CATIA如何画格姆伯茨

粉丝1285获赞6197
相关视频
 10:01查看AI文稿AI文稿
10:01查看AI文稿AI文稿好,我们接着讲啊,接着讲。好,下面我们已经把那个大面给做出来了,接下来我们做细节,细节,细节来说的话不是很难啊,我们在新建一个几何级,这里新建一个几何级也可以,什么插入几何级叫二。嗯, 好,我们把这个隐藏掉,把这个这个大便弄好了,我们也隐藏掉啊,隐藏掉,哎,就把这个显示出来,我们要做一个孔,这个孔啊,实际上 这个很容易吗?是吧?开口就好了。这个这个这个这个啊。呃,这个最难了。是这个,然后我们把这个男的先搞定,然后再搞定女的啊?不啊,不是,哈哈,先把这个男的先搞定啊,这个难一点啊。嗯。 这个思路是什么呢?思路是什么呢?我们一般在看思路的时候啊,就是先把这个啊角给去掉啊。嗯,讲一下这个思路, 因为这个我也是没画过的啊,我讲一下我的想法啊。嗯,首先你肯定假设一下这里没有啊角是一个这样的。哎呀,这个颜色好像换个颜色吧。这个肯定是一个这样东西,是不是这样东西? 嗯,然后呢?他这里有一个轮廓线,这个轮廓线是不是他在这边方向上啊?拉了一个面。 这是怎么拉的?是用什么方向?我们再探讨一下啊?可能就是做了一个方向上拉伸也可以,或者是用什么扫裂也可以啊,都可以。嗯,然后在在这里倒一圈啊,这一圈啊,然后这里一圈 啊就会搞定。嗯,实际上应该也不是很难啊。嗯,也不是很难,我们试一下。呃,试一下,那首先我们肯定要找这个面是哪里的啊?那我们就提这个线,哎,我们我们要求是能提取线啊,但是不能什么啊?不能提取面。 嗯,做一个基本平面,在一般我们安装面,我们认为是平面啊,是平面,我们做一个平面内曲线, 平面曲线啊,平面曲线也是我们用的比较多的啊,平面曲线就是这一些曲线全部落在同一个平面内,同一个平面内,是吧?我们做这个,只有这样子我们才可以 知道我们这个应该要做多大啊,我们要做多大。实际上如果你有这个线的话,你可以直接 直接给他啊,偏移出来啊。哎,但是这样这样子看的话,这里是直线,这里应该不是偏移的啊,不是偏移的好,嗯,怎么做这个轮廓啊?嗯,用草图,用草图先画一个, 先换一个,换一个大一点的,就这么大啊, 好大一个,先画一个面,其实他也是个平面,是不是?是平面, 当然你也可以提这一圈,是不是啊?提这一圈不是不是我们想要的啊, 我们想找的是什么?想找什么?打钱的一个状态啊。那我们 先斜线,用香蕉这个和这个确定保留所有啊,那我们这里就这一个线,这一个线是吧?这两根线 相交的地方就是截止点啊,截止点,这个 这些都是直线啊,让他们俩相交,我们可以用相交的命令做这个点, 点读出来。那现在我们只得出来一个点啊,实际上我们还要得出其他几个其他地方的点啊,这个这个地方的点,同样的办法,我们做一个, 哎,做一个, 呃,做一个点,然后做到了发线啊,曲线的发线, 发线,曲线的发线,这个记得平面去截他去香蕉。 好,我们再看一下这一个线是在哪里,这个在倒压之前的线在哪里?就是这这两个线。 嗯,好,香蕉香蕉叶 好隐藏啊,隐藏一些不不要的东西。好,那是这个点,那我们就知道这个点到这个点 啊,他到底是个什么关系呢? 我们就大概一下好不好?大概一下,这里肯定是个直线啊,然后这里一个弧,大概一下,大概一下的话,那就再做一个吧, 再做一个,因为我们实际上在设计的时候啊,这里只要保证这个平坦面啊, 然后呢出那个冲压的时候保证这个 r 角啊,基本上就是算设计完成啊,这个平台面满足要求 r 角大小可以冲压出来啊,就算是符合要求,这是我们设计的时候 判断了一个基准,就是你这个零件做的好不好的一个基准。你这个好像都弄不出来哦,到这边弄吧,这边弄 同样的办法,再弄一个线点线出来,这里都不是很准确啊, 不是很准确,大概弄一下,因为这个不是直线了啊,不是直线,但是实际上他也八九不离十,八九不离十, 我们这张是啊,我们用曲线去延伸镜就好了,不错的啊,把这个隐藏掉,然后去延伸,就是找到他导航前的一个, 用曲子连续啊,找到他打啊前的一个状态,隐藏掉,隐藏掉,为了大家看 看清楚啊,我们就把这个隐藏掉啊,这些都隐藏掉啊,不要。