我们前面写的这些存储过程,它里面用到的变量都写死了,接下来我们就来看怎么通过参数的形式把变量值传进去。存储过程的参数分为三类,一类是硬类型, 也就是输入参数,默认的就是 in 类型,然后是 out 类型,输出参数,也就是我们说的返回值,最后是 in out 类型,它既可以作为输入参数,也可以作为输出参数。用法是这样的,把前面创建存储过程的语法拿下来, 在参数里面我们可以写 in 或者 out 或者 in out, 如果不指定,默认就是 in, 接着写参数名, 然后是参数类型,这就是存储过程的一个参数,但是如果你想写多个参数,就加逗号继续写就可以了。 ok, 这个懂了之后,我们来实际操作一下,就拿之前的这个存储过程改吧,这个是锅,我们就把它定成参数,首先它是硬类型,然后参数名是锅, 类型是硬的,这样就可以了。这里定义好之后,下面就不需要定义了,然后这个 r e s, 我们可以作为返回值,也定义在参数里面,那就再来一个 out 参数名, r e s 类型,卧叉十六,这样下面这里就不需要了, 这里也不需要打印了,调用它的时候我们可以拿到返回的结果,只不过调用这里我们就需要传餐了。例如我们传一个五十八,注意我们定义的时候需要两个参数是过后 r e s, 虽然 r e s 是返回的参数,我们同样需要传,传一个浪子的参数就可以了。浪子变量怎么声明还记得吗?前面说过不需要声明,直接用就行了, 默认就是了。那我们就写一个 adr es, 这是我们制定的,编的没有声明,也没有复制,默认就是了,这样传进去之后,存储过程内部就给他复制,然后再把它返回出来。我们先创建存储过程,然后调用,调用完之后,返回的结果就 已经复制个 r e s 了,我们来打一下,看看谁 like 来打 r e s 就拿到了不及格,然后我们改成八十八再来执行,就拿到了良好。最后我们再来尝试一下,婴儿的既是输入参数,又是输出参数,我们还是在这个上面来改吧,把它再复制一份 参数,我们只需要是 go 例行改成 in out, 比如我们的逻辑时,把百分之改成十分之,就是把它除以十就完了。 sets 过等于是过除以十,这样就可以了。这里涉及到了除法运算,所以参数类型我们最好就不要用硬打了,因为可能出现小数。我们把它改成大伯 来执行一下, ok, 然后我们来调用它。调用也只需要传一个参数, at 是过,但现在它是没有值的,而我们要传进去计算, 所以它必须先有一个字 set x 过,让它先等于八十八,然后把它转进去计算,计算完之后它又会把结果返回给 s 过,最后我们再打一下 s 过,就得到了八点八分, ok, 这就是婴儿的类型,既是输入又是输出。

粉丝5.4万获赞37.1万
相关视频
 16:51查看AI文稿AI文稿
16:51查看AI文稿AI文稿然后的话,嗯,我们来做几道题吧,我这里面之前找了一些题来给大家练习一下,他考的话大概就是考成这个样子,不至于考的非常难,他考的都肯定是很简单的这种。就我们来看一下第一题,选择题。第一题, 以下关于 my circle 存储过程表述中错误的是哪一个错误的,我们需要看的是错误的, 呃,用这个来框出来吧,用这个来框错误的是什么东西?埋设口,呃,存储过程只能够输出一个整数,这个一看就是错的,所以说这个题肯定是选 a 的。 然后我们看一下第二个, 第二个的话, mac 的 存储过程分为系统存储过程和用户自定义存储过程,这个肯定是对的。然后第三个使用用户存储过程的原因是基于安全性能和模块化的考虑,这个也是对的。然后输出参数使用的是 out 关键词来进行一个说明,所以说这个题的话, b、 c、 d 都是对的, a 是 错的,所以说这个题选的是 a, 这个题选的是 a。 然后我们看一下第二题, my circle 的 存储过程保存在服务器上的,我们前面讲过这个 my circle 的 存储过程和存储函数,它是保存在服务器上的,所以说这个题的话选 c。 我们也可以给大家来看一下 my sql 的 存储过程和存储函数是保存在服务器上的,可以用来执行特定工作的一组 sql 代码的程序段。存储过程和存储函数可以包含 针对数据库操作的 c、 q 语句,还可以在其内部进行流程控制,而且其执行速度快,在数据库应用开发中使用广泛,然后本章的话讲解的就是数据存储过程和存储函数的一个概念。 然后我们看这个第三题了,应该是第二题 c 选出来了,第三题我们看在 micro 的 服务器上,存储过程是一组预先定义并 编写或者说翻译或者说解释的,我们先不看这里,先看第二个可以用哪个语句来定义存储过程。定义存储过程我们知道用的是 great proctorary, 所以 说这个 order 的 肯定就是错的,所以说 c 和 d 不 选。然后我们看一下 a 和 b 的 前面一个,一个是编辑,一个是编译, 嗯,编写的话就是只是把它编写出来,并没有进行一个 编辑器的一个翻译,然后编辑的话就是编写出来了,然后再用这个编辑器已经编已经翻译了一道,所以说翻译是包含的编辑的,所以说同学们就算不知道的话,这个题也应该往大的选,因为编辑是包括了编辑这一个功能的,所以说肯定这个题是选 b 的。 然后我们也可以通过另一种形式来来感看出来。如果说我们在编写存储过程的时候,我他只仅仅只是编写出来的话,我们里面有错误的情况下,他没有经过翻译的话,他是不可能发现的, 所以说当我们里面写的有错误的时候,他给我们发现出来了,就证明这一个存储过程的话,编我们写出来的时候,他是经过 翻译系进行翻译的,不然的话他是不可能发现我们的错误的,所以说这个题的话不是编写,而是编译。