qwen怎么有两个

粉丝7.6万获赞84.4万
相关视频
 01:17查看AI文稿AI文稿
01:17查看AI文稿AI文稿马云曾说,员工离开无非两个原因,要么钱没给够,要么心里受委屈了。今天,阿里用最惨痛的方式验证了自家创始人的这句职场真理。就在昨天,阿里最年轻的时,林俊扬官宣离职,一句再见我爱的千问直接带崩整个核心团队。 训练负责人俞伯文同步出走,核心贡献着开庆立发文告别原计划落地的新加坡海外技术据点也彻底胎死腹中。团队得知消息后,不少同事当场眼面流泪,一夜之间,千万的半壁江山空了。谁能想到,这只一百人的技术小队,曾干出全球开源大模型第一家族,四百家模型硬钢自洁。两千人的 c 的 团队,却为什么会在胜利前夕 崩?李希内部会议泄露了真相,理想主义撞上了商业铁墙。林俊扬坚持的是垂直到底,从预训练后训练到 infa, 必须是一个紧密咬合的团队。而阿里要做的是水平拆解,把团队打散,分成预训练后训练、多模态、一个个等待协同的部门。这就像你把一辆 f 一 赛车拆散,引擎交给 a 组, 盘交给 b 组,电控交给 c 组,然后指望他们用开会和 ppt 把冠军拼出来。商业化管理固然有其价值,流程可控、报表清晰。但当创新中最宝贵的快速迭代与紧密反馈被跨部门评选层层撤走,天才的直觉终将淹没 在官僚的流程里。阿里 ceo 吴永明在紧急会议上说,我应该更早知道这些,但一切都晚了。当最傲慢的玩家开始用最商业的刀法切割自己最天才的团队,我们看到的不是一场人事变动,而是一个时代的隐喻。技术理想主义终究要让位于商业算计。
190科技Lab 01:56查看AI文稿AI文稿
01:56查看AI文稿AI文稿最近科技圈有个消息挺让人唏嘘的,阿里千问的负责人林俊扬带队刚发布了让马斯克都点赞的新模型,转身就提交了离职申请,一同离开的还有多位核心负责人。很多人问为什么,其实这不难理解,这是阿里老毛病的一次集中爆发。 在零到一的阶段,大家称兄道弟,谈的是理想,是技术改变世界,眼睛里是有光的。可一旦到了一到 n 的 阶段,整个组织就变了味,满脑子都是 dau, 都是商业化运营开始接管一切, gmv 成了唯一的信仰。在这种逻辑下,技术理想是什么? 是可以被随时砍掉的成本,是不听话的绊脚石,你看现在的局势多微妙。千问很强,但它处在一个什么位置呢?往上烧钱烧不出边界了。往下打不过全民普及的豆包,干不过偏科的 deepsea, 旁边还有虎视眈眈的 kimi mini max。 技术还没登顶,商业化的刀就已经架在了脖子上。当一个公司把活下去挂在嘴边,把商业化前置到研发之前,那么有理想的技术人就成了最尴尬的奢侈品。 同一时间,阿里还有个事情也是蛮有意思的。春节后开工第一天,马云带着阿里和蚂蚁的核心管理层罕见的集体亮相了, 地点选在杭州云谷学校,蔡崇信、吴永明、邵晓峰、蒋凡,还有蚂蚁的景贤洞、韩新意全都在场。简单来说,就是那些曾经带着阿里走上巅峰的老人们都现身了。这就形成了一个很有意思的对冲。一边是林俊扬这样的年轻人带着技术理想转身离场, 一边是马云这样的商业教父带着核心高管高调现身。阿里到底相信什么?是相信那些成功过的大佬,用他们过往的商业梦想带着阿里再战一次?还是相信像林俊扬这样的年轻人,用代码里的技术理想去博一个未知的未来? 这个问题马云没有回答,但林俊阳的离开或许已经给出了答案。阿里有没有理想我不知道,但如果只有 kpi, 没有远方,只有老人归来,没有新人一家,那烧再多的钱也烧不出下一个未来。
1031AI力场 00:371.5万通义实验室
00:371.5万通义实验室 04:06查看AI文稿AI文稿
