即梦动作模仿生成失败为什么

粉丝685获赞818
相关视频
 35:44查看AI文稿AI文稿
35:44查看AI文稿AI文稿欢迎收看二零二五全新极梦 ai 视频系统教程。明明用的同一个极梦,为什么别人做的视频就能一发入魂,符合预期效果,而你的视频却像脱缰的野马一样浪费积分不说,结果还得全靠运气。今天这期全是技巧,手把手教你从零到一,搞定完整 ai 视频, 不论你是新手小白还是有一定经验的老手,学完都会有所收获。话不多说,咱们直接开整。大家好,我们这期视频来讲解极梦 ai 的 参考图 生图功能,一共有这七项,我们下面逐一进行演示。来到极梦 ai 的 首页,点击左侧的生成选项,将模式修改为图片生成模式。既然是参考图生图,我们首先要上传一张参考图,通过点击这里的加号或者鼠标拖拽的方式将参考图上传上来。我们此次生成就以这张图片为例 来看参考图生图的第一项演示功能,修改颜色,这里我们直接在提示词里面描述将人物的头发修改为暗红色,其他部分保持不变,回车发送。可以看到一段时间后图片就生成好了,整体的修改效果还是非常不错的, 十分稳定的将人物的头发颜色修改为了红色,同时和原图相比,人物在造型和背景上都保持了高度的一致。如果我们想要修改其他部分的颜色,就直接在提示词中描述修改某个部位的颜色即可。我们下面来看第二项功能就是修改环境, 此次生成就以这个站在草地上的人物为例。回到吉梦 ai 的 生成页面,我们将这张参考图上传到预备窗口当中,而提示词方面就直接描述给人物的背景更 更换为健身房,只改变背景不改变人物。现在点击发送可以看到此时我们生成的结果,就在原图的基础上,将人物所处的草坪背景更换为了健身房背景。而相较于原图,我们可以看到人物在造型设计、长相特征上,甚至连打光上都是没有发生改变的,而是让背景的光影和环境 主动去适配人物,一次性会生成四个结果,我们可以从中找一个与人物融合程度更好的。下面再来看第三项功能,就是修改姿势和角度,我们再次更换一张新的参考图,以 这张图片为例,回到极梦 ai 的 生成页面,将参考图上传到预备窗口当中,而提示词方面,我们就直接描述想要人物做的事情 及想要人物所处的环境。例如这里我们就直接描述生成人物在咖啡厅喝咖啡的画面。点击发送可以看到一段时间后图像就生成好了。 现在点击查看大图,可以看到我们新生成的图像在人物的长相特征和穿着上,是不是和原图保持了高度的一致性呢? 同时在人物改变姿势和所处环境的时候,我们也能感受到人物身上的光影也随着环境发生了改变,并不会产生单纯的抠图、 p 图后的违和感,这就是如何修改姿势和视角。下面再来看第四项功能,如何固定造型修改环。 此次生成我们以这张图片为例,因为这项功能经常会应用在一些电商产品宣传图更换背景上,我们依然回到极梦 ai 的 生成页面,将参考图上传到预备窗口当中,在上传好之后,提示词就描述固定产品的造型,给 产品更换一个沙漠的背景,背景中有金字塔和河流。此外,在生成之前,为了能够更好的固定产品的造型,我们可以点击上传产品参考图的位置,再点击之后会弹出一个叫做智能参考的窗口,在窗口中点击左下方这个人像图标, 此时就会识别画面当中的主体内容,在识别好之后,会以淡蓝色的形式覆盖在主体上面,以此来标记选中的区域。可以看到这里我们就成功的选中了产品的保存, 这样一来我们在生成时就能够更好的固定产品的造型设计。下面点击生成,可以看到一段时间后效果就生成好了,成功的生成了我们在提示词中所描述的沙漠、金字塔 和河流的背景,且产品和环境之间在光影上十分统一协调。这里我们同样放置一张原图来对比一下,可以看到产品原本的寿光以及造型是没有任何改变的,而背景的寿光已经 地面上的影子则主动迎合了原本的产品进行了生成。所以和上一个演示不同,这种锁定主体的生成方式是不会改变主体本身原有的受光的。我们下面来看第五个功能,就是参考风格,我们此次生成就以这张图片为例, 到生成页面将图片作为参考图上传到预备窗口当中,在上传好之后,提示词这样书写参考图片的风格,生成配色姿势,设计不同的图片,现在点击发送可以看到,一段时间后符合要求的四张图片就生成好了, 在设计配色和人物姿势上都产生了不同的效果。我们继续来讲解第六项参考图生图功能,那就是 control night。 如果大家使用过 stable fusion 的 话,相信对这项功能并不陌生,或者多少听说过这样的功能,其实在极梦 ai 上同样有这样的 功能。回到极梦 ai, 我 们将下方的图片模型由四点零更换为三点零,在更换好之后,点击图片预备窗口中的图片,此时弹出的窗口在选项上和四点零模型会有很大的差异。 