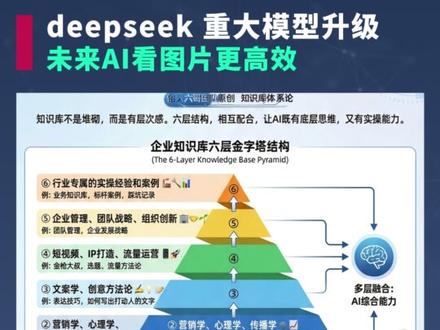
就在刚刚, deepsea 发布 ocr 重大升级,核心突破不仅在于读得准,更在于理得清。传统 ocr 像扫描仪一样,从左到右,从上到下的识别文字,但 deepsea ocr 引入了创新的视觉因果流概念。简单来说,当它识别出表格第一列是菜名, 它会基于因果逻辑预判出跟在它后面的数字,不是数量就是价格。所以它不是盲目扫描光学像素,而是在理解内容逻辑。这种技术的进化让它在 omni dock bench 精准测试中直接登顶,甚至在相同视觉 token 的 预算下, deepsea o c r 模型比 gemini 更优,模型代码及论文已全部开源。

粉丝9.1万获赞107.3万
相关视频
 01:40查看AI文稿AI文稿
01:40查看AI文稿AI文稿万万没想到, deep tech 又一次冲上了热搜,这次他们开源了一个全新的 ocr 模型,直接把文字识别的效率提升十倍。这不是简单的技术更新,而是彻底改变了 ai 阅读的方式。先说结论,以后 ai 再理解文字,可能就需要先转化成图片,再像人类看书一样看图。 我知道这有点不可思议,但事实就是如此。首先,传统 ocr 就是 一个字一个字的扫描图片,先把所有的文字提取出来,再进行阅读,这样不仅会破坏原有的结构,而且遇到双栏文章和复杂的表格则直接傻眼。但 deepsea ocr 会首先阅读图片, 识别出哪里是标题,哪里是正文。即便是表格,它也会先对表格内容进行排序,然后把排序好的文字提取出来。 这样一来,识别准确率直接提升到百分之九十七。而且更重要的是,这项技术还带来了一个意想不到的成果,那就是利用视觉 token 完成对文本 token 的 压缩。当压缩率达到十倍时,仍然能保持百分之九十六点五的精度,这意味着大模型上下文的长度可以立马提升十倍。 想象一下,当我们阅读书籍时,并不是一个字一个字的阅读,而是一目十行就可以理解文章大致的意思。现在的 deep sea 就是 在模拟这个过程, 如果这项技术普及,文字将被彻底抛弃, ai 未来就只会看图了。如果你想要更高效的使用 ai 的 能力,将 ai 落地到自己的行业,不管是融入企业流程,还是策划视频进行互联网获客, 最重要的是搭建自己的行业知识库,加上我们专门优化的提示词结构,可以让 ai 真正懂你的业务。我把所有的技巧都放在了这个文档里面,需要的可以说一下。
 03:12查看AI文稿AI文稿
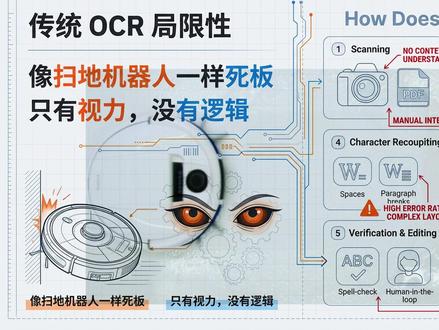
03:12查看AI文稿AI文稿大家敢信吗?就在所有人都还在盯着 deepsea v 三或者 r 一 怎么硬刚 open ai 的 时候,这帮疯子在极其垂直的 ocr 领域悄悄扔下了一颗核弹。这次发布的 deepsea ocr 二,不是简单的版本更新,而是一次彻底的物种突变。 如果说上一代 ocr, 包括 deepsea 自家的早期版本还是在教机器怎么认字,那么 ocr 二是在教机器如何思考他看到的字。这是一次从眼睛到大脑的暴力进化。 咱们来做个残酷的对比。在 ocr 一 点零时代,所有的模型,不管是国外的商业巨头,还是之前的开源霸主,本质上都是光山扫描的努力。他们像个死板的扫地机器人,不管你这页报纸排版多花手,他只能从左上角开始,傻傻的一行一行往右扫。结果是什么? 报纸分栏,他跨栏读插图,把句子切断,他应聘,他看见了所有像素,但他根本不懂这些像素之间的关系。他只有视力,没有逻辑。 但 deepsea ocr 做了什么?颠覆?他们在论文里直接干掉了那个只会被动接收图像的 clip 编码器,换成了一套视觉因果流 vero cosmo flow。 这是 ocr 二最可怕的净化点。他学会了主动提问。以前的模型是图里有什么都报上来,现在的 ocr 二是刚读了这个标题,那下一块内容应该是正文还是配图?我要去找找。 他引入了一组可学习的查询向量,像一群带着任务的侦探。读完总资产,他会自动去表格右边找金额,而不是去读下一行的页码。他不再是被动扫描,而是在进行主动的阅读理解。进化的代价是什么?通常是算力暴涨,对吧?错! deepstack 这波操作反直觉到了极点。 相比于上一代动不动就要消耗几千个微州 token 的 高昂成本, oc 二二通过这种极度聪明的逻辑压缩,把一张一千零二十四的高清大图,死死压在两百五十六到一千一百二十个 token 之间。这意味着什么? 意味着他比上一代更聪明、更懂逻辑,但他吃的粮却变少了。用最少的算力还原最复杂的二 d 结构,这才是 deep 一 贯的即刻暴力美学。 效果差距有多大?数据直接打脸。在欧姆尼多克半指这个专门搞心态的复杂文档测试集上, ocr 在 阅读顺序这项指标上的错误率直接腰斩。以前那些让你抓狂的公式、错位、表格、乱码,在 v 一 时代是常态,但在 v 二眼里,这些都是有迹可循的逻辑链条。