即梦ai怎么生成9张图
今天学习运用 ai 将九宫格一图成片,一张图即刻成片,自带音乐音效提示词已经给大家准备好了,接下来教大家怎么做这样的大片。首先 我们来到小梦,点击图片生成,上传一张人物打斗图,输入这段提示词,风格提示词可以自行修改,选择模型五点零比例十六比九,点击升成,就升成了这样一张九宫格分镜图。接着我们生成视频, 点击视频生成,上传刚才的分镜图片,输入这段视频提示词,可以在该模板上进行修改,选择 cds 二点零模型,选择全能参考,时长十五秒,点击生成这样一个九宫格画面,生成动画大片的视频就完成了,你也来试试吧!

粉丝1004获赞4749
相关视频
 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿只需要给 ai 一 张图,立刻就能推演出连贯的九张分镜,再一键制作成这种连贯的舞蹈视频,并且人物一致性完美。首先在小梦里面切换到图片生成,选择最新的图片,五点零模型, 比例十六比九,上传一张参考图,输入这段提示词,点击生成,我们就得到了电影级的九宫格分镜图片。接着就是生成视频, 以前做视频需要将九宫格里面的画面一个个分离出来再去做视频。现在只需要切换到视频生成模式,选择视频,二点零模型,选择十五秒比例十六比九, 再输入这个提示词,就可以得到这种流畅的跳舞视频吗?这效率直接拉满,现在只用一份积分就能炸出无敌效果了,你也快来试试吧!
1221Ai小课堂 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿现在给 ai 一 张参考图,它就能做出一张连贯的分镜图,再做成这张丝滑的跳舞视频,而且人物的一致性控制的非常好。我们先在同桌小梦这里选择图片,五点零,模型 比例十六比九,放入参考图,输入这段提示词,提交之后,我们就得到了电影级的分镜图,然后我们选择一张满意的保存,我们不需要把分镜图挨个区分,选择 cds 二点零,模型 比例十六比九,把九宫格图丢进去,再填写这段描述词,点击生成丝滑的跳舞视频就完成了。以前做这种视频,要先把九宫格里面的九张图片挨个抠出来,再挨个生成,然后拼接在一起,现在只需要一份积分就能得到。以前需要做九个视频的信息量, 觉得有用,点赞收藏, 记得关注,不然你找不到我。
23菜芽的AI笔记 00:38查看AI文稿AI文稿
00:38查看AI文稿AI文稿太夸张了,只需要一张截图,就能推演出九张连续的风景,直接一步到位,靠的就是这个提示词,用到的 ai 还是这么 nice! 香蕉模型不用会构图,不用懂镜头,一张图就够 上传给詹文爱粘贴提示词,坐等几秒,直接生成九张连贯九宫格分镜,人物一致,光影同步,场景不拖结,连镜头逻辑都精准到离谱,堪比专业导演出的分镜脚本。
233宋跑跑 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿现在你不需要煮一个深省分界视频,用一句话就可以把九宫格图片直接变成连贯的 ai 视频。我还测试了二十五宫格,居然也没有问题,太厉害了。 来的老朋友小梦视频深省选这个模型,给到我们提前做好的九宫格图片,如果你不知道怎么做九宫格,二十五宫格,我也把所有的坑都填好了,描述清楚你的需求,效果就做好了。其他的案例也是一样的方法, ai 有 料到,我们下次见。
5105料到Ai 01:28查看AI文稿AI文稿
01:28查看AI文稿AI文稿如何靠一张图让 ai 源源不断给你生成电影? ok, 那 么刚刚这段由 ai 生成出来的十五秒的视频,其实是从我上周去香港海滨公园拍摄的这张照片,然后一一演练过来的。 那实现的过程其实也很简单,你只需要把这一张照片喂给 ai, 告诉他说我需要生成九个不同景别的画面,那么 ai 就 会去识别这个图片里面符合现实生活中的不同景别的场景, 那么像他第一套是比较符合当时那个场景的,那我就选第一套,然后再把这套九宫格喂给 ai, 跟他说这是一个电影的分镜,然后你需要生成 一个比较自然的电影感的画面,那提示词我也放在这里,大家感兴趣的话也可以直接复制这段,然后根据自己的一些照片,做一些细微的场景的元素的调整, 然后另外的选项,像所谓的比例啊,包括这个模型啊这些,其实你就跟着我这个来选就可以。 那需要注意到一点,就是现在玩这个东西的人实在是太多了,所以你在生存的过程中可能需要排队几个小时甚至更长,但是这个无所谓,你只需要点击上传成功之后,他就会一直在后台生存,你不需要一直在当前这个画面去等,我也希望大家可以拿这套经验,然后分享你自己的作品。
 01:47查看AI文稿AI文稿
01:47查看AI文稿AI文稿cds 二点零刚刚发布就引起不小的轰动,今天给大家整理了九种实用玩法,干货满满,建议码住,随用随看。一、剧本漫画成片这个方法很邪修,把这个漫画或者剧本直接丢给他,然后让他根据参考生成动画片,看看这效果,鸡皮疙瘩都起来了。 二、九、宫格分镜,直出视频给这个模型一张九宫格分镜,加一段简单的描述,就能得到一段炫酷的大片,比自己手搓强太多了,无论是做漫剧、动画、广告、大片都用得上。 三、视频巨写哎,这个功能就有意思了,他可以帮你脑补出视频前后的剧情,不仅能向前退演,更能接着拍剧情,镜头连贯不割裂,这可玩性可太大了呀! 四、运镜控制想要指定的运镜根本难不倒他,随手拍一段运镜给他做参考,分分钟给你还原。五、多语种对话,多人同框,想让谁说就让谁说,支持多种方言语种,几乎没有 ai 感,还可以上传音频文件来精准控制音色。六、动作控制 动作也要精准的要求,只需上传动作视频,加上我们的角色图,填写好咒语,想要的动作就能精准迁移。 七、一句话, p 视频,像 p 图一样 p 视频,把光头强变回来,给他加点杀马特发型, 我怎么变这样了?八、特效参考,不会剪辑不会 ae 也想做特效大片,用这个方法就对了。 九、终极玩法二点零支持图像、视频、音频、文本四种模态输入,这些素材都可以被用作使用对象或参考对象。你可以参考任何内容的动作、特效形式,运镜、人物、转场、声音, 只要提示词写得清楚,模型都能理解。另外还给大家准备好了官方的玩法手册,来一起学习吧!
