javabigdecimal使用教程

粉丝418获赞2479
相关视频
 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿不怕新人不会用大宝,就怕新人不会用贝克得罪某,相信很多做金融支付的人一定都有同感,贝克得罪某呢,这玩意虽然很好用,但是呢,也容易引发很多故障。很多人都知道,因为很多小数他没有办法用二进制精确的表示,所以大波和 flow 的这种浮点数其实都是近四指。 而贝克 dec 某呢,它可以精确地表示所有数字,所以那些涉及到金钱的场景,如果单位是分,大家都用浪,如果单位是圆,那大家都用贝克 dec 某。 但是如果你以为用了贝克 dec 猫就万事大吉了,那就大错特错了。首先呢,当我们 new 一个贝克 dec 猫的时候,我们要用字符串类型,而不能直接用符点数, 因为用一个不精确的数字创造出来的贝格底字母,它也是不精确的。其次,当我们想要比较两个贝格底字母的值是否相等的时候,比如说零点一和零点一零 不能用他的 ecose 方法,你要调用它的 compart two 方法,因为它的 ecose 方法不仅比较直的内容,还会比较它的标度,零点一的标度是一,零点一零的标度是二,所以 ecose 返回的结果是 false。 而 compartile 呢,它比较的是直,所以呢 会返回出。还有就是有的时候,如果我们把一个贝格得 c 某转化成自付串的话,用于前端展示的时候呢, tosri 这个方法也会有意想不到的结果,比如说得到的结果可能是三点一四一加三这种科学技术法的形式。而如果你真的只想得到一个简单的自付串,那么应该用 toprids dream 这个方法, 还有呢就是贝克 decimal 这个类型的数字,在数据库存储的时候呢,也需要使用 decimal 这个字段,否则也会丢失精度的。
4403程序员Hollis 01:51查看AI文稿AI文稿
01:51查看AI文稿AI文稿在金融类的项目中,使用高精度的数学运算,我们常用家务中的 bigger day semo 这个类进行运算,但是 big day semo 有几个使用建议,一、使用死俊类型的参数来构建 big day semo 对象。二、使用 compare to 进行比较大小。 三呢,建议使用 top play instrin 将 big decimo 转换成字符串,使用 set scale 方法设置精度的时候,他是不会改变原对象的,需要重新复制 下来呢。咱们通过代码演示看一下这几个问题。构建贝克得 cmo 对象,一个是自付串类型的,一个是大包类型的,分别打印一下,看一下效果。通过控制台呢,咱们可以看到大包类型呢,丢失了精度, 这是因为大 bo 类型只能保留有限的数字,当这个数字转化为 big dec 某对象时,精度可能丢失,所以咱们建议使用死坠类型。这里有两个数,一个是二点零, 一个是二点零零。然后咱们通过 ecos 和 compare two 分别比较一下它俩是否相等。运行一下看一下效果。这里可以看到呢, ecos 返回的是 force, compare two 返回的是零,我们的预期结果是希望它俩是相等的,所以说这里应该选择 compare two, 零代表相等, 然后呢,一代表大于负,一代表小于。这里分别通过两种方式将 a 转换成死转类型,咱们打印一下,看一下效果。通过结果呢,咱们可以看到图,死转方法呢,会将这个数字变为科学技术法, 所以呢,咱们建议使用 toplins dream 将 big decimal 转换成字符串儿,使用 size scale 方法保留两位小数,咱们执行一下,看一下效果。这里呢,可以看到这个数字没有变,是因为 science scale 不会修改原有的对象。这里呢,咱们需要重新复制,咱们 复制一下,重新打印,看一眼效果。重新复制后可以看到已经保留两位小数了。最后小伙伴们在使用 big dec 某还有哪些需要注意的地方,评论区讨论一下。
