nanobanana九宫格分镜教程
今天和大家分享一个体式词,就能让 banana banana 帮你生成修饰九宫格分镜,你可以从获得龙蛋开始,再到龙宝宝成长,最后成为坐骑一起飞翔。像这样一个完整的故事,三幅图片就搞定。提示词是告诉他我们有一个图像模型可以生成九宫格分镜,你先帮我们构思五个不同的故事, 当然你有自己的故事,也可以继续让它修改。我们把提示词发给 ai, 这里就出现了作为势力的五个故事,那么我们随便选择一个,然后将它复制给 juma, 使用 banana 复制它,这样 banana 就 能给我们复制这个故事的九宫格分镜。那么我们想要放大某个分镜怎么做呢?其实也挺简单,直接提示即可, 后续也可以使用这些分镜去给 ai 视频模型作为起始针了。在这个过程中,九宫格分镜或者放大某个分镜,你都可以提示 ai 继续修改,所以这个流程就极大的提升了我们视觉稀释的速度了。好了,这里是 ai 专利,分享有趣的 ai 技巧,那么我们下期再见。

粉丝1911获赞1.6万
相关视频
 01:31查看AI文稿AI文稿
01:31查看AI文稿AI文稿这是最近很火的邪修九宫格分镜,直接输出给 ai, 你 就能生成像这样的视频画面, 减去等网站生成的时间,我仅耗时两分钟。以前你想要做一个像这样的拍摄分镜,需要确定拍摄的方位、高度、胶段构图。而现在利用了谷歌的香蕉 pro 模型, 我们可以很快地制作像这类分镜图。那它的步骤其实非常的简单,我们只需要打开豆包或者是 jimmy, 想好故事的梗概,让 ai 提供对应的分镜脚本,再将写好的脚本送给香蕉 pro, 把文字转换成图片,稍微检查一下图片是否有需要修改的地方,就可以把图片发送给 vivo 三这一类 ai 生成视频软件。 最后只需要耐心的等待生成成功就结束了。那如果你没有 vivo 三这些直接可以把分镜转换成视频的 ai 工具,那可以把分镜图片用 ps 裁开,当成正常的分镜进行使用。不过每次手动打开 ps 手动切片还是有点麻烦, 所以我自己写了一个 ai 工具,能帮助我进行切片。只需要在秒答里面搜索自动切片工具或者是我的 id 就 可以找到这样的软件,你也可以使用,它是免费的。每个才切好的画面因为分辨率比较小,非常的模糊,这里建议可以放到豆包四点五里面提升一下画质到四 k, 那 这是用奇梦单张生成的视频效果 个人觉得也还不错。以上是用到的提升内容,放在文章当中了,希望会对你有一些用处。那如果你也有一个有趣的故事,也想做成 ai 视频,那不妨点赞关注,我会抽五个评论区的小故事进行视频制作。我是幼琪,那我们下期来点更有意思。
246右岐trail 04:20查看AI文稿AI文稿
04:20查看AI文稿AI文稿今天给大家分享一下,在 gemner enterprise 企业版本里面搭建一个分镜智能体,再结合 nano banana pro 精准控制主体,能够实现分镜画面的一次支出,不需要抽卡制作电影感短片。先给大家看一下我生成的一个视频效果, gemner 企业版本的免费使用和登录情况我上一次分享过,嗯,没有看的小伙伴可以先去看一下。 在他们那企业版本里面,点击左侧的智能体,进去之后,我们可以创建一个自己的智能,创建好之后他会显示在这个下方。这个蓝色的就是我今天做的一个电影分镜的智能体, 如果有需要的小伙伴可以找我把这个分享给你,或者是我把做这个分镜智能体的一个模板发给你,你自己在你的电脑上去做一个就行。点击这个分镜智能体,他会跳转到这样一个对话框的形式,在这里你需要输入一个简短的剧情,再上传一张照片, 它会根据你的剧情和照片去生成嗯,不同的分镜头,在这里我让它生成了一个九个连续的分镜头,你也可以让它生成十几个甚至是二十个连续的分镜头都可以。在这里上传照片,它有着一个很大的一个作用, 就是 ai 在 后面给你生成每一段分镜头提示词的时候,都会严格去遵循你你给他的那个参考图去保证主体,还有背景元素,色调,光影风格这些都是一致的。我忘说了,他在这里给我生成了英文的一个分镜头,你也可以让他直接给你生成中文的分镜头。 然后我们在 gemna 企业版本里面利用 nano banana pro 去生成图像,在首页点击增强对话,这里选择生成图片,这个就是 nano banana pro 的 模型,把我们刚才生成的九个分镜头粘贴到这里,再上传刚才生成分镜头的照片。在这里我们让 nano banana 根据我们提供的图像和下面的九个分镜头提示词,帮我们生成九张分镜图片,并且要求它严格遵循参考图。九张分镜图生成好了, 可以看到这九张图,他的一个色调、光影,人物的主体环境的一致性都是保持的非常好。我发现他把九张图一次性生成出来拼接在一起的时候,他的剧情连续性是最好的,如果是单张单张的让他去出分镜图的话,反而他的一个剧情的连续性 保持的没有那么连贯。九张图拼在一起,他的一个剧情连续性虽然好,但是就是需要你去把它裁切一下,然后再用 number banana 去进行一个高清的放大, 然后再把这个图片去作为首尾帧去生成视频的话,就会效果更好。在康复 ui 里边,我把刚才生成的分镜头提示词复制到千问单独出分镜头的工作流里边,发现生成出来的分镜头效果没有 nano banana 的 好,效果不好,这里没展示。 我把 nano banana 生成的分镜图在 comfui 里边用万象二点二的首尾帧工作流生成视频,就是刚开始大家看到那个视频,今天分享这个,总的来说就是在 gemini 企业版本里面去做一个分镜头的智能体, 然后再利用企业版本里面的 nano banana pro 去生成分镜图,保持多个分镜图它的剧情的一个连续性。但这个这个剧情的连续性的话, nano banana pro 它就会把九张或是多张分镜图给你拼接在一起,这个就需要你重新去 裁切一下,然后再进行一个放大,就是单张出分镜图的效果可能不是很好,这是我试下来的一个技巧吧。