1.6万汽水PPao 04:27查看AI文稿AI文稿
04:27查看AI文稿AI文稿邪魔休走,可笑,看我碾灭你, 嗯,不好喂,救救救,我得罪了, 这身材真顶啊。别误会,我不是故意占你便宜,救人要紧。哈喽,大家好,今天给大家带来一个动漫短剧分镜图,九宫格的一个分镜图的一个工作流。那么先给大家做两个版本,一个是千万二五零九的版本,一个是这个呃,千万二五幺幺的版本,我们先看一下效果, 首先我们上传一张原图啊,这个是原图啊,然后呢,我们让这个 ai 模型,呃,大模型自动去写一个提示词啊,提示词自动反推的啊,生成九个提示词。然后呢,这个是生成出来的九张分镜图 啊,这是第一个版本,那么我说首先说一下如何来使用啊?使用的话非常简单,因为这个工作流我已经发布到中文哈姆网站上,大家打开中文哈姆网站,搜索 ai 随风啊,可以找到这一个工作流啊,千万二五零九的这个版本 啊,千万二五幺幺的话,我待会也会给大家介绍啊,打开以后,点击打开应用啊,点击打开应用,然后这儿上传一张图片啊,写上一个 简单的一个提示词啊,这个提示词就是说你的核心需求是什么,比如说我这有两个人啊,是一个什么样风格,他要干什么你就告诉他就可以了啊,然后,然后他这个里面呢,然后你上传完的时候点击运行啊,就可以了啊,待会等的就给你出了一个风景图, 这是二五零九的版本,然后呢,另外一个呢,是二五幺幺的版本呢?的话呢,这个使用更简单,你直接上传一张图片就可以了,其他什么都不用写 啊,为什么呢?因为我们这里面有它个,有这个千问三啊, v l 的 自动反推的啊,大模型啊,它会根据你的图片自动去反推啊,然后生成一个啊,提示词啊,一二三四五六七八九啊,各种啊,不同的场景,不同的分镜,不同的运镜的 啊,一个提示词,那把这个提示词传给这个大模型,然后呢去生成这个不同的这个角度,不同的这个近景,别的一个风景图啊,然后这些啊,这个呢也也发布在 rolo 哈布网站上了啊,大家打开 rolo 哈布网站,搜索二五幺幺这个版本啊 啊,你可以找到这个工作流,那么我们结合这些分镜图是干什么呢?主要是,呃,昨天我给大家更新的这个极目二点零用分镜图去制作视频的这么一个这个教程,那么也就是说你现在用这种分镜图 啊,这这种玩法啊,直接可以把这个分镜图传给他,那我们看一下分镜图传过去有什么效果呢? 嗯,不好喂,救救救,我得罪了, 这身材真顶啊,别误会,我不是故意占你便宜,救人要紧啊,这非常非常的这个厉害啊,我们上传的是一张这个手阵图,是一个分镜图, 然后呢我们给他的提示词是这样写的,根据分镜图生成连续的动漫视频,然后从零点一秒处开始剪切啊,因为我们首张图是给他的一个啊,分镜图嘛,然后展示的什么?一个过程, 然后从左上角第一个镜头开始,包括了分镜头网格中的每一个镜头啊,然后呢,如果分镜图里面有这个提示词,有就是说有台词,然后让他按照分镜图上的气泡文字说台词,然后自动增加的音效, 中文发音,无字幕啊,这个图片的比例,这个图片的比例他是默认的,是这样子的,根据你传的图片的比例,这个视频的这个比例就是同样的,也就说如果说你要去生成横屏的视频,那么你上传的这个图片去给他生成横屏的啊图片就可以了。 那么所以说我今天给大家介绍了这个生成分帧图的工作流,它的用处啊,就是干这个的啊,就是为了去做图身视频,用分帧图来控制它啊,做的一个准备。好吧,如果大家对这个 工作流感兴趣啊,可以去玩起来。如果说啊,如果想要这个文档的,也可以在评论区留言领取今天的视频,就这样啊,谢谢大家观看,拜拜。
75Ai随风 01:11查看AI文稿AI文稿
01:11查看AI文稿AI文稿今天学习这个漫画视频制作给 ai 两张图,马上就能得到这样连贯打斗的九张分镜,人物一致性和场景保持不变,再制作成这样分镜切换丝滑的打斗视频。废话不多说,直接上实操。 打开我们的老朋友,选择图片生成。选择图片,五点零上传两张漫画图片,输入这段提示词,点击生成就能得到这样的九宫格图片。切换视频生成, 选择这个二点零,点击这个全能,参考时间长度,根据自己的需求设置,最长十五秒。上传三张漫画图片,前两张是两个图片,第三张是生成好的九宫格图,输入这段提示词,对应的图片替换掉即可。图片一艾特里面找图片一即可, 同理,图片二也是这样操作,图片三也是这样操作。最近二点零排队时间较长,耐心等待,点击执行就能得到这样的视频。
187nmAi 00:17
00:17 04:19查看AI文稿AI文稿
04:19查看AI文稿AI文稿cden 四全能模型的三类保姆级玩法,哪怕你半点都没接触过,看完这个视频基本也能掌握好了,开整吧!为了方便讲述,今天所有内容主包都将以自己的这张美照进行说明。 首先,第一类最简单的单图直出,这个图可以是一张全图,也可以是火遍全网的六宫格九宫格图。根据你的喜好,我们以全图为例,将图喂给 seedens, 然后给出一段提示词,只要你的提示词够酷炫,生出的视频也会很酷炫。 那你肯定要说了,我写不出这么酷炫的提示词怎么办? 这很好办,请出我们的 ai 小 伙子豆包,把你的需求告诉他,他就能给你生成一份酷炫拽的提示词。当然,我们也可以生成文艺一点的,比如这样 好了,第一类讲完了,谁想看九宫格生视频,自己去搜一搜一大把。现在我们讲第二类,整合模式, 这也是被运用最广泛的一类,包括图与图整合、图与视频音频整合,以及图与剧本整合。首先,图与图整合,比如我想和这个帅哥在这个海滩上去滑滑板,那我将三张图喂给 simon, 然后就出来了, 这很难吗?一点也不难,当然,我也可以跑到短剧里去过把瘾,把这几张图喂给他,再配合这段提示词,走你 大胆,见了,本王为何不跪?说完图与图的整合,接下来就是图与视频的整合, 那玩法就更多了。首先,视频可以用来作为参考,这就不得不提我们的小云雀中的 cds 入口了。