
粉丝13获赞17
相关视频
 01:34查看AI文稿AI文稿
01:34查看AI文稿AI文稿如何查找网页中的文件?一个网站有很多图片文字代码组成, 当我们拿到网站原代码的时候,如果想去查找里面的文件,我们可以通过 windows 自带的搜索功能去对文件进行检索。我们如果要查找文件里面的一个 压缩文件,首先要知道我们这个压缩文件的后缀名是什么。当得知后缀名的时候,可以在搜索栏这里搜索 点 ir 这个文件格式,这个时候系统就会将所有的 ir 后缀文明 后缀的文件都会给我们检索出来,要查看哪一个就点击这个文件,选择打开文件的位置, 这时候我们就来到了这个文件夹的所在位置,我们在这里可以对这个文件进行粘贴、复制、解压或者是其他处理。好了,今天的分享就这里谢谢你的观看,再见!
28振国说建站 09:28查看AI文稿AI文稿
09:28查看AI文稿AI文稿大家好,我们继续上节课的基础回归篇,来继续讲一下这个。呃,接着讲一下,大家记得上节课我们讲到哪了吗?上节课我们是不是做了,做了时政的回归,对不对?基础回归 r, e, g, h, d, f, e, 然后呢?音变量是我们的这个 roe 对 不对?因为 roe 它是不显著的。然后字变量呢?是啊, size, 然后控制变量,我们还没有选举,对不对?然后逗号, 然后固定向量 a, b, 然后,然后我们用了,呃,个体固定和时间固定,让我们会发现是什么样是 正向不显著,我们可以试一下这个是不是行业来上节课,行业代码和时间对不对? 对,行业固定和时间固定,大家可以看到这是三颗星显著,对不对?怎么看呢?第一列这个回归系数是正的对不对?零点零零三,说明书都要整齐,会促进企业的财务绩效。然后这个 p 值啊, 这一列 p 值可以看到大家 p 值是小于零点零一,它是三颗星显著,对不对?是三颗星显著,然后我们把这个回归代码放到这,那放到这之后呢?我们是不是要选举控制变量?但是有时候随便加控制变量 它是不显著的,那我们怎么该去选举这个控制变量呢?包括我们选举控制变量是要依据什么样的原则去选呢?然后我们接着讲一下啊, 我们讲一下控制变量的部分,在写尽管实证论文的时候,很多同学会有疑问,老师我是不是把所有的控制变量都要加进去啊? 对吧?那看有些论文它控制十个,有些论文控制六个,那我到底是加六个还是加十个?那么什么是控制变量?控制变量加的是越多越好吗?控制变量的原则是什么?我们今天仔细讲一下 控制变量,大家想一下我们时政回归模型当中,它实际上为什么要加控制变量呀?因为我们既然研究数字化转型对财务绩效的影响,那我们直接去把数字化转型财务绩效去做一个回归,不可以吗? 得,这不现在就是我们刚才做这个回归吗?他不是也得出这个正向的影响了吗?那这个论文就可以写了呀,那为什么还要加入一些控制变量呢?实际上加入控制变量的目的啊,它是为了解决我们模型当中一个固有的问题,它叫做内生性问题, 它叫内生性问题。那么内生性问题当中有一种问题叫做什么内生性问题当中有一种问题叫做什么遗漏变量问题啊?那么控制变量的加入目的其实是为了一定程度上缓解内生性问题当中的遗漏变量问题。 我们可以继续说一下,你看我们研究数字化转型对财务绩效的影响,那么现实中对财务绩效有影响的变量难道只有数据化转型吗? 并不是,对不对?比如说 size, 企业的资产对不对?然后企业的啊,那个 gross 营业收入增长率对吧? board 是 不是 formage? 那 这些对企业的这个财务绩效是不是都有一定的影响啊? 对吧?所以说除了自动化转型这个自变量之外,还有一些比较重要的影响因素,也对应变量财务绩效有着比较重要的影响。所以我们在实际回归当中的时候,我们应该把这些对应变量有影响的变量也放到我们的实际的这个回归模型当中去, 他才可以最终得出的这个回归结果,他才是叫做无偏估计,对不对?没有偏误的。所以控制变量的目的,他其实是为了干嘛?