Traefik配置缓存
我是老周,今天说说固态硬盘贷款存跟不贷款存的区别。兄弟,你知道这两个哪个贷款存的吗?简单来说,固态硬盘贷不贷款存,记住核心三点, 速度、稳定和价格。贷款存的硬盘开机、打开软件,加载游戏,这些速度飞快,这是它最大的优点。但是它有两个小毛病,一是贵,二是怕突然断电。不贷款存的硬盘将日常用 存大文件,感觉也挺快,但写满的时候会同时多开,感觉有点会卡顿。所以老周总结一下,如果你是游戏玩家,专业搞设置的,别犹豫, 选择贷款存的。如果你是日常办公,普通家用,预算有限,不贷款存的也够用,自己装机看中的是肯定是长期稳定,所以多数选择贷款存的。我是老周,下次见。

粉丝758获赞9762
相关视频
 03:36查看AI文稿AI文稿
03:36查看AI文稿AI文稿玩 p u b g 玩着玩着突然开始卡 f p s 明显往下掉。这种情况最近真的挺多人在遇到, 一开始还以为是显卡不行了,或者驱动出问题了,但仔细看下来,其实很多时候根源并不在配置,而是长时间游戏后显卡缓存堆积,把性能一点点拖垮了。先说最直观的感受,就是你明明刚进游戏的时候很流畅, 打一会儿之后画面开始不对劲,场景一复杂就掉帧,从空旷地跑进城区或者烟雾弹爆炸特效一多, fps 直接从两百左右掉到六十以下,而且不是那种一闪而过的波动,是会卡住一段时间自己缓不过来。 再严重一点还会发现贴图开始出问题,墙面变糊,人物模型像没加载完整一样,甚至偶尔会出现花屏色块。 这其实就是缓存里的文理数据乱了,显卡不停地去读去加载,却又加载不顺,结果就是画面和帧率一起崩。还有一个很多人容易忽略的点,就是操作变飘, 明明鼠标和键盘没问题,但开枪转身压枪都感觉慢半拍。这就是渲染延迟上来了,输入已经给到显卡了,但画面反馈慢。 fps 游戏里这个影响特别大。而且这种问题有个很明显的特征, 就是游戏时间越长越卡,重启游戏之后马上又顺了,过一会继续卡。原因也很简单, 缓存被清空了,但没从根本解决,跑久了还是会继续堆。在动这些设置之前,我一般会先把网络环境稳一下,因为有时候网络抖动和性能卡顿混在一起,很容易误判。 我自己用的是驯游加速器,主要就是图一个稳定延迟低,像 pubg 这种对网络很敏感的游戏,丢包和高延迟都会放大卡顿感。 而且驯游是二零二五 pcl 官方独家赞助加速器,操作也很简单。打开驯游,在右上角输入口令护芯片,先把七天的加速时长领了,然后直接搜索 pubg, 一 键加速把线路跑顺了,至少能先把网络这一块的干扰因素排除掉, 网络稳住之后再来处理显卡缓存的问题,效果会更明显。第一步就是清理显卡缓存,先把电脑上所有程序都关掉,然后打开 n 卡控制面板, 左侧进到管理三 d 设置,右侧切到全局设置下滑,找到着色器缓存大小,先改成禁用并应用。接着回到桌面,进 c 盘用户 自己的用户名文件夹,找到 appdata, 在 local 里的 nvidia 文件夹中把 g l cache 和 d x c a c e 里的文件全部删掉,再回到 appdata 进 local, 同样找到 nvidia 里的 d x cache, 把里面的文件清空。 做完这些之后再回到 n 卡控制面板,把着色器缓存大小改回驱动默认值应用,然后一定要重启电脑。第二步是游戏内画面设置的取舍, 重点盯着纹理质量、纹理过滤和材质细节这几项,它们是显卡缓存的主要消耗来源,哪怕你其他设置不动,把这几项适当降一档,也能明显减少缓存压力。对应到 p u b g 里就是材质阴影特效别拉太高,稳帧比极限画质重要得多。 总的来说,显卡缓存堆积确实是现在 p u b g 长时间游玩后卡顿的一个高频原因,但也不是唯一答案,建议大家对照前面说的这些特征来判断,如果症状基本吻合,再按这个思路去处理,基本都能有比较明显的改善。
