
粉丝1823获赞1.6万
相关视频
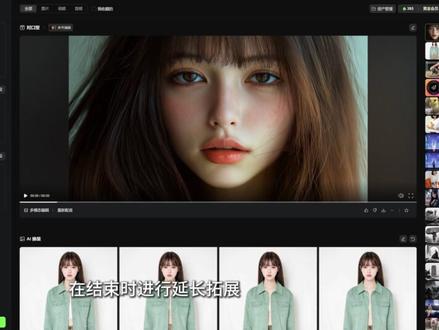 21:32查看AI文稿AI文稿
21:32查看AI文稿AI文稿零基础怎么从零到一制作 ai 视频?这是我今天想和大家分享的内容。明明用着同款 ai 工具,为啥别人的视频能一步到位,完全符合预期,可你呢?调参数, 改提示词,折腾半天,视频却像失控的列车,浪费积分不说,最终效果还全靠运气。别慌,今天这期视频三分钟带你入门, ai 视频制作小白也能轻松上手!入门!话不多说,直接进入正题, 下面我就来介绍一下如何通过四个步骤制作一个 ai 视频。这些步骤包含场景描述、文生图、图生视频和视频剪辑。第一步的场景描述可以用 chat、 七 p t、 文心、一眼通、一千、问豆包等这样的对话类 ai 来生成。第二部文生图对应的有 mid、 journey、 stable、 diffusion、 文心一格通、一万象等。第三部图生视频对应的有 pika、 runway、 pic、 verse, 还有一众国内的视频生成平台。而第四步,我们会使用 工具将生成的视频片段进行剪辑和配音配乐。关于工具可以在我们课程配套的工具资料包当中查找。大家好,我们这节课来讲解可灵 ai 的 视频生成功能。 来到可灵 ai 的 首页,我们点击左侧的视频生成分选项,可以看到当前的页面就是可灵 ai 的 视频生成页面。在最上方有一个下拉菜单,我们在这个位置可以选择不同的视频生成模型。和图片生成模型一样, 通常标号越高的模型生成的效果就越好,所以我们就保持默认的二点一。当然某些模型是不具备部分功能的,例如当前的二点一模型就不具备仅靠伪真生成视频的能力,所以大家也可以根据自己的需求选择更适合的模型。在下方有三个分页,分别是文声视频、图声视频和多模态编辑。 我们首先来看文声视频,顾名思义,文声视频就是我们写出的画面来生成对应的视频。 上节课我们讲过了,可灵 ai 接入了 deep seek 功能,所以当我们不知道该如何描述一幅画面时,也可以直接借助可灵 ai 内置的 deep seek 帮助我们 写一段画面描述提示词用于视频生成。和其他的 ai 视频生成工具不同,可灵 ai 还包含了负面提示词的写入框,不过这个位置并不是必填项,而且就算什么也不写,生成的效果对于崩坏的抑制也非常的好,所以通常这个位置呢就保持默认不填写 在正反面。提示词的右上方有一个预设选项,我们点击展开之后,就会打开预设提示词的选择菜单。如果想要新增预设提示词的话,我们点击展开的右上方的加号,在这里就可以预设提示词,并写明标题, 方便我们后续选择提示词模板。不过这里并不是很建议大家使用文声视频的功能,我们以先前我生成的一段视频为例,我们首先来看这段视频, 可以看到这段视频,它是由纹身视频生成的内容。提示词描述呢是手部特写镜头,女生的手扶过海浪最终呈现的效果,画面有种锐化过度的感觉,并且整个手的美观程度也不尽人意。我们再来看第二段视 频,可以看到这个画面当中的手就明显要好看的多,并且也成功生成了在提示词描述当中手扶过海浪的效果。 而这个视频是以手真图生视频的方式进行生成的,所以在大多数情况下,图生视频要远比文生视频稳定的多,而且本身图片生成的时间和资金成本都比较低,也方便我们先确定图片的风格和质量,再进行图生视频, 能够提高我们制作视频的效率。回到视频生成页面,我们来看最下方,可以看到有这么几个分选项。首先第一个下拉菜单是选择视频的生成模式,标准模式和高品质模式其实对应的就是生成的画质,如果单纯的做视频生成练习的话,选标准模式就好了, 消耗的点数会低一些。第二个下拉菜单是选择视频的生成秒数,目前生成五秒钟左右的视频也偶尔会出现非常不稳定的情况,就更不要说十秒钟的视频了。 