好,我们这些点大概是这样的位置啊,还是这样采用草图 反过来,那他是这样子肯定做一个线啊,我们这里不要问了,这肯定是一根直线是吧。一根直线不用那么大,做一半其实就可以了啊。这个线跟这个点什么相合约束, 然后这里呢会一个这样的弧线。是不是用弧线?这里一个点这里一个点。哎,要不要再做个点呢? 这里吧这里算一个点吧。是不是向前点吧。那我们这一个点横这一个 也是相合然后我们这个线做一个样长线,这样这里可以什么右线啊?等一下啊。然后通过这个点通过这个点 我们这一个线跟这一个线我们先固定这个线右键。哎也不一定右键啊,点的时候呢几个约束固定他就不动了啊。然后这根线按住横竖这个线我们采用什么相切 相亲,然后这个点跟这个点好吗?相合。 哎。为什么不能先喝 奇怪啊。退回来啊。那我们先下个 可以啊,然后再他跟他相合, 然后再看他能跟他能不能够相切啊。 哎有点怪啊有点怪。嗯既然有点怪那我们就再做复杂一点点,我们就不固定他了啊。固定他还可以,我们再给他打个卡。好吧。 这个相接不明显啊不明显,这里可能是有点问题啊。嗯这看上去不是不是相接啊这看上去不是不是相接。那我们再打个啊, 打到阿角他就肯定是相亲了。是不是他跟他直接打一个阿角打一个五吧, 我有点小。嗯打一个十吧。 实际上不是这么倒的实际上这个镶嵌的地方是这个地方啊,你看这个镶嵌结石点应该在这个地方是不是。好那我们再给他退回来。 这根线画的还是有点问题。嗯。怎么画线呢?啊?刚才说了啊,绘画线的才是师傅啊,绘画线的才是师傅。这根线的话是绘制的话是比较有技巧的,比较有技巧。 嗯,这个声音该怎么画?哎?要不就画圆弧跟圆弧吧,这样也可以。嗯,就这样。
28嘎嘣脆 02:51查看AI文稿AI文稿
02:51查看AI文稿AI文稿大家好,今天我们来讲一下内和开槽这两个命令,然后我们首先来看一下内命令,然后这个内命令它需要满足两个元素,一个是轮廓,一个是中心曲线,然后我们现在进槽槽,把这里先把这两个元素给它画出来, 然后我们点击槽槽,然后先画一个轮廓,然后再画那个曲线, 点击这个亮条线,然后我们要退出导入,再点击一,然后再点击内面轮廓画就选刚才画的这个这个长方形,然后中心曲线就选这个内,这个刚才画这个亮条线,然后点击确定这个内就做好了。画这个内的时候我们要注意注意两点, 第一个是我把这个这个按键先删掉,然后你退出图,但它会爆洞,然后爆洞原因就是因为这个这个轮廓它不是一个封闭的轮廓,它是一个开放的,然后它就会爆洞,然后我们再把这个轮廓给它封闭上, 然后再退出来,然后它就不会爆洞,然后点进去它就不会爆洞。还有一个就是在这个冰箱再给他画一条线, 它同样会爆洞,爆洞原因是因为这个冰箱还有根线给它相交了,它也会爆洞,然后我们把这条线给它删掉,然后它就不会爆洞,然后这个内就两个,两个点就是第一个它不能是一个开放轮廓,然后第二个不能有线跟它重叠了。内就是就讲到这里,然后现在我们再讲一下开这个开槽秘密, 然后来看一下它的背面跟内面很相似,然后都是要两个,一个是轮廓,一个是中心曲线,那我们还是一样的进草图,把它的两个元素给它画出来,然后这个按开槽,开槽顾名思义就是在一个物体上开槽,那我们首先我们得先画一个,先画一个几何体,先画一个长方形, 然后点击确定,然后我们再把那个开槽需要的两个元素给它画出来, 我们选择这个面,画一个开槽的轮廓,然后选择这个面, 把它的那个曲线给它画出来,你是要用那个亮条线,然后退出操作, 点击啊定义几何图,然后再点击开槽命令,然后轮廓也是一样,选这个长方形,然后中间曲线,我们选择刚才画这个曲线,然后点击确定,这个开槽就做出来了。然后开槽上也要注意两点,第一个是我们把这个边线给它删掉,然后我们退出槽图,然后发现它,它这个 开槽它不是封闭轮廓,它也能开,但是最好还是要给它搞成封闭轮廓,因为封闭轮廓做出来,它的精度会比没有封闭的精度会更高一些,然后把它缝上。 然后还有一个就是也是重叠的问题,我们同样在这里再给他画一个,画一条线给他重叠我们再退出,然后看他还会报错,然后报错原因就是因为有条线给他重叠了之后,我给他画那条线,我们先把这条线删掉, 删掉之后他就不会报错了,开开槽的这个命也是就是这两个问题,然后今天就讲到这里,然后有什么问题大家评论区留言。
