同学们看这是一个非常简单的程序,那为什么我们运行的时候屏幕上没有打印语句呢?给大家讲一下。那么这里边最根本的原因是这是一个行缓冲,那么缓冲区没有满的时候,程序是不会往屏幕上输出的,那行缓冲区的大小是多少呢?给大家看一个测试程序,你很快就明白了。 大家看,当在我的缓冲区数组当中放幺零二四个字符的时候,那么他会不会输出呢?我们来测试一下, 大家看到是没有输出的,说明我们缓出去当中存得下幺零二四个字符,那么他能存得下更多吗?比如说我把它改成幺零二五, 我们重新的运行一遍,你会发现存不下了,所以通过这样的一个程序,我们做了一个验证,好缓冲区的大小是幺零二四。

粉丝20.9万获赞88.2万
相关视频
 01:38查看AI文稿AI文稿
01:38查看AI文稿AI文稿在 python 编程里, flash 是 个重要概念。简单来说, flash 就 像给管道通一通,能让管道里的水数据马上流出来。在 python 的 输入输出操作中,默认是有缓冲区的。 缓冲区就像一个小仓库,程序产生的数据会先存到这里,等仓库满了或者满足特定条件,才会把数据一次性发送出去。 而 flash 的 作用就是强制把缓冲区里的数据立刻输出。就好比你在给朋友写信,写好的内容并不会马上寄出去,而是先放在一个盒子缓冲区里,等盒子装满了再一起寄走。 但有时候你需要写好一部分内容就马上寄给朋友,这时就可以用 flash 来实现。在 python 里,像文件操作、网络编程都会用到 flash。 在文件操作中,当你往文件里写数据时,数据会先进入缓存区。如果不调用 flash, 可能在程序结束前数据都不会写入文件。 例如以下代码, file equals open test dot txt w file dot round 如果不执行下面这行代码内容,可能不会及时写入文件。 file flash file close 在 网络编程中,当你通过套接字 socket 发送数据时,也会涉及缓冲区,使用 flash 能确保数据及时发送,避免因缓冲区的存在而导致对方接收数据延迟。 总结一下, flash 在 python 里主要用于强制刷新缓冲区,让数据及时输出。如果你希望数据能马上生效,就可以考虑使用 flash 行动。建议是在编辑文件操作或网络编程代码时,根据实际需求合理使用 flash, 确保数据能及时处理。
 10:51查看AI文稿AI文稿
10:51查看AI文稿AI文稿pasa 从零开始学进阶篇 pandas 的 介绍语使用在工作的时候是不是想要效率更高,多出来的时间你可以摸鱼,但是又希望做出的结果准确又高效,美美的升职加薪这个系列的课程我将带大家一起学习如何使用 python 中的 pandas 库实现办公自动化。 pandas 是 python 中最强大的数据分析库,它能够帮你以自动化处理海量数据,让你从重复的劳动中解放出来。 相信大家肯定在工作中遇到过重复枯燥的工作,例如给一千个产品建立 excel 文档的销售情况,每一个产品就要创建一个文档,一千个产品就要创建一千个。假设创建一份文档要五秒钟,创建一千份就要五千秒, 也就是一刻不停歇的工作一个多小时,并且很难保证创建的过程中不会出现遗漏和重复。那么为什么不把重复的工作交给电脑来做呢?反正电脑又不会感觉到累。 我们只需要简单的写几行代码就可以轻松的创建一千个文档,并且需要几十秒的功夫。那么接下来我们就来学习这个非常高效又实用的库 pandas。 首先我们先来下载安装这个第三方库, 大家需要注意的一点是, pandas 不 能够直接读取和保存 excel 文件,因为 excel 不是 文本文档,所以我们需要借助其他的库。也就是我们在安装第三方库的时候需要安装三个库,一个是 pandas, 一个是 open python, 叉 l 和叉 l r d。 在 这是使用 pandas 操作 excel 之前,我们先来看一下 excel 表格的结构,每个 excel 文件都有多个工作表, 每个工作表都可以以表格的形式来储存数据,那么我们如何使用 pandas 来操作 excel? 在 python 中处理其他的文件,那么我们就肯定需要读取文件。首先我们在代码中引入 and a school, 然后使用 read excel 方法直接读取 excel 文件。 但是这样读取的 excel 表只能够读取到 excel 表中的第一个表格。 如果想要读 excel 文件中指定的工作表,也可以在后面写上 sheet name, 然后写上指定表格的名字,或者使用缩引号来读取。缩引号还是从零开始的。 学会了如何读取已经创建好的 excel 表格,我们也可以使用 python 来创建 excel。 首先 excel 表都是有表头的,也就是存在一个对应关系, 这关系在 python 中就使用字典来储存,比如像现在我就创建了一个字典,每一个键名后面都跟着三个值, 键名就相当于 excel 表格中的表头。但是 excel 看不懂 python 中的字典,那么我们想要把数据转化成 excel 的 二维表格形式, 有需要使用的 data free 方法。现在 d f 这个变量中就是转化为二维表格的数据。想要把这个数据保存到 excel 中,就使用 to excel 方法。现在我们就成功创建了这个 excel 表。 使用这个方法保存数据,会自动给我们的第一列加上缩影。如果你不想要这个缩影,觉得有点丑,可以使用 index 等于 false 取消掉这个功能。想要读取 excel 表中具体的内容,那么我们先要读取整个文件,然后根据表头的列名来访问数据。 如果只访问一列,那么就不会出现表头,如果访问多列的话,就会出现表头,并且自动加上缩印号。如果你想要根据条件来筛选想要看到的内容,也可以使用上条件表达式。 比如在这里我查询价格列中大于七千的数据,那么就会访问整个价格列表,然后将里面的数据进行判断。 第一个六千九百九十九没有大于七千显示的就是 false。 三个八千九百九十九大于七千它才会显示出。我们再次使用 df 把它框住,就会显示整个数据中价格大于七千的产品数据。 学会了如何访问文件中的内容,那么我们可不可以修改 excel 表中的内容呢?假设我想要给现有的这个新产品库存表 添加一列折扣价,那么还是需要先读取这个文件。获取到现有的数据之后,我们直接写上一个新列名折扣价,这个折扣价的列名是原价的九折, 这样我们就创建了一个新的列。得到了这个二维表格之后,我们需要将它重新储存到这个新产品库存中, 这样我们就得到了新的一列折扣价。如果你不想要出现新的一列,想要在价格上直接打一个九折,那么你也可以直接改成价格等于原来价格的九折, 覆盖掉原来的值,并且把它储存到对应的 excel 表中。现在我们已经知道了 pandas 处理 excel 表的基本操作,如何运用它来处理大量的 excel 表呢? 接下来的练习时间,我将带大家批量操作创建 excel 数据表格,来感受一下 pandas 在 处理大量数据时的魅力。 我们在拍照中来批量的创建一百个产品的一个 excel 文档。因为我们没有实体的数据,所以我们可以使用随机数来产生这些数据, 这个例子也仅供我们练习的时候使用。现在我们来导入两个库,第一个库是 pandas, 使用 input 给它取上一个别名 pd, 然后需要使用到随机数,那么我们就需要使用 readman 库。导入这两个库之后,我们将产品列表和销售员列表写上, 首先写上产品列表 products, 将上面的这一串复制下来,然后再写上销售员的名字, 朝三礼四,往五朝六。那么我们现在需要来创建一百个 excel 文档。之前我们讲过,在 python 中重复的工作需要使用的就是循环来做,因为我已经明确地知道了要创建多少个产品。 那么使用循环的话,是使用 for 循环还是 while 循环呢?显然我们需要使用到的就是一个 for 循环,因为 while 循环只在不知道要循环多少次时使用。