所以这里建议大家生成五秒钟的视频就足够了,十秒钟的视频有极大的概率会让人物的运动出现意想不到的结果。第三个下拉菜单是选择视频的宽高比的, 目前纹身视频只有三个宽高比可选,就是我们常用的十六比九,九比十六,还有一比一。再往右边这个下拉菜单是选择一次性生成几条视频的,根据我的生成经验,同样建议大家选择默认的一条视频, 这样方便我们在得到不好的结果时,能够及时地修改提示词或者图片。最后一条创意相关,指的就是生成的视频结果是更符合提示词的描述,还是更偏向于让 ai 自由发挥,这里维持默认就可以。 有时过于遵循提示词的描述,一旦提示词当中有我们没有想到的部分, ai 也不会帮我们生成。相反,让 ai 过多的自由发挥,有时可能会误视我们提示词当中描述的内容。纹身视频的效果通过刚才的短视频我们已经看到过了,所以这里就不再重复演示。我们下面来看图声视频。 这里的图生视频又分为首尾帧和多图参考。我们首先来看首尾帧,这也是我们最常用的一个视频生成方式,它允许我们先上传一张或两张图片作为当前视频的开头或结尾。在上传图片之后,下方的输入框我们输入想要人物做出的动作以及镜头的运镜。 这里有必要说一点,通常图生视频我们就只需要描述人物要做的动作和画面的运镜就可以,至于画面的内容具体是什么,图片已经给到了 ai 充足的信息,不需要我们再重复的描述,除非图片当中某些信息很容易被 ai 误判。 比如一件金属反光质感的衬衫被 ai 误识别成了盔甲,这个时候可能需要靠提示词让生成的视频在运动过程中物品保持一定的稳定。我们下面再来看运动笔刷这个功能, 目前这个功能仅在一点五模型下支持使用,我们点击切换,在切换完成后,我们点击去绘制,就会打开一个新的窗口。通常想要便利的使用这个功能,我们可以勾选上方的自动检测区域,此时我们的光标就会变成一个快速选区比对,我们这里选中人物的头发或者上半身,或者整个的身体。 选中完成以后呢,如果有多选的部分,可以点击左上方的橡皮擦选项,去擦除多选的部分。此时画面当中显示为绿色的区域,就是待会我们需要它运动的区域,这些区域不只可以选中一个。如果画面当中存在多个物品, 我们希望每个物品的运动都受到我们的控制。可以看到右侧一共有六种颜色,可以用来标记六种不同的物品。标记完成后,我们用鼠标点击区域右侧的轨迹选项,此时我们的光标就变成了一根用来汇聚移动轨迹的画笔。 例如我们想要人物朝着画面的左手边去运动,我们就用这个画笔从右向左滑动,此时整个的轨迹就会变成一个往左手边纸上的箭头。 生成视频时,人物就会往左手边这个方向进行移动。在右侧下方这个区域还有一个添加静止区域的选项,也就是说,如果我们不希望画面当中的某样物体运动,我们可以点击静止区域这个选项,然后在左侧的图片中进行会制,这样一来生成的视频结果 我们用静止区域选中的部分就不会发生运动了。确认无物之后,我们点击右下方的确认添加,这样一来生成的结果就会更受我们的控制。在运动笔刷下方还有一个运镜控制,我们点击使用,可以看到此时右侧会弹出一个选择菜单,可以支持我们选择一些常规的运镜, 有水平运镜、垂直运镜、推进拉远或者垂直水平摇镜、旋转运镜等。不过我们可以看到,当我们选择一个运镜方式之后,上面的笔刷运动就会提示与运镜控制互斥,使用后将移除运镜控制的提示。这就意味着两种功能无法同时使用, 大家可以根据自己的需求选择其一。不过经过实测,可连 ai 的 这个功能在控制能力上并没有我们想象当中那么好。与此同时,它所使用的模型版本为一点五版本,与目前的二点一版本在版本号上差距过大,所以生成的视频质量不会特别的好, 因此这个功能我们就仅做了解,不再赘述。