他知道这个公式属于这道题,那个注是属于那张图, 它把原本破碎的像素重构成了一条完整的逻辑链。讲到这,你可能觉得这只是个好用的工具,格局小了。 deepsea ocr 的 真正野心是打通通往 agi 的 多模态统一之路,当视觉编码器开始具备因果推理能力时,它就已经不仅仅是眼睛了。 deepsea 在 这里埋下了一个巨大的伏笔, 如果这套架构能看懂复杂的文档逻辑,那未来他能不能看懂股票 k 线的走势逻辑?能不能看懂一部电影的趋势逻辑?他们再把二 d 的 图像事件拆解成一 d 的 因果链条,这才是真正的降维打击, 从死板扫描到因果推理, deepsea 用一篇论文证明了进化的方向不一定是堆参数,而是重构认知的逻辑。这种把机器视觉变成机器阅读的技术跨越,你们觉得会是多模态、大模型的终局吗?我们下期见。
79ITer 01:41查看AI文稿AI文稿
01:41查看AI文稿AI文稿deepsea 悄悄把 deepsea ocr 给开源了,这次他们不卷聊天,卷的是 ai 识字的逻辑。以前的 ocr 往往只是机械的扫描,一遇到多栏论文、报纸或者复杂的报表,就容易出现串行或逻辑断篇的尴尬,读出来的内容像乱码。 deepsea ocr 二的核心突破在于它引入了因果流机制。 通俗点说,它不再是盲目的从左扫到右,而是学会了像人眼一样先扫视大局,判断哪里是标题,哪里是正文,然后再动态决定阅读顺序。这种带着脑子看图的能力,让它的识别准确率直接跑到了百分之九十一点零九。 最有意思的一点是, deepsea 这一次打破了门派偏见,创新性的把阿里克问二五百 m 拿来当视觉编码器。这种把大语言模型直接当成视网膜的操作,让 ocr 从底层就具备了序列和逻辑优势。 加上他沿用了自家的 m o e 混合专家架构,虽然总餐数量有三十亿,但实际推理时只激活五亿参数,在保证顶级性能的同时,把推理成本压到了极低。在实际测评中,无论是处理严爆 合同还是古籍,那些原本让开发者头疼的排版错位问题得到了大幅缓解。甚至在同等算力预算下,它的文档解析精度比谷歌的 jamie 三 pro 还要更甚一筹。对于经常需要处理海量 pdf、 构建 r a g 知识库的需求来说,这或许能成为最优解。 deepsea oc r 二的价值不仅在于它的创新,还有一种趋势, ai 正在从单纯的文本理解走向物理世界的视觉逻辑重构。 在很多巨头选择加高技术围墙的当下, deepsea 坚持代码论文权重、全套开源,甚至第一时间支持了 onslof 微调,这种极致的实用主义确实给开发者社区打了一剂强心针。
21InfoQ 02:49查看AI文稿AI文稿
02:49查看AI文稿AI文稿疯了, deep seek 又又更新了!这次发布的 deep seek ocr 直接废掉了过去十年的机械扫描。你以为现在的 ai 真的 会看图吗?不,在这一代架构出来之前,他们在面对复杂文档时,其实全是瞎子。为了理解这次更新,我们要先搞清楚,看见和注视是两码事。 过去 ai 看图片就像一台笨拙的平面扫描仪,无论面对的是一首诗、一份多栏报纸,还是复杂的财务报表,它只会死板的从左上角一格一格扫到右下角。这种光删扫描顺序最大的问题是,它会强行切断内容的内在联系。 比如报纸上的大标题是横跨两栏的,那么死板的扫描仪读到一半就会被切断,导致 ai 读出来的东西逻辑全是乱的。而 deepsea ocr 引入了一个震动行业的概念,视觉因果流 visual contour flow。 它不再是被动接受像素,而是学会了像人类一样带着脑子去打量。 就像你进餐厅看菜单,你会先扫一眼大标题找主食,再盯着加粗的招牌推荐,最后才看价格。这种带着目的去寻找的束缚,而是根据语义的轻重缓急来重新排队信息。 deepsea 是 怎么做到的呢?他干了一件极其硬核的事。他把视觉编码器,也就是 ai 的 眼睛,彻底换成了 lm 大 语言模型的架构。在 deepencoder v 二中,他扔掉了传统的 clip 架构,塞进了一个带有逻辑推理能力的内核,也就是千万二的零点五 b 语言模型。这有什么好处? 类比一下,以前的 ai, 眼睛只是个普通的摄像头,只负责传图像。现在的 ai 眼睛自带一个预处理器,在看到图像的瞬间就开始思考了。 它的工作原理就像一个逻辑导游。传统的视觉 token 像素块依然负责看清大局,但 deepsea 新加了一组因果流 token, 这组 token 采用了混合注意力机制,你可以把它理解成一种单向事件,约束每个逻辑节点,在决定自己该读什么时,必须参考之前读过的内容逻辑。 这种先思考再排序后阅读的机制,让它在阅读顺序的准确性上, reading order eddy distance 从前代的零点零八五显著降至零点零五七,并且远低于 gemlife 的 零点一幺五。证明模型更懂文档结构 deepseek 解决的不仅仅是读文字,它再重新定义视觉压缩比。