而这里创建一百个 excel 文档,我们需要使用到的就是函数 read 一 百,也就是循环一百次。 那在这个里面,我们先要来填充上一个数据,写上 data, 在 这里使用的是字典的形式来创建数据, 每一个表格中都有产品的名字以及销售语言的名字。写上产品名称之后,我们来随机地生成这个产品,使用 redman 点 choose, 从这个列表中随机生成产品。 除了产品名称之外,我们还需要生成销售语言的名字,那么我们也是从 saleman 这个列表中抽取, 那么这样我们就构成了一条数据,产品的名称就只能从里面抽取一个,销售人员的名字也就一个,如果我想要抽取多条数据的话,我们也可以在这个里面写上一个负循环,用中括号将里面的数据扩起来, 然后这个随机函数的方法写上 for, 使用下划线指代,因为我们暂时在一个里面不需要使用到变量,然后产生五条数据,那么就写上 reach 五, 下面的销售员名字也是这样子的,我们无法考证。现在我们就创建了一个字典,并且循环了一百次,那么创建这个字典 excel 表,它是不能够看懂这个字典是什么意思的,我们需要将这个数据 转化为二维表格形式,写上 p d 点 data 三 free。 现在我们可以来打印一下,看一下是不是产生了一百条这样子的表格数据呢? 运行一下这段代码,可以看出来已经创建了一百条数据,那么我们将这一些数据重新的填充到这个 to excel, d f 点 to excel, 因为是将这一个数据填充到 excel 表中,所以我们使用的是 d f 点 to excel, 然后写上括号,将我们想要创建的文件位置放到这个里面就可以了。 那么文件位置我在这里创建一个新的文件夹,用来专门储存。这个随机生成的一百个 excel 表,叫做 products fill, 创建了之后我们所有的数据都在这个里面,放到这个里面就可以了,那么我们可以复制上这个路径, 然后在这个里面粘贴进去。每一个 excel 文件都有自己独特的名字,我们给这个产品边上号 这个 i, 每一次都是零一二三四五六七八,就是一个天然的编号,我们可以使用这个 i, 然后加上 excel 的 后缀名, 然后取消掉它的序列号。那么我们现在来运行这段代码,看一下能不能够创建一百个 excel 文档。因为 excel 文档比较多,所以创建的比较慢,现在已经创建完毕了。现在我们打开这个目录,可以看到已经成功地创建了这些 excel 表, 进入到这些表中,我们可以右击点击到打开余,然后选择资源管理器。那么现在大家可以看到已经成功的创建了一百个文档,从零到九十九,也就是一百个,每一个文档中都有五条数据。 现在大家是不是能够领略到 panda 对 处理大量数据的魅力了呢?下个视频我还会分享 panda 酷的其他方法操作,如果你感兴趣的话,记得给我点赞关注,或者你有什么感兴趣的 python 相关的操作,也记得在评论区留言。
506话多的小孟 05:10查看AI文稿AI文稿
05:10查看AI文稿AI文稿下面我们看字节艾屋这个类啊这个类啊,嗯,顾名思义是对字节的读写是吧?啊,并且是在内存缓冲区中啊, 那么在内存缓冲区中操作啊,这个结果呀,啊还没有持久化到磁盘啊,等一些戒指是吧?好了,我们来用用一下这个类啊, 那么也是首先呢引入这个对象,引入这个泪啊,泪也是对象, 好了,叫做, 那么首先呢,我们就是声明一个对象, 声明的 boss 我的对象 是你的对象,那么这个对象啊,我们叫 bb, 他就等于啊等于这个 nicel, 那么他会有一些方法是吧?他会有一些方法。 f 点什么 写方法是吧?哎,不,不好意思,必点啊, 那么注意他是写自己啊,那么如果你这个 串啊是中滚的,我们来试一下子 是个中文是吧? 好了,那么我们写中文,我们来试一下子,看看他是个啥结果 啊,他肯定会有什么方法啊。盖头挖流, 我们先看看是什么结果。 他说书这个参数啊,不是自助串类型,那么我们呢可以给给他这个编, 让他变成这个自助刷类型啊,让他变成这个 str 类型, 那么我们按这个 utf 来编码, 这回啊他就是他就可以写了,他就可以写了。 那么同样道理啊,我们 这个对象啊,他会有这个关闭资源啊,这个方法对吧?他会关闭资源,这个方法用完了就把资源关闭啊, 防止什么内存泄露了,内存溢出了之类的问题上资源直接关闭。 那么我们除了这个 方法之外呀,我们还有什么方法呀?还有毒方法是吧? 读方法, 这个读方法他读出了个什么?读出了一个 b 啊? 因为啊,就是 啊,因为我们这个 这串是这个,是吧?所以他读出了这么个东西啊,他读出了这么个东西, 那么你想获取这个所有内容啊?啊? 你想所以获取所有内容啊,那么你还是用这个方法,他,他显示所有内容,是吗?当然呢,这个字节啊,你来看他也没什么意义,是吧?那么他是一个这个 utf 八这个编码格式啊,看他也没什么意义 啊。 看着是没什么意义啊,那么存储的时候那就有意义了,是吧?啊?因为他存储存储啊, 这种编码格式他存储的跨平台,是吧?跨平台,而且他什么哪个国家的这个 啊?字符都能接受,是吧?就是这个,这个字符即是全世界通用,是吧?他有这个好处啊。
 02:47查看AI文稿AI文稿
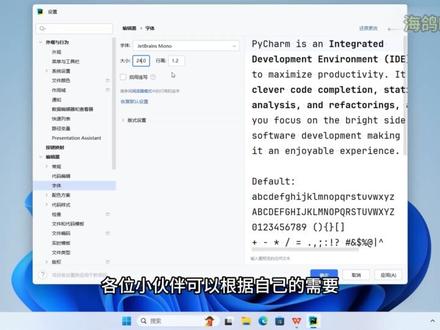
02:47查看AI文稿AI文稿pygone 从零开始学第一章设置 pycharm 大家好,这一讲我们来设置一下 pycharm。 第一次使用 pycharm 有 几个地方我们可以设置一下,第一个就是 pycharm 默认的语言是英文,我们可以把它修改成中文。 第二个就是 pycharm 默认的主题是深色主题,我们可以把它设置成跟随系统,这样如果你的系统是浅色主题, pycharm 也会使用浅色主题。如果你的系统使用的是深色主题,那么 pycharm 也会使用深色主题。 最后一个是设置代码字体的大小,拍叉默认的字体大小可能比较小,不容易看清,我们可以手动的给它设置的大一些。好,接下来我们就来实际操作一下。 打开拍叉, 第一次启动拍唱会,提示我们需要获取许可,我们点击这里的试用三十天获取试用许可。 获取到试用许可之后,接下来我们就来进行相关的配置。 首先我们来设置拍唱的语言,点击这里的自定义,在语言这里我们选择简体中文, 现在 pachum 提示我们需要重启 pachum 才能生效。点击重启, 重启之后我们就能看到 pachum 的 语言已经修改成中文了。接下来我们来修改一下 pachum 的 主题,还是点击自定义,接下来在主题这里我们点击与操作系统同步, 现在 part time 就 修改成浅色主题了。最后我们再来修改一下代码字体的大小,点击所有设置, 展开编辑器,点击字体在大小这里我们就能修改代码字体的大小, 我这里未来大家能够看清使用二十四,各位小伙伴可以根据自己的需要来进行设置,点击确定完成代码字体的大小设置。 好,这讲就到这里。
14海鸽Python 01:12查看AI文稿AI文稿
01:12查看AI文稿AI文稿这期视频来介绍一下列表的大小,可以通过魔术方法 size o 来获取一个变量占用内存的大小,它返回的是变量占用的字节,一个空列表占用的内存是四十个字节。至于空列表为什么是四十个字节, 需要在后期讲解 cps 解释器中列表的具体结构的时候才能解释清楚。再看下面这两个例子,这两个列表都是包含三个元素, 但是不管这三个元素是什么数据类型,不管他们有多大多小,这两个列表占用的内存空间都是六十四个字节。原因就是列表中实际存储的是每个元素的内存地址,也就是 c 语言中的指针, 每一个内存地址占用八个字节。这也是为什么列表可以存储任意其他的数据类型。我们知道列表是一个动态的数据类型,下面来看一下列表是如何扩展它的内存空间的。首先定义一个空列表,此 时占用的空间是四十个字节,然后往里面追加了一个元素,这个时候他扩展了三十二个字节,也就是四个元素的空间。 继续追加到第五个元素的时候,他又扩展了三十二个字节。由此我们可以得出结论,每次超出容量时,他会自动扩展四个元素的空间。