2326PUBG-护心片 01:59查看AI文稿AI文稿
01:59查看AI文稿AI文稿啊,你好啊你好,面试官,这是老师简历哎,好坐。嗯,可以简单地先做个自我介绍吗? 请问一下就是如何在 linux 系统中测试 dns 解析是否正常,以及如何配置本地的 dns 缓存, 可以简单的说一下。好的好的。呃,我平常测试 dns 的 话就是首先最简单的就是用拼命点去拼一个,比如说百度点 com, 就 如果能拼通所显示出对应哪个 ip 地址,那说明节气是好的, 但如果拼不通或者对方的那个服务器禁拼的,也不一定说解析有问题。呃,这时候我可能会用 n s look up 这个工具去或者我们的地格 mini 啊,去试一下,就是 n s look up 三 w 点百度天看我这样子去看一下解析的一个返回的一个 ip 花了多长时间, 也就是说就算拼不通的话,也也能够明确的去判断解析成没成功。另外还会看一下咱们的 etc 里面有个啊你收伏那个文件,就是里面会有一些啊服务器的地址啊这种配置,如果这个文件里面没有配置来,就是说明我们本地的一些网络设置有问题, 那肯定就是解决不了。然后就是本地的一个 dns 缓存的话嘞,因为 dns 系统默认是没有全局的一个 dns 缓存的,所以我最常用的是用另外一个工具叫做 dns master 啊,这个工具也比较清亮,而且好配置。 就是简单地说的话就是测试解析,我们用 d g 或者 n s look up 不是 比较准确的。然后本地缓存去装一个工具,就 d n s ramask 配置一下就可以搞定了,也可以提升我们后续的一个解析速度。 嗯,好的,可以说一下你之前这份工作,你们和业务是怎么进行一个内部协调和沟通的吗?运维测试开发相关的面试资料我都整理好了,留来份快递我发给你。
391Linux运维明哥 04:00查看AI文稿AI文稿
04:00查看AI文稿AI文稿大家好,我是悠悠兔子,相信大家在日常工作中一定会遇到一个问题,就是 c 盘空间不足的问题, 别害怕,我们学习使用优异舞,优异舞的默认缓存空间也是在吸盘,嘿嘿嘿,所以说一定会遇到积分空间不足爆红的问题。今天我们来说一下我们如何更改优异舞的缓存位置。 我们首先需要找到我们由于无软件的安装位置,这里我装到地盘了, 大家自行寻找自己的位置啊。然后呢,我们找到 engine, 下拉,找到逃避一根,再下拉,我们找到 base engine, 点儿 i n i, 我们双 打开它,这里面呢就是由于死的配置文件,像我们这样会有一些采用信息,一些命令。 然后呢,我这边给大家写好了一个啊记事本,里面包括了我们之前的默认的分存储的文件位置,我们复制一下,然后呢,我们在这个记事本下点编辑 找到查找,我们复制这一串命令。好,我们查找,我这里找不到呢,是因为我已经坑改过了啊,大家一定会找的到的这一串命令, 把上面这一串命令切换为下面这一串命令 查找,我这已经成功替换了,就是这样的一个操作啊,稍后呢,我会把这两船命令分别打在我们的评论区下面,好吧, 这样我们就成功更改了我们有一五的缓存位置啊,我们可以检查一下, 在我们的文件夹下面,如果出现了抵外物,该他 catch 这样的文件夹,就代表着我们已经成功的把默认的 c 盘缓存建议到我们的项目缓存下了。 这里呢是来说一嘴我们的各个文件都是干什么用的?第一个 come figu 就是我们的项目配置文件,比如说我们修改了一些光锥在项目里面, 这里面我们点编辑,点项目设置, 然后我们修改了这里面的一些信息啊,他就会默认存储到我们的这个文件下面。