打个比方,传统的 ocr 提取一份文档可能需要消耗六千个头啃,而 deepseek 依靠其钢丹 mode, 也就是多视角裁剪策略。面对小字密集的文档, ai 不 会一股脑把图片放大到变态,而是采用一种分身观察法,它会生成一个局局缩略图和零到六个局部高清特写,所有特写共享逻辑,这就让它能用极少头啃预算就像大脑的代宽,看清报纸上最细微的数字,同时不让算力崩溃。 有趣的是, deep seek 将 token 预算死死压在二五六到一千一百二十之间,这个上限一千一百二十正是与 jameon 三 pro 的 最大视觉 token 预算相匹配。 但相比于谷歌的大力出奇迹的全能 deep seek, ocr 二走的是光学压缩 optical compression 路线,它是一个三 b 参数的小模型 mo e 架构专注于把图像蒸馏成极少量的 token, 它的目标不是做一个全能选手,而是做一个最高效的眼睛,让后续的 lm 能以最低的算力成本读懂文档。 进化论告诉我们,感官的眼睛是为了生存。而今天, deepsea 在 硅基生命身上复刻了这一进化方向,也许这能帮助 ai 开始真正拥有理解物理世界的感官能力。我是老高,关注我,带你了解更多 ai 行业的深度思考,下期见。
543老高AI笔记 02:35查看AI文稿AI文稿
02:35查看AI文稿AI文稿讲一篇有关 deepsea 的 最新论文,叫做 deepsea ocr two, 它引入 deepsea color v two 作为视觉的编码器。这个框架呢,打破了传统的 ocr 模型,或者说是 vr 模型,固定的从左上到右下的扫描图像像素的限制,从而模仿了人类的视觉的因果流,就 color flow 的 逻辑。 首先我们回顾一下二零二五年 deepsea 刚出 ocr 模型的时候,那时候呢,是用视觉方式来压缩信息,减少大圆模型的 token 的 整个的上下文。 deepsea v two 呢,框架做了一定的调整,是模仿人类逻辑来阅读复杂的文档,在多项的基础测试中呢,刷新了搜查。目前呢,从论文到代码到模型都已经开源了,具体怎么做呢?文章中说的是原来呢,传统的视觉语言模型 v i m 通常是用光标扫描的方式处理信息, 理解呢,是强行的把二 d 的 图像呢硬变成了一 d 的 一个训练,就是所谓的像素,而忽略了图像内部的语义关系。那这个是跟人类的视觉的习惯背道而驰的。为了解决这问题呢,他们引入了一个轻量级的大圆模型 queen 二零点五七的原本的 kipp 的 编码器 queen, 二零点五 b 呢,其实呢,是一个大圆模型,它的理解能力会强很多,它的信息的上下文也会大很多。 基于这个圆模型呢,作为它的一个 input 的 上下文,从而呢使整个的 ocr 这个模型呢,主要包含两部分, 就是 vision tokenizer, 就是 通过卷积层的设计,将图像呢转变成一个视觉 token, 而不是像素的信息。第二呢,就是作为视觉编码器的大元模型,就我们刚刚说的这个 queen two 零点五 b 模型,不仅可以处理视觉的 token, 还引入了一组可学习的称为查询 token query tokens, 通过 attention mask 就是 注意力掩码的设计呢,视觉 token 之间呢,采用了双向注意力,保持了全局的感知能力。其实这就是一个 v i t 的 逻辑,就是 transformers 之间的每一个词组之间是有联系的, 它的 vision in transformer 就是 把每一个视觉的模块变成一个 token, 就是 卷积的逻辑。这 token 呢,与 token 之间呢,又产生关联,这把复杂的卷积的流程呢,通过它产生注意力机制的简化。所以在这样的一个架构下呢, deep c o c r two 呢,编码阶段就已经把不相同的信息理解了,而不是一股脑的扔给了编码器。结论呢,就是 token 更少,精准更高。在 omni dot 持这一点五的基本测试上呢, deepsea o c r two 使用了最少的视觉 token, 综合得分高达百分之九一点零九,相比于上一代的提升百分之三点七三。在各项指标上,比如说阅读顺序 outer 的 edit distance 编辑器以上也从上一代的零点零八五降到现在的零点零五七。 所以我们看到了,其实 deepsea 呢,一直在开源的模型和理论上不断的做一些创新。这次创新呢,我觉得很巧妙的是,引入了国产的另外一个大模型和理论上不断的做一些创新呢,我觉得很巧妙的是,引入了国产的另外一个大模型和理论上来做它的 vr 模型的 input 就 是输入,那这样类似的工作其实我们也在尝试,可以看出了整个的国产的生态呢,其实已经非常健全了,尤其是千万的 ecosystem, 从各个维度的模型都有着开源,成为了一个非常好的一个开源的七座,为所有的生态伙伴的应用公司的后续点提供了非常好的基建。
64杨博士说AI 03:21查看AI文稿AI文稿