04:06查看AI文稿AI文稿大家好啊,昨天阿里巴巴开源了千问的一个小模型,三点五系列最小的尺寸模型啊,四款,那其中有一款是零点八 b 和两 b 的 啊,这个是非常小啊,推力虽然很大,但这里面我说的不是他的,我说的是一个三点五 b 的 啊,四 b 这款, 四 b 这款好了,四 b 这款的话呢,我们昨天晚上测试了一下汤,同时话呢,我们先说一个事啊,马斯克在 x 上对这个模型进行了测试,并且给出了一个非常好的体验,他认为这些参数他的智能密度令人印象深刻啊,为什么这么说? 我说这个四 b 的 模型,我建议大家考虑,如果稍微能力强,可以上那个九 b 的 模型。干什么来都知道你们正在养龙虾是吧?就那个大龙虾,那个智能体的集成是吧?号称是贾维斯的出行, 但是他是一个吃 token 大 户啊,什么意思啊?就是我之前试过啊,一个晚上让他给我们做一个程序啊,然后消耗了两百多万 token, 做出来程序还有很多 bug 啊,那,那这个事确实不可持续,虽然说这个 token 现在比较便宜,但两百多万 token 的 话也十几块钱呐,对吧?一个晚上十几块钱这玩意,而且解决一个任务呢,人任务多的话,可能上千万 token 都出去了,那怎么办?对,这个事怎么办? 所以呢,这个端侧部署一个端侧模型来解决这个龙虾啊,在日常应用中的绝大多数的 token 的 使用是当务之急, 那么在这种情况之下,这种小模型的话呢,就比拼,哎,谁能把大模型的这个能力降下来的这个度越小啊, 它寄生能力越好,对吧?这种情况下,所以千门刚刚推出这四款,尤其其中这个四臂,我们正好测试了,我们在昨天测试了,在我们的自己养的龙虾上跑起来非常的舒服啊,百分之八十以上的工作完全由这个端侧的小模型来解决了, 非常好啊,包括数据的处理啊啊,包括图表的处理啊啊,包括我们跟他日常对话包,包括调取这个,哎, skills 包括什么?呃,就是搜索东西啊,包括数据的集成啊,包括 excel 表格处理啊等等,这些东西完全都可以通过端测这个四 b 的 小模型进去, 非常好。所以呢,我说啊,我说这千万这次开源的四个小模型,其实恰恰什么,就是我们现在玩龙虾的最好的助手,也是最适合龙虾发展的模型, 就是这么回事啊,就非常的玄幻,但是现在就是这么回事啊,所以后续的东西,如果你们感兴趣的话啊,你们如果正在养龙虾的话,或者你想探索龙虾的,哎,我建议你好好试试这个模型,这个模型会给你省很多钱,因为它是开源的,你直接不熟以后最少你百分之八十左右的工作, 甚至高一点百分之八十五左右的工作,你是不用再去调取网络的 a p i 的 接接口了,它这个东西就产生更好的应用,懂,懂吗?但对于我们来说的话呢,它一是省钱,另外一个的话就是它的能力还够,而且它还有什么?它关键它有图形的这个 o c r 的 能力啊,然后它有图片的生成能力,这个就很强了, 这就很强了啊,所以这个事我觉得还是非常有意思的,而且小尺寸实现高智能啊,这个是非常强的,而且是少数实现跨级的性能的超越,媲美中型模型啊,中尺寸媲美顶级模型,这样的一个情况,我觉得华为的,哎,不是华为千万,这次做这事非常的好啊,非常的好, 好了,简单大家说一下,如果有需要的话可以好好试一下啊。另外的话呢,说一下呢,很多朋友说,老张,你现在是不是又关注 ai 了?注意关注 ai, 因为这是热点 啊,这是一定的热点,而且我们的这个说,在咱们的这个会议视频当中,热点也是因为我们的分析的快,然后你要说到哪看的话,关注一下我们小程序啊,到底瑞克老张哥不哥啊?我们小程序小程序里面的话呢,说实在的,咱们那个有一个免费的专栏,你说我不想花钱,有免费的专栏,就是咱们在平台上发的内容精选出来放的免费专栏的,不停的更新的,你要需要会看 看一下啊,赶紧的订阅就行,免费的。当然咱们的年度那个会员的话呢,现在是幺六九九啊,而且的话呢,我们是一年一百八十个这个会员视频,三十二场以上的会员直播之前内容都能看,甚至包括以前的付费专栏,包括以后的付费专栏都能免费看,特别划算啊,平均一那个一个视频 喝喝一场直播都十块钱左右啊,所以你觉得对吧?这个一一一一,一瓶两瓶,这个汽水钱啊,就就就解决一次这个抹平新茶的机会,你觉得划算不划算?好不好啊?今天就到这,我是瑞小张,关注我,带大家看中国科技的高度和温度,明天见,拜拜。