我们回到首尾帧,这里刚刚我们只添加了一张图片作为手帧,但其实只要我们的视频模型版本在一点六及以下的话,是可以同时添加首尾帧的,也就是可以控制整个视频的开头和结尾是什么画面。我们以这个视频为例, 可以看到视频当中的狐狸变身为了一个在宫殿当中的少女,之所以会有这样的变身效果,就是得益于首尾针的功能。我们分别生成了两张图片,首针是一个狐狸,而尾针我们生成了一张由这只九尾狐幻化的少女。 这个短视频在生成的时候甚至没有写提示词,就直接达到了这样的效果。由此可见,首尾真生成视频在镜头的过渡上可令 ai 做的还是十分智能的。我们回到视频生成页面来看多图参考,这个选项和图生图的多图参考类似,视频生成的多图参考也允许我们分别上传人物主体、 背景以及画面当中其他需要的元素,最终让这些元素或者风格都出现在生成结果的视频当中。例如此时我们上传一张人物的图片,再上传一只小黄鸡的图片提示词,我们就写少女手捧小黄鸡,然后点击生成,大约五分钟左右,我们的视频就生成好了,来看一看效果如何吧。 可以看到整个视频对于两者的结合还是非常不错的,人物的动作也比较自然,唯一存在一些问题的地方就是手和小黄肌交互的部分,这也是目前绝大多数 ai 视频生成模型的痛点,也就是复杂的结构在与复杂的结构交互时会出现明显的崩坏, 这种情况目前还无法避免,我们只能期待将来视频生成模型能够具备更好的效果。回到视频生成页面,我们最后来看多模态编辑,这个功能也是目前比较少用的一个功能, 他允许我们上传一个视频片段,再上传一张图片,然后通过提示词的描述,将所上传图片当中的某一个内容去替换掉视频当中的某一个内容。我们就以这个视频为例,我们上传一个手轻轻抚摸小牛肚的视频片段。 图片方面,我们依然上传刚刚用过的小黄机提示词,我们就写是图片一中的小黄机替换视频当中的小牛肚,我们可以将鼠标悬置在视频上传窗口的上方,此时右上角就多出了一些图标,分别是编辑从历史选择、本地上传以及删除 后三个都是字面意思,我们来看编辑点击之后呢会展开一个新的窗口,在这个窗口当中我们需要做的事情就是选择增加区域,然后将整个视频片段全部选中,同时点击视频画面,通过自动选区功能将我们需要替换的物品进行选中,然后点击右下方的确定。 至于图片编辑窗口,这里有一个选择主体的功能,点击之后会展开一个窗口,这个窗口就是用来选择框选主体的,如果画面当中有多个物体,我们需要用这个窗口去选择我们需要拿去替换的物品,这里我们也不需要过多的操作, 最后我们直接点击右下方的生成就可以了。 ok, 我 们现在来看一看生成的效果如何吧, 可以看到生成的效果还是非常惊艳的,在将元素进行替换之后,整个手在触摸小黄肌的时候,小黄肌毛发的运动非常自然,并且整个的视频表现也十分稳定。不过相比于正常制作一个图生视频进行元素替换,需要消耗的点数会更高,所以通常这个功能不会用于替换 ai 生成的视频。 更推荐大家实际拍摄一段视频,然后将图片的内容去运作替换实际拍摄视频当中的某项物品,这样的操作会相对更实用一些。我们回到多模态编辑窗口, 除了替换元素之外,可以看到这里还有增加元素、删除元素等操作,这两项功能都是字面意思,具体的操作方法也和我们刚刚讲的没有太多区别,所以这里就不再重复演示。那么到了这里,我们有关于可灵 ai 的 视频生成功能就全部讲解完了, 可以看到这些视频生成功能有好有坏,不同的模型、版本、功能和操作都会对视频生成的结果产生影响。 在众多操作当中,我比较推荐大家使用的依然是徒生视频的方式,先生成手帧、尾帧图片,然后再通过提示词描述让可灵 ai 帮我们生成对应的效果。这样的工作流,无论是最后产出的成品效果,还是时间和资金成本的使用情况, 相比较其他方式而言,都是一种最优的创作方式。我们这节课来讲解可灵 ai 的 音频生成、 ai 试音、 ai 对 口型和视频延长功能。 