看到下方提供了更多的图片参考选项,有智能参考、角色特征、人像写真、主体识别、风格参考、边缘轮廓、紧身和人物姿势。其中后三项就是和 control night 相关的功能,例如我们现在选择这里的边缘轮廓,可以看到右侧就会输出对应的检测图,将 将人物的线稿轮廓进行锁定,点击右下方的保存,此时再生成新的结果,就会生成在轮廓和设计上与参考图非常近似的结果。比如现在我们输入将图片的色调改为黑金色调,现在点击 发送可以看到,由于锁定了人物的线稿轮廓,所以最终生成的效果人物在造型设计上就和我们上传的参考图保持了高度的一致,但同时也不难发现最终生成的结果在环境的表现上并不是很好,同时也并没有很好的理解我们的意图。我们要的是黑金色调相关的设计, 而并非将人物变成金属质感,带有黑色装图的人物,这也是三点零模型和四点零模型之间的差距,对于语言的理解能力,四点零模型会更胜一筹。而其他的三点零模型当中,和 controntight 相关的参考图升图功能亦是如此。 现在我们来看下一项功能,就是景深检测,这项功能通常用来修改一个风景图的四季,例如现在我们上传一张风景图,然后将检测类型改为景深,在修改好之后,可以看到右侧的检测图就成功的检测出了 我们所上传这张风景图片的深度,点击保存。而提示词方面,我们就书写将季节改为冬季,回车发送一段时间后,修改了季节的图片就也生成好了。现在点击大图看一看效果如何吧。 看到最终生成的结果并不是十分理想,虽说整体的画面深度和原参考图相比,确实在深度构图上保持了高度的一致,但也不难发现 整体的美术风格发生了巨大的变化。所以需要大家知道的是,这项功能同样是一个比较过时的功能,大家想要改变图片的季节的话,还是建议将图片生成模型修改回四点零模型,然后直接在提示词中描述将季节改为冬季。 说四点零模型并没有专用的 control night 相关功能,但我们在修改时只需要在提示词中强调其他部分保持不变,然后点击发送可以看到,通常来说就能获得比使用了深度检测更好的转换季节的效果,在美术风格上与原图保持了高度的一致。我们下面再来看第三项 control night 功能, 就是人物的姿势检测, open pose。 现在上传一个人物的图像,我们依然是以这张图片为例,在上传好之后,将图片的生成模型修改为三点零模型,然后点击图片预备窗口中的 图片,将参考方式选择为最右下方的人物姿势。记得在选择好之后,要修改一下生图的比例,改为适配当前参考图的比, 这里我们就选择九比十六。可以看到此时的检测图就非常完整的检测出了人物的骨骼轮廓,这就代表着待会生成的新的图片,在姿势上也会与这张图片的姿势保持高度的统一。而具体的设计 内容和风格就取决于提示词的描述了。在选择任意的参考方式时,包括在使用四点零生成模型参考时,在左下方都会有一个参考强度的选项,这个选项通常保持默认即可, 当然具体要看生成的结果来决定。如果你觉得生成的结果可以再参考多一些原图,就可以将这里的参考强度调整的高一些,反之则调整的低一些,现在点击保存。而提示词方面,我们就先描述一个人物的形象,例如这里我们描述一个穿着 jk 的 高中少女, 点击发送可以看到一段时间后图片就生成好了。不难发现,生成这四张图片在人物的姿势上都与参考图保持了高度的一致,是一个正面双臂自然下垂的站姿。我们最后来看多图参考功能,这项功能很好理解,就是字面意思,可以将多张参考图 同时进行参考,融合在一张图上,例如这里我们首先将图片生成模型修改为四点零,来获取更好的融合效果,然后分别将一件衣服的图片以及一个人物的图片上传到参考图的预备窗口当中。在实际操作时,大家也不仅可以上传两张图片,想要上传第三张、 第四张也是可以的。不过上传的图片越多,在融合的时候可能融合的效果就会越差。在大多数情况下,我们也不需要用到那么多参考图, 现在就在提示词中描述,让图二的人物穿上图一的衣服。这里图二指的就是我们上传的第二张图片, 图一指的是我们上传的第一张图片,以此类推,现在点击生成。需要注意的是,在生成的时候,在宽高比上一定要选择合适的宽高比,例如当前的两张图片都是九比十六的,我们就选择九比十六,或者调节为最左侧的智能选项,让 ai 自行判定什么样的比例是最合适的。 段时间后,图片就生成好了,我们点击查看大图,看一看效果如何吧!可以看到,生成的结果就成功的让人物穿上了在参考图当中,我们所提供的碎花长裙,且人物的长相特征、姿势都是保持不变的,与周围环境的光影也融合的非常恰如其分。 