Colly爬虫使用方法
卡里是一个勾语言实现的爬虫框架,使用卡里,我们可以快速实现一个简单易懂的爬虫。卡里由于是勾语言编写,所以在编译完成后可以直接运行,不必担心运行环境。官网中有很多例子,可以参照写法。

粉丝3.9万获赞42.0万
相关视频
 00:48
00:48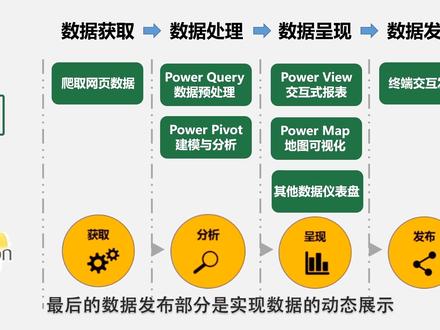 07:38查看AI文稿AI文稿
07:38查看AI文稿AI文稿各位观众老爷大家好,我是憨憨少年小木木,一直游走在摄影边缘的理工男,通过本期视频,你将了解到如何使用 xl 完成网站上的数据扒取。 本视频完全适用于纯小白和零基础的朋友们,当然了,拍损爬虫大佬们也可以给点建议啊,木木甚是感谢,看在木木这么有诚意的份上,动动小手点个赞吧!本期视频将会从以下三个方面进行分享,一、简要介绍数据分析的流程。 二、详细讲解 xl 数据爬起的实操过程及相应知识点。三、数据可视化的呈现。本期内容极干,请自带水杯。话不多说,让我们马上进入第一个环节,数据分析的流程。其实数据分析主要由四个环节 组成及数据获取、数据处理、数据呈现和数据发布。其中数据获取主要是爬取网站上的数据,实现可操作性的编辑。 数据处理模块主要是用于数据的预处理,将获取的数据进行格式调整,方便后续使用。常用的 office 组件为帕沃奎尔和帕沃 perwit。 数据呈现模块主要用于数据可视化、动态的展示数据结果。 最后的数据发布部分则是实现数据的动态展示以及与终端设备的动态交互。由于内容庞大,本期视频主要关注第一个环节数据获取部分。 数据爬取的目标是将网页中展示的数据爬取到可以编辑的文本工具中,从而实现批量操作。在具体的爬取过程中, 经常使用的工具有 xl 和 pass, 要说哪款工具最好用,可能闭着眼睛都会选 pass, 同时 pass 的优点可能会一直讲不完,但是当我们看完 pass 的代码后,对于小白的我来说,内心是这样式的。什么? 相比拍死 xo 清爽而绿油油的界面,清晰可见的汉字之夜难道不香吗?既然对比敲定了工具,那就让我们直接进入第二个部分, xl 数据爬取的实操环节吧。 在打开需要数据爬取界面的高级板块后,我们会发现这个板块主要是由三个模块组成的,一、目标网页。二、响应时间。三、响应标识。首先,目标网页很好理解,就是我们想要爬取数据的网址信息,此处以全国 是房价排行的网址为例。接下来是响应时间。通俗的讲,就是我们每次访问网站的点击频率,假如我们人为的访问网站,一秒内访问一次网站,网站会根据我们的点击呈现相应的内容。但 爬虫比我们能干多了,他不辞辛劳的一秒内向网站发送了 n 条请求,导致网站的防御机制识别到,这不是人干的事,立刻启动反爬虫机制, 阻断了网页内容的呈现。那有没有办法解决这些问题呢?当然有,限制爬虫次数后,将实际的爬虫过程伪装成人为点击就好了。这就是响应时间使用的精髓,有没有 get 到啊?关于响应时间标识,目前包括派森爬虫在内常使用 uzze 标识,但是问题又来了, uzza 标识是个 啥嘞?看完百度的解释以后依旧懵逼不打紧,木木来给你讲个大白话,其实吧,优质粘土标识就相当于每个浏览器的身份证信息,我们通过 xl 中的优质粘土标识 选择指定的浏览器进行网页内容的爬取,最终有效的爬取到页面内容。在使用爬虫的过程中,最为常用的浏览器为骨骼浏览器和火狐浏览器。那讲了这么多,是不是该实操一波了?让我们的友谊小车快快开动吧,抓紧哦朋友们! 第一步,获取浏览器的优泽粘图标识,此处以谷歌浏览器为例,打开浏览器,输入目标网址后,右键点击检查,在检查页面中点击 like you took 后重新加载网页,在检查 like you book 页面中单击 第一个网页信息,因对此 htm l 在右边出现的窗口 hanger 中将页面拉至底部,可查找到浏览器标识。 usbent 复制优质粘土信息即可。第二步,设置响应时间,伪装为用户访问。首先新建 xl, 打开 sl 后点击数据, 点击自网站,在弹出的窗口中选择高级选项,将我们需要爬取的目标网址信息粘贴至 url 位置处,同时在响应时间栏设置一分钟的响应时间。 第三步,设置浏览器标识,在 http 请求标头参数中下拉,选择优质粘土,粘贴浏览器的优质粘土信息。第四步,将数据 载入到 paotyoud 中进行预处理,建立网页链接后选择 top 零,选择编辑,进入 paogleogo 进行数据预处理。处理完数据后,依照惯例小小的制作一波数据可视化地图,来看看成品的效果吧。 最后让我们一起来回顾一下本节视频的重点吧。使用浏览器的检查功能获得浏览器标识, 在 excel 扒取中设置响应时间,伪装为用户浏览设置浏览器标识 uzz, 将数据 载入 paokil 中进行预处理,数据可视化制作及定时刷新是不是并没有那么难啊?相信聪明的你一学就会。 那么关于下一期的视频内容,可以在评论区或弹幕类留言评论哦,你的建议很有可能就是下一期视频的主题呢!好了,以上就是本期视频的所有内容,你的支持是默默更新视频最大的动力,感激!
1765数据农工老孙


















猜你喜欢
最新视频
- 3.3万Bliss