890瑞克老张有话说 13:29查看AI文稿AI文稿
13:29查看AI文稿AI文稿大家好,我是叶哲,今天我将介绍一下千万三点五中小模型的使用体验。这些小模型非常受社区的欢迎,而且很多人都认为他们的能力很不错。从这张图上我们可以看到千万三点五九 b, 它在多个基卷上居然是要超过千万三 s 的 八零 b a 三 b c 型模型,这两个模型呢,规模相差是非常大的, 虽然说一个是重密模型,一个是 m o e 模型,九臂呢,是主力模型,社区里用的会比较多。而且现在这些小模型它的工具调用能力也是有了一个极大的提升。 四 b 的 话也是有非常多的用户的喜欢,比如说你可以用它来和你的手机做一个连接,嗯,操作你的手机。那二 b 模型和零点八 b 模型呢,就可以在我们手机端运行,零点八 b 模型呢,甚至可以运行在浏览器上,非常方便。 而且它是有多个的格式衍生,比如说 g g u f o n n x m m m 还有 m l x 社区里常用的技术站呢,奥拉玛拉玛 c p p 之前我有详细介绍过拉玛 c p p, 嗯,它也有 webui, 使用起来也是比较好用的。 而用 g g u f 的 话,社区里呢大多数会选择啊 onslaught 的 方案,它的动态量化做得非常好。如果你是 mac 电脑的话,当然我们用 m l x 是 比较好的。 tech news 的 反馈呢,如果说你的系统提示词不够像样或者够长模型呢,就会进入很怪的 planning 或者长时间的自我检查模式。 parking face 社区呢,还分享了一个零点八 b webgl 版本,然后可以在我们浏览器上跑的,如果我开的话,我手上拿什么东西,或者说呃摄像头里面是什么场景下方它会立即识别出来。 首次进入这个页面,它会下载八百多兆的模型,那这里呢,用的就是 o n n x 的 格式,它是跨框架的计算图交换标准,主打可移植,可被多种运行时变易器加速。 g g o f 大家非常熟悉了, m n n 呢,它是阿里开源的端侧的推理引擎。 m l x, 这个大家应该也是非常熟悉。 g g o f 呢,它是文件格式偏分发部署 o n n x, 它是一个开放标准,这里有它们的核心的优势,对比大家可以简单了解一下。再来看一下各个模型不同的大小啊,不同的量化程度,它们的显存需求,推荐的硬件和速度, 零点八 b, 基本在任何的 g p u 啊手机上都可以跑起来。二 b 模型呢,如果是四比特量化的话,那需要的显存是一点五 g b, 如果是四 b 四比特量化的模型,显存需求是三 g b, 如果是九 b 四比特量化,那需要的显存是九 g b。 二十七 b a 三 b 四比特 大概是占用二十 gb 显存,在我的 mac 电脑上,我更倾向于使用三十五 b a 三 b 巴比特 m l x 格式的,那它的速度呢?大概是呃七十二 tik 每秒,同样也是巴比特,然后九 b 的 模型, 那呃速度的话,只能是五十多 k 啊每秒,这个速度的话就显著变慢了, 如果是用了二十七 b 这个重密模型的话,那速度会更慢。而我在电脑上跑零点八 b 巴比特量化的时候,速度能达到两百 k 以上,这个速度是相当快的。再看一下各个模型啊,它的性能表现,零点八 b 的 模型呢 啊,它在数学 ocr 方面的话,得分也是非常高,可以适合一些简单的 ocr 任务。之前呃千万三 vl 的 很多模型就将下方的 lvm 里面会漏掉一个字母,因为这一行的文字呢,它是比较小的。 我在本地用巴比特量化的零点八 b 模型,让他去 o c r 的 时候,发现它这里的质量是相当不错, 我肉眼看了一下,是没有什么错误的。而三点五二 b 模型呢,它的得分呢,是超过很多上一代七 b 模型的, 也是非常强。四 b 模型在 m m l u pro 得分呢,接近于千万三三十 b a 三 b 了。