2715灼野AGI 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿只需一张图片就能生成连贯的影视分镜,无论是人物、场景、仪式性保持的都非常好。具体怎么做,我们一起来看。首先上传一张影视风格图片到节目栏,复制即日词,点击生成,生成完毕后将九宫格图片分割出来,这样的一套分镜就可以用于生成视频了。 此外,我还设计了一套六宫格分镜,所有资料全部放在评论区,感兴趣的小伙伴可以去试一试。
270南吴NANWU 04:44查看AI文稿AI文稿
04:44查看AI文稿AI文稿这几天啊,玩那个 nano banana pro 那 个很火的九宫格分镜啊,发现个特别有意思的事,这个过程啊太有意思,给大家分享一下。首先就是网上找的那几种超长的九宫格提示词,在我这用着用着呢,就会出现全部换人的情况, 我估计这提示词里有什么关于地狱的描写啊,我找了半天也没找到。还有就是这个九宫格上标注的编号也是很随机啊,时有时无的,每次出来标注的也不一样。还有就是我们出这个九宫格分镜啊,肯定是为了做视频用的, 怎么能把九宫格里的分镜单独分离出来呢?开始啊,我简单粗暴的把提示词里所有关于三乘三之类的都去掉,改成九张图,单张分镜之类的。完了,在这个 aj 花布的对话框发送。那我用的是 love art 平台的啊, 你可以在任何一个有挨着画布这类功能的平台试试,提示词最后我都会放到视频简介里,大家自取吧。这次确实得到了单独的九张分镜图啊,但我试了很多次后发现啊,这样的飞片率太高了,每次都会出现好几张彻底换人的,甚至还有环境啊,光线都变了的, 确实远不如那种超长的提示词出来的九宫格分镜美的好啊。那现在的问题就是怎么能把九宫格里的某一个图啊提出来,我简单粗暴的直接给他说提取第几行的第几个图, 虽然大概差不多,不过这构图角度什么的差太多了,试着加各种说明, 感觉都不太行。接着我索性把这句话翻译成英文再试,好像差不多了,再试试有编号的九宫格。这次输入提取编号为什么什么什么什么的图片,这次不错,很接近了。 接着我又怕他换人了,添加了一张参考图,又加了句话,确保角色特征与参考图一致。巴拉巴拉巴拉巴拉。这次差不多,看来这抽卡几率也是高啊, 并且多多少少的呀,总会有一些改变。接着我还是把这句话翻译成英文给他,哎,这次出乎意料的一致啊,我看不出有什么差别, 看来这个操作还是英文得到的效果好啊。那现在我得出结论啊,只要是得到带编号的九宫格,用这个英文提示词提取,就可以很高效的得到九宫格内任何一个分镜。 那怎么能让 not banana 每次百分百的输出带编号的九宫格呢?我打开了翻译网页, 研究这个超长提示词里关于编号的描述。可咱这英文太烂了啊,根本无从下手啊。算了,最后我想,既然是 ai 了,索性给他个最简单的指令。我直接用中文给他了一段非常简单的提示词, 把最基本的条件告诉他,看看会有什么结果。 这结果是出乎意料的好啊,再用那个英文的提取提示词试试, 不错啊。接着我又试了试,增加参考图,再提取其他的风景试试,还是用英文给他。 这次出来又变了,看来这条件一多啊,就容易出错。当然这图也不是不能用啊,先放一边一模一样的词,再试一次,这次可以了,一模一样。我壮着胆子把刚才那三乘三改成四乘四,下面这个参数当然是就得是十六张了, 结果依然是非常棒,想象中的画面基本都有,相信你多抽几次卡,画面就会越来越丰富。 最后啊,我在提示词前面尝试着加了一句话,创作一个故事,其他的什么都不变,看看它会出来什么结果。 哎,结果他还真出来一些很有故事性的画面啊,并不再是单纯的走来走去了。大家发现了吗?那么费劲搞半天,还真不如直接用中文简单的几句话,至少对于我这样的案例啊,是这样的,所以玩 ai 啊,有时候他的条件宽松一些, 结果是不是反而会更好?那我这个提示词的结构啊,脍炙人口,大家可以发挥创意,看看还有什么更有意思的玩法,加油!
3107夜不眠Lost 07:50查看AI文稿AI文稿
