sqli-labs靶场怎么才算通关

粉丝1.5万获赞2.6万
相关视频
 03:32查看AI文稿AI文稿
03:32查看AI文稿AI文稿今天看一下天书的第五关,先启动服务,审查代码,这关和之前的不太一样, 飞蛾还是单引号,但是你不管输入什么都是报意外,意女 错误,就没有回血了。添加个额外条件测试 合理就回血了, 然后一等于二不合理就没有回弦了。 因为这里没有办法从回险看到数据库的名字,所以我们 使用兰卡函数查看长度,出入九没有回显说明不合理,就是超出了换乘八有回显,说明数据库就是八个字的长度。 然后我们通过 asci 码表来一位一位进行爆破, 这里也就是第一个字符对应的数字是 s, 数字是一百一十五,换成其他数字就没有回血了。 然后看第二位变成啊,以字符示意对应字母一百零一才会有回显。 然后我就不守错了,直接上脚本 a s、 c r 码表逐次爆破, 打开拍场, 构建 plot, 进行逐字爆破,队上有回险没,队上会继续核对下一个 开始跑脚板 到数据库名,然后因为没有回显,所以看数据库里是不是有表存在,存在我们已经知道有四个表示是大于五,没有回显,所以大于零就是有存在。 然后我们还是上脚板去西克尔气库逐字爆破,表明直接开始跑就行了,跑两个就平了,脚本很慢,耽误时间, 带两个表就可以了。然后去 us 表里对字段还是一样乱起来, 爆出自断,还是展示一下就行了,脚本太慢,再来就是竖 数据爆破,还是展示一下就行了。以上就是天书第五关了,下课。
30X. 01:3571国信安教育
01:3571国信安教育 02:22查看AI文稿AI文稿
02:22查看AI文稿AI文稿上期教大家搭建了 cco 天书,今天教大家闯一下第一关,还是先启动外服务和数据库服务,打开网站开始准备闯关, 选择第一关,还有的人看不懂,台下翻译。 拿到这个之后,我们先去看看元马,元马是破解的关键, 这些前端的代码不用看,只是一些 c s s 样式。找到关键的 c 口语句, 发现这里是单引号,闭合的参数在二,我输入 id 等于一,发现直接进去了, 然后我们加上单引号,验证一下闭合方式,这里吸口语句报错了,验证了带马力的逻辑。然后我们来联合注入,查看一下数据表有几列 正常危险,说明在数据库列的范围之内。我们改成四,发现报错说不知道这一列,看一下数据库是不是只有三列, 确实只有三列内容。然后我们使用 data 被参数和弯神查看一下数据库名称以及版本,通过联合注入我们确实查到了。拿到数据库名之后,我们就可以通过 来西过的系统库查询他这张库有哪些表,可以看到数据库确实是这四张表, 因为之前拿到了表,我们大概率会去他的优泽斯表看账号密码这里去四 k 二七库的优泽斯表查询他的字段内容也是跟数据库对应的, 现在根据自断名再去查询数据库里边用户的账号密码, 中间使用了双数线加 id, 方便区分,成功爆出了 usb 的用户信息,下课。
30X. 06:19查看AI文稿AI文稿
06:19查看AI文稿AI文稿它主要是介绍了一下这个 l l m 的这些大模型跟 c 口之间到底是来怎么来处理的,看看这个大模型能否跟 c 口就是关系型数据库,通过标准的 c 口语句的执行,看看能不能让那个大模型可以获取到关系型数据库里面的这些信息,准确的去回答 一些用户的一些提问。好,那么在蓝签的这个 library 里面,它有多个签的这样的一些关系型数据库, c 口的这样的一些支持,它主要是有两个,一个呢叫 c 口签,还有一个呢就 c 口 langing, 呃,它这个 a p i 里面它有这样两个对象,是专门处理 l l m 大模型跟关系型数据库之间的这样的一个操作的。那么我们这篇博客主要是讲这样的一个问题的,我们清楚是在企业大量的数据是存储在 e c 口的这样的一个关系型数据库里面的这些数据也是非常有价值, 甚至有些企业还是通过工具能够很方便的去查询这些相关的一些数据和信息,他的也是这样,但是毕竟这种关系型数据库或者数据仓库,他还是要通过要懂一些 c 口的这样的一些语句,你才能去操作的。那么你有没有一种通过自然语言 能够直接的去调取这个 c 口数据库里面的这些数据,那么他这篇文章主要是讲这样的,那当然这个答案肯定是肯定的,那关键是我们是怎么做。首先他这篇博客里面也是介绍了目前这个 l、 l m 的这些大模型去写这些 c 口语句,他碰到了一些什么样的难点?他这样 他其实还是碰到了一些比较大的一些难点,就是什么难点,他主要讲了这三个,三个难点,第一个难点因为我们知道每个企业的那个数据库,他的那个表结构啊,包括他那个环境都是很个性化的,每个企业他的那个命名包括描述都不太一样, 所以你要通过相同的自然语言去查这些数据库,他其实是有困难的。那么他的这个解决方案是什么?他这边也讲了一下,那么你需要给行的这些 l、 l m 的模型,他要一些背景,他的这个背景的话呢,主要是一个创建这些表的这些 作为一个输入,包括你对这些数据的这个查询出来的这个样子, select 出来的这些语句,这个就是它的,相当于是你跪给这些 l l m 的这些大模型的这个 context, 类似于这个 背景啊,它等于是这样,有了这个背景,有了个性化的表的这个音风 mation 之后,它就可以通过这个 l m 的这些大模型,它可以生成各种各样的语语句出来,它是等于是通过这种方式去实现的。另外一个问题是在于什么呢?这些大模型它有可能生成出来的语句,它的语法或者是是有些错误的,它等于是这样。所以 我们有可能需要有一个工具或者有个函数要去检查这个 c 口能不能执行准确,他得所所以连签呢?