当然,如果有对应的鞋子或者帽子,或者像眼镜这些内容想要穿在人物的身上的话,我们可以一并将这些内容相关的参考图上传到预备窗口中,并在提示词里面描述对应的要求。 相信大家都具备举一反三的能力,所以这里就不再做庸俗的演示。大家好,我们这节课来讲解极梦 ai 的 视频生成功能。首先来看文声视频, 想使用文声视频功能,我们就需要特别注意,在提示词的书写上要尽可能全面。在先前的课程中,我们讲解了提示词的书写公式,这样的公式在文声视频时同样适用,我们下面来简单演示一下。来到极梦 ai 的 首页,点击左侧的生成选项,将下方的下拉菜单更改为视频生成。 下面来输入提示词。首先是主体元素,例如这里我们描述一个戴着眼镜的猫头鹰,穿着西装,戴着帽子。然后是背景环境,这里我们就描述在办公室中,我们让他看报纸。下面来描述视觉风格,这里描述三 d 高精度建模风格,这 对象色调、文字构成和氛围用语,大家需要的话可以做详细的描述,如果不需要的话就直接生成。但是在生成之前,我们需要注意和生成一张图片有所区别的是,在文声视频时,除了描述图片本身的内容, 还需要额外描述两个内容,一个是镜头的运镜,例如固定镜头、镜头推进、镜头拉远等等。而另一个是画面当中事物的运动状态,例如这里我们书写办公桌上放着一杯冒着热气的咖啡,这样一来就构成了生成一条纹身视频的完整提 现。在点击发送,在等待生成的时间,我们来简单介绍一下生成视频时的参数设置。首先是视频生成模型,和图片生成模型一样,版本标号越高的模型生成效果就越好。然后右侧是视频生成的模式,有首尾帧、智能多帧和主体参考, 接下来都会讲到。然后是视频生成的比例以及视频生成的分辨率,在图生视频时,默认生成的比例和图片是一致的。再往右侧是视频生成的秒数,有五秒和十秒可选,在大多数情况下,选择五秒就足够成为一个分镜头片段了。不是很建议大家生成十秒钟时长的视频, 因为时间越久,画面出现问题的可能性越高,非必要的话还是尽可能选择五秒钟的时长。最后是一些官方所给出的运镜,这里我们用提示词描述或者选择官方给出的镜头都可以。可以看到,现在视频已经生成好了,整体的效果表现还是不 错的,像办公室办公桌冒着热气的咖啡,还有看报纸穿西装的猫头鹰。可以说生成的视频完全符合了提示词的描述。但这里我们必须要强调一下,那就是在百分之九十九点九的情况下,都不建议大家使用纹身视频的方式来生成视频片段,因为这样生成的画面存在很大的不可控性, 怕文字描述的再细致,可能在设计、美术、风格、色调等等方面总会有我们不满意的部分。而相较于修改一张图片,对视频进行后期修改,所要花费的时间成本会非常的巨大,且生成一条视频本身就需要消耗很多的点数,不像生成图片,在极梦 ai 上会员是免费的,几乎是零成本。 所以大家最好还是先生成图片,将画面的内容、色调、风格等方面都确认好之后,再生成视频 一个更加稳妥的方法,成本也会更低。所以我们下面就来讲解关于图生视频相关的操作。想要使用图生视频,自然是要上传一张图片作为手帧图。 和图生图中上传参考图一样,我们将作为手帧图的图片通过拖拽的方式上传到预备窗口中。这里简单解释一下手帧图的意思,它的意思就是将来在生成的视频中,这张图片会作为视频的开头来进行后续的生成。 而伪真图的意思想必大家也清楚了,会作为视频的结尾来生成视频。我们先来尝试手真图生视频,提示词方面,我们就描述镜头的运镜以及画面当中事物的变化。比如这里我们就描述固定镜头, 人物戴上墨镜,可以发现我们这次生成时就不需要描述那么多的提示词内容了,因为图片已经给出了充足的内容信息,所以就只需要描述画面当中镜头的运镜和事物的变化。现在点击生成一段时间后,视频就生成好了,可以看到整体的视频表现还是非常不错的, 人物动作流畅,并且十分稳定的听从了提示词的要求,给人物戴上了墨镜。不过通过手真图升视频的方式,我们是无法决定最终在视频结尾时所呈现的画面效果的。例如我们现在想要人物戴上固定款式的墨镜,通过手真图升视频的方式就无法实现, 此时就要使用首尾真升视频功能了。例如这里我提前使用参考图升图的功能,给人物戴上了一个紫色镜片的墨镜,而其他的部分是保持不变的。现在将这张戴上紫 墨镜的图片作为伪真图上传到预备窗口当中,在上传好之后,提示词方面就保持不变,依然让人物戴上墨镜,现在点击发送一段时间后,视频就生成好了。可以看到此时人物所佩戴的墨镜款式就是我们在伪真图当中指定的有紫色镜片的款式了。 不过每次生成都会伴随着一些随机性,如果没有生成好的话,可以点击下方的再次生成选项,尝试多生成几次。了解了什么是首尾真生视频。 到生成页面,我们将首尾针生视频的下拉菜单展开更换为智能多针。