46库诺智能汽车设计 14:16查看AI文稿AI文稿
14:16查看AI文稿AI文稿我们之前跟一家在线问诊平台合作的时候,就遇到过特别典型的问题,用户问布洛芬和降压药能一起吃吗?结果 ai 给了一篇家庭常备药清单, 看着都跟药沾边,但其实没有达到点上。后来一次数据发现,将近百分之四十的用药咨询给了参考,内容根本不能解决用户的问题。 但加上了 re rank 模型之后,相关答案比例从百分之六十提到了百分之九十二。在医疗领域,这不只是体验差一点,而是直接可能会影响到健康的决策。 其实像金融、法律、企业服务这些对准确性要求高的行业也是一样的道理,你未给 ai 的 上下文越准,他答的就越靠谱。 这期视频呢,我们就用四个问题把 re rank 模型给你讲清楚。首先,聊一聊到底什么是 re rank 模型? 它在 r g 里面的定位是怎么样的?第二,为什么我们需要 re rank 模型?光靠 abandoning 不 行吗?这也是面试里面常考的坑。第三部分,我们对比一下 buying code 和 crossing code 的 底层差异,看懂为什么 re rank 更准, 那你真正理解大模型是怎么读文档的?最后,手把手教你根据业务需求选模型,中文用哪个,多语言用哪个?要快还是要准,直接给你实测推荐。我们先来看第一个问题,什么是 re rank 模型? 简单来说,如果你把整个 r g 系统比作是一个信息解锁系统,那么它的流程呢?大致可以分为三步,召回、重排序和生成。 就好比你在点外卖,第一步你打开 app, 系统给你推了二十五家附近能送餐的店,这叫做召回。第二步呢,你从这二十五家里面挑出了三家最合你口味的,这一步就是重排序,也就是 re rank。 第三步,你下单吃上饭,这对应着大模型生成最终的回答。那么 re rank 模型呢?就是在第二步起作用的那个精挑细选的环节,具体来看,它是整个 r g 流程里面处于嗯解锁和生成之间的中间位置, 我们可以把它看作是一个第二阶段的过滤器。虽然前面的 embedded 模型已经帮我们从海量的文档里面快速捞出了 top 二十五个相关的文档,但是这些文档里面可能有些嗯看起来像,但是其实不相关的,比如说标题匹配,但是内容跑偏的。 这时候我们的 re rank 模型就登场了,它会对这二十五个文档逐个的进行打分,判断它们和用户的问题的相关性到底有多高,然后选出真正最相关的 top 三或者是 top 五,交给大模型来慎重回答。 所以它的核心目的非常的明确,在保证召回率的基础上,大幅提升剪索的准确度。也就是举个例子,假设你问如何治疗感冒, emailing 可能把你知识库里面所有提到感冒发烧咳嗽的文档都拉出来, 其实有些可能是讲感冒引发的鼻炎啊,或者是流感预防之类的,跟你的问题并不是直接相关。而 re rank 模型就会更加精细的判断, 这个文档里面虽然提到了感冒,但是重点在疫苗的接种和治疗关系不大,得分就低一点。这样呢,最后送到大模型面前的上下文,才是真正最相关、最简洁、最有用的信息。说白了, re rank 的 作用就是让大模型看到的资料更加靠谱,从而产生更高质量的回答。 现在呢,你大概明白了 re rank 是 做什么的了。那你可能会问,我们真的需要它吗?毕竟 in benny 已经能够快速找文档了。加一层 re rank 是 不是多此一举啊?这个问题非常关键,接下来我们就聊一聊为什么我们需要 re rank 模型。 首先,我们要认识一个现实, in benny 模型虽然快,但是它有局限性啊。第一个问题是语义理解有限, 编辑会把一段文字压成一段固定长度的向量,比如说五百一十二维,一千零二十四维。