他是提供了这样的一个 c 口 check query, c 口 check 的这样的一个工具,方便我们去检查。如果他发现有一些操作是错误的话,那么他就会提示出来, 提示出来之后,他还会让这个 lm 的这些模型去改正他这个错误,他等于是这样,通过这种反复的检查,反复的思考的这个方式去把这个 c 口语句生成对,他等于是这样,那么生成对了之后,那么他就可以去查询了。我给大家举一个例子,我们来看一下。 我这边也有一个模型,就是 chat g l m 杠六笔,他其实也是可以输出 c 口语句的,我主要是通过中文,你知道根据上述表结构语句查询,他就是查询了这个,他就根据这个上述的这个东西,根据我的这 自然语语言生成的这句 seek。 对,是这样,所以现在这种 l l m 的这个大模型,因为都已经被微调过了,所以它能够生成这些 seek 的语句的。当然这句 seek 语句生成之后,它其实也是要经过它的这个 double check, 要检查他这个语法到底对不对,如果他这个语法不对,他还是可以根据输出的这个语语法的错误再进行修正,确保他这个自然 语言能够自动的获取到我们这个关系性表结构数据库里面的这些准确的这些数据。他等于是这样。呃,连倩他也提供了这样的一个 zampo 的例子,我们可以看一下他叫 cico chen 的 zample, 他这个例子就是给大家做了一个演示怎么样操作这个数据库, 对,是这样,这个是 d b, 它用了一个叫 circle light, 当然你这个输的支付串不一样,你也可以用 mysicc。 嗯,然后它用了一个 oppo ai 的一个 l l m 的这个大模型,它把这个两个结结合起来, 然后生成一个 cycle database 的连签,然后他就问他 how many 对吧?这个这个这个这个雇员一共有多少个雇员?那么他就可以从通过这个数据库里面的这个准确的这个数据去查询, 查询出来是八个,然后他说八个,这个这个是个例子,如果你要做一个 check 的话,他以这个地方也是可以做一个 check 的,他这个地方 user query check two。 当然你这个地方也是可以用自己的自定义的这个模板,他叫提示,提示你也可以用自己定义的,那你这个地方就是一个提示模板,他这个是 default input 音破的就是问题。 table 音 four 就是这个表结构的那个 create 语句,就是我前面给大家看的这个表的这个结构,它也是可以一步一步的把它给记录给打打印出来,它内部到 你是怎么操作的,他也可以把它给输出的每一步是怎么做的,他也是可以去输出的。当然你他这个地方也是可以说你可以返回找条记录,有可能他这个记录比较多,你可以返回三条的,这个就是表结构的类型,这个就是他的,我给他贝斯的这个 secret 那个券,他到底是怎么处理?他主要做两步 一步的话呢,就是是基于这个查询确定哪一张表用,然后根据这张表生成这个 c 口部去查这个数据库,他等于是这样他也可以使用 local 的这个 language, 他也是可以的。所以的话呢,我们看到这个 lanchen, 他这个功能还是非常强大的, 他通过这个框架他就可以把 m 的这个大模型跟我们的那个关系数据库进行结合,去准确的获取一些有价值的这个数据,结合我们的这个场景去回答用户的一些问题。大概是这样,那么对我们 使用者来讲,他就不需要懂太多的那个 sico 的语句,他直接推通过自然语言,那 l m 的这个大模型自动的会帮他把通过这个自然语言可以翻译成这个 sico 的这个查找到数据库里面去检索出这种内容,检索出来的内容之后再结合这个模型去回答用户的一些问题。 好,所以这个功能也是非常强大的,所以我们看到就是 oppo ai 的 chat g p g 类似的这种 l l m 的大模型的话呢,它的用途是越来越广泛了。好,今天补课我就跟大家就介绍到这。
693小工蚁 02:21查看AI文稿AI文稿
02:21查看AI文稿AI文稿这段代码呢,可能天天在写,以一个负循环,循环里查一下数据库没毛病吧?我告诉你,这玩意儿可能让你当众射死。我第一份工作就因为这个,一秒钟发了两千条 c 库,数据库直接挂了。 技术总监当着全组人骂了我二十分钟,什么代码这么狠?就是一个查用户订单的接口,先查出用户列表,然后 for 循环,每个用户在循环里查这个用户的订单代码跑起来没问题,功能正常,我还挺得意,结果上线当天就炸了, dba 跑过来问我,你这接口怎么回事儿? 一秒钟两千条 c 库连接持都被你耗光了?技术总监把我交到会议室,问我知不知道什么叫 n 加一查询。 我当时一脸懵,心想我写的明明是一加 n 啊,先查一次用户,再查 n 次订单,怎么就叫 n 加一了?后来才知道,这就是经典的 n 加一查询问题,新手必踩的坑,面试必问的题。什么叫 n 加一? 你先执行一条 c 口,查出 n 条数据,然后对着 n 条数据,每一条都在执行一条 c 口,总共就是一加 n 条 c 口, n 是 十,你就发十一条, n 是 一千,你就发一千零一条。数据量小,看不出来数据量一大,数据库连接池直接被耗光,整个系统跟着挂。怎么解决?第一,用 john 把两张表关联起来,一条 c 库搞定。但 john 也不能乱用,表太多,数据量太大反而更慢。第二,用 in 查询, 先把所有用户 id 收集起来,然后一条 c 库加 in 条键,一次性查出所有订单,最后在内存里组装 c 库,只有两条,性能好很多。第三, my bodice 可以 用批量查询。 my bodice plus 有 selected batch ids, 一 次性搞定。第四,上缓存,数据不常变的话,先查缓存,没有再查库。 核心原则就一条,能用一条 c 库解决的绝对不要用 n 条。我后来养成习惯,写完代码一定打开 c 库日记,看一眼 这接口到底发了多少条 c 库,循环里有 c 库,立马改掉。现在很多公司代码审查,看到否循环里有数据库操作直接打回,不用解释。所以记住否循环里面别写 c 库, 这是写的教训。我是程序员 mike, 十年 java 老兵,当年那顿骂记了十年。今天分享给你,希望你别踩同样的坑,关注我,少走弯路。