这里有个专门参考的设置,你只需要找到一个你喜欢的视频,把网址拷贝进去,告诉模型你要参考它的什么,比如参考人物、运镜、动作、光影、背景、声音,总之一切皆可参考。 比如我又想和这个帅哥去海边滑滑板,但是我要借鉴这个视频的动作和印记,然后我就得出了这样一段。 其次,我们可以将图片人物整合到视频中,比如这里有一个超级能打的小哥哥,我想去和他打一段,那么我让豆包给我一段这样的提示词,同时将我的服装换一下,走你。 除此之外,我们还可以用图片人物去代替视频中的人物,比如我要用我自己去代替这个二货,替换之后就成了这样。 现在来说,整合模式的最后一类,图片和剧本的整合。比如我想和他一起演一段这个剧本, 那么我们将图片和剧本截图一起喂给模型,根据提示词,让模型生成视频片段,它就能直接根据。你又在这里等我,但说实话,这个方法只有你对它的比昨日更少,不太高时可以玩玩,反正主播试出来的效果,人间魔气真有意,需以自身纤缘为已的耐, 这是我的宿命。好了,讲完两类,最后我们来讲第三类视频修改。比如我想对视频进行续写,我们以之前生成的这段视频为例,直接将视频喂给模型,告诉他你想续写的内容,他就能生成接下去的内容。 再比如,我们可以直接对视频元素进行替换,可以角色替换,可以背景替换,也可以补充点运镜进去,总之,元素、光影、动作、运镜,一切皆可替换。好了,这就是我们今天的三大类玩法, 只要玩转这三大类基本就够了,如果还想了解更多,对不起,那也没有了,今天就到这里下课。
351朵克力 18:01查看AI文稿AI文稿
18:01查看AI文稿AI文稿今天给大家分享一个很炸裂的工作流,它是可以一键生成二十五宫格慢剧分镜图,从此告别抽卡,保持人物场景的一致性。它可以结合极梦 cedison 二点零视频模型直接生成 ai 动漫短剧。 今天给大家分享的工作流呢,它是可以生成动漫的九宫格呀,二十五宫格呀,还有十六宫格分镜图的这样的一个工作流。 这个工作流它最大的好处就是说它可以保持人物和场景的一致性,那这些呢,都是它漫剧里面的分镜图,大家可以看到 不管是人物还是场景,它的一致性都保存的非常好。首先我会带大家看这几个案例,案例看完之后,我会带着大家跟着我们这个搭建步骤一步一步的来进行搭建,即使你是零基础的小白,只要能跟上我们这个搭建大纲和搭建步骤,那么你也可以搭建出来属于你自己的工作流。好,先带大家去看一下案例图片, 首先第一个呢,他是二十五宫格的黑悟空跟哪吒的一个漫剧脚本分镜图片,那像这张图片呢,他跟我们上一张图片其实区别不大,主要就是我改变了一点点的提示词。那大家可以看到这个是我上传的一个参考图,这个参,那这个参考图呢,也是我用豆包 然后来给我生成的。那像我们上传参考图其实是可以上传多张的,因为这里我为了节省时间,我就只上传了一张图片。上传完之后,底下呢还有我上传了一个剧本,剧本也是我通过豆包来写的, 我们把这个剧本和参考图给到他以后,他就会根据我们上传的参考图以及我们的脚本来给我们生成十二张或者说是二十五宫格或者十六宫格或者九宫格的一个风景图的图片,也就是我们刚才的给大家展示的这个图片,那大家可以看到他生成的人物形象和场景的一致性就是非常完美 好。第二个呢,我们拿到的是十六宫格的一个图片,这里呢我们同样上传的还是哪吒和白悟空的图片,那我们的工作流呢,就会根据我们的脚本和我们上传的参考图给我们生成十六宫格的分镜图图片,那同样的大家可以看到 他不管是场景还是人物的一致性保持的都是比较好的。那么第三个呢,就是一个九宫格的,同样的我们是上传的剧情和图片给我们生成九宫格的分镜图图片, 我们以上的场景他适用的范围可以带大家去看一下。首先我们九宫格他最大的优点就是简单,而且他的画面呢比较大,比较清晰, 包括他人物的表情和动作都看得非常的清楚。那么我们的十六宫格呢,他就是比较平衡的,他的画面的节奏也是比较适中,我们二十五宫格的话,他的画面的细节展示就是比较细节。然后呢就像漫画一样,他适合的场景,就比如说是转场比较多的,适合那种打斗的,悬疑的,就 适合我们比较复杂的剧情来使用。好,那么试用场景给大家介绍完之后,再给大家说一下本期的这一个知识点。首先第一个它是固定我们角色人物的一个形象,第二个呢就是我们可以告别抽卡,保持我们人物和场景的一致性。第三个呢就是它支持九宫格,十六宫格和二十五宫格分镜图, 那我们这一期的工作流,它生成的图片主要就是适用于动漫短剧啊,还有游戏短片,都是现代剧,武侠剧、仙侠剧等等,像各种题材都是可以的。 那么我们有了以上的图片之后,我们就可以利用吉梦的 cici 二点零视频模型,然后来直接生成 ai 的 动漫短剧。 我们这个吉梦 cici 二点零的使用手册我也放在了我的文档里面了,如果说有不会的小伙伴,那就可以看一下我们这个使用手册。那么接下来呢,我就教大家手把手去搭建这个工作流,我们先把搭建大纲给它复制一下, 然后我们来到扣子空间,找到这个扣子编程,我们点击扣子编程,然后我们点击资源库,再点击右上角的资源,然后我们下拉找到工作流,点击工作流,这里呢我们就是去创建一个新的工作流,首先 我们需要给工作流取一个名称,这里的名称呢我们需要注意的是必须是英文或者说是拼音,不能用汉字,那么工作流的描述我们就可以用汉字进行描述就可以了。描述,这里就是告诉大家这个工作流它的作用是什么? 好,我们的名字和描述填写完之后,我们点击下方的确认,这个时候呢我们就来到了工作流的一个搭建页面,首先他会给到我们一个开始节点和一个结束节点, 我们刚刚是不是复制了我们的搭建大纲,鼠标放在下方这里,这个符号这边他会显示注是两个字,我们点击注是,然后我们把我们刚刚复制的搭建大纲粘贴在这里,我们跟着我们的搭建大纲去搭建, 思路呢就会比较清晰。好,结束节点我们先不管它,先给它放到一边。好,首先我们来看一下开始节点的一个配置,那开始节点首先我们要上传人物角色的一个图像,也就是说上传我们的那个参考图像。