而在 呃 omega dos 编制得分上,它是击败了 g b t 五 nano。 再看一下九 b 模型,在长上下文基准上,它是打败上一代的千万三三十 b a 三 b 的。 而在 m m m u pro 基准上, 超过 g p t 五 nano。 那 社区的用户反馈呢,二比特和三比特量化质量又开始有明显下降,六比特呢,几乎没有可测量的性能损失。那千万的这几个模型,社区对他们有些评价, 比如说啊,很多用户对二十七 b 还是非常青睐的,认为它的知识库很丰富,能力也很强。社区呢,给到三十五 b a 三 b 是 三分。说到这里呢,非常推荐大家在使用千万三点五的时候呢,看一下 onslos 的 它的一个使用指南, 它在这里就详细介绍了啊, sync 模式下,那我们的各方面的参数怎么设置?现在就来看一下千万三点五中小模型在我本地进行的一些实际体验,那我在这里呢,用到的都是它们的 m l x 格式 巴比特量化的模型,现在看到的是让 a 三 b 模型反推 ai 绘图提示词,在下方,我们看到它回复的内容还是非常多的,我把这里的提示词发给 nano blender pro。 二、 它帮我生成的图片呢,和我一开始发给的原图非常相像, a 三 b 帮我解读图片也是比较好。 这张图呢,呃,我们可以看到各个模型,它并没有明确说这个模型。呃,它的 swbench pro 的 得分是多少,那这里 a 三 b 它是自己估摸出来说啊,千万三 coldest 它的性能达到了约百分之四十四,这张图呢,是我从网络上获取的。再讲呢,千万二点五零点五 b 模型和现在的千万三点五零点八 b 在 回答同一个问题的时候, 已经有了非常大的进步。那我现在就让 a 三 b 模型来解读一下它。在这里呢,解读的非常好啊,每个模型的名称,包括每个具体的回答, 然后还来了句幽默的话,说这张图呢,主要目的就是炫耀千万三点五相比千万二点五的进步,就模型呢,就是太听话了,你问什么他姓什么,甚至呢能编造事实。而篮筐呢,他更聪明,能识别出常识性的错误, 不会一本正经的胡说八道。我在使用 a 三 b 的 时候呢,有的时候它的思考过程会一直循环,那我们可以通过重建对话,或者在提示词里面加一句,让它不要过度思考来解决这个问题。在呃,这张图里呢,我们看到这是九 b 回答的, 我呢是希望模型识别出这张图里的所有的配件,八五四是一个垫片,九臂模型呢,它说这里是连接圆盘和固定件,这里的说法的话还有待加强。之后我又让九臂模型帮我做一个音乐格式化合成器,这是它第一次生产的效果, 点击自动演奏,点击的话是没什么反应的,当我点击粒子喷发, 那效果的话也能出来,但是和我的琴键上是不是一一对应的,而且控制台是有一些报错的,所以呢,我需要他给到完整的啊。最后修改后的文件能听出来他正在弹奏小星星,但是我们可以感知到他发出来的声音和琴键的按键的 啊,按下去是不对应的,所以这里还是有比较大的问题。再让九臂做一个赛博朋克的个人信息仪表盘,再看一下它身上的效果, 在这里的话,它身上的这个页面就要比刚刚要好很多了。再接着呢,我将一张模糊的小票发给九臂模型,让它识别一下。这张图下方呢有四个字比较模糊, 那九 b 呢,模型在这里没有识别出来,其他的文字内容的话,我看了一下,没有什么太大的问题,我再尝试了一下,这次呢,他将五音良品下方的文字都是展示出来了, 这样的千活字减字盘 a 三 b 模型也能非常很好的识别出来,这是他的思考过程,内容非常非常多, 真的就是一个一个字在识别,最终是能识别出大部分文字的。如果说你在连接 ml studio 让它识别图片的时候出现这样的问题的时候,那你可以考虑,一是将整个模型它的上下纹长度变小一点。 第二呢,是限制一下啊,整个图片的一个尺寸,我一开始给它设置的是不超过四零九六,那经常会有内存溢出的情况, 而改成二零四八之后就会好很多。这个画面里呢,我让他数一下有多少只火烈鸟模型呢?是,呃,思考了十一分钟,最终呢,一直都在重复,所以我就终止他任务了。