这个过程呢,就像是把一本厚书塞进一个标准的信封,信息一定会丢失。举个例子,假设你问为什么我不能在晚上喝咖啡, 系统就召回了两个文档。第一个文档是晚上喝咖啡的好处,第二个文档呢,是严禁在睡前摄入咖啡因。 第一个听起来很相关,因为都有晚上喝咖啡这几个字。第二个呢,其实是负面的,建议是你真正要的内容。这时候 in body 模型可能会因为咖啡晚上这些词都出现了,给这个第一个文档打个高分。但是 re rank 模型它会更深入的理解上下文,它知道 好处不等于可以喝,而严禁摄入才是真正的答案。所以 re rank 模型能够识别出文档二,才是真正相关的复相匹配。第二个问题是维度限制,什么意思呢?编辑模型会把文本压成固定维度的向量,这就意味着它很难完整表达长文本或者是内容丰富的文档。 比如一篇几千字的技术报告,被压成了一个五百一十二维的向量,那么很多细节呢,就会被挤掉。这就像是你用一张 a 四纸总结一本书,再怎么精炼,总有一些关键信息啊,会被忽略掉。 第三个问题是泛化能力弱。现在很多的编辑模型是基于特定文档集来训练的,面对用户千变万化的提问啊,他容易认错人。比如说用户问的是如何缓解焦虑,但是如果知乎里面只有抑郁症的治疗方案,那么编辑可能会觉得和情绪问题差不多就行了,结果呢,就给了错误的答案。 所以呢,综合我们上面讲的,那么应该你就是擅长广撒网,但是不擅长精准的捕捞。那我们之所以需要 re rank, 其实还有一个关键的原因啊, 现在呢,为了提高召回率,我们往往会把更多的文档喂给大模型。比如以前只给 top 五,现在可能给 top 二十,甚至 top 五十。虽然我们现在的模型,比如说 cloud 三 gemini, 这是超长上下文,但是这也带来了新的问题,那就是大模型开始吃不下了。 这里就有两个典型的现象,首先是中间信息丢失,丢失 in the middle。 因为研究发现啊,画模型对输入文档的注意力分布往往是两端强中间弱的。 比如说,你给了他十个文档,第一个和最后一个他记得最清楚,但是中间第五个文档的内容呢,他可能根本没有注意到。就像是你一口气读完一整本书,开头和结尾记得牢,这能够理解吧?那另外一个现象呢,是指令遵从能力下降。 也就是说,当上下文太长的时候啊,大模型更容易走神,容易忘掉你的原始指令。比如说,你刚刚明明说的是只回答医学建议,结果呢?他突然开始聊心理学的理论了,因为他被中间某一个段落给带偏了。 那怎么办呢?结论其实非常清晰,我们需要 re rank 模型,把 top 二十五缩减为最精准的 top 三。注意啊,这里的二十五呢,和这个三只是举个例子, 应用中可能是 top 十到 top 五,或者 top 五十到 top 八。关键是让大模型只看到最相关、最干净的信息。 这样做的好处是提升解锁的准确性,避免误诊。同时减少了大模型的信息噪音,让他能够专注思考,最终输出的回答也更加准确、更简洁、更可控。 行业角度来看, re rank 已经成为了生产级 rng 系统的标配,尤其是在金融、医疗、法律这些对准确性要求极高的场景。没有 re rank, 直接用 in banning 为大模型,很容易出错,甚至引发合规的风险。 ok, 我 们刚才聊了,为什么要用 re rank? 因为它能够解决 in banning 的 语义模糊、信息丢失的问题,还能够帮大模型避免吃太多消化不良。 那接下来的问题是,为什么 re rank 会更加准呢?它和 inbounding 到底有什么本质区别?其实啊,这背后的关键在于它们的模型设计思路完全不同。我们可以把 inbounding 和 inbound 看作是两种不同的阅卷老师。 inbounding 呢,像是一个速读阅卷员,他先把所有的考卷提前打个分存好,等你上交了作文题,他就快速翻出分数最接近的几份。 而 re rank 呢,则更像是一个语文特级教师,他会把你的作文题和每一份考卷放在一起,逐字逐句的对照, 看看这篇泛文到底是不是真的能够回答你的问题。