03:21查看AI文稿AI文稿这里是奇观正界,你的 ai 前沿视野窗口。你有没有遇到过这种情况?好不容易找到一篇重要论文,想把里面的内容复制出来,结果 ocr 识别完,左边一栏,右边一栏全混到一起,表格数据乱成一锅粥,公式直接变成了火星文。 但就在今天,二零二六年一月二十七日, deepshik 发布了一个王炸级的开源模型 deepshik ocr 二,它号称能让 ai 像人一样读懂文档,到底有多强,我们一起来看看。 deepshik ocr 二,顾名思义,是 deepshik 专门为 ocr 和文档理解打造的专业模型。 它已经在 getop 上完全开源,采用 appch 二点零许可证,你可以免费下载使用。三 b 参数的版本显存需求只要七个 g 左右,普通显卡就能跑。传统 ocr 怎么工作的呢?简单说,就是从左到右,从上到下,像复印机一样一行一行扫。但问题是,人类读文档可不是这么读的, 我们会先看标题,再看摘要,遇到双栏排版,会自然地先读右边。 deepico 二二,要解决的就是让 ai 学会像人一样有逻辑的阅读。 deepchip ocr 的 核心武器叫做 deep encoder vr, 它引入了一个非常酷的概念,视觉因果流。听起来很玄乎,其实原理并不复杂。整个过程分两步,第一步, encoder 负责理解阅读逻辑,也就是搞清楚这张图应该按什么顺序来读。 第二步, decoder 再根据这个顺序把内容转成文字。这就像是先画好阅读路线图,再沿着路线走一遍。这里面有个关键设计,叫双流注意力机制, 简单理解图像的每个部分之间可以互相看见对方,这叫双向注意力,保证不漏掉任何细节。但是在决定阅读顺序的时候,模型会像我们写作文一样,先写第一句,再写第二句,后面的内容只能参考前面的,不能剧透,这叫因果注意力。两种机制配合,既保证了大局视野,又保证了输出的逻辑顺序。 更厉害的是效率,以前的模型处理一页文档,动不动就要两三千个视觉 token, 而 deepseek ocr 二通过极致的信息压缩,把 token 数量控制在二百五十六到一千一百二十之间。 token 少了,计算量就少,速度自然就快,成本也降起来了。 说了这么多技术效果到底怎么样?我们看数据说话。在权威的 omni zap 基础测试中, deepseekocr 二拿下来百分之九十一点零九的综合得分。作为对比, openai 的 gpt 四只有百分之六十九点九, 谷歌的 gemini 二点五 pro 更低,只有百分之六十二点二,这个差距不是一点点。特别值得一提的是阅读顺序准确度,衡量这个的指标叫编辑距离越低越好。 deepsea go c r 把这个数字从零点零八五降到了零点零五七,也就是说,在处理那些复杂的多兰排版嵌号表格时, 他犯错的概率大大降低了。这么强的能力,能用在哪?第一,金融审计领域,自动识别美国国税局的复杂税表,手写和打印混合的也能准确提取。第二,物流供应链处理那些格式千奇百怪的送货单和签收单。 第三,医疗保险,从体检报告里精准提取检查数据。第四,也是我个人最期待的学出场景。它能把满市公示的 pdf 论文高保证转成 markdown 格式, 这对搞研究的朋友简直是福音。但 deepseek 的 野心不止于此,按照官方的说法, deepseek ocr 的 架构设计预留了很强的拓展性,本来目标是打造一个统一的全模太编码器,能同时理解文字、图像、语音甚至视频。 而且就在最近,代码库里还曝光了一个代号叫 model 一 的新模型,业内预测 deepseek v 四可能在下个月就会发布,这节奏属实是卷疯了。
7琦观智界 01:15查看AI文稿AI文稿
01:15查看AI文稿AI文稿今日 ai 圈大世界速报一月二十八日一、 deepseek ocr 全新发布,像人一样按语义读复杂文档,视觉因果流超智能识别性能直接涨了百分之。三点七。三、读文档的顺序更准,生产用起来也更稳,还不额外耗资源,复杂表格公式都能轻松读懂。二、 kimi k 二点五悄然上线即封神, 原生多模态架构加持,能识图转代码生三 d 模型,还能调度一百个子智能体并行干活,复杂任务效率拉满。 以开源且性能比肩顶尖模型用户实测经验,国产 ai 又添猛将!三、广告费直逼超级晚! open ai 开启看 gpt 广告,内测定价远超行业均值,其每千次展示费用高达六十美元左右, 接近顶级电视节目的黄金时段。广告报价基于 ai 用户行为特点,采用按展示付费模式,以应对商业化压力。 四、 cloud ai 助手集成 slack、 figma、 可画等多款办公设计应用,聊天框里就能用,不用来回切软件 靠 m c p 协议实现实时写作,还能提词做流程图,生成换灯片,办公效率直接拉满。想入局 ai 视频无从下手,实操处处碰壁,传统传媒转型育祖,看我们的 ai 视频全链路实战课就够了!七大章节从入门到变现,官方认证实战派带你轻松成专业制作人,课程就在主页,别错过!