07:50查看AI文稿AI文稿这绝对是网上最简单最快捷的方法来制作电影感十足的 ai 影片。我知道这话说的有点大,但在这个视频里,我会让你心服口服。而且不光是最快,这更是最高效的法子,既能保持角色形象一致,又能从多个不同角度获取画面。 因为我手握秘密提示词配方加微信云强 net 免费获取提示词最爽的是我们全程只用免费的 ai 工具,所以我超期待的。废话不多说,咱们直接开整。 我们要用到的工具是 nano banana pro, 而且有好几种白嫖它的方法,比方说,你可以在 alarina 上用, 也可以在 ismate ai 上用,还可以在 german ai 上用。关于这个话题,我之前已经做过一期详细教程了,大家一定要去看一下。这里要特别感谢 underwood 的 大佬分享了这么牛的提示词给我们。用这个方法,你只需要上传一张图片, 它就能基于这一张图生成各种不同角度、不同构图的画面,这简直太神了!不过呢,这个提示词写的是又臭又长,但它的缺点就是只认单张图片。但如果我们想逐场景生成一个完整的故事呢? 举个例子,我在 chat gpt 里已经写好了一个完整的故事,我给他的提示是给我创作一个为惊人的故事,这个故事要围绕一个核心人物展开。于是我稍微调整了一下提示词,让它能适用于每一个场景。 比方说,我想为第一个场景生成配图,你看,在第一个场景里,唯一的角色就是埃里克,于是我生成了埃里克的形象,我还在图片上标注了角色埃里克。接下来我只需上传这个角色的图片。 为了提供背景信息,我会把第一个场景的故事内容复制过来。我必须把这段故事放在提示词的开头。放在具体指令之前。 请务必记住,要把故事内容放在提示词的开头指令之前,不然的话,这招就不灵了。现在我们点击生成,看看效果如何。加微信云桥奈,免费获取提示词。 瞧出来了,现在我们得到了九张从不同角度描述的图片,他们延续着同一个故事线。 故事是这样的,他回到了故乡。第一张图清晰地展现了他归乡的情景。接着,他发现村庄已被摧毁,他面露悲伤,他探索着已成废墟的村庄,神情哀伤。 而且,我们无需生成一堆不同的图片,仅凭一个提示词,我们就得到了所有这些场景和画面。而且镜头角度也多种多样,有低角度镜头,有高角度镜头, 有特写镜头,有广角镜头。这样一来,你就有多种镜头可以自由搭配使用。这里有个专业小窍门,别只生成一次就完事, 一定要用同一个提示词多生成几次,这样就算第一次生成的效果不尽如人意,你也肯定能在第二次生成里找到更棒的镜头。这样一来,你手头就会有一大堆图片,可以从中挑选最好的镜头。这样一来,你手头就会有一大堆图片,可以从中挑选最好的镜头。这样一来,你手头就会有一大堆图片。会不会受损? 那肯定会啊,不过别担心,这个问题我也有办法解决,我稍后会在视频里告诉大家。不过首先咱们还是继续讲故事。那么第二个场景是,故事里说他穿行在空无一人的村庄中,每个地点都会勾起他的一段回忆。 所以在这个场景里涉及三个不同的角色,分别是他父亲、兄弟和妻子的记忆。 因此我之前所说,最好给所有角色都起好名字, 不然的话可能会出现一些惨不忍睹,你根本不想看到的结果。现在我们来一步步分解这个任务,我们先只生成与他父亲相关的场景,那么我直接复制这段内容,加微信云乔奈,免费获取提示词。再次提醒,一定要在指令部分之前做好修改, 不然的话操作就会失败。这次我故意不上传他父亲的照片,就是想让大家看看不上传照片会是什么结果。那么这是他进入房间后生成的结果,他由此触发了关于父亲的回忆。但你会发现, ai 把他自己当成了他父亲。 因为我们没提供他父亲的照片, ai 就 蒙了,搞不清楚状况,所以他就把主角自己生成了父亲的样子。后来我上传了他父亲的照片,并指明着就是他父亲。我在图片描述里也提到了埃里科的父亲, 结果如下,因此在图片描述中指明具体角色直观重要。在这个例子中,我就没有说明这是艾里克的父亲。我上传了这两张图片,大家看提示词部分,我上传了这两张图,但 a i 却犯迷糊了,可以看到生成的图里有艾里克的父亲, 却没有艾里克本人,所以点名角色这一点非常关键。接下来我们需要生成他兄弟的图片,同样的,我来复制这段提示词,然后只替换提示词里的这部分内容,再点击生成。好了,搞定。 现在他兄弟的图片就生成了。这是关于他兄弟的闪回记忆画面,画面中他神情悲伤, 正在回忆他的兄弟。正如我之前所说,最好多生成几次,因为在下一组结果里,你会发现效果更理想。这样你就可以从这两批生成的图片里挑出最好的进行组合,最终效果会更出色。 生成他妻子的图片时,方法也一样。在那里,他脑海中闪回了与妻子共度的记忆片段,在那里,他曾向妻子许下诺言,承诺自己一定会归来。 而且我们这里用了多个不同的镜头来呈现,而且角色形象始终保持高度一致。因此用同样的方法,你想把故事延续多长都可以。 现在咱们来聊聊如何提升画质。因为直接下载下来的效果画质会非常差,所以你可以先简单裁剪一下图片。如果图片上还有文字,你可以再次打开 nano banana 这个工具,然后给他一个简单的指令就行, 比如去掉文字,增强画质。这样你就能得到一张同样的图片,但细节会丰富的多。看,现在我们面前就是一张细节丰富的图片了。接下来要生成视频,我们会用到 graph ai, 因为它是一个免费的 ai 工具。使用方法很简单,找到 imagine 这个选项, 然后上传你的图片就行了。 graph ai 最棒的一点在于,它生成的图片是带音效的,所以最终效果可以达到 vol 三级别的水准。 对了,你还能注意到,视频里还包含了背景音乐,因此,想去除背景音乐,只需在提示词里加上无音乐即可,效果如下, 那么为什么这一点很重要呢?因为这样一来,你就可以自行添加喜欢的背景音乐了。现在,你可以对每个视频片段都如法炮制,在展示最终成片之前,如果你觉得这个方法好用,加微信云墙内免费获取提示词, 接下来请欣赏成片吧!
