retrieval是什么意思

粉丝407获赞2669
相关视频
 09:29
09:29 01:45
01:45 06:55查看AI文稿AI文稿
06:55查看AI文稿AI文稿的一篇博客叫 conversation retrieval ins 这样一篇文章啊,这篇文章它主要是还是讲就是目前基于知识库的这样一个啷签的应用啊,啊,增长非常快,但是呢,利用知识库的话,目前要跟聊天,呃,要跟那个一些 memory 的它的那个记忆, 我要根据那个搜索到限量数据库里面去搜索的一些工具要相结合啊,之前他们通过一个叫 conversation 的那个 retrieval 券来实现的,呃,但那个工具呢?他们现在的又把它做了一个升级,呃,通过一个 agent 呃来实现,嗯,他把这个三个功能又合在一起,嗯, 我们来一起看一下他到底能够达到一个什么样的一个作用,再通过那个知识库获取内容,然后结合在大模型里面做一些知识问答啊。在之前的一些应用当中,他每次都要到 知识库里面去问啊,都要去检索他,等于是这样啊,或者有一个很简单的,比如说他可能问候了一句 hello 啊,那他也要到知识库里面去查,所以他可能会造成有些很奇怪的一些笑话。那么用了 ad 成他有个好处是什么呢?他 可以根据这个大模型自己去判断它到底是否需要去调用这个到史亮数据库去搜索的这样的一步操作啊。 如果他发现他不需要搜索,他已经有了这些知识点了之后,那么他就不会到这个史亮数据库里面去搜索,或者说他去判断他的这个内容是否要到史的量数据库去搜索,如果不需要的话,他就不会到 实量数据库里面去搜索相应的一些知识点,所以的话呢,他更加智能啊。另外他也是可以把那个对话跟呃之前对话的那个上下文啊,然后放在那个内存里面,有些内容,有些知识点,他其实在内存里也有了,他 也就不需要到质量数据库里面去去获取了啊。那但是呢,它这个带来的另外一个问题是它的那个 context 就是它的那个 上下纹啊, context window 它要变得更加长啊。那么目前的话呢,那个 chat g l m 二代六 b 的这个模型目前已经支持到了那个三十二 k 的这样的一个上下纹啊,所以的话,我觉得就是说随着这个大模型上下纹越来越长啊,这种应用的话呢,可能 会越来越多,他都是利用上下文多轮对话啊,去解决同一个问题啊,他等于就不一定要求我们的那个 指指令啊,一下子提交给大模型就会非常简啊,会要求他就很明确,或或者你这个指令要很完整啊,他就不需要,他可以通过多人对话去补充,不断的去问这个大模型啊,他是这样,那么他会自动去判断他是否要到适量数据库里面去检查,或者说他这个 a d, 他还会去 控制他是否还可以利用其他的一些工具来支持这样一个回答,他是这样的。好,前面我也讲过了啊,前面的话呢,他们主要是用了这样的一个类啊,叫 conversation retrieval qa 这样的一个类啊,去作为一个呃机器人交互的这样一个类啊,那目前他们就用了一个新的类叫 edent, 我给大家看一下,我把它原码给拿下来,它核心就这个类,我也改了一下啊,用了我自己本地的一些知识库啊,它等于是这样啊,那它原则上的话呢?它主要是, 呃,要初始化一个,我用了两个工具,一个工具,一个工具。呃,财税方面的一些问题啊,他如果不知道,他可以去通过这个工具去搜索返回相应的文档啊。第二个工具的话呢,我定义了一个这个计算器啊,如果要回答一些数学问题,就可以用这个计算器来回答一些,那相对来讲他会比较准一点。好,我们看看啊, 这个的话呢,你要他的 agent, 你要初始化一下啊,要初始化他一个模板,模板这个模板告诉他你是一个财税方面的这样一个智能的一个技能,你要解答财税方面的一些东西啊,他主要是做这样一件事情啊,要初始化一下这个 print, 那它这个里面就是要定一个 agent, 就 open ai 函数的这样一个 agent。 呃,这个 agent 就把那个 l l m 的大模型注入进去,把那个 to 是我前面定义的两个 to 是注入进去,把这个提示注入进去。 他有了这个 ajint 之后的话呢,通过这个 ajint 的 execute 就是执行器,他就可以跑了。这个是个 memory memory, 就是这个 ajint 那个的的,他也可以记录这个人跟系统的这样的一个交互的这样一个过程,包括,呃 ai 跟 trus 交互的这样一个过程,他都可以把它给记录下来,放在这 这个 memory 里面。他掉的话呢,他其实也是比较简单,他主要是掉这个有一个这个东西进去 executor, 然后把 print 和 history 扔进去,然后再把它运行就好了。我给大家看一下他跑出来的效果,我前面已经跑过一些了啊,给大家演示一下, 因为他结合了我本地知识库之后,呃,我里面有八千多条的相应的那个法律法规啊,所以的话,他基本上都解答的都是中国的一些,中国的一些那个税收的一些东西啊。好,我们继续再看啊。他这个里面呢,主要是讲了两点啊,一点他主要是调用了这个欧邦 ai function 的这样一个 agent 啊,然后它 trust 里面,它主要是定义了一个这样的一个一个从,呃,从那个质量数据库里面去调取相应的那个文档的这样一个功能。不,它的 memory, 它不但是记录这个用户跟 ai 之间的交互,它也记录 ai 跟这个工具之间这个相互 调用的这样的一个记啊,交互他都会,他都会记的。那么用这样的一个工具,他也提了两点要求,第一个,他这个 contacts 的 window 啊,他一定要足够的长,要长一些。另外一个的话呢,就是他的这个 language model 啊,他的那个 推理能力要够强啊,如果他的推理能力不强,他基本上是跑,跑不起来的,跑不起来的他等于是这样,他目前呢,也可以,他们目前他是通过叫 long smith 进行 trace trees, 就是进行跟踪他的执行的。嗯,但是我这边呢,因为现在 lan smith 这个工具我也安装了一下,嗯,就会发现他还是有些问题, 目前他还是处于在贝塔板测试啊,他还没公开,所以的话我还不能用啊。他这个虽然我已经注册完了,但是他还不能用,好,我们再看看啊。好啊,这个的话呢,主要就是这篇文章的这 一个改善啊,它的改善的话主要是改善一个集 a r a g 的这样的一个应用啊,本地知识骨结和大模型啊,进行知识问答啊,他们用了一个更新的一个技术啊,我前面介绍的用了一个这个类啊,就 open ai function agent 啊来实现啊,他可以通过这个 a 进程来判断他到底是使用,是否是需要使用工具,然后用什么样的工具。我目前的话呢,我自己是用的那个这个 chat g l m 二代 杠六 b 三十二 k 的这个模型,我用下来感觉还可以的。这个模型还可以,但有些推理能力还是有些问题,我也让他做过一些数学,但是他好像有些做的不是很好, 他好像除法,我觉得他好像有点问题,对,还是对的,但有些时候我我来看一下,我给他做道数学题,一家企业销售收入一千万,英案百分之十三, 要交多少水晶?需要交多少针织,这个地方不对,所以我觉得他有些时候做数学还是有点不对的。对啊,他应该是二十六万,不是五十万,所以他他的这个数学的智商还是比较低的,他这个。
356小工蚁 54:05查看AI文稿AI文稿