控制一些可以观测到的对变量有影响的因素,然后其他减少加因素的影响,让我们的回归结果更加稳健,对不对?所以控制变量就这样的目的。 那么选举控制变量应该怎么选?选举控制变量的话,我们控制变量越多越好吗?并不是啊,控制变量并不是越多越好,我们实际当中呢,控制变量选举八个左右,企业数据选举八个左右就足够了啊?八个左右就足够了。 那么控制变量怎么选举呢?其实选举的原则就是选举这个常用的一些控制变量,比如说我们企业数据当中有这个啊, size 对 不对?资产规模 l e v 资产负债率 growth 应收入增长 board 独立董事会规模 in deep 独立董事比例啊 do, 那那个是否两值合一对不对? loss 是 否亏损 for each 啊?且成立年限对不对?有好多比较常用的控制变量,我们从这长的控制变量里选举一些就可以。那么选举的原则啊,我个人认为控制变量选举的原则最最最最重要的一点是什么?要让我们的主回归能够显著, 就是你选举这些控制变量加进去之后,我们的主回归依然是显著的,我们可以随便选一下啊,我们随便选,你看现在是这个因变自变量,因变量自变量,对不对?后面加控制变量,我们比如加一些 size, l, e, v, 对 不对?然后 cash, flow, growth, loss, board, deep, 对 吧?然后是,呃, form, age, 对 不对?我们加这些 加进去之后,大家会发现回归结果产生了什么样的变化?产生了什么样的变化,是不是啊?本来是那个应该是正常显著的,对不对?但实际做出来成了什么样的显著了? 实际做出来之后变成了负向的一个不显著,对不对?那说明什么呢?没有加入控制变量之前,回归结果是显著的,那么加入控制变量之后,回归结果反而不显著了,那是不是由于控制变量的原因啊?对不对?由于控制变量的原因,所以我们要对控制变量进行一个筛选, 那么对控制变量进行筛选的时候,手工筛选其实非常非常慢的,手工筛选非常非常慢,所以我们可以通过一个代码,那么有个大神他编写了一个代码啊,他叫做这个 one click, one click 这个代码啊, one click 这个代码有个大神编,呃,编写这个代码, one click 这个代码,它的工作原理是对这个控制变量进行一个排列组合,但是对样本数据呢? 不造成任何影响,但它不是万能的,只是在一定程度上可以对我们这个工作量进行一个减轻啊?工作量进行一个减轻, 然后我们大概讲一下这个 one click, one click 后面首先放 y 音变量,再放 control, 再放控制变量,然后放自己的回归的方法,放自己希望的 p 值,然后 fix 的 里面,呃,是你需要每次都要出现的这个,呃,每次都要出现的这个 啊,叫做什么啊?组合 fix 里面什么意思?都需要出现的一些组合啊,然后 o 呢?是里面要放的是这个什么啊?回归方法加选项啊,比如说固定效应之类的啊,然后我们对这个啊,回归啊,做一个控制边做一个筛选啊, 我们可以找一下这个回归的代码。 嗯,找一下 winclick 的 代码啊, 先放 y, 再放一些控制变量。那么控制变量啊,可以放 size, l, e, v, cash, flow, growth, loss or, 我们可以先放一些啊,因为它运行速度会有一些慢啊,它运行速度会有些慢,所以可以先放一些。但是我们实际在操作中的时候, on click 里面控制量放的越多越好啊,然后 fix 点 x 里面, fix 里面放你自变量,自变量数值化转型, 然后 p 值,我们希望小于零点零五吧,希望有两颗星,然后固定向于是行业和时间,对吧?行业和时间, 我们直接运行一下这个 one click, 然后运行的时候,他说啊,有一个具体预估的时间啊,我们等一下他啊,具体预估这个时间,让大家可以往后加速啊,一会儿是直接加速跳到他啊。