这两种方式呢,一个快,一个准,而它们背后的技术架构就分别叫做 by encoder 和 cross encoder。 我 们先说 in bend 模型,用的 by encoder 双向编码器, 核心思想是分别处理 query 和文档。然后呢,比对向量,具体是怎么做的呢?他先把用户的问题 query 和知识库里面的文档 command 分 别送进 word 模型,每个都经过一个独立的编码过程,生成各自的向量。最后呢,通过计算这两个向量之间的余弦相似度来判断相关性。 这就有点像什么呢?像你在相亲网站上去找对象,系统会先把你的资料和对方的资料分别打分,然后看看两个分数有多接近。 但问题是,你俩有没有真正聊过天,有没有互相了解?可能你们的兴趣爱好很像,但是其实性格完全不合,这就是 by encode 的 局限,它只看到了表面的匹配,没有做深度交互。 它的特点也很明显,速度快,文档向量可以提前算好,存在向量数据库里面爬的时候呢,只需要算一次。 query 向量适合大规模的海选, 但是它精度较低,因为它是独立的编码,信息会被压缩,容易丢掉上下文细节,所以它很适合做第一阶段的广撒网快,省资源,但是不够精细。 而 re rank 模型用的是 cross in code 交叉编码器,这个名字里面的交叉就暗示了它的核心,它的设计思路完全不同,把 query 和文档拼接在一起,一次性分析。有的它会把输入变成这样, c l s。 然后为什么我们不能在晚上喝咖啡 加一个 s c p? 严禁在睡前摄入咖啡因 s c p。 然后呢?把这个完整的序列扔进 book 模型里面,让它直接分析每个词之间的关系。关键来了,它不是分开看,而是让 query 的 每个字都能够看到文档的每个字,这就是所谓的 all to all attention。 注意力集中, 你可以想象成你请了一个专业的心理的咨询师,不是只看过你的简历和对方的简历,而是让你们俩坐下来面对面的聊聊天, 看看你们的每一句话怎么回应,再判断你们是不是真的合适。这种深度的互动就带来了两个核心优势,精度极高,它能够捕捉到语义上的细微差别。我听到过一种说法,这是一种一对一的 vip 服务,没有信息压缩,也没有,也没有预判偏差。 最后,他不给你两个向量,而是直接输出一个零到一之间的相关性分数,比如说零点九八二,非常直观。但是他的代价是什么呢?速度慢,开销大。因为每次查询都要实时计算整个训练, 而且计算量远大于简单的向量点击,所以它只能用于第二阶段。比如说只对前二十五个召回结果做成排序,不能用来全库解锁。说了这么多,你可能会问,市面上这么多 ray rank 模型,到底该选哪一个?是越大越好还是越快越好呢?有没有一个万能选手? 答案是,没有万能的模型,只有最适合你业务的那一个。就像你买手机,有人要拍照好,有人要续航强,有人呢只在乎价格。选 raytr 模型也是一样的,得看你的核心需求是什么。我们可以从三个维度来选。如果你追求的是性能和准确度,那么呢,你就要请那些精度天花板级别的模型。 先看左边这一个, v c re rank face v e, 它是网易出品,在中文和中英混合任务上表现非常突出。在 q n s 的 测试里面,它的效果甚至超过了部分更早期的。比如说日元的模型,特别适合做中文场景下的高精度检测,比如客服问答、知乎查询这类对准确率要求极高的应用。 再看右边这个 b g 一 react layerwise 版本,这是正源推出来的搜特级的模型,代表了当前最先进的技术之一。它最大的特点就是支持多层的输出,你可以选择不同的层级的注意力结果来做排序,相当于给模型开了个多档位的调节,灵活性非常高。 在英文和多语言任务上,它的精度通常是行业的天花板。所以如果你不差算力,又想把召回质量做到极致,这两个是首选。 那如果你需要多语言支持呢?那你就不能只盯着中文模型看了,推荐你用,嗯, bg rewrite v 二 m 三。请注意,这里呢是 rewrite 版本,不是那个用来做向量的 embedded 模型。