后看到有下一个就点下一个,然后呢又继续刚刚的流程啊,继续图像分类,然后呢把城堡选出来,选出来之后点检查, 然后这样一个流程就结束了吧,是不是?所以呢,我们得有这样一个功能啊,就是能够模拟我们人的动作来呃,做这些,呃滚动啊,点击的操作啊,这是其一。其二我们得有一个呃 图像分类的模型,能够分辨出来哪张图里面是体育场,哪张图里面是城堡,是不是?好?然后呢接下来就是,呃,我们这样一个模型,他需要数据 是不是?那这个图片数据怎么拿呢?我们再刷新一下,比如说我点这个,我是人类, 我刷新完之后啊,我这里是有多少张图啊?十张图,是不是?我是不是应该写个爬虫把他的这些图片爬下来,对不对?或者叫下载下来?然后呢这十张图片完了之后呢,我这里是不是有个刷新按钮,我点一下, 你看新的图片又出来了,那么我是不是又可以把这些图片给下下来?所以我们这个模型的数据啊,应该就是从这个网站里面爬下来, 对吧?所以呢,整个这样一个小项目啊,大概是分为三个部分,第一个部分就是爬取数据,也就是这个爬虫。第二个部分 就是我图像的一个分类,分辨我这个图片里面到底是有体育场啊,还是有城堡之类的。然后呢,还有一个就是啊,我这个程序啊,能够自动的打开这个页面。然后呢来过这样一个验证码,总共三个部分。
 04:42查看AI文稿AI文稿
04:42查看AI文稿AI文稿拍 touch 的安装 g p u 版二,好,如果你库打安装好了,你接下来要去看一看库打是否安装成功,就可以在命令提示服里面在这里输入一个 m v c 杠 v, 哎,写错了啊,是杠 v 回车,那么此时它就会返回你当前安装的 quad 版本。诶,哦,是当前安装的 quad 版本呢,是十一点七,所以同学们,你要注意好了,你所能够支持的 quad 版本到底是多大,你就最多只能安装到 quad 十一点七这个版本, 你不要去安装酷打驱动软件,不要去安装十一点八,不要去安装啊,一定要安装他最多能够支持的,像老师这里最多能够支持的是十一点七,因此老师就安装了一个十一点七的版本的酷打软件。然后安装完之后,你通过 n v c c 啊,已经确定好了酷打安装成功了,那么接下来呢,你就可以直接 来安装库打了啊,就通过这个命令,现在我们已经确定了老师的库打是十一点七。好,你接下来就通过这个命令,可以直接来安装了,在这里呢,你放下来就可以来安装了。但是呢,由于这个软件非常大,我们刚才讲了安装的这个 torq 啊,他可能有一个多 g 啊,应该确定是有一个多 g。 如果你的网络但凡出现一点波动,这个地方他就你下载下载,下载,好不容易下载了五百多兆,七百多兆,哎,他就给你断掉了,因为网络有点波动,他就给你停掉了,那么怎么办呀?哎,其实这地方他给了你一个网址,同学们, 这个网址啊,你可以打开看一看,其实对应的就是 py torch 的服务器,那么在这里呢,它有很多关于 py torch 知识的软件,比如我们需要安装的 torch, 还有呢 torch audio, 还有呢 torch worship, 它都有,那么现在 你不就是要安装 touch 和 touch watching, 还有 audi 吗?那么你直接在这里来进行安装也是没有问题的。那么在这里一点开之后啊,我们刚才点击了 托起,我们先来安装托起啊,那么你到底应该安装哪一个版本的托起呢?你看前面这个托起二零,然后呢 cpu 什么什么的什么的什么的,你也不知道他到底代表什么含义啊?我们来分析一下,托起二点零零就代表你当前下载的托起版本是二点零零版本的, 然后呢,后面加上一个 cpu, 就代表你当前安装的是 cpu 版本的,然后呢,这个地方一个 cp, 不是说你要处一个 cp 啊,不是啊,这里的 cp 它表示的是 python 的版本,例如老师现在这个地方啊,我现在把这个删掉啊,不这样去安装, 老师在这里呢,默认使用的拍子呢,是三点七点九版本,所以你就去找到 cp 三点七点九这个版本,那么就是三七这个版本啊,你去找到这个版本就可以了, cp 三七这个版本就好了,哎,这个地方默认呢,比如这个,他表示 cp 三点十版本就是拍子三点十版本,然后呢操作系统是另一个操作系统的,那么显然这 一个文件并不是我们需要去安装的,我们要去安装拍摄三点七这个版本,所以呢,你通过 ctrl f 在这里呢,输入 c p 三七,就能够确立你当前拍摄的版本。好,我们将往下找找找,那你到底要安装哪一个版本呢?哎,你可以跟着老师一样的版本来进行安装啊,例如老师安装的呢? 修一下,我们查看一下 top 的版本。老师安装的是一点一三点一这个版本, 在这里我们也不建议同学们安装最新的 touch 版本好不,建议安装和老师差不多的版本就行了,但是同学们,你千万不要去安装啊,后面特别老的一些版本,例如我们往下翻啊,一点五一这个版本你就不要建议去安装了啊。 