这个 one click 结果出来的时候, 好啦,我们已经看到这个 one click 的 结果,它就运行出来了。运行出来之后呢,在你的文件夹的部分,它会出现一个 subset 这个选项,我们打开它, 我们首先把我们数据保存一下,保存之后我们打开这个 subset, 它会生成一个 d, t, a, 然后打开数据编辑,那么这里就是你的这个回归能够达到显著的组合啊,能够达到显著组合 positive, positive 就是 它积极的选项嘛?积极就是它能够显著的,你看这就它给我们筛选出来的,我们可以随便复制一下这个控制变量,然后呢?呃,把它放在我们的控制变量部分,然后打开之前的这个回馈数据, 打开这个回馈数据,然后运行一下, 我们会发现最终得出的回归结果就是什么样的,正向的显著,并且是三颗星对不对?而且控制边呢大部分也都是显著的,大家看到没有?这就是汪克利的魔力啊,它能代表帮助我们通过这个啊,减少一些手工,筛选一些繁琐工作 啊,就是排列组合,然后呢我们可以做起来快一些啊,然后今天就讲到这里,然后下一期开始讲中介调节,继续分析。好,谢谢大家。
 04:34查看AI文稿AI文稿
04:34查看AI文稿AI文稿准备好了吗?来喽,三二一走,我是学长,今天给大家去讲解的是我们的第二节,第二节就尽量继续学,然后首先我们要去先去了解就我们数据有几种格式,那 我们目前来看,我们数据有三种格式,一个是界面数据,一个是时间系列数据,还有一个就是面板数据,面板数据其实就是界面数据和时间系列数据的一个情况,那么很多同学他的初学的,他其实分不清的。然后我们来去看一下定义, 从第一上来我们可以看到洁面式数据就是它的,其实我们这三个数据的分类主要是看对象和时间节点,如果是多个对象,单一个时间的话, ok, 我 们就叫做洁面数据,它的反义词就是单个研究对象,但是有多个时间节点的时候,我们就叫做时间系列数据。 然后还有这个是面板数据,大家可以看到那面板数据其实有两位数据,有三维数据,八八八有有好几维的数据,对,那紧接着我们来看来举我这个干巴巴,讲理论不可信,大家其实也是不懂,那我们就直接上干货吧。 什么叫做洁面数据?看到没有?这就洁面数据是我们只研究一个时间节点,一一年但是有 n 个研究对象,这个这个就叫洁面数据。什么叫面板时间序列数据?看到没有?只有一个一个研究对象,但是有 n 个时间,这时候是有时间序列数据,那面板所有面板数据看下,综合有 n 个年份, n 个研究对象,看到没有?这个就是面板数据。 那姐姐那下面我们来看一下,就我们讲到正题了,我们的这个数据,对,那我们数据应该是怎么去操作呢?其实我们最最初的话啊,很多同学他大部分都是从 ig 回归的命令才开始学谁他的在回归之前我们还有两个,两个命令是描述和相关, 这大家可以看看到啊。首先我们来学一下相关相关性,这个相关性就学我们就呃毕业论文,大家会发现都会有这个东西的。对,那它仅仅描述了变量和变量之间的关系,在这里,呃,我想调调是, ok, 大家现在已经不用它,它,它已经被政委了。为什么?第一,最近五年的 top, 呃, top paper 或者是这个 q e 的 这个刊, 大家没有人用它,所以我们不需要讨论。第二个问题,就是说最近呃的高级钢琴选那本书上也已经认证了,就相关性,它只影响系数大小,它不影响系数的显著性和正负号,所以它对我们来讲不重要。呃,具体大家如果呃有什么不懂的可以随时私聊我。对,说一下来问我。对, 然后这个就画图,画矩阵的散点图,对,然后这个就直方图的命令,其实就是英文单词的缩写嘛。对,然后在这里会会有 b i n 是 以主数就牛,要划分为几组,这个宽度也就是主句,然后这是它的平数。对, 然后这是核密度图,这是我们最常用的三三个图,一个是散点图,一个是直方图,还有一个是核密度图,然后散点图看到没?如果我们要把散点图和礼盒图放在一起的话,我们就说是看的,然后两边的 left 就 礼盒子看到没有? 