13叁陆玖AIGC 02:19查看AI文稿AI文稿
02:19查看AI文稿AI文稿朋友们注意了, deepsea 又扔出了一枚核弹,直接把文档识别的游戏规则炸毁了。开源模型 ocr 二来了,它彻底改变了 ai 阅读文档的方式。传统 ocr 是 让 ai 扫描文档, 而 ocr 二采用视觉因果流的核心技术,让 ai 能像人一样智能地浏览文档结构,先抓住标题和图标重点,再理清细节逻辑。比如处理一份带流程图的技术手册,传统 ocr 会把文字顺序打乱,但 ocr 二能看懂结构, 把流程图注视和正文章节清晰区分,按人类逻辑输出,它不是在识别文字,而是在理解内容。这意味着复杂文档的识别准确率大幅提。生产出的本本可以直接用于分析和大模型训练。想快速上手这个模型, 下面我就带你在阿拉丁一键部署 deep seek oc 二二。首先打开 vs code, 登录阿拉丁插件,新建一个 workshop, 填写名称,选择 deep seek oc 二二的镜像,选择 cpu, 点击提交,等待一下创建, 选择信任插件,安装完后会弹出一份 redmi, 我 们可以按照 redmi 的 内容操作。首先我们需要新建一个终端,将 deep seek ocr 的 项目复制到 root 目录下,可以看到左侧就出现了 deep seek ocr。 接着我们分别复制这三行命令,激活一下, ctrl, 出现这些内容就代表环境已经安装好了。接下来我们打开左侧的 o c r 文件,找到 excel 脚本,点击运行,会弹出一个创建绘画的窗口。 继续选择 deep seek ocr 的 镜像, gpu 数量选择一,类型选择 h 八百八零 g, 选择一下 python 高级配置中工作目录,选择 deep seek ocr 二,最后点击提交可以看到它已经在运行当中了,然后我们耐心等待一下, session 运行成功后,可在当前目录下看到一个深层的 result 点 m d 文档,它就是将图像一点 p n g 转成可编辑文档之后的结果。 在这里就可以看到 result 点 m n d 文档,是不是很简单?关注我,带你学习更多部署知识,感谢收看,下期再见!
 00:41查看AI文稿AI文稿
00:41查看AI文稿AI文稿两天时间, ai 模型再次迭代, deepsea 发布了 ocr 二升级版,短短时间就斩获了一点五 k star。 它引入了一种叫 deepsea code v 二的全新编码器架构,不像传统 ocr 的 扫描仪, deepsea 的 ocr 能够根据图像的语义、内容,动态的对视觉信息进行重新排序, 简单说就是理得清。当他知道表格第一列是建筑材料时,他就会根据因果关系判断出后面的数字不是价格就是数量, 也就是不再会盲目扫描,而是一个理解逻辑的 o c r。 并且他在 omni darkbench 精准测试中登顶,沿相同视觉 tiktok 预算下的对比, deepseek o c r 二都比 gemini 更优秀一点,真正做到让模型先学会怎么看,再学会读。
28AIGC前端老陈 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿deepseek 今天甩出的 o c 二二,直接颠覆传统图文识别逻辑。 openai 联合创始人看完都直呼要改写历史 传统 o c 二啥套路?扣字成 txt 再识别又慢又机械。但 deepseek o c 二二直接反着来,它让 ai 像人一样按逻辑顺序看图,不是死板从左到右扫,而是跟着图像含义动态重排内容。更炸裂的是效率和精度。 别人要六千个视觉 token 干完的活,他一百个 token 直接拿下,效率狂飙十倍,识别准确率干到百分之九十七。理解准确度和复制粘贴文字没差,单张 a 一 百一天狂处理二十万页, mit 协议直接开源,现在 ai 都学会用看代替读了, 这进化速度谁顶得住啊?未来所有大模型备料都可能直接扔图像,传统玩法真要被扔进历史垃圾桶了。
34AI趣谈家 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿一分钟看完每天 ai 大 事,这里是 ai 早知道 deepsea 新模型更新新架构,引入低潘 call 的 v 二视觉编码器,打破了传统模型按固定顺序扫描图像的限制,能让 ai 根据内容语义灵活调整阅读顺序。该模型在精准测试中综合得分高达百分之九十一点零九, 相比前代提升了百分之三点七三,这意味着模型生成的文本更加干净准确,成本还更低。全国首例 ai 幻觉侵权案宣判平台无 则案件起因于二零二五年六月,用户梁某在利用 ai 查询高校报考信息时, ai 生成了不准确的地址信息。在梁某指出错误后,该 ai 仍坚称信息属实, 甚至承诺如果生成内容有误,将赔偿十万元,可前往杭州互联网法院起诉。随后,梁某以此为由将研发公司报上法庭,要求赔偿九千九百九十九元。
 02:45查看AI文稿AI文稿
02:45查看AI文稿AI文稿卷王 deepsea 最近又放大招了,这次全新开源的 deepsea ocr 二,首创因果流视觉推理性能,直接干翻了 demonet。 传统的视觉模型就像一个没有感情的扫描仪,机械地从左上角扫到右下角, 不管你是标题、表格还是根号,通通给你压扁成一串字母,完全不误。文章的逻辑效率低下,还容易错。而 d o c 历史推出的全新的 deep encode v 二架构,核心就是用一个小型的语言模型,比如千万二零点五 b 模型来当做视觉的大脑,并引入因果流的查询机制, 这相当于给 ai 装上人类的阅读逻辑,它的运行机制非常的优雅。想象一下,你要理解一张复杂的财报图,传统模型是无脑的扫描, 而 deep sea ocr 会先派出一组侦察兵,快速地浏览全局,然后根据语义重要性重新排兵布阵,把最重要的信息,比如标题、关键数据排在前面,再让后面的主力部队解码器 按这个理顺的逻辑顺序进行深度的理解。实战的效果也非常大,令在衡量阅读顺序合理性的指标上,错误率对比前一代的模型大幅度降低百分之三十三,证明他真的能看懂反面的逻辑。 在文档解析的准确率上,以零点一零零的编辑距离优于 gemini 三 pro 的 零点幺幺五, 用开源模型实现了超越。在处理真实 pdf 和日历图片时,文本重复率显著下降, 这意味着用它来清洗海量文档,作为大模型的训练,数据质量会高出一大截。更深远的意义是,这不仅是 ocr 升级,更是通向原生多模态的关键一步,它验证了 llm 作为通用编码器的可行性。 在未来同一个架构就能处理图像、文本、音频了,真正实现一个模型理解万物。目前模型、代码、论文均已在 github 和哈根 face 上全部开完了。你觉得这种因果流的视觉推理 下一步会最先颠覆哪个行业呢?智能的文档处理、自动驾驶的视觉感知,还是多模态的 ai 助手呢?在评论区留下你的高见吧!