54:05查看AI文稿AI文稿中国科学院大学塔山协会 r a g 的未来与发展主讲人陈昭宇今天跟大家交流一下关于这个 i g 发展与未来的一些知识, 也希望跟大家多多学习和交流。这个 ig 他的意思就是检索、增强、生成,这就是我要讲的一个大致的一个目录。第一个就是为什么需要这个 ig, 因为我们都知道这个大语言模型就是他的这个功能很强大,但实际上现在也大家都知道他也并非是万能的,因为我们也都知道这个大语言模型他是受到一个知识截止点的一个限制,因为从他这个收集数据清洗这里开始, 只能收集他以前的一些知识,然后在后面的训练测试到使用这一段时间,以及他将来的这个呃最新每一天出现的这些内容,他都是不知道的,就相当于我们一个 呃考试这个学生他考官以外的一些知识,以及考试以后的知识,那么这个这个学生他没有学的话,他肯定就不知道了,他只能根据他以前所学的一些这个内容去进行一个推理,他的推理就是这个大于模型里面的一个概率计算,然后呢提供可能的一个答案, 因为你是必须要让他提供一个答案的话,他也不能说他不知道,他就根据他的一个肚子里有的这些呃这个知识去进行提供答案,那么这些答案其实是他是有一定不确定性的呃,而且这里面比方说没 领域里面他还有一些这个专业词汇啊,约定是说成说成的一些词汇啊,他也压根不知道,所以说啊,这个呃大于模型,他的这个他的不足也是我们要通过这个 ig 来进行一个弥补的。 然后第三个就是深层的内容,他是可能会出现幻觉,呃,因为我们知道大于魔仙就相当于是我们一个人的大脑,他这个大脑里面的这,他这个知识都已经是结构化了,就相当于已经被训练成了这个样子了,他里面的这个每一个知识点或者哪一些这个关系都已经确定了。 那么你训练以后呢,他这个已经出现了一种知识的,相当于是一个基本上的一个大致的一个概率的一个固化了啊。那么然后他通过这里的这个所提供的一些答案的话,其实都是推理出来, 通过这些概率,那么这个推理的话完全取决于你所提出的一个什么问题。然后去匹配他这个大脑里面的这个知识点,那么他这个在生成的这个内容里面,因为他以前的这个 呃,在这个大于模型里面训练的这个参数那么多,记得这个知识点那么多,所以说在表面上看起来他所生成的内容的话,他调理是非常清晰的,逻辑也很合理,但实际上他这个答案他是经不起推敲的,或者是有一些是他捏造出来的。 那么这就是我们所说的这个他是一本正经的胡说八道。那么那么看上去呢,他又是哎像一个人,但是实际上呢,他又是这里面他就是这恍恍惚惚的这种感觉。 那么第四一个,那么我们要怎么让这个大语言模型那个更靠谱啊?那么我们从这里可以看出这个 时间轴,这个时间轴往后的这些是我们这个 ig 要做的一些事。那么在这个 ig 这个之后的这些问题的话,我们是需要进行一些查询的,然后就更新这些知识库,那么通过这个查询来获取弥补后面的这个知识不足。那么呃, 这个让大雨,这个让这个大雨魔仙他不光只是靠这个记忆,他还能够这个后面这一段就是随时可以在图书馆或者这个网上去查询呢,进行一个实时的一个从这个知识以后来进行提供一个答案。 那么大元魔仙他本身呢?以前呢?比方说我,我给他提提一个问题,我做一个,呃,把它比喻成一个厨师的话,我做一个辣椒炒肉,他就直接可能就拿一个辣椒一个肉,然后就可以炒了,就可以给你提供出来。那么这个 就是我们用的一个一个早期的一个比较自,就是一个自动的锅去做了,哎,就可以使同大量大量供应的时候,哎,那我们就可以做出一个也看上去像一个辣椒炒肉的一个一个菜出来了。 实际上但是对于一些这个呃有这个比较高要求的一些这个人的话,他这个辣椒炒肉根本是不够,不够看的就是不够符合这个用户的需求的。那么这个时候可能我们要找出更多的这种食材, 符合要求的还有配料等等,可能就很多,包括制作的这个工序都有很高的要求的。那么这里找出来这些食材的话呢,相当于是我们搜索用谷歌或者百度去搜索, 而以前的谷歌百度去搜索出来的内容的话,他只是把这些东西找出来了以后给你可能肉有很多种,辣椒很多种,其他的这个配料也很多种, 一股脑给你,你这一个个自己去查,去看,看了以后选其中的一些资料,然后你再去做菜,那么五个百度的话,他只是提供这个原材料给你,后续的话你怎么去做他就不管了。 好,那么好,现在的这个大语言模型来了以后呢,相当于把这些提供给他以后呢他这里就有一个厨子了,这个厨师就是相当于是他就是个大语言模型 l l m, 那么他这里有可能是这个很高档的一个厨师,也可能是比较很高级的一个一个机器样的,反正这就是他的一个能力,他可以自己去做菜了,那做出来这个菜,哎,这个时候就呃他的这个就符合一个 一个高要求的一个一个菜品呢,那么这就是我们现在这个呃 ig 的一个原理。那么在这个 ig 的这个呃里面 的这个每一个过程,他这里就是在这个早期到这个呃检索准备数据,到这个检索到生成内容,因为我们是这个检索增强生成,对吧?检索那么增强的话,这里就是用这个与这个提示值这些 再次生成。那么这这三个过程,这三个字母里面的三个过程,第一个检索的话呢,你就要首先有一个地方去检索,那么这个地方的话相当于就是你要有一个好的一个这个素材库, 那么这个素材库的话,以前我们说说一些简数,就是真的是可见即可得的那一种,就是呃, ddf 也好,这个 word 也好,或者是网页也好等等,你是可以人可以读得懂的这一些。 那么但是我们这个机器这里面的这个,呃, ig 里面的这个他就可能就不是这样了,他就没有那么简单了。 那么我们在这里在做的时候,需要把这些这个原始的这些数据进行一个分切, 然后呢把它这个整理就是,然后把它里面的信息进行一个维度化,就是向量化,那么这个向量化就是可能把它做成这个,呃,比如说七百六十八维啊,或者一百二十一这个幺零二四维啊等等, 那么这一个就相当于是把它根据这个,因为他每一个姿势或者每一个数据这个文本,他可以把它分解成从各个不同的角度去看,他或者把它做一个数据的一个定义,然后从这些角度把它定义完了以后,你要把这些数据保存下来,他每一个时都把它分解成很多维度, 那么你然后保存下来,保存下来以后相当于是我们做菜一样的,你把一头牛给宰了以后,他可以分解出很多很多 累出来,那这个就相当于分切了。分切以后,那么我们再把它这里面的,比方说牛排他是什么特性,什么什么什么,你一个一个把它记录下来,对吧?啊?这就相当于是维度化,向量化, 那么你还有什么其他的这个各种食材都要把它这么去分的很细的这种就把它给记录下来,这就是像是 indexy, 就是一个呃 啊,一个锁引,就是文档的锁引,然后那么这个锁引以后别人来找你的时候,就根据这个锁引来找他,不是根据你这个食材,然后一个一个去去看的,然后这么去找他,对他的这个方式是不一样的。 那么我们这个在这个检索的时候呢,他这个 returers 就相当于是我们就提出一个问题,相当于我们这个下一个菜单。那你这个所以的话,他那边记录的方式,就是按照他这个专业的方式去记记录 啊每一道这个菜或者每一道食材。我说你们的他,他有他的个记录方式,就不是那个他是专业的一种记录方式,就相当于是厨房系统的一种记录方式。那么我们这个食客在下单的时候,他只能说说我要一道什么菜,对吧?那么这个菜他提出的这个问题 和你那边库房里记录的那个格式是不一样的,那你得把它这个菜的这个下单的这个菜,然后把它也转成这种各种这个匹配的这个像呢,每一道菜里面也没有很多这个需要的这个原材料 啊。然后呢把它也进行一个这个维度化,把它向向量化分成度维度以后,再用这一个拿到这个库房里面去,跟别跟他那边这个锁影进行一个相似度的一个匹配,然后把这一个把它给原材料,把它给匹配出来找出来。 当然他可能有些匹配的就是一模一样的,有一些可能只是相似的,就是这个相似度,就是根据这相似度去匹配,就是概率计算把它这个匹配出来,那么这个匹配出来了以后, 那么其实以前的这个谷歌搜索的话,他就只能根据这个,我要肉就是肉,要什么肉就是什么肉,或者这个百度搜索啊,就是名字去搜索的,他这里就是根据他这个特性把他维度化以后,根据他特性去搜索,他这个就就完全不一样了。 以前的话可能我们要一个淀粉,对吧?可能有玉米淀粉,还有土豆淀粉,那不都一样吗?对吧?所以说这个,那你这个这个以前的收数就跟现在就不一样了,匹配的, 那么我们这个项链,这个是搜索的话,相当于是语音匹配啊,他只要符合你的要求就行了。然后这个再用这个大于 模型,就像那一个大厨师根据你这里弄来的这些东西,那么我就再去做这道菜,那么做这道菜的话,这就算生成就是生成这个这个结果,那么这里面他有一个上下文的一个提示,就相当于我们在这个 在这个生成一个内容的时候,我们要跟这个时刻,他如果要求很高的话,我反复的问他有哪些,哪些要求这个等等, 或者我了解他是哪人,他有什么这个这个词的一个偏好等等。把这些弄好了以后,那么这个厨师在生成这个,这个在做这道菜的时候,或者这个魔性在生成这个答案的时候,那么他才会有有这个针对性的去做。 那么他其实在这里做的工人中间,或者他这个这个东西拿来的时候,可能食材或者什么匹配了很多,那么这里他进行一个排序或者过滤,有一些不用的拿过来我也不要 啊,有一些这个拿过来好几种我都要排序用哪一种就够了,那么是就是这么一个过程。