好,首先我们点击我们开始节点,我们给它配置一下, 第一个呢就是人物的一个角色图像,我们给它复制过来粘贴在这里,那么我们上传人物的细节会展示的更加的完美, 然后图片的一次性也会更加的完美。好,后面变量类型这边我们需要注意的是,我们打开下拉栏,找到 erin, 鼠标放在 erin 这边,不要点击 erin, 放在这里,然后左滑找到 file, 然后我们再左滑 找到 image, 我 们点击这个 image, 那 这个变量类型就是说它可以让我们上传多张参考图片,所以说如果说大家以后在搭建工作流想上传多张参考图的时候,就可以选择这样的变量类型, 然后后面呢我们选择必填,然后这里的符号我们点击一下展开,就可以对我们这个变量名进行一个描述,上传多张参考图片。 好,然后我们把这个关掉,然后第二个是上传故事的内容文案,那我们这个工作流是需要根据我们上传的这个故事情节和参考图, 然后去生成我们的场景图片,就是人物的分镜图以及场景的一个分镜图。我们点击加号添加一下,把 text 添加一下, 这个 text 就是 我们上传的文本人案,也就是我们上传的脚本。这里的变量类型呢,我们就保持默认就可以了。同样的我们把后面的展开给它进行个描述,这里呢我们是上传剧本, 然后我们把这里关掉,然后还有第三个就是分镜的数量,所以我们在这里还是需要再添加一个加号。今天我们带大家演示的是九宫格分镜,十六宫格分镜以及二十五宫格分镜, 所以呢,我们在这里需要去设置它的一个数量,你是想生成九宫格的还是十六宫格的,或者说是二十五风格的分镜图,那么我们分镜这边的变量类型,我们要下拉菜单,找到第二个 int, 因为这里我们会输入九或者十六或者是二十五。好,同样后面这里我们可以展开对它进行一个描述。 好,我们把这里关掉,我们还要增加一项,这一项就是我们需要用到的一个 api k, 这个 api k 就是 我们生图片 需要用到的一个算力。好,那我们开始节点到这边就设置完成了,我们给它关掉。接下来我们看一下我们的搭建步骤。首先呢,我们会生成九宫格,十六宫格,二十五宫格分进的一个提示词, 但凡所有跟提示词和文案相关的,我们都需要用到大模型来帮我们完成这一步的工作。所以呢,在这里我们就需要去添加一个大模型,我们双击大模型,给大家改个名字,我们先生成一个九宫格的吧, 接下来呢我们来配置一下这个节点,首先模型这里我们要下达菜单,我们要找到豆包一点六视觉理解这个模型呢,大家可以看到视觉理解它里面有个图片理解, 选择这个模型,它就会将我们开始的时候上传的参考图,然后进行一个分析,然后呢再去生成一个相对应的分镜的参考图片的提示词,输入这边呢,我们就需要拿到我们开始的时候上传的这个 text, 也就是我们开始的时候上传的剧本变量名,我们也给它改一下,改成 text。 然后我们视觉理解输入项这边我们点击加号,我们这里需要添加一下,这里的话,我们就需要拿到我们开始的时候上传的这一个图片,就是我们开始的时候上传的这个参考图。好,那么视觉理解输入这边我们就配置完成了,接下来我们看一下他的这个系统提示词, 这边呢我已经写好了,我们直接去给他复制过来就可以了,我们直接点击复制,然后粘贴在系统提示值这边,那么大家可以看到,首先他会给你定一个角色,你是专业的三乘以三宫格分镜图生成的助手, 能够一键根据故事内容和视觉参考图生成每个分镜提示词。极简的 jason 格式分镜方案,你的核心目标是高效拆解剧本为九个连贯场景,并为每个分镜匹配精准风格的标签。那像下面这些呢,就是它的一个核心的技能, 它这里就是将每个分界的提示值压缩为二十到三十个英文单词,它为什么会用到一个英文单词呢?因为我们后面生图的插件会用到一个 nano banana 香蕉生图的一个插件,它这个插件如果说你用英文的话, 它的效果是比较好的,那么我们接着看下面的用户提示词,这边呢就比较简单,我们只需要将上面的电量给它引入进来就可以了。那这里我们需要注意的就是我们要在英文输入法的状态下,按住 shift 键加左括号键,首先我们把那个文案剧本给它引入进来,我们可以给它备注一下, 然后第二个呢就是我们的参考图片,然后输出,这边我们不用管它,保持默认就可以了,我们看一下下面的异常处理,如果说我们在开始的时候,我们给到的它的那个剧本脚本的文案比较多,那么它这边运行超时的话, 工作里就会容易包错,所以呢我们需要把这个操持时间给他改的长一点,给他改成六百秒,然后重试次数,这边我们下拉,我们点击重试两次,然后下面他会出现一个备选模型,我们下拉菜单,这里呢我们可以找一个备选模型,我们用这个豆包一点五 pro 视觉理解, 同样的它里面也有图片理解,所以我们在选备用模型的时候,也是需要选有图片理解的模型。那 如果说我们第一个大模型它运行失败,那么我们第二个模型它就会继续去理解我们这个图片它里面的信息,这样的话就会防止我们的大模型它运行超时。好,那么我们九宫格分镜图片提示指这个节点我们就设置完成了,我们给它关掉,我们可以针对这一个节点进行一个单独的测试,这里有个 三角形,看到没有,我们点击测试该节点,单节点测试的好处就是说他只会消耗我们这一个节点的算力,就会比较节省我们测试的一个成本。好,首先参考图这边我们需要上传一下, 我就传这一张吧,哪吒和白悟空的图片,然后下面呢是他的一个剧本,剧本的话我们去豆包里面复制一下,这个呢是我让豆包给我写的一个剧本,然后我们点击,然后我们下滑看一下我们输出的一个结果, 我们点击下方的预览,我们这边呢设置的是九个镜头,它呢给我们设置的是根据我们剧情的发展,给我们设置成了三个阶段,然后大家可以看到它对于我们的每一个分镜的镜头,在这里做了一个详细的描述,那大家可以看到这边呢它是没有问题的,是不是?好,没有问题之后我们接着去搭建这个工作流。 好,我们的分镜提示值有了之后,我们是不是就可以去生成图片了?