我换成 a 三 b 呢,让他识别图片中有多少只火烈鸟。 它这里的话啊,识别还是相当不错的。同样的,剪字盘发给 a 三 b, 让它解读图片,并且 ocr 图片里的所有内容, 它能很好地指出这是活字印刷的字模,必须是反字镜像。之前是只有一些比较大的模型,它能识别出来, 那像 jammer 二点五, flash 这种,它是识别不出来的。所以现在啊, jammer 三点五,它的能力还真的是非常不错的。当我提示九 b 模型呢,让它数一数图片中有多少只火烈鸟,不要过度思考,那我们看到它思考了三分半钟, 最终就给到非常好的回答。如果说,嗯,大家也遇到同样的他模型,一直在思考,那就可以将提示词改一下。我还让零点八 b 模型呢,反推 ai 绘图提示词, 最终将这里生成的提示词呢啊,发给 ai。 最后 ai 生成的图片和原图呢,是有一些区别。 换成四 b 模型之后,将这样的提示词发给 ai 身上后的图片就和原图非常接近了。在这里呢,呃,用到了四 b 的 思考模型。而在这里呢,大家可以看一下,这里是没有思考模式的,那这个是怎么设置呢?我们来到啊 l m studio 里面找到模型, 然后右侧呢,我们可以点击一下这样的一个设置按钮,在推的这个界面有一个提示词模板,在这最上方呢,在这最上方添加一下这样的一个设置, 它就会关掉思考了。最后呢,我也测试了一下 a 三 b 模型,它的工具调用能力,我是通过在 client 里面和 open code 里页计划模式让它来编码来测试的。我们现在看到的是一个理发应用,右侧有 three js 的 元素。 在我个人看来啊 s m b 它能达到这样的效果还是非常不错的,这是它生成的方便面自动化工厂,包含多个步骤。其实和我之前用一些比较大的模型 啊生成的已经是很接近了,这是它生成的火星体数生物研究站的啊,一个场景,我们仔细看的话会有一个透明的球, 它生成的这个透明的球的话,效果肯定是比不上 mini max m 二点五或者呢是 office 四点五。 但我个人觉得对于啊,它在我本地运行这样的一个 a 三 b 巴比特的模型,质量也是很不错了。现在我们来看一下咱们在 opencode 里使用 lm studio 的 模型。那首先呢,我们可以通过这行命令 来确认一下 l m studio 当前暴露的真实模型 id。 然后呢,可以啊,打开配置文件路径修改粘贴以下部分,再之后呢,就可以重启。 以上呢,就是今天介绍的关于千问三点五中小模型的一些使用体验,我个人对它来说是非常喜欢的,因为它文本能力也强啊,原声支持二百五十六 k, 而且 它是多模态的,现在无论是 m、 l、 s 还是拉曼 c, p、 p 都是支持批量调用的, 所以大家可如果有一些批量的啊,一些任务不复杂的,那完全可用它来在本地来做,因为它输出的质量是相当不错的。四 b 模型、九 b 模型和 a 三 b 模型都是非常非常推荐的。
209kate人不错 00:49查看AI文稿AI文稿
00:49查看AI文稿AI文稿兄弟们,我这个一百二十八 g 的 电脑安装了这个千万三千五二十七 b 的 大模型啊,把它提供服务,然后给这个 openclaw, 接入 openclaw 之后就可以和它对话聊天。很多人不会安装这个 openclaw, 其实非常简单,一共就这,其实就是三步,第一步使用这个命令安装,第二步 设置向导,并且把它安装为系统服务。第三步 openclock on board, 就是 打开这个外部界面, 当你丢失的话,你可以使用这个命令打开啊,然后这个是 start, 是 启动,你可以改成 stop 关闭,然后第五步的话就查看它的状态,总体上非常简单, ok。
314沪上码仔AI 04:19729电磁波Studio
04:19729电磁波Studio 01:05查看AI文稿AI文稿