好,就是这个下面的航腾腾,航腾腾是存足我们一些文件信息的,比如说我们的模型信息啊,还有我们的贴图信息 是纯属这些东西的默认的,肯定这个比较重要啊,在下面呢就是我们的默认火存位置啊, dyod 卡尺,嗯,火存位置, 然后呢 intermediate, 这里存储的是一些啊,我们的构建信息啊之类的讲不是特别重要。还有下面的 siri 啊,里面存储的是一些我们的 什么日志啊,消息日志啊,还有我们比如说崩溃日志啊,还有我们的项目截图啊,只有来这里的现有的下面脚本就不多说了,所以说呢,最后的这一个我们补充一下,这是我们的启动文件, 所以说呢,我们想把一个项目发发送给别人,我们只需要发送前两个文件夹就可以了。 这里有同学会问啊,我们为什么不把我们的项目缓存一起发过去呢?嘿嘿,这里我觉得啊,如果是发给甲方爸爸,我们就发钱养就好了,让甲方爸爸看着爆红的细盘头痛去吧,好,今天就这样了。
859UE5兔子 08:04查看AI文稿AI文稿
08:04查看AI文稿AI文稿我们每天都在和各种 url 追踪参数打交道, utm source, utm medium f clyde 这些参数本身是为了方便我们分析流量来源,但他们却成了现代外部应用中一个隐秘的性能杀手。 今天我们就来深入剖析这个由参数滥用引发的缓存噩梦。大家看这张图,一个爆款文章通过不同渠道被访问 url, 后面跟着五花八门的追踪参数。 对于传统的 http 缓存来说,比如 c、 d、 n 或者浏览器缓存,他们可不认这些参数是追踪用的,他们只认 url 不 一样。这意味着什么?意味着服务器要为每一个带不同参数的 url 生成一份独立的缓存副本。 这就好比你家仓库里明明是同一款产品,因为包装上的标签不同,就得存成不同的货,空间浪费不说,效率也低的可怕。 结果就是缓存命中率直线下降, c、 d、 n 形同虚设,大量请求直接打到你的应用服务器上,贷款成本蹭蹭上涨,服务器压力山大,用户体验自然也就一落千丈,这简直是灾难性的。 面对这种局面,业界其实也尝试过一些土办法,比如某些 c、 d、 n 允许你在控制台设置,忽略某些查询参数,但这往往是特定厂商的私有方案。 如果你用了多家 c、 d、 n 或者搞多云架构,那配置起来简直要命。还有些人想用 very 头或者自定义头来绕弯子,但实现复杂容易出错,还可能带来新的问题。 最极端的,干脆彻底禁用查询字幕串的缓存,但这又阴晦费时,像搜索页面 q 等于 keyword 的 这种真正需要参数区分内容的场景也缓存不了,所以我们需要一个标准声明式能被广泛支持的 http 级解决方案。 这就是 nova research 应运而生的意义所在。它是由 i e t f 的 http 工作组标准化的服务器,可以通过它明确告诉所有缓存系统,在判断 url 是 否命中缓存时,可以安全地忽略掉查询字串的一部分或全部。 这就像给缓存系统下达了一个军令状,让它们变得更聪明。 noverysearch 这个响应头,它的值是由一系列指令组成的,非常灵活。 最常用的指令是 perims。 你 可以用 perims 来告诉缓存。所有查询参数都不重要,都可以忽略。 比如 paramus 等于引号 u t m source 引号、空格引号 u t m medium 引号。这样所有带这两个参数的 url 都会被视为同一个资源。 更精细一点,可以用 paramus 等于左括号引号 pyrome 引号右括号、逗号、左括号引号 pyrom 二引号、右括号来指定只忽略哪些参数。 有时候我们只想保留某个关键参数,忽略其他所有。这时候可以用 perims 逗号 except 等于左括号引号 perim 引号右括号。比如搜索页除了 q 参数,其他都忽略。 还有一个 ko 的 指令,它会忽略参数的顺序,比如 a 等于一和 b 等于二,以及 b 等于二和 a 等于一,在它看来就是一回事。