169MuscleCoding 04:58查看AI文稿AI文稿
04:58查看AI文稿AI文稿挑战,每天讲透一个 python 基础知识,今天 why 循环配套学习文档学习资料直播公开课主页粉丝群。 大家好,我是马可,欢迎来到我们 python 零基础系列的第六节。今天呢,我们来看一下一个新的内容,叫做微摇循环, 那在之前的话,我们已经学过一个叫破循环的东西,对不对?那 will 循环的什么呢?来我们来看一下他是怎么介绍的,他说 will 循环是 python 中最基本的循环之一,它的核心作用是指定布尔条件重复执行一段代码块。 好,你看到这里的时候呢,你就会有点感觉,什么感觉呢?根据指定布尔值条件执行一段代码块,那这个是啥?这个好像是我们的异父吧,用的这里加了一句话叫做重复, 对吧?啊,他说只要给定的判断条件的违规啊,循环体内的代码就会不断的运行,他非常适合处理那些事先不知道具体循环次数,但知道终止条件的场景。 那我们来看一下,我们举个例子啊,即使啊,你看这个代码的话呢,我们如果说直接去看,哎,他其实非常的简变,他好像跟我们的衣服也长得差不多,对吧?啊,前面呢是一个关键字,后面呢是我们的什么?是我们的条件对不对?我们的条件表达式对不对?好,里面的内容呢,就是说只要为真就会执行你们的代码。 好,那他的逻辑其实是这样的,来,我们看到这个位置,他会做这样的一个事情啊,假设我们现在呢要开始运行或说执行这个对应的一个 vr 代码了,那首先会怎么样呢?哎,首先呢这里会进行一个判断,我画出来 来在这里,这里呢会执行个判断。好,那假设这里如果是缺的话,哎,就会执行下面的代码,执行完成之后,如果是我们的衣服会怎么样啊?会结束对不对?会执行下面的代码对不对? 对吧?啊?但是不一样啊,如果是我们的胃啊,他会回过头来,回到这个位置继续去判断,如果为缺继续执行下面的代码啊,继续执行, 然后呢再回到上面,哎,形成一个循环啊,并且同学们,这个循环他是怎么样的?他是一直重复的对不对?一直不会有变动,对不对啊?这就是我们喂养循环的一个特点, 那你看我们喂养循环的一个基本用法是什么样的呢?首先啊,必须使用关键字喂养,后面紧跟一个条件表达式啊,然后呢再加上冒号和我们统一的一个缩进, 然后呢如果初设条件就为 false, 那 么循环填的代码一次也不会执行啊,那好,那同学们,你们看一下这个代码他会执行几次呢? 你们思考一下,他会执行几次啊?你看这里呢,他还做了一件事情,什么事情呢?他在这里面呢写了一个勘测啊,勘测加一对不对,为什么会写这个呢?同学们,你想如果说我直接小于个三,什么都不动的话,那好,那我每次过来判断是不是都是一样的呀?对不对啊?注意,如果是这样的话,他就是一个死循环, 他就是个死循环,他永远出不来,对不对啊?那好,如果说我们的条件每次都在增加啊,从零加到一,加到二,加到三,等到了三的时候,这里的条件还能执行吗?不能,他就会跳出这个循环,而这样的方式我们就可以控制 他的一个循环次数了,这也是我们微奥的一个灵活之处。那我们往下看,那在这里呢,有一个叫做数字计数器的东西, 他说通过计数器视力可以直观理解到循环的一个过程啊,你看他呢,哎,先写了个 i 等于一,然后呢? will i 小 于等于五,然后 print 当前的数字。是啊,这是一个格式化字母串,对不对?好 好,如果说每次进来对不对,他都会去执行,那他就会怎么样?从一开始打印,打印到哪里啊?打印到五结束,对吧?打印到五来结束对不对啊?最后完成我们的一个循环数字计数器,那再往下看啊,你看还有一些对应的一些模拟,对不对?比如说,如果啊,你再做一个游戏那么好, 那么 v 啊,就可以用于处理这种持续的状态啊,只要玩家的血量大于多少啊,怎么怎么样,或者说怎么怎么样,都可以去进行一个对应的处理啊。但是这里大家一定要注意, 一定要小心,一个东西叫死循环。为什么这么说呢?因为刚才我们发现啊,就说如果说这个条件如果没有改变的话,同学们会怎么样? 会一直执行,不会停止,对不对啊?你看死循环呢,是指循环条件永远满足,导致程序无法停止的一个现象啊,这通常是因为忘记在循环内部更新变量啊,那我们前面的那个 ctrl 加等于一的操作,是不是就是在更新变量啊?或者说判断逻辑有误,比如说我写了一个 if 这个异物导致呢?我的一个更新变量的操作无法执行啊?那他每次是不是会选择同样的一个分支,导致永远无法执行这个更新变量的一个操作,对不对啊?他说死循环会大量消耗 cpu 的 资源,导致系统或甚至操作系统这个卡死啊。所以说注意微量循环的是我们特别需要小心注意 的一个循环,而不像我们过之前那么的一个什么随意了。好吧。啊,那你学会了 v 二循环,那你就掌握了自动化或说编程自动化的第一把钥匙啊。那还有什么更新的内容,我们下节课再看。配套学习文档,学习资料,直播公开课主页粉丝群。
38程序员马可 03:28查看AI文稿AI文稿
03:28查看AI文稿AI文稿拍张从零开始学第三张,三点四,文件的打开与关闭。今天我们要学习的是了解文件的打开与关闭。首先文件分为两个类型,一个文本文件由字母组成,通常有明确的编码, 如遇 tf 杠八以纯文本形式存储数据的文件。另一个就是二帧制文件,由二帧制格式存储数据的文件,没有统一的字符编码,用于存储非文本数据,如图片的点 png 或点 jpg。 然后我们首先要先学会打开文件,所以我们需要使用文本函数打开文件,这个是文本函数的基本语法, 它就是用来打开指定的文件,并返回一个 file 变量,这里的文件名就是指定文件的路径。如果文件和当前派藏脚本在同一个目录下,就可以直接写文件名就行。我们可以通过运行程序来查看派藏脚本所在的目录,这里我们的派藏脚本的位置在 c 盘, 所以我们在文件夹中创建一个 txt 的 文本文件,并给它取名为派藏学习资料。然后我们再看到代码,直接在文件名这样写, 一定要把文件的类型也加上。如果我们的文件在其他盘里面该咋办呢?我们看到我的文本文件不小心创建到了 d 盘的零六文件夹里面了,然后我们可以这样,但是这里就要注意一下,在文件名前添加字母。二,它是原始字符串, last ring 是 它的完整体, 它的作用是把普通字母串标记为原始字母串。然后这边的反斜杠是转移字母的意思,用于特殊字母,就像制表符,直接反斜杠 t 就 能代表,但是前面加了二原始字母串,会让反斜杠失去转移功能,所以文件名的路径就能正确识别查找到文件。 接下来我们要讲打开模式,它就是决定我们打开的方式是什么样子的。常见的打开模式分别为二 w a 表示只读模式二是默认的打开模式,只可以读文件的内容,不能修改或添加文件内容。文件必须存在,否则报错。写入模式 double u, 打开文件时,文件不存在则创建,存在则清空原有内容。 非加模式 a, 文件必须存在,否则也报错。如果在追加模式下打开文件,会在文件的末尾添加新的内容,而不会删除原来的内容。 如果我们在使用 open 函数打开文件后,对文件的内容进行操作后,我们需要及时关闭文件,因为计算机对打开的文件数量是有限的,所以你不操作关闭文件就可能会导致数据丢失等问题。 所以接下来我们来学习怎么关闭文件。关闭文件我们使用 close 方法即可。我们来看到代码就像这样,然后这里有一个需要注意的事项,就是你在读取文件的时候,文件不小心被你删除了,这时候程序就可能会报错, 然后就会导致 code 方法不会被执行,就会导致文件没有被关闭。然后我们为了避免这一类事情发生,我们就可以用 try file 里,无论 try 中是否发生异常, file 里快中的代码都会执行。我们看到下面代码,我们先使用 try, 在 try 中打开派放学习资料的文本。文件二代表,止步文件并拷定中的 u t f 杠八是用来解决乱码的, 读取文件就会是中文,如果没有添加就会是乱码。然后我们再用 file 变量要用力来读一打开的文件中的全部内容,再使用 print 输出看片,我们就可以得到文件里面的内容 了。在执行到 find 中,无论 try 中是否发生异常, find 中中都会执行 code 方法,我们也可以在下面使用 print 提示是否关闭文件, print 执行了,那也就说明 code 方法已经关闭文件了。还有最后一种 word 语句, word 语句是派单资源管理的最优方案,相比于 print 语句更简洁更安全的方法。 我们看到下列代码, file 就是 将 open 函数返回的文件对象复制给变量 file, 我 们发现没有写关闭的文件的代码。没错,未可以自动关闭文件,无需手动使用 cos 来关闭。 本节课我们学习文件的打开和关闭的基础知识。下节课我们将进一步学习文件的读写等操作。然后我在最后给大家整理了课后笔记,希望大家能在课后去复习巩固知识。这节课我们就结束了,下节课我们学习文本文件的读写操作。