然后呢从这个我们前面讲的就是 ig 的话,他这个首先第一个就是要有一个一个库,那个知识库,那这个学习的这个知识库的话, 呃,就是这个内容,那么这个内容的话,根据以前的这一种内容的话,那么就是一个标量数据库,他有结构化的,非结构化的这个抖友,对吧?呃,这个原始的这个文件他这个存储,他这个空间很大,有一些因为就是扫描过来的 啊,可能他的空间很大,然后他所储存的信息可能就没那么多,但是占用的空间很大,他这个需要这个关系性数据库啊,这个 cpu 去检索啊等等。那么这个就相当于说我们这是原始的这些数据,相当于是原始的这个牛羊 啊或者鱼啊什么菜之类的,你要把它这个拿过来的话,它重量就很重,真正我把它宰了弄好了以后可能就没那么多了啊。那么这个那么现在的这个就是我们要把它这个原材料进行一个加工,这个牛羊鱼啊,什么这些蔬菜我把它加加工好,能够直接做的, 而且要建立一个这个缩影的一个表单,那么这个时候相当于说我们就把这些原则的这个数据就把它进行个清洗,有些重复的一些没用的啊,一些的这个这个造绳呢,把它给它去掉,去掉以后把它分切好,根据他的羽翼一段一段分切好,或者他的这个长度 是五幺二,还是这个一千或者是两千个 top 这种把它分好,就相当于把这个肉一块一块分好,各种的分类分好,然后它都有什么特性,做什么用啊?等等,把它这个这个相对是个 inbending, 就是就是这个,把它这个信息把它归类好啊,这 就是我们这个这个整个过程,那这个整个过程的话,这个文本的话呢?第一个过程的话呢,这里就是 ocr, 就是提取嘛,就是提取它里面的文本啊,然后再做这个也硬斑点,就相当于是也是国内的模型,这一个 manayu, 这个 bge, 还有这个 mimiverse 等等,这一些都是有国内有现成的这个模型, 那么这里都每一个都是设计的模型,都涉及到有算力的,如果当你有大量的这个东东西都要通过去计算的时候去做的时候,那么这个成本就是比较高的。当然我们现在对于个人的有一些 呃使用的话,现在也有很多平台,比方说我们用了也用了一些这个,比如说直接跳动他们的这个火山引擎里面的,他有豆包啊啊,当然他们自己那里也有一些其他的一些模型,比方说,嗯, 呃,这个 tipsiger, 对吧?呃,那么我们在里面都可以去用,呃,而且它的这个知识库它是做的比较这个智能的, 我们一直也在有一些也在可以直接使用他们的,因为这样的话可能成本比较低一些,我们对于一些小型的一些用户调用的话,我们就直接就可以租用他们的这种 好,那么这里的话,这个当然这里面他这个每一步,这个比方说这个 mill 是他是建立这个项链这个数据库,那么这里的话有一些是开源的,这里很多这其实这些都是有开源的,你可以去去去做的。当然这些要图便宜,或者图图图这个 呃简简便,如果用量不大的话,直接就可以在这个扣子里面呢啊,或者火山引擎里面呢,火山方舟里面呢?都可以 去去做直接用起来啊。当然我们这个我们自己的这个平台里面也有,我们有一些也在调用他们的这个模型,所以说这个是呃深度的这个嵌入在一起用的, 那么这里的话就是相当于是通过这些几个模型把它建立起来一个锁引库,然后把它切片弄好,都放在这里啊,这个锁引其实是很小的,就是呢我们把这些东西这个数据把它给提炼出来了,对吧?那你这个分切的这个分切的这个原材料他可能要大一些。 然后这还只是一个呃,最基础的一个 ig 的一个模型,就是这里提出个问题,然后把这个问题进行一个这个向量化,以前就可以直接就是跟这个大模型就生成答案了,因为他这个生成答案就只是模型里面一个知识就很有限。 现在就把这个数据库把它加进来以后啊这然后把里面的文本提取出来,再生成这个答案。这是一个很基础的一个模型或者一个原理,但实际在应用过程中可就没有那么简单了啊,那就比这个复杂多了。那么我们来看, 那么在实际应用的场景里面呢?呃,首先呢比方说我们,呃对于一般的这个企业里面的一些知识问答,他比方说产品的介绍啊,很多这些他就可以把它做成一个知识库。因为这个大模型他新的产品有很多他是没有的 啊,有一些这个淡薄性,不可能全部去把这些收集进去,就太碎了。那么他这个就是相对于一个比较小型的一个数据库,把这个做的话,比方说就可以直接用这个扣子里面的一些这个纸库可以自己去做啊。那么 呃,还有其他的一些平台里面也有这种啊,这个是比较比较简单的,这就是直接用一个豆包大模型一接上去又快又方便。 那么再专业一些领域的话,或者大型的一些领域的话,比方说医疗辅助这个整整疗的,还有金融的,金融里面他每一天都会产生大量的数据,那么这一个尤其是基本上在这个中旬的这中旬的这个范围数据里面 啊,那么这个就可能有一些需要是自己去建立他的这个相册数据库,就像我们前面所说的这个, 这里的这个要用这些模型自己去做啊,一个一个去做,但这个在做的过程中间也是有很多要注意的这个细节的。不是说我们一看啊,这么一说直接上这用起来的时候,里面的很多是有技术门槛的啊,所以说在这里的话,这个,呃这是中型的这个 数据库,然后还有法律啊,还有这个法律里面主要是有很多案例啊,大量的案例啊,是吧?每一天,或者说每一年的这个全世界各种各个地方的这种案例都会有。那么还有科研的话,他有科研文献,现在科研文献的话有几亿片科研文献,这个如果你要做一个全库的话, 那哪怕是你做一个一个大型的专业的,比方说这个医疗的,对吧?生物医药的啊,这个这一些他都是属于比较的比较大型的,它里面还有很多这个一些一线的,这些诊诊断的一些数据 啊,这些专业的啊。然后那么像这里的话还有一些是专利的,科研里面他不光是是有个有,有这个科研文献,还有专利,现在专利的话也是好几千万,全球有一亿、一亿多两亿,现在所以说那么这个你要是做成一个平台的话, 那么这个是一个大型的数据库,还有这个教育,个性化教育,那么这里面的话也会有有很多这种呃各种场景的这种数据全部要放进去的话,那么也是相当庞大的。 那么我们这个第三个就是 ij 它面临的一个问题,就是前面我们在说了这么多场景,实际上如果我们把它这个呃构造场景都要去解决, 那么这个就就面临问题,就是其实就一个字,多。这个多就体现在你供应的这个数据来源很多,需求的场景很多很复杂, 那你都要去满足。既然你要是如果是说呃做这个 ig 要去所有的问题都能做的话,都能解决的话,那么这就是工程化的大量的生成的一个内容,就相当于一个吃饭一样的啊。你这个有家庭 吃饭的,有大食堂的,有酒店里的、高档的,有这个这个食品要求的什么这个米其林的,还有快餐的等等,那么这种食材就是一个很庞大的一个体系,从供应到这个生成,每一天供应那么多人的这个使用,那么这相当于是我们 再看一下他这个在这个生成的过程中间,那么你这里在供应的时候,首先是你要有一个庞大的一个供应体系,比方说有这个市场,菜市场 或者你这个批发市场,然后把这些批发来了以后,那么你要把里面的有一些东西要进行在这个更早的地方进行一些屠宰,或者说是分拣 等等。那么分享好了以后,你到最终生成的是各种场景里面的一个应用,比方说这个各种这个复杂的这个食堂也好,家庭也好,对吧?这个大厅的酒店也好,那么这个从从前面 这个原材料供应到最后到这餐桌上来,这餐桌上的这个满意度,那么这里整个是一个非常庞杂的一个体系, 那么这个体系里面他出现的其实这里的有一个问题,就是第一个,那么这里这个爱今年的问题啊,就是一个检索召会不足,漏掉关键信息,也就是我们在做这个采购的时候, 你总会漏掉一个,漏掉一些,或者说我买了这个以后啊,发现听别人说,哇那里还有一个什么东西更好,你的这个信息你不可能所有的你都跟踪的好,跟踪不了, 那么这里就会在这过程中间有一些东西,他是这个类型特别多,那你在这个检索的时候,可能他就检索不到,或者他习惯性的检索了其他的一些内容啊,这个漏掉的是就是就很正常,那么但是为了保证他这个漏掉更少,可能你在采购的时候,或者在这个检索的时候就会 尽量的多,但是一多了以后呢?他又有很多这种这个噪声,或者是很多这个无用的信息又会被这个填充进来,那么这个就是是个矛盾的一个体系,要么我又怕丢掉一多,多了以后又是又是一些这个呃过滤的话又很繁杂。 这还有一个就是利用不足的话,可能这个就模型可能忽视他一些简史简锁的一些重要的一些内容,就相当于是你这东西买来了以后,到大厨那里在使用的时候,哎,他可能就有一些你认为买的不错的,或者真的是有些不错的,他在用的时候他就 用不上那些最好的,或者说是符合他这种要求的。