还有一个点就是编译是包括了这个编辑的,编译大于这个编辑,所以说这个题的话是选 b 这个答案。 然后我们看第四题 my circle 存储过程中使用哪个命令来执行?执行存储过程的话用的是这个括语句,所以说我们选择答案 b, 我们选择答案 b, 这里选择答案的也是 b, 然后看第五题有下面这一个存储过程。 呃, great 这个 procreate 这个名字,然后 begin, 然后 select 星号 from student where 这个东西 and 下面选项中。嗯,能够 能对上述存储过程正确调用的是调用,用的是括,肯定是在 b 和 c 里面选,然后调用存储过程的话,有一个标志是这个括号,所以说这个题选择答案 b, 他 考的话肯定就是考这种不会考你那些非常细的概念,他只会考你这一些。呃呃,基本的一些用法,他不会考你很细的那种概念。所以说同学们也不用怕这个存储过程,或者说存储函数 以及后面要学到的仕途,没怎么听过,也没怎么用过,你就觉得有一点难。但其实的话,他考的并不是那些呃很细的一些概念,他只会考这些基本的一个用法,不会考那种很难的,很 很基础很理论的那一些概念,他会考的是这种很很简单的一些用法,或者说是很简单很简单的一些概念, 所以说同学们不用担心。然后我们看一下有如下存。第六题有如下存储过程,然后先用这个 delete 命令来修改双斜线,然后里面 修改的结束符为双斜线,然后里面的话有一条语句用的是这个创建这个存储过程,他的名字是这个,然后他有两个参数,一个是硬参数输入参数,一个是输出参数,然后这个语句里面的话有这个一个语句,然后结束之后用这个分号来进行结尾, 然后用改把结束符改为分号,然后我们看一下下面这个选项中,能对上述存储过程实现正确调用的是正确调用的是我们在调用有参的存储 过程,或者说存储函数的时候,输入参数是不需要精心经过一个特别的标记的, 输出参数的话需要用这个 at 符号来进行一个标记,然后 in out 的 话,它也是一个既可以输入也可以输出的,所以说 in out 的 参数也需要用这个 at 符来进行一个标记。 所以说这个题的话,然后我们调用的话用的是括号语句,所以说这个 select 不 选这个 d 不 选,所以说 b 和 c 不 选,在 a 和 d 里面选,然后 a 和 d 里面你选的话, a 他的一个标记不用要标记输入参数,不用要这个音标记,然后输出参数的话,他需要用 at 来标记,但不需要加 out 来标记。所以说这个题的话不选 a, 而是选择答案 d 输出参数,用 at 来进行一个标记,输入参数的话就直接写对应的值就行了,然后我们这个题的话选的就是 d, 也也 d, 然后我们紧跟着看第七题,第七题的话就是呃一个 c q 代码的一个片段,然后用到了这个变量,以及对应的这一个衣服的一个流程控制。我们先定义出来这个变量,然后需要注意没有给默认值,没有给默认值的话,这一个 where 这一个变量没有附用其他变,没有用其他语句来复制,比如 set 或者说是来复制的情况下,它的默认值就为空, 然后定义的这个变量他的职位空,之后就来一个一幅判断,如果说他一幅他是空的话,然后刃就输出出他是一个空到 else, 如果说他不是空的话,就输出出他不是空, 然后就结束了 n 的 一幅。所以说我们定义的这个变量没有负值,没有给默认值的情况下,他的值为空,所以说他为空的话,这个值是不是空的话就是对的,所以说就执行的是任后面这个语句,然后输出的就是这个 where is 浪,所以说输出的就是这个 where is 浪,然后我们就选择答案 a。 好,我们看一下第八题下面选项中用于定义存储过程中变量的关键字,定义变量的关 键字用的是修,用于修改对应的呃及命令行的一个结束符,然后这一些的话就完全是错的。 set de limit 和 set 这个 decry 肯定是错的,就选的是 b decry 是 用于定义变量, 然后看一下第九题下面选项中用于读取光标的关键字,读取光标的话,我们用的是这个废弃这个关键字, 我们刚刚讲到了用的是废弃这个关键字,然后光标使用之前需要用 open 来打开对应的光标,然后这个点也需要注意,所以说这个题的话选 c 耶 c。 然后看一下第十题下列用于声明存储过程。这个 my pro 语句中,正确的是声明存储过程,正确的是用的是 great, 前面这些都是对的,都是用的是 great procreate 这个关键字。然后需要注意的是这个是小括号,这个是小括号,这个是中括号不对,这个是大括号也不对,然后中括号 不对的,这就不惯。然后小框后面跟的一个大框号也不对,所以说这个小框后面跟着 begin, 然后 end 结束的这个是对的。所以说这个题的话,选择答案 a, 也也这个题的话选择答案 a。 然后我们看一下第十一题,下面选项中用于表示存储过程中输出参数,输出参数的是就是这个 out, 所以 说选的答案 c 输出参数选的是 c 啊。第十二题下列选项中用于在删除存储过程时,检测存储过程是否存在的关键字,用的是这个 is 呃, x t s 这个关键字,我们可以在这里来看到这个哦。 if if 这个 if, 这个是 x t s, 用的是这个 if。 十十二题用的是这个 if x t s。 选择着按 a, 然后我们看一下第十三题下列选项中用于修改存储过程的关键字是这个 alter, 同学们需要注意, alter 的 一个写法是 a l t e r 是 这个不是 d, 那 个选 项选 c 哦,选 c。 然后我们看一下第十四题 下列用于删除存储过程的 c 口语句中,正确的是删除用的是作谱,所以说这个 delete 的 b 和 d 就 不用选,然后作谱。