可以看到此时在这个位置会出现一个新的图片上传窗口,用来上传第三针图片, 此时我们刚刚所上传的第二针图片就变成了一个中间针,而第三张图片才是画面的尾针。这个时候如果我们想要人物连贯的做出很多不同的行为,比如先戴上墨镜,然后拿出汉堡吃汉堡,我们就可以使用智能多针功能,一次性生成人物做出多个行为的视频。 例如现在我们将这张图片作为第三针进行上传,而这张图片作为第四针进行上传。在上传好之后,可以看到图片与图片之间会有一个添加提示词描述的部分,点击这个部分会弹出一个提示词输入窗口, 用来描述两张图片之间是如何进行转换的。例如在戴墨镜和戴墨镜拿出汉堡之间,我们就描述人物拿出汉堡,在拿出汉堡和吃汉堡之间,我们就描述人物吃汉堡点 确认,需要注意的是,添加的生成图片越多,在生成时所消耗的点数就越多,同时也有更高的概率会使得生成的画面出现不好的情况,所以非必要的话,大家也不要一次性生成太长的视频, 现在点击发送看一看效果如何吧。最终生成的效果还是非常不错的。可以看到在画面中,人物先拿出了墨镜,然后戴上墨镜,之后又掏出了汉堡,把汉堡对着镜头进行了展示,然后就是吃汉堡的画面, 整个画面非常的连贯流畅自然。不过这样的生成同样也存在随机性,特别是当图片与图片之间,在美术风格、人物姿势、场景环境跨度较大时, 很多时候可能就无法达成有逻辑的转换了。所以大家在使用智能多帧功能时,尽量使用固定镜头,同时人物在造型和角度上也 不要有过大的转换。我们最后来看参考图生视频功能,回到极梦 ai 的 生成界面,将下方的智能多帧下拉菜单更改为主体参考,这项功能和参考图生图功能非常类似, 只不过生成的结果由图片换成了视频。例如现在我们依然以这个人物和这个裙子为例,分别将人物的图片和裙子的图片上传到预备窗口当中。 而提示词方面,我们就书写图一的人物穿着图二的裙子在公园散步,镜头跟随。在生成之前,可以看到在右下方有一个艾特符号,我们点击这个符号,上方会弹出主体内容,选定这个内容, 此时可以对图片当中的主体进行引用,相比于单纯的描述图一当中的人物或者图二当中的裙子,这样的引用指向性会更加明确,所以我们现在来修改一下书写格式,就修改为镜头跟随图一的人物穿图二的裙子, 持图一和图二为引用的状态,然后加上在公园散步,在书写好提示词之后,就点击右下方的生成,可以看到最终我们就成功的生成了人物穿着裙子在公园当中散步的画面。不过不得不说这项功能整体的表现并不是很好,人物的造型和 服装的款式在生成之后都发生了一定的变化,且动作也不是十分流畅自然,而环境方面也更倾向于原图的环境,而并非是我们所描述的公园, 这项功能目前还不推荐使用。以上就是极梦 ai 的 视频生成功能讲解,我这里也整理了一份视频生成的提示词技巧相关攻略,如果大家需要的话,可以查看评论区的置顶,如果觉得本节课的内容对你有帮助,也不妨点赞关注支持一下。大家好,我们这节课讲解动漫与电影。 一次性生成多分镜视频片段,一共分为三个部分, ai 生成手帧图、生成运镜提示词以及生成视频。 首先来看 ai 生成手帧图,来到豆包 ai 当中,我们首先来获取生成图片的提示词,这里我们这样填写,你是一个提示词书写大师,给我三个可以生成新海城电影风格的中文提示词,要求包括主体、背景、 风格、色调、氛围的描述。现在点击发送一段时间后,我们就获取了非常详细的提示词描述,现在将任意一段提示词复制下来,然后来到极梦 ai 的 生成页面,将生成模式更改为图片生成,将提示词复制粘贴过来。这里的生成参数方面竟然是要生成电影相关的分镜头, 比例自然是选择十六比九,然后直接点击生成,可以看到一段时间后我们就获得了新海城风格十足的电影分镜头画面。 可以看到生成的这几张结果效果都是不错的,不仅人物的长相和穿着特征十分符合新海城电影当中的风格,像人物所处的环境以及画面当中光照的设定也和新海城电影的风格十分契合。现在我们从中挑选一张自己较为满意的结果,将其下载到电脑本地, 在下载好之后,回到豆包 ai 中,将刚刚下载好的本地图片上传到豆包 ai, 我 们下面来进行第二步生成运镜提示词,提示词方面我们可以这样书写,请以这张图片作为起始镜头,打造一个多机位视频, 呈现出壮观的氛围。需要四个连贯分镜,分镜头脚本包含景别、视角、运镜画面等内容, 每个分镜用不同的运镜方式,要求用词简洁,字数不超过四百字,下面点击发送。