我们生成图片之前,我们去看一下我们的第四步提示词拼接保持风格一致性, 所以在这里我们就需要去添加一个文本处理主键,这里找到文本处理,文本处理这里我们就需要拿到我们九宫格分镜图片提示时它的这个 output。 好, 那制服钻拼接这里,我们就需要把上面这个时序一给它引入进来,同样还是在英文输入法的状态下,我们按住 shift 键加着括号键就可以进行一个引入。 这里呢还需要输入一段话,那这里呢还要输入一句话,我带大家看一下啊,以参考图为主体,注意环境的空间布局, 空间中人物与所有内容物品的相对位置,并生成不同角度的符合剧情发展的连贯性的分镜图。 注意一定要保持与图片美术风格的一致,这个呢就是要保证我们风格的一致性。好,那这一步我们就配置完成了,我们给他关掉,那接下来我们就可以去生图了,这里呢我们需要去添加一个插件,我们在插件里面点击搜索, 我们找到这个,那二图像生成,然后我们打开选择添加我们这个插件呢,它生成的图片质量还是非常高的,我们双击给它改个名次。 然后呢我们来配置一下这个节点,首先这个 k, 这里的 k 呢就需要用到我们开始节点这个 ipk, 然后第二个呢是提示词,这个呢我们就需要拿到我们刚刚的文本处理它的这个 output。 那 第三个呢就是图片,我们开始的时候设置的是数组的形式,大家可以看到这个 a ring image, 这个意思就是说它是字不串数组的意思,所以呢我们需要把开始的参考图片给到它 这里呢有提示没有关系,它是不影响我们正常运行的。这里呢是一个比例,比例的话我们选择十六比九, 当然比例这些大家可以根据自己的需求去填写,不一定非要填写的跟我的是一样的,因为十六比九它是一个横屏的,然后最后一下呢就是它的一个分辨率,分辨率的话我们可以选择二 k 的, 一 k、 四 k 都可以,根据大家的需求去填写就可以了。 好,那么到这里呢,我们这个节点就配置完成了,我们给它关掉。那么到这里呢,我们的九宫格图片就做好了,我们把结果拿过来,然后给到结束,那么结束这边我们就需要拿到图像生成他的这个 u r l 的 链接。 好,那我们结束节点就配置完成了,接下来呢我们就点击试运行,点击下方的试运行,首先 ipa k, 那 ipa k 的 获取方式呢?我已经放到了我的文档里,这里呢不方便多说。然后分镜数量这里我们填写九就可以了, 因为我们的提示值它是生成九宫格分镜图提示词的。然后接下来就是我们上传参考图片,那我们还是上传白悟空跟哪吒的这张图片吧, 这里大家是可以上传多张参考图片的,我为了省事,我就直接上传了一张,只是为了带大家演示一下这个过程。然后就是剧本,剧本我们还是复制刚刚豆包给我们写的剧本,然后我们点击试运行。好,那么大家可以看到我们的工作流呢,它现在已经运行成功了, 我们看一下他的输出变量,我们可以看一下他这个人物的一致性保持的还是非常好的,非常不错。那他的风格呢?跟我们上传的参考图的风格呢,也是一致的,而且他的画面也比较清晰。那么我们现在九宫格的已经做好了,我们是不是还有 十六宫格和二十五宫格的,那么他们的逻辑都是一样的,只是说在提示纸这边呢,它是不同的,所以呢我们只需要把我们的大模型这个节点复制一下,我们复制两个,然后我们把它这个线给它连起来,再去换一下大模型里面的提示词就可以了,下面这些呢我们都不用动,就是保持默认就可以了, 然后我们再看一下二十五宫格的提示词。好,那么当我们到这一步的时候,我们如果点击试运行,那么他三个大模型他都会去运行, 为了让我们想让他运行九宫格就运行九宫格,想让他运行十六宫格就运行十六宫格的,我们需要再添加一个插件,这个插件就是说 当我们输入九宫格,他就会走这条线,当我们输入十六宫格,他就会走这条线,当我们输入二十五宫格,他就会走这条线,所以呢我们在这边就需要去添加一个意图识别,在业务逻辑这里我们找到意图识别, 我们点开意图识别,首先大家可以看到我们下了菜单,我们换一个模型, 我们下拉菜单,找到豆包一点五 pro 三十二 k, 选择这个模型,首先输入这边我们需要拿到我们开始节点输入的这个分镜的一个数量,那我们输入多少,他就会走我们相对应的一个模型, 这里呢我们可以先输入九,然后我们在后面再添加一项,然后这里呢我们输入十六,再添加一项,再输入二十五,这里呢就可以通过我们输入的数字,然后来判断我们走哪一条线路, 我们先把这一条线给他删掉,然后十六宫格呢?我们是走这一个线,二十五宫格呢,我们是走这一条线,那其他的话我们也可以连到二十五宫格,就说如果你不输数字的话,他会直接走二十五宫格这一条线,那么这边我们是不是要把我们的数据给到我们的文本处理, 那如果说我们直接给到我们文本处理的话,他会出现一个问题,因为我们把所有数据给到他之后,他呢会发生一个拥堵,就会容易报错,所以呢我们就需要去将大模型输出的所有的数据 给他们进行一个汇总,汇总之后然后再给到我们这个文本处理,所以呢我们就需要在这里再去添加一个节点,这个节点的名字叫变量聚合,我们在业务逻辑这里可以找到变量聚合, 我们把这个线先给他删掉,然后把这条线给他连起来,我们要把前面的数据在变量聚合这边进行一个汇总,汇总之后再给到我们的文本处理好,我们点开变量聚合这个节点,对他进行个配置,首先这里我们要拿到九宫格的提示词,然后就是十六宫格的提示词, 还有这是二十五宫格的提示词。好,那么变量聚合这边我们就配置完成了,然后我们再看一下我们文本处理这里呢,我们需要拿到的就是变量聚合它的这个数据。好,那么到这边呢,我们这个工作流算是完完整整的搭建完了,那搭建完之后我们可以再试运行,看一下它的一个效果,我们点击下方的试运行, 同样它的,我把这个分镜图改一下吧,分镜九宫格我们改成十六,然后图片还是刚刚的分镜九宫格,我们直接点击下方的试运行, 那么大家可以看到我们现在所走的就是十六宫格分镜图片贴纸这一条线。好,那么大家可以看到我们的工作流呢,他已经运行完成了,我们看一下输出变量,他给到我们这个链接,我们点击一下,那这个呢就是他给我们生成的一张 十六宫格分镜图的一个图片,大家可以看到他人物的一致性啊,还有我们的场景都是保持的非常好,那么我们的工作流呢,到这里就算全部搭建完了,也带着大家分享完了,对于我们想做慢剧的同学可以参考一下我们这个工作流, 然后参考我们这个工作流,把人物场景的一次性给它保持完整,那么保持完整生成之后呢,我们就可以再根据我们的极梦 c d 值二点零来给它生成一个视频。那 我们这个极梦 c d 值二点零的使用手册呢,我已经放在了我的飞速云朵里面,跟我们的提示词一起都是放在了一起,然后呢来供大家使用。好,那么我们今天的教学分享到这里就完成啦,感谢大家的观看,我们下期再见。