309程序员Mike 19:54查看AI文稿AI文稿
19:54查看AI文稿AI文稿本视频共计二十分钟,带你一口气吃透 my skill 重点面试题, ctrl 一 ctrl 先 ctrl 念名的区别那我们来看一下这道面试问题啊。呃,我相信有同学,呃经常在公司里面啊,做开发工作啊,呃,你们的 leader 或者说项目经理会说啊,我们要尽量用 ctrl 一, 对吧,不要用 ctrl 星啊。那我可以告诉你啊,这其实是一种误导啊, 我们来看一下为什么这么来说啊。首先待会其实你要知道啊,这三种啊,就统计方式啊,他们呃的结果到底有什么区别啊?那首先大家要知道, count 一 啊,它实质上是统计表中的 行的数量啊,就是它是包含所有行的,不管你知道行中是什么值,比方说是 l 值还是非 l 值,它都会统计。那其实它统计的结果我告诉你啊,跟 count 星是一样的,没有什么太大区别。 count 星也是类似的啊,它也是统计所有行的数量 啊,包括所有列啊,就是呃,就是不管你这个列值啊,它是否围绕值,它都会统计。也就说白了, counter 一 跟 counter 星,它的功能它的结果是类似的 呃,而且我告诉你啊,它们俩的性能其实是差不太多的,特别说,比方说你用 my circle 啊,用的是这种 indo d beta 这种隐形啊,其实,呃, counter 星, 甚至它的性能会比 ctrl 一 还要高,因为 macos 在 底层啊,特别 intel d b 的 存储引擎啊,对抗核芯做了很多优化啊,所以我们更推荐大伙儿如果你用的 macos, 又用的是 intel d b 的 存储引擎,更推荐大伙儿去用 ctrl 七二来统计所有的行数 啊,所以这是很多可能呃,你在公司里面开发,有的同事跟你说啊,尽量用 control 一 一啊,不要用 control 星啊,当然,呃,这种情况你要看数据库啊啊,就是至少在 microsoft intel d b 存储引擎下面啊。 control 十二它的性能可能比 control 一 它的性能更高啊,所以其实你用 control 星 control 一 其实差不了太多啊,所以不要被再被误导啊。 那然后我们再来看一下 control 之段啊,那 control 之段它稍微有一点点区别在哪里?就是呃,它主要是统计我们嗯列里面的非 lo 值的函数, 也就说白了,如果说你现在有十列里面有两列它是绕值,它是不会统计的,也就你通过 ctrl 这一个置断得到结果就是八 ok, 所以 它是呃就 ctrl 置断啊,这是它跟我们 ctrl 一 和 ctrl 新的典型的区别。 ok 啊,这个大伙要知道它们的结果级的区别啊。那其实就我们来看下性能对比,就我们刚说的 ctrl 十二和 ctrl 一 其实差不了太多啊,很多数据库其实对 ctrl 十二它是做过一些优化的,因为它们两个性能差不太多的,其实 我们刚说了,如果是买收口 intel d p 纯正型,推荐你更多的可以去用 ctrl 键啊。那然后我们说的 ctrl 呃至断的话,它性能肯定会慢一些,为什么?因为它需要便利每列数据,它要看你是不是落值,你不是落值,我要把它排除掉, 那所以它的性能肯定是不如 ctrl 二和 ctrl 一 的啊,这是大伙儿要注意的。那以上就是我们说的这几种 ctrl 类型它的区别所在, 买收口的深度分页如何优化?我们来看一下。正面是问题啊啊,首先待会要知道买收口深度分页的一些问题啊,其实说白了就当你的偏移量也 offset 比较大的时候啊,它整个的查询性能会有显著下降,因为说白了买收口底层啊,它会做大量的扫描啊,以及跳过大量的行,它才能够查到你所想要的偏移量, 对吧?那这里面它始终是有大量的磁盘 i o 以及内存消耗,它会严重影响我们的性能啊,那它的一些优化手段啊,主要有这么几种啊,第一种我们可以基于组建或说唯一锁影做优化啊,什么意思?其实就是呃,比方说你在呃上一次查询的时候,你可以把你查询的结果级的最大的那个 id 值把它记录下来, 那我们下一次查询的时候怎么做?我们其实只需要通过先用 id 值跟你上一次查询的结果集的最大的 id 做一次比对,先把一些数据过滤下来,对不对?也就把过往数据过滤下来,然后干嘛再加上你那个分页的限制,那这样的话时常就能减少很很多数据的扫描。 但但但是这种情况大伙要注意啊。呃,它它需要你的数据,也就你的 id 数据,它是连续并且唯一的至真的点, 这种情况才适合。 ok, 其他情况不是特别合适啊。那然后第二种情况就是我们可以通过只查询来做优化,什么意思?就是大伙可以看一下啊,我们可以先比方说我们要查第五十页的数据,对不对?我们可以先通过这么一个只查询, 注意这个只查询我们只查每一行进入的 id, 那 这样的话它扫描的数据量就会小一些,对不对?最终再拿到通过只查询拿到我们表里面,把这十条 id 的 数据给它全部查出来, 那这种方式的话,它其实在性能上面也会比你直接去分页查所有的行的记录,行的所有列数据会稍微高一点 啊,这也是一种优化方式啊。