 03:29查看AI文稿AI文稿
03:29查看AI文稿AI文稿今天的播课我们要聊的是一个比较有意思的话题,就是如何通过模拟人类的视觉因果流。嗯,来提升文档 ocr 的 性能。对,这个话题很有意思, 那我们就直接开始吧。好的,咱们先来看看这个 deep seek ocr 二这个模型,它的核心的创新点是什么?就是这个 deep encodevr 这个编码器,它到底是怎么模拟人类视觉的因果流,然后来提升 ocr 识别效果的呢?嗯, 这个 deepencoder v 二呢,它其实就是特别针对文档 ocr 里面那些复杂的布局啊,公式啊,表格啊这些东西。 ok, 那 它里面用了这个 llm 风格的架构。 对,然后引入了这个所谓的视觉因果流,那这个视觉因果流到底是怎么在模型里面起作用的?就是它里面用了这个双流注意力机制。嗯,那其中一个分支呢,是对视觉的 token 进行双向的注意力,这样的话可以保证它能够获取到局的信息。 然后另外一个分支呢,是加了这种因果流的查询 token 在 它用的是因果注意力,它只能够看到它前面的 token 哦,所以它其实是在模拟 我们人类在阅读的时候的那种与异依赖的关系。明白了,然后我们来看看这个实验的结果,就是这个 deepsea ocr, 它在实际的测试当中到底表现怎么样?呃,这个模型它是在这个 omodebench v 一 点五上面, 就是一个包含了九种不同的中英文文档类型的一个数据集上面做的评测,然后他的这个综合性能啊,达到了百分之九十一点零九, 嗯,这比之前的基线要高了百分之三点七三。哇,这个提升幅度挺明显的呀,那其他的那些具体的指标呢?就是他的这个文本的编辑距离从零点零七三降到了零点零四八, 然后阅读顺序的编辑距离也从零点零八五降到了零点零五七。嗯,所以就是说他在面对这种复杂的布局的时候,他的阅读顺序是更加准确的。 然后还有就是在生产环境下面,他的这个重复率也是下降的非常明显。 ok, 在 线日记里面的重复率从百分之六点二五降到了百分之四点一七, 然后 pdf 数据里面的重复率从百分之三点六九降到了百分之二点八八。 ok, 最后我们来看看这个 deepsea oc 二二,它的主要的贡献和存在的一些局限啊, 就它到底在哪些方面给我们带来了新的突破?然后还有哪些地方是它目前还做的不够好的?首先它的这个最大的亮点就是把这个因果推理,嗯,引入到了这个视觉编码里面,它是第一个用这种 llm 风格的视觉编码器, 然后把这个二维的图像的信息和一维的语言的建模很好的连接在一起,而且他的这个压缩比很高,是十六倍的压缩比, 所以他可以很高效的和这个大模型的流水线去对接。听起来确实很厉害啊,但是他有没有什么应用场景上的限制呢?呃,目前来看的话,他在那种文本非常密集的,比如说报纸这种文档上面提升还是有限的。嗯,然后他的这个训练数据还是需要去 加大这方面的文本密集型文档的数据。然后第二个就是它现在还没有在通用的视觉任务上面去做这种泛化能力的验证。对,今天我们聊聊这个 deepsea ocr 二,这个模型它是怎么通过 模拟人类的视觉的因果流,然后在各种文档的 ocr 上面取得一个比较大的提升的。然后同时我们也聊了它的一些应用上面的边界。没错,那这期节目咱们就到这里了,然后感谢大家的收听,咱们下次再见,拜拜。拜。拜拜。
28青稞社区 00:47查看AI文稿AI文稿
00:47查看AI文稿AI文稿deepsea 刚刚开源了全新的 ocr 二模型,最大突破是什么?让 ai 像人一样读懂复杂文档,而不是死板的扫描?只需两百五十六个视觉 token, 它能看懂复杂表格数学公式,多栏排版,还能按照人类的语义逻辑理解内容顺序。背后的技术创新就是用极少的视觉 token 完成超高效解析,信息压缩能力直接拉满,算力和成本都大幅下降。 在权威测试中, deepseek ocr 二拿下了百分之九十一点零九的综合高分,错误率也明显降低。模型和论文全部开源,任何团队都能用。这不仅仅是 ocr 的 升级, 更是 ai 大 脑向全模态进化的关键一步,未来图文声音视频都能统一处理。你觉得 deepseek ocr 二会先颠覆哪个行业?评论区聊聊你的看法。
12AI算力通 01:28查看AI文稿AI文稿