85十七|AI智能体 00:35查看AI文稿AI文稿
00:35查看AI文稿AI文稿极梦二点零刚刚发布,全网都在吹他技术有多牛,别光顾着看热闹,聪明人已经看到了九种新的搞钱机会,特别是这几个功能,直接把做视频的门槛打到了地板上。看这个九宫格分镜加一段描述,一段连贯的大片直接生成。 再看这个动作控制,随便传一段动作视频, ai 模特就能精准还原。最离谱的是这个视频延续功能,这意味着 ai 能自己给你匹配你脑海里的画面了。这次更新的九大玩法,简直是把饭喂到嘴边。我把官方的玩法手册和对应的变现 sop 都整理好了,评论区扣二点零。
646AI有搞头 01:03查看AI文稿AI文稿
01:03查看AI文稿AI文稿用 ai 能做什么?赛道第二期谱解万物,一百三十个作品直接涨粉,一十三点七万作品都是几千上万点赞。今天用三步带大家制作这个爆款视频。第一步,生成 ai 提示词,直接用豆包的 ai 智能体谱解万物,输入关羽的提示词,点击发送,很快就会为你设置好。点击复制 破解万物的智能体已经打包好了工具箱,点击使用像生成张飞的提示词,生成赵云的提示词,生成马超的提示词,生成黄忠的提示词,都是一样,只需输入就可以生成好。第二步,纹身图,在积木选择图片生成模型选择五点零, 比例是九比十六,粘贴生成好提示词,点击提交, ai 很 快就会为你生成四张图片,挑选一张合适的,后面人物生成同样的原理。第三步,剪辑,你可以直接发图文,也可以直接做成视频,导入生成好的图片,给每张图片加上动画,再配上背景音乐来看效果。
32衡思远 00:21查看AI文稿AI文稿
00:21查看AI文稿AI文稿宝子们不要再找了,像这样的九次发型变装秀视频竟然是 ai 一 键生成的,不会做的跟我学起来,跟着我一起这样操作!点这里再戳这个,然后找到这个软件,接着打开即梦工具,在放大镜里搜索我们想要的视频名字,比如选择九次发型变装秀, 打开之后再点击改编,在这里替换自己的分身,什么都不用自己修改,直接发送即可。如果没有分身的,在这里创建自己的分身就可以了。
1每天好运 00:19查看AI文稿AI文稿
00:19查看AI文稿AI文稿今天教大家制作这种九次发型变装秀 ai 特效,方法非常简单,只需要创建分身就可以制作了。首先打开即梦 ai, 没有的话去下载一个,然后在个人中心处创建自己的分身,接着在首页搜索转头变装九次,选择一个喜欢的模板,点这个做同款,在这里替换成自己分身,这里不用管,最后点生成了就可以了。
0糖糖❤️ 02:11查看AI文稿AI文稿
02:11查看AI文稿AI文稿最近二点零上线简直炸裂了,今天我们也来浅尝一下。首页,打开小梦梦页面,选择图片四点五,选择十六比九,输入这段提示词, 如果不满意可以多次抽卡,选择满意的保存备用。接着我们再输入第二段提示词, 选择满意的保存,依次按照上面步骤输入第三段提示词, 选择一张你满意的图片,点击视频生成,选择 c 点四,二点零,输入运镜提示词,点击下载 c 点四,二点零,可以一次放入多张图和三个视频。然后我们依次把刚刚生成好的两张图片和一个视频放进来,这里只要艾特第一张图,让它作为手帧,然后输入运镜提示词,再艾特第二张图片过渡, 最后艾特上传的视频,一个动态弹窗海报就做好了。一点四,二点零,视频的丝滑和转盘程度也非常 nice, 更可控的多模态创作。 结尾我试了一个海报拍摄场景,一起来看看吧!
3488李大喜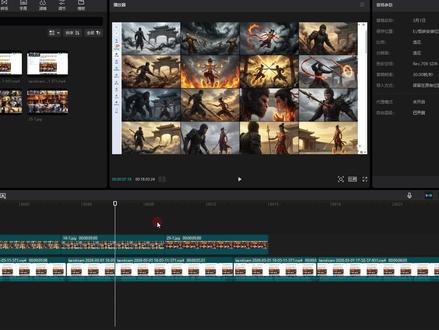 18:05查看AI文稿AI文稿
18:05查看AI文稿AI文稿今天给大家分享一个很炸裂的工作流, ai 生成二十五宫格漫剧风景图,从此告别抽卡,保持人物场景的一致性。它可以结合极梦塞斯二点零视频模型,直接生成 ai 动漫短剧这个工作流,它可以生成动漫的九宫格、十六宫格,还有二十五宫格的风景图, 它最大的好处就是告别抽卡,保持人物和场景的一致性。这期视频我会教大家用扣子工作流来一键生成二十五宫格的风景图做动漫短剧。 下面这些图片的话是我用工作流生成的动漫九宫格、十六宫格和二十五宫格的风景图。好在这里的话,我们先看这个几个案例,接下来以后我会手把手按照这个步骤教大家搭建这个工作流。好,首先第一个,这个是用斗破苍穹里边的 椒盐和美杜莎的一个形象去生成的二十五宫格的风景图片,我们可以看一下这个工作流。好在这里的话上传的是消炎, 这个是美杜莎的一张形象图片,这个图片的话可以让豆包去生成,然后在这里的话上传我们自己的剧本,也就是脚本给到他以后,他会按照这个脚本去给我们生成一个二十五宫格的图片 啊,也就是刚才的这个图片,可以看出他生成的人物形象和场景的一致性保持的还是比较好的。 那么第二个的话是生成一个十六宫格的图片,我们上传的是一张哪吒的图片和一个黑悟空的图片啊,他根据这个剧情去给我们生成一个相对应的风景图片,同样的他这个场景包括人物的一致性保持的还是比较好的。那么第三个的话是一个九宫格的 啊,同样的也是一个哪吒和黑悟空的根据剧情去给我们生成一个九宫格的风景图片 啊。