那还有种方式就是我们可以通过覆盖锁影去做优化。什么意思?就是,呃,你在这边去 select 新的时候,你自己去简从业务的角度去思考一下,我是不是需要把这一行的所有记录都查出来?如果不需要,我们尽可能的减少我们查找的那个字段数, 我可能只需要我这一行可能十个字段,我可能只需要查三个字段,那我可以怎么做?那如果这三个字段恰巧都是我们所引字段,那说白了它就是我们说的覆盖,所以嘛,对吧?那你查询的话,你只需要扫描我们的,所以就完事了,它是可以减少我们的回表查整行所有 质段数据的次数的,那他时常在性能上面也是能够得到一定提升的。这我们说的覆盖所有的优化机制上,那还有种其实就我们说的缓存优化机制,但是这种方式可能用到的机会不是特别多,因为他有些前提条件就是需要你 数据变,就是你的数据变动不是很频繁,而且每次查找的结果集要又又达到一定的程度,对不对?如果你缓存命中率很低,没有意义, 对不对?那这是我们说的缓存这种机制啊,他是要看你的业务情况。那还有一种就是我们可以呃,就是根据你的业务情况来做一些优化,比方说呃,有的有的系统啊,他可以提前的,就他的,当然他前提也是你数据量变动不大,这种情况下你可以提前的, 对吧?把一些数据查到我们前端缓存起来,那这样的话,你后续呃,你再去查的时候,你实际上只需要在前端 你的缓存里面去过滤数据就行了,不需要到后端来去查啊,那这也是可以提高我们整个系统性能的。那那当然这种情况你要就我们说说,你要试你的业务允不允许,对吧?而且你的数据变动,你后端的数据的修改啊,变化其实不大的情况下面才能用这种 方式,也就提前我把很多数据啊,我查询好放到前端,然后在前端做涨分页啊,就这种情况也是一种优化的方式。那还有种就是我可以从业务的角度啊,限制你最大查询的页数, 对吧?比方说你一个用户,他一直往后面去分页,一直往后面去翻页,那其实你你思考要从业务角度,你翻的翻了几十上百页之后,后面的数据还有意义吗?其实大多数业务场景下面那些个数据其实没有什么太大意义的,那么其实就可以从业务角度去做一些限制,比方说你可以提示他,比方说翻到了第二十页或者第五十页,第一百页的时候,你可以提示他, 当然这个要根据你的业务情况来定啊,你可以提示他数据太旧,货已过时,请重新查询,或者说你输一些过滤条件给他这样的提示,那这也是可以从业务的角度去优化我们整个系统性的 啊。以上就是我给会列的几种情况啊,分库分表后如何进行跨库卷,我们来看一下。这方面是题啊。呃,其实,呃,说到跨库卷啊,我们大多情况下面都是非常不推荐的,因为大家都知道跨库关联其实性能是非常差的, 对吧?所以其实我们很多时候在做分在分分秒的系统啊,一定要从设计层面就要避免跨库关联查询啊,当然,如果,当然也不是所有情况,对吧?都能够避免的,可能有些情况他就是要跨库关联,怎么办?好,我这里提供几种方案啊 啊?一种我们是可以在应用层面啊,就在你的 java 应用层面啊,做一些关联,也就我们实际上是在多个数呃,分库里面拿到数据,最后再在 java 代码里面做组装,做排序,做结果规定 啊,那这是一种方案,就我们可以在应用层面啊去去做一些结果的整合,那当然啊,第二种方案是我们比较推荐一点的,我们可以做一些数据领域的存储,对吧?比方说,呃,我们有一个订单啊,订单数据库和一个用户数据库,那有的时候我们在查订单的时候啊, 订单里面有一个用户 id, 那 我们可能展示的时候希望把用户名眼展示出来,那这时候如果说你在订单里面只存了一个订单 id, 那 意味着你查询的结果,你要关联一下用户库里面的 数据,拿到用户名,对不对?那这时候如果说你在订单表上面啊,你涌余了,也把用户名涌余进去了啊,哎,那你这时候你就不用再跨库查询了呀,你就查订单库就有结果了,对 不对?那这是我们说数据涌余是比较推荐的一种方案啊。那然后,呃,对于一些中间件啊,它实际上原生就支持我们说的跨库跨表关联查询,比方香菲尔、 my cat, 对 吧?他他们其实也是在多个库里面查到结果,然后再帮你把结果规定整合, 对吧?过滤啊,只不过这些事情他是在中间店层面帮你已经做好了,我们前面说了,应用层面去做,实际上是我们自己去做,对不对啊?如果你用中间店,他会帮你去做,但是我告诉你效率也不会很高啊。 那还有一种方案就是你可以用数据数数据仓库,也就是说白了你可以把很多很多数据啊,都抽取到我们一个大的存储的仓库里面去, 我们对于这种需要跨库跨表关联的查询都走数据仓库,那这样的话他就不存在什么啊,就跨库关联这种问题了。那这也是很多大型的公司啊去做的做的方案之一啊。但是,但是你要知道你加了数据仓库的话,干嘛你就有额外的系统啊,以及运维的运维的成本啊, 对吧?所以这种方案一般是大公司才会去做啊,中小公司一般不会这么干啊。那然后啊,还可以用像缓存啊,对吧?就是,呃,就是对于一些跨库挂表关联的结果啊,如果你能确定这些结果的,呃,关联的数据如果变基本上不不怎么会变动的话,干嘛?你其实可以把结果缓存起来, 对吧?这样的话你下次查询就不用再去跨库跨表关联查询一次,对吧?减少了我们整个系统的查询呃的计算负荷, 对吧?那这也是一种方案,那当然,我说我,我这边也说到了一些风险啊,啊,很注意事项,就我们说性能问题,对吧?我们刚说应用层面啊,你去做跨库跨表关联查询,虽然能实现能得到结果,但是说白了他肯定在性能上面不会很高,对 吧?你想从多个数据库里面查到结果,再统一集中到我们应用层面,应用层面还要做各种规定排序、过滤,那肯定性能不可能高,所以我们一般是说白了不到万不得已不这么来做,一般都要从表里分公分表做设计的时候尽可能 呃的把啊路由键,对吧?