1939云桥网络 05:41查看AI文稿AI文稿
05:41查看AI文稿AI文稿每天讲透一个 ai 知识点,今天是最强 ai 生图 nanobana 玩法大全,太炸裂了!哎,大家看这张图,这是我,这是特朗普,然后呢,这是我俩在白宫的合影,是不是觉得有点离谱?哈哈,没错,你没看错,不过别急啊,这还只是个开胃小菜呢! 那么这么神奇的照片到底是怎么来的呢?噔噔噔噔!就是它,最近火爆全网,被好多人叫做地表最强 ai 生图模型的 nanobana。 好,那这个 nano banana 它到底强在哪呢?为什么敢叫地表最强?别急,咱们今天就把它八个底朝天来!这是咱们今天的路线图,一共五个部分,咱们一个一个聊。首先咱们来看看第一部分,这个模型啊,来头可不小,据说背后的大佬是谷歌,而且啊,它一出来就直接解决了 ai 绘画里一个困扰大家很多很多的天大的难题, 那这个难题到底是什么呢?我相信玩过 ai 画画的朋友们肯定都深有体会,就是那个最大的痛点,一致性对吧?尤其是画人脸啊,你想让同一个人换个表情,或者换个发型,结果呢,换直接给你换了个人面目全非,根本认不出来了。 而这就来到了咱们的第二部分,也就是奈诺巴娜娜的看家本领,他的秘密武器,也是他能引爆整个圈子的核心原因,那就是无与伦比的惊人的一致性! 来,咱们口说无凭,直接上对比,你看啊,左边这张是原图,是我,我给 ai 下个指令,很简单,让我笑一笑, 结果呢,左边这些就是其他模型的常规操作,妥妥的翻圈现场,对吧?这脸都换了,完全不是我了。但是你再看右边, banana banana 哇,他做到了!你仔细看,我的脸被完美的保留了下来,只是换了个表情,这感觉就好像是同一个人拍了两张照片一样,太牛了! 好,咱们继续上难度,挑战一下他的极限。来,把背景给我换成火山,你看,没问题。再来,把我的长发变成短发。哎,脸还是那张脸,还不够,把 t 恤换成红色的毛衣,甚至咱再狠一点,直接换个发色,怎么样?经过这么一通折腾,你再对比一下原图,我这张脸是不是几乎就没变?这个一致性,我只能说,真的太炸裂了! ok, 既然他的一次性这么厉害,那光说不练假把式,他具体能干嘛呢?就到了咱们的第三部分了,聊聊他那些足以颠覆行业的玩法。首先,第一个玩法,绝对是 p 图神器,怎么说呢,就是那种真正的指哪打哪,你都不用自己动手了,动动嘴,告诉 ai 要改哪,他就帮你搞定, 不信你看啊。比如把海报上的数字二十八改成八十二,你看看这效果,光影质感都对得上,还要什么 photo 照吧。再来修复一张破损褪色的老照片,小菜一碟。这修复效果简直了,还能玩的更大一点,让一个坐着的人直接站起来,你看,姿势变了,但人和环境都保持的特别好,太强了! 好!第二个玩法,这对所有内容创作者来说,绝对是个福音,那就是创作连贯的角色。以前搞漫画搞动画的,最头疼的就是角色,换个场景换个角度,脸就画的不一样了。现在好了,有了 banana, 你 可以彻底告别这种换场如换脸的尴尬了。 咱们看个例子,你看这个女孩,先让他在森林里跑起来, ok, 没问题。然后场景大挪移,让他去一个哥特式的城堡里探险,顺便还得换一身行头。你再看,虽然背景和衣服全变了,但这张脸,这个神态,是不是还是同一个人?完美? 如果刚才的还不够,那这张六宫格图绝对是王炸级别的证明了同一个角色,六个完全不同的场景,六个不同的姿势,六套不同的服装。但你看,他还是他,这对于动画师、漫画家、小说家来说,简直就是解放生产力啊,这绝对是一个巨大的突破。 当然了,他的能量还远不止世界线。对于做电商和设计的朋友们来说,这东西同样是个大杀器。 举个例子啊,比如说,你是个鞋子设计师,这里有一双普普通通的白色运动鞋,然后旁边呢,是一幅你很喜欢的艺术画,现在你让 i 把这幅画的风格迁移到鞋子上去,咚!你看,一双充满创意和设计感的新鞋就这么诞生了,质感、配色、光影,全都给你安排的明明白白,你说酷不酷? 好!如果说前面这些还只是在技术层面秀肌肉,那接下来要讲的就有点智能的味道了。咱们进入第四部分,来看看这个 ai 让人细思极恐的深度思考能力。 我们来给他出个难题,一个需要懂点物理和化学知识才能回答的问题,你听好了,如果把画面里这个披萨放进四百度的烤箱里烤上整整两个小时,会发生什么? 结果来了,简直让人惊掉下巴。你看其他的 ai 可能会傻乎乎的给你生成一个烤的金黄酥脆的完美的披萨,但是那那吧那呢?他给出的答案是一块黑乎乎的完全烤焦炭化了的黑暗料理。我的天,他知道高温长时间烘烤的后果,他离决了因果关系, 还不信。再来一个问他,冰淇淋在太阳底下会怎样?你看他生成的图片,就是冰淇淋正在融化的样子。这已经不是简单的 p 图了,这说明 banana banana 真的 具备了一定的常识推理能力,这可太牛了! 好了,看到这里,大家是不是已经摩拳擦掌,也想亲自上手体验一下了?哎,好消息来了,咱们进入最后一部分,告诉你怎么免费玩到它。 想玩的话,方法其实很简单哦,记一下啊,你只要去一个叫 l m o rina 的 网站,这个是一个大模型对战平台,进去之后呢,点击 image, 然后上传你的照片,再输入你的指令,也就是提示词,最后点击升成就行了。 不过呢,这里要提醒一下它,这个是盲测,就像抽卡一样,你得多试几次才有机会抽到这个超强的纳娜娜模型,虽然稍微有点看运气,但重点是它完全免费。 当然了,咱们也得实事求是,它也不是万能的,目前还不是完美的。比如说在处理一些特别精细的细节,你看像这个裙子的吊带,它就可能处理不好,容易露馅儿。还有,如果背景特别复杂,你想让它去掉水印,它有时候也会有点力不从心。 不过呢,侠不掩瑜, nano bana 的 强大是毋庸置疑的。那么今天咱们的分享就到这儿,最后也留一个问题给大家思考一下,当 ai 工具变得这么强大,这么好用的时候,你最想用它来创造点什么呢?
