git 如何修改本地文件777

粉丝1428获赞2.7万
相关视频
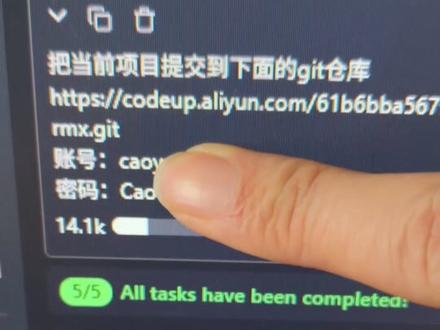 00:43查看AI文稿AI文稿
00:43查看AI文稿AI文稿分享一个 ai 技巧,五秒钟教会你用 get 仓库提交代码,非常简单啊,你有这个仓库的地址, http 的 这个地址,然后呢,有账号密码就可以了,就当前项目,你打开 ai 工具, 你告诉他把当前项目提交到下面的这个 get 仓库。哎呢,就是拉取呢,其实也一样啊,就把下面的 仓库代码拉取到本地,他就开始自己操作了啊,有如果有冲突的,他也自己解决啊。这个非常简单啊,非常适合小白,你不用再想什么命令了,可以试试。
52元叔说开发 02:06查看AI文稿AI文稿
02:06查看AI文稿AI文稿我来看一个在 get 里面一个非常常见的问题啊,这个问题你要不小心的话,到时候调能调死你。比如说目前一个工程啊,它已经被 get 所跟踪了,现在呢,有一天啊,你不知道抽什么风,你把这个文件的大小写呢给我改了,比如那个 arata, 你 把这个首字母呢变成小写了,然后这个文件牙呢,你把首字母变成小写了, 改了之后呢,你会发现一个神奇的现象啊,但很多同学其实是没有注意到的,就这个 get 呢,没有对这个改动进行跟踪,你看,没有任何跟踪哎,但是如果说你去改这个文件的话,那没问题啊,把文 键也跟着变成小写,是吧?把路径也跟着变成小写啊,这个玩意呢,肯定是能被跟踪的,你看这里呢,是不是被跟踪了,对吧?这里呢,也得到跟踪了。好,于是呢,你把这个玩意推送到 get 仓库了,那就要出问题了,为啥呢?为啥前边没有跟踪,后边跟踪了呢?前边没有跟踪是因为 get 呢?默认情况下,它是忽略掉文件或者是什么文件夹路径的大小写的,它忽略了,它认为没有变化, 但是个文件内容变化肯定不行,是吧?它肯定要被跟踪,那于是就会出现一个什么情况呢?你本地是一个什么大写的文件名? 远程仓库呢,也是一个大写的文件名,对吧?推送过去了嘛?现在呢,你把本地的文件仓库的文件名呢变成小写了,但这个小写呢,没有被 diss 所跟踪。于是呢,你再推送到远程仓库的时候,远程仓库那边文件的名字是没有变化的,它还是大写,但是你这个玩意是能推送的,是吧? 这些路径变成小写了,是能推送的,那么推送上去了过后呢,就是远程仓库,他文件是大写,但是路径是小写,你说出不出问题,这个直观的问题就是你本地开发啥问题没有?但是一旦推送到远程仓库,那么服务器呢,再从远程仓库去拿取,那也就是生产环境,它的运行呢,它就要出问题,到时候调能调死你, 因为这个玩意很不好调,你很难定位,到底是什么原因导致的?你要掉很多头发,你才能知道是这里的原因,所以这种问题呢,最好是在最开始的时候就给它规避掉。怎么规避呢?就是你在创建的工程的时候啊,你就输入一行命令, 这个命令呢就是 git config call ignore case, 给它做一个配置,把这个忽略大小写呢,给它禁用了就完事了。忽略大小写一旦禁用,你看一下这些对文件名的大小写改动,就全部被跟踪了, 那么到这里推送到服务器的时候,那么服务器那边也有对应的小写的文件名呐,对吧?这样呢,才不会导致出问题啊,这是一件小事啊,但是这件事特别重要,朋友们以后建工程的时候呢,把这句话运想一遍啊。
636渡一前端提薪课 06:44查看AI文稿AI文稿
06:44查看AI文稿AI文稿同学们大家好,我是金城智能马工,今天我们来学习一下 get def 这个命令,它可以用来查看文件在工作区、暂存区以及版本库之间的差异,它还可以查看文件在两个特定版本之间的差异,或者文件在两个分支之间的差异。我们平时开发过程当中 更多的使用的是一些图形化工具,但是了解一下 git diff 这个命令还是很有必要的,因为有的时候我们需要在一些没有图形化工具的服务器上使用 git git diff 命令后面如果什么都不加的话,会默认比较工作区和暂存区之间的内容,它会显示发生更改的文件 以及更改的详细信息。下面我们来演示一下还是使用上一节课创建的仓库,这个仓库目前有三个文件,而且有三次提交, 每一次提交都是新增了一个文件,比如说 file 一 点 test, 里边是幺幺幺,然后第二次提交增加了 file 二点 test, 第三次提交 file 三点 test。 get diff 这个命令非常的简单,我们先来修改一下 file 三这个文件, 这里我们把内容改成 hello world, 保存退出一下。我们现在使用 get def 这个命令查看一下它默认比较的是工作区和暂存区之间的差异,可以看出刚才的差异已经显示出来了, 这里输出的第一行表示发生更改的文件,第二行我们稍微解释一下。 get 会将文件的内容使用哈希算法生成一个四十位的哈希值,这里只显示了哈希值的前七位, 后面的幺零零六四四,它代表的是文件的权限。再往下就是修改的内容了,红色文字表示删除的内容, 绿色文字代表刚刚添加的内容。我们现在比较的是工作区和暂存区之间的差异,因为我们修改的内容还没有添加到暂存区,现在我们来添加一下,然后再看一下输出结果, 可以看出刚刚比较的差异性现在已经不存在了。除了比较工作区和暂存区之间,我们还可以比较工作区和版本库之间的差异,在命令后边直接加上 hit 就 可以了, 比如我们现在还没有将添加的内容提交到仓库里边,而这个差异的内容又出现了,这是因为我们刚刚还没有进行提交操作,所以说工作区和版本库之间的内容是不相同的。我们还可以比较一下暂存区和版本库之间的差异, 在 get diff 命令后边加上 catch 就 可以了, 可以看到输出的内容是相同的,那我们现在来提交一下, 然后我们再使用 get diff 来比较一下, 可以看出暂存区和版本固之间的差异已经不存在了。 