或者说分库的一键设计好,避免跨库跨表关联查询,这是最好的方式,那其实我们刚说的对一次性他也是有一些风险的,对吧?比方你做数据总与我们刚说的,你把订单库里面存了一些用户的信息,对吧?那你如果说用户信息变了, 对吧?你是不是还要改一下那个订单库里面相关的信息啊,对吧?那你就要注意维护好数据的一致性,如果你忘记修改,那数据就不一致了, 对吧?那然后还有就我们说的复杂性,就这就我们刚说的,如果说你再搞一个数据仓库,对吧?那这个不是一个小系统啊,对吧?就是他可能需要专门的人去做这件事,可能还有单专门的运维,对吧?这其实带来额外的研发成本啊,这是你需要考虑的。那当然我这边也写了几个最佳实践啊,就是,呃尽量的减少这种跨库的 操作对不对?包括我们的在数据设计的阶段,我刚说了,比方说你做分库分表,你在那个呃分库分表的路由 k, 对 吧?拆分 k 的 设计的时候,你就要尽可能考虑到我们最频繁查询的那种业务场景, 在设计分库分表的时候,就尽可能要规避这种跨步跨表的课程查询。当然这里面我可能今天没办法去举一些实际的案例啊,我之前有专门的那种分库分表的一些实战案例的课程,或者大伙儿如果想要,到时候评论区打个六六六,找找 up 主去领取一下就行了 啊。那当然对于这种情况我们肯定要做一些持续的监控,对吧?比方说如果说跨跨表关联查询很慢的话,我们肯定要监控持续的做优化啊,那这就我们关于分布分表后,我们做跨跨关联查询的一些啊方案以及注意事项。 买蛇口中耐克蘑菇查询如何优化?我们来看一下这个问题啊,就是呃正常情况下面啊,我们很多同学我们可能会用耐克做蘑菇查询,对不对?那比方说像这蛇口语句啊,如果你是这么来写的话,刚好这个 your name 有 缩影的话啊,这是我们比较推荐的一种耐克蘑菇查询啊,它能够很好的利用我们的缩影。 那如果说啊,你现在有个需求啊,你希望把百分号写在前面啊,那这种模糊查询的话,即便你这个 url 这个字段有缩影的话,它也不会用缩影,它会全标扫描,那这种对我们整个的查询性能肯定是有很大影响, 那这种方式有什么优化手段呢啊?我提供几种方式啊?首先,呃,这边这边有一种叫反向缩影的优化方式,什么意思啊?就是,呃,我们可以对你这个字段啊,又比方说我们刚说 url 字段啊,你把它的所有存储的这个制服啊,做一个反向,再存另外一个字段, 比方说你这边是这个时段是转,对不对?那我可以再存另外一个时段,叫 n h o j, 把它反过来再存另外一个时段, ok。 那 我如果说当我要在查正常的这种需求,我要在前面加百分号的时候,那因为他没办法很好的走缩影,对不对?那我可以,那我就可以在另外的那个时段,哎, 用这个时段来去查询,在他的后面加百分号,对不对?那这样的话,这个时段,当然这个时段,这个溶于的这个反向的呃锁影的时段也是需要加锁影,那这种情况的话,他只要是可以走锁影的, ok。 但是这种方式呢,我们也不是说特别推荐啊,因为这种方式的话,你想一下你是不是要多维护一个时段, 对不对?包括这个时段如果说有真删改查操作的话,你这个时段是不是也要对应的做维护?其实没有那么方便啊?那其实我们经常说到的,对于,呃你的百分号,如果,如果说要放在前面的这种模糊查询啊,我们更多的如果你真真的想优化这种情况,我们更多的推荐你可以通过一些搜索引擎 对,比方说像 e s 这样的一些受限型去做,可能会更加方便一点啊,那这也是一种关于模糊查询的优化手段啊。那还有就是我们如果说在做模糊查询的时候,因为模糊查询它可能要匹配很多数据,数量会比较大,对不对?那我们要尽可能的缩小它的一些搜索范围哎,比方说你,你这边做了一个模糊查询对不对?你是不是还可以加一些其他的时段, 把我们的查询的范围尽可能的缩小一点,那这也是能够提高我们性能的。那然后还有一块啊,对于一些呃查询结果啊,如果说它的 呃查询比较频繁,然后它数据的变动又不大的,就它的变动不是很频繁,也就这种情况啊,你其实可以通过缓存来去做的,比方通过 release 把一些经常查询的结果缓存起来,因为它变动数据的变化不是很频繁的话,那其实是可以利用缓存,对吧?只要它命中率 呃,还 ok 的 话,我们其实是可以通过缓存来提高我们整个的查询效率的啊。那以上就是我们经常说到的,像 mac 啊,就是支持耐克模糊查询,你可以做的一些优化手段。 阿里开发者手册啊,为什么禁止超过三张表转啊?那我们来看一下这道面试问题啊,那其实在很多大型的这种供暖公司啊,他的系统病发比较高,数量比较大,一般都是不太建议啊。啊,就是 频繁的使用超多表的关联啊,特别是超过三张表的关联啊,这个是在阿里巴巴的那个开发者手册里面是有明确规定的啊,那这里面的主要涉及到的一些原因,还有就是从可维护性啊,还有就架构设计上面那些 思考啊,那我们来分别来看一下,比方说呃从性能上面思考啊,因为多表关联啊,它就是呃底层是需要有非常复杂的计算的,如果说大伙了解过像表关联之间它底层的执行流程,你就知道啊,它呃表关联,表连接,它底层有大量的哈希连接,包括各种合并连接, 它的整个的计算开销是非常大的,所以其实多表连接它对我们整个的性能开销是有很大影响。那还有一块就是资源的消耗啊,那其实在多表关联的过程中啊,底层啊,它会有大量的内存, cpu 资源的消耗,特别是你的表,如果比较大的话啊,就是比方说有 五六百万,好像甚至千万级别的这种表的话,它底层当你在做关联的时候,它会有大量的内存以及 cpu 资源的消耗啊,我当我们说的是多表,比方超过三张表以上的这种情况,那还有一块就是锁影依赖啊,那对于多表关联啊,如果说呃,你在关联的过程中啊,锁影如果使用不当的话,其实你整个的性查询性能会非常低 啊,就这这条车口就会变成非常慢的查询啊,那这主要是从性能角度去思考啊,那还有一块就是从可扩展性啊,那呃,大伙如果说你有做过那种分库分表的系统的话就知道啊,如果说你做多表关联啊,那很有可能你的这个查询结果的数据啊,会存在多个节点上面, 那意味着你这个关联你做精准操作就会跨多个节点去取数据,那也会导致我们呃大量的数据在多节点之间的数据传输,那会严重的增加我们系统的负担啊。