21众创AI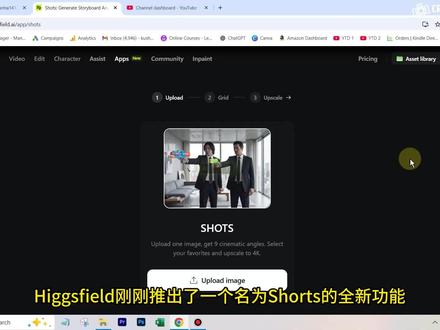 07:27查看AI文稿AI文稿
07:27查看AI文稿AI文稿pixiv 刚刚推出了一个名为 shorts 的 全新功能,你只需上传一张图片,就能获得九种不同的电影感视角,完全无需输入任何提示词。最妙的是它采用了 nano banana pro 模型,因此画质和一致性简直绝了,你甚至还能将这些画面超彩样至四 k 分 辨率。 接下来我们就来看看他的实际效果。我会给大家展示大量不同的案例,包含人像摄影、房地产摄影、美食摄影、产品摄影等多个领域,乃至他在影视制作中能如何助你一臂之力。话不多说,我们直接看案例。这是第一个案例,我们只有这张人像的原始照片。 那么第一步就是打开 shorts 功能。如果你点击菜单栏这里的应用板块,只需找到名为 nano bananas 的 类别,就能看到这个 shorts 功能。接下来的操作就非常简单了,说白了就是一键搞定。我们直接上传这张照片到这里,然后点击生成。好,我们开始吧。 好了,照片已经上传完成,接着可以看到,这大概需要消耗四个积分。现在请注意一个关键点,你会在这里找到这个画面比例按钮。 这个设置决定了你最终会得到什么样的照片。网格,这个网格里会包含各种不同的角度。网格里所有照片都会遵循你在这里选定的比例,因此你需要选择这个比例。这取决于你需要那九张照片用来做什么。 举个例子,假设我想要这张人像的不同遍体,并且我想把它们发布到 instagram 上。 instagram 的 帖子通常使用正方形比例,那么我就会选择一比一,并不是所有的比例选项都可用,所以这取决于你上传的原始图像的比例,也就是你上传到这里的那张原始图像。 只有与原图比例接近的选项才可用。请记住这一点,那么我就在这里选择一比一,说白了就是个正方形,就像我前面提到的,这只需要消耗我四个积分,官方说大概需要三十秒左右,但实际通常得等个五到十分钟。 不过相信我,这等待绝对物超所值,那咱们就稍等片刻,等这个网格生成出来 好了。这次其实特别快,大概就一两分钟,大家看,就这么简单,我们一下子就得到了九张不同的图。现在你看这个网格预览图显得有点小,这时候你有几个选择?第一,我可以选中任何一张我喜欢的图,然后点这个放大按钮,这里确实提供了四 k 或者二 k 的 选项, 它最初生成的图是一 k 分 辨率,用来发社交媒体也完全够用了。这是我首先要强调的一点,在你决定放大之前,有个关键步骤,看到旁边这个下载按钮了吗? 你点一下它就会弹出两个选项。第一个是下载整个网格图,这样它就会把整个网格打包成一张图下载下来,方便你仔细端详每一张。但还有个更棒的操作, 点下一个选项,也就是下载选定图像。因为这个网格里足足有九张 e k 分 辨率的图,这质量已经相当不错了,所以我更愿意直接点这里,一次性获取全部九张图片。然后它会自动打包成一个 zip 文件供你下载。咱们解压一下,来看看这些图片吧,搞定!就这么简单,九张图片全到手了! 你看,即便是这个分辨率,如果只是发社交媒体,轻轻一点,九张这样的图就到手了。 当然,你也能看出来,这生成的是 nano banana pro, 所以 你看,人物、脸部、身体、服装的一致性简直绝了!它连姿势都是自动生成的。 要知道,以前手动写提示词,光构思这些姿势就够让人头疼的,但现在整个过程都实现自动化了, 就连特写镜头效果也是杠杠的。这在以前可是个老大难问题。比如这种相机一百八十度转向从背后拍摄的镜头,现在不费吹灰之力就能轻松生成。 最妙的是,现在你还能用它玩出更多花样。比方说,我从中挑一张,再选一张正面角度的,然后我在 clean 软件里把这两张图分别设为起始帧和结束帧,我只需要输入一句指令,让椅子旋转一百八十度,直到人物面向镜头,然后就能得到这样的动画效果。 你看,这效果简直绝了!不过,如果我们回到 hex 厂,我们还可以把任何喜欢的图片进行超轻放大。比方说这九张图里,我特别中意这张特写镜头,那我直接选中它,一路拉到四 k 分 辨率,把这张图也超轻放大。那咱们就稍等一下结果 好了。好了,我们的图片处理完了,可以下载了。你还可以多选几张图,一次性对它们进行超轻放大,所以这也是一个可用的功能选项。你点开这张图看看,这将会是一张视觉效果超赞的四 k 图片, 这效果绝对惊艳,甚至拿去打印都完全没问题。好了,现在你已经知道这个功能怎么用了,接下来我再给你看几个其他不同领域的应用案例。 咱们就以房地产摄影为例吧。假如我们手头只有这么一张卧室原图,直接把它丢进去处理,处理之后,我就得到了这样一个九宫格。咱们快速过一遍这些图,你看每一张效果都很出彩, 而且仅凭一张原图,我们就能把房间里的各个细节都照顾到,再也不用分别去拍他们了,所以这真是个绝佳的应用场景。再看这个,我有一张看起来平平无奇的香水瓶照片。 首先,我直接用普通的 nano banana 就 把这个变成了专业的产品。拍摄效果指令很简单,只需把它变成看起来专业的产品照片。 如果你愿意,也可以额外指定一些其他要求,因为这一点很关键,要记住,它只负责生成不同的拍摄角度,它不会在生成的九宫格内改变原图的内容。所以你首先得有一张看起来不错的原始照片,而这就是我用它生成的九宫格效果图。可以看到,其中一些效果图看起来简直绝了。 同样一共生成了九种不同的变体,而用 nano banana pro 来做这个简直不要太轻松。这个工具对于视频或电影制作也大有補益,因为很多时候,比方说你手头只有这么一个镜头,比如画面里是两个人正在对话,为了让画面保持动态感,不显得单调,你就需要在不同机位角度之间来回切换, 而这个工具正好能派上用场,那么这是原始图像,这是我得到的九宫格。我得到了几张像这样的效果图,然后你就可以把它们用在视频制作里了。 再看看这惊人的一致性。尽管我们无法看清画面中两个人的完整面部,在原图中,我其实也保留了这些场景的真实照片。如果你将真实照片与生成结果进行对比,与 nano banana 生成的效果,你会发现生成的人脸与真实照片非常接近。由此可见,它在还原人物样貌方面表现非常出色。 这样一来,你就不必投入大量资金购置视频制作设备了,因为只需轻轻一点,你就能生成所有这些不同角度的画面。即便是美食摄影也不例外。 你只需要一张拍的不错的原始照片,或者哪怕只是一张普通的随手拍。同样,先用 nasa 来处理这张照片,然后就能轻松获得九种不同的效果变体。这些变体从不同角度呈现,比如特写镜头等,各种视角一应俱全。 这样一来,你的工作就变得超级轻松,即使是这种随意的户外人相照。你看,这是原图,这是生成的网格。再次强调一致性令人惊叹!所有这些生成的照片看起来都超级养眼。 请注意,此功能不包含在免费计划中,因为它确实会消耗积分,你至少得开通每月九美元的基础套餐才行。不过这工具确实非常实用,要是这期视频帮到你了,别忘了点个赞支持一下。想获取更多这类 ai 教程,记得关注云桥网络频道,那我们下期再见!