get diff 命令除了可以比较工作区、暂存区、版本固之间的差异以外,还可以比较两个特定版本之间的差异,用法就是在后边加上两个版本的提交 id。 我 们先来看一下当前仓库的提交记录, 我们比较一下最新两次提交的版本, 可以看出最新两次提交版本也已经显现出来了。 除了使用提交 id 之外,我们还可以使用 head 来表示当前分支的最新提交。 head 是 get 当中一个非常重要的概念,它指向分支的最新提交节点,在后面的学习当中我们也会经常用到,我们可以使用某一个版本的提交 id 和 head 进行比较, 这里我们可以改一下, 可以看出和刚才的输出结果是一样的。当然如果我们每次比较都要查看 id 的 话,确实有些麻烦。 我们经常用到的就是比较当前版本和上一个版本之间的差异,这里 get 也给我们提供了一个更加简变的方式,就是我们使用 head 加上波浪线来表示上一个版本,那么刚刚的比较就可以改一下, 可以看出和刚才的输出内容还是一样的。当然这里的波浪符号也可以改成尖角号,也是表示上一个版本。我们还可以在波浪线前面加上具体的数字,它表示当前版本的前几个版本。 head 波浪线二,它代表当前版本的前两个版本和当前版本的一个比较, 我们可以看一下波浪线三,这里我们查一下提交日期 前面的这个 head 波浪号三,它代表的其实就是第一次提交,而第一次提交和当前提交有哪些区别?就是新增了两个文件 file 二和 file 三,这里也体现出来了多了一个 file 二文件和一个 file 三文件。 get def 后面加上文件名也可以查看这个文件的差异,当然如果这样比较的话,就只会显示当前文件的一个差异,其他的差异就不再显示了,这里我们来比较一下, 我们比较一下 there 三点 test, 可以 看出它只显示了一个 hello world, 刚刚显示的这里的 第二个文件 feel, 二点 test 已经没有显示了。 get diff 还可以比较两个分支之间的差异,加上两个分支的名字就可以了。这个等到我们后面学习完分支的内容再来讲解。好,今天的内容就到这里,我们下节课再见,谢谢大家。
10金橙嵌入式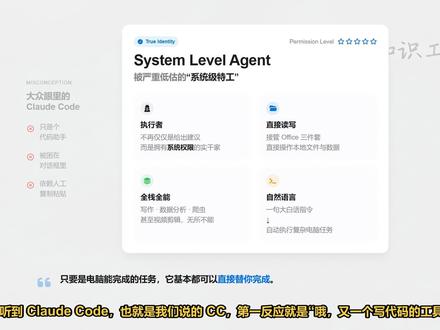 07:26查看AI文稿AI文稿
07:26查看AI文稿AI文稿很多人一听到 clock code, 也就是我们说的 cc, 第一反应就是,哦,又一个写代码的工具,大错特错。如果你只拿它写代码,那真是大材小用了。 这东西根本就不是一个简单的编辑器插件,它本质上是一个系统级 a 人。什么叫系统级?就是只要你给了权限,它就能直接接管你的电脑。它不像网页版的 gpt, 说完话还得你自己动手复制粘贴。 c c 是 能直接帮你改本地文件,跑数据分析爬虫,甚至读写 word 和 excel 的。 简单说,他就是一个住在你命令行里的超级管家,只要你一句大白话指令,凡是你电脑能干的事,他基本都能直接替你干了。 要想把这尊大神请进电脑,得先查查户口,他依赖 node js 和 git 这两个环境。别管你是 windows 还是 mac, 打开你的终端或者命令行, 照着屏幕敲这两个命令,只要能蹦出具体的版本号,说明环境没问题。要是报错说找不到命令,那就赶紧去官网下一个装上,这不属于基本功,咱就不展开手把手教了。环境搞定后,安装其实就是一句话的事, 把屏幕上这行 m p o 命令复制进终端,千万注意中间这个杠 g 的 参数。这是局安装的意思? 逗了,他回头,不管是调用还是升级都一堆麻烦,输完直接回车等着进度条跑完就行。装完了别急着兴奋,我们先验个货,在命令行里输入 clod, 后面跟两个杠 version, 只要他痛快地吐出一个具体的版本号,比如零点二点二九,那就起火了。 这就意味着这套系统级 agent 已经在你的电脑里安家落户了, c c 装好只是第一步,现在他还是个没脑子的空壳。 默认的 cloud 模型 a p i 申请极其麻烦,还得搞定海外支付,对国内用户来说纯属劝退。这里我直接给个最优解,别折腾原生的了,直接用国产平替。比如智普的 glm 四点七,我实测下来 再写代码,这个垂直领域,如果说满血版 gl 的 能打九十八分,国产这几个模型基本都在九十分以上,日常用起来体感差距非常小。 关键是门槛和成本完全是一个天一个地。方案定了,咱们准备两样东西,去智普开放平台注册个号,在后台复制你的 api key, 这串字母自己留好,别乱发。关键是第二步,记得在里面订阅一个叫 coding plan 的 套餐,这个非常重要,它是专门针对写代码优化的,而且价格很香,一个月也就一杯奶茶钱,比你按量付费划算的多,能省不少银子。 拿到 key 之后,千万别去手动改什么环境变量,哪怕多打一个空格都得报错。直接用智普官方出的这个自动化工具,一行命令全搞定。在终端里输入屏幕上这行 npx 指令,回车之后,它会弹出一个全中文的界面, 你只需要跟着提示选中文确认套餐。把刚才复制的 key 粘贴进去,它会自动帮你把底层的连接配置全部写好,新手绝对不会出错。 把 c c 叫醒之后,你得适应一下他的工作方式,这不是咱们习惯的图形界面,没那么多按钮,给你点全靠键盘。第一件事,你得给他划进个工作区,也就是告诉他该读哪里的文件。最简单的办法,直接用 cd 命令进到你的项目文件夹,再启动它。 如果在聊的过程中想加别的文件夹,直接敲斜杠 a d 二,把它拉进上下文里。记住,对 c c 来说,文件夹不仅仅是存东西的地方,那是它的知识边界。 这里教大家一个极其好用的隐藏操作。