来到可灵 ai 的 首页,我们点击左侧分选页当中的音效生成,这样就可以来到音效生成的页面,这里提供了两个窗口,其中上方这个窗口是用来写入提示词的,这些提示词用来描述我们想要生成的音效,例如此时我们在这里写入干杯杯子碰撞,然后点击生成, 可以看到片刻之后,可灵 ai 就 为我们生成了四段干杯杯子碰撞相关的音效。我们来试听一下, 可以听出这四段音效其中有三段都生成了不错的杯子碰撞的效果,而其中有一段把杯子碰撞理解成了喝彩, 可见生成的结果依然存在一定的随机性。不过好在生成我们想要效果的概率还是比较高的。我们继续来看下方的上传窗口,这个位置是用来自动给视频配音的,我们需要做的就是点击这个位置,然后上传一段需要进行配音的视频 上传完成后,上方会提示已通过视频匹配到创意描述是否替换,我们点击替换,最后点击右下方的生成, ok, 几十秒后, ai 自动进行的配音就配好了。同样是生成了四段配音,我们分别来看一下效果。 通过这四段配音结果,我们可以感受到由 ai 对 视频自动匹配的音效效果并不尽人意,虽然确实生成了手指抚摸皮毛的效果,也生成了牛叫的效果, 但是这些效果出现的时机和画面中播放的内容并不是十分匹配,部分效果还出现了一些我们不需要的杂音,所以目前可连 ai 自动根据视频匹配音效的功能不推荐大家使用,我们可以期待未来能够优化的更好。 其实相比之下,如果大家不做商用的话,可以直接来到剪映当中,点击上方的音效选项,在这里我们可以根据左侧的标签来选择自己需要获取的配音配乐,也可以直接在上方的搜索栏搜索我们想要的效果。例如我们搜索自行车的效果,这里呢就会显示自行车铃铛、自行车路过等等音效, 点击就可以进行试听。如果需要使用这段音频的话,可以直接将这段音频拖拽到下方的时间轴上,与视频内容进行匹配。 大部分音效都可以在剪映当中的在线素材库里找到,因此目前可灵 ai 的 音效生成功能并不是十分实用。不过如果大家对视频有商用的需求,需要原创一段音频的话,我们使用它的音效生成效果也是可以的。我们接下来再来看 ai 试一功能,点击左侧的 ai 试一分选页,我们就来到了 ai 试一的操作页面。 使用这个功能一共分为两个步骤,第一个步骤就是生成一个 ai 模特,在这里我们选择性别、年龄、肤色以及对这个模特基础造型的描述。当然如果不想生成模特的话,我们也可以直接点击上方的 ai 换装。在二级分页当中有官方预设的模特造型,或者我们点击右侧的自定义分页, 在上方的窗口可以上传一张自定义的模特照片,不过可连 ai 对 我们上传的照片有一定的要求。我们将鼠标悬置在右侧的模特规则这里 可以看到,这里有对图片尺寸、文件大小的要求,同时也给出了推荐图片和不推荐图片的案例,像多人合照、坐姿或者严重遮挡、衣服姿势过于复杂等情况都是不推荐的。想要成功的给模特进行换装,像上方这些单人照、正面全身或者半身 或者未对衣服区域进行遮挡、姿势简单的图片等都是可以的。在下方这个窗口就是上传服装的位置,我们同样将鼠标悬置在服装规则这里,可以看到这里同样描述了对服装图片的尺寸要求、大小要求 以及上传的形式。像平铺的服装、单件的服装、没有遮挡的服装都是推荐的。而像同一张图片,存在多个衣服或者背景过于杂乱,花纹过于复杂,亦或是透视角度过大, 服装重叠遮挡的情况,都是不推荐的。如果我们想一次性上传多个服装,可以在左侧的分选项当中由单件切换为多件,这样就可以分别上传上衣和下装,以此来让模特一次性试穿全身的衣物。我们这里就以官方提供的模特为例,选择好之后, 我们再在下方选择一件官方提供的衣服,在最下方的位置,我们可以选择一次性生成多少张图片,以及图片的清晰度如何。