那包括你做数据分片也是一样的,就是你的数据可能落在多个节点分片上面,那整个我们的查询效率是非常低的 啊,那这是从可扩展性的角度去思考,那然后还有一块,就我们说的那个维护以及复杂度啊,那大家知道如果说你的呃 小关联比较多,就一条烧烤鱼就非常长的话,那其实整对后来的开发者,他的维护成本是非常高的啊。那包括如果说你这条烧烤鱼查询的结果有问题,或者说查询性能有问题,你真的要去定位问题以及解决问题,其实也是非常麻烦的。 那这是从我们说的维护以及复杂度的角度去思考,那其实还有就是我们可以从架构的设计的角度去思考一下,比方说你们公司如果做呃领域模型的这种架构的话,那你多你这种多表撞其实也会有影响,对吧?因为呃你的领域模型往往都是单独的一块,那你多表 关联的话,往往会把多个领域模型全部关联在一起,它其实跟我们领域模型设计上是呃背道而驰的,那包括像微幅架构的这种设计思想,也是 呃跟他是相冲突的。比方说我们一个电商系统,那拆了十个微服务,比方说有订单微服务、有库存微服务、有用户微服务等等,有很多,如果说你一条是否有据,你一下查了七八张表,对吧?涉及到五六个微服务,那这其实也是跟我们微服务架构的设计也是相违背的, 那从架构设计上面其实我们也是不建议太多表关联啊。那当然可能有同会问,呃,那,呃如果说我不多表关联啊,我在业务开发过程中啊,可能要呃写很要要要做很多复杂的操作, 对不对?那确实是这样,在一些大厂如果对性能要求非常高的场景啊,那确实是有这种情况发生。但如果说你是一个小公司,系统不是很复杂,数据量也不大,泵也不高,对性能要求也没那么大,多表观点其实也没什么问题啊。这个我们要说一下,我们说的这个问题更多是在一些大厂高泵发海量数据的场景下面, 对吧?我们说像阿里为什么会禁止超过三张表的关联,一般是在那种,对吧?他也不是说阿里内部全部都禁止超过三张表关联,他也是对于那种对性能要求极致,数据量非常大的这种极端的一一些比较核心的系统层面有这些规定,那 当然可能有的问,那我如果不做关联,有没有些什么好的一些替代的一些策略,那我这边也罗列了一些啊。一个是你可以做一些呃反泛式化的设计,比方说你把一些需要关联的数据多存几份,做一些荣誉, 这样的话你就可以减少你的关联需求,那比方说你做数据笼鱼,对吧?你比方你,你在不同表中间,你存一些公共的质段。我举个例子啊,假设我们有一些这种规格啊,或商品规格,或说编码的一些,呃属性 要存储,对吧?那我们往往有一个那个规格编码,可能还有个规格名称,对不对?那特别对这种规格名称的这个质段啊,其实你是可以在多张表里面 做一下荣誉存储的,那这样的话,你在真正查询的时候,你就不不需要说,因为我查一个规格的编码,再去另外一张规格表里面,再把它的名字查出来,你就减少了一张表的关联,那这也是一种数据荣誉的设计,那它其实跟我们,呃,就是数据库的这种范式化的设计啊,实际上是相相冲突的,但是在这种情况下面是可以使用的。 那包括还有就是分而治之,就是我们可以把复杂的查询拆拆为多个简单的查询,查询最终在我们的应用层,也就是比如我们 java 的 web 应用层里面做数据的组合。那有同,就我们刚刚上面说的很多同可能会觉得这种方式,那我 java 里面肯定要写很多的代码。没错,我告诉你,真的如果说在一些高应用开发的要求很高,数量非常大的 这种系统里面,其实我们都这么来干的。这么干虽然你 java 代码可能写的比较复杂,写的比较多,但你要知道 java 程序 web 应用它的扩展 呃容易程度啊,比我们说的数据库会容易很多很多啊。所以这也是我们在婚恋公司我们经常干的一件事啊。那包括还可以采用就是预计算的这种模式。什么意思?就是如果说你有那些,比如说你一些报表查询, 对吧?或者说一些对实时性要求没有那么高的一些场景的话,其实我们是可以把一些结果啊,需要大表关联那些呃呃才能得到的结果,我们可以通过一些预计算的一些任务把它提前算好,当我们查的时候,我们就从之前已经算好的数据结果集里面去拿出去就行, 对吧?这也是一种替代的策略啊。那还有种就是我们说的 no circle 的 数据库啊,那比方说像一些呃文档数据库啊,或者说建值数据库啊,对一些呃你的特定业务场景如果能知识很好的话,那你可以用这种 no circle 的 数据库,它的性能会更高啊。那以上就是我们给大家伙说的一些替代的策略,那如果你面试能把这些点达到,那我们觉得这道问题应该问题不大了啊。
958程序员面试突击 01:41查看AI文稿AI文稿