很多人都不知道,以前在命令行里输文件路径得敲半天,还容易错。在 c c 里, 你直接把要把要分析的文件或者整个代码库文件夹用鼠标拖进这个黑框框里,松手回车。这一招叫物理投喂,不管是几十个代码文件还是复杂的文档,拖进去他就能瞬间读取。 这是扩充他上下文最快最暴力的手段,没有之一。最后说个最容易让人抓狂的坑,就是粘贴在终端这块地盘上,千万别在那狂按 ctrl v, 把键盘按烂了也没反应。想粘代码或者文本,直接按鼠标右键。如果要发图片给他看,快捷键是 alt v, 但是注意听,这里有个大坑。你不能在文件夹里复制那个图片文件,你得把图片打开或者直接截图复制图片的内容,这时候按 alt v 才能传上去, 这点非常反直觉,一定要记住了,熟悉了交互,接下来这几个斜杠指令,就是你每天都要打交道的工具了。第一个是斜杠 clear, 每当你打算开始一个新任务的时候,一定要记得先执行它,这相当于给 ai 换个干净的大脑,防止之前的对话干扰它的逻辑。 第二个是斜杠 comp, 这个太有用了,如果一个任务聊得太久,你会发现 c c 反应变慢,或者开始胡言乱语。 这时候用它给对话设个身,它会把之前的废话压缩成摘药瞬间,节省大量内存和费用。最后就是斜杠 cost, 建议你没事就敲一下,看看这波操作花了多少钱。毕竟咱们用的虽然是平替,但也得精打细算不是? 如果你觉得每次改文件都要点确认太麻烦,那咱们就玩点大的。启动 c c 的 时候,在后面加上两个杠, dangerously skip permissions, 这就进入了传说中的危险模式。这个模式的精髓就六个字, 别问我,直接干!比如你想把几百个文件名全部统一规范化,如果是普通模式,你得点几百次确认。 但在危险模式下,你把要求一丢,去喝杯咖啡回来,他就已经全部改好了,他会自动尝试报错重试,直到把结果交到你手里。不过丑话说在前头,这个模式权限非常大,用之前一定要做好备份,千万别在系统核心目录下乱玩。 如果你觉得危险模式已经很强了,那 m c p 简直就是给 cc 穿上了一套外挂机甲。简单说,这个协议能让 ai 走出终端, 直接去操控你的浏览器、数据库或者其他软件。举个最接地气的例子,很多博主每天要统计公众号后台数据,手动点开复制粘贴到 excel 表格,这活干半小时能让人心力交瘁。现在你只要装上这个 chrome 调试外挂, 一句话, cc 就 会自己打开浏览器,一页一页翻把数据抓下来,最后再亲手给你做一个 excel 表格发过来。整个过程你只需要看着原来半小时的体力活,现在五分钟全自动搞定, 这才是真正的生产力解放。最后再给你安利一个神器叫 skills, 你 可以把它理解成别人已经封装好的顶级工作流,你只需要借过来用就行了。最牛的一点是,它用完即走,不占你的大脑内存,也就是不浪费 top。 比如这个前端设计技能包,简直是审美救星。你只需要把一个长得挺丑的网页链接丢给他,让他优化一下, cc 就 会调用设计技能,自动重构布局、调整配色。几分钟功夫,一个极具现代感的网页就出来了, 而且里面的链接全都能真实点击。最棒的是,现在用国产模型也能完美运行这些技能不需要登录任何海外账号。以后不管是写代码还是改 u i, 只要你有 c c, 你 就不是一个人在战斗,你背后站着一整套官方技能库。
2420AI赚钱研究社 06:15查看AI文稿AI文稿
06:15查看AI文稿AI文稿有段时间,公司需要统计每个人的 commit 改了多少行代码,于是我一个不小心把一个七夕学习模型 git commit 了好几万行。我的 git 目录一下变成了几百页。 结果就是同事要克隆我这个仓库,得等十几分钟。于是我赶紧删掉模型,再次 commit, 但 git 并没有变更小。然后我试了各种办法, git ignore 等等等等都没有用。那一刻,我突然意识到,我其实根本不懂 git 是 怎么工作的,我只是记住了各种命令。 这个视频将用五分钟向你解释 git 是 怎么工作的。我保证,看完这期视频,你会是周围人中最懂 git 的 那个。简单来说, git 其实是依靠三种对象的引用来工作的。 三个对象分别叫做 commit tree 和 blob。 commit 就是 我们每次改动代码后的提交,它会指向一个 tree 对 象, tree 对 象表示这次 commit 发生时的目录,然后 tree 对 象再指向 blob 对 象。 blob 对 象就存储了文件的具体样子, 这些对象都存储在 get 目录中的 object 里。举个例子,这是我一个全新的项目,它还没有任何 commit。 我 刚刚新增了一个文件 text 一, 里面只有一行文本,然后我要提交一个 commit, 叫 commit one, 然后提交。 提交之后我们就可以看到这里有了我们刚刚的提交,它的哈希值是 e, d, d, f。 如果你不太了解哈希值,可以查看我之前的一个视频。简单来说,它是根据这个 commit 内容产生的唯一标识。 我们来看一下这个 commit 具体里面是什么样子的。我们需要使用一个 get 命令, get hit file, 然后参数 p 后面接。这次 commit 哈希值只需要写前几位就可以了。 于是我们就可以看到了这个 commit 里面的东西。我们可以看到它引用了一个去对象,这个去对象的哈希值是 c, a, a, e 以及这个 commit 的 作者是谁,这个 commit 的 提交者是谁,以及这个 commit messaging。 我 们继续看一下这个去对象里面是什么。 同样只用这个命令,然后使用去对象的哈希值, 就会看到这个 tree 对 象引用了一个 blob 对 象。 