这里不能够简写, my circle 里面是不支持这样的简写的形式的,所以说必须写全是这个样子的,所以说选择答案 c。 然后我们看一下十五题下面申明,因为这个 student 的 一个邮标的语句中语法格式正确的是这个,嗯 嗯,用的是这个 decoy 这个语句,然后后面跟上对应的光标的一个名字,然后用的是 co sir for, 不是 co sir of co sir for。 我 们来看一下这一个 油标, 油标用的是这个 decoy 这个命名,跟上对应的名字,然后 co sir for co sir for。 所以 说这个题的话就是选择答案, 嗯, c co sir for 对 应的这个,呃 select, 然后后面跟上对应的 s, name, s, g, g 等,然后 from 这个 student 的 这个表,所以说这个题的话选择答案, c, 然后我们紧跟着看接下来的,耶,我们紧跟着看接下来的判断题,嗯,看第一题, 目前 mac 口还不提供对已存在的存储过程代码的一个修改,如果说必须要修改存储过程嗯,的一个代码的话,则需要先删除它,再重新 因编码创建一个新的存储过程,这个的话是对的,这个是对的。需要注意的是,这个存储过程的一个 代码部分是不能够直接进行一个修改的,我们可以来给大家看一下这个。呃,我特呃这个修改存储过程这个语句的话是这个,然后他下面有一个解释,以上语句成功执行之后的话,他会那个,然后需要看一下这个。 这个语句的话是只能用于修改存储过程的某些特征的。如果说需要修改存储过程的内容,也就是他的代码的话,是可以先删除原有的存储过程,再以相同的命名创建一个新的存储过程。 如果说是需要修改存储过程的名称的话,也是可以先删除原有的存储过程,再以不同的名字创建一个新的存储过程, 所以说需要修改存储过程的一个名字,或者说是修改存储过程的一个原本的一个内部代码的时候,是不能够直接进行修改的。这个沃特,呃,这个命令修改存储过程的话,他只能够修改他的某些特征, 就比如他的一个数据的一个访问权限,这些是可以改的,所以说需要修改的话是不能够直接进行修改的,所以说我们这个题的话是对的,这个题的话是对的, 他是不能够直接进行修改的,需要先删除他,再编一个新的存储过程的。然后我们看第二题。在 my circle 存储过程中,参数的类型分为三种,输入参数、输出参数和输入输出参数。定义存储过程时必须有参数就错了, 不是必须有的,是可以不用有的,所以说我们这个题的话是错了,这个题是错的。 然后我们紧跟着看第三题。在 my circle 中,除了可以使用 set 语句为变量复制外,还可以使用 select into 为一个或者多个变量进行复制,这个是对的。 然后我们看第四题,声明完油标之后就可以使用了,在使用之前需要先打开油标是对的,然后打开油标,用的是 open 的 一个命令,这个是对的。 然后我们看一下第五题。在编辑存储过程时,查询语句可能会返回多条记录,如果说数据量非常大,则需要使用油标来逐条读取结,查询结果集中的记录,这个是对的,也对的。 然后这样的话就给大家讲完了。所以说这些题的话他都是一些很简单的,不是说你看到他的一些概念有很复杂, 又是什么流程控制,又是什么定义局部变量,又是什么带参数不带参数的,这些看起来很复杂,但其实他考的时候就是考这些很简单的, 比如什么一个语句,他的命令是什么呀?然后他调用的一个语句是什么呀?然后还有就是,呃,还有就是带参数的呀,或者说加不加括号这种细节呀?还有就是对应的这个参数的一个使用方法呀,输入参数直接写输出参数加艾特呀, 然后这些都是很简单的。然后还有就是用的定义关键,定义存储过,定义变量的一个关键字是多少啊?定义有读取邮标的关键字是什么呀?还有就是对应的一些具体的一些使用场景的情况下,都是很简单的,不会说很复杂很复杂。还有就是这个 非常简单,输出参数是 out, 输出参数 out, 所以 说同学们不用把这个想的很复杂,他考的肯定都是这样的很简单的题,所以说同学们 可以多练习一下这些简单题,然后而且他考的很多都是一些基本的题目,所以说不用怕,然后就讲到这里吧这一节,然后谢谢大家。
2樂小宝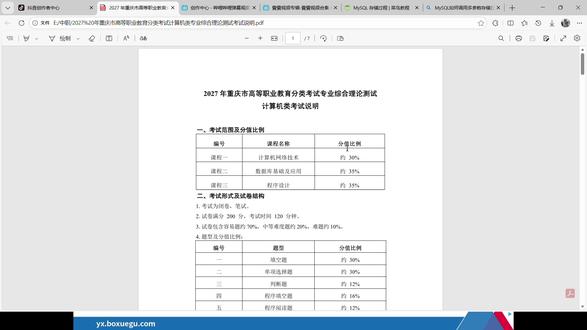 21:35查看AI文稿AI文稿
21:35查看AI文稿AI文稿同学们大家好,下面我们一起来接着学习存储过程,然后我上一次的话去看了一下这一个 呃计算机考试的重庆市二零二七年的一个考试说明,然后我看了一下这个 mac, 这里面的话,他对于存储过程和存储函数的话是都需要考的, 他这里说的需要了解存储过程的创建和管理方法,了解存储过程的调用方法以及了解函数的创建和管理,了解函数的调用的用法。所以说存储过程和存储函数的话是都需要讲的,所以说我这里的话就重新把存储函数也给大家来讲一下, 然后先复习一下前面的这一个呃存储过程吧。存储过程就是一条或者说多条 c q 语句的集合,然后这一个创建存储过程的关键字用的是这个 great procurry 这一个关键字, 然后这个 sp 链的话是存储过程的名字是可以自己定义的。然后这一个后面这一个的话是用于指定存储过程的一个参数列表,然后存储过程的参数列表的话, 存储过程的参数列表的话一共有三种,一个是 in, 一个是 out, 一个是音 out, 然后音表示输入参数, out 表示输出参数,音 out 表示既可以是输入参数,也可以是输出参数。 