 03:30查看AI文稿AI文稿
03:30查看AI文稿AI文稿pixon 零基础入门第三张三点七文件路径你知道怎么在 python 中使用别的文件吗?在 python 中,我们除了编辑自己的代码之外,常常还需要操作其他类型的文件,比如文本、文档、图片、音乐或视频等。 那么我们如何在 python 中打开其他的文件呢?我们在电脑中打开文件时,需要知道文件保存的位置,然后点击打开。 python 也同样需要知道我们要打开的文件存放在哪里。 这个问题就需要我们查找到文件的路径。文件的存放路径主要分为两种,绝对路径和相对路径。 先来看什么是绝对路径。在电脑中,文键通常储存在各个分区盘符之下,我们可以把文件想象成一片叶子,而盘符就像是它的根。绝对路径的意思就是从根开始,一步步查找到目标文件。 在这个过程中,我们需要依次经过一系列文件夹,这些文件夹在 python 中被称为目录,我们将这些目录按顺序串联起来, 每个目录之间用反斜杠分割。写完目录之后,我们要把目标文件的文件名补充到后面。需要注意的是,在 python 中,反斜杠符表示转一字符不能直接输出。 如果我们想在字母串中表示一个反斜杠,可以采用两种方式,一是把它作为特殊字母使用两个反斜杠输出来。二是在字母串开头加上 r, 表示取消掉反斜杠符的转移,字母正常输出反斜杠符。 在电脑中,我们也可以飞快地粘贴上文件路径,鼠标右击查找到目标文件,选择属性,就会弹出窗口,找到目标文件在电脑中的位置,直接复制目标文件的绝对路径,但是要记住还是需要加上目标文件的名字。除了绝对路径,还有相对路径。 绝对路径是从根目录开始查找目标文件,而相对路径则是基于当前文件所在的位置去查找目标文件。例如,我现在想要在 demo 文件中查找 test 文件,而我们要找的 test 文件与 demo 文件都在同一个名为 study 的 目录下,我们使用点反斜杠来表示当前所在的目录。 我们需要查找的是当前同一个目录下的 test 文件,那么我们就直接写上点反斜杠,加上目标文件的名字就可以了。 在同一个目录下点反斜杠可以省略,我们直接写上目标文件的名字也可以找到。那么如果不在同一个目录下呢?例如,现在我们想要查找的还是 test 文件,它是 demo 文件所处的当前文件上一集目录后目录下的文件, 我们使用两个点反斜杠表示上一级目录。找到了同属的共同目录之后,就能够按照顺序输出目标文件的相对路径,这样我们就能够成功查找到上一级目录下的文件。如果想要查找更上层的文件,则继续往前面加上点点反斜杠就行了。 在所属文件中使用相对路径查找目标文件,最重要的一点就是用清两个文件都同属于哪一个目录,下面是所处于文件的上几级目录, 上一级目录就写一个点点反斜杠,上两级目录就写两个点点反斜杠。相比于绝对路径,我更推荐大家使用相对路径,因为我们编辑代码后,通常需要将代码和相关文件一起打包给用户,如果使用绝对路径,用户存放文件的路径和你的不相同的话,程序就无法正确找到文件。 而使用相对路径的话,只要将整个文件夹打包,用户把整个文件打开,引用的位置还是正确的。这个视频我们主要学习了在 python 中如何查找文件的位置,具体的文件操作我们下期视频再见。
123靠谱的乐一 10:30查看AI文稿AI文稿
10:30查看AI文稿AI文稿这一小节呢,我们将来讲解 p e p 八规范。好的,各位,欢迎回到大师编程,我是阿森老师,那么在上一小节中呢,我们有提到拍省中的标识符, 那么它本质上就是一种命名规范啊,我们按照它的要求去做就 ok 了。那么这一小节呢,我们将来讲解 p e p 八规范。 那么 python 呢,是用这个 pep 八作为一个编码规范的啊,就我们之前讲的所有的规范都是基于这个 pep 八的,其中的 pep 呢,是这三个单词的缩写,它翻译成中文叫做 python 的 增强建议书, 八代表的是 python 代码的样式指南。好,这些东西你可以不去理解,你就,你就认定一个理啊,就 p p 八就是 python 的 规范就 ok 了。 好,我们来看一下。第一点,叫每个 import 的 语句只导入一个模块,尽量避免一次性导入多个模块。好,这个我们等会去演示啊。第二个,不要在行的末尾添加分号,也不要用这个分号将两条命令放在同一行 啊。第三个的话呢,就建议每行不超过八十个字符,如果超过了,你用这个小括号去连接起来,当然我们也可以用反斜杠连接,但它不推荐。 第四点,我们可以使用必要的空行来增加代码可读性啊,至于它的一个空格函数啊,我们到时候给大家演示一下。好吧。 第五点,就通常情况下,在运算符的两侧,函数的参数之间以及逗号两侧,都建议使用空格来进行分割。好,那么这五点呢,是特别重要的规范,我们一起看一下。 好,那么现在呢,我尝试第一个啊,就是每个 input 的 语句,我只导入一个模块,尽量避免导入多个。好 错误的写法。是这样的,叫 import requests, 然后加上一个 import smtp lab 啊,那么你同一行导入了多个模块,就是一个不对的写法,就是一个不规范的写法啊, 那么这个你可以怎么换呢?换成 requests 和 smtp lab 啊, 所以我把这里标示一下,这个是一的错误示范,这是一的正确写法。 ok, 好,那么第二个点呢,叫做不要在行尾加分号,也不能够用分号分割同一行的两个命令啊,写一下。好,我们先来写那个错误示范吧。 呐,在这个位置啊,我可以定一个 x 等于五,也可以定一个 y 等于六,并且呢,我用那个分号去分割几个不同的内容, 这都是不规范的啊,它虽然不报错,对不对?它不规范啊,你看它都是提示的 p e p 八,对不对?就不满足 p e p 八的规范。好,那么正确的写法呢,其实非常简单啊, 你不要定义三个变量吗?那就是 a 等于一, b 等于二, c 等于三,你用这种最常规的写法就 ok 了。好,这是第二个,那么第三个呢,叫做建议每行不超过八十个字母。好,我们这里又定一个, 定一个变量吧,来,我把它写一下啊, 好,用,这个反斜杠连接对不对? ok 啊,然后呢,就不推荐这个反斜杠啊,当口误了。好,然后呢,我们来尝试一下,现在我定义了一个变量叫 s, 它的长度挺长的,对不对?来这里写上一个,全都是 a 啊,我写很多个,很多个。 好,那我们现在来看一下吧,这个 a 究竟有多少个啊?在这里我可以 print 一下这个 s 点棱好行, 直行好,一百二十个啊,肯定超过了八十个,对不对?那么这种情况呢,你可以从中间把它隔开,那么它就会使用一个括号给它包起来,这个叫隐式的连接,当然这个括号我们也可以换成什么呀?也可以换成那个 s 和 p 吧,我们写上一个好,当然这个呢,我们可以换成那个反斜杠,它一样是可以的,但我们不推这种写法,好吧。呃,这是第三个啊, 第四个,我们来看一下,叫做使用必要的空行来增加代码可读性。好, 具体的内容呢,我就不写了,对吧?