blob 对 象的哈希值是七三七 c 以及这个 blob 对 象所对应的文件的名称。我们再看一看这个 blob 对 象里面是什么。 改成 blob 的 哈希值就会看到它存储了文件原本的内容。通过这个例子,我们看到了 commit tree 和 blob 之间的引用。这样做的好处在于节省空间, 因为每个 commit 它都需要记录完整的结构信息,但如果将所有的文件都存储一遍,那这样耗费的空间就太大了。所以通过引用的方式,对于没有变化的文件,新的 commit 依然引用原本的 blob。 对 于变化或者新增的文件才引用新的 blob。 比如说我现在要新增一个文件,叫做 text 二,然后对于这个新增的 text 二,我提交一个 commit, 这 commit 就 叫 commit 二。简单点,那我们回到我们的提交历史,可以看到 commit 二,它的哈希值是九五七 c, 我 们再来看这个九五七 c 里面是什么样的。 可以看到同样有 tree or the commit 和 message 四个蓝位,但多出了一个刚刚我们没有见过的蓝位,叫做 parent。 parent 是 e、 d, d, f, 刚好和我们的 commit 一 的哈希值是一样的,所以这个阈尾它表示的是这一次 commit, 它是从哪个 commit 衍生而来。那我们再看看这个 commit 二所引用的 tree 对 象是什么样的。使用这个 tree 对 象的哈希值看一下啊, 可以看到它引用了两个 blob 对 象,一个依然是我们刚刚用的七三七 c, 就 像这里用的是七三七 c。 另一个是新增的一个 block 对 象一六九 d, 它对应的是我们新增的 text 二。 这样 text 一 的 blob 对 象就被再次利用了,不需要再存储一遍,节省了一些空间。但是 blob 对 象一旦被创建, 就不会再被修改或者删除。也就是说,即使我修改或者删除了 text 二,这个一六九 d 的 blob 对 象都将永远存在。比如我现在删除这个 text 二,然后再提交一个 commit, 可以 看我现在提交了第三个 commit, 删除了 text 二文件。那么看一看我们的 git object, 下面 我们还是可以找到这个一六九 d。 这个文件就是我们的 blob 对 象,它的命名方式是文件夹的名称加上文件的名称,就是全部的哈希值。到这里 你应该就能明白视频开头我的 get 步入那么大的原因了,因为表示我模型的 blob 对 象一旦生成了就不会消失。 但解决方案你可能也想到了,我可以先删除提交模型的这次 commit, 让模型的 blob 对 象成为没有被引用的悬空对象,再删除掉没有被引用的对象。 总之, commit tree、 blob 这三种对象就是 get 工作的本质。你可能会疑惑,哎,我们熟悉的 branch 去哪了? branch 不是 一个对象, 只是对某个 commit 的 引用。我们每次 check 到一个分支上,其实也只是跳到某个 commit 而已。我们随时可以指定任何 commit 作为任何 branch。 我 们还可以删除 branch, 但不会影响 commit。 你 可以在 git 目录下的 revs 下面找到各个 branch, 它存储在 head 下面。 像我的这个仓库,目前就只有 main 分 支。打开看看,你可以看到它的文件内容是九八 e a, 刚好和我的 commit 三的哈希值是一样的。以上就是本次视频的全部内容,现在的你应该完全理解了 git 是 怎么工作的,并且应该再也没有任何 git 问题会难住你了。感谢你的观看,我们下次再见。
3.3万Hucci写代码 12:08查看AI文稿AI文稿
12:08查看AI文稿AI文稿大家好,今天给大家介绍下如何在 c n b 中使用 gitlives 实现大文件存储, 也就是模型持久化存储的问题。整个内容按照仓库的复刻,模型的下载和 gitlives 的 使用这几个方面展开。首先复刻仓库 哦,复刻完毕,我们现在启动开发环境 哦。开发环境进入以后, 我们先确认一下,现在的数据存储目录中没有任何模型存在。我们使用势力的下载文件, 下载 ge 一 枚值的这几个模型,把这个 主模型文本 v e 现在开始下载模型文件。 第一个是主模型正在下载, 我们耐心的等待一下模型下载完成, 下载完毕,现在是检验模型的完整性。模型下载完毕, 文本编码器下载完毕。好,三个模型全部下载完毕,一共用时是两分钟二十 gb。 我 们现在看一下模型的存储目录。 主模型文本编码器 v e 下面开始进入到 getlives 的 设置。 首先第一步是确认系统是否支持 delete 的 大文件存储 输入命令,我们在 doc file 当中已经安装了 delete。 下一步是执行 delete 的 出使化, 因为在原始的这个仓库当中已经执行过 gitleafs 的 初步化,所以这里会提示你原始仓库已经执行过 gitleafs 的 初步化。 初步化完成后,下一步是创建一个文件,文件名是 get attribute。 回车打开这个文件,输入需要跟踪的大文件的相关信息,大家可以根据自己的需要, 一般如果只使用这个 cptencil 格式的话,就可以只选择它,其他可以省略好。编辑完毕后,我们需要 提交这个新建的文件给 get 仓库,然后添加提交 显示已经提交,然后复制。 这个操作完成以后,下面是需要检查 delete 的 规则是否生效,我们可以输入跟踪命令检查一下, 没有任何问题,对这四个文件,四种类型的文件进行跟踪。 