它专门针对多语言场景优化, 支持中文、英文、法语、西班牙语等一百多种语言。如果你的系统要服务全球的用户,或者知识库里面有大量的外语内容,那么这就是你的标配。举个例子,一个跨国企业的内部知识库,可能既有中文的策略文件,又有英文产品手册,这时候呢,如果你只用纯中文模型, 就会漏掉关键信息,而 b g re rank v 二 m 三就能够帮你跨语言精准匹配。那么如果你更看重效率和响应速度呢?那就要考虑轻量级模型了。比如 b g re rank face, 这是一套专门为平衡速度和效果而生的模型,参数适中,但是在 gpu 的 加持下,推理速度非常的快。比如实时聊天,机器人搜索框及时反馈。 想象一下,用户打完一句话,等了好几秒才出结果,那肯定不好啊。而用这种轻量级 re rank, 能在非常短的时间内完成重排序,让用户感受到秒回,大大提升了交互体验。当然,它的代价是精度略低一些,但是如果你已经通过了 embedding 做了初步的过滤, 只要保证 top 里面有答案就行了,那这点精度损失啊,还是可以接受的。那么到底该怎么选呢?我的建议是,别盲目跟风,先拿数据试一试。通常推荐的顺序是先试试 b c re rank base 或者是 b g re rank base, 这两个在大多数场景下都能够取得不错的平衡。如果你发现精度还不够,尤其是处理复杂与意识容易出错呢?那就升级到 b g l vise 版本。 那如果你要支持多语言,直接上 b g re rank v r m 三,如果系统卡顿,响应慢,就回到 b g re rank space, 并且减少重排序的文档数量来提速。 记住一句话,模型不是越贵越好,而是越合适越好。好了,那么今天的分享就到这里了。今天我们从什么是 re rank 一 路聊到了怎么选模型。它只是在 r i g 流程中扮演了一个精挑细选的角色, 用更精细的方法把大模型看到的上下文变得更干净更相关,从而让最终的回答更靠谱。在实际落地中,很多人一开始只用 in banning, 结果发现深圳的答案经常答非所问,后来加了 re rank, 才发现原来质量能提升那么多。可以说, re rank 已经是生产级 r g 系统的标配组建,尤其是在金融医疗法律这些容错率低的场景几乎是必不可少的一环。
379AI大模型学习 09:52查看AI文稿AI文稿
09:52查看AI文稿AI文稿好,刚才那个直线线呢,我们就讲完了,下面我们讲圆形扫略啊,圆形扫略,圆形扫略的话我们在做管道啊,或者是其他的时候呢,是也是经常用到啊,这个讲三条引导线的第一条三条引导线啊,就是 g 一、 g 二、 g 三三条引导线啊,做出一个圆弧的扫略面,圆弧扫略面。好,下面我们演示一下。画三条直线,把这个先删掉啊, 把坐标系显示出来啊,三条线,实际上这三条线也不一定是直线啊,我们做难度大一点好不好。做三条, 做两条直线,两条直线,两条直线和一条非直线,这样子来演示啊。嗯,呃,这样子的话,再偏一个平面出来, 在这里吧,这里,呦,不对啊,再偏移一下,二十可能没有二十十吧。十,确定,这里再画一个,再画一根线 啊,摆正摆正回来啊,那就是在这两条线的上面,这两条线的这里画一个这样的线,试试看啊,画点圆弧吧。这样这样这样啊, 这样能不能行啊?我也没试过啊,能不能行?应该是可以的啊,试一下啊, 试一下啊,这样三条三条线来圆形扫略一下,点击扫略。 扫略啊,这个 g 一 g 二 g 三,就相当于 g 一 g 二 g 三,是不是哦,我们把这个打上一下吧,刚才也是同样的,这里这里是两个吧,这个打上一下, 不打算的话,他依然是同时选择了啊。好,点击扫略三条引导线选择第一条,这就好了,第一条,第二条,第三条,他是默认的直线, 就是这个十二。第一条是为直线啊,直线啊,预览一下,你看能做出来是不是能做出来啊,这个极限很重要啊,如果你选择这条线为极限,你极限他的形状是不一样的啊, 你看又不一样了。嗯,你选择哪条线为底线?