45云桥网络 00:44176浴室沉思录
00:44176浴室沉思录 01:30查看AI文稿AI文稿
01:30查看AI文稿AI文稿用 ai 去划分境提示词该怎么写?我们只需要抓住主体格式、分镜列表和风格这四项就可以了。主体假设我们要做一个青鸟牌易拉罐啤酒的广告格式,一张专案的电影分镜表,三乘三,网格布局,角色形象连贯统一镜头列表。 我们就直接让 ai 写一个啤酒广告分镜,脚本复制粘贴风格,照片级真实质感,电影级色彩调色景深,根据镜头类型自然变换,整体高度一致。做横笔,十六比九, 十六比九,这个还挺重要的,如果你不写的话,他可能会生成正方形的分镜。好,就这样我们深层看一下。那要是说我已经有了角色和场景,就是想要生成不同的镜头角度,该怎么办? 直接上传照片轴起,改为图片内容格式,这里再加一个焦距视角丰富多变镜头列表这一块,广角与全景,中景与美视,近景与特写,动态角度镜头。把你想要的角度或者你想要的剧情放进来, 风格这块就不说了,你想要什么风格你自己填,咱们这块保持不变。好,我们生成看一下。 最后再说一下生成的九宫格照片,如果想放大其中的某一张,可以把它放进吉梦这样写,放大这张九宫格照片的第几排,第几张就可以了。多余的话你不要说,说了他可能会出错,收工。
82Ai 的小鹿 17:09查看AI文稿AI文稿
17:09查看AI文稿AI文稿ai 生成的图像可以看起来惊艳无比,但一旦你尝试构建一个连贯的序列,它们就原形毕露了。 nano banana pro 和 gemni 三扭转了这一局面。 今天我就来教大家如何仅凭一张初识图像,仅用一个提示词就能导出无数个视角一致的新图像。 你能确保角色、场景、世界和艺术风格在每一帧中都保持高度一致。当然,一旦我们掌握了这项能力,我们便终于能够解锁创作逼真影像序列的可能性。 我是 a i e samson, 欢迎回到我的频道。我们将分三个层次循序渐进地来实现它。每深入一个层次,你对生成结果的控制力就会更强。 那么我们这次影像叔事之旅的第一步就是创建主角。这张机准图像将为我们整部影片的创作奠定基础。为此,我建议大家,生成的图像角色至少要露出上半身,光线要清晰, 姿势要明确,背景要包含足够的信息,确保脸部完全清晰可见,身体部分也尽量多展现一些。你可以用任何你喜欢的图像生成模型来创建这张精准图。 你可以从 nano banana pro 入手,当然,你也可以用 midjourney, 它是我最钟爱的 ai 图像生成工具之一,因为我非常欣赏它那种独特的 ai 图像生成工具之一,因为我非常欣赏它那种独特的核心美学风格。你们可以直接用它来生成这类图像, 你们只需替换其中任意变量即可保准能生成符合流程要求的图像。视频里用到的所有提示词请加微信云桥奈免费获取云桥网络感谢关注与支持, 算是送给大家的一点小心意。这个提示词通用性很强,在多个 ai 生图工具里都好使。接下来我会用下面这张图来演示,我选了这位来自亚马逊丛林的美丽战士公主,由她来带领我们展开冒险。 那么下一步就是使用 nano banana pro 这个工具,仅凭一个提示词就能生成一整组图像。这里有一个特别实用的提示词,我们马上就用它。 它内容比较长,你们直接复制粘贴就行。从我提供的文档里复制,然后粘贴到提示词输入框。好了,现在来看这个提示词, 这是我们看到的第一个版本提示词。这个提示词最初是由 x 原推特上一位名叫 takala 的 创作者制作的,所以必须为它在这个领域的杰出成果点个大大的赞。接下来我将使用 google flow 来运行 nano banana pro, 同时我也会分享一个可以完全免费体验的替代方案。 那么把提示词输入进去,我们直接点击上传,把主角的图片添加进去, 看它出来了。 google flow 让我喜欢的一点是,它可以一次性生成最多四张图片供你挑选。这非常实用,因为它能让我们得到一组各不相同的图片,然后我们可以选出自己最喜欢的那一张。 好了,直接点击生成吧。趁着加载的空档,我来给大家演示另一个完全免费的用法,也就是在 gemini 里面使用这个功能, 也就是说,你可以在 gemini 里免费使用 nano banana pro。 操作很简单,直接把提示词输入对话框,用同样的方式上传图片即可。为了展示多样化,我这里换一张稍微不同的图片,我用一个动画片段来给大家演示一下。另一个很棒的点是用它来处理动画效果也完全没问题, 然后点击发送。但是我生成的这张图片被拒绝了。这是因为我的衣着落腹度有点儿太高了,所以我换了一套更保守的装扮,重新跑了一遍。 如果你对无审查模型感兴趣,看完本期视频后不妨看看这个。那期视频全面介绍了最新的完全无审查 ai 图像模型。不过现在咱们言归正传,大家可以看到这里的每一个镜头都排列的井井有条。 为了让大家更清楚背后的机制,这个提示词的作用是分析图像的构图,然后它会生成一个网格,展示这个图像在不同场景下的样子,这样就能得到一组非常具体的镜头。 首先是一个极远景,也就是左上角的第一个镜头,接着是远景,然后是中远景,其余的镜头也都以网格形式排列好了。这意味着我们美丽的主角拥有了各式各样的角度。接着我们就可以用它们来生成每个场景的全尺寸大图。大家看,我输出了四个版本, 关键点在于他有时不会输出镜头标注。这些标注很重要,因为对下一步操作很有帮助,也就是我们需要分别导出每一帧的环节, 所以如果遇到这种情况,直接重新跑一遍就行,你还可以从中选出自己最中意的那一帧。我个人就挺喜欢这一个的。 