那这个你说这个在这里面整个过程里面他哪一个环节都有可能存在这个这个问题。因为当你面临一个一个庞大的一个一个工程体 的时候啊,那么然后我为了做的这满足这个所有这些一个大城市里面所有这个场景的这个应用的话,那么这个成本是非常高的。那么你需要维护这个香芋是这个整个这个体系,从这个原材料到这个最终的供应的这个体系里面很大,那么这个那么呃到这个呃 呃科学数据库里面来看的话,那么整个就是从这个缩影到最后生成这里面整个数据库是非常非常庞大的。那么我们看这里这个是这个这个知识库里面他有这个原始的这个数据, 还有这个向量数据,那么这个整个这里面每一步都还涉及到很多这种各种模型的应用,模型的应用里面也有更新啊,然后他还有对比等等。那么这里面的话,你上面的这个是原始的数据库啊,这个相当于一个大城市,你这里这些东西都要配齐, 一旦没弄好,可能就你这里就要出问题了啊,有一些地方买不着了,有一些就不够了,有时出现这种粮食荒啊,或者说有些菜荒啊等等啊 啊,这个下面你这里建立的好一个这个分拣体系,以后还得要很好的一个锁引,别人根据你这个锁引能够匹配的上,所以整个这个体系是非常庞大的。 那么对于这里面的这个每一个过程都这么复杂的话,那我们就相对还是要做一些这个呃 一些优化改进优化。那么那么既然是这个检索增强生成的话,那么首先是这里是检索, 对吧?这个检索环节的一个优化,那么这个检索这个这个优化的话,这里就第一个就是一个稠密度的一个一个一个检索,稠密度检索的话,就稠密的一个检索的话就 强,于是他有一个更强的一个理解力,就是你这个采购经理,他能够在市场上去找到更好的,就是更符合要求的一个这个原材料 啊,这个就是更强的理解力,因为他每一个环节都是有一个大模型,相对是有一个很能力很强的一个人在那里去负责。 那么这个还有一个这个混合检索,因为我们如果只是根据这个维度就是向量化的去检索的话, 因为他像的话,他只要相似,对吧?那你比方说买这个淀粉,我到底是玉米淀粉还是土豆淀粉还是什么淀粉?可能有一些他就指定的就只有土豆淀粉最好的,但是你去买的时候你就不能这个只是说我就只要是个淀粉就行了, 对吧?所以说他这个要有明确的,有一些他可能有明确指定的是更好的啊,那么这个就相当于是这个 就是这个,呃,明确的一个一个检索,还有加了一些关键词的。这还有这个从排序就是我拿过来的一些东西 买了很多来了,我,我哪一个是最优先要选的?那你这个大厨或者你这个在使用的时候,那有一个就是我,我就一个一个去看他的这个好坏,那么就是这个点这个排序 啊,就只看他本身。那么还有一些我就相互之间对比一下啊,这个是对比的。这还有一个我把所有的放在一起做一个这个表单了以后,从中间去选一个这个排序,这里也分很多种,这里面都是会涉及到一些模型,在这里面 可能这种排序可能就相当于是每一个里面都有一个专一个专业的一个人士在这里做这个事,相当于是都有一个一个专业的一个模型在做,那么在这是 作为一个体系化的那个,那么这就是一个。第二个是知识管理,就相当于第二环了。那么第二环的话这里所设计的就是文档的这个预加工,小明说我们这个原材料要把它进行一个清洗,去虫没有用的, 然后在分拆的时候,我不能把有一些这个比方说你在这个做鸡翅的时候,你不能把它身体一大块也也也放进去了,是吧?那么你这个智能分拆的时候分拆的更精准啊,你牛排里面不能把其他的也都一起混进去了,骨头都混进去很多了 啊。那么这还有这个知识图谱,知识图谱的话呢,就相当于是 graphrag 的话,它的主要就是相当于是建立一个关系,就是你做这个知识点和那个知识点,这个知识点之间的相互的这个关系啊,都有多少他们 关系之间的这个链,这个这个链接啊,不知道他这个比例啊,啊,这概率啊,大概的他也他也都知道,对吧?啊?像这一些,你说你比方说你遇上一个四川人,这里点他的话大概率都要用这个,这个麻辣,对吧?就是一个意思,这个知识图补就相当于是这种关系, 那么还有一个原数据的一个增强,因为原数据的话就是我们对这个数据,他比方一篇文献以来了以后,它里面的这个作者标题再要关键词,那么这些都是属于原数据,他还有属于哪一个期刊等等, 那么这一些如果他在这个检索的时候,他有可能有一些,他就固定了,我就要哪一哪几年的,对吧?我还有可能就是哪几个作者的,哪个国家的,那么这一些原数据他也是可以作为一个检索顾虑 的一个重要的一个信息,而且这样的话就过滤效率高,速度快啊。那知识化结构,就是知识结构化的话,就是抽取里面的一些结构化的信息, 这构建一些这个分成的一些,所以就是我们前面所说的,假如他有一些这个文字,有一些这个数据一拿来以后,他可能里面就没有这个关键词, 他可能关键词他就没获取,要你去自己去这里面去获取。或者他还有某一些这个年份他在读取的时候,他他也没放进去,或者还有一些摘药他没有放进去,你就把他这个这些这个原数据把他给补齐了,然后把它放到里面去建好他这个结构化, 因为只有这个结构化建的越精细越好,那么将来他在在检索的过程中间才会过滤这个最快。这还有一个动态的更新机制,因为有一些这个 数据的话,他是是需要最新的。你比方说有些金融行业的,他可能就那么几个小时的最新的数据,他拿来马上用就可能就才会有价值。时间一长了过了以后他的这个有效期就过了, 就相当于我们这个买菜一样的,他有一些新鲜的菜,他就当天能用,你这个,对吧?你这个那么这个最新的这个增量的这些,那你要怎么去把它减速过来,然后减速到你相应的 这还有一些这个过期的一些数据的处理,那么你过去的一些数据,你怎么把它保存下来,然后去发挥到将来的一个价值,这个也是要做的。这个是 不是说他有一些数据他是当时是没用的啊?在当天的一些使用里面,他是过去过去的就没用了,但是他将来可以做一些案例分析啊,他有其他的价值,对吧? 那么这个就是查询里面的会涉及到一些过程啊,然后这个有什么重排啊等等,这个是优化的过程。再一个在生成的这个环节就是相当于炒菜的这个环节了,这生成就是,那么你这里在这个 就第一个就增强这个提示工程,就是 prompt。 呃,一一经理,那么他这里的这个增强这个工程的话,相当于是你这里有一个指令约束思维链, 然后引用标注,那么这个相当于是我们在这个做菜的时候,你把这个跟这个用户之间的提前做好一些沟通,你有什么忌口 啊?你有什么这个偏好?你是哪人啊?等等,你这些有没有小孩等等,那么这些你要把他这些尽量的去多收集这些信息,然后把这些信息反馈一点 这个这个厨师,对吧?那么他这里反馈给他们以后,那么这个他在做的时候,他才会有偏好性,这样才会更好的去满足这个用户的这个需要,这就是这个提示词。那么还有这个单元模型,他进行一个选择微调,那那有一些就是 我就要选一个这个香菜的这个厨子,有些我就要选一个这个卤菜的厨子,那么等等,那么像这些的话,他就一个适配的场景啊,然后进行一个对比的一个优化, 那么还有多人的这个交互优化,像有一些是,有一些是他今天吃了以后,哎呀,我提一个小问题啊,下一次来的时候,你这么按照我的意思去做改进一下,那经过多人的这种这个这个改进以后,嗯,我有些人吃辣一点,你下次多放点辣的,对吧?等等。那么 像这些的话,就是经过这种多人的这种交汇以后,那么相当于是他就会更能满足这个用户的需求,所以说这就是相当于回头客一样了,那么就会抓把住更多的这个这个信息了, 还有这个系统工程和这个评估。那么这里面的话,因为你作为一个城市里面各种场景的这个使用的时候,那你要一定要去做一些这个性能呢,或者说这个扩扩扩扩展性,那么这扩展性有一些地方他可能只是扩或者什么他不够,你要去保证他能够很方便的扩展, 还有些监控你对这个信息的反馈,还有这个安全合规。就像这个跟我们那个工程几乎就是一个类比一样的 啊,只是不同的一个领域,那么还有典型的工具链的一个评估,就是我们这个整个这个模型里面可能过程中间还要用到很 其他的一些工具,还有数据库啊,大模型呢等等,这个都是在这个整个过程中间呢,所设计的这个每一个环节都可以进行评估以后去进行优化, 那么这样子就改进完了以后,我们就会发现原来的这个提一个问题,相当于是最后用这大魔性生成答案,现在这个过程里面来回会经过很多轮的这种这个反馈,然后再优化,然后再提供在最后生成一个答案出来 啊,当然这个是呃,对于将来的一个相遇中间经过几轮的这种反反复复的这个确认以后再提供出来。 