当然这里大家也可以更改连贯分镜头的数量,通常来说五秒钟的视频,两三个分镜头就已经比较多了,一段时间后我们需要的分镜头多机位描述就生成好了, 直接将这些描述复制下来,然后回到极梦 ai, 将生成模式修改为视频生成,然后将刚刚我们下载好的参考图上传到手帧图的位置, 而提示词方面就直接将豆包 ai 中生成好的不同分镜头画面提示词内容粘贴过来,这里可以根据我们的需求来修改生成的时间,像四个分镜头画面的话,其实十秒钟的时间也是可以的,不过此次演示我们就暂且选择五秒,然后直接点击发送 一段时间后视频就生成好了,来看一看效果如何吧。可以看到整体的画面表现还是非常连贯流畅的,且画面和画面之间也存在逻辑和风格上的关联。用相同的方式我们想要制作怎样的电影多分镜头片段,也可以使用类似的方法。 重新向豆包 ai 提问。给我三个可以生成阿凡达电影风格的中文提示词,要求包含主体、背景、风格、色调、氛围的描述。现在点击发送一段时间后,提示词就生成好了。我们将提示词复制下来,一共有三个,大家都可以尝试生成一下,从中挑选一个自己最满意的。 在复制好之后,回到极梦 ai 的 生成页面,将提示词粘贴到输入框中,尺寸方面依然保持十六比九的比例,现在点击发送 可以看到一段时间后,我们所需要的阿凡达电影风格对应的分镜头图片就也生成好了,这样的生成效果是不是和电影当中的截图非常相近呢?再来看第二张,同样有着非常好的生成效果。再来看第三张,还有第四张,我们就从中挑选一张效果不错的,将其下载到本地, 在下载完成之后,重复刚刚的方法,将参考图上传到豆包 ai 当中,而提示词方面我们就稍加修改,之后使用 具体的内容填写。请以这张图片作为起始镜头,打造一个多机位视频,呈现出星球环境的壮观和飞行的场面。需要设计四个连贯分镜,包括景别、视角、 运镜画面等内容,每个分镜用不同的运镜方式,要求用词简洁,字数不超过四百字。现在点击发送,片刻之后提示词就生成好了,我们将这些提示词直接复制下来,回到极梦 ai 当中,将生成模式修改为视频生成,然后上传我们刚刚下载好的手帧图, 而提示词就使用多包 ai 帮我们生成的,然后直接点击生成,一段时间后,包含了多个分镜头的阿凡达视频片段就生成好了,来看一看效果如何吧。可以看到整体的效果还是非常连贯的,并且从多个角度展现了人物和场景,不过这样的生成通常会伴随一些随机性, 如果觉得效果不好的话,可以点击再次生成来挑选一个更加满意的结果。以上就是本期视频的全部内容,其实不仅仅是我们今天所说的新海城风格或者是阿凡达风格, 很多知名电影的风格大家都可以尝试用今天所学的知识举一反三来生成类似的多角度的分镜头视频。我这里也给大家准备好了一些一次性生成多分镜头视频片段的相关提示词素材,需要的话可以查看评论区的置顶。最近在抖音上我们能够看到很多这样的 ai 像素风视 频,这些视频的热度都非常的高,甚至有些能够达到几十万播放量,所以我们今天就来讲解一下如何用 ai 生成像素故事视频 一共有三个步骤, ai 生成像素手帧图,手帧图生成像素视频,最后剪辑成片。我们首先来到极梦 ai 的 首页,点击左侧的生成选项, 将下方的生成模式选择为图片生成模式,然后在这里描述我们想要生成的内容。提示词的书写非常简单,核心关键在于像素风格。接下来描述我们要生成的主要画面,例如一个父亲骑着三轮车,三轮车上坐着儿子,背景视 田间小路,尺寸方面就选择适配于手机的尺寸,这里我们选择九比十六,然后直接点击生成,一段时间后图片就生成好了,可以看到最终生成的结果还是十分符合提示词的描述的。生成的这四张图片都是像素风格,且没有出现明显的崩坏。对比这些在抖音上的视频,是不是在风格上即 都是一样的像素风格呢?当然,如果想要像素风格有所差异,比如让人物更偏向于绘画的风格,或者想要控制画面的人物特征,我们也可以不直接生成像素风格,而是在原有的基础上将原图修改为像素风格。 以上节课我们生成的新海城风格的图片为例,将图片上传好之后,提示词方面我们就书写将图片修改为像素风格,然后调整生成的比例, 最后点击发送。可以看到一段时间后,我们就将现有的图片修改为了像素风格。点击查看大图,可以看到上面的像素质感还是非常明显的, 我们下面要做的事情是将生成好的图片进一步的升成为动态视频。这里直接选择上方已经生成好的四张图片,挑选一个最为满意的效果,例如像第三张是最符合描述的。在打开这张图片查看之后,如果觉得图片的清晰度不够,也可以点击右下方的智能超清或者超清选项, 此来提升画面的清晰度。或者也可以选择下方的细节修复选项,让画面在像素风的基础上,光影表现上更加的细腻。现在点击生成可以看到最终生成好的结果,是不是在光影的表现上有着更加出色的效果呢? 取了效果更好的图片后,我们下面就来开始生成视频。点击右侧的生成视频选项,将生成好的结果导入到手珍图的预备窗口中。