这些指令组合起来就能精确控制缓存行为,避免不必要的涌跃。 理论讲完了,怎么落地呢?配置其实很简单,如果你用 n g x, 就 在对应的 location 块里加一行 add header novery search parameters 等于 utm source, utm medium 和 pach。 用户呢? 在 mod headers 模块里,用 header always set novery search parameters 等于 utm source, utm medium note js 开发者用 express 的 话,写个中间件 rest set header, noverysearch, params 等于 u t m source, u t m medium。 如果是 next js, 可以 在 next 点 co n fig 打 js 的 headers 函数里配置。你看,无论你用什么技术,占添加这个头都非常直接。关键是 你要根据自己的业务场景,准确识别出哪些参数是纯粹的追踪参数,然后把它们加进去,比如常见的 u t m 系列, clyde, f ply 等等,都可以考虑纳入忽略列表。 配置好了,怎么知道生效了吗?很简单,打开浏览器的开发者工具 network 标签下,刷新一下带有追踪参数的页面,看看响应头里有没有 noverysearch 这一项值是不是你期望的。 或者用 curl 命令 curl ihtps 冒号斜杠斜杠, your site 点 com 斜杠 article 问号 utm 下划线 source 等号 test, 检查返回的头部信息, 更重要的是观察后续请求的 size 或 from memory cache, 并且请求时间极短,那说明缓存命中了。 这里有几个最佳实践提醒大家,第一,可以先从流量小的页面施水,没问题了再推广到全站。第二,不要一刀切,不同页面类型策略要不同, 比如文章页和搜索页肯定不一样。第三,也是最重要的,部署前仔细分析你的访问日记,找出那些高频出现但又不影响内容的参数,精准打击才能发挥最大效果。 虽然现在手动配置 nova research 已经很有效了,但这只是开始,未来我们可以想象更智能的场景。 比如利用 ai 模型自动分析生产环境的访问日记,找出哪些参数的值,变化频繁,但响应内容却一模一样,然后自动推荐,把这些参数加入 nova research 的 忽略列表, 就像 google page speed insights 那 样,未来可能会有工具直接告诉你配置这个参数预计能提升多少缓存命中率。 更进一步,结合边缘计算和边缘 ai, 当一个请求到达边缘节点时,轻量级的 ai 模型可以实时分析 url 参数、 user agent 甚至简单的行为特征,动态判断这次请求的个性化程度。 如果判断为高度可缓存,即使 url 带有一些看似个性化的参数,边缘节点也能动态地应用类似 noverysearch 的 逻辑,让它命中公共缓存, 这将实现缓存策略的真正智能化和动态化。总结一下, noverysearch 作为新一代 http 缓存优化标准,为我们解决 url 参数带来的缓存难题提供了强有力的武器。 他通过声明式的响应头,让服务器能够明确知道缓存系统,从而显著提升命中率,降低待宽和服务器成本,最终改善用户体验。 虽然目前支持范围还在扩大中,但 chrome 已经走在前面了,现在正是部署的最佳时机。 提前适配不仅能立刻优化 chrome 用户的体验,更是为未来全面支持做好准备。让我们一起拥抱这项技术,为 web 性能的极致优化贡献力量。