选择完成之后,我们就直接点击立即生成, 可以看到最终生成的效果还是非常出色的,不仅完整的保留了人物的长相特征,同时像衣服的款式以及穿戴之后的光影效果都还原的十分自然,甚至生成的结果还非常贴心的给这件上衣搭配了一件颜色和款式匹配的裤子。 我们回到生成页面,在 ai 十一操作面板的右上方有一个使用指南,我们点击之后就可以来到可灵 ai 使用指南 ai 十一的页面,在这个页面我们可以查看 ai 十一这个功能的介绍以及使用指南和注意事项,以此来学习这个功能。同时官方也提供了一些视频教程, 我们下面再来讲解可灵 ai 的 对口型功能,不同于 ai 数字人让图片开口说话,对口型功能是让视频当中原本没有说话的人物开口说话,并根据说话的内容来生成对应的口型。要想使用这个功能有两种方式,第一种方式,如果我们生成的视频是一个人物正面的近景特写, 我们就可以使用这个功能。可以看到在右侧的预览窗口,视频的下方有一个对口型的选项,我们点击之后就可以来到对口型的页面,当然我们也可以手动的点击左侧的对口型选项,来到当前的页面,这个页面存在两个上传文件的窗口,其中上方这个窗口是用来上传视频文件的, 我们这里就选择一个官方推荐的视频,将视频上传以后会弹出一个窗口,在这个窗口当中我们可以预览视频的效果。 同时在窗口的右侧我们可以选择用 ai 进行配音或者上传本地的配音文件。如果我们选择用 ai 进行配音的话,可以在这个位置输入需要配音的内容,例如我们输入接天连夜无穷碧,映日荷花别样红。 输入好内容之后,在下方我们选择配音的音色,点击之后就可以试听接天连夜无穷碧,映日荷花别样红。每一种音色都可以在下方调节它的语速, 以适配视频的时长。除此之外,部分音色是可以调节朗读时的感情的,例如我们将下方的感情调整为高兴,然后再次点击试听接天连夜无穷碧,映日荷花别样红,可以明显感受到人物的语气变得更加开心了。 当然朗读诗歌我们就以中性的情绪来朗读就可以,至于上传本地配音的话,我们就直接点击上传或者拖拽的形式上传到这个窗口当中就可以了, 们这次演示就直接用 ai 来生成朗读的内容吧。确认好配音内容和音色情绪之后,我们点击右下方的添加配音,可以看到此时左侧的预览窗口下方会出现音频的时间轴,我们配音的总时长是四点五秒,因此并不是人物全程都在开口说话的,可以通过鼠标拖拽的方式来移动配音的位置, 以此来决定人物在什么时间段开口说话。确认无物之后,我们就直接点击右下方的立即生成,等待一段时间后视频就生成好了,我们来看一看最终对口型的效果吧。接天连夜无穷碧, 映日荷花别样红。可以看到,尤其是对于这种近景特写,人物朗读的内容和 ai 生成的口型还是十分匹配的。 我们最后再来看一看可灵 ai 的 视频延长功能,我们点击左侧的视频延长分选项,来到视频延长的操作界面。顾名思义,视频延长就是将已有的视频在结束时进行延长拓展,通过提示词的描述来延续视频的内容, 其实就相当于将一个视频结束时的画面作为图升视频时的手帧来生成新的画面。不过当前这个功能就只支持我们从历史创作中去选择,我们就以这个视频为例,先来查看一下这个视频的效果, 可以看到当前这个视频就是一个简单的人物动态效果,我们可以尝试将这个视频进行延长内容,我们就描述 人物伸手挡住镜头,镜头变暗。如果觉得自己的提示词描述内容并不能得到理想的效果,也可以通过 deepsea 来优化我们的描述。最后我们在下方选择相应的参数,然后直接点击立即生成。 ok, 延长后的视频生成好了,我们来看一看效果如何吧。 可以看到最终生成的效果还是十分流畅的,不仅在后半段相对的符合提示词的描述,同时在第五秒和第六秒之间, 就是原视频和延长视频之间的衔接处也并没有发生明显的衔接卡顿或者是画面突变的情况。因此,各位同学想要延长某一个由 ai 生成的视频片段的话,不妨尝试一下视频延长功能,效果还是不错的。