那么在这里呢,老师安装的是一点一三这个版本,那么你可以去找一下关于一点一三这个版本啊,直接就是搜一点一三这个版本。好,在这里呢,传是一点一三这个版本啊,一点 一三点一,那么好,再加个点一,现在就确定好了。在这,现在你去找到 c p 三点七,是不是只有这两个是 c p 三点七啊?哎,但是我们发现他好像只有慢了,嗯,这是怎么搞的?这是因为他是 c p u 版本,他并没有写 g p u 啊。那么 g p u 版本在哪里啊?你往下翻,下面还有 下面还有,我们往下翻,在这个地方,你看它这块有图形啊,这个地方是 touch c u, 看到没有?这个才是扩大啊,我们要去安装扩大一一七,那么扩大一一七在这儿,所以你一开始也可以直接定位扩大幺幺七,就代表你现在安装的是扩大 幺幺七这个版本。而老师安装的版本呢,是幺幺三点一,那么就找到幺幺三点一,就这个地方,然后呢找到 python 三点七这个版本,那么 python 三点七满足和老师一样的版本呢?是不是只有他们俩了呀?你看 torch 一点一,三点一,并且他的扩大版本呢是幺幺七,并且他的 python 版 版本呢是三点七,对不对?然后呢有一个 linu 系统版本,有一个 window 系统版本,那么此时我们就去下载 windows 系统版本,你把它下载一下,点击一下它就可以来下载了,你看二二点,一个 g 非常大,如果你用命令提示符的形式直接去下载安装啊,它经常性的可能会中断两个 g 的内容啊,你可能要下一个小时,那么一个小时的过程中,你突然就网络中断了,就会导致你下载失败。 所以呢,建议同学们你直接把这个网址啊,在这个地方下载,或者直接到迅雷啊,或者用其他这些下载专门的下载软件把它下载一下,这样的话下载速度就非常快了啊,关注我,学习计算机知识。
312计算机李老师 03:47查看AI文稿AI文稿
03:47查看AI文稿AI文稿看一个主流的深度学习框架,拍拓曲,拍拓曲这个框架是 facebook 出的,然后拍前面 py 这两个单词代表的就是拍摄,然后其实拍拓曲的前身是 另外一个 facebook 出的框架,我们把它叫做唾弃,然后唾弃是其实是一个很好用的框架,他和安排很类似,然后操作起来特别的灵活和简洁。但是他有一个 不算是缺点,就是它采用的编程语言,不是一些主流的编程语言,而采用的是一个比较小众的编程语言, 这地方叫做撸啊,是葡萄牙语,是一个巴西的教授发明的。然后因为这个编程语言流行度不高,所以基于透 touch, 然后 facebook 又出了一个 touch 加拍神的一个新的计算框架,把它命名为拍 touch。 然后除了 facebook 之外,其他很多比较大的机构都用的拍拖曲,还有就是呃,很多学术论文所用的深度学习框架都是用的拍拖曲,因为因为他的语法很简单,非常的灵活。 下面我们可以来看一下拍拖曲拍有哪些特点,让他变成一个非常热门的计算框架。 拍拖曲不是简单的在 c 加加的框架上绑定拍摄出来的一个语言,而他是在非常细腻度的程 程度上就支持拍森的访问,所以我们每次在访问拍透去的时候,他的语法其实就是像我们平时用 non 排用 sipe 这样简单,这又大大的降低了入门的一个门槛,他也可以保证代码和原声的拍摄代码实现起来是一致的。 拍拖车还有一个很大的优点就是他用了动态的神经网络,这点我们可以和 tsflow 一来比较一下, tsflow 一用的就是一个静态的计算图,不是一个动态的神经网络,就主要的意思,如果大家用过 tyflow 一都知道,我们在计算之前先要 建好整个计算图,先要把计算的流程都给规定好,然后再打开 c 审,然后位数据进去,然后再取出特 定节点的一个返回值,然后这是静态的计算图。这种静态的计算图为什么 我们要先定义好计算图呢?因为当我们在定义好计算图进定义好计算流程之后,他的一个优点就是他可以非常合理的分配电脑的一个计算资源和内存空间,这是静态计算图的一个优点,然后拍拖去用的是动态的 神经网络。动态的一个计算图他的一个优点就是我在运行的时候就可以生成动态的计算图,这样的这样的话我们就非常好堤坝, 然后开发者就可以直接在调试器里面停掉解释器,然后查看某个节点的一个输出,这种很易于 dbug 的这个优点是 two 一这版本没有的,当然当然现在 flo 更新到。二,然后他现在使用的也是一这种动态的计算图开拓器还有一个很大的优点就是同时支持 cpu 和 gpu 并行预算,当然这是很多深度学习框架都具有的优点,然后这是。
17精彩网络技术 20:16
20:16