537程序员老魏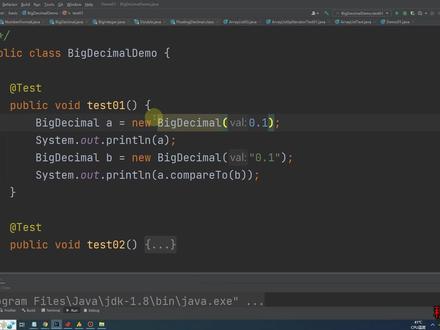 02:06查看AI文稿AI文稿
02:06查看AI文稿AI文稿今天我们说一个小的知识点, big decimal 的使用注意事项,第一个就是我们 big decimal 使用的时候不要直接使用 new big decimal 来看一下,看一下这两段代码,一个是传入零点一的 double 类型,一个是零点一的死针类型,比较出来的大小是多少?是一会发现我们的 a 是要比我们的 b 大的是, 其实这是因为 big decimal 在对 double 类型进行处理的时候,其实是有精度丢失的,其实这个零点一并不是零点一,因为我 double 类型其实小数点后面还有好多位,所以你想表达的是零点一的时候就要尽量使用 big good decimal 点 off 传入零点一,这样的话它 比较出来就是一样的,对吧?这个小的知识点就是在除法使用的时候,一定要设置我们的除后的数据精度,假设我们不设置,在除不尽的情况下就会出现报错,这个报错也很经典,就表达的是我 我们的除法未除尽,所以除法的时候一定要设置我们的除后的数据精度。第三个知识点就是我们交往内置的有两个格式化 biggestimal 数据的操作类,一个是我们的金额类型的,一个是我们的百分比类型,假设这里的金额是金额是幺四九六点 点五四,然后他的百分比是零点一二,最后计算出来他的利息是多少,然后打印一下,他就帮我们用千分位进行分割了我们的金额,并标志了我货币类型,然后对我们的百分比增加了百分号。来我们总结一下,第一点,尽量使用 big decimal 点 value off 进行数据类型转换,使用 new big decim 可能会出现精斗丢失。第二点,除法使用设置精确的销售点,避免出现这个异常。第三,内置两个格式化素质类,格式化货币以及格式化百分。 第四点,需要精确的小数计算时,在使用 big decim, 一般的精度计算没必要使用 big decim。 加点乘除求余计算要比 big decib 计算性能要高。其实 所有的计算计算的本质都是对数据位的操作,对吧?我们的加减乘除除于对就少了这一层数据包装,当然要比我们的 biggestm 计算性能要高一些。好,今天的视频我就分享到这里,谢谢大家! nice。
216程序员老郭 05:52查看AI文稿AI文稿
05:52查看AI文稿AI文稿big decimal 的常见陷阱你知道几个?关于 big decimal 呢,它是用来处理精确计算的,想必从事金融相关项目的小伙伴呢,肯定都能用到,如果说还有一些小伙伴呢,他不清楚,不了解 big decimal 呢,也希望大家呢,都可以把本视频看完,这样呢,避免以后在使用 big decimal 的时候呢,掉落相应的一个陷阱里面。 那么接下来我们来看一下第一个陷阱,也就是呢第一个 demo, 那么在这个 demo 里面呢,就通过了两种方式,分别创建了两个 bidsm 对象,那么第一种方式呢,就直接溜了一个 bidsm, 传入了一个符点数。 那么第二种方式呢,就是调用 began 什么类的挽留和方法,也传入一个浮点数。然后呢,分别进行了一个输出打印。关于这个问题的详细文字版,我已经整理了一份八十万字的专门民事发展笔记,放在视频的最后面,坚持看完,一定对你有帮助。那么大家呢,也可以猜测一下,我们这个 began 什么一和 began 什么二呢?他们的一个输出结果是怎样的?