那么在这个过程中间我们这通过这个改进与优化以后,我们就会看到假如这是我们自己的这个平台里面的一个应用场景的这个来举例,比方说我们会看到我们这个平台上面有这个 cd, 有这么多一个个的讲,先讲这个从这个小型的讲起,就是这个资料库,这个资料库呢就是个人的资料库,就相当于我们自己有一些论文, 我要去在某些领域的一些论文,我自己选出来的,我想去精读,他想去详细了解里面那些内容的时候,那么我就可以把它上传到这里面来一点了以后上传进来我还可以分类分很多这文件夹,分类分进来以后,一上传进来以后, 他这个后台就会这个就会把它自动做成这种切片,做好了以后,你随时哪一天进来一问,哎,他就可以随时回答,不用你现现场再去再去分解他用的。 因为你现场每一次去用这个魔性去把它再分一次的话,都是要要要消耗算力的,那么这里的话就可以直接用了放进来以后,而且这里面所对话或者你提问的一些 这里点击进来以后,他都会保存在这里啊,也可以把你这些内容啊什么的都把它做一些,这个保存以后相当于是记录你的一些偏好,哎,这些对你将来的这个问答的时候,他也会有提供一些这个优化, 那么这个就是这个知识库啊,然后我们再看一下这里面这个 就是这个上面这个知识图谱,这个知识图谱不是说了吗?这个最早是呃,微软他们先做出来的一个用这种方式,因为这个知识之间,你看这里有各种各样链接关系,那你因为这里面有很多的话,我们是把每一天的都做了这么一个关系图 啊,然后你就可以发现他们有知识点之间相互的关联都在这里,尤其是做的一些交叉学口比较多的这一些,那么他们 你就可以看出这里面的一些这个他的一个发散性,或者他的关联性有多大,他是不是孤立的等等。那么然后这里的资料我们就可以进行一个,一个是这个这个定位,你这里放进去一搜他就会出来,你就可以看到他们这个这个这个关系图了 啊,这些关系的话在后面我们在生成内容的时候,那么这些关系他会起到一些很重要的作用,这是一个定位。 呃,然后呢再就是我们看的下的这个数呢,就是啊开五数呢,就是说我每一天出现的这个新的一些论文跟我们相关的。那开五是最大的一个运营本的一个平台吗?里面涉及到这个很多专业,那么在这里的话我们相当于是就是到菜市场去采购这个最新的一些食材, 因为这些是我们是需要每天要用的。可能是这个在这里的话,我们会看到这个, 我们会把它每一天出的这些,把它提前把它给提取好。因为我们这里做完的话,基本上就是跟他这里他这个原始的平台开过,他一发布以后,我们大概就一两分钟吧,就可以全部把它给提取出来, 包括它的文章的这个 pdf, 把它提出来以后都做好了这个,呃,详细的这个解答我们看 啊,哦,这个是刚刚是讲的是,嗯,这个 检索,这个这个检索从这里开始的话,我们进行一个提问的话,就输入问题,对某一个专业里面的进行一个很复杂的一个检索的话,那么如果你知道他是属于哪一个主题,属于哪一方面的问题,可以先输入进去,还有关键词,还有他的时间。 如果你不从这里输入进去的话,也可以,你在提问的时候这里说啊,我要问一个什么方方面的问题,我的这个这个角色是什么?然后里面有什么什么东西啊?大概是发生什么时间?那你提完了以后, 好,那么在这里比方我们提一个问题以后,好,他就会把这里面的这个问题把它给拆解,拆解以后自动到这个里面去填到这个几个过滤的里面去。我们上面说的这个过滤其实就是我们前面所讲到的 这个混合过滤,混合检索就把它进行这个关键词啊,就是那些标量的就是原始数据的一个过滤原数据, 那么这里过滤的话,他就会把这里面的关键词把它提取出来,提取出来以后放进去,然后这就是找到了这个文章,这文章里面再去进行排序,排序的话那里几万 篇文章里面,我们可能只用前面的这个一两百篇文章,从一两百篇文章里面再去找里面的片段,把里面的一个个片段找出来,找出来以后再生成这个答案。 所以说在这个前面这里,在这个检索的过程这里可能我们要用到很多其他的一些这个,呃一些技术在这里面, 比方说前面的这个混合过滤啊,还有那些知识图谱啊,在这个生成的过程中,这里他这里就还用了知识图谱啊,把前面的所讲到的一些技术全部应用进来,才能够生成这么一个答案。 所以说我们看到的这个答案就相当于一道菜样的。只是你去尝的时候,哎,是不是真的符合我的要求?但是实际上在后面会调用很多这个一些技术或者是一些工具来完成这个事啊,这个就是我们刚刚讲的这个开始 的。呃,这个阿卡五的这个树懒的这个,那么在这里的话,他这里就是呃把每一天的把它给提取出来以后,那么这个 我们去看一下,这就是把它做了一个,把这边的英文把它做了一个提炼,分了几条,然后你要听的话呢,这里就有一个语音,就直接听他的,那么听了以后,那么他就可以呃 再去,如果我觉得这个跟我很相关,哎,我觉得很不错,那我又可以去去点他的这个一个详细的一个讲解,用这个 ai 做的那详细的讲解的话,他就可能就不是这个一分钟、一分半钟了,他这里有六分多钟,六七分钟,一般是六七分钟左右的这种, 那么把它做做出来以后,你再去听他详细的,而且这个详细的里面还有文稿,就是你他念出的文稿这里都有,那么这个 的话,你这里在这个听完了以后,当然我们在这个选择的时候,每一天有一些专业可能出来比较多,那我们这里还可以做一些过滤,比方说我这个三级学科的过滤,我可能会选个两个, 选完了以后,这一进入确定以后,那么他下一次你点击进来,他就直接顾虑到了你想要的,其他的跟你不相关的,你也可以不用去看, 那么我们可以来这里的话,我们可以看一下他这个 就是实际的一个应用场景,我们可以来看看 这里就是正在加载这个。 好,这就是我们加载过来的一些这个知识图谱,他哪一个哪一个相关的,在这里都能够有个动态的一个演示,他会自动在这里这个飘,呃,飘动让你来看,就是那么在这里的话, 我们看这是我们已经打开了一个,就是刚刚讲的这个知识库,这里那还有共享啊、分享啊这些,那么点击这个就可以打开了,这个上传啊、删除啊,这里都有啊。然后这个呢就是我打开了其中的一个, 就是这里来直接提问的,你点击以后打开以后就直接提问各种各样的问题啊,提完了以后可以把这些还可以保存下来,这里面有问题的话可以来这里进行一个搜索,要定位某一个功能的某某一个这个词汇的话啊,然后呢搜索以后这里一点他就会自己定位过去, 这就是我们刚刚讲的这个, 这里就是他对这个文章的一个讲解,然后这里讲解,你听完以后觉得有用的话,就点他这个,他就会弹出来。 下面先介绍一下研究背景,本文研究了自相互作用,这里面每一个可以在本地的爱情系及其卫星中的影响 研究通过,然后觉得这个门口一看完我差不多我就可以直接跳下一个,每一个就可以直接跳着看。然后我们再探讨一下每一个跳着看以后还可以继续收藏,是从一个模拟中选择一个孤立爱收藏以后我还可以打个标签进去以后找他,方便 模拟高分辨率区域覆盖拉格朗收藏的是每一页,不是整个形成每一页的话,你将来可以更精准的去定位选择信息,保证了模拟结果的可靠性和代表性物理过程方, 那么这就是我们现在这个在实际应用中间的一个案例,这个应用起来以后 比比以前来说的话确实方便了很多。在这个效率方面,我们这平台上面,呃,除了用这个豆包以外,我们自己也还部署了一些这个模型 啊,还有这个一些算力存储,我们当然有很多也都在这边用,跟他们这个呃算是在这个第三方平台里面用的比较多的啊。 那么我们对这个将来的一个发展趋势,爱奇将来发展这个趋势的话,就是我们现在也看到其实在这个使用的过程中间有一个长上下纹的单元模型,他可以减少这个对这个简属的依赖。对于少量文本就是说内容的这个回答, 就是一般是这个照这种 token 的,就是百万 token 以内的左右的这种,哎,这个内容回答的话,我们有一些这个论文,比方说有个几篇呢,哎,就可以直接把它放到这个上下文里面去。我们前面讲的那个是放在知识库里面,他不是在上下文里面, 但放到上下文里面去的话,那么他就不用去每一次去问问题的时候再一个个去找。那么但是这里面要注意的一个就是这一个文本内容的话,不要超过他 他这个内存的百分之七十,如果堆的太多的话,你再问的时候,他这里面这个响应的这个速度啊,还有他这个计算呢,他会受到很大的影响。那么这个时候如果你, 你比方说一百万 token 的这个常上下文,你超过了这个百分之七十,他就很难这个效果就急剧下降了, 这相当于我们这个一个厨房里面的这个放的食材操作台还有冰箱,像这些的话,你堆得太满了,我都没法做菜了,我都长不开了,是吧?