好,下一步就到了最关键的步骤了,我们看一下远端的仓库,远端的仓库现在 my data 目录下是没有模型目录的,现在我们在 my data 目录下的默带儿目录下已经下载了三个文件,下面需要把这三个文件提交到远端仓库。 首先复制文件的路径,然后输入命令地址 add, 这里需要加一个撇 f, 表示强制性的添加,因为我们已经在我们的 get 里边省略掉了这些大模型,省略掉了这个 model 思路 被撤,因为模型比较大,所以这这个提交会需要一定时间,我们耐心的等待, 现在添加已经完成, 此时需要确认的是添加状态是否成功。输入命令 下面已经看到了 l f, 看到了这个标识,必须要有 l f o s 标识才能确认已经被正确的添加到了大文件的系统, 这是第一个文件,然后我们现在添加第二个文件, 添加 好第二个文件,添加完成,添加第三个文件, 添加完成之后一定要运行 状态查询的这个命令,看一下是否使用的是 lives 系统。 我们看到三个文件都已经是下面的这个是我们刚才修改了这个 file list 的, 这个可以大家不要管它。 确认好三个文件的 left 标识之后,我们可以统一进行提交, 我们看到已经提交, 可以再次运行一下,这里已经显示提交完成,等待部署好最后一步部署, 这时候我们可以确认一下,在远端的模型目录下是没有这三个模型文件的好部署, 我们布置成功,我们看到这里面有一个标识显示的是上传了 大文件存储对象,一共有三个,总共二十一 gb 完成,这就证明我们的文件已经上传成功,我们可以看一下远端的仓库,更新一下, 现在已经出现了这三个文件文本编码 v e, 就是 说现在这三个大文件已经被提交到了远端仓库。好,我们确认好之后 关闭系统重启,你们可以看到已经 最新的这个 c c 已经关闭,下面我们重新打开,或者是直接在代码仓库当中 启动。 因为上传了三个二十 g 的 文件,所以在每次启动的过程当中会耗费一定的时间去 远端拉取这个文件,不会像平时开机的时候速度那么快, 这是需要,这是持久化存储必须承受的一个小小的缺点,在启动的过程当中可能会拖慢一下速度 哦。下面这个容器已经启动成功,我们看一下目录文件已经要去完成, 这就是可以直接使用不需要再下载的文件, 这就是在 cnb 当中通过 gitlives 实现 大模型的持续化存储的一个简单的介绍,大家有什么问题可以留言随时交流,今天就到这里,谢谢大家。
 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿昨天有个粉丝问,提到代码的时候如果有冲突怎么解决?可以看一下这一个图,它一般是报这样子的错误, 然后我们用 get status 可以 看一下它的状态,它会告诉我们 boost modifier, 就是 说两个用户同时修改了这一个文件,那这种情况下我们要怎么去解决? 这有个使用技巧,就是我们先从源头上解决,避免经常遇到冲突。第一个是每次你修改代码的时候,你就先拉一下远端的最新的代码,修改后呢你要立刻去提交,你不要攒着攒很久再提交。 第二点是作为测试工程师,一般是分模块测试的,每个模块你最好是用不同的文件,每一个模块有不同的负责人,所以就是不同的负责人,你去负责对应的测试文件,那你每次 只改自己的文件,只提交自己的文件的话,那遇到冲突的可能性是比较小的。但是如果还是遇到的冲突,你要做的就是首先你要确定留哪一部分,比如说刚才这个报错的冲突是这样子的,上面这一片是我自己的代码,下面这个是远端的代码, 然后这两个代码这个同一个位置,它不一样,要手动的去改这一部分,怎么样?手动修改,重新确定保留哪一部分,或者是合并两边的逻辑也是可以的。修改代码之后,删掉所有的不是代码的这一部分,然后重新去提交就可以了。 另外如果你想放弃本地的改动,直接用远端,那你也可以用这两个命令强制去拉取远端的代码,但是这个一定要小心一点,因为你本地的所有的改动都会被覆盖。 另外如果命令不太熟的话,你也可以直接用 get 的 可缩化工具,比如说 sos tree 这种工具。
58Yoyo慢 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿a a 编程会出现乱改的情况怎么办?目前来说无法避免。 a a 不 会乱改,所以我们一定要在使用技巧上面去改进。那第一个,呃,如果我们改某个具体的功能的时候,我们最好是指定某个文件, 指定某个文件之后再给他说我改某个功能有加一个删除功能,或者修改一个什么功能,直接给他说他只会在这个文件上面去改这个,避免他乱改。如果这个时候你乱笼统的去讲,他就会全截去改啊,这个一定要注意点。第二个, 如果让他改了某个功能,他改了一大堆文件,你这个时候你要去验证一下,你要去看一下,看他是不是你想要的,还有那功能有没有其他影响,如果发现他乱改了,这个时候这里有个全部撤回的功能, 一撤回他就回到原来版本,这里也有学会使用。第三一个就是,呃, ai 编程工具上面应该现在都会有一个原代码管理工具, 把这个开通掉,开通好了之后,在你每次改好每一个功能的时候,你都有让他去帮你提交,提交如果出错了,他会自己帮你解掉。 好,这个时候你后面再改乱了,你可以回滚到当前提交的一个点上面,所以尽最大的方式避免乱改。
19余品灵说AI 02:57查看AI文稿AI文稿