那接下来呢,我们就直接运行一下这个 m, 观察一下他的输出结果, 那么这个时候呢,我们可以通过我们这个结果可以看到,那么 big that 什么一呢,它其实是零点零一的一个近似值,而 big that 什么二呢,它是精确地显示了零点零一的。 那么为什么 big nation 为一最终输出的结果是一个近似值呢?那么其实呢,是由于零点零一呢,它无法被一个有限位的二键之小数给精确的展示出来,所以呢它是一个零点零一的近似值,然后保存到我们这个 big dance one 里面,而我们 big nation 二呢,它其实呢是我们这个 wenry off 呢,它底层做了一定的处理,那么我们可以看一下它的实线, 那其实呢他就通过了我们这个 double 来进行了一个转换,最终呢保存到我们这个 b x 文里面,对不对?这样呢他就不会有一个精度问题,但是有一点需要注意的就是如果说我们传入的这个数值超过了我们这个 double 的这个范围,那么他呢也会有一个精度的问题, 但是呢我们可以通过我们这个 one new off 呢就得到一个信息,其实它底层呢其实就是直接传入我们这一个支付串,对不对?那么这个时候呢,我们是不是可以先绕过我们这个 double 转换的一个过程, 我们直接呢在创建 bg 单什么的时候,就使用六关键字,然后我们传入一个字母串,那么这样不就可以绕过这一个问题了吗?那么我们这里就做一个简单测试,我们随便的传入一个很大的数值,然后呢进行一个输出打印测试一下,那么这个时候呢我们在运 进行这个 demo, 现在我们观察这个输入结果,是不是我们这个 big decimal 三,其实我们没有命名出来啊,就是我们最终打印的就跟我们刚刚输入的是一样的, 那么现在我们是不是就知道我们该如何避免第一个陷阱了?那么接下来我们再看一下第二个陷阱,那么其实第二个陷阱呢,其实跟我们这个 big 带什么它的一个比较方法有关系,那么这里呢就有两种方法,第一种就是 equals, 第二个就是 compare two, 那么接下来我们也运行一下这个 demo, 观察它的输入结果来进行一个分析。 那么首先第一个呢就是 equals 的结果,它呢是一个 force, 那么我们再观察一下这两个对象他们的一个数字,那么 big dysmo 一是不是零点零一? big dysmony 呢是零点零一零,那么我们看起来是不是两个数值呢是相等的,那么为什么我们这个 equals 的结果是一个 force 呢? 那么这其实呢跟我们这个 big dysmo 他的这个 equals 方法有关系,因为他重写了 oppo jk 的这个 equals 方法,那么他重写之后的逻辑呢,就有一个很关键性的代码也是这一行,那么他呢除了会比较素 值之外呢,他还会去比较我们这一个精度,也就是呢比较我们这个小数位,那比如说我们 big dysmo 一,他是不是两位小数啊? big dysmo 二呢,他是三位小数,因此呢他就发现了这个精度不同,那么呢他立马就返回了一个 force, 那么这个 compare two 呢?他呢就只比较了我们这个数值, 它的返回结果呢就有三个数,第一个呢是负一,第二个是零,第三个呢是一,那么零呢就代表我们这两个数字呢是相等的,那么一呢就是大于,负一呢就是小于,那我们这里输出结果是不是就是一个零, 那么零呢就其实是代表呢,我们这个 b 单字母 e 和 b 单字母二呢是相等的,这也就是我们 big 单字母呢在比较的时候的一个坑,那么就推荐大家呢使用我们这个 compare to 的方法呢来进行数值比较。那么当然在一些系统里面,他严格要求我们这个精度相同的话,那么我们就可以使用这个 equal 方法,那么大家呢又灵活的使用, 那接下来我们再看一下第三个常见的陷阱,那么第三个陷阱呢,其实就是我们使用这个 big nation 们呢来进行运算的时候呢,就会有一些问题,那比如说我们正使用除法的时候呢, 他如果说我们这一个得到的结果是一个无限小数的话,那么他就会出现一个异常,我们再看一下我们这个 b 代什么一,他的数值是不是一,那 b 代什么二呢?