那做出来这个这个过程肯定就慢了,有时候就会忙这个一忙起来就出错了,就这个就是一个意思 啊,但是他的这个好处就是你把我要用的东西全部放到我这个手缝里来,放到这里以后随时可以用,就不需要到现场去采购,是吧?啊?就这个食材做那么但是这里面一个一个缺点就是我每 每一次用完,用完了以后,做完以后就清空了,相当于这个厨房我做完这一顿这个宴席以后就清空了,那么这就是常上下文的一个他在这里面的一个为一个问题, 这还有一个就是微调,就是浙江的一个趋势。呃,虽然现在的这个模型他的这个综合能力已经很强了,包括现在这模型都是基本上用的这个 moe, 就是混合专家,模型里面也混合了很多,可能几十个专家 在里面,但这种混合专家魔性,他只是在每一个领域里面做了一些加强,还是一些一些好的一些高质量的一些信息放进去了,把它做了一些增强。但是实际上他在某一些专专很专业的领域里面,他没有把它做的一个呃, 极致,你不可能做到那么细,那么极致。那么在这一方面的话,他有些独特要求的一些这个领域的话,他是需要他去另外去再进行微调的,就相当于我们这个 啊,这是这个上面一个一个案例。那么如果是这种的话,比方说我们有一些在这个做这个蘑菇, 现在你云南人他就吃蘑菇吃的很多,如果你这个厨师对蘑菇的很多信息你不了解,那你做出来可能就要出问题了, 对吧?或者说做出来也不好吃啊,就浪费了他的这个这个食材了。这个这些的厨师你就得要去进行一个特殊的训练和特殊的学习,那这个这个模型也是一样的,你在某一些特定的领域里面, 你可能就必须要去做做一些微调,就是去训练,那么在还有这个 a 技能的工具的调用, 那么在将来的话, a 技能工具段的话,因为 a 技能的话就是智能体,他本身他自己就有一个自主决策与这个任务执行啊,还有实施环境交互啊,还有这状态管理与持续学习啊,这个复杂这个任务的拆解 啊,这是这个工具集成的扩展等等。那么在这个过程中间,他这里面其实 a 技能的话,就是他一个脑子不够用, 要用很多领域里面的一些这个呃工具,其实每一个工具他有很多也是用的模型,其实也是用的一个小的专家, 把它都一起参与进来做这个事。讲了你你这个一个厨房里面其实不只是一个大厨,他每一个环节都有一个很牛的人在这里把关,那联合起来一起做这个事,那么才有可能把这个这个将来的这个发展的更好。就是这个这个每 一个都有很专业的分工了,在集合在一起,在不断的反馈,不断的优化,这是这个 agent 是将来的一个很很这个很重要的一个发展方向,也可能是以将来的一个主流发展方向,所以这个是放在最后这里讲的。 那么还有那么我们再对比一下,看他这个 i j 的这个灵活,是他这个这个有一些他这个使用的话,他的优缺点的一个对比的话,在将来我们在使用的时候就心里就有数。 麦吉本身的话他是比较灵活的,因为我把它全部分类分好了,裁剪好了,然后放这里, 如果是用以前标量的这种方式去做一些这个检索了以后再去生成答案,我写一个报告可能要一周,或者做一个这个开题可能要一个月, 那么现在这里的话可能就一天就做完了。如果把这些用的非常好的话,用的很熟练的话,那么那么这个就就是一个最大的一个优势, 只是针对你个人来说的话,那成本也很低。如果用第三方的话,我可能就几十块钱就做完了这个事了。要以要要给以前去做的话,做一个月,你一个博士后或者一个博士做一个月,这个成本就是非常高了,对吧?所以说艾灸他有这么一个好处啊, 这里他在调用的过程中间就是就是调用第三方的一个 a p i, 我就可以直接去做这个事,调用他们数据过去商量,我一个食堂也好,我一个一个一个酒店也好,我就在一个大型的一个一个超市旁边, 一个大型的一个市场旁边的话,那么他这样子我直接去用的话,又又快捷又方便,又这个成本又低, 不需要自己去建这么一个库了啊,因为你自己建这个库的话,这个成本是非常高的。 那么对于这里面这个有一个要注意的,就是我们在这个使用这个 ij 里面这个检索的时候,我们同时还要注意,就是不要去太盲性,他所检检索过来的一些这个切片或者那些来源,所以对这些来源的话,我们还是 要定期的去做一个这个呃检查或者这个复合,就相当于你这个做厨师的,你不能总是别人采过来的什么东西我就直接拿着用,我可能有些东西我还要去素颜,我就看看到 看看他这个原材料这个这个加工的市场那边去看看他到底是不是符合我们要求。因为现在这种这个这个这个有很多这个以次从好的或者看上去好的,实际上没那么好的, 他是有区别的,野生的和这个人工的他是有很大区别的。等等。所以说这个对这个原材料的这个来源做复合也是保证他质量的一个很重要的一个环节,就是随时去关注他的这个,因为这个 ig 的本身来说,他就是一个原这个这个原材料这个来源的 这个一个起了一个决定性的一个作用,相当于是你做饭一样的,你做不是你做一个菜,这个食材是很关键的一步,对吧?好的烹饪只要简单,好的是这个食材只要简单的烹饪,就是这么一个道理。 那么微调的话,这里他的一个就是有点就是效果好,稳定,但是成本很高,而且他这个更新就没那么没那么快了,比较慢啊,但是他可以比较明确的适用一些这个场景, 所以说要注意他的一个隐私和这个合规,因为他的这个场景是是有一些这个约定的,或者是有一些限定的。 这这第三个就是长上下纹,那么这个长上下纹的话,就是呃在这里面的话,相当于是就不需要再到市场上去买了,去临时去检索这些数据拿来用,那么已经就直接放在你这个里面,相当于做菜已经放到厨房里面来了,都已经摆在这里了,你随时可以用, 但是这个就是需要你厨房大,相当于你这个模型比较大,能够放得下这么多东西, 如果是你对于一些这个小魔仙的话,他这个存不了这么多,他就溢出了,对吧?那你这个厨房里面也是一样的,你要大的这个厨房那东西堆多了,你又做了些菜的话,可能这个上上下下 用时间多了以后这个床上下文的这个腐烂相当于我们这里的这个东西堆多了,他这些食材他可能就在里面相互相互交叉,然后有这种,有这种这个腐烂就是一个道理。 那么 a 景的话,就智能体的话,是将来的一个重要的一个方向的话,他们在这个自主理解感知啊,还有规划啊,还有这个实现这个目标,这个导向啊,完成一些复杂的任务啊,就自动执行呢,这些东西都是不需要人工干干预 啊。就像我们做的那个去去讲解,做了一个 ai 的这个 详细的这个讲解,包括的前面的一个简单的一些讲解,像这些我们包括那个知识库,哦不是那个知识图谱,那全都是自动完成,包括我们里面的很多其他的任务全都是自动 完成,都是用的这个 a 键的。那么这个呃,包括以后还有其他的一些更复杂的一些场景,有一些调这种 a 键的里面调用一些这个插件,各种任务调的几十个、上百个的都有的。 那么他的这个缺点就是你这里面的场景各个地方的都要做一次反馈决策,那么这个在这个过程中间他可能就时间就比较长了。我们平常问一个问题或做一些什么事,可能就是秒急的或者几秒钟的, 那么他这个可能就时间就几十秒,对吧?上百秒、几分钟、十分钟、二十分钟的都有可能有的。那么呃,那么像这种的话, 你对于有一些要进行一个及时的一个反馈的,可能就用不上了,就就没法做的这么快的速度。再一个他在一些 复杂常见的这个决策的时候,他也可能是出现一些这个太复杂的话,他会出现一些错误,当然也有这种幻觉的出现,当然这一些的话也是要将来不断的去突破去改进的。 那么这个他将来的还有一个发展趋势,就是 ig 的话,他一个多模态,现在我们这里一般是做的比较多的话,就是文本的做的比较多一些,那对图像音频呐、音视频呐,对吧?还有其他的一些这个数据格式的,那么将来这些数据的话 都是可以拿来做的啊,那么这些数据当你这个量到了一定程度以后,他是他可以释放一些更多的一些这个数据的价值 啊。那么还有呃我们在这个多模态里面的话,他这个可以再做一些这个优 画他的这个交互的体验,因为因为你以前的话一个单模太的话,那么他这里呃在使用的时候,比方我只看一个文本,现在我们把这个声音加进去了,甚至我还可以把声音和图像把它做一定的这个呃读取就是 跟你嘴型合上来,就像你自己人这里跟你的这个声音做一个匹配以后,呃模拟自己的声音等等,那么这个场景加进去以后是可以节约这个自己的很多这个呃经历的。那么这个这个优化这种体验的话在讲的也是一个重要的一个方向。 