02:57查看AI文稿AI文稿兄弟们大家好,今天我给大家分享一下关于我平时 get 的 使用。首先第一个就是 get clone, 是 比如说平时我们要拉拉一些开源的项目,或者拉我们自己呃工作当中要拉的系统的话, 嗯,那原码的话,其实我们要通过 get clone 把项目拉下来。其次就是 get add, 比如说我们在项目当中改动了一个需求,那其实 get states 是 去看这个需求的变更, get add 是 相当于是把啊这个需求提交了,而 get commit 其实就相当于一个 commit 的 命令。之后一般我们 get commit 的 时候会比如说添加一些备注,比如说文档, 文档内容的优点,而 get pushed 就是 相当于我们本地的提交和远程的提交,我平常那个,呃,其次还有 get remote, 就是 就是 remote, remote 就是 比如说我们拉到一个本地的一个项目之后,要和远程的项目建立一个连接,通过 get remote。 其次还有一个平时不不怎么用的,就是我们平时可能项目当中其实会遇到一些什么问题呢?就是我们要回滚一个版本,回滚一个版本的话,那其实,嗯 嗯,那其实我们其实要回滚到某个版本,相当于我们可能会跨越版本之后把那个版本回滚了。那首先我们要 get log 先找到那个版本,比如说我现在要回滚的版本是回滚到变更标题的这个版本,也就说前面的版本我现在不要了, 那我们其实通过 git log, 呃呃,那个 git logs 先找到,先找到我们,呃要跳的那个版本,也就是变更标题这个版本,对吧?我们把它的 版本拉过来,拉过来之后 git 这个版本号 啊,那我们看一下是不是这个相当于这个版本就已经提交过来了。那如果说我们,嗯,当然啊,这个我们在通过 getstate 状态,其实发现我们已经跳过两个版本了。嗯,如果说我们不需要, 呃,跳过这个版本,我们也可以,比如说,呃通过 git pull 的 话还原,如果我们就是需要提交的话,正常的 git push 是 提交不了的,要 git push 杠 f 之后提交到远程的 master, 远程的 master origin master 才行。今天就分享这一点点吧。嗯,感谢大家。
 05:29查看AI文稿AI文稿
05:29查看AI文稿AI文稿嘿,大家好,如果你想在编程这个世界里闯出一片天,那 github 绝对是你绕不过去的一座山。别担心,今天呢,我们就来当你的向导,带你从零开始,一步一步地把 github 给玩明白了。我们的目标很简单,让你不光能看懂还好了,那咱们就正式进入主题吧。 首先呢,我们得把一个最基础,但也是最多新手会搞荤的概念给弄清楚,就是这个 git 和 github。 你 看啊,它俩名字长得特像,但说实话,它们完全是两回事儿。 你可以这么理解, get 呢,它就像是你电脑上的一个本地存储工具,一个能让你吃后悔药的神器。你写的每一行代码儿,做的每一次修改,它都帮你记得清清楚楚。那 github 是 什么呢?它就是一个在云上的大仓库,专门存放你用 get 保存下来的这些项目。这样一来,你就可以在任何地方访问你的代码,更重要的是,还能跟别人一起写作。 所以, git 的 核心作用到底是什么呢?嗯,它的学名叫版本控制系统,英文是 vcs。 我 知道啊,这名字听起来有点唬人,但你别怕,说白了,它就是你项目的专属时光机。你想想,万一代码写崩了,或者老板突然说还是用上周的版本吧,怎么办?有了 git 没问题,咱们坐上升光机,嗖一下就能回到过去任何一个你保存过的版本,是不是很酷? 好吧,基本概念我们搞清楚了,那接下来咱们就来看看,作为一个开发者,你每天具体要做些什么。更重要的,我们怎么才能把你这些日常的工作包装成一份闪闪发光的个人作品集,让他在求职的时候帮你拿到心仪的 offer, 那 这就是每个开发者几乎天天都要重复的。四步五。 第一步, git clone, 就是 从 git hub 上把项目整个克隆到你自己的电脑里,然后你开始写代码。写完之后,第二步, git, 告诉 git, 嘿,这些是我新改的内容,准备一下。 第三步, git commit, 就是 正式地打一个存档点,并写下备注,说清楚你这次都改了啥。最后一步, git push, 把你在本地打好的这些存档一次性推送回 git hub 的 云端仓库。记住这四步,你就抓住了 git 和 git hub 的 核心脉络, ok! 当你把这套流程玩得滚瓜烂熟之后,一个更重要的问题就来了,我怎么才能让我的这些努力被别人看到呢?特别是那些潜在的雇主和合作伙伴。 答案其实很简单,就是用心去打造你的 github 个人资料。你可以把你的个人资料、 readme 文件想象成是你在 github 上的一个大广告牌,或者说是你的个人主页。那怎么才能让这个广告牌吸引人呢?你看这里有几个关键点。首先,一个简单明了的自我介绍是必须的。然后把你掌握的技术战用酷炫的小图标展示出来, 这个比干巴巴的文字强多了。当然,别忘了放上你最得意的那几个项目的链接,还有一些能动态展示你贡献度的统计卡片。最后加点你自己的社交媒体链接,甚至来一个好玩的 gif 动图,展示一下你的个性。你的主页上最多可以置顶六个项目,所以啊,一定要精挑细选, 记住,质量永远比数量重要,那什么样的项目才值得被放上去呢?你看,首先它最好是能解决一个真实世界里的小问题。其次,你的代码得写得干净漂亮,注视也要清楚。 千万别忘了一个高质量的 readme 说明文档,里面有截图,有怎么运行的指南,这绝对是超级加分享。如果还能提供一个 online demo 的 链接,那就更完美了。好了,等你把自己的门面收拾的漂漂亮亮之后,咱们就可以走出去看看更大的世界了。接下来咱们就来聊聊 github 最有魅力的一个部分,如何与他人合作。 来,我们来想象一个场景,比如说你正在参与一个项目,为了开发一个新功能,你创建了一个属于自己的分支, 你可以把这个分支理解成一个独立的平行的代码宇宙,你在里面做的任何修改都不会影响到主项目。现在你在你的平行宇宙里已经把这个新功能做的非常棒了。