那个具体的那个描述不写了,当然那个演示我还是得有,就比如说现在啊,我定义了一个函数 df, 叫做 f 一 好,它里面什么都不写。 好,你看啊,那如果把那个 f r 紧跟着它去写了,好,这个时候它就会标出一个黄色的提示,对吧?呃,它让你干嘛呢?让你去格式化这个文件,因为你不符合要求,就函数与函数之间呢,它建议是空两行,好, 对吧?当然这里还有一个格式化,来看一下啊,它还是两行吧,对不对?好,注意啊, 然后有一些情况呢,你要空一行啊,就是当我们写上一个累的时候啊, class and 就 叫 person 吧。好,当然这个语法的话呢,你们现在不用去掌握啊,我先写给你们看,在这里面去定义方法啊,注意,在内里面就不叫函数了,它叫方法好,比如一个吃饭的对不对? 以及一个什么呢?一个 snape 睡觉的,就是人总要吃饭和睡觉,对不对?好喽,就这两个啊,你发现 当我们写这个累的时候它里面的这个 d f 就 只要空一行,好吧,呃,那么这些都是记载在那个 p e p 八里边的,所以呢你用到了你再去记它是没问题的,而且当你有了 id 之后呢,如果你的格式 不太符合标准啊,你可以直接的一键格式化。好,那么这个呢,就是第五个点啊,哎,这是第几个?这是第一个,第二个,第三个。哦,第四个点对不对?好,写一下啊。 好,那么第五个点叫什么呢?叫做通常情况下在运算符两侧,逗号两侧。 呃我们以及这个什么参数之间啊,我们都用空格来分割一下。说那一题啊,如果你写了一个注示我也建议你打个空格。 ok 啊,你不要去接着这个注示去写啊。 好,那么这一点呢相当于我额外补充的。那么这个是什么意思呢?就你看我在写代码的时候啊,我不管是 a 等于一, b 等于二, c 等于三我都怎么写的,我都加了一个空格,当然你不加空格可不可以呢?也没问题,但是你不标准,你加空格就是标准的 好,但这里是因为有了一个 x 了对吧?喏,这样写没问题啊,但如果你没有这个空格的话呢你就不标准了对不对?好,行。呃,这是第一个啊,就是运算符两侧, 然后是函数的参数之间,逗号两侧啊,都用空空格来隔开啊。那你像我们之后会学到一种数据类型啊, 叫做列表啊,这里面如果你要去定义内容的话一二三四五。 ok 啊,你看上去没什么问题,但是呢他建议你每个逗号后边要隔上一个空格,那么这种呢是符合规范的写法,再者就当你去定一个函数的时候。 好,这里面有两个参数,分别是 x 和 y。 好, 就不写 x y 吧,因为他之前定义过对吧,那么这里写上一个。呃 l a 和 na 对 吧?我随便写的啊,然后再写上一个 pass。 好, 那么注意啊,现在呢你的 test 里面就有两个参数,你中间有个空格对吧?啊那么这个是符合规范的写法。 那么顺带一题你去调用这个 test 的 时候呢,你传第一个参数,传第二个参数你也要干嘛呢?去进行一个空格,而这个地方你如果不空格呢,它同样会提示你不标准啊,所以这个就是最常见的五种 p p 八规范啊。那如果说你想了解更多的这个规范呢,你就去在这一个网站里边查看啊,那在这里 都是英文的啊,没关系啊,我们可以去翻译一下。什么叫翻译为英语啊?我们已经是英语嘛,来给它翻译成中文 哈。翻译成英语啊,它本身是英语怎么翻译啊?呃我换一个浏览器看一下。它没有另外的浏览器,我换一下 i e 啊。喏,这可以翻译吗?试一下啊。翻译成。呃怎么还是英语啊? 好,我再翻译成 中文啊,翻译一下啊,这个就可以了啊。呃所以呢它里边呢是有很多描述啊,如果说你有兴趣的话可以去看一下,但一般情况下呢你记住我们这五点就差不多了。 好,那么以上呢就是关于 p e p 八规范的一个讲解了,这一小集就到这里结束了。
 03:43查看AI文稿AI文稿
03:43查看AI文稿AI文稿这个视频给大家来介绍怎么样给 pycharm 配置不同的拍摄环境。当我们在写项目的时候,因为要用到不同的库,所以每次写项目的时候配置的拍摄环境是不一样的,尤其是我们在打包的时候,你不同的环境打包的时候差别会非常非常的大。 那么现在我们就来给大家介绍一下怎么样给 pycharm 配置我们需要的一个拍摄环境。现在我这个 d 盘里面有一个叫做测试的文件夹,然后我在这个文件夹上点右键, 然后点这个 open pycharm, 就 用这种方式,我们可以新建一个 python 项目,这个时候我的 python, 我 的 pycharm 就 打开了,打开之后因为我没有给它配置任何的东西,所以它是空白的,现在我们来给它配置 python 环境。 呃,前面给大家介绍的视频里面,我们已经新建了这几个拍摄环境,三个拍摄环境,这个环境一和环境二是不太一样的,他们俩差别在哪里呢?这个环境一里面没有 panda 这个库,而这个环境二里面是有这个环境库的,是有这个 panda 那 个库的,我们来看一下它的差别在哪里。 在这个 pypum 的 左上角四条横线的这个地方,点一下主菜单,然后点这个设置, 点完设置之后,我们来给它配置 python 解释器,就右面这个地方,我点添加解释器,添加本地解释器,这个地方出来这样一个对话框,我不用生成新的啊,我用选择现有, 选择现有之后,在这个地方就是这个文件夹,把它点开,点开之后选到我们这个文件夹里面来,我们看到了有环境一、环境二和环境三,我先选环境一,就是打开这个文件夹里面这个 python, 点 exe, 点打开,然后点确定,然后点,大家可以看到点完之后啊,它给我给我们显示出来的这个软件包一共只有三个,对不对? 一共只有三个,我们直接点确定这个环境就 ok 了,就已经配置好了。当我们现在站在这里面新建项目的时候,比如我新建一个 python 文件, 我叫它啊,我也叫它测试,或者叫 test 吧,写个单词吧,别写拼音了,说记一下 python 文件,好,新建了一个 python python 文件,我们来随便写个代码 print, 你 好,现在我们来执行一下 右键运行,我们可以看到就打印出来了,你好,对吧?那么我们怎么样来验证它有没有安装 pandas 呢? 回车一下,把它往下搞一搞,然后在这个地方用 import pandas as pd。 大家可以看到写完了这句代码之后,这个 pandas 下面它有一个红色的波浪线,就代表这个库没有安装,我们来跑一下右键运行,大家可以看到 这个报错, no model 就是 没有这个库,对吧?那么现在我们来把这个环境啊给他来换一下,刚才我们配置的是环境一,对不对?我们再来重新配置一下,同样的设置方法是一样的啊,只是这个添加显示器这个地方我换了,我换成另外一个, 依然是选择现有,然后选择这个文件夹,刚才我们选择的是环境一里面的这个 python 点 exe, 对 不对?现在我们换成这个这个环境二里面的这个 python 点 exe, 同样的点,这个点打开点确定, 大家看现在在加载,对吧?大家看到加载出来的这个 python 库了吧?已经是有了,然后点确定这个时候 pycharm 更新之后,刚才那个红色的波浪线是不是就已经消失了?这右键运行 大家可以看运行无误,对吧?这个就是给 pycharm 配置不同的发送环境,这个视频就给大家介绍到这里。
28杨哥教你学函数 13:43查看AI文稿AI文稿