但是这里面要注意的就是一个伦理问题了啊,还有一个主动检索,那么将来的话这个模型他可以决定是否需要去进行检索啊。 有一些问题我们不论是只要是见了一个问题,都去到这个大库里面去找一遍,那这样的话他这个效率就低了,成本也高了, 那么将来的这个模型的话,他自主减速就是相当于说你要做一个蛋炒饭,我没必要到市场上再去买各种各样的东西,买了再拿来对比啊,对吧?我冰箱就有直接拿来,像那个大模型里面就有,直接拿来就可以生成就用了, 所以说就是就这么个意思。那么还有一个 ij 的这个与这个知识图谱原数据库的结构,就是我们前面已经看过的 已经也在用了的这个原数据,相当于是先做过滤这个知识图谱的话,呃,这个效果对这个生存内容是有很大的一个提升的,它的效果是是呃立竿见影的。那么在这个推理能力的这个增强,推理能力的增强的话,就是相当于是我们这个模型本 真的能力加强了以后,他中间过程他有一个多次的一个检索,还有逻辑推理,推理完了以后再去进行一个一个反复的这个检索, 这不断的去反馈啊,还有这个推理与这个简属的深度融合,就是把它的这个这个混合在一起, 不断的去加强。这还有个性化的这个服务的这个提升,就是我们呃,在这个建立用户模型,提供这个个性化的这个用户体验,就是用户模型,就像我们前面用户在里面提了各种问题,他跟别人交流,然后这个互动 啊,他提问等等这些数据把它给收集起来以后,在用户再去进行个性化的一些提问的时候,我们就知道,哦,就根据他的这里面的一个用户画像去提供更好的一个呃回答, 就是可以提高他的一个个个人的一个体验,这就是将来的这个 ig 在这些方面发展,只有把这些方面发展这个不断的去优化,去改进,才有可能在这方面不断的去加强。不然的话这个 ig 在将来的这个模型能力越来越强,越来越大的时候, 就大家都习惯于用这个床上下完了就可以解决很多问题了。就相当于我以后的这个竹缝里的冰箱越来越大,以后,我一般的这种这个这个问题可能百分之七八十的问题我都可以在竹缝里面就一次性解决了 啊。所以说这个 ig 将来发展还是有他的这个很大的一个应用市场的。
1.1万中科院物理所 06:35查看AI文稿AI文稿
06:35查看AI文稿AI文稿large language models they are everywhere they get some things amazingly right and other things very interestingly wrong my name is marina denolevsky, i am a senior research scientist here at ibm research and i want to tell you about a framework to help large language models be more accurate and more up to date retrieval, augmented generation or rag let's just talk about the generation part for a minute, so forget the retrieval augmented, so the generation this refers to large language models or lms that generate text in response to a user query referred to as a prompt these models can have some undesirable behavior, i want to tell you an anecdote to illustrate this so my kids they recently asked me this question in our solar system what planet has the most moves my response was oh, that's really great that you're asking this question i loved space when i was your age of course that was like thirty years ago but i know this i read an article and the article said that it was jupiter and eighty moves so that's the answer now actually, there's a couple of things wrong with my answer first of all i have no source to support what i'm saying so even though i confidently said i read an article i know the answer i'm not sourcing it i'm giving the answer off the top of my head and also i actually haven't kept up with this for a while and my answer is out of date, so we have two problems here one is no source and the second problem is that i am out of date and these in fact are two behaviors that are often observed serve as problematic when interacting with large language models, there are lm challenges now what would have happened? if i had taken a beat and first gone and looked up the answer on a reputable source like nasa well, then i would have been able to say ah okay so the answer is saturn with a hundred and forty six moons and in fact this keeps changing because scientists keep on discovering more and more moots so i have now grounded my answer in something more believable i have not hallucinated or made up an answer oh and by the way i didn't leak personal information about how long ago it's been since i was obsessed with space all right so what does this have to do with large language models? well, how would a large language model have answered this question? so let's say that i have a user asking this question about moves a large language model would confidently say okay i have been trained and from what i know in my parameters during my training the answer is jupiter the answer is wrong but