提示词方面,我们就描述生成视频所需要的内容有两个方面,一个是镜头的运镜,一个是画面当中事物的变化。 首先是镜头的运镜方面,通常像这样的走路骑车的画面,我们就描述镜头跟随,而内容方面我们就描述父亲骑着三轮车,带着儿子行驶在乡间小道, 风吹动脉田和路边的杂草。大家在生成画面中有一些植物的视频时,也可以尝试描述风吹动植物这样的提示词, 以此来让画面的生成结果变得更加生动。现在点击生成一段时间后,视频就生成好了,来看一看效果如何吧。可以看到整个画面的运镜还有人物的动作都是十分自然流畅的,我们下面要做的事情就是将这条视频拖入剪辑软件当中,准备剪 成片。当然我们今天演示的仅仅是一个镜头片段的故事,如果大家想要生成带有连贯剧情的像素风格的 ai 视 频,其实方法和我们先前所讲解的是一样的,那便是先利用豆包 ai 生成剧本脚本,再根据剧本脚本生成对应的分镜头图片,最后再将分镜头图片生成为 ai 视频片段,然后导入剪辑软件剪 成片。相信大家都有举一反三的能力,所以这里就不再做荣誉的演示。我们今天就演示这么一个片段,现在点击上方的文本分选项,将这里的默认文本拖拽到剪辑轨道上。内容方面我们就填写和画面较为契合的内容, 由这里我们就书写,小时候父亲总是骑着三轮车带我到镇上村,路两旁是金色的麦田。在书写好提示词之后,可以在上方的预览窗口当中选择文本的部分,拖拽边缘来改变大小, 拖拽中间来改变位置。同时在右上方的参数设置区域,可以选择字体的各种参数,例如给字体加一圈黑边,让其在画面当中更加明显。 在下方的剪辑轨道中,可以通过拖拽文本文件边缘的方式来延长或者缩短在整个视频片段当中它所显示的时长。我们下面来添加音乐和音效。首先来添加音乐,点击左上方的音频分选项,在音乐库中搜索比较契合当前画面的音乐, 我们就搜索悠闲乡村,在搜索结果中点击试听, 如果觉得效果不错的话,就将试听的结果拖拽到剪辑轨道上,然后将多余的片段将白色的剪辑指向移动到对应的位置, 按下 w 键向右侧进行裁剪。在结尾的位置,为了让声音能够结束的更加平滑流畅,我们将鼠标悬浮在音频文件上方,可以看到右侧有一个小圆圈,我们将这个小圆圈向左拖动,此时会出现一个 黑色的区域,这片区域就是被裁剪掉的声音,这就意味着声音会以渐出的方式逐渐减弱,让整个视频结尾的声音以更加自然的形式退场。我们接下来来搭配相应的音效, 点击左上方的音效库分选项,然后来思考一下像当前的画面可能会出现哪些音效。例如我们搜索自行车,可以看到这里有一个蹬自行车的音效,点击试听, 整体的音效表现还是不错的,我们将这个音效拖拽到剪辑轨道上之后,我们还需要一个轮胎在地面上滚动的音效,所以继续在搜索栏中搜索胎噪,同样在下方的内容当中点击试听,寻找一个合适的音效,比如当前这个音效, 这个音效就非常适合作为骑三轮车时三轮车的转轴不太稳定的声音。我们同样将其拖拽到剪辑轨道上,然后重复刚刚的操作,将多余的片段在选中相应的文件之后,对其进行长度裁剪,然后让音频以 现出的方式出现在视频结尾的位置。当然如果需要的话,我们也可以添加相应的特效效果,如果说有多个视频片段的话,也可以选择添加相应的转场效果,这些就交给大家自由把控了,我们最后来看一看最终的成片效果如何吧, 可以看到最终的成片表现还是非常惊艳的。以上就是关于 ai 生成像素故事的提示词资料,需要的话可以到评论区置顶领取。 大家好,我们这期视频来讲解抖音上那些非常热门的爆款视频该如何制作,一共来讲解三种类型,分别是萌宠类创意视频、萌宠走秀类创意视频 和微缩场景类创意视频。首先来到极梦 ai, 和制作其他的创意视频一样,先来获取提示词,以此来进行图片的创作。在搜索栏我们直接搜索萌宠, 可以看到此时在搜索结果当中就展示了很多极具创意的由其他作者制作的萌宠类 ai 作品,我们可以从中挑选一个在展示形式和创意上都比较喜欢的,然后点击查看大图,在右侧将作者生成这张图片时使用的提示词复制下来,然后打开豆包 ai, 将提示词 直接粘贴到输入栏中,按下 shift 键加回车进行换行,然后书写请帮我根据上述提示词再编辑五条萌 萌宠创意图片的提示词,然后点击发送可以看到,片刻之后我们就获取了五条极具创意的萌宠图片的提示词,现在将提示词复制下来,然后来到极梦 ai 的 生成页面,在左下方将模式切换为图片生成, 粘贴刚刚我们复制的提示词,然后设置合适的生成参数,比如这里的比例我们就先设置为十六比九,下面点击生成大家在生成时具体的比例可以根据将来要发布的平台来决定,一段时间后就生成好了,可以看到此时生成的结果还是非常富有创意的,整体的画面质量也非常高。 