那紧接着我们来去去去就说到这个回归了,比较简单的回归,那回归大家可以看到, ok, 回归后面跟被解释变了,解释变了条件,条件就是用 if 函数来表示的权重选项,大家可以看到,对, 然后条件权重这里有。 vce 是 均位文件标准物, l e v e l 就是 自新度区间贝塔这个系数,这个是无场就没,没有,没有,那个不设定那个常数项的一个, 呃,因为我跑出来的时候很多时候是需要有洁具的,但是,但是大部分就少部分情况下,我们又不需要有洁具,那不需要有洁具的时候,就你就直接加 no constant 就 ok 了,好吧,但这种情况很少,但是不排除大家不用它,有时候大家会做 topic 模型啊, ok, 那 就是需要无洁具的这个回归模型了,然后这时候我们就需要在后面加一个 no constant 就 ok 了,好不好? 然后紧接着我们来去看下面,这里有检验结果,具体的这个检验结果 这我就不多说了,因为我们写 paper 的 时候确实用不到它。对,然后这时候还有还有最关键的就是我们要把这结果直接输出入呃, word 或 text 里面,所以我们有两个导出,大家一定要去看一下,有两个导出命令啊,一定要记住。 呃,有两个导出命令,一个就是这个 e s t, 那 还有个 out rank, 两个都可以,有没有优劣势之分?你看。然后我们来去读一下这个结果,首先我们要去这个是它原声带的这个这个这个结果,那我们直接去研究呃, mpg 和 ip 七八对价格的一个影响,然后这是结果, 这就是一个回归面板的,对,这是一个回归的几个结果的这个三个区域,大家一定要去记住,这就我们回归结果,就这三个区域的结果,这个是,呃,这个 ssr, 呃,还还有 d f dfr 的 这个结果, msr 的 一个结果,然后它是算 f f 值的和这个 square 的, 然后这里你看就就具体的 square 的 和调整的 square 的, 还有这个 mse 的 值。然后这个就是我们具体的系数,第一列是系数标准,它 t 值 p 值百分之九十五的执行度区间。对,那我们来去看一下命念解读,这里都有,大家如果有需要的话可以私聊我。对, 然后这就是他的回归结果的方方程了。但是我们写配报可不能这样去写,我们写配报是需要导出命令,导出到这个三线表,就比如, ok, 我 来给大家去解释一下,就用这个,我们这个导出命令,其实是是这样的,看到没?这是我们回归结果,其实我们只需要阿芳和 n, 亮不亮?好吧?大家有什么不懂的可以私聊我。
 00:51查看AI文稿AI文稿
00:51查看AI文稿AI文稿nasa 平时在本地用的挺顺手,但一到异地就很难直接访问。其实装了内网客户端就能解决。客户端连接后会自动创建一个虚拟局域网。 nice 就 能被外地电脑识别成内部设备, 你在不同城市也能像在办公室一样打开共享文件夹。接下来只要做一件事,像这样设置一下,把 nice 要共享的目录设置一下,远程挂载,挂载成功后文件拖动复制,搜索 编辑速度很稳定。做设计的能开大图,做行政的能直接改 excel, 做项目的能看历史文档,不用再反复传来传去。 如果团队多人协助,还能给他们设置不同的查看权限。管理层可以局访问,还能查看历史版本,备份文件,特别安全。整套方案流程简单,效果稳定。我们也准备了完整的 nice 地访问教程,跟着步骤设置,一次就能跑通。
15文件共享管理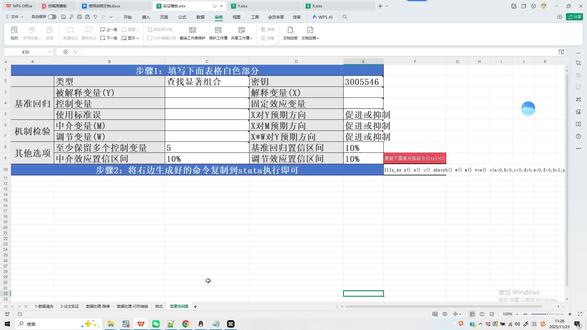 04:1313假如计量会说话
04:1313假如计量会说话 01:33查看AI文稿AI文稿