13:43查看AI文稿AI文稿欢迎来到 kuda tile python 内存模型讲解教程。在现代 gpu 编程中,理解内存模型是实现高效并行计算的关键。 q tile 提供了一个强大而灵活的内存模型,让开发者能够精确控制县城间的数据同步。 本教程将深入讲解 q tile 的 两大核心概念, memory order 内存顺序和 memory scope 内存范围。通过本课程,你将掌握如何使用这些机制来构建安全高效的运行程序。让我们开始这段精彩的学习之旅。现在让我们了解 q tile 内存模型的核心概念。 首先, qtyl 采用了一个允许冲排序的内存模型,这意味着为了提高性能,编仪器和硬件可以对操作进行冲排序。如果我们不使用显示同步,县城之间的内存访问就没有保证的顺序。 为了解决这个问题, qtyl 提供了两个核心机制。第一个是 memory order, 也就是内存顺序,它定义了原子操作的内存顺序语义。 memory order 包含四种模式, relax 只保证原则性,不保证顺序。 acquire 用于读操作,确保能看到之前的写入。 release 用于写操作,确保写入。对后续读曲。可见, aqure 用于读改写操作,结合了 acquire 和 release 的 特性。第二个核心机制是 memory scope, 也就是内存范围,它定义了参与内存顺序的现成范围。 memory scope 有 三个级别, block 范围用于同一 block 内的现成同步,这是最快的同步方式。 device 范围用于同一 gpu 上所有现成的同步 可以跨 block。 c s 范围用于整个系统的同步,包括多个 gpu 和 cpu。 理解这两个机制是掌握酷 tile 内存模型的关键,为什么我们需要内存模型呢?让我们通过一个经典的问题场景来理解。 假设我们有两个县城在写作,县城 a 是 生产者,他要做两件事,步骤一,写入数据, data 树组的第零个元素设置为四十二。步骤二,设置就绪标志 ready flag 树组的第零个元素设置为一,县城 b 是 消费者,他也要做两件事。 步骤三,检查就绪标志。如果 ready flag 的 第零个元素等于一,步骤四就读取数据,把 data 第零个元素复制给 result。 看起来很简单,对吧?但是这里有严重的问题,由于变易器和硬件的指令重排序优化,县城 a 可能先执行步骤二,再执行步骤一,这就导致县城 b 在 步骤四可能读到旧的未始化的 data 零值,即使他已经在步骤三看到了就绪标志为一, 最终结果就是程序出现不确定行为,数据不一致。这就是典型的数据竞争问题。这就是为什么我们需要内存模型来显示的控制内存访问的顺序。现在让我们来看解决方案,使用内存顺序同步。 在生产者县城 a 中,我们依然先写入数据 data 零等于四十二。但是在设置就绪标志时,我们使用 atomic store 原子存储函数,并指定 order 参数为 release。 这个 release 语义非常关键,它确保了之前的所有写入操作,也就是 data 零等于四十二,在标志写入时一定已经完成。在消费者县城 b 中,我们使用 atomic load 原子加载函数来读取就绪标志,并指定 order 参数为 acquire。 这个 acquire 语义保证如果获取到 flag 等于一,那么一定能看到生产者 release 之前的所有写入。现在我们建立了一个同步关系, release 确保之前的所有写入在标志写入时完成。 quire 确保能看到 release 之前的所有写入。这样当消费者读到 flag, flag 等于一时,就一定能正确读取到 data。 零等于四十二问题完美解决。这就是 acquire 和 release 内存顺序的强大之处。现在让我们深入了解 memory order 的 第一种 relaxed, 也就是松弛续。 relaxed 有 三个核心特性,第一,它保证原子性操作不会被打断。第二,它没有顺序,保证不能防止重排序。第三,它不能用于县城间同步。那 relax 适合在什么场景使用呢?它适合简单的计数器和独立的原子操作。让我们看一个代码实力,这是一个简单的计数器,实现 每个县城使用 atomic add 原子加法来增加计数器的值。注意,这里的 order 参数设置为 memory ordered。 relaxed 这个操作只关心原子性,也就是确保多个县城同时增加计数器时不会出现数据错误。但是它不关心序,不需要与其他内存操作同步。执行顺序的可知化是这样的,假设有两个县城可能的执行顺序是 data 等于一, 然后 counter 加加,然后 data 等于二,然后 counter 加加。但这个顺序是不确定的,可能会被重排。重要的是 counter 的 原则性得到了保证,记住, relax 只保证原则性,不提供同步能力。接下来是 memory order 的 第二种 acquire。 acquire 获取序用于读操作。 acquire 有 三个核心语义,第一,它专门用于读操作,也就是 load 操作。第二,后续的读写操作不能重排到该操作之前。 第三,也是最重要的,当读到由 release 写入的值时, release 之前的所有写入都变得可见。让我们通过时间线来理解,在 acquire 操作作之前,其他操作可以重排,但是 acquire 就 像一个同步点,后续的所有操作都不能重排到它之前,这就保证了内存访问的顺序性。 来看代码视例,这是一个消费者读取的场景,我们使用 atomic load 来读标志,并指定 order 参数为 memory order 啊。 acquire 这个 acquire 语义确保如果获取到 flag 等于一,那么生产者在 release 之前的所有写入都是可见的,这就建立了现成间的同步关系。 acquire 通常与 release release 配对使用,一个用于读,一个用于写,共同构建同步机制。现在来看, memory order 的 第三种 release 释放序用于写操作 release 同样有三个核心语义,第一,它专门用于写操作,也就是 store 操作。第二,之前的读写操作不能重排到该操作之后。 第三,也是最关键的,当 acquire 读到该值时, release 之前的所有写入对读取现成。可见。通过时间线来理解, release 在 release 操作之前的所有操作都不能重排到它之后。这就像一个战篮,确保了所有之前的写入都已完成, 而 release 之后的操作可以重排。来看代码示意,这是一个生产者写入的场景,我们使用 atomic store 来写入标志值,并指定 order 参数为 memory order。 release 这个 release 寓意确保当消费者通过 acquire 读到 flag 等于一时, 生产者在 release 之前的所有写入都是可见的。 release 与 acquire 配对使用,形成了一个完整的同步机制。 release 发布数据, acquire 获取数据。接下来是 memory order 的 第四种,也是最后一种。 xqrow 获取释放序,用于读改写操作。 escape 的 核心特点是结合了 acquire 和 release 的 语义,它专门用于读改写操作,比如 atomic add, 原子加法, atomic exchange, 原子交换等。具体来说, escape 有 两个层面的语义,第一,读操作具有 acquire 语义,能看到之前的写入。第二,写操作具有 release 语义,确保写入对后续读曲可见。 从时间线来看, sql 提供双向限制,操作之前的所有指令不能重排到之后,操作之后的所有指令不能重排到之前。这是最严格的内存顺序保证之一。来看代码是例,这是一个原子交换操作,用于实现锁机制。 我们使用 atomic exchange 尝试获取锁,并指定 order 参数为 memory ordered a c q l。 这个操作同时具有 acquire 和 release 语义。 acquire 确保能看到之前持有锁的现成的修改。 release 确保当前现成的修改对下一个获取锁的现成。可见, a q, r l 是 实现复杂同步源语如锁信号量的关键。现在让我们通过对比表格来总结 memory order 的 四种模式。 首先看 relaxed 松弛序,它保证原子性,但没有同步能力,也不能防止冲排序。适用于 load 和 store 操作,主要用于简单计数器场景。 