下一步就是把它加到提示词里,接下来我们要提取出喜欢的镜头,我们只需用一个简单的提示词就能搞定。提取净帧,然后你可以利用标注功能输入那一帧的名称, 所以我特别想提取出那个低角度镜头。同样的,我们可以生成这个镜头的多个版本。输入提示词。趁它加载的功夫,我也给你看看它在 demo pro 里生成的效果有多棒。 在我们的动画版本里,这位花盆先生出现在所有这些不同的场景中。瞧,正如你看到的,我们得到了一张绝对惊艳的图片, 而且它与原始提示词以及我们的底图保持了高度一致。需要提醒一下,这个方法并不是次次都灵,先给你打个预防针,免得你遇到问题的时候有点懵,不知道是咋回事, 尤其是当你一次只处理一张图的时候。你看这四张里面,有两张我觉得能达到百分之九十九的准确度,一张大概有百分之七十的准确度,还有一张怎么说呢,算是翻车了,我可以再跑一次,让它生成一张不同的图, 而且你想试多少次都行。整个过程的核心就是把你选好的所有图片都导出来,以便将它们转换成你最终想要的画面系列。好了,搞定,现在我们生成了这个中远景镜头, 激动人心的时刻到了,因为现在我们就能把这些静态图片变成动态视频了。而实现这一步的最佳方法就是在制作视频时设定一个起始针, 也就是说,我们要精确的设定视频的开场画面。接下来我会分别用一款付费工具和一款免费工具来演示具体操作, 咱们先来看看付费工具怎么用,我要用的就是 google v o 三一,我们还是在 google flow 这个平台里来操作它。使用方法就是找到帧到视频这个功能,然后直接把第一帧图片添加进去就行。我这里就用这位女士的图片,你可以输入提示词来描述你想要的动作。 我建议大家从这几个方面构思,角色怎么动,镜头怎么动,还有环境怎么动,比如树木摇曳。那么我们就可以输入女人射箭固定镜头这个提示词,然后提交,当然得确认这第一帧就是我们刚才生成的那张图。 如果想完全免费的实现,我推荐使用 grog imagine, 它目前非常给力,让我们有机会完全免费的生成视频。要实现这个效果,请访问 g r o k 点 com。 斜杠 i m a g i n e 进入上传文件页面,插入提取的竞真,并确保选择视频模式。 grack 的 一大优点就是速度超快,它完全免费,而且审核限制比 google v o 三点一宽松得多。如果你对 grack imagine 感兴趣,我专门做过一期视频来介绍它,你可以看完这期视频后再去观看,所有链接都在视频简介里。好了, 咱们一起来对比一下免费版和高级版的输出效果。首先我们来看免费版 rock 的 表现效果不错,物理模拟良好,场景保持的也很连贯。唯一要挑刺的话就是他卧弓的姿势看起来不太标准,他的手只是轻轻搭在弓弦和弓身之间,但整体效果依然出色。 现在来看高级版,专为追求极致 ai 视频效果的用户打造,很明显,细节表现确实更加精细。不过射箭动作的物理模拟这里似乎有点小问题。你看这里,他做出射箭动作,但箭好像没有射出去。 如果突然出现这种情况,建议重新生成视频,我马上演示一下,然后你就会得到一个完全不同的结果,接下来才是重头戏。而让这个方法威力大增的是,它能实现不同镜头之间的无缝转场,我们只需利用视频的首帧和尾帧就能实现。 目前这个功能仅在 v o 三点一及其他高端 ai 视频模型中提供。 grok imagine 里没有这个功能,但它能让我们完全控制我们所运用的电影技法。 我来给你详细演示一下具体操作。所以你需要做的第一步是选一张图作为起始针,我们就用提取出来的这个镜头作为第一针,然后用这个作为最后一针。在勾勾 flow 里,你只需点击添加到提示按钮。看这里我们已经把这个设为首针,这个设为尾针, 然后输入一个基本提示就行,哪怕是简单的两者过渡,然后发送即可。操作之后,我们就得到了这个效果。 下一步就是对其他镜头重复这个流程,我们可以继续沿用这种首尾帧的方法,这样就能把各个片段无缝拼接在一起。 这里的关键在于要确保把上一个片段的尾帧用作下一个片段的首帧。这样当你把两段素材接在一起时,就看不出明显的剪辑痕迹,整个流程会自然衔接,毫无剪辑痕迹,从而获得这种流畅的一镜到底的蓄势效果。沉浸感十足,冲击力强劲。 这标志着真正的 ai 电影摄影术时代已经来临。我们不再仅仅追求漂亮的画面,而是掌握了真正的电影语言、远景、中景、特写、故事节奏以及镜头连贯性。但这还没完,我们还能更进一步,我们可以增加一层复杂度,从而获得更强大的蓄势表现力。 那么问题出在哪呢?问题在于,我们手头是一堆相当零散的镜头,这些镜头拍的是同一个角色,也属于同一个场景,但是缺少一条能把各个镜头串联起来的虚实线。所以整个看下来,这些镜头之间似乎没啥关联。这更像是一段蒙太奇拼贴, 而不是一个真正的故事。为了解决这个问题,我们要用上这个提示词的二点零版本。它的作用是为每个镜头都规划好一系列特定的构图,从而构建出更强大的故事序势。顺便一提,这个提示词最初来自 tag collar, 后来由一位名叫 underwood 的 网友进行了增强。 好了,我们这就动手把它粘贴到提示框里,然后重复之前的操作。这次我们换一张稍有不同的图片作为起点,但角色还是同一个,现在我把它丢给 ai 去处理。 接下来,咱们可以翘起二郎腿,坐等 ai 大 显身手。此刻,幕后正在运作的是,他正在借助 gemini 三的强大能力,仅凭我们给的第一张图就能定义并生成一个完整的故事,然后再根据这个故事来确定最终成片里每一帧的具体画面。 也就是说,他先分析图像,再据此构思故事。他把这个故事拆解成了九个不同的镜头,从而能更全面的呈现故事内容。