01:41查看AI文稿AI文稿大专生勇闯网络安全,从啥都不会到靠挖漏洞,自给自足。今天给大家分享两个我刚入门时用过的网安靶场,很适合零基础入门的朋友。靶场资料我都放在评论区了。首先要说的是封神台,他为初学者提供了模块化的漏洞学习环境,含盖 cq、 二注入、 xss 等常见漏洞类型, 通过渐进式实验,帮助建立系统化的安全测试思维,为后续实战测试打下扎实基础。第二个, d v w a。 作为 get up 上最经典的开元靶场之一, d v w a 将难度进行分级,从低到高逐步加码。刚入门可以从最基础的 low 级别开始,一边了解攻击手法,一边理解背后的防御机制。这种边攻边守的思维锻炼,恰恰是网络安全的绝大部分核心场景, 尤其是主流 top 十漏洞。当你一步一步走完这个训练流程,你不仅会熟悉各种漏洞的利用方式,更能理解它们是如何产生、如何被防御的。 这时候你再去看真实的系统,心里就不会发怵,也大概知道该从何处入手了。不过说到底,靶场终究只是前期练手的地方,真正提升技术、积累经验的还得是实战。比如 y s i c 漏洞,低位漏洞门槛较低, 一个能有几十到几百,要是有幸挖到高危漏洞,那就是几百到几千。前期呢,我也只能挖血低微,后来慢慢技术精进之后才挖到高危。我现在还记得我第一次挖到高危的时候,高兴的一整晚没睡着觉。所以说,挖洞这个事也是很考验耐心和技术水平的, 如果你也对网安感兴趣,但又不知从何下手,我可以把我这些年用过的学习资料和挖洞经验无常分享给大家。正是因为我当年淋过雨,所以想给大家撑把伞,希望对迷茫无助的朋友们有帮助。
16阿猫讲网安 02:38
02:38 01:06查看AI文稿AI文稿
01:06查看AI文稿AI文稿用黑客技术把攻防靶场打穿了,要负责吗?首先你要知道黑客常用的靶场是什么?一句话说,靶场就是一个专为安全人员打造的虚拟战场,里面附刻了真实环境中的服务器、数据库, 甚至可以模拟银行和电商这类高价值系统。你可以在上面合法练习所有黑客技术。真的把靶场打穿了,那也只能证明你练出了真本事。 新手入门推荐 d v w a 和皮卡丘的两个靶场,界面简单易操作,漏洞类型全覆盖,从 s a、 l 注入 x、 s、 s 到文件上传,新手能快速积累实战经验,把基础漏洞挖得明明白白。等你能熟练拿捏靶场里的主流漏洞,就可以冲真正的变现战场。 五天漏洞盒子这些平台上面常年开放上万家企业的漏洞悬赏低门槛漏洞几十到上百块一单,高危漏洞直接上千起步。不少白帽师傅靠挖漏洞月入五位数,还能拿到官方漏洞证书,为简历加分。 但千万记住,任何在线的渗透都必须要在授权范围内进行。你要是真想学好网安技术,我把网安从零到进阶的学习路线、笔记以及视频都梳理出来,主流的网安攻防技术都有讲到,记住,多学多积累才是关键。
14网络安全锦洋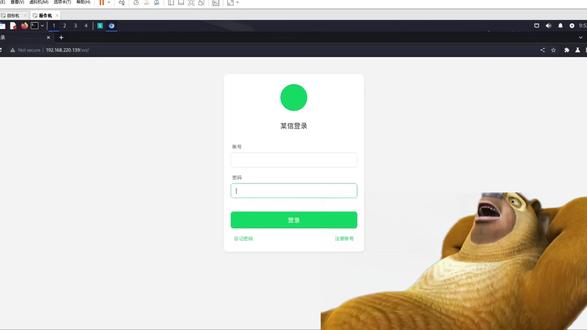 10:58查看AI文稿AI文稿
10:58查看AI文稿AI文稿这个网站是我们要攻击的一个目标,但是我不知道这个网站的账号和密码怎么办?这个时候呢,我们可以输入一个万能密码,点击登录就可以登录成功了, 这究竟是怎么做到的?我们今天要去讲解,内容是卡点挖漏洞,实战之手把手教你挖掘收口,输入漏洞。 特别提醒大家,接下来所有操作都在拔草环境中进行,绝对符合网络安全法规定,大家实操也必须在拔草环境或授权环境下操作,未经授权攻击他人网站是违法行为。我们先讲解实战,然后再去讲解原理。在实战的第一步中,我们的目标机与操作机,大家需要明白, 给大家准备中的这一个目标机是在左手边的这一个,然后操作机就是我们的卡点 linux, 卡点 linux 的 目的是作为操作机去攻击我们的目标机,所以说我的目标机提前已经把把伞搭建好了,大家只需要拿到我的这个目标机,一旦开机之后就可以访问了,那怎么访问呢?大家可以直接 ip config, 这就是我们目标机的 ip。 拿过来我们再切回到操作机,我们打开这个 b p, 我们在里面点一个代理的时候,可以打开一个浏览器,把那个粘过来,我们就回收,这里面显示了 hello world, 就 代表我们已经可以访问到这里的目标机的靶场环境了。 再切回到操作机,那么我们只需要在后面加一个网站,这样的话就访问到了我们的这一个目标靶场。 我们进入第二步,在访问的过程中使用万能密码去探索,注意这个是网络安全的真实面试题,之前就有面试官问过我,请你说一下万能密码是怎么玩的?我们现在就在讲我们的万能密码, 我打开我们这个操作机,在操作机这里面我确实是不知道账号和密码的,那怎么办?我们可以这样写,这样写,然后呢?我们的密码也这样写,这样的话就是我们的万能密码的形式,关于这个万能密码的原理,我们后面会专门讲解的。 好,那我就登录成功了,也就是根据第二步使用忘恩密码直接走到了第三步,我们拿到了我们登录的成果,我们不知道用户名和密码的情况下,也得知了,也进入了这个登录的首页, 有需要操作机与目标机的小伙伴们,只需要私信我发送目标机与操作机即可。接着后我们进入这个原理片的一个环节,为什么会存在社口出入的这种漏洞呢? 大家需要明白。首先我们在这个环节中,我们用这个 app 也好,电脑应用也好,浏览器也好等等,它是不是可以访问到这个服务器?这个服务器有可能是用 java 写的,有可能是 ppt 写的,有可能是构员写的,都有可能,因为它会访问到数据库, 数据库的话有很多种类型,我这就不是电脑那么这样一种服务器架构,其实无论是腾讯系、阿里系、京东系等等,全球所有网站的服务器大概就是这样设计的。 哎,这个时候我们在网站的这个这个环节中,我们输入框里面输入的东西不是正常内容,而是会输入这些受苦语句怎么办呢?这样的话就可以骗过数据库,最终可以达到骗数据库的执行,达到偷数据、删除数据、创改数据等等。 哎,我刚才所讲的这个环节中,这里面不是有个浏览器吗?这个浏览器就相当于我们在前面讲了这个环节的浏览器,这个是一样的, 大家可以去思考,以后无论是挖漏洞、打互网、各种比赛,或者是从事安全工作等等,是不是会有这样的场景,一定会有这种登录框或者是注册框,以这种形式就一定会跟数据库打交道。 如果说他跟数据库打交道,那么是不是又得从这个登录框?注册框这种输入框是可以访问到服务器,服务器再访问到数据库,那我们是不是在传递的时候不会传递一些正常数据,而是说访问一些这种受苦数据,是不是可以欺骗到他这个数据库了? 