01:33查看AI文稿AI文稿不转格式不生成,查看 stp 一 身轻,怎么我一打开 stp 文件,它就生成一堆子零件啊?你这样查看 stp 文件, 电脑文件夹都要撑爆了!今天教你一个只看不动的好方法。平时直接用软件打开 stp 文件, 软件会自动把它转换成 prt 格式,连带里面的子零件也全部分解出来,跟解压压缩包似的,一堆文件乱糟糟的,明明只想单纯查看而已, 这时候换个思路就行。先新建一个空白的建模文件,再在这个空白文件里用导入功能打开 stp 文件。 选好要查看的 s t p 文件后,重点来了,在对话框下方找到展屏装配选项,把它勾选上,再点击确定。 这样操作之后, s t p 文件就不会以装配形式散开,而是以多实体的样式完整展示出来。 而且不管文件多大,都不会在文件夹里生成多余的 prt 文件,查看完直接关掉就行,超清爽!当然,缺点也很明显,每次查看都得重复,这个步骤花费的时间也一样长。 不过话说回来,这不正好适合摸鱼,也算是另一种意义上的优点了。
198吾思UG知识分享君 02:41查看AI文稿AI文稿
02:41查看AI文稿AI文稿大家讲解一下,呃,我们如何去计算这个贸易便利化以及这个。呃, gvc, gvc 和贸易便利化的这个, 这个这个计算方式啊,基本上是差不多的。对,我不知道大家有没有了解这个,呃,了解这方面就是关于贸易便利化和还有这个全球价值链, 嗯,基本都是用主成分分析法和因子分析法。对,那么今天我我将以这个贸易便利化来给大家讲解。第一个课就是贸易便利化的这个理论部分。 首先大家可以看到的贸易便利化我们最明确定义的就是在国际贸易中存在需要对货物流动的数据进行手机传递以及处理的过程中,贸易化便利化就是对这个库存涉及的这个行为管理和手续进行简化和 协调,其也就是对这个贸易数据的一个优化协合作。那么贸易吧,贸易便利化简称 rca, 记住大家一定要记住贸贸易便利化的这个是简称是 r a c, 然后 g v c 是 全球价值链。对,那么大家可以看到这它其实是没有一个共共同的一个定义的,但指标没有一个标准的一个指标,但是大概有这四个方面和四个方面分别是效率、海关环境 environment、 over retail environment 和 e。 其实 e 就是 电子啊, e, business using, 然后这四个二级维度,然后再加上八个二级指标来构成的。当然也有人去把它作为商值法去计算,其其实做商值法计算的还是比较少的,我们来看一下它指标构成,大家可以看到对,这是主要的一些指标。 那我们最后最后怎么来去测算呢?大家先可以看到我,因为我这个是以 r c e p 十五个,这个十五个成员国来计算的,对,然后考虑到二级指标,哎,首先我们要进行标准化, 标准化完了过后,我们就开始进行巴特勒和 k m o 值检验,大家可以看到,呃,巴特勒和 k m o 值,尤其 k m o 值要大于零点七以上,呃,至于呃,如果你要全部大于零点,其实有时候是不现实的问题,尽呃就是尽可能大于 k 呃零点七以上吧。对,这就 k m o 值的一个结果, k m o。 就 结果确定完了过后,我们就去做左方差啊解释左方差解释我们就可以去得到一个因子,提取几个因子,其实大家可以看到,哎,这里我们其实可以在这里可以看到,最小的是零点六八八,最大是零点九六二,所以它的整个公因子方差是在零点八以上。然后左方差解释在这里看到没有,提取了两个因子,两个因子它的这个解释程度可以达到百分之八十六 啊,其实这已经就符合我们的标准,其实我们标准是百分之七十五以上,就对,这个结果就 ok, 就 说明两个因子就足够代表这十六个指标。那从这时那我们再看溯溯图,看到没有?溯溯图大于一以上,大于大于一以上的这个只有两个点,所以我们就只有两个,取两个因子就好了,然后这是我们具体的因子得分。 对,然后这时候我们就开始进行计算,看到没有,这就计算,计算贸易便利化的一个得分,对,计算完了过后,我们就正常去做呃时政分析了,然后大家可以看到这就 rca 的 这个计算,对,时政分时政的一个过程。好吧,大家有什么不懂的可以问我一下啊,下节课去呃,具体的用数据来去给大家去展示我们如何去做 rca。 对。













猜你喜欢
- 107一碗