那就是在这个几线上 做的任何一点做法线平面去和这三根线相交,三根线相交不得到三个点吗?这三个点做成一个圆弧,三个点可以确定个圆弧是不是然后 所有的圆弧一个集合,就是这个扫略的这个结果啊,就这个结果。嗯,希望我能够讲清楚啊,能讲清楚再讲一次啊,因为这个,呃,如果是听的次数比较少的话,真的是很难理解啊。我我要不这样吧,我,我先点确定,我给大家演示一下是什么意思? 就是说底线刚成这个底线吗?底线上任何一点啊,做法线、曲面、法线、平面,然后与这三根线相,而这三根线相交,这个 他与这个三根线啊这里相交。我们讲一下啊,可以一个这个平面同时交三根线啊,点击这个,点击这个啊,就可以选择一根、两根、三根可以同时相交啊。 完毕点确定,这时候就出来三个点,这三个点啊,一个、两个,三个点。嗯,过这三个点可以做圆弧啊,我做一下啊,这三个点做圆弧,嗯 啊,这个三点可以做一个圆点。圆,是不是我们选择三点做一个圆啊?这实际上可以做圆弧,是不是第一点,第二点,第一点,第三点, 好,刚好就是这个圆,好确定,如果这个圆弧全部落在这个曲面上,就说明我说的肯定是对的,是不是?那怎么检验这个圆弧是不是全部落在这个曲面上呢?你去切一下, 如果线能够切面,那肯定这个线是在这个切面上,要不然就是不能成功啊。那好,我们切一下试试看能不能成功啊。 啊,我也没试过啊,应该是肯定可以成功的啊,听一下啊,来看可以剪切,是不是就证明我说的这个原理是百分之一百正确的啊?就是几线上任何一点做法,线平面与三条线相交得三点,三点确定一个圆弧,确定一个圆弧啊, 这是这圆弧线,然后所有的圆弧线的集合就是这个扫略的一个结果啊,这已经解释的很清楚了啊,我觉得。嗯嗯,好好, 接下来我们讲这个扫略的第三种啊,圆形扫略啊,圆形扫略啊,讲此此类型里面两个点和半径。两个点和半径。嗯,下面稍微解释一下。嗯,这两个点 实际上也就是两条引导线啊,引导线一,引导线二,加上一个半径啊,加上一个半径 r, 所以 这一个少率的一个特点是什么?他的 r 都是一样的,都是一样的啊。好,我们下面演示一下,所以要做两个引导线,嗯,做两个引导线, 这也这也是直线啊,我们其实也可以不是直线啊。嗯,画两根线啊。嗯,我们画一根直的,画一根不是直的,试一下啊,画一根直线啊,画一根这个 样条线,这样确定。好,这样这样两条线我们打散一下, 打散一下。好,这两条线我们点击扫略, 点击扫略。好两个啊,圆形,圆形是圆形吧,看下这俩字啊,圆啊,就是圆啊,其实这样是圆形扫略啊, 好,两个点和半径,两个点和半径选择引导线一好,引导线二好,我们再数输入一个半径,这个半径如果输的太小啊,就不能成立啊,我们就输入一个五试试看啊。 确定啊?没有?你看此运算没有任何解法,也就是说这两个线可能的最小距离啊,他都已经大于五,所以你输入五是没用的啊。嗯,这里有一个极限的概念啊,极限我们先选啊,这个,这边这边有极限啊。 好,我们加大一点,五十啊,看一下啊,你看五十就出来了啊,大一般都没问题,就是小了容易出问题啊。二十看能不能行。二十二十也可以的啊,这里面有好几个减啊,有六个减,那我们可以点下一个下一个下一个下一个下一个 下一个,这样子,下一个下一个下一个。好,一般情况下我们是这种,是我们想要的,是不是?我们来预览一下,确定一下啊?好,这个就做出来了。这个有什么特点?有什么特点?就是所有的圆弧啊,几线上 所有的圆弧,几线上任何一点的法线平面与这个面相交得出的圆弧啊,半径全部一致啊。我测量一下, 测量一下,这个是二二十,是不是这个是吧?那肯定也是二十,是不是刚才几线?我们选这个几线是不是几线?好,我们这个上面任何一点,我们做任何一点 任何一点,然后做法线平面跟他相交得出来的交线,他肯定也是一个圆弧线,并且是 r 二十啊,这证明我的那个解释是完全正确啊。 r 二十这两下,你看是 r 二十,是不是 r 二十,就是这么一个问题,如果 你选这边为底线啊,那就要从这边开始啊,双击可以更改,是不是?