3领码科技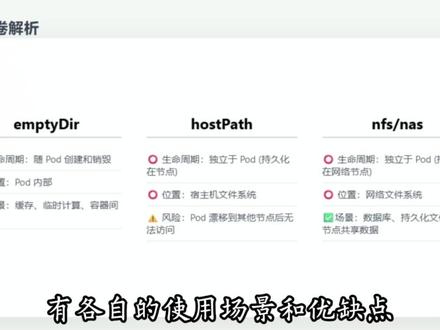 01:59查看AI文稿AI文稿
01:59查看AI文稿AI文稿在扩展中, pod 是 短暂的,当 pod 被删除或崩溃时,里面的数据通常会丢失, 我们需要存储卷来保存数据。第一种, mkdr 是 pod 挂载到内存的一个临时目录,它的生命周期与 pod 绑定。如果 pod 崩溃重启, 数据还在,但是如果 pod 被删除, mp d r 也会随之消失,数据永久丢失。适用场景,缓存临时计算结果, hold 一 pass 直接挂在数据库上的文件目录数据实际上是存储在数据库的硬盘上的。如果 pod 重建并被调度的极品其他节点,比如 node 二、 note 二上没有这个文件,那么数据就无法访问。一般配合 note snk 节点选择器使用。适用场景,系统日制或者绑定特定节点数据情况下,使用。 第三种,网络存储,网络存储独立于集询节点存在,比如 pos 地在 note 一 上写入数据到网络存储中,如果 pos 挂了,漂移到了 note 二,因为连接的是同一个数据卷, 数据依然完好无损,可以正常进行读写。适用场景,数据库持久化文件跨节点共享数据总结,三种存储卷有各自的使用场景和优缺点,可以根据需求选择合适的存储卷。 下面演示一下三种数据卷的使用。这里在容器里定义了三个挂载点, 下面分别定义了三个存储券,分别是 mkdr、 红色 pass 和 nfs。 存储券,使用都非常简单,就 nfs 服务需要提前准备好,这样就实现了使用不同的存储券。
113云计算运维老梁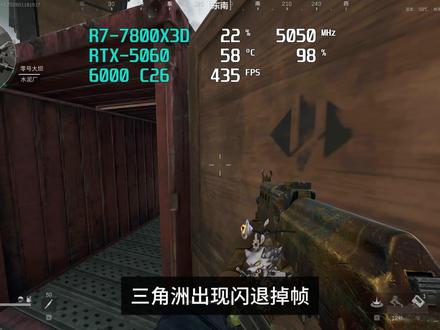 00:42查看AI文稿AI文稿
00:42查看AI文稿AI文稿三角洲出现闪退掉帧,可能是着色器缓存堆积导致的,下面教大家如何解决。首先在桌面右击,打开英伟达控制面板,点击管理三 d 设置,找到着色器缓存大小,把它设置为无限制, 然后点击更改分辨率,把刷新率设置为最大,最后点击应用,接着按键加 r 键,输入 abd, 然后点确定,如果提示报错,需要把显示隐藏文件选项打开,打开 logo 文件夹,找到 excel 文件夹,把 d、 c、 c 和文件里面的所有文件删除,这样就可以解决卡顿掉帧问题。
1061钢铁侠DIY超频电脑(测试游戏) 01:49查看AI文稿AI文稿
01:49查看AI文稿AI文稿每天两分钟学习很轻松,学好自动化,加班也不怕,做好端对端,薪资翻三翻。今天我们继续学习 e two e 全局配置。 首先勾选行为快照,点击运行测试,测试过程飞速快进哦。测试结束后,会生成一个文件到桌面。打开文件夹是每个操作后生成的页面截图,可以帮助做合规同学快速完成截图。 开启记录行为记录,关闭行为快照,打开行为记录,点击运行测试,测试过程飞速快进哦。测试结束后,同 样会生成一个文件到桌面。打开文件夹是一个点 trace 点 zip 的压缩包,不要解压文件。点击 e test 的痕迹,选择压缩包上传。 点击面板,可以看到测试用力的、执行的每条用力的的信息和请求的资源信息,可以帮助我们分析数据状况。结合测试用力和测试报告定位问题。 设置缓存,关闭行为记录。打开设置缓存,点击脚本配置,打开脚本文件,可以看到脚本的第一条用力含有 cookie 和 sense 信息。开启缓存后,会自动把第一个分组内的所有文件的 cookie 和 session 一同设置到浏览器中, 可以解决一些需要登录验证的问题或者其他问题。可以参考掘金上的一篇文章。通过设置缓存自动登录,帮助我们实现每日打卡功能。 今天我们就讲到这里了,下节课我们继续深入了解自动化测试。点赞点关注,下次不迷路,记得关注点赞哦!