那么问题来了,你怎么才能安全的万无一失的把你做的这些改动合并回项目的主干道上,还不把原来的东西给搞坏呢? 答案就是通过一个叫做拉取请求的东西,我们通常管它叫 pr, 你 要知道, pr 可不仅仅是一个请求合并的按钮,它更像是一个专门的讨论区,你在这里正式的提出你的修改建议,邀请你的同事们来审查你的代码,大家一起讨论,确保这些新代码的质量是过关的,然后才能最终合并进去。 整个 pr 的 工作疗程大概是这样的,首先你把自己在分支上的工作推送到 github, 然后在 github 页面上创建一个新的拉取请求。接着你需要指定以两个同事为审查者,请他们来检查你的代码, 大家会给你提一些反馈和修改意见,你根据这些意见再调整你的代码。最后,当所有人都觉得没问题了,点击那个绿色的合并按钮,大功告成。这个流程是保证团舵项目质量的生命线。 好了,到这里你已经掌握了个人工作和团队协助的精髓了,但 github 的 强大之处还远不止于此。最后,让我们来解锁它的终极超能力,自动化。这个超能力的名字叫做 github actions, 你 可以把它想象成是你的私人自动化小助手,或者说是一群住在你代码仓库里的小 robot。 你 只要提前给它们设定好指令,它们就能帮你处理各种重复性的繁琐的任务。这样你就能把宝贵的精力完全集中在写代码这点核心的事情上了。 它们能做什么呢?我们来看几个例子。比方说你可以设置一个触发器,规定每当你把代码部署到主分支的时候,就自动运行所有的测试,确保没问题。 或者每当有人提交一个 pr 的 时候,就自动检查一下代码的格式是不是符合团队规范。再或者,一旦一个 pr 成功合并了,就自动把最新的版本部署到 siri 上,你看这些操作是不是能帮你省下大把的时间和精力。 好了,我们回顾一下从最开始的 git 是 什么,到怎么打造个人作品集,再到如何用 pull request 和团队协助,最后,我们还解锁了 github actions 这个自动化神器, 可以说现在你手上已经有了一份相当完整的 github 生态系统使用地图了。那么有了这张地图,你下一步的开发之之旅准备去向哪里呢?
620数智先行者 08:49查看AI文稿AI文稿
08:49查看AI文稿AI文稿说人话重山讲干货。你好,欢迎来到 it 老七的架构九百讲,我是你们的 it 私人顾问老七,到现在我已经录制了十多门与编程架构的最新课程,同时还会提供简历优化、模拟面试、 offer 选择、课程指导、工作建议等多种服务。只要我有经验的事情一定坦诚相待,有兴趣的小伙伴可以看一下评论区。 今天我们来说一个与我们每一个人都可以关系到的事情。只要做软件开发,离不开代码库,只要做代码库就离不开通过 get 进行信息的发布和提交,那这个提交的信息该怎么写呢?哎,这里边有大学问,我们来看一下吧。 好的,老规矩,我们回到笔记来进行讲解。在谷歌内部一开始所推行的一整套 get 信息提交的规范,现在呢,已经成为了行业中的普遍共识, 它是一套标准化且非常规则的一套提交的规范。所有的提交都会包含一个具体的 hard 代表的是本次提交的内容,其中前面的部分代表本次提交的类型,后面是摘要和描述。 如果 hard 这个头部的部分它没有办法准确地表达信息,中间空一行,注意一定是空一行。然后在下面附加我们本次提交的具体内容,通过具体内容进行详细表达。 相应的比如还有一些额外的辅助信息的话,比如本次我们的修复关闭了,那你还可以在 额外的增加一个空格,在下面再次增加关于注角的部分,注角的部分中是咱们整体的一个结尾,比如说 close 代表的是,哎这个关闭了多少多少号的一个特性, 或者下面增加了一个 breaking change, 代表本次的特性和之前是不兼容的,通过这样的注角标识来进行额外的说明。所以一份完整的谷歌提交规范,它就会包含主要四部分, 第一部分是头部,而头部中又分成了提交的类型和咱们的主题,之后额外增加一个空行,空行下额外增加我们本次提交的主体内容,然后再增加一个空行,再额外附加我们的注角, 其中主体和注角的部分是选填的。那理解了这个基本结构以后,那下面咱们看一下每一项具体的含义是什么。我们最重要的是它的类型,类型在谷歌当中,它呢被划分为了以下这 大概十来种不同的样式,包括 feature, 代表的是增加一个新功能,本次我们提交新增了一些特性, 同时呢, fix 呢是修复已有的 bug, box 呢是文档变更,还有 style 代码格式的调整, refactor 代码重构,性能优化测试构建。 通过这个类型的前缀,我们去说明本次提交它的目的是什么。那你可能会说,本次我做了多种不同的工作,既进行了修复,也进行了新功能的增加,该怎么办呢? 作为谷歌也给出来对应的建议,希望呢变成多次提交,每一次尽量保证职责单一,解决一件事情,这个我们认为还是非常有必要的,这方便我们进行代码的跟踪和迭代。 那紧接着在头部的部分还有一个额外的小项叫做 scope 作用域,作为作用域中它去说明了,哎,本次我修改的是哪一个?比如说咱们的 ui 层,或者是咱们的认证的逻辑,这些不是必须的,一般我们自己也不会去写这块。 在头部的部分中还有一个 subject 简短的描述,用尽量简短的话术来说明本次提交的变更信息。 如果本次咱们的描述能说清楚的话,那就是最好的说不清楚,那你就可以在下边 空一行以后来说明咱们的包底,也就是提交的主体部分来详细进行说明,说明中来描述为什么要修改以及怎么进行修改。现在 ai 工具非常的流行,你甚至可以用 ai 工具帮我们生成这个请求体。 最后就是注角的部分了,注角的部分它有主要两个目的,第一个,一个不兼容性的变动,我们通常会增加一个叫 breaking change, 当看到这一项以后,它说明现在我们本次提交的这个版本和以前不兼容。