you know we don't know the large language model was very confident and what an answered now what happens when you add this retriever retriever retrieval augmented part here what does that need that means that now instead of just relying on what the l l m knows we are adding a hunt store this can be open like the internet this can be closed like some collection of documents, collection of policies whatever, the point though now is that the lm first goes and talks to the content store and says hey can you retrieve for me information that is relevant to what the user's query was and now with this retriever augmented answer it's not jupiter anymore we know that it is saturn what does this look like well first user prompts the l l m with their question they say this is what my question was and originally if we're just talking to a journary of model the journary of model says oh okay i know the response here it is here's my response but now in the rab framework, the general model actually has an instruction that says no, no, no first go and retrieve relevant content combine that with the user users question and only then generate the answer so the prompt now has three parts the instruction to pay attention to the retrieve content together with the user's question now give a response and in fact now you can give evidence for why your response was what it was so now hopefully you can see how does rad help the tool on challenges that i had mentioned before so first of all i'll start with the out of date part now instead of having to retring your model if new information comes up like hey, we found some more moves now at the jupiter again, maybe we saturn again in the future, all you have to do is you augment your data store with new information update information so now the next time that a user comes and asks the question we're ready we just go ahead and retrieve the most update information the second problem source, well the large language model is now being instructed to pay attention to primary source data before giving its response and in fact now being able to give evidence this makes it less likely to hallucinate or to leak data because it is less likely to rely only on information i don't learn during training it also allows us to get the model to have a behavior that can be very positive which is knowing when to say i don't know if the user's question cannot be reliably answered based on your data store the model should say, i don't know instead of making up something that is believable and may mislead the user this can have a negative effect as well though because if the retriever is not sufficiently good to give the large language model the best most highest quality grounding information then maybe the user is clearly that is answerable doesn't get an answer so this is actually why lots of folks including many of us here ibm are working the problem in both sides, we are both working to improve the retriever to give the large language model the best quality ah data on which to ground its response and also the generative part, so that the l l n can give the richest best response finally to the user when it generates the answer thank you for learning more about rag and like and subscribe to channel thank you。
 04:120刘通老师
04:120刘通老师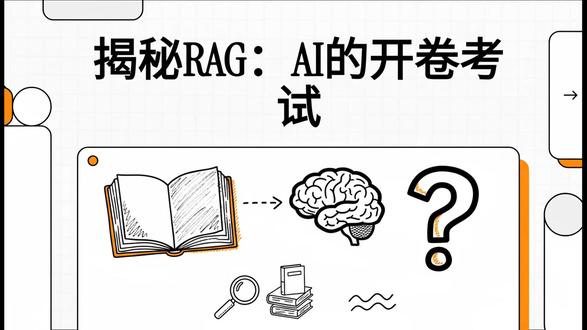 07:0225燃犀照水
07:0225燃犀照水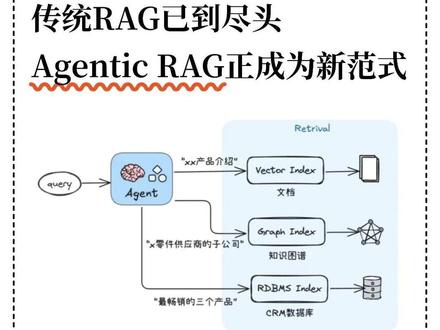 00:19
00:19












猜你喜欢
- 6063凌凌上将—