然后这个呃最后这一个单词的话,它是用于指定存储过程的一个特性,存储过程的特性的话,它是总共有这些的 存储过程的特性,存储过程的特性的话是有下面这一些,然后这个的话就同学们只需要看一下有一个了解就行了。然后需要注意的就是这下面这里 存储过程体的话是 c q 代码的内容,可以用 begin 和 end 来标志 c q 代码的开始和结束。 然后由于 my circle 中默认的结束符是分号,而存储过程中的 c q 语句也可以用分号来结作为结束符。 若需要通过命令行程序来创建存储过程的话,为了避免冲突,则需要临时使用 delete 命令修改绘画的命令结束符,等存储过程执行结束后, 再把结束符修改为分号。例如先使用这个 delete 双斜线,将 my circle 的 结束符设置为双斜线,然后在这个存储过程 创建完成之后的话,再使用这个 delete 分 号将结束符设置为分号,它的语法框架的话就是下面这个样子的。先用 delete 这个命令双斜线,然后来把结束符换成双斜线,然后再创建这一个存储过程,用的就是 great procreate 这一个 呃关键字,然后跟上对应的存储过程的名字,然后这个小括号是必不可少的,即使你没有参数,这个小括号也是不可以省去的。 然后后面紧跟的就是 begin 和 end, 然后 begin 和 end 中间的话就写的是内部的这些 c q 语句,然后内部是可以用分号进行结束的,因为我们前面 已经替换的这一个结束符为这一个双斜线,所以说在内部写分号的时候,他这一个创建存储过程的这一个语句的话,是还没有结束的。然后等 end 结束之后,我们再利用双斜线来结束这个创建存储过程的一个语 语句。然后在存储过程创建完成之后,我们再把结束符换为这一个分号,这样的话就是一个基本的语法框架。 然后的话,呃,我们来看一下这一个变量,变量的定义在 my circle 中,变量可以在语句中声明用于保存数据过程中的值,这些变量的作用范围在 begin 和 end 中。然后变量的语法 定义变量的语法,像下面这个样子的,用的命令是这个迪克瑞,后面跟上对应的变量的名字,然后你有多个的话,可以用逗号进行分割,然后后面跟的是对应的数据的一个类型,然后也可以给默认值用的就是这个 default 这个值句 后面跟上的这个 v 六的话,就是你想要设置的那一个值是多少,如果说没有给这个默认值的话,他默认是为空的,也就是浪 n u l l, 然后这个 value 的 话为局部变量的名称,是可以自己定义的。然后这个 default value 的 子句是给变量提供一个默认值,该值可以被申明为一个常数或者一个表达式。如果说没有这个子句的话,变量的初值值为浪, 然后的话未变量设置值的话有两种,一个是用 set 语句为变量赋值,另一个是用 select 音符为变量赋值,然后 set 变量赋值的话 用的是 set value 的 名字。呃,这个那个变量的名字等于对应的它的一个值或者是一个表达式也是可以的。然后如果说需要有多个变量赋值的话,用逗号来进行分割, 然后变量和值是一对应的,然后后面用这个 select into 来为变量赋值的话,用的就是这个 select。 后面会有一个输出的一个字段列表,然后字段列表后面紧跟着写 into 对 应的这一个你的变量的一个列表。你如果前面的输出列表有两个字段,你后面的这一个 变量的字列表的话也有,也需要有两个变量名。你如果说前面有三个输出的一个字段的话,后面的这个变量的列表也需要有三个变量,然后后面就是 from 来自哪一个表,根据哪个条件来进行一个查询,然后查询到的结果返回回来给我们放到对应的这个变量里面去, 然后在这里面来看的话就是这样的,在存储过程或者说存储函数中可以定义和使用变量。定义变量用的是这个 decor 这个语句,定义 在存储过程或者说存储函数中的变量称之为局部变量,其作用范围在本存储过程或者说本函数定义后,就可以给变量赋值。定义变量用的是这个 decore 语句,他的格式是这个样子的,然后的话也可以设置默认值,如果说没设置的话,默认值就为空, 然后给变量赋值。有两种,一个是用 set 语句来赋值,其语法格式是这个样子的变 set 变量一等于表达是一,变量二等于表达是二,中间用逗号的音分格,然后十二。第二种的话就是用这个 select into 语句来为变量赋值,它的语法格式是 select 字断一,然后逗号字断二,然后 into 变量一,逗号变量二,然后 from 来自哪个表,然后 where 根据哪个条件来查询出来的结果 的一个字段放到对应的这些变量里面去,就比如这里的,在学生表中查询出学号为这个的学生所在的班级,并把它的值赋值给这个 myware。 首先我们需要定义这一个变量 myware, 然后它是一个微差类型的三十个字节的长度,然后定义出来之后,我们用这个 select, 然后这一个班级的一个名字 into 到这个 my where 这个变量上去,然后 from 来自 student 这个表 where 条件是它的学号等于这个值,这样的话我们就可以达到这个效果。在学生表中查询数学号为这个的它的班级,放到这个 my where 这个变量里面去, 然后我们紧跟着看后面的,然后我们还可以定义条件,定义条件是指事先定义程序执行过程中遇到的问题。 耶,遇到的问题。定义条件的使用的是这个 decoy 语句,它的语法格式是下面这个样子的,然后,呃耶,不对吧, 少了一点好像。 哦对对对,这里的 定义条件是指事先定义程序执行过程中遇到的问题,定义条件用的是这也是用的这个 dickory 语句,他的语法格式是这个样子的。 