他是一个三,那么我们一除以三,他最终的结果呢?是不是零点三三三,然后呢是无限位小数,那么如果说我们可以正常的运行,是不是我们这个最终结果呢?就会将这个进行输出,我们呢也简单的运行一下这个 demo, 看一下他的一个结果, 那么现在他是不是就提示了我们这一个错误,那么其实这个错误他代表是什么意思呢?就是我们这一个结果呢,他是一个无限小数位,但是我们想得到的是什么呢?是不是一个精确的数字,所以呢他就出现了这个异常, 那么在这个时候呢,我们就要正确的使用我们这一个四舍五入和一个精度的问题,也就是呢我们在 bigaism 在运运算的时候呢,我们可以指定它的一个精度值,那比如说我们这里两位小数,那么我们这个结果呢,我们也可以保留两位小数,而且呢我们这个无限小数,我们通常是不是会进行一些四舍五入的一个过程,或者是直接抹掉多少位之后的一个数值,那么这里呢 bigai 什么呢? 都可以提供我们这一个处理方式,那么接下来我们就简单的进行一个演示,那么这里的话呢,我们还是保留两位小数,那么第三个呢,第三个参数就是我们这一个 random model, 那么这个 random model 呢,他其实呢就是代表了我们这个运算的过程中呢,他最终的多少位小数之后,他的数值呢,究竟是四舍五入还是进行抹掉还是什么规则?这个时候呢,我们已经修改完成了,是不是?所以呢我们再运行一下这个 demo, 现在我们这个结果是不是就输出正常了?那么其实呢,我们这个 half up 呢,就是一个四舍五入的一个过程,也许我们的 up 是不是一半,然后呢 up 呢是向上的, 于是呢我们大于五的话呢,就直接往上取一位,那么如果说是小于呢,我们就直接抹掉了,后面的数值呢我们就不要了,那么我们就可以通过这种方式呢,就保证我们这一个得到的结果,他是一个精确的数值,对不对?这个精确的数值呢,其实呢 也是我们在可以接受的范围之内的一个精确数字,那比如说有的系统呢,他就可以接受四位,有的呢接受六位,有的接受八位,那么大家呢就可以根据自己系统的一个容忍度来设置我们这一个保留位 技术,而且最终的这一个曲子,也就是我们这个 rody model 呢,大家呢可以根据相应系统呢来进行我们这一个曲子,那么他的曲子其实还有很多,那么大家呢也可以了解一下,那么我们刚刚讲解的这一部分内容,其实我这边呢已经整理成了一个完整的笔记,那么刚刚我们讲解的这个 rody model 呢?其次这边呢我已经汇总了 我们这个柔迪 model up 啊,柔迪 model 档啊,那么这里呢其实都是有一些相应的特定意思的,那么我们刚刚使用的就是这个哈 bap 也是四舍五入,那么除此之外,我们刚刚讲解的这几个常见陷阱之呢,我这里都已经完整的整理好了, 那么有需要的小伙伴呢,可以在评论区扣一,然后私信获取本篇笔记,那么加深一下理解,那么大家呢可以拿这几个 demo 来进行测试一下,而且如果说有小伙伴在使用的过程中还有其他的一些陷阱呢,也可以在评论区留言或者是弹幕呢发表一下自己的见解,那么本节课的讲解呢就到这里了,谢谢大家的观看,我是百里,我们下期再见。
982Java小叮当 00:18查看AI文稿AI文稿
00:18查看AI文稿AI文稿你们知道在比格迪生活中传入打宝后福豆的类型会导致精度丢失吗?这里运行看下结果。那么如何去解决这个问题呢?我们只需要将打宝和福豆的类型转换成顺利性集团。这里运行看下结果。你 get 到了吗?
557程序员郑清 02:10
02:10











猜你喜欢
- 1802克拉拉财经
最新视频
- 8995九柒.