acquire 获取序,它保证原子性,具有同步能力,能防止后续操作冲排到之前, 专门用于 load 读操作,典型场景是读取同步标志 release 释放序同样保证原子性和同步。能力能防止之前的操作重排到之后,专门用于 store 写操作,典型场景是设置同步标志 acq real 获取释放序,它保证原子性和同步能力,提供双向限制,既防止后续操作前移,也防止之前操作后移。 用于 rmw 读改写操作,如原子交换和原子加法。从上到下,同步能力越来越强,性能开销也相应增加。选择合适的内存顺序是在正确性和性能之间找到平衡。记住 relax 最快,但不同步。 acquire 和 release 配对使用实现同步。 a square 最强,但开销最大。现在让我们了解 memory scope 内存范围的第一种 block 快范围,用于同一 block 内的同步。 block 范围有三个核心特性,第一,顺序保证只适用于同一 block 内的县城, 同一 block 内的县城可以看到内存操作。第二,这是最快的同步范围,性能开销最小。第三,它不能跨 block 同步,不同 block 之间无法通过 block 范围建立同步关系。 block 范围的使用场景主要有两个, block 内的共享内存同步以及同一 block 县城间的协助。 让我们看 gpu 的 结构格式化。 block 零是同步范围,其中的 thread 零和 thread one 可以 通过 block 范围进行同步,而 block one 是 独立的,它的线程无法与 block 零的线程同步。代码示意了 block 范围的使用。 我们使用 atomic store 写入共享缓冲区,指定 order 为 release, scope 为 memory scope block, 这样这个写入操作只对同一 block 内的县城可见。记住 block 范围是最快的,但只能在 block 内使用。如果需要跨 block 同步,就需要使用 device 或 cis 范围。现在来看, memory scope 的 第二种 device 设备范围用于同一 gpu 上所有县城的同步。 device 范围有三个核心特性,第一,顺序保证适用于同一 gpu 上的所有线程,包括所有 block 中的线程。第二,性能开销中等,比 block 慢,但比 sis 快。 第三,可以跨 block 同步,这是它与 block 范围的主要区别。 device 范围的使用场景主要是多 block 协助以及全据数据同步。 从可视化来看,整个 gpu 都是同步范围。 block 零 block v block her block 三。所有这些 block 都可以通过 device 范围进行同步。代码示意展示了跨 block 同步的场景。我们使用 atomic add 原子加法操作全局计数器,指定 order 为 acq, rail scope 为 memory scope device, 这样所有 block 中的县城都可以安全地访问这个全局计数器。 device 范围是实现跨 block 写作的关键,适合需要全局同步,但不涉及多 gpu 的 场景。现在来看, memory scope 的 第三种,也是最后一种 system 范围,用于整个系统所有县城的同步。 cs 范围有四个核心特性,第一,顺序保证,适用于整个系统的所有线路。第二,包括多个 gpu 和 cpu。 第三,这是最慢的同步范围,性能开销最大。第四,提供最强的一致性保证。 cs 范围的使用场景主要是多 gpu 协助以及 gpu 与 cpu 之间的同步。 从格式化来看,整个系统都是同步范围, gpu 零 gpu 一 以及 cpu。 所有这些处理器上的线程都可以通过 science 范围进行同步。代码市里展示了跨 gpu 和 cpu 同步的场景, 我们使用 atomic store 写入系统标志,指定 order 为 release, scope 为 memory scope sis, 这样这个写入操作对所有 gpu 和 cpu 上的线程都是可见的。记住 sis 范围提供最强的同步保证,但性能开销也最大。 只在真正需要跨 gpu 或 gpu cpu 同步时,使用三种 memory scope, 从 block 到 device 再到 cis, 播放量越来越广,性能开销也越来越大。现在让我们通过对比表格来总结 memory scope 三种模式。 block 块范围覆盖范围是同一 block 性能,三颗闪电,最快 使用场景是 block 内的共享数据。 device 设备范围覆盖范围是同一 gpu 上的所有 block 性能,两颗闪电中等,使用场景是多 block 写作 sis 系统范围 覆盖范围是整个系统,包括多个 gpu 和 cpu, 性能亦可。闪电最慢。使用场景时多 gpu 或 gpu cpu 同步,从上到下覆盖范围越来越广,但性能越来越慢。让我们看性能优化建议,第一,优先使用 block, 这是最快的同步方式。第二,必要时使用 device 用于跨 block 协作。 第三,谨慎使用四 s, 因为性能开销最大。第四,选择最小满足需求的范围。记住这个原则,使用最小的 scope 来满足你的同步需求。 不要用 device 来做 block 能完成的事情,也不要用 sis 来做 device 能完成的事情,这样才能获得最佳性能。现在让我们看一个完整的实战视力生产者这消费者模式。 这是一个经典的多线城写作场景,生产者现成写入数据并设置就绪标志,消费者现成等待标志后读取数据, 让我们看完整的代码实现。首先是生产者部分使用 release 羽翼。如果当前是生产者现成,第一步,写入数据,我们创建一个 tile, 填充值为 block id, 然后使用 store 函数存储到 data array 数据库中。 第二步,使用 release 写入标志,调用 atomic store 函数设置 ready flag 为一,并指定 order 为 memory order 的 release。 这个 release 语义非常关键,它确保之前的数据写入操作对后续读取可见。接下来是消费者部分使用 acquire 语义。如果当前使用 acquire 读取标志, 调用 atomic load 函数读取 ready flag, 并指定 order 为 memory order acquire 这个 acquire 语义确保。如果读到 flag 等于一,那么生产者在 release 之前的所有数据写入都是可见的。通过 acquire 和 release 的 配合,我们建立了一个完整的同步机制,确保。
15岁月静好@宁@君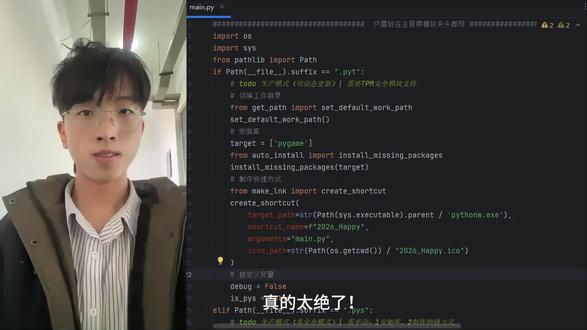 05:58查看AI文稿AI文稿