那么以上就是本视频的全部内容了,到了这里,有关于可怜 ai 的 全部内容也都给大家讲解完了。 可以感受到,虽然可怜 ai 主打的是一个视频生成,但像图片生成、图片编辑、对口型视频延长等功能,使用的体验和生成的效果也都相当不错。其实我们的视频更新到这里, 已经和大家一起看了不少 ai 视频创作平台,也鉴赏了很多其他作者生成的优秀短片。我们不难发现,虽然每个视频平台有着不同的功能和视频生成的特性,但最终想要取得好的 ai 视频生成工具, 在给人们带来便利的同时,也对使用它的人提出了更高的要求。 ai 时代是一个容易诞生超级个体的时代,繁琐枯燥的工作被 ai 接管之后,人的价值会更加突出。因此,如何让自己的思维能力和学习能力在更深更广的维度上实现突破,这才是我们需要聚焦的问题。
294AI视频制作教学 03:00
03:00 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿这种视频都是怎么制作的?难不难?其实操作非常简单,首先你复制视频链接, 然后去打开可疑,这个时候会自动识别链接电影需暂停,会跳转到一件同步替换你自己的照片,然后等待生成就行,看效果。
 01:49查看AI文稿AI文稿
01:49查看AI文稿AI文稿不是,三姐,我想问一下,咱家研究新品的那些个老师们,是不是一天二十四小时不停歇?你看看谁家出新品,一出就一大桌子,好玩的东西也太太太多了吧!揪一位铁粉宝一起分享我的快乐! 第一个是可以调制神秘药水的女巫调香式和磨药铺,包含两个透明小瓶子,红蓝色素和各种素材,在瓶子里放入亮片,再滴入少许色素来点水, 一瓶月光水就制作完成了,还可以用制作好的魔法药水玩女巫的毒药游戏哦!果冻贴游戏本来了,包含八款游戏,美甲、俄罗斯方块制作、汉堡、淘金币等各种很有趣的小游戏。四折叠,怎么叠都倍有面! 我宣布,最哇塞的弹力被我找到了!就是这个哇塞!女孩的贴天日历,每月都是不同的图案,苹果、葡萄、番茄、糖果、太阳花, 每过一天就贴一个贴贴,好有趣的日历。第三个是磁力安静书,可以造景和收纳,很解压哦! 做完你的,做你的做完你的做你的鸡排主理人磁力安静书登场,都是切磨好的素材,扣下来就能用。两本游戏闯关书,每一页都是不同的游戏,不敢想和鬼魅一起玩会多有意思哈哈哈,不用熨斗烫的拼斗本也是让我玩上了。有方块、 圆点和十字三种图案造景贴纸合集本,这本是童话主题, 这本是末世和微孔主题本宝宝真的超喜欢微孔主题,有和我同款的贝贝吗?还有能把我看手机时间都夺走了!这四大袋有机灵姐爆改盲袋毛毡安静书,这个还从没玩过,一会要先玩这个 女官升职攻略,沉浸式剧情权谋宫斗游戏,看看你能火几一套全家桶捏捏盲袋,我森姐就是权威!
708鱼小丸子 00:31查看AI文稿AI文稿
00:31查看AI文稿AI文稿特效是变身恶灵骑士的视频,太酷了,怎么拍三秒教会你拍一段骑自行车并离开的控场景视频,保存恶灵骑士素材之相册备用。 打开剪映,导入视频,在人物刚要停车和刚离开的位置分割删除中间部分,添加画中画,导入素材色度,抠图抠出绿色,在两段视频之间添加特效,闪黑搞定看效果。
1.4万阿瑶学姐 01:02
01:02 00:25查看AI文稿AI文稿
00:25查看AI文稿AI文稿这视频刚发出就七十万点赞,我教你拍,你给我火。拍摄一段骑车并离开留控场景的视频,导入到剪辑软件,再准备起跳处,点分割车子骑出画面处再分割删除中间多余部分,点画中画,导入素材,点 色度抠图移动取色系到绿色位置,抠掉背景,添加这个滤镜和这两个特效,配上音乐导出看效果。王牌飞行员申请出战。
899三江(手机摄影)











猜你喜欢
最新视频
- 1931梦娃娃