那这也就意味着在我们进行版本发布的时候,按照标准的语义化版本发布,比如说十点,十点十 三个时,那么第一个呢?叫做 major 主版本,第二个 minor, 第三个是最后的 patch, 那 作为 minor 代表的是大版本号,当大版本号发生变更的时候,说明不会兼容之前的版本, 中间版本来新增了以后,说明对之前的版本没有发生这个彻底性的变化,是可以兼容的。而最后一个这个 patch 补丁的部分则是进行局部的修复,所以如果我们增加了这个 breaking change, 往往这就意味着咱们具体的大版本号要进行自动增加了。 同时在 footer 中我们还要可以额外增加一些具体的额外关联,比如说对于井号一二三这样的一个啊,甭管是需求也好,还是之前发布的某一个编号的一个任务也好,进行了关闭或者修复了什么什么样的 bug。 具体的这个井号呢?在公司内部他不同的环境,纸袋也不一样,在平时使用的时候就可以遵循这样的一些过程呢来使用和开发就可以了。这里你可能会说,那谷歌这玩意做出来对我们有什么帮助吗?好像也没有什么了不起,不就增加了一个格式吗? 老话讲,没有规矩不成方圆,当我们基于谷歌来进行开发了以后,实际上针对软件行为就可以进行二次扩展。比如说拿一个最简单的例子, 如果我们本次提交是 fix 类型的,则代表针对咱们的版本号进行修复,所以,哎,自动的在版本命名的时候,我们 版本的管理工具就是在最后一项来进行自增加一,而如果是这个 feature 来增加的话,那么中间的 minor 版本号则自动加一。那如果在 footer 上额外的咱们标注了这个 breaking change, 代表 对之前不兼容,则意味着咱们 major 版本号儿自增加一。通过咱们提交的这些包含的关键信息,可以有效地指导我们流水线来 确定版本号到底是加哪里,它还可以帮助我们有效地生成更新目制。大家会发现,如果在 git hub 或者是在 git 上,那它每一次 release 新版本出来的时候,会有一系列的,比如说新增了哪些特性,修复了什么 bug, 这些怎么来的呢? 这些就其实把之前每一次提交的信息呢,哎,给他整理出来,分门别类的放在那就完事了,相当于每一个步骤其实他都是把我们具体做的事情给他进行了从新的梳理。 而第三个就是提交时的代码的质量检查,在业务构建的时候,因为我们按照统一的格式来进行了说明, 所以你在提交的时候,比如就像上面的啊 fix 什么什么 bug, 那 么它作为流水线来说,或者作为代码的提交工具就可以进行预检查,发现你这玩意儿它不符合我们的提交要求,然后必须进行调整, 以这种方式来让我们整个团队沿着相同的规则来进行程序的提交,让整个的让代码变成可控的扩展。而最后就是在 c i c d 我 们的流水线的部分中, 如果读取到本次提交信息是 docs 的 话好,那么作为 c i 流水线可能只会去进行额外的文档的构建和生成,如果遇到了 c i build, 那 可能是不出发应用的部署,只进行脚本的构建,那如果是 feature 和 fix 的 时候好,那 出发完整的流程看到没有?根据本次提交的信息,也决定了流水线执行具体的哪些行为。 第三部分关于工具的应用,这里我就不给大家扩展来絮絮叨叨了,大家看一下工具的名称和对应的作用,如果觉得有用,把它呢?再进行一个呃扩展学习,希望以后你提交信息的时候能按照这个标准来进行。
6IT老齐 01:32
01:32 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿当你要生成相同格式的 word 时,还在一个一个复制吗?当然不是了。第一步,我们先制作 word 模板,将需要填充的列标题放到 word 中,并用双大括号括起来,保存为 model text。 第二步,我们来编辑一段拍脏代码。首先定义一个 word 生成的方法,方法中读取 word 模板, 替换模板中的数据,指定保存目录。如果目录不存在,则创建指定文件名称并保存文件,顺便打印生成净度。 然后定义入口函数,入口函数中读取要生成的数据,并将数据改为列表格式,循环列表,调用生成 word 的 方法。最后,我们进入脚本所在目录,打开 power shell, 执行派脏命令,运行脚本目标,目录中已经生成了 word 文件,打开 word 查看效果, okay, finish!
 01:15查看AI文稿AI文稿
01:15查看AI文稿AI文稿我无语了呀,接手一个老项目 git commit 里全都是 a b fix test, 浑身难受啊,谁来救救我,我来助你!用这个 github 上开源的免费工具 g r e c 一 行命令,就能用 ai 把整个项目的 git message 改写成有意义并且规范的内容, 只需要两个步骤。步骤一,配置环境。以 mac 为例,先安装 node js, 然后配置单元模型,可以选择本地部署的欧拉玛,或者用远端的 open ai api get message 是 软文本,推荐使用欧拉玛来调用本地部署的小模型, 效果足够,数据安全还没有成本。用 homebrew 安装欧莱玛,用欧莱玛酷 jimmy。 三,安装模型,用欧莱玛 server 启动服务,然后用 run jimmy。 三,来测试本地安装模型的效果,这样环境就配置好了。 步骤二,重写项目的 commit 来到项目文件夹,执行这样的一行命令,就可以重写最近的十条 commit message。 以我的切图小项目为例,效果是这样的啊,改完太舒服了!关注我,玩转 ai 编程!
33唐斩AI编程