05:58查看AI文稿AI文稿真的太绝了!二十三个月,我独立琢磨的开创代码动态加密方案终于重磅落地,我愿称他为喜家之绝唱,前无古人后无来者,毕竟我翻遍所有资料都没有找到同类思路。 先看运行效果,假设这个路径目录下的 p 模块是我们需要加密的, 这是有关二零二六跨年盛典的烟花秀代码,只有程序员才懂得浪漫。点击运行,可见在本地运行成功了, 欣赏一下烟花秀吧,在这里也后知后觉的祝大家新年快乐! 愿你遍历山河,觉得人间值得,所求皆如愿,所行化坦途。新的一年,做自己的光,不需要太阳,足以照亮远方。凡事过往,皆为序章。 愿你眼里有光,心中有爱,目光所致,皆是星辰大海。保持热爱,奔赴山海。二零二六,万事胜意。 我们回到正题,导航的魔改拍摄案以 xc 目录启动 cvd, 并命名为 btcp, 在上面执行派发 siri 命令,即运行 siri 模块, 在开始监听八八八八端口前,会自动检测 p 外库是否安装。这里执行成功了,没有报错截上图。这里的 siri 模块是动态的,从云主机上请求加密数据得到的, 其中主机 m d c p 上有该模块的派藏源码。除此之外,我们还需要指定 p o i 模块源码存储目录,这里我指定了,就是刚刚那个烟花秀。 接下来我们在远程客户端上尝试访问一下我们刚刚经过 t c p 服务器加密之后的 p y 模块。我们在虚拟主机上打开 c m d 命令窗口, 测试一下通透性。我这里已经修改好目标请求的主机地址了,然后执行派往魅点 p y 命令, 这样就能运行主机电脑上这个魅模块里的代码了。这里出了点问题,是因为我这里是临时身份登录, 所以对添加参数 david 进入开发者模式进行测试。 我们再次运行命令,开放魅度 p y 这里由于网速太慢了,导致下载依赖非常慢,加速处理了。 我们根据提示再次执行命令, 可以看到成功在虚拟机上运行了该代码。 我们回去观察主机 tcp 服务器控制台,这里有详细的日志,由此可见,虚拟主机是通过 tcp 服务器请求获取贝加密的拍放程序。 接下来让你看看该目录下的结构。 这个 p 存键是从目标主机上动态加密后加载过来,都在它安全模块中进行加解密的,所以 p 存键大小为零配比, 其中 p 外库都是冻结的库存键,这又进一步的保证了安全性,而且还提高了加载效率。接下来是实时更新的演示, 为了方便,我就用了简单的打印来演示虚拟机中运行的结果是二零二六新年快乐,与主机中的一致, 可以看到主机上修改了打印内容, 虚拟机上重新运行也能同步最新的内容。最后想了解具体的一站式解决方案,请后台 t t。
8银杏一荤 08:52查看AI文稿AI文稿
08:52查看AI文稿AI文稿上节课呢,做这么一个事,说一个列表它等于什么呀?等于一个两个列表项,一个是 o e、 z, 一个是一二三,那么我这个列表呢,它就不能缩它了。为什么不能缩它呢?是因为 这个 o e、 z 和一二三他俩是没法比较大小的。那怎么才能让他能比较呢?那就得喊救命了。去哪喊救命啊?哎,去力斯点嗦,他这个方法里边找到。 找到什么呢?找到这个 key, 这个 key 呢?就是这个关键。这个 key 是 什么呢?如果一个关键的函数被给予了,那么应用它就可以得到这个列表项在排序,也就是说在排序之前,我们可以给他一个函数, 我们试一下啊,作为这个列表来说,我给它 k k 是 什么呢?是 str。 str 怎么理解?哎,我们看一下, str 就是 它把一二三 转成了字母串,然后呢,它再把 o e、 z、 o e z 其实本身就字母串,既然它都是字母串,那它就可以比较了,那它怎么比较的呢?其实就是看第一。先看第一个呗,一的序号是不是小于 o 的 序号,那是真的,是真的,之后比较出来结果,因为一这个字母的序号小于 o 这个字母的序号,所以一二三这个字母串就小于 o e、 z 这个字母串。所以呢,这个列表排序就是什么,先是一二三,后是 o e、 z, 即使你是个数值型的,但是呢,经过 string 之后,把你都转化成字母串了,那它就可以进行排序了。那我可以反过来吗?我都转成什么呀?转成 int 型行不行? 转到 int 型,那不行, y 六 l 值错误,也就是说它作为 o e、 z 来说是没法转成 int 型的,那 o e z 没法转成 int 型怎么办呢?我们先把这个 o e、 z 从字串中删掉,然后呢,我们再加一个什么呀?加一个 新的字母串是什么呢?比如说是一二、一二,那 l、 s、 t 是 什么呢?第一个是一个数值型的一二、三,第二个呢是字母串型的一二,我们再让它去排序。按什么排序? 按照 int 型的方式去排序,这个时候它怎么样?它是可以排的,你看一二就排到前面了。为什么呀?因为 int 型的一二,它是多少?是十二,它肯定就小于这个 int 型的一二、三呗。 那小于的结果不就是比出来结果了吗?比出能比就能排序,能排序就能解决这个问题, 是这么一个过程,是吧?这么一个过程,那这个还有什么函数能当这个 key 吗?我们来看一下,比如说有个 string list 是 什么呢?三个字母串,第一个是 o e、 z, 第二个呢是 o 二 z z, 第三个呢是 o 三 z。 那 这三个字母串啊,我们组成一个字母串列表,那这个字母串列表我想排序了,这个排序怎么排啊? 使用这么一个 key, 这个 key 是 什么呢?是 length, 这个 length 得到什么呀?一个新的结果啊?这怎怎么个意思呢?首先 o 三 z 它的 长度是三 o 二 z z 它的长度是四,而 o 一 z 它的长度是几啊?是五。哎,所以它就完成了这样一个三小于四,小于五的排序, 是这么一个过程。那甚至我其实可以写成什么呀?那字串列表的第零个列表项是三字串列表的第一个列,列表项是四字串列表,第二个列表项是五,得到三四五,它就是这么一个排布的过程,对吧?传入过程, 那还有什么参数呢?继续喊救命呗,对着绿色列表的缩方法喊 self 是 自己,谁自己,谁调用,缩它就是谁自己,对吧?那么 key 呢?就是这个方法,还有一个什么呢? reverse? reverse 我 们见过,但以前是一个 reverse 方法,这回呢,是这个 reverse 参数, 什么意思呢啊? sending o, descending? 升序还是降序?那么根据是什么呢?根据它们的值来判,判别这个逆序的这么一个 flag 旗帜, 就可以被用做这个降序的这么一个排序。比如说默认是什么?是 false, 默认不逆序,默认是升序。但是一旦你把这个 flag, 这个旗帜,这个标志给它 设置好了,哎,这有个旗子,只要见着这旗子就怎么样就降序,那么它就会降序,是吗?我们试一下,让他先自己排一次序,是吧? 这个时候它就变成 o 二 z z 在 这了,因为它是按字母串的排序方式,二小于三,小于 e 这么一个结构。那 reverse 怎么怎么用呢?我们可以看 sl 点缩它,这个时候啊,可以让它是让它是 reverse, 等于什么呢?等于处,这个时候是怎么样?就一大于三,大于二,就变成这种这种形式,是吧?那它跟这个嗯 reverse 有 什么关系啊? reverse 就是 颠倒,但是 so 呢,是在排序的基础之上颠倒,这怎么理解?比如说现在我要按 list 排序, sl 是 这样, sl 点缩它,我是按照 length 排序, length 之后呢?是不是还得 reverse 一 次才能得到五大于四大于三,对吧?但现在不一样了,现在我,嗯 直接怎么样?直接缩它?缩它什么呀? key 等于 length, 然后让 reverse 等于处,这样的话一步到位。五大于四,大于三,就完整排序了。这个就是两种方式,一个呢是用 s l 的 方法,甭管原来是什么样的序列,直接 reverse, 就 头变尾,尾变头,调转反转这个序列。但如果说是我用它是一个参数呢?那其实就是把这个排序先排好了,排好了之后出来一个结果, 这个结果是正序呢还是逆序呢?那就是看 reverse 这个参数就是逆序。如果没有这个参数或者 reverse 是 force 的 话, 那就是什么呀?就是正序。你看这个就相当于什么呀?就相当于没有 reverse 这个参数。因为它是默认值嘛, 就是三小于四,小于五这么一个状态,有了这参数之后,你再做它这一步的时候,就可以先排序,再反转一步完成,等于是就更快速了。 它有两个参数是吧? key 也是一个参数,这个 reverse 也是一个参数,我可以把 reverse 排在前面了, s s 点缩它什么呀? reverse 等于 force, 然后呢,让它 key 等于 length, 它也是可以的。这两个参数呢,其实是没有次序的,我们可以把 reverse 放前面,也可以把 key 放前面,但是在这个帮助的时候,它却是有次序的。 嗯? list 列表的缩它,它有什么次序呢?先是 key, 后是 reverse。 那 为什么这个时候先放 key, 后放 reverse 呢?我们下次再说 o e z 教程。