dickory 后面跟上对应的这个名字,然后后面跟上这个康的心货,然后跟上对应的一个类型啊,类型的话有两种, 这里的话就是一个解释,这个康的星 name 的 话表示定义的条件的一个名称,我们是可以自己定义一个名称的,然后这个康的星 type 的 话表示一个条件的类型,然后后面它有两种类型,一个是 c q set value, 或者说这个 my circle your q 的, 然后这两个的话表示的是 my circle 的 一个错误。 c q set value 的 话是长度为五的一个制服串类型的一个错误代码。 然后 my circle your q 的 话为数值类型的一个错误代码。例如它如果说报错为这个 your 幺幺四二,然后括号里面写四二零零零的话,这个 c q set value 的 值就等于这个括号里面的这个四二零零,然后它是一个制服型制服串形的一个长度为五的一个 呃,值啊,这个 my circle your q 的 话,它的值就是这个 your 后面紧跟的这个数字幺幺四二,然后它是一个数字类型的一个错误代码。这就是一个呃讲解这一个语句的讲解,然后我们看一下下面这一个定义。定义处理程序, 处理程序,定义了在程序执行过程中遇到问题时应当采取的处理方法,并且保证存储过程中在遇到警告或错误时能够继续执行处理过程。使用这一个 decore 语句定义 它的语法格式是这个样子的 decore 啊, hunter type, 它的一个类型,然后 hunter for, 然后康的星 value 它的值,然后这个 s p, 这个 st ment, 然后还有这个 hander type, 然后对这一个的描述的话是这个样子的。这个 hander type 的 话为错误处理的一个方式,它的参数区只有三个,一个是这个康 continue, 还有这个 exe exet, 还有这个 on do, 还有这个 on do, 这第一个参数的话,表示遇到错误时不处理,继续执行,然后这个 exit 的 话,表示遇到错误马上就退出,然后这个 on do 的 话,表示遇到错误后撤回之前的一个操作,然后在 my circle 中暂时不支持这样的操作。嗯, 在 my circle 中暂时不支持这样的操作。 s p 这一个 statement 参数 为我,参数为程序为程序语句段,表示在遇到定义的错误时需要执行的存储过程,然后这个康低心 value 表示一个错误的一个类型,然后这一个嗯 sp spst 的 话表示一个程序段,相当于当我们遇到这个错误的时候的话,需要执行的一个存储过程,相当于这个 sp state 么? statement 的 话是一个存储过程,然后的话当遇到错误的时候,他会去执行这一个 spa statement 指定指向的这一个存储过程,他是这个意思。然后我们看一下下面一个概念,就是光标在编辑存储过程时,查询语句可能会返回多条记录,如果说数据量非常大,则需要使用光标来逐行读取 查询结果集中的一个记录。光标是一种用于轻松处理多行数据的机制。光标的声明用的是也是这个 decoy 语句,然后后面跟上这个 caller name 就是 光标的一个名字,然后 caller for course for 这个 select 这一个 segment, 然后它的视力的话就是这个 decre dictionary, 然后 course 这个 student, 它的名字是这个 course 光标学生表里面的一个光标,然后 course for, 然后 select 呃,查询的是这个学生的名字,然后学生的一个呃班级,然后来 from 来自这个学生表, 然后光标的使用的话,就是需要定义了光标之后,我们需要打开这个光标,打开光标的话,用的就是这个 open 对 应的这个光标的名字来打开这个光标,打开了之后用的是这个这个废废废弃这个命令来, 哎,绑定这个光标,使用上这个光标,然后这个用的就是废弃这一个 coser name into 对 应的这一个呃 v 二 name 和这个对应的变量的名字,就比如这里的 使用上这个学生表的一个光标,然后 into 上对应的他前面的这个 s name 和 s g g 的 这一个呃这两个字段,然后光标的关闭的话,就是用这这个 close 对 应的光标的名字就行了。 然后的话我来看一下这边有没有光标的一个解释啊?这边目前没有光标的一个解释, 应该是我当时弄的时候弄溜弄漏了,但是光标的话他应该不会考,只需要你能够使用光标以及关闭光标就行了。 使用光标以及关闭光标还有就是知道光标使用之前需要先打开对应的一个光标,还有就是你需要知道使用光标的一个命令是这个废弃,废弃这个命令 和关闭光标用的是这个 clos 这个对应的光标的光标的名字,然后下面的话就是流程控制,然后存储过程 中的流程控制语句,用于将多个 c q 语句划分或组合成符合业务逻辑的一个代码块。 my circle 中的流程控制语具有七个,第一个是 e f 语句,它的语法格式是 e f 而一个表达式, 然后刃,然后一个片段,然后呃 n 的 e f, 呃,或者也可以配合 s 来进行一个使用,当满足条件的时候, e f 后面这个表达是为真的时候,就执行刃后面的一个呃程序片段,然后如果说 e f 后面的这个表达是为假的话,就去执行 s 后面的这一个程序片段, 然后最后用 n 的 e f 来进行一个结尾。对于流程控制的话,同学们也只需要了解就行了,因为考的不会很多,基本上就是考一个题的话,就是考 e f 的 一个题,就很简单, 当条件为真的时候,就执行任后面的一个语句快,当 e f 后面的表达是为假的时候,就执行 a l 是 后面的这个语句快,然后用 n 的 e f 来进行结尾。 