他上面这些场景的话,适用的范围我们来可以看一下,不像九宫格的话,他最大的优点就是简单,而且画面的话是比较大清晰,然后人物的话表情动作都看的比较清楚, 那么十六宫格的话是平衡的,画面中的节奏的话也是比较适中。二十五宫格的话,这个画面是比较细的,就像漫画一样,他这个适合的场景的话,比如说啊转场比较多的,适合打斗的,悬疑的。好,那么接下来以后我会手把手教大家搭建这个工作流。搭建之前我们看一下本期的这个知识点, 第一个是固定人物的一个形象,第二个的话是告别抽卡,保持人物和场景的一致性。 第三个这个工作流程,它支持九宫格、十六宫格和二十五宫格的风景图啊,它适用的范围的话就是动漫短剧、游戏短片,还有一个都市的现代剧、武侠、仙侠剧等各种题材的一个短剧都可以去做啊。有了这些图片以后,我们可以利用 sims 二点零的视频模型 就可以直接生成这个 ai 功能的句,那么极梦三大四二点零的使用手册的话,我也会放到这个文档里边,如果说有不会的小伙伴的话,可以去参考一下这个使用手册。那么接下来以后手把手教大家搭建这个工作流啊,这个是工作流的搭建大纲,我先找到自己的扣子空间,然后选择这个资源库, 然后右边的话有个资源,这里我们选择工作流,这里是新建工作流的地方啊,工作流名称这里大家需要注意一下,这里只能输入英文或者是字母,那么工作流描述的话,就是描述我们这个工作流,它能帮我们做什么事情, 然后点击确认。好,这就来到工作流的搭建界面,我们先把这个搭建步骤入过来。 好,这里有个注试,你可以把这个搭建步骤放在这,按照这个搭建步骤去搭建就可以了,我们看一下开始节点的配置。好,开始的话我们需要上传人物的角色图片,上传它这个参考图片,我们再开始去设置一下。 好,这个的话是人物的角色图片,把这个复制过来,那么上传人物这个角色的图片的话,我们需要上传多张,因为我们麦剧的话,人物的话有好多个,所以说呢,在这个变量类型这里我们选择 array, 这个是数字,数字里边包含了 file, 然后 image 来的这个 array file, image, 这样的话就是可以上传多张这个参考图片,而这里的话选择 b 填,这里展开以后可以对这个节点进行一个描述,可以对这个变量进行描述。 好,这里的话是上传这个我们人物的参考图片。那么还有第二个上传故事的内容文案,这里的话我们需要去根据这个故事情节去让它生成我们所谓的场景,还有人物的每个风景的镜头。我在这里添加一下 这个 text, 就是 我们上传的文本内容。好,也就是我们自己的剧本好,这个变量类型的话保持默认就可以了,同样的这里展开以后,对这个节点进行描述, 好上传文案或者剧本,然后在这就可以了。那么还有第三个就是我们一个分帧数量,并且呢我们生成的是一个九宫格的,十六宫格的和二十五宫格的,那么在这里的话我们需要去设置它这个数量, 就是这个分镜就把它复制过来。 好,这个分镜这个数量,这里的话这个变量类型我们需要选择这个,而这个是整数的意思,因为我们会输入九十六或者是二十五。 好,这里的话同样可以去描述一下, 好,开始的话就设置好了,那我们看一下这个搭建步骤,它首先的话会生成一个九宫格、十六宫格和二十五宫格的一个风景提示词,那么提示词的话我们需要去添加个大模型,在这里添加一个大模型,我们先生成一个九宫格的图片的提示词。 好,那么这个模型这里的话我们需要去用到一个视觉理解的 往下拉,有一个豆包一点六,这里我们需要特别注意啊,它这里面最主要的有一个图片理解,我们会用到这个模型,因为它会将我们上传的这个参考图片就是人物的角色图片进行一个深度的理解,然后再去生成相对应的分镜的图片。记日词。 好,那么输入这里的话,我们需要拿到开始的 x 我 们的剧本好,这个变量名的话改一下 好,那么视觉理解这里的话添加一下,那么这里的话需要拿到开始的这个是人物的参考图片,把这个拿到,那么系统提示词这里的话就是九宫格的封境信息啊,这里的话我已经写好了。 好,直接把这个复制过来,我们来看一下这个系统提示词,首先在这里它定义了一个角色,你是专业的三乘三宫格封境图片的生成助手, 能一键根据故事的内容和视觉参考图片,然后生成每个封境题日词理解的节省格式的封境文案。核心的目标是高效的拆解剧本,为九个连贯场景,并且为每个封境匹配精准的风格标签。下面这些的话是他的核心技能, 它这里的话就是每个分镜提示词压缩为二十到三十个英文单词。它为什么会用到一个英文单词?因为我们后面升图的插件的话,会用到一个香蕉 pro 的 一个升图插件,它这个插件用英文的话是效果是比较好的,那么用户提示词把上面的变量引用进来就可以了。 首先第一个是上传的文本, 好,这个的话是文本的内容,然后还有一个图片, 好,这个的话是参考的人物图片,那么输出的话保持默认就可以了。好,这里大家需要注意哈,这里有个异常处理,因为我们给的剧本比较多的情况下呢,这个大模型有时候会超时,那么可以把这个一百八十改成六百,就是把它这个超时时间改大一些。 好,这里的话点击重试,重试两次,重试两次,然后下面有个备用模型,备用模型的话我们可以去选和它这个模型类似的。 好,这里有个豆包一点五,它同样的里边有一个图片理解,我们选备用模型的时候也需要选这个图片理解,如果说第一个大模型失败以后,第二个大模型继续去理解图片的信息。 好,这样的话这个防止大模型超时。好,这个大模型这里的话就设置好了,那么来测试一下这个大模型,点击这里有个测试按键,那么这里的话上传人物的图片。好,人物的图片的话,这里是一个突破仓群里边的消炎和美杜莎。 好,这里的话是需要我们输入一个文本或是剧本,剧本的话在这里我让豆包写了一篇。 好,这里就是美度鲨鱼消炎的这个故事。好,有文案给到它复制过来。好,粘贴到这里,然后点击运行。好,运行结束以后我们看一下它输出的内容。