01:28查看AI文稿AI文稿一月二十七日, deepsea 又扔下了一颗核弹, deepsea cr 二正式发布。别以为这只是个简单的文字识别工具,看懂了这篇论文,你才会明白 deepsea cr 二到底在憋什么大招。这次更新的核心叫视觉因果流,什么意思呢? 以前的 ai, 看图就像小学生读课文,死板的从左读到右。但 deep coco ocr 二搭载了最新的 deepencoder v 二架构,它让 ai 拥有了人类的扫视逻辑。比如看一张复杂的报表或数学题, 它不再是傻傻地扫描像素,而是能像人眼一样理解哪里是重点,哪里是逻辑关联。论文显示,这种新架构在处理复杂文档时,效率和准确率直接吊打了传统的 clip 模型。为什么要在这个结果研发 ocr 二?很简单, r 已解决了推理问题,而 ocr 二 解决了看见的问题。 deepsea 实际上是用一个小型的语言模型替换了传统的视觉编码器。这意味着,即将发布的 r 二,极有可能是一个拥有人类级阅读逻辑的真动模态大模型。它不仅能做题, 还能像专家一样看懂复杂的图表和论文。从元旦的理论铺垫到一月二十七日的视觉突破, deepsea 这套组合拳打得太丝滑了。今年春节,中国 ai 可能真的要从追随者变成定义者。 二究竟有多强?关注我,见证历史。欢迎关注乔哥 ai 创业腔,乔哥带你一起爱创业!
 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿deepsea 又拿第一了,这次不是降价,而是直接在视觉上把谷歌和 open a 按在地上摩擦。 deepsea 刚推出了一个 osr two, 让 ai 直接开了天眼。它首创了一个黑科技,叫做视觉因果流。这就是 ai 进化史上的第一次。机器不再是死版的扫描像素,而是学会了像人类一样带着脑子去看图。 别的 ai 呢,还在像傻瓜一样从左到右的去扫描。而 deep seek 的 视线呢,是跳跃的,有逻辑的。先抓标题,再锁数据,最后看备注再乱的表格扔进去,它只需要扫一眼,瞬间就能给你还原一个完美的三 d 逻辑。这波升级真的是太强大了。
12条形马 02:19查看AI文稿AI文稿
02:19查看AI文稿AI文稿二零二六年一月二十七日,人工智能公司 deepsea 正式发布了其新一代视觉语言模型 deepsea oc 二二。此次发布通过全球主要的开源平台进行,同时团队也公开了详细表述其技术路径的学术论文 deepsea oc 二二 v s o a l cosmos flow。 此次发布的新模型标志着其技术路径的一次重要转向。此前的视觉语言模型在处理图像信息时,普遍采用类似机器扫描的固定顺序, 即从上到下、从左到右逐行读取画面内容。这种方式在面对财务报表、学术论文等多栏图文混合的复杂版面时,往往难以准确捕捉内容之间的内在逻辑关系。全新的 deep c o c 二二模型指向突破这一局限。 它采用了名为 deep n coder v 二的创新架构,其核心是赋予人工智能一种因果推理能力。这意味着模型不再机械地扫描像素, 而是尝试像人类一样,根据图像中不同元素的意义和关联,动态地理解并重新组织信息,从而实现对复杂文档布局的智能化理解。 根据 deepsea 官方发布的技术报告,新模型在多项评估中展现出显著优势。在文档理解权威机准测试 amidobench v 一 五中, deepsea oc 二二取得了百分之九十一点零九的成绩,相比其前代模型,性能提升了百分之三点七三。报告同时指出,该模型在追求高性能的同时,也注重计算效率的优化, 将其视觉处理单元的规模控制在与国际主流模型相近的水平。在实际数据处理中,该模型有效降低了输出内容的重复率, 显示出良好的实用性和成熟度。业界观点指出, deep c o c r 二的发布不仅是一次光学字体识别性能的升级,其背后 deep n coder v 二架构的探索更具深意。他尝试将大型语言模型中成熟的架构思路应用于视觉编码任务, 这为未来多模态人工智能的发展提供了新的技术可能性。目前,相关模型与代码已向开发者和研究社区开放。
 05:06查看AI文稿AI文稿
05:06查看AI文稿AI文稿大家好啊,就在昨天, diffic 又发模型了,而且古代的一个很详细的论文啊,它发布了新一代的这个大语言视觉模型啊,叫做 diffic ocr 二啊,你记得几个月之前,他发过一个 ocr, 那 么这个是 ocr 二, 它是在升级版啊,而且呢,它发了同步的论文,这不仅是 ocr 技术的迭代,更是视觉编码从固定格式扫描向与因果推理的一次跃迁啊。而 且在相关的基本测试中,它以百分之九十一点零九的综合准确率刷新了相关的榜单,叫前代呢,提升了百分之三点七三,已经大幅领先 欧美其他的这些 ocr 的 模型啊,更重要,它用了一个让 ai 具备人类的阅读逻辑,而非简单的文字扫描。这个事咱们先解决什么叫 ocr, 你 们记得那个扫描仪吗? 