然后第二个的话就是 case 语句, case 语句的语法格式的话,就是这个样子的, case 对 应的一个表达式后面跟上这个, 当为当这个表达式的值为多少的时候执行哪个,当表达式的只为另一个的时候,又任执行另外一个,就是当这个 case 后面的值与这下面的进行匹配的时候,匹配到哪一个,你去执行任何面的那一个代码块就行了,然后结尾的时候用这用的是 n 的 case, 然后看一下下面这一个流程控制语句。第三条路谱语句,路谱语句的格式是这个样子的, 嗯,是路谱后面跟上对应的这个代码片段,然后用 n 的 路谱来进行一个结尾,然后而且有这个前面需要给他一个路谱的一个标记,相当于说 当我们到某需要重新回到这个地方的时候,就是用这用的这个路谱标记来进行一个呃,回到这个地方来,然后面就是这个 leave 语句, leave 语句的语法格式的话,就是 leave 后面跟上一个标记,然后这些同学们就看一下就行了。然后第五个是这个 intuit 这个语句, intuit 的 语句的语法格式也是很简单的,也就是 intuit labor, 然后第六个是这个 呃 repeat 语句, repeat 语句的语法格式的话是这个样子的, repeat 的 一个标记,然后后面跟上这个 repeat 这一个关键字,然后跟上代码片段,然后这个 on t, 哦,直到什么情况的时候,哦就去执行哪一个东西,然后结束的话是用的这一个 n 的 repeat 来进行一个结束的,然后后面也需要跟上对应的前面的这一个标记, 然后第七条的话就是这个 yoyo 语句, yoyo 语句语法格式是也有一个 yoyo 标记,然后后面跟的是这个 yoyo 的 一个关键字,然后跟上对应的这个 呃表达式的一个这个东西,然后丢上这个丢,然后后面跟上对应的这个程序片段,然后程序片段之后结束,用这个 yoyo 标记来进行一个写,在后面来进行一个结束, 然后的话调用存储过程,我们前面也已经讲到了,用的就是这个括 sp 链来进行一个调用的, 就很简单。然后需要注意的是这个括号是必不可少的,就算你的这一个存储过程或者说存储函数是没有参数的,他的这个小括号也是必不可少的。 然后我们来看一下执行存储过程,执行存储过程的话,呃存储过程是存储在服务器端的 c q 语句的集合,使用这些定义好的存储过程必须通过调用的方法来实现。 存储过程被调用后,数据库系统将执行存储过程中的语句,执行存储过程需要拥有这个 execute 的 权限,然后调用存储过程的语句是这个 core 语句起语法格式是 core 对 应的存储过程的名字,然后你需要的一个小小括号,然后小括号里面写对应的实际的参数的一个列表, 就比如这里调用存储过程这个呃存,调用这个存储过程,然后他的有一个参数是这个字母串类型的,需要用这个 呃定界符框起来,然后里面写对应的这个参数的一个值,然后就是括号对应的值这个存储过程的名字,然后括号,括号里面写对应的参数,如果没有参数的话,这个括号也是必不可少的,然后我们紧跟着看下一个, 嗯,查看存储过程的状态的话,就是用的这个也查看存储过程的一个状态的话,就是用的这个 show great 对 应的存储过程的一个米 show great 后面跟上这个 procreate 这一个字关键字,然后跟上这个对应的存储过程的名字,然后也可以用这个另外的语句来进行查询,也就是 select 信号 from 这个 information 啊,对应的点上这一个 呃 route ins, 然后 where 对 应的这个条件, ctrl con counter proctor 一 and 这一个对应的这个类型等于这个的情况查询出来这个类型为这一个呃存储过程的一个 呃结果就得用的就是这个语句,然后这些的话同学们有个了解就行了,基本上不会考到这一个查看存储过程的一个状态的一个语句, 然后我们看一下修改存储过程用的语句是这个 word 语句来修改存储过程,然后这一个后面跟的话是这个 proctory, 或者说是这个 function 表表示存储过程,然后 function 表示的就是存储函数。啊,对应的这个 spname 呢?就是你需要修改的那一个存储过程,或者说存储函数的一个名称,然后后面的话表示修改的存储过程的哪个部分? 取值可以分为八个部分,然后这些都是做一个了解,然后删除存储过程的话,用的就是作辅语句来进行一个删除存储过程用的是作辅,然后 proctorary 或者说是 functionary 表示存储函数, functionary 表示存储过程,然后 functionary 表示存储函数,然后这个一夫一克斯 if x t 的 话表示就是这个存储过程,或者说这个存储函数是否存在,存在的话就把它删除,如果不存在的话就干嘛干嘛。那后面跟上的,对呢?就是这一个, 呃,他的一个名字,然后的话,嗯,我们来做几道题吧。
3樂小宝 01:24查看AI文稿AI文稿