紧接着我们来看一下牲口猪肉能够带来哪些危害,包括之前的这个淘宝账号被盗,还有这个酒店预定数据库被黑客入侵等等,这种事件都是由牲口猪肉所带来的这种危害。当然还有很多很多很多事件,我们这里面这个 ppt 列不上来了,所以说这里面的话只列了这两个, 因为你要明白这种软件和我们的这个软件是一样的,我们往这个软件里面只录了一种收口语句,或者是说恶意的收口语句,那么就能干嘛?就能去绕过服务器再到达这个数据库,那么这样的话就可以欺骗这个数据库,来做各种控制数据库响应的事情,所以说才会有这件事件的诞生, 我们开始对这一个原理的分析,这个图想表达意思就是说我们想解释清楚这两句话是什么样的原理。过程 在看我们的 app 的 时候,你会发现一个点,这里面的东西,我们可能说现在还看不懂,是因为我们还没开始专门的讲解。回进来为什么说我们传出这两个玩意,它就能够把我们这个信息给推送进去呢?这是为什么呢?是不是?好?我们在这个疑惑就开始来去讲解,我要把它给它放小一点,我们这里的话是什么是用户名输入的, 哎,这里面是密码输入的,也就是把这个给它发到这里来,密码输入的也这个是用户名输入的,发到这里来 这个关系大家都是非常清楚的。 然后紧接着我们对于这个攻击者的猜测来一步一步的分析。 首先我们需要明白它这个执行过程中在数据库里面长什么样子, 还记得前面吗?因为最终这个语句也好,这个语句也好,他会一定会到达我们的数据库,也就是他一定会从我们的这个输入框浏览器开始,一直会到达我们的服务器,再到达我们的数据库,是一个这样的过程。那我们想知道在数据库大概是长什么样子,在这里面 数据库里面是什么样的方式呈现的,这个是我们想知道的。所以说我们回到这里来,我们会有个猜测,首先这边的话是数据库的语法,我们写一下, 当然这是表明,然后这边就是用户等于账号,也就是等于我们的这个账号,而密码是等于这个密码, 这个是我们数据库大概的猜测,那么我们可以衍生出这一步,那么既然我们现在知道是这种情况的话,可能它会变成这个样子,就是说这里面传的是我们账号的输入框,然后这边传的是密码的输入框, 那么是以什么样的条件来个代表他是登陆成功呢? 那么这边会有一个公式回正来,也就是在这里面的时候,只要说在这里面他满足一个真,那么这个是真,那么就代表他是登陆成功。 注意所有的网站,无论是京东系、淘宝系、阿里系,全球所有网站他都是这样设计的,在数据库这方面, 只要条件都为真,它就代表你登录成功。说回来这个是真,这个也需要是真,也就是传的这个是真的,这个也是真的,就代表登录成功。那什么情况下是登录失败呢?如果说假设这个是假, 这个也是假,这是登录失败。如果说这个是假,这个是真,也登录失败。如果说这个是真, 这个是假,他也登录失败。就是必须要用户名与密码两个都为真,才算登录成功。那如何做到这个效果呢?那么可以这样来玩这三条登录失败的我们不看,想登录成功的话可以这样做, 只要说我们写的语句是这个样子的,它就能够代表成功。这样写这个其实是表达了真的意思,咱们这个 a、 b、 c、 d、 e、 f、 g 可以 不写,就长这个样子。就这一节它其实是表达了一个真的意思, 然后这里的这个密码也可以放到这里来,然后呢这个也可以不写,也可以写,随便你过来。这句话它也表达了一个真的意思, 这个是真,那么这一条也是真,那么就代表登录成功了。也就是这句话其实是表达了等于真, 这句话是表达了等于真, 但什么时候让它等于假呢?等于假的话可以这样写,我们看一下。好,一等于二吗?那肯定是错的吧?一怎么可能等于二呢?那它就是假。 一等于九吗?那肯定是错的吧?一怎么可能等于九呢?这是错的。那么一等于一吗?肯定等于一啊,是真的,那么这就表达了真的含义。说这句话我们现在要把它给传递到这里去, 然后这句话我们把它给传递到这里去,那么所最终达到的效果就相当于这里面其实它的本质传了一个真,那么这里面的话也是表达了一个真, 那么既然是这里是真,这里是真的话,就代表登录成功。所以说我们再回到这里来,你会发现一个点,就是这里面表达的一个形式,账号的输入框与密码的输入框对应起来,只要表达的用户名与真密码也真的话,就代表登录成功。这是全球所有网站的整个逻辑,是这样走的。 那之前还有面试官问你为什么是这样写的?那时候你会觉得很奇怪,因为他想问你的点就是说,为什么前面没有开始号,后面也没有一个结束号,这是为什么呢?为什么长这么奇怪呢?为什么又长这个样子呢? 好,你看前面有一个开始号呀,后面又没有结束号呀,注意了,为什么长这样子?为什么长这样子?是因为他从这里面拷贝出来我当前所选中的这个,他怎么拷贝这个区域啊?你看我剪切掉看到了吗?我再恢复 看到区别了吗?所以说你会导致说前面有一个开始号,后面写了些东西,把它给挡住了, 因为我前面讲了吗?这里面可以写东西,这是可以写东西的,也可以不写东西的,这样他们是等价的,这个效果和这个效果和这个效果商者是等价的。那我说这样写嘞就变成这个样子了吗?那我来个空格嘞,也是等价的效果, 看区别了吗?所以说就会解释清楚为什么是这种奇奇怪怪的符号,为什么这里面有结束?是因为从这里面拷贝出来的, 我把它给剪切掉,剪切好看没有?这还留下什么?留下一个开头和结尾,到时在拷贝出来之后,我们放到这里来,是不是长这个样子了?好,这就是之前一些面试题的细节问题,我们给大家解释了一下, 我们来总结一下,我们一共有三步核心,第一步,我们去激活网络靶场。第二步,我们访问的过程中并使用万能密码去探测。第三步,验证注入好之后的成果,进行一个登录。
46喵叔讲攻防