扫描仪把那个纸放进去,或者把图片放进去,把它夸夸夸,把里面东西转成文字啊,这个东西的过程就叫 ocr, 就 把图片上的东西转成文字啊。所以他发的这个模型呢,不是 v 四,他发的模型依然是一个图形的解决模型,但这个模型的话呢,唯一的点就是说他让 ai 做了阅读逻辑,而不是以前的竹行的去扫描啊,以前的那个模型的话呢,长期依赖的这个编码器就是 c l i p 啊,这种编码器, 它就是光山扫描的顺序处理图像就是咵,扫出来发现这个东西一次是文字把它提炼出来啊,就从左上到右下,竹行呢,来 一行一行的来切分图像为固定的这样的一个一个行,然后强行将二维图像降为一维区域,忙扫,并不是这个里面有什么栏目布局,就直接把文字提炼出来,有什么样的标序什么的都不用管,段落也不管啊,甚至表格也不管啊,乱序的只要文字都提炼出来。是这样的一个东西, 这个 o c r, 它这个模型精妙在哪呢?它用了一个叫做 devin connor 这样的 v 二这样一个架构,然后这个架构用 l l m t 在 c l a p, 它实际上就让大模型自己去理解,它不用那个编码器了,用大模型就去开源相关的大模型作为这个编码的骨 啊,用重编码器而轻解码器的这个方式,将语言模型的因果推理能力注入视觉处理流程,这是一个。另外一个,他又做了一个因果查询机制,他那里面引入因果查询,通过独立的注意力机制演码策略实现两级的推理。一个全感知层,就是 把整个的东西呢感知做一遍啊,就把整个这张图上的所有东西他都理解一遍。另外一个是因果逻辑,他要推理每个部分之间是什么样一个关系啊,每个查询只能关注前面的,不能关注 其他的,他把这个因果逻辑弄明白,那这样打磨星就知道了啊。这张图上到底谁跟谁是什么关系?我是不是要给你做个表格啊?我是不是要这样留出段落,我是不是要这空格啊?他这样的最终产生的是一个非常类似于原本这样文字这样一个 o c r 结果啊, 淘汰结果,而且他在做动态的语气排语序排列,他根据大模型对这事理解,最后还是要去叫,对啊,而且呢,更关键的是什么?他在保持高精度的同时控制着计算成本? 他视觉 token 的 数量控制在多少呢?二百五十六到一千一百二十之间,也就是最多他就一千个左右的 token。 然后呢,跟那个 jimmy 三 pro 相当,但是它的规模参数呢?只是三 b 啊, jimmy 三 pro 是 多么庞大一个概念,而且它通过混合专家模式来实现的,所以在实际的生产测试环境中啊, 它在处理现行日制和 pdf 的 预训练的时候,识别的重复率分别下降了百分之二点零八和百分之零点八一, 极强的稳定性,而且得益于相关的压缩器的使用啊,它的模型支持动态分辨率是一零二四乘一零二四和一百加的语言,就是各种各样的语言的 ocr 移动端也可以实现文档处理。所以这个东西想什么啊,只要你要去识别图片中的文字,这个场景它都是可以使用的。更关键它是开源的啊,免费,它把什么都打在屏上了,而且它的成本极低,对吧?像那个拆 g p t 五点二啊,用这个事儿,它要大概要多少 token 呢?要用一万八千多个 token, 它有多少 token 呢?它最多用幺幺二零的 token, 所以 它的整个的算力的覆盖率和整体的成本的下降,那是限性的啊,而且它的开源,它的代码,它的论文全部都开出来了,所有人都可以在上面继续去 补刀,是吧?这个事就特别有意思了,而且昨天台元社区已经对这个事做了一个深度的解读,并且好多人就开始去尝试在自己的业务中接入这样的一个模型,而且我相信它逐渐的把这个事做了一个很多特性,大家都能看见了, 是吧?好吧,有朋友昨天晚上直播的人问我,老张,到哪去看你的会员视频,你会员视频好像很精致。这周的会员视频咱们着重在讲大芯片以及大芯片。为什么叫大芯片啊?为什么要用大芯片是吧?大芯片辅助有什么样的一些新的机会啊?这个东西呢?请大家关注小程序奥特斗斗与瑞克老张科普课。 关注这个啊,上面有那金卡,那是会员卡,点击那就可以了啊,咱们现在的会员幺三九九是平台给补贴的啊,一年一百八十个视频,三十二场以上的直播,是吧?所有专栏免费看,你说我不想加会员,没关系,我们有免费的专栏啊,那专栏是我们各个平台的内容精选,你就一网打尽了啊,就可以在这 进购,以后看,对吧?比如说我不知道我们会员讲的是啥,我们有会员的直播的回放,我们是特价九块九啊,可以买一个,可以先看一下,看一下对你有没有帮助,好不好啊?而且我们上面有客服的,可以加他啊,跟他好好聊。好吧,今天就到这,我是瑞克老张,关注我,带大家看中国科技的高度和温度,我们下期见,拜拜。
456瑞克老张有话说


猜你喜欢
最新视频
- 3.7万老知青