这里我们一共获取了五条提示词内容,如果对生成的结果不够满意,可以回到豆包 ai 再复制一条新的提示词,我们再来尝试生成一个用新提示词生成的结果,可以看到再一次生成的结果也非常不错,整个的图片内容是非常富有创意的, 生成的动物也十分可爱。而我们下面要做的事情就是将图片生成为视频了,从众多生成结果当中挑选一个我们最为满意的,然后将鼠标悬置在上方,点击弹出菜单,当中的生成视频选项就是这个位置,再点击之后将图片加入到视频生成的预备窗口中。 而提示词方面我们就书写镜头的运镜和画面当中事物的变化,这里运镜方面我们就书写固定镜头,而事物的变化我们可以不做书写,也可以书写一些简单的内容,例如狗充满好奇的看着镜头,现在点击发送一段时间后,视频就生成好了,来看看效果如何吧。 可以看到整个视频的质量还是非常高的,这也得益于我们生成的图片质量本身也极具创意,且画质也相当不错。我们下面再来看第二类创意视频,萌虫走秀类创意视频 依然是回到极梦 ai, 来到首页,在搜索栏中搜索萌宠走秀,可以看到此时就获得了很多萌宠走秀的搜索结果,我们从中挑选一张自己喜欢的,然后点击查看大图,同样的在右侧将作者在生成图片时使用的提示词复制下来 到豆包 ai, 重复刚刚的操作,将提示词粘贴到输入窗口,按下 shift 加回车进行换行,然后添加要求,请帮我根据上述提示词再编辑五条萌虫走秀创意图片的提示词,现在点击发送,一段时间后提示词就生成好了。当然生成的这些提示词都是跟小狗相关的, 如果我们想要生成不同动物的内容,也可以在要求当中要求生成的提示词要包含各种动物。我们下面要做的事情就是将提示词复制下来, 然后回到极梦 ai 的 生成页面,将提示词粘贴到图像生成的提示词输入框中,下面点击发送,可以看到一段时间后图片就生成好了,整体的生成效果还是非常不错的。同样如果对生成的结果不够满意,想尝试其他的风格,也可以继续复制当前生成好的 提示词。我们不光可以要求豆包 ai 一 次生成五条,如果想要选择面更加宽泛的话,可以让它一次性生成二十条,从 中挑选我们想要的。不过相信大家都具备这样的能力,所以这里就不再做荣誉的演示,我们直接来生成视频,从生成的四张图片中选择一个还不错的,将鼠标悬置在上方,然后点击弹出菜单中的生成视频选项。而提示词方面需要描述镜头的运镜和画面当中事物的变化。 运镜方面,像这种人物向前走的视频,我们通常描述镜头跟随而事物的运动,我们就描述主 体向前走,因为此时图片当中并不是一个人,而是一个拟人形态的狗,所以我们描述主体是比较稳妥的描述方式。下面点击发送一段时间后,视频就生成好了,来看看效果如何吧。可以看到整体的生成效果还是不错的,当然如果大家想要发布平台的话,不妨多做几条类似的视 频,将它们在剪辑软件上整合成一个视频来发布,这样观感上会更好一些。我们下面来看最后一种爆款类视频的制作,就是微缩场景类创意视频, 依然是回到极梦 ai 的 首页,在搜索栏中搜索微观,可以看到此时就出现了很多由其他作者生成的微缩景观类的创意图片,我们依然是从中挑选一张,然后点 击查看大图,将作者生成图片时使用的提示词复制下来,然后回到豆包 ai, 将提示词粘贴,按下 shift 加回车键,紧接着提出要求, 请帮我根据上述提示词再编辑五个微缩场景类的创意提示词,点击发送一段时间后,提示词就生成好了,我们任选一个将其复制下来,然后回到极梦 ai 的 生成页面,将 将提示词粘贴到图片生成的提示词输入框中,然后直接点击发送,片刻之后图片就生成好了,可以看到整体的生成效果还是不错的。同样的,如果对当前生成的风格和效果不够满意,可以再次的回到豆包 ai 当中,复制一个新的提示词,然后返回极梦 ai 粘贴提示词点 生成,可以看到这次生成的结果还是十分讨喜的,与我们刚刚所看到的作者生成的图片非常相像,其实整个的氛围给人的感受也非常新奇。其实很多爆款视频之所以能够成为爆款视频, 大部分都是因为视角比较独特,给人的观感比较新奇,而这类微缩场景类的视频正是如此。我们下面就点击生成视频,将图片分为动态的, 这次方面我们就分别书写固定镜头,然后根据画面现有的内容来描述需要的事物变化。例如最上方的小人在挤抹茶酱,下方拿着铲子的小人在用铲 子铲奥利奥碎。现在点击发送一段时间后,视频就生成好了,可以看到整体的生成效果充满了趣味,且人物的行动也符 了提示词的描述。我这里也整理了一些生成今天所讲解的爆款类视频的提示词,如果大家需要的话,可以查看评论区的置顶评论。以上就是本期视频的全部内容,如果觉得对你有帮助,也不妨点赞、关注、支持一下,我们就下期视频再见!