双击更改,我们把这个底线选这边这个,哎,把引导引导线二,就是这个曲线作为底线,我们确定一下, 我们做出来这个跟它看上去有点像,是不是实际上是不一样的啊?实际上是不一样的,你再去切这个可能就不是, 那他就不是 r 二十啊,你看这个线刚才切的吧,我隐藏掉,我再去以这边的切,因为他这不是极限了啊,我再去切他就不一不一样了啊,那不一样了,你看这一个就不一定啊,不一定,不一定是二十,你看这是是不是啊?十九点九五,不一定是二十,那我们 在这个圆弧上去切就一定是。嗯啊,这随便啊。这个,这个是极限吗?刚才啊,跟他相交 香蕉出来,这个肯定是什么 r 二十,吃两下啊,对, r 二十,是不是?好,这个已经解释清楚了啊,好。
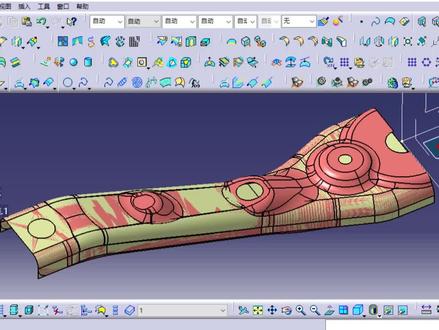
338强哥_CATIA视频课程 00:54查看AI文稿AI文稿
00:54查看AI文稿AI文稿这种形状本不该存在,他叫格姆博茨,是人类发现的第一种自复位几何体。绝大多数几何形状都至少拥有四个平衡点,包括稳定平衡点与不稳定平衡点。比如你把一颗牛油果尖端朝下立起来,那个尖端就是一个不稳定平衡点, 一旦松手,他就会倾倒,最后稳定在一个能躺平的位置上。除了格姆博茨,所有已知形状都至少拥有四个这样的平衡点,无论他是稳定还是不稳定的,而格姆博茨的平衡点却连三个都不到,他只有两个。 这意味着,无论你以什么角度将它放下,它最终都会滚动回到同一个位置。但它和我们熟悉的不倒翁完全不同。不倒翁能复位是因为内部重心偏向一侧,而哥姆勃磁的质量分布是完全均匀的。 后来科学家在自然界中发现了相似的存在,经过数百万年的演化,大自然早已创造出了自己的哥姆勃磁,那就是乌龟的壳。这正是乌龟不小心四脚朝天时总能自己翻过身来的关键原因。
2708大脑补给站 00:47查看AI文稿AI文稿
00:47查看AI文稿AI文稿上海胶带又来送硬核福利了!这套瓢开源的动手学大模型教程,直接把大模型学习的门槛拉低了一大截!张卓胜教授领衔打造的干货,完全免费开源,主打一个手把手带你实操!不管是预训练模型微调部署、 l p i 调用推理, 还是语言模型编辑、文本水印、业余攻击,甚至是当下超火的多模态模型,这套教程全都给你安排的明明白白,为啥说他值得充?不仅内容全、 实操强实、配度还广,不仅适合新手轻松入门,有基础的研究者也能挖到,实用技巧,课程项目、科研、公关、工程落地都能用得上。我不光整理好了教程链接和配套 ppt, 海内外打包了深度学习入门必备的余书和包含 c m n g n t s f r m 的 基础模型代码库。全套资料已经准备就绪,想在大模型领域稳步进阶的朋友,可别错过这次机会!
12AI不会绝迹 01:53查看AI文稿AI文稿
01:53查看AI文稿AI文稿好,今天讲解的是布尔操作的应用,布尔操作主要分为添加艺术香蕉以及联合修剪和艺术块。首先是联合修,首先是添加,添加的话就是将这块加到这里, 这个就他就变成一个块,这个就没有像刚才这样像这个边线了。再然后就是移除,移除的话就是相当于把这个相当于把这个块从这个和这个块相交的地方给挖掉,相当于从比如这个地方我们就不要了,我们在这里画一个块, 老将它从这个上面去掉,相当于这个地方我们就给挖掉了。然后艺术块的话就相当于是点选选中这个,把这个多余的地方我们给它挖掉下去, 像它达到这个类似效果的还有艺术面,艺术面的话就需要把这个我不要这个块所有的面都给选上,才能达到小艺术掉,艺术块的话就相当于要方便一些。然后还有就是 香蕉饼,香蕉饼的话就是相当于这两块香蕉的这一部分我们把它保留下来, 而联合修剪的话就相当于是我们可以选择只消只修剪掉这个部分多余出来的,而不是 有这个地方,而不是像他那样只保留这中间的地方,我们可以选择保留我们想要的,就这样 这就是相,这就是波尔操作,然后波尔操作实际运用中的话就是这个替代, 像我们这些画这些键的时候就很多都运用到这些波尔操作的命令。好,本次的讲解就到此结束,有什么问题请在评论区底下留言。
43库诺智能汽车设计