01:24查看AI文稿AI文稿我们知道在麦收扣里面,库对面是文件夹,表对面是文件,对吧?再来看一下安装部落 对他们演讲,还是 d b 六这个苦,我们有一个 com 表,这里就对有两个 com 文件 f r m 我们之前说过是表结构文件, i b d 是表数据文件, 更准确的说应该叫它表空间文件。需要注意的是,在八点零之后的版本,表结构文件就不在 fm 里面了,而是存在的一个 s i d 字典里面, s i d 又仅存在 ibd 表空间文件里面,所以在八点零之后,一张表就只对应了一个文件,就是 ibd 结尾的表空间文件。但在八点零以前,表结构文件和表空间文件就是分开的表结构文件 fm 表空间文件 abd。 当然表空键文件里面除了记录数据之外,所应也是存在表空键文件里面的。 ok, 这个清除之后,我们再来看一下 indeed b 的存储结构,刚刚我们说一张表就对应一个表空键文件,对吧?这叫 table space。 然后每个表空键文件里面又分为多个 segment, 这叫段,然后一个段里面又包含多, 这个叫蛆,然后一个蛆里面又分为多个配置,这个叫液。当然液里面还分为所营养数据液,这个我们后面讲,所有的时候再说,然后一个液里面又分为多个肉,也就是行, 这个行就是我们常说的一行数据,或者说一行记录,然后在一行里面又分为这几个信息。最后一次操作收入的 id, 然后是相关的指针,接着就是断了。在印度地币逻辑结构里面,一个区的大小固定是一兆,然后一个页的大小也是固定的,是十六 k, 所以说一个区可以有六十四页,而且也是印度 db 指盘插座最小单元。 ok, 这就是印度 db 存储结构,你先一个了解。
265小飞有点东西 04:06查看AI文稿AI文稿
04:06查看AI文稿AI文稿我去面试一个架构师岗位,面试官问我说一亿数据的 my circle 如何秒击平滑扩容?答,一般来说,并发量大、吞吐量大的互联网分层架构是什么样的呢?数据库的上层都有一个微服务 服务层,它会记录业务库与数据库实力配置的硬蚀关系,通过数据库的连接池向数据库路由 siri 语句。如上图所示, 服务层配置的用户库优者对应的数据库实力的 ip。 那 么这个分层架构是如何应对数据库的高可用的呢?数据库的高可用很常见的一种方式是使用双主同步 keep live d c i p 的 方式来进行的。 如上图所示,两个相互同步的主库使用相同的 c i p, 当主库挂掉的时候, c i p 会自动地漂移到另外一个主库上, 整个过程对于调用方是透明的。那这种分层架构是如何应对数据量的暴涨的呢?随着数据量的增大,数据库要进行水平切分,分库之后将数据分布到不同的数据库实力上,甚至物理机器上,以达到降低数据量,增强性能的扩容的目的。 如上图所示,用户库 u 则分布在两个实体上, ip 零和 ip 一。 服务层通过用户标识 u i d 来取模进行寻路,路由模二与零访问 ip 零上的 u 则库,模二与一访问 ip 一 上的 u 则库。 此时数据库水平切分的集群读写实力加倍了,整个实力的数据量减半了,性能增长可不止一倍哦。那么数据量持续的增大,两个库的性能扛不住了,此时要怎么办呢? 此时需要继续水平切分拆成更多的库,降低单库的数据量,增加主库的读写实力个数来提高性能,这就是秒集扩容要解决的问题。整体来说分为三步骤。步骤一,修改配置主要修改两个地方啊,第一个地方,数据库实力所在的机器做双需 ip 啊,原来模二于零的库,它的需 ip 是 ip 零,现在增加一个需 ip ip 零,零,原来模二于一的库,需 ip 是 ip 一, 现在增加一个需 ip ip 一, 一。 第二个地方,修改服务的配置,将两个库的数据库配置改为四个库的数据库配置。修改的时候要注意旧库与新库的硬蚀关系, 模二于零的库会变成模四于零与模四于二的库,而模二于一的库会变成模四于一与模四于三的两个库,这样就能够保证依然路由到正确的数据上去。 步骤二, reload 的 配置实力扩容 reload 的 配置可能有这么几种方式,比较,原始的重启服务,读新的配置文件,高级一点的配置中心给服务发新号,重新读配置文件,重新出使化数据库连接尺。 不管哪种方式, reload 之后,数据库的实力扩容就完成了。原来有两个数据库实力提供服务,现在变成有四个数据库提供服务, 这个过程一般可以在秒级完成,这整个过程是可以逐步重启的,对服务的正确性和可用性都没有影响。你们看啊,即使模二巡库和模四巡库同时存在,也不会影响数据的正确性, 因为此时双主的数据仍然是同步的,而且即使模似于零与模似于二的寻库落到同一个数据库实体上也不影响数据的正确性,因为此时仍然是双主同步的。完成了实力的扩容,你会发现每个实力的数据量仍然没有下降,所以还需要做一些收尾的工作。 步骤三,收尾工作,数据收缩。这里主要有这样的一些收尾工作,其一,把双需 ip 修改回单需 ip。 其二,解除旧的双组同步,让原来的数据库队不再进行双组同步。其三,增加新的双组同步,来保证新库的高可用, 最后删除掉涌入的数据。到了这一步,数据库单立的数据量就简单稍作总结,互联网大数据量高、吞吐量高、可用的微服务分层架构,数据库可以实现秒级平滑扩容。三个步骤,其一,修改配置,主要是双需 ip 与数据库服务器的路由配置。 其二, reno 配置,实力 double 完成。其三,删除融资数据等收尾工作,数据量减半完成。我问了一下我们的架构师,现在都花钱买第三方的服务了,不用自己扩容了。你这个方案没用啊,还是回去等通知吧,下一位。
142架构师之路 06:24查看AI文稿AI文稿