45AI视频制作教学 04:32查看AI文稿AI文稿
04:32查看AI文稿AI文稿大家好,我是准哥,今天给大家实操一下 cden 四二点零傻瓜式操作,后续还有成品展示。首先在浏览器搜索极梦,点开第一个就是官网 对话框的第一个选项里,选择视频生成模型,选择 cden 四二点零。 如果没有这个模型,那么就点击左边的会员开一个新用户,有一个一块钱的会员可以充 a b, 这里已经充过了,充完之后记得点击刷新按钮,刷新一下网页,然后就能正常选择生成十二点零模型了。选好模型后,第三个选项我们选择全能参考。 接下来我们要上传参考内容,比如你想生成赛文奥特曼大战赛罗奥特曼,那么你就上传这两个奥特曼的图片给 ai 做参考, 对话框里就写你想要生成的内容,比如恶补组想看他们两个打架,就在对话框里,且生成图一角色和图二角色战斗的画面,风格迂迂,参考日本特色。 这时候肯定有人要问了,我们为什么不告诉 ai 它们是奥特曼呢?答,因为奥特曼是有版权的字节,可不想被告所有,其他有版权的人物也一样。你可以上传人物的参考图片来让 ai 生成,但不要直接在输入框输入角色名字, 否则就会因为违规导致生成失败。最后的比例和秒数自己选就行。好了,接下来让我们看成品 ten two three 啊,咦呀咦呀,没有没有,还有还有! yeah ah ah ah love you have she need to go to the end of the world while you love love me i can't do it i can't do it i can't do it i can't do it i can't do it i can't do it 呀呀呀!
132准哥AI 01:25
01:25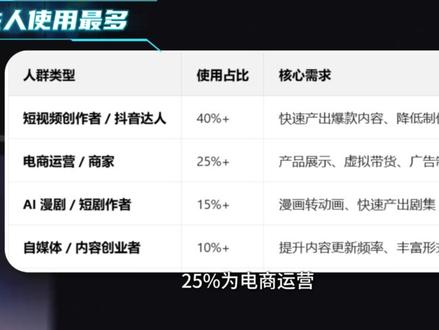 00:56查看AI文稿AI文稿
00:56查看AI文稿AI文稿新发布的极梦二点零耗费价格多少?在哪用?有哪些玩法?不足之处是什么?先说价格,每秒视频六积分,约等于六毛钱,单次生成视频可选择,最短四秒钟,最长十五秒。第二个问题在哪用?目前使用最多的是在极梦电脑网页端,仅会员用户可用, 手机极梦 app 暂不可用。值得一提的是,小云雀有极梦二点零模型选项。第三个问题有哪些玩法?二点零模型中文声视频片段静态变动态 全能参考,也就是多模态融合支持,同时上传十二个参考文件,适合专业级内容创作。复杂去式 ip 角色还原。哪些人用极梦二点零模型最多?超过百分之四十为短视频创作者,百分之二十五为电商运营,百分之十五为短剧、慢剧创作者。 不足之处一、复杂视频仍需较长时间,多次测试海贼王经典打斗动作镜头用时二十分钟左右。二、画面偶尔闪回,极少数情况下有杂音。
363AI探险家 01:20查看AI文稿AI文稿
01:20查看AI文稿AI文稿吸电二点零,很多人都没办法上传这个真人的这种素材照片了,那么都会显示失败,那么我今天总结的有两种解决方案。先说第一种吧,你们可以看到我这里上传本人的照片都是失败的呀,然后呢?后面我为什么这里就成功了呢? 这里成功了是因为我做了一个三四图啊,这是我三四图啊,用这个纳洛本纳的把它合并成三四图,合并完之后呢?嗯,直接上传就可以了,他就识别你是 ai, ai 的 这种三四图就可以生成了。 对了,忘了说,你们这里最好这个分辨率选择这个四 k 啊。然后呢,这个提示词就这样子,很简单的把三张图片合拼为一个三四图,非常简单。 然后如果你们不会用工作流的话,你们也可以用别的这种 ai 的 模型去把它这个素材给转一下,变成 ai 的 素材,它就可以生成了。 然后剩下另外一种方法我就先不说,我也不知道说这种方法他会不会马上被下架,所以你们能用即用吧,好吧,等有需要我再更新第二种,好吧,哈哈哈哈。
109张从文













猜你喜欢
最新视频
- 2318木易杨