01:05查看AI文稿AI文稿阿里的千问一口气发布了一系列 callen 三五小模型,有零点八 b, 二 b, 四 b, 九 b 啊二十七 b, 今天就让大家一分钟在 windows 上用上这个本地小模型。 首先去 l m 服务 studio 官网下载这个模型,加载软件,点击下载你就去装,下载完成后安装那个 l m studio, 然后等安装好启动后,来到软件主界面,点击左侧有个小放大镜的图标,就可以搜索这个模型了, 输入很快就看到结果,那今天我们就用库莱三五到四 b 作为例子,点击下载,然后下载好之后就可以点击左侧第一个按钮,然后点击上面加号,然后加载刚下好的模型。然后呢,这里我们可以设置模型的参数, 我们来测试一下这个模型的基本常识, 对比下其他的模型的基本常识,但这个回答效果还是很不错的。
 05:48查看AI文稿AI文稿
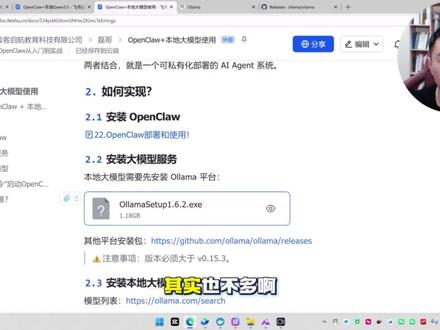
05:48查看AI文稿AI文稿龙虾加困三点五能擦出什么样的火花呢?我们知道困三点五在除夕夜正式发布了,它呢也是号称最强的开源模型,它的能力可以说拳打 g p t, 五点二 叫 t cloud, 四点五是可以和国际的这些顶级的大模型搬一搬手腕的。那好,那么这样一个国产的重量级的开源大模型,我们能不能在龙虾里面免费调用呢? 答案是可以的,接下来一个视频,带着你从零到一的在龙虾里面去接入困三点五,完成免费的调用。好,那话不多说,咱们直接进入正片吧。那么接入的步骤呢?其实也不多啊,总共呢四步就搞定了。首先第一步啊,如果你本地没有欧拉玛的情况下, 你先下载一个欧拉玛,注意下载最新版的,如果你的欧拉玛很长时间没有更新的,那么也是一样先更新到最新版本啊,那么这个没啥好说的,你呢,就把它下载下来,一路下一步就可以安装了 啊,安装完了之后呢,接下来咱们要在我的欧拉玛上去安装你的问三点五的模型。好,那么安装的话怎么安装啊啊?复制这行命令,然后这时候呢,把命令输进去就行了, 这个就是开源的问三点五的模型了。好,然后这时候敲回车,咱们只需要等待欧拉玛去安装千问就行了,很快咱们就可以看到。哎,我的千问三点五就已经安装到本地了啊,这时候呢,我知道有同学就说了,说,磊哥啊, 我本地的电脑配置不是特别高,问三点五能不能部署啊?这个还真能,为什么呢啊?因为在欧拉玛里面的这个问三点五的这个模型,大家可以看到了,后面跟了一个谁呀? cloud, 这个是欧拉玛新推出的一种 云端的模型啊,这些新模型呢? ok, 大家可以看到它都是有 cloud 标识的,像 win 三点五呀,智普的五呀,还有像 mini max 的 二点五啊,都是 cloud 的, 那么这个 cloud 是 什么意思啊? 啊?它指的是欧拉玛远程帮你已经部署好了满血版的这些模型了,你只要有欧拉玛的这个客户端,你就可以快速的去连接欧拉玛帮你部署好的这个开源模型了,所以这时候你不需要担心自己的电脑不好,因为这个满血版的大模型, 它的本质上是没有在你本地部署的,而是在欧拉玛的服务器上部署的,你有欧拉玛,你是可以直接去用的啊,所以它是这样的一个逻辑,因此呢,你电脑不好没有关系,是可以去用的。好, ok, 那 么很快咱们就部署好了啊,部署好了之后呢,接下来第三步啊,咱们就去登录我的欧拉玛账号。好,这时候复制这行命令, 来到命令窗口里面输入这行指令敲回车,然后敲回车之后呢,它会自动打开页面啊,这个是欧拉玛的登录页面,如果说他没有出现,大家看这个地址了没,复制这个地址,手动的粘贴到你的浏览器里面就行了。好,那这时候 ok, 去填写你的欧拉玛账号。那有人说,哎,那磊哥我没有欧拉玛账号怎么办?那没有邮箱的情况下呢,我们就去点击底下这个注册按钮啊,然后点击完成之后呢,然后接下来 在上面这个输入框里面去填写你的邮箱信息啊,那我就填写我的这个邮箱信息,点击继续。好,这时候呢,他让你去输入创建一个密码啊,那你就输入密码,然后点击继续, 然后点击下一步。