好,这里有一个预览,我们可以看一下预览, 我们这里设定的是九个镜头,他给我们输出的话是根据剧情的发展,然后把剧情划分成这三个阶段,然后每个镜头的话在这里去做了详细的一个设定,这里的话是没问题啊, 没问题以后我们接着往下去做,那么现在风景提示词有了以后,我们需要去生成图片,那么在生成图片之前的话,我们需要看一下第四步。好,提示词的拼接,然后它的目的干什么?就是保持风格的一致性,在这里的话我们去添加一个文本处理 好,选择这个文本处理。文本处理这里的话,我们需要拿到九宫格图片提示词的 alt foot, 那 么字幕窗拼接,这里的话,把上面这个变量一把它引入进来, 这里大家需要注意啊,引入进来以后它会变成一个蓝颜色,有时候它自己会掉啊,掉完以后我们需要去检查一下。好,这里的话需要输入一句话,这里的话我把这个日过来 我们看一下,这里。好,以参考图为主题,注意环境的空间布局,空间中人物与所有内容物品的相对位置,并生成不同角度的符合剧情发展的连贯性的风景图。 这里需要注意的是啊,一定要保持与原图美术风格的一致。好,这就是保持我们风格的一致性。好,现在的话有了这个这个词以后,我们去生成图片,好,在插件里边搜索。 好,搜索这个纳尔的图片,生成好,记住这个图标哈,这个生成的质量还是比较高的,然后给它改个名称, 那么这里的话这个插件需要 key 啊,要,需要算力,那么再开始去设置一下,好,开始添加一下, 好,再来到这个插件这里,这个 key 的 话,把刚才设置的 api key 啊给到它。 好,这个提示词的话,我们需要拿到这个文本处理的提示词,这个文本处理它是设定了我们图片风格的一致性 参考图片,在这里大家需要注意啊,它是数字格式的,那么开始的话设置的是 array 一 面纸,它就是字母串数字啊,需要拿到这种格式的就是把开始的参考图片给到它, 这里会爆红啊,这是没关系的,因为它是一个是字母串,一个是一面纸,这个的话是都可以去用的。 好,这里的比例的话,我们选择十六比九。好,横屏的这个是分辨率,分辨率的话我们可以选择二 t 的, 这吸力度越高,但是它运行的时间是越久的。好,这里的话就设置好了,到这一步以后,我们这个九宫格的话就做好了,然后把结果给它结束,结束,把线连起来,结束。这里的话我们需要拿到图像生成的 u r l。 好, 点击试用型, 这里话需要输入 a p i k 啊, a p i k 的 话就是这个插件它需要的一个算力,这个获取方法我会放到文档里边,那么封禁数量的话,这里我们选择九个,因为是九宫格,我上传参考图片。好,我们还是选择这个 换一个吧,哪吒和黑悟空,那把这个文案给到它。 好,点击试用型。好,运行结束以后,我们来看一下它输出的数据,这里一个输出变量,它就是我们输出的九宫格的图片, 我们可以看一下它这个人物一致性的话保持的还是挺可以的,这个风格的话和原图的风格也是一致的。啊。好,现在是九宫格的已经做好了,那么现在还有一个六宫格和二十五宫格的这个逻辑是一样的,那我们把这个大模型复制两个就可以了。 好,给他改个名字。好,这个是二十五公分的, 我把线给他连起来, 我们换一下里边的记事词就可以了。好,这个十六公分的。 好,下面这些不用去换啊,这个是二十五公分的。 好,其他的设置它都是一样的。好,现在有个问题,我们点击试用型的时候,它所有的都会去运行,那么在这里的话我们需要去添加个意图识别。 好,当我们输入是九的时候,它会运行九宫格,当我们输入是十六的时候,它会运行十六宫格,那么当我们输入二十五的时候,它会运行这个二十五宫格。这里的话我们需要去添加个意图识别。好,这里有个意图识别。 好,这里有个模型,模型的话这里显示马上就下架了,我们换一个模型,这里的话换一个包,一点五三十二 k 都可以, 这个匹配意图意图,这里的话我们需要拿到开始的好分镜的数量,好,分镜数量在这里我们输入多少,它会走相对应的一个路线。好,这里的话我们先输入九, 然后在这添加一下,好,这个的话是十六,再添加一下,下面这个是二十五。好,它会自动的去判断我们这个所需要的一个数据,它会走相对应的路线就可以了。接下来把线连起来, 把这个线给它拿掉啊,十六公格的话,我们是走这个线,把这个二十五公格走下面这条线,然后这个其他的话我们保持默认啊,然后连到九公格就可以了,如果说你不输的话,它会默认的去生成九公格的这个词。 好,在这里的话我们需要去把文本处理的权限全部给到他,但是这个文本处理的话,他在这里输入的时候,他会出现一个问题啊,所有的数据给到他以后,他会发生拥堵,然后会报错, 那么在这里的话,我们需要去将大模型输出的所有数据进行一个汇总,然后再给到这个文本处理好,在这里去添加一个变量聚合 好,把这个线给到它,将这三个大模型输出的数据在这个变量聚合这里进行汇总以后,然后把汇总后的数据给到这个文档处理,让它去处理 好。这里的话,首先第一个是九宫格的提示册,再添加一下六宫格的提示册,还有一个二十五宫格的提示册。 好,这个文本处理这个数据,这里的话我们需要去换一下。好,这里话需要拿到变量聚合输出的数据。 好,这个工作流的话就搭建完了,搭建完以后我们再试用行一下。好,点击试用行, 还是哪吒和这个黑悟空,还是这个,然后这里的话我们选择十六宫格,让他去生成一张十六宫格的图片。好,点击试用型,看他会走哪条线。 好,我们输入十六宫格以后,他会去走中间这条线去生成十六宫格的风景图,图片记事词。 好,运行结束以后,我们看一下输出的数据啊,这个的话是我们这个六宫格的图片啊,这个人物一致性的话确实还是可以的啊,就是这张图片的话好像有点变化,其他的都还是非常不错的啊。 好,这个工作流的话就算搭建完了,那么对于想做麦剧的同学可以去参考一下这个工作流啊。首先把这个人物的场景一致性这些图片给他生成,生成完以后我们可以利用三大四二点零这个使用手册啊,去生成这个麦剧的视频。 关于这个三大四二点零这个使用手册的话,我这边也有一份,然后我会放到这个文档里边,和这个提示放在一起供大家使用。
264欢哥AI智能体