06:24查看AI文稿AI文稿上个视频就是选择聊天记忆存储的隔离功能,我们当时是大家可以想一下,我们是在这个 chat memory 就是 有一个默认的存储里边去存储的,是吧?那默认的存储大家可以看一下,我们之前 呃默认存储使用的是这个,大家可以点进去,我们去构建的时候,一个 chat memory provider 其实在我们的内存里边去存储,但对于我们如果说是大公司其实无所谓。但是对于如果说是个人开发者来说,这个内存存储,因为你电脑, 你的服务器,它的内存就只有这么多,你没办法把所有的东西全部放在这里边,但对于大公司来说,他们把像 linux 这能作为一个主流的这种介去用,但我们是没有办法的,所以说我们就可以去构建一套属于自己的 这种存储。那之前我们在 spring ai 里边,大家可以想一下,我们在 spring ai 里边,我们那个项目里边存储的在那里边去进行存储, 而且我们当时还看过他有很多,比如说 reddit 是 吧?还有说是像 clayhouse 那 种大数据量的一个存储库,但是这里我们今天说的是这个 micro, 好 吧? micro, 好 吧, micro 存储的话,我们首先你要给项目里面去引入一些东西,比如说我们首先先说一下聊天消息的一个存储表,其实就是一个消息 id, 比如说呃,消息 id id, 用户 id, 其实就是 message id 吧,还有我们的听写时间和更时间, 还有一个具体的聊天的一个内容,我这边就采用 longtest, 就是 一个大文本,好吧, 大家如果想用其他的数据库存储,其实和这里是一模一样的啊,我们这里就以 micro 为例,哇,我们依赖我这边就采用了 microsoft 和 micro micro 的 这个号,大家自由选择啊。 我们根据呃表结构,你去创建出来一个 chatmessage 的 一个实体类及 chatmap。 chatmessage 的 一个 map, map 里边我们需要去查一些东西,比如说我们去 excel 段 excel 的 时候,然后像这种这种 option 大家都去选择一下,像我们去根据 id 查询, 查询的时候根据 user id, 你 可以去呃删除,是吧?根据 user id 进行一个删除,或者说是节点代码。 ok, 那 通过这样的方式,然后我们就能把基础的框架搭建起来。那下来我们去如何去做?做的话其实很简单,我们和之前一样, 首先我们去创建一个 my circle 的 一个 star, 这个 star 你 要去实现一个 chat memory 的 star, 实现这个 chat memory, 那 实现之后我们去注我们的 chat memory 的 一个 member, 我 们把自己的通过这个 memory id, 因为实现之后它会有很多要继承的东西。 ok, 有 了它之后,我们先去查出来我们的 magic, 大家可以看一下当前的一个聊天结构,他其实是里边属于一个数组,像他其实对于同一个用户所有的内容都是在一个 ctrl 里边去存储,是吧?你存储完成之后,我们如果说你这个是空他查询, 因为他聊天对话的时候,他每次会默认先去取一次,他是这样运行的,就说我们第一次对话, 它会从你的数据库里边如果有给你加进去吧,如果没有,没有吧是这个样子, 那如果说不等于呢?我们去给它转一下,我们这 message 采用这个 send 给它转成这种类型,好吧?转过来之后,这里 转过来之后,如果说他是一个空的,我们直接返回一个空集合,可以,然后对于更新来说其实是一样的,如果说查出来的,那不等于空,我们是去更新,对吧?如果说是为空,那我们就去隐私而办。 对于删除来说其实是一样的,我们点类 user id, 因为它这里只提供了 memory id, memory id 针对于我们来说其实就是一个 user, 是 吧?那针对这情况,我们就这样去做这里的这个 start, 写完之后,我们要去写一个注册类,那这个注册类就是 mycircle 的 一个进程,那我们这里就采用的是 chatchatmember, 呃呃, mycircle 的 provider, 是 吧?这个配置完成之后,我们在 copy 里边继续沿用之前的东西, 把之前的这个 chat member provider 们复制下来,在这里去创建属于我们自己的 my circle 的 provider chat member store, 我 们采用的 store 就是 我们自己去创建的这个 circle chat member, 好 吧, 那这样呢,我们就可以去把这个项目构建起来,我们在自己的十二层你就可以去使用这个东西,比如说我现在去自动, 我把数据这个数据删掉,我们等待一下自动。好,我们打开这里,我们去访问一下,比如说我这里就在 id, 我 给一个二,好吧?比如说我是王,我们点发送,大家可以看一下这里没有任何报错,前面这里他说 少了,我们可以刷新一下这里,这个你是王同学,是一个 ai 助手,大家这个是一个系统的提示词,其实是这样,就是说我们在 构建它的助手的时候,就已经给了它一个 system 的 一个 message, 所以 说当项目运行的时候,它会首先把这个呃替日词当做一个内置的类型,大家可以看一下, system 已经放进去了,这里的 type 类型是 ai, 我 们还有比如说, 你好,我是小王同学, type 类型大家可以看一下,这个 type 类型应该是一个 user, 就是 一个 user message 就是 我们用户对话的一个消息,所以说这里我们把系统消息就已经构建进去了。比如说我现在问我是谁,看大家,呃,小王同学这里应该也会加载出来相对应的一些数据, 对吧?比如说我现在改,改成一,我再问一下,你说我是谁?他说你是我的用户啊。对,这里我们去翻新一下, 也已经做好隔离了,所以说我们的现在项目就已经集成了这个 my circle 作为我们的一个消息的一个存储空间,好吧,那这页的话是这个样。
12写代码的王同学















猜你喜欢
- 8243云影同学