好,点击完成之后呢,他要求登录到你的邮箱了,他把这个验证码收到你的邮箱了。好,输入完邮箱之后呢,他要求绑定一个手机号啊,那我们这时候呢,就去填写我们的手机号, 然后点击发送验证码。好,然后拿到手机上的验证码之后呢进行输入啊,输入完成之后呢,咱们就完成了登录了啊,大家看到没?我就登录了 啊,登录完了之后呢, ok, 去点击呃,底下的 connection, ok, 它就显示已经登录成功了,那么到这咱们的第三步就已经完成了啊,完成之后呢,接下来咱们就可以执行最后一步了, 使用这行命令来去启动你的 open class 啊,就可以完成 open class 接入欧拉玛里面的问三点五的模型了。好,那这时候呢,咱们最后一步啊,使用这行命令 来启动进行交互了。好,那这时候咱们来试着启动一下,回到命令窗口里面,把这行命令呢输入进去。好,稍回车。好,那么等待片刻之后呢,咱们可以看到啊,咱们的 open class 了,并且使用的模型呢,是欧拉玛的千问三点五的 cloud 模型啊,但是能不能用呢啊,那么接下来咱们可以打开命令窗口, 或者是打开咱们的飞书啊,来测一下。那我这呢就打开我的命令窗口啊,然后完了之后呢?好,接下来咱们就呃给他新开一个 new session 吧, 新开一个窗口啊,然后咱们来问一下他,我给你更换了新的大模型,告诉我你使用的大模型是啥,那咱们就给他一行这个命令啊,然后点击 send。 好, 那这时候咱们来看一下他给咱们返回的模型是啥,看到没?那他说的是我现在用的就是啥呀,问三点五的模型了,那这样的话,咱们就使用 openclo, 可以 免费的使用 欧拉玛里面的问三点五的模型了,好,这时候可能有人就问了,说,难道这么简单吗?我可以这样免费的去使用欧拉玛的云端模型吗?有没有限制啊?答案是有的啊,比如说欧拉玛的云端模型,人家也是有成本的吧, 所以说那么欧拉玛的调用云端模型的调用也是有额度限制的,然后这个额度限制在哪呢?给大家来看一下啊。这时候呢去点击账号右上角的这个账号啊,点击完了之后呢,在这大家看到没, 这块呢就是云端模型的使用限制啊,它是有一个百分比的,那么每周它会有一定的额度,然后每四个小时会有一定的额度,那么当你把这个额度用完之后呢,那么云端的模型就不能掉了, 所以我刚才问了两个问题,那么基本上就消耗了百分之一点二,所以这个免费的模型的话,每四个小时应该是能够调用一百次左右啊,根据你的这个上下文的这个计费是不一样的, 所以总体来看,这个免费的额度相比于其他的免费的额度来说啊,欧拉玛还是更实在一些。那么到这儿咱们就完成了在 opencloud 里面去接入问三点五的功能了。我是李哥,每天分享一个干货内容。
5187磊哥聊AI 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿太突然了,林俊阳深夜官宣绕比亚里千问团队。这事离奇的点在于,前一天晚上,千问团队张张重磅拆原了千问三点五轻量化模型,热度刚起来,甚至连马斯克都点了赞。 林俊阳的上一条动态也停留在相关讨论的回复中,结果转头人就专宣离开了。更让人意外的是,在他宣布不久后,又有两位核心团队成员也相近宣布离开。现在几人去向尚未明确。其实在国内大幕星权,林俊阳一直是个很年轻但分量很重的人物。 一九九三年出生的他,今年仅三十二岁,是阿里最年轻的 p 十级别技术负责人。二零一九年从北大硕士毕业后就加入阿里, 仅用两年就成为 m 六项目的核心开发者,这可是当时全球首个十万亿参数的多模态模型。后来,林俊扬转向通用大模型方向,又成为千万项目的技术负责人,带着团队把千万系列大模型做出来,并一路推进拆园,其骨折学术背景量已经超过四万。 现在他的离职帖子下面基本被祝福刷屏了。但更让人好奇的是,这波核心成员同时离开了。但正让人好奇的是,这波核心成员同时离开了。但正让人好奇的是,这波核心成员可能很快又有新故事了。
3584量子位