这样一来,就不再只是单一角色在单一场景里换几个角度拍摄了,而是构建出了一个更加完整、有血有肉的叙事片段。 现在我们得到了这个输出的镜头叙列,如你所见,这让我们的蓄势能力大大增强了。每一个镜头都让我们对故事的走向有了更清晰的感知,我们还能更好的运用推进聚焦于角色和场景的细节来搊鸣剧情。 我试了几个例子,这个大概是我最中意的一个,那么我们就用同样的方法从这里导出几帧画面,大家可以参考注视。好,我们现在就来提取。然后我们可以在其中几帧之间制作动画,就能得到这个漂亮的镜头叙列。 在开始讲解最高阶的方法之前,我想先给大家介绍另一种解决这个问题的思路。这是一个不同的工作流程,能让你多一个角度来探索这个概念,而且还能每天利用免费额度来实践。如果你想把它和平面设计相关的工作结合起来,这个方法就特别合适。 这就是今天的赞助商环节。让我为大家介绍一下 ideagram, 这是一款 ai 图像生成工具,它能帮你让笔下的角色始终保持完美的一致性,无论什么场景,无论什么项目。咱们一起来看个例子。 我创建了一个角色,就叫它玛丽好了。我把玛丽放进了几个截然不同的场景里,从充满未来感的东京天际线,再到西雅图一家温馨的咖啡馆, 而他的样貌却始终如一,就连他脸颊上那颗精致的小痣,无需手动调整,也无需猜测,同一个角色就能无缝融入我所有的创作。 无论是用于社交媒体、帖子、网站、视觉,还是品牌素材,甚至打造一个 ai 虚拟网红。 ideogram 能让你生成完全一致的角色,让他穿梭于各种环境,却始终保持高度一致。这对于维护品牌形象来说再合适不过了,也能保证故事须臾的连贯性,帮你省下大把时间,这样你就能腾出手来 去专注于更宏大、更出色、更有创意的项目。那么,如果你已经准备好让工作流程更上一层楼,那就快来免费试用 ideogram 吧!亲身体验一下保持角色一致性能有多轻松。不过我们当然可以再进一步,何不升级一下,引入更强大的功能?方法就是 精确的定义我们想要讲述的故事。为此,我专门打造了一个专属提示词,有了它,我们只需输入一个简短的故事梗概,然后让 nano banana pro 为我们生成九张图片,这九张图就能完整呈现故事的主要情节。关键在于 它能保持角色形象的一致性,同时还能为我们构建出一个完整的蓄势脉络,这意味着我们可以把自己的概念和想法放进去。 这个提示词的使用方法是,首先在 gemini 里用它来生成提示词,然后导出这个提示词,再到 nano banana pro 里用它来生成图像。那我们现在就一起来操作一下。这个最进阶的流程需要两个输入项,第一个当然是基础图像,第二个则是一个简短的故事梗概。 我准备的故事梗概是一位来自南美洲的部落女子正沿着一条海岸小径行走,当她偶遇一条体型硕大的巨蟒时, 他随即与这条巨蟒展开搏斗,最终一剑将其刺穿,随后他将巨蟒的尸身带回了村庄。至此,我们这位年轻女主角的故事已经有了几个关键情节。 现在你可以把这段故事概要放在提示词的开头部分。这是指南里提供的第三个提示词模板,也就是第三个版本,我称之为导演剪辑版提示词。 你基本上可以先把故事概要放在开头,然后再接上具体的提示词内容。我建议把这段完整的提示词输入到 gemini ai 模型里。接下来你就会得到一个像这样内容详尽的超长提示词,里面会详细定义出我们所需的所有不同镜头。 我们可以拿着这个提示词,用同样的流程来生成图像。先输入提示词,再附上我们的基础底图。 提交之后,接下来就是见证奇迹的时刻,简直令人兴奋到难以置信,因为整个史诗篇章的蓝图已经在此铺开,每一个镜头都得到了完美而精致的定义。于是画面中出现了他沿着海岸小径行走的身影。接着画面切换到他与这条巨型蟒蛇对峙的场景。 我们迎来了那个让人倍感满足的美好瞬间,他一径射穿了蛇皮,接着是一个绝妙的俯拍大全景,镜头里是那条死去的蛇,随后他拖着蛇回去向部落众人展示他的战利品。 那么我们就以此为基础制作动画,将所有元素整合起来,最终呈现出一段史诗般的画面。最终效果就是这样,砰! 现在你可能会问,这些步骤能不能自动化呢?这正是有趣之处。我想给大家介绍一个由多尔兄弟打造的工具,他们是 ai 领域的牛人,他们开发了这个工具。这个工具能自动完成生成不同故事版的部分流程。 操作很简单,上传一张图片,进入故事版功能,让它生成一个网格,它就能自动创建出这样一组图像。这个工具的好处在于,它让流程实现了一定程度的自动化,但缺点是你无法像自己手动设计提示词那样掌控大局,无法获得同等的操控自由度。 但我还是想展示给大家,因为它无疑预示了未来的发展方向。未来,我们将看到更多自动化流程,用于创建像这样的复杂工作流。我们的做法是 先找到主角的一个基础形象,也就是底图,将他们优雅的姿态呈现出来。接着,我们用这些素材打造了多个风格各异的镜头。借助 nano banana pro 的 强大威力, 我们引入了故事结构,对这个流程进行了深入拓展。在最终用我们的导演剪辑版提示将所有元素融合之前,这个功能让我们可以设定基础画面和故事框架,从而生成九个精准的序式节拍,确保整体连贯,让角色、场景和风格意图之间和谐统一。 我们还探索了如何利用起始帧和结束帧,在这些不同镜头之间实现顺滑的序列动画,最终确保我们能获得一个美妙的一镜到底,长镜头完整讲述一个故事, 这就是我们现在掌握的能力,一张图片就能演化出整个场景、整个故事,乃至整个世界,现在就去创造些天马行空的作品吧。
4258云桥网络










猜你喜欢
最新视频
- 10.5万童年日记✨